Использование UTF-8 в HTTP заголовках
Как известно, HTTP 1.1 — это текстовой протокол передачи данных. HTTP сообщения закодированы, используя ISO-8859-1 (которую условно можно считать расширенной версией ASCII, содержащей умляуты, диакритику и другие символы, используемые в западноевропейских языках). При этом в теле сообщений можно использовать другую кодировку, которая должна быть обозначена в заголовке «Content-Type». Но что делать, если нам необходимо задать non-ASCII символы не в теле сообщения, а в самих заголовках? Наверное, самый распространенный кейс — это проставление имени файла в «Content-Disposition» заголовке. Это, казалось бы, довольно распространенная задача, но ее реализация не так очевидна.
TL;DR: Используйте кодировку, описанную в RFC 6266, для «Content-Disposition» и преобразуйте текст в латиницу (транслит) в остальных случаях.
Небольшая вводная в кодировки
В статье упоминаются и используются кодировки US-ASCII (часто именуемую просто ASCII), ISO-8859-1 и UTF-8. 8 = 256 вариантов.
8 = 256 вариантов.
ISO-8859-1 — кодировка, предназначенная для западноевропейских языков. Содержит французскую диакритику, немецкие умляуты и т.д.
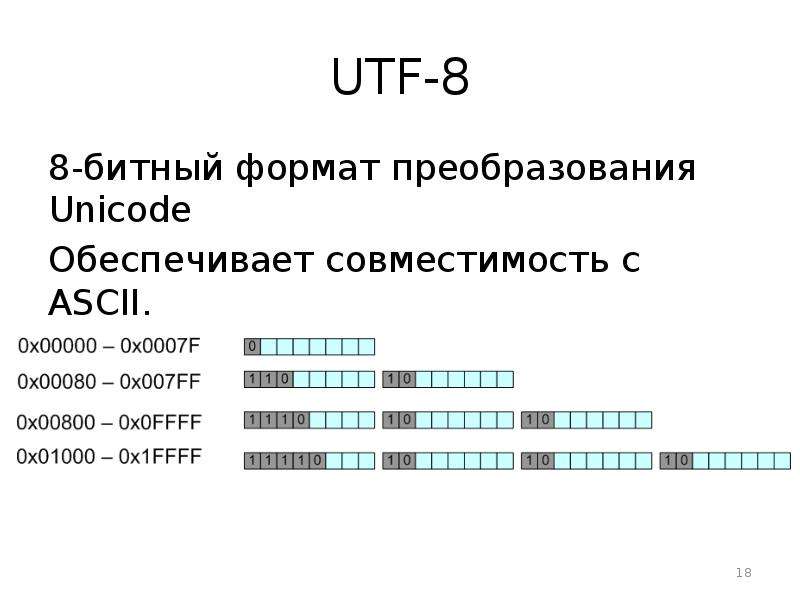
Кодировка содержит 256 символов и, таким образом, может быть представлена одним байтом. Первая половина (128 символов) полностью совпадает с ASCII. Таким образом, если первый бит = 0, то это обычный ASCII символ. Если 1, то это символ, специфичный для ISO-8859-1.
UTF-8 — одна из самых известных кодировок наравне с ASCII. Способна кодировать 1.112.064 символов. Размер каждого символа варьируется от 1-го до 4-х байт (раньше допускались значения до 6 байт).
Программа, работающая с этой кодировкой, определяет по первым битам, как много байтов входит в символ. Если октет начинается с 0, то символ представлен одним байтом. 110 — два байта, 1110 — три байта, 11110 — 4 байта.
Как и в случае с ISO-8859-1, первые 128 символов полностью соответствуют ASCII. Поэтому тексты, использующие только ASCII символы, будут абсолютно идентичны в бинарном представлении, вне зависимости от того, использовалась ли для кодирования US-ASCII, ISO-8859-1 или UTF-8.
Использование UTF-8 в теле сообщения
Прежде чем перейти к заголовкам, давайте быстро взглянем, как использовать UTF-8 в теле сообщений. Для этого используется заголовок «Content-Type».
Если «Content-Type» не задан, то браузер должен обрабатывать сообщения, как будто они написаны в ISO-8859-1. Браузер не должен пытаться отгадать кодировку и, тем более, игнорировать «Content-Type». Но, что реально отобразится в ситуации, когда «Content-Type» не передан, зависит от реализации браузера. Например, Firefox сделает согласно спецификации и прочитает сообщение, будто оно было закодировано в ISO-8859-1. Google Chrome, напротив, будет использовать кодировку операционной системы, которая для многих российских пользователей равна Windows-1251. В любом случае, если сообщение было в UTF-8, то оно будет отображено некорректно.
