0001278: GetFileComment (комментарии) и кодировка descript.ion (для файлов с русскими именамии)
| View Issue Details [ Jump to Notes ] | [ Issue History ] [ Print ] | ||||
| Reporter | Dook | ||||
|---|---|---|---|---|---|
| Assigned To | Alexx2000 | ||||
| Priority | normal | Severity | minor | Reproducibility | always |
| Status | closed | Resolution | fixed | ||
| Projection | none | ETA | none | ||
| Product Version | 0.7.0 (trunk) | Product Build | |||
| Target Version | Fixed in Version | ||||
| Summary | 0001278: GetFileComment (комментарии) и кодировка descript. | ||||
| Description | При кодировке descript.ion отличной от CP866 (пробовались-1251,UTF8) GetFileComment (комментарии) для файлов с русскими именами в панели отображаются только сразу после загрузки DoubleCommander. Если сменить папку, комментарии для файлов с русскими именами с панели исчезают, но при этом остаются доступны по Ctrl+Z и редактируются нормально. | ||||
| Tags | No tags attached. | ||||
| Fixed in Revision | 6906-6912 | ||||
| Operating system | |||||
| Widgetset | |||||
| Architecture | |||||
| Attached Files |
| ||||
| Relationships | |
| Relationships |
| Notes | |
~0001635 Alexx2000 (administrator) 2016-01-17 21:26 | Не могу воспроизвести. Файл descript.ion полностью в одной кодировке? Файл descript.ion полностью в одной кодировке? |
~0001636 Dook (reporter) 2016-01-17 21:50 | Полностью. Прикрепил для примера в кодировке 1251. Для 1251 даже по Ctrl+Z не показывает комментарии и не копирует их при копировании файла. Для UTF8 — как я и описал: отображаются только сразу после загрузки DoubleCommander, если сменить папку исчезают, но при этом доступны по Ctrl+Z и редактируются нормально, и копируются вместе с файлом. |
Alexx2000 (administrator) 2016-01-17 22:52 Last edited: 2016-01-17 22:53 View 2 revisions | Дело в том что автоопределение кодировки работает не всегда. В приведенном примере как раз невозможно автоматически определить кодировку файла. Похоже единственным приемлемым решением будет добавление глобальной настройки какую кодировку использовать для descript. ion (UTF-8, ANSI, OEM), а из окна редактирования выбор кодировки убрать. ion (UTF-8, ANSI, OEM), а из окна редактирования выбор кодировки убрать. |
~0001638 Dook (reporter) 2016-01-17 23:01 | Да, видимо, это будет оптимальным вариантом. Как в Totalе. |
~0001744 Alexx2000 (administrator) 2016-06-12 19:23 Last edited: 2016-06-12 19:27 View 2 revisions | Кодировку можно указать в настройках на странице «Разное». Требуется тестирование. |
~0001745 Dook (reporter) 2016-06-12 20:42 | Идеально. Только для чего нужна опция «Создавать новые с кодировкой:»? Если это не внутренняя кодировка, то почему такой странный выбор для новых кодировок: UTF8BOM,UTF16LE,UTF16BE? И, если не трудно, посмотрите почему не обрабатываются комментарии при файловых операциях — http://doublecmd.  sourceforge.net/mantisbt/view.php?id=1415 . Тестировал на 6910 sourceforge.net/mantisbt/view.php?id=1415 . Тестировал на 6910 |
~0001746 Alexx2000 (administrator) 2016-06-12 21:05 | >>> Только для чего нужна опция «Создавать новые с кодировкой:»? Если это не >>> UTF8BOM,UTF16LE,UTF16BE? Ну например у нас есть старые descript.ion в кодировке ANSI, а теперь мы хотим использовать Unicode (все три кодировки с BOM, поэтому нет проблем с автоопределением). Используя данные опции мы можем выбрать в какой кодировке читать уже существующие файлы, а в какой создавать новые (идея взята из Far manager). |
~0001749 Dook (reporter) 2016-06-12 22:00 | Ясно |
| Notes |
| Issue History | |||
| Date Modified | Username | Field | Change |
|---|---|---|---|
| 2016-01-17 17:46 | Dook | New Issue | |
| 2016-01-17 21:26 | Alexx2000 | Note Added: 0001635 | |
| 2016-01-17 21:26 | Alexx2000 | Status | new => feedback |
| 2016-01-17 21:42 | Dook | File Added: descript. ion ion | |
| 2016-01-17 21:50 | Dook | Note Added: 0001636 | |
| 2016-01-17 21:50 | Dook | Status | feedback => new |
| 2016-01-17 22:52 | Alexx2000 | Note Added: 0001637 | |
| 2016-01-17 22:52 | Alexx2000 | Status | new => feedback |
| 2016-01-17 22:53 | Alexx2000 | Note Edited: 0001637 | View Revisions |
| 2016-01-17 23:01 | Dook | Note Added: 0001638 | |
| 2016-01-17 23:01 | Dook | Status | feedback => new |
| 2016-06-12 18:40 | Alexx2000 | Assigned To | => Alexx2000 |
| 2016-06-12 18:40 | Alexx2000 | Status | new => assigned |
| 2016-06-12 19:23 | Alexx2000 | Fixed in Revision | => 6906,6907 |
| 2016-06-12 19:23 | Alexx2000 | Note Added: 0001744 | |
| 2016-06-12 19:23 | Alexx2000 | Status | assigned => resolved |
| 2016-06-12 19:23 | Alexx2000 | Resolution | open => fixed |
| 2016-06-12 19:27 | Alexx2000 | Note Edited: 0001744 | View Revisions |
| 2016-06-12 19:28 | Alexx2000 | Fixed in Revision | 6906,6907 => 6906-6908 |
| 2016-06-12 20:03 | Alexx2000 | Fixed in Revision | 6906-6908 => 6906-6910 |
| 2016-06-12 20:42 | Dook | Note Added: 0001745 | |
| 2016-06-12 21:05 | Alexx2000 | Note Added: 0001746 | |
| 2016-06-12 21:59 | Alexx2000 | Fixed in Revision | 6906-6910 => 6906-6911 |
| 2016-06-12 22:00 | Dook | Note Added: 0001749 | |
| 2016-06-12 22:54 | Alexx2000 | Fixed in Revision | 6906-6911 => 6906-6912 |
| 2020-06-19 21:52 | Alexx2000 | Status | resolved => closed |
| Issue History |
Основные принципы работы с Dreamweaver
ГЛАВА 2. 3. Основные принципы работы с Dreamweaver
3. Основные принципы работы с Dreamweaver
Настройка Dreamweaver
Учим русский
Настраиваем скорость интернет-соединения
Добавляем программы просмотра Web-страниц
Добавляем внешний HTML-редактор
Настройка Dreamweaver
А сейчас самое время настроить наш Dreamweaver так, чтобы он нормально понимал русский язык. Заодно мы расскажем о других настройках, которые могут вам пригодиться в дальнейшем.
Вся работа будет происходить в многофункциональном окне настройки программы,
состоящем из множества вкладок с разными элементами управления. Чтобы вызвать
его, выберите пункт Preferences меню Edit или нажмите комбинацию клавиш
<Ctrl>+<U>. В левой части окна настройки отображен список вкладок,
а в правой появляется само содержимое выбранной вкладки.
Учим русский
Выберем в списке вкладок пункт New Document.
Окно настройки примет вид, показанный на рис.
Рис. 2.35. Вкладка New Document диалогового окна Preferences
Но прежде чем начать разговор о русификации Dreamweaver, немного поговорим об особенностях национального Web-творчества. А именно о кодировках русского языка и борьбе с ними.
Вероятно, вы знаете, что каждый символ, который может быть введен с клавиатуры и отображен на экране, имеет уникальный номер, называемый кодом символа. Совокупность таких кодов вместе с описанием, какой код какому символу соответствует, образует кодировку. Каждая кодировка имеет свое наименование, например 1251 или КОИ-8.
Поскольку любой язык использует свой набор
символов, для каждого языка кодировки, как правило, различны. (Исключение —
некоторые западноевропейские языки.) Но на этом путаница с кодировками не
кончается. Дело в том, что разные операционные системы используют различные
кодировки. Например, западноевропейская версия Windows использует кодировку
1250, русская — 1251, американская версия MS-DOS— 437, а русская -866 (она же
ISO-8859-5). Ну, американская с западноевропейской — бог с ними, обойдемся без
иноземцев! Однако русских кодировок, как видите, уже две. А если добавить сюда
еще кодировку, используемую русской версией операционной системы UNIX — КОИ-8,
и русской версией компьютеров Macintosh — MacCyrillic, кодировок станет уже
четыре. И это только главные, на памяти автора существовали еще штуки четыре менее
распространенных кириллических кодировок («основная» кодировка ГОСТ,
«болгарская», «американская», «югославская» и еще
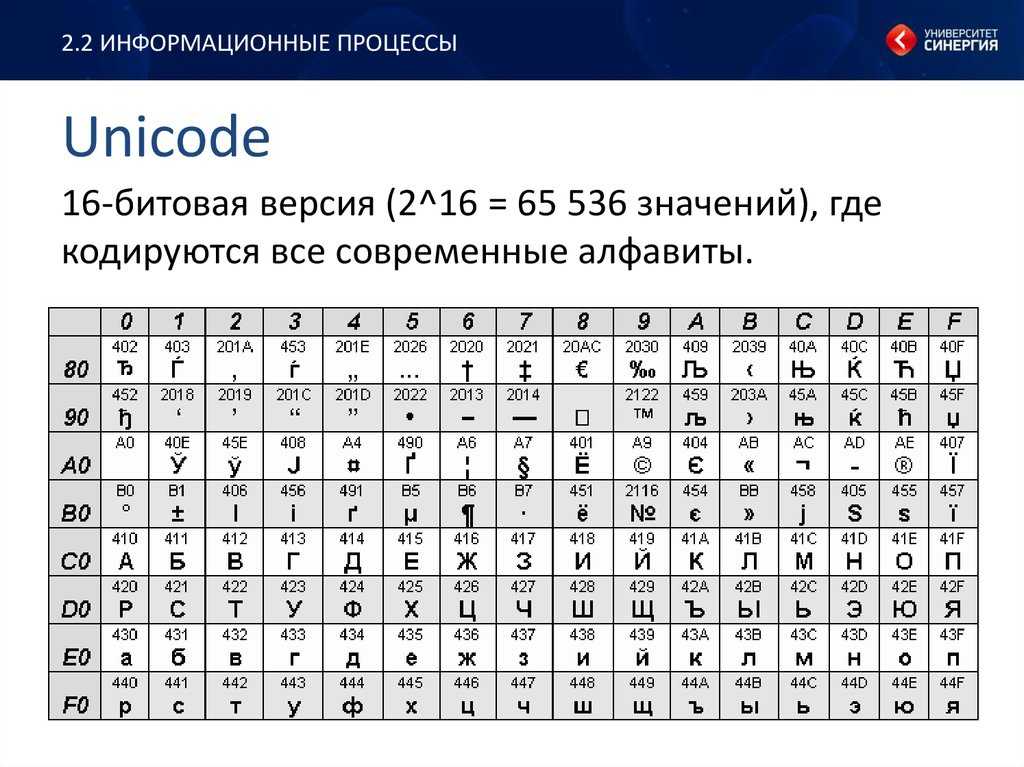
какие-то). Кроме того, в последнее время появилась кодировка Unicode,
поддерживающая ВСЕ имеющиеся на Земле языки. Настоящая тирания кодировок!..
