Оператор SELECT. Простой SQL-запрос, синтаксис, примеры
За выборку данных из таблиц базы данных в SQL отвечает оператор SELECT. В этой статье будет рассмотрен его простейший синтаксис и примеры.
Чтобы выполнить простой запрос к базе данных достаточно указать всего 2 условия (предложения):
- Какие столбцы необходимо выгрузить;
- Из какой таблицы необходимо выгрузить столбцы.
На языке SQL это выглядит следующим образом:
SELECT <Перечень столбцов> FROM <Перечень таблиц>
Имена столбцов перечисляются через запятую сразу после ключевого слова SELECT. Затем следует ключевой слово FROM с наименованиями таблиц. Если таблиц несколько, то они так же указываются через запятую.
Запросы к нескольким таблицам не рассматриваются в данном материале, так как это тема относится к соединению таблиц либо требует знания предложения WHERE.
Столбцы и таблицы могут быть перечислены в любом порядке и повторяться несколько раз.
Подключение к базе данных
На сервере часто присутствует более одной базы данных. Поэтому, прежде чем выполнить запрос, потребуется подключиться к конкретной базе. Научимся это делать в SQL Server Management Studio:
Теперь любой запрос будет выполняться именно в ее контексте.
Создание SQL-запроса
Выполним первую задачу:
Необходимо получить Фамилии, Имена и Отчества всех сотрудников.
В поле запроса введите следующий SQL-код:
SELECT Фамилия, Имя, Отчество FROM Сотрудники
Первая строка запроса содержит выгружаемые столбцы, вторая строка указывает таблицу столбцов. На самом деле, код напоминает обычное предложение: «Выбрать столбцы Фамилия, Имя, Отчество из таблицы Сотрудники».
Нажмите на кнопку «Выполнить» на панели редактора SQL. Внизу окна запроса должен появиться результат его выполнения. Под результатом отображается статус и продолжительность запроса, а также количество выгруженных строк. Если Вы все сделаете правильно, то статус будет сообщать «Запрос успешно выполнен», а количество строк равняться 39.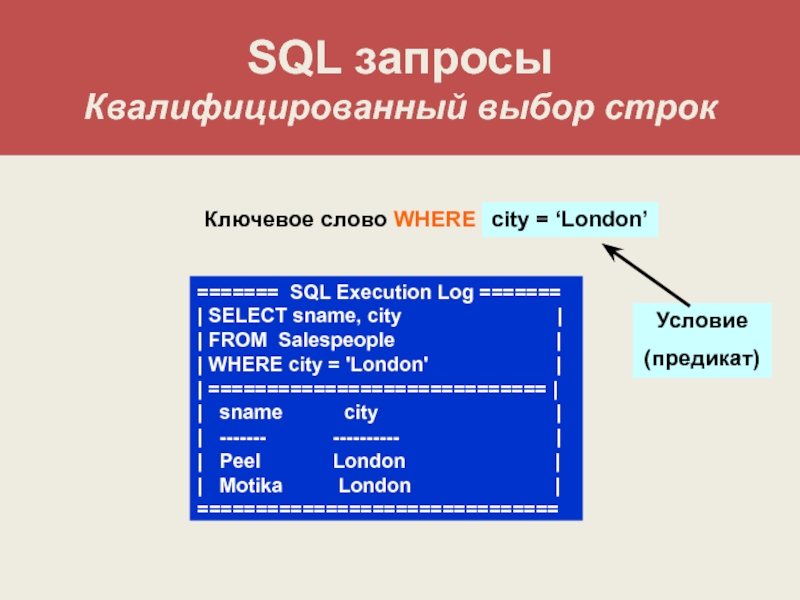
Пояснения синтаксиса
Не имеет значения в каком регистре будут написаны ключевые слова и наименования. Такой вариант полностью идентичен предыдущему:
select ФаМиЛия, иМЯ, ОтчествО froM сотрудники
Также можно не начинать каждое условие с новой строки.
Рекомендуем писать запросы аккуратно, чтобы их было проще понимать и искать ошибки.
Иные варианты запроса
Перед написанием кода говорилось о необходимости подключения к БД. Но можно обойтись и без подключения в этом конкретном случае (в некоторых программах это обязательное требование). Достаточно в предложении FROM дополнительно указать имя базы данных и имя схемы (по умолчанию dbo):
SELECT Фамилия, Имя, Отчество FROM CallCenter.dbo.Сотрудники
SELECT [Имя_таблицы.]Имя_столбца[, [Имя_таблицы.]Имя_столбца2 …] FROM [[Имя_базы_данных.]Имя_Схемы.]Имя_таблицы
Дополнительные имена загромождают код запроса, поэтому можно использовать инструкцию USE. Она переключит контекст на указанную базу данных:
USE CallCenter SELECT Фамилия, Имя, Отчество FROM Сотрудники
Такой подход обеспечит подключение к нужной базе.
Многословные имена столбцов и таблиц могут содержать пробелы между словами. В таких случаях их имена заключаются в квадратные скобки, чтобы запрос сработал корректно. Например, [имя столбца].
- < Назад
- Вперёд >
Если материалы office-menu.ru Вам помогли, то поддержите, пожалуйста, проект, чтобы я мог развивать его дальше.
Добавить комментарий
Примеры сложных запросов для выборки данных в СУБД MySQL
Всего лишь пару лет назад, в проектах, которые предусматривали работу с базами данных и построением статистики, основным изобилием используемых SQL-запросов, преобладало в основном множество запросов, ориентированных на стандартную выборку данных и нечасто можно было увидеть другие, которые безо всяких сомнений можно было бы отнести к “эксклюзиву”. Хотя сложность запроса и зависит от количества используемых таблиц, но если мы всего лишь возьмем и выведем данные полей трех или более таблиц имеющих стандартное объединение, то явная сложность такого запроса не выйдет за пределы стандартной.
Хотя сложность запроса и зависит от количества используемых таблиц, но если мы всего лишь возьмем и выведем данные полей трех или более таблиц имеющих стандартное объединение, то явная сложность такого запроса не выйдет за пределы стандартной.
В данной статье по мере возможности будут рассматриваться те запросы, примеры которых мне найти не удалось и которые, по моему мнению, не относятся к классу простых.
Сравнение данных за две даты
Хотя данная статистика из рода задач довольно редко встречаемых, но все-таки необходимость в ее получении иногда существует. И получить такую статистику ничуть не сложнее других.
Работать мы будем с двумя таблицами, структура которых представлена ниже:
Структура таблицы products
CREATE TABLE IF NOT EXISTS `products` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ShopID` int(11) NOT NULL, `Name` varchar(150) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=10 ;
Структура таблицы statistics
CREATE TABLE IF NOT EXISTS `statistics` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ProductID` bigint(20) NOT NULL, `Orders` int(11) NOT NULL, `Date` date NOT NULL DEFAULT '0000-00-00', PRIMARY KEY (`id`), KEY `ProductID` (`ProductID`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=20 ;
Дело в том, что стандарт языка SQL допускает использование вложенных запросов везде, где разрешается использование ссылок на таблицы.
SELECT stat1.Name, stat1.Orders, stat1.Date, stat2.Orders, stat2.Date FROM (SELECT statistics.ProductID, products.Name, statistics.Orders, statistics.Date FROM products JOIN statistics ON products.id = statistics.ProductID WHERE DATE(statistics.date) = '2014-09-04') AS stat1 JOIN (SELECT statistics.ProductID, statistics.Orders, statistics.Date FROM statistics WHERE DATE(statistics.date) = '2014-09-12') AS stat2 ON stat1.ProductID = stat2.ProductID
В итоге имеем такой результат:
+------------------------+----------+------------+----------+------------+ | Name | Orders1 | Date1 | Orders2 | Date2 | +------------------------+----------+------------+----------+------------+ | Процессоры Pentium II | 1 | 2014-09-04 | 1 | 2014-09-12 | | Процессоры Pentium III | 1 | 2014-09-04 | 10 | 2014-09-12 | | Оптическая мышь Atech | 10 | 2014-09-04 | 3 | 2014-09-12 | | DVD-R | 2 | 2014-09-04 | 5 | 2014-09-12 | | DVD-RW | 22 | 2014-09-04 | 18 | 2014-09-12 | | Клавиатура MS 101 | 5 | 2014-09-04 | 1 | 2014-09-12 | | SDRAM II | 26 | 2014-09-04 | 12 | 2014-09-12 | | Flash RAM 8Gb | 8 | 2014-09-04 | 7 | 2014-09-12 | | Flash RAM 4Gb | 18 | 2014-09-04 | 30 | 2014-09-12 | +------------------------+----------+------------+----------+------------+
Подстановка нескольких значений из другой таблицы
Необходимость в данном запросе не является повседневной, но возникает не совсем уж и редко. Самый распространенный пример, это обычная сетевая игра. Где создается сессия на два игрока. Соответственно в таблице с данными об играх имеются два поля с идентификаторами зарегистрированных игроков. Для того чтобы вывести информацию об имеющихся играх, мы не можем обойтись стандартным объединением таблицы с данными об игроках и таблицы об имеющихся играх. Так как мы имеем два поля с идентификаторами неких игроков. Но мы можем обратиться опять за помощью к псевдонимам таблиц.
Самый распространенный пример, это обычная сетевая игра. Где создается сессия на два игрока. Соответственно в таблице с данными об играх имеются два поля с идентификаторами зарегистрированных игроков. Для того чтобы вывести информацию об имеющихся играх, мы не можем обойтись стандартным объединением таблицы с данными об игроках и таблицы об имеющихся играх. Так как мы имеем два поля с идентификаторами неких игроков. Но мы можем обратиться опять за помощью к псевдонимам таблиц.
Демонстрация данного запроса будет происходить на другом примере, а не на примере сетевой игры. Это чтобы не создавать заново все необходимые таблицы. В качестве данных возьмем таблицу
CREATE TABLE IF NOT EXISTS `replace_com` ( `id` int(11) NOT NULL AUTO_INCREMENT, `sProductID` int(11) NOT NULL, `rProductID` int(11) NOT NULL, `Date` date NOT NULL DEFAULT '0000-00-00', PRIMARY KEY (`id`), KEY `sProductID` (`sProductID`,`rProductID`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=4 ;
Предположим, что у нас есть некий компьютерный салон и мы проводим модификации некоторых компьютерных составляющих, а все операции по замене комплектующих заносим в базу данных. В таблице replace_com интересующими нас полями являются: sProductID и rProductID. Где sProductID – идентификатор заменяемого модуля, а rProductID – идентификатор заменяющего модуля. Запрос, реализующий вывод данных о совершенных операциях выглядит следующим образом:
В таблице replace_com интересующими нас полями являются: sProductID и rProductID. Где sProductID – идентификатор заменяемого модуля, а rProductID – идентификатор заменяющего модуля. Запрос, реализующий вывод данных о совершенных операциях выглядит следующим образом:
SELECT sProducts.Name AS sProduct, rProducts.Name AS rProduct, replace_com.Date FROM replace_com JOIN products AS sProducts ON sProducts.id = replace_com.sProductID JOIN products AS rProducts ON rProducts.id = replace_com.rProductID
Результирующая таблица данных:
+-----------------------+------------------------+------------+ | sProduct | rProduct | Date | +-----------------------+------------------------+------------+ | Процессоры Pentium II | Процессоры Pentium III | 2014-09-15 | | Flash RAM 4Gb | Flash RAM 8Gb | 2014-09-17 | | DVD-R | DVD-RW | 2014-09-18 | +-----------------------+------------------------+------------+
Вывод статистики с накоплением по дате
Предположим, что у нас имеется склад с некими товарами. Товары периодически поступают, и нам бы хотелось видеть в отчете остатки товаров по дням. Поскольку данные о наличии товаров необходимо накапливать, то мы введем пользовательскую переменную. Но есть одно небольшое “но”. Мы не можем использовать в запросе переменные пользователя и группировку данных одновременно (вернее можем, но в итоге получим, не то, что ожидаем), но мы можем использовать вложенный запрос, вместо явно указанной таблицы. Данные в таблице будут предварительно сгруппированы по дате. И уже затем на основе этих данных мы произведем расчет статистики с накоплением.
Товары периодически поступают, и нам бы хотелось видеть в отчете остатки товаров по дням. Поскольку данные о наличии товаров необходимо накапливать, то мы введем пользовательскую переменную. Но есть одно небольшое “но”. Мы не можем использовать в запросе переменные пользователя и группировку данных одновременно (вернее можем, но в итоге получим, не то, что ожидаем), но мы можем использовать вложенный запрос, вместо явно указанной таблицы. Данные в таблице будут предварительно сгруппированы по дате. И уже затем на основе этих данных мы произведем расчет статистики с накоплением.
На первом этапе требуется установить переменную и присвоить ей нулевое значение:
SET @cvalue = 0
В следующем запросе, мы созданную ранее переменную и применим:
SELECT products.Name AS Name, (@cvalue := @cvalue + Orders) as Orders, Date FROM (SELECT ProductID AS ProductID, SUM(Orders) AS Orders, DATE(date) AS Date FROM statistics WHERE ProductID = '1' GROUP BY date) AS statistics JOIN products ON statistics.ProductID = products.id
Итоговый отчет:
+-----------------------+--------+------------+ | Name | Orders | Date | +-----------------------+--------+------------+ | Процессоры Pentium II | 1 | 2014-09-04 | | Процессоры Pentium II | 2 | 2014-09-12 | | Процессоры Pentium II | 4 | 2014-09-14 | | Процессоры Pentium II | 6 | 2014-09-15 | +-----------------------+--------+------------+
Получить используемую в примерах базу данных можно здесь.
Access SQL. Основные понятия, лексика и синтаксис
Для извлечения данных из базы данных используется язык SQL. SQL — это язык программирования, который очень напоминает английский, но предназначен для программ управления базами данных. SQL используется в каждом запросе в Access.
Понимание принципов работы SQL помогает создавать более точные запросы и упрощает исправление запросов, которые возвращают неправильные результаты.
Это статья из цикла статей о языке SQL для Access. В ней описаны основы использования SQL для выборки данных и приведены примеры синтаксиса SQL.
В этой статье
Что такое SQL?
SQL — это язык программирования, предназначенный для работы с наборами фактов и отношениями между ними. В программах управления реляционными базами данных, таких как Microsoft Office Access, язык SQL используется для работы с данными. В отличие от многих языков программирования, SQL удобочитаем и понятен даже новичкам. Как и многие языки программирования, SQL является международным стандартом, признанным такими комитетами по стандартизации, как ISO и ANSI.
На языке SQL описываются наборы данных, помогающие получать ответы на вопросы. При использовании SQL необходимо применять правильный синтаксис. Синтаксис — это набор правил, позволяющих правильно сочетать элементы языка. Синтаксис SQL основан на синтаксисе английского языка и имеет много общих элементов с синтаксисом языка Visual Basic для приложений (VBA).
При использовании SQL необходимо применять правильный синтаксис. Синтаксис — это набор правил, позволяющих правильно сочетать элементы языка. Синтаксис SQL основан на синтаксисе английского языка и имеет много общих элементов с синтаксисом языка Visual Basic для приложений (VBA).
Например, простая инструкция SQL, извлекающая список фамилий контактов с именем Mary, может выглядеть следующим образом:
SELECT Last_Name
FROM Contacts
WHERE First_Name = 'Mary';
Примечание: Язык SQL используется не только для выполнения операций над данными, но еще и для создания и изменения структуры объектов базы данных, например таблиц. Та часть SQL, которая используется для создания и изменения объектов базы данных, называется языком описания данных DDL. Язык DDL не рассматривается в этой статье. Дополнительные сведения см. в статье Создание и изменение таблиц или индексов с помощью запроса определения данных.
Та часть SQL, которая используется для создания и изменения объектов базы данных, называется языком описания данных DDL. Язык DDL не рассматривается в этой статье. Дополнительные сведения см. в статье Создание и изменение таблиц или индексов с помощью запроса определения данных.
Инструкции SELECT
Чтобы описать набор данных с помощью SQL, нужно написать заявление SELECT. Инструкция SELECT содержит полное описание набора данных, которые вы хотите получить из базы данных. К ним относятся файлы со следующими элементами:
-
таблицы, в которых содержатся данные;
-
связи между данными из разных источников;
-
поля или вычисления, на основе которых отбираются данные;
-
условия отбора, которым должны соответствовать данные, включаемые в результат запроса;
-
необходимость и способ сортировки.

Предложения SQL
Инструкция SQL состоит из нескольких частей, называемых предложениями. Каждое предложение в инструкции SQL имеет свое назначение. Некоторые предложения являются обязательными. В приведенной ниже таблице указаны предложения SQL, используемые чаще всего.
Предложение SQL | Описание | Обязательное |
|---|---|---|
|
SELECT |
Определяет поля, которые содержат нужные данные. |
Да |
|
FROM |
Определяет таблицы, которые содержат поля, указанные в предложении SELECT. |
Да |
|
WHERE |
Определяет условия отбора полей, которым должны соответствовать все записи, включаемые в результаты. |
Нет |
|
ORDER BY |
Определяет порядок сортировки результатов. |
Нет |
|
GROUP BY |
В инструкции SQL, которая содержит статистические функции, определяет поля, для которых в предложении SELECT не вычисляется сводное значение. |
Только при наличии таких полей |
|
HAVING |
В инструкции SQL, которая содержит статистические функции, определяет условия, применяемые к полям, для которых в предложении SELECT вычисляется сводное значение. |
Нет |


Термины SQL
Каждое предложение SQL состоит из терминов, которые можно сравнить с частями речи. В приведенной ниже таблице указаны типы терминов SQL.
Термин SQL | Сопоставимая часть речи | Определение | Пример |
|---|---|---|---|
|
идентификатор |
существительное |
Имя, используемое для идентификации объекта базы данных, например имя поля. |
Клиенты.[НомерТелефона] |
|
оператор |
глагол или наречие |
Ключевое слово, которое представляет действие или изменяет его. |
AS |
|
константа |
существительное |
Значение, которое не изменяется, например число или NULL. |
42 |
|
выражение |
прилагательное |
Сочетание идентификаторов, операторов, констант и функций, предназначенное для вычисления одного значения. |
>= Товары.[Цена] |

К началу страницы
Основные предложения SQL: SELECT, FROM и WHERE
Общий формат инструкций SQL:
SELECT field_1
FROM table_1
WHERE criterion_1
;
Примечания:
-
Access не учитывает разрывы строк в инструкции SQL. Несмотря на это, каждое предложение рекомендуется начинать с новой строки, чтобы инструкцию SQL было удобно читать как тому, кто ее написал, так и всем остальным.

