ТОП-5 способов выполнения SQL-запрос в PySpark
Если вы знаете SQL, но еще не освоились с фреймворком Apache Spark, то вы можете выполнять запросы различными способами. В этой статье вы узнаете, как писать SQL-выражения в PySpark, какие способы выполнения запросов существуют, как конкатенировать строки, фильтровать данные и работать с датами.
Способы выполнения в SQL-запросов в Apache Spark
Выполнять SQL-запросы можно выполнять различным образом, но все они в итоге дают тот же результат. Причем только один из них является полноценным запросом, все остальные является вызов функции, принимающей SQL-выражение. Вот некоторые из них:
- напрямую через
spark.sql("QUERY"); - выборка столбцов через метод
selectв связке с функциейexprизpyspark.sql.functions; - выборка столбцов через метод
selectExpr; - добавление результата вычисления SQL-выражения к исходной таблице через метод
withColumn; - фильтрация данных через методы
whereилиfilterв связке с функциейexprизpyspark.;. sql.functions
sql.functions
 sql.functions
sql.functionsДопустим, имеется следующий DataFrame:
df = spark.createDataFrame([
('py', 'Anton', 'Moscow', 23),
('c', 'Anna', 'Omsk', 27),
('py', 'Andry', 'Moscow', 24),
('cpp', 'Alex', 'Moscow', 32),
('cpp', 'Boris', 'Omsk', 55),
('py', 'Vera', 'Moscow', 89), ],
['lang', 'name', 'city', 'salary'])
Тогда чтобы напрямую выполнить SQL-запрос (1-способ), нужно создать так называемое представление (view). Это делается для того чтобы Spark знал о созданной таблице. Представление создается вызовом метода, в который нужно передать желаемое имя таблицы:
df.createOrReplaceTempView("prog_info")
Теперь можно выполнять запросы, так же, как это делается при работе с базами данных:
spark.sql("select lang from prog_info").show()
"""
+----+
|lang|
+----+
| py|
| c|
| py|
| cpp|
| cpp|
| py|
+----+
"""
Этот способ наиболее универсален, поскольку не нужно знать о различных функциях, а просто нужно дать необходимый запрос.
Второй способ заключается в использовании метода select в связке с функцией expr. Она уже не требует создания представления. Однако она применяется к конкретному DataFrame, поэтому операторы SELECT FROM должны быть опущены. В этом случае следует говорить о SQL-выражении, ведь не является полным запросом. Например, вот так выглядит тот же самый запрос, что и выше, но только с использованием функции expr:
# На самом деле именно для этого случая, `expr` может быть опушен,
# но далее вы увидите, что его обязательно нужно использовать
import pyspark.sql.functions as F
df.select(F.expr('lang')).show()
"""
+----+
|lang|
+----+
| py|
| c|
| py|
| cpp|
| cpp|
| py|
+----+
"""
Далее следуют метод selectExpr. Второй метод точно такой же, как и select, но принимает на вход SQL-выражения, поэтому не нужно отдельно вызывать функцию expr.
df.selectExpr('lang').show()
# Или что то же самое:
df.select('lang').show()
+----+
|lang|
+----+
| py|
| c|
| py|
| cpp|
| cpp|
| py|
+----+
Различие заключается в том, что в select передаются именно столбцы, поэтому такая запись неправильная:
# Ошибка selectExpr(df.lang).show() # А вот так можно: select(df.lang).show()
Самый последний способ использования SQL-выражений — это метод withColumn в связке с функцией expr. В отличие от предыдущих он добавляет к имеющейся таблице новый столбец, полученный на основе SQL-выражения. Его можно рассматривать как оператор SELECT * FROM.
Анализ данных с Apache Spark
Конечно, на примере операции выборки столбца всю силу SQL-выражений не показать, поэтому рассмотрим более интересные операции, включая фильтрацию данных, о которой мы еще не поговорили.
