Что такое кодирование алкоголизма: методы и преимущества
Кодированием называют общую большую группу разнообразных процедур и методик, влияющих на центральную нервную систему человека. После прохождения комплекса, тяга к спиртному заметно уменьшается, зависимый уверен в том, что алкоголь является опасным для его жизни. Наиболее распространенными методами кодирования в Украине является гипнотическое влияние, методика Довженко и иглоукалывание.
В некоторых случаях врачи советуют использовать химические средства: подшивают определенный препарат или химическая защита. В клинике «Брик» лечение алкозависимых строится на результатах проведенных анализов и исследовании общего состояния пациента.
Не смотря на то, какой именно вариант был выбран для лечения больного, кодирование и суть процедуры всегда одинакова. Главная задача – стимулировать у человека страх, как он снова начнет употреблять спиртное, то умрет. В организм специалисты вводят определенный медикамент, который имеет довольно долгий действие. Он попадает в кровь, и при появлении алкоголя, смешивается с ним, превращая в яд.
В организм специалисты вводят определенный медикамент, который имеет довольно долгий действие. Он попадает в кровь, и при появлении алкоголя, смешивается с ним, превращая в яд.
Всего за несколько секунд опасная смесь атакует жизненно важные органы, что приводит к серьезным проблемам со здоровьем, а иногда и к смерти. В настоящее время существует два типа кодирования:
- По применению медикаментов. Химическое вещество вводится в организм больного через обычную инъекцию в вену, мышцы или вшивается в виде ампул до мышечных тканей. Перед началом операции врач предупредит зависимого относительно вреда, к которому может привести употребление алкоголя после процедуры.
- С применением гипноза. С задачей хорошо справится проверенный, опытный психолог или психотерапевт. Он вводит человека в гипнотический сон, и складывает в подсознание определенные каноны. Например, при употреблении хотя бы капли спиртных напитков человек тяжело заболеет или умрет.
Специалисты уверяют, что оба методы эффективны, и способны повлиять на зависимого, но большинство пациентов отдают предпочтения первому варианту.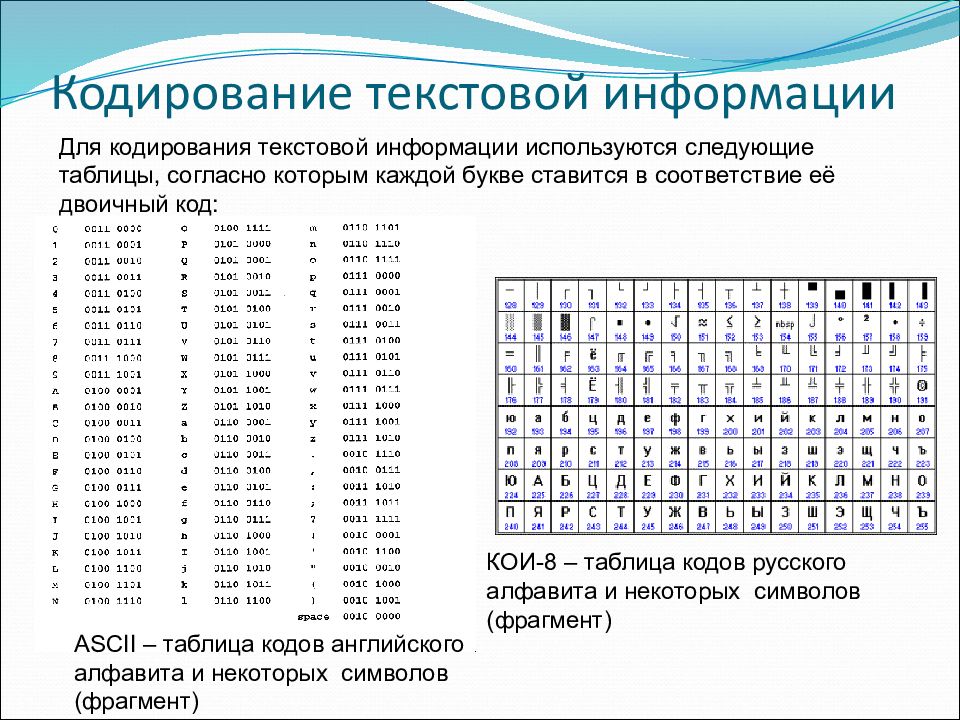 Это объясняется недоверием людей к гипнозу и психологических методов. Существуют ситуации, когда использование медикаментозного кодирования невозможно по состоянию здоровья и противопоказаниями, тогда приходится довериться психологам.
