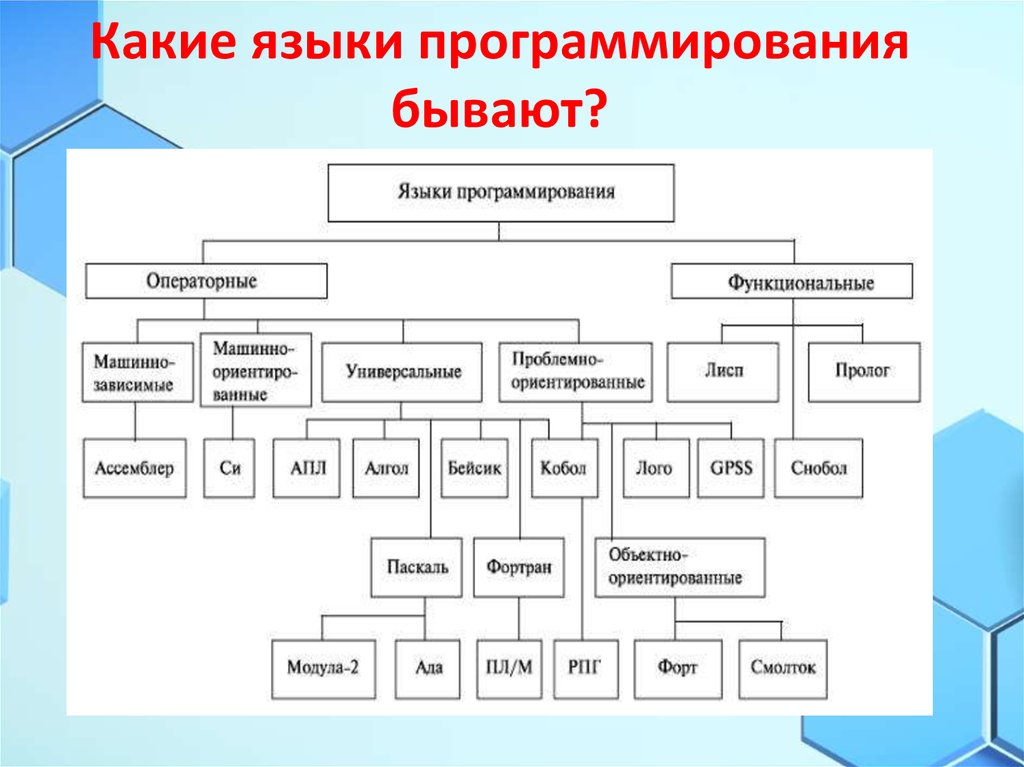
Конец эпохи динамических языков / Хабр
Несколько последних месяцев я программирую преимущественно на Scala (по работе) и на Haskell (для души). На этой неделе я, правда, ещё немного пописал на Ruby (по работе) и Clojure (для души).
Ruby вывел меня из равновесия почти сразу. Нет, ну ещё в плане «добавить небольшую фичу к уже имеющемуся коду» писать на нём можно. Вы просто добавляете юнит тест, запускаете его на старом коде, делаете правку, запускаете тест снова — вуаля, готово, забирайте. Но замахиваться на что-то большее становится уже слишком сложно.
Но вот что касается моего новенького, с иголочки, проекта-любимца на Clojure… О, Clojure! Глоток свежего воздуха! Благодатная земля хорошо скомпонованных функций, иммутабельных структур данных и всего такого. Как прекрасен твой синтаксис и как мудра твоя чувствительность! Вся твоя суть в функциях, принимающих мэпы и возвращающих мэпы. И твой SQL-генератор, и слой доступа к БД, и HTML-парсер, и URL-роутер являют собой одну и ту же завораживающую картину мэпов, гоняемых туда-сюда тактами процессора, прекрасную с своём ритме хорошо собранных швейцарских часов.
Вернуться к Clojure после долгого времени это всё равно, что почувствовать себя дома. Это просто окрыляет программиста. Но почему-то в этот раз я ощутил и ещё одно, неожиданное для себя чувство: неопределённость.
Мой диалог с Clojure выглядел как-то так:
— О, свет мой, Clojure! Спасибо тебе за эту восхитительную иммутабельную структуру данных с мэпом для запроса. Могу ли я спросить, что там внутри?