Конкатенация строк с использованием ||
Самый простой способ объединения нескольких строк в одну — это использование SQL-выражения со знаком ||. Такая операция называется конкатенация строк. Итак, чтобы конкатенировать строки используйте один из вышеперечисленных способов.
spark.sql('SELECT name || "_" || lang AS name_lang FROM lang_info').show()
df.select(F.expr('name || "_" || lang AS name_lang')).show()
df.selectExpr('name || "_" || lang AS name_lang').show()
"""
+---------+
|name_lang|
+---------+
| Anton_py|
| Anna_c|
| Andry_py|
| Alex_cpp|
|Boris_cpp|
| Vera_py|
+---------+
"""
# Возвращает всю таблицу
df.withColumn('name_lang', F.expr('name || "_" || lang')).show()
"""
+----+-----+------+------+---------+
|lang| name| city|salary|name_lang|
+----+-----+------+------+---------+
| py|Anton|Moscow| 23| Anton_py|
| c| Anna| Omsk| 27| Anna_c|
| py|Andry|Moscow| 24| Andry_py|
| cpp| Alex|Moscow| 32| Alex_cpp|
| cpp|Boris| Omsk| 55|Boris_cpp|
| py| Vera|Moscow| 89| Vera_py|
+----+-----+------+------+---------+
"""
Фильтрация данных в PySpark
Для фильтрации существуют методы filter и where (это синонимы, они делают то же самое). Фильтрация данных может быть выражена двумя способами: в виде SQL-выражения или так, как это делается в библиотеке Pandas. Например, найдем те записи, которые содержат одинаковые значения.
Фильтрация данных может быть выражена двумя способами: в виде SQL-выражения или так, как это делается в библиотеке Pandas. Например, найдем те записи, которые содержат одинаковые значения.
# В виде SQL-выражения
df.filter('salary > 30 AND city like "Moscow"').show()
# Как в Pandas:
df.filter((df.salary > 30) & (df.city == 'Moscow')).show()
"""
+----+----+------+------+
|lang|name| city|salary|
+----+----+------+------+
| cpp|Alex|Moscow| 32|
| py|Vera|Moscow| 89|
+----+----+------+------+
"""
При использовании Pandas-стиля выражения заключается в скобки; если требуется произвести логические операции между ними, то ставится знак & (AND, побитовое И) или | (OR, побитовое ИЛИ). В нашем примере мы использовали знак И. Также стоит отметить, что его использование ограничено использованием имен с латинскими буквами и цифрами (как например, обратиться к имени столбца, содержащий пробел).
Также можно использовать обычный SQL-запрос в spark.sql.
spark.sql('SELECT * FROM lang_info WHERE salary > 30 AND city like "Moscow"')
Использование CASE WHEN в PySpark
В PySpark эквивалентом оператор CASE WHEN является использование функций when().otherwise(). Он необходим для выбора того или иного результата в зависимости от выполнения условия. Аналогичный оператор можно встретить в Python, который состоит if\elif\eles. Синтаксис у оператора `CASE WHEN в SQL такой:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;
Допустим из неполных названий языков мы хотим получить полные. В этом случае можно поступить таким образом:
sql = """
CASE
WHEN (lang LIKE 'c') OR (lang LIKE 'cpp') THEN 'C/C++'
WHEN (lang LIKE 'py') THEN 'Python'
ELSE 'unknown'
END"""
df. withColumn('FullLang', F.expr(sql)).show()
"""
+----+-----+------+------+--------+
|lang| name| city|salary|FullLang|
+----+-----+------+------+--------+
| py|Anton|Moscow| 23| Python|
| c| Anna| Omsk| 27| C/C++|
| py|Andry|Moscow| 24| Python|
| cpp| Alex|Moscow| 32| C/C++|
| cpp|Boris| Omsk| 55| C/C++|
| py| Vera|Moscow| 89| Python|
+----+-----+------+------+--------+
"""
withColumn('FullLang', F.expr(sql)).show()
"""
+----+-----+------+------+--------+
|lang| name| city|salary|FullLang|
+----+-----+------+------+--------+
