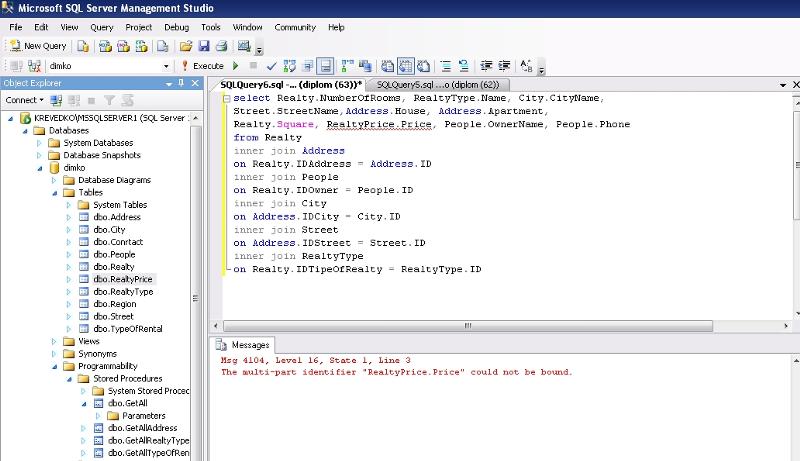
Запуск запросов: режим «только для чтения», планировщик, SQL-журнал
Консоль запросов
По опыту знаем, что консоль запросов — лучшее место для повседневной работы с SQL. Для каждого источника данных предусмотрена собственная консоль по умолчанию. Чтобы ее открыть, выберите Open Console в контекстном меню или нажмите F4.
Здесь вы можете написать SQL-запрос, запустить его и получить результат. Все просто.
Если вы вдруг захотите создать другую консоль для источника данных, сделайте это в меню: Context menu → New → Console.
Переключатель схем
Создавайте столько консолей запросов, сколько вам нужно, и запускайте запросы одновременно. У каждой консоли есть переключатель схем и баз данных. Если вы работаете с PostgreSQL , составьте здесь search_path.
Запуск выделенного фрагмента
Выделите фрагмент кода и запустите только его. Выбранный запрос посылается в базу «как есть», без дополнительной обработки jdbc-драйвером. Это может быть полезно, когда по той или иной причине IDE думает, что в запросе есть ошибка.
Это может быть полезно, когда по той или иной причине IDE думает, что в запросе есть ошибка.
Настройки выполнения
Выполнять запрос можно несколькими способами. Поведение запуска запросов под кареткой можно настраивать. Возможные варианты того, что можно запустить: подзапрос, весь запрос, все после каретки, весь скрипт или предложить выбор.
Можно настроить три варианта поведения для запуска (Execute). По умолчанию, сочетание клавиш есть только у первого, но вы можете выбрать их и для остальных. Например, настроим два поведения: «показать выбор» и «запустить весь скрипт».
На видео пример, как сначала выполнено одно действие, затем второе.
Режим «только для чтения»
Режим «только для чтения» включайте в настройках источника данных: флажок Read-Only. Этот флажок включает сразу два режима: на уровне IDE и на уровне jdbc-драйвера .
На уровне jdbc-драйвера в режиме «для чтения» запросы, которые вносят изменения, нельзя запускать в базах: MySQL,
PostgreSQL, AWS Redshift, h3 и Derby. В других СУБД этот режим не работает.
В других СУБД этот режим не работает.
Поэтому мы сделали свой режим «только для чтения». Он включается одновременно с режимом на уровне драйвера. IDE понимает, какие запросы приведут к изменениям, и подчеркивает их. При запуске запроса DataGrip покажет предупреждение. Такой запрос можно запустить, нажав Execute на всплывающей панели, если вы точно уверены в том, что делаете.
DataGrip также индексирует все исходники функций и процедур и строит внутри дерево вызовов. Это значит, что если вы запускаете процедуру, которая запускает процедуру (повторите
Контроль транзакций
Выберите контроль транзакций, который больше подходит вашей работе. Эта настройка есть в свойствах источника данных. В автоматическим режиме (флажок Auto) вам не надо каждый раз фиксировать транзакцию, а вот в ручном режиме (Manual), очевидно, надо.
Быстрый просмотр результата
Результаты запроса или выражения можно посмотреть во всплывающем окне.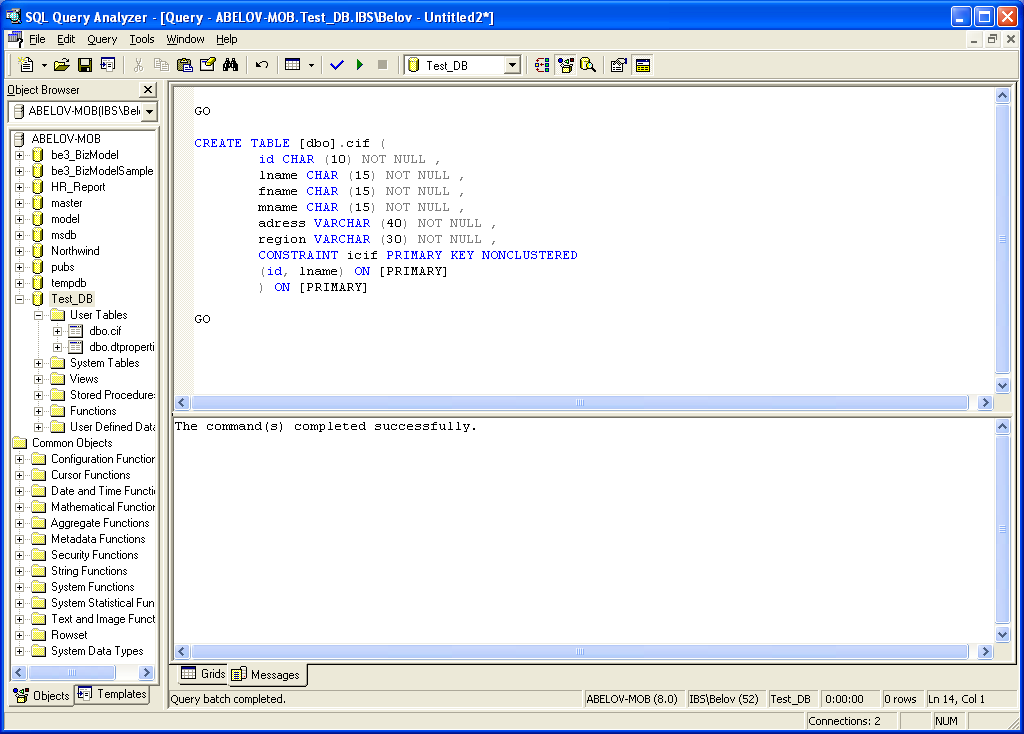 В других IDE на платформе IntelliJ Ctrl+Alt+F8 показывает результат вычисления выражения. В DataGrip то же самое работает для отображения результатов запуска. Если нажать эту комбинацию когда курсор на столбце, вы увидите ожидаемые значения этого столбца в результатах запроса. Та же самая операция на любом ключевом слове запроса покажет всплывающее окно с результатом. Клик мышкой при зажатом Alt работает так же.
В других IDE на платформе IntelliJ Ctrl+Alt+F8 показывает результат вычисления выражения. В DataGrip то же самое работает для отображения результатов запуска. Если нажать эту комбинацию когда курсор на столбце, вы увидите ожидаемые значения этого столбца в результатах запроса. Та же самая операция на любом ключевом слове запроса покажет всплывающее окно с результатом. Клик мышкой при зажатом Alt работает так же.
История запущенных запросов
На панели инструментов каждой консоли есть такая кнопка: . Нажмите ее, чтобы увидеть историю всех запросов, выполненных в этом источнике данных из DataGrip. Еще здесь работает быстрый поиск!
Не забудьте и о локальной истории каждого файла.
Полный SQL-журнал
Буквально все запросы, которые запускает DataGrip, записываются в текстовый файл. Чтобы открыть его, используйте меню Help | Show SQL log.
