Системы управления базами данных. Назначение СУБД. Классификация СУБД. Основные функции СУБД.
⇐ ПредыдущаяСтр 9 из 12Следующая ⇒
Важная информация,комментарии для понимания.
Система управления базами данных (СУБД) —совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
Примеры СУБД – Oracle, Microsoft Access, Paradox, Firebird, Sqlite, еще очень много.
Назначение СУБД:
1. Компактное хранение данных (без дублирования)
2. Оптимизация доступа к данным
3. Логическая целостность (согласованность данных)
4. Универсальный интерфейс (язык или протокол), позволяющий задавать структуру данных, изменять и извлекать их неизвестному заранее алгоритму.
Если уж вы доучились до ГОСов, то для вас тут комментировать нечего, все очевидно.
Классификация СУБД (нашел 6 видов классификаций):
1. По модели данных (в классической теории баз данных, модель данных есть формальная теория представления и обработки данных в системе управления базами данных (СУБД), которая включает, по меньшей мере, три аспекта:
1) аспект структуры: методы описания типов и логических структур данных в базе данных;
2) аспект манипуляции: методы манипулирования данными;
3) аспект целостности: методы описания и поддержки целостности базы данных.
Аспект структуры определяет, что из себя логически представляет база данных, аспект манипуляции определяет способы перехода между состояниями базы данных (то есть способы модификации данных) и способы извлечения данных из базы данных, аспект целостности определяет средства описаний корректных состояний базы данных.):
a. Иерархические
(здесь и ниже внимательно смотрите, что именно я комментирую. СУБД Х типа построена на основе Х типа модели данных. Значит если я описываю модель данных, то это не прямое описание СУБД, а описание модели данных, с которой она работает;
Иерархическая модель данных — это модель данных, где используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами (в программировании применительно к структуре данных дерево устоялось название братья).
Первые системы управления базами данных использовали иерархическую модель данных.)
b. Сетевые
(Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков.
Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L;
каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L)
c. Реляционные
(Реляционная модель данных включает следующие компоненты:
Структурный аспект (составляющая) — данные в базе данных представляют собой набор отношений.
Аспект (составляющая) целостности — отношения (таблицы) отвечают определенным условиям целостности. РМД поддерживает декларативные ограничения целостности уровня домена (типа данных), уровня отношения и уровня базы данных.
Аспект (составляющая) обработки (манипулирования) — РМД поддерживает операторы манипулирования отношениями (реляционная алгебра, реляционное исчисление).
Кроме того, в состав реляционной модели данных включают теорию нормализации.)
d. Объектно-ориентированные
Объектно-ориентированная (объектная) СУБД — система управления базами данных, основанная на объектной модели данных.
Эта система управления обрабатывает данные как абстрактные объекты, наделённые свойствами и использующие методы взаимодействия с другими объектами окружающего мира.
e. Объектно-реляционные
(Объектно-реляционная СУБД (ОРСУБД) — реляционная СУБД (РСУБД), поддерживающая некоторые технологии, реализующие объектно-ориентированный подход: объекты, классы и наследование реализованы в структуре баз данных и языке запросов.
Объектно-реляционными СУБД являются, например, широко известные Oracle Database, Informix, DB2, PostgreSQL.)
2. По степени распределенности:
a. Локальные СУБД
(все части локальной СУБД размещаются на одном компьютере)
b. Распределенные СУБД
(части СУБД на двух и более компьютерах)
3. По способу доступа к БД:
a. Файл-серверные
(универсальный интерфейс (язык или протокол), позволяющий задавать структуру данных, изменять и извлекать их неизвестному заранее алгоритму. В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД располагается на каждом клиентском компьютере (рабочей станции). Доступ СУБД к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на процессор файлового сервера. Недостатки: потенциально высокая загрузка локальной сети; затруднённость или невозможность централизованного управления; затруднённость или невозможность обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность. Применяются чаще всего в локальных приложениях, которые используют функции управления БД; в системах с низкой интенсивностью обработки данных и низкими пиковыми нагрузками на БД.
На данный момент файл-серверная технология считается устаревшей, а её использование в крупных информационных системах — недостатком.
Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.
b. Клиент-серверные
(Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет доступ к БД непосредственно, в монопольном режиме. Все клиентские запросы на обработку данных обрабатываются клиент-серверной СУБД централизованно. Недостаток клиент-серверных СУБД состоит в повышенных требованиях к серверу. Достоинства: потенциально более низкая загрузка локальной сети; удобство централизованного управления; удобство обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность.
Примеры: Oracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL, Caché, ЛИНТЕР.)
c. Встраиваемые
(Встраиваемая СУБД — СУБД, которая может поставляться как составная часть некоторого программного продукта, не требуя процедуры самостоятельной установки. Встраиваемая СУБД предназначена для локального хранения данных своего приложения и не рассчитана на коллективное использование в сети. Физически встраиваемая СУБД чаще всего реализована в виде подключаемой библиотеки. Доступ к данным со стороны приложения может происходить через SQL либо через специальные программные интерфейсы.
Примеры: OpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server Compact, ЛИНТЕР.)