-
Каждая инструкция SELECT заканчивается точкой с запятой (;). Точка с запятой может стоять как в конце последнего предложения, так и на отдельной строке в конце инструкции SQL.
Пример в Access
В приведенном ниже примере показано, как в Access может выглядеть инструкция SQL для простого запроса на выборку.
1. Предложение SELECT
2. Предложение FROM
Предложение FROM
3. Предложение WHERE
Эту инструкцию SQL следует читать так: «Выбрать данные из полей «Адрес электронной почты» и «Компания» таблицы «Контакты», а именно те записи, в которых поле «Город» имеет значение «Ростов».
Разберем пример по предложениям, чтобы понять, как работает синтаксис SQL.
Предложение SELECT
SELECT [E-mail Address], Company
Это предложение SELECT.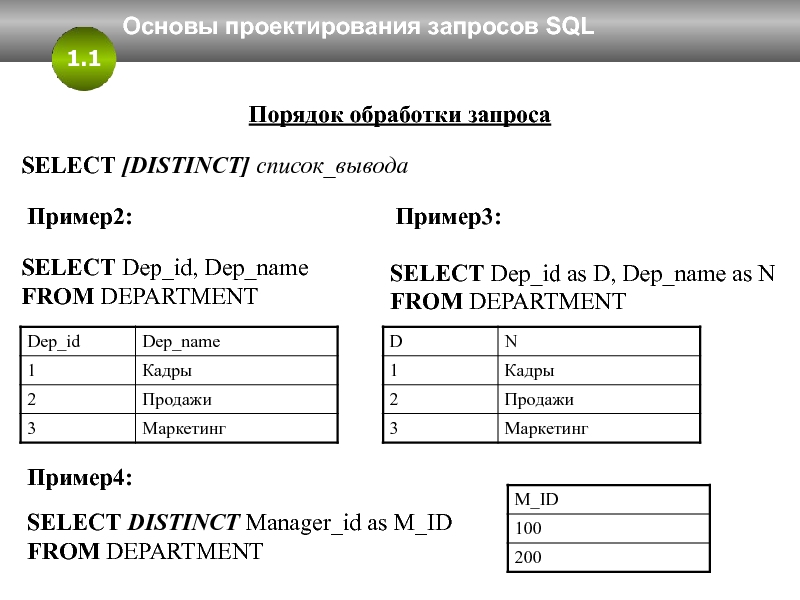 Оно содержит оператор (SELECT), за которым следуют два идентификатора («[Адрес электронной почты]» и «Компания»).
Оно содержит оператор (SELECT), за которым следуют два идентификатора («[Адрес электронной почты]» и «Компания»).
Если идентификатор содержит пробелы или специальные знаки (например, «Адрес электронной почты»), он должен быть заключен в прямоугольные скобки.
В предложении SELECT не нужно указывать таблицы, в которых содержатся поля, и нельзя задать условия отбора, которым должны соответствовать данные, включаемые в результаты.
В инструкции SELECT предложение SELECT всегда стоит перед предложением FROM.
Предложение FROM
FROM Contacts
Это предложение FROM. Оно содержит оператор (FROM), за которым следует идентификатор (Контакты).
Оно содержит оператор (FROM), за которым следует идентификатор (Контакты).
В предложении FROM не указываются поля для выборки.
Предложение WHERE
WHERE City=»Seattle»
Это предложение WHERE. Оно содержит оператор (WHERE), за которым следует выражение (Город=»Ростов»).
Примечание: В отличие от предложений SELECT и FROM, предложение WHERE является необязательным элементом инструкции SELECT.
С помощью предложений SELECT, FROM и WHERE можно выполнять множество действий. Дополнительные сведения об использовании этих предложений см. в следующих статьях:
Дополнительные сведения об использовании этих предложений см. в следующих статьях:
К началу страницы
Сортировка результатов: ORDER BY
Как и в Microsoft Excel, в Access можно сортировать результаты запроса в таблице. Используя предложение ORDER BY, вы также можете указать способ сортировки результатов при выполнении запроса. Если используется предложение ORDER BY, оно должно находиться в конце инструкции SQL.
Предложение ORDER BY содержит список полей, для которых нужно выполнить сортировку, в том же порядке, в котором будут применена сортировка.
Предположим, например, что результаты сначала нужно отсортировать по полю «Компания» в порядке убывания, а затем, если присутствуют записи с одинаковым значением поля «Компания», — отсортировать их по полю «Адрес электронной почты» в порядке возрастания. Предложение ORDER BY будет выглядеть следующим образом:
ORDER BY Company DESC, [E-mail Address]
Примечание: По умолчанию Access сортирует значения по возрастанию (от А до Я, от наименьшего к наибольшему). Чтобы вместо этого выполнить сортировку значений по убыванию, необходимо указать ключевое слово DESC.
Дополнительные сведения о предложении ORDER BY см.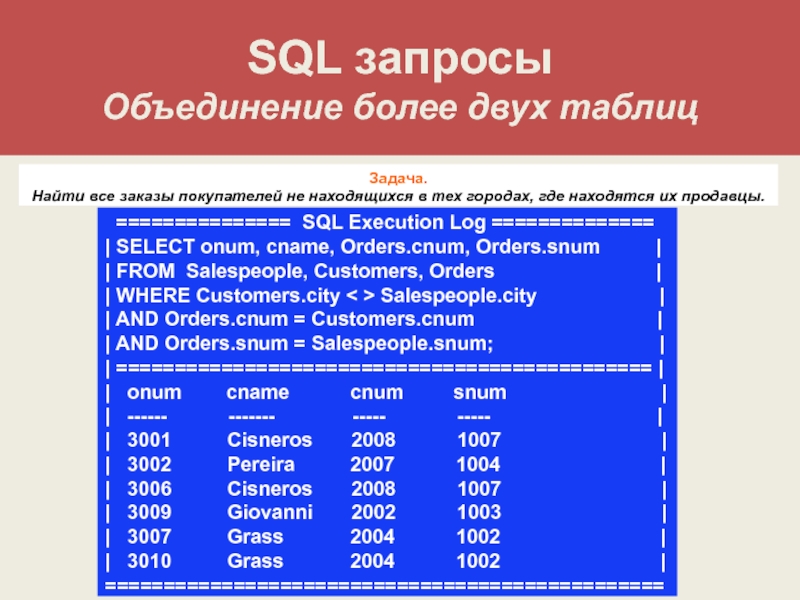 в статье Предложение ORDER BY.
в статье Предложение ORDER BY.
К началу страницы
Работа со сводными данными: предложения GROUP BY и HAVING
Иногда возникает необходимость работы со сводными данными, такими как итоговые продажи за месяц или самые дорогие товары на складе. Для этого в предложении SELECT к полю применяется агрегатная функция. Например, если в результате выполнения запроса нужно получить количество адресов электронной почты каждой компании, предложение SELECT может выглядеть следующим образом:
SELECT COUNT([E-mail Address]), Company
Возможность использования той или иной агрегатной функции зависит от типа данных в поле и нужного выражения. Дополнительные сведения о доступных агрегатных функциях см. в статье Статистические функции SQL.
Дополнительные сведения о доступных агрегатных функциях см. в статье Статистические функции SQL.
Задание полей, которые не используются в агрегатной функции: предложение GROUP BY
При использовании агрегатных функций обычно необходимо создать предложение GROUP BY. В предложении GROUP BY указываются все поля, к которым не применяется агрегатная функция. Если агрегатные функции применяются ко всем полям в запросе, предложение GROUP BY создавать не нужно.
Предложение GROUP BY должно следовать сразу же за предложением WHERE или FROM, если предложение WHERE отсутствует. В предложении GROUP BY поля указываются в том же порядке, что и в предложении SELECT.
Продолжим предыдущий пример.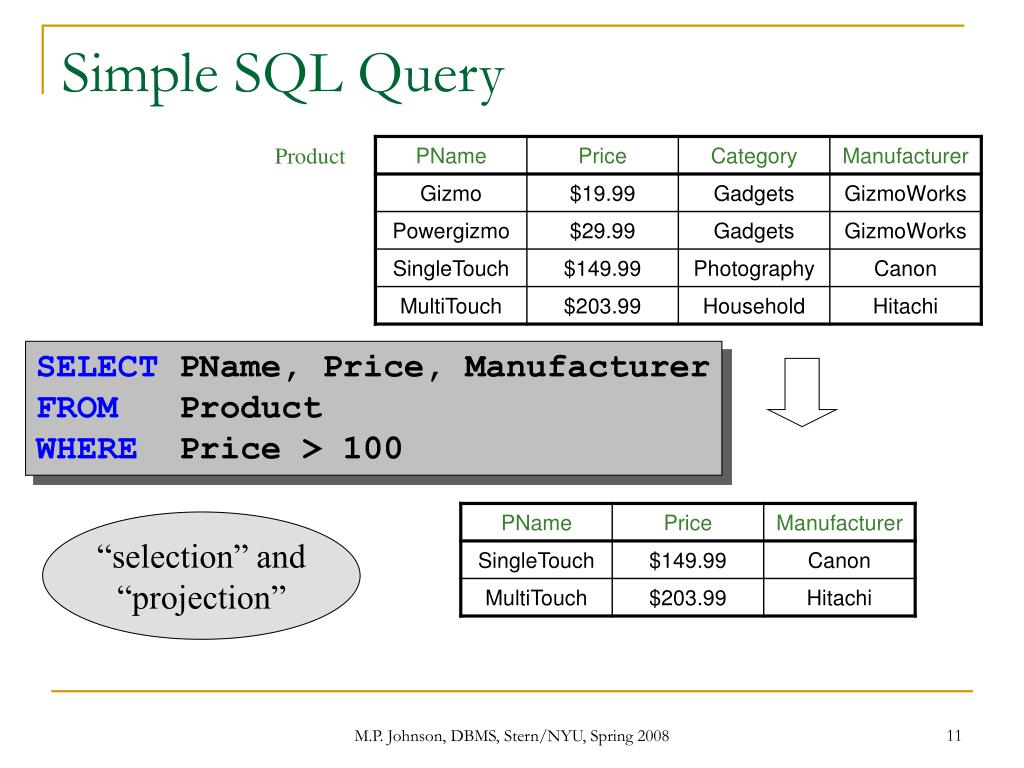 Пусть в предложении SELECT агрегатная функция применяется только к полю [Адрес электронной почты], тогда предложение GROUP BY будет выглядеть следующим образом:
Пусть в предложении SELECT агрегатная функция применяется только к полю [Адрес электронной почты], тогда предложение GROUP BY будет выглядеть следующим образом:
GROUP BY Company
Дополнительные сведения о предложении GROUP BY см. в статье Предложение GROUP BY.
Ограничение агрегированных значений с помощью условий группировки: предложение HAVING
Если необходимо указать условия для ограничения результатов, но поле, к которому их требуется применить, используется в агрегированной функции, предложение WHERE использовать нельзя. Вместо него следует использовать предложение HAVING. Предложение HAVING работает так же, как и WHERE, но используется для агрегированных данных.
Вместо него следует использовать предложение HAVING. Предложение HAVING работает так же, как и WHERE, но используется для агрегированных данных.
Предположим, например, что к первому полю в предложении SELECT применяется функция AVG (которая вычисляет среднее значение):
SELECT COUNT([E-mail Address]), Company
Если вы хотите ограничить результаты запроса на основе значения функции COUNT, к этому полю нельзя применить условие отбора в предложении WHERE. Вместо него условие следует поместить в предложение HAVING. Например, если нужно, чтобы запрос возвращал строки только в том случае, если у компании есть несколько адресов электронной почты, можно использовать следующее предложение HAVING:
HAVING COUNT([E-mail Address])>1
Примечание: Запрос может включать и предложение WHERE, и предложение HAVING, при этом условия отбора для полей, которые не используются в статистических функциях, указываются в предложении WHERE, а условия для полей, которые используются в статистических функциях, — в предложении HAVING.
Дополнительные сведения о предложении HAVING см. в статье Предложение HAVING.
К началу страницы
Объединение результатов запроса: оператор UNION
Оператор UNION используется для одновременного просмотра всех данных, возвращаемых несколькими сходными запросами на выборку, в виде объединенного набора.
Оператор UNION позволяет объединить две инструкции SELECT в одну. Объединяемые инструкции SELECT должны иметь одинаковое число и порядок выходных полей с такими же или совместимыми типами данных. При выполнении запроса данные из каждого набора соответствующих полей объединяются в одно выходное поле, поэтому выходные данные запроса имеют столько же полей, сколько и каждая инструкция SELECT по отдельности.
Объединяемые инструкции SELECT должны иметь одинаковое число и порядок выходных полей с такими же или совместимыми типами данных. При выполнении запроса данные из каждого набора соответствующих полей объединяются в одно выходное поле, поэтому выходные данные запроса имеют столько же полей, сколько и каждая инструкция SELECT по отдельности.
Примечание: В запросах на объединение числовой и текстовый типы данных являются совместимыми.
Используя оператор UNION, можно указать, должны ли в результаты запроса включаться повторяющиеся строки, если таковые имеются. Для этого следует использовать ключевое слово ALL.
Запрос на объединение двух инструкций SELECT имеет следующий базовый синтаксис:
SELECT field_1
FROM table_1
UNION [ALL]
SELECT field_a
FROM table_a
;
Предположим, например, что имеется две таблицы, которые называются «Товары» и «Услуги». Обе таблицы содержат поля с названием товара или услуги, ценой и сведениями о гарантии, а также поле, в котором указывается эксклюзивность предлагаемого товара или услуги. Несмотря на то, что в таблицах «Продукты» и «Услуги» предусмотрены разные типы гарантий, основная информация одна и та же (предоставляется ли на отдельные продукты или услуги гарантия качества). Для объединения четырех полей из двух таблиц можно использовать следующий запрос на объединение:
Обе таблицы содержат поля с названием товара или услуги, ценой и сведениями о гарантии, а также поле, в котором указывается эксклюзивность предлагаемого товара или услуги. Несмотря на то, что в таблицах «Продукты» и «Услуги» предусмотрены разные типы гарантий, основная информация одна и та же (предоставляется ли на отдельные продукты или услуги гарантия качества). Для объединения четырех полей из двух таблиц можно использовать следующий запрос на объединение:
SELECT name, price, warranty_available, exclusive_offer
FROM Products
UNION ALL
SELECT name, price, guarantee_available, exclusive_offer
FROM Services
;
Дополнительные сведения об объединении инструкций SELECT с помощью оператора UNION см. в статье Просмотр объединенных результатов нескольких запросов с помощью запроса на объединение.
в статье Просмотр объединенных результатов нескольких запросов с помощью запроса на объединение.
К началу страницы
Пример создания запроса в MS SQL Server
Пример создания запроса (Query) в базе данных MS SQL Server. База данных размещена в локальном файле *.mdf
Содержание
Поиск на других ресурсах:
Условие задачи
Задана база данных, которая размещается в файле Education.mdf. База данных содержит две связанные между собою таблицы Student и Session.
Таблицы связаны между собою за полем ID_Book.
Используя средства Microsoft Visual Studio создать запрос с именем Query1, который будет иметь следующую структуру:
| Название поля | Таблица |
| Num_Book | Student |
| Name | Student |
| Mathematics | Session |
| Informatics | Session |
| Philosophy | Session |
| Average | Вычислительное поле |
Выполнение (пошаговая инструкция)
1.
 Загрузить Microsoft Visual Studio
Загрузить Microsoft Visual Studio2. Подключить базу данных Education.mdf к перечню баз данных утилиты Server Explorer
Чтобы не тратить время на разработку и связывание таблиц базы данных Education.mdf, архив ранее подготовленной базы данных можно загрузить здесь. После загрузки и сохранения в некоторой папке, базу данных нужно разархивировать и подключить к перечню баз данных утилиты Server Explorer.
Подключение базы данных реализуется одним из нескольких стандартных способов:
- выбором команды «Connect to Database…» с меню Tools;
- выбором кнопки (команды) «Connect to Database…» из утилиты Server Explorer.
В результате, откроется окно мастера, в котором с помощью нескольких шагов (окон) нужно настроить подключение базы данных.
Рис. 1. Способы добавления/подключения базы данных
Подробное описание того, как осуществляется подключение базы данных типа Microsoft SQL Server в Microsoft Visual Studio, приведено в теме:
После подключения, окно утилиты Server Explorer будет выглядеть как показано на рисунке 2.
Рис. 2. Утилита Server Explorer с подключенной базой данных Education.mdf
3. Добавление нового запроса. Команда «New Query»
К базе данных можно создавать запросы. В нашем случае нужно создать запрос в соответствии с условием задачи.
Запрос создается с помощью команды «New Query», которая вызовется из контекстного меню (рисунок 3). Чтобы вызвать команду, достаточно сделать клик правой кнопкой мышки в области поля, которое выделено для отображения элементов базы данных Education.mdb. Следует отметить, что запросы не сохраняются системой. Для отображения сохраненных (сложных) запросов используется представление (Views).
На рисунке 3 отображено контекстное меню, которое вызывается при нажатии на вкладке Views (представление). В этом меню нужно выбрать команду «New Query». Эта команда есть в перечне контекстных меню других составляющих базы данных (таблиц, диаграмм и т.п.).
Рис. 3. Команда New Query
В результате откроется окно «Add Table», в котором нужно выбрать таблицы, данные из которых будут использоваться в запросе (рисунок 4).
Рис. 4. Выбор таблиц, которые будут использоваться в запросе
Для нашего случая нужно выбрать обе таблицы.
В результате окно Microsoft Visual Studio будет выглядеть, как показано на рисунке 5.
Рис. 5. Окно MS Visual Studio после создания запроса
В таблицах нужно выделить поля, которые будут использоваться в запросе. Порядок выбора полей должен соответствовать отображению их в запросе в соответствии с условием задачи. Это означает, что сначала выбираются поля таблицы Student (NumBook, Name), а потом выбираются поля таблицы Session (Mathematics, Informatics, Philosophy).
Для нашего случая выбор полей изображен на рисунке 6.
Рис. 6. Выбор полей для запроса
Как видно из рисунка 6, в нижней части окна отображается запрос на языке SQL, сформированный системой
SELECT Student.Num_Book, Student.Name, Session.Mathematics,
Session.Informatics, Session.Philosophy
FROM Session INNER JOIN
Student ON Session. ID_Book = Student.ID_Book
ID_Book = Student.ID_Book4. Добавление вычисляемого поля Average
Чтобы создать вычисляемое поле Average, нужно в окне, где отображается SQL-запрос изменить текст этого запроса. Например:
SELECT Student.Num_Book, Student.Name, Session.Mathematics, Session.Informatics, Session.Philosophy,
(Session.Mathematics + Session.Informatics + Session.Philosophy) / 3.0 AS Average
FROM Session INNER JOIN
Student ON Session.ID_Book = Student.ID_BookДобавляется вычислительное поле Average, которое есть средним арифметическим (рисунок 7).