Проставляем UTF-8 сообщение в значение заголовка
С телом сообщения все достаточно просто. Тело сообщения всегда следует после заголовков, поэтому здесь не возникает технических проблем. Но как быть с заголовками? В спецификации недвусмысленно заявляется, что порядок заголовков в сообщении не имеет значения. Т.е. задать кодировку в одном заголовке через другой заголовок не представляется возможным.
Но как быть с заголовками? В спецификации недвусмысленно заявляется, что порядок заголовков в сообщении не имеет значения. Т.е. задать кодировку в одном заголовке через другой заголовок не представляется возможным.
Что будет, если просто взять и записать UTF-8 значение в значение заголовка? Мы видели, что такой трюк с телом сообщения приведет к тому, что значение будет просто прочитано в ISO-8859-1. Логично было бы предположить, что то же самое произойдет с заголовком. Но это не так. Фактически, во многих, если не в большинстве, случаях такое решение будет работать. Сюда включаются старые айфончики, IE11, Firefox, Google Chrome. Единственным из находящихся у меня под рукой браузеров, когда я писал эту статью, который не захотел работать с таким заголовком, является Edge.
Такое поведение не зафиксировано в спецификациях. Возможно, разработчики браузеров решили облегчить жизнь разработчиков и автоматически определять, что в заголовках сообщение закодировано в UTF-8. В общем-то, это не является такой сложной задачей. Смотрим на первый бит: если 0, то ASCII, если 1 — то, возможно, UTF-8.
Смотрим на первый бит: если 0, то ASCII, если 1 — то, возможно, UTF-8.
Нет ли в этом случае пересечения с ISO-8859-1? На самом деле, практически нет. Возьмем для примера UTF-8 символ из 2-х октетов (русские буквы представлены двумя октетами). Символ в бинарном представлении будет иметь вид: 110xxxxx 10xxxxxx. В HEX представлении: [0xC0-0x6F] [0x80-0xBF]. В ISO-8859-1 этими символами едва ли можно закодировать что-то, несущее смысловую нагрузку. Поэтому риск того, что браузер неправильно расшифрует сообщение, очень мал.
Однако, при попытке использовать этот способ можно столкнуться с техническими проблемами: ваш веб-сервер или фреймворк может просто не разрешить записывать UTF-8 символы в значение заголовка. Например, Apache Tomcat вместо всех UTF-8 символов проставляет 0x3F (вопросительный знак). Разумеется, это ограничение можно обойти, но, если само приложение бьет по рукам и не дает что-то сделать, то, возможно, вам и не нужно это делать.
Но, независимо от того, разрешает ли вам ваш фреймворк или сервер записать UTF-8 сообщения в заголовок или нет, я не рекомендую этого делать. Это не задокументированное решение, которое в любой момент времени может перестать работать в браузерах.
Это не задокументированное решение, которое в любой момент времени может перестать работать в браузерах.
Транслит
Я думаю, что использовать транслит — eto bolee horoshee reshenie. Многие крупные популярные русские ресурсы не брезгуют использовать транслит в названиях файлов. Это гарантированное решение, которое не сломается с выпуском новых браузеров и которое не надо тестировать отдельно на каждой платформе. Хотя, разумеется, надо подумать, как преобразовывать весь спектр возможных символов, что может быть не совсем тривиально. Например, если приложение рассчитано на российскую аудиторию, то в имя файла могут попасть татарские буквы ә и ң, которые надо как-то обработать, а не просто заменять на «?».
RFC 2047
Как я уже упомянул, томкат не позволил мне проставить UTF-8 в заголовке сообщения. Отражена ли эта особенность поведения в Java docs для сервлетов? Да, отражена:
Упоминается RFC 2047. Я пробовал кодировать сообщения, используя этот формат, — браузер меня не понял. Этот метод кодировки не работает в HTTP. Хотя работал раньше. Вот, например, тикет на удаление поддержки этой кодировки из Firefox.
Этот метод кодировки не работает в HTTP. Хотя работал раньше. Вот, например, тикет на удаление поддержки этой кодировки из Firefox.