Ну, американская с западноевропейской — бог с ними, обойдемся без
иноземцев! Однако русских кодировок, как видите, уже две. А если добавить сюда
еще кодировку, используемую русской версией операционной системы UNIX — КОИ-8,
и русской версией компьютеров Macintosh — MacCyrillic, кодировок станет уже
четыре. И это только главные, на памяти автора существовали еще штуки четыре менее
распространенных кириллических кодировок («основная» кодировка ГОСТ,
«болгарская», «американская», «югославская» и еще
какие-то). Кроме того, в последнее время появилась кодировка Unicode,
поддерживающая ВСЕ имеющиеся на Земле языки. Настоящая тирания кодировок!..
Чем все это грозит? А вот чем. Вы, наверно, пытались открыть текстовый документ, созданный в Блокноте, в Norton Commander. Видели, что при этом получается — текст абсолютно нечитаем. А все потому, что русские кодировки 866 (MS-DOS) и 1251 (Windows) не совпадают! В них одному и тому же символу присвоены разные коды!!!
Каков же выход?
Выхода нет. Можно надеяться только на то, что
какая-то из кодировок станет стандартом и постепенно вытеснит конкурентов. Пока
что на роль такого (негласного) стандарта претендует 1251, хотя интернетчики
старого поколения, пользующиеся UNIX-совместимыми системами,
«пропихивают» КОИ-8. Во всяком случае, сейчас большинство
Web-страниц, имеющихся в русском сегменте Сети, написано в кодировке 1251.
Можно надеяться только на то, что
какая-то из кодировок станет стандартом и постепенно вытеснит конкурентов. Пока
что на роль такого (негласного) стандарта претендует 1251, хотя интернетчики
старого поколения, пользующиеся UNIX-совместимыми системами,
«пропихивают» КОИ-8. Во всяком случае, сейчас большинство
Web-страниц, имеющихся в русском сегменте Сети, написано в кодировке 1251.
Здесь стоит упомянуть еще два момента. Современные программы Web-обозревателей поддерживают все доступные сейчас кодировки и корректно их распознают. Это первое. Второе: Web-сервер (точнее, его администратор) может потребовать, чтобы публикуемые вами странички были закодированы в какой-либо конкретной кодировке, например в КОИ-8. Это стоит иметь в виду, когда вы будете выбирать кодировку для своего Web-творения.
Когда вы создаете в Dreamweaver Web-страницу,
используемая в ней кодировка прописывается в ее заголовке с помощью особого
тега <МЕТА>. Например, так:
Например, так:
<МЕТА HTTP-EQUIV=»Content-Type» CONTENT=»text/html; charset=windows-1251″></HEAD>
Как вы поняли, эта страница создана с использованием кодировки Windows, т. е. 1251. Подробнее о теге <МЕТА> мы поговорим далее в этой книге.
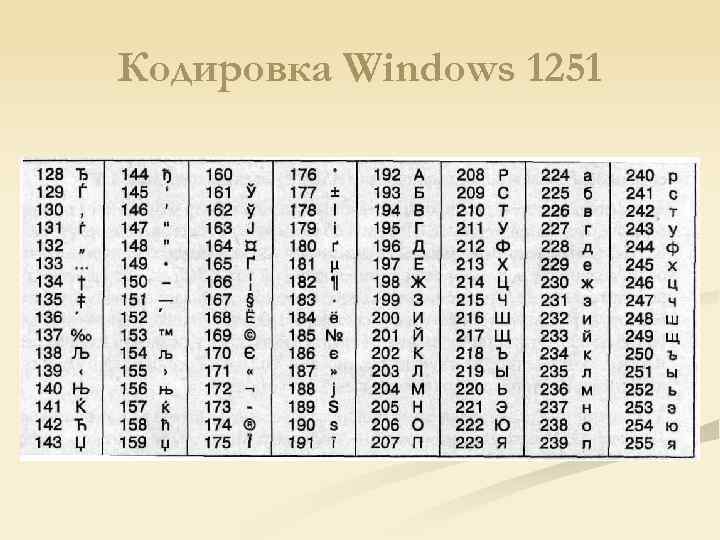
Итак, какие же кодировки поддерживает Dreamweaver? (Имеются в виду, конечно же, русские кодировки.) Все они перечислены в табл. 2.4 и задаются с помощью раскрывающегося списка Default Encoding.
Таблица 2.4. Кодировки русского текста, поддерживаемые Dreamweaver
|
Обозначение |
Описание |
|
ISO-8859-5 |
Русская версия MS-DOS |
|
КОИ8 (KOI-8R) |
Русские версии UNIX-совместимых систем |
|
MacCyrillic |
Русская версия ОС Macintosh |
|
Windows-1251 |
Русские версии Windows,
начиная от версии 3. |
|
Western (Latin1) |
Это не русская кодировка, она включена в этот список только для справки. Поддерживает западноевропейские языки |
 0
0Какую же кодировку выбрать? Ответ прост. Если вы не связаны какими-либо специфическими требованиями администратора Web-сервера, на котором будет опубликован ваш сайт, смело выбирайте пункт Windows-1251. В противном случае выберите ту кодировку, которую требует сервер. Если вы создаете странички на английском языке, ваш выбор — Western (Latinl).
Теперь переключитесь на вкладку Fonts (рис.
2.36). На этой вкладке вы сможете настроить шрифты, которыми будет отображаться
текст вашей страницы. В списке Font Settings выберите шрифтовой набор, который
будет использован для отображения ваших Web-страниц. Здесь альтернатива еще
проще: если текст русский — выбирайте Cyrillic, если английский — Western
(Latinl).
Что касается начертаний и размеров шрифтов, используемых для отображения текста, автор может только посоветовать, но никак не порекомендовать. Автор предпочитает в качестве пропорционального шрифта (раскрывающийся список Proportional Font) Arial, в качестве моноширинного (Fixed Font) — Lucida Console, а для отображения исходного HTML-кода в редакторе кода (Code Inspector) — тоже Lucida Console. Размеры шрифтов (раскрывающийся список Size) автор обычно ставит равным 10 пунктам (малый размер, Small). Но, еще раз повторим, что это дело вкуса.
А теперь еще одна важная деталь. К сожалению, все программы имеют ошибки, даже самые лучшие из них. Dreamweaver в этом случае не исключение. Из-за ошибки он некорректно открывает Web-страницы, в которых не прописана с помощью тега <МЕТА> используемая в них кодировка. Для того чтобы вразумить его, нам придется сделать следующее.
Прежде всего, закройте Dreamweaver. Далее
откройте в Проводнике или в другом диспетчере файлов папку, в которой у вас
установлен Dreamweaver. Обычно это папка Program Files/Macromedia/Dreamweaver
MX. В ней вы увидите папку Configuration. Откройте в ней подпапку Encodings. В
этой подпапке находится файл EncodingMenu.xml. В этом файле перечислены все
поддерживаемые Dreamweaver кодировки.
Обычно это папка Program Files/Macromedia/Dreamweaver
MX. В ней вы увидите папку Configuration. Откройте в ней подпапку Encodings. В
этой подпапке находится файл EncodingMenu.xml. В этом файле перечислены все
поддерживаемые Dreamweaver кодировки.
Рис. 2.36. Вкладка Fonts диалогового окна Preferences
Ниже приведен фрагмент этого файла, в котором перечисляются русские кодировки, интересующие нас:
<mm:encoding name=»Cyrillic
(ISO-8859-5)» charset=»iso-8859-5″
fontgroup=»Cyrillic» winfontcharset=204 macfontscript=7
filename=»iso88595.xml»/>
<mm:encoding name=»Cyrillic (KOI8-R)»
charset=»KOI8-R»
fontgroup=»Cyrillic» winfontcharset=204 macfontscript=7
filename=»KOI8R.xml»/>
<mm:encoding name=»Cyrillic (MacCyrillic)»
charset=»x-mac-cyrillic»
fontgroup=»Cyrillic» winfontcharset=204 macfontscript=7
filename=»MacCyrillic. xml»/>
xml»/>
<mm:encoding name=»Cyrillic (Windows-1251)»
charset=»windows-1251″
fontgroup=»Cyrillic» winfontcharset=204 macfontscript=7
filename=»Win1251.xml»/>
Кстати, данные в этом файле записаны в формате XML. Dreamweaver понимает этот формат и очень часто использует его для сохранения конфигурационных данных.
Дело в том, что из-за ошибки Dreamweaver использует для представления текста страниц с непрописанной кодировкой ту, которая встретится ему первой. В данном случае это кодировка MS-DOS — ISO-8859-5. Нам нужно поместить на первое место кодировку 1251. Для этого исправьте файл EncodingMenu.xml так:
<mm:encoding name=»Cyrillic
(Windows-1251)» charset=»windows-1251″
fontgroup=»Cyrillic» winfontcharset=204 macfontscript=7
filename=»Winl251.xml»/>
<mm:encoding name=»Cyrillic (ISO-8859-5)»
charset=»iso-8859-5″
fontgroup=»Cyrillic» winfontcharset=204 macfontscript=7
filename=»iso88595. xml»/>
xml»/>
<mm:encoding name=»Cyrillic (KOI8-R)»
charset=»KOI8-R»
fontgroup=»Cyrillic» winfontcharset=204 macfontscript=7
filename=»KOI8R.xml»/>
<mm:encoding name=»Cyrillic (MacCyrillic)»
charset=»x-mac-cyrillic»
fontgroup=»Cyrillic» winfontcharset=204 macfontscript=7
filename=»MacCyrillic.xml»/>
После этого сохраните этот файл и закройте его. Теперь можете запускать Dreamweaver — он станет корректно открывать все Web-страницы.
Настраиваем скорость интернет-соединения
Выше было сказано, что строка статуса окна документа содержит секцию, где показывается примерный размер открытой в окне Web-страницы и время ее загрузки. И еще упоминалось, что это время считается с учетом скорости 28,8 Кбит/с, заданной по умолчанию в настройках Dreamweaver. Вы можете изменить эту скорость.
Выберите в окне настроек вкладку Status Bar. На экране появится вкладка настройки
строки статуса (рис. 2.37). Среди всех элементов управления, размещенных на
ней, нас интересует только раскрывающийся список Connection Speed, в котором
выбирается скорость соединения в килобитах в секунду. Выберите нужную вам
скорость или введите ее вручную.
На экране появится вкладка настройки
строки статуса (рис. 2.37). Среди всех элементов управления, размещенных на
ней, нас интересует только раскрывающийся список Connection Speed, в котором
выбирается скорость соединения в килобитах в секунду. Выберите нужную вам
скорость или введите ее вручную.
Добавляем программы просмотра Web-страниц
Если на вашем компьютере установлена одна программа Web-обозревателя, настройка закончена, и вы можете нажать кнопку ОК. Если же таких программ у вас несколько (например, Microsoft Internet Explorer и Netscape Navigator), то вы, скорее всего, захотите добавить вторую из них в список Dreamweaver, чтобы впоследствии просматривать в ней разрабатываемые Web-страницы. Как это сделать, сейчас объясним.
Рис. 2.37. Вкладка Status Bar диалогового окна Preferences
Выберем вкладку Preview in Browser. To, что
вы увидите, показано на рис. 2.38.
2.38.
В списке Browsers перечислены все программы просмотра, которые смог найти Dreamweaver при установке. Сейчас там всего одна строка: iexplore. Но мы исправим это положение.
Нажмите кнопку со знаком «плюс», расположенную выше списка. На экране появится окно ввода сведений о программе просмотра, показанное на рис. 2.39.
