Организация циклов в Ассемблере. Команды управления циклами. Организация циклов
Цикл, как известно, представляет собой важную алгоритмическую структуру, без использования которой не обходится, наверное, ни одна программа. Организовать циклическое выполнение некоторого участка программы можно, к примеру, используя команды условной передачи управления или команду безусловного перехода jmp. При такой организации цикла все операции по его организации выполняются “вручную”. Но, учитывая важность такого алгоритмического элемента, как цикл, разработчики микропроцессора ввели в систему команд группу из трех команд, облегчающую программирование циклов. Эти команды также используют регистр ecx/cx как счетчик цикла. Дадим краткую характеристику этим командам:
loop
метка_перехода (Loop) — повторить цикл. Команда позволяет
организовать циклы, подобные циклам
for в языках высокого уровня с автоматическим
уменьшением счетчика цикла. Работа
команды заключается в выполнении
следующих действий:
Работа
команды заключается в выполнении
следующих действий:
декремента регистра ecx/cx;
сравнения регистра ecx/cx с нулем:
если (ecx/cx) > 0, то управление передается на метку перехода;
если (ecx/cx) = 0, то управление передается на следующую после loop команду.
loope/loopz метка_перехода (Loop till cx <> 0 or Zero Flag = 0) — повторить цикл, пока cx <> 0 или zf = 0. Команды loope и loopz — абсолютные синонимы, поэтому используйте ту команду, которая вам больше нравиться. Работа команд заключается в выполнении следующих действий:
декремента регистра ecx/cx;
сравнения регистра ecx/cx с нулем;
анализа состояния флага нуля zf:
если (ecx/cx) > 0 и zf = 1, управление передается на метку перехода;
если (ecx/cx) = 0 или zf = 0, управление передается на следующую после loop команду.

loopne/loopnz метка_перехода (Loop till cx <> 0 or Not Zero flag=0) — повторить цикл пока cx <> 0 или zf = 1. Команды loopne и loopnz также абсолютные синонимы. Работа команд заключается в выполнении следующих действий:
декремента регистра ecx/cx;
сравнения регистра ecx/cx с нулем;
анализа состояния флага нуля zf:
если (ecx/cx) > 0 и zf = 0, управление передается на метку перехода;
если (ecx/cx)=0 или zf=1, управление передается на следующую после loop команду.
Команды loope/loopz и loopne/loopnz по принципу своей работы являются взаимообратными. Они расширяют действие команды loop тем, что дополнительно анализируют флаг zf, что дает возможность организовать досрочный выход из цикла, используя этот флаг в качестве индикатора.
Недостаток
команд организации цикла loop,
loope/loopz и loopne/loopnz в том, что они реализуют только короткие
переходы (от –128 до +127 байт). Для работы
с длинными циклами придется использовать
команды условного перехода и команду
jmp, поэтому постарайтесь освоить оба
способа организации циклов.
Для работы
с длинными циклами придется использовать
команды условного перехода и команду
jmp, поэтому постарайтесь освоить оба
способа организации циклов.
Режимы адресации операндов в командах Ассемблера. Косвенная адресация. Модификация адресов, и индексирование.
Косвенная адресация По аналогии с регистровыми и непосредственными операндами адрес операнда в памяти также можно не указывать непосредственно, а хранить в любом регистре. До 80386 для этого можно было использовать только BX, SI, DI и BP, но потом эти ограничения были сняты и адрес операнда разрешили считывать также и из EAX, EBX, ECX, EDX, ESI, EDI, EBP и ESP (но не из AX, CX, DX или SP напрямую — надо использовать EAX, ECX, EDX, ESP соответственно или предварительно скопировать смещение в BX, SI, DI или BP). Например, следующая команда помещает в регистр AX слово из ячейки памяти, селектор сегмента которой находится в DS, а смещение — в BX:
mov ax,[bx]
Как
и в случае прямой адресации, DS используется
по умолчанию, но не во всех случаях: если
смещение берут из регистров ESP, EBP или
BP, то в качестве сегментного регистра
используется SS. В реальном режиме можно
свободно пользоваться всеми 32-битными
регистрами, надо только следить, чтобы
их содержимое не превышало границ
16-битного слова.