4. По степени универсальности:
a. Специального назначения
(Ориентированы на какую-либо конкретную предметную область или на информационные потребности конкретной группы пользователей; пример – IMBASE для автоматизации проектных и конструкторских разработок)
b. Общего назначения
(не ориентированы на какую-либо… смотри выше)
5. По применению (эта классификация есть далеко не во всех источниках, она довольно условна, так что можно и не писать наверное):
a. Профессиональные
b. Персональные
6. По стратегии работы с внешней памятью (не факт, что это является классификацией, это скорее еще один способ деления, но как классификация он ни в одном источнике не указан, советую не расписывать данный пункт, но если вдруг спросят, к сведению принять)
a. СУБД с непосредственной записью
(СУБД, в которых все измененные блоки данных незамедлительно записываются во внешнюю память при поступлении сигнала подтверждения любой транзакции. Такая стратегия используется только при высокой эффективности внешней памяти)
b. СУБД с отложенной записью
(СУБД, в которых изменения аккумулируются в буферах внешней памяти до наступления любого из следующих событий:
1.контрольной точки;
2.конец пространства во внешней памяти, отведенное под журнал — СУБД выполняет контрольную точку и начинает писать журнал сначала, затирая предыдущую информацию;
3.останов (не остановка, а именно «останов», опечатки тут нет) — СУБД ждёт, когда всё содержимое всех буферов внешней памяти будет перенесено во внешнюю память, после чего делает отметки, что останов базы данных выполнен корректно;
4.При нехватке оперативной памяти для буферов внешней памяти.
Такая стратегия позволяет избежать частого обмена с внешней памятью и значительно увеличить эффективность работы СУБД)
Основные функции СУБД (писал с лекций Платоновой):
1. Хранение, извлечение и обновление данных
2. Каталог, доступный конечным пользователям
3. Поддержка транзакций
4. Службы управления параллельной работой
5. Службы восстановления
6. Службы контроля доступа к данным
7. Поддержка обмена данными
8. Службы поддержки целостности данных
9. Службы поддержки независимости от данных
10. Вспомогательные службы
http://www.bseu.by/it/tohod/lekcii5_3.htm
https://ru.wikipedia.org/wiki/Система_управления_базами_данных (и ссылки с нее)
http://gos.translate23.ru/bd/102-naznachenie-subd-arkhitektura-i-osnovnye-komponenty-subd
Рекомендуемые страницы:
lektsia.com
| Реализации систем управления базами данных |
|---|
dic.academic.ru
Система управления базами данных — это… Что такое Система управления базами данных?
Систе́ма управле́ния ба́зами да́нных (СУБД) — совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных[1].
Основные функции СУБД
Обычно современная СУБД содержит следующие компоненты:
- ядро, которое отвечает за управление данными во внешней и оперативной памяти, и журнализацию,
- процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода,
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД
- а также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
Классификации СУБД
По модели данных
Примеры:
По степени распределённости
- Локальные СУБД (все части локальной СУБД размещаются на одном компьютере)
- Распределённые СУБД (части СУБД могут размещаться на двух и более компьютерах).
По способу доступа к БД
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД располагается на каждом клиентском компьютере (рабочей станции). Доступ СУБД к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на процессор файлового сервера. Недостатки: потенциально высокая загрузка локальной сети; затруднённость или невозможность централизованного управления; затруднённость или невозможность обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность. Применяются чаще всего в локальных приложениях, которые используют функции управления БД; в системах с низкой интенсивностью обработки данных и низкими пиковыми нагрузками на БД.
На данный момент файл-серверная технология считается устаревшей, а её использование в крупных информационных системах — недостатком[2].
Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.
Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет доступ к БД непосредственно, в монопольном режиме. Все клиентские запросы на обработку данных обрабатываются клиент-серверной СУБД централизованно. Недостаток клиент-серверных СУБД состоит в повышенных требованиях к серверу. Достоинства: потенциально более низкая загрузка локальной сети; удобство централизованного управления; удобство обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность.
Примеры: Oracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL, Caché, ЛИНТЕР.
Встраиваемая СУБД — СУБД, которая может поставляться как составная часть некоторого программного продукта, не требуя процедуры самостоятельной установки. Встраиваемая СУБД предназначена для локального хранения данных своего приложения и не рассчитана на коллективное использование в сети. Физически встраиваемая СУБД чаще всего реализована в виде подключаемой библиотеки. Доступ к данным со стороны приложения может происходить через SQL либо через специальные программные интерфейсы.
Примеры: OpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server Compact, ЛИНТЕР.
См. также
Примечания
Литература
Отечественная
- Когаловский М.Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с. — ISBN 5-279-02276-4
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. — ISBN 978-5-94774-736-2
Переводная
- Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: Вильямс, 2005. — 1328 с. — ISBN 5-8459-0788-8 (рус.) 0-321-19784-4 (англ.)
- Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: Вильямс, 2003. — 1436 с. — ISBN 0-201-70857-4
- Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс = Database Systems: The Complete Book. — Вильямс, 2003. — 1088 с. — ISBN 5-8459-0384-X
Иностранная
Ссылки
На русском языке
На английском языке
dic.academic.ru
СУБД
Чем крупнее компания, чем дольше она существует на рынке, тем больше данных скапливается в ее архивах. Причем, в соответствии с реалиями сегодняшнего дня, вся информация хранится в электронной форме. По данным исследования Aberdeen Group, три года назад в крупных компаниях объемы хранимой информации увеличивались на 32% ежегодно. Сегодня бизнес-аналитика оперирует уже многотерабайтными объемами данных, а сами хранилища отчетливо перемещаются на облачные платформы.