Здесь все просто. В поле ввода Name вводится имя программы, которое будет появляться в списке и меню Dreamweaver. Это имя желательно сделать более вразумительным, чем малопонятное «iexplore». В поле ввода Application вводится путь доступа к исполняемому файлу программы. Но т. к. вы вряд ли помните его наизусть, нажмите кнопку Browse, выберите нужный файл в стандартном диалоговом окне открытия файла и нажмите кнопку открытия.
А что делают флажки Primary Browser и Secondary Browser? Вот на них стоит остановиться подробно.
Рис. 2.38. Вкладка Preview in Browser диалогового окна Preferences
Рис. 2.39. Окно сведений о программе просмотра
2.39. Окно сведений о программе просмотра
Dreamweaver позволяет вам из всех занесенных в его список программ просмотра выбрать двоих «любимчиков». Этих «любимчиков» вы сможете впоследствии вызывать нажатием одной клавиши или комбинацией клавиш. Один из них станет первичным (primary) и будет вызываться клавишей <F12> (по умолчанию это Internet Explorer), а второй — вторичным (secondary), и «отвечать» за него будет комбинация клавиш <Ctrl>+<F12>. Как вы уже поняли, флажок Primary Browser задает первичного «любимчика», а Secondary Browser — вторичного. Остается только добавить, что из этих флажков может быть включен только один, т. е. программа просмотра может быть только первичным или только вторичным «любимчиком» либо не является таковым вообще.
Закончив ввод данных о новой программе просмотра, нажмите кнопку ОК. Внесенная вами программа добавится в список Browsers.
Как вы уже заметили, флажки Primary Browser и
Secondary Browser имеются также в окне настройки.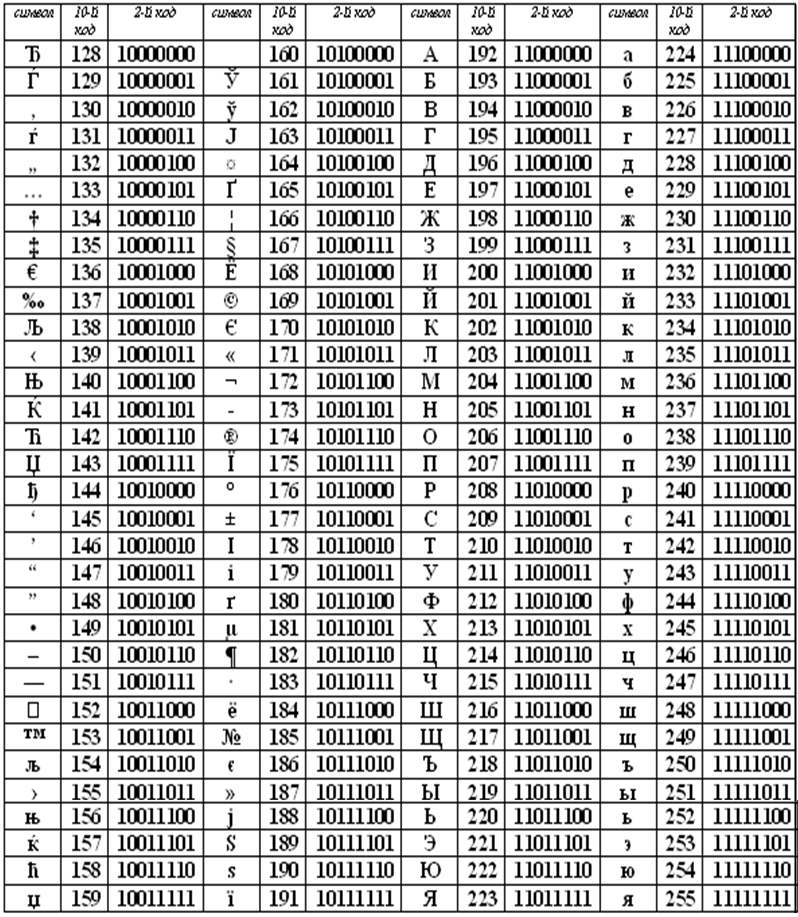 Это позволит вам изменить
статус программы просмотра, не открывая окна параметров: просто выделите в
списке необходимую строку и включите или отключите нужный флажок. Кнопка Edit
позволит вам изменить сведения о программе просмотра; при ее нажатии на экране
появится окно параметров. Кнопка со знаком «минус», расположенная
выше списка Browsers, позволит вам удалить ненужную программу просмотра. Но
будьте осторожны: программа удаляется из списка сразу же, без всякого
предупреждения!
Это позволит вам изменить
статус программы просмотра, не открывая окна параметров: просто выделите в
списке необходимую строку и включите или отключите нужный флажок. Кнопка Edit
позволит вам изменить сведения о программе просмотра; при ее нажатии на экране
появится окно параметров. Кнопка со знаком «минус», расположенная
выше списка Browsers, позволит вам удалить ненужную программу просмотра. Но
будьте осторожны: программа удаляется из списка сразу же, без всякого
предупреждения!
Добавляем внешний HTML-редактор
Всем хорош Dreamweaver. И Web-страницы позволяет редактировать, и до HTML-кода добраться несложно. Однако иногда возникает необходимость во внешнем HTML-редакторе. Например, если нужно сделать что-то такое, чего Dreamweaver не поддерживает (да-да, может быть и так), или просто немного поработать в привычном HTML-редакторе. Как это можно сделать?
Во-первых, просто запустить необходимую
программу из меню Пуск и открыть в ней нужный файл. Это удобно, если вы
прибегаете к внешнему HTML-редактору изредка.
Это удобно, если вы
прибегаете к внешнему HTML-редактору изредка.
Во-вторых, можно интегрировать внешний редактор в среду Dreamweaver. Эта возможность незаменима для тех, кто часто пользуется подобными программами.
Переключитесь на вкладку File Types/Editors диалогового окна настроек (рис. 2.40). В поле ввода External Code Editor введите путь и имя файла программы внешнего редактора. Но проще всего будет щелкнуть кнопку Browse и выбрать нужный файл в появившемся на экране диалоговом окне открытия файла Windows.
Какую программу лучше всего использовать в качестве внешнего HTML-редактора? Здесь все зависит от ваших вкусов. Можно использовать какой-либо простейший текстовый редактор для редактирования «сырого» HTML-кода: Блокнот или его более мощный аналог — Notepad+, доступный по адресу http://dimonius.da.ru, а можно пользоваться старым добрым Arachno-philia. Также можно работать со сложным визуальным Web-редактором, например FrontPage Express, поставляемым стандартно с Microsoft Internet
Explorer.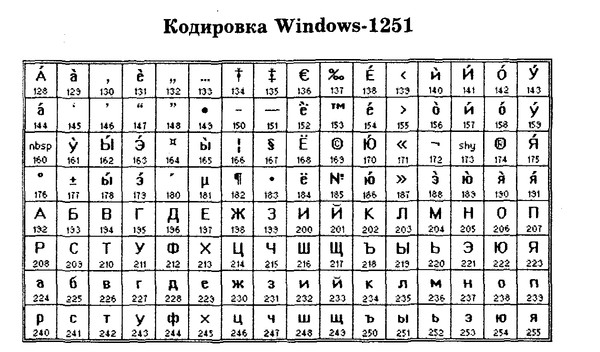 (Кстати, некоторые вещи,
специфичные для Internet Explorer, лучше делать во FrontPage Express.) В общем,
никто не ограничивает вас в выборе внешнего HTML-редактора по своему вкусу.
(Кстати, некоторые вещи,
специфичные для Internet Explorer, лучше делать во FrontPage Express.) В общем,
никто не ограничивает вас в выборе внешнего HTML-редактора по своему вкусу.
Рис. 2.40. Вкладка File Types / Editors диалогового окна Preferences
По окончании настройки Dreamweaver нажмите кнопку ОК, чтобы сохранить сделанные установки. Конечно, возможности настройки, предлагаемые этой программой, очень велики, но мы не будем о них рассказывать. Все необходимые сведения вы можете получить из интерактивной справки. Мы рассказали только о тех настройках, без которых вам будет трудно работать с Dreamweaver.
Поддержка «плохих» кодировок — ftfy: исправляет текст для вас
Модуль ftfy.bad_codecs дает Python возможность декодировать некоторые распространенные,
некорректные кодировки.
Python не хочет, чтобы вы писали текст небрежно. Его кодеры и декодеры
(«кодеки») по возможности следуют соответствующим стандартам, а это означает, что
когда вы получите сообщение о том, что не соответствует этим стандартам, вы, вероятно, потерпите неудачу
расшифровать его. Или вы можете успешно расшифровать его для конкретной реализации
причин, что, пожалуй, хуже.
Его кодеры и декодеры
(«кодеки») по возможности следуют соответствующим стандартам, а это означает, что
когда вы получите сообщение о том, что не соответствует этим стандартам, вы, вероятно, потерпите неудачу
расшифровать его. Или вы можете успешно расшифровать его для конкретной реализации
причин, что, пожалуй, хуже.
Существуют некоторые кодировки, которых Python не желает, чтобы существовали. широко используется за пределами Python:
«варианты utf-8», семейство кодировок не совсем UTF-8, включая всегда популярный CESU-8 и «Java модифицированный UTF-8».
«Неаккуратные» версии кодировок карт символов, где байты, которые не соответствуют вместо этого все будет отображаться в символ Unicode с тем же номером.
Простой импорт этого модуля или фактически любой части ftfy пакет, будет
сделать эти новые «плохие кодеки» доступными для Python через стандартные кодеки
API. Вам никогда не придется вызывать какие-либо функции внутри ftfy. . bad_codecs
bad_codecs
Однако, если вы хотите вызвать что-то, потому что на этом настаивает программа проверки кода,
вы можете вызвать ftfy.bad_codecs.ok() .
Краткий пример декодирования текста, закодированного в CESU-8:
>>> импортировать ftfy.bad_codecs
>>> print(b'\xed\xa0\xbd\xed\xb8\x8d'.decode('utf-8-варианты'))
😍
«Небрежные» кодировки
ftfy.bad_codecs.sloppy предоставляет кодировки карт символов, которые заполняют свои «дыры»
запутанным, но распространенным способом: путем вывода кодовых точек Unicode с одинаковыми
числа.
Это невероятно уродливо, и это также соответствует стандарту HTML5.
Однобайтовая кодировка сопоставляет каждый байт с символом Unicode, за исключением некоторых байты остаются неотображенными. В широко используемой кодировке Windows-1252 для например, байты 0x81 и 0x8D, среди прочего, не имеют значения.
Python, желая сохранить некоторое чувство приличия, будет обрабатывать эти байты
как ошибки. Но Windows знает, что 0x81 и 0x8D являются возможными байтами, и они
отличаются друг от друга. Он просто не определил, что они представляют собой с точки зрения
Юникод.
Но Windows знает, что 0x81 и 0x8D являются возможными байтами, и они
отличаются друг от друга. Он просто не определил, что они представляют собой с точки зрения
Юникод.
Программное обеспечение, которое должно взаимодействовать с Windows-1252 и Unicode, например все обычные веб-браузеры — выберут некоторые символы Unicode для сопоставления к, и символы, которые они выбирают, являются символами Unicode с тем же самым номера: U+0081 и U+008D. Это то же самое, что и Latin-1, и результирующие символы, как правило, попадают в диапазон Unicode, отведенный для в любом случае устаревшие управляющие символы Latin-1.
Эти небрежные кодеки позволяют Python делать то же самое, взаимодействуя, таким образом, с другое программное обеспечение, которое работает таким образом. Он определяет небрежную версию многих однобайтовые кодировки с дырками. (Нет необходимости в неряшливой версии кодировка без дырок: например, не существует такой вещи, как sloppy-iso-8859-2 или sloppy-macroman.)