— Разве это не очевидно? Там HTTP-запрос.
— Да-да, конечно. Но в каком же именно виде? Что там за ключи и что за значения?
— Разве это не очевидно? Там HTTP-запрос.
— Да-да, конечно. Я почитаю исходники и документацию в поисках ответа.
— Да, почитай и разберись.
— Я почитал. И что же такое переменные attr и f? А когда я вызываю функцию wrap-params — какие ключи добавляются в мэп?
— Забудь. Я просто добавлю вот сюда и сюда отладочный вывод.
Всё это бьёт по продуктивности. Каждый вызов библиотечной функции, если вы только его не выучили наизусть, требует рыться в исходниках в попытках понять, как же его использовать. Каждый мэп, полученный после вызова, требует отладочного вывода чтобы понять, что с ним делать.
Каждый вызов библиотечной функции, если вы только его не выучили наизусть, требует рыться в исходниках в попытках понять, как же его использовать. Каждый мэп, полученный после вызова, требует отладочного вывода чтобы понять, что с ним делать.
Да, Clojure — мощная вещь. Но мощь эта неуправляема, она не имеет вектора и без кого-то, способного дать совет, она может лишь разрушать. И я сейчас не о философских понятиях — только о коде. Кто из нас не страдал от метапрограммирования в Ruby или мэпов в Clojure? Мы сами себе и жертвы и виновники наших страданий.
Вот вам пример: предметно-ориентированные языки (DSL) — это способ решения проблем, или ещё один способ их создания? Давайте поговорим о деструктивной мощи DSL в Clojure. Программисты на Clojure любят DSL-и, структура языка предрасполагает к их использованию. Но я считаю, что что-то здесь не так. Давайте, например, представим такой-себе генератор HTML. Вот вы вместо
<span>bar</span>
пишете:
[:span {:class "foo"} "bar"]
Знаете, какой DSL лучше всего описывает HTML? Я открою вам секрет: это HTML. Так зачем же вы, скажите пожалуйста, придумываете вместо него свой собственный DSL, который точно ничем не лучше (а скорее всего хуже) и уж наверняка игнорирует все те десятилетия опыта и развития, что были у HTML со всеми его фичами, инструментами и опытом дизайнеров?
Так зачем же вы, скажите пожалуйста, придумываете вместо него свой собственный DSL, который точно ничем не лучше (а скорее всего хуже) и уж наверняка игнорирует все те десятилетия опыта и развития, что были у HTML со всеми его фичами, инструментами и опытом дизайнеров?
Посмотрите как сделаны enlive и yesql и вы поймёте, о чём я говорю.
Но что ещё хуже с DSL, так это то, что я не уверен, верно ли я использую ваш DSL до того самого момента, пока я не получу ошибку на рантайме. Давайте посмотрим на bidi, миленькую библиотеку для URL-роутинга. Её приятно использовать, но есть одно «но». Скажем, мы хотим прописать маршрут для запроса GET /notes. В bidi мы определяем маршруты вот так:
(def my-routes ["/notes" :index-handler])
Мы можем протестировать этот обработчик:
(bidi/match-route my-routes «/notes»)
;; {:handler :index-handler}
;; Success!
Выглядит просто. Но что, если мне нужно добавить ещё пяток маршрутов:
GET /
GET /notes
GET /notes/:id
POST /notes
POST /notes/:id
Какая ерунда! Всего-то несколько Ctrl+F по документации, внимательное чтение исходников, пару догадок, десяток экспериментов, невероятное количество исключений, выброшенных прямо мне в лицо и вот я чудом дохожу до требуемого результата:
(def my-routes
["" {"/" :home-page-handler
"/notes"
{:get {"" :index-handler}
:post {"" :create-handler}
["/" :id] {:get {"" :show-handler}
:post {"" :update-handler}}}}])
Я думаю, во всём этом есть некий неуловимый паттерн, но вот вы видите его с первого взгляда? Вы запомните его раз и навсегда, или в следующий раз снова будете идти по тому же устеленному граблями пути творческого поиска?
Проблема неопределенности
Не поймите меня превратно: при использовании типизированных языков тоже возникают негативные ощущения. Замешательство, разочарование, отчаяние. Но неопределённость хуже их всех. Вы можете бороться со всеми остальными методом «надо посидеть и разобраться раз и навсегда». Но как разобраться с неопределённостью? Только с помощью определённости. А что, если сам язык не предоставляет никаких средств, чтобы нащупать эту твёрдую почву под ногами?