Это объясняется недоверием людей к гипнозу и психологических методов. Существуют ситуации, когда использование медикаментозного кодирования невозможно по состоянию здоровья и противопоказаниями, тогда приходится довериться психологам.
На протяжении многих лет кодирование успело зарекомендовать себя, как эффективный и надежный метод. С его помощью было спасено множество людей, а реабилитационные центры все время совершенствуют процедуру. Этому помогает развитие инновационных технологий, появление новых средств и медикаментов, научные исследования и открытия. Кроме эффективности, методика имеет и другие преимущества:
- Не требуется долгое лечение в клинике: если человек полностью трезвый, то максимальное количество приемов, потребуется три визита к врачам. Хотя в большинстве случаев достаточно и одного;
- Цена на избавление от зависимости таким путем гораздо ниже, чем при комплексной реабилитации больного;
- Анонимность – большой плюс метода.
 Пациент не должен сообщать о своей проблеме родственникам или близким, уже через несколько часов он будет дома;
Пациент не должен сообщать о своей проблеме родственникам или близким, уже через несколько часов он будет дома; - Отсутствует потребность в отпуске или больничном. Современная клиника Брик идет навстречу клиентам, выбирая удобное для них время.
Посещение специалиста – это большой шаг к избавлению от пагубной привычки, но кроме гипноза или медикаментов нужно придерживаться дополнительных правил:
- В течение долгого времени полностью воздерживаться от употребления спиртного, даже в маленьких дозах;
- Изменить образ жизни и круг общения;
- Найти замену алкоголю на психологическом уровне – заняться интересным делом, хобби, найти работу;
- Избавиться от физической зависимости – на пользу пойдут спортивные тренировки, пробежка, прогулки на свежем воздухе перед сном.
С зависимостью надо бороться комплексно, все перечисленные стадии связаны между собой. Врачи берут на себя ответственность за саму процедуру кодирования, дополнительные меры принимает сам пациент.
Эффективный и распространенный метод борьбы с зависимостью имеет определенные особенности, которые нужно принимать во внимание прежде чем прибегать к лечению:
- Запрет употребления спиртного базируется на запугивании человека. Ему угрожают смертью и болезнями. Это отражается на психологическом состоянии, может приводить к депрессивному состоянию, нервозности и агрессивном поведения.
- Процедуру нужно регулярно повторять. Действие медицинских препаратов, что были введены больному, со временем ослабевает. В зависимости от лекарств, продолжительность действия колеблется от трех месяцев до трех лет. Психологический запрет теряет свою силу через определенный период.
- Химические средства могут иметь побочные свойства для некоторых людей.
- Довольно трудно найти настоящего профессионала своего дела, особенно в настоящее время. В клинике «Брик» работают опытные специалисты, готовые оказать комплексную поддержку и помощь больному.

- Эффективность психологического кодирования будет высокой только при условии дальнейшего сотрудничества с психологом. Он должен контролировать состояние пациента, поддерживать его, давать советы и помощь в случае необходимости.
Любые кардинальные изменения в жизни – это всегда стресс для организма. Даже если это изменения в лучшую сторону, нужно поддержать собственное тело в трудный, переходный период. Чтобы сделать отказ от алкоголя не таким сложным заданием, после кодирования нужно:
- Наладить отношения с родными и близкими людьми;
- Заниматься спортом;
- Достаточно спать и отдыхать;
- Ежедневно проводить несколько часов на свежем воздухе;
- Скорректировать режим питания и отказаться от вредной пищи;
- Принимать витамины и минералы для восстановления внутренних органов.
Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования.
 Обобщение и детальный разбор / Хабр
Обобщение и детальный разбор / ХабрДанная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 2 8=256).
Первые 7 бит (128 символов 27=128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:
Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и 6F в шестнадцатиричном. Переведем это в двоичную систему —
Переведем это в двоичную систему — 01101111. Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную — 01101011. Итого строка «ok» закодированная в ASCII будет выглядеть так — 01101111 01101011. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII —
 А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т. д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111. В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111. И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.