Будут определены следующие кодировки:
sloppy-windows-1250 (Центральноевропейская, вроде на основе ISO-8859-2)
sloppy-windows-1251 (кириллица)
sloppy-windows-1252 (западноевропейский, на основе латиницы-1)
sloppy-windows-1253 (греч.
 , вроде на основе ISO-8859-7)
, вроде на основе ISO-8859-7)sloppy-windows-1254 (турецкий, на основе ISO-8859-9)
sloppy-windows-1255 (иврит, на основе ISO-8859-8)
sloppy-windows-1256 (арабский)
sloppy-windows-1257 (Балтийский, на базе ISO-8859-13)
sloppy-windows-1258 (вьетнамский)
sloppy-cp874 (тайский, на основе ISO-8859-11)
sloppy-iso-8859-3 (наверное, мальтийский и эсперанто)
sloppy-iso-8859-6 (другой арабский)
sloppy-iso-8859-7 (греческий)
неаккуратный-iso-8859-8 (иврит)
sloppy-iso-8859-11 (тайский)
Псевдонимы, такие как «sloppy-cp1252» для «sloppy-windows-1252», также будут определенный.
Пять из этих кодировок (от sloppy-windows-1250 до sloppy-windows-1254 )
используются внутри ftfy.
Вот несколько примеров использования ftfy. для иллюстрации того, как
sloppy-windows-1252 объединяет Windows-1252 с Latin-1: explain_unicode()
>>> импорт из ftfy, объяснение_юникода
>>> некоторые_байты = b'\x80\x81\x82'
>>> объясните_юникод (некоторые_байты. декодировать ('латиница-1'))
U+0080 \x80 [Копия] <неизвестно>
U+0081 \x81 [Копия] <неизвестно>
U+0082 \x82 [Копия] <неизвестно>
>>> объясните_юникод (некоторые_байты.декодировать ('windows-1252', 'заменить'))
U+20AC € [Sc] ЗНАК ЕВРО
U+FFFD � [So] ЗАМЕНЯЮЩИЙ СИМВОЛ
U + 201A ‚ [Ps] ОДИНАРНАЯ МЛАДШАЯ-9 КАВАТЫ
>>> объясните_юникод (некоторые_байты. декодировать ('sloppy-windows-1252'))
U+20AC € [Sc] ЗНАК ЕВРО
U+0081 \x81 [Копия] <неизвестно>
U + 201A ‚ [Ps] ОДИНАРНАЯ МЛАДШАЯ-9 КАВАТЫ
Варианты UTF-8
Этот файл определяет кодек под названием «utf-8-variants» (или «utf-8-var»), который может
декодировать текст, закодированный популярной нестандартной версией UTF-8.
Это включает в себя CESU-8, случайное кодирование, созданное путем наложения UTF-8 поверх
UTF-16, а также вариант Java с CESU-8, который содержит двухбайтовую кодировку для
кодовая точка 0.
Это особенно актуально для Python 3, который не предоставляет другого способа расшифровка ЦЭСУ-8 1.
Самый простой способ использовать кодек — просто импортировать ftfy.bad_codecs :
>>> импортировать ftfy.bad_codecs
>>> результат = b'а вот и ноль! \xc0\x80'.decode('utf-8-var')
>>> print(repr(result).lstrip('u'))
'а вот и ноль! \x00'
Кодек совсем не обеспечивает «правильность» CESU-8. Например, Юникод Не совсем стандартное описание консорциума CESU-8 требует наличия только одна возможная кодировка любого символа, поэтому она не позволяет смешивать действительные УТФ-8 и ЦЕСУ-8. Этот кодек допускает ли это , точно так же, как UTF-8 Python 2 декодер делает.
Символы в базовой многоязычной плоскости по-прежнему имеют только одну кодировку. Этот
кодек по-прежнему применяет правило внутри BMP, согласно которому символы должны отображаться в
их кратчайшая форма. Есть одно исключение: последовательность байтов 0xc0 0x80 ,
вместо 0x00 может использоваться для кодирования нулевого символа U+0000 , например
в Яве.
Если вы кодируете с помощью этого кодека, вы получаете легитимный кодек UTF-8. Расшифровка с помощью этого кодек и затем перекодирование не является идемпотентным, хотя кодирование и затем расшифровка есть. Так что этот модуль вам CESU-8 производить не будет. Ищите это функциональность родственного модуля «Разрыв текста для вас» появится примерно никогда.
- 1
В крайнем случае вы можете декодировать CESU-8 в Python 2, используя кодек UTF-8: сначала декодировать байты (неправильно), потом кодировать их, потом декодировать опять же, каждый раз используя UTF-8 в качестве кодека. Но Python 2 мертв, поэтому используйте вместо этого ftfy.
Проблема 16322: файл time.tzname на Python 3.3.0 для Windows декодируется неправильной кодировкой
Issue16322
➜
Это средство отслеживания проблем было перенесено на GitHub 9.0178 ,
и в настоящее время только для чтения .
Для получения дополнительной информации,
см. часто задаваемые вопросы GitHub в Руководстве разработчика Python.
| Название: | time.tzname на Python 3.3.0 для Windows декодируется неправильной кодировкой | ||
|---|---|---|---|
| Тип: | поведение | Стадия: | решено |
| Компоненты: | Модули расширения, Windows | Версии: | Python 3.6, Python 3.4, Python 3.5 |
| Статус: | закрытый | Разрешение: | дубликат |
|---|---|---|---|
| Зависимости: | Заменитель: | time.tzname возвращает пустую строку в Windows, если кодовая страница по умолчанию является кодовой страницей Unicode. Вид: 36779 | |
| Назначено: | Любопытный список: | амауры. форгеотдарк, белопольский, ериксун, йцеа, мсмхрт, оушен-сити, п-ганссле, прикрыл, встиннер форгеотдарк, белопольский, ериксун, йцеа, мсмхрт, оушен-сити, п-ганссле, прикрыл, встиннер | |
| Приоритет: | обычный | Ключевые слова: | 3.3 регрессия, исправление |
Создано 25.10.2012 11:56 автор msmhrt , последнее изменение 11.04.2022 14:57 автор admin . Эта проблема теперь закрыта .
| Имя файла | Загружено | Описание | Редактировать |
|---|---|---|---|
| tzname_bug.py | прикрыл, 2015-09-18 17:25 | Пример загружен как есть. |
| URL | Статус | Связано | Редактировать |
|---|---|---|---|
| PR 3740 | закрытый | денис-осипов, 2017-09-25 07:07 |
| msg173755 — (просмотреть) | Автор: Масами ХИРАТА (msmhrt) | Дата: 25. 10.2012 11:56 10.2012 11:56 | |
|---|---|---|---|
ОС: Windows 7 Starter Edition SP1 (32-разрядная версия), японская версия
Python: 3.3.0 для Windows x86 (python-3.3.0.msi)
time.tzname на Python 3.3.0 для Windows декодируется неправильной кодировкой.
C:\Python33>python.exe
Python 3.3.0 (v3.3.0:bd8afb90ebf2, 29 сент. 2012, 10:55:48) [MSC v.1600 32 бит (In
тел)] на win32
Введите «помощь», «авторское право», «кредиты» или «лицензия» для получения дополнительной информации.
>>> время импорта
>>> время.tzname[0]
'\x93\x8c\x8b\x9e (\x95W\x8f\x80\x8e\x9e)'
>>> time.tzname[0].encode('iso-8859-1').decode('mbcs')
'東京 (標準時)'
>>>
«東京 (標準時)» означает «Токио (стандартное время)» на японском языке.
time.tzname на Python 3.2.3 для Windows работает корректно.
C:\Python32>python.exe
Python 3.2.3 (по умолчанию, 11 апреля 2012 г., 07:15:24) [MSC v.1500 32 бит (Intel)] при победе
32
Введите «помощь», «авторское право», «кредиты» или «лицензия» для получения дополнительной информации. | |||
| msg173758 — (просмотреть) | Автор: Сергей Сторчака (serhiy.storchaka) * | Дата: 25.10.2012 13:47 | |
Я вижу, что в 3.3 PyUnicode_DecodeFSDefaultAndSize() был заменен на PyUnicode_DecodeLocale(). Что показывают sys.getdefaultencoding(), sys.getfilesystemencoding() и locale.getpreferredencoding()? | |||
| msg173772 — (просмотреть) | Автор: Amaury Forgeot d’Arc (amaury.forgeotdarc) * | Дата: 25.10.2012 17:31 | |
Глядя на исходный код CRT, tznames следует декодировать с помощью mbcs. См. также http://mail.python.org/pipermail/python-3000/2007-August/009290.html. | |||
| msg173784 — (просмотреть) | Автор: Сергей Сторчака (serhiy.storchaka) * | Дата: 25.10.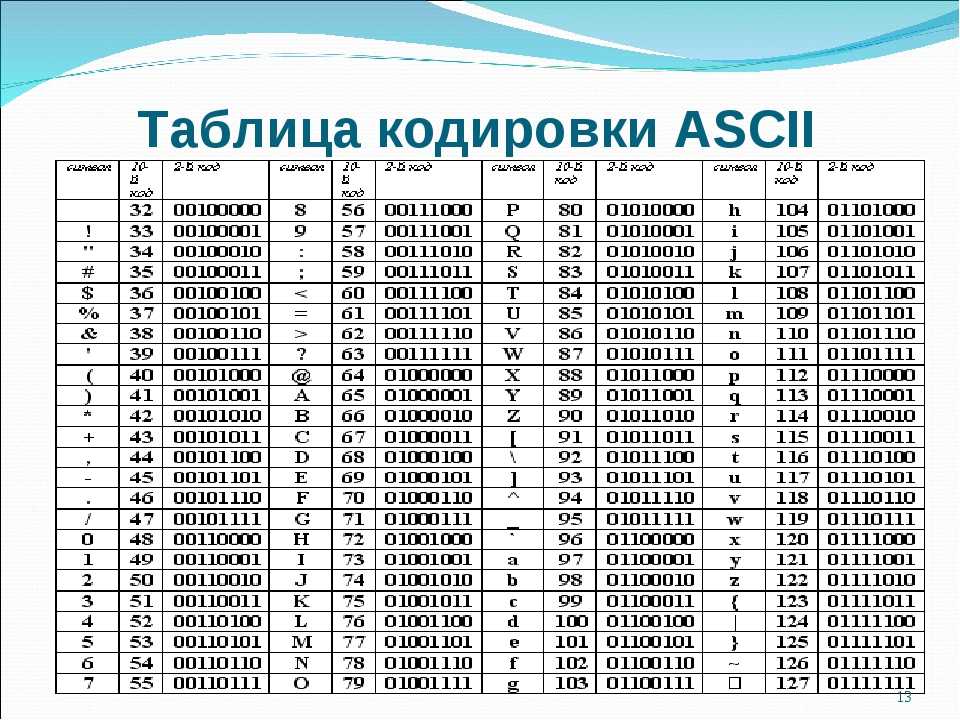 2012 18:06 2012 18:06 | |
Насколько я понимаю, OP имеет локаль UTF-8. | |||
| msg173798 — (просмотр) | Автор: STINNER Виктор (vstinner) * | Дата: 2012-10-25 20:30 | |
>Я вижу, что в 3.3 PyUnicode_DecodeFSDefaultAndSize() был заменен > с помощью PyUnicode_DecodeLocale(). Связанные изменения: - 8620e6901e58 для выпуска №5905 - 279b0aee0cfb за выпуск №13560 Я написал 8620e6901e58 для Linux, когда отсутствует функция wcsftime(). Проблема в наборе изменений 279b0aee0cfb: вводит регрессию в Windows. Похоже, что PyUnicode_DecodeFSDefault() и PyUnicode_DecodeFSDefault() используют другую кодировку в Windows. Я предполагаю, что нам нужно добавить #ifdef MS_WINDOWS, чтобы использовать PyUnicode_DecodeFSDefault() в Windows и PyUnicode_DecodeFSDefault() в Linux. См. также проблему № 10653: time.strftime() использует strftime() (bytes) вместо wcsftime() (unicode) в Windows, потому что wcsftime() и tzname по-разному форматируют часовой пояс. | |||
| msg173806 — (просмотреть) | Автор: Масами ХИРАТА (msmhrt) | Дата: 25.10.2012 22:55 | |
> Что показывают sys.getdefaultencoding(), sys.getfilesystemencoding() и locale.getpreferredencoding()? C:\Python33>python.exe Python 3.3.0 (v3.3.0:bd8afb90ebf2, 29 сентября 2012 г., 10:55:48) [MSC v.1600 32 бит (в тел)] на win32 Введите «помощь», «авторское право», «кредиты» или «лицензия» для получения дополнительной информации. >>> импорт систем >>> sys.getdefaultencoding() 'утф-8' >>> sys.getfilesystemencoding() «МБК» >>> импортировать локаль >>> locale.getpreferredencoding() 'ср932 ' >>> «cp932» совпадает с «mbcs» в японской среде. | |||