Замешательство, разочарование, отчаяние. Но неопределённость хуже их всех. Вы можете бороться со всеми остальными методом «надо посидеть и разобраться раз и навсегда». Но как разобраться с неопределённостью? Только с помощью определённости. А что, если сам язык не предоставляет никаких средств, чтобы нащупать эту твёрдую почву под ногами?
Давайте посмотрим на несколько текущих попыток решить эту проблему
Частичное введение типов (Gradual typing)
Есть фантастически интересные попытки скрестить бульдога с носорогом и прикрутить к динамическим языкам элементы статической системы типов: Typed Racket, Typed Clojure, TypeScript, Typed Lua. Даже для Python есть «type hints»
Всё это хорошие вещи, их давно не хватало. Они показывают наличие проблемы неопределённости, о которой я здесь говорю, и каких-то попытках её решить.
К сожалению, у меня есть подозрение, что частичного введения типов будет не достаточно. Во-первых, нужно затратить прилично усилий, чтобы описать типы во всех уже существующих библиотеках. Может ли сообщество Clojure быть достаточно дисциплинированным, чтобы добавить описание типов для всех своих библиотек? Сколько из них уже описаны? Я не вижу активной работы в этом направлении.
Может ли сообщество Clojure быть достаточно дисциплинированным, чтобы добавить описание типов для всех своих библиотек? Сколько из них уже описаны? Я не вижу активной работы в этом направлении.
Мы можем на словах бороться за культуру ответственности и заботы о коде, но знаете, рано или поздно доходит до того, что вы пишете какой-нибудь комментарий по принципу «ай, сойдёт», а не стараетесь сделать его максимально полезным и эффективным. Почему же так происходит?
Фундаментальная проблема в том, что язык программирования — это не только код. В сообществе языка также воплощаются некоторые идеи его создателей, подходы, школы, философия. И всё это очень тяжело потом изменить.
Этого не достаточно
А что на счёт юнит тестов, тестов стиля кода, контрактов, парного программирования, ревью кода? Какое множество полезных инструментов! Наверняка уж с ними-то можно и на динамических языках писать!
Нет, нельзя. Юнит тесты полезны для тестирования некоторой известной функциональности, а не для определения того, насколько что-то в результатах соответствует вашим явным или неявным ожиданиям.
Тесты стиля кода для динамических языков бессмысленно ущербны в том плане, что заботятся они о внешнем виде кода, а не о его качестве. Да, проблему с лишним пробелом они найдут, но в пробеле ли действительно проблема?
В то же время использование hlint в Haskell (поскольку это типизированный язык) даёт весьма ощутимый результат. Инструмент знает о вашей программе намного больше, чем просто синтаксис её кода. Он способен находить такие структурные проблемы, как:
- Есть две эквивалентные анонимные функции, которые можно заменить одной и вызывать из двух мест
- Вы написали код, который уже содержится в какой-нибудь доступной в проекте библиотеке
- Вы не перебрали все возможные варианты в case-выражении
Создаётся впечатление, что мы тут говорим об искусственном интеллекте. Ок, а что если мы начнём с инструментов, которые помогут нам предотвращать некоторые рантайм-ошибки и помогут писать качественный код? Хотели бы вы иметь такие штуки, правда?
Ок, а что если мы начнём с инструментов, которые помогут нам предотвращать некоторые рантайм-ошибки и помогут писать качественный код? Хотели бы вы иметь такие штуки, правда?
Короткая история
Так, хватит теории, сделаем небольшую паузу, где я расскажу как мы используем наши языки программирования для искоренения некоторого класса ошибок из нашей кодовой базы.
На прошлой неделе я работал с одним проектом на Scala и по ходу дела заметил, что в нём очень легко сделать ошибку, приводящую к записи неверных значений в поисковый кластер Solr. Например, Solr с лёгкостью соглашается записывать значение null в булевое поле. Я потратил неделю на рефакторинг этого хаоса, разбив этот огромный подверженный багам монолитный кусок на маленькие симпатичные модули, крутящиеся вокруг иммутабельных структур данных, как в Clojure. Вначале я был очень доволен собой и кодом. Его было легко читать и легко тестировать. Всё было прекрасно, пока я не обнаружил, что пишу те же самые баги, что и раньше.