В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8.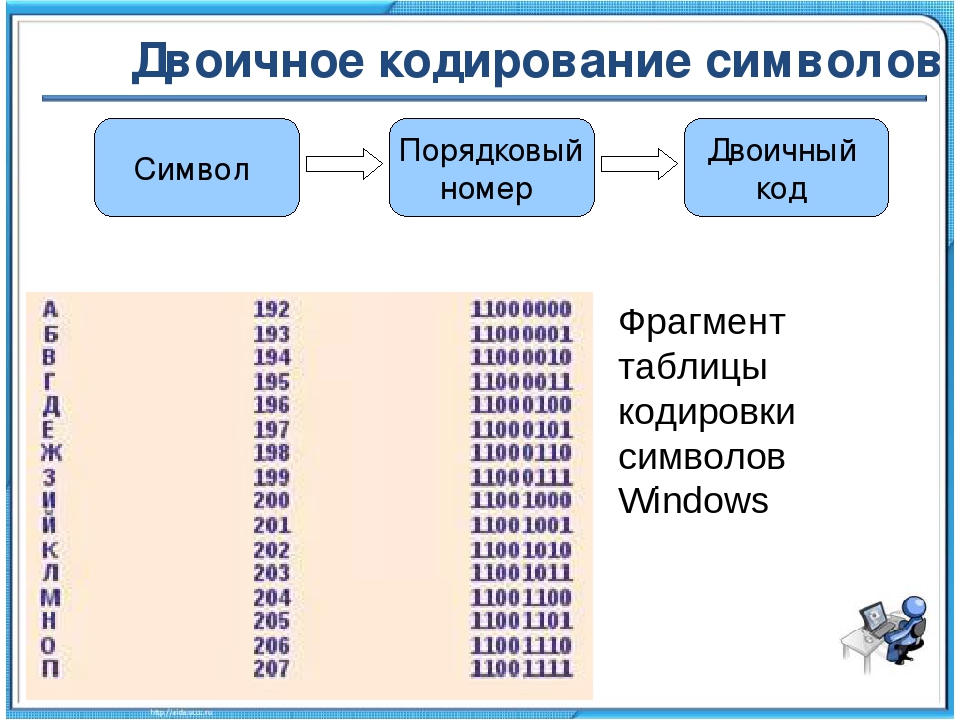 То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
11010000 10111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся (10000111100), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
11101000 10000111 101010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто (10000001111010101)
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110100 10001111 10111111 10111111 — U+10FFFF это последний допустимый символ в таблице юникода (100001111111111111111)
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Разберем это на практике, думаю станет понятнее.
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 =
0000000000 1111010101(ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять)) - 0 + D800 = D800 (
1101100000000000) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат - 3D5 + DC00 = DFD5 (
1101111111010101) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат - итого данный символ в UTF-16 —
1101100000000000 1101111111010101
Теперь наоборот раскодируем. Допустим что у нас есть вот такой код — 1101100000100010 1101111010001000:
- переведем в шестнадцатиричный вид = D822 DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
1101100000100010— десятый бит (справа) нулевой, значит первый суррогат1101111010001000— десятый бит (справа) единица, значит второй суррогат- отбрасываем по 6 бит отвечающих за определение суррогата, получим
0000100010 1010001000(8A88) - прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649.
 Компоненты тангутского письма.
Компоненты тангутского письма.
Спасибо тем кто смог дочитать до конца, надеюсь было полезно и не очень занудно.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символов
Ну и собственно куда же без нее
ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4 — юникод
ru.wikipedia.org/wiki/ASCII — ASCII
ru.wikipedia.org/wiki/UTF-8 — UTF-8
ru.wikipedia.org/wiki/UTF-16 — UTF-16
Значение кодирования: шаги для кодирования сообщения
Кодирование означает преобразование идеи в слова или жесты, которые передают смысл. Он состоит в преобразовании информации в некоторую форму логического и закодированного сообщения.
Процесс кодирования основан на цели связи и отношениях между отправителем и получателем. В формальной ситуации кодирование предполагает:
- выбор языка;
- выбор средства связи; и
- , выбрав соответствующую форму связи.

Оставшуюся часть статьи мы потратим на более глубокое изучение каждого из них.
1. Выбор языка
Выбор правильного языка имеет важное значение для эффективного кодирования. Вербальные сообщения нуждаются в общеязыковом коде, который может быть легко расшифрован получателем.