| msg173824 — (просмотреть) | Автор: STINNER Виктор (vstinner) * | Дата: 26.10.2012 07:07 | |
> >>> sys.getfilesystemencoding() > 'МБК' > >>> импортировать локаль > >>> locale. | |||
| msg173827 — (просмотреть) | Автор: Масами ХИРАТА (msmhrt) | Дата: 26.10.2012 09:08 | |
> И каково значение .of locale.getpreferredencoding(False)? >>> импортировать локаль >>> locale.getpreferredencoding(False) 'cp932' >>> | |||
| msg174161 — (просмотреть) | Автор: STINNER Виктор (vstinner) * | Дата: 29.10.2012 23:19 | |
См. также выпуск № 836035. | |||
| msg174164 — (просмотреть) | Автор: STINNER Виктор (vstinner) * | Дата: 29.10.2012 23:59 | |
Согласно исходному коду CRT: - tzset() использует WideCharToMultiByte(lc_cp, 0, tzinfo. | |||
| msg174165 — (просмотр) | Автор: STINNER Виктор (vstinner) * | Дата: 2012-10-30 00:28 | |
"Вместо того, чтобы пытаться спорить о том, какая кодировка правильная, было бы проще (и безопаснее) прочитать Unicode-версию массива tzname: StandardName и DaylightName из GetTimeZoneInformation(). | |||
| msg176408 — (просмотреть) | Автор: Масами ХИРАТА (msmhrt) | Дата: 26.11.2012 12:14 | |
Есть ли прогресс в этом вопросе? | |||
| msg224325 — (просмотреть) | Автор: Марк Лоуренс (BreamoreBoy) * | Дата: 2014-07-30 16:50 | |
Кто-нибудь, пожалуйста, ответьте автору. | |||
| msg251013 — (просмотр) | Автор: Петр Прикрыл (prikryl) * | Дата: 2015-09-18 17:25 | |
Я только что наблюдал поведение для чешской локали. Я пытался избежать коллизий с кодировкой stdout, записывая строки в файл с использованием кодировки UTF-8:
tzname_bug.py
--------------------------------------------------
#!python3
время импорта
импорт системы
с open('tzname_bug.txt', 'w', encoding='utf-8') как f:
f. | |||
| msg251068 — (просмотреть) | Автор: Eryk Sun (eryksun) * | Дата: 2015-09-19 09:34 | |
Для декодирования строк tzname Python вызывает mbstowcs, который в Windows использует Latin-1 в локали «C». | |||
| msg251098 — (просмотр) | Автор: Петр Прикрыл (prikryl) * | Дата: 2015-09-19 18:34 | |
Я работал немного по-другому -- фрагмент кода:
result = time. | |||
| msg251259 — (просмотр) | Автор: Eryk Sun (eryksun) * | Дата: 21.09.2015 20:49 | |
> local_encoding = locale. | |||
| msg251264 — (просмотреть) | Автор: Петр Прикрыл (prikryl) * | Дата: 21.09.2015 21:43 | |
@eryksun: Понятно. В моем случае я могу установить локаль перед импортом модуля времени. Однако код (asciidoc3.py) будет использоваться как модуль, и я не могу знать, импортировал ли пользователь модуль времени или нет. | |||
| msg251289 — (просмотр) | Автор: Eryk Sun (eryksun) * | Дата: 22.09.2015 06:07 | |
> импортировать локаль > locale.setlocale(locale.LC_ALL, '') > > импортировать импортную библиотеку > время импорта > importlib. | |||
| msg251308 — (просмотреть) | Автор: Петр Прикрыл (prikryl) * | Дата: 22.09.2015 11:30 | |
@eryksun: Спасибо за помощь. Я наконец закончил с твоим...
«Вызовите setlocale (LC_CTYPE, ''), а затем вызовите time.strftime ('% Z'), чтобы получить имя часового пояса». | |||
| msg302936 — (просмотреть) | Автор: STINNER Виктор (vstinner) * | Дата: 25. 09.2017 09:36 09.2017 09:36 | |
bpo-31549 помечен как дубликат этой проблемы. | |||
| msg302937 — (просмотр) | Автор: STINNER Виктор (vstinner) * | Дата: 2017-09-25 09:37 | |
Форматирование часового пояса в Windows в правильной кодировке — старая проблема Python (особенно Python 3): https://bugs.python.org/issue1040 https://bugs.python.org/issue8304 https://bugs.python.org/issue10653 https://bugs.python.org/issue16322#msg174164 | |||
| msg388209 — (просмотр) | Автор: Eryk Sun (eryksun) * | Дата: 2021-03-06 16:21 | |
Решение для bpo-36779 изменило init_timezone(), чтобы получить tzname непосредственно из WinAPI GetTimeZoneInformation(). К сожалению, разработчики не подумали о поддержке time.tzset(), поэтому значение может быть устаревшим, и его невозможно обновить, или, возможно, отличаться от того, что возвращает time. | |||
 >>> время импорта
>>> время.tzname[0]
'東京 (標準時)'
>>>
>>> время импорта
>>> время.tzname[0]
'東京 (標準時)'
>>> 
 getpreferredencoding()
> 'cp932'
> >>>
>
> «cp932» — это то же самое, что и «mbcs» в японской среде.
И каково значение locale.getpreferredencoding(False)?
getpreferredencoding()
> 'cp932'
> >>>
>
> «cp932» — это то же самое, что и «mbcs» в японской среде.
И каково значение locale.getpreferredencoding(False)?  StandardName, -1, tzname[0], _TZ_STRINGS_SIZE - 1, NULL, &defused) с lc_cp = ___lc_codepage_func().
- wcsftime("%z") и wcsftime("%Z") используют _mbstowcs_s_l() для декодирования имени часового пояса
Я попытался вызвать ___lc_codepage_func(): он возвращает 0. Я полагаю, это означает, что mbstowcs() и wcstombs() используют кодовую страницу ANSI.
Вместо того, чтобы делать ставки на правильную кодировку, было бы проще (и безопаснее) прочитать Unicode-версию массива tzname: StandardName и DaylightName из GetTimeZoneInformation().
Если что-то изменилось, необходимо проверить time.strftime(), time.strptime(), datetime.datetime.strftime() и time.tzname (в формате "%Z").
StandardName, -1, tzname[0], _TZ_STRINGS_SIZE - 1, NULL, &defused) с lc_cp = ___lc_codepage_func().
- wcsftime("%z") и wcsftime("%Z") используют _mbstowcs_s_l() для декодирования имени часового пояса
Я попытался вызвать ___lc_codepage_func(): он возвращает 0. Я полагаю, это означает, что mbstowcs() и wcstombs() используют кодовую страницу ANSI.
Вместо того, чтобы делать ставки на правильную кодировку, было бы проще (и безопаснее) прочитать Unicode-версию массива tzname: StandardName и DaylightName из GetTimeZoneInformation().
Если что-то изменилось, необходимо проверить time.strftime(), time.strptime(), datetime.datetime.strftime() и time.tzname (в формате "%Z").  "
GetTimeZoneInformation() корректно форматирует имена часовых поясов, но вновь возникает проблема #10653: time.strftime("%Z") по-другому форматирует имена часовых поясов.
См. также выпуск №13029.который является дубликатом # 10653, но содержит полезную информацию.
--
Пример в Windows 7 с французскими настройками, настроенными на часовой пояс Токио.
Используя GetTimeZoneInformation(), time.tzname будет ("Токио", "Токио (heure d\u2019\xe9t\xe9)"). U+2019 - это "ПРАВИЛЬНАЯ ОДИНАРНАЯ КАВАЧКА". Этот символ обычно заменяется на U+0027 (АПОСТРОП) в ASCII.
time.strftime("%Z") дает "Токио (heure d'\x81\x66ete)" (если это реализовано с использованием strftime() или wcsftime()).
--
Если я правильно понял, у Python 3.3 есть две проблемы в Windows:
* time.tzname декодируется из неправильной кодировки
* time.strftime("%Z") выдает неверный вывод
Настоящая проблема блокировщика — это ошибка в функциях strftime() и wcsftime() в Windows CRT. Решение состоит в том, чтобы заменить "%Z" на имя часового пояса перед вызовом strftime() или wcsftime(), также известным как работа с ошибкой Windows CRT.
"
GetTimeZoneInformation() корректно форматирует имена часовых поясов, но вновь возникает проблема #10653: time.strftime("%Z") по-другому форматирует имена часовых поясов.
См. также выпуск №13029.который является дубликатом # 10653, но содержит полезную информацию.
--
Пример в Windows 7 с французскими настройками, настроенными на часовой пояс Токио.
Используя GetTimeZoneInformation(), time.tzname будет ("Токио", "Токио (heure d\u2019\xe9t\xe9)"). U+2019 - это "ПРАВИЛЬНАЯ ОДИНАРНАЯ КАВАЧКА". Этот символ обычно заменяется на U+0027 (АПОСТРОП) в ASCII.
time.strftime("%Z") дает "Токио (heure d'\x81\x66ete)" (если это реализовано с использованием strftime() или wcsftime()).
--
Если я правильно понял, у Python 3.3 есть две проблемы в Windows:
* time.tzname декодируется из неправильной кодировки
* time.strftime("%Z") выдает неверный вывод
Настоящая проблема блокировщика — это ошибка в функциях strftime() и wcsftime() в Windows CRT. Решение состоит в том, чтобы заменить "%Z" на имя часового пояса перед вызовом strftime() или wcsftime(), также известным как работа с ошибкой Windows CRT.
 write(sys.version + '\n')
f.write('Должно быть: Первая Европа (первый час) | Первая Европа (летний час)\n')
f.write('но это: ' + time.tzname[0] + ' | ' + time.tzname[1] + '\n')
f.write(' типы: ' + repr (type (time.tzname [0])) + ' | ' + repr (type (time.tzname [1])) + '\ n')
f.write('Должно быть ascii: ' + ascii('Стр. Европа (первый час) | Стр. Европа (летний час)') + '\n')
f.write('но это ascii: ' + ascii(time.tzname[0]) + ' | ' + ascii(time.tzname[1]) + '\n')
--------------------------------------------------
Он создает файл tzname_bug.txt с содержимым (копирование/вставка из редактора с поддержкой UNICODE (Notepad++, индикатор в правом нижнем углу показывает UTF-8.