RFC 6266
В тикете, ссылка на который содержится в предыдущем разделе, есть упоминания, что даже после прекращения поддержки RFC 2047, все еще есть способ передавать UTF-8 значения в названии скачиваемых файлов: RFC 6266. На мой взгляд, это самое правильно решение на сегодняшний день. Многие популярные интернет ресурсы используют его. Мы в CUBA Platform также используем именно этот RFC для генерации «Content-Disposition».
RFC 6266 — это спецификация, описывающая использование “Content-Disposition” заголовка. Сам способ кодировки подробно описан в другой спецификации — RFC 8187.
Параметр “filename” содержит название файла в ASCII, “filename*” — в любой необходимой кодировке. При наличии обоих атрибутов “filename” игнорируется во всех современных браузерах (включая IE11 и старые версии Safari). Совсем старые браузеры, напротив, игнорируют “filename*”.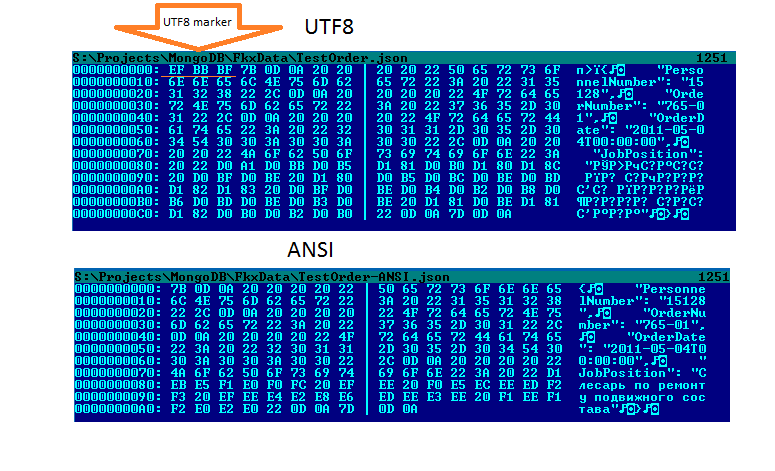
При использовании данного способа кодирования в параметре сначала указывается кодировка, после » идет закодированное значение. Видимые символы из ASCII кодирования не требуют. Остальные символы просто пишутся в hex представлении, со стоящим «%» перед каждым октетом.
Что делать с другими заголовками?
Кодирование, описанное в RFC 8187, не является универсальным. Да, можно поместить в заголовок параметр с * префиксом, и это, возможно, будет даже работать для некоторых браузеров, но спецификация предписывает не делать так.
В каждом случае, где в заголовках поддерживается UTF-8, на настоящий момент есть явное упоминание об этом в релевантном RFC. Помимо «Content-Disposition» данная кодировка используется, например, в Web Linking и Digest Access Authentication.
Следует учесть, что стандарты в этой области постоянно меняются. Использование описанной выше кодировки в HTTP было предложено лишь в 2010. Использование данной кодировки именно в «Content-Disposition» было зафиксировано в стандарте в 2011. Несмотря на то, что эти стандарты находятся лишь на стадии «Proposed Standard», они поддержаны повсеместно. Вариант, что в будущем нас ожидают новые стандарты, которые позволят более унифицировано работать с различными кодировками в заголовках, не исключен. Поэтому остается только следить за новостями в мире стандартов HTTP и уровня их поддержки на стороне браузеров.
Несмотря на то, что эти стандарты находятся лишь на стадии «Proposed Standard», они поддержаны повсеместно. Вариант, что в будущем нас ожидают новые стандарты, которые позволят более унифицировано работать с различными кодировками в заголовках, не исключен. Поэтому остается только следить за новостями в мире стандартов HTTP и уровня их поддержки на стороне браузеров.
Инструкция по переходу на UTF-8
Вычислительная система кафедры перешла на использование многобайтовой кодировки UTF-8 для файловых систем и пользовательского окружения вместо однобайтовой кодировки KOI8-R. В данной инструкции рассматриваются типичные проблемы, которые могли возникнуть у пользователей в связи с данным переходом и предлагаются способы их решения (изменения настроек, команды и т.п.).
Основные понятия
Юнико́д, или Унико́д (англ. Unicode™) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков.
UTF-8 (от англ. Unicode Transformation Format — формат
преобразования Юникода) — кодировка, реализующая представление Юникода,
совместимое с 8-битным кодированием текста.
