MySQL и JOINы / Хабр
Поводом для написания данной статьи послужили некоторые дебаты в одной из групп linkedin, связанной с MySQL, а также общение с коллегами и хабролюдьми 🙂
В данной статье хотел написать что такое вообще JOINы в MySQL и как можно оптимизировать запросы с ними.
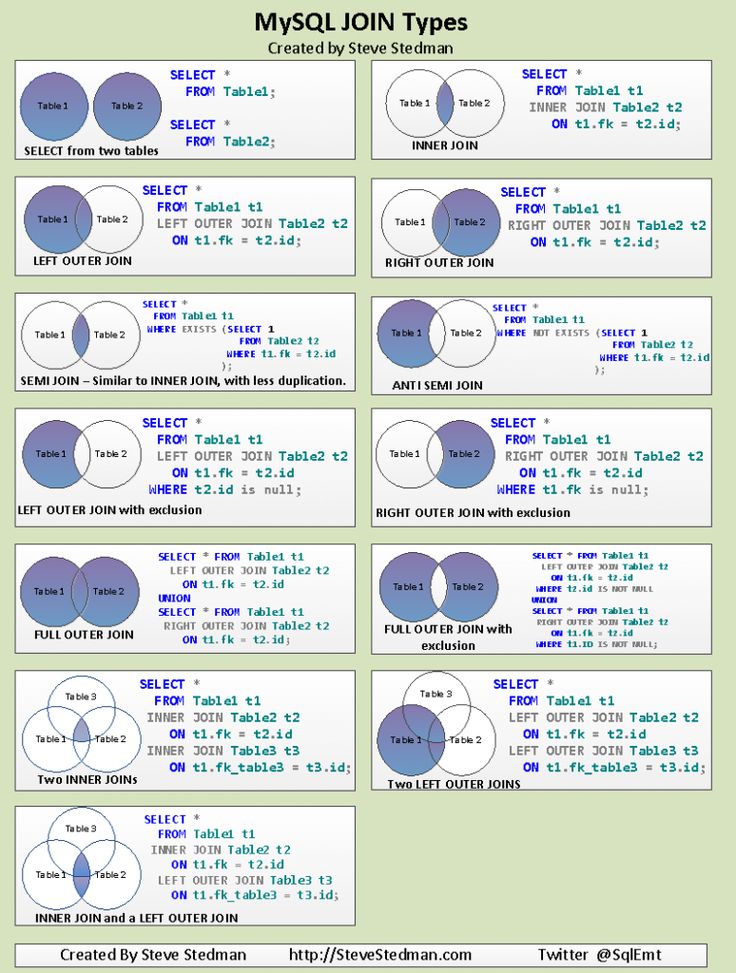
Что такое JOINы в MySQL
В MySQL термин JOIN используется гораздо шире, чем можно было бы предположить. Здесь JOINом может называться не только запрос объединяющий результаты из нескольких таблиц, но и запрос к одной таблице, например, SELECT по одной таблице — это тоже джоин.
Все потому, что алгоритм выполнения джоинов в MySQL реализован с использованием вложенных циклов. Т.е. каждый последующий JOIN это дополнительный вложенный цикл. Чтобы выполнить запрос и вернуть все записи удовлетворяющие условию MySQL выполняет цикл и пробегает по записям первой таблицы параллельно проверяя соответствия условиям описанных в теле запроса, когда находятся записи, удовлетворяющие условиям — во вложенном цикле по второй таблице ищутся записи соответствующие первым и удовлетворяющие условиям проверки и т. д.
д.
Прмер обычного запроса с INNER JOIN
SELECT
*
FROM
Table1
INNER JOIN
Table2 ON P1(Table1,Table2)
INNER JOIN
Table3 ON P2(Table2,Table3)
WHERE
P(Table1,Table2,Table3).
* This source code was highlighted with Source Code Highlighter.где Р — условия склейки таблиц и фильтры в WHERE условии.
Можно представить такой псевдокод выполнения такого запроса.
FOR each row t1 in Table1 {
IF(P(t1)) {
FOR each row t2 in Table2 {
IF(P(t2)) {
FOR each row t3 in Table3 {
IF P(t3) {
t:=t1||t2||t3; OUTPUT t;
}
}
}
}
}
}
* This source code was highlighted with Source Code Highlighter.где конструкция t1||t2||t3 означает конкатенацию столбцов из разных таблиц.
Если в запросе встречаются OUTER JOINs, например, LEFT OUTER JOIN
SELECT
*
FROM
Table1
LEFT JOIN
(
Table2 LEFT JOIN Table3 ON P2(Table2,Table3)
)
ON P1(Table1,Table2)
WHERE
P(Table1,Table2,Tabke3)
* This source code was highlighted with Source Code Highlighter.то алгоритм выполнения этого запроса MySQL будет выглядеть как-то так
FOR each row t1 in T1 {
BOOL f1:=FALSE;
FOR each row t2 in T2 such that P1(t1,t2) {
BOOL f2:=FALSE;
FOR each row t3 in T3 such that P2(t2,t3) {
IF P(t1,t2,t3) {
t:=t1||t2||t3; OUTPUT t;
}
f2=TRUE;
f1=TRUE;
}
IF (!f2) {
IF P(t1,t2,NULL) {
t:=t1||t2||NULL; OUTPUT t;
}
f1=TRUE;
}
}
IF (!f1) {
IF P(t1,NULL,NULL) {
t:=t1||NULL||NULL; OUTPUT t;
}
}
}
* This source code was highlighted with Source Code Highlighter.
