Что такое документная база данных?
Документная база данных – это тип нереляционных баз данных, предназначенный для хранения и запроса данных в виде документов в формате, подобном JSON. Документные базы данных позволяют разработчикам хранить и запрашивать данные в БД с помощью той же документной модели, которую они используют в коде приложения. Гибкий, полуструктурированный, иерархический характер документов и документных баз данных позволяет им развиваться в соответствии с потребностями приложений. Документная модель хорошо работает в таких примерах использования, как каталоги, пользовательские профили и системы управления контентом, где каждый документ уникален и изменяется со временем. Документные базы данных обеспечивают гибкость индексации, производительность выполнения стандартных запросов и аналитику наборов документов.
В следующем примере документ в формате, подобном JSON, описывает книгу.
[
{
"year" : 2013,
"title" : "Turn It Down, Or Else!",
"info" : {
"directors" : [ "Alice Smith", "Bob Jones"],
"release_date" : "2013-01-18T00:00:00Z",
"rating" : 6.
2,
"genres" : ["Comedy", "Drama"],
"image_url" : "http://ia.media-imdb.com/images/N/O9ERWAU7FS797AJ7LU8HN09AMUP908RLlo5JF90EWR7LJKQ7@@._V1_SX400_.jpg",
"plot" : "A rock band plays their music at high volumes, annoying the neighbors.",
"actors" : ["David Matthewman", "Jonathan G. Neff"]
}
},
{
"year": 2015,
"title": "The Big New Movie",
"info": {
"plot": "Nothing happens at all.",
"rating": 0
}
}
]Управление контентом
Документная база данных – отличный выбор для приложений управления контентом, таких как платформы для блогов и размещения видео. При использовании документной базы данных каждая сущность, отслеживаемая приложением, может храниться как отдельный документ. Документная база данных позволяет разработчику с удобством обновлять приложение при изменении требований. Кроме того, если необходимо изменить модель данных, то требуется обновление только затронутых этим изменением документов. Для внесения изменений нет необходимости обновлять схему и прерывать работу базы данных.
Для внесения изменений нет необходимости обновлять схему и прерывать работу базы данных.
Каталоги
Документные базы данных эффективны для хранения каталожной информации. Например, в приложениях для интернет‑коммерции разные товары обычно имеют различное количество атрибутов. Управление тысячами атрибутов в реляционных базах данных неэффективно. Кроме того, количество атрибутов влияет на производительность чтения. При использовании документной базы данных атрибуты каждого товара можно описать в одном документе, что упрощает управление и повышает скорость чтения. Изменение атрибутов одного товара не повлияет на другие товары.
Amazon DocumentDB (совместима с MongoDB)
Amazon DocumentDB (совместима с MongoDB) — это быстрая, масштабируемая, высокодоступная и полностью управляемая документная база данных, которая поддерживает рабочие нагрузки MongoDB. Разработчики могут использовать в Amazon DocumentDB такой же код приложения, драйверы и инструменты для запуска, управления и масштабирования рабочей нагрузки, что и в MongoDB, при этом получая высокопроизводительную, масштабируемую и готовую к работе базу данных и не тратя время на управление базовой инфраструктурой.
Начать работу с Amazon DocumentDB сегодня.
Вход в Консоль
Подробнее об AWS
- Что такое AWS?
- Что такое облачные вычисления?
- Многообразие, равенство и инклюзивность AWS
- Что такое DevOps?
- Что такое контейнер?
- Что такое озеро данных?
- Безопасность облака AWS
- Новые возможности
- Блоги
- Пресс‑релизы
Ресурсы для работы с AWS
- Начало работы
- Обучение и сертификация
- Библиотека решений AWS
- Центр архитектуры
- Вопросы и ответы по продуктам и техническим темам
- Аналитические отчеты
- Партнеры AWS
Разработчики на AWS
- Центр разработчика
- Пакеты SDK и инструментарий
- .NET на AWS
- Python на AWS
- Java на AWS
- PHP на AWS
- JavaScript на AWS
Поддержка
- Свяжитесь с нами
- Обратиться в службу поддержки
- Центр знаний
- AWS re:Post
- Обзор AWS Support
- Юридическая информация
- Работа в AWS
Amazon. com – работодатель равных возможностей. Мы предоставляем равные права представителям меньшинств, женщинам, лицам с ограниченными возможностями, ветеранам боевых действий и представителям любых гендерных групп любой сексуальной ориентации независимо от их возраста.
com – работодатель равных возможностей. Мы предоставляем равные права представителям меньшинств, женщинам, лицам с ограниченными возможностями, ветеранам боевых действий и представителям любых гендерных групп любой сексуальной ориентации независимо от их возраста.
Поддержка AWS для Internet Explorer заканчивается 07/31/2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari. Подробнее »
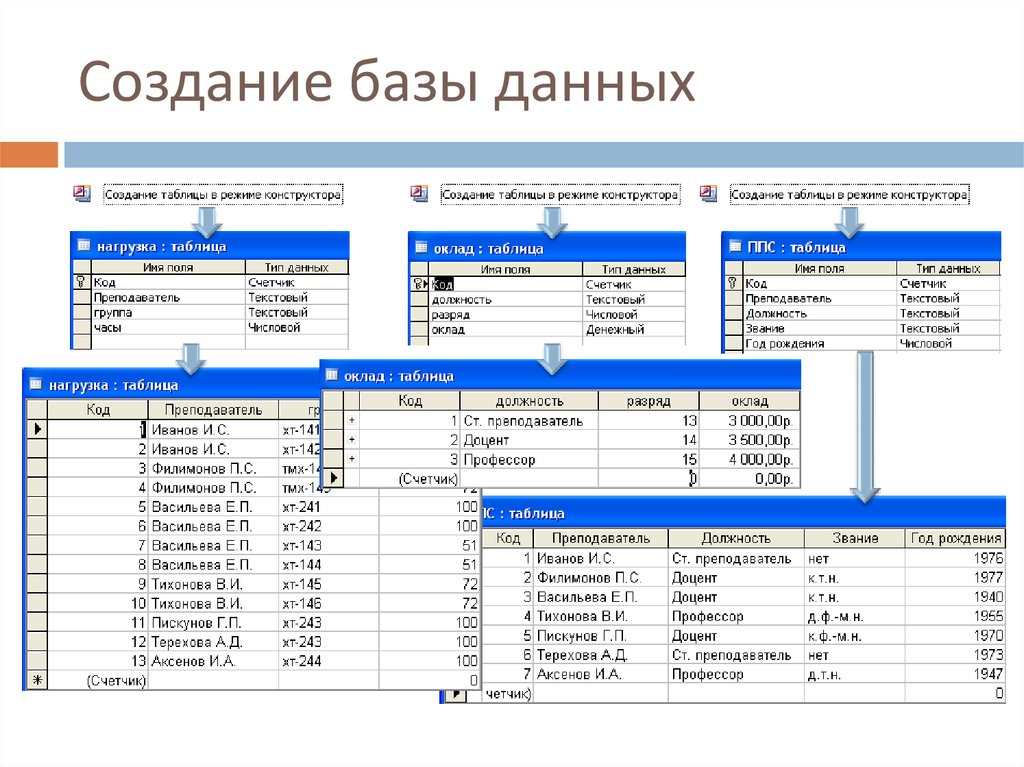
Примеры создания базы данных и таблиц. SQL запросы примеры
Итоговое проектное задание. SQL запросы примеры
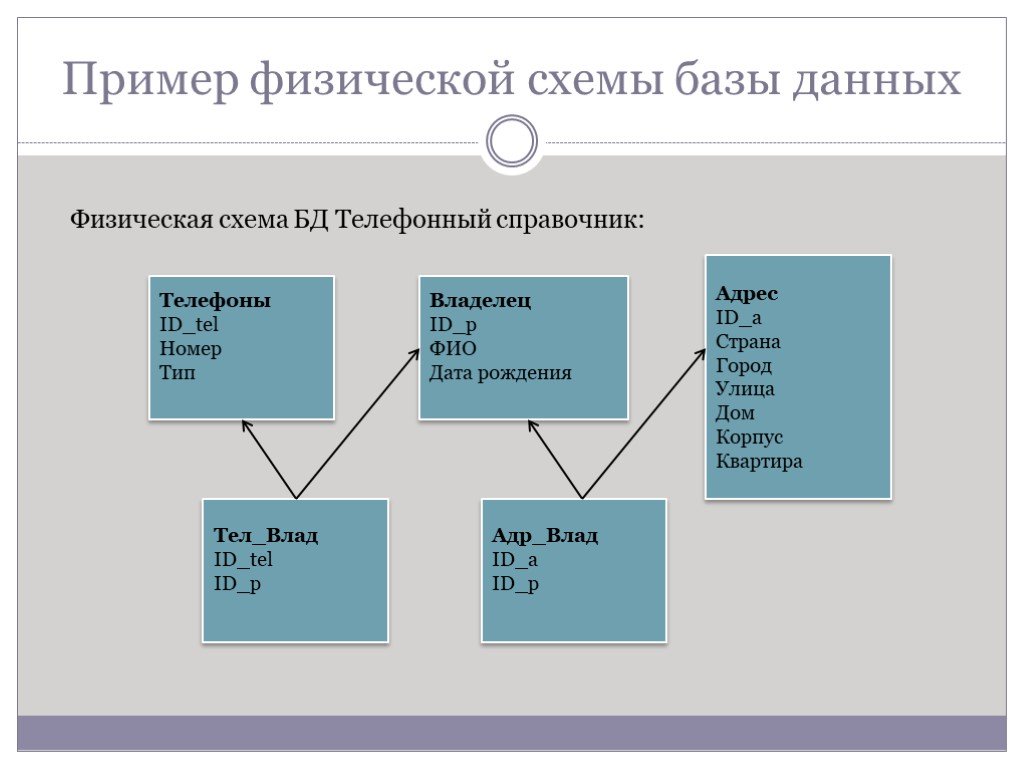
Создание структуры базы данных Корабли
Предлагаем рассмотреть sql запросы примеры, предназначенные для решения рядовых задач по выборке данных из базы данных Корабли.