| py|Anton|Moscow| 23| Python|
| c| Anna| Omsk| 27| C/C++|
| py|Andry|Moscow| 24| Python|
| cpp| Alex|Moscow| 32| C/C++|
| cpp|Boris| Omsk| 55| C/C++|
| py| Vera|Moscow| 89| Python|
+----+-----+------+------+--------+
"""
Опять же мы могли бы вызвать select, но получили бы только один столбец, также в этом случае следует добавить оператор AS или метод alias, иначе название столбца будет состоять из всего оператора CASE WHEN. Например, так:
df.select(F.expr(sql).alias('FullLang')).show()
"""
+--------+
|FullLang|
+--------+
| Python|
| C/C++|
| Python|
| C/C++|
| C/C++|
| Python|
+--------+
"""
Либо, как уже говорили, и вовсе сделать с помощью функций when-otherwise. Советуем при этом соблюдать структурные отступы для читабельности кода:
Советуем при этом соблюдать структурные отступы для читабельности кода:
case_when = (
F.when(F.expr('lang LIKE "c" OR lang LIKE "cpp"'), 'C/C++')
.when(F.expr('lang LIKE "py"'), 'Python')
.otherwise('uknown')
)
df.withColumn('FullLang', case_when)
Работаем с датой и временем
Одними только числовыми и строковыми не отделаешься, иногда приходится работать с датами и временем. Для них тоже имеются различные функции, похожие на те, которые встречаются в SQL. Например, вот так можно найти разницу между датами в днях в Spark:
df2 = spark.createDataFrame([
('2020-01-01', '2022-10-25'),
('2021-05-12', '2022-05-12'),],
['before', 'after'])
df2.withColumn('diff', F.expr('DATEDIFF(after, before)')).show()
"""
+----------+----------+----+
| before| after|diff|
+----------+----------+----+
|2020-01-01|2022-10-25|1028|
|2021-05-12|2022-05-12| 365|
+----------+----------+----+
"""
Заметим, что мы могли бы не писать так, как это делается в SQL, а могли бы использовать функции из pyspark.. Более того, это хороший способ узнать, есть ли такая-то функция, заглянув в документацию. Однако полностью полагаться на документацию не стоит, так как есть еще незадокументированные функции, которые нет в языке SQL, но могут в некоторых случаях пригодится(например,  sql.functions
sql.functionsstack — обратная операция функции pivot, см. [5]).
Еще больше подробностей об SQL-операциях в PySpark вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Записаться на курс
Смотреть раcписание
Источники
- expr
- select
- selectExpr
- withColumn
- Как развернуть таблицу
основы и применение — Boodet.
 online
onlineПоделиться
Твинтнуть
Поделиться
Запинить
Отправить
SQL: простыми словами
Аббревиатура «SQL» расшифровывается как «язык структурированных запросов». Это своеобразный язык программирования, предназначенный для того, чтобы извлекать конкретную информацию из баз данных (database) было несложно. Другими словами, это язык баз данных.
Зачем нужен SQL, какие там есть команды и чем этот язык лучше других — рассказывают специалисты Boodet.Online.
Зачем нужен SQL
Большинство компаний хранят свои сведения в базах данных. Говоря «компании», мы имеем в виду и бизнес, и разработку, и науку, и развлечения. Все они используют хотя бы одну из СУБД (например, MySQL, PostgreSQL, Microsoft SQL Server) и большинство их них «говорят» на SQL.
Независимо от того, какой язык программирования используют для реализации процессов в компании (Python, C, C++), SQL все равно нужен для того, чтобы извлекать необходимую информацию из СУБД.
Основные преимущества SQL:
точность — можно не хранить избыточные данные;
гибкость — даже самые сложные запросы легко выполнить;
масштабируемость — с одной БД могут работать множество пользователей;
безопасность — доступ к данным в таблицах есть только у определенных пользователей.

