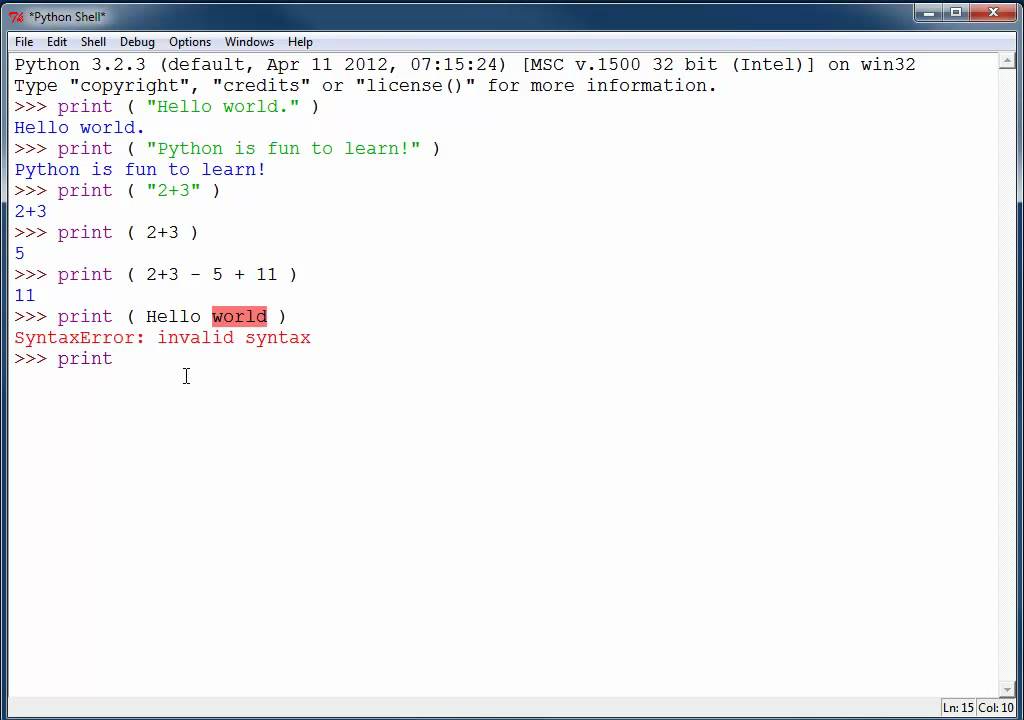
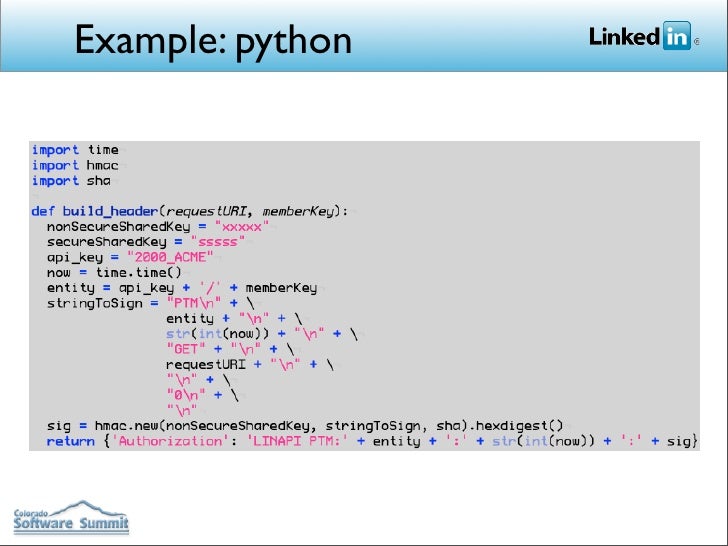
10 популярных сайтов, созданных на языке Python
Вообще в интернете десятки тысяч сайтов, созданных на основе Python. Этот мощный язык программирования разработал Гвидо ван Россум, а произошло это еще в 1991 году. Сегодня Python популярен как среди начинающих, так и среди опытных разработчиков.
Многие наиболее успешные технологические компании выбирают Python для создания бэкенда своих продуктов. Давайте рассмотрим десятку знаменитых сайтов, при разработке которых использовался (и продолжает использоваться) Python.
Instagram — это крупнейшее в мире приложение для обмена фотографиями. А для бэкенда там используется Python. По словам разработчиков этой платформы, Instagram в настоящее время это показательный пример использования фреймворка Django, а ведь он написан полностью на Python.
Google это самый широко используемый поисковик в мире. Он занимает больше 75% рынка. Алекс Мартелли, инженер, уже давно работающий в этой компании, рассказал, почему они начали использовать Python в своем техническом стеке:
«Это пошло, как мне кажется, еще от самых первых «гуглеров» (Сергея, Ларри, Крейга,…), принявших очень хорошее инженерное решение: «Python — везде, где это возможно, C++ — где необходимо»».
Spotify — это стриминговый сервис, позволяющий прослушивать отдельные музыкальные треки или целые альбомы практически без задержки (благодаря заблаговременной буферизации). Приложение Spotify было выпущено в 2008 году, а в настоящее время оно имеет больше 113 миллионов платных подписчиков.
Хотя сайт Spotify построен на WordPress, приложение создавалось на Python. Один из разработчиков, Джефф ван дер Меер, объясняет, почему команда Spotify использовала именно этот язык для бэкенда приложения:
«Бэкенд Spotify состоит из большого количества независимых сервисов. И примерно 80% этих сервисов написаны на Python»
.Netflix — крупнейшая телевизионная сеть в мире. Фильмы и сериалы на этой платформе смотрят 167 миллионов людей из более чем 190 стран. Как написано в технологическом блоге компании,
«Разработчики Netflix вольны выбирать технологии, наиболее подходящие для решения их задач. И все больше разработчиков обращаются к Python. Этому способствует богатство стандартной библиотеки, сжатый, понятный и при этом выразительный синтаксис, многочисленное сообщество и обилие сторонних библиотек, которыми в любой момент можно воспользоваться для решения насущной задачи».
Этому способствует богатство стандартной библиотеки, сжатый, понятный и при этом выразительный синтаксис, многочисленное сообщество и обилие сторонних библиотек, которыми в любой момент можно воспользоваться для решения насущной задачи».
При помощи Uber, сервиса для поиска попутчиков, происходит больше 15 миллионов поездок ежедневно. По словам разработчиков приложения Uber, на более низких уровнях они преимущественно пишут на Python, Node.js, Go и Java. Начинали они с двух основных языков: Node.js для команды Marketplace и Python для всех остальных. Сегодня эти два первых языка по-прежнему используются для большинства сервисов Uber.
Dropbox — это тихая гавань для ваших фотографий, документов, видео и всяких других файлов.
Вам когда-нибудь было любопытно, как
приложению вроде Dropbox удалось
масштабироваться от 2000 до 200 миллионов
пользователей? При разработке серверов
этой компании Python используется буквально
повсеместно. И это неудивительно: с
начала 2013 и до октября 2019 года в Dropbox
работал Гвидо ван Россум, создатель
языка Python.
Pinterest — это социальный сайт-фотохостинг, на котором пользователи могут делиться своими фотографиями. Изображения при этом можно собирать в тематические коллекции.
«На прикладном уровне мы используем Python и очень сильно модифицированный Django. А что касается веб-серверов — используем Tornado и Node.js»
, — Пол Скьяра, соучредитель Pinterest.Instacart — компания, осуществляющая быструю доставку продуктов из магазинов. Приложение этой компании является одним из самых популярных в данном сегменте: им пользуются больше 500 тысяч людей.
«У нас есть команда специалистов по Data Science, они работают на R и Python. Код, написанный на этих языках, используется, например, для прогнозирования: предварительных оценок, чтения данных, прикидок, сколько закупщиков нам понадобится в следующие пару недель и т. п.», — команда разработчиков Instacart.
У этого сайта 330 миллионов активных пользователей.
«Самое важное, что побуждает нас использовать Python?. . собственно, есть два основных довода в его пользу. Во-первых, это библиотеки. Во-вторых (и это важнее) — его легкость для чтения и написания кода. Когда мы нанимаем новых сотрудников, я предупреждаю, что все, что они пишут, должно быть на Python — чтобы я смог прочесть. И это круто. Я могу просто проходить через комнату и, глянув на экран, понять, хороший код у человека или нет. Потому что у хорошего кода на Python очень понятная структура. Это весьма облегчает мою жизнь»
. собственно, есть два основных довода в его пользу. Во-первых, это библиотеки. Во-вторых (и это важнее) — его легкость для чтения и написания кода. Когда мы нанимаем новых сотрудников, я предупреждаю, что все, что они пишут, должно быть на Python — чтобы я смог прочесть. И это круто. Я могу просто проходить через комнату и, глянув на экран, понять, хороший код у человека или нет. Потому что у хорошего кода на Python очень понятная структура. Это весьма облегчает мою жизнь»
В США Lyft это самый быстрорастущий сервис для поиска попутчиков. Компания работает в больше чем 200 городах, с ее участием происходит 14 миллионов поездок в месяц.