Задание: Создать базу данных Корабли
Задание: В созданной базе данных Корабли, добавить таблицы, согласно схеме:
Важно: При заполнении таблиц следует обязательно учесть, что сначала заполняются главные таблицы!!! В нашем случае это таблицы Классы и Сражения.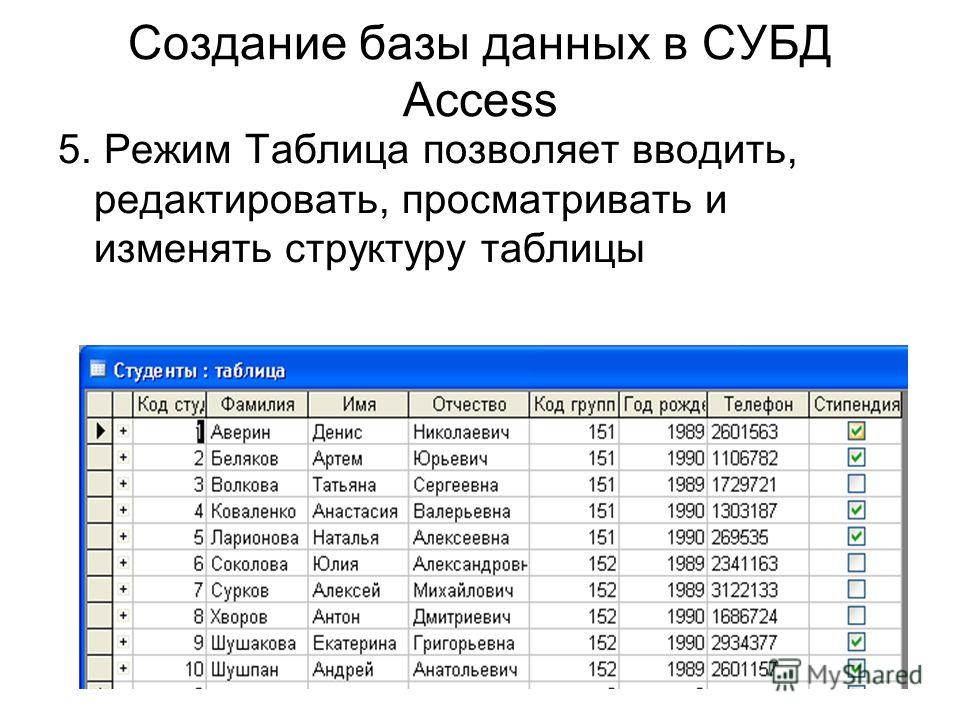 И только потом данные вставляются в подчиненные таблицы. Иначе возникнет ошибка!
И только потом данные вставляются в подчиненные таблицы. Иначе возникнет ошибка!
Важно: При вставке поля типа Дата и время (date and time) чаще всего используется формат ГГГГ-ММ-ДД (для mySQL и некоторых других СУБД)
Задание: Заполните таблицы данными (согласно изображениям таблиц ниже), либо используя возможности СУБД, либо при помощи запроса INSERT
| Таблица Классы: |
| Таблица Сражения: |
| Таблица Корабли: |
| Таблица Результаты: |
Список заданий
| # | Задание | Сложность | ||
|---|---|---|---|---|
| 1 | Вывести классы всех кораблей США. Вывод: страна, класс | 1 | ||
| 2 | Перечислить названия всех кораблей, имеющихся в базе. Упорядочить их по алфавиту | 1 | ||
| 3 | Перечислить все сражения и их даты, упорядочить по дате | 1 | ||
| 4 | Найти все корабли (из таблицы Корабли), имена классов которых заканчиваются на букву «о». Упорядочить по названию Упорядочить по названию | 1.1 | ||
| 5 | Найти все корабли, имена классов которых заканчиваются на букву «о», но не «го» | 1.1 | ||
| 6 | Найти все корабли, название которых начинается на букву «М» | 1.1 | ||
| 7 | Вывести максимальное число орудий | 1.2 | ||
| 8 | Вывести минимальный калибр | 1.2 | ||
| 9 | Вывести средний показатель водоизмещения, используя функцию | 1.2 | ||
| 10 | Удалить сведения о классах кораблей в таблице Классы, у которых число орудий равно 1 | 2 | ||
| 11 | Удалить из таблицы Сражения битву, которая произошла 12.12.1924 | 2 | ||
| 12 | Удалить сведения о корабле, который был спущен на воду в 1872 году | 2 | ||
| 13 | Измените результат битвы, в которой участвовал корабль Киришима, на «Поврежден» | 3 | ||
| 14 | В таблице Корабли измените название корабля «Мирури» на «Мисури» | 3 | ||
| 15 | Установите число орудий для класса «Мото» равный 3 | 3 | ||
| 16 | По Вашингтонскому международному договору от начала 1922 г. запрещалось строить линейные корабли водоизмещением более 35 тыс.тонн. Укажите корабли, нарушившие этот договор (учитывать только корабли с известным годом спуска на воду). Вывести названия кораблей и водоизмещение запрещалось строить линейные корабли водоизмещением более 35 тыс.тонн. Укажите корабли, нарушившие этот договор (учитывать только корабли с известным годом спуска на воду). Вывести названия кораблей и водоизмещениеПоказать решение:
| 4 | ||
| 17 | Укажите название корабля, участвовавшего в Битве А | 4 | ||
| 18 | Определить названия всех кораблей из таблицы Корабли, которые удовлетворяют, по крайней мере, комбинации любых четырех критериев из следующего списка: число орудий = 8, калибр = 15, водоизмещение = 32000, тип = bb, год спуска = 1915, класс = Конго, страна = СШАПоказать решение:
| 4 |
 Название FROM классы
INNER JOIN корабли ON классы.Класс=корабли.класс
WHERE ЧислоОрудий=9 OR Калибр=15 OR Водоизмещение=32000
OR Тип="bb" OR Год=1915 OR классы.Класс="Конго"
OR Страна="США"
Название FROM классы
INNER JOIN корабли ON классы.Класс=корабли.класс
WHERE ЧислоОрудий=9 OR Калибр=15 OR Водоизмещение=32000
OR Тип="bb" OR Год=1915 OR классы.Класс="Конго"
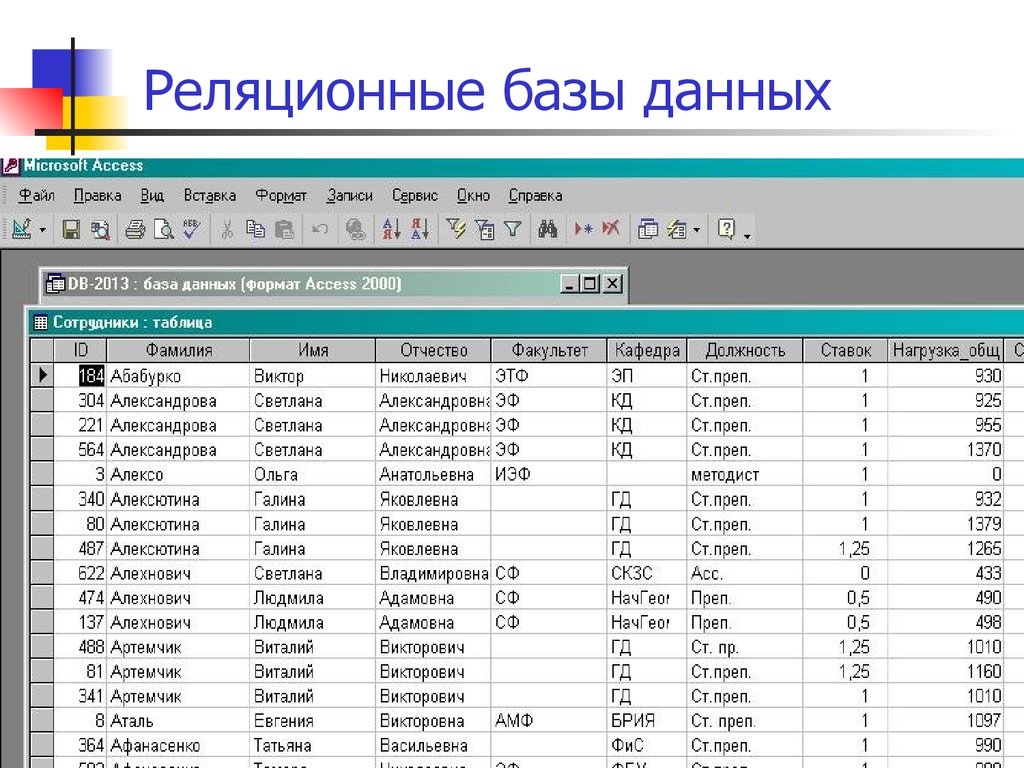
OR Страна="США"Список заданий для базы данных «Компьютерный магазин»
Структура и создание базы данных здесь.
1. Найти номер, скорость и размер жесткого диска для компьютера стоимостью менее 30000. Вывести с псевдонимами: Модель, Процессор, Винчестер
2. Укажите производителя и скорость тех компьютеров, которые имеют жесткий диск объемом не менее 500Гб
3. Выведите номера, типы и цены всех продуктов (любого типа), выпущенных производителем Россия.
Использовать: Innter Join, Union
4. Выведите производителя, выпускающего компьютеры, но не ноутбуки.
Использовать подзапрос
5. Выведите производителей компьютеров с процессором не менее 2000МГц. Вывести: Производитель.
Можно использовать подзапрос (IN)
6. Выведите ноутбуки, скорость которых меньше скорости любого из компьютеров. Вывести: Тип, Номер, Скорость
Выведите ноутбуки, скорость которых меньше скорости любого из компьютеров. Вывести: Тип, Номер, Скорость
7. Выведите производителей самых дешевых цветных принтеров
Итоговое индивидуальное задание: проектирование и разработка БД
- Разработать проект базы данных по какой-либо теме (выбрать самостоятельно):
- База данных включает не менее двух таблиц.
- Организовать связи между таблицами и отобразить их на схеме.
- Используя интерфейс phpMySQL (или другой) создать базу данных.
- Заполнить базу записями.
- 3 запроса на простую выборку (SELECT).
- 3 запроса на выборку с условием (WHERE, LIKE).
- 2 запроса с применением агрегатных функций и переименованием столбцов.
- 3 запроса с объединением таблиц (INNER JOIN, UNION).
- 1 запрос на вставку (INSERT).
- 2 запроса на обновление с условием (UPDATE … WHERE).
- 1 запрос на удаление.
- Титульный лист (наименование учреждения, название дисциплины, название работы, выполнил…).
- Проект БД, включающий схему со связями (описание ключевых полей).
- Постановка заданий к запросам и реализация запросов.
Введение | MongoDB
Узнайте, как нереляционные базы данных могут работать на вас.
При принятии решения о том, какой тип базы данных использовать в вашем проекте, может оказаться полезным ознакомиться с некоторыми реальными примерами для различных типов данных. Это может помочь вам решить не только, какой тип базы данных использовать, но и как данные могут быть смоделированы.
В этой статье вы увидите несколько примеров для различных типов баз данных и типов данных, которые могут в них храниться.