--------------------------------------------------
3.5.0 (v3.5.0:374f501f4567, 13 сентября 2015 г., 02:27:37) [MSC v.1900 64 бит (AMD64)]
Должно быть: Střední Evropa (běžný čas) | Střední Evropa (летний час)
но это: Støední Evropa (bìný èas) | Støední Evropa (летни иас)
типы: <класс 'str'> | <класс 'ул'>
Должно быть в виде ascii: 'St\u0159edn\xed Evropa (b\u011b\u017en\xfd\u010das) | St\u0159edn\xed Evropa (letn\xed \u010das)'
но это как ascii: 'St\xf8edn\xed Evropa (b\xec\x9en\xfd \xe8as)' | 'St\xf8edn\xed Европа (letn\xed \xe8as)'
----------------------------------
write(sys.version + '\n')
f.write('Должно быть: Первая Европа (первый час) | Первая Европа (летний час)\n')
f.write('но это: ' + time.tzname[0] + ' | ' + time.tzname[1] + '\n')
f.write(' типы: ' + repr (type (time.tzname [0])) + ' | ' + repr (type (time.tzname [1])) + '\ n')
f.write('Должно быть ascii: ' + ascii('Стр. Европа (первый час) | Стр. Европа (летний час)') + '\n')
f.write('но это ascii: ' + ascii(time.tzname[0]) + ' | ' + ascii(time.tzname[1]) + '\n')
--------------------------------------------------
Он создает файл tzname_bug.txt с содержимым (копирование/вставка из редактора с поддержкой UNICODE (Notepad++, индикатор в правом нижнем углу показывает UTF-8.
--------------------------------------------------
3.5.0 (v3.5.0:374f501f4567, 13 сентября 2015 г., 02:27:37) [MSC v.1900 64 бит (AMD64)]
Должно быть: Střední Evropa (běžný čas) | Střední Evropa (летний час)
но это: Støední Evropa (bìný èas) | Støední Evropa (летни иас)
типы: <класс 'str'> | <класс 'ул'>
Должно быть в виде ascii: 'St\u0159edn\xed Evropa (b\u011b\u017en\xfd\u010das) | St\u0159edn\xed Evropa (letn\xed \u010das)'
но это как ascii: 'St\xf8edn\xed Evropa (b\xec\x9en\xfd \xe8as)' | 'St\xf8edn\xed Европа (letn\xed \xe8as)'
----------------------------------  Однако в этой локали строки tzname на самом деле кодируются с использованием системной кодовой страницы ANSI (например, 1250 для Центральной/Восточной Европы). Таким образом, он в конечном итоге декодирует строки ANSI как моджибаке Latin-1. Например:
>>> с
'Стршедни Европа (бежевый час) | Střední Evropa (летни час)'
>>> s.encode('1250').decode('latin-1')
'Стёдни Европа' (bì\x9ený èas) | Støední Evropa (letní èas)'
Вы можете обойти это несоответствие, вызвав setlocale(LC_ALL, "") до того, как что-либо импортирует модуль времени. Это должно установить локаль, отличную от «C», и в этом случае кодовая страница должна быть согласованной. Конечно, это не поможет, если вы не можете контролировать, когда модуль времени впервые импортируется.
Последнее не было бы проблемой, если бы time.tzset был реализован в Windows. По крайней мере, вы можете использовать ctypes для вызова функции CRT _tzset. Это решает проблему с time.strftime('%Z'). Вы также можете получить tzname CRT, вызвав экспортированную функцию __tzname.
Однако в этой локали строки tzname на самом деле кодируются с использованием системной кодовой страницы ANSI (например, 1250 для Центральной/Восточной Европы). Таким образом, он в конечном итоге декодирует строки ANSI как моджибаке Latin-1. Например:
>>> с
'Стршедни Европа (бежевый час) | Střední Evropa (летни час)'
>>> s.encode('1250').decode('latin-1')
'Стёдни Европа' (bì\x9ený èas) | Støední Evropa (letní èas)'
Вы можете обойти это несоответствие, вызвав setlocale(LC_ALL, "") до того, как что-либо импортирует модуль времени. Это должно установить локаль, отличную от «C», и в этом случае кодовая страница должна быть согласованной. Конечно, это не поможет, если вы не можете контролировать, когда модуль времени впервые импортируется.
Последнее не было бы проблемой, если бы time.tzset был реализован в Windows. По крайней мере, вы можете использовать ctypes для вызова функции CRT _tzset. Это решает проблему с time.strftime('%Z'). Вы также можете получить tzname CRT, вызвав экспортированную функцию __tzname. Вот пример Python 3.5, который устанавливает текущий поток для использования русского языка и создает новый кортеж tzname:
импорт ctypes
импортировать локаль
kernel32 = ctypes.WinDLL('kernel32')
ucrtbase = ctypes.CDLL('ucrtbase')
MUI_LANGUAGE_NAME = 8
kernel32.SetThreadPreferredUILanguages(MUI_LANGUAGE_NAME,
'ru-RU\0', нет)
locale.setlocale(locale.LC_ALL, 'ru-RU')
# сбросить tzname в текущей локали
ucrtbase._tzset()
ucrtbase.__tzname.restype = ctypes.POINTER(ctypes.c_char_p * 2)
c_tzname = ucrtbase.__tzname()[0]
tzname = tuple(tz.decode('1251') для tz в c_tzname)
# вывод символов кириллицы в консоль
ядро32.SetConsoleOutputCP(1251)
стандартный вывод = открытый (1, 'w', буферизация = 1, кодировка = '1251', closefd = 0)
>>> print(tzname, file=stdout)
('Время в формате UTC', 'Время в формате UTC')
Вот пример Python 3.5, который устанавливает текущий поток для использования русского языка и создает новый кортеж tzname:
импорт ctypes
импортировать локаль
kernel32 = ctypes.WinDLL('kernel32')
ucrtbase = ctypes.CDLL('ucrtbase')
MUI_LANGUAGE_NAME = 8
kernel32.SetThreadPreferredUILanguages(MUI_LANGUAGE_NAME,
'ru-RU\0', нет)
locale.setlocale(locale.LC_ALL, 'ru-RU')
# сбросить tzname в текущей локали
ucrtbase._tzset()
ucrtbase.__tzname.restype = ctypes.POINTER(ctypes.c_char_p * 2)
c_tzname = ucrtbase.__tzname()[0]
tzname = tuple(tz.decode('1251') для tz в c_tzname)
# вывод символов кириллицы в консоль
ядро32.SetConsoleOutputCP(1251)
стандартный вывод = открытый (1, 'w', буферизация = 1, кодировка = '1251', closefd = 0)
>>> print(tzname, file=stdout)
('Время в формате UTC', 'Время в формате UTC')  tzname[0] # упрощенная версия исходного кода.
# Из-за ошибки в библиотеках Windows Python 3.3 попытался обойти
# некоторые вопросы. Однако дерьмо попало в вентилятор, и ошибка запузырилась здесь.
# Элементы `time.tzname` представляют собой строки (юникод); однако они были
# заполнено плохим содержимым. Подробнее см. https://bugs.python.org/issue16322.
# На самом деле, вместо хороших символов были переданы неправильные символы.
# Этот код следует пропустить в более поздних версиях Python, которые исправят
# проблема.
импортная платформа
если platform.system() == 'Windows':
# Конкретный пример для чешской локали:
# - в качестве родной кодировки используется cp1250 (windows-1250)
# - time.tzname[0] должно начинаться с "Střední Evropa"
# - ascii('Střední Evropa') должен возвращать "'St\u0159edn\xed Европа'"
# - из-за бага возвращает "'St\xf8edn\xed Evropa'"
#
# Символ 'ř' имеет кодовую точку Юникода `\u0159` (то есть шестнадцатеричный)
# и код `\xF8` в cp1250.
tzname[0] # упрощенная версия исходного кода.
# Из-за ошибки в библиотеках Windows Python 3.3 попытался обойти
# некоторые вопросы. Однако дерьмо попало в вентилятор, и ошибка запузырилась здесь.
# Элементы `time.tzname` представляют собой строки (юникод); однако они были
# заполнено плохим содержимым. Подробнее см. https://bugs.python.org/issue16322.
# На самом деле, вместо хороших символов были переданы неправильные символы.
# Этот код следует пропустить в более поздних версиях Python, которые исправят
# проблема.
импортная платформа
если platform.system() == 'Windows':
# Конкретный пример для чешской локали:
# - в качестве родной кодировки используется cp1250 (windows-1250)
# - time.tzname[0] должно начинаться с "Střední Evropa"
# - ascii('Střední Evropa') должен возвращать "'St\u0159edn\xed Европа'"
# - из-за бага возвращает "'St\xf8edn\xed Evropa'"
#
# Символ 'ř' имеет кодовую точку Юникода `\u0159` (то есть шестнадцатеричный)
# и код `\xF8` в cp1250. `\ xF8` был использован неправильно
# как кодовая точка Unicode `\u00F8` -- это для Unicode
# символ 'ø', который наблюдается в строке.
#
# Чтобы исправить это, строка `result` должна быть переинтерпретирована с другим
# кодировка. При работе со строками Python 3, возможно,
# делается только через строковое представление и `eval()`. Здесь
# `eval()` не очень опасен, потому что строка была получена
# из библиотеки ОС, а значения ограничены определенным подмножеством.
#
# Литерал `ascii()` имеет префикс префикса типа `binary`,
# `вычисляется`, и двоичный результат декодируется в правильную строку.
local_encoding = locale.getdefaultlocale () [1]
b = eval('b' + ascii(результат))
результат = b.decode(local_encoding)
`\ xF8` был использован неправильно
# как кодовая точка Unicode `\u00F8` -- это для Unicode
# символ 'ø', который наблюдается в строке.
#
# Чтобы исправить это, строка `result` должна быть переинтерпретирована с другим
# кодировка. При работе со строками Python 3, возможно,
# делается только через строковое представление и `eval()`. Здесь
# `eval()` не очень опасен, потому что строка была получена
# из библиотеки ОС, а значения ограничены определенным подмножеством.
#
# Литерал `ascii()` имеет префикс префикса типа `binary`,
# `вычисляется`, и двоичный результат декодируется в правильную строку.
local_encoding = locale.getdefaultlocale () [1]
b = eval('b' + ascii(результат))
результат = b.decode(local_encoding) 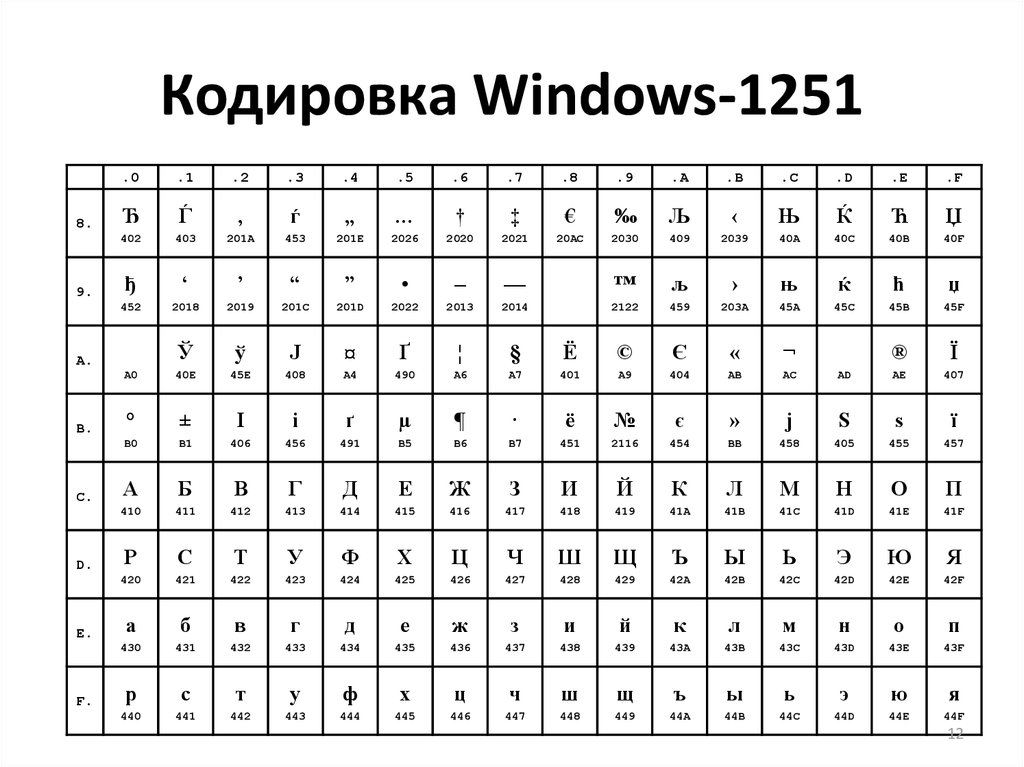 getdefaultlocale () [1]
Используйте locale.getpreferredencoding().