Тогда я и мой коллега Адам поставили цель: превратить все эти потенциальные ошибки на рантайме в ошибки на этапе компиляции. Мы хотели получить пусть большое и страшное, но генерируемое компилятором сообщение об ошибке, когда мы попытаемся записать null в булевое поле.
У нас заняло 2 дня чтобы выяснить как это всё можно завязать на систему типов Scala. Но в конце концов мы сделали это. Наша система типов стала проще, мы смогли конвертировать все имеющиеся раньше потенциальные ошибки рантайма в ошибки при компиляции. Адам отрефакторил всю нашу кодовую базу для использования новой системы типов всего за пару часов.
Сегодня я обновил один из моих проектов с использованием данной библиотеки. Получил ошибку от компилятора. Это действительно был баг, я никогда не видел его раньше. Исправлено!
Подобная мощь никогда не будет доступна в языках вроде Ruby и, наверное, Clojure тоже. Но она существует. И вы тоже можете использовать её.
Но она существует. И вы тоже можете использовать её.
На всякий случай уточню: вы и ваша команда не станете писать идеальный код прямо в тот же день, когда перейдёте с Ruby на что-то другое. На самом деле вас ждёт приличный этап падения производительности и, возможно, крепких выражений, звучащих в офисе. Но это боль растущего профессионализма — она неизбежна при изучении чего-то нового. А потом придёт уверенность и мастерство.
Конец эпохи
Вот моя ставка: эпоха динамических языков заканчивается. Больше не будет новых успешных чисто динамических языков. Но они нас многому научили. Теперь мы знаем, что код библиотеки должен поддаваться расширению другими программистами (польза миксинов и мета-программирования), что мы хотим понимать и контролировать структуры данных, что мы презираем многословность. Ах, и ещё мы научились получать удовольствие от использования языков программирования.
Но время двигаться дальше. Мы вскоре увидим сияние восхода нового поколения языков программирования — приятных в использовании, как Clojure, но типизированных. Вместе с ними придут и новые, невиданные доселе инструменты, которые не сможет проигнорировать даже самый отъявленный аскет.
Вместе с ними придут и новые, невиданные доселе инструменты, которые не сможет проигнорировать даже самый отъявленный аскет.
Чтобы всё это произошло, нам необходимо дать нашим инструментам ту информацию, которая им необходима, чтобы нам помочь. Даже хороший психолог не может помочь абсолютно молчаливому пациенту. Мы начнём с предоставления информации о типах, ограничив тем самым область неопределённости. Новые языки программирования, такие как Elm и Crystal находятся на верном пути, равно как и уже существующие Haskell и Scala. Нам нужно больше языков подобного типа.
Мы думаем, что видели в жизни уже всё, что нет в программировании новых идей, которые были бы способны удивить. Хуже того — мы отказываемся даже изучить что-то, что не согласуется с нашим предыдущим опытом. Ну, знаете, вот это «Боже, посмотрите только на синтаксис!». Но вспомните, как тяжело вам было тогда, когда вы учили свой первый язык программирования — там что, было понятнее? Но ведь оно того стоило, правда? Не нужно бояться проделать это захватывающее путешествие ещё раз.
Теолог Герхард Вос однажды описал человеческую жизнь как «уже, но всё ещё нет». С его точки зрения верующим людям судьбой предопределено счастье в загробной жизни, но вот пока ещё им приходится мириться с мирскими бедами и тягостями. Эта метафора хорошо описывает и то, где сейчас находимся мы, программисты. Да, у нас пока нет идеальных языков программирования и действительно умных инструментов, но с моей точки зрения блистательное будущее этой сферы человеческой деятельности уже предопределено. Многие из сегодняшних разработок уже идут по правильному пути, а чему-то ещё только предстоит появиться. Нам ещё предстоит длинная дорога, но мы определённо сможем её пройти.
Почему динамические языки программирования создают трудности при сопровождении больших объемов кода
Евгений Брикман — ведущий разработчик Play Framework для LinkedIn сказал в видео-презентации, записанной на JaxConf 2013, что большие кодовые базы труднее поддерживать, если они написаны на динамических языках.