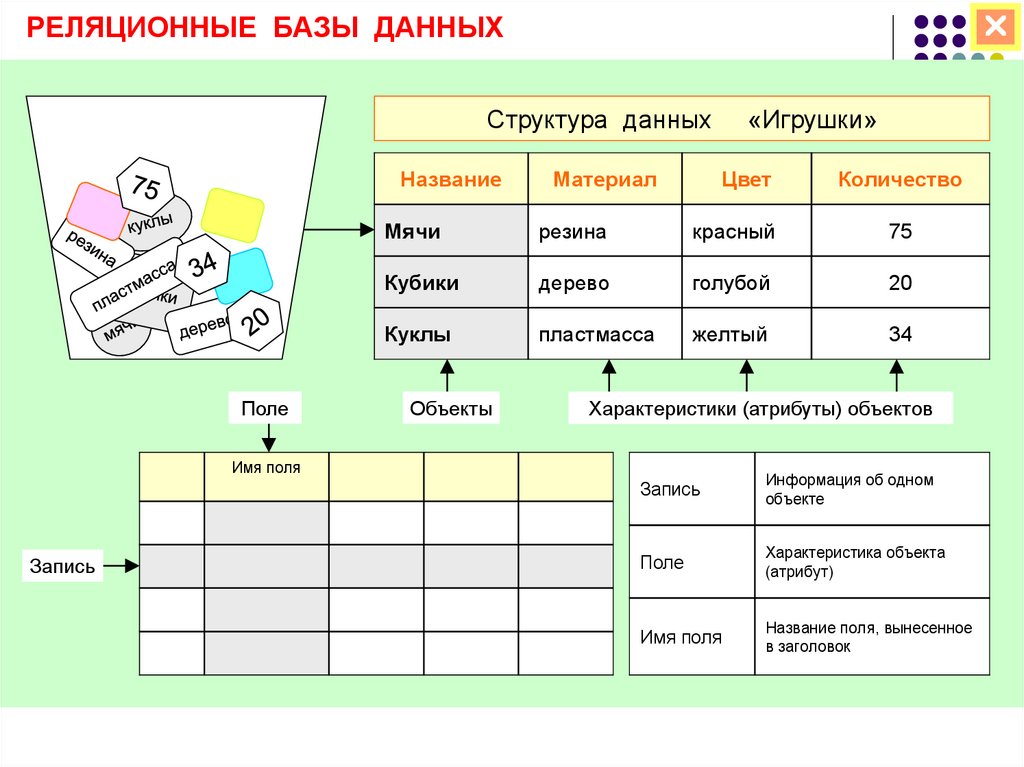
Пример реляционной базы данных
Реляционные базы данных, или базы данных SQL, как их иногда называют (из-за языка, который используется для запросов к ним), используют таблицы, столбцы и строки для хранения данных.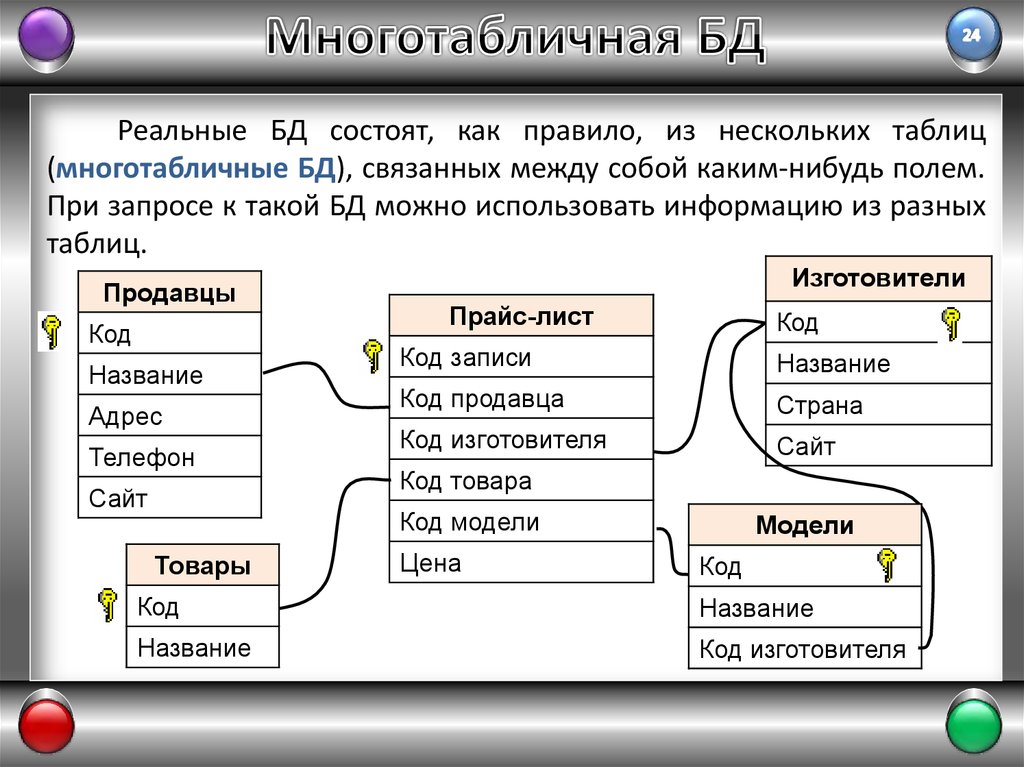 Столбцы, общие для таблиц, помогают формировать отношения между данными.
Столбцы, общие для таблиц, помогают формировать отношения между данными.
Пример базы данных Healthcare
Одним из распространенных вариантов использования реляционных баз данных является хранение медицинских данных пациентов.
Например, у одного поставщика медицинских услуг может быть несколько кабинетов, в которых он принимает пациентов. Это привело бы к созданию таблицы «Офис», в которой хранится такая информация, как название и адрес офиса.
В кабинете может быть много врачей, что означает, что между кабинетами и врачами существует отношение «один ко многим». Точно так же существует связь «один ко многим» между офисами и пациентами. Сущности с отношениями «один ко многим» обычно хранятся в отдельных таблицах. Это будет означать отдельные таблицы для «Врача» и «Пациента». Эти таблицы будут иметь такие столбцы, как их уникальный идентификатор, адрес и другую соответствующую информацию.
Связь между таблицами будет формироваться из общих столбцов. Например, столбец в таблице «Доктор» будет хранить
Например, столбец в таблице «Доктор» будет хранить значение officeId из таблицы «Офис», чтобы представить местоположение их офиса. Пациент также будет связан с врачом через его doctorId , а также офис, который он посещает для встреч с атрибутом officeId .
Пример нереляционной базы данных
Нереляционная база данных или база данных NoSQL — это любой тип хранилища данных, который не использует традиционные функции таблиц, столбцов и строк (иногда называемые записями) традиционной реляционной базы данных/базы данных SQL. . Это означает, что существует множество типов нереляционных баз данных. В этом разделе мы обсудим примеры для графовых баз данных, иерархических баз данных, распределенных баз данных и баз данных документов.
Чтобы узнать больше, у нас есть статья о примерах баз данных NoSQL.
Пример базы данных графа
База данных графа использует узлы для хранения данных, а ребра определяют отношения между ними.
База данных фильмов
Одним из примеров данных, которые вы можете хранить в графовой базе данных, является информация о фильмах и людях, которые их снимают. Узлы содержат информацию о таких вещах, как человек или фильм. Края определяют отношения между ними, например, человек, действующий, направляющий или производящий фильм.
Это полезно при создании запросов для предложений фильмов. Если зритель смотрел фильм с участием актера, ему могут быть показаны рекомендации других фильмов, в которых снимался этот актер, или фильмов, снятых кем-то.
Пример иерархической базы данных
Иерархические базы данных представляют данные в древовидной форме. У каждого «родительского» узла может быть много «дочерних». Узел без родителя считается корневым узлом.
Организационная структура
Организационная диаграмма — отличный пример данных, которые можно легко смоделировать в иерархической базе данных. Корневым узлом будет главный исполнительный директор (CEO), который, возможно, будет иметь «EmployeeID» 1 и значение «Level» 0, поскольку они являются корневыми.
Генеральный директор может иметь много прямых подчиненных, таких как главный технический директор (CTO), главный финансовый директор (CFO) и главный операционный директор (COO). У них тоже будет много прямых подчиненных. Эта древовидная структура будет продолжаться до тех пор, пока вы не достигнете уровня сотрудника без прямых подчиненных.
Пример распределенной базы данных
Распределенная база данных — это база данных, в которой данные логически связаны, но хранятся в нескольких базах данных на разных географических объектах.
Служба доменных имен
Система доменных имен (DNS) использует распределенную базу данных. Интернет-пользователи повсюду используют веб-адреса или URL-адреса, как их еще называют, для доступа к веб-сайтам и другим интернет-сервисам. Однако на самом деле эти имена сопоставляются с уникальными IP-адресами.
Серверы имен используются для хранения этих сопоставлений, и их несколько по всему миру. Разные серверы имен принадлежат разным компаниям. Тем не менее, все они доступны одинаково при поиске в Интернете. Пользователь вводит адрес, к которому он хочет получить доступ, а все остальное уже сделано. Информация распределена, но доступ ко всей ней осуществляется через одну большую систему управления базами данных.
Тем не менее, все они доступны одинаково при поиске в Интернете. Пользователь вводит адрес, к которому он хочет получить доступ, а все остальное уже сделано. Информация распределена, но доступ ко всей ней осуществляется через одну большую систему управления базами данных.
Пример базы данных документов
База данных документов хранит информацию, чаще всего в структурах, подобных JSON, в виде документов. Это позволяет хранить связанные данные в одном месте, а не распределять их по таблицам.
Подобно реляционным базам данных, базы данных документов могут работать с вариантами использования общего назначения, что делает их подходящими для многих типов приложений и данных.
Пример базы данных Healthcare
База данных документов — это отличная база данных для организации здравоохранения и такая информация, как кабинеты, врачи и пациенты.