В реальном режиме можно
свободно пользоваться всеми 32-битными
регистрами, надо только следить, чтобы
их содержимое не превышало границ
16-битного слова.
Модификация адресов
В
ПК используется так называемая модификация
адресов. Если в команде операнд берется
из памяти, тогда сослаться на него можно
указав некоторый адрес и некоторый
регистр. В этом случае команда будет
работать с так называемым исполнительным
адресом, который вычисляется как сумма
адреса, указанного в команде, и
текущего значения указанного регистра.
Именно из ячейки с таким адресом
команда и будет брать свой операнд.
Выгода от такого способа задания операнда
заключается в том, что, меняя значение
регистра, можно заставить одну и ту
же команду работать с разными ячейками
памяти, что, например, полезно при
обработке массивов, когда одну и ту же
команду надо применять к разным элементам
массивов. Замена адреса, указанного в
команде, на исполнительный адрес
называется модификацией адреса, а
используемый при этом регистр
называется модификатором.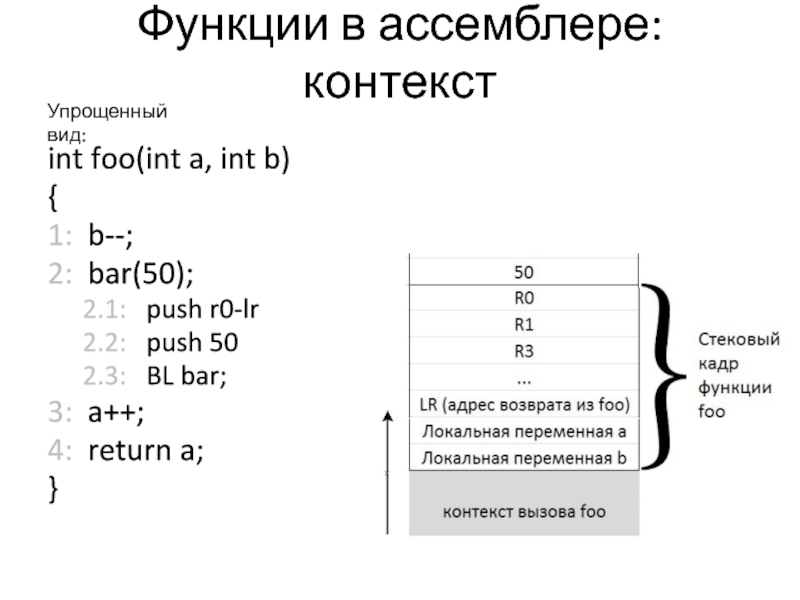
Тип переменной и ее адрес. Циклы и ветвления
Похожие презентации:
Программирование на Python
Моя будущая профессия. Программист
Программирование станков с ЧПУ
Язык программирования «Java»
Базы данных и язык SQL
Основы web-технологий. Технологии создания web-сайтов
Методы обработки экспериментальных данных
Программирование на языке Python (§ 62 — § 68)
Микроконтроллеры. Введение в Arduino
Программирование на языке Python (§ 54 — § 61)
1.
 Есть ли у вас вопросы?
Есть ли у вас вопросы?2. Краткое содержание предыдущей серии
• Как в ассемблере осуществляется сложение ивычитание?
• В чем опасность умножения?
• А деления?
• Как в ассемблере осуществляется сравнение
двух чисел?
3. Краткое содержание этой серии
• Разбор полетов• Как же все-таки связан тип переменной и ее адрес
• Подробнее о сравнениях и флагах
• Как в ассемблере осуществляются циклы и
ветвления
• Операции языка С (продолжение)
4. Оформление
Отчет нормального человекаОтчет, от которого вытекают глаза
5. Вот так тоже не надо
6. Вот так тоже не надо
7. Вот так тоже не надо
8. Отступы
9. Отступы
10. Отступы
11. Отступы
12. Отступы
13. Как же связан тип переменной и ее адрес?
Адрес переменной кратен ее размеру вбайтах!
Это называется «выравнивание» — alignment
14. Зачем нужно выравнивание?
Вспоминаем, какустроена память
• Если хочется читать, например, по 4 байта за такт, то в памяти одну
«ячейку» делают размером в 4 байта.