Из истории
История этого языка началась в конце 70 годов, когда основали компанию Relational Software, Inc. Первым ее продуктом стал Oracle, который написали на C. Чтобы продукт был гибким и простым для тех, кто не изучал программирование, создали внутренний язык — SQL. Авторство принадлежит исследователям IBM Раймонду Бойсу и Дональду Чемберлину. В 1970 SQL назывался «SEQUEL» и служил для извлечения и обработки Big Common Data (больших общих данных).
SQL — это сертифицированный ANSI-язык взаимодействия с реляционными БД. Его можно менять под свои нужды, но все распространенные продукты работают именно на той версии, которую утвердили ANSI.
Как работает SQL
Реляционная база данных — это пространство, в котором связанную информацию хранят в нескольких таблицах. При этом есть возможность запрашивать информацию в нескольких таблицах одновременно.
А теперь о том же самом, но простым языком. Допустим бизнесмен желает видеть информацию о продажах своего товара. Для этого можно настроить электронную таблицу в «Excel» со всей информацией, которую надо отслеживать, в виде отдельных столбцов:
Для этого можно настроить электронную таблицу в «Excel» со всей информацией, которую надо отслеживать, в виде отдельных столбцов:
Эта сработает, когда заказ от покупателя всего один. А когда их несколько или десятки, сотни? Если продолжать вносить сведения в таблицу Excel, обнаружится, что одинаковая информация (имя, адрес и номер телефона) хранятся в нескольких строках электронной таблицы. Так появляются избыточные данные.
По мере роста бизнеса и увеличения количества отслеживаемых заказов эти избыточные данные будут занимать место, снизят эффективность этой примитивной системы отслеживания продаж. Также можно столкнуться с проблемами с целостностью данных. Например, нет гарантии, что каждое поле будут заполнять правильным типом информации или что имя и адрес будут вводить каждый раз одинаково.
С реляционной SQL таких проблем не будет. Можно настроить две таблицы: одну — для заказов, вторую — для клиентов. Таблица «клиенты» будет включать уникальный идентификационный номер для каждого, а также имя, адрес и номер телефона, которые уже отслеживают.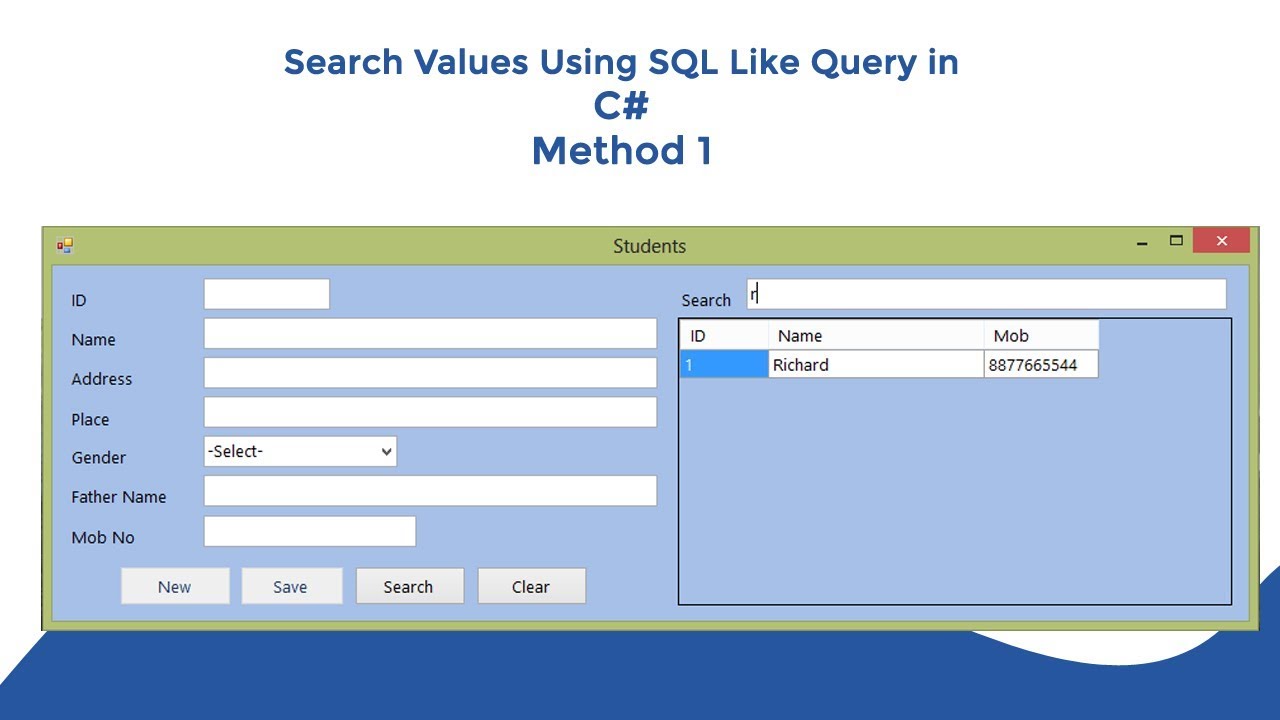 Таблица «заказы» будет включать номер заказа, дату, сумму к оплате, номер накладной. А вместо отдельного поля для каждого элемента данных о заказчике будет столбец для «идентификатора клиента».