Каждый пациент, например, имеет единый документ, который содержит всю информацию о нем, такую как имя, адрес, дата рождения, врач, местный отдел здравоохранения, список предыдущих или текущих заболеваний и любые лекарства, которые он принимает.
Модель документа позволяет встраивать связанные данные вместе. Благодаря совместному хранению информации, доступ к которой осуществляется вместе, данные могут быть извлечены невероятно быстро без каких-либо дорогостоящих объединений, а данные легче формировать так, чтобы они соответствовали приложению.
MongoDB Atlas: преимущества облачных баз данных
Нереляционные базы данных, включая базы данных документов, имеют множество преимуществ, таких как масштабируемость, гибкость и высокая доступность. MongoDB Atlas предоставляет все преимущества базы данных документов, доступной в облаке, что означает, что ваша база данных полностью управляема и имеет высокую доступность, а также возможность масштабирования в зависимости от спроса.
Если вы хотите попробовать нереляционную базу данных, вы можете начать работу с MongoDB Atlas, используя уровень бесплатного пользования уже сегодня.
Готовы начать?
Резюме
В этой статье вы узнали о различных примерах использования различных типов баз данных и увидели диаграммы, показывающие, как данные могут выглядеть при использовании в этой базе данных.
Чтобы узнать больше о типах баз данных и о том, когда вы можете их использовать, вы можете прочитать эту статью о реляционных и нереляционных базах данных.
Часто задаваемые вопросы
Что такое база данных?
База данных – это любой электронный контейнер для хранения информации. Примеры включают реляционные базы данных, которые хранят информацию в таблицах и столбцах, а также нереляционные или NoSQL базы данных. Существуют и другие типы хранения данных, и вы можете узнать больше в нашей статье базы данных, хранилища данных и озера данных.
Какие есть примеры баз данных?
Существуют разные типы баз данных, но полезно рассмотреть примеры данных из повседневной жизни, которые будут храниться в базах данных.
Сюда входят веб-сайты социальных сетей, такие как Twitter, киносервисы, такие как Netflix, ваши медицинские карты пациентов и даже банковские услуги.
Как создать базу данных?
Способ создания базы данных зависит от типа создаваемой базы данных. База данных документов MongoDB является универсальной и подходит для большинства сценариев. Однако перед началом проекта всегда следует учитывать, когда использовать базу данных NoSQL.
База данных документов MongoDB является универсальной и подходит для большинства сценариев. Однако перед началом проекта всегда следует учитывать, когда использовать базу данных NoSQL.
Чтобы воспользоваться преимуществами облака и управляемой базы данных в качестве модели обслуживания, используйте MongoDB Atlas. Существует даже бесплатный уровень, чтобы вы могли почувствовать продукт и то, как вы можете моделировать свои данные.
Как это работает и примеры структуры
Чтобы помочь вам лучше понять NoSQL, эта страница охватывает:
- Что такое NoSQL и для чего нужна база данных NoSQL?
- Зачем использовать NoSQL?
- Как работает NoSQL?
- Заключение
Базы данных NoSQL хранят данные в документах, а не в реляционных таблицах. Соответственно, мы классифицируем их как «не только SQL» и подразделяем их по множеству гибких моделей данных.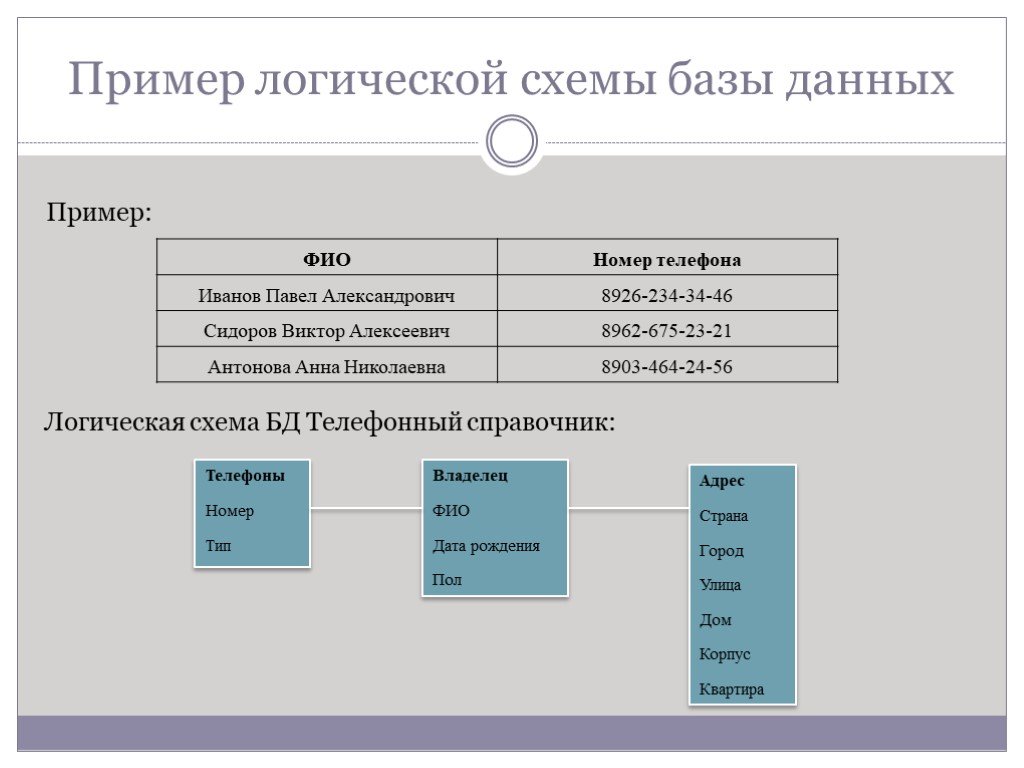 Типы баз данных NoSQL включают чистые базы данных документов, хранилища ключей и значений, базы данных с широкими столбцами и базы данных графов. Базы данных NoSQL создаются с нуля для хранения и обработки огромных объемов данных в масштабе и поддержки растущего числа современных предприятий.
Типы баз данных NoSQL включают чистые базы данных документов, хранилища ключей и значений, базы данных с широкими столбцами и базы данных графов. Базы данных NoSQL создаются с нуля для хранения и обработки огромных объемов данных в масштабе и поддержки растущего числа современных предприятий.
Что такое NoSQL и что такое база данных NoSQL?
База данных NoSQL Технология хранит информацию в документах JSON вместо столбцов и строк, используемых реляционными базами данных. Чтобы было ясно, NoSQL означает «не только SQL», а не «без SQL». Это означает, что база данных NoSQL JSON может хранить и извлекать данные буквально «без SQL». Или вы можете объединить гибкость JSON с мощью SQL, чтобы получить лучшее из обоих миров. Следовательно, базы данных NoSQL созданы гибкими, масштабируемыми и способными быстро реагировать на требования современного бизнеса к управлению данными. Ниже приведены четыре самых популярных типа баз данных NoSQL:
- Базы данных документов в основном созданы для хранения информации в виде документов, включая, помимо прочего, документы JSON.
 Эти системы также можно использовать для хранения XML-документов, например, для базы данных NoSQL.
Эти системы также можно использовать для хранения XML-документов, например, для базы данных NoSQL. - Хранилища пар «ключ-значение» группируют связанные данные в коллекциях с записями, которые идентифицируются уникальными ключами для облегчения поиска. Хранилища ключей и значений имеют достаточную структуру, чтобы отражать значения реляционных баз данных (в отличие от нереляционных баз данных), сохраняя при этом преимущества структуры базы данных NoSQL.
- Базы данных с широкими столбцами используют табличный формат реляционных баз данных, но допускают большие различия в том, как данные именуются и форматируются в каждой строке, даже в одной и той же таблице. Как и хранилища ключей и значений, базы данных с широкими столбцами имеют некоторую базовую структуру NoSQL, сохраняя при этом большую гибкость .
- Базы данных графов используют структуры графов для определения взаимосвязей между сохраненными точками данных.