Более подробно почитать об этом можно здесь — dev.mysql.com/doc/refman/5.1/en/nested-joins.html
Итак, как мы видим, JOINы это просто группа вложенных циклов. Так почему же в MySQL и UNION и SELECT и запросы с SUBQUERY тоже джоины?
MySQL оптимизатор старается приводить запросы к тому виду к которому ему удобней обрабатывать и выполнять запросы по стандартной схеме.
С SELECT все понятно — просто цикл без вложенных циклов. Все UNION выполняются как отдельные запросы и результаты складываются во временную таблицу, и потом MySQL работает уже с этой таблицей, т.е. проходясь циклом по записям в ней. С Subquery та же история.
Приводя все к одному шаблону, например, МySQL переписывает все RIGHT JOIN запросы на LEFT JOIN эквиваленты.
Но стратегия выполнения запросов через вложенные циклы накладывает некоторые ограничения, например, в связи с такой схемой MySQL не поддерживает выполнение FULL OUTER JOIN запросов.
Но результат такого запроса можно получить с помощью UNION двух запросов на LEFT JOIN и на RIGHT JOIN
Пример самого запроса можно посмотреть по ссылке на вики.
План выполнения JOIN запросов
В отличии от других СУРБД MySQL не генерирует байткод для выполнения запроса, вместо этого MySQL генерирует список инструкций в древовидной форме, которых придерживается engine выполнения запроса выполняя запрос.
Это дерево имеет следующий вид и имеет название «left-deep tree»
В отличии от сбалансированных деревьев (Bushy plan), которые применяются в других СУБД (например Oracle)
JOIN оптимизация
Теперь перейдем к самому интересному — к оптимизации джоинов.

Для выбранного плана можно узнать стоимость путем выполнения команды
SHOW SESSION STATUS LIKE ‘Last_query_cost’;
после выполнения интересующего нас запроса. Переменная Last_query_cost является сессионной переменной. Описание переменной Last_query_cost в MySQL документации можно найти здесь — dev.mysql.com/doc/refman/5.1/en/server-status-variables.html#option_mysqld_Last_query_cost
Оценка основана на статистике: количество страниц памяти, занимаемое таблицей и/или индексами для этой таблицы, cardinality (число уникальных значений) индексов, длинна записей и индексов, их распределение и т.д. Во время своей оценки оптимизатор не рассчитывает на то, что какие-то части попадут в кеш, оптимизатор предполагает, что каждая операция чтения это обращение к диску.
Иногда анализатор-оптимизатор не может проанализировать все возможные планы выполнения и выбирает неправильный. Например, если у нас INNER JOIN по 3м таблицам, то возможных вариантов у анализатора — 3! = 6, а если у нас склейка по 10 таблицам, то тут возможных вариантов уже 10! = 3628800… MySQL не может проанализировать столько вариантов, поэтому в таком случае он использует алгоритм «жадного» поиска.
И вот как раз для решения данной проблемы, нам может пригодиться конструкция STRAIGHT_JOIN. На самом деле я противник подобных хаков как FORCE INDEX и STRAIGH_JOIN, точней против их бездумного использования везде где только можно и нельзя. В данном случае — можно 🙂 Выяснив (либо экспериментальным путем делая запросы с STRAIGH_JOIN и оценивая Last_query_cost, либо эмпирическим путем) нужный порядок джоинов можно переписать запрос с таблицами в соответствующем порядке и добавить STRAIGH_JOIN к данному запросу, таким образом мы сразу убьем двух зайцев — определим правильный план выполнения запроса (это главный заяц) и сэкономим время на стадии «Statistic» (Все стадии выполнения запроса можно посмотреть установив профайлинг запросов командой SET PROFILING =1, я описывал это в своей предыдущей статье по теме профайлинга запросов в MySQL )
Но не стоит применять этот хак ко всем запросам, расчитывая произвести оптимизацию на спичках и сэкономить время на составление плана выполнения запроса оптимизатором и добавлять STRAIGH_JOIN ко всем запросам с джоинами, т.
Также, как уже говорилось выше, результаты джоинов помещаются во временные таблицы, поэтому зачастую уместно применять «derived table» в котором мы накладываем все необходимые нам условия на выборку, а также указываем LIMIT и порядок сортировки. В данном случае мы избавимся от избыточности данных во временной таблице, а также проведем сортировку на раннем этапе (по результату одной выборки, а не финальной склейки, что уменьшит размеры записей которые будут сортироваться).
Стандартный пример подхода описанного выше. Простая выборка для отношения много к многим: новости и теги к ним.