На митапе в Сан-Франциско в 2018 году разработчик из Lyft, Рой Вильямс, рассказал:
«Lyft — большой поклонник Python. Обычно в сервисах используются NumPy, Pandas и PuLP для обработки запросов через Flask, Gevent и Gunicorn.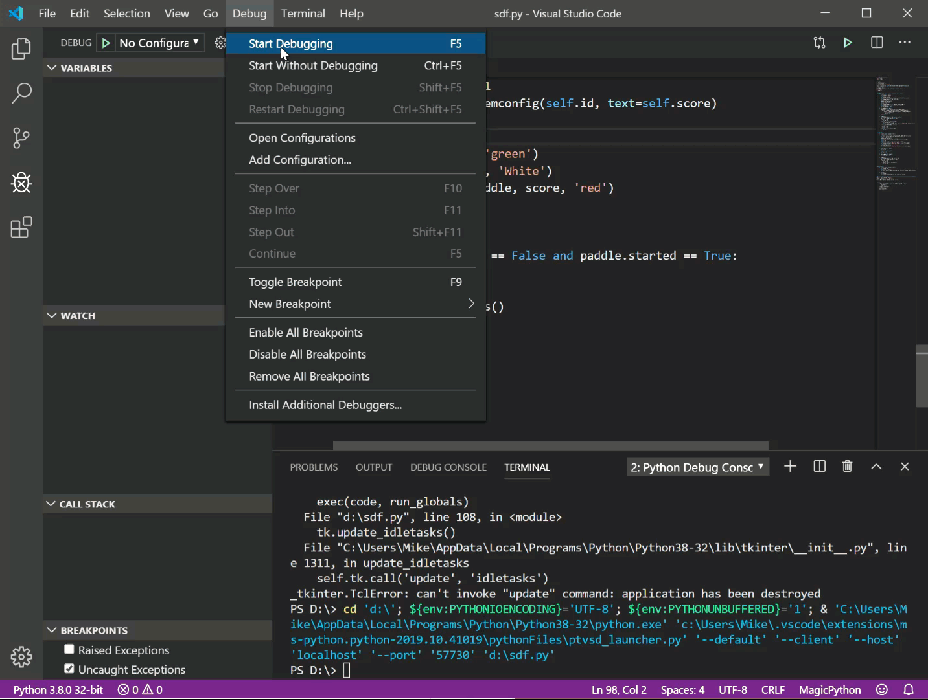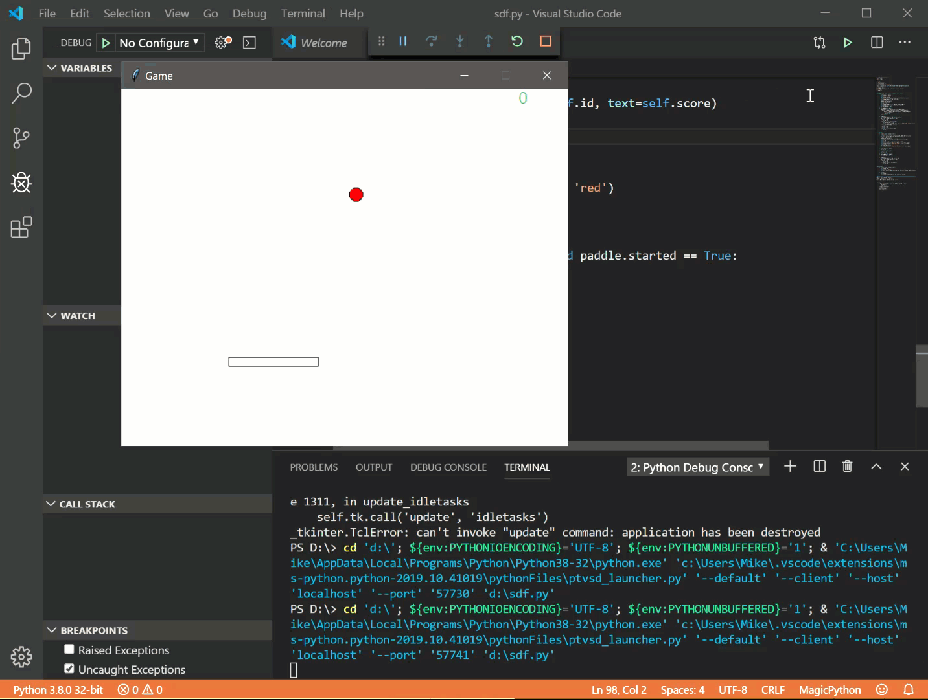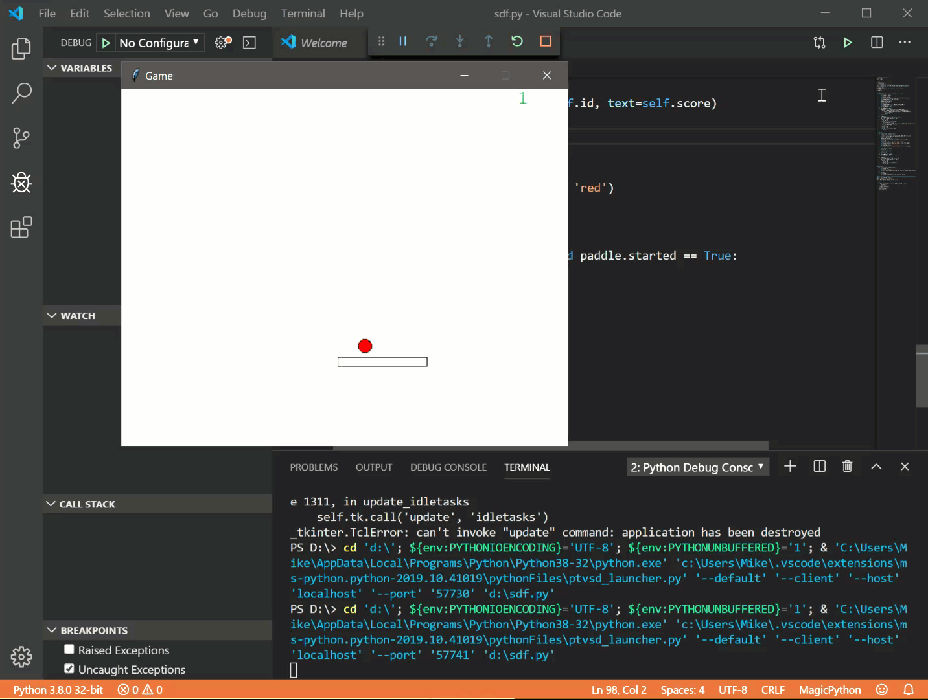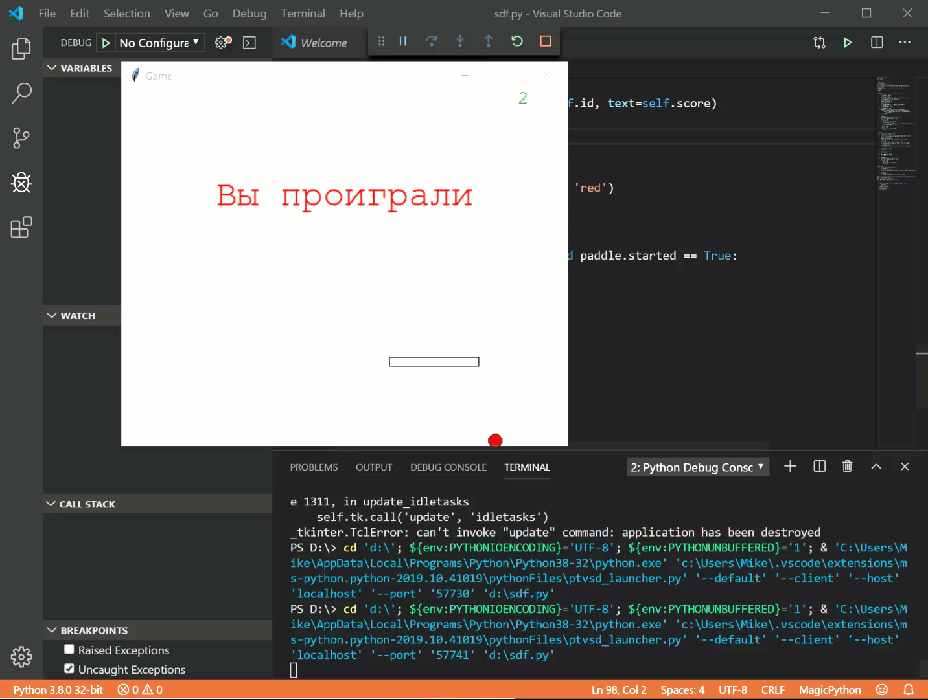 Для борьбы с мошенничеством мы используем SciPy».
Для борьбы с мошенничеством мы используем SciPy».
Пишем игрового бота на Python для Web
Подготовка
Этот туториал, и код в нем, требует установки нескольких дополнительных библиотек для Python. Они обеспечивают обертку Python’а в кусок низкоуровневого C-кода, который значительно упрощает создание и скорость исполнения.Некоторые библиотеки существуют только под Windows. У них могут быть эквиваленты под Mac или linux, но мы не будем их рассматривать.
Вам нужно скачать и установить следующие библиотеки:
Все представленные библиотеки комплектуются установщиками. Запуск их автоматически установит модуль в директорию \lib\site-packages и, теоретически, добавит соответствующий pythonPath. Однако, на практике это происходит не всегда. Если Вы получите сообщение об ошибке после установки, добавьте их вручную в переменные Path.
Последний инструмент это графический редактор. Я предлагаю использовать Paint.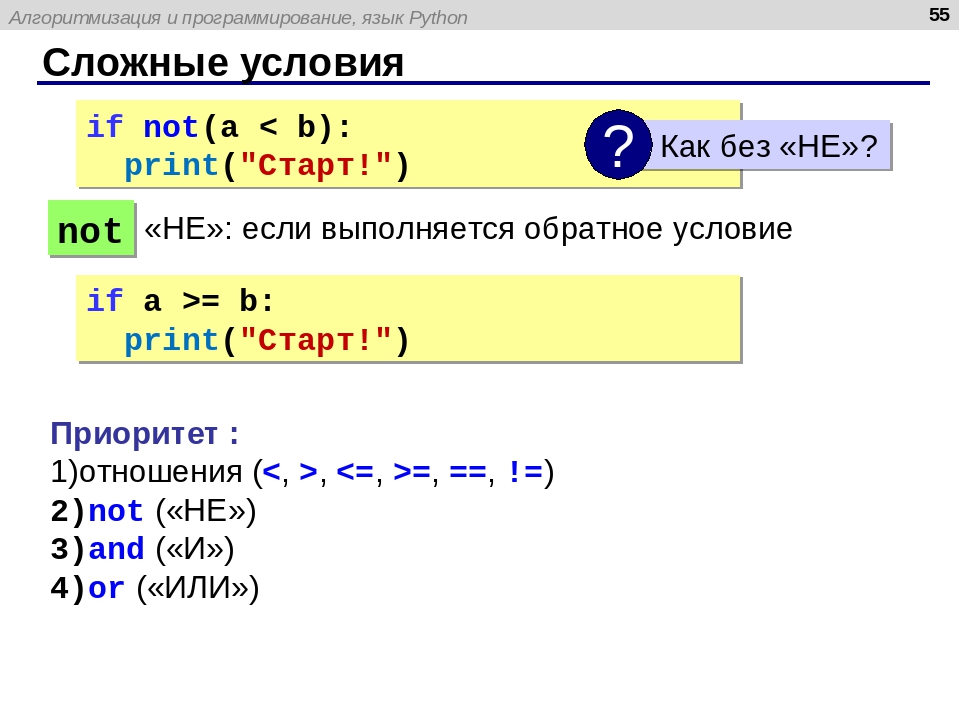 Net как лучший из бесплатных, но подойдет любая программа с линейками и измерениями в пикеслях.
Net как лучший из бесплатных, но подойдет любая программа с линейками и измерениями в пикеслях.
Мы будем использовать несколько игр в качестве примеров.
Введение
Это руководство написано с целью дать базовое понимание основы разработки ботов для браузерных игр. Подход, который мы собираемся дать, вероятно немного отличается от того, что многие ожидают услышать говоря о ботах. Вместо того, чтобы сделать программу, вставляющую код между клиентом и сервером (как боты для Quake или CS), наш бот будет находиться чисто снаружи. Мы будем опираться на методы Компьютерного зрения и вызовы Windows API для сбора необходимой информации и выполнения движений.
С этим подходом мы теряем часть деталей и контроля, но сокращаем время разработки и получим простоту в использовании. Автоматизирование специфичных игровых функций может быть создано в несколько строк кода, и полноценный бот, от начала до конца (для простой игры) может быть собран за несколько часов.
Когда вы привыкните к тому, что компьютер может видеть, начнете смотреть на игры по-другому.
Эти боты могут быть также очень полезны для тестирования простых игр — в отличии от реальных игроков, боту не надоест играть один сценарий снова и снова.
Исходники примеров из курса, а также одного законченного бота можно найти здесь.
Шаг 1: Создание проекта
В папке с проектом создайте текстовый файл quickGrab, измените расширение на ‘py’ и откройте его в редакторе кода.
