рассказали, какие виды баз данных существуют и что выбрать / Skillbox Media
#статьи
- 0
Когда вы начинаете работу над новым проектом, важно понять, по каким критериям выбирать базы данных и какие вообще есть решения.
Vkontakte Twitter Telegram Скопировать ссылку com / Graphue / Freepik / nadine shaabana / Unsplash / Дима Руденок для Skillbox Media
com / Graphue / Freepik / nadine shaabana / Unsplash / Дима Руденок для Skillbox MediaРедакция «Код» Skillbox Media
Онлайн-журнал для тех, кто влюблён в код и информационные технологии. Пишем для айтишников и об айтишниках.
Существует много различных семейств баз данных, которые различаются структурой хранения, обработки и индексации данных. От основных пользовательских сценариев зависит, какая модель лучше подойдёт в том или ином случае. Иногда вполне оправданно использовать сразу несколько различных баз данных, копируя одни и те же данные несколько раз.
Вот наиболее важные критерии для выбора базы данных:
- какие данные в ней должны храниться,
- каким будет объём данных,
- какого рода запросы будут выполняться при обращении к базе данных.

Реляционные базы данных — самые распространённые. Вот лишь самые популярные из них: Oracle, Microsoft SQL Server, PostgreSQL, MySQL. Такие базы данных обеспечивают построчное хранение данных в таблицах, что подразумевает строгую структуру данных. А ещё подразумевается, что за одно обращение к базе вы будете запрашивать относительно небольшое количество записей.
Такие решения, как правило, довольно хорошо работают, если общий объём ваших данных не превышает нескольких терабайт (конечно, при наличии подходящей инфраструктуры), что в целом делает их подходящими для большинства проектов — особенно на начальном этапе разработки.
Реляционные базы данных стоит выбирать, если вам важны следующие характеристики:
- транзакционность;
- частые изменения данных;
- поиск по индексам;
- запросы небольшого количества записей за раз;
- объём данных не превышает нескольких терабайт.
Выбор конкретной реляционной базы данных зависит от дополнительных требований к безопасности, поддержке и других факторов. Например, в банковской сфере предпочитают использовать Oracle и Microsoft SQL Server. Однако это платные решения — а открытая и бесплатная PostgreSQL тоже показывает очень хорошую производительность, активно развивается и распространяется по свободной лицензии. Если у вас совсем небольшой проект, можно использовать любую реляционную БД.
Альтернативой для реляционных баз данных являются NoSQL-базы. Это могут быть документоориентированные графовые базы данных или key-value-хранилища.
Документоориентированные базы (например, MongoDB, Amazon DocumentDB, CouchDB и другие) хранят данные сразу готовыми «документами», а не в таблицах и строках — как реляционные БД. Этот способ хранения подходит, когда структура данных может изменяться или ваши основные сценарии использования подразумевают загрузку составной структуры.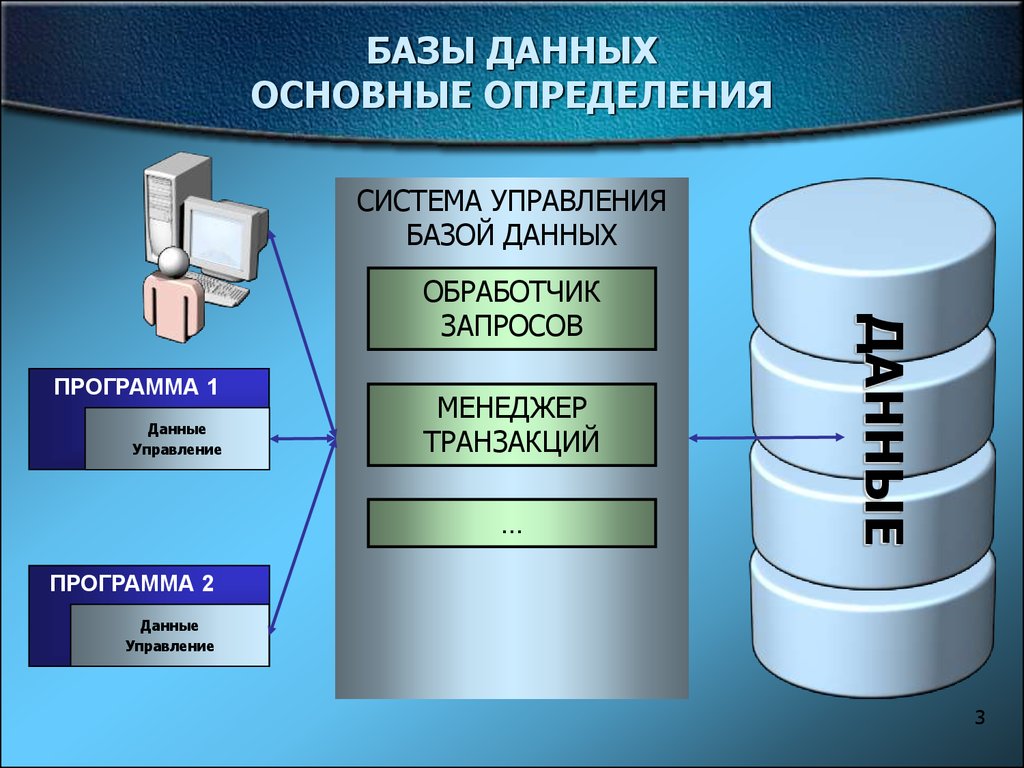 Документоориентированные базы очень близки к формату ресурсов, которыми обмениваются клиент и сервер, что упрощает подготовку данных для передачи по сети.
Документоориентированные базы очень близки к формату ресурсов, которыми обмениваются клиент и сервер, что упрощает подготовку данных для передачи по сети.
В статьях и книгах в качестве типового примера работы таких БД часто приводят сценарий загрузки страницы пользователя в социальной сети. В этом случае у человека есть основные данные: ФИО, дата рождения, пол — и дополнительная информация, которая может включать в себя несколько элементов и требовать разной структуры. Например, места учёбы, проживания, работы.
Как известно, у одного человека может быть много мест учёбы или проживания, а адреса в разных странах могут состоять из разных сущностей. В России это область → город → улица → дом, а во Франции — провинция → регион → город → улица → дом. Да, такие структуры можно собирать и на реляционных БД, однако в этом случае придётся выполнить несколько дополнительных запросов, чтобы собрать всю информацию о человеке и отрисовать его страницу.
Документоориентированные базы данных позволяют хранить подобную информацию о пользователе целиком, в одном месте и получать её одним запросом.
При этом документоориентированные базы данных поддерживают возможность использования ссылок на другие записи в базе — а это позволяет приблизиться к реляционной модели. Кстати, реляционные модели тоже двигаются в сторону поддержки составных структур данных — таких как JSON — и позволяют выполнять поиск по содержимому «сложного, составного» поля.
Таким образом, главное преимущество документоориентированных баз данных — возможность хранения данных без строгого ограничения по структуре.
Key-value-хранилища (Redis, Aerospike, DynamoDB и другие) хранят данные в виде хеш-таблицы. В такой модели у каждой записи есть только один индекс. При этом нет строгого ограничения на структуру значения. Как правило, такие базы данных изменяют данные по принципу логов, то есть всегда дописывают значения в конец, а удаление выполняется при помощи добавления специальной записи.
Графовые базы данных хранят все данные в виде узлов и связей между ними. Этот подход может ускорять запросы в некоторых случаях и применяется в рекомендательных движках и приложениях, связанных с геопозиционированием. Так что, если вы делаете подобное приложение, возможно, вам стоит обратить внимание на графовые хранилища. Хотя надо признать — это специфические решения.
Для аналитических систем, которые предполагают работу с огромными объёмами данных — в десятки терабайт, а то и несколько петабайт, — существует отдельный класс хранилищ, которые хранят данные в колонкоориентированной модели.
В отличие от реляционной модели данных, где последовательно хранится вся строка таблицы, или документоориентированной модели, где последовательно хранится весь документ, здесь последовательно хранятся значения одной колонки, и подразумевается, что в одной и той же позиции каждой колонки хранятся значения, относящиеся к одной строке. Такая модель позволяет эффективно сжимать данные и строить над ними различные агрегаты: сумма, среднее, количество и другие.
Такая модель позволяет эффективно сжимать данные и строить над ними различные агрегаты: сумма, среднее, количество и другие.
OLAP-системы позволяют добавлять данные непрерывным потоком или загружать порциями — а вот удалять или изменять их обычно не разрешают. Их главная задача — позволить аналитикам и менеджменту компаний анализировать данные. Следовательно, они должны хранить историю событий, в то время как остальные БД подразумевают хранение лишь текущего состояния каждой сущности. Обычно OLAP-хранилища поддерживают синтаксис SQL-запросов, поскольку он хорошо подходит для аналитических задач.
Большинство решений в этой области — например, Vertica, Teradata, BigQuery — стоят довольно дорого. Однако есть и решения с открытым исходным кодом, такие как ClickHouse, Apache Druid и другие.