Однако какая бы бесценная для бизнеса информация не хранились на серверах компании, она должна соответствовать нескольким критериям, так как если данные заносятся бессистемно и хранятся в разных форматах – польза от затраченных для этого ресурсов весьма сомнительна.
СУБД представляет собой набор программ, которые в общей сложности управляют организацией, хранением данных в БД. В целом такие системы классифицируются в зависимости от их структуры данных и их типов. СУБД принимает запросы прикладных программ и инструктирует операционную систему для передачи соответствующей информации. Новые категории данных, могут быть добавлены в БД без нарушения существующей схемы. Организации могут использовать один вид СУБД для осуществления ежедневных операций, а затем размещать необходимую информацию на другой машине, которая работает с другой системой управления, более подходящей для случайных запросов и анализа. Серверами резервного копирования баз данных, как правило, являются многопроцессорные системы с большим объемом ОЗУ и крупными дисковыми RAID-массивами. СУБД фактически является сердцем большинства приложений для работы с БД.
Каким требованиям должна отвечать современная СУБД?
Информационное хранилище должно постоянно пополняться новыми данными в соответствии с ритмом жизни компании, это же касается и формирование новых категорий учета.
При этом вносить информацию должен иметь возможность любой новый сотрудник. То же касается и обслуживания данной инфраструктуры со стороны системного администратора, формирования новых выборок данных со стороны аналитиков с разным уровнем допуска к информации и с разными профилями анализируемых данных.
Необходимо отметить, что количество информации увеличивается не только в объеме, но и качественно. В результате появляется необходимость одновременной работы с ней нескольких экспертов. Кроме того, появляется возможность привлечения специализированных экспертов для выполнения сложных процедур анализа данных (Data mining — об интеллектуальном анализе данных). Сегодня не только для формирования будущей стратегии, но и для выполнения повседневных задач все большее значение имеет прогнозная аналитика, которая для формирования верного вектора развития использует объективные, а не субъективные данные.
Помимо этого единая база данных упрощает формирования отчетности как отдельным подразделениям компании, так и всей компании в целом для подачи документов в государственные инстанции или их предоставления для ознакомления внешним экспертным комиссиям. Единая база позволяет в автоматическом режиме обновлять документацию, относящуюся к нормативно-справочной информации (НСИ). Дополнительно общая база данных позволяет оперировать информацией в своеобразной унифицированной форме, делая процедуры анализа информации более единообразными в рамках компании.
Еще одним плюсом от единого подхода к хранению информации является гораздо более простая процедура резервирования, снижение времени простоя после сбоя, обеспечение безопасности данных в плане распределения прав доступа, более прозрачная процедура миграции на новые версии программного и аппаратного обеспечения.
Рынок СУБД в России
Российские СУБД на сегодняшний день находятся в довольно тяжелом положении — разработки крупных компаний выдавливают из рынка российские системы. Однако, до сих пор есть несколько СУБД, которые продолжают оставаться на плаву за счёт внедрения в государственные структуры.
Классификация
В зависимости от архитектуры построения системы управления базами СУБД могут подразделяться на следующие типы:
Файловые системы
Представим себе, что имеется некоторый носитель информации определенной емкости, устройство для чтения-записи на этот носитель в режиме произвольного доступа и прикладные программы, которые используют конкретный носитель для ввода-вывода информации во внешнюю память. В этом случае, каждая прикладная программа должна знать где и в каком месте хранятся необходимые данные. Так как прикладных программ больше, чем носителей информации, то несколько прикладных программ могут использовать один накопитель. Что произойдет, если одной из прикладных программ потребуется дозаписать свои данные на диск? Может произойти наложение: ситуация в которой данные одной программы будут перезаписаны другой программой. Важным шагом в развитии информационных систем явился переход к использованию централизованных систем управления файлами. С точки зрения прикладной программы, файл – именованная область внешней памяти, в которую можно записывать данные, и из которой можно их считывать. Для того чтобы была возможность считать информацию из какой либо области внешней памяти необходимо знать имя этого сектора(имя файла), размер самой области и его физическое расположение. Сама система управления файлами выполняет следующие функции:
- распределение внешней памяти;
- отображение имеет файлов в соответствующие адреса во внеш-ней памяти;
- обеспечение доступа к данным.
Рассмотрение особенностей реализации отдельных систем управления файлами выходит за рамки данной темы. На данном этапе достаточно знать, что прикладные программы видят файл как линейную последовательность записей и могут выполнить над ним ряд операций. Основные операции сфайлами в СУФ:
- создать файл (определенного типа и размера)
- открыть ранее созданный файл
- прочитать из файла определенную запись
- изменить запись
- добавить запись в конец файла
СУБД крупных ЭВМ
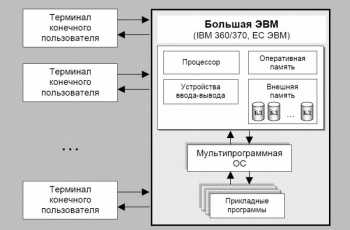
Данный этап развития связан с организацией баз данных на больших машинах типа IBM 360/370, ЕС-ЭВМ и различных моделях фирмы Hewlett Packard. В таком случае информация хранилась во внешней памяти центральной ЭВМ. Пользователями баз данных были фактически задачи, запускаемые в основном в пакетном режиме. Интерактивный режим доступа обеспечивался с помощью консольных терминалов, которые не обладали собственными вычислительными ресурсами (процессором, оперативной памятью, внешней памятью) и служили только устройствами ввода-вывода для центральной ЭВМ. Программы доступа к БД писались на различных языках программирования и запускались как обычные числовые программы. Особенности данного этапа:
- Все СУБД базируются на мощных мультипрограммных ОС (Unix и др.).