SELECT
t.tid, t.description, n.nid, n.title, n.extract, n.modtime
FROM
(
SELECT
n.nid
FROM
news n
WHERE
n.type = 1321
AND n. published = 1
published = 1
AND status = 1
ORDER BY
n.modtime DESC
LIMIT
200
) as news
INNER JOIN
news n ON n.nid = news.nid
INNER JOIN
news_tag nt ON n.nid = nt.nid
INNER JOIN
tags t ON nt.tid = t.tid
* This source code was highlighted with Source Code Highlighter.Ну и на последок небольшая задачка, которую я иногда задаю на собеседованиях 🙂
Есть новостной блоггерный сайт. Есть такие сущности как новости и комментарии к ним.
Задача — нужно написать запрос, который выводит список из 10 новостей определенного типа (задается пользователем) отсортированные по времени издания в хронологическом порядке, а также к каждой из этих новостей показать не более 10 последних коментариев, т.е. если коментариев больше — показываем только последние 10.
Все нужно сделать одним запросом. Да, это, может, и не самый лучший способ, и вы вольны предложить другое решение 🙂
SQL: несколько Join к одной таблице / связи
Бывают случаи, когда нужно создать несколько Join запросов к одной таблице, то есть когда у нас есть много элементов в таблице ссылающихся на тот же внешний ключ. Это не сложная задача, если вы имели дело с этим раньше, но может немного сбить с толку новых пользователей БД. Вот почему я создал эту статью — чтобы объяснить, как правильно проектировать и связывать таблицы в SQL.
Это не сложная задача, если вы имели дело с этим раньше, но может немного сбить с толку новых пользователей БД. Вот почему я создал эту статью — чтобы объяснить, как правильно проектировать и связывать таблицы в SQL.
Пример двойного ключа — команды и игры
Как простой пример возьмем две команды играющие в игру, например футбол. Каждая команда будет иметь уникальный столбец в таблице. Давайте рассмотрим следующую простую таблицу в качестве примера того, как может выглядеть команда (примеры в этой статье написаны для MySQL, но по аналогии можно делать для любых ANSI-92 совместимых БД):
CREATE TABLE team ( id INT NOT NULL AUTO_INCREMENT, name VARCHAR(255) NOT NULL, PRIMARY KEY (id) ) TYPE=InnoDB;
Пока все просто… Это основа базы данных. Что ж, давайте перейдем к играм.
Две ссылки
Каждая игра состоит из двух команд и места встречи. Самый простой способ установить место встречи это сослаться на команду хозяев с таблицы игр.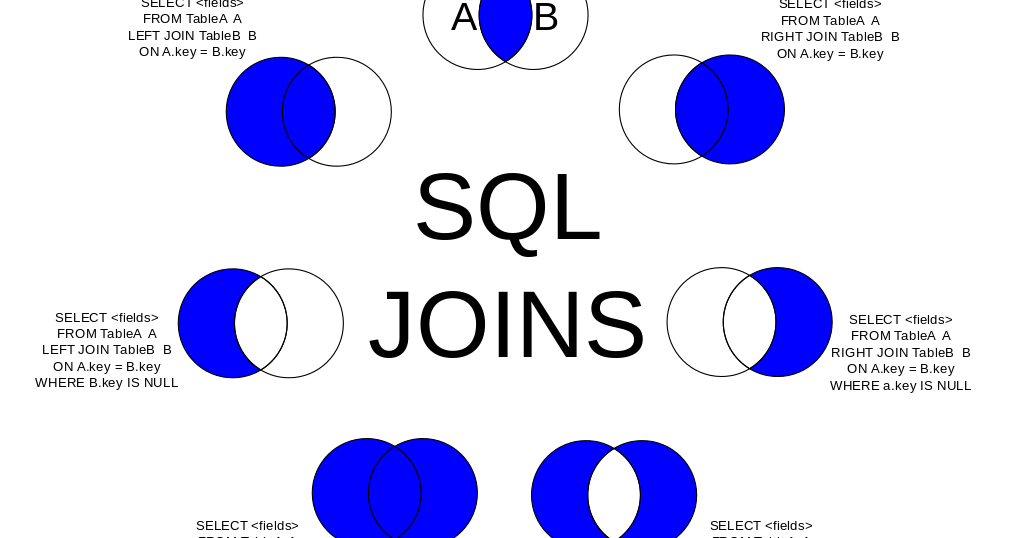
CREATE TABLE game (
id INT NOT NULL AUTO_INCREMENT,
home_team_id INT NOT NULL REFERENCES team(id),
guest_team_id INT NOT NULL REFERENCES team(id),
home_score INT NULL,
guest_score INT NULL,
game_date DATE NOT NULL,
PRIMARY KEY (id)
) TYPE=InnoDB;Дважды соединенные
Работа с данными будет повеселее. При соединении двух таблиц, вам придется сделать join дважды, и подойти творчески к вопросу о том, как манипулировать join-ами, для того, чтобы получить данные надлежащим образом. Вот простая выборка всех игр и результатов.