Важно понимать, что один символ в кодировке UTF-8 может быть представлен более чем одним байтом. С этим связано, например, то, что файл, содержащий текст в кодировке UTF-8 будет иметь больший размер по сравнению с файлом, содержащим тот-же текст в кодировке KOI8-R.
Пример: команда wc имеет ключ -c для подсчета байтов и ключ -m для подсчета символов.
$ echo -n "Слово." | wc -c 11 $ echo -n "Слово." | wc -m 6
Имена файлов
Имена файлов были перекодированы автоматически с помощью утилиты convmv:
convmv -r -f koi8-r -t utf-8 --notest <каталог>
Каждому пользователю, в домашнем каталоге которого утилита convmv переименовала хотя бы один файл, был автоматически выслан журнал переименований.
При необходимости можно выполнить обратное преобразование:
convmv -r -f utf-8 -t koi8-r <файлы и каталоги>
После проверки вывода команды повторить с ключем —notest. Ключ -r включает рекурсивный обход каталогов.
Содержимое файлов
Для того, чтобы преобразовать содержимое файлов из кодировки KOI8-R в кодировку UTF-8 можно воспользоваться командой:
recode koi8-r..utf-8 <filename>
Для потокового перекодирования используется команда:
iconv -f koi8-r <filename>
Редактор Emacs может автоматически распознать кодировку текста при открытии файла. Принудительно задать кодировку открытия или сохранения файла в редакторе Emacs можно следующим образом:
- Ввести комбинацию клавиш
C-x RET c. - Внизу экрана будет запрошена кодировка, которую вы хотите применить для следующей команды.
- Введите команду, которая будет выполнена с применением введенной на предыдущем шаге кодировки, например:
- комбинацию клавиш для открытия файла:
C-x C-f; - комбинацию клавиш для сохранения файла:
C-x C-s.
- комбинацию клавиш для открытия файла:
Приложения
Текстовый терминал из Windows
Для корректного отображения русского текста при входе на серверы кафедры с помощью терминального клиента PuTTY нужно указать в настройках:
- Раздел Window/Translation
- Character set translation on recieved data: UTF-8
Текстовый терминал из Linux
Если системная локаль не UTF-8, то необходимо запустить X-терминал с поддержкой UTF-8 и выполнить вход по ssh из него.
Если системная локаль UTF-8, то никаких дополнительных действий предпринимать не надо.
Если по какой-то причине при входе по ssh не установились правильно переменные окружения локали (вывод команды locale не содержит строки LANG=ru_RU.UTF-8), то необходимо выполнить команду:
export LANG=ru_RU.UTF-8
WinSCP
Для корректного отображения русских имен файлов:
- Раздел Environment
- UTF-8 encoding for filenames: On
TEX
- После выполнения перекодировки содержимого tex-файла (см. Содержимое файлов) необходимо сменить кодировку в преамбуле:
Было:
\usepackage[koi8-r]{inputenc}
Стало:
\usepackage[utf8x]{inputenc}
- Также необходимо подключить пакет ucs:
\usepackage{ucs}
- Для установки диакритических знаков (ударений) нужно использовать полную форму стандартной записи \’, т.е.:
Б\'{о}льшую
Bibtex
Bib-файлы, содержащие описание литературы, хранятся в кодировке KOI8-R. После выполнения команды bibtex
необходимо сначала перекодировать получившийся bbl-файл в кодировку
UTF-8 (см. Содержимое файлов), а затем выполнять трансляцию
tex-файлов, подключающих этот список литературы.
После выполнения команды bibtex
необходимо сначала перекодировать получившийся bbl-файл в кодировку
UTF-8 (см. Содержимое файлов), а затем выполнять трансляцию
tex-файлов, подключающих этот список литературы.
8(7) — страница руководства Linux
utf-8(7) — страница руководства LinuxИМЯ | ОПИСАНИЕ | СМОТРИТЕ ТАКЖЕ | |
UTF-8(7) Разное информационное руководство UTF-8(7)
ИМЯ топ
UTF-8 - многобайтовая кодировка Unicode, совместимая с ASCII.
ОПИСАНИЕ верхний
Набор символов Unicode 3.0 занимает 16-битное кодовое пространство.
самая очевидная кодировка Unicode (известная как UCS-2) состоит из
последовательность 16-битных слов. Такие строки могут содержать — как часть
многие 16-битные символы — байты, такие как '\0' или '/', которые имеют
особое значение в именах файлов и других функциях библиотеки C
аргументы. Кроме того, большинство инструментов UNIX ожидают кодировку ASCII.