- Поддерживается работа с централизованной БД в режиме распределенного доступа. Функции управления распределением ресурсов выполняются операционной системой.
- Поддерживаются языки низкого манипулирования данными, ориентированные на навигационные методы доступа к данным. Значительная роль отводится администрированию данных.
- Проводятся серьезные работы по обоснованию и формализации реляционной модели данных. Была создана первая система (System R), реализующая идеологию реляционной модели данных.
- Проводятся теоретические работы по оптимизации запросов и управлению распределенным доступом к централизованной БД, было введено понятие транзакции.
- Большой поток публикаций по всем вопросам теории БД. Результаты научных исследований активно внедряются в коммерческие СУБД.
- Появляются первые языки высокого уровня для работы с реляционной моделью данных (SQL), однако отсутствуют стандарты для этих языков.
Настольные СУБД
Компьютеры стали ближе и доступнее каждому пользователю. Исчез благоговейный страх рядовых пользователей перед непонятными и сложными языками программирования. Появилось множество программ, предназначенных для работы неподготовленных пользователей. Простыми и понятными стали операции копирования файлов и переноса информации с одного компьютера на другой, распечатка текстов, таблиц и других документов. Системные программисты были отодвинуты на второй план. Каждый пользователь мог себя почувствовать полным хозяином этого мощного и удобного устройства, позволяющего автоматизировать многие аспекты собственной деятельности. И, конечно, это сказалось и на работе с базами данных. Новоявленные СУБД позволяли хранить значительные объемы информации, они имели удобный интерфейс для заполнения, встроенные средства для генерации различных отчетов. Эти программы позволяли автоматизировать многие учетные функции, которые раньше велись вручную. Постоянное снижение цен на персональные компьютеры сделало такое ПО доступным не только для организаций и фирм, но и для отдельных пользователей.
Компьютеры стали инструментом для ведения документации и собственных учетных функций. Это все сыграло как положительную, так и отрицательную роль в области развития баз данных. Кажущаяся простота и доступность персональных компьютеров и их программного обеспечения породила множество дилетантов. Много было создано систем-однодневок, которые не отвечали законам развития и взаимосвязи реальных объектов. Однако доступность персональных компьютеров заставила пользователей из многих областей знаний, которые ранее не применяли вычислительную технику в своей деятельности, обратиться к ним. И спрос на развитые удобные программы обработки данных заставлял поставщиков программного обеспечения поставлять все новые системы, которые принято называть настольными СУБД. Значительная конкуренция среди поставщиков заставляла совершенствовать эти конфигурации, предлагая новые возможности, улучшая интерфейс и быстродействие систем, снижая их стоимость. Наличие на рынке большого числа СУБД, выполняющих сходные функции, потребовало разработки методов экспорта-импорта данных для этих систем и открытия форматов хранения данных. Но и в этот период появлялись любители, которые вопреки здравому смыслу разрабатывали собственные СУБД, используя стандартные языки программирования. Это был тупиковый вариант, потому что дальнейшее развитие показало, что перенести данные из нестандартных форматов в новые СУБД было гораздо труднее, а в некоторых случаях требовало таких трудозатрат, что легче было бы все разработать заново, но данные все равно надо было переносить на новую более перспективную СУБД. И это тоже было результатом недооценки тех функции, которые должна была выполнять СУБД. Особенности этого этапа следующие:
- Стандартизация высокоуровневых языков манипулирования данными (разработка и внедрение стандарта SQL92 во все СУБД).
- Все СУБД были рассчитаны на создание БД в основном с монопольным доступом. И это понятно. Компьютер персональный, он не был подсоединен к сети, и база данных на нем создавалась для работы одного пользователя. В редких случаях предполагалась последовательная работа нескольких пользователей, например, сначала оператор, который вводил бухгалтерские документы, а потом главбух, который определял проводки, соответствующие первичным документам.
- Большинство СУБД имели развитый и удобный пользовательский интерфейс. В большинстве существовал интерактивный режим работы с БД как в рамках описания БД, так и в рамках проектирования запросов. Кроме того, большинство СУБД предлагали развитый и удобный инструментарий для разработки готовых приложений без программирования.
- Во всех настольных СУБД поддерживался только внешний уровень представления реляционной модели, то есть только внешний табличный вид структур данных.
- При наличии высокоуровневых языков манипулирования данными типа реляционной алгебры и SQL в настольных СУБД поддерживались низкоуровневые языки на уровне отдельных строк таблиц.
- В настольных СУБД отсутствовали средства поддержки ссылочной и структурной целостности базы данных. Эти функции должны были выполнять приложения, однако скудость средств разработки приложений иногда не позволяла это сделать, и в этом случае эти функции должны были выполняться пользователем, требуя от него дополнительного контроля при вводе и изменении информации, хранящейся в БД.
- Наличие монопольного режима работы фактически привело к вырождению функций администрирования БД.