Если получатель не может декодировать или понять сообщение, обмен данными невозможен. Например, человек, не понимающий тамильского языка, не может расшифровать сообщение, закодированное на тамильском языке.
Обычно мы используем наш родной язык (L 1) в неформальных ситуациях, в то время как мы предпочитаем официальный язык в официальных деловых, академических или профессиональных ситуациях.
2. Выбор среды связи
Поскольку выбор правильного средства связи включает в себя правильный выбор из множества доступных вариантов, он определяет эффективность кодирования. Это очень важно, поскольку коммуникатору доступно так много возможностей для передачи межличностных сообщений, что он или она могут запутаться.
Правильный выбор — начало эффективного общения. Существуют основные варианты отправки межличностных сообщений, то есть речь, письмо и невербальные знаки и символы.
Устное слово включает вокализацию Открывается в новом окне , в то время как невербальные подсказки сообщений обычно являются визуальными (слуховыми и тактильными Открывается в новом окне ). Невербальные сигналы играют важную роль в устной коммуникации. К таким сигналам относятся движения тела. Открывается в новом окне 9.0031 , мимика Открывается в новом окне , трогательные узоры, речевые манеры.
3. Выбор формы связи
Выбор подходящей формы общения во многом зависит от отношений отправитель-получатель и общей цели коммуникативной ситуации.
Устное общение может быть личным межличностным общением, групповым общением, общением говорящего с аудиторией или общением по телефону. Выбор зависит от потребности и цели общения.
Написание включает в себя выбор правильной письменной формы, то есть письмо, записка, уведомление, отчет, предложение и т. д. См. формы сообщения ниже.
| Форма сообщения | Примеры |
|---|---|
|
|
| |
|
|
|
|
|
|
Основная проблема при устной передаче любого сообщения заключается в том, что слова имеют разное значение для разных людей. Когда недопонимание возникает из-за пропущенных значений, это называется обходомОткрывается в новом окне .
Когда недопонимание возникает из-за пропущенных значений, это называется обходомОткрывается в новом окне .
Понимая, как легко быть непонятым, опытные коммуникаторы выбирают знакомые конкретные словаОткрывается в новом окне . При выборе правильных слов и знаков Открывается в новом окне , отправители должны учитывать коммуникативные навыки получателя, его отношение, образование, опыт и культуру. Включение смайлика в объявление по электронной почте для акционеров может отключить их.
Что такое кодирование и транскодирование?
Эта статья является частью серии Streaming Media «What Is».
Резюме Потоковое медиапроизводство начинается с бесконечного реального мира, снятого объективами наших видеокамер, и заканчивается сильно сжатыми файлами, необходимыми для потоковой доставки. Попутно видео оцифровывается, кодируется, перекодируется и часто перекодируется с возможными остановками по пути для переоценки, преобразования размера и преобразования.
Эти термины мы используем каждый день, но немногие из них имеют точные определения. До настоящего времени. Продолжайте читать нашу попытку внести ясность в лексикон рабочих процессов и процессов потокового мультимедиа, поскольку мы следим за жизнью видео от захвата до потребления (конечно, на нескольких платформах).
Видео, снятое видеокамерой
Начнем с видео, снятого видеокамерой, в данном случае Panasonic AG HMC150 (рис. 1). Мы снимаем в формате 1080 30p (разрешение 1920×1080, прогрессивная развертка, 30 кадров в секунду), а видео сохраняется в формате AVCHD со скоростью 24 Мбит/с.
Рис. 1. Видеокамера Panasonic AG HMC150
В рамках этого процесса видео оцифровывается или преобразуется из аналогового в цифровой, кодируется (или сжимается) или сохраняется в формате, используемом для хранения или передачи .
Видео скопировано на жесткий диск
Затем мы переносим видео с видеокамеры на жесткий диск. При работе с аналоговым видео эта передача называлась видеозахватом, который, как и процесс, происходивший в видеокамере Panasonic, включал как оцифровку, так и (в большинстве случаев) сжатие. Однако при работе с цифровой видеокамерой видео уже сохраняется в сжатом цифровом формате. Соответственно, процесс переноса видео с видеокамеры на жесткий диск может быть как простым копированием файла, так и перекодированием, в зависимости от того, какой редактор вы используете.
Однако при работе с цифровой видеокамерой видео уже сохраняется в сжатом цифровом формате. Соответственно, процесс переноса видео с видеокамеры на жесткий диск может быть как простым копированием файла, так и перекодированием, в зависимости от того, какой редактор вы используете.