Таблица «заказы» будет включать номер заказа, дату, сумму к оплате, номер накладной. А вместо отдельного поля для каждого элемента данных о заказчике будет столбец для «идентификатора клиента».
Это позволит получить всю информацию о клиенте для любого конкретного заказа, но благодаря SQL нужно сохранить ее только один раз, а не выводить повторно для каждого отдельного заказа.
Какие базы SQL существуют
Какими продуктами чаще всего пользуются при работе с БД:
Oracle Database. Помимо основных функций, Oracle Database автоматизирует управление серверами и данными. Совместим с тремя основными операционными системами: MacOS, Windows и Linux.
MySQL. Эта БД с открытым исходным кодом, разработана Oracle. Ей пользуются такие крупные бренды, как Facebook, Adobe и Google. MySQL бесплатен как для юридических, так и для частных лиц.
Microsoft SQL. Реляционная БД, идеально совместимая с операционными системами Linux и Windows. Она идеально подходит для веб-серверов под управлением Windows, а также для потребительского софта.
Amazon Relational Database Service (RDS). Облачная реляционная СУБД, простая в настройке и использовании. Есть инструменты бюджетирования облака, безопасности и мониторинга.
Структура SQL-запросов
Язык SQL очень простой. Он состоит из команд для выполнения различных функций. Эти функции включают в себя:
создание объектов;
манипулирование объектами;
заполнение таблиц;
обновление таблиц;
удаление данных;
выполнение запросов;
управление доступом и общее администрирование.
Чтобы любому человеку было проще ориентироваться, SQL состоит из нескольких основных подгрупп.
Для определения данных (DDL)
Команды:
create;
drop;
alter;
rename.
Для манипулирования данными (DML)
Команды:
insert;
delete;
update.

Триггеры
Триггеры — это действия, которые делаются при выполнении определенных условий. Любой триггер состоит из трех частей:
событие — изменение, которое он активирует;
состояние — запрос или тест, который выполняется при активации;
действие — процедура, выполняемая при срабатывании триггера и выполнении условия.
Технология клиент-сервер и удаленный доступ
Технология клиент-сервер поддерживает отношения «многие-к-одному» клиентов (многие) и сервера (один). В SQL есть команды, которые управляют тем, как клиентское приложение может получить доступ к database по сети.
Безопасность и аутентификация
SQL предоставляет механизм для управления БД. То есть, он гарантирует, что пользователю будет показана только конкретная информация, а исходная версия будет защищена СУБД.
