Курс Алгоритмы и структуры данных. Базовый курс.. Эффективные решения вычислительных задач | Обучение программированию онлайн | GeekBrains
Бесплатная помощь в подборе профессии
Бесплатная помощь в подборе курса
Бесплатная помощь в подборе профессии
Бесплатная помощь в подборе курса
Бесплатная помощь в подборе профессии
Бесплатная помощь в подборе курса
ближайшее время10:0010:3011:0011:3012:0012:3013:0013:3014:0014:3015:0015:3016:0016:3017:0017:3018:0018:3019:00
8 800 700-68-41Бесплатно по России
Эффективные решения вычислительных задач
Фундаментальный курс «прокачивает» базовые знания computer science. Дает понимание, как работает язык программирования и действуют применяемые в коде команды и решения. На примере языка С студенты смогут «пощупать» механизмы, которые лежат в основе современных фреймворков. Курс дает знания, отличающие программиста от «юзера», пишущего код.
Чему Вы научитесь
- Владеть основами программирования на языке C;
- Знать структуры данных и алгоритмы, которые лежат в основе их работы;
- Владеть общими подходами и полезными методиками для решения сложных задач;
- использовать инструменты оценки сложности решаемых задач;
- Создавать консольные программы на языке C в среде разработки QT;
- Создавать программы, используя собственные алгоритмы;
- Создавать собственные структуры данных: стеки, списки, деревья и др.
 ;
;
- Оценивать производительность программ;
- Использовать «незащищенный» режим работы с памятью, основанный на указателях;
- Динамически выделять и освобождать память;
- Использовать рекурсию.
 ;
;
Что Вы получите
Видеозаписи всех онлайн-занятий
Методички и практические задания
Общение с одногруппниками
Сертификат об окончании обучения
Средние оценки
4.7 / 5
Программа
4.8 / 5
Преподаватель
Преподаватели
Иван Овчинников
4.9
Ср. оценка
Дмитрий Анзин
4.8
Ср. оценка
Сергей Камянецкий
4.8
Ср. оценка
GeekBrains
4.8
Ср. оценка
Ярослав Меньшиков
4.7
Ср. оценка
Максим Горозий
4.7
Ср.
 оценка
оценкаАндрей Заярный
4.7
Ср. оценка
Татьяна Жданова
4.3
Ср. оценка
Михаил Цуканов
4.3
Ср. оценка
- Программа курса
- Отзывы выпускников • 521
1
Урок 1. Простые алгоритмы
Введение в C. Структуры. Алгоритмы.
2
Урок 2. Асимптотическая сложность алгоритма. Рекурсия
Асимптотическая сложность алгоритма. Рекурсивный перебор. Ханойская башня.
3
Урок 3. Поиск в массиве. Простые сортировки
Поиск в одномерном массиве. Интерполяционный поиск. Сортировка массива.
4
Урок 4. Динамическое программирование. Поиск возвратом
Наибольшая общая подпоследовательность. Динамическое программирование. Поиск с возвратом.
 Задача о восьми ферзях.
Задача о восьми ферзях.5
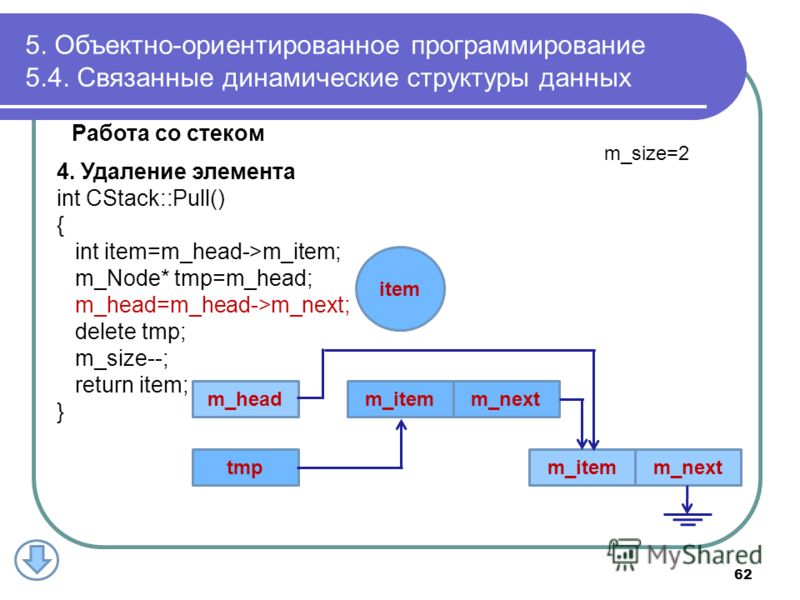
Урок 5. Динамические структуры данных
Стек, очередь. Создание стека с использованием массива. Динамические структуры данных.