Например, Adobe Premiere Pro работает с файлами AVCHD изначально или в исходном формате без какого-либо преобразования. Предпочтительным рабочим процессом для Premiere Pro будет копирование файлов с видеокамеры на компьютер вне приложения, возможно, с помощью проводника Windows в Windows или диспетчера файлов на Mac, а затем импорт файлов в Premiere Pro. Это не предполагает никакого преобразования или потери поколений.
Рис. 2. Загрузка AVCHD в Final Cut Pro 7 включает перекодирование из AVCHD в ProRes.
Напротив, как показано на рис. 2, Final Cut Pro 7 преобразует все файлы AVCHD в формат ProRes как часть процесса загрузки. Вы можете выбрать вариант ProRes, который определяет скорость передачи данных, но во всех случаях скорость передачи данных будет как минимум в два раза выше, чем у видеозаписи AVCHD (45 Мбит/с для ProRes 422 Proxy), и более чем в 13 раз выше (330 Мбит/с для ProRes 4444). ), что означает минимальное ухудшение качества.
), что означает минимальное ухудшение качества.
Это преобразование будет транскодированием, т. е. преобразованием из одного формата в другой такого же или подобного качества, которое обычно выполняется для обеспечения совместимости содержимого с другим процессом или приложением. Все преобразования из одного формата в другой формат с потерями технически связаны с потерей поколения, хотя, если бы вы использовали один из форматов ProRes с более высокой скоростью передачи битов, практическое влияние этой потери поколения не имело бы значения.
Создание мезонинного файла
С определением все становится сложнее, когда вы выводите мезонинный файл из редактора, который затем можно ввести в программу кодирования для создания файлов для распространения (рис. 3). С Premiere Pro вы, вероятно, будете выводить в формате H.264, возможно, с той же или даже более высокой скоростью передачи данных, чем исходный файл. Тем не менее, если вы настроите глобальные параметры, такие как яркость или цвет, это перекодирование повлечет за собой некоторую потерю поколений, пусть и небольшую.
Рис. 3. Создание мезонинного файла в Adobe Media Encoder. Перекодирование, кодирование, транскодирование или трансрейтинг?
Это можно назвать перекодированием, особенно если мезонинный файл использовался для архивирования. Вы также можете назвать это транскодированием, поскольку мезонинный файл будет иметь такое же или близкое качество к оригиналу. Вы также можете привести доводы в пользу трансрейтинга, когда вы конвертируете файл в другую скорость передачи данных, используя тот же кодек, хотя это не классическое применение трансрейтинга, которое обсуждается ниже. Однако, возможно, проще и правильнее всего будет назвать это перекодированием или процессом сохранения файла обратно в существующий формат после выполнения какого-либо процесса редактирования.
Вернемся к созданию файла мезонина. В Final Cut Pro, если вы выводите в ProRes в качестве промежуточного формата, транскодирование не происходит, хотя опять же, если есть глобальное изменение, такое как яркость или цвет, произойдет некоторая техническая потеря поколения, пусть и небольшая. Однако, если вы выводите данные в формате H.264 с гораздо более низкой скоростью, это почти наверняка является кодированием, поскольку вы конвертируете кодек с более низкими потерями для целей хранения или передачи. С другой стороны, промежуточный файл будет визуально неотличим от ProRes, что говорит в пользу обозначения транскодирования. Я бы проголосовал за транскодирование, но это серая зона.
Однако, если вы выводите данные в формате H.264 с гораздо более низкой скоростью, это почти наверняка является кодированием, поскольку вы конвертируете кодек с более низкими потерями для целей хранения или передачи. С другой стороны, промежуточный файл будет визуально неотличим от ProRes, что говорит в пользу обозначения транскодирования. Я бы проголосовал за транскодирование, но это серая зона.
Кодирование для распространения
Вы вводите мезонинный файл в кодировщик, такой как Sorenson Squeeze, для кодирования видео в формат MPEG-2 для записи на DVD, универсальный файл MP4 с высоким битрейтом 720p для многократного использования и файл WebM (I знаете, на самом деле никто, кроме YouTube, не использует WebM, но идите со мной). Это явно кодирование, так как вы конвертируете файл для передачи.
Рисунок 4. Кодирование нашего мезонинного файла в окончательные форматы дистрибутива.