На одном из Q&A сайтов был задан этот вопрос, и лучший ответ на него дал пользователь Эрик Липперт.
Итак, его ответ.
Предупреждение: я не смотрел презентацию.
Я работал в проектных комитетах по JavaScript (очень динамический язык), C # (в основном статический язык), и Visual Basic (который как статический, так и динамический), у меня есть несколько мыслей по данному вопросу.
Начнем с того, что трудно поддерживать большую кодовую базу, и точка. Большой объем кода очень трудно написать, несмотря на то, какие инструменты есть в вашем распоряжении. Ваш вопрос не означает, что сопровождение большого кода в статически типизированных языках будет простым, а вопрос предполагает только то, что вы встретите больше проблем, если будете поддерживать код в динамическом языке, а не в статическом. Есть причины, почему усилия, затраченные для поддержки большой кодовой базы в динамическом языке несколько больше, чем затраченные усилия на статически типизированных языках. Я рассмотрю только некоторые из них.
Я рассмотрю только некоторые из них.
Немного забегаю вперед. Мы должны четко определить, что мы понимаем под «динамическим» языком: под «динамическим» языком я имею в виду противоположное «статическому» языку.
Статически типизированный язык – это язык, разработанный для облегчения автоматической проверки правильности при помощи инструментов, которые имеют доступ только к исходному коду, а не к данным в рабочем состоянии программы. Те данные, что выводятся с помощью средств называют типами. Разработчики языка создают набор правил, которые делают программу типобезопасной, и средства пытаются проверить, что программа следует этим правилам.
Динамически типизированный язык в отличие от статического не облегчен такого рода проверкой. Значения данных, хранящихся в любом конкретном месте, могут быть определены только путем проверки во время работы программы.
Мы могли бы привести различия между динамической областью видимости и лексически ограниченными языками, но давайте не будем отходить от целей данного обсуждения.
Динамически типизированный язык не должен быть с динамической областью видимости и статически типизированный язык не должен быть лексически ограничен, однако часто присутствует взаимосвязь между ними.
Так как у нас есть конкретные условия вопроса, давайте прямо поговорим о больших кодовых базах. Большие кодовые базы, как правило, имеют некоторые общие характеристики.
Все эти характеристики создают препятствия на пути к пониманию кода, и, следовательно, создают препятствия для правильного изменения кода. Короче говоря: время = деньги и сделать правильные изменения в массивном коде дорого из-за характера этих проблем.
Также бюджет конечен, и мы хотим сделать столько, сколько можем, с ресурсами, которые имеем. Люди, которые сопровождают крупные кодовые базы стремятся снизить стоимость при помощи принятия правильных решений для смягчения этих препятствий. Некоторые способы для преодоления проблем:
- Модульность: код разделен на модули, где каждый модуль имеет четкую задачу.
 Логика кода может быть задокументирована и понятна без того, чтобы пользователю нужно было понимать подробности его реализации.
Логика кода может быть задокументирована и понятна без того, чтобы пользователю нужно было понимать подробности его реализации. - Инкапсуляция: в модулях проведены различия между их «внешней» поверхностью и их «внутренними» деталями реализации, таким образом, что последние могут быть улучшены без ущерба для правильности работы программы в целом.
- Повторное использование: когда проблема решена правильно один раз, она решается так всегда. Результат может быть повторно использован в решении других проблем. Такие технологии, как создание библиотеки полезных функций, или создание функциональности базового класса, которые могут быть расширены с помощью производного класса, или архитектуры, в которой приветствуется содержимое, состоящее из методов, реализованных повторным использованием кода. И все это для того, чтобы снизить затраты.
- Аннотации: аннотированный код описывает допустимые значения, которые могут принимать переменные.

- Автоматическое обнаружение ошибок: команде, которая работает над большой программой, имеет смысл создать приспособление, которое сразу определит ошибку и расскажет о ней, чтобы она была решена быстро. Такие технологии, как написание набора тестов, использование статического анализатора попадают в эту категорию.
Статически типизированный язык является примером последнего. Вы получаете прямо в самом компиляторе возможность увидеть ошибки связанные с типами данных, и компилятор сообщит об этом. Явно типизированный язык требует, чтобы в местах объявления переменных, были примечания, несущие информацию о том, что может содержаться в этих переменных.