Запуск хранимых процедур
DataGrip умеет генерировать код для запуска процедур. Укажите значения для параметров и нажмите OK.
Укажите значения для параметров и нажмите OK.
Когда процедура открыта в редакторе, вы можете ее запустить, нажав Run на панели инструментов. Или используйте контекстное меню и выберите пункт Execute…
Небезопасные запросы
DataGrip предупредит, если вы собираетесь запустить запросы DELETE и UPDATE без предложения WHERE.
Планировщик запросов
План запросов покажет, как база данных собирается выполнить ваш запрос. Это помогает в оптимизации.
План запросов может быть представлен в виде дерева или диаграммы.
Запросы с параметрами
В запросе могут быть параметры. DataGrip умеет запускать такие запросы.
Описать синтаксис параметров можно в Settings/Preferences → Database → User Parameters. Регулярные выражения для их описания подсвечиваются, а еще для каждого вида параметров можно указать SQL-диалект.
Структурный вид
Каждую консоль или файл можно открыть в структурном виде: в окне появится список запросов. Чтобы открыть структурный вид, используйте сочетание клавиш Ctrl+F12.
Чтобы открыть структурный вид, используйте сочетание клавиш Ctrl+F12.
Результат запроса
Результат запроса
В DataGrip данные в результате простого запроса можно изменять. Используйте все возможности редактора данных: добавляйте, удаляйте строки, выбирайте режим контроля транзакций.
Сравнение результатов
Два результата можно сравнить, используя инструмент поиска различий. DataGrip подсветит те строчки, которые не являются общими для двух результатов. Параметр Tolerance используется для того, чтобы указать, сколько колонок могут иметь разные значения, чтобы строчки все равно считались одинаковыми. Из сравнения можно исключить любой столбец.
Нажмите кнопку сравнения на панели инструментов и выберите результат запроса, с которым нужно сравнить текущий результат.
Имена вкладок
Вы сами можете называть вкладки результатов: напишите имя в комментарии перед запросом.
Если вам не нравится, что любой предшествующий комментарий становится именем, укажите слово, после которого будет идти строка для заголовка. Это делается в соответствующих настройках: поле Prefix.
Это делается в соответствующих настройках: поле Prefix.
Быстрое изменение размера страницы
Меняйте размер страницы в редакторе данных, не заходя в настройки.
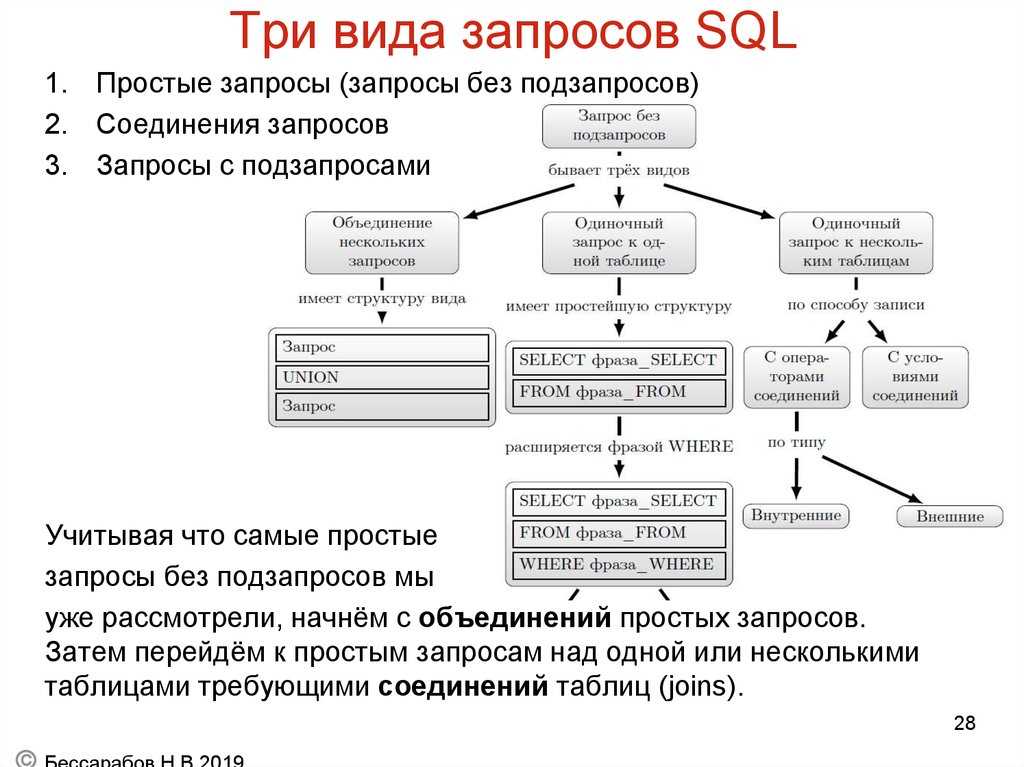
MySQL. Вложеные запросы. JOIN LEFT/RIGHT….
В SQL подзапросы — или внутренние запросы, или вложенные запросы — это запрос внутри другого запроса SQL, который вложен в условие WHERE.
Вложеные запросы
SQL подзапрос — это запрос, вложенный в другой запрос.
Подзапрос используется для возврата данных, которые будут использоваться в основном запросе, в качестве условия для дальнейшей фильтрации данных, подлежащих извлечению.
Существует несколько правил, которые применяются к подзапросам:
- Подзапросы должны быть заключены в круглые скобки.
- Подзапрос может иметь только один столбец в условии SELECT, если только несколько столбцов не указаны в основном запросе для подзапроса для сравнения выбранных столбцов.

- Подзапросы, которые возвращают более одной строки, могут использоваться только с несколькими операторами значений, такими как оператор IN.
- Команда ORDER BY не может использоваться в подзапросе, хотя в основном запросе она использоваться может. В подзапросе может использоваться команда GROUP BY для выполнения той же функции, что и ORDER BY.
- С подзапросом не может использоваться оператор BETWEEN. Однако оператор BETWEEN может использоваться внутри подзапроса.
- Не рекомендуется создавать запросы со степенью вложения больше трех. Это приводит к увеличению времени выполнения и к сложности восприятия кода.
SELECT
Подзапросы чаще всего используются с инструкцией SELECT. При этом используется следующий синтаксис
SELECT имя_столбца FROM имя_таблицы WHERE часть условия IN
(SELECT имя_столбца FROM имя_таблицы WHERE часть условия IN
(SELECT имя_столбца FROM имя_таблицы WHERE условие)
.
..