- Сравнительно скромные требования к аппаратному обеспечению со стороны настольных СУБД. Вполне работоспособные приложения, разработанные, например, на Clipper, работали на PC 286. В принципе, их даже трудно назвать полноценными СУБД. Яркие представители этого семейства — очень широко использовавшиеся до недавнего времени СУБД Dbase (DbaseIII+, DbaseIV), FoxPro, Clipper, Paradox.
Продукты
Каталог СУБД-решений и проектов доступен на TAdviser.
История
Базы данных использовались в вычислительной технике с незапамятных времен. В первых компьютерах использовались два вида внешних устройств – магнитные ленты и магнитные барабаны. Емкость магнитных лент была достаточно велика. Устройства для чтения-записи магнитных лент обеспечивали последовательный доступ к данным. Для чтения информации, которая находилась в середине или конце магнитной ленты, необходимо было сначала прочитать весь предыдущий участок. Следствием этого являлось чрезвычайно низкая производительность операций ввода-вывода данных во внешнюю память. Магнитные барабаны давали возможность произвольного доступа, но имели ограниченный объем хранимой информации. Разумеется, говорить о какой-либо системе управления данными во внешней памяти, в тот момент не приходилось. Каждая прикладная программа, которой требовалось хранить данные во внешней памяти, сама определяла расположение каждого блока на магнитной ленте. Прикладная программа также брала на себя функции информационного обмена между оперативной памятью и устройствами внешней памяти с помощью программно-аппаратных средств низкого уровня.
Такой режим работы не позволяет или очень затрудняет поддержку на одном носителе нескольких архивов долговременно хранимой информации. Кроме того, каждой прикладной программе приходилось решать проблемы именования частей данных и структуризации во внешней памяти. История БД фактически началась с появлением магнитных дисков. Такие устройства внешней памяти обладали существенно большей емкостью, чем магнитная лента и барабаны, а также обеспечивали во много раз большую скорость доступа в режиме произвольной выборки. В отличие от современных систем управления, которые могут применяться для самых различных баз данных, подавляющее большинство ранее разработанных СУБД были тесно связаны с пользовательской базой для того, чтобы увеличить скорость работы, хоть и в ущерб гибкости. Первоначально СУБД применялись только в крупных организациях с мощной аппаратной поддержкой, необходимой для работы с большими объемами данных.
Рост производительности персональных вычислительных машин спровоцировал развитие СУБД, как отдельного класса. К середине 60-х годов прошлого века уже существовало большое количество коммерческих СУБД. Интерес к базам данных увеличивался все больше, так что данная сфера нуждалась в стандартизации. Автор комплексной базы данных Integrated Data Store Чарльз Бахман (Charles Bachman) организовал целевую группу DTG (Data Base Task Group) для утверждения особенностей и организации стандартов БД в рамках CODASYL — группы, которая отвечала за стандартизацию языка программирования COBOL. Уже в 1971 году был представлен свод утверждений и замечаний, который был назван Подход CODASYL, и спустя некоторое время появились первые успешные коммерческие продукты, изготовленные с учетом замечаний вышеупомянутой рабочей группы. В 1968 году отметилась и компания IBM, которая представила собственную СУБД gпод названием IMS.
Фактически данный продукт представлял собой компиляцию утилит, которые использовались с системами System/360 на шаттлах Аполлон. Решение было разработано согласно коцпетам CODASYL, но при этом была применена строгая иерархия для структуризации данных. В свою очередь в варианте CODASYL за базис была взята сетевая СУБД. Оба варианта, меж тем, были приняты сообществом позднее как классические варианты организации работы СУБД, а сам Чарльз Бахман в 1973 году получил премию Тьюринга за работу Программист как навигатор. В 1970 году сотрудник компании IBM Эдгар Кодд, работавший в одном из отделений Сан Хосе (США), в котором занимались разработкой систем хранения, написал ряд статей, касающихся навигационных моделей СУБД. Заинтересовавшись вопросом он разработал и изложил несколько инновационных подходов касательно оптимальной организаци систем управления БД. Работа Кодда внесла значительный вклад в развитие СУБД и является действительным основоположником теории реляционных баз данных. Уже 1981 году Э.Ф.Кодд создал реляционную модель данных и применил к ней операции реляционной алгебры.
Ссылки
Официальный сайт MySQL
Ресурс об SQL и клиент/серверные технологии
Официальный сайт СУБД ЛИНТЕР
Инструмент для поддержки администрирования MySQL сервера через WWW
Лекции для студентов СКГМИ (СТУ)
Российское системное ПО
Курсы по СУБД (Microsoft SQL Server, Access, Oracle, MySQL)
Курсы по СУБД CronosPRO (Официальный сайт)
См. также
информация
Способы организации СУБД
Иерархические СУБД
Многомерная СУБД
Реляционная СУБД
Сетевая СУБД
Объектно-ориентированная СУБД
Объектно-реляционная СУБД
Информатика
Логика в информатике
www.tadviser.ru
Вопрос 48 . Системы управления базами данных субд: назначение и функции.
Система управления базами данных СУБД — это совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД другими пользователями.
Современные СУБД позволяют:
1. обеспечить пользователей языковыми средствами описания и манипулирования данными
2. обеспечить поддержку логических моделей данных схему представления физических данных в компьютере
3. обеспечить операции создания и манипулирования данными выбор, вставка, обновление и т.п.