файлов и не может читать 16-битные слова как символы без основного
модификации. По этим причинам UCS-2 не подходит.
внешняя кодировка Unicode в именах файлов, текстовых файлах,
переменные окружения и так далее. Универсальный стандарт ISO/IEC 10646
Набор символов (UCS), надмножество Unicode, занимает четное
большее кодовое пространство - 31 бит - и очевидное кодирование UCS-4 для него
(последовательность 32-битных слов) имеет те же проблемы.
Кодировка UTF-8 Unicode и UCS не имеет этих
проблемы и является распространенным способом использования Unicode в UNIX-
стиль операционных систем.
Свойства
Кодировка UTF-8 имеет следующие приятные свойства:
* Символы UCS от 0x00000000 до 0x0000007f (классический код US-ASCII).
символы) кодируются просто как байты от 0x00 до 0x7f (ASCII
совместимость). Это означает, что файлы и строки, которые
содержат только 7-битные символы ASCII, имеют одинаковую кодировку
как в ASCII, так и в UTF-8.
Кроме того, большинство инструментов UNIX ожидают кодировку ASCII.
файлов и не может читать 16-битные слова как символы без основного
модификации. По этим причинам UCS-2 не подходит.
внешняя кодировка Unicode в именах файлов, текстовых файлах,
переменные окружения и так далее. Универсальный стандарт ISO/IEC 10646
Набор символов (UCS), надмножество Unicode, занимает четное
большее кодовое пространство - 31 бит - и очевидное кодирование UCS-4 для него
(последовательность 32-битных слов) имеет те же проблемы.
Кодировка UTF-8 Unicode и UCS не имеет этих
проблемы и является распространенным способом использования Unicode в UNIX-
стиль операционных систем.
Свойства
Кодировка UTF-8 имеет следующие приятные свойства:
* Символы UCS от 0x00000000 до 0x0000007f (классический код US-ASCII).
символы) кодируются просто как байты от 0x00 до 0x7f (ASCII
совместимость). Это означает, что файлы и строки, которые
содержат только 7-битные символы ASCII, имеют одинаковую кодировку
как в ASCII, так и в UTF-8. 31 могут быть закодированы с использованием UTF-8.
* Байты 0xc0, 0xc1, 0xfe и 0xff никогда не используются в
Кодировка UTF-8.
* Первый байт многобайтовой последовательности, представляющей
одиночный символ UCS, отличный от ASCII, всегда находится в диапазоне от 0xc2 до
0xfd и указывает длину этой многобайтовой последовательности. Все
последующие байты в многобайтовой последовательности находятся в диапазоне от 0x80 до
0xbf. Это упрощает повторную синхронизацию и делает
кодирование без сохранения состояния и устойчивость к отсутствующим байтам.
* Символы UCS в кодировке UTF-8 могут иметь длину до шести байтов,
однако стандарт Unicode не определяет символы выше
0x10ffff, поэтому символы Unicode могут быть не более четырех байтов.
длинный в UTF-8.
31 могут быть закодированы с использованием UTF-8.
* Байты 0xc0, 0xc1, 0xfe и 0xff никогда не используются в
Кодировка UTF-8.
* Первый байт многобайтовой последовательности, представляющей
одиночный символ UCS, отличный от ASCII, всегда находится в диапазоне от 0xc2 до
0xfd и указывает длину этой многобайтовой последовательности. Все
последующие байты в многобайтовой последовательности находятся в диапазоне от 0x80 до
0xbf. Это упрощает повторную синхронизацию и делает
кодирование без сохранения состояния и устойчивость к отсутствующим байтам.
* Символы UCS в кодировке UTF-8 могут иметь длину до шести байтов,
однако стандарт Unicode не определяет символы выше
0x10ffff, поэтому символы Unicode могут быть не более четырех байтов.
длинный в UTF-8.
Кодировка
Следующие последовательности байтов используются для представления символа.