Шаг 2: Создаем приложение, которое делает скриншот экрана
Начнем работу с изучения базовой функции, которая делает скриншот экрана. Один раз создав и запустив, мы будем строчка за строчкой, как эту функцию, создавать каркас нашего кода.
Вставим в наш файл с проектом quickGrab.py следующий код:
ImageGrab
import os
import time
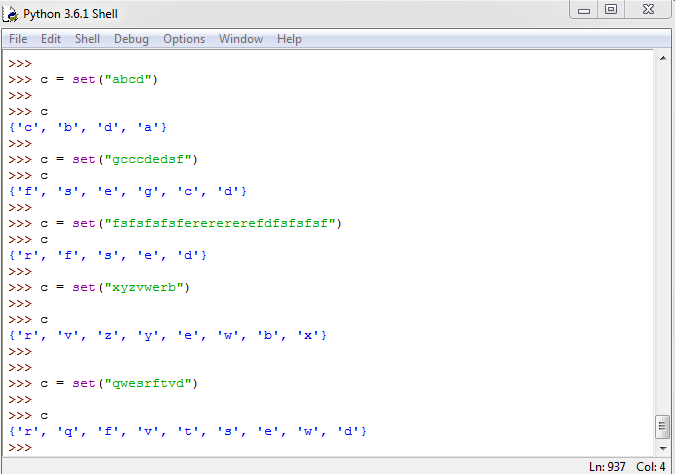
def screenGrab():
box = ()
im = ImageGrab. grab()
im.save(os.getcwd() + '\\full_snap__' + str(int(time.time())) + '.png', 'PNG')
def main():
screenGrab()
if __name__ == '__main__':
main()
grab()
im.save(os.getcwd() + '\\full_snap__' + str(int(time.time())) + '.png', 'PNG')
def main():
screenGrab()
if __name__ == '__main__':
main()
 grab()
im.save(os.getcwd() + '\\full_snap__' + str(int(time.time())) + '.png', 'PNG')
def main():
screenGrab()
if __name__ == '__main__':
main()
grab()
im.save(os.getcwd() + '\\full_snap__' + str(int(time.time())) + '.png', 'PNG')
def main():
screenGrab()
if __name__ == '__main__':
main()
Запустив этот код, вы получите скриншот экрана:
Данный код забирает всю ширину и высоту области экрана и сохраняет в PNG файл в директорию проекта.
Давайте пошагово разберем код, чтобы понять как это работает. Первые три строки:
import ImageGrab
import os
import time
…называются ‘import statements’. Они говорят Pytjon’у какие модули загружать во время выполнения. Это дает доступ к методам этих модулей через синтаксис module.attribute .
Первый модуль Python Image Library мы установили ранее. Как следует из названия, он дает нам функциональность взаимодействия с экраном на которую ссылается бот.
Вторая строка импортирует модуль операционной системы (OS — operating system). Он дает возможность простой навигации по директориям в операционной системе. Это пригодится, когда мы начинаем размещать файлы в разных папках.
Это пригодится, когда мы начинаем размещать файлы в разных папках.
Последний импорт создает модуль работы со временем. Мы используем его для установки текущей даты скриншота, также он может быть очень полезным как таймер для ботов, которые выполняют действие в течение заданного количества секунд.
Следующие четыре строки определяют функцию screenGrab().
def screenGrab(): box = () im = ImageGrab.grab() im.save(os.getcwd() + '\\full_snap__' + str(int(time.time())) + '.png', 'PNG')
Первая строка def screenGrab() определяет имя функции. Пустые скобки означают, что она не принимает аргументов.
Строка 2, box = () присваивает пустое значение переменной «box». Мы заполним это значение дальше.
Строка 3, im = ImageGrab.grab() создает полный скриншот экрана и возвращает RGB изображение в переменную im .
Строка 4, может быть немного сложнее если вы не очень хорошо знакомы с тем как работает Time module. Первая часть
Первая часть im.save( вызывает метод «save». Он принимает два аргумента. Первый это директория в которую нужно сохранить файл, а второй это формат файла.
Здесь мы устанавливаем директорию вызовом метода os.getcwd() . Функция получает текущую директорию в которой выполняется код и возвращает её как строку. Далее мы добавим «+». Сложение нужно использовать между каждым новым аргументом для соединения всех строк вместе.
Следующая часть '\\full_snap__ дает нам простое описание в имени файла. Обратный слеш является экранирующим символом в Python, и мы добавили два, чтобы избежать отмены одного из символов.
Далее идет эта сложная конструкция: str(int(time.time())). Она использует встроенные функции Питона. Мы рассмотрим работу этого куска кода изнутри:
time.time() возвращает количество секунд с начала Эпохи, тип данных Float (число с плавающей точкой). Так как мы используем дату для именования файлов, мы не можем использовать десятичное число, поэтому мы обернем выражение в int(), чтобы конвертировать в целое число (Integer). Это делает нас ближе к решению, но Python не может соединить тип Integer с типом String, поэтому следующим шагом мы обернем все в функцию str(). Далее остается только добавить расширение как часть строки
Это делает нас ближе к решению, но Python не может соединить тип Integer с типом String, поэтому следующим шагом мы обернем все в функцию str(). Далее остается только добавить расширение как часть строки + '.png' и добавить вторым аргументом функции снова расширение: «PNG».
Последняя часть кода определяет функцию main(), которая вызывает функцию screenGrab(), когда исполняется.
И, наконец, условное обозначение, которое позволяет интерпретатору определить, какую функцию запускать в случае, если файл запущен как основной (а не просто импортирован в другой скрипт). В противном случае, если он загружен как модуль другого скрипта — он только передает доступ к этому методу, вместо выполнения.
def main():
screenGrab()
if __name__ == '__main__':
main()
Шаг 3: Область видимости
Функция ImageGrab.grab() принимает один аргумент, который определяет область видимости. Это набор координат по шаблону (x,y,x,y), где
Это набор координат по шаблону (x,y,x,y), где
- Первая пара значение (x,y… определяет левый верхний угол рамки;
- Вторая пара …x,y) определяет правый нижний.
Это дает нам возможность скопировать только часть экрана, которая нам нужна.
Рассмотрим это на практике.
Для примера рассмотрим игру Sushi Go Round (Довольно увлекательная. Я Вас предупредил). Откройте игру в новой вкладке и сделайте скриншот использую существующий код screenGrab():
Шаг 4: Задание координат
Пришло время задания координат для нашей области видимости.
Откройте скриншот в редакторе картинок.
Координаты (0,0) это всегда левый верхний угол изображения. Мы хотим заполнить X и Y таким образом, чтобы нашему новому скриншоту функция установила координаты (0,0) в крайний левый угол игровой области.
Этому есть две причины. Во-первых, это упрощает нахождение координат, когда мы должны определять координаты относительно игровой области, по сравнению со всем экраном монитора. Во-вторых, захват меньшей части экрана уменьшает нагрузку на процессор. Полноэкранные скриншоты производят довольно много данных, чтобы их можно было циклично повторять несколько раз в секунду.
Во-вторых, захват меньшей части экрана уменьшает нагрузку на процессор. Полноэкранные скриншоты производят довольно много данных, чтобы их можно было циклично повторять несколько раз в секунду.
Если вы это еще не сделали, включите линейки в вашем графическом редакторе и приблизьте верхний угол игровой области до той степени, пока не увидите рамки пикселей.
Наведите курсор на первый пиксель игровой области и запишите координаты на линейках. Это будут первые два значения для нашей функции. У меня получились значения (305, 243).
Затем следуйте к нижнему краю и запишите вторую пару координат. У меня получилось (945, 723). Вместе эти пары дают область с координатами (305,243,945,723).
Давайте добавим координаты в код:
import ImageGrab
import os
import time
def screenGrab():
box = (305,243,945,723)
im = ImageGrab.grab(box)
im.save(os.getcwd() + '\\full_snap__' + str(int(time.time())) +
'. png', 'PNG')
def main():
screenGrab()
if __name__ == '__main__':
main()
 png', 'PNG')
def main():
screenGrab()
if __name__ == '__main__':
main()
png', 'PNG')
def main():
screenGrab()
if __name__ == '__main__':
main()
На строке 6 мы обновили массив для хранения координат игровой области.
Сохраните и запустите код. Откройте новое сохраненное изображение и вы увидите следующее:
Отлично! Это идеальный снимок игровой области. Нам не всегда будет требоваться эта напряженная охота за координатами. После того, как мы узнаем о win32api, мы рассмотрим более быстрые методы для установки координат, когда нам нужна идеальная точность.
Шаг 5: Перспективное планирование для гибкости
На данный момент, мы жестко прописали координаты по отношению к текущей настройке, исходя из нашего браузера и нашего разрешения монитора. Вообще, это плохая идея — жестко прописывать координаты таким образом. Если, например, мы хотим запустить код на другом компьютере, или, скажем, что-то на сайте немного сдвинет позицию игровой области — нам придется вручную скрупулезно фиксировать все наши координаты заново.
Давайте создадим две новые переменные: x_pad и y_pad. В них будет храниться расстояние между игровой областью и остальным экраном. Это поможет легко портировать код с места на место, так как каждая новая координата будет задаваться относительно двух глобальных переменных, которые мы создадим. Чтобы настроить изменения экрана нужно сбросить эти две переменные.
Так как мы уже сделали измерения, установить отступы для нашей текущей системы достаточно просто. Мы собираемся установить отступы, чтобы хранить положение первого пикселя за пределами игровой площадки. От первой пары координат нашего кортежа вычесть по 1. Получается 304 и 242.
Давайте добавим это в наш код:
# Globals
# ------------------
x_pad = 304
y_pad = 242
Теперь, когда они установлены, мы скорректируем координаты игровой области относительно них.
def screenGrab():
box = (x_pad+1, y_pad+1,945,723)
im = ImageGrab. grab(box)
im.save(os.getcwd() + '\\full_snap__' + str(int(time.time())) + '.png', 'PNG')
 grab(box)
im.save(os.getcwd() + '\\full_snap__' + str(int(time.time())) + '.png', 'PNG')
grab(box)
im.save(os.getcwd() + '\\full_snap__' + str(int(time.time())) + '.png', 'PNG')
Для второй пары значений мы собираемся сначала найти разницу между первой и второй парой координат, чтобы получить размер игрового окна, а затем использовать эти значения с нашими переменными.
def screenGrab():
box = (x_pad+1, y_pad+1, x_pad+641, y_pad+481)
im = ImageGrab.grab(box)
im.save(os.getcwd() + '\\full_snap__' + str(int(time.time())) + '.png', 'PNG')
Для координаты x значение стало 945 — 304 = 641, а для y стало 723 — 242 = 481.
Сперва это может показаться излишним, но это дополнительный шаг к более легкому обслуживанию в будущем.
Шаг 6: Создание документации
Перед тем как перейти дальше, создадим документацию в начале нашего проекта. Так как большая часть нашего кода будет базироваться на особых координатах экрана и отношении к этим координатам, важно понимать окружение в котором всё будет работать правильно. Например, таких условия как разрешение монитора, браузер, включенная панель инструментов (так как это меняет размер окна браузера), и другие настройки необходимые для центровки игровой области на экране, все это влияет на относительные позиции координат. Документирование всего этого сильно помогает в решении проблем, когда код запускается на разных браузерах и компьютерах.