SELECT
g.*,
t1.name AS home_team_name,
t2.name AS guest_team_name
FROM
game AS g
INNER JOIN team AS t1 ON g.home_team_id = t1.id
INNER JOIN team AS t2 ON g.guest_team_id = t2.id;
ORDER by game_date DESCОбратная ссылка
Поиск расписания одной команды включает в себя объединение домашних и выездных игр, с созданием идентификатора метаданных места встречи.
SELECT * FROM (
SELECT
t1.*,
g.id AS game_id,
g.game_date,
t2.id AS opponent_id,
t2.name AS opponent_name,
'home' AS venue
FROM
game AS g
INNER JOIN team AS t1 ON g.home_team_id = t1.id
INNER JOIN team AS t2 ON g.guest_team_id = t2.id
UNION ALL
SELECT
t1.*,
g.id AS game_id,
g.game_date,
t2.id AS opponent_id,
t2.name AS opponent_name,
'away' AS venue
FROM
game AS g
INNER JOIN team AS t1 ON g.guest_team_id = t1.id
INNER JOIN team AS t2 ON g.home_team_id = t2.id
) AS schedule
WHERE schedule.id = 1
ORDER BY schedule.game_date ASCВот и все! Углубляйтесь, и получайте удовольствие!
Источник: http://www.transio.com/content/sql-multiple-joins-single-table-relationship
INNER JOIN в MySQL с примерами.
 | Джошуа Отвелл
| Джошуа Отвелл Чтобы нормализовать данные, мы часто храним их в нескольких таблицах в данной базе данных. Хотя запросы к этим таблицам по отдельности могут дать ответы на многочисленные вопросы, связанные с этими данными, в большинстве случаев это оставляет нас «недостающими» для полного ответа , который нам нужен.
В связи с этим возникает вопрос, как извлечь все эти данные из нескольких таблиц, которые зависят друг от друга, чтобы предоставить ответы на основе данных?
Одним из проверенных и надежных методов является использование операции JOIN .
Примечание. Все данные, имена или имена, найденные в базе данных, представленной в этом посте, используются строго для практики, обучения, обучения и тестирования. Он ни в коем случае не отображает фактические данные, принадлежащие или используемые какой-либо стороной или организацией.
ОС и база данных:
- Xubuntu Linux 16.04.3 LTS (Xenial Xerus)
- MySQL 5.
 7.22
7.22
Существует несколько типов JOIN в MySQL (и SQL в целом), однако в этой статье мы сосредоточимся на INNER JOIN .
Этот тип JOIN позволяет связать столбцы из нескольких таблиц по совпадающим значениям .
Я выберу эти три таблицы из базы данных проката DVD-дисков Sakila.
Таблицы городов, стран и адресов.Мне нужно сузить набор результатов до чего-то более удобного с точки зрения вывода, краткости и отображения на экране для этой записи в блоге. Итак, для начала я сразу присоединюсь к двум из этих столов.
Я сосредоточу запрос вокруг страны с количеством городов , равным 6. НАЛИЧИЕ даст мне возможность работать.
mysql> ВЫБЕРИТЕ СЧЕТ(город), страна
-> ИЗ города
-> ВНУТРЕННЕЕ СОЕДИНЕНИЕ страна
-> ON city.country_id = country.country_id
-> ГРУППИРОВАТЬ ПО стране
-> ИМЕЕТ СЧЁТ (город) = 6;
+ — — — — — — — + — — — — — +
| COUNT(город) | страна |
+ — — — — — — —+ — — — — — +
| 6 | Колумбия |
| 6 | Египет |
| 6 | Украина |
| 6 | Вьетнам |
+ — — — — — — — + — — — — — +
4 строки в наборе (0,00 сек)
Давайте посмотрим на INNER JOIN и что он делает.
Вы заметите, что обе таблицы имеют своего рода «общий» столбец с именем country_id .
В таблице страна это PRIMARY KEY , а в таблице город это FOREIGN KEY .
Мы можем использовать эти столбцы, чтобы «связать» или СОЕДИНИТЬ эти таблицы, где их значения совпадают.
Для этого мы используем предложение ON как часть JOIN (подробнее см. ниже).
Примечание:
- В MySQL ключевое слово
INNERявляется необязательным для этого типаJOIN. Согласно документации в разделе 13.2.9.2 Синтаксис соединения,CROSS JOINтакже является взаимозаменяемым синтаксисом. Я протестировал (не показано) все три варианта:JOIN,INNER JOINиCROSS JOIN; Все совместимы с запросом выше. Важно: это поведение применимо только к MySQL и не совместимо со стандартным SQL.
- Предложение
ONназывает условиеJOINв том, как таблицы связаны в соответствующей строке. - Без
ИМЕЮЩИЙиGROUP BY, этот запрос вернет всех совпадающих строк. Повторюсь, я в основном использую их здесь в запросе, чтобы продемонстрировать лучший вывод на экран для сообщений в блоге. Эти упомянутые пункты не являются обязательными или даже синтаксисомJOIN.
Тем не менее, вполне нормально и часто бывает полезно фильтровать по одному или по комбинации доступных предложений при соответствующем использовании в контексте.