Таким образом, по одной только этой причине, в динамически типизированных языках труднее сопровождать объемную кодовую базу, потому что работу, которая выполняется компилятором «бесплатно», вы должны делать в виде написания набора тестов. Если вы хотите комментировать свои переменные, то вы должны продумать четкую систему, и если новый член вашей команды случайно нарушит ее, то вы должны найти нарушение как можно раньше.
Теперь я бы хотел упомянуть ключевой момент: есть сильная взаимосвязь между динамической типизированностью языка и нехваткой возможностей, которые могли бы снизить расходы на содержание, и этот ключевой момент — причина, почему труднее поддерживать большой код в динамическом языке. И такая же взаимосвязь есть между статической типизированностью и наличием средств, которые делают программирование легче.
Давайте возьмем JavaScript в качестве примера. (Я работал на оригинальных версиях JScript в Microsoft с 1996 по 2001 год) цель проекта заключалась в том, чтобы обезьяна танцевала, при наведении на нее курсором. Скрипты зачастую состояли из одной строки. Мы рассматривали десятистрочные скрипты, и было довольно неплохо, скрипты из сотни строк уже считались большими, а скрипты из тысячи строк были неслыханно огромными. Язык абсолютно не предназначен для программирования объемных задач, и наши решения при реализации, контрольные задачи, и так далее, были основаны на этом предположении.
JavaScript был специально разработан для программ, которые велики настолько, чтобы один человек мог видеть все это на одной странице, так же JavaScript не только динамически типизирован, но так же в нем присутствует мало средств, которые помогают программировать большие кодовые базы:
- Нет модульной системы, нет классов, интерфейсов, или даже пространств имён. Эти элементы есть в других языках, чтобы помогать организовывать объемные кодовые базы.
- Система наследования, а так же наследование прототипов развиты довольно слабо. И не понятно, как правильно строить глубокие иерархии (вроде: капитан вид пирата, пират вид человека, человек вид чего-то там…) в out-of-the-box JavaScript.
- Нет инкапсуляции: каждое свойство каждого объекта может изменяться по желанию какой-либо части программы.
- Там нет никакого способа, чтобы обозначить какое-либо ограничение по памяти: любая переменная может содержать любое значение.
 Но это не просто недостаток тех самых возможностей, которые облегчают программирование. Есть также функции, которые делают его более трудным.
Но это не просто недостаток тех самых возможностей, которые облегчают программирование. Есть также функции, которые делают его более трудным. - Система управления ошибок в JavaScript разработана с предположением, что скрипт выполняется на веб-странице, и что цена ошибки невелика, и что пользователь, который увидит неточности скорее всего не будет способен их исправить. Поэтому, как бы много ошибок ни было, программа попытается выполниться до конца. Это разумно, для данных целей языка, но она, безусловно, делает программирование больших объемов кода в разы сложнее, потому что это увеличивает сложность написания тестов. Зачастую искать ошибки в таких программах труднее, чем писать тесты, которые их выявят.
- Код может изменить сам себя на основе данных с пользовательского ввода через объекты, такие как Eval или при помощи добавления новых блоков сценариев в DOM динамически. Любые инструменты статического анализа не могут даже знать, что код сделает с программой!
- И так далее.
Ясно, что возможно преодолеть все эти препятствия и создать большую программу в JavaScript. В настоящее время существует много программ JavaScript состоящих из миллионов строк. Но большие команды, которые сопровождают эти сложные проекты используют различные инструменты и у них присутствует строгая дисциплина, чтобы преодолевать препятствия, которые JavaScript бросает на вашем пути:
- Они пишут тест-кейсы для каждого идентификатора использующегося в программе. В мире, где орфографических ошибки игнорируются, это необходимо. Это экономически выгодно.
- Пишут код в типизированных языках, таких как TypeScript, и компилируют как JavaScript.
- Они используют фреймворки, которые способствуют программированию в стиле, который лучше поддается анализу, более склонен к модульности и менее вероятно воспроизведет на свет наиболее распространенные ошибки.
- У них хорошая дисциплина в именовании, в разделении обязанностей, и так далее.
 Опять же, это снижает стоимость, и все эти задачи будут выполнены компилятором в типичном статически типизированном языке.
Опять же, это снижает стоимость, и все эти задачи будут выполнены компилятором в типичном статически типизированном языке.