Например, таких условия как разрешение монитора, браузер, включенная панель инструментов (так как это меняет размер окна браузера), и другие настройки необходимые для центровки игровой области на экране, все это влияет на относительные позиции координат. Документирование всего этого сильно помогает в решении проблем, когда код запускается на разных браузерах и компьютерах.
Напоследок, нужно следить за постоянно меняющимся рекламным пространством на популярных игровых сайтах. Если функция захвата экрана перестает себя вести, как ожидалось, стоит добавить координатам немного смещения.
Для примера, я обычно добавляю подобный комментарий в начало моего кода:
"""
All coordinates assume a screen resolution of 1280x1024, and Chrome
maximized with the Bookmarks Toolbar enabled.
Down key has been hit 4 times to center play area in browser.
x_pad = 156
y_pad = 345
Play area = x_pad+1, y_pad+1, 796, 825
"""
Добавление всей этой информации в начало файла позволяет быстро и легко перепроверить все настройки и выравнивание экрана без необходимости корпеть над кодом, пытаясь вспомнить, где вы сохранили
Как работает Python? / Мастерская интернет-разработчика
22 августа 2009 г. Windows Python FreeBSD
Windows Python FreeBSD
Всем еще раз привет, сейчас расскажу о том, как работает Python, что такое интерпретатор, как работает компилятор и что такое байт-код, далее расскажу о виртуальной машине (PVM) и о производительности Python. Также о альтернативных реализациях интерпретатора.
После того, как вы установили себе Python, перейдем к теоретически-практической части и начнем с того что из себя представляет интерпретатор.
Интерпретатор
Интерпретатор — это такая программа, которая выполняет другие программы. Когда вы пишете программу на языке Python, интерпретатор читает вашу программу и выполняет содержащиеся в ней инструкции. В действительности, интерпретатор — это слой программной логики между вашим программным кодом и аппаратурой вашего компьютера.
Когда вы пишете программу на языке Python, интерпретатор читает вашу программу и выполняет содержащиеся в ней инструкции. В действительности, интерпретатор — это слой программной логики между вашим программным кодом и аппаратурой вашего компьютера.
В зависимости от используемой версии Python сам интерпретатор может быть реализован как программа на языке C, как набор классов Java и в каком-либо другом виде, но об этом позже.
Запуск сценария в консоли
Давайте запустите в консоле интерпретатор:
# python
Теперь он ожидает ввода комманд, введите туда следующую инструкцию:
print 'hello world!'
ура, наша первая программа! 😀
Запуск сценария из файла
Создайте файл «test.py», с содержимым:
# вывести "hello world" print "hello world" # вывести 2 в 10 степени print 2 ** 10
и выполните этот файл:
# python /path/to/test.
 py
py
Вы увидите в консоли результат, поехали дальше!
Динамическая компиляция и байт-код
После того, как запустите сценарий, Python сначала компилирует исходный текст сценария в байт-код для виртуальной машины. Компиляция — это просто этап перевода, а байт-код это низкоуровневое платформонезависимое представление исходного текста программы. Python транслирует каждую инструкцию в исходном коде сценария в группы инструкций байт-кода для повышения скорости выполнения программы, так как байт-код выполняется намного быстрее. После компиляции в байт-код, создается файл с расширением «.pyc» по соседству с исходным текстом сценария.
В следующий раз, когда вы запустите свою программу интерпретатор минует этап компиляции и отдаст на выполнение откомпилированный файл с расширением «.pyc». Однако, если вы изменили исходные тексты вашей программы, то снова произойдет этап компиляции в байт-код, так как Python автоматически следит за датой изменения файла с исходным кодом.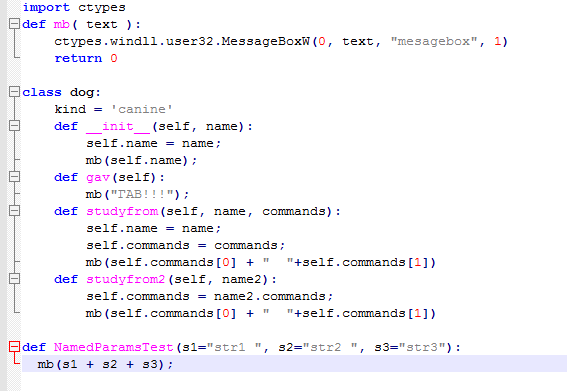
Если Python окажется не в состоянии записать файл с байт-кодом, например из-за отсутствия прав на запись на диск, то программа не пострадает, просто байт-код будет собран в памяти и при завершении программы оттуда удален.
Виртуальная машина Python (PVM)
После того как пройдет процесс компиляции, байт-код передается механизму под названием виртуальная машина, которая и выполнит инструкции из байт-кода. Виртуальная машина — это механизм времени выполнения, она всегда присутствует в составе системы Python и это крайняя составляющая системы под названием «Интерпретатор Python».
Для закрепления пройденного еще раз проясним ситуацию, компиляция в байт-код производится автоматически, а PVM — это всего лишь часть системы Python, которую вы установили вместе с интерпретатором и компилятором. Все происходит прозрачно для программиста, и вам не надо выполнять эти операции вручную.
Производительность
Программисты имеющие опыт работы с такими языками как C и C++, могут заметить некоторые отличия в модели выполнения Python. Первое — это отсутствие этапа сборки или вызова утилиты «make», программы на Python могут быть сразу же запущены после написания исходного кода. Второе отличие — байт-код не является двоичным машинным кодом (например инструкции для микропроцессора Intel), он является внутренним представлением программы на языке Python.
Первое — это отсутствие этапа сборки или вызова утилиты «make», программы на Python могут быть сразу же запущены после написания исходного кода. Второе отличие — байт-код не является двоичным машинным кодом (например инструкции для микропроцессора Intel), он является внутренним представлением программы на языке Python.
По этим причинам программы на Python не могут выполняться также быстро как на C/C++. Обход инструкций выполняет виртуальная система, а не микропроцессор, и чтобы выполнить байт-код, необходима дополнительная интерпретация, инструкции которой требуют большего времени, чем машинные инструкции микропроцессора.
Однако, с другой стороны, в отличии от традиционных интерпретаторов, например как в PHP, здесь присутствует дополнительный этап компиляции — интерпретатору не требуется каждый раз анализировать исходный текст программы.
В итоге, Python по производительности находится между традиционными компилирующими и традиционными интерпретирующими языками программирования.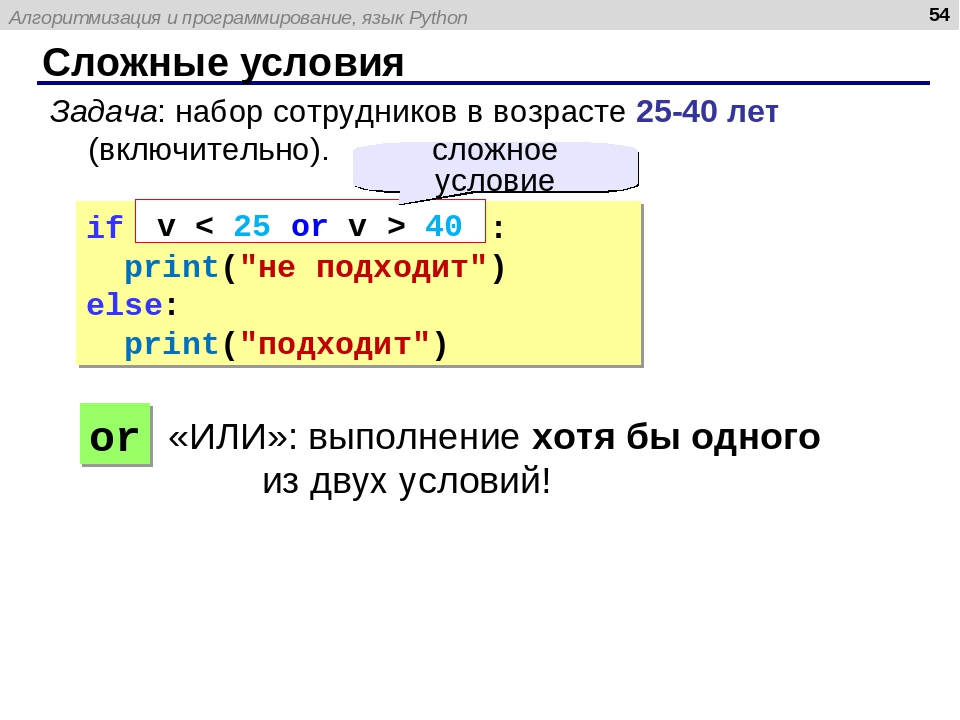
Альтернативные реализации Python
То что было сказано выше о компиляторе и виртуальной машине, характерно для стандартной реализации Python, так называемой CPython (реализации на ANSI C). Однако также существует альтернативные реализации, такие как Jython и IronPython, о которых пойдет сейчас речь.
CPython
Это стандартная и оригинальная реализация Python, названа так, потому что написана на ANSI C. Именно ее мы установили, когда выбрали пакет ActivePython или установили из FreeBSD портов. Поскольку это эталонная реализация, она как правило работает быстрее, устойчивее и лучше, чем альтернативные реализации.
Jython
Первоначальное название JPython, основная цель — тесная интеграция с языком программирования Java. Реализация Jython состоит из Java-классов, которые выполняют компиляцию программного кода на языке Python в байт-код Java и затем передают полученный байт-код виртуальной машине Java (JV
Обучение информационным технологиям | HSG
информационные технологии УСЛУГИ ОБУЧЕНИЯ
Hartmann Software Group проводит обучение по информационным технологиям, которое позволяет
компаниям, чтобы создавать лучшие приложения и умело управлять программным обеспечением
процесс разработки. Наши курсы ориентированы на две области: самые актуальные
и критически важные объектно-ориентированные и компонентные инструменты, технологии
и языки; и основы эффективного развития
методология.Наши программы предназначены для предоставления необходимых технологий
при повышении производительности труда разработчиков.
Наши курсы ориентированы на две области: самые актуальные
и критически важные объектно-ориентированные и компонентные инструменты, технологии
и языки; и основы эффективного развития
методология.Наши программы предназначены для предоставления необходимых технологий
при повышении производительности труда разработчиков.
Hartmann Software Group также предлагает индивидуальные курсы для
уникальные потребности бизнеса и технологий. Опытный тренер и
преподаватель определит индивидуальное обучение клиента
требований, а затем соответствующим образом адаптировать и адаптировать курс. Наши
индивидуальные решения для обучения сокращают время, риски и затраты при сохранении
команды разработчиков мотивированы.Факультет Hartmann Software Group
состоит из опытных инженеров-программистов, некоторые из которых в настоящее время преподают в
несколько университетов Колорадо. Богатство знаний нашего факультета
в сочетании с их постоянным опытом консалтинга в реальном мире позволяет
для разработки более эффективных программ обучения, чтобы наши клиенты
получить самые качественные и актуальные инструкции.
Инструктаж доступен у клиентов или на различных тренингах.
объекты, расположенные в столичном районе Денвера.