Я также напрямую предоставлю важную информацию из официальной документации (ссылка в конце раздела), расположенной в том же 13.2.9..2 Раздел синтаксиса JOIN, как указано выше.
Условное_выражение, используемое с ON, представляет собой любое условное выражение в форме, которая может использоваться в предложении WHERE. Как правило, предложение ON служит для условий, указывающих, как соединять таблицы, а предложение WHERE ограничивает, какие строки включать в результирующий набор.

Другими словами, мы используем ON в этом запросе, чтобы указать условие соответствия для строк, где значение столбца country_id из таблицы город точно такой же, как столбец country_id в таблице страна .
Это логическое условие, которое выполняется так же, как условие WHERE .
В принципе, тест на правда .
Если строка соответствует указанному условию, она считается истинной .
У меня есть идея.
Как насчет того, чтобы включить столбец country_id в список SELECT для большей ясности:
mysql> ВЫБЕРИТЕ СЧЕТ(город), страна, country_id
-> ИЗ города
-> ВНУТРЕННЕЕ СОЕДИНЕНИЕ страна
-> ВКЛ city.country_id = country.country_id
-> ГРУППИРОВАТЬ ПО стране
-> ИМЕЕТ СЧЁТ (город) = 6;
ОШИБКА 1052 (23000): Столбец «country_id» в списке полей неоднозначен
Итак, какой country_id мы имели в виду? Это интересно. MySQL также хотел бы знать.
MySQL также хотел бы знать.
Помните об этом при объединении и запросе из нескольких таблиц, которые могут иметь столбца с одинаковыми именами .
Вы должны быть конкретными и четко указать базу данных (MySQL), какой столбец вы запрашиваете.
Возможно, вы думаете, что столбец страна не выдавал эту неоднозначную ошибку ? Правильно.
Потому что этот столбец существует только в таблице страны , и MySQL без сомнения знает, на какую из них мы ссылаемся.
Так как же избежать этих неоднозначных ошибок?
Вы «квалифицировать» столбцы с одинаковыми именами.
Префикс имени столбца с соответствующим именем родительской таблицы позволяет избежать путаницы, и MySQL будет знать, какой столбец (столбцы) из какой таблицы (таблиц) вы запросили.
Я включу столбец country_id из таблицы city в этот запрос:
mysql> SELECT COUNT(city), country, city.country_id
-> FROM city
-> INNER JOIN country
-> ON city.country_id = country.country_id
-> СГРУППИРОВАТЬ ПО стране, city.country_id
-> ИМЕЕТ СЧЁТ (город) = 6;
+ — — — — — — —+ — — — — — + — — — — — — +
| COUNT(город) | страна | идентификатор_страны |
+ — — — — — — —+ — — — — — + — — — — — — +
| 6 | Колумбия | 24 |
| 6 | Египет | 29 |
| 6 | Украина | 100 |
| 6 | Вьетнам | 105 |
+ — — — — — — — + — — — — — + — — — — — — +
4 ряда в наборе (0,01 сек)
Указав country_id из таблицы city , MySQL точно знает, какой столбец из какой таблицы нам нужен.
Прикосновение к псевдонимам… Псевдонимы — это альтернативный синтаксис для ссылок на имена таблиц.
Вместо того, чтобы использовать полное имя таблицы для определяющего префикса, вы можете использовать псевдоним имени таблицы в предложении FROM :
mysql> SELECT COUNT(ci.city), co.country, ci.country_id
-> FROM город AS ci
-> INNER JOIN страна AS co
-> ON ci.country_id = co.country_id
-> ГРУППИРОВАТЬ ПО co.country, ci.country_id
-> ИМЕЕТ СЧЁТ (ci.city) = 6;
+ — — — — — — — — + — — — — — + — — — — — — +
| COUNT(город) | страна | идентификатор_страны |
+ — — — — — — — — + — — — — — + — — — — — — +
| 6 | Колумбия | 24 |
| 6 | Египет | 29 |
| 6 | Украина | 100 |
| 6 | Вьетнам | 105 |
+ — — — — — — — — + — — — — — + — — — — — — +
4 строки в наборе (0,00 с)
Мы можем использовать ссылку на таблицу с одной из двух синтаксических структур:
имя_таблицы AS требуемое_имя_ссылки имя_таблицы требуемое_имя_ссылки
Таким образом, в этом запросе
ОТ города КАК ciИЗ города 5
и
ci
эквивалентны и вполне приемлемы в этом контексте.