Как правило, в большинстве проектов достаточно реляционных баз данных, среди которых можно выбрать подходящие бесплатные решения.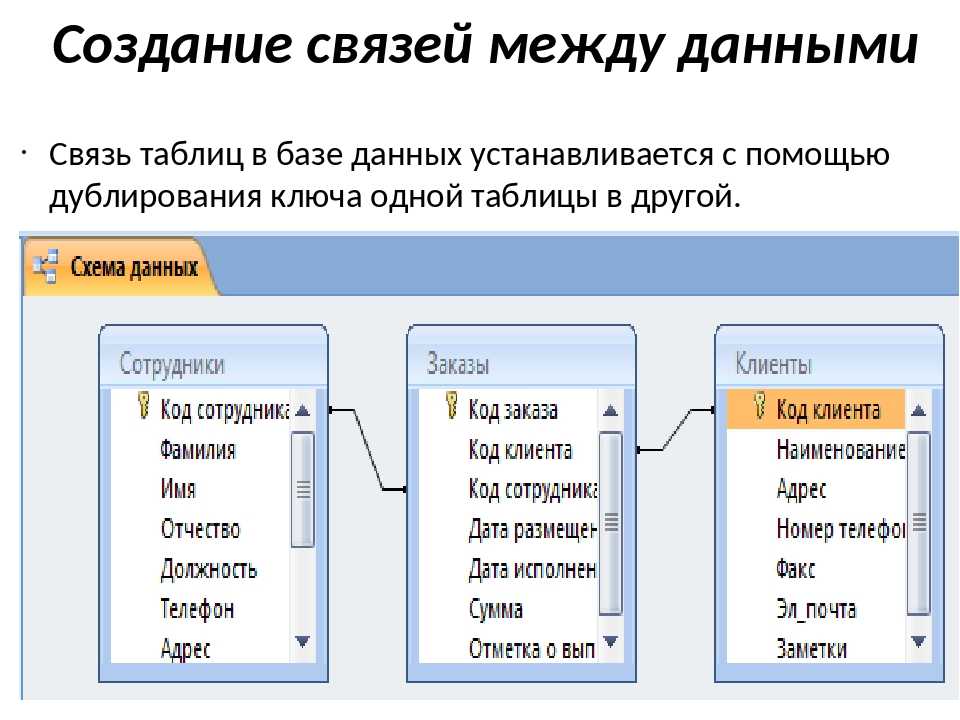 Однако под некоторые специфические сценарии использования лучше подходит документоориентированная модель хранения данных.
Однако под некоторые специфические сценарии использования лучше подходит документоориентированная модель хранения данных.
Конечно, стоит учитывать, что сейчас многие реляционные базы данных поддерживают возможность хранения данных в формате JSON или XML, что в какой-то степени позволяет им конкурировать с документоориентированной моделью.
Если же ваш проект вырос до такого размера, когда этих решений недостаточно, имеет смысл добавлять key-value-хранилища в качестве кэша или искать другую гибридную модель управления данными.
А вот если вам необходимо построить систему аналитики с обработкой огромных объёмов данных, то, скорее всего, вам придётся рассматривать хранилища из категории OLAP. К ним относятся колонкоориентированные хранилища или хранилища категории семейства столбцов, такие как HBase или Google Cloud Bigtable.
Читайте также:
Vkontakte Twitter Telegram Скопировать ссылку Научитесь:ChatGPT запустили на старом компьютере IBM, работающем из-под MS-DOS 28 мар 2023
Microsoft сделала бесплатным сервис Loop — это аналог Notion c фишками на основе ИИ 24 мар 2023
Новая библиотека от NVIDIA ускоряет литографию процессоров в 40 раз 22 мар 2023
Понравилась статья?
Да
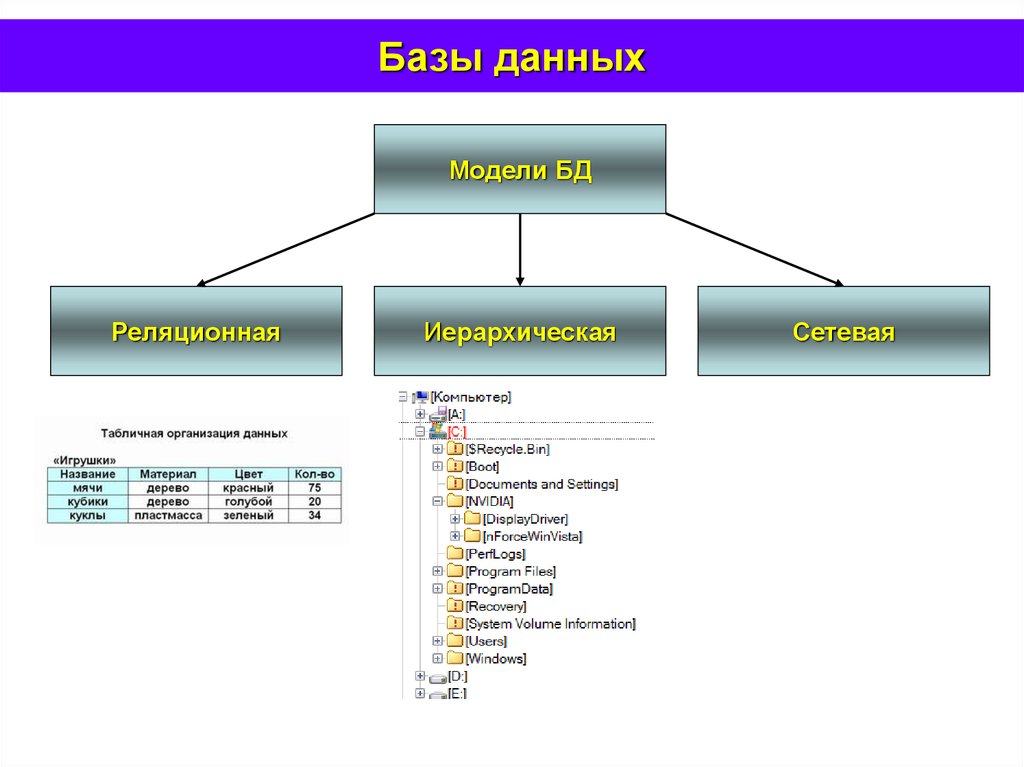
Виды баз данных — реляционные и другие подходы к организации БД в программировании
В этой статье мы рассмотрим основные виды баз данных. На конкретных примерах выявим преимущества и недостатки каждой модели, изучим сценарии их применения.
На конкретных примерах выявим преимущества и недостатки каждой модели, изучим сценарии их применения.
Что такое база данных
База данных — это набор сведений об объектах, структурированный определенным образом. Обычно базы данных управляются специальным ПО, или системами управления базами данных (СУБД).
В зависимости от вида логическая структура базы данных может иметь различное описание. Это различие влияет на то, какая именно БД используется в разработке конкретного продукта или технологии.
Простейшие типы баз данных
К таким базам данных относятся БД, где хранятся данные с простой структурой: например, список разрешенных IP-адресов для доступа к сети, настройки окружения проекта, список подписчиков на рассылку компании и прочее. Они все еще широко распространены.
Текстовые файлы
Информация об объектах собирается в простых по структуре файлах различных форматов – txt, csv и др. Для разделения полей применяются пробелы, табуляция, запятые, точка с запятой и двоеточие.
Примеры: etc/passwd и etc/fstab в Unix-подобных системах, csv-файлы, ini-файлы и др.
Особенности:
- Просто использовать. Для работы с файлами достаточно примитивного текстового редактора.
- Удобно работать с конфигурационными данными приложений (учетные данные, настройки подключения к удаленным серверам и устройствам, порты и пр.).
Ограничения:
- Сложно установить связи между компонентами данных.
- Не для всех типов информации.
Иерархические базы данных
В отличие от текстовых файлов здесь между хранимыми объектами устанавливаются связи. Объекты делятся на родителей (основные классы или категории объектов) и потомков (экземпляры этих классов или категорий). При этом у каждого потомка может быть не более одного родителя.
Пример иерархической базы данных.Графическим представлением такой базы данных является древовидная структура.
Примеры: Организация файловых систем; DNS и LDAP-соединения.
Особенности:
- Отношения между объектами реализованы в виде физических указателей. Например, в файловой системе путь к папке или файлу строится из имен корневых и вложенных каталогов;
- Моделирование отношений вложенности и подчиненности.
Ограничения: Технология иерархической организации не предполагает связи «многие-ко-многим», а значит, система хранения данных довольно ограничена.
Сетевые базы данных
Эта технология развивает иерархический подход за счет моделирования сложных отношений между объектами. Здесь потомки могут иметь более одного родителя, однако ограничения иерархического подхода сохраняются.
Пример сетевой базы данных.Пример: IDMS — специализированная СУБД для мейнфреймов.
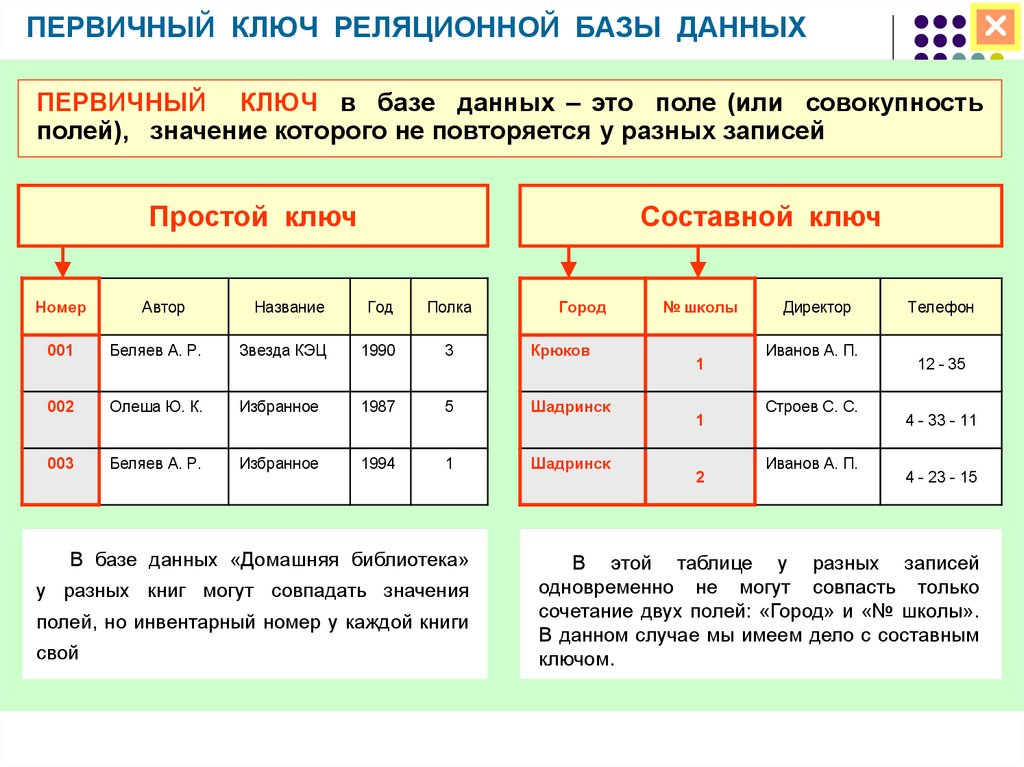
Реляционные базы данных
Данный тип БД является старейшим: теоретические основы подхода заложены британским ученым Эдгаром Коддом в 1970 году. Здесь данные формируются в таблицы из строк и столбцов. В строках приводятся сведения об объектах (значения свойств), а в столбцах — сами свойства объектов (поля).