Используемая последовательность зависит от номера кода UCS
характер:
0x00000000 - 0x0000007F:
0 ххххххх
0x00000080 - 0x000007FF:
110 ххххх 10 хххххх
0x00000800 - 0x0000FFFF:
1110 хххх 10 ххххх 10 хххххх
0x00010000 - 0x001FFFFF:
11110 ххх 10 хххххх 10 хххххх 10 ххххххх
0x00200000 - 0x03FFFFFF:
111110 хх 10 хххххх 10 хххххх 10 хххххх 10 хххххх
0x04000000 - 0x7FFFFFFFF:
1111110 x 10 xxxxxx 10 xxxxxx 10 xxxxxx 10 xxxxxx 10 xxxxxx
Битовые позиции xxx заполняются битами символа
кодовое число в двоичном представлении, старший бит идет первым
(с обратным порядком байтов).
Только самая короткая многобайтовая последовательность
который может представлять кодовый номер символа, который может быть использован.
Значения кода UCS 0xd800–0xdfff (суррогаты UTF-16), а также
0xfffe и 0xffff (несимволы UCS) не должны появляться в
соответствующие потоки UTF-8. Согласно RFC 3629нет пункта выше
Следует использовать U+10FFFF, что ограничивает количество символов четырьмя байтами.
Пример
Символ Unicode 0xa9 = 1010 1001 (знак авторского права)
кодируется в UTF-8 как
11000010 10101001 = 0xc2 0xa9
и символ 0x2260 = 0010 0010 0110 0000 ("не равно"
символ) кодируется как:
11100010 10001001 10100000 = 0xe2 0x89 0xa0
Замечания по применению
Пользователи должны выбрать локаль UTF-8, например, с помощью
экспорт LANG=en_GB.UTF-8
чтобы активировать поддержку UTF-8 в приложениях.
Прикладное программное обеспечение, которое должно знать об используемом символе
кодировка всегда должна устанавливать локаль, например,
установить локаль (LC_CTYPE, "")
и программисты могут затем проверить выражение
strcmp(nl_langinfo(CODESET), "UTF-8") == 0
чтобы определить, была ли выбрана локаль UTF-8 и
поэтому весь стандартный ввод и вывод открытого текста, терминал
связь, содержимое файла открытого текста, имена файлов и среда
переменные кодируются в UTF-8. Программисты, привыкшие к однобайтовым кодировкам, таким как US-ASCII
или ИСО 8859должны знать, что два предположения, сделанные до сих пор,
больше не действует в локалях UTF-8. Во-первых, один байт делает
не обязательно больше соответствовать одному символу.
Во-вторых, поскольку современные эмуляторы терминала в режиме UTF-8 тоже
поддерживают китайские, японские и корейские символы двойной ширины в качестве
а также объединение символов без пробелов, вывод одного
символ не обязательно продвигает курсор на одну позицию
как это было в ASCII. Библиотечные функции, такие как mbsrtowcs(3) и
wcswidth(3) следует использовать сегодня для подсчета символов и курсора
позиции.
Официальная последовательность ESC для переключения с кодировки ISO 2022.
схема (используемая, например, терминалами VT100) в UTF-8 - это ESC
%G("\x1b%G"). Соответствующая последовательность возврата из UTF-8 в
ISO 2022 — это ESC % @ ("\x1b%@").
Программисты, привыкшие к однобайтовым кодировкам, таким как US-ASCII
или ИСО 8859должны знать, что два предположения, сделанные до сих пор,
больше не действует в локалях UTF-8. Во-первых, один байт делает
не обязательно больше соответствовать одному символу.
Во-вторых, поскольку современные эмуляторы терминала в режиме UTF-8 тоже
поддерживают китайские, японские и корейские символы двойной ширины в качестве
а также объединение символов без пробелов, вывод одного
символ не обязательно продвигает курсор на одну позицию
как это было в ASCII. Библиотечные функции, такие как mbsrtowcs(3) и
wcswidth(3) следует использовать сегодня для подсчета символов и курсора
позиции.
Официальная последовательность ESC для переключения с кодировки ISO 2022.