)
;
Ниже представлена струтура таблицы для демонстрации примеров
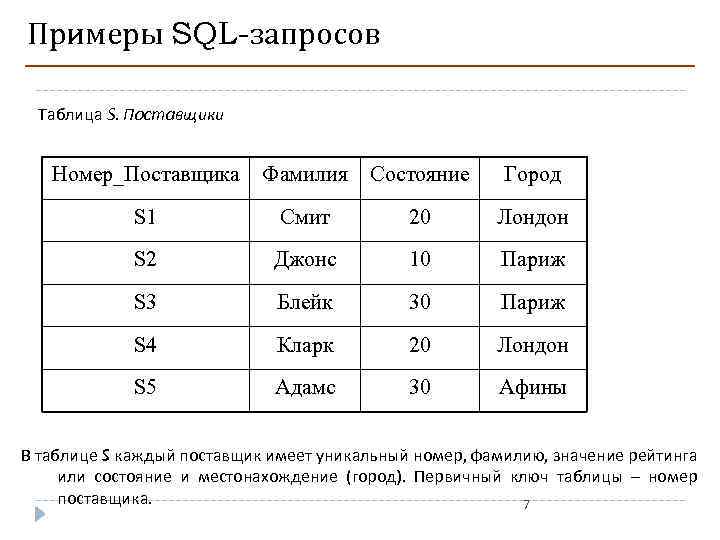
| snum | sname | city | comm |
|---|---|---|---|
| 1 | Колованов | Москва | 10 |
| 2 | Петров | Тверь | 25 |
| 3 | Плотников | Москва | 22 |
| 4 | Кучеров | Санкт-Петербург | 28 |
| 5 | Малкин | Санкт-Петербург | 18 |
| 6 | Шипачев | Челябинск | 30 |
| 7 | Мозякин | Одинцово | 25 |
| 8 | Проворов | Москва | 25 |
| cnum | cname | city | rating | snum |
|---|---|---|---|---|
| 1 | Деснов | Москва | 90 | 6 |
| 2 | Краснов | Москва | 95 | 7 |
| 3 | Кириллов | Тверь | 96 | 3 |
| 4 | Ермолаев | Обнинск | 98 | 3 |
| 5 | Колесников | Серпухов | 98 | 5 |
| 6 | Пушкин | Челябинск | 90 | 4 |
| 7 | Белый | Одинцово | 85 | 1 |
| 8 | Чудинов | Москва | 89 | 3 |
| 9 | Проворов | Москва | 95 | 2 |
| 10 | Лосев | Одинцово | 75 | 8 |
| onum | amt | odate(YEAR) | cnum | snum |
|---|---|---|---|---|
| 1001 | 420 | 2013 | 9 | 4 |
| 1002 | 653 | 2005 | 10 | 7 |
| 1003 | 960 | 2016 | 2 | 1 |
| 1004 | 320 | 2016 | 3 | 3 |
| 1005 | 200 | 2015 | 5 | 4 |
| 1006 | 2560 | 2014 | 5 | 4 |
| 1007 | 1200 | 2013 | 7 | 1 |
| 1008 | 50 | 2017 | 1 | 3 |
| 1009 | 564 | 2012 | 3 | 7 |
| 1010 | 900 | 2018 | 6 | 8 |
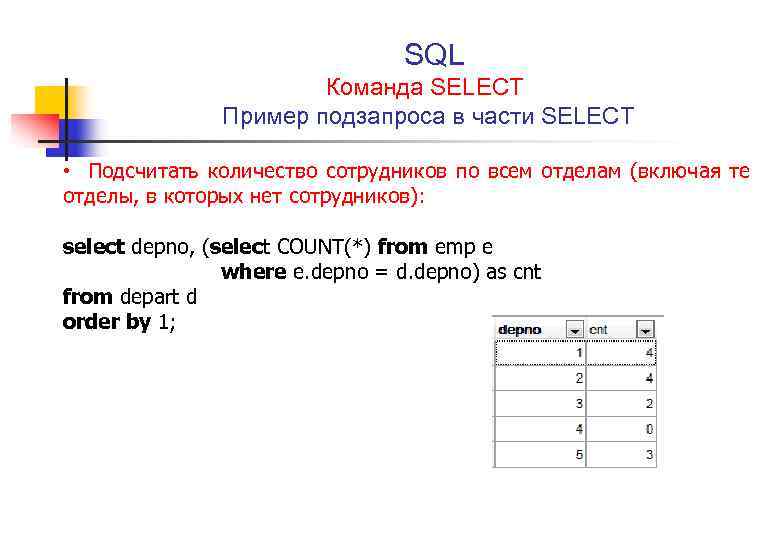
Вывести суммы заказов и даты, которые проводил продавец с фамилией «Плотников».
Начнем с такого примера и для начала вспомним, как бы делали этот запрос ранее: посмотрели бы в таблицу SALES(или выполнили отдельный запрос), определили бы snum продавца «Плотников» — он равен 3. И выполнили бы запрос SQL с помощью условия WHERE.
SELECT amt, odate
FROM orders
WHERE snum = 3
| amt | odate |
|---|---|
| 320 | 2016 |
| 50 | 2017 |
Такой запрос, очевидно, не очень универсален, если нам захочется выбрать тоже самое для другого продавца, то всегда придется определять его snum. В SQL предусмотрена возможность объединять такие запросы в один путем превращения одного из них в подзапрос (вложенный запрос).
SELECT amt, odate
FROM orders
WHERE snum = ( SELECT snum
FROM sales
WHERE sname = 'Плотников')
В этом примере мы определяем с помощью вложенного запроса идентификатор snum по фамилии из таблицы SALES, а затем, в таблице ORDERS определяем по этому идентификатору нужные нам значения.
Показать уникальные номера и фамилии продавцов, которые провели сделки в 2016 году.
SELECT snum, sname
FROM sales
WHERE snum IN ( SELECT snum
FROM orders
WHERE odate = 2016)
Этот SQL запрос отличается тем, что вместо знака = здесь используется оператор IN.
Оператор IN следует использовать в том случае, если вложенный подзапрос SQL возвращает несколько значений.
То есть в запросе происходит проверка, содержится ли идентификатор snum из таблицы SALES в массиве значений, который вернул вложенный запрос. Если содержится, то SQL выдаст фамилию этого продавца.
| snum | sname |
|---|---|
| 1 | Колованов |
| 3 | Плотников |
Предыдущие примеры, которые мы уже рассмотрели, сравнивали в условииWHEREодно поле.Это конечно хорошо, но стоит отметить, что в SQL предусмотрена возможность сравнения сразу нескольких полей, то есть можно использовать вложенный запрос с несколькими параметрами.
Вывести пары покупателей и продавцов, которые осуществили сделку между собой, но не позднее 2014 года
Запрос чем то похож на предыдущий, только теперь мы добавляем еще одно поле для сравнения.
SELECT cname as 'Покупатель', sname as 'Продавец'
FROM customers cus, sales sal
WHERE (cus.cnum, sal.snum) IN ( SELECT cnum, snum
FROM orders
WHERE odate < 2014 )
| Покупатель | Продавец |
|---|---|
| Проворов | Кучеров |
| Лосев | Мозякин |
| Белый | Колованов |
| Кириллов | Мозякин |
В этом примере мы сравниваем сразу два поля одновременно по идентификаторам.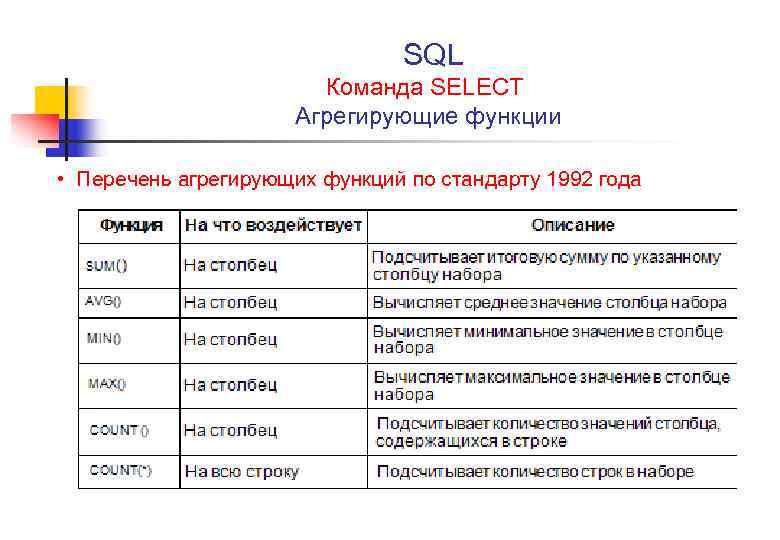 То есть из таблицы
То есть из таблицы ORDERS берутся те строки, которые удовлетворяют условию не позднее 2014 года, затем вместо идентификаторов подставляются значение имен покупателей и продавцов.
На самом деле, такой запрос SQL используется крайне редко, обычно используют оператор INNER JOIN.
Оператор as нужен для того, чтобы при выводе SQL показывал не имена полей, а то, что мы зададим. И после оператора FROM за именами таблиц стоят сокращения, которые потом используются — это псевдонимы. Псевдонимы можно называть любыми именами, в этом запросе они используются для явного определения поля, так как мы несколько раз обращаемся к одному и тому же полю, только из разных таблиц.