В строках приводятся сведения об объектах (значения свойств), а в столбцах — сами свойства объектов (поля).
Нормализация
Сложные взаимоотношения объектов в реляционных БД моделируются с помощью внешних ключей – ссылок на другие таблицы. Это позволяет подходить к вопросу проектирования базы данных с позиций нормализации – минимизации избыточности при описании свойств объектов.
Например, если речь идет о меню ресторана, то у каждого блюда есть вес, цена, наименование, калорийность и категория, к которой оно относится — горячие закуски, холодные закуски, первые блюда, десерты, салаты и так далее. Связь между блюдами и категорией выполняется посредством ссылочного поля индекса категории в таблице блюд.
Такой подход позволяет:
- Минимизировать объем базы данных: не нужно каждому блюду прописывать название категории.
- Повысить целостность системы: в указанном примере все блюда привязаны к категориям меню. Добавление блюда без категории невозможно, равно как и указание в качестве ссылки индекса несуществующей категории.

- Упростить масштабирование: новые блюда могут быть добавлены в существующие категории. Также не исключается добавление новых категорий, привязка новых блюд к ним и перераспределение блюд по категориям.
- Повысить отказоустойчивость: за счет оптимальной организации схемы таблиц запросы на выборку и агрегацию будут работать с меньшим объемом данных, а значит, быстрее, чем без нормализации. При увеличении числа записей в таблицах со временем это позволит поддерживать положительный пользовательский опыт.
Наглядный пример моделирования сложных взаимоотношений в реляционных БД приведен на рисунке выше. Здесь мы видим модель базы данных учебного заведения, где есть следующие объекты: ученик, курс, преподаватель, отдел, направление обучения.
Связь преподавателя с отделом организована через секцию и курс (внешние ключи id курса и id преподавателя в таблице Секция, а также Отдел в таблице Курс). Связь ученика с направлением обучения реализована через таблицу Направление обучения студента (внешние ключи id студента и id направления обучения).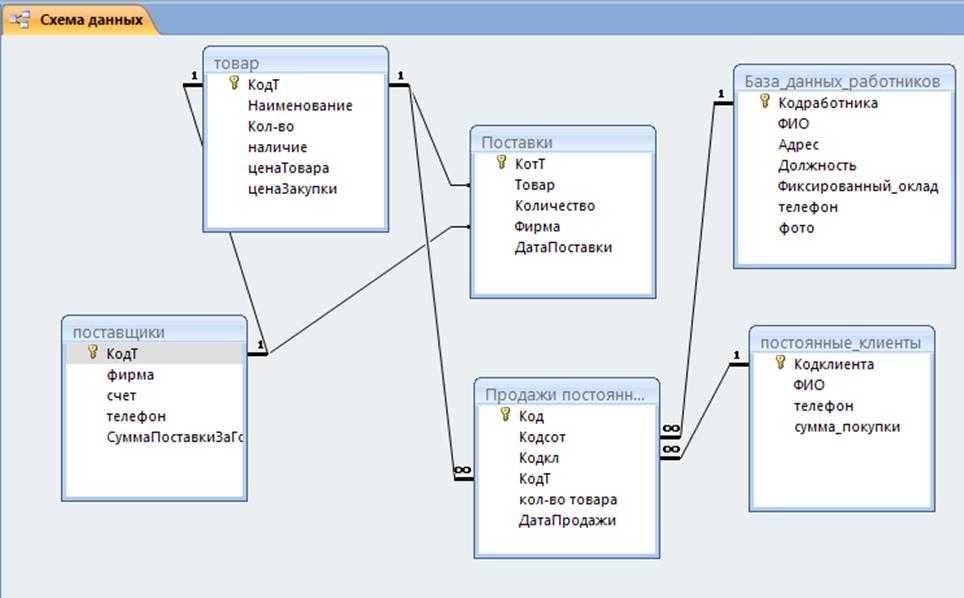
Таким образом, чтобы посчитать, например, количество студентов на курсе и детализировать статистику по преподавателям, необходимо написать запрос с присоединением учеников к направлению, курсу и преподавателям, сделав соответствующую группировку по преподавателям.
Язык запросов SQL
Запросы в реляционных базах данных формируют с помощью структурированного языка SQL. Его предложения позволяют:
- делать выборки,
- проводить агрегации и группировки,
- изменять и удалять данные,
- модифицировать структуру БД (создавать таблицы, поля),
- управлять доступом пользователей к тем или иным операциям и пр.
Денормализация
Помимо нормализации, в реляционных БД существует и обратный процесс — денормализация. Он направлен на перенос наиболее часто используемых полей из внешних таблиц во внутренние. Рассмотрим это на примере мессенджера.
Пользователь (user) оставляет сообщения (messages) в чатах (chat). Структура данных такова, что сообщения связаны с пользователем и чатом через внешние ключи (user_from и user_to, а также chat_id в таблице сообщений; user_id и chat_id в таблице user_chat_link). Поскольку схема нормализована, то различные запросы на выборку, подсчет и агрегацию статистики по чатам, пользователям и сообщениям необходимо выполнять с помощью присоединения внешних таблиц.
Поскольку схема нормализована, то различные запросы на выборку, подсчет и агрегацию статистики по чатам, пользователям и сообщениям необходимо выполнять с помощью присоединения внешних таблиц.
На относительно небольших объемах данных эти запросы будут отрабатывать быстро, а с увеличением размера базы – замедляться. Причина кроется в механизме присоединения. Он основан на построчном сравнении двух и более таблиц по условию соединения — например, равенство chat_id в messages и id в chat. А это дает нагрузку на сервер базы данных, которая с ростом ее размера только увеличивается. Для оптимизации такого рода запросов и существует механизм денормализации.
В таблицу связи пользователя и чата user_chat_link добавлены дублирующие поля имени чата (chat_name) и аватара (chat_logo). Также туда выводятся последнее сообщение (last_msg) и количество непрочитанных сообщений (unread_msg_count).
Теперь для получения указанных выше полей и проведения аналитики по ним можно использовать таблицу user_chat_link без необходимости соединения с таблицей сообщений. Тем не менее, такой подход имеет ограничения.
Тем не менее, такой подход имеет ограничения.
За счет дополнительных полей оптимизируются запросы на чтение и агрегацию данных, однако ценой этого является вынужденная избыточность и усложнение бизнес-логики приложения. В частности, усложняется написание запросов изменения данных (update и delete), а также модификации структуры базы (create).
Использование денормализации должно быть тщательно осмыслено. Нужно быть уверенным в том, что нормализованная структура, оптимизированные запросы и правильно настроенные индексы более не способны удовлетворять критерию быстродействия.
Преимущества реляционного подхода:
- определение сложных отношений между объектами,
- нормализация и денормализация данных,
- структурированный язык запросов,
- богатая история развития и широкое распространение (основной инструмент при разработке различных приложений и сервисов).
Недостатки подхода: жесткая структура сведений об объектах.
Примеры: MySQL, MariaDB, PostgreSQL, SQLite и др.
NoSQL и нереляционные базы данных
Все преимущества и недостатки реляционных БД основаны на жесткой структуризации и типизации сведений об объектах. С одной стороны, можно оптимизировать хранение и индексирование данных за счет нормализации или же денормализации. С другой — сложно организовать хранение и обработку плохо структурированных (например, объекты кэша) или вовсе не структурированных данных (например, данные из нескольких источников).
Для борьбы с этими ограничениями было разработано семейство нереляционных БД. Рассмотрим их подробнее.
Базы данных «Ключ-значение»
Это простейшая разновидность нереляционных БД. Данные хранятся в виде словаря, где указателем выступает ключ.
Особенности:
- Хранение и обработка разных по типу и содержанию данных: в одном хранилище под разными ключами могут находиться файлы, строки, текст, числа, JSON-объекты и другие типы данных.

- Высокая скорость доступа к данным за счет адресного хранения.
- Легкое масштабирование. Можно создать правила шардирования по определенным ключам – например, сессии пользователей разных сайтов хранятся в различных сегментах БД.
Ограничения: Поскольку подход не предполагает жесткой типизации и структуризации данных, то контроль их валидности, а также нейминг ключей отдаются на откуп разработчику.
Примеры: Amazon, DynamoDB, Redis, Riak, LevelDB, различные хранилища кэша – например, Memcached и пр.
Документоориентированные БД
В отличие от баз типа «Ключ-значение» данные здесь хранятся в структурированных форматах – XML, JSON, BSON. Тем не менее, сохраняется адресный доступ к данным по ключу. При этом содержимое документа может иметь различный набор свойств.