 Базы данных графов полезны для выявления закономерностей в неструктурированной и полуструктурированной информации.
Базы данных графов полезны для выявления закономерностей в неструктурированной и полуструктурированной информации.
Зачем использовать NoSQL?
Качество обслуживания клиентов быстро стало самым важным конкурентным преимуществом и открыло деловой мир в эпоху монументальных перемен. В рамках этой революции предприятия взаимодействуют в цифровом формате — не только со своими клиентами, но и со своими сотрудниками, партнерами, поставщиками и даже со своими продуктами — в беспрецедентных масштабах. Это взаимодействие поддерживается Интернетом и другими технологиями 21 века, и в основе революции NoSQL лежат корпоративные приложения больших данных, облачных вычислений, мобильных устройств, социальных сетей и Интернета вещей.
Чем эти приложения отличаются от устаревших корпоративных приложений, таких как ERP, HR и финансовый учет? Современные веб-, мобильные и IoT-приложения имеют одну или несколько (если не все) следующих характеристик. Им необходимо:
- Поддерживать большое количество одновременных пользователей (десятки тысяч, возможно, миллионы)
- Предоставление высокочувствительного интерфейса глобально распределенной базе пользователей
- Будьте всегда доступны — без простоев
- Обработка полуструктурированных и неструктурированных данных
- Быстрая адаптация к изменяющимся требованиям благодаря частым обновлениям и новым функциям
Создание и запуск этих широко интерактивных приложений предъявляет новые технологические требования. Архитектура новой корпоративной технологии NoSQL должна быть намного более гибкой, чем когда-либо прежде, и требует подхода к управлению данными в реальном времени, который может обеспечить беспрецедентный уровень масштабирования, скорости и изменчивости данных. Реляционные базы данных не могут удовлетворить этим новым требованиям, и поэтому предприятия обращаются к технологии баз данных NoSQL.
Архитектура новой корпоративной технологии NoSQL должна быть намного более гибкой, чем когда-либо прежде, и требует подхода к управлению данными в реальном времени, который может обеспечить беспрецедентный уровень масштабирования, скорости и изменчивости данных. Реляционные базы данных не могут удовлетворить этим новым требованиям, и поэтому предприятия обращаются к технологии баз данных NoSQL.
Предприятия Global 2000 быстро используют базы данных NoSQL для поддержки своих критически важных приложений:
- Tesco , розничный продавец № 1 в Европе, развертывает NoSQL для электронной коммерции, каталогов продуктов и других приложений
- Ryanair , самая загруженная авиакомпания в мире, использует NoSQL для поддержки своего мобильного приложения, обслуживающего более 3 миллионов пользователей
- Marriott развертывает NoSQL для своей системы бронирования, которая ежегодно обслуживает 38 миллиардов долларов
- Gannett , издатель газет № 1 в США, использует NoSQL для своей собственной системы управления контентом Presto .
- GE развертывает NoSQL для своей платформы Predix, чтобы помочь управлять промышленным Интернетом

Пять тенденций, создающих новые технические проблемы, которые решают базы данных NoSQL
Эти и сотни других компаний обращаются к NoSQL из-за пяти тенденций, создающих технические проблемы, которые слишком сложны для большинства реляционных баз данных.
Тенденции цифровой экономики | Требования |
|---|---|
| 1. Больше клиентов уходит в интернет | • Масштабирование для поддержки тысяч, если не миллионов пользователей • Соответствие требованиям UX при неизменно высокой производительности • Поддержание доступности 24 часа в сутки, 7 дней в неделю |
2. Интернет соединяет все Интернет соединяет все | • Поддержка множества разных вещей с разными структурами данных • Поддержка обновлений аппаратного/программного обеспечения, создание различных данных • Поддержка непрерывных потоков данных в реальном времени |
| 3. Большие данные становятся больше | • Хранение полуструктурированных/неструктурированных данных, созданных клиентами • Совместное хранение разных типов данных из разных источников • Хранение данных, созданных тысячами/миллионами клиентов/вещей |
| 4. Приложения перемещаются в облако | • Масштабирование по запросу для поддержки большего числа клиентов и хранения большего объема данных • Операционные приложения в глобальном масштабе – клиенты по всему миру • Минимизация затрат на инфраструктуру, ускорение выхода на рынок |
5. Мир стал мобильным Мир стал мобильным | • Создание приложений с приоритетом офлайн – подключение к сети не требуется • Синхронизация мобильных данных с удаленными базами данных в облаке • Поддержка нескольких мобильных платформ с одним бэкендом |
Что насчет SQL?
Мы называем некоторые реляционные базы данных базами данных SQL из-за того, что они полагаются на SQL (также известный как «язык структурированных запросов») для получения соответствующей информации. SQL, впервые представленный в 1979 году, теперь используется разработчиками и аналитиками данных по всему миру для поиска и составления отчетов о данных, хранящихся в реляционных системах, таких как Oracle.
Почему реляционные базы данных терпят неудачу
Реляционные СУБД (системы управления базами данных) родились в эпоху мэйнфреймов и бизнес-приложений — задолго до появления Интернета, облачных вычислений, больших данных, мобильных устройств и современных массовых интерактивных предприятий.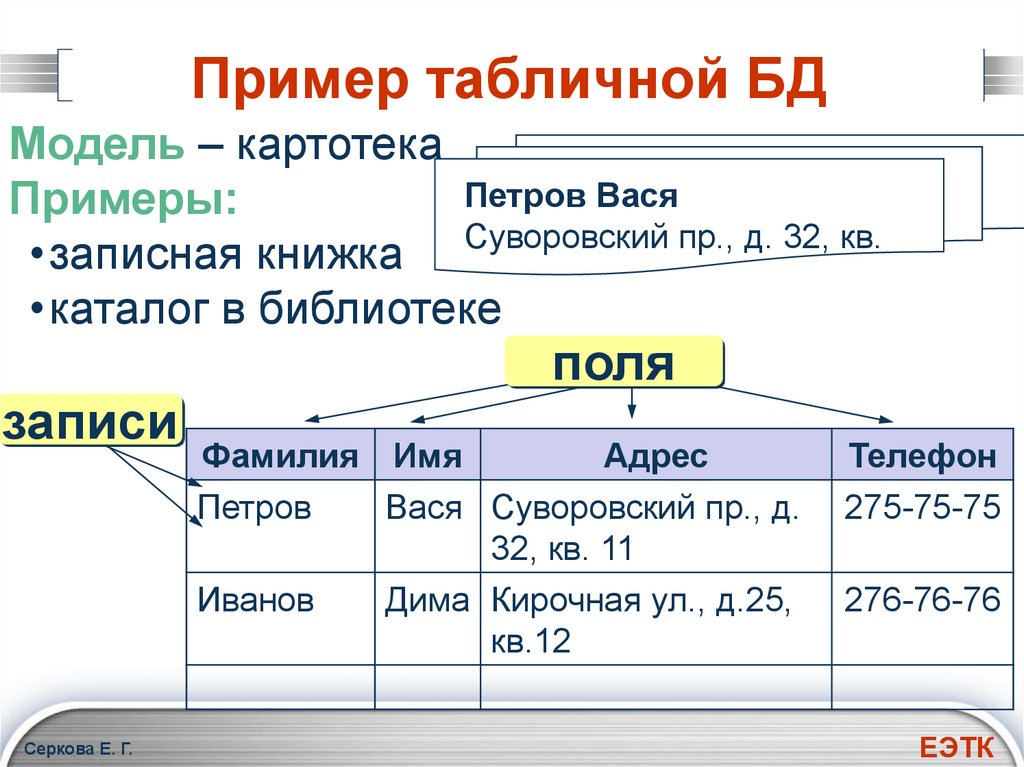 Эти базы данных были спроектированы для работы на одном сервере — чем больше, тем лучше. Единственным способом увеличить емкость этих баз данных было обновление серверов — процессоров, памяти и хранилища — для масштабирования.