6
Урок 6. Деревья
Двоичные деревья поиска. Хеш-функция. MD5. Хеш-таблицы.
7
Урок 7. Графы. Алгоритмы на графах.
Графы, обход графа в ширину и глубину. Волновой алгоритм. «Жадные алгоритмы».
8
Урок 8. Сложные сортировки
👨🎓️ Алгоритмы и структуры данных на C++ для новичков. Часть 1: Основы анализа алгоритмов
Если хочешь подтянуть свои знания, загляни на наш курс «Алгоритмы и структуры данных», на котором ты:
- углубишься в решение практических задач;
- узнаешь все про сложные алгоритмы, сортировки, сжатие данных и многое другое.

Ты также будешь на связи с преподавателем и другими студентами.
В итоге будешь браться за сложные проекты и повысишь чек за свою работу 🙂
Интересно, хочу попробовать
***
Цель цикла
Этот цикл статей представляет собой краткое введение в алгоритмы и структуры данных. Будучи кратким руководством, он не является исчерпывающим пособием, а охватывает только самые важные темы. Целевая аудитория – читатели, желающие узнать об алгоритмах, но не имеющие времени на чтение книг, глубоко освещающих этот предмет. Например, серия должна заинтересовать читателей, готовящихся к предстоящему собеседованию. Статьи не требуют от читателя предварительной подготовки, связанную с алгоритмами и структурами данных, но определенные знания в программировании на C++ необходимы.
Что такое алгоритм?
Алгоритм – это совокупность четко сформулированных инструкций, которые решают точно обозначенную задачу, если им следовать. Здесь решение задачи подразумевает преобразование входных данных в желаемый конечный результат. К примеру, сортировка – это задача упорядочивания последовательности чисел в порядке возрастания. Более формально мы можем определить эту проблему в виде входных и выходных данных: входными данными является любая последовательность чисел, а выходными – перестановка входной последовательности, при которой меньшие элементы располагаются перед большими. Алгоритм можно считать правильным, если для каждого из возможных входных данных он дает желаемый результат. Алгоритм должен быть однозначным, то есть инструкции должны быть понятными и иметь только единственное толкование. Алгоритм также не должен выполняться бесконечно и завершаться после конечного числа действий.
Здесь решение задачи подразумевает преобразование входных данных в желаемый конечный результат. К примеру, сортировка – это задача упорядочивания последовательности чисел в порядке возрастания. Более формально мы можем определить эту проблему в виде входных и выходных данных: входными данными является любая последовательность чисел, а выходными – перестановка входной последовательности, при которой меньшие элементы располагаются перед большими. Алгоритм можно считать правильным, если для каждого из возможных входных данных он дает желаемый результат. Алгоритм должен быть однозначным, то есть инструкции должны быть понятными и иметь только единственное толкование. Алгоритм также не должен выполняться бесконечно и завершаться после конечного числа действий.
Важность алгоритмов в информатике трудно переоценить. Они позволяют программисту реализовать эффективные, надежные и быстрые решения за короткий промежуток времени. Почти любые сложные программы на современных компьютерах в значительной степени опираются на алгоритмы. Операционные системы пользуются алгоритмами планирования, которые организуют и распределяют процессорное время между процессами, создавая иллюзию, что они выполняются одновременно. Многие умные алгоритмы, такие как растеризация, отсечение, back-face culling и сглаживание, служат для создания потрясающих 3D-миров в реальном времени. Алгоритмы позволяют найти кратчайший маршрут к месту назначения в городе, содержащем тысячи улиц. Благодаря алгоритмам машинного обучения произошла революция в таких областях, как распознавание изображений и речи. Перечисленные алгоритмы – это только вершина айсберга, и изучение этого предмета откроет множество дверей в карьере программиста.