* Примечание. Как уже упоминалось, ключевое слово AS в этом контексте является необязательным.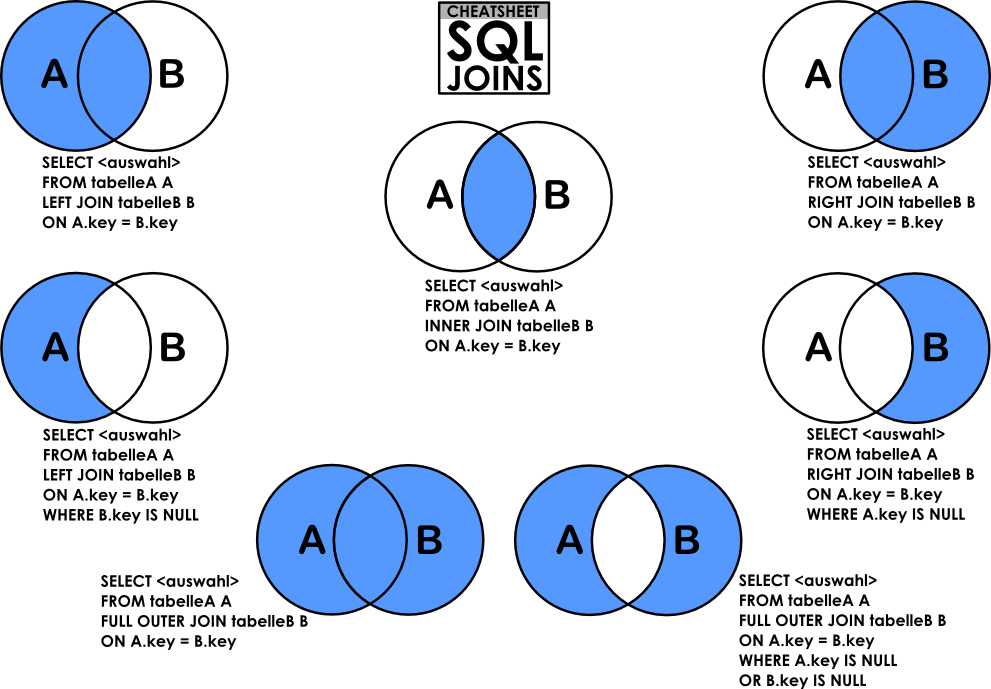 Однако его включение может улучшить читаемость и ясность. Поэтому я стараюсь постоянно включать его в эти конкретные варианты использования.
Однако его включение может улучшить читаемость и ясность. Поэтому я стараюсь постоянно включать его в эти конкретные варианты использования.
Теперь везде, где вы ссылаетесь на столбец из таблицы city или country , используйте ci или co соответственно вместо полного имени таблицы.
Для указания условия JOIN доступно альтернативное предложение.
Пункт USING .
Столбцы, названные в предложении USING , должны присутствовать в обеих таблицах.
Вот пример:
mysql> SELECT COUNT(город), страна
-> ИЗ города AS ci
-> ВНУТРЕННЕЕ СОЕДИНЕНИЕ страны AS co
-> USING(country_id)
-> GROUP BY co.country
-> HAVING COUNT(ci.city) = 6;
+ — — — — — — —+ — — — — — +
| COUNT(город) | страна |
+ — — — — — — —+ — — — — — +
| 6 | Колумбия |
| 6 | Египет |
| 6 | Украина |
| 6 | Вьетнам |
+ — — — — — — — + — — — — — +
4 ряда в наборе (0,00 с)
* Примечание: скобки вокруг country_id требуются в пункте USING .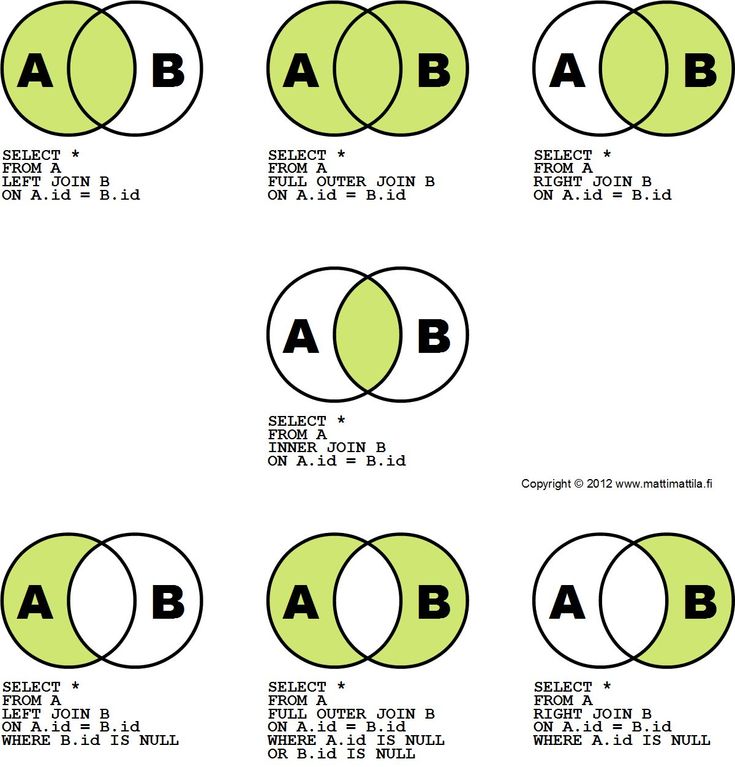
Хотя здесь это не показано, USING может принимать несколько имен столбцов, разделенных запятыми, для условия JOIN .
Что делать, если ваш набор результатов должен исходить из более чем 2 таблиц?
Могут ли JOIN сделать это?
Конечно можно.