Вы записываете файл MPEG-2 на DVD, загружаете файл WebM на свой веб-сайт, совместимый с HTML5, и отправляете один файл на OVP, на котором запущен Wowza Media Server 3 где-то в конце 2011 года. Вот тут-то и начинается самое интересное.
Вот тут-то и начинается самое интересное.
Трансрейтинг и трансмультиплексирование
На выставке NAB 2011 Wowza анонсировала Wowza Media Server 3, в котором представлена новая архитектура подключаемых модулей для надстроек, разработанных для Media Server. Первые два подключаемых модуля от Wowza обеспечивают функциональность сетевого видеорегистратора и механизм транскодера, последний из которых имеет отношение к данному обсуждению.
Рисунок 5. Wowza Media Server 3 может осуществлять трансрейт, транскодирование и трансмуксирование.
В процессе работы я отправлял файл MP4 720p на сервер, где транскодер преобразовывал потоки H.264 в несколько потоков с более низким разрешением/скоростью передачи данных для использования в адаптивной потоковой передаче. Например, транскодер может преобразовать поток 720p в четыре файла, настроенные на 848×480@1000, 640×360@700, 480×270@500 и 320×180@200Kbps
Технически это называется трансрейтингом, поскольку транскодер преобразует потоки H. 264. на более низкий битрейт с использованием того же кодека, хотя вы также можете поспорить за преобразование размера, потому что выходное разрешение также меняется. Тем не менее, как общий термин, транскодирование также является точным и используется гораздо шире. Если транскодер затем преобразует эти потоки в формат WebM (я знаю, я знаю) для адаптивной доставки (я знаю, я знаю), это явно будет транскодирование.
264. на более низкий битрейт с использованием того же кодека, хотя вы также можете поспорить за преобразование размера, потому что выходное разрешение также меняется. Тем не менее, как общий термин, транскодирование также является точным и используется гораздо шире. Если транскодер затем преобразует эти потоки в формат WebM (я знаю, я знаю) для адаптивной доставки (я знаю, я знаю), это явно будет транскодирование.
Я должен сказать, что транскодер Wowza будет транскодировать только живые потоки в своем первоначальном выпуске, хотя конвертация по требованию будет. Никогда не позволяйте реальности мешать хорошему примеру.
В первом выпуске будет доступно трансмуксирование, при котором сервер изменит формат контейнера, но не базовый файл. Например, для распространения файлов через HTTP Live Streaming пакеты для наших четырех файлов должны храниться как транспортные потоки MPEG-2 (файлы .ts), а не файлы MP4. Кодировка H.264 в оболочке в порядке; нужно изменить только формат контейнера.
Wowza Media Server 2 сегодня может динамически переупаковывать файлы MP4 в транспортные потоки MPEG-2, как и службы Microsoft IIS и Akamai HD Network посредством переупаковки «в сети». На NAB 2011 Adobe объявила о планах сделать то же самое с будущей версией Flash Media Server.
Резюме
При определении преобразования файла из цифрового в цифровой необходимо изучить как цель преобразования, так и то, что на самом деле происходит во время преобразования. Это приводит к следующим определениям.
Кодирование (или сжатие)
Для преобразования для хранения или передачи, особенно когда новый файл использует более низкую скорость передачи данных, чем исходный, или кодек с большими потерями.
Перекодировать
Процесс сохранения файла обратно в существующий формат после выполнения какого-либо процесса редактирования.
Transcode
Преобразование в другой формат аналогичного качества для обеспечения совместимости с другой программой или приложением
Transrate
Преобразование на другую скорость передачи данных с использованием того же формата.
Transsize
Преобразование в другое разрешение с использованием того же формата.
Transmux
Преобразование в другой формат контейнера без изменения содержимого файла.
Если вы твердо придерживаетесь какого-либо из этих определений, вы слишком серьезно относитесь к себе (и к этому документу).
Бесплатно
для квалифицированных подписчиков
Подписаться Текущий выпускПрошлые выпуски
Включите JavaScript для просмотра комментариев с помощью Disqus.
Статьи по Теме
Что такое H.264?
Обзор H.264, самого популярного в мире видеокодека, включая параметры кодирования и лицензионные отчисления.
04 апр 2011
Что такое кодек?
Если вы собираетесь разбираться в онлайн-видео, вам нужно разбираться в кодеках.