Операционные системы пользуются алгоритмами планирования, которые организуют и распределяют процессорное время между процессами, создавая иллюзию, что они выполняются одновременно. Многие умные алгоритмы, такие как растеризация, отсечение, back-face culling и сглаживание, служат для создания потрясающих 3D-миров в реальном времени. Алгоритмы позволяют найти кратчайший маршрут к месту назначения в городе, содержащем тысячи улиц. Благодаря алгоритмам машинного обучения произошла революция в таких областях, как распознавание изображений и речи. Перечисленные алгоритмы – это только вершина айсберга, и изучение этого предмета откроет множество дверей в карьере программиста.
Больше полезной информации вы найдете на нашем телеграм-канале «Библиотека программиста».
Интересно, перейти к каналу
Пример алгоритма
Начнем мы наше путешествие в мир алгоритмов со знакомства с алгоритмом, который называется сортировкой вставками. Данный алгоритм является одним из многих методов решения ранее упомянутой задачи сортировки. Сортировка вставкой во многом напоминает то, как некоторые сортируют карты в своих руках. Представим, что у нас в руке имеются карты, которые уже отсортированы. Когда крупье передает нам новую карту, мы сразу кладем ее в правильное положение, чтобы карты оставались отсортированными. Мы повторяем это до тех пор, пока все карты не будут сданы. Концептуально сортировка вставкой делит массив на две части: отсортированную и неотсортированную. Поначалу отсортированная часть состоит только из первого элемента массива, а остальная его часть не отсортирована. Сортировка вставками на каждой итерации извлекает один элемент из несортированной части, определяет его местоположение в отсортированном списке и вставляет его туда. Этот процесс продолжается до тех пор, пока в несортированной части не останется ни одного элемента. Визуализация сортировки вставками:
Сортировка вставкой во многом напоминает то, как некоторые сортируют карты в своих руках. Представим, что у нас в руке имеются карты, которые уже отсортированы. Когда крупье передает нам новую карту, мы сразу кладем ее в правильное положение, чтобы карты оставались отсортированными. Мы повторяем это до тех пор, пока все карты не будут сданы. Концептуально сортировка вставкой делит массив на две части: отсортированную и неотсортированную. Поначалу отсортированная часть состоит только из первого элемента массива, а остальная его часть не отсортирована. Сортировка вставками на каждой итерации извлекает один элемент из несортированной части, определяет его местоположение в отсортированном списке и вставляет его туда. Этот процесс продолжается до тех пор, пока в несортированной части не останется ни одного элемента. Визуализация сортировки вставками:
Здесь отсортированный подмассив выделен синим цветом. Данная диаграмма не показывает, как именно сортировка вставками перемещает элементы из несортированного подмассива в сортированный.
- Сохраняет значение элемента во временной переменной;
- Перемещает все элементы, которые больше чем вставляемый элемент (расположенные перед этим элементом) на одно место вправо;
- Помещает значение временной переменной в освободившееся место.
Давайте подробнее рассмотрим этот процесс на примере:
Здесь, единственный элемент, который осталось вставить в отсортированный подмассив – это 4. Мы сохраняем это значение во временною переменную.
Мы сравниваем 4 с 7, и поскольку 7 больше, мы копируем его на позицию справа (значения, которые мы сравниваем с вставляемым элементом, обозначены фиолетовым).
Сравниваем 4 с 6, и поскольку 6 больше, копируем его на позицию справа.
Сравниваем 4 с 5, а поскольку 5 тоже больше чем 4, его тоже копируем его на позицию справа.
Наконец, мы сравниваем 4 с 3, и так как 3 меньше чем 4, мы присваиваем значение временной переменной на позицию рядом с ним. И теперь наша работа выполнена; мы расположили 4 в правильное положение.