Встроенный SQL
SQL предоставляет возможность встраивания основных языков, таких как C, COBOL, Java, для запросов от них во время выполнения.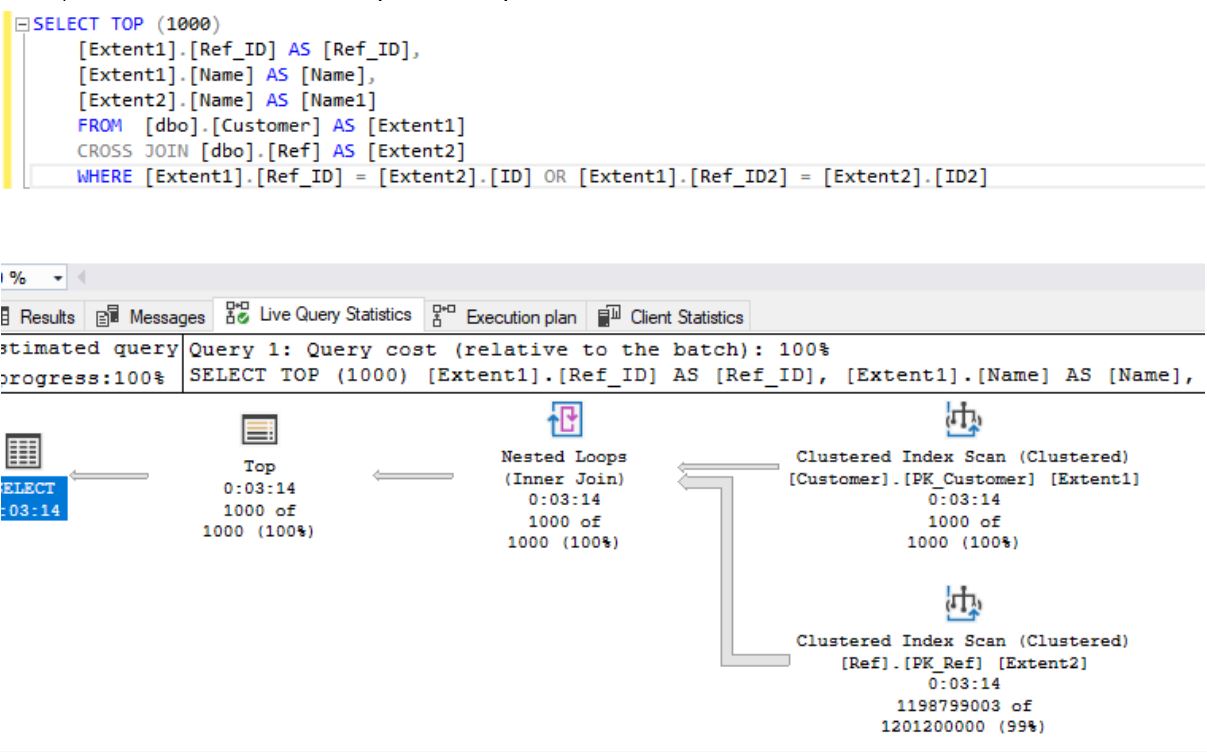
Управление транзакциями
Транзакции — это важный элементом СУБД. Для управления ими используется TCL, который имеет команды:
Commit;
RollBack;
Savepoint.
Расширенный SQL
Расширенный SQL включает в себя такие запросы, как рекурсивные, поддержки принятия решений, интеллектуальный анализ данных, пространственные данные и XML (eXtensible Markup Language).
Как используется SQL
Почему многие выбирают именно SQL:
простые запросы можно использовать для очень быстрого и эффективного извлечения большого объема данных из СУБД;
SQL легко изучить, почти каждая СУБД поддерживает;
управлять СУБД с помощью SQL несложно, поскольку не требуется большого количества кода.