4. обеспечить защиту и целостность согласованность данных, поскольку при коллективном режиме работы многих пользователей возможно использование общих физических данных.
и многие другие функции.
49 . СУБД Access: объекты и средства их создания.
Одним из наиболее распространенных БД в России является Access, входящий в комплект Майкрософт Офиса для профессиональной работы, представляющий собой простое, но мощное средство хранения и обработки данных.
Рассмотрим основные понятия теории реляционных баз данных.
Таблица — это основной объект базы данных, предназначенный для хранения элементарных данных, состоящий из записей строк и полей столбцов.
Элементарное данное — единица данных, описывающая один признак характеристику одного объекта предметной области. Его аналогом в структуре двумерной таблицы является информация, расположенная в одной ячейке таблицы.
Поле — совокупность логически связанных элементарных данных, описывающих один и тот же признак для всех объектов предметной области. В структуре двумерной таблицы его аналогом является столбец.
Запись — это совокупность логически связанных полей, данные из которых описывают все признаки одного объекта предметной области. В структуре
двумерной таблицы ее аналогом является строка.
50 . Создание бд. Описание поля: тип, размер, формат и прочие свойства поля ms Access.
Основные свойства полей базы данных:
Имя поля — определяет, как следует обращаться к данным этого поля при автоматических операциях с базой по умолчанию имена полей используются в качестве заголовков столбцов таблиц. Имя поля может содержать до 64 символов буквы, цифры, пробелы и специальные символы, за исключением точки, восклицательного знака, квадратных скобок.
Имя поля не может начинать с пробела.
Тип поля — определяет тип данных, которые могут содержаться в данном поле.
Размер поля — определяет предельную длину данных, которые могут размещаться в данном поле.
Формат поля — определяет способ форматирования данных в ячейках, принадлежащих полю.
Маска вода — определяет форму, в которой вводятся данные в поле.
Подпись — определяет заголовок столбца таблицы для данного поля. Если подпись не указана, то в качестве заголовка столбца используется свойство Имя поля.
Значение по умолчанию — то значение, которое вводится в ячейки поля автоматически.
Условие на значение — ограничение, используемое для проверки правильности ввода данных. Это средство автоматизации ввода используется, как правило, для данных, имеющих числовой тип, денежный тип или тип даты.
Сообщение об ошибке — текстовое сообщение, которое выдается автоматически при попытке ввода в поле данных, не удовлетворяющих условиям, заданным в свойстве Условие на значение. — ограничение, используемое для проверки правильности ввода данных. Это средство автоматизации ввода используется, как правило, для данных, имеющих числовой тип, денежный тип или тип даты.
Обязательное поле — свойство, определяющее обязательность заполнения данного поля при наполнении базы.
Пустые строки — свойство, разрешающее ввод пустых строковых данных. От свойства Обязательное поле отличается тем, что относится не ко всем типом данных, а лишь к текстовым.
Индексированное поле — если поле обладает этим свойством, все операции, связанные с поиском или сортировкой записей по значению, хранящемуся в данном поле, существенно ускоряется. Кроме того, для индексированных полей можно сделать так, что значение в записях будут проверяться по этому полю на наличие повторов, что позволяет автоматически исключить дублирование данных.
studfiles.net
Система управления базами данных (субд), назначение и основные функции
База данных – это информационная модель, позволяющая упорядоченно хранить данные о группе объектов, обладающих одинаковым набором свойств. Программное обеспечение, предназначенное для работы с базами данных, называется система управления базами данных (СУБД). СУБД используются для упорядоченного хранения и обработки больших объемов информации.
СУБД организует хранение информации таким образом, чтобы ее было удобно:
просматривать,
пополнять,
изменять,
искать нужные сведения,
делать любые выборки,
осуществлять сортировку в любом порядке.
Классификация баз данных:
По характеру хранимой информации: — Фактографические (картотеки),— Документальные (архивы)
По способу хранения данных: — Централизованные (хранятся на одном компьютере),— Распределенные (используются в локальных и глобальных компьютерных сетях).
По структуре организации данных: — Табличные (реляционные),— Иерархические,
Информация в базах данных структурирована на отдельные записи, которыми называют группу связанных между собой элементов данных. Характер связи между записями определяет два основных типа организации баз данных: иерархический и реляционный.
В иерархической базе данных записи упорядочиваются в определенную последовательность, как ступеньки лестницы, и поиск данных может осуществляться последовательным «спуском» со ступени на ступень. Иерархическая база данных по своей структуре соответствует структуре иерархической файловой системы.
Реляционная база данных, по сути, представляет собой двумерную таблицу. Столбцы таблицы называются полями: каждое поле характеризуется своим именем и топом данных. Поле БД – это столбец таблицы, содержащий значения определенного свойства.
В реляционной БД используются четыре основных типов полей:
Числовой,
Символьный (слова, тексты, коды и т.д.),
Дата (календарные даты в форме «день/месяц/год»),
Логический (принимает два значения: «да» — «нет» или «истина» — «ложь»).
Строки таблицы являются записями об объекте. Запись БД – это строка таблицы, содержащая набор значения определенного свойства, размещенный в полях базы данных.
Системы управления базами данных позволяют объединять большие объемы информации и обрабатывать их, сортировать, делать выборки по определенным критериям и т. п.