> b = eval('b' + ascii(результат))
> результат = b.decode(local_encoding)
Проще и надежнее использовать «latin-1» и «mbcs» (ANSI). Например:
результат = результат.encode('latin-1').decode('mbcs')
Если перед импортом модуля времени вызывается setlocale(LC_CTYPE, ""), то tzname уже является правильным. В этом случае вышеуказанное либо безвредно, либо вызывает ошибку UnicodeEncodeError, которую можно обработать. OTOH, ваш подход незаметно искажает значение:
>>> результат = 'Střední Evropa (běžný čas)'
>>> b = eval('b' + ascii(результат))
>>> b.decode('1251')
'Св\\ u0159ednн Evropa (b\\u011b\u017enэ\\u010das)'
Вернемся к вопросу. В обзоре при первоначальном импорте модуля времени, если CRT использует локаль по умолчанию «C», у нас есть это несоответствие, при котором функции времени кодируют/декодируют tzname как ANSI, а mbstowcs декодирует tzname как Latin-1. (Кроме того, strftime в новой CRT вызывает wcsftime, что добавляет еще один уровень транскодирования, чтобы усугубить качество моджибаке.
getdefaultlocale () [1]
Используйте locale.getpreferredencoding().
> b = eval('b' + ascii(результат))
> результат = b.decode(local_encoding)
Проще и надежнее использовать «latin-1» и «mbcs» (ANSI). Например:
результат = результат.encode('latin-1').decode('mbcs')
Если перед импортом модуля времени вызывается setlocale(LC_CTYPE, ""), то tzname уже является правильным. В этом случае вышеуказанное либо безвредно, либо вызывает ошибку UnicodeEncodeError, которую можно обработать. OTOH, ваш подход незаметно искажает значение:
>>> результат = 'Střední Evropa (běžný čas)'
>>> b = eval('b' + ascii(результат))
>>> b.decode('1251')
'Св\\ u0159ednн Evropa (b\\u011b\u017enэ\\u010das)'
Вернемся к вопросу. В обзоре при первоначальном импорте модуля времени, если CRT использует локаль по умолчанию «C», у нас есть это несоответствие, при котором функции времени кодируют/декодируют tzname как ANSI, а mbstowcs декодирует tzname как Latin-1. (Кроме того, strftime в новой CRT вызывает wcsftime, что добавляет еще один уровень транскодирования, чтобы усугубить качество моджибаке.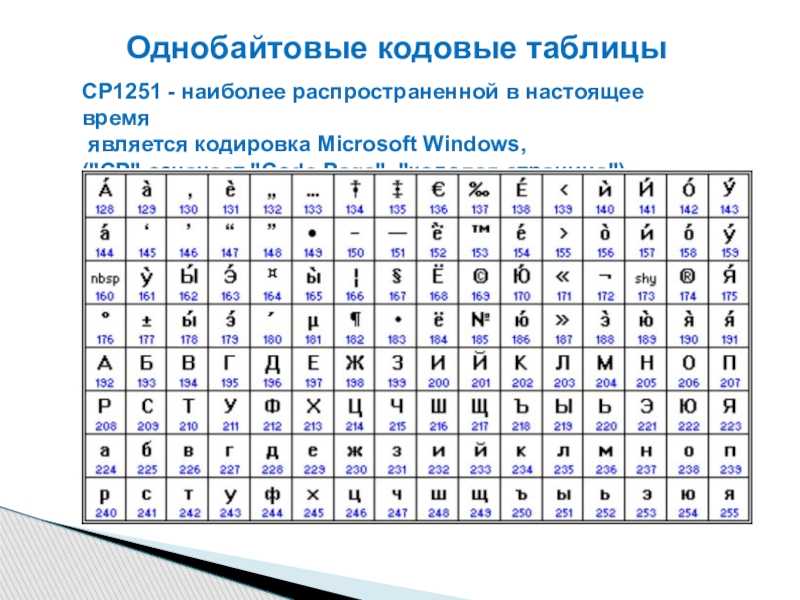 )
Если time.tzset реализован в Windows, то при запуске приложение может установить локаль (в частности, LC_CTYPE для tzname и LC_TIME для strftime), а затем вызвать time.tzset().
Пример с русской локалью системы:
Изначально мы находимся в локали "C", а tzname CRT - в ANSI. time.tzname неправильно декодирует это как Latin-1, так как это то, что mbstowcs использует в локали «C»:
>>> время.tzname[0]
'\xc2\xf0\xe5\xec\xff \xe2 \xf4\xee\xf0\xec\xe0\xf2\xe5 UTC'
Способ реализации strftime CRT усугубляет проблему:
>>> time.strftime('%Z')
'A?aiy a oi?iaoa UTC'
Это реализуется вызовом функции расширенных символов wcsftime. Как и Python, он получает строку расширенных символов, вызывая mbstowcs для имени ANSI tzname. Затем strftime ЭЛТ кодирует строку расширенных символов обратно как наиболее подходящую строку ANSI, и, наконец, time.strftime декодирует результат как Latin-1 с помощью mbstowcs. В результате получается мутировавший моджибаке:
>>> time.tzname[0].
)
Если time.tzset реализован в Windows, то при запуске приложение может установить локаль (в частности, LC_CTYPE для tzname и LC_TIME для strftime), а затем вызвать time.tzset().
Пример с русской локалью системы:
Изначально мы находимся в локали "C", а tzname CRT - в ANSI. time.tzname неправильно декодирует это как Latin-1, так как это то, что mbstowcs использует в локали «C»:
>>> время.tzname[0]
'\xc2\xf0\xe5\xec\xff \xe2 \xf4\xee\xf0\xec\xe0\xf2\xe5 UTC'
Способ реализации strftime CRT усугубляет проблему:
>>> time.strftime('%Z')
'A?aiy a oi?iaoa UTC'
Это реализуется вызовом функции расширенных символов wcsftime. Как и Python, он получает строку расширенных символов, вызывая mbstowcs для имени ANSI tzname. Затем strftime ЭЛТ кодирует строку расширенных символов обратно как наиболее подходящую строку ANSI, и, наконец, time.strftime декодирует результат как Latin-1 с помощью mbstowcs. В результате получается мутировавший моджибаке:
>>> time.tzname[0].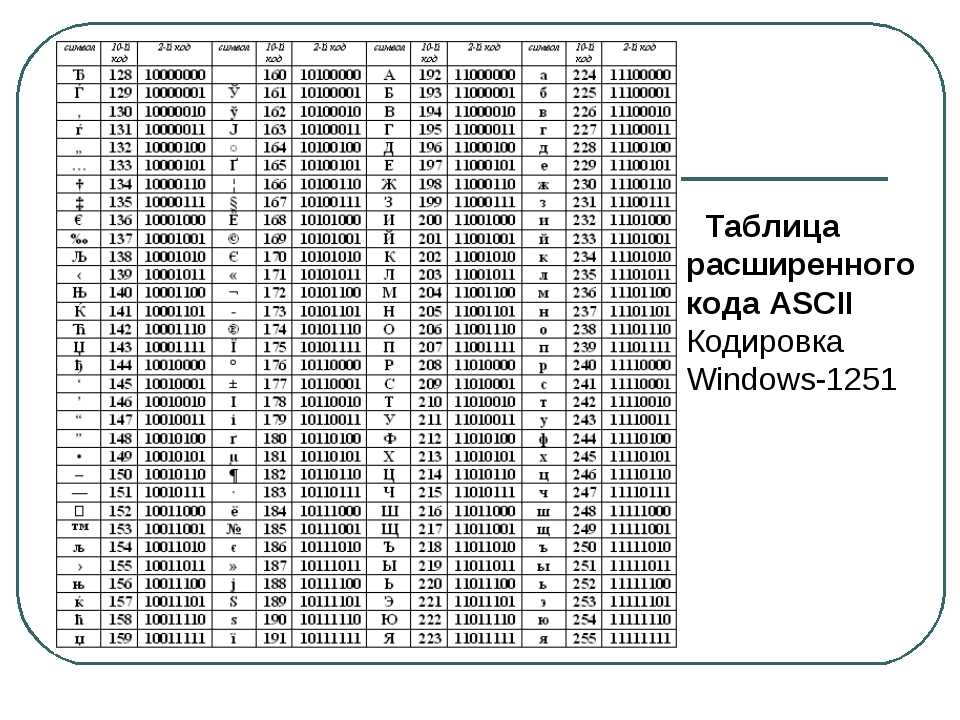 encode('mbcs', 'replace').decode('latin-1')
'A?aiy a oi?iaoa UTC'
По иронии судьбы Python перестал вызывать wcsftime в Windows из-за этих проблем, но изменения в коде с тех пор, а также новая CRT вернули проблему, и даже хуже. См. мой комментарий в выпуске 10653, msg243660.
Исправьте это, установив локаль и вызвав _tzset:
>>> импорт ctypes, локаль
>>> locale.setlocale(locale.LC_ALL, '')
'Русский_Россия.1251'
>>> ctypes.cdll.ucrtbase._tzset()
0
>>> time.strftime('%Z')
'Время в формате UTC'
Если бы time.tzset был реализован в Windows, его вызов перезагрузил бы кортеж time.tzname.
encode('mbcs', 'replace').decode('latin-1')
'A?aiy a oi?iaoa UTC'
По иронии судьбы Python перестал вызывать wcsftime в Windows из-за этих проблем, но изменения в коде с тех пор, а также новая CRT вернули проблему, и даже хуже. См. мой комментарий в выпуске 10653, msg243660.