• Поэтому из памяти ВСЕГДА будет читаться по 4 байта за такт, даже если
2 из них не нужны
• Но как отсюда вытекает необходимость выравнивания?
15. Выравнивание
Как выглядит невыровненный доступ?16. Последствия
• Выровненный доступ быстрее (особенно если есть кэшпамять)• Невыровненный доступ поддерживается не всегда (в
Cortex M3 – только к 4 и 2 байтам)
• Байт всегда выровнен
• Для выравнивания требуется больше памяти?
Нет, порядок расположения переменных компилятор
может менять при оптимизации
• Padding в структурах
17. Что такое padding?
• Порядок элементов внутри структуры менять нельзя (дажепри оптимизации)
• Но элементы должны быть выровнены!
• Итог: размер структуры не всегда равен сумме размеров
ее элементов
• Padding – пустые байты между элементами
Обычно есть спец. слова вроде __packed, чтобы паддинг убрать (не
стандартизированные)
18. Арифметика в ассемблере Какие еще есть флаги?
• С – флаг Carry (перенос)• N – флаг Negative (отрицательный результат)
• Z – флаг Zero (результат 0)
• V – флаг oVerflow (знаковое переполнение,
«неверная» смена знака)
Есть и другие, но к арифметике они не относятся
19.
 Сравнения в ассемблере• CMP r0, r1
Сравнения в ассемблере• CMP r0, r1temp = r0 – r1, обновить регистр
состояний, отбросить temp (аналогично SUBS
temp, r0,r1)
• CMN r0,r1
temp = r0 + r1, обновить регистр
состояний, отбросить temp (аналогично ADDS
temp, r0,r1)
• TEQ r0,r1 (test equality), аналог ==, компилятором используется
редко
20. Как работает сравнение и зачем их два?
Мы хотим сравнить два числа А и В.Как узнать, какое из них больше с помощью арифметики?
Вычесть одно из другого!
Если С = А-В отрицательное, значит А меньше В.
Команда CMP a,b это и делает (и обновляет регистр
состояний).
Знак результата показывает флаг N (1 если Negative).
21. А зачем CMN?
Вторым аргументом команды может быть регистр или число.Число должно лежать прямо в коде команды.
А если это число отрицательное?
Из-за дополнительного кода в нем будет очень много единиц
в старших битах.
Но A-(-B) = A+B!
CMN a,b – это сравнение a – (-b), через сложение.

Если результат отрицательный, значит a < b. Флаг тот же.
22. Что означает флаг V?
V – от слова oVerflow означает знаковое переполнение.Зачем он нужен?
Знак при арифметических операциях может меняться
неправильно.
Например:
int8_t a = -128; // 1000 0000 в двоичном коде
a = a-1; // чему равно а?
a будет равно +127, потому что -129 не влезает в один
байт.
(можно сказать, что флаг С – тоже переполнение, только
беззнаковое)
23. Что означает флаг V?
Неверная смена знака – знаковое переполнение.В языке С это undefined behavior.
При сравнениях это тоже может происходить (ведь
сравнения – это вычитания).
Поэтому операции, которые используют результаты
сравнений, проверяют и флаг V.
24. А какие команды используют результаты сравнений?
Где в языке С используется сравнение?– if – else
– for, while, do-while
– switch
Следовательно,
команды
ассемблера,
которые
реализуют циклы и ветвления, используют результаты
сравнений.

В основном, это команды перехода (передачи
управления).
25. Переходы в языке С
if – else
for
while
do – while
switch
goto
break, continue, return
вызов функции
26. Несколько слов о goto
goto – оператор безусловного перехода:… some code…
P:
// метка
… some code..
goto P; // безусловный переход к метке Р
Этот оператор есть в огромном количестве языков программирования, но
используется крайне редко.
«В течение нескольких лет я знаком с точкой зрения, что
качество программистов это убывающая функция от
плотности операторов go to в коде, который они пишут.
Недавно я понял почему использование оператора go to
имеет такой катастрофический эффект, и теперь я убежден,
что оператор go to следует убрать из всех языков
программирования «высокого уровня» (то есть из всех за
исключением, возможно, машинного кода)…“
Эдсгер Дейкстра
28. goto позволяет писать «спагетти-код»
Чему равны а, b, c к строке с точкой останова? Достижима ли точка останова?29.