Например, каталог профилей пользователей: один в качестве предпочтений указал любимое блюдо, а другой – видеоигру. Поскольку эти сведения нельзя хранить в одном поле ввиду логической и структурной разобщенности, они записываются в отдельные свойства отдельных документов.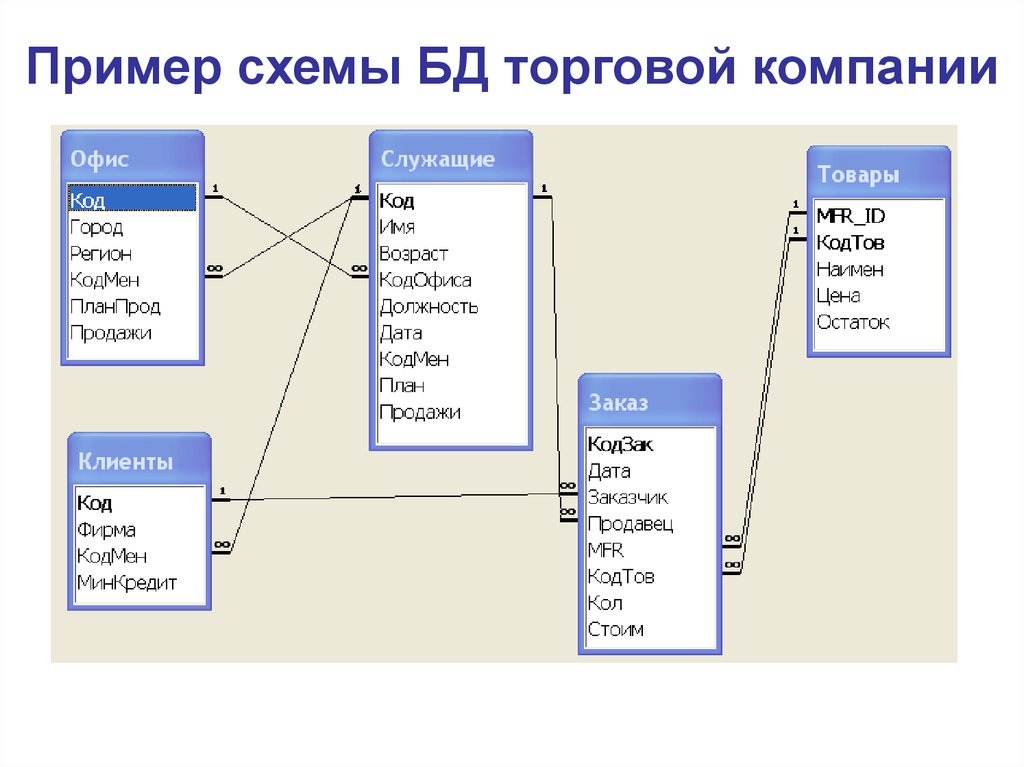 При необходимости можно добавить в документы новые свойства, не нарушив при этом общей целостности данных.
При необходимости можно добавить в документы новые свойства, не нарушив при этом общей целостности данных.
Особенности:
- хорошо подходят для быстрой разработки систем и сервисов, работающих с по-разному структурированными данными,
- легко масштабируются и меняют структуру при необходимости.
Примеры: MongoDB, RethinkDB, CouchDB, DocumentDB.
Графовые базы данных
Это семейство баз предназначено для моделирования сложных отношений с помощью теории графов, где связями выступают ребра графа, а сами объекты – это узлы или вершины.
Пример структуры графовой базы данных.Такой подход может пригодиться при анализе профилей пользователей социальных сетей. Один пользователь подписан на обновления второго, другой пользователь подписан на определенное сообщество и так далее. Также технология может использоваться при анализе экономической активности контрагентов для выявления различных схем мошенничества. Например, можно отследить использование определенных счетов, карт или реквизитов контрагентов в различных операциях.
Особенности: высокая производительность, поскольку обход ребер и вершин значительно быстрее анализа множества внешних и внутренних таблиц и их соединения по условию отбора в реляционных БД.
Примеры: Neo4J, JanusGraph, Dgraph, OrientDB.
Колоночные базы данных
Как можно понять из названия, записи в таких базах хранятся не по строкам, а по столбцам (колонкам). Вместо таблиц здесь используются колоночные семейства. Они содержат ключи, указывающие на формат строки записи информации об объекте. Каждая строка имеет свой набор свойств, что позволяет хранить в рамках одного семейства разно структурированные данные.
Технология активно используется при построении аналитических систем и сервисов, работающих с большими объемами данных.
На рисунке приведен пример колоночного хранения информации о фруктах. Известно три типа фруктов: яблоки, виноград, бананы. Все они объединены в семейство фруктов.
У каждого фрукта индивидуальный набор свойств. Для яблок это цвет, цена и наличие. У винограда это цвет, цена, число ягод в связке и происхождение (импортный или нет). У бананов же это цвет, цена, число в связке и зрелость.
Для яблок это цвет, цена и наличие. У винограда это цвет, цена, число ягод в связке и происхождение (импортный или нет). У бананов же это цвет, цена, число в связке и зрелость.
Чтобы получить детальную сводку по одному типу фруктов, достаточно в запросе указать его идентификатор. При этом можно построить аналитический запрос по общим для всего семейства признакам – например, посчитать число фруктов с группировкой по цвету, вычислить среднюю цену на все фрукты в магазине и т.д.
Особенности:
- С группировкой свойств по колонкам при запросе индексируется меньший объем данных, что обеспечивает высокую скорость его выполнения.
- Широкие возможности масштабирования и модификации структуры — так, при добавлении новых колонок не придется их жестко формализовывать, как в случае с реляционными базами.
Примеры: Cassandra, HBase, ClickHouse.
Базы данных временных рядов
Данный тип БД можно использовать при необходимости отслеживания исторической динамики по ряду показателей. Здесь данные группируются по временным меткам. Базы временных рядом чаще ориентированы на запись, чем на построение сложных аналитических запросов.
Здесь данные группируются по временным меткам. Базы временных рядом чаще ориентированы на запись, чем на построение сложных аналитических запросов.
На рисунке выше приведен пример использования такой БД для отслеживания состояния ПК во времени по ряду показателей – температуре процессора, загрузке системы и потреблению оперативной памяти.
Особенности: Можно обрабатывать постоянный поток входных данных.
Ограничения: Производительность зависит от объема поступающей информации, количества отслеживаемых метрик, а также временного лага между записью новых данных и запросами на чтение
Примеры БД: OpenTSDB, Prometheus, InfluxDB, TimescaleDB
Комбинированные базы
Эта разновидность баз совмещает в себе SQL- и NoSQL-подходы к организации хранения и обработки данных. Этот класс баз включает в себя NewSQL и многомодельные решения. Рассмотрим их подробнее.
Базы данных NewSQL
Данный тип решений для хранения информации стремится обеспечить компромисс между масштабируемостью и согласованностью при сохранении реляционного подхода.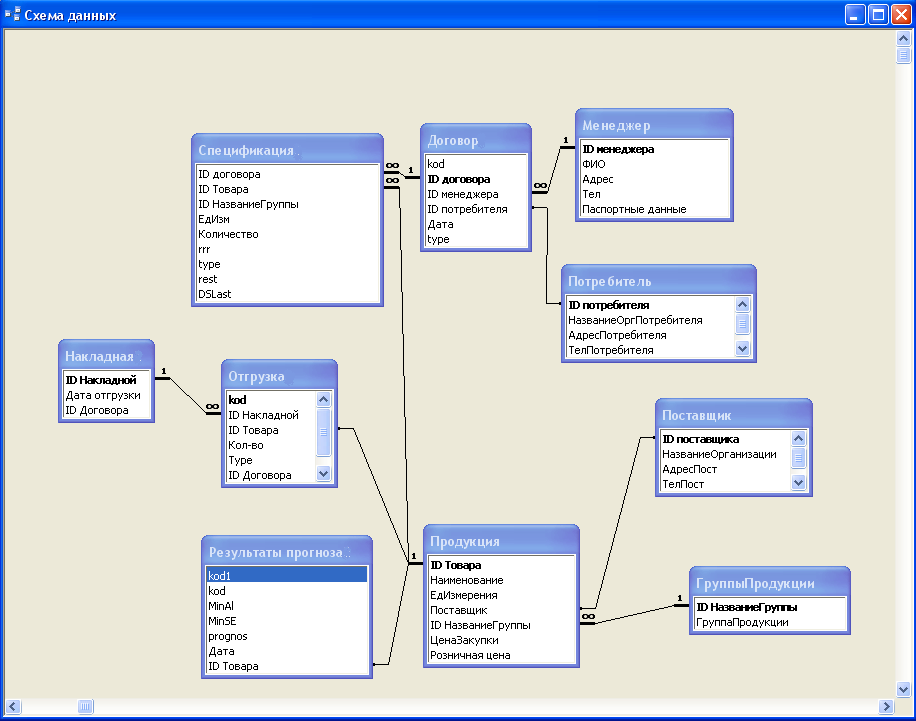
Термин предложил в 2011 году аналитик компании 451 Group Мэтью Аслет. Он отмечал высокую потребность в таких системах для сфер, работающих с критическими данными, — здравоохранение, FinTech и пр. Характерными признаками этих решений являются: использование алгоритмов обеспечения консенсуса (алгоритм Paxos, Raft и др.), шардирование и заточка под горизонтальное масштабирование.
Особенности:
- широкие возможности масштабирования,
- высокая производительность и доступность данных.
Ограничения: Высокие требования к аппаратным ресурсам разработчиков. Но если разрабатываемый продукт является высоконагруженной системой, то применение такой БД имеет смысл.