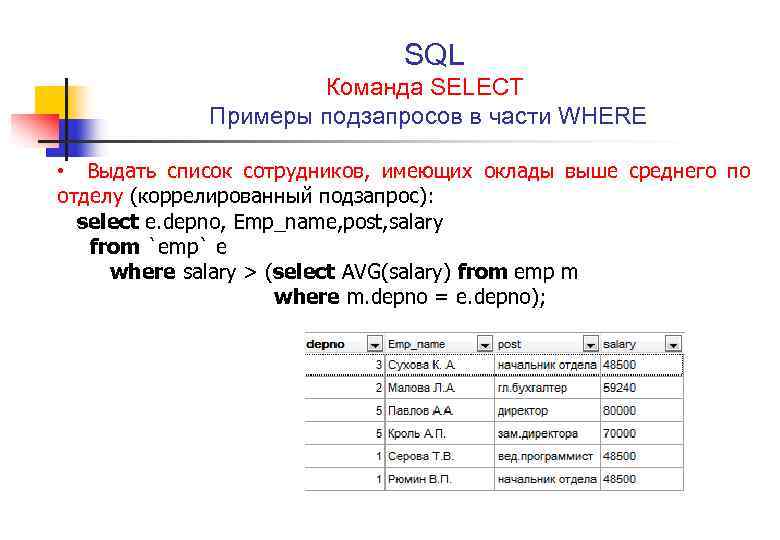
Подзапросы могут использоваться с инструкциями SELECT,INSERT,UPDATEиDELETEвместе с операторами типа=,<,>,>=,<=,IN,BETWEENи т.д.
Далее будут показы примеры использования вложеных запросов с использованием базы данныхworld. БД находится в папке_lec\7\dbвместе с лекцией.
CREATE
Данный пример несовсем относится к теме занятия, но по жизни он очень может пригодиться.
Задача — создать копию существующей таблицы.
Копия существующей таблицы может быть создана с помощью комбинации CREATE TABLE и SELECT.
Новая таблица будет имеет те же определение столбцов, могут быть выбраны все столбцы или отдельные столбцы. При создании новой таблицы с помощью существующей таблицы, новая таблица будет заполняться с использованием существующих значений в старой таблице.
CREATE TABLE NEW_TABLE_NAME AS
SELECT [ column1, column2.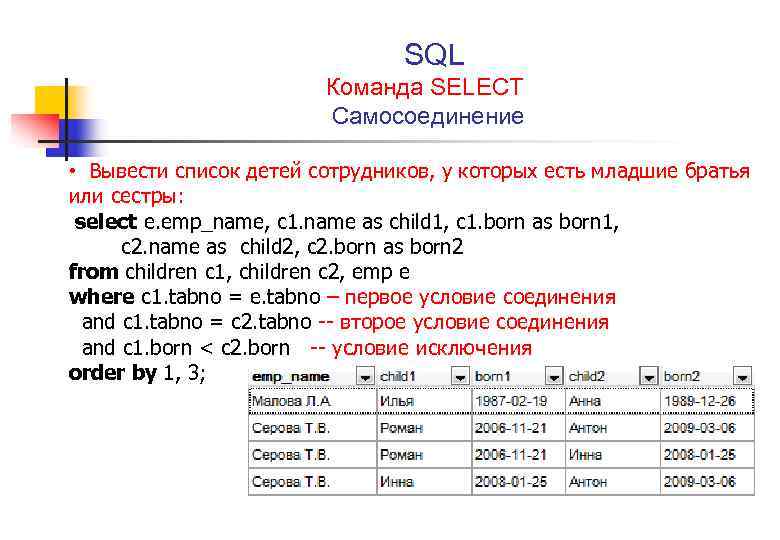 ..columnN ]
FROM EXISTING_TABLE_NAME
[ WHERE ]
..columnN ]
FROM EXISTING_TABLE_NAME
[ WHERE ]
Создадим копию таблицы city. Вопрос — почему 1=0?
CREATE TABLE city_bkp AS
SELECT *
FROM city
WHERE 1=0
INSERT
Задача — создать копию существующей таблицы.
Подзапросы также могут использоваться с инструкцией INSERT. Инструкция INSERT использует данные, возвращаемые из подзапроса, для вставки в другую таблицу. Выбранные в подзапросе данные могут быть изменены. Основной синтаксис следующий.
INSERT INTO table_name [ (column1 [, column2 ]) ]
SELECT [ *|column1 [, column2 ]
FROM table1 [, table2 ]
[ WHERE VALUE OPERATOR ]
Копирование всей таблицы полностью
INSERT INTO city_bkp SELECT * FROM city
Копируем города которые находся в стране с численостью не меньше 500тыс. человек, но не больше 1 миллиона.
человек, но не больше 1 миллиона.
INSERT INTO city_bkp
SELECT * FROM city
WHERE CountryCode IN
(SELECT Code FROM country
WHERE Population < 1000000 AND Population > 500000)
UPDATE
Подзапрос может использоваться в сочетании с инструкцией UPDATE. Один или несколько столбцов в таблице могут быть обновлены при использовании подзапроса с помощью инструкции UPDATE. Основной синтаксис следующий.
UPDATE table
SET column_name = new_value
[ WHERE OPERATOR [ VALUE ]
(SELECT COLUMN_NAME
FROM TABLE_NAME)
[ WHERE) ]
Исходя из того, что у нас есть таблица CITY_BKP, которая является резервной копией таблицы CITY, в следующем примере для всех записей, для которых Population больше или равно 100000, применяет коэффициент 0,25.
UPDATE city_bkp SET Population = Population * 0.25
WHERE Population IN (
SELECT Population FROM city
WHERE Population >= 100000 )
DELETE
Подзапрос может использоваться в сочетании с инструкцией DELETE, так же как и со всеми описанными выше инструкциями. Основной синтаксис следующий.
DELETE FROM TABLE_NAME
[ WHERE OPERATOR [ VALUE ]
(SELECT COLUMN_NAME
FROM TABLE_NAME)
[ WHERE) ]
Далее будут показы примеры использования вложеных запросов с использованием базы данныхworld. БД находится в папке_lec\7\dbвместе с лекцией.
Внутреннее объединение
Вывести идентификатор и название города, а так же страну нахождения
Для этого проще всего обратиться к таблице CITY
SELECT ID, Name, CountryCode FROM city
Но, что если нам необходимо, чтобы в ответе на запрос был не код страны, а её название? Вложенные запросы нам не помогут. А нам надо получить данные из двух таблиц и объединить их в одну. Запросы, которые позволяют это сделать, в SQL называются объединениями. Синтаксис самого простого объединения следующий:
А нам надо получить данные из двух таблиц и объединить их в одну. Запросы, которые позволяют это сделать, в SQL называются объединениями. Синтаксис самого простого объединения следующий:
SELECT city.ID, city.Name, country.Name FROM city, country
Получилось не совсем то, что мы ожидали. Такое объединение научно называется декартовым произведением, когда каждой строке первой таблицы ставится в соответствие каждая строка второй таблицы.
Чтобы результирующая таблица выглядела так, как мы хотели, необходимо указать условие объединения. Мы связываем наши таблицы по идентификатору, это и будет нашим условием.
SELECT city.ID, city.Name, country.Name
FROM city, country
WHERE city.CountryCode = country.Code
Т.е. мы в запросе сделали следующее условие: если в обеих таблицах есть одинаковые идентификаторы, то строки с этим идентификатором необходимо объединить в одну результирующую строку.
Как вы понимаете, объединения дают возможность выбирать любую информацию из любых таблиц, причем объединяемых таблиц может быть и три, и четыре, да и условие для объединения может быть не одно.
JOIN LEFT/RIGHT
JOIN — оператор языка SQL, который является реализацией операции соединения реляционной алгебры. Входит в предложение FROM операторов SELECT, UPDATE и DELETE.
JOIN используется для объединения строк из двух или более таблиц на основе соответствующего столбца между ними.