Как правило, программисты описывают алгоритмы в виде псевдокода. Псевдокод – это неформальный способ описания алгоритмов, который не имеет строгого синтаксиса, свойственного языкам программирования и не требует соблюдения технологических соображений. Приведем пример псевдокода сортировки вставками:
PseudocodeInsertionSortn ← Array.size
For i=2 to n
j ← i – 1
temp ← Array[j]
While Array[j-1]>temp and j>0
Array[j] ← Array[j-1];
j ← j-1
Array[j] ← temp
Написание алгоритмов в псевдокоде порой бывает полезным, но поскольку эти статьи посвящены алгоритмам на C++, в дальнейшем мы сосредоточимся на реализации алгоритмов на C++. Пример программы на C++, которая реализует сортировку вставками:
Пример программы на C++, которая реализует сортировку вставками:
void insertionSort(int *array, int n)
{
for(int i=2;i<=n;++i)
{
int j=i-1;
int temp = array[j];
while(array[j-1]>temp)
{
array[j]=array[j-1];
--j;
}
array[j]=temp;
}
}
Основы анализа
Разработав алгоритм для решения задачи, нам необходимо определить, сколько ресурсов, таких как время и память, он потребляет. Ведь если алгоритму требуются годы для получения правильного результата или он занимает сотни терабайт, то на практике он непригоден. Также, алгоритмы, решающие одну и ту же задачу, могут потреблять разное количество ресурсов в зависимости от входных данных, поэтому при выборе алгоритма необходим тщательный анализ.
При изучении алгоритмов мы редко обращаем внимание на детали реализации языков программирования и компьютеров.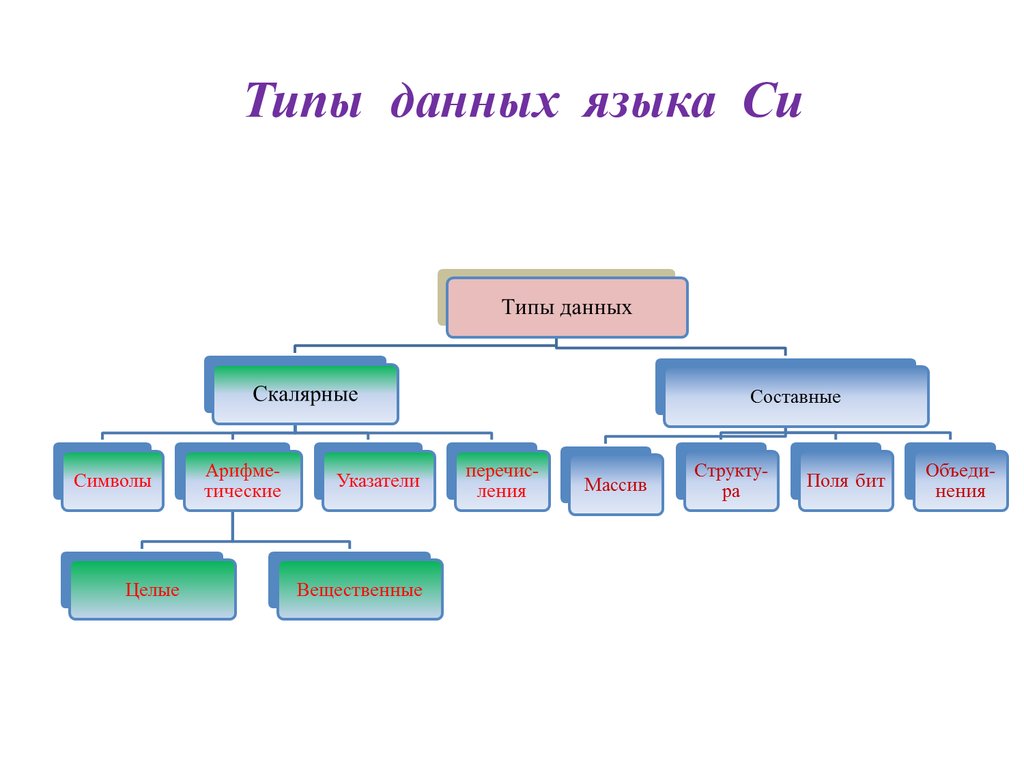 Учитывая, насколько быстро развивается компьютерная индустрия, такие детали постоянно меняются. С другой стороны, алгоритмы сами по себе неподвластны времени. Следовательно, нам нужен метод оценки производительности алгоритма в независимости от компьютера, на котором он работает. Два основных средства, используемые нами для этой цели, это – абстрактная модель машины (компьютера) и асимптотический анализ.