 Типичный сценарий использования gotohttp://xkcd.com/292/
Типичный сценарий использования gotohttp://xkcd.com/292/Вывод: лучше не использовать goto. Без него всегда можно обойтись.
30. Ветвление и циклы в ассемблере
Безусловные переходы
Условные переходы
Другие команды с условным исполнением
Сравнение с переходом
Команда IT (If-then), «придающая условность»
В некоторых ассемблерах есть спец. команды для циклов
(напр. loop)
31. Условное исполнение
Что это такое?Это когда команда выполняется по условию!
Какие бывают условия?
Сочетания флагов состояния!
Условие задается постфиксом.
Список постфиксов см. cortex m3 user guide стр. 61 табл. 3-4
32. Условное исполнение
Примеры постфиксов и расшифровка:LT – Less Then (если меньше, знаковое)
GE – Greater or Equal (если больше или равно, знаковое)
HI – Higher (если больше, беззнаковое)
NE – Not Equal (не равно)
MI – Minus (отрицательный результат)
Пример:
CMP
R3, #0x07; сравнить содержимое R3 и число 7
BGE
0x080003BA ; Если R3 >= 7 – перейти по адресу
MOVS r0, #0x01
33.
 Условное исполнениеВ некоторых наборах команд (например, ARMv5) почти все
Условное исполнениеВ некоторых наборах команд (например, ARMv5) почти всекоманды могли иметь условное исполнение.
В ARMv7 «сами по себе» условны только команды перехода.
Для придания «условности» остальным командам
используется команда IT. C ее помощью до 4 команд могут
быть выполнены по условию:
CMP
ITTE
ADDNE
ADDNE
MOVEQ
R4,
NE
R0,
R2,
R2,
5
;
;
R0, R1 ;
R2, #1 ;
R3
;
сравнить R4 и число 5
три следующие команды – условные
(если не равно – R0=R0+R1)
(если не равно – R2=R2+1)
(иначе – R2=R3)
34. Команды перехода
Названия в разных ассемблерах разное, суть одна ита же
• В x86 – команда jmp (от слова jump)
• В ARM – команда B (от слова branch)
В некоторых ассемблерах специальной команды нет, используется запись в
регистр-счетчик команд. В ARM так делать можно, но не рекомендуется.
35. Команда B
• B адрес – переход по адресу (±16 Мб от текущегоположения)
• BX r0– переход по адресу, который храниться в r0
• Условные переходы:
– BLT – переход, если «меньше или равно»
– BGE – переход, если «больше или равно» и т.
 д.
д.• BL и BLX – переход в функцию (а зачем отдельная
команда?)
36. Ветвление
Псевдо-СПсевдо-ASM
code 1;
asm code 1
if( a > b)
{
code 2;
}
cmp a, b
BLE code 3 // если меньше
code 2
code 3;
code 3
Разумеется, возможны и другие варианты реализации ветвления.
Выбор за компилятором
Псевдо-С
Псевдо-ASM
code 1;
0: asm code 1
while( a > b)
code 2;
a—;
}
1:
2:
3:
4:
5:
code 3;
6: code 3
b
asm
sub
cmp
bgt
4
code 2
a,1
a, b
2 // если больше
English Русский Правила
условий и циклов используются на языке ассемблера.
Условия и циклы с кодом на ассемблере
Условный запуск на языке ассемблера сопровождается множеством инструкций циклов и ветвлений. Сначала мы обсуждаем здесь условия в сборке, а затем циклы в сборке.
Условия в ассемблере
Условное выполнение на ассемблере осуществляется с помощью нескольких инструкций цикла и ветвления. Эти инструкции могут изменить поток управления в программе. Условное исполнение наблюдается в двух сценариях:
Эти инструкции могут изменить поток управления в программе. Условное исполнение наблюдается в двух сценариях:
- Безусловный переход
Это выполняется командой JMP. Условное выполнение часто включает в себя передачу управления на адрес инструкции, которая не следует за выполняемой в данный момент инструкцией. Передача управления может быть прямой для выполнения нового набора инструкций или обратной для повторного выполнения тех же шагов.