Богатство знаний нашего факультета
в сочетании с их постоянным опытом консалтинга в реальном мире позволяет
для разработки более эффективных программ обучения, чтобы наши клиенты
получить самые качественные и актуальные инструкции.
Инструктаж доступен у клиентов или на различных тренингах.
объекты, расположенные в столичном районе Денвера.
Курсы обучения на выезде
В рамках наших усилий по обеспечению доступного и успешного обучения учебной программы, мы проводим обучение в классе для групп из 3 или больше студентов. Основываясь на нашем опыте, мы обнаружили, что студенты более восприимчивы к обучению в знакомой обстановке, чем в незнакомой.
Государственные курсы повышения квалификации
Благодаря обширному каталогу предлагаемых курсов, мы можем проводить только небольшое количество этих курсов на публичной основе. Пожалуйста, свяжитесь с нами, чтобы получить список наших текущих публичных курсов.
Пожалуйста, свяжитесь с нами, чтобы получить список наших текущих публичных курсов.
Live, под руководством инструктора, онлайн-обучение
Мы успешно проводим онлайн-обучение под руководством инструкторов в течение ряда лет. Независимо от того, проводятся ли эти занятия с использованием вашего программного обеспечения для веб-конференций или нашего, преимущества этого типа обучения огромны:- Отсутствие командировочных расходов Вы можете пройти обучение на своем рабочем месте и тем самым отказаться от расходов, связанных с поездкой в Денвер или наличием на месте одного из наших инструкторов.
- Расширенные возможности обучения Вы можете пройти обучение, которое может не предлагаться в вашем регионе. Благодаря обширному предложению курсов, из которых вы можете выбрать, вы можете пройти индивидуальное или очень персонализированное обучение по различным дисциплинам, не дожидаясь, пока оно будет предложено на открытом форуме рядом с вами. Просто выберите курс, сообщите нам о своих интересах, и мы сделаем все возможное, чтобы вы прошли необходимое обучение.
- Большая аудитория Другие студенты из того же офиса, удаленных офисов или разных компаний могут записаться в класс.Изучение опыта других, безусловно, поможет повысить ваш собственный опыт.
- Нет конфигурации оборудования / программного обеспечения. Вам не нужно с трудом настраивать комнаты и / или компьютеры. Каждому ученику просто нужно подключиться к предоставленному сайту.
- Повышенная продуктивность Поскольку поездки не являются необходимостью, учащиеся могут быть доступны вне уроков для решения любых нерешенных проблем.
 Просто выберите курс, сообщите нам о своих интересах, и мы сделаем все возможное, чтобы вы прошли необходимое обучение.
Просто выберите курс, сообщите нам о своих интересах, и мы сделаем все возможное, чтобы вы прошли необходимое обучение.ключевых слов и идентификаторов Python (обновлено)
Давайте поговорим о ключевых словах и идентификаторах Python .Недавно мы также рассмотрели полное руководство по установке и настройке Python для начинающих в этом руководстве по Python.
Ключевые слова Python
Проще говоря, ключевые слова Python — это слова, которые зарезервированы. Это означает, что вы не можете использовать их в качестве имени каких-либо сущностей, таких как переменные, классы и функции.
Итак, вы можете подумать, для чего нужны эти ключевые слова. Они предназначены для определения синтаксиса и структуры языка Python.
На момент написания этого руководства вы должны знать, что в языке программирования Python есть 33 ключевых слова.Хотя со временем количество может меняться. Также ключевые слова в Python чувствительны к регистру. Так что они должны быть написаны как есть. Вот список всех ключевых слов в программировании на Python.
Если вы посмотрите на все ключевые слова и попытаетесь вычислить все сразу, вы будете поражены. Так что пока просто знайте, что это ключевые слова. Мы изучим их использование соответственно. Вы можете получить список ключевых слов python через справку оболочки python.
Список всех ключевых слов Python
| и | Логический оператор |
| as | Псевдоним |
| assert | Для отладки |
| break | Разрыв петель Python |
| class | Используется для определения классов в Python |
| continue | Ключевое слово, используемое для продолжения цикла Python путем пропуска существующего |
| def | Ключевое слово, используемое для определения функции |
| del | Используется для удаление объектов в Python |
| elif | Часть условного оператора if-elif-else в Python |
| else | То же, что и выше |
| , за исключением | Ключевое слово Python, используемое для перехвата исключений |
| FALSE | Логическое значение |
| наконец | Это ключевое слово используется для запуска фрагмента кода при отсутствии исключений |
| для | Определите цикл Python для |
| из | Используется, когда вам нужно импортировать только определенный раздел модуля |
| global | Укажите область действия переменной как глобальную |
| if | Используется для определения условия «если» |
| import | Ключевое слово Python, используемое для импорта модулей |
| in | Проверяет, соответствуют ли указанные значения присутствует в повторяемом объекте |
| — это | Это ключевое слово используется для проверки равенства. |
| лямбда | Создание анонимных функций |
| Нет | Ключевое слово None представляет нулевое значение в PYthon |
| нелокальное | Объявление переменной с нелокальной областью действия |
| не | Логический оператор для отрицания условия |
| или | Логический оператор, используемый, когда одно из условий должно быть истинным |
| pass | Это ключевое слово Python передает и позволяет функции продолжить |
| поднять | Поднимает исключение при вызове с указанным значением |
| return | Выход из работающей функции и возвращение указанного значения |
| ИСТИНА | Логическое значение |
| try | Часть команды try… except |
| , а | Используется для определения цикла Python while 90 052 |
| с | Создает блок, упрощающий обработку исключений и файловые операции |
| yield | Завершает функцию и возвращает объект-генератор |
Ниже приведен простой пример, показывающий использование if-else в программе на Python.
var = 1;
если (var == 1):
print ("нечетный")
еще:
print ("даже")
Когда мы запускаем указанную выше программу, Python понимает блок if-else из-за фиксированных ключевых слов и синтаксиса, а затем выполняет дальнейшую обработку.
Что такое идентификаторы Python?
Python Identifier — это имя, которое мы даем для идентификации переменной, функции, класса, модуля или другого объекта. Это означает, что всякий раз, когда мы хотим дать объекту имя, оно называется идентификатором.
Иногда переменную и идентификатор часто неправильно понимают как одно и то же, но это не так.Что ж, для ясности давайте посмотрим, что такое переменная?
Что такое переменная в Python?
Переменная, как видно из названия, — это нечто, значение которой может изменяться с течением времени. Фактически, переменная — это место в памяти, где может храниться значение. Позже мы сможем получить значение для использования. Но для этого нам нужно дать этому участку памяти псевдоним, чтобы мы могли ссылаться на него. Это идентификатор, псевдоним.
Это идентификатор, псевдоним.
Правила написания идентификаторов
Есть некоторые правила для написания идентификаторов.Но сначала вы должны знать, что Python чувствителен к регистру. Это означает, что Name и name — два разных идентификатора в Python. Вот несколько правил написания идентификаторов в Python.
- Идентификаторы могут быть комбинацией прописных и строчных букв, цифр или символа подчеркивания (_). Итак, myVariable , variable_1 , variable_for_print — все это действительные идентификаторы Python.
- Идентификатор не может начинаться с цифры. Таким образом, если переменная1 действительна, то 1 переменная недействительна.
- Мы не можем использовать специальные символы, такие как!, #, @,%, $ И т. Д. В нашем Идентификаторе.
- Идентификатор может быть любой длины.
Хотя это жесткие правила для написания идентификаторов, также существуют некоторые соглашения об именах, которые не являются обязательными, а скорее рекомендуются передовыми методами.
- Имена классов начинаются с заглавной буквы. Все остальные идентификаторы начинаются со строчной буквы.
- Начало идентификатора с одного символа подчеркивания в начале указывает, что идентификатор является частным.
- Если идентификатор начинается и заканчивается двумя символами подчеркивания, это означает, что идентификатор является определяемым языком специальным именем.
- Хотя c = 10 допустимо, запись count = 10 будет иметь больше смысла, и было бы легче понять, что он делает, даже если вы посмотрите на свой код спустя долгое время.
- Несколько слов можно разделить подчеркиванием, например this_is_a_variable .
Вот пример программы для переменных Python.
myVariable = "привет, мир" печать (myVariable) var1 = 1 печать (var1) var2 = 2 печать (var2)
Если вы запустите программу, результат будет как на изображении ниже.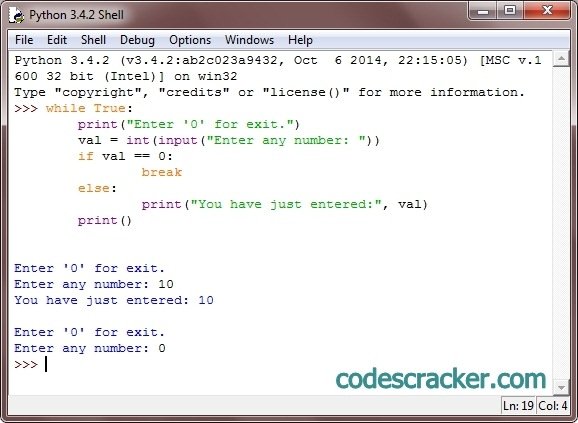
Заключение
Итак, на сегодня все. В следующем руководстве мы узнаем об утверждениях и комментариях Python. А пока #happy_coding 🙂
Что такое база данных NoSQL? Учимся, написав один на Python
NoSQL — это термин, который стал повсеместным в последние годы.Но что значит На самом деле имеется ввиду «NoSQL»? Чем и почему это полезно? В этой статье мы ответим эти вопросы, создав игрушечную базу данных NoSQL на чистом Python (или, как мне нравится чтобы назвать это «слегка структурированным псевдокодом»).
OldSQL
Для большинства SQL является синонимом «базы данных». SQL , аббревиатура от языка структурированных запросов ,
Однако сама по себе технология баз данных не является. Скорее, он описывает язык
с помощью которого извлекаются данные из RDBMS или Relational Database Management
Система .MySQL, PostgreSQL, MS SQL Server и Oracle — все это примеры
СУБД.
Слово «Relational» в сокращении RDBMS является наиболее информативным. Данные
организован в таблицу , каждая с набором из столбца с
связанный тип . Описание всех таблиц, их столбцов и
Типы столбцов называются схемой базы данных . Схема полностью
описывает структуру базы данных с описанием каждой таблицы.Например, таблица Car может иметь следующие столбцы:
- Марка: шнур
- Модель: шнур
- Год: четырехзначное число; как вариант, дата
- Цвет: шнурок
- VIN (идентификационный номер автомобиля): строка
Отдельная запись в таблице называется строкой или записью . Чтобы отличить один
запись от другого, обычно определяется первичный ключ . Первичный ключ для
таблица — это один из столбцов (или их комбинация), который однозначно определяет
каждый ряд.В таблице Car VIN является естественным выбором в качестве первичного ключа таблицы, поскольку он
гарантированно будет уникальным среди автомобилей. Две строки могут иметь одно и то же
значения для марки, модели, года и цвета, но относятся к разным автомобилям, то есть
у них будут разные VIN-номера. Если две строки имеют одинаковый VIN, мы даже не
необходимо проверить другие столбцы, они должны относиться к той же машине.