схема (используемая, например, терминалами VT100) в UTF-8 - это ESC
%G("\x1b%G"). Соответствующая последовательность возврата из UTF-8 в
ISO 2022 — это ESC % @ ("\x1b%@").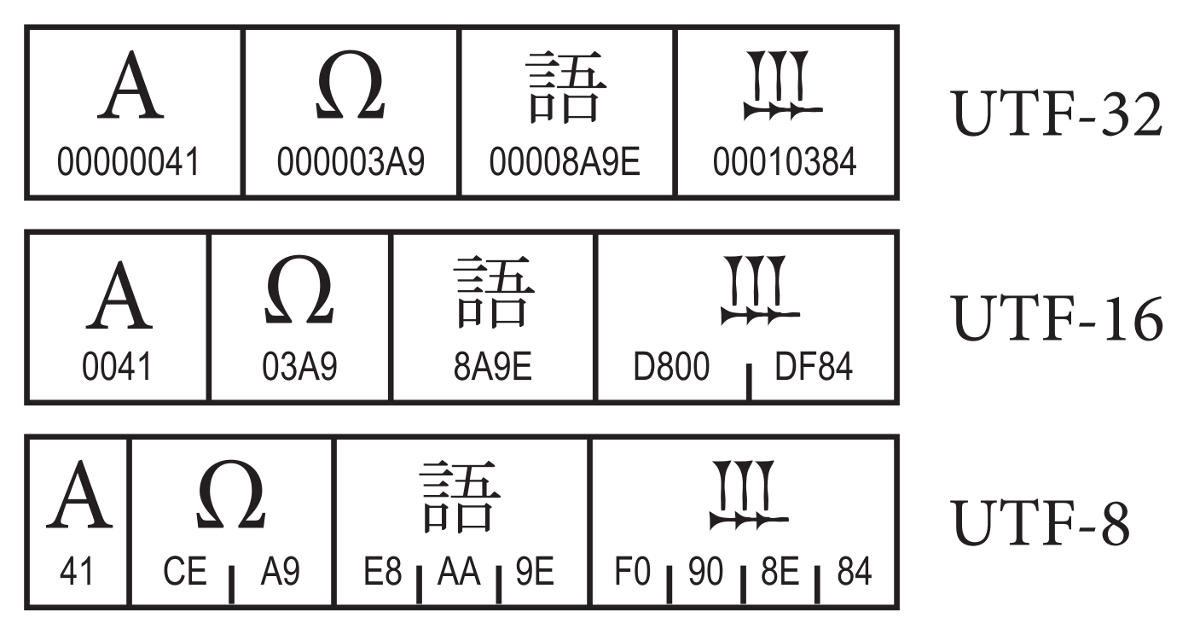
Другие последовательности ISO 2022 (например,
что касается переключения наборов G0 и G1) не применимы в UTF-8
режим.
Безопасность
Стандарты Unicode и UCS требуют, чтобы производители UTF-8
должен использовать максимально короткую форму, например, производя
двухбайтовая последовательность с первым байтом 0xc0 является несоответствующей. Юникод
3.1 добавлено требование о том, что соответствующие программы не должны
принимать некратчайшие формы на входе. Это для безопасности
причины: если пользовательский ввод проверяется на предмет возможной безопасности
нарушений, программа может проверять только ASCII-версию
"/../" или ";" или NUL и упускают из виду, что есть много не-ASCII
способы представления этих вещей в не самой короткой кодировке UTF-8.
Стандарты
ISO/IEC 10646-1:2000, Unicode 3.1, RFC 3629, план 9.
СМ. ТАКЖЕ вверх
локаль (1), nl_langinfo (3), setlocale (3), наборы символов (7), юникод (7)
Справочные страницы Linux 6. 04 12 марта 2023 г. UTF-8(7)
04 12 марта 2023 г. UTF-8(7)
Страницы, ссылающиеся на эту страницу: юникод_старт (1), юникод_стоп(1), локаль (5), оружие-8(7), ascii(7), кодировки (7), ср1251(7), ср1252(7), iso_8859-10(7), iso_8859-11(7), iso_8859-13(7), iso_8859-14(7), iso_8859-15(7), iso_8859-16(7), iso_8859-1(7), iso_8859-2(7), iso_8859-3(7), iso_8859-4(7), iso_8859-5(7), iso_8859-6(7), iso_8859-7(7), iso_8859-8(7), iso_8859-9(7), кои8-р(7), кои8-у(7), локаль (7), справочные страницы (7), юникод (7), ури (7), установить шрифт(8)
кодировок Unicode, UTF-8 и ASCII — это просто | Апил Таманг
4 минуты чтения·
3 февраля 2018 г.Итак, у меня есть объявление: если вы программист, работающий в 2017 году, и вы не знаете основ символов, наборов символов, кодировок и Unicode, и я лови тебя, я накажу тебя, заставив чистить лук на 6 месяцев на подводной лодке.
Клянусь, я буду.
— (Джоэл Спольски. Соучредитель stack-overflow. Взято из статьи здесь)
Вернее слов не было сказано.