На картинке, представленной в начале поста, вы видите третью таблицу адресов . Давайте добавим сюда эту таблицу.
Предположим, нам нужно определить все названия городов и адреса, доступные в базе данных для страны «Египет» .
Это можно решить с помощью мультитаблицы JOIN .
Приведенный ниже запрос включает необходимые JOIN , чтобы вернуть этот конкретный набор результатов:
Так что же происходит со всем этим объединением?
Давайте рассмотрим наш пример запроса построчно и лучше поймем операцию.
mysql> ВЫБЕРИТЕ ci.city, a.address, a.postal_code, co.country
-> ИЗ города КАК ci
-> Адрес ВНУТРЕННЕГО СОЕДИНЕНИЯ КАК
-> ВКЛ ci.city_id = a.city_id
-> ВНУТРЕННЕЕ СОЕДИНЕНИЕ страна КАК co
-> ВКЛ ci.country_id = co.country_id
-> ГДЕ co .country = 'Египет';
- Строка 1 предоставляет столбцы, которые мы запрашиваем через предложение
SELECT. - Строки 2 и 3: MySQL объединяет каждую строку, присутствующую в таблице
city(названную в предложенииFROM), с каждой строкой в адресетаблица (названная как таблицаJOIN). - Строка 4: На этом этапе объединенный набор результатов может не соответствовать желаемым результатам. Вот где на сцену выходит предложение
ONилиUSING. При использованииONустанавливается условие «соответствие» , которое должно выполняться (истина) для каждой «совпадающей/связанной» строки для обеих таблиц, участвующих в условииJOIN. Здесь стоит упомянуть два мини-указателя: - Это условие должно быть для «подобных» типов данных (например, 2 = 2, «Программист» = «Программист», «2012–10–08» = «2012–10–08»).

- Однако они также должны иметь смысл . Другими словами, только потому, что строки «Египет» и «Колумбия» на самом деле являются символьными типами данных; в этом контексте сопоставление с ними не имеет смысла и, скорее всего, не даст правильных результатов. Помните, это проверка на истину. «Египет» = «Египет» вернет значение true, а «Египет» = «Колумбия» — нет.
- Промыть и повторить, так как строки 5 и 6 идентичны операциям из строк 2 и 3. Все строки из таблицы
городсоединяются со всеми строками в таблицестрана. Затем предложениеONуказывает, что значение столбцаcountry_idиз обеих таблиц должно совпадать или быть равным. - Строка 7: Здесь предложение
WHEREфильтрует строки, которые должны соответствовать определенным критериям, чтобы окончательный результирующий набор возвращался из базы данных. Для этого запроса 9Столбец 0009 страна из таблицыстранадолжен иметь значение«Египет»в строке «сопоставление» .
Используя JOIN , мы можем объединять связанные или связанные данные из нескольких таблиц, возвращая значимые метрики и идеи.
JOIN может помочь в ответах на такие вопросы, как, например, авторы и книги, которые они написали, производители и автомобили, которые они производят, музыканты и альбомы, которые они выпустили, и т. д.
Следует отметить, хотя это и не рассматривается в этом сообщении в блоге, JOIN также применимы к многотабличным операциям UPDATE и DELETE .
Изучите официальное онлайн-руководство по MySQL 5.7 для получения дополнительной информации.
Спасибо, что нашли время прочитать этот пост. Я искренне надеюсь, что вы открыли для себя что-то интересное и поучительное. Пожалуйста, поделитесь своими выводами здесь с кем-то из ваших знакомых, кто также получит от этого такую же пользу.
Посетите страницу «Портфолио-Проекты», чтобы увидеть публикации в блоге/технические статьи, которые я написал для клиентов.
Я уже говорил, как сильно люблю кофе?!?!
Чтобы получать по электронной почте уведомления о последних сообщениях от «Digital Owl’s Prose», подпишитесь, нажав кнопку «Нажмите, чтобы подписаться!» на боковой панели главной страницы!
Будьте уверены и посетите страницу «Лучшее из» для коллекции моих лучших сообщений в блоге, пока вы там!
Джош Отвелл страстно желает учиться и развиваться как разработчик SQL и блогер. Другие любимые занятия заставят его уткнуться носом в хорошую книгу, статью или командную строку Linux. Среди них он разделяет любовь к настольным ролевым играм, чтению фантастических романов и проведению времени с женой и двумя дочерьми.
Отказ от ответственности: примеры, представленные в этом посте, являются гипотетическими идеями о том, как достичь подобных результатов. Это не самое лучшее решение(я). Ваши конкретные цели и потребности могут отличаться. Используйте те методы, которые лучше всего подходят для ваших нужд и целей. Мнения мои собственные.
Первоначально опубликовано на joshuaotwell.com 9 мая 2018 г.0003 Email Blast , 🐦 Follow CodeBurst on Twitter , view 🗺️ The 2018 Web Developer Roadmap , and 🕸️ Learn Full Stack Web Development .