Две строки могут иметь одно и то же
значения для марки, модели, года и цвета, но относятся к разным автомобилям, то есть
у них будут разные VIN-номера. Если две строки имеют одинаковый VIN, мы даже не
необходимо проверить другие столбцы, они должны относиться к той же машине.
Запрос
SQL позволяет нам запросить эту базу данных для получения полезной информации. Для запрос просто означает задавать вопросы РСУБД на структурированном языке и интерпретировать строки, которые она возвращает, как ответ.Представьте, что в базе данных представлены все автомобили, зарегистрированные в США. Получить все записи, мы могли бы написать следующий SQL-запрос к базе данных:
ВЫБЕРИТЕ марку, модель автомобиля; |
Перевод SQL на простой английский может быть:
- «ВЫБРАТЬ»: «Покажи мне»
- «Марка, модель»: «значение марки и модели»
- «ИЗ вагона»: «для каждой строки в таблице автомобилей»
Или «Покажите мне значение марки и модели для каждой строки в таблице автомобилей» . Мы возвращали список результатов, каждый с маркой и моделью. Если
мы заботились только о цвете машин 1994 года, можно сказать:
Мы возвращали список результатов, каждый с маркой и моделью. Если
мы заботились только о цвете машин 1994 года, можно сказать:
ВЫБЕРИТЕ цвет ОТ автомобиля, ГДЕ Год = 1994; |
В этом случае мы вернем список вроде
Черный Красный Красный Белый Синий Черный Белый Желтый
Наконец, используя первичный ключ таблицы , мы можем найти конкретную машину по поиск VIN:
SELECT * FROM Car, где VIN = '2134AFGER245267'; |
Это даст нам особые свойства этого автомобиля.
Первичные ключи определены как уникальные . То есть конкретная машина с определенным VIN должен появляться в таблице только один раз. Почему это важно? Давайте посмотрите на пример:
Отношения
Представьте, что мы занимаемся ремонтом автомобилей. Помимо прочего, нам нужно отслеживать
истории обслуживания автомобиля: запись всех ремонтов и настроек, которые мы
выступал на этой машине. Мы могли бы создать таблицу
Мы могли бы создать таблицу ServiceHistory с
следующие столбцы:
- VIN
- Марка
- Модель
- Год
- Цвет
- Выполнено обслуживание
- Механик
- Цена
- Дата
Таким образом, каждый раз, когда машина приезжает на сервис, мы добавляем новую строку в таблицу со всей информацией об автомобиле, а также о том, что мы с ним сделали, кто механик была, сколько это стоило и когда была оказана услуга.
Но подождите. Все столбцы, относящиеся к самому автомобилю, всегда одинаковы для такая же машина. То есть, если я привезу свой черный Lexus RX 350 2014 года 10 раз для обслуживания, Мне нужно будет каждый раз записывать марку, модель, год и цвет, даже если они не изменится. Вместо того, чтобы повторять всю эту информацию, имеет смысл храните его один раз и ищите при необходимости.
Как бы мы это сделали? Мы бы создали вторую таблицу: Vehicle , со следующими
столбцы:
- VIN
- Марка
- Модель
- Год
- Цвет
Для таблицы ServiceHistory теперь мы хотим сократить до следующего
столбцы:
- VIN
- Выполнено обслуживание
- Механик
- Цена
- Дата
Почему VIN указан в обеих таблицах? Потому что нам нужен способ указать, что это Автомобиль в таблице ServiceHistory относится к , который автомобиль в Автомобиль стол. Таким образом, нам нужно сохранить информацию о конкретном автомобиле только один раз.
Каждый раз, когда он поступает в ремонт, мы создаем новую строку в
Таким образом, нам нужно сохранить информацию о конкретном автомобиле только один раз.
Каждый раз, когда он поступает в ремонт, мы создаем новую строку в ServiceHistory .
таблица , но не таблица Vehicle ; в конце концов, это та же машина.
Мы также можем выдавать запросы, которые охватывают неявную связь между Vehicle и ServiceHistory :
ВЫБЕРИТЕ Автомобиль.Модель, Автомобиль.ГОД ОТ ТС, ServiceHistory ГДЕ Автомобиль.VIN = ServiceHistory.VIN И ServiceHistory.Price> 75.00; |
Этот запрос пытается определить модель и год для всех автомобилей, для которых были произведены затраты на ремонт.
более 75 долларов США. Обратите внимание, что мы указываем способ сопоставления строк из
Таблица транспортных средств со строками в таблице ServiceHistory должна соответствовать значениям VIN.
Он возвращает нам набор строк со столбцами обеих таблиц. Мы
уточните это, сказав, что нам нужны только столбцы «Модель» и «Год» в таблице «Транспортное средство».
Если в нашей базе данных нет индексов (или, вернее, индексов), запрос выше должен быть выполнить сканирование таблицы , чтобы найти строки, соответствующие нашему запросу. Сканирование стола — это проверка каждая строка в таблице по порядку и заведомо медленная. Конечно, они представляют собой самый медленный из возможных методов выполнения запроса.
Сканирования таблицы можно избежать, используя индекс для столбца или набора столбцов.
Думайте об индексах как о структурах данных, которые позволяют нам найти конкретное значение.
(или диапазон значений) в индексированном столбце очень быстро, предварительно отсортировав
значения.То есть, если бы у нас был индекс в столбце Price, вместо того, чтобы искать
поочередно через все строки, чтобы определить, была ли цена выше
чем 75.00 , мы могли бы просто использовать информацию, содержащуюся в индексе
«прыгнуть» в первую строку с ценой больше 75,00 и возвращать каждые
последующая строка (которая будет иметь цену не ниже 75,00 , поскольку
индекс упорядочен).
При работе с нетривиальными объемами данных индексы становятся незаменимым инструмент для повышения скорости запросов.Однако, как и все, за них приходится платить: структура данных индекса потребляет память, которая в противном случае могла бы использоваться для хранить больше данных в базе данных. Это компромисс, который нужно изучить в каждом индивидуальный случай, но это очень часто индексирует часто запрашиваемые столбцы.
Ящик
Расширенные функции, такие как индексы, возможны благодаря способности базы данных проверить схему таблицы (описание типа данных в каждом столбце держит) и принимать рациональные решения на основе данных.То есть к базе данных Таблица — это противоположность «черного ящика» (чистого ящика?).
Помните об этом факте, когда мы говорим о базах данных NoSQL. Это становится важная часть обсуждения относительно возможности запроса различных типы движков баз данных.
Схемы
Схема таблицы , как мы узнали, является описанием имен столбцов.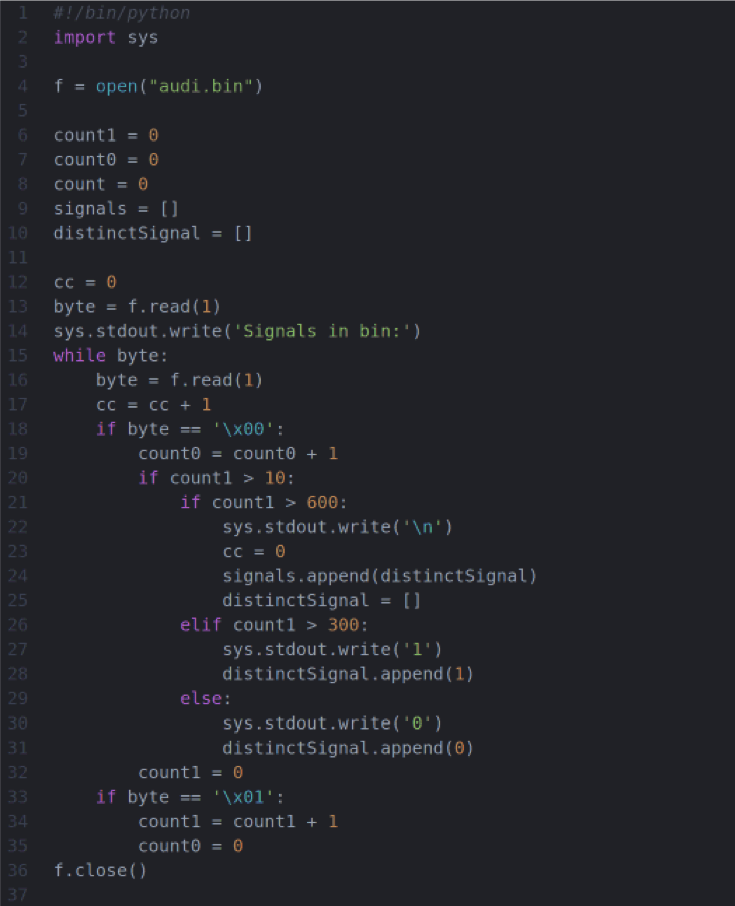 и тип данных, которые они содержат. Он также содержит такую информацию, как
столбцы могут быть пустыми, которые должны быть уникальными, и все другие ограничения на значения столбцов.Таблица может иметь только одну схему в любой момент времени.
и все строки в таблице должны соответствовать схеме .
и тип данных, которые они содержат. Он также содержит такую информацию, как
столбцы могут быть пустыми, которые должны быть уникальными, и все другие ограничения на значения столбцов.Таблица может иметь только одну схему в любой момент времени.
и все строки в таблице должны соответствовать схеме .
Это важное ограничение. Представьте, что у вас есть таблица базы данных с миллионы строк информации о клиентах. Ваша команда продаж хотела бы начать сбор дополнительных данных (скажем, возраста пользователя) для повышения точности своего алгоритма электронного маркетинга. Для этого вам необходимо изменить таблицу, добавив столбец. Вам также необходимо решить, нужно ли каждой строке в таблице значение для этот столбец.Часто имеет смысл сделать столбец обязательным, но для этого потребуется информация, к которой у нас просто нет доступа (например, возраст каждого пользователя уже в базе данных). Поэтому в этом отношении часто идут на компромиссы.
Кроме того, изменение схемы очень больших таблиц базы данных редко
простое дело. Важно иметь план отката на случай, если что-то пойдет не так,
но не всегда возможно отменить изменение схемы после того, как оно было сделано. Схема
обслуживание, вероятно, одна из самых сложных частей работы администратора баз данных.
Важно иметь план отката на случай, если что-то пойдет не так,
но не всегда возможно отменить изменение схемы после того, как оно было сделано. Схема
обслуживание, вероятно, одна из самых сложных частей работы администратора баз данных.
Хранилища ключей / значений
Задолго до того, как появился термин «NoSQL», хранилище данных ключей / значений , например, memcached предоставил хранилище для данных без накладных расходов на схему таблицы. Действительно, в K / V
магазинов, «столиков» нет вообще. Есть просто ключи и значения .
Если хранилище ключей / значений звучит знакомо, это потому, что оно построено на том же
принципы, как Python dict и , устанавливают классы : использование хэш-таблиц для предоставления
быстрый ключевой доступ к данным.Самая примитивная база данных NoSQL на Python
был бы просто большим словарем.