2. Условный переход
Выполняется набором инструкций перехода j<условие>
в зависимости от условия. Условные инструкции передают управление, прерывая последовательный поток, и делают это, изменяя значение смещения в IP.Безусловный переход
Выполняется командой JMP. Условное выполнение часто включает в себя передачу управления на адрес инструкции, которая не следует за выполняемой в данный момент инструкцией. Передача управления может быть прямой для выполнения нового набора инструкций или обратной для повторного выполнения тех же шагов.
Синтаксис
Инструкция JMP предоставляет имя метки, по которой поток управления передается немедленно. Синтаксис инструкции JMP:
Пример
MOV AX, 00 ; Инициализация AX в 0 MOV BX, 00 ; Инициализация BX в 0 MOV CX, 01 ; Инициализация CX до 1 Л20: ДОБАВИТЬ AX, 01 ; Приращение AX ДОБАВИТЬ BX, AX ; Добавить AX к BX ШЛ СХ, 1 ; сдвиг CX влево, это, в свою очередь, удваивает значение CX JMP L20 ; повторяет операторы
Условный переход
Если какое-то заданное условие выполняется при условном переходе, поток управления передается целевой инструкции. Существует множество инструкций условного перехода в зависимости от условий и данных. Синтаксис набора инструкций J<условие>.
Пример:
CMP AL, BL JE РАВНО CMP AL, BH JE РАВНО CMP AL, CL JE РАВНО НЕ РАВНО: ... EQUAL: ...
Пример
Следующая программа отображает наибольшую из трех переменных. Переменные являются двузначными переменными. Три переменные num1, num2 и num3 имеют значения 47, 22 и 31 соответственно:
section .text global _start ; необходимо объявить для использования gcc _start: ;указать точку входа компоновщика mov ecx, [num1] cmp ecx, [num2] jg check_ Third_num mov ecx, [число2] чек_третий_номер: cmp ecx, [num3] jg _exit mov ecx, [num3] _Выход: mov [самый большой], ecx mov ecx,msg mov edx, лен mov ebx,1 ;дескриптор файла (стандартный вывод) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov ecx,самый большой мов edx, 2 mov ebx,1 ;дескриптор файла (стандартный вывод) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov eax, 1 интервал 80 ч.раздел .данные msg db "Самая большая цифра: ", 0xA,0xD len equ $- msg число1 дд '47' число2 дд '22' число3 дд '31' сегмент .bss самый большой член 2
ВЫВОД:
Наибольшая цифра:
47
Использование циклов в ассемблере
Команда JMP может использоваться для реализации циклов. Например, следующий фрагмент кода можно использовать для выполнения тела цикла 10 раз.
МОВ КЛ, 10 L1:ДЕК КЛ JNZ L1
Однако набор инструкций процессора включает группу инструкций цикла для реализации итерации. Базовая инструкция LOOP имеет следующий синтаксис:
LOOP метка
Где метка — это целевая метка, которая идентифицирует целевую инструкцию, как в инструкциях перехода. Инструкция LOOP предполагает, что регистр ECX содержит количество циклов. Когда инструкция цикла выполняется, регистр ECX уменьшается, и управление переходит к целевой метке до тех пор, пока значение регистра ECX, т. е. счетчик, не достигнет нулевого значения. Приведенный выше фрагмент кода можно записать так:
е. счетчик, не достигнет нулевого значения. Приведенный выше фрагмент кода можно записать так:
mov ECX,10 л1: <тело цикла> петля л1
Пример
Следующая программа выводит на экран числа от 1 до 9:
section .text global _start ; необходимо объявить для использования gcc _start: ;указать точку входа компоновщика мов экх, 10 перемещение ах, '1' л1: mov [число], eax мов акс, 4 мов ебкс, 1 нажать ecx mov ecx, число мов эдкс, 1 интервал 0x80 mov eax, [число] вспомогательный акс, '0' вкл. добавить eax, '0' поп экс петля л1 mov eax,1 ;системный номер вызова (sys_exit) int 0x80 ;вызвать ядро раздел .bss число соотв. 1
ВЫХОД
123456789:
Ларавель | 0 комментариев