Операция соединения, как и другие бинарные операции, предназначена для обеспечения выборки данных из двух таблиц и включения этих данных в один результирующий набор.
Особенности операции соединения
- в схему таблицы-результата входят столбцы обеих исходных таблиц
- каждая строка таблицы-результата является «сцеплением» строки из одной таблицы со строкой второй таблицы
Определение того, какие именно исходные строки войдут в результат и в каких сочетаниях, зависит от типа операции соединения и от явно заданного условия соединения. Условие соединения, то есть условие сопоставления строк исходных таблиц друг с другом, представляет собой логическое выражение (предикат).
Условие соединения, то есть условие сопоставления строк исходных таблиц друг с другом, представляет собой логическое выражение (предикат).
Ниже представлена струтура таблицы для демонстрации примеров
| id | name | city_id |
|---|---|---|
| 1 | Колованов | 1 |
| 2 | Петров | 3 |
| 3 | Плотников | 12 |
| 4 | Кучеров | 4 |
| 5 | Малкин | 2 |
| 6 | Иванов | 13 |
Ниже представлена струтура таблицы для демонстрации примеров
| id | name | population |
|---|---|---|
| 1 | Москва | 100 |
| 2 | Нижний Новгород | 25 |
| 3 | Тверь | 22 |
| 4 | Санкт-Петербург | 80 |
| 5 | Выборг | 18 |
| 6 | Челябинск | 30 |
| 7 | Одинцово | 5 |
| 8 | Павлово | 5 |
INNER JOIN
Оператор внутреннего соединения INNER JOIN соединяет две таблицы. Порядок таблиц для оператора неважен, поскольку оператор является симметричным.
Порядок таблиц для оператора неважен, поскольку оператор является симметричным.
Заголовок таблицы-результата является объединением (конкатенацией) заголовков соединяемых таблиц.
SELECT * FROM Person
INNER JOIN
City
ON Person.city_id = City.id
| Person.id | Person.name | Person.city_id | City.id | City.name | City.population |
|---|---|---|---|---|---|
| 1 | Колованов | 1 | 1 | Москва | 100 |
| 2 | Петров | 3 | 3 | Тверь | 22 |
| 4 | Кучеров | 4 | 4 | Санкт-Петербург | 80 |
| 5 | Малкин | 2 | 2 | Нижний Новгород | 25 |
INNER JOINТело результата логически формируется следующим образом. Каждая строка одной таблицы сопоставляется с каждой строкой второй таблицы, после чего для полученной «соединённой» строки проверяется условие соединения (вычисляется предикат соединения). Если условие истинно, в таблицу-результат добавляется соответствующая «соединённая» строка.
Каждая строка одной таблицы сопоставляется с каждой строкой второй таблицы, после чего для полученной «соединённой» строки проверяется условие соединения (вычисляется предикат соединения). Если условие истинно, в таблицу-результат добавляется соответствующая «соединённая» строка.
В SQL существуют разные типы объединений. Мы рассмотрим только некоторые из них.
LEFT JOIN
Возвращает все строки из левой таблицы, даже если в правой таблице нет совпадений.
LEFT JOIN
SELECT * FROM Person
LEFT JOIN
City
ON Person.city_id = City.id
Для записей неудовлетворяющих условия объединения поля правой таблицы заполняются значениями NULL
| Person.id | Person. name name | Person.city_id | City.id | City.name | City.population |
|---|---|---|---|---|---|
| 1 | Колованов | 1 | 1 | Москва | 100 |
| 2 | Петров | 3 | 3 | Тверь | 22 |
| 3 | Плотников | 12 | NULL | NULL | NULL |
| 4 | Кучеров | 4 | 4 | Санкт-Петербург | 80 |
| 5 | Малкин | 2 | 2 | Нижний Новгород | 25 |
| 6 | Иванов | 13 | NULL | NULL | NULL |
RIGHT JOIN
Возвращает все строки из правой таблицы, даже если в левой таблице нет совпадений.
RIGHT JOIN
SELECT * FROM Person
RIGHT JOIN
City
ON Person.city_id = City.id
Для записей неудовлетворяющих условия объединения поля левой таблицы заполняются значениями NULL
Person. id id | Person.name | Person.city_id | City.id | City.name | City.population |
|---|---|---|---|---|---|
| 1 | Колованов | 1 | 1 | Москва | 100 |
| 2 | Петров | 3 | 3 | Тверь | 22 |
| 4 | Кучеров | 4 | 4 | Санкт-Петербург | 80 |
| 5 | Малкин | 2 | 2 | Нижний Новгород | 25 |
| NULL | NULL | NULL | 5 | Выборг | 18 |
| NULL | NULL | NULL | 6 | Челябинск | 30 |
| NULL | NULL | NULL | 7 | Одинцово | 5 |
| NULL | NULL | NULL | 8 | Павлово | 5 |
Что такое запрос в SQL?
SQL означает язык структурированных запросов. Он используется в компьютерном программировании для обработки или управления базами данных. Мы используем запросы в SQL для обработки баз данных.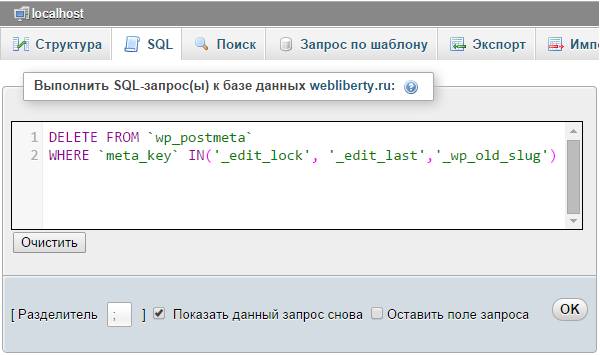 Запрос больше похож на вопрос или просьбу простыми словами. Предположим, у вас есть запрос — Пожалуйста, предоставьте мне идентификатор сотрудника всех сотрудников, работающих в бухгалтерии. Или запрос вроде — сколько мест забронировано на шоу? Следовательно, мы запрашиваем или запрашиваем для некоторой информации.
Запрос больше похож на вопрос или просьбу простыми словами. Предположим, у вас есть запрос — Пожалуйста, предоставьте мне идентификатор сотрудника всех сотрудников, работающих в бухгалтерии. Или запрос вроде — сколько мест забронировано на шоу? Следовательно, мы запрашиваем или запрашиваем для некоторой информации.
В общих чертах, запрос в SQL — это запрос к базам данных на выборку (или извлечение) информации. Мы используем общий язык — SQL, для запросов к нашим базам данных. Он используется всякий раз, когда у компаний есть масса данных, которыми они хотят манипулировать. Если вы храните свои данные в реляционной базе данных , вы также можете использовать SQL!
Прежде чем углубляться в запросы, давайте кратко рассмотрим SQL.
Краткий обзор SQL
SQL означает язык структурированных запросов. Это один из основных языков запросов, используемых для обработки потоков данных и управления реляционными базами данных.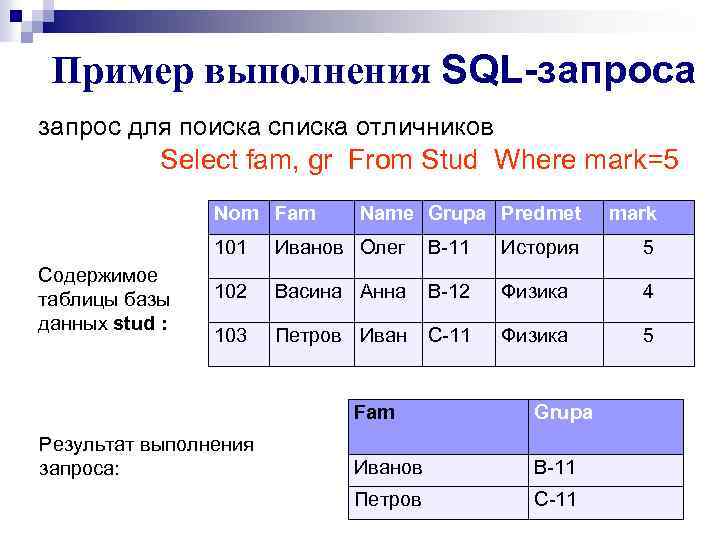 SQL позволяет нам получать доступ к базам данных и управлять ими. SQL имеет широкий спектр приложений в современном мире.