Чтобы понять, как они работают, напишем сами! Начнем с очень простой дизайн:
- Python
dictв качестве основного хранилища данных - Поддерживает только строки в качестве ключей
- Поддержка хранения целых чисел, строк и списков
- Простой сервер TCP / IP, использующий строки ASCII для обмена сообщениями
- Немного продвинутые команды, такие как
INCREMENT,DELETE,APPENDиSTATS
Преимущество построения хранилища данных с интерфейсом TCP / IP на основе ASCII:
что мы можем использовать простую программу telnet для взаимодействия с нашим сервером; нет
нужен специальный клиент (хотя написание его было бы хорошим упражнением и может быть
сделано примерно в 15 строках).
Нам нужен «формат провода» для сообщений, которые мы отправляем на сервер, и для ответы он отправляет обратно. Вот приблизительная спецификация:
Поддерживаемые команды
- PUT
- Аргументы: ключ, значение
- Цель: вставить новую запись в хранилище данных
- GET
- Аргументы: ключ
- Цель: получить сохраненное значение из хранилища данных
- PUTLIST
- Аргументы: ключ, значение
- Цель: вставить новую запись списка в хранилище данных
- GETLIST
- Аргументы: Ключ
- Цель: получить сохраненный список из хранилища данных
- ПРИЛОЖЕНИЕ
- Аргументы: ключ, значение
- Цель: добавить элемент в существующий список в хранилище данных
- INCREMENT
- Аргументы: ключ
- Цель: увеличить значение целого числа в хранилище данных
- УДАЛИТЬ
- Аргументы: Ключ
- Цель: Удалить запись из хранилища данных
- СТАТИСТИКИ
- Аргументы: Н / Д
- Цель: запросить статистику о количестве успешных / неудачных выполнений каждой команды было выполнено
Теперь давайте определим саму структуру сообщения.
Структура сообщения
Запрос сообщений
Сообщение запроса состоит из команды, ключа, значения и типа значения. В
последние три необязательны в зависимости от сообщения. A ; используется как разделитель.
Всегда должно быть три ; символов в сообщении, даже если некоторые необязательные
поля не включены.
КОМАНДА; [КЛЮЧ]; [ЗНАЧЕНИЕ]; [ТИП ЗНАЧЕНИЯ]
- КОМАНДА — это команда из списка выше
- KEY — строка, которая будет использоваться в качестве ключа хранилища данных (необязательно)
- ЗНАЧЕНИЕ — целое число, список или строка, которая должна быть сохранена в хранилище данных (необязательно).
- Списки представлены в виде последовательностей строк, разделенных запятыми, например.г. «красный, зеленый, синий»
- VALUE TYPE описывает, какой тип VALUE следует интерпретировать как
- Возможные значения: INT, STRING, LIST
Примеры
«PUT; foo; 1; INT»
«GET; foo ;;»
«СПИСОК; bar; a, b, c; LIST»
«ПРИЛОЖЕНИЕ; бар; d; СТРОКА
«GETLIST; bar ;;»
«СТАТИСТИКА ;;;»
«ПРИЛОЖЕНИЕ; foo ;;»
«УДАЛИТЬ; foo ;;»
Ответные сообщения
Ответное сообщение состоит из двух частей, разделенных точкой ; . Первая часть всегда
Первая часть всегда Истина | Ложь в зависимости от того, была ли команда успешной. Вторая часть — это командное сообщение.
В случае ошибок это будет описывать ошибку. При успешных командах, которые не
ожидайте возврата значения (например, PUT ), это будет сообщение об успешном завершении. За
команды, которые ожидают возврата значения (например, GET ), это будет значение
сам.
Примеры
«True; для ключа [foo] установлено значение [1]»
«Истина; 1»
«True; Key [bar] установлен на [[‘a’, ‘b’, ‘c’]]»
«Верно; к ключу [bar] добавлено значение [d]»
«Верно; [‘a’, ‘b’, ‘c’, ‘d’]
«True; {‘PUTLIST’: {‘success’: 1, ‘error’: 0}, ‘STATS’: {‘success’: 0, ‘error’: 0}, ‘INCREMENT’: {‘success’: 0, ‘error’: 0}, ‘GET’: {‘success’: 0, ‘error’: 0}, ‘PUT’: {‘success’: 0, ‘error’: 0}, ‘GETLIST’: { ‘success’: 1, ‘error’: 0}, ‘APPEND’: {‘success’: 1, ‘error’: 0}, ‘DELETE’: {‘success’: 0, ‘error’: 0}} »
Покажи мне код!
Я представлю код по частям. Весь сервер работает только на
менее 180 строк кода, поэтому его можно быстро прочитать.
Весь сервер работает только на
менее 180 строк кода, поэтому его можно быстро прочитать.
Настройка
Ниже приведен стандартный код установки, необходимый для нашего сервера:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | "" "База данных NoSQL, написанная на Python." ""
# Импорт стандартной библиотеки
импортный сокет
ХОСТ = 'локальный'
ПОРТ = 50505
РАЗЪЕМ = socket.socket (socket.AF_INET, socket.SOCK_STREAM)
СТАТИСТИКА = {
'PUT': {'успех': 0, 'ошибка': 0},
'GET': {'успех': 0, 'ошибка': 0},
'GETLIST': {'успех': 0, 'ошибка': 0},
'PUTLIST': {'успех': 0, 'ошибка': 0},
'INCREMENT': {'успех': 0, 'ошибка': 0},
"ПРИЛОЖЕНИЕ": {"успех": 0, "ошибка": 0},
'УДАЛИТЬ': {'успех': 0, 'ошибка': 0},
'СТАТИСТИКА': {'успех': 0, 'ошибка': 0},
}
|
Здесь особо не на что смотреть, только импорт и некоторая инициализация данных.
Настройка (продолжение)
Теперь я пропущу немного кода, чтобы показать остальную часть кода установки. Запись
что это относится к функциям, которые еще не существуют. Это нормально, раз уж я прыгаю
вокруг. В полной версии (представленной в конце) все в правильном
заказ. Вот остальной код установки:
Запись
что это относится к функциям, которые еще не существуют. Это нормально, раз уж я прыгаю
вокруг. В полной версии (представленной в конце) все в правильном
заказ. Вот остальной код установки:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 год 22 23 24 25 26 27 28 29 30 31 год 32 33 34 35 год 36 37 38 39 40 41 год 42 43 44 | COMMAND_HANDLERS = {
'PUT': handle_put,
'GET': handle_get,
'GETLIST': handle_getlist,
'PUTLIST': handle_putlist,
'INCREMENT': handle_increment,
"ПРИЛОЖЕНИЕ": handle_append,
'УДАЛИТЬ': handle_delete,
"СТАТИСТИКА": handle_stats,
}
ДАННЫЕ = {}
def main ():
"" "Основная точка входа для скрипта."" "
SOCKET.bind ((ХОЗЯИН, ПОРТ))
SOCKET.listen (1)
а 1:
соединение, адрес = SOCKET.accept ()
print 'Новое соединение от [{}]'. формат (адрес)
data = connection.recv (4096) .decode ()
команда, ключ, значение = parse_message (данные)
если command == 'STATS':
ответ = handle_stats ()
команда elif в (
'ПОЛУЧИТЬ',
'GETLIST',
"УВЕЛИЧЕНИЕ",
'УДАЛЯТЬ'
):
response = COMMAND_HANDLERS [команда] (ключ)
команда elif в (
'ПОЛОЖИТЬ',
"СПИСОК",
"ПРИЛОЖЕНИЕ",
):
response = COMMAND_HANDLERS [команда] (ключ, значение)
еще:
response = (False, 'Неизвестный тип команды [{}]'. |
 формат (команда))
update_stats (команда, ответ [0])
connection.sendall ('{}; {}'. формат (ответ [0], ответ [1]))
connection.close ()
если __name__ == '__main__':
главный()
формат (команда))
update_stats (команда, ответ [0])
connection.sendall ('{}; {}'. формат (ответ [0], ответ [1]))
connection.close ()
если __name__ == '__main__':
главный()
Мы создали так называемую справочную таблицу с именем COMMAND_HANDLERS . Это работает
связывание имени команды с функцией, используемой для обработки команд
тот тип. Так, например, если мы получаем команду GET , говоря COMMAND_HANDLERS [команда] (ключ) то же самое, что сказать handle_get (ключ) .Помните, что функции можно рассматривать как значения и сохранять в dict , например,
любое другое значение.
В приведенном выше коде я решил обрабатывать каждую группу команд, требующих одного и того же
количество аргументов отдельно. Я мог бы просто заставить все handle_ функции для принятия ключа и значения , я просто решил, что это было сделано
функции обработчика более понятны, легче тестируются и меньше подвержены ошибкам.
Обратите внимание, что код сокета минимальный.Хотя весь наш сервер основан на Связь TCP / IP, на самом деле мало взаимодействия с низкоуровневыми сетевой код.
Последнее, на что стоит обратить внимание, настолько безобидно, что вы могли его пропустить: DATA толковый словарь. Здесь мы будем хранить пары ключ-значение, которые составляют
наша база данных.
Командный синтаксический анализатор
Давайте посмотрим на синтаксический анализатор команд , отвечающий за понимание входящие сообщения:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | def parse_message (данные):
"" "Вернуть кортеж, содержащий команду, ключ и (необязательно)
значение приведено к соответствующему типу."" "
команда, ключ, значение, тип_значения = data.strip (). split (';')
если value_type:
если value_type == 'LIST':
значение = значение.split (',')
elif value_type == 'INT':
значение = int (значение)
еще:
значение = str (значение)
еще:
значение = Нет
команда возврата, ключ, значение
|
Здесь мы видим, как происходит преобразование типа. Если значение должно быть списком,
мы знаем, что можем создать правильную стоимость, позвонив по адресу
Если значение должно быть списком,
мы знаем, что можем создать правильную стоимость, позвонив по адресу str.split (',') на
строка. Для int мы просто используем тот факт, что int () может принимать
струны. То же для струнных и str () .
Обработчики команд
Ниже приведен код обработчиков команд. Все они довольно прямолинейны и (надеюсь) выглядеть так, как вы ожидаете. Обратите внимание, здесь много ошибок проверка, но, конечно, не исчерпывающая. Пока вы читаете, попытайтесь найти случаи ошибок, которые код пропускает, и опубликуйте их в обсуждении.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 год 22 23 24 25 26 27 28 29 30 31 год 32 33 34 35 год 36 37 38 39 40 41 год 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 год 82 83 84 85 86 87 88 89 90 91 92 93 | def update_stats (команда, успех):
"" "Обновите STATS dict информацией о том, выполняется ли
* команда * была * успешной *. |
 "" "
в случае успеха:
СТАТИСТИКА [команда] ['успех'] + = 1
еще:
СТАТИСТИКА [команда] ['ошибка'] + = 1
def handle_put (ключ, значение):
"" "Вернуть кортеж, содержащий True и сообщение
отправить обратно клиенту."" "
ДАННЫЕ [ключ] = значение
return (True, 'Ключ [{}] установлен на [{}]'. формат (ключ, значение))
def handle_get (ключ):
"" "Вернуть кортеж, содержащий True, если ключ существует и сообщение
отправить обратно клиенту. "" "
если ключ не в ДАННЫХ:
return (False, 'ОШИБКА: ключ [{}] не найден'. формат (ключ))
еще:
return (True, DATA [ключ])
def handle_putlist (ключ, значение):
"" "Вернуть кортеж, содержащий True, если команда выполнена успешно и сообщение
отправить обратно клиенту. "" "
return handle_put (ключ, значение)
def handle_getlist (ключ):
"" "Вернуть кортеж, содержащий True, если ключ содержит список и
сообщение для отправки обратно клиенту."" "
return_value = существует, значение = handle_get (ключ)
если не существует:
return return_value
elif not isinstance (значение, список):
возвращение (
Ложь,
'ОШИБКА: ключ [{}] содержит значение, не входящее в список ([{}])'.