Scoping — одна из сверхспособностей, которые Eloquent предоставляет разработчикам при запросе модели. Области позволяют разработчикам добавлять ограничения к запросам для данной модели. Проще говоря, область действия laravel — это просто запрос, запрос, чтобы сделать код короче и быстрее. Мы можем…
Области позволяют разработчикам добавлять ограничения к запросам для данной модели. Проще говоря, область действия laravel — это просто запрос, запрос, чтобы сделать код короче и быстрее. Мы можем…
Чтение | 0 Комментариев
ОТРЫВОК ДЛЯ ЧТЕНИЯ 1: Тылацин Q1. carnivorous ключевые слова: выглядело так, как будто собака съела ряд полосок, диета съела целиком 1 ………………………….. ………. диета (2-й абзац 3-я и 4-я строчка) 1-й и 2-й абзац, 1-й абзац,подобие…
Чтение | 0 комментариев
ОТРЫВОК 1 Q1 (Неверно) (Многие мадагаскарские леса уничтожены нападениями насекомых.) Леса Мадагаскара превращаются в сельскохозяйственные угодья со скоростью один процент каждый год. Большая часть этих разрушений вызвана выращиванием основных…
Чтение | 0 Комментариев
Здесь мы обсудим плюсы и минусы всех вопросов прохождения с пошаговым решением, включая Советы и Стратегии. Reading Passage 1 – Roman Tunnels IELTS Cambridge 16, Test 4, Модуль академического чтения, Reading Passage 1 Вопросы 1-6. Подпишите диаграммы…
Подпишите диаграммы…
Чтение | 0 комментариев
Отрывок для чтения 1: Римское судостроение и навигация, Решение с ключом ответа , Отрывок для чтения 1: Римское кораблестроение и навигация IELTS Cambridge 16, Тест 3, Модуль академического чтения Cambridge IELTS 16, Тест 3: Отрывок для чтения 1 – Римское кораблестроение и …
Чтение | 0 комментариев
Отрывок для чтения 1: Белая лошадь из Уффингтона, Решение с ключом к ответу Белая лошадь из Уффингтона IELTS Cambridge 16, Тест 2, Модуль академического чтения, Отрывок для чтения 1 Cambridge IELTS 16, Тест 2: Отрывок для чтения 1 — Белый Лошадь Уффингтона…
Сборка на примере: Вычисление хэша строки. Часть 2: петли | by Benjamín Guzmán
Опубликовано в·
Чтение 9 мин.·
19 мая 2022 г.Если вы не читали часть 1, я настоятельно рекомендую вам это сделать, потому что в этом вторая часть предполагается, что вы уже знаю, что там объяснялось.
Помните, что цель состоит в том, чтобы вычислить хэш строки, заданный следующим уравнением.
Как вы помните из части 1, нам нужно написать две вспомогательные функции: strlen и pow31. Первый очень простой, а второй более сложный, но, как мы увидим позже, на самом деле он вообще не нужен. Обе функции требуют циклов, поэтому мы начнем с изучения циклов в ассемблере.
Мы еще не видели, как считывать аргументы cli или печатать числа в стандартный вывод, поэтому я постараюсь максимально упростить примеры, выполнив две вещи:
- Поскольку в большинстве примеров результатом является целое число без знака, кажется удобным выводить результат как код состояния выхода из программы. Конечно, это не очень хорошая практика, и проблема заключается в том, что код состояния выхода представлен одним байтом, поэтому мы не можем выводить числа больше 255.
- Мы будем использовать жестко закодированные тестовые примеры. Опять же, не очень хорошая практика, но давайте оставим это для простоты.
Помните, что вы можете проверить результат, напечатав код состояния исполняемого файла с помощью echo $?
В отличие от структурированных языков ассемблер не имеет управляющих структур, таких как циклы for, while, do-while. У нас есть прыжки.
У нас есть прыжки.
Перед рассмотрением некоторых примеров важно знать, что циклы for и for-each — это просто синтаксический сахар для циклов while, и все, что вы можете сделать с циклом for , можно сделать с помощью в то время как цикл. Это важно для понимания циклов в ассемблере, поэтому вам действительно нужно понять, что я имел в виду, прежде чем продолжить.