Учитывая, насколько быстро развивается компьютерная индустрия, такие детали постоянно меняются. С другой стороны, алгоритмы сами по себе неподвластны времени. Следовательно, нам нужен метод оценки производительности алгоритма в независимости от компьютера, на котором он работает. Два основных средства, используемые нами для этой цели, это – абстрактная модель машины (компьютера) и асимптотический анализ.
Абстрактная модель машины
В процессе анализа алгоритмов мы представляем, что выполняем их на простой гипотетической компьютерной модели. Как и все современные компьютеры, наша модель выполняет инструкции последовательно. Модель поддерживает ряд простых операций, таких как сложение, вычитание, умножение, присвоение, сравнение, доступ к памяти и т.д. Но в отличие от текущих компьютеров, все эти простые операции занимают одну единицу времени. Поэтому время работы алгоритма эквивалентно количеству выполняемых им примитивных операций. Также предполагается, что машина имеет бесконечную память, а целые числа имеют фиксированный размер. Время, необходимое для завершения цикла, пропорционально количеству итераций умноженному на стоимость итерации.
Также предполагается, что машина имеет бесконечную память, а целые числа имеют фиксированный размер. Время, необходимое для завершения цикла, пропорционально количеству итераций умноженному на стоимость итерации.
Асимптотический анализ
Когда представлены два алгоритма, решающие одну и ту же задачу, и нам нужно определить, какой из них быстрее, один из возможных способов – реализовать эти алгоритмы, запустить их с разными входными данными и измерить время выполнения. Но это не лучшее решение, поскольку один алгоритм может быть быстрее при небольшом количестве входных данных и медленнее при большем. Чтобы точно проанализировать производительность, программисты спрашивают, как быстро увеличивается время выполнения при увеличении входных данных. Например, когда размер входных данных удваивается, увеличивается ли время работы пропорционально? Или оно увеличивается в четыре раза, а может быть, даже экспоненциально?
Те же вопросы можно задать и о производительности алгоритма в различных условиях. Для большинства алгоритмов размер входных данных не является единственным фактором, но особенности входных данных также влияют на время выполнения. В качестве примера можно привести линейный поиск. Это простой алгоритм для нахождения элемента в списке. Он последовательно проверяет каждый элемент списка до тех пор, пока не обнаружит совпадение или пока не просмотрит весь список. Очевидно, что время работы этого алгоритма может резко отличаться для списков с одинаковым размером n. В лучшем случае, если искомый элемент является первым в списке, алгоритму требуется только одно сравнение. С другой стороны, если в списке отсутствует нужный элемент или он оказался последним, алгоритм выполнит ровно n сравнений. В целом, при анализе используется один из следующих двух подходов: либо можно считать входные данные случайными и анализировать среднюю производительность, либо мы можно подобрать худшие входные данные и исследовать наихудшую производительность. В этой серии статей мы будем придерживаться анализа наихудшего случая, поскольку это гарантирует, что для любого примера входных данных размера n время работы не превысит полученного предела.
Для большинства алгоритмов размер входных данных не является единственным фактором, но особенности входных данных также влияют на время выполнения. В качестве примера можно привести линейный поиск. Это простой алгоритм для нахождения элемента в списке. Он последовательно проверяет каждый элемент списка до тех пор, пока не обнаружит совпадение или пока не просмотрит весь список. Очевидно, что время работы этого алгоритма может резко отличаться для списков с одинаковым размером n. В лучшем случае, если искомый элемент является первым в списке, алгоритму требуется только одно сравнение. С другой стороны, если в списке отсутствует нужный элемент или он оказался последним, алгоритм выполнит ровно n сравнений. В целом, при анализе используется один из следующих двух подходов: либо можно считать входные данные случайными и анализировать среднюю производительность, либо мы можно подобрать худшие входные данные и исследовать наихудшую производительность. В этой серии статей мы будем придерживаться анализа наихудшего случая, поскольку это гарантирует, что для любого примера входных данных размера n время работы не превысит полученного предела. Кроме того, как мы определяем «средние» данные, может повлиять на результат анализа.