Примеры баз такого типа: MemSQL, VoltDB, Spanner и др.
Многомодельные базы
Такие БД сочетают в себе несколько подходов к организации данных одновременно. Это обеспечивает функциональное разнообразие при разработке систем с их использованием.
Особенности:
- возможность в одном запросе работать с данными, хранящимися в разных типах баз, не нарушая при этом согласованности;
- обширные возможности масштабирования за счет легкой интеграции новых моделей баз данных в существующую инфраструктуру проекта.
Пример решения данного типа: ArangoDB.
Базы данных в Selectel
В Selectel вы можете запустить готовые облачные базы данных — поддерживаем такие СУБД, как PostgreSQL (в том числе для 1С:Предприятие), MySQL, Redis, TimescaleDB.
Облачные базы данных позволяют исключить работу с инфраструктурой: поднять нужное количество нод можно за несколько минут в панели управления компании. Решение отказоустойчивое и легко масштабируется. На экстренный случай создаются резервные копии для отката состояния базы на срок до семи дней.
Большинство рутинных операций по системному администрированию (настройка, конфигурация, обслуживание и обеспечение безопасности) выполняются специалистами Selectel.
→ Как начать работу с облачными базами данных
Запустите свою базу данных в облаке
Быстрое развертывание самых популярных реляционных и NoSQl-баз данных.
Подробнее
Заключение
В данной статье мы рассмотрели 11 видов баз данных. Каждый имеет свои особенности и ограничения. Решение о выборе того или иного вида необходимо принимать с учетом:
- сложности хранимых данных и взаимосвязей между ними,
- производительности операций чтения/записи и модификации структуры БД на планируемом объеме данных,
- опыта команды разработки,
- стадии жизненного цикла разрабатываемого продукта (производите ли вы доработку действующего решения либо создаете что-то принципиально новое, каковы ваши текущие и перспективные ресурсные возможности).
Автор: Роман Андреев.
Что такое база данных? Типы, примеры и преимущества
Обновлено 29 марта 23 г. 1168 Views
Ниже перечислены некоторые темы, которые помогут вам глубже и проще понять концепцию баз данных. Сначала мы начнем с изучения данных.
Сначала мы начнем с изучения данных.
- Что такое данные?
- Что такое база данных?
- Развитие базы данных
- Компоненты базы данных
- Применение базы данных
- Types of Databases
- Database Architecture
- Advantages of Databases
- Database Languages
- Database Management System
- Examples of Database
- Advantages of the Database Management System
- Недостатки системы управления базами данных
- Заключение
Дальновидные предприятия используют базы данных в своих интересах, выходя за рамки базовых требований к хранению данных и транзакций и анализируя свои данные из нескольких систем.
Данные — это не что иное, как информация, которая собирается в различных форматах, таких как числа, текст, мультимедиа и другие. В контексте вычислений данные могут быть преобразованы в двоичную цифровую форму, что обеспечивает гибкость перемещения и эффективную обработку. Например, Intellipaat может располагать такими данными, как имена, возраст и образовательная квалификация своих студентов, сведения о различных курсах, которые он предлагает, и т. д.
Термин «данные» может использоваться как в единственном, так и во множественном числе. Время от времени мы сталкиваемся с термином необработанные данные. Это не что иное, как данные в самом простом цифровом формате. На заре своего существования, когда важность данных начала набирать обороты, такие термины, как «электронная обработка данных» или просто «обработка данных», стали широко использоваться в ИТ-индустрии.
По мере экспоненциального роста данных с годами, продолжали расти и единицы измерения данных. PwC упомянула, что в 2019 году было сгенерировано 4,4 ZB (зеттабайта) данных.Мировой. С другой стороны, IDC предсказывала, что к 2025 году он вырастет до 175 ZB. Для организации всех этих данных быстро возникли базы данных, системы управления базами данных (СУБД) и системы управления реляционными базами данных (RDBMS).
Что такое база данных?База данных представляет собой систематизированный или организованный набор связанной информации, которая хранится таким образом, чтобы к ней можно было легко получить доступ, получить ее, управлять ею и обновлять. Именно здесь хранятся все данные, очень похожие на библиотеку, в которой хранится широкий спектр книг разных жанров. Думайте о данных как о книгах.
В базе данных вы можете организовать данные в строках и столбцах в виде таблицы. Индексация данных позволяет легко находить и извлекать их снова по мере необходимости. Многие веб-сайты во всемирной паутине управляются с помощью баз данных. Чтобы создать базу данных, чтобы данные были доступны пользователям только через один набор программ, используются обработчики базы данных.
Многие веб-сайты во всемирной паутине управляются с помощью баз данных. Чтобы создать базу данных, чтобы данные были доступны пользователям только через один набор программ, используются обработчики базы данных.
MySQL, SQL Server, MongoDB, Oracle Database, PostgreSQL, Informix, Sybase и т. д. — все это примеры разных баз данных. Эти современные базы данных управляются СУБД. Язык структурированных запросов, или более известный как SQL, используется для работы с данными в базе данных.
Вы также должны проверить различия между популярными базами данных, например Mongodb и Postgresql.
База данных обычно представлена цилиндрической структурой.
Эволюция базы данныхБаза данных началась с файловой системы около 50 лет назад. В свое время она прошла через поколения эволюции.
- Базы данных были впервые представлены в 1968 году как базы данных на основе плоских файлов.
- Затем появилась иерархическая база данных, которая просуществовала до 1980 года.
 На ней была основана первая база данных IBM, IMS (система управления информацией).
На ней была основана первая база данных IBM, IMS (система управления информацией). - Чарльз Бахман разработал первую сетевую модель данных, названную Integrated Data Store (IDS). Она была представлена в начале 1960-х годов и стандартизирована в 1971 году.
- В 1970 году была представлена реляционная база данных.
- Сегодня наступила эра реляционных баз данных и управления базами данных.
Аппаратное обеспечение:
Физические электронные устройства, такие как устройства хранения данных, устройства ввода-вывода и многое другое. Он может действовать как интерфейс между компьютерами и реальными системами.
Программное обеспечение:
Программы для управления и контроля всей базы данных. Сама СУБД является программным обеспечением. Операционная система, прикладные программы базы данных, которые обеспечивают доступ к данным в СУБД, сетевое программное обеспечение, которое совместно использует данные, и т. д. — все это примеры.
д. — все это примеры.
Данные:
Это информация, которая собирается, хранится, используется и обрабатывается СУБД, например, фактические данные, рабочие данные и метаданные.
Процедура:
Это особый набор инструкций и правил по использованию базы данных для проектирования и запуска СУБД, а также для обучения пользователей тому, как работать с ней и управлять ею.
Язык доступа к базе данных:
Это помогает экспортировать данные и получать к ним доступ из базы данных. Чтобы ввести новые данные или обновить или получить данные из базы данных, вы можете написать команды на языке доступа к базе данных. Затем СУБД отображает результаты в удобочитаемой форме.
Watch this video on Oracle SQL Tutorial For Beginners Applications of Database| Field | Application |
| Railways | Reservation information, tickets, train schedules, etc |
| Библиотека | Информация о книге, дата выпуска и т. д.0160 д.0160 |
| Образование | Информация о студентах, курсы, оценки и т. д. |
| Обмен кредитной карты | Информация о карте, платежи и т. д. |
| Широковещательная рассылка | Информация о пользователе, счета и т. д. |
| Учетные записи | Информация об учетной записи, транзакции и т. д. |
| Электронная коммерция0160 | |
| HR Management | Employee information, salary, paychecks, etc. |
| Manufacturing | Supplier information, bills, inventory, etc. |
| Airline | Flight information, schedules, etc. |
В некоторых приложениях вам лучше подойдет хранилище данных. Узнайте об этом в блоге Data Warehouse vs Database.
Типы баз данныхРеляционная база данных:
Это наиболее эффективный способ доступа к структурированной информации.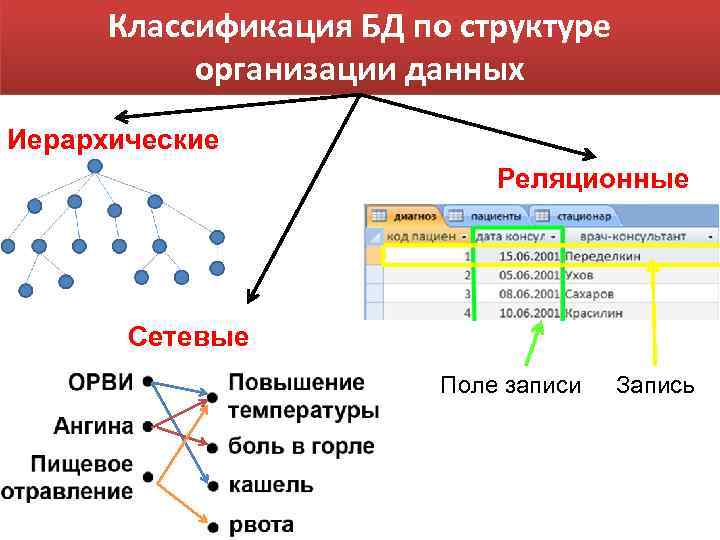 Данные организованы в виде набора таблиц со столбцами и строками.
Данные организованы в виде набора таблиц со столбцами и строками.
Объектно-ориентированная база данных:
Здесь данные представлены в виде объектов, как в объектно-ориентированном программировании.
Распределенная база данных:
Имеет два или более файла, расположенных в разных местах. База данных может находиться в одном физическом месте на нескольких компьютерах или разбросана по разным сетям.