Сумма натуральных чисел до n
Чтобы вычислить сумму натуральных чисел до n, мы могли бы использовать формулу Гаусса
Но поскольку мы хотим узнать, как циклы работают в ассемблере, мы не будем ее использовать. Вместо этого мы будем использовать цикл while.
Давайте изучим следующий пример.
Думаю, несложно понять, как работает программа. Тем не менее, позвольте мне объяснить некоторые вещи, которые мы не видели в части 1.
цикл: — это метка для первой инструкции в цикле.
cmp eax, ebx сравнивает оба регистра посредством вычитания, после чего флаговые регистры модифицируются. Интересующий нас реестр флагов — это реестр ZF (нулевой флаг), который устанавливается в 1, если оба регистра равны (a-b = 0, если a = b).
Интересующий нас реестр флагов — это реестр ZF (нулевой флаг), который устанавливается в 1, если оба регистра равны (a-b = 0, если a = b).
je end (je: переход при равенстве) — это условный переход , который переходит к метке end , если ZF = 1 (устанавливается предыдущей операцией, в данном случае сравнением). jz end (переход, если ноль) тоже можно использовать.
jmp loop — это безусловный переход , который переходит к метке loop .
Вспомним, что переход через означает загрузку адреса в IP (указатель инструкций), чтобы он выполнялся следующим.
Предполагая, что строка завершается нулем (заканчивается на 0x0), мы можем получить ее длину с помощью следующего кода
Код довольно прост. Единственная строка, которая может потребовать объяснения, это cmp BYTE [строка + eax], 0x0 .
Во-первых, строка — это указатель на первый символ строки. Это очень похоже на объявление
Это очень похоже на объявление char* в C. Давайте посмотрим на это в gdb.
Если мы говорим о кодировке ASCII (1 байт на символ), то байт по адресу [строка + i] , где i — целое число, является i-м символом в строке. Конечно, если мы говорим о другой кодировке, где на символ приходится более 1 байта, код не сработает. Например:
Фактическая длина строки — 21, но наша программа говорит, что длина строки равна 23, потому что 🥰 хранится в 4 байтах. Для исправления этой «ошибки» потребуется значительно больше строк кода, чем требуется для фактического вычисления длины строки, поэтому мы не будем вдаваться в подробности.
Теперь должно быть ясно, что cmp BYTE [string + eax], 0x0 проверяет, является ли i-й байт (символ) в строке символом NULL. Важно указать размер операции, иначе мы получим ошибку размер операции не указан , потому что подумайте об этом, как компилятор узнает, что вы хотите сравнить один байт?
Операция довольно неоднозначная, если не указывать размер операции, так как вполне разумно сравнивать более 1 байта. Например, если мы хотим сравнить символы UTF-8.
Например, если мы хотим сравнить символы UTF-8.
Допустим, мы ищем символ 🤘, который также хранится в 4 байтах, тогда сравнение будет производиться с cmp DWORD [string], " ✌️ " или cmp DWORD [string], 0x98a49ff0 . Вы можете подумать, что шестнадцатеричное значение 0x98a49ff0 дает компилятору подсказку о размере операции, но это не совсем так. Однако, если мы переместим непосредственное значение 0x98a49ff0 в реестр, скажем, eax , нам больше не нужно указывать операцию размера, поскольку компилятор уже знает, что eax является 32-битным реестром, поэтому подразумевается, что размер операции DWORD .
Если у вас все еще есть сомнения, может помочь следующий код C, который является переводом ассемблерного кода.
Java-инженеры очень умно подошли к выбору хеш-функции, потому что она имеет следующие оптимизации:
- Вспомогательная функция
pow31на самом деле не нужна. Возьмем следующее расширение для строк длины 4:
Возьмем следующее расширение для строк длины 4:
Общий случай можно определить следующим образом:
Где h sub j — это хэш строки от char с индексом 0 до char с индексом j (включительно).
В более понятных терминах мы могли бы вычислить хэш строки с помощью следующего псевдокода.
ч := 0
для i = 0; я < |s|; i++ {
h = 31 * h + s[i]
}
- 31 — действительно хороший выбор. Вот почему.
Мы будем использовать эти оптимизации в части 3, поэтому, пожалуйста, проверьте ее.