SQL и Big Data
В настоящее время существует тенденция аккумулирования больших объемов данных. Феномен Big Data требует наличия набора навыков, чтобы обрабатывать и извлекать информацию в любой области — медицина, образование, бизнес, спорт и т. д. На основании анализа Big Data принимают стратегические и обоснованные решения, которые могут повысить прибыль компаний и решить реальные проблемы. Например, с помощью SQL разрабатывают модели, которые делают общественный транспорт простым и удобным. Это язык, которые используется практически в любой сфере жизни человека, решает реальные проблемы и помогает создавать новые технологии.
д. На основании анализа Big Data принимают стратегические и обоснованные решения, которые могут повысить прибыль компаний и решить реальные проблемы. Например, с помощью SQL разрабатывают модели, которые делают общественный транспорт простым и удобным. Это язык, которые используется практически в любой сфере жизни человека, решает реальные проблемы и помогает создавать новые технологии.
SQL позволяет изучить набор данных, визуализировать его, определить структуру и узнать, как на самом деле он выглядит. Это помогает узнать, есть ли какие-либо пропущенные значения. Благодаря нарезке, фильтрации, агрегации и сортировке SQL позволяет понять, как распределяются значения и как организован набор Data.
Подключение клиентских приложений
SQL эффективен для организации доступа к данным, при запросах и манипуляциях. Но он ограничен в визуализации. Как это решить? Он хорошо интегрируется с другими языками сценариев, например, R и Python.
Кроме того, специализированные библиотеки интеграций для SQL, такие как SQLite и MySQLdb, применяют при подключении клиентского приложения к ядру базы данных, что позволяет работать с СУБД совместно.
Чем открыть SQL-файл
Прежде чем открыть SQL-файл, спросите себя, зачем вам это. Если вы пользуетесь СУБД, все уже настроено и работает. Например, когда вы выбираете песню на айпаде, вы фактически делаете запрос на определенный набор данных из базы.
Если вы хотите просто посмотреть, что внутри SQL-файла, можно воспользоваться обычным текстовым редактором («Блокнот» для Windows или TextEdit для Mac). В этих программах можно не только посмотреть, но и вручную отредактировать сценарий. Прежде чем что-нибудь открывать и менять, рекомендуем сделать копию исходного файла. Если нужно потренироваться в работе с SQL, арендуйте безопасное облачное пространство.
Поделиться
Твинтнуть
Поделиться
Запинить
Отправить
Facebook
YouTube
Telegram
sql-запрос, что такое «C» в этом запросе
спросил
Изменено 4 года, 11 месяцев назад
Просмотрено 3к раз
выбрать
C. CMPNAME,
C. МИНИМАЛЬНОЕ ЗНАЧЕНИЕ,
К.ПРЖИД,
C.ALLOTDATE
от
(
выбирать
min(A.bidvalue) как MINBIDVALUE,
А.пржид,
П.аллотдата,
A.cmpname
от
выделено А,
проекты П
где
A.prjid = P.projectid
группа по
prjid
) С
CMPNAME,
C. МИНИМАЛЬНОЕ ЗНАЧЕНИЕ,
К.ПРЖИД,
C.ALLOTDATE
от
(
выбирать
min(A.bidvalue) как MINBIDVALUE,
А.пржид,
П.аллотдата,
A.cmpname
от
выделено А,
проекты П
где
A.prjid = P.projectid
группа по
prjid
) С
что ‘C’ (я знаю, что он используется как псевдоним, но для него не объявлено имя таблицы). ->здесь A начинает использоваться в качестве псевдонима для выделенного n P начинает использоваться для проекта.
1
C — псевдоним для результатов подзапроса (выберите min(A.bidvalue) как ….). Этот подзапрос создаст набор результатов, который ведет себя как таблица на протяжении всего запроса. Чтобы сослаться на этот набор результатов и его столбцы, ему был присвоен псевдоним «C», и все C.stuff являются столбцами из подзапроса.
Это подзапрос. Подзапросы являются анонимными, поэтому им должен быть присвоен псевдоним с использованием ключевого слова AS . SQL позволяет опустить ключевое слово
SQL позволяет опустить ключевое слово AS .