"" "
в случае успеха:
СТАТИСТИКА [команда] ['успех'] + = 1
еще:
СТАТИСТИКА [команда] ['ошибка'] + = 1
def handle_put (ключ, значение):
"" "Вернуть кортеж, содержащий True и сообщение
отправить обратно клиенту."" "
ДАННЫЕ [ключ] = значение
return (True, 'Ключ [{}] установлен на [{}]'. формат (ключ, значение))
def handle_get (ключ):
"" "Вернуть кортеж, содержащий True, если ключ существует и сообщение
отправить обратно клиенту. "" "
если ключ не в ДАННЫХ:
return (False, 'ОШИБКА: ключ [{}] не найден'. формат (ключ))
еще:
return (True, DATA [ключ])
def handle_putlist (ключ, значение):
"" "Вернуть кортеж, содержащий True, если команда выполнена успешно и сообщение
отправить обратно клиенту. "" "
return handle_put (ключ, значение)
def handle_getlist (ключ):
"" "Вернуть кортеж, содержащий True, если ключ содержит список и
сообщение для отправки обратно клиенту."" "
return_value = существует, значение = handle_get (ключ)
если не существует:
return return_value
elif not isinstance (значение, список):
возвращение (
Ложь,
'ОШИБКА: ключ [{}] содержит значение, не входящее в список ([{}])'.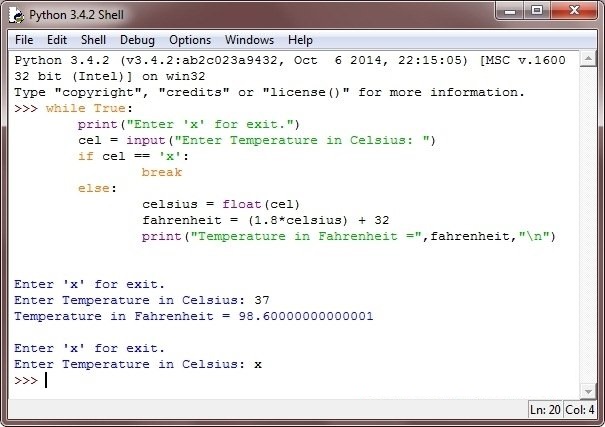 Формат (ключ, значение)
)
еще:
return return_value
def handle_increment (ключ):
"" "Вернуть кортеж, содержащий True, если значение ключа можно увеличить
и сообщение для отправки обратно клиенту. "" "
return_value = существует, значение = handle_get (ключ)
если не существует:
return return_value
elif not isinstance (значение, целое число):
возвращение (
Ложь,
'ОШИБКА: Ключ [{}] содержит значение, отличное от int ([{}])'.формат (ключ, значение)
)
еще:
ДАННЫЕ [ключ] = значение + 1
return (True, 'Ключ [{}] увеличен'. формат (ключ))
def handle_append (ключ, значение):
"" "Вернуть кортеж, содержащий True, если значение ключа можно добавить к
и сообщение для отправки обратно клиенту. "" "
return_value = существует, list_value = handle_get (ключ)
если не существует:
return return_value
elif not isinstance (list_value, list):
возвращение (
Ложь,
«ОШИБКА: ключ [{}] содержит значение, не входящее в список ([{}])».
Формат (ключ, значение)
)
еще:
return return_value
def handle_increment (ключ):
"" "Вернуть кортеж, содержащий True, если значение ключа можно увеличить
и сообщение для отправки обратно клиенту. "" "
return_value = существует, значение = handle_get (ключ)
если не существует:
return return_value
elif not isinstance (значение, целое число):
возвращение (
Ложь,
'ОШИБКА: Ключ [{}] содержит значение, отличное от int ([{}])'.формат (ключ, значение)
)
еще:
ДАННЫЕ [ключ] = значение + 1
return (True, 'Ключ [{}] увеличен'. формат (ключ))
def handle_append (ключ, значение):
"" "Вернуть кортеж, содержащий True, если значение ключа можно добавить к
и сообщение для отправки обратно клиенту. "" "
return_value = существует, list_value = handle_get (ключ)
если не существует:
return return_value
elif not isinstance (list_value, list):
возвращение (
Ложь,
«ОШИБКА: ключ [{}] содержит значение, не входящее в список ([{}])». формат (ключ, значение)
)
еще:
ДАННЫЕ [ключ] .append (значение)
return (True, 'Ключ [{}] имел значение [{}] добавлено'. формат (ключ, значение) »
def handle_delete (ключ):
"" "Вернуть кортеж, содержащий True, если ключ можно удалить и
сообщение для отправки обратно клиенту. "" "
если ключ не в ДАННЫХ:
возвращение (
Ложь,
«ОШИБКА: ключ [{}] не найден и не может быть удален». Формат (ключ)
)
еще:
del DATA [ключ]
def handle_stats ():
"" "Вернуть кортеж, содержащий True и содержимое словаря STATS."" "
return (True, str (STATS))
формат (ключ, значение)
)
еще:
ДАННЫЕ [ключ] .append (значение)
return (True, 'Ключ [{}] имел значение [{}] добавлено'. формат (ключ, значение) »
def handle_delete (ключ):
"" "Вернуть кортеж, содержащий True, если ключ можно удалить и
сообщение для отправки обратно клиенту. "" "
если ключ не в ДАННЫХ:
возвращение (
Ложь,
«ОШИБКА: ключ [{}] не найден и не может быть удален». Формат (ключ)
)
еще:
del DATA [ключ]
def handle_stats ():
"" "Вернуть кортеж, содержащий True и содержимое словаря STATS."" "
return (True, str (STATS))
Две вещи, на которые следует обратить внимание: использование множественного назначения и повторное использование кода. А
количество функций - это просто оболочки вокруг существующих функций с небольшим
больше логики, например, handle_get и handle_getlist . Поскольку мы
иногда просто отправка результатов существующей функции и других
раз проверяя, что эта функция вернула, используется множественное присваивание .
Посмотрите на handle_append . Если мы попытаемся вызвать handle_get , а ключ не
существуют, мы можем просто вернуть именно то, что вернул handle_get . Таким образом, мы хотели бы
чтобы иметь возможность ссылаться на кортеж, возвращаемый handle_get , как на один возврат
значение. Это позволяет нам просто сказать, что возвращает return_value , если ключ не существует.
Если это действительно существует, нам нужно проверить значение, которое было возвращено. Таким образом,
мы также хотели бы называть возвращаемое значение handle_get отдельным
переменные.Чтобы обработать как описанный выше случай, так и случай, когда нам нужно обработать
результаты по отдельности, мы используем множественное присвоение. Это дает нам лучшее из
оба мира, не требующие нескольких строк, где наша цель неясна. return_value = exists, list_value = handle_get (key) явно указывает, что мы
будет ссылаться на значение, возвращаемое handle_get как минимум в двух
различные пути.
Как это база данных?
Вышеупомянутая программа определенно не является СУБД, но она определенно квалифицируется как База данных NoSQL.Причина, по которой это было так легко создать, заключается в том, что у нас нет реальное взаимодействие с данными . Мы выполняем минимальную проверку типов, но в остальном просто сохраните все, что отправляет пользователь. Если нам нужно было хранить более структурированные данные, нам, вероятно, потребуется создать схему для базы данных и ссылаться на нее, пока хранение и получение данных.
Итак, если базы данных NoSQL проще писать, легче поддерживать и проще Причина в том, почему бы нам всем просто не запустить экземпляры mongoDB и покончить с этим? Конечно, есть компромисс за всю эту гибкость данных, которую NoSQL базы данных предоставляют нам: возможность поиска.
Запрос данных
Представьте, что мы использовали нашу базу данных NoSQL, указанную выше, для хранения ранее полученных данных об автомобилях. Мы
может хранить их, используя VIN в качестве ключа и список значений в каждом столбце
значение, например
Мы
может хранить их, используя VIN в качестве ключа и список значений в каждом столбце
значение, например 2134AFGER245267 = ['Lexus', 'RX350', 2013, черный] . Конечно,
мы потеряли , что означает каждого индекса в списке. Мы просто должны помнить
где-то один индекс хранит марку автомобиля, а второй индекс хранит
Год.
Хуже того, что происходит, когда мы хотим выполнить некоторые из предыдущих запросов? Чтобы
найти цвета всех автомобилей с 1994 года становится кошмаром.Мы должны идти
через каждое значение в ДАННЫЕ , каким-то образом определить, хранит ли значение автомобиль
data или что-то еще, посмотрите на индекс два, затем возьмите значение индекса
три, если индекс два равен 1994. Это намного хуже, чем сканирование таблицы, поскольку
он не только сканирует каждую строку в хранилище данных, но и должен применять несколько
сложный набор правил для ответа на запрос.
Авторы баз данных NoSQL, конечно, знают об этих проблемах, и (поскольку
запросы, как правило, полезная функция) придумали несколько способов
сделать запросы возможными.-min-250x250.png) Один из способов - структурировать данные, используя, например, JSON и
разрешить ссылки на другие строки для представления отношений. Кроме того, большинство
Базы данных NoSQL имеют некоторую концепцию пространств имен, в которых данные одного типа могут
храниться в собственном «разделе» базы данных, что позволяет механизму запросов выполнять
использование того факта, что ему известна "форма" запрашиваемых данных.
Один из способов - структурировать данные, используя, например, JSON и
разрешить ссылки на другие строки для представления отношений. Кроме того, большинство
Базы данных NoSQL имеют некоторую концепцию пространств имен, в которых данные одного типа могут
храниться в собственном «разделе» базы данных, что позволяет механизму запросов выполнять
использование того факта, что ему известна "форма" запрашиваемых данных.
Конечно, существуют (и реализуются) гораздо более сложные подходы к повысить удобство запросов, но всегда будет существовать компромисс между хранением данные без схемы и возможность запросов.Наша база данных, например, поддерживает только запрос по ключу. Все стало бы намного сложнее, если бы нам нужно было поддерживать более богатый набор запросов.
Сводка
Надеюсь, теперь понятно, что означает «NoSQL». Мы немного изучили SQL и
как работают СУБД. Мы видели, как данные извлекаются из СУБД (с использованием запросов SQL ).
Мы создали игрушечную базу данных NoSQL, чтобы изучить компромиссы между запросами. и простота. Мы также обсудили несколько способов решения этой проблемы авторами баз данных.
и простота. Мы также обсудили несколько способов решения этой проблемы авторами баз данных.
Тема баз данных, даже простых хранилищ ключей и значений, невероятно глубока. Мы просто коснулись здесь поверхности. Надеюсь, вы узнали немного о том, что означает NoSQL, как он работает и когда его следует использовать. Вы можете продолжить разговор в Чате для умных людей, доска обсуждений для этого сайта.
Опубликовано , Джефф Кнупп .