База данных NoSQL:
NoSQL — это нереляционная база данных, содержащая неструктурированные и частично структурированные данные. Его популярность росла по мере того, как веб-приложения стали широко использоваться и стали более сложными.
База данных Graph:
Хранит данные в виде сущностей и отношений между ними.
Облачная база данных:
Эта база данных работает на платформе облачных вычислений, и доступ предоставляется «как услуга».
Централизованная база данных:
CDB располагается, хранится и обслуживается в одном централизованном месте, например, на мейнфрейме, настольном компьютере или ЦП сервера.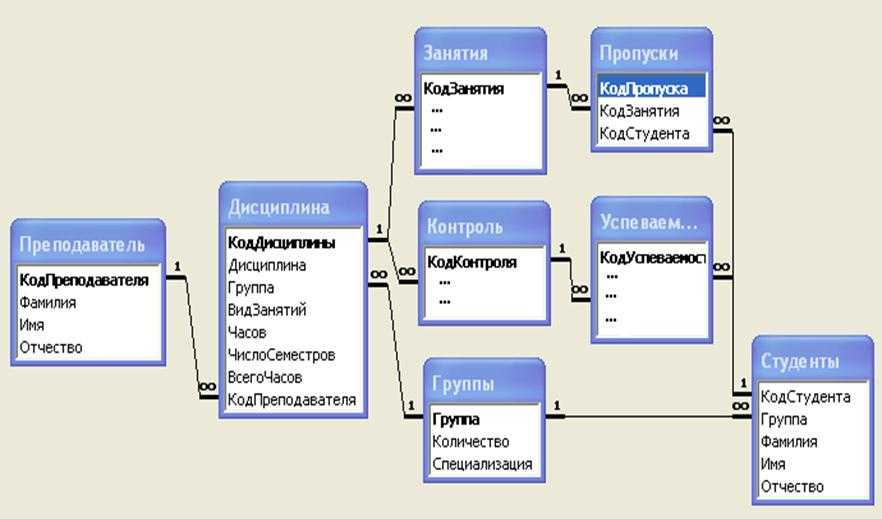
Оперативная база данных:
Также известная как OLTP или онлайновая база данных обработки транзакций, она предназначена для создания или обновления больших объемов данных и хранения транзакций, выполняемых несколькими пользователями в режиме реального времени.
Хранилища данных:
Это центральное хранилище данных. Он хранит текущие и исторические данные в одном месте для аналитической отчетности по всему предприятию.
Архитектура баз данныхАрхитектура баз данных в компаниях и организациях включает применение языков программирования для разработки программного обеспечения. В основном это включает в себя проектирование, внедрение, разработку и обслуживание компьютерных программ, которые хранят и управляют данными для бизнеса.
Архитектура определяет структуру СУБД. Архитектура может быть одноуровневой или многоуровневой, например, одноуровневая, двухуровневая, трехуровневая, многоуровневая и т. д.
Преимущества баз данных- Минимальная избыточность данных
- Повышенная безопасность данных
- Повышенная согласованность
- Меньшее количество ошибок обновления языки
- Более высокая целостность данных из прикладных программ
Ознакомьтесь с нашим курсом SQL, чтобы получить полное представление о концепциях SQL.
СУБД предоставляет пользователям соответствующий язык для выполнения запросов к базам данных и обновлений. По сути, он создает и поддерживает базу данных. Некоторыми примерами языков баз данных являются SQL, Oracle, dBase, MS Access, FoxPro и т. д. Языки баз данных обычно делятся на язык определения данных (DDL), язык управления данными (DCL), язык манипулирования данными (DML) и язык управления транзакциями ( ТКЛ).
Язык определения данных (DDL): помогает определять данные и их связь с другими типами данных и создает базы данных, файлы, таблицы и словари данных в базах данных
Язык управления данными (DCL): управляет доступом к данным и базе данных
Язык манипулирования данными (DML): поддерживает основные операции по обработке данных, например позволяет пользователям вставлять, извлекать, обновлять и удалять данные из базы данных
Управление транзакциями Язык (TCL): Управляет изменениями в базе данных, сделанными оператором DML
Intellipaat предоставляет курсы по базам данных для своих учащихся промышленными экспертами.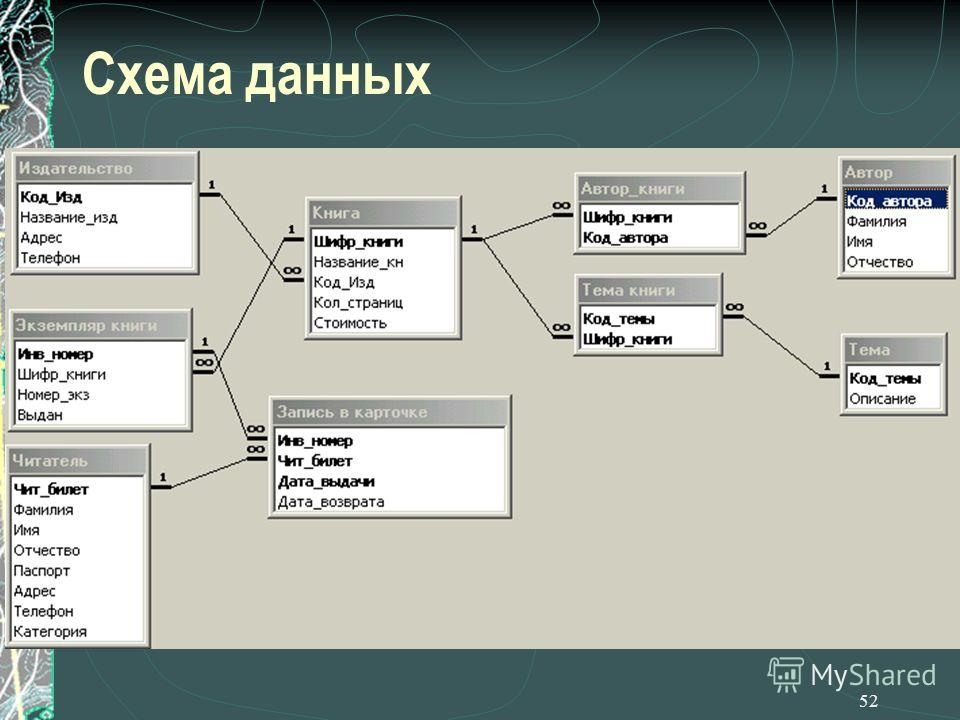 Зарегистрируйтесь сейчас и будьте готовы узнать больше.
Зарегистрируйтесь сейчас и будьте готовы узнать больше.
Система управления базами данных или СУБД — это тип программного обеспечения, помогающего управлять базой данных. Он используется для поиска и хранения информации в базе данных. Он может быть изменен в соответствии с потребностями пользователя. Это добавляет уровень безопасности к базе данных.
Получите 100% повышение!
Овладейте самыми востребованными навыками прямо сейчас!
Примеры базы данныхНесколько примеров базы данных:
Microsoft SQL Server
SQL Server, разработанный Microsoft, представляет собой систему управления реляционными базами данных. Он построен на SQL, стандартном языке запросов для систем управления базами данных.
База данных Oracle
База данных Oracle, разработанная корпорацией Oracle, основана на мультимодельной СУБД.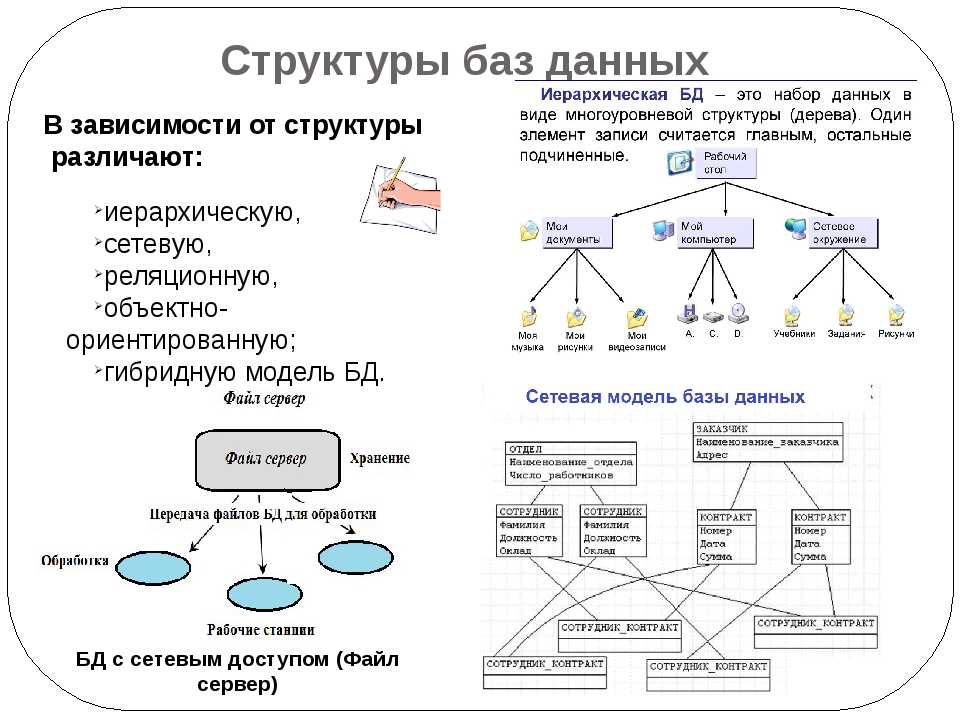 Он широко используется при обработке онлайн-транзакций.
Он широко используется при обработке онлайн-транзакций.
MySQL
Основанная на языке структурированных запросов (SQL), MySQL представляет собой систему управления реляционными базами данных. Он используется на платформах электронной коммерции, хранилищах данных и т. Д. Он широко используется в качестве системы управления веб-базами данных.