В заключение скажу, что далеко не только динамичный характер типизации увеличивает расходы на содержание большого кода. Это конечно приводит к повышению затрат, но это далеко не все. К примеру, я мог бы спроектировать вам язык, который был бы динамически типизирован, но имел бы и пространство имен, и модули, и наследование, и библиотеки, и закрытые данные, и так далее, и кстати говоря, C# 4 является подобным языком. Он достаточно динамичен и очень удобен в программировании больших кодовых баз.
Чаще всего то, что часто отсутствует в динамических языках, в результате и повышает расходы в сопровождении больших программ. Динамические языки, которые включают в себя средства для хорошего тестирования модульности, повторного использования, инкапсуляции и так далее, на самом деле могут существенно снизить затраты при программировании больших кодовых баз, но многие часто используемые динамические языки не имеют эти полезные приспособления. Кто-то должен их создать, и это увеличит затраты.
Кто-то должен их создать, и это увеличит затраты.
Перевод статьи «Why do dynamic languages make it difficult to maintain large codebases?»
Динамические языки — Javatpoint
В области программирования много изобретений, каждый год вводится множество языков программирования. Каждый раз программисты вводят новый язык, который должен исправить некоторые проблемы, возникшие с предыдущим. Некоторые считают, что все языки программирования одинаковы и используют стандартное программное обеспечение и язык программирования. Но почему программисты каждый год изобретают новые программы? В качестве примера рассмотрим java, он введен для исправления некоторых проблем с C++. Динамические языки были созданы таким образом, чтобы решать некоторые проблемы лучше, чем существующие языки. Общепринятого определения динамических языков не существует. Мы можем определить, что любой язык программирования, допускающий модификацию во время выполнения, является динамическим языком. Динамические языки позволяют программистам изменять даже структуру во время работы. Это известно как модификация во время выполнения. Язык высокого уровня — это не что иное, как язык с более высоким уровнем абстракции. C является языком высокого уровня, потому что он имеет более высокий уровень абстракции. Python и другие динамические языки имеют другой уровень абстракции. Функции, ожидаемые от динамических языков, включают автоматизацию, управление памятью и обработку исключений, более абстрактные встроенные типы данных, такие как списки и словари, механизмы нестатической типизации и специальные варианты синтаксиса для улучшения читаемости кода и значительного снижения его многословности. Некоторые из самых популярных языков динамического программирования:
Самые популярные динамические языки были разработаны для решения технических проблем, с которыми сталкивались их изобретатели, и, как правило, по-прежнему ориентированы на решение технических проблем, а не на то, чтобы быть инструментами для продвижения корпоративной повестки дня. Эти языки построены на
Философия оптимизации времени человека вместо времени компьютера — они жертвуют эффективностью ради повышения производительности. Сама разработка этих языков значительно отличается от традиционной модели разработки языков программирования, это настолько глубоко открытый исходный код, что существует почти полная прозрачность того, как язык развивался благодаря записям отслеживания ошибок, журналам программного обеспечения контроля версий и обсуждениям в списки рассылки. Все это публично. Использование динамических языков:
|
 Модификация во время выполнения — это не что иное, как изменение программы во время ее работы. Исходное определение также включало необходимость того, чтобы язык был высокоуровневым, динамически типизированным и с открытым исходным кодом. Наиболее востребованными динамическими языками являются Python, Perl и Ruby.
Модификация во время выполнения — это не что иное, как изменение программы во время ее работы. Исходное определение также включало необходимость того, чтобы язык был высокоуровневым, динамически типизированным и с открытым исходным кодом. Наиболее востребованными динамическими языками являются Python, Perl и Ruby. Динамические языки разрабатываются исходя из предположения о наличии некоторых предопределенных компонентов для простого создания приложений. Динамические языки часто интерпретируются, а не компилируются. Это означает, что исходный код читается во время выполнения интерпретатором — компьютерной программой, которая переводит исходный код в целевое представление, которое он немедленно выполняет и оценивает. Этот процесс противоположен компиляции, при которой компилятор читает исходный код, а язык, использующий динамическую типизацию, считается языком с динамической проверкой, поскольку проверка типов происходит во время выполнения (во время выполнения), а не во время компиляции, как это происходит с статическая типизация. Проверка типов состоит из проверки того, что код соблюдает ограничения типов, предотвращающие применение операций к объектам несовместимых типов. Если язык не требует, чтобы тип переменной был известен во время компиляции, то говорят, что язык имеет динамическую типизацию.