SQL позволяет нам получать доступ к базам данных и управлять ими. SQL имеет широкий спектр приложений в современном мире.
Давайте взглянем на обязательное использование SQL для сбора, хранения и обработки данных и т. д. —
- SQL можно использовать для выполнения (или выполнения) запросов к базе данных.
- SQL может вставлять, обновлять, удалять или извлекать данные из баз данных.
- SQL может создавать новые таблицы или хранимые процедуры, представления и т. д.
- SQL может устанавливать разрешения для таблиц, процедур и представлений.
Зачем использовать SQL-запрос?
SQL Query используется для запроса или извлечения информации из баз данных. Мы можем выполнять следующие операции с помощью SQL-запроса:
- Использовать SQL-запрос для создания новой базы данных и вставки данных в базу данных .
- Используйте SQL-запрос для извлечения (или извлечения) данных из базы данных.
 Кроме того, для изменения или обновления существующих данных в базе данных.
Кроме того, для изменения или обновления существующих данных в базе данных. - Чтобы удалить или удалить данные или таблицу из базы данных с помощью SQL-запроса . Кроме того, после этого мы можем создать новую таблицу, .
- Использование SQL-запроса для установки разрешений для таблиц, представлений и процедур. Также для создания функций, представлений и хранимых процедур.
Как написать SQL-запрос?
Основой запроса в SQL Server является предложение SELECT , которое позволяет выбрать отображаемые данные.
Оператор SQL SELECT извлекает записи из таблицы базы данных согласно пунктам (например, FROM и WHERE ), которые определяют критерии, на основании которых будут выбираться наши данные. Синтаксис оператора SQL SELECT:
SELECT столбец1, столбец2. ИЗ таблицы1, таблицы2 ГДЕ столбец1 = 'xyz' и столбец2 = 'abc';
В приведенном выше операторе SQL:
- Предложение SELECT указывает один или несколько столбцов, которые необходимо получить из базы данных.
 Чтобы указать несколько столбцов, мы должны использовать запятую и пробел между именами столбцов. Однако, если мы хотим получить все столбцы, мы можем использовать подстановочный знак * (звездочка) SELECT * FROM … .
Чтобы указать несколько столбцов, мы должны использовать запятую и пробел между именами столбцов. Однако, если мы хотим получить все столбцы, мы можем использовать подстановочный знак * (звездочка) SELECT * FROM … . - Предложение FROM указывает одну или несколько таблиц, которые должны быть запрошены . Мы можем использовать запятую и пробел между именами таблиц при указании нескольких таблиц, например, FROM Names, Addresses, Phone_Numbers , где Names, Addresses и т. д. — это имена таблиц.
- Предложение WHERE выбирает только те строки , в которых указанный столбец содержит указанное значение. WHERE позволяет отфильтровать запрос, чтобы сделать его более конкретным. Значение обычно заключается в одинарные кавычки (например, WHERE color = ‘teal’ ).
- Точка с запятой (;) является терминатором оператора .
 Однако если у вас есть однострочный оператор SQL-запроса, вы можете пропустить точку с запятой (;). Но это обязательно, если у вас многострочный запрос. Как правило, рекомендуется включать точку с запятой после каждого завершающего оператора SQL-запроса.
Однако если у вас есть однострочный оператор SQL-запроса, вы можете пропустить точку с запятой (;). Но это обязательно, если у вас многострочный запрос. Как правило, рекомендуется включать точку с запятой после каждого завершающего оператора SQL-запроса.
В приведенном выше объяснении и синтаксисе мы использовали заглавные буквы для каждого предложения SQL. Однако обратите внимание, что SQL не чувствителен к регистру . То есть SELECT совпадает с select , FROM совпадает с из и т. д.
Примеры SQL-запросов
Давайте рассмотрим несколько примеров, чтобы лучше понять SQL-запросы. Предположим, у нас есть таблица с именем Customers . Давайте выполним некоторые операции SQL для извлечения данных из нашей таблицы и управления ими.
Пример 1. Оператор SELECT
Чтобы получить все столбцы нашего SQL из таблицы «Клиенты», мы можем использовать следующий оператор SQL:
SELECT * FROM Customers;
После выполнения вышеуказанного запроса мы получим следующий вывод:
Вывод:
Следовательно, использование * (звездочка) дает нам в качестве вывода всю таблицу.
Теперь предположим, что мы хотим получить на выходе только имя, фамилию и страну, в которой они живут. Для этого мы выполним следующий SQL-запрос:
ВЫБЕРИТЕ имя, фамилию, страну ИЗ Клиентов;
Выполнение вышеуказанного запроса даст нам следующий вывод:
Вывод:
| имя | фамилия | страна | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Джон | Доу | 6 | СШАРоберт | Луна | США | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Дэвид | Робинсон | Великобритания | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Джон | Райнхардт | Великобритания | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Бетти | Доу | ОАЭ | 63 2 В приведенном выше выводе вы можете видеть, что мы получили только имя, фамилию и страну. после выполнения вышеуказанного запроса. Это связано с тем, что мы указали только эти имена столбцов в нашем запросе на выборку. Давайте также возьмем пример, где мы меняем порядок имен наших таблиц и проверяем, получаем ли мы выходные данные в том же порядке или нет. ВЫБЕРИТЕ страну, customer_id ОТ клиентов; Вывод: Следовательно, мы можем заключить, что изменение порядка имен таблиц в операторе select на противоположное также меняет порядок в выводе. Пример 2. Пункт FROMПредположим, у нас есть другая таблица Orders . Во-первых, давайте посмотрим содержимое таблицы Orders. Код: ВЫБЕРИТЕ * ИЗ Заказов; Вывод: Итак, приведенное выше является содержимым таблицы Orders. Давайте выполним некоторые операции, объединив таблицы Customers и Orders, чтобы узнать больше о работе предложения FROM. Код: ВЫБЕРИТЕ first_name как имя, last_name как фамилия, пункт ОТ клиентов, заказов; Вывод:
В приведенном выше выводе вы можете видеть, что мы попытались выбрать имя, фамилию и элемент из обеих таблиц, что привело к приведенному выше выводу. Кроме того, мы использовали ‘как’ , который используется как псевдоним. Команда AS используется для переименования столбца или таблицы с помощью псевдонима. Псевдоним существует только на время выполнения запроса. Следовательно, после этого запроса имена столбцов/имена таблиц будут такими же, как и в оригинале. Следует заметить, что в обеих таблицах есть общее имя столбца, которое представляет собой столбец идентификатора клиента . Таким образом, для отображения идентификатора клиента нам нужно явно указать имя таблицы, за которым следует оператор точки (.), а затем указать имя столбца. Давайте посмотрим на это на примере. Код: ВЫБЕРИТЕ Customers.customer_id в качестве идентификатора, first_name в качестве имени, элемент ОТ клиентов, заказов; Вывод:
Следовательно, в приведенном выше примере кода после явного упоминания идентификатора клиента с именем его таблицы мы можем получить приведенный выше вывод. Давайте также рассмотрим пример использования DISTINCT. Оператор SELECT DISTINCT используется для возврата только различных или отличающихся значений. Внутри таблицы столбец иногда содержит много повторяющихся значений, и вам часто нужно перечислить только разные значения. Итак, давайте посмотрим на его использование. Код: ВЫБЕРИТЕ РАЗЛИЧНУЮ позицию, количество ОТ Заказов; Вывод: В приведенном выше выводе мы получили только разные значения товара и суммы. Мы не получили никаких значений, которые были бы дублированы повсюду. Пример 3. Предложение WHERE Наконец, давайте подробнее рассмотрим использование предложения where. Как вы уже знаете, предложение WHERE используется для фильтрации записей. Он используется для извлечения только тех записей, которые удовлетворяют заданному условию. Код: ВЫБЕРИТЕ имя, страну, предмет, сумму ОТ клиентов, заказы ГДЕ сумма > 400; Вывод: В приведенном выше выводе вы можете видеть, что мы отфильтровали наши вышеуказанные записи только к записям, в которых количество больше 400. Следовательно, вы можете видеть, что мы получили только эти записи в качестве вывода. где сумма больше 400. Давайте напишем еще несколько запросов, используя предложение WHERE с использованием И, ИЛИ и НЕ. Код: ВЫБЕРИТЕ имя, страну, предмет, сумму ОТ клиентов, заказы ГДЕ страна НЕ "США" И сумма < 400; Вывод: В приведенном выше примере мы использовали оператор И. Оператор AND отображает запись, если все условия, разделенные оператором AND, ИСТИННЫ. Код: ВЫБЕРИТЕ имя, страну, товар, сумму ОТ клиентов, заказы ГДЕ Customers.customer_id = Orders. Вывод: В приведенном выше примере мы получили только клиентов, которые приобрели товары с помощью оператора сравнения '=' . Мы сравнили идентификаторы клиентов с их заказами. Давайте посмотрим на последний пример, где мы удаляем некоторые данные из нашей таблицы. Код: УДАЛИТЬ ИЗ Customers WHERE first_name='John'; Вывод: Оператор DELETE используется для удаления существующих записей в таблице. В приведенном выше примере все записи с именем first_name равны 9.0003 "Джон" удален. Заключение
Примеры запросов SQL | Cloud Logging Этот документ содержит примеры запросов к записям журнала, которые хранятся в
сегменты журналов, обновленные для использования Log Analytics.