Современные СУБД дают возможность включать в них не только текстовую и графическую информацию, но и звуковые фрагменты и даже видеоклипы. Простота использования СУБД позволяет создавать новые базы данных, не прибегая к программированию, а пользуясь только встроенными функциями. СУБД обеспечивают правильность, полноту и непротиворечивость данных, а также удобный доступ к ним. Популярные СУБД — FoxPro, Access for Windows, Paradox. Для менее сложных применений вместо СУБД используются информационно-поисковые системы (ИПС), которые выполняют следующие функции:
хранение большого объема информации;
быстрый поиск требуемой информации;
добавление, удаление и изменение хранимой информации;
вывод ее в удобном для человека виде.
studfiles.net
Типы систем управления базами данных и их преимущества
- Подробности
- января 26, 2016
- Просмотров: 22046
База данных используются для сбора, хранения и группировки данных. Хорошая система управления базами данных (СУБД) обеспечивает эффективное управление сохраненными данными, предоставляет пользователям и администратору доступ к ней, а также поддерживает безопасность данных. В этой статье я перечислю и опишу различные типы систем управления базами данных и их преимущества.
Проще говоря
Система управления базами данных или менеджер базы данных — это набор компьютерных программ, которые позволяют пользователям создавать и получать доступ к данным, и предоставляет им способы извлечения и изменения этих данных.
Базы данных организуют связанные данные таким образом, чтобы они могли быть легко доступны для пользователей. СУБД предназначена для управления информацией, которая включает в себя управление правами доступа пользователей для просмотра, добавления, удаления и изменения записей. IBM для информационной системы менеджмента (IMS) была одной из первых систем управления базами данных.
База данных обрабатывает запросы пользователей и обеспечивает целостность данных. Это означает, что данные защищены, хотя всегда открыта для доступа.
На основе числа поддерживаемых пользователей, система управления базами данных может быть классифицирована как однопользовательская или многопользовательская. Однопользовательская база данных поддерживает только одного пользователя одновременно, что означает, что другие пользователи должны ждать, пока первый закончит с ней работу. Многопользовательская база данных, как следует из ее названия, позволяет нескольким пользователям получить доступ к данным одновременно, но с ограниченными правами для каждого пользователя.
Базы данных системы могут также быть классифицированы как централизованные или распределенные. Централизованная база данных системы состоит из процессора, который обрабатывает несколько запоминающих устройств вместе. Централизованная база данных поддерживает центральное расположение при обращении к данным с нескольких сайтов. Распределенная база данных имеет данные распределенные по нескольким компьютерам или сетям. Эта база данных также как централизованная может иметь центральное расположение. Безопасность достигается за счет сохранения основной базы данных в центральном расположении с копией данных по другим адресам. Данные периодически синхронизируются так, что изменения, внесенные в одном месте, отражались на остальных.
Типы систем управления базами данных и их преимущества.
Flat File
База данных с двумерными файлами. Двухмерная модель наиболее простая. Каждая строка текста содержит одну запись обычно через запятую. Также могут быть использованы другие разделители. База данных может содержать записи без ссылок между ними. Она не может содержать несколько таблиц, как в реляционных БД. Для реализации двумерных файлов используется электронная таблица или текстовый процессор. Примерами базы данных с двумерными файлами являются Excel и filemaker.
Преимущества
- Все записи хранятся в одном месте. Простая структура.
- Хорошо работает для небольших баз данных и имеет минимальные программные и аппаратные требования.
Иерархическая
Иерархическая база данных состоит из записей, которые связаны друг с другом. Каждая запись-это набор полей, каждое из которых содержит одно значение. Иерархическая база данных устроена таким образом «родитель-ребенок». Для лучшего понимания, представьте, что это перевернутая елка.
Иерархическая база данных представлена в виде коробки. Отношения между родителем и ребенком может быть один-к-одному или один-ко-многим». Родитель может иметь или не иметь стрелку, указывающую на ребенка, но ребенок должен иметь стрелку, указывающую в направлении своего родителя. Иерархическая база данных может не справиться с такой структурой данных как «многие-ко-многим», для них применяются реляционные базы данных. Примером иерархической базы данных является программа adabas (Адаптируемая база данных).
Преимущества
- Так как большинство связей имеют тип «один к одному», структура базы данных проста для понимания даже для непрограммистов. После нахождения первой записи, вам не нужно делать просмотр индекса. Вы можете просто следовать за родителями, по указателям, которые направят вас к следующей записи.
- Так как данные хранятся в единой базе, просматривать их становится легче. Модификации, если таковые имеются, могут быть легко добавлены в файл, заменяя существующие данные.
- Иерархическая база данных легка для администрирования и поддержания путем изменения записей в соответствующих областях.
Реляционная
Реляционная база данных — это набор элементов, организованных в таблицы, состоящие из строк, называемых записями, и столбцов, называемых полями, с которых данные могут быть доступны в любое время. Реляционная база данных может быть доступна с использованием языков запросов таких как SQL. Запросы используются для создания, изменения или извлечения данных.
В реляционной базе данные как правило, хранятся в виде таблиц. Каждая таблица имеет первичный ключ. В первичный ключ используется как уникальный идентификатор для каждой записи. Никакие две записи не могут иметь одинаковый первичный ключ. Понятие внешние ключи используется для установления отношения между двумя или более таблицами. Внешний ключ — это поле одной таблицы, который однозначно определяет строку в другой таблице. Он используется для перекрестных ссылок и связывание данных между таблицами. Примерами реляционной базы данных являются MySQL и SQL.