Эти базы данных были спроектированы для работы на одном сервере — чем больше, тем лучше. Единственным способом увеличить емкость этих баз данных было обновление серверов — процессоров, памяти и хранилища — для масштабирования.
Базы данных NoSQL появились в результате экспоненциального роста Интернета и появления веб-приложений. Google выпустил исследовательский документ Bigtable в 2006 году, а Amazon выпустила исследовательский документ Dynamo в 2007 году. Эти базы данных были разработаны для удовлетворения корпоративных требований нового поколения: и в устранить преобразование данных .
Разработка с ловкостью
Чтобы оставаться конкурентоспособными в современной цифровой экономике, ориентированной на опыт, предприятия должны внедрять инновации — и делать это быстрее, чем когда-либо прежде. А поскольку эта инновация сосредоточена на разработке современных веб-приложений, мобильных приложений и приложений IoT, разработчики должны предоставлять приложения и услуги быстрее, чем когда-либо прежде. Скорость и гибкость имеют решающее значение, поскольку эти приложения развиваются гораздо быстрее, чем устаревшие приложения, такие как ERP. Реляционные базы данных являются основным препятствием, потому что они не очень хорошо поддерживают гибкую разработку из-за их фиксированной модели данных.
Скорость и гибкость имеют решающее значение, поскольку эти приложения развиваются гораздо быстрее, чем устаревшие приложения, такие как ERP. Реляционные базы данных являются основным препятствием, потому что они не очень хорошо поддерживают гибкую разработку из-за их фиксированной модели данных.
Определение масштабов изменения требований
Основной принцип гибкой разработки — адаптация к изменяющимся требованиям приложений: когда требования меняются, меняется и модель данных. Это проблема для реляционных баз данных, поскольку модель данных фиксирована и определяется статической схемой. Таким образом, чтобы изменить модель данных, разработчики должны изменить схему или, что еще хуже, запросить «изменение схемы» у администраторов базы данных. Это замедляет или останавливает разработку не только потому, что это ручной и трудоемкий процесс, но и потому, что это влияет на другие приложения и службы.
Напротив, база данных NoSQL полностью поддерживает гибкую разработку и не определяет статически, как данные должны быть смоделированы. Вместо этого NoSQL уступает приложениям и службам и, следовательно, разработчикам в отношении того, как следует моделировать данные. В NoSQL модель данных определяется моделью приложения. Приложения и службы моделируют данные как объекты.
Вместо этого NoSQL уступает приложениям и службам и, следовательно, разработчикам в отношении того, как следует моделировать данные. В NoSQL модель данных определяется моделью приложения. Приложения и службы моделируют данные как объекты.
Устранение преобразования данных
Приложения и службы моделируют данные как объекты (например, сотрудник), многозначные данные как наборы (например, роли) и связанные данные как вложенные объекты или наборы (например, менеджер). Однако реляционные базы данных моделируют данные как таблицы строк и столбцов — связанные данные как строки в разных таблицах, а многозначные данные как строки в одной таблице.
Проблема с реляционными базами данных заключается в том, что данные считываются и записываются путем дизассемблирования или «измельчения» и повторной сборки объектов. Это объектно-реляционное «несоответствие импеданса». Обходной путь заключается в преобразовании данных с помощью фреймворков объектно-реляционного сопоставления, которые в лучшем случае неэффективны, а в худшем проблематичны.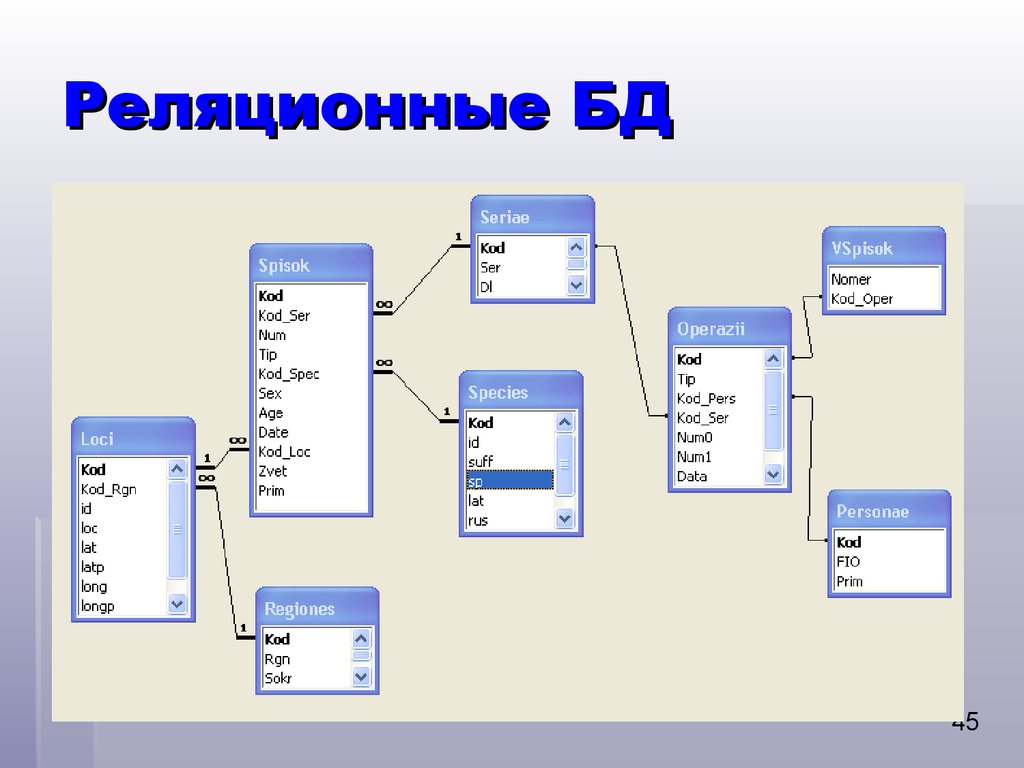 Базы данных NoSQL обычно обрабатывают данные так, как они представлены .
Базы данных NoSQL обычно обрабатывают данные так, как они представлены .
Как работает NoSQL?
Чем отличается NoSQL? Давайте посмотрим поближе. В следующем руководстве по NoSQL показано приложение, используемое для управления резюме. Он взаимодействует с резюме как объект (т. е. пользовательский объект), содержит массив навыков и коллекцию позиций. В качестве альтернативы запись резюме в реляционную базу данных требует, чтобы приложение «уничтожило» пользовательский объект.
Для сохранения этого резюме приложение должно вставить шесть строк в три таблицы, как показано на рис. 3 .
И для чтения этого профиля приложению потребуется прочитать шесть строк из трех таблиц, как показано на рис. 4 .
Напротив, в ориентированной на документы базе данных, определяемой как NoSQL, JSON является де-факто форматом для хранения данных — полезно, это также является стандартом де-факто для потребления и создания данных для веб-приложений, мобильных приложений и приложений IoT. JSON не только устраняет несоответствие объектно-реляционного импеданса, но также устраняет накладные расходы фреймворков ORM и упрощает разработку приложений, поскольку объекты считываются и записываются без их «измельчения» (т. е. один объект может быть прочитан или записан как отдельный документ). , как показано на Рисунок 5 .
JSON не только устраняет несоответствие объектно-реляционного импеданса, но также устраняет накладные расходы фреймворков ORM и упрощает разработку приложений, поскольку объекты считываются и записываются без их «измельчения» (т. е. один объект может быть прочитан или записан как отдельный документ). , как показано на Рисунок 5 .
Как насчет запросов и SQL?
Некоторые могут возразить, что выполнять запросы к базам данных NoSQL сложнее, но это распространенное заблуждение. Присущая документо-ориентированным базам данных NoSQL гибкость позволяет одинаково хорошо обрабатывать структурированные и неструктурированные данные, а новые инструменты позволяют выполнять запросы быстрее, чем когда-либо прежде.