Несмотря на то, что мы видели pow31 , функция на самом деле не нужна, я пока проигнорирую эти математические приемы и все равно напишу ее. В конце концов, цель этой серии постов — научиться ассемблеру на примере.
Наивная реализация
Как видите, код довольно прост. Я думаю, это не требует пояснений. Преобразование в код C будет очень похоже на следующее:
Если вы запустите программу, она может сказать, что код состояния выхода равен 193, потому что помните, что код состояния выхода ограничен одним байтом, а последний байт 961 = 0b1111000001 равен 0b11000001 = 193.
Эффективная реализация O(log(n))
Теперь давайте реализуем алгоритм двоичного возведения в степень для неотрицательных целых показателей степени. В основном это говорит о следующем
Первое, что может прийти вам на ум, — это рекурсия. Но, как вы, возможно, уже знаете, это не так эффективно, как итеративное решение. Я рекомендую вам прочитать итеративное решение, представленное на этой странице. Здесь я объясню это и переведу на ассемблер.
Объяснение
Я объясню алгоритм на примере. Допустим, мы хотим вычислить 31¹¹. Двоичное представление 11 = 0b1011 говорит нам все.
Итерация 1 92 * a (эти множители получены из двоичного представления b, 11 = 8 + 2 + 1). Мы еще не вычислили 31⁸ 31² = 31¹⁰, поэтому давайте оставим эту операцию как в ожидании и установим результат Итерация 3 . К настоящему времени результат *= a . Другими словами, мы умножаем общий результат на a , если LSB b включен, и оставляем остальные операции как в ожидании .
a = a * a . Эта вспомогательная переменная будет хранить частичный результат для в ожидании операции с предыдущего шага. Нам нужно возвести эту переменную в квадрат, потому что на следующем шаге мы разделим показатель степени на 2, и нам нужно это компенсировать. Чтобы понять это более четко, проанализируйте, что произойдет, если мы пропустим этот шаг. b = 11 на один бит вправо. б >> 1 = 0b1011 >> 1 = 0b0101 = 5 . Теперь мы можем записать наш общий результат в терминах b , результат и a , потому что 31¹¹ = (31) 94 * . Поскольку b = 5 нечетно, мы устанавливаем результат *= a и оставляем (31²)⁴ как в ожидании . a = a * a = (31*31) * (31*31) . b = 5 на один бит вправо.
б >> 1 = 0b0101 >> 1 = 0b0010 = 2 . Теперь 31¹¹ = (31) (31²)⁵ = (31)[(31²) (31²)⁴ ]. = 31*31*31 92 . Поскольку b = 2 четно, мы ничего не делаем с результатом и оставляем (31⁴)² как в ожидании . a = a * a = [(31*31) * (31*31)] * [(31*31) * (31*31)] . b = 2 на один бит вправо. б >> 1 = 0b0010 >> 1 = 0b0001 = 1 . Теперь 31¹¹ = (31) (31²)⁵ = (31)[(31²) (31²)⁴ ] = (31)[(31²) (31⁴)² ]. 98
- Незавершенная операция была (31⁴)² =
a. Посколькуb = 1нечетно, мы устанавливаем результат*= aи не оставляем никаких операций как ожидающих .
- Квадратная вспомогательная переменная
a = a * a(это бесполезно, так как нет незавершенной операции) - Сдвиг
b = 1на один бит вправо.б >> 1 = 0b0001 >> 1 = 0b0000 = 0. Теперь 31¹¹ = (31)(31²)⁵ = (31)[(31²)(31²)⁴] = (31)[(31²)(31⁴)²]. 911 иb = 0, так что мы закончили 👏.Теперь, когда мы поняли алгоритм, давайте посмотрим на ассемблерный код.
Я думаю, что код прост, и что может показаться сложным, так это алгоритм, но я надеюсь, что предыдущее объяснение помогло вам ясно его понять. Тем не менее, я объясню некоторые особенности этого кода.
-
ииshr(сдвиг вправо) оба устанавливают ZF (нулевой флаг), если результат операции равен0. Вот почему мы можем использоватьjz(переход, если ноль) иjnz(переход, если не ноль) сразу после выполнения тех операций. - Память стека используется для хранения временной переменной (строки 19 и 22).

-