В этих корзинах вы можете выполнять SQL-запросы из Страница Log Analytics в консоли Google Cloud. Дополнительные образцы см. В этом документе не описывается SQL или способ маршрутизации и хранения записей журнала. Для информацию по этим темам см. в разделе «Что дальше». Перед началом работы
Журналы фильтрацииSQL-запросы определяют, какие строки таблицы обрабатывать, затем они группируются строки и выполнять агрегатные операции. Когда нет группировки и агрегации перечислены операции, результат запроса включает строки, выбранные работа фильтра. Примеры в этом разделе иллюстрируют фильтрацию. Фильтр по времени Одним из вариантов фильтрации по времени является использование функции Например, следующий запрос считывает данные за последний час, сортирует данные по возрастанию метки времени, а затем отображает 100 самых старых записей: ВЫБЕРИТЕ отметка времени, имя_журнала, серьезность, json_payload, ресурс, метки ОТ ` ТАБЛИЦА ` ГДЕ отметка времени > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), ИНТЕРВАЛ 1 ЧАС) ЗАКАЗАТЬ ПО отметке времени ASC ПРЕДЕЛ 100 Другой вариант — использовать функцию отметки времени SELECT
отметка времени, имя_журнала, серьезность, json_payload, ресурс, метки
ОТ
` ТАБЛИЦА `
ГДЕ
метка времени >= TIMESTAMP("2022-08-25 13:00:00", "Америка/Нью-Йорк") И
метка времени <= TIMESTAMP("2022-08-25 17:00:00", "Америка/Нью-Йорк")
ЗАКАЗАТЬ ПО отметке времени ASC
ПРЕДЕЛ 100
Дополнительные сведения о фильтрации по времени см. Фильтр по ресурсу Для фильтрации по ресурсу добавьте ограничение Например, следующий запрос считывает данные за последний час, а затем
сохраняет те строки, тип ресурса которых соответствует ВЫБРАТЬ отметка времени, имя_журнала, серьезность, json_payload, ресурс, метки ОТ ` ТАБЛИЦА ` ГДЕ отметка времени > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR) И resource.type = "gce_instance" ЗАКАЗАТЬ ПО отметке времени ASC ПРЕДЕЛ 100 Фильтр по серьезности Вы можете фильтровать по определенной серьезности с ограничением, например Например, следующий запрос считывает данные за последний час и
затем сохраняет только те строки, которые содержат ВЫБОР отметка времени, имя_журнала, серьезность, json_payload, ресурс, метки ОТ ` ТАБЛИЦА ` ГДЕ отметка времени > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR) И серьезность НЕ NULL И серьезность IN («ИНФОРМАЦИЯ», «ОШИБКА») ЗАКАЗАТЬ ПО отметке времени ASC ПРЕДЕЛ 100 Предыдущий запрос фильтрует по значению поля Информацию о перечисляемых значениях см. Для фильтрации по имени журнала можно добавить ограничение на значение Например, следующий запрос считывает данные за последний час, а затем
сохраняет те строки, где значение в поле В предыдущем примере указывается частичное имя и используется Большинство отслеживаемых дескрипторов ресурсов определяют метки, которые используются для идентификации
конкретный ресурс. Например, дескриптор экземпляра Compute Engine
включает метки для зоны, идентификатор проекта и идентификатор экземпляра. Когда
запись в журнал записывается, каждому полю присваиваются значения. Следующее
например: Поскольку тип данных поля Например, следующий запрос считывает самые последние данные, а затем сохраняет
те строки, где ресурс является экземпляром Compute Engine,
находится в Для получения информации обо всех функциях, которые могут извлекать и преобразовывать JSON.
данные, см. функции JSON. Чтобы отфильтровать таблицу, чтобы включить только те строки, которые соответствуют HTTP-запросу
или ответьте, добавьте ограничение Следующий запрос включает только строки, соответствующие Чтобы фильтровать по статусу HTTP, измените предложение Чтобы определить тип данных, хранящихся в поле, просмотрите схему или отобразите
поле. Результаты предыдущего запроса показывают, что Чтобы извлечь значение из столбца с типом данных JSON, используйте функцию Рассмотрим следующие запросы: и Предыдущие запросы проверяют значение столбца В другой строке столбец Обе предыдущие строки удовлетворяют ограничению Чтобы вернуть подстроку, соответствующую регулярному выражению, используйте функцию Следующий запрос отображает самые последние полученные записи журнала, сохраняет
эти записи с полем Дополнительные примеры см. Запрос, показанный в этом примере, неэффективен. Для совпадения подстроки, например
показано, используйте функцию Этот раздел основывается на предыдущих примерах и иллюстрирует, как вы можете
группировать и агрегировать строки таблицы. Каждое выражение Для группировки данных по времени используйте функцию Следующий запрос считывает данные за последние 10 часов, а затем сохраняет
те строки, где значение Дополнительные образцы см. Следующий запрос считывает данные за последний час, а затем группирует
строки по типу ресурса. Затем он подсчитывает количество строк для каждого типа,
и возвращает таблицу с двумя столбцами. Следующий запрос считывает данные за последний час, а затем сохраняет строки.
которые имеют поле серьезности. Затем запрос группирует строки по серьезности и
подсчитывает количество строк для каждой группы: Результатом следующего запроса является таблица с двумя столбцами. Следующий запрос иллюстрирует группировку по нескольким столбцам и вычисление
среднее значение. Запрос группирует строки по URL-адресу, содержащемуся в HTTP-запросе.
запросом и значением поля В предыдущем выражении для извлечения значения требуется Следующий запрос иллюстрирует, как можно отобразить среднее число
байтов, отправленных по местоположению. Запрос считывает данные за последний час, а затем сохраняет только эти строки.
чей столбец типа ресурса равен Результатом предыдущего запроса является таблица, в каждой строке которой указано местоположение
и среднее количество байтов, отправленных для этого местоположения. Для получения информации обо всех функциях, которые могут извлекать и преобразовывать JSON.