Динамические языки разрабатываются исходя из предположения о наличии некоторых предопределенных компонентов для простого создания приложений. Динамические языки часто интерпретируются, а не компилируются. Это означает, что исходный код читается во время выполнения интерпретатором — компьютерной программой, которая переводит исходный код в целевое представление, которое он немедленно выполняет и оценивает. Этот процесс противоположен компиляции, при которой компилятор читает исходный код, а язык, использующий динамическую типизацию, считается языком с динамической проверкой, поскольку проверка типов происходит во время выполнения (во время выполнения), а не во время компиляции, как это происходит с статическая типизация. Проверка типов состоит из проверки того, что код соблюдает ограничения типов, предотвращающие применение операций к объектам несовместимых типов. Если язык не требует, чтобы тип переменной был известен во время компиляции, то говорят, что язык имеет динамическую типизацию.
 Еще одна особенность процесса разработки заключается в том, что ядро языка развивается отдельно от библиотек. Ядро контролируется небольшой командой людей, которые обеспечивают язык.
Еще одна особенность процесса разработки заключается в том, что ядро языка развивается отдельно от библиотек. Ядро контролируется небольшой командой людей, которые обеспечивают язык.Динамический язык программирования — Academic Kids
From Academic Kids
вводятся или удаляются, могут создаваться новые классы объектов, могут появляться новые модули. В качестве побочного эффекта этого динамизма большинство динамических языков программирования имеют динамическую типизацию, что сторонники статической типизации считают недостатком (см. Также статическую типизацию). Однако, по мнению сторонников динамических языков программирования, гибкость динамических языков компенсирует эти недостатки и даже дает столь значительные преимущества, что делает это необходимым свойством, например, для интерактивного программирования. Более поздние исследователи утверждают, что с немного большим количеством накладных расходов и синтаксиса возможно и выгодно сочетать статическую типизацию с динамическими функциями для достижения интерактивности, а также обеспечивая преимущества безопасности и производительности строго типизированного языка.
Более поздние исследователи утверждают, что с немного большим количеством накладных расходов и синтаксиса возможно и выгодно сочетать статическую типизацию с динамическими функциями для достижения интерактивности, а также обеспечивая преимущества безопасности и производительности строго типизированного языка.
Обычно программирование состоит из написания вместе битов компьютерного кода, известного как функций, которые работают с данными. Эти функции физически представлены компьютерным кодом в некотором месте памяти. В большинстве языков программирования вызовы функций в исходном коде заменены инструкциями по запуску кода в этом физическом местоположении (точное место определяется компоновщиком). Одна из проблем с этим подходом заключается в том, что он не позволяет модифицировать код после его компиляции. Например, если в коде обнаружена ошибка, единственным решением является исправление исходного кода и перекомпиляция приложения.
Динамические языки полагаются на адреса функций, которые ищутся во время выполнения, вместо того, чтобы компилироваться в адреса во время компиляции. Это позволяет изменять символы, чтобы они указывали на новые функции, позволяя изменять определения. Многие динамические языки также выполняют поиск данных таким же образом, позволяя модифицировать «статические» объекты, такие как классы.
Это позволяет изменять символы, чтобы они указывали на новые функции, позволяя изменять определения. Многие динамические языки также выполняют поиск данных таким же образом, позволяя модифицировать «статические» объекты, такие как классы.
Однако это вводит поиск во время выполнения, поскольку каждый вызов функции требует поиска символа, а затем указателя функции. По этой причине динамические языки часто работают медленнее, чем нединамические, что является еще одним «поцелуем смерти» в 19 веке.90-е. На практике эту задержку можно значительно сократить почти до нуля, однако, например, язык программирования Objective-C использовал предварительно загруженный кэш и небольшой фрагмент кода на ассемблере, чтобы сократить эти накладные расходы до одной операции.
Степень динамичности зависит от языка. Objective-C был основан на компиляторе GNU/GCC и допускал динамизм только вызовов функций (называемых категоризацией по несвязанным причинам) путем перезаписи кода диспетчеризации метода.