IBM Db2
Db2 — это система управления реляционными базами данных, разработанная IBM. Он предназначен для эффективного анализа, хранения и извлечения данных.
PostgreSQL
Система управления реляционными базами данных с открытым исходным кодом. PostgreSQL можно использовать бесплатно. Он широко используется для хранения данных.
Преимущества системы управления базами данных- Данные хранятся более аккуратно и, следовательно, можно хранить больше данных.
- СУБД — это высоконадежная платформа, поэтому конфиденциальные данные и данные с высокой степенью риска также могут безопасно храниться и получать к ним доступ.

- СУБД делает обработку данных очень простой.
- Несогласованность данных значительно снижается благодаря хорошо спроектированной СУБД.
- Доступ к данным возможен быстро.
- Обслуживание программного и аппаратного обеспечения, необходимого для СУБД, обычно дорого.
- Чем больше данных загружается в СУБД, тем больше места на диске она занимает.
- Использование СУБД может показаться очень сложным для человека, не имеющего технического образования.
- Поскольку все данные хранятся в одной СУБД, в случае сбоя программного обеспечения могут быть потеряны все данные организации.
С помощью баз данных и других средств бизнес-аналитики и вычислительных инструментов специалисты в организациях могут использовать организованные данные для улучшения и повышения эффективности принятия решений, повышения гибкости и масштабируемости. Различные типы баз данных, а также изменения в подходах к технологиям, достижения в области автоматизации и облачных вычислений заставляют базы данных двигаться в новых направлениях.
Различные типы баз данных, а также изменения в подходах к технологиям, достижения в области автоматизации и облачных вычислений заставляют базы данных двигаться в новых направлениях.
Расписание курсов
Схема базы данных: типы, примеры и преимущества
Дата публикации
Автор Джули Полито
Наличие правильной схемы является ключевым фактором, поддерживающим современный анализ данных. Схемы баз данных могут сбивать с толку, но эта статья поможет вам спроектировать правильную схему для ваших хранилищ данных, начиная с самого определения «схемы базы данных».
Что такое схема базы данных?
В контексте моделей данных «схема» означает общую модель данных и дизайн структур данных. Процесс разработки схемы известен как моделирование данных.
Процесс разработки схемы известен как моделирование данных.
Частично структурированные данные — это быстрорастущая часть постоянно растущего разнообразия данных в современной аналитике данных. «Схема» — это логическая схема, существующая в полуструктурированном документе.
Однако слово «схема» может также означать физическую часть базы данных. Многие платформы облачных данных, в том числе Amazon Redshift, Snowflake и Azure Synapse Analytics, используют концепцию «базы данных» в качестве основной структурной единицы. Одна база данных может содержать множество схем, а схемы содержат объекты схемы, такие как таблицы, столбцы и ключи данных.
Типы моделей схемы базы данных
Самый простой тип схемы базы данных — это плоская модель . Плоская модель содержит отдельные таблицы, не связанные друг с другом. Это также означает, что все столбцы представляют собой простые строки и числа, а не полуструктурированные. Наиболее широко используемыми схемами плоской базы данных являются файлы CSV.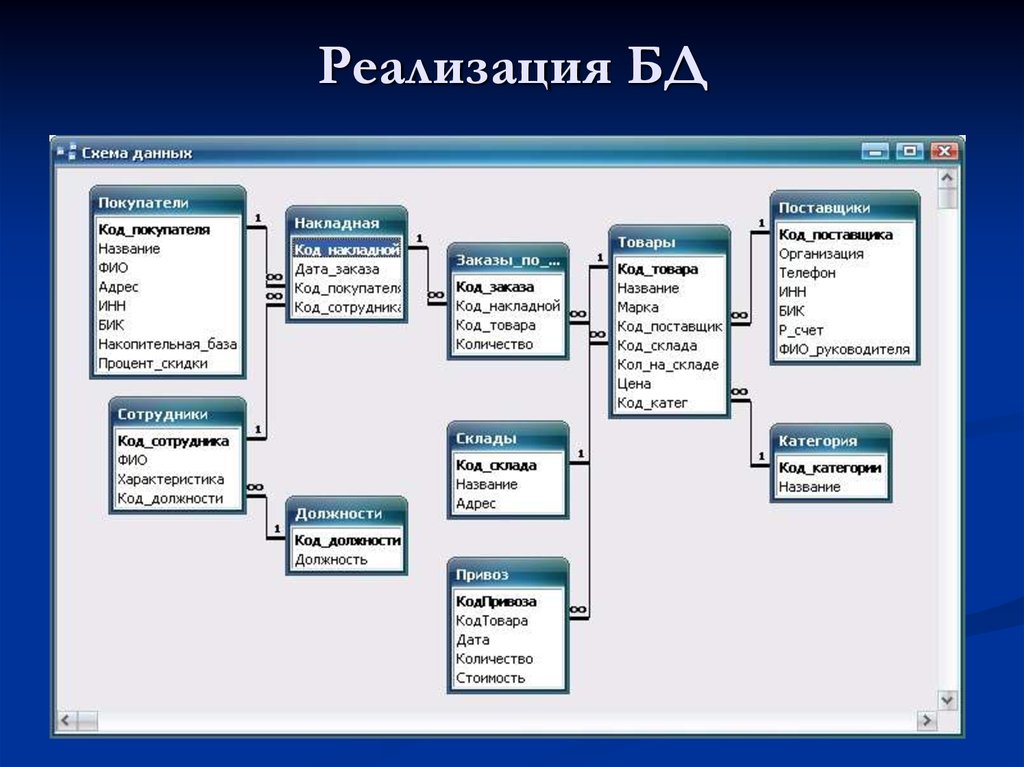
Иерархическая модель схемы базы данных содержит отношения родитель-потомок, точно так же, как генеалогическое древо. Иерархические модели используются уже более 50 лет, особенно для высокопроизводительных систем OLTP, таких как Adabas. Каждый документ JSON или XML содержит иерархическую модель данных.
В модели графа точки данных, известные как узлы, связаны друг с другом с помощью «ребер». Как и в реальном мире, нет никаких ограничений на то, какие узлы могут быть связаны. Это делает графовые модели идеальными для кодирования знаний в виде RDF, например, с использованием Neo4j или Gremlin. Модели Network представляют собой подмножество графовых моделей, в которых схема определяет четкую иерархию. Например, одна учетная запись содержит много транзакций, а не наоборот.
Реляционные модели имеют таблицы, которые связаны друг с другом с помощью столбцов первичного и внешнего ключа.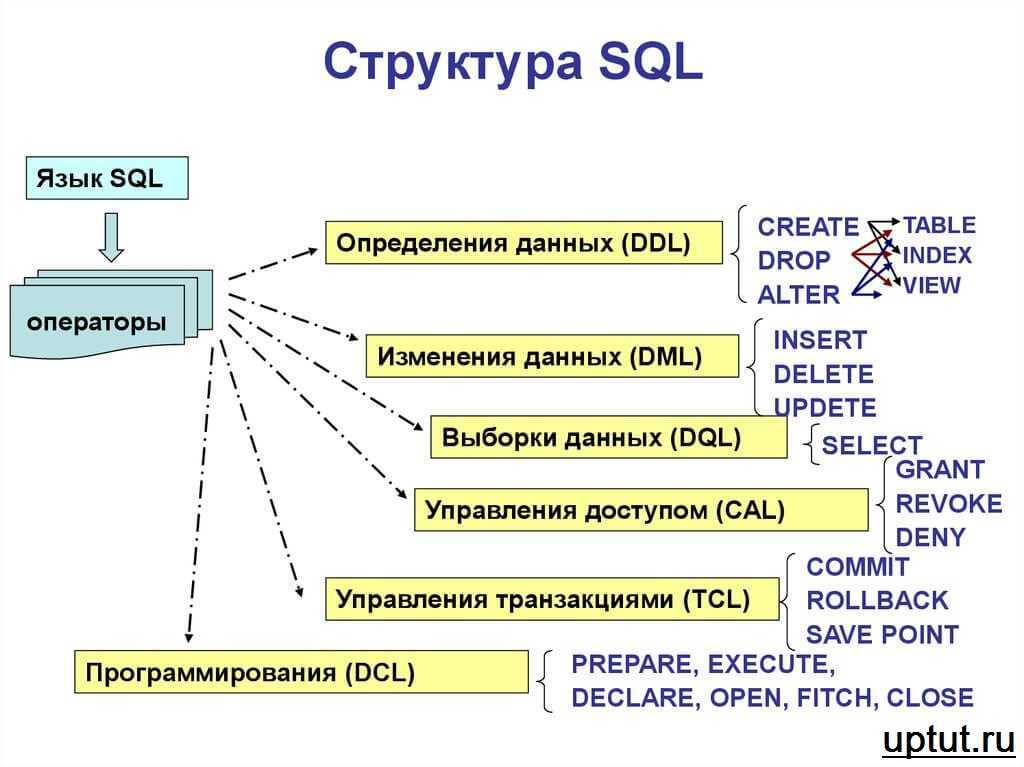 В графическом виде схема реляционной базы данных называется диаграммой отношений сущностей (ERD). Если у вас есть ERD, у вас есть реляционная модель данных.
В графическом виде схема реляционной базы данных называется диаграммой отношений сущностей (ERD). Если у вас есть ERD, у вас есть реляционная модель данных.
Для целей представления данных ничто не сравнится с простотой наличия одной таблицы транзакционных фактов, связанной со многими таблицами измерений «по» критериям. При рисовании в виде ERD такая модель имеет форму звезды и поэтому известна как 9.0455 звездная схема .