Рис. 7. Добавление вычисляемого поля Average
5. Запуск запроса на выполнение. Команда «Execute SQL»
Чтобы запустить на выполнение запрос, используется кнопка «Execute SQL» (рисунок 8).
В нижней части окна на рисунке 8 изображен результат выполнения запроса.
Рис. 8. Кнопка «Execute SQL» запуска запроса на выполнение и результат выполнения запроса
Другой способ запуска запроса на выполнение – команда «Execute SQL» из меню «Query Designer».
Связанные темы
ТОП 30 статей для изучения языка T-SQL – Уровень «Начинающий» | Info-Comp.ru
Приветствую Вас на сайте Info-Comp.ru! В этом материале я представляю Вам 30 лучших своих статей, посвященных языку T-SQL, которые отлично подойдут начинающим программистам для изучения языка T-SQL.
Заметка! Рейтинг популярности систем управления базами данных (СУБД).
Данную подборку статей я назвал – Уровень «Начинающий», ведь все представленные здесь статьи не требуют особой подготовки и знаний языка T-SQL и Microsoft SQL Server.
Статьи упорядочены в порядке увеличения сложности и специфичности, иными словами, в начале этого списка я расположил статьи с базовыми знаниями, а затем постепенно осуществляется переход к более сложным и специфичным задачам.
Таким образом, данный материал можно было бы смело назвать «Курс по изучения языка T-SQL для начинающих», так как последовательно читая все представленные здесь статьи Вы будете изучать язык T-SQL примерно так же, как на специализированных курсах по T-SQL.
Однако за счет того, что здесь отсутствует какая-либо методика обучения, направленная на комплексное изучение языка T-SQL, а представлена всего лишь подборка подходящих статьей, при этом даже такое количество статей не охватывает тот объем информации, который требуется начинающим, данный материал я назвал именно так, т.е. – «ТОП 30 статей для изучения языка T-SQL – Уровень «Начинающий».
Почему Уровень «Начинающий»? Потому что это — первый материал из цикла статей на данную тему, будут еще подборки: Уровень «Продвинутый» и Уровень «Эксперт». Поэтому следите за выходом новых статей в наших группах в социальных сетях: ВКонтакте, Facebook, Одноклассники, Twitter и Tumblr.
Все статьи написаны лично мной (некоторые уже достаточно давно, поэтому не судите строго) и расположены они на этом же сайте в открытом доступе, поэтому Вам не придётся посещать какие-то сторонние ресурсы для того, чтобы прочитать их.
Итак, давайте приступать.
Что такое SQL
Статья – Что такое SQL. Назначение и основа
Из данного материала Вы узнаете, что такое SQL вообще, для чего нужен и используется данный язык, я расскажу про диалекты языка SQL, а также про базы данных и системы управления базами данных. Здесь представлена основа, база, с которой необходимо начать свое знакомство с языком T-SQL (Что такое T-SQL?).
Как создать и выполнить SQL запрос
Статья – Как создать и выполнить SQL запрос к базе данных. Обзор основных инструментов
Из этой статьи Вы узнаете, какими инструментами создавать и выполнять SQL запросы к базе данных, будут рассмотрены инструменты не только для Microsoft SQL Server, но и для других популярных СУБД. Таким образом, в материале представлены основные инструменты, с которыми Вам придётся работать при разработке инструкций на языке SQL.
Создание базы данных
Статья – Создание базы данных в Microsoft SQL Server – инструкция для новичков
В этом материале представлена подробная инструкция для новичков по созданию базы данных в Microsoft SQL Server. Здесь рассмотрены основные этапы создания базы данных, а также два способа создания БД. Без знаний, представленных в этой статье, создать базу не получится.
Здесь рассмотрены основные этапы создания базы данных, а также два способа создания БД. Без знаний, представленных в этой статье, создать базу не получится.
Создание таблиц
Статья – Создание таблиц в Microsoft SQL Server (CREATE TABLE) – подробная инструкция
В этой статье рассмотрен процесс создания таблиц в Microsoft SQL Server, Вы узнаете, как это делается в графическом интерфейсе, а также как создавать таблицы на языке T-SQL. Здесь, как и во всех других материалах, представлены практические примеры со скриншотами и пояснениями.
Изменение таблиц
Статья – Изменение таблиц в Microsoft SQL Server или как добавить, удалить, изменить столбец в таблице?
В материале подробно рассмотрен процесс изменения таблиц в Microsoft SQL Server, Вы научитесь добавлять или удалять столбцы в таблицах, а также изменять свойства столбцов.
Переименование столбцов
Статья – Как переименовать столбец таблицы в Microsoft SQL Server на T-SQL?
Из данного материала Вы узнаете, как переименовать столбец таблицы в Microsoft SQL Server на языке T-SQL уже после создания этой таблицы. В некоторых случаях это бывает очень полезно, так как Вам не нужно пересоздавать всю таблицу целиком.
В некоторых случаях это бывает очень полезно, так как Вам не нужно пересоздавать всю таблицу целиком.
Добавление данных
Статья – Инструкция INSERT INTO в Transact-SQL – несколько способов добавления данных в таблицу
В этой статье рассмотрено несколько способов добавления данных в базу Microsoft SQL Server. Иными словами, Вы узнаете, как добавляются новые строки в таблицы на языке T-SQL с использованием инструкции INSERT INTO.
Обновление данных
Статья – Инструкция UPDATE в T-SQL — обновление данных в Microsoft SQL Server
В этом материале подробно рассмотрена инструкция UPDATE языка T-SQL, с помощью которой происходит обновление данных в таблицах Microsoft SQL Server. Таким образом, Вы узнаете, как изменять уже существующие данные в базе.
Вычисляемые столбцы
Статья – Вычисляемые столбцы в Transact-SQL
В данной статье рассмотрены вычисляемые столбцы в таблицах Microsoft SQL Server, Вы узнаете, для чего они нужны и как они создаются.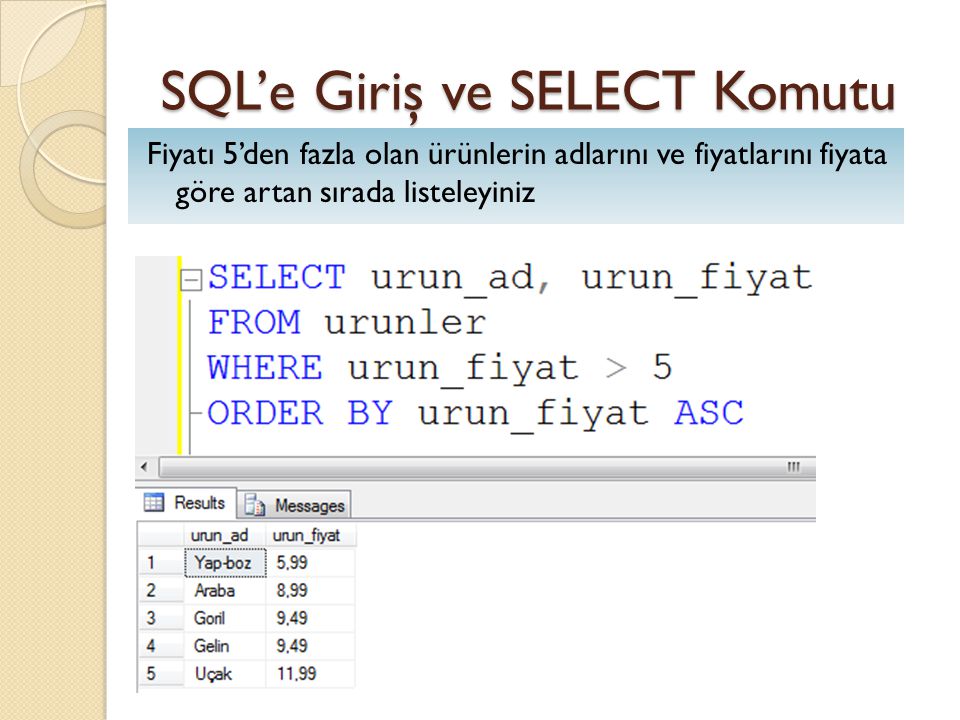
Инструкция SELECT INTO
Статья – Инструкция SELECT INTO в T-SQL или как создать таблицу на основе SQL запроса?
Из данного материала Вы узнаете, как создать таблицу на основе результата SQL запроса в Microsoft SQL Server с использованием инструкции SELECT INTO. Будет рассмотрено несколько примеров с подробным описанием.
Типы данных в T-SQL
Статья – Типы данных в T-SQL (Microsoft SQL Server)
В этой статье подробно рассмотрены все типы данных языка T-SQL, а также приоритеты и синонимы типов данных. Вы узнаете, какие существуют типы данных, какие у них особенности, а также в каких случаях использовать тот или иной тип данных.
Оператор BETWEEN
Статья – BETWEEN в T-SQL – примеры использования логического оператора
В данном материале будет рассмотрен логический оператор BETWEEN языка T-SQL, с помощью которого можно проверить, входит ли значение в определённый диапазон. Мы разберем несколько примеров его использования в разных секциях SQL запроса.
Мы разберем несколько примеров его использования в разных секциях SQL запроса.
Оператор EXISTS
Статья – Логический оператор EXISTS в T-SQL. Описание и примеры
Из данной статьи Вы узнаете, как работает логический оператор EXISTS в языке T-SQL, который принимает и обрабатывает вложенный SQL запрос (SELECT) с целью проверки существования строк. В качестве результата возвращает значения TRUE или FALSE. Здесь будет рассмотрено несколько примеров его использования в разных конструкциях.
Команда USE
Статья – Как изменить контекст базы данных в Microsoft SQL Server? Команда USE
Из данного материала Вы узнаете, как можно сменить контекст базы данных в Microsoft SQL Server, будет рассмотрена команда USE, которая используется в T-SQL как раз для этого.
Составные операторы присваивания
Статья – Составные операторы присваивания в Transact-SQL
Из данной статьи Вы узнаете, какие существуют составные операторы в языке Transact-SQL, которые используются для упрощения написания операций присваивания, и как их использовать.
Инструкция TRUNCATE TABLE
Статья – Инструкция TRUNCATE TABLE в Transact-SQL
В этом материале рассмотрена инструкция TRUNCATE TABLE, которую можно использовать для удаления данных. Вы узнаете, чем отличается TRUNCATE TABLE от DELETE, и какие преимущества нам дает эта инструкция.
Группировка данных GROUP BY
Статья – Transact-SQL группировка данных GROUP BY
В данной статье рассмотрена конструкция GROUP BY языка T-SQL, которая используется для группировки данных. Данная конструкция очень полезна, и она используется достаточно часто для анализа различных данных.
Объединение JOIN
Статья – Язык SQL – объединение JOIN
В этом материале рассмотрены основы объединения данных из разных таблиц, Вы узнаете, что такое INNER, LEFT, RIGHT и CROSS JOIN, и, конечно же, посмотрите на примеры использования этих конструкций.
Объединение UNION и UNION ALL
Статья – Объединение UNION и UNION ALL в SQL – описание и примеры
В этой статье рассмотрено объединение UNION и UNION ALL, которое используется для объединения результирующего набора данных нескольких SQL запросов. Вы узнаете, для чего может потребоваться этот тип объединения, и посмотрите на примеры использования UNION и UNION ALL.
Хранимые процедуры
Статья – Хранимые процедуры в T-SQL — создание, изменение, удаление
Из данной статьи Вы узнаете, что такое хранимые процедуры в языке T-SQL, научитесь создавать, изменять и удалять хранимые процедуры.
Ограничения
Статья – Ограничения в Microsoft SQL Server — что это такое и как их создать?
Ограничения – это специальные объекты в Microsoft SQL Server, с помощью которых можно задать правила допустимости определенных значений в столбцах с целью обеспечения автоматической целостности базы данных.
В данной статье будут рассмотрены основы и примеры создания ограничений в Microsoft SQL Server, таких как: PRIMARY KEY, FOREIGN KEY, CHECK и других.
Основы индексов
Статья – Основы индексов в Microsoft SQL Server
В этой статье рассмотрены основы индексов в Microsoft SQL Server, Вы узнаете, для чего нужны индексы, какие типы индексов бывают, а также как создаются, оптимизируются и удаляются индексы на языке T-SQL.
Вложенные запросы
Статья – Вложенные запросы в T-SQL – описание и примеры
Из данного материала Вы узнаете, что такое вложенные запросы SQL, где и в каких конструкциях их можно использовать, будут рассмотрены примеры их использования, а также я расскажу про особенности и некоторые ограничения вложенных SQL запросов.
Выражение CASE
Статья – Примеры использования выражения CASE в Transact-SQL
CASE – это инструкция, которая проверяет список условий и возвращает соответствующий результат. Если говорить в целом о программировании, то CASE – это что-то вроде многократного использования конструкции IF-ELSE, во многих языках есть похожая конструкция SWITCH.
Если говорить в целом о программировании, то CASE – это что-то вроде многократного использования конструкции IF-ELSE, во многих языках есть похожая конструкция SWITCH.
В этом материале рассмотрено выражение CASE языка Transact-SQL: описание, синтаксис, а также примеры использования выражения CASE.
Как получить первые (или последние) строки запроса
Статья – Как в SQL получить первые (или последние) строки запроса? TOP или OFFSET?
Из данного материала Вы узнаете два способа получения первых или последних строк SQL запроса, первый — с применением фильтра TOP, второй — используя конструкцию OFFSET-FETCH.
Операция MERGE
Статья – Операция MERGE в языке Transact-SQL – описание и примеры
MERGE – операция в языке T-SQL, при которой происходит обновление, вставка или удаление данных в таблице на основе результатов соединения с данными другой таблицы или SQL запроса. Другими словами, с помощью MERGE можно осуществить слияние двух таблиц, т.е. синхронизировать их.
Другими словами, с помощью MERGE можно осуществить слияние двух таблиц, т.е. синхронизировать их.
В этом материале будут рассмотрены основы и примеры использования операции MERGE.
Оператор DROP IF EXISTS
Статья – Инструкция DROP IF EXISTS в языке T-SQL
У инструкции DROP, которая используется для удаления объектов базы данных, есть дополнительный параметр IF EXISTS, благодаря которому можно предварительно проверить существование объекта, перед его непосредственным удалением.
В этой статье рассмотрена инструкция DROP IF EXISTS и примеры ее использования.
Конструкция OFFSET-FETCH
Статья – OFFSET-FETCH в T-SQL – описание и примеры использования
OFFSET-FETCH – это конструкция языка T-SQL, которая является частью ORDER BY, и позволяет применять фильтр к результирующему, уже отсортированному, набору данных.
В данном материале рассмотрена конструкция OFFSET-FETCH, а также приведены примеры использования этой конструкции.
Как вывести повторяющиеся значения в столбце
Статья – Как вывести повторяющиеся значения в столбце на T-SQL? Microsoft SQL Server
Из данного материала Вы узнаете, как вывести повторяющиеся значения в столбце таблицы на языке T-SQL, будут рассмотрены конкретные примеры.
Основы программирования на T-SQL
Статья – Основы программирования на T-SQL
В этом материале рассмотрены основы программирования на языке T-SQL, Вы узнаете, что такое пакеты, переменные, научитесь использовать условные конструкции, циклы, а также познакомитесь с командами GOTO, WAITFOR, RETURN и другими.
Виталий Трунин
Автор всех статей. Разработчик T-SQL
Задать вопрос
Для комплексного и последовательного изучения языка T-SQL рекомендую пройти мой курс по T-SQL для начинающих, который включает, не только текстовый материал, но и видео, задания, тесты, а также поддержку ментора и сертификат о прохождении.
На сегодня это все, до новых встреч на сайте Info-Comp.ru!
Нравится3Не нравится1Используйте возможности SQL для создания запросов в Excel и напрямую к таблицам Excel
Порой таблицы Excel постепенно разрастаются настолько, что с ними становится неудобно работать. Поиск дубликатов, группировка, сложная сортировка, объединение нескольких таблиц в одну, т.д. — превращаются в действительно трудоёмкие задачи. Теоретически эти задачи можно легко решить с помощью языка запросов SQL… если бы только можно было составлять запросы напрямую к данным Excel.
Инструмент XLTools «SQL запросы» расширяет Excel возможностями языка структурированных запросов:
Создание запросов SQL в интерфейсе Excel и напрямую к Excel таблицам
Автогенерация запросов SELECT и JOIN
Доступны JOIN, ORDER BY, DISTINCT, GROUP BY, SUM и другие операторы SQLite
Создание запросов в интуитивном редакторе с подстветкой синтаксиса
Обращение к любым таблицам Excel из дерева данных
Перед началом работы добавьте «Всплывающие часы» в Excel
«SQL запросы» – это один из 20+ инструментов в составе надстройки XLTools для Excel. Работает в Excel 2019, 2016, 2013, 2010, десктоп Office 365.
Скачать XLTools для Excel
– пробный период дает 14 дней полного доступа ко всем инструментам.Как превратить данные Excel в реляционную базу данных и подготовить их к работе с SQL запросами
По умолчанию Excel воспринимает данные как простые диапазоны. Но SQL применим только к реляционным базам данных. Поэтому, прежде чем создать запрос, преобразуйте диапазоны Excel в таблицу (именованный диапазон с применением стиля таблицы):
- Выделите диапазон данных На вкладке «Главная» нажмите Форматировать как таблицу Примените стиль таблицы.
Выберите таблицу Откройте вкладку «Конструктор» Напечатайте имя таблицы.
Напр., «КодТовара».
Повторите эти шаги для каждого диапазона, который планируете использовать в запросах.
Напр., «КодТовара», «ЦенаРозн», «ОбъемПродаж», т.д.
Готово, теперь эти таблицы будут служить реляционной базой данных и готовы к SQL запросам.
Как создать и выполнить запрос SQL SELECT к таблицам Excel
Надстройка «SQL запросы» позволяет выполнять запросы к Excel таблицам на разных листах и в разных книгах. Для этого убедитесь, что эти книги открыты, а нужные данные отформатированы как именованные таблицы.
- Нажмите кнопку Выполнить SQL на вкладке XLTools Откроется окно редактора.
В левой части окна находится дерево данных со всеми доступными таблицами Excel.
Нажатием на узлы открываются/сворачиваются поля таблицы (столбцы).
Выберите целые таблицы или конкретные поля.
По мере выбора полей, в правой части редактора автоматически генерируется запрос SELECT.Внимание: редактор запросов SQL автоматически подсвечивает синтаксис.
Укажите, куда необходимо поместить результат запроса: на новый или существующий лист.
- Нажмите «Выполнить» Готово!
Операторы Left Join, Order By, Group By, Distinct и другие SQLite команды в Excel
XLTools использует стандарт SQLite. Пользователи, владеющие языком SQLite, могут создавать самые разнообразные запросы:
LEFT JOIN – объединить две и более таблиц по общему ключевому столбцу
ORDER BY – сортировка данных в выдаче запроса
DISTINCT – удаление дубликатов из результата запроса
GROUP BY – группировка данных в выдаче запроса
SUM, COUNT, MIN, MAX, AVG и другие операторы
Совет: вместо набора названий таблиц вручную, просто перетягивайте названия из дерева данных в область редактора SQL запросов.
Как объединить две и более Excel таблиц с помощью надстройки «SQL запросы»
Вы можете объединить несколько таблиц Excel в одну, если у них есть общее ключевое поле. Предположим, вам нужно объединить несколько таблиц по общему столбцу «КодТовара»:
Нажмите Выполнить SQL на вкладке XLTools Выберите поля, которые нужно включить в объединённую таблицу.
По мере выбора полей, автоматически генерируется запрос SELECT и LEFT JOIN.
Укажите, куда необходимо поместить результат запроса: на новый или существующий лист.
- Нажмите «Выполнить» Готово! Объединённая таблица появится в считанные секунды.
SQL примеры запросов
- ТОП 10 или Выбрать все строки из таблицы city и упорядочить по имени name
(desc — по убыванию, т.е выводить с конца алфавита к началу). Ограничить вывод 10 значениями:
select * from city
order by name desc
limit 10
- Объединение таблиц city и country по колонке id, с условием id>=0 и имя Россия или Румыния, вывод упорядочить по city.name
select * from city
inner join country on city.region_id=country.id
where country.id>=0 AND (country.name=’Россия’ or country.name=’Румыния’)
order by city.name
select * from city
inner join country on city.region_id=country.id
where country.id>=0 AND country.name IN (‘Россия’,’Румыния’)
order by city.name
Select * From city
Where country.name Like ‘Руан%’
Возможно использование в блоке HAVING:
Select id, name,region_id From city
Group By name, id,region_id
Having name Like ‘Ryb%’
order by id
select *,
CASE
when region_id>=1000 then ‘Кирилица’
when region_id>=100 then ‘Латиница’
else ‘middle’
end as Tags
from city
order by name
Select id, name,region_id From city
Group By name, id,region_id
Having name Like ‘Ryb%’
order by id
Select country.name, SUM(city.id) TotalSum From city — вывести сумму колонки ID в колонку с названием TotalSum из таблицы City
Left join country on city.region_id=country.id —присоединить к таблице City(все данные) таблицу Country(отсутствующие данные допишутся Null)
where country.name is not Null — выводить только заполненные поля
group by country.name —сгруппировать в одну строку все одинаковые имена
order by country.name —Упорядочить по алфавиту
Select country.name, MIN(city.id) MinID, MAX(city.id) MaxID From city — вывести MAX, MIN в колонки MinID и MaxID из таблицы City
Left join country on city.region_id=country.id —присоединить к таблице City(все данные) таблицу Country(отсутствующие данные допишутся Null)
where country.name is not Null — выводить только аполненные поля
group by country.name —сгруппировать в одну строку все одинаковые имена
order by country.name —Упорядочить по алфавиту
Выбрать топ 5 стран у которых максимальное количество регионов
Select country.name,
Count (Distinct region.name) OriginalRegions
From country
Left Join region on country.id=region.country_id
Left Join city on city.region_id=region.id
Group by country.name
Order By Count(Distinct region.name) desc
Limit 5
Выбрать топ 5 стран c наибольшим количеством городов
Select country.name,
Count (Distinct city.name)
From country
Left Join region on country.id=region.country_id
Left Join city on region.id=city.region_id
Group By (country.name)
—Having country.name Like ‘Бел%’
Order by Count (Distinct city.name) desc
Limit 5
Вывести инфу по всем странам (страна — количество регионов — количество городов)
Select country.name,
Count (Distinct region.name) Regions,
Count (Distinct city.name) Cities
From country
Left Join region on country.id=region.country_id
Left Join city on region.id=city.region_id
Group By (country.name)
Order by (country.name)
- Вложенный запрос
вывести список регионов из Беларуси и Украины
Select * From region
Where country_id IN
—Where country_id=ANY — каждому из списка
—Where country_id !=ALL —не из данного списка
—Where country_id NOT IN —не в списке
—Where EXISTS
—вложенный запрос на id стран Беларусь и Украина:
(Select id from country
Where (country.name=’Беларусь’ or country.name=’Украина’))
Как писать простые запросы
Как запросить базу данных SQL:
- Убедитесь, что у вас есть приложение для управления базой данных (например, MySQL Workbench, Sequel Pro).
- Если нет, загрузите приложение для управления базой данных и поработайте с вашей компанией, чтобы подключить вашу базу данных.
- Изучите свою базу данных и ее иерархию.
- Узнайте, какие поля находятся в ваших таблицах.
- Начните писать SQL-запрос, чтобы получить желаемые данные.
Вы когда-нибудь слышали о компьютерном языке под названием SQL? Возможно, вы слышали об этом в контексте анализа данных, но никогда не думали, что это применимо к вам как к маркетологу.Или вы, возможно, подумали: «Это действительно для , действительно опытных пользователей данных . Я никогда не смогу этого сделать».
Что ж, более ошибаюсь! Наиболее успешные маркетологи руководствуются данными, и одна из наиболее важных составляющих работы на основе данных — это возможность быстро собирать данные из баз данных. SQL оказался одним из лучших и самых популярных инструментов для этого.
SQL расшифровывается как язык структурированных запросов и используется, когда у компаний есть тонны данных, которыми они хотят легко и быстро манипулировать.Если ваша компания уже хранит данные в базе данных, вам может потребоваться изучить SQL для доступа к данным. Но не волнуйтесь — вы находитесь в правильном месте, чтобы начать работу!
Прежде чем мы начнем, убедитесь, что у вас есть приложение для управления базой данных, которое позволит вам извлекать данные из вашей базы данных. Некоторые варианты включают MySQL Workbench или Sequel Pro. Начните с загрузки одного из этих вариантов, а затем поговорите со своей компанией о том, как подключиться к базе данных. Выбранный вами вариант будет зависеть от серверной части вашего продукта, поэтому проконсультируйтесь со своей командой разработчиков, чтобы убедиться, что вы выбрали правильный.
Давайте прыгнем прямо.
Зачем нужен SQL?
Прелесть SQL в том, что любой, кто работает в компании, которая хранит данные в реляционной базе данных, может его использовать. (И, скорее всего, ваш.)
Если вы работаете в компании-разработчике программного обеспечения и хотите получить данные об использовании своих клиентов, вы можете сделать это с помощью SQL. Если вы работаете в компании электронной коммерции, у которой есть данные о покупках клиентов, вы можете использовать SQL, чтобы узнать, какие клиенты какие продукты покупают. Конечно, это лишь некоторые из многих-многих примеров.
Подумайте об этом так: открывали ли вы когда-нибудь очень большой набор данных в Excel только для того, чтобы ваш компьютер зависал или даже выключался? SQL позволяет вам получить доступ только к определенным частям ваших данных за раз, поэтому вам не нужно загружать данные в CSV, манипулировать ими и, возможно, перегружать Excel. Другими словами, SQL заботится об анализе данных, который вы, возможно, привыкли делать в Excel. (Если вы хотите немного углубиться в этот аспект SQL, вот статья в блоге, с которой вы можете начать.)
Как писать простые запросы SQL
Понять иерархию вашей базы данных
Прежде чем вы начнете, важно привыкнуть к вашей базе данных и ее иерархии.Если у вас есть несколько баз данных, вам нужно сосредоточиться на том, где находятся данные, с которыми вы хотите работать.
Например, давайте представим, что мы работаем с несколькими базами данных о людях в Соединенных Штатах. Введите запрос «ПОКАЗАТЬ БАЗЫ ДАННЫХ;». Наши результаты могут показать, что у вас есть несколько баз данных для разных мест, в том числе одна для Новой Англии.
В вашей базе данных у вас будут разные таблицы, содержащие данные, с которыми вы хотите работать. Используя тот же пример выше, допустим, мы хотим узнать, какая информация содержится в одной из баз данных.Если мы воспользуемся запросом «ПОКАЗАТЬ ТАБЛИЦЫ в Новой Англии;», мы обнаружим, что у нас есть таблицы для каждого штата Новой Англии: people_connecticut, people_maine, people_massachusetts, people_newhampshire, people_rhodeisland и people_vermont.
Наконец, вам нужно выяснить, какие поля находятся в таблицах. Поля — это определенные фрагменты данных, которые вы можете извлечь из своей базы данных. Например, если вы хотите получить чей-то адрес, имя поля может быть не просто «адресом» — оно может быть разделено на address_city, address_state, address_zip.Чтобы в этом разобраться, воспользуйтесь запросом «Describe people_massachusetts;». Это предоставит список всех данных, которые вы можете получить с помощью SQL.
Давайте быстро рассмотрим иерархию на примере Новой Англии:
- Наша база данных: NewEngland.
- Наши таблицы в этой базе данных: people_connecticut, people_maine, people_massachusetts, people_newhampshire, people_rhodeisland и people_vermont.
- Наши поля в таблице people_massachusetts включают: address_city, address_state, address_zip, hair_color, first_name и last_name.
Теперь, чтобы научиться писать простой SQL-запрос, давайте воспользуемся следующим примером:
Кто эти люди с рыжими волосами в Массачусетсе, родившиеся в 2003 году, в алфавитном порядке?
ВЫБРАТЬ
SELECT выбирает поля, которые вы хотите отобразить на диаграмме. Это конкретная информация, которую вы хотите извлечь из своей базы данных. В приведенном выше примере мы хотим найти человек , которые соответствуют остальным критериям.
Вот наш SQL-запрос:
ВЫБРАТЬ
first_name,
last_name
ИЗ
FROM определяет таблицу, из которой вы хотите извлечь данные. В предыдущем разделе мы обнаружили, что существует шесть таблиц для каждого из шести штатов Новой Англии: people_connecticut, people_maine, people_massachusetts, people_newhampshire, people_rhodeisland и people_vermont. Поскольку мы ищем людей конкретно в Массачусетсе, мы будем извлекать данные из этой конкретной таблицы.
Вот наш SQL-запрос:
ВЫБРАТЬ
first_name,
last_name
FROM
people_massachusetts
ГДЕ
WHERE позволяет вам фильтровать ваш запрос, чтобы быть более конкретным. В нашем примере мы хотим отфильтровать наш запрос, чтобы он включал только людей с рыжими волосами, родившихся в 2003 году. Начнем с фильтра рыжих волос.
Вот наш SQL-запрос:
ВЫБЕРИТЕ
first_name,
last_name
FROM
people_massachusetts
ГДЕ
hair_color = «red»
hair_color могло бы быть частью вашего начального оператора SELECT, если бы вы хотели посмотреть на всех людей в Массачусетсе вместе с их конкретным цветом волос.Но если вы хотите отфильтровать только человек с рыжими волосами, вы можете сделать это в инструкции WHERE.
И
AND позволяет добавлять дополнительные критерии к вашему оператору WHERE. Помните, что мы хотим фильтровать людей с рыжими волосами в дополнение к людям, родившимся в 2003 году. Поскольку наше выражение WHERE основано на критериях рыжих волос, как мы можем фильтровать и по определенному году рождения?
Вот где на помощь приходит оператор AND. В этом случае оператор AND является свойством даты, но это не обязательно.(Примечание. Уточняйте формат дат с командой разработчиков продукта, чтобы убедиться, что он указан в правильном формате.)
Вот наш SQL-запрос:
ВЫБЕРИТЕ
first_name,
last_name
FROM
people_massachusetts
ГДЕ
hair_color = «red»
AND
Дата рождения AND BETWEEN ‘2003-01-01’ 2003-12-31 ‘
ЗАКАЗАТЬ В
Когда вы создаете SQL-запросы, вам не нужно экспортировать данные в Excel.Расчет и организация должны выполняться в рамках запроса. Вот тут-то и пригодятся функции «ORDER BY» и «GROUP BY». Сначала мы рассмотрим наши SQL-запросы с функциями ORDER BY и затем GROUP BY соответственно. Затем мы кратко рассмотрим разницу между ними.
Предложение ORDER BY позволяет выполнять сортировку по любому из полей, указанных в операторе SELECT. В этом случае будем заказывать по фамилии.
Вот наш SQL-запрос:
ВЫБЕРИТЕ
first_name,
last_name
FROM
people_massachusetts
ГДЕ
hair_color = «red»
AND
Дата рождения AND BETWEEN ‘2003-01-01’ 2003-12-31 ‘
ЗАКАЗАТЬ ПО
фамилия
;
ГРУППА ПО
«GROUP BY» похожа на «ORDER BY», но объединяет данные, имеющие сходство.Например, если у вас есть дубликаты в ваших данных, вы можете использовать «GROUP BY» для подсчета количества дубликатов в ваших полях.
Вот ваш SQL-запрос:
ВЫБЕРИТЕ
first_name,
last_name
FROM
people_massachusetts
ГДЕ
hair_color = «red»
AND
Дата рождения AND BETWEEN ‘2003-01-01’ 2003-12-31 ‘
ГРУППА ПО
фамилия
;
ЗАКАЗ VS.ГРУППА BY
Чтобы ясно показать вам разницу между оператором «ORDER BY» и оператором «GROUP BY», давайте ненадолго выйдем за пределы нашего примера с Массачусетсом и рассмотрим очень простой набор данных. Ниже приведен список идентификационных номеров и имен четырех сотрудников.
Если бы мы использовали оператор ORDER BY в этом списке, имена сотрудников были бы отсортированы в алфавитном порядке. Результат будет выглядеть так:
Если бы мы использовали оператор GROUP BY, сотрудники были бы подсчитаны на основе того, сколько раз они появлялись в исходной таблице.Обратите внимание, что Петр дважды появлялся в исходной таблице. Результат будет выглядеть так:
Со мной так далеко? Хорошо. Вернемся к создаваемому нами SQL-запросу о рыжеволосых людях из Массачусетса, родившихся в 2003 году.
ПРЕДЕЛ
В зависимости от количества данных в базе данных выполнение запросов может занять много времени. Это может быть неприятно, если вы обнаружите, что долго ждете выполнения запроса, с которого вы действительно не хотели начинать.Если вы хотите протестировать наш запрос, отлично подойдет функция LIMIT, поскольку она позволяет ограничить количество получаемых результатов.
Например, если мы подозреваем, что в Массачусетсе есть миллионы людей с рыжими волосами, мы можем протестировать наш запрос с помощью LIMIT, прежде чем запускать его полностью, чтобы убедиться, что мы получаем нужную информацию. Скажем, например, мы хотим видеть только первых 100 человек.
Вот наш SQL-запрос:
ВЫБЕРИТЕ
first_name,
last_name
FROM
people_massachusetts
ГДЕ
hair_color = «red»
AND
Дата рождения AND BETWEEN ‘2003-01-01’ 2003-12-31 ‘
ЗАКАЗАТЬ ПО
фамилия
LIMIT
100
;
Вот и все по основам!
Чувствуете себя хорошо? Вот еще несколько способов улучшить ваши SQL-запросы.
Бонус: расширенные советы по SQL
Теперь, когда вы освоили создание SQL-запроса, давайте рассмотрим некоторые другие приемы, которые вы можете использовать, чтобы поднять его на ступеньку выше, начиная со звездочки.
*
Когда вы добавляете звездочку к одному из ваших SQL-запросов, она сообщает запросу, что вы хотите включить все столбцы данных в свои результаты. В примере, который мы использовали, у нас было только два имени столбца: first_name и last_name. Но предположим, что у нас есть данные размером 15 столбцов, которые мы хотим видеть в наших результатах — было бы довольно сложно ввести все имена 15 столбцов в операторе SELECT.Вместо этого, если вы замените имена этих столбцов звездочкой, запрос будет извлекать все столбцы из результатов.
Вот как будет выглядеть SQL-запрос:
ВЫБЕРИТЕ
*
ИЗ
people_massachusetts
ГДЕ
hair_color = «red»
И
дата рождения МЕЖДУ ‘2003-01-01’ И ‘2003-12-31 ‘
ЗАКАЗАТЬ ПО
фамилия
LIMIT
100
;
ПОСЛЕДНИЕ 30 ДНЕЙ
Когда я начал регулярно использовать SQL, я обнаружил, что один из моих постоянных запросов включал попытку выяснить, какие люди выполняли действия или выполняли определенный набор критериев в течение последних 30 дней.Поскольку этот тип запросов был очень полезен для меня, я хотел поделиться с вами этой возможностью.
Давайте представим, что сегодня 1 декабря 2014 года. Вы, , могли бы создать эти параметры , сделав интервал Birth_date между 1 ноября 2014 года и 30 ноября 2014 года. Этот SQL-запрос будет выглядеть так:
ВЫБЕРИТЕ
first_name,
last_name
FROM
people_massachusetts
ГДЕ
hair_color = «red»
AND
Дата рождения И Дата рождения BETWEEN ‘2014-11-01’ 2014-11-01 ‘ 2014-11-30 ‘
ЗАКАЗАТЬ ПО
фамилия
LIMIT
100
;
Но это потребовало бы размышлений о том, какие даты охватывают последние 30 дней, и это означало бы, что вам придется постоянно обновлять этот запрос.Вместо этого, чтобы даты автоматически охватывали последние 30 дней независимо от того, какой это день, вы можете ввести это в поле AND: Birth_date> = (DATE_SUB (CURDATE (), INTERVAL 30.
)(Примечание: вам нужно перепроверить этот синтаксис со своей командой разработчиков продукта, потому что он может отличаться в зависимости от программного обеспечения, которое вы используете для получения запросов SQL.)
Таким образом, ваш SQL-запрос будет выглядеть так:
ВЫБЕРИТЕ
first_name,
last_name
FROM
people_massachusetts
ГДЕ
hair_color = «red»
AND
Дата рождения> = (DATE_SUB) (CURS 30))
ЗАКАЗАТЬ ПО
фамилия
LIMIT
100
;
СЧЕТ
В некоторых случаях вы можете захотеть подсчитать, сколько раз появляется критерий поля.Например, предположим, вы хотите подсчитать, сколько раз появлялись разные цвета волос у людей, которых вы подсчитываете из Массачусетса. В этом случае вам пригодится COUNT, так что вам не придется вручную складывать количество людей с разными цветами волос или экспортировать эту информацию в Excel.
Вот как будет выглядеть этот SQL-запрос:
ВЫБРАТЬ
цвет_ волос,
СЧЕТ (цвет_ волос)
ИЗ
people_massachusetts
И
дата рождения МЕЖДУ ‘2003-01-01’ И ‘2003-12-31’
ГРУППА ПО
цвет волос
;
ПРИСОЕДИНЯЙТЕСЬ
Может быть, в какой-то момент вам понадобится получить доступ к информации из двух разных таблиц в одном SQL-запросе.В SQL для этого можно использовать предложение JOIN. (Для тех из вас, кто знаком с формулами Excel, это похоже на то, как вы использовали бы формулу ВПР, когда вам нужно объединить информацию из двух разных листов в Excel.)
Например, предположим, что у нас есть одна таблица, в которой содержатся данные об идентификаторах пользователей всех жителей Массачусетса и их датах рождения. Допустим, у нас также есть полностью отдельная таблица, в которой есть данные об идентификаторах пользователей всех жителей Масачусетса и их цвете волос. Если мы хотим выяснить цвет волос жителей Массачусетса, родившихся в 2003 году, нам потребуется получить доступ к информации из обеих таблиц и объединить их.Это работает, потому что обе таблицы имеют совпадающий столбец: идентификаторы пользователей жителей Массачусетса.
Поскольку мы вызываем поля из двух разных таблиц, наш оператор SELECT также немного изменится. Вместо того, чтобы просто перечислять поля, которые мы хотим включить в наши результаты, нам нужно указать, из какой таблицы они берутся. (Примечание: здесь может пригодиться функция звездочки, поэтому ваш запрос включает обе таблицы в ваши результаты.)
Чтобы указать поле из определенной таблицы, все, что нам нужно сделать, это объединить имя таблицы с именем поля.Например, в нашем операторе SELECT будет сказано «table.field» — с точкой, разделяющей имя таблицы и имя поля.
Давайте посмотрим, как это выглядит в действии.
В этом случае мы предполагаем несколько вещей:
- Таблица дат рождения в Массачусетсе включает следующие поля: first_name, last_name, user_id, Birthdate
- Таблица цветов волос Массачусетса включает следующие поля: user_id, hair_color
Таким образом, ваш SQL-запрос будет выглядеть так:
ВЫБРАТЬ
Birthdate_massachusetts. first_name,
Birthdate_massachusetts. фамилия
ИЗ
Birthdate_massachusetts ПРИСОЕДИНЯЙТЕСЬ 31 ‘
ЗАКАЗАТЬ ПО
фамилия
;
Этот запрос объединит две таблицы с помощью поля «user_id», которое появляется как в таблице Birthdate_massachusetts, так и в таблице haircolor_massachusetts.После этого вы увидите таблицу с людьми, родившимися в 2003 году с рыжими волосами.
Поздравляем: вы готовы приступить к работе со своими собственными SQL-запросами! Хотя с SQL вы можете сделать гораздо больше, я надеюсь, что этот обзор основ оказался для вас полезным, чтобы вы могли запачкать руки. Обладая прочными основами, вы сможете лучше ориентироваться в SQL и работать над некоторыми из более сложных примеров.
Какие данные вы хотите получать с помощью SQL?
базовых SQL-запросов — обзор для начинающих с примерами
Сегодня у меня есть статья для начинающих.Он будет полон примеров sql-запросов. Мы начнем с самых простых и продолжим. Запросы SQL будут организованы в хронологическом порядке в соответствии с их сложностью. Я добавлю больше позже.
Знание SQL в настоящее время является обязательным для любого ИТ-отдела. Но в наши дни не только ИТ-специалисты , но также аналитики и люди, работающие с отчетами , используют SQL-запросы , поскольку это делает их работу намного более эффективной.
Примеры того, как SQL-запрос может помочь вам в вашей работе:
1 Простейший SQL-запрос без условий
Запрос с выбором всех столбцов с использованием * без ограничивающих условий (руководство по выбору пункта здесь):
ВЫБРАТЬ *
ИЗ [AdventureWorksDW2014].[dbo]. [udv_SalesByProducts];
2 SQL-запроса с условием WHERE
Запрос с ограничивающим условием для 2010 года в where (руководство по разделу where здесь):
ВЫБРАТЬ *
ИЗ [AdventureWorksDW2014]. [Dbo]. [Udv_SalesByProducts]
ГДЕ [Год] = 2010;
3 Состояние соединения в ГДЕ
SQL-запрос, в котором мы использовали множество условий и некоторые базовые операторы IN, BETWEEN, LIKE и>
ВЫБРАТЬ *
ИЗ [AdventureWorksDW2014].[dbo]. [udv_SalesByProducts]
ГДЕ [Подкатегория продукта] НРАВИТСЯ ('% bike%')
И [Год] В (2013,2014)
И [Месяц] МЕЖДУ 1 И 6
И [AverageAmount]> 0;
4 Выбор первых 10 записей в порядке возрастания (ASC) или убывания (DESC) с использованием ORDER BY
Мы выбираем 10 (ТОП) самых высоких продаж за 2013 год в порядке убывания (ORDER BY
ВЫБРАТЬ ТОП 10 *
ИЗ [AdventureWorksDW2014].[dbo]. [udv_SalesByProducts]
WHERE [Год] = 2013
ORDER BY [Amount] DESC;
5 Агрегирование записей с использованием функций и условий GROUP BY
Мы применяем функции агрегирования SUM, COUNT, AVG, MAX, MIN для продаж за календарный год. Обычны аналогичные sql-запросы с использованием хотя бы одной функции агрегирования:
SELECT
[Год],
SUM ([Amount]) AS [Amount],
COUNT (*) AS [Sales Count],
AVG ([Amount]) AS [Средняя сумма ],
MAX ([количество]) AS [Max Amount] ,
MIN ([Amount]) AS [Min_Amount]
FROM [AdventureWorksDW2014].[dbo]. [udv_SalesByProducts]
ГРУППА ПО [ГОДУ]
ЗАКАЗАТЬ ПО [ГОДУ] ASC;
6 Базовое применение предложения HAVING — условие для агрегированных данных
SQL-запрос о том, как ограничить результат для записей, удовлетворяющих условию после агрегации, используя имеющийся (мы будем использовать базу запроса, как в примере 5)
SELECT
[Год],
AVG ([Количество]) AS [Среднее]
FROM [AdventureWorksDW2014].[dbo]. [udv_SalesByProducts]
ГРУППА ПО [ГОДУ]
ИМЕЕТ СРЕДНЕЕ ([Количество]) <5000
ЗАКАЗ ПО [Году] ASC;
Ing. Ян Зедничек - разработчик бизнес-аналитики, финансовый контролер
Меня зовут Ян Зедничек, я работаю разработчиком бизнес-аналитики в Kentico Software в Брно. В основном вы можете видеть меня там работающим в офисе, но я также частично работаю как фрилансер. Я работаю фрилансером во многих компаниях более 5 лет, но Кентико - дело моего сердца.Раньше я работал финансовым контролером в таких компаниях, как «Аэро-Водоходы» или «Сбербанк», а также был менеджером облигационной программы в группе Unicapital Investment. Когда я не на работе, мне нравится играть в волейбол, шахматы, тренироваться в тренажерном зале и мне нравится дегустировать ром лучшего качества. Я пытаюсь обобщить все свои знания на этом сайте, чтобы не забыть их (из-за эффекта рома, знаете ли =) и поделиться ими с кем угодно. Не беспокойтесь о том, чтобы попросить о помощи или написать несколько комментариев.
Учебное пособие по простым запросам и утверждениям
В этой статье объясняется, как писать простые SQL-запросы, начиная с самых простых, и постепенно улучшать сценарий для решения некоторых математических задач и задач, связанных с датой. Кроме того, мы собираемся прояснить концепции, связанные с SQL-запросами.
Хотя эта статья предназначена в первую очередь для начинающих, она содержит советы, которые будут полезны для любого уровня опыта.
Что такое SQL-запрос в базе данных?
Давайте сначала поговорим немного о SQL-запросах, чтобы правильно их понять, прежде чем получить практический опыт написания.
SQL означает структурированный язык запросов , который является важным языком, используемым для запросов к реляционным базам данных.
T-SQL vs SQL - в чем разница?
T-SQL или Transact-SQL - это версия SQL от Microsoft с большим количеством функций и возможностей, чем в традиционном языке SQL, также известном как ANSI SQL.
Следовательно, T-SQL - это традиционный язык SQL, плюс дополнительные возможности, добавленные Microsoft. Он чаще используется и упоминается, когда мы говорим о SQL.
Эта статья будет относиться к версии Microsoft SQL независимо от того, используем ли мы слово SQL или T-SQL.
Почему мы используем запросы SQL в реляционной базе данных?
Реляционная база данных - это база данных с ключами, которые используются для соединения таблиц, а не для физического соединения таблиц.
Например, у вас есть таблица с именем Book , которую вы связываете с другой таблицей с именем BookType с помощью ключей, чтобы добавить больше значений к записям.
Таблицы на иллюстрации связаны ключом. Их не нужно связывать физически. Это фундаментальное правило реляционных баз данных - вы создаете отношения между двумя таблицами с помощью ключа (ов).
Читайте также реляционная база данных против NoSQL - что выбрать для управления большими данными?
Что такое запросы к базе данных?
Вы запрашиваете базу данных, чтобы получить ответы на вопросы, связанные с этой базой данных. Другими словами, вы пишете запросы к базе данных, чтобы получить информацию о содержащихся в ней данных.
Например, вы хотите просмотреть все книжные записи вместе с их типами в конкретной базе данных. Вам нужно запросить эту базу данных, чтобы просмотреть требуемые данные. Для этого вы должны написать и запустить сценарий для базы данных.
Что нужно для запроса?
Для запроса к базе данных должны присутствовать некоторые предварительные условия, поскольку мы не можем просто написать и выполнить запрос где-либо к чему-либо.
Следующие вещи являются обязательными для запроса к базе данных:
- Сервер базы данных, например SQL Server (установленный локально или удаленно), на котором вы храните базу данных.
- Инструмент управления базой данных, такой как SQL Server Management Studio или dbForge Studio для SQL Server, который вы будете использовать для написания и выполнения ваших запросов.
- База данных, для которой вы запускаете свои запросы. Вы можете создать любую примерную базу данных в учебных целях.
Кроме того, вы должны иметь общее представление о своей базе данных, например, какая таблица содержит нужную информацию и т. Д. Понимание концепций реляционных баз данных тоже является плюсом.
Мы предполагаем, что вы уже выполнили указанные выше требования.Но вы также можете обратиться к следующей статье для получения более подробной информации:
Основы SQL Server Management Studio (SSMS) - Часть 1
Что нужно сделать перед написанием запросов в SQL
Теперь мы собираемся написать простые SQL-запросы.
Настройте среду, чтобы начать писать запросы SQL. Подготовьте инструменты. Откройте dbForge Studio для SQL Server или SQL Server Management Studio и подключитесь к экземпляру SQL. Здесь мы начинаем наше путешествие по SQL:
После успешного подключения нажмите CTRL + N или перейдите в Файл> Создать> Запрос с текущим подключением :
Теперь вы успешно подключились к главному серверу (системной базе данных) подключенного в данный момент сервера.
Важный совет: Всегда создавайте образец базы данных для выполнения ваших запросов (сценариев) к ней. Запросы к системным базам данных не рекомендуется, за исключением трех случаев:
- Вы работаете с образцом базы данных, а затем созданный для него сценарий будет выполняться в системной (главной) базе данных.
- Вы запрашиваете основную базу данных с целью получить из нее некоторую информацию.
- Запросы можно безопасно запускать к системной (главной) базе данных.
Настройка образца базы данных
Давайте создадим образец базы данных с именем BookSimple без каких-либо таблиц. Напишите следующий сценарий для основной базы данных, чтобы создать образец базы данных и Нажмите F5 , чтобы выполнить запрос:
- Создать образец базы данных BookSimple
ИСПОЛЬЗУЙТЕ МАСТЕР
ИДТИ
СОЗДАТЬ БАЗУ ДАННЫХ BookSimple
ИДТИ
ИСПОЛЬЗОВАТЬ BookSimple
Основанная на множестве концепция, лежащая в основе SQL-запросов
Непосредственно перед тем, как вы напишете даже простейший SQL-запрос, вы должны понять, что SQL - это язык, основанный на наборах.
Это означает, что когда вы хотите запросить свою базу данных с помощью SQL, вы должны думать о наборах или группах.
SQL разработан и по умолчанию очень эффективен для обслуживания запросов на основе наборов. Если вы разрабатываете свои сценарии (запросы) с учетом логики, основанной на наборах, вы понимаете и реализуете SQL быстрее, чем те, которые следуют типичному пути обучения (который имеет свои преимущества).
Давайте подумаем о естественном множестве, таком как класс или группа. Когда мы говорим о классе, мы имеем в виду всех учеников этого класса.SQL может помочь запросить этот класс в целом.
Точно так же Книга - это таблица с книгами. Он содержит все записи для книг. Мы можем просто запросить эту таблицу, как если бы мы говорили об одной книге, но на самом деле мы запрашиваем всю таблицу книг, представленную таблицей Book .
Мы увидим больше преимуществ концепции, основанной на множествах, позже, когда рассмотрим некоторые базовые примеры.
Простой оператор SQL SELECT
SELECT - это оператор T-SQL, который извлекает все или выбранные строки и столбцы (на основе критерия) из базы данных.
Другими словами, SELECT позволяет нам просматривать (выбирать) данные из таблицы или ряда таблиц на основе определенных критериев, которые, если не упоминаются в целом, показывают все данные.
Следовательно, SELECT - это первый оператор, который нужно искать, если мы хотим получить строки и столбцы из базы данных. Самая простая форма синтаксиса SELECT следующая:
ВЫБРАТЬ * ИЗ <Таблицы> Помните, что со временем мы будем изменять синтаксис, чтобы постепенно улучшать процесс обучения.
Другой способ использования оператора SELECT:
ВЫБРАТЬ <Выражение> Выражение может быть различным, включая следующее:
- Константа (например, фиксированное число, например 1).
- Переменная (например, @X, которая может быть изменена на любое число).
- Комбинация констант или переменных (например, 1 + 2 или @X + @ Y).
Однако, независимо от того, используете ли вы SELECT Давайте сделаем запрос к базе данных BookSimple , обновив узел Базы данных в обозревателе объектов . Щелкните правой кнопкой мыши BookSimple > Новый запрос : Запишите простейший запрос SQL - напишите и запустите следующий сценарий для образца базы данных: Выполнение запроса (нажатие F5) покажет следующие результаты: Итак, SELECT 1 возвращает 1, но с безымянным столбцом (без имени столбца). 1 - постоянная величина. Он останется равным 1, поэтому мы ожидаем, что результат тоже будет 1. Однако необходимо понять еще одну важную вещь: наш вывод преобразуется в набор из 1 столбца и 1 строки. Поскольку мы не указали имя для столбца и не задействована таблица (чтобы получить имя), мы получаем значение 1 для безымянного столбца безымянной таблицы (набора). Язык на основе наборов автоматически вернул предоставленное нами значение в безымянный столбец безымянной таблицы, имеющей одну строку. Назовем столбец, изменив скрипт следующим образом: Запустите сценарий, чтобы на этот раз увидеть следующий набор результатов: Поскольку этот запрос всегда возвращает одно и то же значение (число), которое мы вводим (предоставляем), особо нечего обсуждать, кроме понимания того, почему мышление, основанное на множествах, жизненно важно для понимания того, как работают запросы. Давайте воспользуемся приведенным выше случаем для быстрых вычислений в SQL - мы превратим единичное значение в выражение. Например, мы хотим быстро сложить два числа 1000 и 200. Мы можем просто написать следующий запрос без упоминания какой-либо таблицы, используя только оператор SELECT: Результат ниже: Точно так же мы можем складывать, умножать, делить и вычитать числа. Полезно добавить два столбца в таблицу, содержащую числовые значения. Однако мы также можем использовать этот подход для добавления двух переменных.Использование переменных полезно, поскольку мы можем сложить любые два числа, инициализировав эти переменные желаемыми значениями. Это иллюстрируется следующим сценарием: Запуск сценария показывает нам следующий результат: Мы можем сохранить этот запрос, чтобы повторно использовать его в любое время для сложения любых двух чисел (изменяя значения @X и @Y).Если мы думаем об этом с точки зрения набора, мы можем сказать, что выходные данные возвращаются как безымянная таблица (набор) с одной строкой и следующими тремя столбцами: Однако вы можете сделать больше с помощью SELECT Здесь мы собираемся использовать функцию GETDATE (), чтобы получить текущую дату и ожидаемую дату доставки неизвестного заказа, который еще не является частью нашей таблицы. Предположим, у нас еще нет таблицы заказов, но мы хотим быстро рассчитать ожидаемую дату доставки заказа продукта. Если мы добавим какое-либо число в функцию GETDATE (), она сообщит нам добавленную дату с указанным числом дней. Другими словами, если мы ожидаем, что срок доставки заказа будет через два дня после размещения заказа, мы можем рассчитать его, используя SELECT с GETDATE () + 2. Чтобы увидеть это в действии, запустите следующий сценарий SQL: Набор результатов выглядит следующим образом: На этот раз мы могли рассчитать ожидаемую дату доставки заказа напрямую, используя оператор SELECT с функцией GETDATE () при отсутствии какой-либо таблицы. Однако, если бы у нас была таблица, мы бы получили ожидаемую дату доставки для всех заказов в этой таблице. Еще раз, если мы проанализируем этот вывод с точки зрения логики набора, у нас будет одна безымянная таблица (набор) с двумя столбцами и одной строкой. SQL - это язык, основанный на наборах, который очень быстро работает с наборами, такими как таблицы. Если таблиц нет, он обрабатывает входные значения (подлежащие обработке) как безымянные наборы. Короче говоря, SQL-запрос требует оператора SELECT, за которым следует выражение для выполнения некоторых числовых или датированных вычислений даже в отношении пустой базы данных (без таблиц). Поздравляем! Вы изучили основы SQL-запросов и с помощью оператора SELECT написали несколько простых запросов к образцу базы данных. Оставайтесь на связи, ведь написание простых SQL-запросов к таблицам базы данных еще впереди. Теперь, когда вы можете написать несколько базовых запросов SQL, попробуйте выполнить следующие упражнения: Он начал свою профессиональную жизнь в качестве компьютерного программиста более 10 лет назад, работая над своим первым предприятием данных по миграции и переписыванию экзаменационной системы, управляемой базами данных государственного сектора, с IBM AS400 (DB2) на SQL Server 2000 с использованием VB 6.0 и Classic ASP наряду с разработкой отчетов и архивированием данных за многие годы. Его работа и интересы связаны с архитектурами, ориентированными на базы данных, а его опыт включает проектирование, разработку, тестирование, внедрение и миграцию баз данных и отчетов, а также управление жизненным циклом баз данных (DLM). В этом руководстве мы будем работать с набором данных из службы проката велосипедов Hubway, который включает данные более чем о 1.С сервисом совершено 5 миллионов поездок. Мы начнем с небольшого изучения баз данных, того, что они такое и почему мы их используем, прежде чем приступить к написанию некоторых собственных запросов на SQL. Если вы хотите продолжить, вы можете загрузить файл Реляционная база данных - это база данных, которая хранит связанную информацию в нескольких таблицах и позволяет запрашивать информацию в нескольких таблицах одновременно. Проще понять, как это работает, на примере. Представьте, что вы работаете в бизнесе и хотите отслеживать информацию о продажах. Вы можете настроить электронную таблицу в Excel со всей информацией, которую вы хотите отслеживать, в виде отдельных столбцов: номер заказа, дата, сумма к оплате, номер для отслеживания отгрузки, имя клиента, адрес клиента и номер телефона клиента. Эта настройка отлично подходит для отслеживания информации, которая вам нужна для начала, но когда вы начнете получать повторные заказы от одного и того же клиента, вы обнаружите, что их имя, адрес и номер телефона хранятся в нескольких строках вашей электронной таблицы. По мере роста вашего бизнеса и увеличения количества отслеживаемых заказов эти избыточные данные будут занимать ненужное место и в целом снизят эффективность вашей системы отслеживания продаж. Вы также можете столкнуться с проблемами с целостностью данных. Например, нет гарантии, что каждое поле будет заполнено правильным типом данных или что имя и адрес будут вводиться каждый раз точно так же. С реляционной базой данных, подобной той, что показана на диаграмме выше, вы избегаете всех этих проблем.Вы можете настроить две таблицы, одну для заказов и одну для клиентов. Таблица «клиенты» будет включать уникальный идентификационный номер для каждого клиента, а также имя, адрес и номер телефона, которые мы уже отслеживаем. Таблица «заказы» будет включать номер вашего заказа, дату, сумму к оплате, номер отслеживания и, вместо отдельного поля для каждого элемента данных о клиенте, в ней будет столбец для идентификатора клиента. Это позволяет нам получить всю информацию о клиенте для любого конкретного заказа, но нам нужно сохранить ее в нашей базе данных только один раз, а не выводить ее повторно для каждого отдельного заказа. Давайте начнем с взгляда на нашу базу данных. В базе есть две таблицы, С этой информацией и командами SQL, которые мы вскоре узнаем, вот несколько вопросов, на которые мы попытаемся ответить в ходе этого поста: Для ответа на эти вопросы мы будем использовать следующие команды SQL: Для целей этого руководства мы будем использовать систему баз данных под названием SQLite3.SQLite входит в состав Python начиная с версии 2.5, поэтому, если у вас установлен Python, у вас почти наверняка будет SQLite. Python и библиотеку SQLite3 можно легко установить и настроить с помощью Anaconda, если у вас их еще нет. Использование Python для запуска нашего кода SQL позволяет нам импортировать результаты в фреймворк Pandas, чтобы упростить отображение наших результатов в удобном для чтения формате. Это также означает, что мы можем выполнять дальнейший анализ и визуализацию данных, которые мы извлекаем из базы данных, хотя это выходит за рамки данного руководства. В качестве альтернативы, если мы не хотим использовать или устанавливать Python, мы можем запустить SQLite3 из командной строки. Просто загрузите «предварительно скомпилированные двоичные файлы» с веб-страницы SQLite3 и используйте следующий код для открытия базы данных: Отсюда мы можем просто ввести запрос, который хотим запустить, и мы увидим данные, возвращенные в нашем окне терминала. Альтернативой использованию терминала является подключение к базе данных SQLite через Python.Это позволит нам использовать записную книжку Jupyter, чтобы мы могли видеть результаты наших запросов в аккуратно отформатированной таблице. Для этого мы определим функцию, которая принимает наш запрос (сохраненный в виде строки) в качестве входных данных и отображает результат в виде отформатированного фрейма данных: Первая команда, с которой мы будем работать, - это В дополнение к столбцам, которые мы хотим получить, мы также должны указать базе данных, из какой таблицы их получить. Для этого мы используем ключевое слово В этом примере мы начали с команды Одна важная вещь, о которой следует помнить при написании SQL-запросов, заключается в том, что мы хотим заканчивать каждый запрос точкой с запятой ( Следующая команда, которую нам нужно знать, прежде чем мы начнем выполнять запросы в нашей базе данных Hubway, - это Запрос Мы просто добавили команду Мы будем часто использовать Давайте запустим наш первый запрос к базе данных Hubway. Сначала мы сохраним наш запрос в виде строки, а затем воспользуемся функцией, которую мы определили ранее, чтобы запустить его в базе данных.Взгляните на следующий пример: В этом запросе Вы часто будете видеть, что люди используют ключевые слова команды в своих запросах (соглашение, которому мы будем следовать в этом руководстве), но это в основном вопрос предпочтений.Использование заглавных букв упрощает чтение кода, но на самом деле никоим образом не влияет на работу кода. Если вы предпочитаете писать запросы с командами в нижнем регистре, запросы по-прежнему будут выполняться правильно. В нашем предыдущем примере возвращены все столбцы в таблице Последняя команда, которую нам нужно знать, прежде чем мы сможем ответить на первый из наших вопросов, - это Чтобы использовать его, мы просто указываем имя столбца, по которому хотим выполнить сортировку. По умолчанию Например, если мы хотим отсортировать таблицу С помощью команд Чтобы ответить на этот вопрос, полезно разбить его на разделы и определить, какие команды нам понадобятся для решения каждой части. Сначала нам нужно извлечь информацию из столбца продолжительности Использование этих команд таким образом вернет единственную строку с самой длинной продолжительностью, которая даст нам ответ на наш вопрос. Еще одно замечание: по мере того, как ваши запросы добавляют больше команд и усложняются, вам может быть легче читать, если вы разделите их на несколько строк. Это, как и использование заглавных букв, зависит от личных предпочтений. Это не влияет на выполнение кода (система просто считывает код с самого начала до точки с запятой), но может сделать ваши запросы более понятными и понятными. В Python мы можем разделить строку на несколько строк, используя тройные кавычки. Давайте продолжим и запустим этот запрос и выясним, как долго длилась самая длинная поездка. Теперь мы знаем, что самая длинная поездка длилась 9999 секунд, или чуть более 166 минут. Однако при максимальном значении 9999 мы не знаем, действительно ли это длина самой длинной поездки или база данных была настроена только для четырехзначного числа. Если это правда, что база данных сокращает особенно длинные поездки, то мы можем ожидать увидеть много поездок на 9999 секундах, где они достигают предела.Давайте попробуем выполнить тот же запрос, что и раньше, но отрегулируйте Что мы видим здесь, так это то, что на 9999 не так много поездок, поэтому не похоже, что мы сокращаем верхний предел нашей продолжительности, но все же трудно сказать, является ли это реальная длина поездка или просто максимально допустимое значение. Hubway взимает дополнительную плату за поездки продолжительностью более 30 минут (кто-то, кто держит велосипед в течение 9999 секунд, должен будет заплатить дополнительные 25 долларов США), поэтому вполне вероятно, что они решили, что четырех цифр будет достаточно для отслеживания большинства поездок. Предыдущие команды отлично подходят для извлечения отсортированной информации для определенных столбцов, но что, если есть определенное подмножество данных, которые мы хотим просмотреть? Вот где появляется Вы также заметите, что в этом запросе используются кавычки. Это потому, что Давайте напишем запрос, который использует Как мы видим, этот запрос вернул 14 различных поездок, каждая длительностью 9990 секунд или более.Что выделяется в этом запросе, так это то, что все результаты, кроме одного, имеют подтип Мы уже видим, как команда SQL даже для начинающих может помочь нам ответить на бизнес-вопросы и найти понимание наших данных. Возвращаясь к Вот еще одна личная рекомендация: используйте круглые скобки для разделения каждого логического теста, как показано в блоке кода ниже.Это не является строго обязательным для работы кода, но круглые скобки упрощают понимание ваших запросов по мере увеличения сложности. Теперь давайте запустим этот запрос. Мы уже знаем, что он должен возвращать только один результат, поэтому будет легко убедиться, что мы все правильно поняли: Следующий вопрос, который мы задали в начале поста, - «Сколько поездок совершили« зарегистрированные »пользователи?» Чтобы ответить на него, мы могли бы выполнить тот же запрос, что и выше, и изменить выражение Однако на самом деле в SQL есть встроенная команда для этого подсчета: В этом случае не имеет значения, какой столбец мы выбираем для подсчета, потому что каждый столбец должен содержать данные для каждой строки в нашем запросе.Но иногда в запросе могут отсутствовать (или быть "нулевые") значения для некоторых строк. Если мы не уверены, содержит ли столбец нулевые значения, мы можем запустить наш Мы также можем использовать Давайте взглянем на запрос, чтобы ответить на наш вопрос. Мы можем использовать Этот запрос сработал и вернул ответ на наш вопрос.Но заголовок столбца не особо описательный. Если бы кто-то другой взглянул на эту таблицу, он не смог бы понять, что это значит. Если мы хотим сделать наши результаты более читабельными, мы можем использовать Итак, чтобы ответить на наш третий вопрос, "Какова была средняя продолжительность поездки?" , мы можем использовать функцию Получается, что средняя продолжительность поездки составляет 912 секунд, то есть примерно 15 минут. В этом есть смысл, поскольку мы знаем, что Hubway взимает дополнительную плату за поездки продолжительностью более 30 минут. Услуга предназначена для любителей коротких поездок в одну сторону. Что насчет нашего следующего вопроса: зарегистрированные или случайные пользователи совершают более длительные поездки? Мы уже знаем один способ ответить на этот вопрос - мы могли бы запустить два запроса Но давайте сделаем по-другому. SQL также включает способ ответить на этот вопрос в одном запросе с помощью команды Чтобы лучше понять, как это работает, давайте взглянем на столбец Когда мы используем Когда у нас есть две отдельные стопки, база данных будет выполнять любые агрегатные функции в нашем запросе для каждой из них по очереди. Если бы мы использовали, например, Давайте подробно рассмотрим, как написать запрос, чтобы ответить на наш вопрос, совершают ли более длительные поездки зарегистрированные или случайные пользователи. Вот как выглядит код, если собрать все вместе: Вот это большая разница! В среднем зарегистрированные пользователи совершают поездки продолжительностью около 11 минут, тогда как обычные пользователи тратят почти 25 минут на поездку.Зарегистрированные пользователи, вероятно, будут совершать более короткие и частые поездки, возможно, по дороге на работу. С другой стороны, обычные пользователи тратят примерно вдвое больше времени на поездку. Возможно, что случайные пользователи, как правило, происходят из демографических групп (например, туристов), которые более склонны совершать длительные поездки, убедитесь, что они передвигаются и смотрят все достопримечательности. Как только мы обнаружим эту разницу в данных, компания сможет исследовать ее разными способами, чтобы лучше понять, что ее вызывает. Однако для целей этого урока давайте продолжим. Наш следующий вопрос был , какой велосипед использовался для большинства поездок? . Мы можем ответить на этот вопрос, используя очень похожий запрос. Взгляните на следующий пример и посмотрите, сможете ли вы выяснить, что делает каждая строка - позже мы рассмотрим это шаг за шагом, чтобы вы могли убедиться, что все правильно: Как видно из выходных данных, наибольшее количество поездок ездил на велосипеде Наш последний вопрос немного сложнее остальных. Мы хотим знать средней продолжительности поездок зарегистрированных участников в возрасте старше 30 . Мы могли бы просто вычислить год, в котором 30-летние родились в наших головах, а затем подключить его, но более элегантное решение - использовать арифметические операции непосредственно в нашем запросе. SQL позволяет нам использовать До сих пор мы рассматривали запросы, которые извлекают данные только из таблицы Наша база данных по прокату велосипедов содержит вторую таблицу, Прежде чем мы начнем работать с некоторыми реальными примерами из этой базы данных, давайте вернемся к гипотетической базе данных отслеживания заказов из ранее. В этой базе данных у нас было две таблицы, Допустим, мы хотели написать запрос, который возвращал бы К сожалению, столбец Чтобы ответить на первые два из этих вопросов, мы можем включить имена таблиц для каждого столбца в нашу команду Чтобы сообщить базе данных, как связаны таблицы Мы собираемся использовать внутреннее соединение, что означает, что строки будут возвращаться только тогда, когда есть совпадения в столбцах, указанных в Как мы обсуждали ранее, эти таблицы связаны по столбцу Мы снова используем Этот запрос вернет порядковый номер каждого заказа в базе данных вместе с именем клиента, который связан с каждым заказом. Возвращаясь к нашей базе данных Hubway, теперь мы можем написать несколько запросов, чтобы увидеть Прежде чем мы начнем, мы должны взглянуть на остальные столбцы в таблице Как и раньше, мы попробуем ответить на некоторые вопросы в данных, начиная с , какая станция является наиболее частой отправной точкой? Давайте поработаем пошагово: Если вы знакомы с Бостоном, вы поймете, почему это самые популярные станции. Южный вокзал - одна из главных станций пригородной железной дороги в городе, Чарльз-стрит проходит вдоль реки рядом с красивыми живописными маршрутами, а улицы Бойлстон и Бикон находятся в самом центре города, рядом с несколькими офисными зданиями. Следующий вопрос, который мы рассмотрим, - это , какие станции наиболее часто используются для поездок туда и обратно? Мы можем использовать почти тот же запрос, что и раньше. Мы будем Как мы видим, количество этих станций такое же, как и в предыдущем вопросе, но их количество намного меньше. Самые загруженные станции по-прежнему остаются самыми загруженными, но в целом более низкие цифры говорят о том, что люди обычно используют велосипеды Hubway, чтобы добраться из точки A в точку B, а не какое-то время кататься на велосипеде, прежде чем вернуться туда, откуда они начали. Здесь есть одно существенное отличие - Esplande, которая не была одной из самых загруженных станций по нашему первому запросу, кажется, самая загруженная для поездок туда и обратно. Почему? Что ж, картинка стоит тысячи слов. Это определенно похоже на хорошее место для велосипедной прогулки: Переходим к следующему вопросу: сколько поездок начинается и заканчивается в разных муниципалитетах? Этот вопрос продвигает дальше. Мы хотим знать, сколько поездок начинается и заканчивается в другом районе Для этого мы должны создать псевдоним для таблицы Например, мы можем использовать следующий код для Вот как будет выглядеть окончательный запрос, когда мы его запустим. Обратите внимание, что мы использовали Это показывает, что около 300 000 из 1.5 миллионов поездок (или 20%) закончились в другом муниципалитете, чем они начали, - еще одно свидетельство того, что люди в основном используют велосипеды Hubway для относительно коротких поездок, а не для длительных поездок между городами. Если вы зашли так далеко, поздравляем! Вы начали осваивать основы SQL. Мы рассмотрели ряд важных команд, После завершения этого учебника по SQL для начинающих вы сможете выбрать базу данных, которая вам интересна, и написать запросы для получения информации. Хорошим первым шагом может быть продолжение работы с базой данных Hubway, чтобы посмотреть, что еще вы можете узнать. Вот еще несколько вопросов, на которые вы, возможно, захотите ответить: Если вы хотите сделать еще один шаг вперед, ознакомьтесь с нашими интерактивными курсами SQL, которые охватывают все, что вам нужно знать, от начального уровня до SQL продвинутого уровня для работы аналитиком данных и специалистом по данным. Вы также можете прочитать наш пост об экспорте данных из ваших SQL-запросов в Pandas или просмотрите нашу шпаргалку по SQL и нашу статью о сертификации SQL. Если вы хотите получить данные из базы данных, вы запрашиваете данные с помощью языка структурированных запросов или SQL. SQL - это компьютерный язык, который очень похож на английский, но его понимают программы баз данных. Каждый запрос, который вы выполняете, использует SQL за кулисами. Понимание того, как работает SQL, может помочь вам создавать более качественные запросы и упростить понимание того, как исправить запрос, который не возвращает желаемых результатов. Это одна из серии статей о Access SQL. В этой статье описывается базовое использование SQL для выбора данных и используются примеры для иллюстрации синтаксиса SQL. SQL - это компьютерный язык для работы с наборами фактов и отношениями между ними.Программы реляционных баз данных, такие как Microsoft Office Access, используют SQL для работы с данными. В отличие от многих компьютерных языков, SQL нетрудно читать и понимать даже новичку. Как и многие компьютерные языки, SQL - это международный стандарт, признанный такими организациями по стандартизации, как ISO и ANSI. Вы используете SQL для описания наборов данных, которые могут помочь вам ответить на вопросы. При использовании SQL необходимо использовать правильный синтаксис. Синтаксис - это набор правил, по которым элементы языка правильно сочетаются.Синтаксис SQL основан на английском синтаксисе и использует многие из тех же элементов, что и синтаксис Visual Basic для приложений (VBA). Например, простой оператор SQL, который извлекает список фамилий для контактов, имя которых Мэри, может выглядеть следующим образом: Примечание. SQL используется не только для управления данными, но также для создания и изменения структуры объектов базы данных, таких как таблицы.Часть SQL, которая используется для создания и изменения объектов базы данных, называется языком определения данных (DDL). В этом разделе не рассматривается DDL. Дополнительные сведения см. В статье Создание или изменение таблиц или индексов с помощью запроса определения данных. Чтобы описать набор данных с помощью SQL, вы пишете оператор SELECT. Оператор SELECT содержит полное описание набора данных, которые вы хотите получить из базы данных.Это включает следующее: Какие таблицы содержат данные. Как связаны данные из разных источников. Какие поля или вычисления будут производить данные. Критерии, которым должны соответствовать данные для включения. Следует ли и как сортировать результаты. Как и предложение, в операторе SQL есть предложения. Каждое предложение выполняет функцию для оператора SQL. Некоторые предложения требуются в инструкции SELECT. В следующей таблице перечислены наиболее распространенные предложения SQL. Пункт SQL Что он делает Требуется ВЫБРАТЬ Перечисляет поля, содержащие интересующие данные. Есть ИЗ Перечисляет таблицы, содержащие поля, перечисленные в предложении SELECT. Есть ГДЕ Задает критерии поля, которым должна соответствовать каждая запись, чтобы включить ее в результаты. Нет ЗАКАЗАТЬ ПО Указывает, как сортировать результаты. Нет ГРУППА ПО В операторе SQL, содержащем агрегатные функции, перечисляются поля, которые не суммированы в предложении SELECT. Только если есть такие поля ИМЕЕТ В операторе SQL, содержащем агрегатные функции, определяет условия, которые применяются к полям, которые суммированы в операторе SELECT. Нет Каждое предложение SQL состоит из терминов, сопоставимых с частями речи.В следующей таблице перечислены типы терминов SQL. Условие SQL Сопоставимая часть речи Определение Пример идентификатор существительное Имя, которое вы используете для идентификации объекта базы данных, например имя поля. Клиенты. [Телефон] оператор глагол или наречие Ключевое слово, представляющее действие или изменяющее действие. как постоянная существительное Неизменяемое значение, например число или NULL. 42 выражение прилагательное Комбинация идентификаторов, операторов, констант и функций, вычисляющая одно значение. > = Товары.[Цена за единицу] Верх страницы Оператор SQL имеет общую форму: Примечания: Access игнорирует разрывы строк в операторе SQL.Однако рассмотрите возможность использования строки для каждого предложения, чтобы улучшить читаемость ваших операторов SQL для себя и других. Каждый оператор SELECT заканчивается точкой с запятой (;). Точка с запятой может стоять в конце последнего предложения или в отдельной строке в конце оператора SQL. Ниже показано, как может выглядеть инструкция SQL для простого запроса выбора в Access: 1.Предложение SELECT 2. ИЗ пункта 3. ГДЕ пункт Этот пример оператора SQL гласит: «Выберите данные, которые хранятся в полях с именем E-mail Address и Company из таблицы с именем Contacts, в частности те записи, в которых значением поля City является Сиэтл». Давайте рассмотрим пример, по одному предложению за раз, чтобы увидеть, как работает синтаксис SQL. ВЫБЕРИТЕ [адрес электронной почты], компания Это предложение SELECT.Он состоит из оператора (SELECT), за которым следуют два идентификатора ([Адрес электронной почты] и Компания). Если идентификатор содержит пробелы или специальные символы (например, «Адрес электронной почты»), он должен быть заключен в квадратные скобки. Предложение SELECT не должно указывать, какие таблицы содержат поля, и не может указывать какие-либо условия, которым должны удовлетворять включаемые данные. Предложение SELECT всегда появляется перед предложением FROM в операторе SELECT. ОТ КОНТАКТЫ Это предложение FROM. Он состоит из оператора (FROM), за которым следует идентификатор (Контакты). В предложении FROM не перечислены поля, которые нужно выбрать. ГДЕ Город = "Сиэтл" Это предложение WHERE. Он состоит из оператора (WHERE), за которым следует выражение (City = "Seattle"). Примечание: В отличие от предложений SELECT и FROM, предложение WHERE не является обязательным элементом оператора SELECT. Многие действия, которые позволяет выполнять SQL, можно выполнять с помощью предложений SELECT, FROM и WHERE. Более подробная информация о том, как вы используете эти пункты, представлена в этих дополнительных статьях: Верх страницы Как и Microsoft Excel, Access позволяет сортировать результаты запроса в таблице.Вы также можете указать в запросе, как вы хотите сортировать результаты при выполнении запроса, используя предложение ORDER BY. Если вы используете предложение ORDER BY, это последнее предложение в операторе SQL. Предложение ORDER BY содержит список полей, которые вы хотите использовать для сортировки, в том же порядке, в котором вы хотите применять операции сортировки. Например, предположим, что вы хотите, чтобы ваши результаты сначала были отсортированы по значению поля Компания в порядке убывания, а - если есть записи с таким же значением для Компании - отсортированы затем по значениям в поле Адрес электронной почты в возрастающем порядке. заказывать.Предложение ORDER BY будет выглядеть следующим образом: ЗАКАЗАТЬ ПО компании DESC, [адрес электронной почты] Примечание. По умолчанию Access сортирует значения в порядке возрастания (A – Z, от наименьшего к наибольшему). Вместо этого используйте ключевое слово DESC для сортировки значений в порядке убывания. Дополнительные сведения о предложении ORDER BY см. В разделе Предложение ORDER BY. Верх страницы Иногда требуется работать со сводными данными, такими как общий объем продаж за месяц или самые дорогие товары в инвентаре.Для этого вы применяете агрегатную функцию к полю в предложении SELECT. Например, если вы хотите, чтобы в вашем запросе отображалось количество адресов электронной почты, перечисленных для каждой компании, ваше предложение SELECT может выглядеть следующим образом: ВЫБЕРИТЕ СЧЕТЧИК ([Адрес электронной почты]), Компания Агрегатные функции, которые вы можете использовать, зависят от типа данных, содержащихся в поле или выражении, которое вы хотите использовать. Дополнительные сведения о доступных агрегатных функциях см. В статье Агрегатные функции SQL. При использовании агрегатных функций обычно необходимо также создать предложение GROUP BY. В предложении GROUP BY перечислены все поля, к которым вы не применяете агрегатную функцию. Если вы применяете агрегатные функции ко всем полям в запросе, вам не нужно создавать предложение GROUP BY. Предложение GROUP BY следует сразу за предложением WHERE или предложением FROM, если предложение WHERE отсутствует.В предложении GROUP BY перечислены поля в том виде, в котором они указаны в предложении SELECT. Например, продолжая предыдущий пример, если ваше предложение SELECT применяет агрегатную функцию к [E-mail Address], но не к Company, ваше предложение GROUP BY будет выглядеть следующим образом: ГРУППА ПО КОМПАНИИ Дополнительные сведения о предложении GROUP BY см. В разделе Предложение GROUP BY. Если вы хотите использовать критерии для ограничения результатов, но поле, к которому вы хотите применить критерии, используется в агрегатной функции, вы не можете использовать предложение WHERE.Вместо этого вы используете предложение HAVING. Предложение HAVING работает как предложение WHERE, но используется для агрегированных данных. Например, предположим, что вы используете функцию AVG (которая вычисляет среднее значение) с первым полем в предложении SELECT: ВЫБЕРИТЕ СЧЕТЧИК ([Адрес электронной почты]), Компания Если вы хотите, чтобы запрос ограничивал результаты на основе значения этой функции COUNT, вы не можете использовать критерий для этого поля в предложении WHERE.Вместо этого вы помещаете критерии в предложение HAVING. Например, если вы хотите, чтобы запрос возвращал строки только в том случае, если с компанией связано несколько адресов электронной почты, предложение HAVING может выглядеть следующим образом: HAVING COUNT ([E-mail Address])> 1 Примечание: Запрос может иметь предложение WHERE и предложение HAVING - критерии для полей, которые не используются в агрегатной функции, указываются в предложении WHERE, а критерии для полей, которые используются с агрегатными функциями, входят в предложение HAVING. Дополнительные сведения о предложении HAVING см. В разделе Предложение HAVING. Верх страницы Если вы хотите просмотреть все данные, возвращаемые несколькими похожими запросами на выборку вместе, как объединенный набор, вы используете оператор UNION. Оператор UNION позволяет объединить два оператора SELECT в один. Комбинируемые операторы SELECT должны иметь одинаковое количество выходных полей в одном порядке и с одинаковыми или совместимыми типами данных.Когда вы запускаете запрос, данные из каждого набора соответствующих полей объединяются в одно выходное поле, так что выходные данные запроса имеют такое же количество полей, что и каждый из операторов выбора. Примечание: Для целей запроса на объединение типы данных Number и Text совместимы. При использовании оператора UNION вы также можете указать, должны ли результаты запроса включать повторяющиеся строки, если таковые существуют, с помощью ключевого слова ALL. Базовый синтаксис SQL для запроса на объединение, который объединяет два оператора SELECT, выглядит следующим образом: Например, предположим, что у вас есть таблица с именем Products и другая таблица с именем Services. В обеих таблицах есть поля, которые содержат название продукта или услуги, цену, гарантию или наличие гарантии, а также то, предлагаете ли вы продукт или услугу исключительно.Хотя в таблице «Продукты» хранится информация о гарантии, а в таблице «Услуги» - информация о гарантиях, основная информация остается неизменной (независимо от того, содержит ли конкретный продукт или услуга обещание качества). Вы можете использовать запрос на объединение, например следующий, чтобы объединить четыре поля из двух таблиц: Дополнительные сведения о том, как объединить операторы SELECT с помощью оператора UNION, см. В разделе Объединение результатов нескольких запросов на выборку с помощью запроса объединения. Верх страницы SQL предоставляет базовые и расширенные концепции SQL. Наше руководство по SQL предназначено для начинающих и профессионалов. SQL ( язык структурированных запросов ) используется для выполнения операций с записями, хранящимися в базе данных, таких как обновление записей, удаление записей, создание и изменение таблиц, представлений и т. Д. SQL - это просто язык запросов; это не база данных.Для выполнения SQL-запросов необходимо установить любую базу данных, например, Oracle, MySQL, MongoDB, PostGre SQL, SQL Server, DB2 и т. Д. Все СУБД, такие как MySQL, Oracle, MS Access, Sybase, Informix, PostgreSQL и SQL Server, используют SQL в качестве стандартного языка баз данных. Требуется SQL: Учебное пособие по SQL База данных SQL Таблица SQL Вставка SQL Выбор SQL Пункт SQL Заказ SQL по Обновление SQL Удалить SQL Соединение SQL Ключи SQL Разница Учебное пособие по PL / SQL Интервью Викторина Операторы SQL чем-то похожи на простые английские предложения. Стандартный SQL ANSI - это lingua franca для реляционных баз данных. SQL был разработан для ввода с консоли, а результаты будут отображаться обратно на экран.
Сегодня SQL в основном используется программистами, которые используют SQL внутри своего языка для создания приложений, которые обращаются к данным в базе данных. Четыре основные операции, применимые к любой базе данных: В совокупности они обозначаются как CRUD (создание, чтение, обновление, удаление). Далее представлена общая форма для каждой из этих 4 операций в SQL., вы должны думать в терминах множеств.
Как написать простой SQL-запрос
- Дисплей 1
ВЫБРАТЬ 1
- Показать значение 1 для столбца Номер безымянной таблицы (набор)
ВЫБЕРИТЕ 1 КАК Число
в выписке Select
- Сложение двух чисел 1000 и 200
ВЫБЕРИТЕ 1000 + 200 КАК [Сумма 1000 и 200]
- SQL-скрипт для сложения любых двух чисел
ОБЪЯВИТЬ @X INT, @Y INT, @Addition INT
SET @ X = 550 - Инициализировать переменную X значением (числом)
SET @ Y = 350 - Инициализировать переменную Y значением (числом)
НАБОР @ Сложение = @ X + @ Y - СУММА X и Y
ВЫБЕРИТЕ @X как FirstNumber_X, @ Y как SecondNumber_Y, @ Addition как SumOfNumbers
Еще один пример расчета данных
- Расчет даты заказа и ожидаемой даты доставки
ВЫБЕРИТЕ GETDATE () как [Дата заказа], GETDATE () + 2 как [Ожидаемая дата доставки]
Что нужно узнать, как лучше писать SQL-запросы
Глубокий интерес Харуна к логике и рассуждениям в раннем возрасте его академической карьеры проложил ему путь к тому, чтобы стать профессионалом в области данных. Основы SQL - Практическое руководство по SQL для начинающих Анализируя совместное использование велосипедов
hubway.db здесь (130 МБ). Основы SQL: реляционные базы данных
Наш набор данных
поездок и станций . Для начала просто посмотрим на таблицу trips . Он содержит следующие столбцы: id - Уникальное целое число, которое служит ссылкой для каждой поездки duration - Продолжительность поездки, измеряется в секундах start_date - Дата и время начала поездки start_station - Целое число, которое соответствует столбцу id в таблице station для станции, на которой началось путешествие с end_date - Дата и время окончания поездки end_station - 'id' станции, на которой завершилась поездка bike_number - Уникальный идентификатор Hubway для велосипеда, использованного в поездке sub_type - Тип подписки пользователя. «Зарегистрированный» для пользователей с членством, «Обычный» для пользователей без членства zip_code - Почтовый индекс пользователя (доступен только для зарегистрированных пользователей) Birth_date - Год рождения пользователя (доступно только для зарегистрированных участников) пол - пол пользователя (доступно только для зарегистрированных пользователей) Наш анализ
ВЫБРАТЬ ГДЕ ПРЕДЕЛ ЗАКАЗАТЬ В № ГРУППА ПО И ИЛИ МИН МАКС СРЕДНЕЕ СУМ СЧЕТ Установка и настройка
~ $ sqlite hubway.db Версия SQLite 3.14.0 2016-07-26 15: 17: 14 Введите ".help" для использования hints.sqlite>
Конечно, нам не обязательно использовать Python с SQL. Если вы уже являетесь программистом R, наш курс «Основы SQL для пользователей R» станет отличным местом для начала. импорт sqlite3
импортировать панд как pd
db = sqlite3.connect ('hubway.db')
def run_query (запрос):
вернуть pd.read_sql_query (запрос, db) ВЫБРАТЬ
SELECT . SELECT будет основой почти каждого написанного нами запроса - он сообщает базе данных, какие столбцы мы хотим видеть. Мы можем указать столбцы по имени (через запятую) или использовать подстановочный знак * для возврата каждого столбца в таблице. FROM , за которым следует имя таблицы.Например, если бы мы хотели видеть start_date и bike_number для каждой поездки в таблице trips , мы могли бы использовать следующий запрос:
ВЫБРАТЬ start_date, bike_number ИЗ поездок; SELECT , чтобы база данных знала, что мы хотим, чтобы она нашла нам некоторые данные. Затем мы сообщили базе данных, что нас интересуют столбцы start_date и bike_number .Наконец, мы использовали FROM , чтобы сообщить базе данных, что столбцы, которые мы хотим видеть, являются частью таблицы trips .; ). Не каждая база данных SQL на самом деле требует этого, но некоторые требуют, поэтому лучше сформировать эту привычку. ПРЕДЕЛ
LIMIT . LIMIT просто сообщает базе данных, сколько строк вы хотите вернуть. SELECT , который мы рассмотрели в предыдущем разделе, будет возвращать запрошенную информацию для каждой строки в таблице trips , но иногда это может означать большой объем данных. Мы можем не захотеть всего этого. Если бы вместо этого мы хотели видеть start_date и bike_number для первых пяти поездок в базе данных, мы могли бы добавить LIMIT к нашему запросу следующим образом:
ВЫБРАТЬ start_date, bike_number ИЗ поездок LIMIT 5; LIMIT , а затем число, представляющее количество строк, которые мы хотим вернуть.В этом случае мы использовали 5, но вы можете заменить его любым числом, чтобы получить соответствующий объем данных для проекта, над которым вы работаете. LIMIT в наших запросах к базе данных Hubway в этом руководстве - таблица trips содержит более 1,5 миллиона строк данных, и нам определенно не нужно отображать их все!
query = 'ВЫБРАТЬ * ИЗ ОТКЛЮЧЕНИЯ ОГРАНИЧЕНИЯ 5;'
run_query (запрос) id продолжительность начальная_дата start_station end_date конечная станция номер велосипеда под_тип почтовый индекс дата рождения пол 0 1 9 2011-07-28 10:12:00 23 2011-07-28 10:12:00 23 B00468 Зарегистрировано '97217 1976 г.0 Мужской 1 2 220 2011-07-28 10:21:00 23 2011-07-28 10:25:00 23 B00554 Зарегистрировано '02215 1966,0 Мужской 2 3 56 2011-07-28 10:33:00 23 2011-07-28 10:34:00 23 B00456 Зарегистрировано '02108 1943 г.0 Мужской 3 4 64 2011-07-28 10:35:00 23 2011-07-28 10:36:00 23 B00554 Зарегистрировано '02116 1981,0 Женский 4 5 12 2011-07-28 10:37:00 23 2011-07-28 10:37:00 23 B00554 Зарегистрировано '97214 1983 г.0 Женский * используется как подстановочный знак вместо указания возвращаемых столбцов. Это означает, что команда SELECT дала нам каждый столбец в таблице отключений . Мы также использовали функцию LIMIT , чтобы ограничить вывод первыми пятью строками таблицы. поездок . Если бы нас интересовали только столбцы duration и start_date , мы могли бы заменить подстановочный знак именами столбцов следующим образом:
query = 'ВЫБЕРИТЕ продолжительность, начальная_дата ИЗ ПРЕДЕЛ 5 отключения'
run_query (запрос) продолжительность начальная_дата 0 9 2011-07-28 10:12:00 1 220 2011-07-28 10:21:00 2 56 2011-07-28 10:33:00 3 64 2011-07-28 10:35:00 4 12 2011-07-28 10:37:00 ЗАКАЗАТЬ В
ORDER BY .Эта команда позволяет нам отсортировать базу данных по заданному столбцу. ORDER BY сортируется в порядке возрастания. Если мы хотим указать, в каком порядке база данных должна быть отсортирована, мы можем добавить ключевое слово ASC для возрастания или DESC для убывания. поездок от самой короткой продолжительности к самой длинной, мы могли бы добавить следующую строку в наш запрос:
ЗАКАЗАТЬ ПО продолжительности ASC SELECT , LIMIT и ORDER BY в нашем репертуаре, мы теперь можем попытаться ответить на наш первый вопрос: Какова была продолжительность самой длинной поездки? таблицы поездок . Затем, чтобы определить, какая поездка самая длинная, мы можем отсортировать столбец длительность в порядке убывания. Вот как мы можем проработать это, чтобы придумать запрос, который получит информацию, которую мы ищем: SELECT для получения столбца продолжительности FROM отключает таблица ORDER BY для сортировки столбца длительности и используйте ключевое слово DESC , чтобы указать, что вы хотите отсортировать в порядке убывания LIMIT , чтобы ограничить вывод одной строкой
запрос = '' '
ВЫБРАТЬ ДЛИТЕЛЬНОСТЬ ИЗ поездок
ЗАКАЗАТЬ ПО длительности DESC
LIMIT 1;
'' '
run_query (запрос) LIMIT так, чтобы он возвращал 10 самых высоких значений продолжительности, чтобы проверить, так ли это:
запрос = '' '
ВЫБЕРИТЕ ДЛИТЕЛЬНОСТЬ ОТ поездок
ЗАКАЗАТЬ ПО длительности DESC
ПРЕДЕЛ 10
'' '
run_query (запрос) продолжительность 0 9999 1 9998 2 9998 3 9997 4 9996 5 9996 6 9995 7 9995 8 9994 9 9994 ГДЕ
WHERE . Команда WHERE позволяет нам использовать логический оператор, чтобы указать, какие строки должны быть возвращены.Например, вы можете использовать следующую команду, чтобы получить информацию о каждой поездке на велосипеде B00400 :
ГДЕ bike_number = "B00400" bike_number хранится в виде строки. Если столбец содержит числовые типы данных, в кавычках нет необходимости. WHERE для возврата каждого столбца в таблице поездок для каждой строки с продолжительностью дольше 9990 секунд:
запрос = '' '
ВЫБРАТЬ * ИЗ поездок
ГДЕ длительность> 9990;
'' '
run_query (запрос) id продолжительность начальная_дата start_station end_date конечная станция номер велосипеда под_тип почтовый индекс дата рождения пол 0 4768 9994 2011-08-03 17:16:00 22 2011-08-03 20:03:00 24 B00002 Повседневный 1 8448 9991 2011-08-06 13:02:00 52 2011-08-06 15:48:00 24 B00174 Повседневный 2 11341 9998 2011-08-09 10:42:00 40 2011-08-09 13:29:00 42 B00513 Повседневный 3 24455 9995 2011-08-20 12:20:00 52 2011-08-20 15:07:00 17 B00552 Повседневный 4 55771 9994 14.09.2011 15:44:00 40 14.09.2011 18:30:00 40 B00139 Повседневный 5 81191 9993 2011-10-03 11:30:00 22 2011-10-03 14:16:00 36 B00474 Повседневный 6 89335 9997 2011-10-09 02:30:00 60 2011-10-09 05:17:00 45 B00047 Повседневный 7 124500 9992 2011-11-09 09:08:00 22 2011-11-09 11:55:00 40 B00387 Повседневный 8 133967 9996 2011-11-19 13:48:00 4 2011-11-19 16:35:00 58 B00238 Повседневный 9 147451 9996 23.03.2012 14:48:00 35 23.03.2012 17:35:00 33 B00550 Повседневный 10 315737 9995 2012-07-03 18:28:00 12 2012-07-03 21:15:00 12 B00250 Зарегистрировано '02120 1964 Мужской 11 319597 9994 2012-07-05 11:49:00 52 2012-07-05 14:35:00 55 B00237 Повседневный 12 416523 9998 2012-08-15 12:11:00 54 2012-08-15 14:58:00 80 B00188 Повседневный 13 541247 9999 26.09.2012 18:34:00 54 26.09.2012 21:21:00 54 T01078 Повседневный из «Случайный» . Возможно, это показатель того, что «зарегистрированных» пользователей больше осведомлены о дополнительных сборах за дальние поездки. Возможно, Hubway сможет лучше донести свою структуру ценообразования до обычных пользователей, чтобы помочь им избежать дополнительных расходов. WHERE , мы также можем объединить несколько логических тестов в нашем предложении WHERE , используя AND или OR . Если, например, в нашем предыдущем запросе мы хотели вернуть только поездки с продолжительностью более 9990 секунд, которые также имели подтип Зарегистрированный, мы могли бы использовать И , чтобы указать оба условия.
запрос = '' '
ВЫБРАТЬ * ИЗ поездок
ГДЕ (продолжительность> = 9990) И (sub_type = "Зарегистрировано")
ЗАКАЗАТЬ ПО длительности DESC;
'' '
run_query (запрос) id продолжительность начальная_дата start_station end_date конечная станция номер велосипеда под_тип почтовый индекс дата рождения пол 0 315737 9995 2012-07-03 18:28:00 12 2012-07-03 21:15:00 12 B00250 Зарегистрировано '02120 1964 г.0 Мужской WHERE , чтобы вернуть все строки, где под_тип равен 'Registered' , а затем подсчитать их. COUNT . COUNT позволяет перенести вычисления в базу данных и избавить нас от необходимости писать дополнительные скрипты для подсчета результатов. Чтобы использовать его, мы просто включаем COUNT (column_name) вместо (или в дополнение) столбцов, которые вы хотите SELECT , например:
ВЫБРАТЬ СЧЕТЧИК (id)
ИЗ поездок COUNT в столбце id - столбец id никогда не будет нулевым, поэтому мы можем быть уверены, что наш счетчик ничего не пропустил. COUNT (1) или COUNT (*) для подсчета каждой строки в нашем запросе. Стоит отметить, что иногда нам может потребоваться запустить COUNT для столбца с нулевыми значениями.Например, нам может потребоваться узнать, сколько строк в нашей базе данных имеют отсутствующие значения для столбца. SELECT COUNT (*) для подсчета общего количества возвращенных строк и WHERE sub_type = "Registered" , чтобы убедиться, что мы подсчитываем только поездки, совершенные зарегистрированными пользователями.
запрос = '' '
ВЫБРАТЬ КОЛИЧЕСТВО (*) ИЗ поездок
ГДЕ sub_type = "Зарегистрировано";
'' '
run_query (запрос) AS , чтобы дать нашему выводу псевдоним (или псевдоним). Давайте повторно выполним предыдущий запрос, но дадим заголовку нашего столбца псевдоним Всего поездок по зарегистрированным пользователям :
запрос = '' '
ВЫБЕРИТЕ СЧЕТЧИК (*) КАК "Общее количество поездок зарегистрированных пользователей"
ИЗ поездок
ГДЕ sub_type = "Зарегистрировано";
'' '
run_query (запрос) Всего поездок по зарегистрированным пользователям 0 1105192 Агрегатные функции
COUNT - не единственный математический трюк, который SQL использует в своих рукавах.Мы также можем использовать SUM , AVG , MIN и MAX для возврата суммы, среднего, минимального и максимального значения столбца соответственно. Они, наряду с COUNT , известны как агрегатные функции. AVG в столбце длительности (и, опять же, использовать AS , чтобы дать нашему выходному столбцу более информативное имя):
запрос = '' '
ВЫБЕРИТЕ СРЕДНЮЮ (продолжительность) КАК "Средняя продолжительность"
ОТ поездок;
'' '
run_query (запрос) Средняя продолжительность 0 912.409682 SELECT AVG (duration) FROM trips с предложениями WHERE , которые ограничивают один до «зарегистрированных» и один до «случайных» пользователей. GROUP BY . ГРУППА ПО
GROUP BY разделяет строки на группы на основе содержимого определенного столбца и позволяет нам выполнять агрегатные функции для каждой группы. пол . Каждая строка может иметь одно из трех возможных значений в столбце пол , «Мужской» , «Женский» или Нулевой (отсутствует; у нас нет данных пол для случайных пользователей). GROUP BY , база данных разделяет каждую из строк в другую группу на основе значения в столбце пол , почти так же, как мы могли бы разделить колоду карт на разные масти. . Мы можем представить себе создание двух куч, одну из всех самцов, одну из всех самок. COUNT , запрос подсчитал бы количество строк в каждой стопке и вернул бы значение для каждой отдельно. SELECT , чтобы сообщить базе данных, какую информацию мы хотим видеть. В этом случае нам понадобится подтип и AVG (продолжительность) . GROUP BY sub_type , чтобы разделить наши данные по типу подписки и отдельно вычислить средние значения зарегистрированных и случайных пользователей.
запрос = '' '
ВЫБЕРИТЕ sub_type, AVG (продолжительность) AS "Средняя продолжительность"
ИЗ поездок
GROUP BY sub_type;
'' '
run_query (запрос) под_тип Средняя продолжительность 0 Повседневный 1519.643897 1 Зарегистрировано 657.026067
запрос = '' '
ВЫБЕРИТЕ bike_number как "Номер велосипеда", COUNT (*) как "Количество поездок"
ИЗ поездок
ГРУППА ПО номеру велосипеда
ЗАКАЗАТЬ ПО КОЛИЧЕСТВУ (*) УДАЛ.
LIMIT 1;
'' '
run_query (запрос) Номер велосипеда Количество поездок 0 B00490 2120 B00490 .Давайте разберемся, как мы туда попали: SELECT , чтобы сообщить базе данных, что мы хотим видеть столбец bike_number и количество каждой строки. Он также использует AS , чтобы указать базе данных отображать каждый столбец с более удобным именем. ИЗ , чтобы указать, что данные, которые мы ищем, находятся в таблице поездок . GROUP BY , чтобы указать функции COUNT в строке 1 подсчитывать каждое значение для bike_number отдельно. ORDER BY , чтобы отсортировать таблицу в порядке убывания и убедиться, что наш наиболее часто используемый велосипед находится наверху. LIMIT , чтобы ограничить вывод первой строкой, которая, как мы знаем, будет велосипедом, который использовался в наибольшем количестве поездок, из-за того, как мы отсортировали данные в четвертой строке. Арифметические операторы
+ , - , * и / для выполнения арифметической операции сразу над всем столбцом.
запрос = '' '
ВЫБРАТЬ СРЕДНЕЕ (продолжительность) ИЗ поездок
ГДЕ (2017 - дата рождения)> 30;
'' '
run_query (запрос) AVG (продолжительность) 0 923.014685 ПРИСОЕДИНЯЙТЕСЬ
, переходящей в таблицу . Однако одна из причин, по которой SQL является настолько мощным, заключается в том, что он позволяет нам извлекать данные из нескольких таблиц в одном запросе. станций . Таблица станций содержит информацию о каждой станции в сети Hubway и включает столбец id , на который ссылается таблица поездок . заказов и клиентов , и они были связаны столбцом customer_id . номер_заказа и имя для каждого заказа в базе данных. Если бы они оба хранились в одной таблице, мы могли бы использовать следующий запрос:
ВЫБРАТЬ номер_заказа, имя
ОТ заказов; order_number и столбец name хранятся в двух разных таблицах, поэтому нам нужно добавить несколько дополнительных шагов. Давайте поразмышляем над дополнительными вещами, которые должна знать база данных, прежде чем она сможет вернуть нужную нам информацию: order_number ? name ? orders связана с информацией в таблице customers ? SELECT .Мы делаем это просто путем записи имени таблицы и имени столбца, разделенных . . Например, вместо SELECT order_number, name мы должны написать SELECT orders.order_number, customers.name . Добавление сюда имен таблиц помогает базе данных находить нужные столбцы, сообщая ей, в какой таблице искать каждый. заказов и клиентов , мы используем JOIN и ON . JOIN указывает, какие таблицы должны быть соединены, а ON указывает, какие столбцы в каждой таблице связаны. ON . В этом примере мы захотим использовать JOIN для той таблицы, которую мы не включили в команду FROM . Таким образом, мы можем использовать FROM orders INNER JOIN customers или FROM customers INNER JOIN orders . customer_id в каждой таблице. Следовательно, мы захотим использовать ON , чтобы сообщить базе данных, что эти два столбца относятся к одному и тому же объекту, например:
ON orders.customer_ID = customers.customer_id . , чтобы убедиться, что база данных знает, в какой таблице находится каждый из этих столбцов. Итак, когда мы сложим все это вместе, мы получим запрос, который выглядит следующим образом:
ВЫБРАТЬ заказы.order_number, customers.name
ИЗ заказов
INNER JOIN клиенты
ON orders.customer_id = customers.customer_id JOIN в действии. station . Вот запрос, показывающий нам первые 5 строк, чтобы мы могли увидеть, как выглядит таблица station :
запрос = '' '
ВЫБРАТЬ * ИЗ станций
LIMIT 5;
'' '
run_query (запрос) id вокзал муниципалитет лат lng 0 3 Колледжи Фенуэй Бостон 42.340021 -71.100812 1 4 Tremont St., Berkeley St., Бостон 42.345392 -71.069616 2 5 Северо-восток / Северная парковка Бостон 42,341814 -71.0 3 6 Кембридж-стрит, Джой-стрит, Бостон 42,361284999999995 -71.06514 4 7 Fan Pier Бостон 42,353412 -71.044624 id - Уникальный идентификатор для каждой станции (соответствует столбцам start_station и end_station в таблице trips ) станция - Название станции муниципалитет - муниципалитет, в котором находится станция (Бостон, Бруклин, Кембридж или Сомервилль) lat - Широта станции lng - Долгота станции SELECT для возврата столбца station из таблицы station и COUNT количества строк. JOIN , и говорим базе данных подключить их ON столбец start_station в таблице trips и столбец id в таблице station . GROUP BY столбец station в таблице station , чтобы наш COUNT подсчитывал количество поездок для каждой станции отдельно ЗАКАЗАТЬ ПО нашим COUNT и LIMIT вывод на управляемое количество результатов
запрос = '' '
ВЫБЕРИТЕ станции.станция AS "Станция", COUNT (*) AS "Count"
ИЗ поездок INNER JOIN станции
ВКЛ. Trips.start_station = station.idGROUP BY station.station ORDER BY COUNT (*) DESC
LIMIT 5;
'' '
run_query (запрос) Станция Граф 0 Южный вокзал - 700 Атлантик авеню 56123 1 Публичная библиотека Бостона - 700 Boylston St. 41994 2 Charles Circle - Charles St.на Кембридж-стрит 35984 3 Beacon St / Mass Ave 35275 4 MIT, Mass Ave / Amherst St 33644 ВЫБРАТЬ те же выходные столбцы и JOIN таблицы таким же образом, но на этот раз мы добавим предложение WHERE , чтобы ограничить наш COUNT поездками, где start_station совпадает с конечная_станция .
query = '' 'ВЫБРАТЬ станции. Станция КАК "Станция", СЧЁТ (*) КАК "Счетчик"
ИЗ поездок INNER JOIN станции
ПО поездкам.start_station = station.id
ГДЕ trips.start_station = trips.end_station
ГРУППА ПО станциям. Станции
ЗАКАЗАТЬ ПО КОЛИЧЕСТВУ (*) УДАЛ.
LIMIT 5;
'' '
run_query (запрос) Станция Граф 0 Эспланада - Бикон-стрит на Арлингтон-стрит 3064 1 Чарльз Серкл - Чарльз-стрит, Кембридж-стрит, 2739 2 Публичная библиотека Бостона - 700 Boylston St. 2548 3 Бойлстон-стрит на Арлингтон-стрит 2163 4 Beacon St / Mass Ave 2144 .Чтобы достичь этого, нам нужно JOIN , дважды подключает таблицу к таблице станций . После ON столбец start_station , а затем ON столбец end_station . station , чтобы мы могли различать данные, относящиеся к start_station , и данные, которые относятся к end_station . Мы можем сделать это точно так же, как мы создавали псевдонимы для отдельных столбцов, чтобы они отображались с более интуитивно понятным именем, используя AS . ПРИСОЕДИНЯЙТЕСЬ к к таблице станций к таблице поездок , используя псевдоним «начало». Затем мы можем объединить «начало» с именами столбцов, используя . для ссылки на данные, которые поступают из этого конкретного JOIN (вместо второго JOIN мы будем делать ON в столбце end_station ):
INNER JOIN станции AS start ON trips.start_station = start.id <> для обозначения «не равно», но ! = также будет работать.
запрос =
'' '
ВЫБЕРИТЕ СЧЕТЧИК (trips.id) КАК "Счетчик"
ИЗ поездок ВНУТРЕННИЕ СОЕДИНЯЙТЕ станции КАК старт
ВКЛ. Trips.start_station = start.id
INNER JOIN станции как конец
ВКЛ. Trips.end_station = end.id
ГДЕ start.municipality <> end.municipality;
'' '
run_query (запрос) SELECT , LIMIT , WHERE , ORDER BY , GROUP BY и JOIN , а также агрегатные и арифметические функции.Это даст вам прочную основу для дальнейшего развития SQL. Вы освоили основы SQL. Что теперь?
Access SQL: основные понятия, словарь и синтаксис
В этой статье
Что такое SQL?
ВЫБРАТЬ Фамилию
ИЗ контактов
ГДЕ Имя = 'Мэри';
Операторы SELECT
Пункты SQL
Термины SQL
Базовые предложения SQL: SELECT, FROM и WHERE
ВЫБРАТЬ поле_1
ИЗ таблицы_1
ГДЕ критерий_1
;
Пример в Access
Предложение SELECT
Предложение FROM
Предложение WHERE
Сортировка результатов: ЗАКАЗАТЬ ПО
Работа с обобщенными данными: GROUP BY и HAVING
Указание полей, которые не используются в агрегатной функции: предложение GROUP BY
Ограничение совокупных значений с помощью групповых критериев: предложение HAVING
Объединение результатов запроса: UNION
SELECT field_1
FROM table_1
UNION [ALL]
SELECT field_a
FROM table_a
;
ВЫБЕРИТЕ имя, цену, доступность_гарантии, эксклюзивное_предложение
ИЗ ПРОДУКТОВ
СОЮЗ ВСЕ
ВЫБЕРИТЕ имя, цену, доступность_гарантии, эксклюзивное_предложение
ИЗ Услуги
;
Учебное пособие по SQL - javatpoint
Учебник Что такое SQL
Зачем нужен SQL
Что делает SQL
Индекс SQL
Синтаксис SQL - с примерами
Как выглядит оператор SQL?
Ключевые слова включают SELECT, UPDATE, WHERE, ORDER BY и т. Д.
Между прочим, синтаксис языка описывает элементы языка. Синтаксис SQL
Общая форма SQL SELECT
ВЫБЕРИТЕ имена столбцов
ОТ имя-таблицы
ГДЕ условие
ORDER BY sort-order
ВЫБЕРИТЕ имя, фамилию, город, страну
ОТ Заказчика
ГДЕ Город = 'Париж'
ЗАКАЗАТЬ ПО ФАМИЛИ
Общая форма SQL INSERT
ВСТАВИТЬ имя-таблицы (имена-столбцов)
ЗНАЧЕНИЯ (значения столбцов)
ВСТАВИТЬ поставщика (имя, контактное имя, город, страну)
ЦЕННОСТИ («Оксфорд Трейдинг», «Ян Смит», «Оксфорд», «Великобритания»)
Общая форма SQL UPDATE
ОБНОВЛЕНИЕ имя-таблицы
УСТАНОВИТЬ имя-столбца = значение-столбца
ГДЕ условие
ОБНОВЛЕНИЕ OrderItem
НАБОР Количество = 2
ГДЕ Id = 388
Общая форма SQL DELETE
УДАЛИТЬ имя-таблицы
ГДЕ условие
УДАЛИТЬ клиента
ГДЕ Email = 'alex @ gmail.com '
.