Исправьте это, установив локаль и вызвав _tzset:
>>> импорт ctypes, локаль
>>> locale.setlocale(locale.LC_ALL, '')
'Русский_Россия.1251'
>>> ctypes.cdll.ucrtbase._tzset()
0
>>> time.strftime('%Z')
'Время в формате UTC'
Если бы time.tzset был реализован в Windows, его вызов перезагрузил бы кортеж time.tzname.  Вместо вашего предложения
результат = результат.encode('latin-1').decode('mbcs')
Я думал создать модуль, скажем, wordaround16322.py следующим образом:
---------------
импортировать локаль
locale.setlocale(locale.LC_ALL, '')
импортировать импортную библиотеку
время импорта
importlib.reload(время)
---------------
Я думал, что перезагрузка модуля времени будет такой же, как и импорт позже, после установки локали. Если бы это сработало, модуль можно было бы просто импортировать, куда бы он ни понадобился. Однако это не работает при импорте после времени импорта. Какова причина? Работает ли перезагрузка ()
только для модулей, закодированных как исходники Python? Есть ли другой подход, реализующий модуль workaroundXXX.py?
Вместо вашего предложения
результат = результат.encode('latin-1').decode('mbcs')
Я думал создать модуль, скажем, wordaround16322.py следующим образом:
---------------
импортировать локаль
locale.setlocale(locale.LC_ALL, '')
импортировать импортную библиотеку
время импорта
importlib.reload(время)
---------------
Я думал, что перезагрузка модуля времени будет такой же, как и импорт позже, после установки локали. Если бы это сработало, модуль можно было бы просто импортировать, куда бы он ни понадобился. Однако это не работает при импорте после времени импорта. Какова причина? Работает ли перезагрузка ()
только для модулей, закодированных как исходники Python? Есть ли другой подход, реализующий модуль workaroundXXX.py? 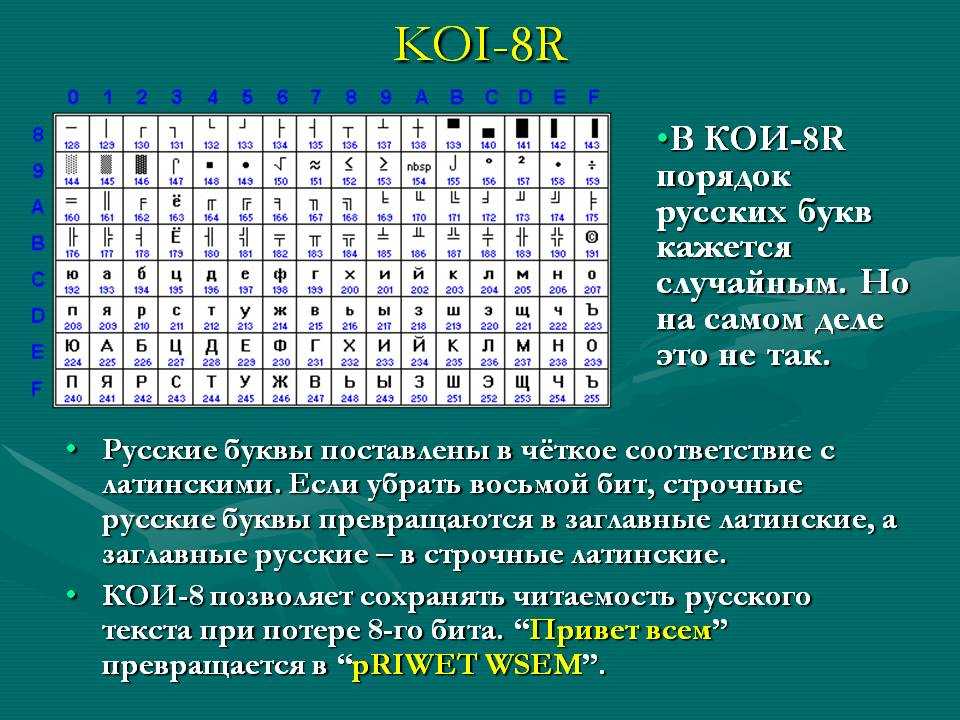 reload(время)
>
> не работает при импорте через время импорта.
> В чем причина? Reload() работает только для
> модули, закодированные как исходники Python?
Система импорта не будет повторно инициализировать встроенный или динамический модуль расширения. Перезагрузка просто возвращает ссылку на существующий модуль. Он даже не перезагрузит PEP 489.многофазный модуль расширения. (Но вы можете создать и запустить новый экземпляр многофазного модуля расширения.)
> Есть ли другой подход, который реализовывал бы
> обходной модульXXX.py?
Если локаль пользователя по умолчанию и предпочитаемый язык текущего потока совместимы с системной кодировкой ANSI [1], вам не нужно ни вызывать _tzset, ни беспокоиться о time.tzname. Вызовите setlocale(LC_CTYPE, ''), а затем вызовите time.strftime('%Z'), чтобы получить имя часового пояса.
Если вы используете Win32 напрямую вместо CRT, то все эти дела ANSI не будут проблемой. Просто вызовите GetTimeZoneInformation, чтобы получить стандартные и дневные имена в виде строк с расширенными символами.
reload(время)
>
> не работает при импорте через время импорта.
> В чем причина? Reload() работает только для
> модули, закодированные как исходники Python?
Система импорта не будет повторно инициализировать встроенный или динамический модуль расширения. Перезагрузка просто возвращает ссылку на существующий модуль. Он даже не перезагрузит PEP 489.многофазный модуль расширения. (Но вы можете создать и запустить новый экземпляр многофазного модуля расширения.)
> Есть ли другой подход, который реализовывал бы
> обходной модульXXX.py?
Если локаль пользователя по умолчанию и предпочитаемый язык текущего потока совместимы с системной кодировкой ANSI [1], вам не нужно ни вызывать _tzset, ни беспокоиться о time.tzname. Вызовите setlocale(LC_CTYPE, ''), а затем вызовите time.strftime('%Z'), чтобы получить имя часового пояса.
Если вы используете Win32 напрямую вместо CRT, то все эти дела ANSI не будут проблемой. Просто вызовите GetTimeZoneInformation, чтобы получить стандартные и дневные имена в виде строк с расширенными символами. У вас есть такая возможность через ctypes.
[1]: пользователь может выбрать локаль (язык) по умолчанию, которая не связана с локалью ANSI системы (настройка ANSI для каждой машины находится в разделе «Регион» -> «Администрирование»). Кроме того, предпочтительный язык можно выбрать динамически, вызвав SetThreadPreferredUILanguages или SetProcessPreferredUILanguages. Все три могут быть несовместимы друг с другом, и в этом случае вы должны явно указать локаль (например, «ru-RU» вместо пустой строки) и вызвать _tzset.
У вас есть такая возможность через ctypes.
[1]: пользователь может выбрать локаль (язык) по умолчанию, которая не связана с локалью ANSI системы (настройка ANSI для каждой машины находится в разделе «Регион» -> «Администрирование»). Кроме того, предпочтительный язык можно выбрать динамически, вызвав SetThreadPreferredUILanguages или SetProcessPreferredUILanguages. Все три могут быть несовместимы друг с другом, и в этом случае вы должны явно указать локаль (например, «ru-RU» вместо пустой строки) и вызвать _tzset.  strftime('%Z'), в зависимости от того, когда ucrt выглядит до часового пояса. Например, запустите Python и импортируйте время. Затем измените часовой пояс и вызовите time.strftime('%Z'). Значение будет отличаться от time.tzname.
strftime('%Z'), в зависимости от того, когда ucrt выглядит до часового пояса. Например, запустите Python и импортируйте время. Затем измените часовой пояс и вызовите time.strftime('%Z'). Значение будет отличаться от time.tzname. | Дата | Пользователь | Действие | аргументы | 14:57:37 ериксуннабор | статус: открыт — > Closed superseder: time.tzname возвращает пустую строку в Windows, если кодовая страница по умолчанию является кодовой страницей Unicode сообщения: + сообщение 388209 разрешение: дубликат | ||
|---|---|---|---|---|---|---|---|
| 2017-09-25 15:53:06 | BreamoreBoy | набор | любопытный:
— BreamoreBoy | ||||
| 25.09.2017 09:37:31 | vstinner | set | сообщения: + msg302937 | ||||
| 25.09.2017 09:36:47 | vstinner | набор | сообщения: + msg302936 | ||||
| 2017-09-25 08:01:52 | сергий.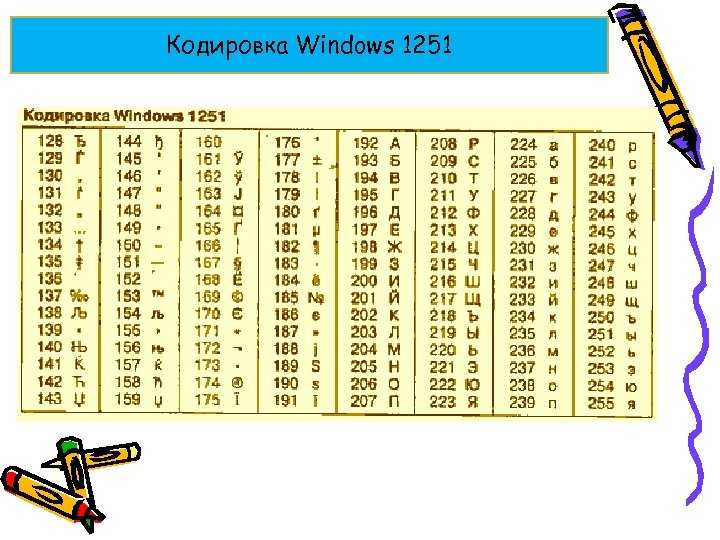 сторчака сторчака | ссылка | issue31549 superseder | 9018 5 07:07:34 | денис-осипов | сет | ключевые слова:
+ patch stage: обзор патча pull_requests: + pull_request3726 |
| 2015-09-22 11:30:54 | прикрыл | набор | сообщения: + сообщение 251308 | ||||
| 2015-09-22 06:07:23 | eryksun | набор | сообщения: + msg251289 | ||||
| 2015-09-21 21:43:01 | прикрыл | набор | сообщения: + msg251264 | ||||
| 2015-09-21 20:49:45 | eryksun | set | сообщения:
+ msg251259 версии: + Python 3.6 | ||||
| 2015-09-19 18:34:55 | прикрыл | набор | сообщения: + сообщение 251098 | ||||
| 2015-09-19 09:34:48 | ериксун | комплект | любопытный:
+ эриксун сообщения: + msg251068 | ||||
| 2015-09-18 17:25:39 | прикрыл | набор | файлы:
+ tzname_bug. py py любопытный: + прикрыл сообщения: + msg251013 | ||||
| 2014-07-30 16:50:45 | BreamoreBoy | набор | любопытный:
+ BreamoreBoy сообщений:
+ msg224325 | ||||
| 2012-11-26 12:14:57 | msmhrt | набор | сообщения: + msg176408 | ||||
| 2012-10-30 10:03:40 | сергий.сторчака | набор | любопытный:
— сергий.сторчака | ||||
| 2012-10-30 00:28:26 | встиннер | набор | любопытный:
+ Ocean-City сообщения: + msg174165 | ||||
| 2012-10-29 23:59:23 | встиннер | набор | сообщения: + msg174164 | ||||
| 2012-10-29 23:19:11 | vstinner | set | сообщения: + msg174161 | ||||
| 2012-10-28 03:55:38 | jcea | набор | любопытный:
+ jcea | ||||
| 2012-10-26 09:08:31 | msmhrt | set | сообщения: + msg173827 | ||||
| 2012-10-26 07:07:48 | vstinner | набор | сообщения: + msg173824 | ||||
| 2012-10-25 22:55:46 | msmhrt | set | сообщения: + msg173806 | ||||
| 2012-10-25 20:30:20 | vstinner | set | сообщения: + msg173798 | ||||
| 2012-10-25 19:12:46 | r. Оставить комментарий
|