данные, см. функции JSON. Информацию о Чтобы вернуть подстроку, соответствующую регулярному выражению, используйте функцию Следующий запрос сохраняет записи журнала, для которых значение
поля Дополнительные примеры см. В этом разделе описываются два разных подхода, которые можно использовать для поиска
несколько столбцов таблицы. Для поиска в таблице записей, соответствующих набору условий поиска,
используйте функцию Следующий запрос сохраняет только те строки, в которых есть поле
точно соответствует «35.193.12.15»: В предыдущем запросе обратные кавычки заключают в себе искомое значение. Этот
гарантирует, что Если в строке запроса опущены обратные кавычки, строка запроса разделяется
на основе правил, определенных в документации Предыдущий оператор В запрос можно включить несколько операторов Предыдущий оператор ищет всю таблицу, в то время как исходный оператор
ищет только столбец Чтобы выполнить множественный поиск по столбцу, разделите отдельные строки символом
пространство. Например, следующий оператор соответствует строкам, в которых поле
содержит «Hello World», «happy» и «days»: Наконец, вы можете искать определенные столбцы таблицы вместо поиска
весь стол. Для получения информации о том, как обрабатываются параметры функции Чтобы выполнить тест без учета регистра, чтобы определить, существует ли значение в
выражение, используйте функцию Например, следующий запрос извлекает все записи журнала аудита с
определенный IP-адрес, временные метки которого находятся в определенном диапазоне времени. Предыдущий запрос выполняет проверку подстроки. Таким образом, строка, содержащая
"35.193.12.152" соответствует Для получения информации о маршрутизации и хранении записей журнала см.
см. следующие документы: Справочную документацию по SQL см. |
 Если бы мы не упомянули Customers.customer_id , то получили бы ошибку Error: ambiguous column name: customer_id .
Если бы мы не упомянули Customers.customer_id , то получили бы ошибку Error: ambiguous column name: customer_id .
 customer_id;
customer_id;

 Например, чтобы запросить представление
Например, чтобы запросить представление 
 Функции времени и функции отметки времени.
Функции времени и функции отметки времени. и укажите набор допустимых значений.
и укажите набор допустимых значений. серьезность_число > 200
серьезность_число > 200 
 labels.zone) зона AS, json_payload, ресурс, метки
ОТ
` ТАБЛИЦА `
ГДЕ
отметка времени > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR) И
resource.type = "gce_instance" И
JSON_VALUE(resource.labels.zone) = "us-central1-f"
ЗАКАЗАТЬ ПО отметке времени ASC
ПРЕДЕЛ 100
labels.zone) зона AS, json_payload, ресурс, метки
ОТ
` ТАБЛИЦА `
ГДЕ
отметка времени > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR) И
resource.type = "gce_instance" И
JSON_VALUE(resource.labels.zone) = "us-central1-f"
ЗАКАЗАТЬ ПО отметке времени ASC
ПРЕДЕЛ 100
 request_method IN ('GET', 'POST')
ЗАКАЗАТЬ ПО отметке времени ASC
ПРЕДЕЛ 100
request_method IN ('GET', 'POST')
ЗАКАЗАТЬ ПО отметке времени ASC
ПРЕДЕЛ 100

 googleapis.com/google.cloud.scheduler.logging.AttemptFinished"
jobName: "проекты/мой-проект/местоположения/us-central1/jobs/test1"
относительный URL: "/food=торт"
статус: "НЕ НАЙДЕНО"
targetType: "APP_ENGINE_HTTP"
}
googleapis.com/google.cloud.scheduler.logging.AttemptFinished"
jobName: "проекты/мой-проект/местоположения/us-central1/jobs/test1"
относительный URL: "/food=торт"
статус: "НЕ НАЙДЕНО"
targetType: "APP_ENGINE_HTTP"
}
 jobName
jobName  Если вы не укажете группировку, но сделаете
указать агрегацию, печатается один результат, поскольку SQL обрабатывает все
строки, которые удовлетворяют предложению
Если вы не укажете группировку, но сделаете
указать агрегацию, печатается один результат, поскольку SQL обрабатывает все
строки, которые удовлетворяют предложению  payload.status
payload.status  В первом столбце перечислены ресурсы
тип, а второй столбец — количество строк для этого типа ресурса:
В первом столбце перечислены ресурсы
тип, а второй столбец — количество строк для этого типа ресурса: Первый
столбце перечислены имена журналов, а во втором столбце указано количество
записи журнала, которые были записаны в этот журнал за последний час.
запрос сортирует результаты по количеству записей:
Первый
столбце перечислены имена журналов, а во втором столбце указано количество
записи журнала, которые были записаны в этот журнал за последний час.
запрос сортирует результаты по количеству записей: latency.seconds) AS сек, http_request.request_url
ОТ
` ТАБЛИЦА `
ГДЕ
отметка времени > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR) И
http_request НЕ NULL И
http_request.request_method IN ('GET')
СГРУППИРОВАТЬ ПО http_request.request_url, местоположение
ЗАКАЗАТЬ ПО МЕСТОПОЛОЖЕНИЮ
ПРЕДЕЛ 100
latency.seconds) AS сек, http_request.request_url
ОТ
` ТАБЛИЦА `
ГДЕ
отметка времени > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR) И
http_request НЕ NULL И
http_request.request_method IN ('GET')
СГРУППИРОВАТЬ ПО http_request.request_url, местоположение
ЗАКАЗАТЬ ПО МЕСТОПОЛОЖЕНИЮ
ПРЕДЕЛ 100


 jobName), r".*(test.*)$") Имя AS,
COUNT(*) КАК считать
ОТ
` ТАБЛИЦА `
ГДЕ
отметка времени > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR) И
json_payload.jobName НЕ НУЛЕВОЕ
СГРУППИРОВАТЬ ПО имени
ЗАКАЗАТЬ ПО количеству
ПРЕДЕЛ 20
jobName), r".*(test.*)$") Имя AS,
COUNT(*) КАК считать
ОТ
` ТАБЛИЦА `
ГДЕ
отметка времени > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR) И
json_payload.jobName НЕ НУЛЕВОЕ
СГРУППИРОВАТЬ ПО имени
ЗАКАЗАТЬ ПО количеству
ПРЕДЕЛ 20

 193.12.15")
193.12.15")
 Например, следующий оператор ищет только
столбцы с именами
Например, следующий оператор ищет только
столбцы с именами 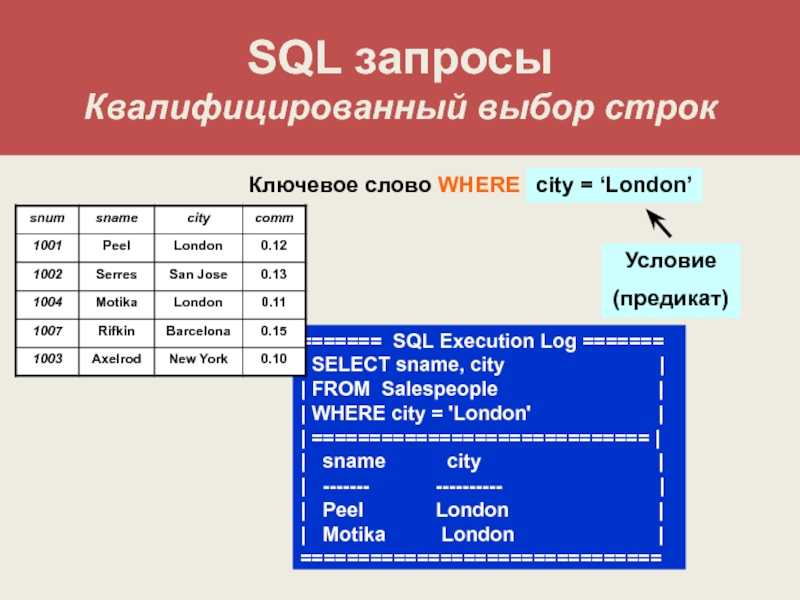 Наконец, запрос сортирует результаты, а затем отображает 20 самых старых результатов:
Наконец, запрос сортирует результаты, а затем отображает 20 самых старых результатов: