Базовый синтаксис SQL запроса
Одна из основных функций SQL — это получение выборок данных из СУБД. Для этого в SQL используется оператор SELECT. Давайте рассмотрим несколько простых запросов с его участием.
Для начала важно понимать, что через оператор SELECT можно выводить данные не только из таблиц базы данных, но и произвольные строки, числа, даты и т.д. Например, так можно вывести произвольную строку:
SELECT "Hello world"
Для вывода всех полей из определённой таблицы используется символ *. Давайте взглянем на схему базы данных и выведем данные одной из таблиц.
SELECT * FROM FamilyMembers
| member_id | status | member_name | birthday |
|---|---|---|---|
| 1 | father | Headley Quincey | 1960-05-13T00:00:00.000Z |
| 2 | mother | Flavia Quincey | 1963-02-16T00:00:00.000Z |
| 3 | son | Andie Quincey | 1983-06-05T00:00:00. |
| 4 | daughter | Lela Quincey | 1985-06-07T00:00:00.000Z |
| 5 | daughter | Annie Quincey | 1988-04-10T00:00:00.000Z |
| 6 | father | Ernest Forrest | 1961-09-11T00:00:00.000Z |
| 7 | mother | Constance Forrest | 1968-09-06T00:00:00.000Z |
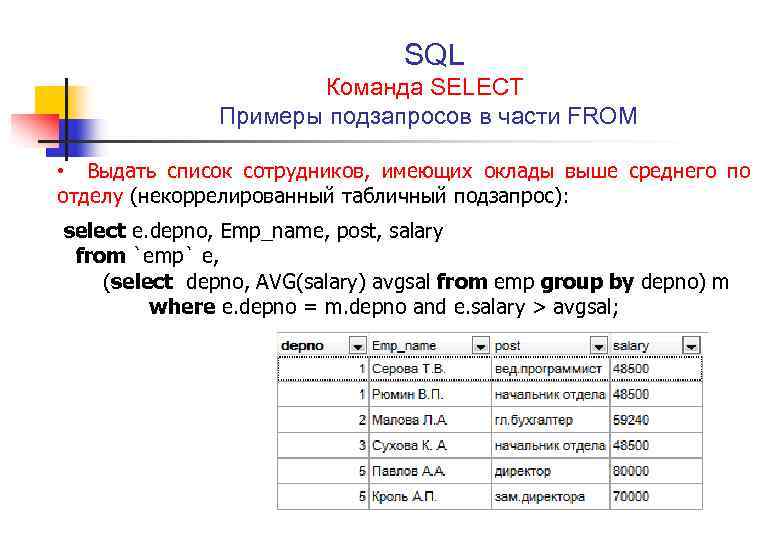
Если необходимо вывести информацию только по определённым столбцам таблицы, а не всю сразу, то это можно сделать перечисляя названия столбцов через запятую:
SELECT member_id, member_name FROM FamilyMembers
| member_id | member_name |
|---|---|
| 1 | Headley Quincey |
| 2 | Flavia Quincey |
| 3 | Andie Quincey |
| 4 | Lela Quincey |
| 5 | Annie Quincey |
| 6 | Ernest Forrest |
| 7 | Constance Forrest |
В случае, если мы хотим вывести какие-то столбцы таблицы, но чтобы в итоговой выборке они были названы иначе,
мы можем использовать псевдонимы (их также называют алиасами).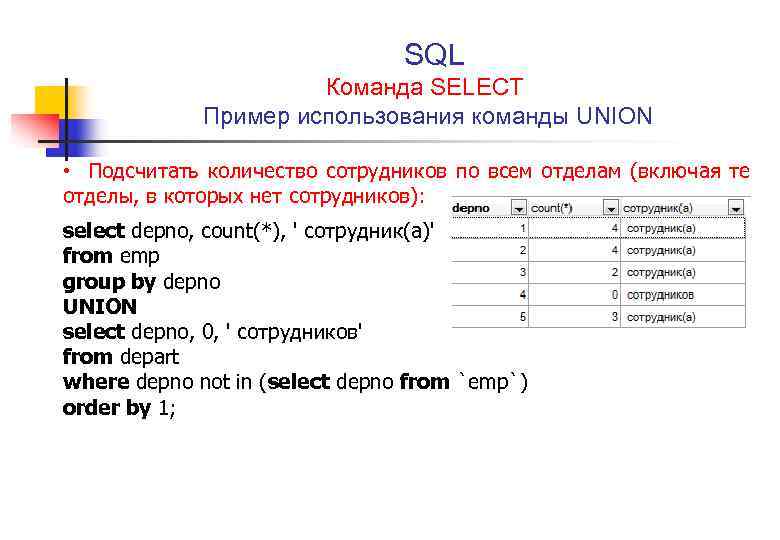
Их синтаксис достаточно простой, мы должны использовать оператор AS. Как в примере ниже:
SELECT member_id, member_name AS Name FROM FamilyMembers
| member_id | Name |
|---|---|
| 1 | Headley Quincey |
| 2 | Flavia Quincey |
| 3 | Andie Quincey |
| 4 | Lela Quincey |
| 5 | Annie Quincey |
| 6 | Ernest Forrest |
| 7 | Constance Forrest |
Или же можно обойтись и без него, просто написав желаемое наименование поля через пробел.
SELECT member_id, member_name Name FROM FamilyMembers
Псевдонимы могут содержать до 255 знаков (включая пробелы, цифры и специальные символы)
Это наш первый урок практического модуля. До этого были лишь теоретические, направленные на восполнение потенциальных пробелов в теории реляционных баз данных. После каждого практического урока мы предлагаем группу заданий для самостоятельной работы, чтобы сразу же закрепить полученную информацию.
После каждого практического урока мы предлагаем группу заданий для самостоятельной работы, чтобы сразу же закрепить полученную информацию.
Если вы пропустили модуль «Введение», а именно статью «Структура курса» , где описывался принцип работы и интерфейс блока «Самостоятельные упражнения», то рекомендуем вернуться к нему .
Сложные SQL-запросы
Сложные SQL-запросы Пожалуйста, включите JavaScript в браузере!Сложные SQL-запросы
С помощью строки поиска вы можете вручную создавать SQL-запросы любой сложности для фильтрации событий.
Чтобы сформировать SQL-запрос вручную:
- Перейдите в раздел События веб-интерфейса KUMA.
Откроется форма с полем ввода.
- Введите SQL-запрос в поле ввода.
- Нажмите на кнопку .
Отобразится таблица событий, соответствующих условиям вашего запроса. При необходимости вы можете отфильтровать события по периоду.
Поддерживаемые функции и операторы
SELECT– поля событий, которые следует возвращать.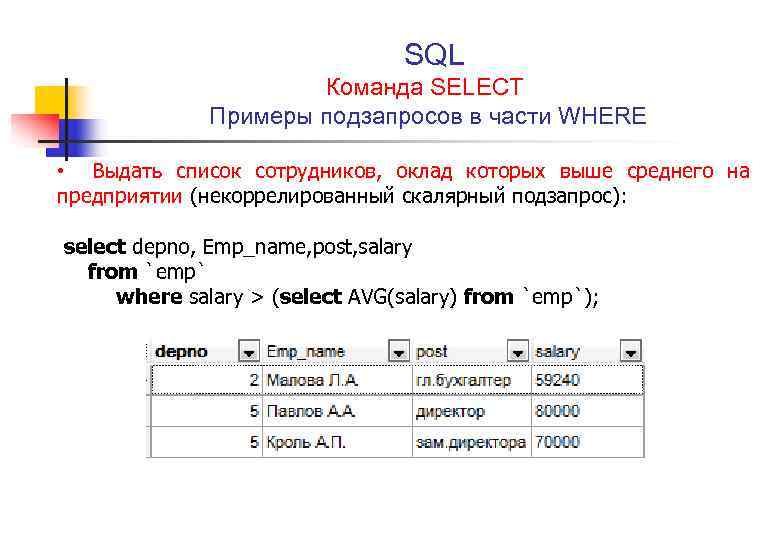
Для
SELECTв программе поддержаны следующие функции и операторы:- Функции агрегации:
count, avg, max, min, sum. - Арифметические операторы:
+, -, *, /, <, >, =, !=, >=, <=.Вы можете комбинировать эти функции и операторы.
Если вы используете в запросе функции агрегации, настройка отображения таблицы событий, сортировка событий по возрастанию и убыванию, получение статистики, а также ретроспективная проверка недоступны.
- Функции агрегации:
FROM– источник данных.При создании запроса в качестве источника данных вам нужно указать значение events.
WHERE– условия фильтрации событий.AND, OR, NOT, =, !=, >, >=, <, <=INBETWEENLIKEILIKEinSubnetmatch(в запросах используется синтаксис регулярных выражений re2)
GROUP BY– поля событий или псевдонимы, по которым следует группировать возвращаемые данные.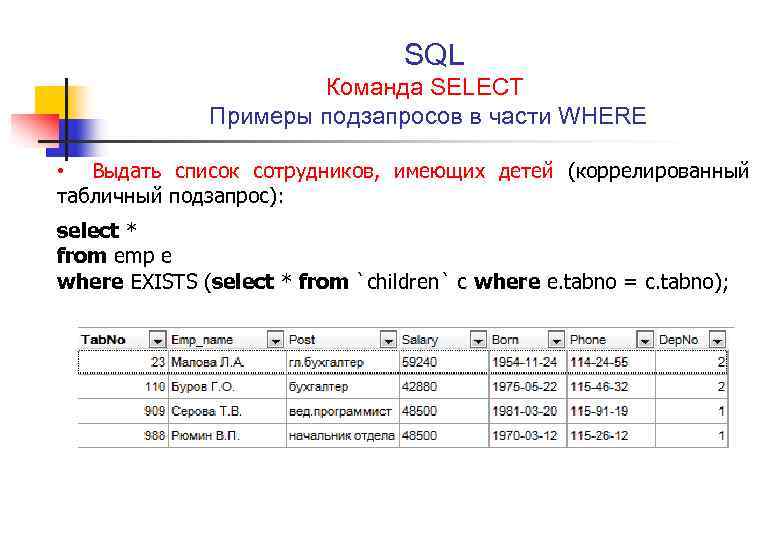
Если вы используете в запросе группировку данных, настройка отображения таблицы событий, сортировка событий по возрастанию и убыванию, получение статистики, а также ретроспективная проверка недоступны.
ORDER BY– столбцы, по которым следует сортировать возвращаемые данные.Возможные значения:
DESC– по убыванию.ASC– по возрастанию.
OFFSET– пропуск указанного количества строк перед выводом результатов запроса.LIMIT– количество отображаемых в таблице строк.Значение по умолчанию – 250.
Если при фильтрации событий по пользовательскому периоду количество строк в результатах поиска превышает заданное значение, вы можете отобразить в таблице дополнительные строки, нажав на кнопку Показать больше записей. Кнопка не отображается при фильтрации событий по стандартному периоду.
Примеры запросов:
SELECT * FROM `events` WHERE Type IN ('Base', 'Audit') ORDER BY Timestamp DESC LIMIT 250Все события таблицы events с типом Base и Audit, отсортированные по столбцу Timestamp в порядке убывания.
 Количество отображаемых в таблице строк – 250.
Количество отображаемых в таблице строк – 250.SELECT * FROM `events` WHERE BytesIn BETWEEN 1000 AND 2000 ORDER BY Timestamp ASC LIMIT 250Все события таблицы events, для которых в поле BytesIn значение полученного трафика находится в диапазоне от 1000 до 2000 байт, отсортированные по столбцу Timestamp в порядке возрастания. Количество отображаемых в таблице строк – 250.
SELECT * FROM `events` WHERE Message LIKE '%ssh:%' ORDER BY Timestamp DESC LIMIT 250Все события таблицы events, которые в поле Message содержат данные, соответствующие заданному шаблону
в нижнем регистре, и отсортированы по столбцу Timestamp в порядке убывания. Количество отображаемых в таблице строк – 250.%ssh:%SELECT * FROM `events` WHERE inSubnet(DeviceAddress, '10.0.0.1/24') ORDER BY Timestamp DESC LIMIT 250Все события таблицы events для хостов, которые входят в подсеть 10.0.0.1/24, отсортированные по столбцу Timestamp в порядке убывания.
 Количество отображаемых в таблице строк – 250.
Количество отображаемых в таблице строк – 250.SELECT * FROM `events` WHERE match(Message, 'ssh.*') ORDER BY Timestamp DESC LIMIT 250Все события таблицы events, которые в поле Message содержат текст, соответствующий шаблону
ssh.*, и отсортированы по столбцу Timestamp в порядке убывания. Количество отображаемых в таблице строк – 250.SELECT max(BytesOut) / 1024 FROM `events`Максимальный размер исходящего трафика (КБ) за выбранный период времени.
SELECT count(ID) AS "Count", SourcePort AS "Port" FROM `events` GROUP BY SourcePort ORDER BY Port ASC LIMIT 250Количество событий и номер порта. События сгруппированы по номеру порта и отсортированы по столбцу Port в порядке возрастания. Количество отображаемых в таблице строк – 250.
Столбцу ID в таблице событий присвоено имя Count, столбцу SourcePort присвоено имя Port.
Если вы хотите указать в запросе специальный символ, вам требуется экранировать его, поместив перед ним обратную косую черту (\).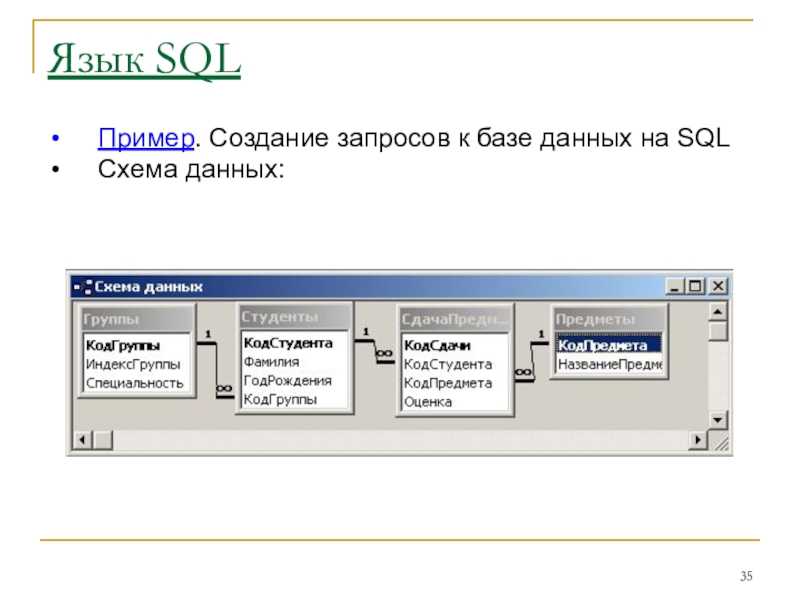
Пример:
Все события таблицы events, которые в поле Message содержат текст, соответствующий шаблону |
При переключении на конструктор параметры запроса, введенного вручную в строке поиска, не переносятся в конструктор: вам требуется создать запрос заново. При этом запрос, созданный в конструкторе, не перезаписывает запрос, введенный в строке поиска, пока вы не нажмете на кнопку Применить в окне конструктора.
После обновления KUMA до версии 1.6 при фильтрации событий с помощью SQL-запроса, содержащего условие inSubnet, может возвращаться ошибка Code: 441. DB::Exception: Invalid IPv4 value. В таких случаях необходимо на серверах хранилища (на каждой машине кластера ClickHouse) в файле /opt/kaspersky/kuma/clickhouse/cfg/config.d/users.xml в разделе profiles → default добавить директиву
В таких случаях необходимо на серверах хранилища (на каждой машине кластера ClickHouse) в файле /opt/kaspersky/kuma/clickhouse/cfg/config.d/users.xml в разделе profiles → default добавить директиву
Подробнее об SQL см. в справке ClickHouse.
В начало
Примеры SQL
❮ Предыдущий Далее ❯
Синтаксис SQL
Выбрать все записи из определенной таблицы («Клиенты»)
Объяснение примера
SQL SELECT
ВЫБЕРИТЕ столбец SELECT *
Объяснение примеров
SQL SELECT DISTINCT
ВЫБЕРИТЕ ОТЛИЧНЫЙ SELECT COUNT (DISTINCT имя_столбца) SELECT COUNT(DISTINCT column_name) обходной путь для MS Access
Объяснение примеров
SQL ГДЕ
ГДЕ Предложение Текстовые поля и числовые поля
Объяснение примеров
Операторы SQL И, ИЛИ и НЕ
И ИЛИ НЕТ Комбинация И, ИЛИ и НЕ
Объяснение примеров
SQL ORDER BY
СОРТИРОВАТЬ ПО ЗАКАЗАТЬ ПО DESC ORDER BY Несколько столбцов
Объяснение примеров
SQL INSERT INTO
ВСТАВИТЬ В Вставка данных в определенные столбцы
Объяснение примеров
Значения SQL NULL
ЕСТЬ НУЛЕВОЙ оператор IS NOT NULL Оператор
Объяснение примеров
Обновление SQL
ОБНОВЛЕНИЕ Таблица ОБНОВИТЬ несколько записей UPDATE Предупреждение (если вы опустите предложение WHERE, все записи будут обновлены)
Объяснение примеров
SQL DELETE
УДАЛИТЬ УДАЛИТЬ все записи
Объяснение примеров
SQL SELECT TOP
ВЫБЕРИТЕ ВЕРХ ПРЕДЕЛ ВЫБЕРИТЕ ВЕРХНИЙ ПРОЦЕНТ SELECT TOP и добавьте пункт WHERE
Объяснение примеров
SQL MIN() и MAX()
МИН() MAX()
Объяснение примеров
SQL COUNT, AVG() и SUM()
СЧИТАТЬ() СРЕДНЕЕ() SUM()
Объяснение примеров
SQL LIKE
LIKE — выбрать все строки таблицы, начинающиеся с «a» LIKE — выбрать все строки таблицы, оканчивающиеся на «a» НРАВИТСЯ — выбрать все строки таблицы, в которых есть «или» в любой позиции НРАВИТСЯ — выбрать все строки таблицы, в которых «r» стоит во второй позиции LIKE — выбрать все строки таблицы, которые начинаются с «a» и заканчиваются на «o» LIKE — выбрать все строки таблицы, которые НЕ начинаются с «a»
Объяснение примеров
Подстановочные знаки SQL
Использование подстановочного знака % Использование подстановочного знака _ Использование подстановочного знака [charlist] Использование подстановочного знака [!charlist]
Объяснение примеров
SQL IN
В НЕ В
Объяснение примеров
SQL МЕЖДУ
МЕЖДУ НЕ МЕЖДУ МЕЖДУ с В МЕЖДУ текстовыми значениями НЕ МЕЖДУ текстовыми значениями
Объяснение примеров
Псевдонимы SQL
Псевдоним для столбцов Два псевдонима Псевдоним для таблиц
Объяснение примеров
Соединения SQL
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ЛЕВОЕ СОЕДИНЕНИЕ ПРАВОЕ ПРИСОЕДИНЕНИЕ Self JOIN
Объяснение примеров
SQL UNION
СОЮЗ СОЮЗ ВСЕХ СОЮЗ с ГДЕ UNION ALL с WHERE
Объяснение примеров
SQL GROUP BY
ГРУППА ПО СГРУППИРОВАТЬ ПО И ЗАКАЗАТЬ ПО GROUP BY с JOIN
Объяснение примеров
SQL HAVING
HAVING и GROUP BY HAVING и ORDER BY
Объяснение примеров
SQL EXISTS
EXISTS
Объяснение примера
SQL ЛЮБОЙ и ВСЕ
ЛЮБОЙ ВСЕ
Объяснение примеров
SQL INSERT INTO SELECT
ВСТАВИТЬ В ВЫБОР INSERT INTO SELECT с WHERE
Объяснение примеров
SQL CASE
ДЕЛО 1 СЛУЧАЙ 2
Объяснение примеров
Комментарии SQL
Однострочные комментарии Однострочные комментарии в конце строки Многострочные комментарии
Объяснение примеров
База данных SQL
Учебные пособия по базе данных SQL можно найти здесь:
SQL Create DB БД SQL Drop Резервная копия базы данных SQL Создание таблицы SQL Таблица удаления SQL Таблица изменений SQL Ограничения SQL SQL не нулевой Уникальный SQL Первичный ключ SQL Внешний ключ SQL Проверка SQL SQL по умолчанию Индекс SQL Автоматическое увеличение SQL Даты SQL Представления SQL SQL-инъекция Хостинг SQL
Начните свою карьеру
Получите сертификат, пройдя курс
Получите сертификат
w3schoolsCERTIFIED. 2023
2023❮ Предыдущий Следующий ❯
ВЫБОР ЦВЕТА
Изучение SQL: примеры запросов SQL
В предыдущей статье мы практиковали SQL, и сегодня мы продолжим с еще несколькими примерами SQL. Цель этой статьи — начать с довольно простого запроса и перейти к более сложным запросам. Мы рассмотрим вопросы, которые могут вам понадобиться на собеседовании, а также некоторые из них, которые могут вам понадобиться в реальных жизненных ситуациях. Итак, пристегнитесь, мы взлетаем!
Модель данных
Как всегда, давайте сначала кратко рассмотрим модель данных, которую мы будем использовать. Это та же самая модель, которую мы используем в этой серии, так что вы уже должны быть знакомы. В случае, если это не так, просто взгляните на таблицы и на то, как они связаны.
Мы разберем 6 примеров SQL, начиная с довольно простого. Каждый пример будет добавлять что-то новое, и мы
обсудите цель обучения, стоящую за каждым запросом. Я буду использовать тот же подход, который описан в статье Изучаем SQL: как написать сложный запрос SELECT? Давайте начнем.
Я буду использовать тот же подход, который описан в статье Изучаем SQL: как написать сложный запрос SELECT? Давайте начнем.
#1 Пример SQL — SELECT
Мы хотим изучить, что находится в таблице вызовов в нашей модели. Следовательно, нам нужно выбрать все атрибуты, и мы отсортируйте их сначала по employee_id, а затем по start_time.
1 2 3 4 5 6 | — Список всех звонков (отсортированных по сотрудникам и времени начала) SELECT * ИЗ звонка ЗАКАЗ ПО call.employee_id ASC, call.start_time ASC; |
Это довольно простой запрос, и вы должны понять его без проблем. Единственное, что я хотел бы отметить здесь, это то, что мы упорядочили наш результат сначала по идентификатору сотрудника (call.employee_id ASC), а затем по времени начала звонка (call.start_time). В реальных ситуациях это то, что вы должны сделать, если хотите выполнить аналитику в течение времени по заданным критериям (все данные для одного и того же сотрудника упорядочены друг за другом).
#2 Пример SQL — функция DATEDIFF
Нам нужен запрос, который должен возвращать все данные о звонках, а также продолжительность каждого звонка в секундах. Мы будем использовать предыдущий запрос в качестве отправной точки.
1 2 3 4 5 6 7 8 | — Список всех вызовов вместе с продолжительностью вызова SELECT call.*, DATEDIFF(«SECOND», call.start_time, call.end_time) AS call_duration ИЗ call. ORDER BY call.employee_time ASCcall, 9 0 003 9 0 002; |
Возвращаемый результат почти такой же, как и в предыдущем запросе (те же столбцы и порядок), за исключением добавления одного столбца. Мы назвали этот столбец call_duration. Чтобы получить продолжительность вызова, мы использовали функцию SQL Server DATEDIFF.
Он принимает 3 аргумента, единицу измерения разницы (нам нужны секунды), первое значение даты и времени (время начала, нижний
значение), второе значение даты и времени (время окончания, более высокое значение).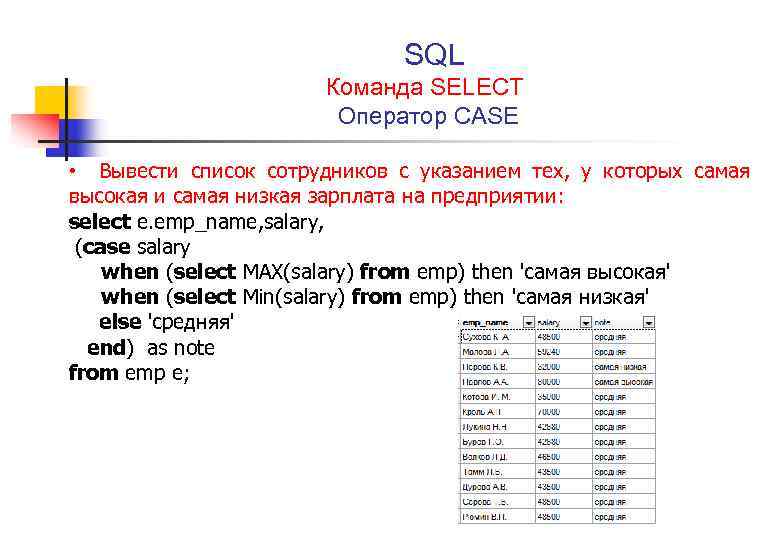 Функция возвращает разницу во времени в заданных единицах измерения.
Функция возвращает разницу во времени в заданных единицах измерения.
- Примечание. SQL Server имеет ряд функций (дата и время), и мы рассмотрим наиболее важные из них в следующих статьях.
#3 Пример SQL — DATEDIFF + функция агрегирования
Теперь мы хотим вернуть суммарную продолжительность всех звонков для каждого сотрудника. Итак, мы хотим иметь 1 строку для каждого сотрудника и сумму продолжительности всех звонков, которые он когда-либо делал. Мы продолжим с того места, на котором остановились в предыдущем запросе.
1 2 3 4 5 6 7 8 10 110003 12 13 14 | — Сумма продолжительности вызовов на каждый сотрудник SELECT Employee.id, Employee.first_name, holdoeee.last_name, Sum (Datediff («Second», Call. SUM (Datediff («Second». ) AS call_duration_sum Из звонка Внутреннее объединение сотрудников по вызову. Employee_id = employee.id Группа на Employee. |
 start_time,
start_time,По результату добавить особо нечего – мы получили именно то, что хотели. Но давайте прокомментируем, как мы этого добились. Несколько вещей, которые я хотел бы подчеркнуть здесь:
- Мы объединили таблицы call и employee, потому что нам нужны данные из обеих таблиц (детали сотрудника и продолжительность звонка).
- Мы использовали агрегатную функцию SUM(…) вокруг ранее рассчитанной продолжительности разговора для каждого сотрудника.
- Поскольку мы сгруппировали все на уровне сотрудников, у нас есть ровно 1 строка для каждого сотрудника.
- Примечание: При объединении результата, возвращаемого любой функцией, и агрегатной функции особых правил не существует.
 В нашем случае вы можете без проблем использовать функцию SUM с DATEDIFF.
В нашем случае вы можете без проблем использовать функцию SUM с DATEDIFF.
#4 Пример SQL — расчет коэффициента
Для каждого сотрудника нам нужно вернуть все его звонки с указанием их продолжительности. Мы также хотим знать процент времени, которое сотрудник потратил на этот звонок, по сравнению с общим временем всех его звонков.
- Подсказка: Нам нужно объединить значение, рассчитанное для одной строки, с агрегированным значением. Для этого мы будем использовать подзапрос для вычисления этого агрегированного значения, а затем присоединимся к соответствующей строке.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | — % продолжительности звонков на каждого сотрудника по сравнению с продолжительностью всех его звонков Выбрать employee. Employee.first_name, Employee.last_name, Call.start_time, Call.end_time, Datedif call_duration, duration_sum.call_duration_sum, CAST(CAST(DATEDIFF(«SECOND», call.start_time, call.end_time) AS DECIMAL(7,2)) / CAST(duration_sum.call_duration_sum AS DECIMAL(7,2)) AS DECIMAL(4,4)) AS call_percentage Из Call Внутренний соединительный сотрудник на Call.employee_id = employee.id Внутреннее соединение ( SELECT Optainee.id, SUM (Datatediff («Second», Call.start_time, call.end_time)) Как call_duration_sum из Call Inner Jointemee in incolide on call.employee_id = employee.id Группа по employee.id ) как DOURETION0003 employee.id ASC, call.start_time ASC; |
 id,
id, Вы можете заметить, что мы достигли комбинирования значений строки с агрегированным значением. Это очень полезно, потому что вы
могли поместить такие вычисления в запрос SQL и избежать дополнительной работы позже. Этот запрос содержит еще несколько
интересные концепции, которые следует упомянуть:
Этот запрос содержит еще несколько
интересные концепции, которые следует упомянуть:
- Самое главное, что мы поместили весь запрос, возвращающий агрегированное значение, в подзапрос (т. часть, начинающаяся со 2-го ВНУТРЕННЕГО СОЕДИНЕНИЯ (ВНУТРЕННЕЕ СОЕДИНЕНИЕ() и заканчивающееся на ) AS duration_sum ON employee.id = duration_sum.id. Между этими скобками мы поместили слегка измененный запрос из части № 2 Пример SQL — Функция DATEDIFF. Этот подзапрос возвращает идентификатор каждого сотрудника и СУММУ продолжительности всех его звонков. Только подумайте об этом как об одной таблице с этими двумя значениями
- Мы присоединили «таблицу» из предыдущего пункта к таблицам вызовов и сотрудников, потому что нам нужны значения из этих двух таблиц.
- Мы уже проанализировали функцию DATEDIFF(…), используемую для расчета продолжительности одного вызова, в части № 2 Пример SQL — функция DATEDIFF
- Эта часть CAST( CAST(DATEDIFF(«SECOND», call.
 start_time, call.end_time) AS DECIMAL(7,2)) /
CAST(duration_sum.call_duration_sum AS DECIMAL(7,2)) AS DECIMAL(4,4)) AS call_percentage очень важно.
Сначала мы преобразовали оба дивиденда (CAST(DATEDIFF(«SECOND», call.start_time, call.end_time) AS DECIMAL(7,2))) и
делитель (CAST(duration_sum.call_duration_sum AS DECIMAL(7,2)) как десятичные числа. Хотя они являются целыми числами,
ожидаемый результат — десятичное число, и мы должны «сообщить» это SQL Server. В случае, если мы не CAST-ed
их, SQL Server будет выполнять деление целых чисел. Мы также преобразовали результат в десятичное число. Этот
не был нужен, потому что мы ранее определили это при приведении делимого и делителя, но я хотел отформатировать
результат будет иметь 4 числовых значения, и все 4 из них будут десятичными знаками (это процент в десятичном
формат)
start_time, call.end_time) AS DECIMAL(7,2)) /
CAST(duration_sum.call_duration_sum AS DECIMAL(7,2)) AS DECIMAL(4,4)) AS call_percentage очень важно.
Сначала мы преобразовали оба дивиденда (CAST(DATEDIFF(«SECOND», call.start_time, call.end_time) AS DECIMAL(7,2))) и
делитель (CAST(duration_sum.call_duration_sum AS DECIMAL(7,2)) как десятичные числа. Хотя они являются целыми числами,
ожидаемый результат — десятичное число, и мы должны «сообщить» это SQL Server. В случае, если мы не CAST-ed
их, SQL Server будет выполнять деление целых чисел. Мы также преобразовали результат в десятичное число. Этот
не был нужен, потому что мы ранее определили это при приведении делимого и делителя, но я хотел отформатировать
результат будет иметь 4 числовых значения, и все 4 из них будут десятичными знаками (это процент в десятичном
формат)
Из этого примера мы должны помнить, что мы можем использовать подзапросы для возврата дополнительных значений, которые нам нужны. Возвращение
агрегированное значение с помощью подзапроса и объединение этого значения с исходной строкой — хороший пример, когда мы могли бы
сделать именно это.
Возвращение
агрегированное значение с помощью подзапроса и объединение этого значения с исходной строкой — хороший пример, когда мы могли бы
сделать именно это.
#5 Пример SQL — среднее значение (AVG)
Нам нужно два запроса. Первый должен вернуть среднюю продолжительность звонка на одного сотрудника, а второй должен вернуть средняя продолжительность вызова для всех вызовов.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | — средняя продолжительность разговора на одного сотрудника SELECT employee.id, employee.first_name, employee.last_name, 9 employee.first_name, employee.last_name ORDER BY employee.id ASC;
— средняя продолжительность вызова — все вызовы SELECT AVG(DATEDIFF(«SECOND», call. ОТ вызова; |
 start_time, call.end_time)) AS call_duration_avg
start_time, call.end_time)) AS call_duration_avgНет необходимости объяснять это более подробно. Расчет средней продолжительности вызовов на одного сотрудника аналогичен расчету СУММЫ длительностей вызовов на одного сотрудника (пример № 3 SQL — DATEDIFF + функция агрегирования). Мы только что заменили агрегатную функцию SUM на AVG.
Второй запрос возвращает продолжительность вызова AVG для всех вызовов. Обратите внимание, что мы не использовали GROUP BY. Нам это просто не нужно, потому что все строки идут в эту группу. Это один из случаев, когда агрегатную функцию можно использовать без предложение GROUP BY.
#6 Пример SQL — сравнение значений AVG
Нам нужно рассчитать разницу между средней продолжительностью разговора по каждому сотруднику и средней продолжительностью разговора продолжительность всех звонков.
1 2 3 4 5 6 7 8 10 110003 12 13 14 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 39000 3 9000 3 9000 3 9000 3 0002 1718 19 20 21 22 23 24 25 26 27 28 29 30 9000 2129 30 31 310003 2829 30 9000 21 | — разница между продолжительностью звонка AVG на одного сотрудника и длительностью звонка AVG0002 single_employee. single_employee.call_duration_avg — avg_all.call_duration_avg as avg_difference из ( Select 1 ock_id, . AVG(DATEDIFF(«SECOND», call.start_time, call.end_time)) AS call_duration_avg FROM call ВНУТРЕННЕЕ СОЕДИНЕНИЕ сотрудник ON call.employee_id = employee.id Group By Officeee.Id, Outloceee.first_Name, Employee. («СЕКУНДА», call.start_time, call.end_time)) AS call_duration_avg FROM call ) avg_all ON avg_all.join_id = single_employee.join_id; |
 call_duration_avg,
call_duration_avg,Этот запрос действительно сложный, поэтому давайте сначала прокомментируем результат. У нас есть ровно 1 строка на каждого сотрудника со средней продолжительностью звонка на одного сотрудника и разницей между этой средней и средней продолжительностью всех звонков.
Итак, что мы сделали для этого. Отметим наиболее важные части этого запроса:
- Мы снова использовали подзапрос для возврата агрегированного значения — средней продолжительности всех вызовов.
- Кроме того, мы добавили это — 1 AS join_id. Он служит для объединения этих двух запросов с использованием идентификатора. Это же значение мы «сгенерируем» и в основном подзапросе.
- «Основной» подзапрос возвращает данные, сгруппированные на уровне сотрудника. Еще раз мы «сгенерировали» искусственный ключ, который мы будем использовать для соединения этих двух подзапросов — 1 AS join_id
- Мы объединили подзапросы с помощью искусственного ключа (join_id) и посчитали разницу между средними значениями
Заключение
Надеюсь, вы многому научились в сегодняшней статье. Главное, что я хотел бы, чтобы вы запомнили после этого, это то, что вы можете выполнять многие статистические вычисления непосредственно в SQL, а затем использовать веб-форму или Excel для представления результатов с помощью блестящих таблиц и графиков. Мы продолжим практиковаться в следующей статье, так что следите за обновлениями.
Содержание
| Изучение SQL: операции CREATE DATABASE & CREATE TABLE |
| Изучите SQL: ВСТАВЬТЕ В ТАБЛИЦУ |
| Изучение SQL: первичный ключ |
| Изучение SQL: внешний ключ |
| Изучение SQL: инструкция SELECT |
| Изучение SQL: ВНУТРЕННЕЕ СОЕДИНЕНИЕ и ЛЕВОЕ СОЕДИНЕНИЕ |
| Изучение SQL: сценарии SQL |
| Изучение SQL: типы отношений |
| Изучение SQL: объединение нескольких таблиц |
| Изучение SQL: агрегатные функции |
| Изучение SQL: как написать сложный запрос SELECT? |
| Изучение SQL: база данных INFORMATION_SCHEMA |
| Изучение SQL: типы данных SQL |
| Изучение SQL: теория множеств |
| Изучение SQL: пользовательские функции |
| Изучение SQL: определяемые пользователем хранимые процедуры |
| Изучение SQL: представления SQL |
| Изучение SQL: триггеры SQL |
| Изучение SQL: Практика SQL-запросов |
| Изучение SQL: примеры запросов SQL |
| Изучение SQL: создание отчета вручную с помощью SQL-запросов |
| Изучение SQL: функции даты и времени SQL Server |
| Изучение SQL: создание отчетов SQL Server с использованием функций даты и времени |
| Изучение SQL: сводные таблицы SQL Server |
| Изучение SQL: экспорт SQL Server в Excel |
| Изучение SQL: введение в циклы SQL Server |
| Изучение SQL: курсоры SQL Server |
| Изучение SQL: передовые методы SQL для удаления и обновления данных |
| Изучение SQL: соглашения об именах |
| Изучение SQL: задания, связанные с SQL |
| Изучение SQL: неэквивалентные соединения в SQL Server |
| Изучение SQL: SQL-инъекция |
| Изучение SQL: динамический SQL |
| Изучение SQL: как предотвратить атаки SQL Injection |
- Автор
- Последние сообщения
Эмиль Дркусич
Эмиль — специалист по базам данных с более чем 10-летним опытом работы во всем, что связано с базами данных.