И позвольте мне добавить, что после того, как я провел свой срок на подводной лодке, чистя лук с покрасневшими глазами, вы не хотите быть в одной лодке (э-э-э, подводная лодка) !
Этот пост действительно будет более сжатым изложением того, что мне удалось почерпнуть из блога Джоэла. Удивительно, но после более чем часа поиска в Интернете дополнительной информации о кодировках я случайно попал на этот блог. Это, безусловно, наиболее краткое и понятное чтение по этому вопросу, и оно заслуживает того, чтобы им поделились.
Сначала был язык программирования C, потом ASCII. В ASCII каждая буква, цифра и символ, которые имеют значение (a–z, A–Z, 0–9, +, -, /, “, ! и т.д.) были представлены числом от 32 до 127 . Тогда большинство компьютеров использовали 8-битные байты. Это означало, что каждый байт мог хранить 2⁸-1= 255 чисел. Таким образом, в каждом байте (или единице хранения) было более чем достаточно места для хранения основного набора английских символов.
Таким образом, в каждом байте (или единице хранения) было более чем достаточно места для хранения основного набора английских символов.
Жизнь была хороша. Черт возьми, они даже отправили людей на Луну! Это если вы говорили по-английски.
Чтобы вместить неанглийские символы, люди начали немного сходить с ума от того, как использовать числа от 128 до 255 по-прежнему доступен в одном байте . Разные люди использовали разные символы для обозначения одних и тех же чисел. Очевидно, это был не только дикий дикий запад, но и быстро стало ясно, что дополнительные доступные числа даже близко не могут представить полный набор символов для некоторых языков.
Unicode был смелой попыткой создать единый набор символов, который мог бы представлять все символы во всех мыслимых языковых системах. Это потребовало смены парадигмы в интерпретации символов. И в этой новой парадигме каждый персонаж был идеализированной абстрактной сущностью. Кроме того, в этой системе вместо числа каждый символ представлялся цифрой 9.0105 кодовая точка. Кодовые точки были записаны как: U+00639, , где U означает «Юникод», а числа шестнадцатеричные.
Кроме того, в этой системе вместо числа каждый символ представлялся цифрой 9.0105 кодовая точка. Кодовые точки были записаны как: U+00639, , где U означает «Юникод», а числа шестнадцатеричные.
Последняя часть, которую нам не хватает на данный момент, — это система для хранения и представления этих кодовых точек. Этому служат стандарты кодирования . После нескольких удачных попыток родился стандарт кодирования UTF-8.
В UTF-8 каждая кодовая точка от 0 до 127 хранится в одном байте. Кодовые точки выше 128 хранятся с использованием 2, 3 и фактически до 6 байтов.
Помните, что каждый байт состоит из 8 бит, и количество разрешенной информации экспоненциально увеличивается с битами, используемыми для хранения. Таким образом, с 6 байтами (и не обязательно всегда 6) можно хранить до 2⁴⁸ символов. Это сделало бы очень (очень) большую игру в скрэббл!
Другие преимущества UTF-8 означали, что ничего не изменилось по сравнению с ASCII, поскольку рассматривался базовый набор символов английского языка. Жизнь для англоязычных продолжала складываться (совпадение?). Всем остальным пришлось прыгать через несколько поездов, но в конце концов все согласились использовать один и тот же набор стандартов.
Жизнь для англоязычных продолжала складываться (совпадение?). Всем остальным пришлось прыгать через несколько поездов, но в конце концов все согласились использовать один и тот же набор стандартов.
Пожалуй, самая важная вещь, которую следует помнить из обсуждений выше, это то, что НЕТ строки или текста без сопутствующего стандарта кодирования . Если вы, как и я, являетесь веб-разработчиком, вы будете иногда сталкиваться с этим текстом: Content-Type: text/plain; charset=»UTF-8″ в коде. По сути, это сообщает браузерам (или любым анализаторам текста) конкретную используемую кодировку.
Теперь, когда мы знаем, что такое UTF-8, экстраполяция нашего понимания на UTF-16 должна быть довольно простой. UTF-8 назван в честь того, как он использует минимум 8 бит (или 1 байт) для хранения кодовых точек Unicode. Помните, что он по-прежнему может использовать больше битов, но делает это только в случае необходимости.
UTF-16, с другой стороны, использует минимум 16 бит (или 2 байта) для кодирования символов Юникода .