Couchbase Server 4.0 представил N1QL (произносится как «никель»), мощный язык запросов, который расширяет SQL до JSON, позволяя разработчикам использовать как мощь SQL, так и гибкость JSON. Он не только поддерживает стандартные операторы SELECT/FROM/WHERE, но также поддерживает агрегацию (GROUP BY), сортировку (SORT BY), объединение (LEFT OUTER/INNER), а также запросы к вложенным массивам и коллекциям. Кроме того, производительность запросов можно повысить с помощью составных, частичных, покрывающих индексов и т. д.
- SQL
- N1QL
SQL
SELECT RTRIM(p.FirstName) + ' ' + LTRIM(p.LastName) AS Имя, d.City
ОТ AdventureWorks2016.Person.Person AS p
ВНУТРЕННЕЕ СОЕДИНЕНИЕ AdventureWorks2016.HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
(ВЫБЕРИТЕ bea.BusinessEntityID, a.City
ОТ AdventureWorks2016.Person.Address КАК
INNER JOIN AdventureWorks2016.Person.BusinessEntityAddress AS bea
ON a.AddressID = bea.AddressID) AS d
ON p.BusinessEntityID = d.BusinessEntityID
ORDER BY p.LastName, p.FirstName; N1QL
SELECT RTRIM(p.FirstName) || ' ' || LTRIM(p.LastName) AS Имя, d.City
ОТ AdventureWorks2016. Person.Person AS p
ВНУТРЕННЕЕ СОЕДИНЕНИЕ AdventureWorks2016.HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
(ВЫБЕРИТЕ bea.BusinessEntityID, a.City
ОТ AdventureWorks2016.Person.Address КАК
INNER JOIN AdventureWorks2016.Person.BusinessEntityAddress AS bea
ON a.AddressID = bea.AddressID) AS d
ON p.BusinessEntityID = d.BusinessEntityID
ORDER BY p.LastName, p.FirstName; Подробнее о запросах
Учебник по N1QL Что такое N1QL? Запустите свой первый запрос Попробовать бесплатноРабота в любом масштабе
Базы данных, поддерживающие веб-приложения, мобильные приложения и приложения IoT, должны работать в любом масштабе. Хотя реляционную базу данных, такую как Oracle, можно масштабировать (например, с помощью Oracle RAC), это обычно сложно, дорого и не совсем надежно. Например, в Oracle масштабирование с использованием технологии RAC требует множества компонентов и создает единую точку отказа, что ставит под угрозу доступность. Напротив, распределенная база данных NoSQL, разработанная с масштабируемой архитектурой и не имеющей единой точки отказа, обеспечивает убедительные эксплуатационные преимущества.
Эластичность для производительности в масштабе
Приложения и службы должны поддерживать постоянно растущее число пользователей и данных — от сотен до тысяч и миллионов пользователей, а также от гигабайт до терабайтов операционных данных. В то же время они должны масштабироваться, чтобы поддерживать производительность, и они должны делать это эффективно.
База данных должна иметь возможность масштабировать операции чтения, записи и хранения.
Это проблема для реляционных баз данных, которые ограничены масштабированием (т. е. добавлением дополнительных процессоров, памяти и хранилища на один физический сервер). В результате возможность эффективного масштабирования по требованию является сложной задачей. Это становится все более дорогим, потому что предприятиям приходится приобретать все более и более крупные серверы, чтобы вместить больше пользователей и больше данных. Кроме того, это может привести к простою, если базу данных необходимо перевести в автономный режим для выполнения обновлений оборудования.
Однако распределенная база данных NoSQL использует обычное оборудование для масштабирования, т. е. для добавления дополнительных ресурсов просто путем добавления дополнительных серверов. Возможность горизонтального масштабирования позволяет предприятиям масштабироваться более эффективно за счет (а) развертывания не большего количества оборудования, чем требуется для удовлетворения текущей нагрузки; (b) использование менее дорогого оборудования и/или облачной инфраструктуры; и (c) масштабирование по запросу и без простоев.
Помимо возможности эффективного масштабирования, распределенные базы данных NoSQL легко устанавливать, настраивать и масштабировать. Они были разработаны для распределения операций чтения, записи и хранения, а также для работы в любом масштабе, включая управление и мониторинг малых и больших кластеров.
Доступность для постоянного глобального развертывания
Поскольку все больше и больше взаимодействий с клиентами происходит в Интернете через веб-приложения и мобильные приложения, доступность становится серьезной, если не главной проблемой. Эти критически важные приложения должны быть доступны 24 часа в сутки, 7 дней в неделю — без исключений. Обеспечение доступности 24×7 является сложной задачей для реляционных баз данных, развернутых на одном физическом сервере или использующих кластеризацию с общим хранилищем. При развертывании в виде отдельного сервера и его сбоя или в случае сбоя кластера и общего хранилища база данных становится недоступной.
В отличие от реляционной технологии, распределенная база данных NoSQL разделяет и распределяет данные по нескольким экземплярам базы данных без общих ресурсов. Кроме того, данные могут быть реплицированы на один или несколько экземпляров для обеспечения высокой доступности (межкластерная репликация). В то время как для реляционных баз данных, таких как Oracle, требуется отдельное программное обеспечение для репликации (например, Oracle Active Data Guard), базы данных NoSQL этого не требуют — оно встроено и работает автоматически. Кроме того, автоматический переход на другой ресурс гарантирует, что в случае сбоя узла база данных сможет продолжать выполнять операции чтения и записи, отправляя запросы на другой узел.
По мере того, как взаимодействия с клиентами переходят в онлайн, необходимость быть доступной в нескольких странах и/или регионах становится критической. Развертывание базы данных в нескольких центрах обработки данных повышает доступность и помогает при аварийном восстановлении, а также повышает производительность, поскольку все операции чтения и записи могут выполняться в ближайшем центре обработки данных, что снижает задержку.
Обеспечить глобальную доступность для реляционных баз данных сложно в тех случаях, когда требования отдельных надстроек увеличивают сложность (например, Oracle требует Oracle GoldenGate для перемещения данных между базами данных) или когда репликация между несколькими центрами обработки данных может использоваться только для аварийного переключения, потому что только одновременно активен один центр обработки данных. Кроме того, при репликации между центрами обработки данных приложения, созданные на основе реляционных баз данных, могут столкнуться со снижением производительности или обнаружить, что центры обработки данных серьезно не синхронизированы.
Распределенная база данных NoSQL включает встроенную репликацию между центрами обработки данных — отдельное программное обеспечение не требуется. Кроме того, некоторые из них включают как однонаправленную, так и двунаправленную репликацию, что позволяет выполнять полное развертывание «активный-активный» в нескольких центрах обработки данных, что позволяет развертывать базу данных в нескольких странах и/или регионах и предоставлять локальный доступ к данным локальным приложениям и их пользователям. Это не только повышает производительность, но и обеспечивает немедленную отработку отказа с помощью аппаратных маршрутизаторов — приложениям не нужно ждать, пока база данных обнаружит сбой и выполнит собственную отработку отказа.
Заключение
Так что же такое базы данных NoSQL и почему они важны сейчас? По мере того как предприятия переходят на цифровую экономику, обеспечиваемую облачными технологиями, мобильными технологиями, социальными сетями и большими данными, разработчикам и операционным группам приходится создавать и поддерживать веб-приложения, мобильные приложения и приложения IoT все быстрее и в большем масштабе. Гибкая, высокопроизводительная NoSQL становится все более предпочтительной технологией баз данных для поддержки современных веб-приложений, мобильных приложений и приложений IoT.
Сотни предприятий из списка Global 2000, а также десятки тысяч малых предприятий и стартапов внедрили NoSQL. Для многих использование NoSQL началось с кэша, проверки концепции или небольшого приложения, затем было расширено до целевых критически важных приложений и теперь является основой для разработки всех приложений.