Кроме того, как мы определяем «средние» данные, может повлиять на результат анализа.
«O» большое
Пример правила 1: Взгляните на реализацию алгоритма, который вычисляет сумму всех элементов в массиве, на языке C++.
sum.cppint sum(int* array, int n)
{
int sum = 0;
for(int i=0;i<n;++i)
{
sum+=array[i];
}
return sum;
}
Пример правил 2 и 3: Приведенная ниже программа складывает две квадратные матрицы.
matrixAddition.cppvoid matrixAddition(int** m1, int** m2, int** dest, int n)
{
for(int i = 0; i < n; ++i)
{
for(int j = 0; j < n; ++j)
{
dest[i][j]=m1[i][j]+m2[i][j];
}
}
}
Пример правил 4 и 5: Обратите внимание на программу ниже
function. cpp
cppvoid function(int** dest, int n)
{
for(int i = 0; i < n; ++i)
{
for(int j = 0; j < n; ++j)
{
dest[i][j]=1;
}
}
for(int i = 0; i < n; ++i)
{
for(int j = 0; j < n; ++j)
{
for(int k = 0; k < n; ++k)
{
dest[i][j]=2;
}
}
}
}
Часто встречающиеся функции времени выполнения
В этом разделе мы рассмотрим несколько наиболее распространенные функции времени выполнения, которые встречаются при анализе алгоритмов. Знакомство с этими функциями даст вам хорошее представление об особенностях различных времен выполнения и поможет определить, является ли сложность вашего алгоритма приемлемой.
displayPairsvoid displayPairs(int* array, int n)
{
int count = 0;
for(int i = 0; i < n; ++i)
{
for(int j = 0; j < n; ++j)
{
count++;
cout<< "Pair #"<<count<<':'<< array[i] <<'-' << array[j] <<endl;
}
}
}
Визуализация функций
Визуализация функций времени выполнения вам
наглядно покажет, почему выбор алгоритма с оптимальной сложностью имеет такое
большое значение.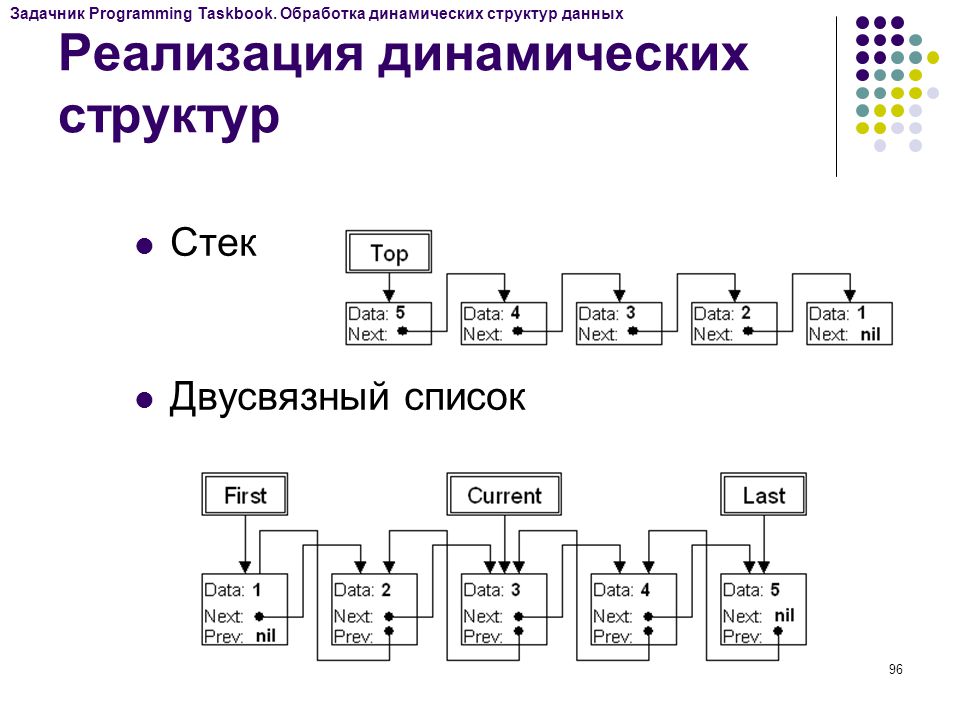 В таблице ниже приведены несколько значений для функций,
описанных в предыдущем разделе.