MySQL | INNER JOIN с примерами
Рассмотрим следующую таблицу о некоторых студентах:
student_id | fname | lname | day_enrolled | age | username |
|---|---|---|---|---|---|
1 | Sky | Towner | 2015-12-03 | 17 | stowner1 |
2 | Ben | Davis | 2016-04-20 | 19 | bdavis2 |
3 | Travis | Apple | 2018-08-14 | 18 | tapple3 |
4 | ARTHUR | DAVID | 2016-04-01 | 16 | 3 91111111111111111111111111111111111111111111111111111111111111111111111111111111119н0521 |
5 | Benjamin | Town | 2014-01-01 | 17 | btown5 |
The above sample table can be created using the code here .
Также обратите внимание на следующую таблицу о внеклассной деятельности студентов:
student_id | club | date_entered |
|---|---|---|
1 | Football | 2016-02-13 |
2 | Boxing | 2016-05-25 |
3 | Apple | 2018-08-17 |
4 | Fishing | 2017-01-01 |
5 | NULL | NULL |
Приведенный выше образец таблицы можно создать с помощью приведенного здесь кода.
Основное использование
Для получения информации об учащихся и их внеклассной деятельности с помощью общего столбца student_id :
ВЫБЕРИТЕ имя, имя, возраст, клуб ОТ студентов ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ внеклассное ВКЛ student. +----------+--------+------+----------+ | имя | имя | возраст | клуб | +----------+--------+------+----------+ | Небо | Таунер | 17 | Футбол | | Бен | Дэвис | 19 | Бокс | | Трэвис | Яблоко | 18 | Шахматы | | Артур | Дэвид | 16 | Рыбалка | | Бенджамин | Город | 17 | НУЛЕВОЙ | +----------+--------+------+----------+ student_id = extracurricular.student_id;
student_id = extracurricular.student_id;
Здесь мы возвращаем информацию о fname , lname и age из таблицы student и соответствующую информацию club из внеклассной таблицы , когда есть совпадение между student_id значением в обеих таблицах.
Используя псевдонимы, приведенный выше запрос можно сократить до:
ВЫБЕРИТЕ имя, имя, возраст, клуб ОТ УЧЕНИКОВ s ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ внеклассное e ON s.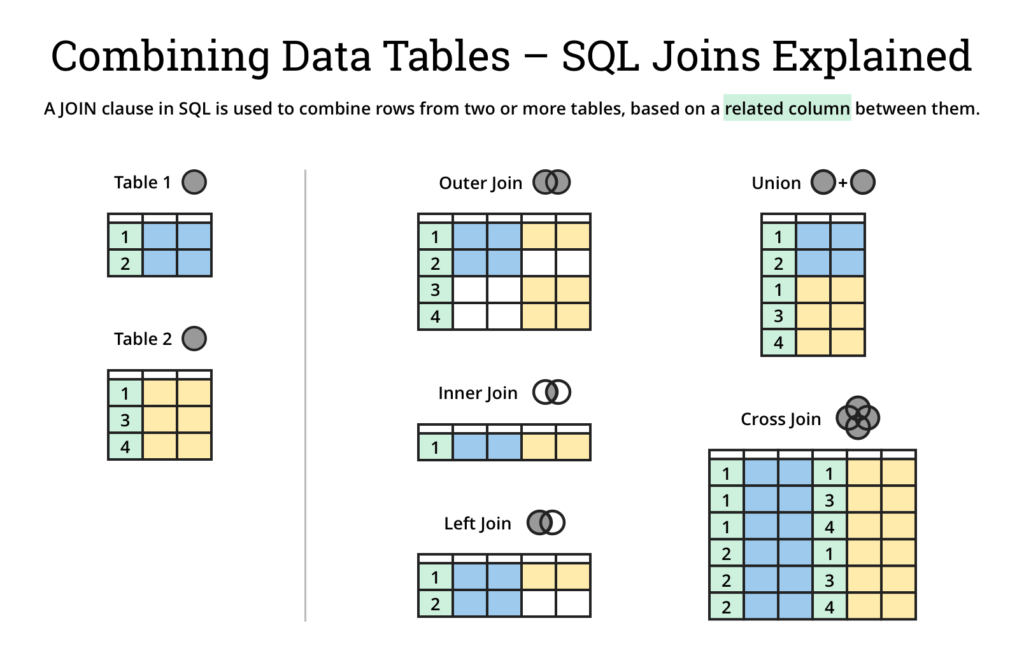 student_id = e.student_id;
student_id = e.student_id;
Неоднозначные имена столбцов
Столбец student_id появляется как в таблицах студентов , так и в таблицах внеклассных занятий . В таких случаях, если мы не укажем, на какой столбец student_id таблицы мы ссылаемся, запутанный сервер MySQL выдаст ошибку:
SELECT student_id, fname, lname, age, club ОТ студентов INNER JOIN внеклассный ON student.student_id = extracurricular.student_id; ОШИБКА 1052 (23000): столбец 'student_id' в списке полей неоднозначен
Правильный способ указать выше, если мы хотим получить student_id из внеклассных , будет:
SELECT extracurricular.student_id, fname, lname, age, club ОТ студентов INNER JOIN внеклассный ON student.