В звездообразной схеме может быть значительное количество повторений. Например, в измерении даты каждый отдельный атрибут уровня года повторяется 365 раз. Вы можете каскадировать их в подтаблицы, например, день – месяц – год. Это делает ERD более похожим на снежинку, поэтому она известна как схема снежинки .
Примеры диаграмм взаимосвязей сущностей
В реляционных моделях наиболее распространенной связью является связь «один ко многим». Например, если одна группа может содержать много проектов, она будет отображаться следующим образом:
Иногда отношения более сложные.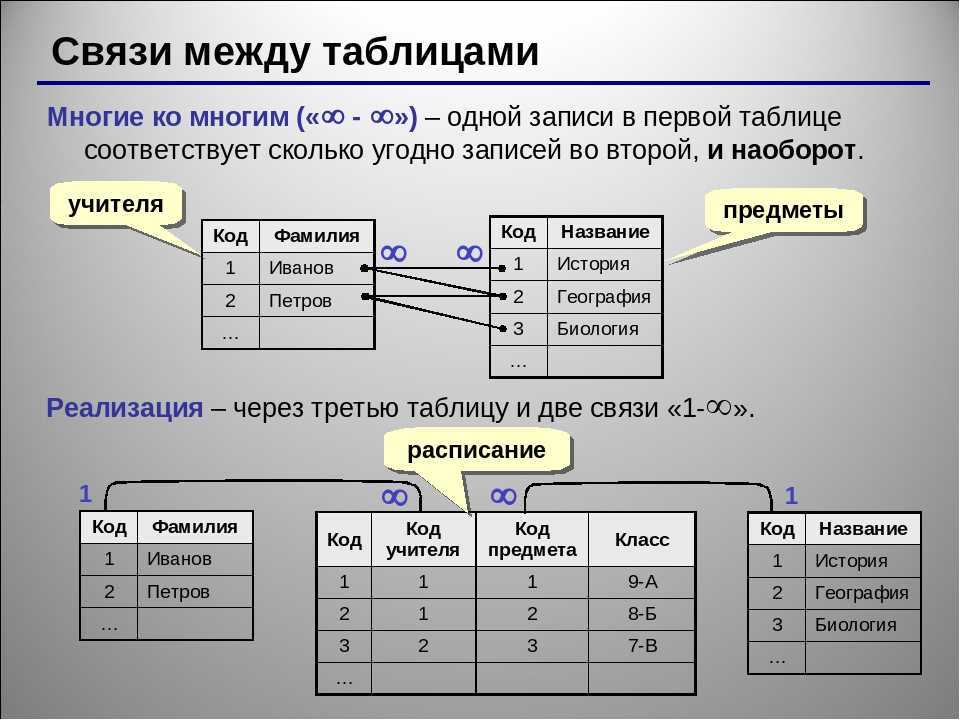 Например, один студент посещает много классов, а в одном классе много студентов. Отношение «многие ко многим» обычно заменяется сущностью-пересечением, подобной этой:
Например, один студент посещает много классов, а в одном классе много студентов. Отношение «многие ко многим» обычно заменяется сущностью-пересечением, подобной этой:
В качестве схемы «звезда» с фактологической таблицей посещаемости занятий она может выглядеть следующим образом:
3
3
3
И, наконец, схема снежинки, вот так. Обратите внимание на добавление подтаблиц, что приводит к меньшему повторению данных, но большему количеству объединений:
Как обрабатывать полуструктурированные данные
Основная особенность полуструктурированных данных, таких как JSON, заключается в том, что это наиболее удобный формат для записи данных.
На самом деле, полуструктурированные данные хорошо структурированы, но гибким образом, что оставляет бесконечное пространство для маневра для изменений — известное как «дрейф схемы ». ” Строки в полуструктурированной таблице могут не иметь абсолютно одинаковых атрибутов, и нет никакого способа выяснить это, кроме как пойти дальше и прочитать их. Это называется «9Схема 0455 при чтении. »
Это называется «9Схема 0455 при чтении. »
Целью интеграции данных является повышение пригодности данных при сохранении исходного высокого качества данных. Обычно это означает «выравнивание» полуструктурированных данных путем преобразования их в реляционную модель.
- Иерархии → Несколько таблиц
- Схема при чтении → Именованные столбцы
Однако полуструктурированные форматы все еще могут быть полезным способом отложить интеграцию данных, например, в таблицах Data Vault Satellite.
Что такое нормализация данных и почему она так важна?
Нормализация данных — это процесс моделирования данных (разработка схемы). Это гарантирует, что реляционная модель придерживается основных средств контроля качества. Основной стандарт известен как третья нормальная форма (3NF) и имеет следующие требования:
- Таблицы имеют уникальный идентификатор, устраняющий дублирование
- Отношения относятся «один ко многим», а не «многие ко многим», что снижает путаницу
- Столбцы имеют определенные типы данных, что позволяет избежать несогласованности
- Столбцы содержат отдельные значения, такие как строки и числа, открывая путь для эффективной интеграции, которая решает проблемы децентрализации
На самом деле звездообразные схемы, используемые почти в каждом хранилище данных, намеренно несколько денормализованы .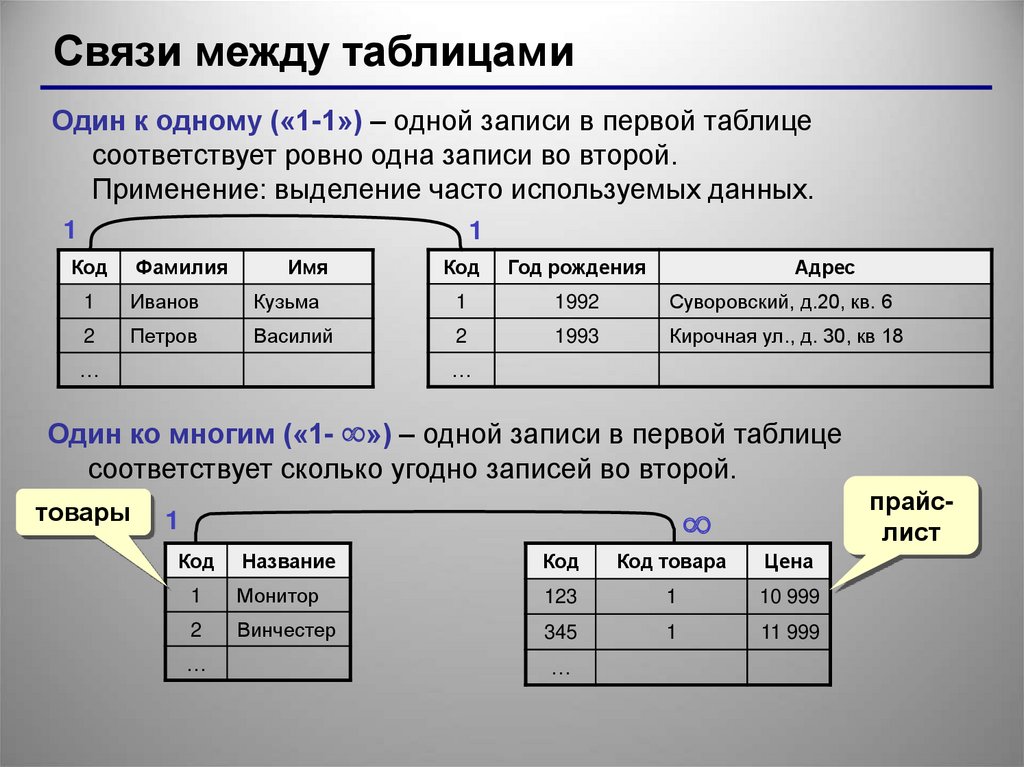 Они часто содержат дублирование, чтобы сделать запросы проще и быстрее. Ключом к успешной реализации звездообразной схемы является использование преобразованного и нормализованного уровня данных в качестве источника. Таким образом, осуществляется контроль качества данных, чтобы гарантировать, что данные сохранят свою ценность.
Они часто содержат дублирование, чтобы сделать запросы проще и быстрее. Ключом к успешной реализации звездообразной схемы является использование преобразованного и нормализованного уровня данных в качестве источника. Таким образом, осуществляется контроль качества данных, чтобы гарантировать, что данные сохранят свою ценность.
Важность и преимущества хорошего дизайна базы данных
Наличие архитектуры данных с четко определенной и, в идеале, нормализованной схемой помогает поддерживать качество данных за счет использования ограничений базы данных, таких как согласованное форматирование и обеспечение ссылочной целостности во время поиска. Это также помогает свести к минимуму дублирование данных. Обе эти вещи лежат в основе надежной аналитики.
С точки зрения безопасности наличие схемы помогает управлять доступом к данным. Это особенно актуально при защите информации, позволяющей установить личность (PII), которая обычно требует дополнительных уровней защиты, таких как токенизация.
Узнайте о различиях между моделированием предметной области, физическим моделированием и логическим моделированием.
Понимание модели данных базы данных
Лучший способ понять систему интеграции данных на верхнем уровне — это посмотреть, какие модели данных или схемы использовались в различных логических слоях данных.
По мере того, как потребление данных проходит через бронзовую, серебряную и золотую стадии, модели данных также меняются. По этой причине вы должны знать все о том, как сравнивать хранилище данных, звездообразную схему и 3NF.
- На ранних этапах, на бронзовой стадии, модели данных диктуются источниками и могут быть полуструктурированными или даже неструктурированными. Это место для плоских, иерархических, графических и сетевых моделей.
- На промежуточном, серебряном уровне преобладают реляционные модели, такие как 3NF и Data Vault
- Для представления пользователям лучше всего использовать схемы «звезда» или «снежинка»
Как лучше всего перемещать данные между этими слоями? Короткий ответ — процесс извлечения, загрузки и преобразования (ELT).