В таблице ниже приведены несколько значений для функций,
описанных в предыдущем разделе.
На приведенном ниже изображении показаны графики распространенных функций времени выполнения.
Заключение
Чтобы извлечь
максимальную пользу из алгоритма, необходимо понимать не только то, как он
работает, но и его производительность. В этой главе мы объяснили нотацию
Большого О, которая используется для анализа производительности алгоритма. Если
вам известно, как выглядит асимптотическое время работы алгоритма, вы можете
оценить, насколько изменится время работы при изменении размера задачи.
Advanced Concepts in C — Structures | by Christian Walter
Photo by Adi Goldstein on Unsplash Сегодня я хотел бы поделиться с вами некоторыми передовыми концепциями C. Я сталкиваюсь с этими концепциями, которые являются хорошими функциями, но редко используются, или, по крайней мере, я не вижу их частого использования. Сегодня мы обсудим…
Сегодня мы обсудим…
Мне кажется, мало кто пользуется конструкциями или знает, что они из себя представляют и для чего нужны.
Структура создает тип данных, который можно использовать для группировки элементов, возможно, разных типов в один тип.
Структуры нужны для удобства чтения. Мы можем группировать переменные, которые принадлежат друг другу. Предположим, вам нужно обработать чей-то адрес. Вместо этого:
void main() {
char street[50] = "Somestreet";
инт номер дома = 123;
почтовый индекс [5] = {4,3, 2, 1, 0};
символов city[20] = "SomeCity";
} Мы можем сгруппировать это в структуру. Во-первых, мы должны объявить структуру. Мы объявляем структуру, которая содержит название улицы, номер дома, 5-значный почтовый индекс и город.
struct address {
char street[50];
внутренний номер дома;
почтовый индекс[5];
символов города[20];
}; Теперь мы можем определить переменную в нашей основной функции и инициализировать ее следующим образом: 5},
«Некоторый Город»
};
printf(«Номер дома: %u\n», myAddress. housenumber)
housenumber)
}
Что дает нам Номер дома: 123 .
Со структурами можно обращаться как с любой другой переменной. Вы можете передать его в функцию, построить массив структур или вложить структуры в структуры.
Структуры очень полезны для группировки данных. Если вам нужно работать с данными, т. е. memcpy , будет намного проще, если вы уже сгруппируете их в структуру. Но будьте осторожны: структуры могут быть больше в памяти из-за заполнения. Но как это работает?
Структура памяти «Структур»
Когда мы используем структуры, нам нужно знать, как они выравниваются в памяти. Элементы структуры данных хранятся в памяти последовательно, так что размер структуры будет точно равен кратному числу содержащегося в ней члена. Позволь мне привести пример. Следующая структура
struct data {
uint8_t val1;
uint8_t значение2;
uint8_t значение3;
}; — это ровно три байта. Выравнивание здесь — один байт, потому что каждый член — это uint8_t , то есть один байт, так что сама структура кратна своим членам, трем байтам.
Выравнивание структуры зависит от типов внутри структуры.
Когда мы использовали структуры смешанного типа, выравнивание может быть немного сложнее. Следующая структура
struct data2 {
uint8_t val1;
uint32_t значение2;
uint8_t значение3;
}; технически шесть байтов — верно? У нас есть два однобайтовых значения, а одно четырехбайтовое значение составляет шесть. К сожалению, это неверно . Мы забыли прокладку. Если мы создадим смешанные структуры, отступы будут обычно также соответствует самому большому типу, который мы использовали в структуре. Но обратите внимание — это зависит от реализации! Давайте посмотрим, как структура struct data2 выглядит в памяти.
Как я уже говорил, выравнивание структуры в памяти будет равно самому большому типу, используемому в нашей структуре — так что это будет uint32_t : 4 байта. Это означает, что структура будет помещаться в память кусками по 4 байта. Если следующее значение больше не помещается в 4-байтовый фрагмент, текущий фрагмент будет заполнен нулями (дополнен) и будет использован новый фрагмент. На самом деле структура
Это означает, что структура будет помещаться в память кусками по 4 байта. Если следующее значение больше не помещается в 4-байтовый фрагмент, текущий фрагмент будет заполнен нулями (дополнен) и будет использован новый фрагмент. На самом деле структура struct data2 — это 12-байтовый большой в памяти.