В этом конкретном запросе подзапрос не добавляет полезности: внутренний подзапрос можно использовать сразу после перестановки столбцов в соответствии с внешним запросом.
1
«C» — псевдоним для «набора результатов» подзапроса, определенного
выбрать
min(A.bidvalue) как MINBIDVALUE,
А.пржид,
П.аллотдата,
A.cmpname
от
выделено А,
проекты П
где
A.prjid = P.projectid
группа по
prjid
Подзапрос
выбрать
min(A.bidvalue) как MINBIDVALUE,
А.пржид,
П.аллотдата,
A.cmpname
от
выделено А,
проекты П
где
A.prjid = P.projectid
группа по
prjid
имеет псевдоним «C».
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Пожалуйста, помогите мне понять SQL и C как программирование?
Позвольте мне попробовать. Я выбираю долгий путь сюда, так что потерпите меня.
Я выбираю долгий путь сюда, так что потерпите меня.
В конечном итоге все программы, данные и т. д. на компьютере состоят из одного и того же материала: единиц и нулей. Ни больше ни меньше. Так как же компьютер понимает, что один набор единиц и нулей следует рассматривать как изображение, а другой набор — как исполняемый файл?
Ответ зависит от контекста. Это то, в чем люди ужасно хороши, поэтому неудивительно, что это лежит в основе большей части того, что делает компьютер. Механизмы сложны, но конечный эффект сводится к компьютеру, который постоянно меняет перспективу, чтобы делать невероятно гибкие вещи с невероятно ограниченным набором данных.
Я говорю об этом, потому что компьютерные языки похожи. В конце концов, ВСЕ компьютерные языки заканчиваются серией кодов операций, проходящих через процессор. Другими словами, это язык ассемблера полностью. Все компьютерные языки являются ассемблером, включая любую реализацию SQL.
Причина, по которой мы беспокоимся, заключается в следующем: языки программирования позволяют нам создать полезную иллюзию подхода к проблемам с новой точки зрения. Они дают нам способ взять проблему и переформулировать решение.
Они дают нам способ взять проблему и переформулировать решение.
Рискуя показаться клише, когда нам не нравится ответ на проблему, другой язык программирования позволяет нам задать другой вопрос.
Итак, когда вы приближаетесь к языку, будь то язык запросов, объектно-ориентированный язык или процедурный язык, ваш первый вопрос должен звучать так: «Какова перспектива этого языка? Каков его взгляд на задачу решения проблем? » Я бы даже предположил, что язык без ясного видения самого себя доставляет больше проблем, чем пользы.
Что касается C, то я бы предположил, что перспектива такова: «Даже самые низкоуровневые операции совершенно разных процессоров могут быть описаны простым общепринятым языком». C предназначен для того, чтобы сесть за руль любого процессора, но при этом иметь тот же старый руль, педали и приборную панель.
Так что с C вы делаете все. Вот почему его называют «языком ассемблера высокого уровня». Или, по словам моего друга, «C — это латынь компьютерных языков. Язык ассемблера — это ворчание обезьян на деревьях».
Язык ассемблера — это ворчание обезьян на деревьях».
SQL — это совершенно другой зверь с совершенно другой перспективой… или нет? Перспектива SQL такова: «Даже самые сложные команды самых разных баз данных можно описать простым, общепринятым языком».
Звучит знакомо, а? SQL предназначен для того, чтобы вы могли сесть за руль любого программного обеспечения базы данных и иметь такое же рулевое колесо, педали и т. д.
Таким образом, C — это язык, используемый для передачи общепонятных команд любому произвольному процессору. в то время как SQL — это язык, используемый для предоставления общепонятных команд любой произвольной серверной части базы данных.
Итак, где они пересекаются? Это на самом деле довольно просто.
Что делает процессор? Он получает, преобразует и отправляет информацию. Итак, если ваша цель состоит в том, чтобы интерпретировать и представлять данные или принимать команды от конечного пользователя, вы работаете в C. C предназначен для процедур , которые вам нужно автоматизировать с помощью компьютера.