Преимущества
- Права пользователя могут быть ограничены в зависимости от того, какие данные должны быть видимыми или модифицируемыми. Это предоставляет большую безопасность.
- Для работы с иерархической базой данных, необходимо открыть корневой каталог. В отличие от этого, реляционная база данных дает большую гибкость доступа.
- Можно избежать дублирования данных, таким образом, это уменьшит размер базы данных. Это снижает требования к памяти и повышает работоспособность.
Сетевая
Сетевая база данных была создана для представления сложных данных более эффективно. Она похожа на иерархическую модель, но в этом случае потомок может иметь несколько родителей и наоборот. Она формирует общее граф или сеть иерархий.
Схема, подсхемы, и язык управления данными являются ключевыми компонентами этой базы данных. Схема является концептуальным представлением базы данных в то время как подсхемы, содержат данные в базе данных. Язык управления данными определяет характеристики и структуру данных для того, чтобы манипулировать данными. В конечном итоге она была заменена на реляционную модель, что сделало хранение и изменение данные одновременно более простым. Примеры систем сетевых базы данных включает интегрированное хранилище данных (IDS) и интегрированные системы управления базами данных (IDMS).
Преимущества
- Как и в иерархической базе данных, компоненты сетевой базы данных могут иметь несколько-родительских отношений.
- Так как всегда есть связь между родителем и потомком, целостность данных сохраняется.
- База данных тратит меньше времени на ведение учета устранения избыточных таблиц, что повышает эффективность и общую производительность.
Объектно-ориентированная
Как видно из названия, это база данных, состоит из объектов, используемый в объектно-ориентированном программировании. Эти базы данных хорошо работают с объектно-ориентированными языками, такими как Perl, C++, Java, smalltalk и другие.
Похожие объекты группируются в класс и каждый объект определенного класса, называется экземпляром. Классы позволяют программисту определять данные, которые не включены в программу. Так как классы определяют только те данные, которые запускаются, они не смогут получить доступ к другим данным, таким образом исключается возможность повреждения данных и обеспечивается безопасность. Классы обмениваться данными между собой через сообщения, называемые методами. Они имеют свойство наследования, которое означает, что если класс определен, подкласс может наследовать свойства, не определяя его собственные методы. Это означает, что подкласс может реализовать тот же код. Это ускоряет разработку программ. Примеры объектно-ориентированных систем баз данных включают Versant.
Преимущества
- Классы позволяют группировать объекты, имеющие сходные характеристики. Суперклассы могут быть созданы для объединения всех классов. Это приводит к уменьшению избыточности данных и возможности повторного использования класса, что позволяет упростить обслуживание данных.
- База данных может хранить различные типы данных, такие как аудио, видео, изображения, и т.д.
- Язык запросов может быть не нужен, так как все изменения происходят прозрачно при доступе к объектам.
Многомерная
Многомерная база данных тесно связана с оперативной аналитической обработкой, которая является частью бизнес-аналитики и хранилища данных. Интерактивная аналитическая обработка (OLAP) позволяет легко извлекать и просматривать данные через разные точки. Она может быть использован для доступа к многомерным данным. Многомерные базы данных могут быть визуализированы в виде кубов данных, представляющих различные размеры имеющихся данных. Она сочетает в себе преимущества иерархических и реляционных баз данных. Примеры многомерных баз данных включают Oracle Essbase и Microsoft SAS.
Преимущества
- Она отвечает на запросы быстрее, чем реляционные базы данных, за счет многомерного индексирования и оптимизированного хранения.
- Вывод многомерных баз данных имеет табличный вид, который не достижим в случае реляционных баз данных.
Объектно-реляционная
Объектно-реляционная база данных предлагает лучшее из обоих миров. Она обладает всеми преимуществами реляционной базы данных в сочетании с понятиями объектно-ориентированного программирования, такими как объекты, классы, наследование и полиморфизм. Она функционирует аналогично реляционным базам данных. Примеры включают IBM DB2.
Преимущества
- Она может легко получать данные через полиморфизм. Повторное использование данных становится проще.
- Поскольку она вбирает в себя лучшее из реляционных и объектно-ориентированных баз данных, масштабируемость — не является для нее проблемой. Внутри классов могут храниться огромные объемы данных.
Гибридная
Гибридная система представляет собой комбинацию из двух или более баз данных. Гибриды используются, когда один тип базы данных не является достаточным для обработки всех запросов. Она поддерживает хранение и на диске, и в памяти. При доступе к базе данных используется оперативная память, в то время как для хранения основной базы используется диск. При использовании оперативной памяти повышается производительность, в то время как данные на диске более долговечны и экономичны. Гибридная база данных сочетает в себе оба этих преимущества. Примеры включают ALTIBASE HDВ.
Преимущества
- Гибридная конструкция предназначена, чтобы пожинать преимущества двух или более типов баз данных, из которых она составлена.
- Извлечение данных из памяти вместо диска, делает операции намного быстрее. Это дает гибридным базам данных высокий балл по производительности.
Это были различные типы систем управления базами данных. Каждый Тип имеет свои преимущества, но решающим выбором является та, которая наилучшим образом подходит для конкретной организации и зависит от характера и объема данных, которые она должна обрабатывать.
Читайте также
juice-health.ru