Теперь, если мы перестроим структуру следующим образом
struct data3 {
uint8_t val1;
uint8_t значение3;
uint32_t значение2;
}; Структура памяти data3 содержит то же количество значений, но в памяти выглядит совершенно иначе.
Как видите, val1 и val3 умещаются в один фрагмент. Очевидно, что val2 больше не подходит, поэтому кусок дополняется и val2 переходит в следующий фрагмент. Порядок переменных внутри структуры оказывает огромное влияние на размер структуры. Знание этого чрезвычайно важно, если вы думаете о memcpying данных непосредственно в структуру или наоборот.
Изменить выравнивание
Существует несколько способов изменить выравнивание конструкции. Все они специфичны для компилятора, но должны работать для большинства компиляторов. Если вы хотите установить однобайтовое выравнивание, чтобы в памяти структуры не было заполнения, вы можете использовать __упаковано ключевое слово. Определите свою структуру следующим образом:
struct __attribute__((__packed__)) data {
uint8_t val1;
uint32_t значение2;
uint8_t значение3;
}; Память Структура данных __packed__И ваш компилятор не добавит дополнение к структуре. В памяти это выглядит так.
Размер структуры ровно шесть байт. Имейте в виду, что удаление заполнения приведет к замедлению кода. Это следует использовать только для сценариев, где размер соответствует на самом деле имеет значение или где вы хотите memcpy данные непосредственно из входного потока, например. сериал в структуру.
Вы можете получить тот же эффект, если используете pragma в C. Директива
Директива pragma pack изменяет максимальное выравнивание. Всегда разумно устанавливать пакет прагмы только для той структуры, которую вы хотите, а не для всего проекта. Если вы хотите изменить выравнивание, это работает следующим образом:
#pragma pack(push)
#pragma pack(1)struct data {
uint8_t значение1;
uint32_t значение2;
uint8_t значение3;
};#pragma pack(pop)
#pragma pack(push) помещает фактические настройки выравнивания во внутренний стек, чтобы мы могли восстановить эти настройки позже. #pragma pack(1) устанавливает максимальное выравнивание в один байт, за которым следует определение структуры. После этого мы снова восстанавливаем предыдущие настройки выравнивания с помощью #pragma pack(pop) , извлекая из внутреннего стека.
Структуры могут быть очень полезны, если вы работаете с данными, которые можно как-то сгруппировать. Даже если это не сэкономит вам памяти, ваш код станет более читабельным.
Спасибо за внимание!
Structures-c · Темы GitHub · GitHub
Вот 22 публичных репозитория соответствует этой теме…
Ратешпрабакар / C-полная практика
Звезда 61амантивари8861 / C_Batch_11_to_12
Звезда 16Хафиз-Сакиб / Вложенные циклы-строки-массивы-указатели
Звезда 5ПракхарПиперсана / Алгоритмы планирования
Звезда 3Звездорождение / С
Звезда 1h5rithd / Структуры данных и алгоритмы
Звезда 1Гоутамрайк / Структура и указатели в C
Звезда 1Наведуран / простая_оболочка
Звезда 1смешанное хозяйство / C-кульминация
Звезда 1самуэльселаси / alx-low_level_programming
Звезда 1сетфрикинроллсин / С
Звезда 0Деррик1908 / Примеры C-кода
Звезда 0БехнамАрдалани / Инвентарь для видеоигр
Звезда 0АлексейЛепов / ConsoleCrudApp
Звезда 0Мчл-крпч / Список
Звезда 0Адвайтск / основные-cprograms
Звезда 0ДиегоМюриэльГ / Проекто-ЭДА-Экипо-10
Звезда 0Стефаниойр / crivo_eratostenes
Звезда 0эдфвр / alx-low_level_programming
Звезда 0никселько / игральные карты
Звезда 0Улучшить эту страницу
Добавьте описание, изображение и ссылки на
структуры-c
страницу темы, чтобы разработчикам было легче узнать о ней.