Как прописать ключевые слова для сайта, вставка и выделение в тегах и тексте
Содержание:
Сколь высокое значение тегам в формировании поисковой выдачи вы бы не придавали, переоценить их влияние будет сложно. При помощи тегов поисковой бот выделяет главные компоненты ресурса — заголовки, ключевые слова и фразы, ссылки. Собственно, заключенные в теги слова определяют ранжирование сайта в выдаче поисковика. Однако, во избежание проблем важно не переборщить с тегами.
Для поисковой оптимизации страницы под ключевые слова зачастую используются мета-теги title, description и keywords. Они содержат служебные сведения в документе HTML. Кроме этих, вебмастеры применяют и другие теги. К примеру, теги strong и em, а также другие. И, конечно, не стоит забывать о тегах Н1 — Н6. Обо всех этих тегах мы тоже поговорим в этой статье.
Мета-теги: title, description и keywords
Наиважнейшая часть страницы, которая имеет максимальное значение для сео-продвижения, это ее заголовок. Тег <title> позволяет содержимое заголовка страницы указать поисковому боту, к которому он обращается в первую очередь при осуществлении сопоставления запроса. Текст тега составляется, опираясь на семантическое ядро ресурса, по которому идет продвижение, и содержит в себе определенные ключи.
Тег <title> позволяет содержимое заголовка страницы указать поисковому боту, к которому он обращается в первую очередь при осуществлении сопоставления запроса. Текст тега составляется, опираясь на семантическое ядро ресурса, по которому идет продвижение, и содержит в себе определенные ключи.
В самом начале title должен содержать основную ключевую фразу в прямом вхождении. Сам по себе тег заголовка должен быть уникален (и в пределах одного сайта, и, желательно, в рамках интернета), он прописываться или генерироваться так, чтобы заинтересовать пользователя или органично включать в себя основные ключевые запросы. Количество символов в title желательно уместить до 70.
На информацию, вписываемую в мета-тег <description>, отводится на 100 символов больше, чем на предыдущий, т. е. — 170 знаков. В этот объем нужно уместить краткое описание страницы, сюда также нужно внедрить ключевые слова. Тег предназначен для краткого описания страницы, обычно из него формируется снипет в Google. Что бы вы здесь не написали — это должна быть ценная информация для пользователей. Только тогда сниппет будет способствовать приросту трафика и повышению позиций в поиске.
Что бы вы здесь не написали — это должна быть ценная информация для пользователей. Только тогда сниппет будет способствовать приросту трафика и повышению позиций в поиске.
Description может влиять на продвижение сайта, например, Google учитывает его. Но последние SEO-эксперименты показывают, что у него небольшая роль в оптимизации страницы, и иногда этим тегом пренебрегают.
В данный момент тег <keywords> поисковиками никак не учитывается, его можно не использовать. Ранее там прописывали перечень ключевых слов страницы.
Работа с текстом в HTML
Для расстановки акцентов на отдельных словах, выделения их жирным либо курсивом, применяются теги <strong> и <em>. Для достижения результата, вы просто выделяете нужные слова тегами. Получится:
<strong>Нужное слово, написанное жирным шрифтом</strong> <em>Нужное слово, написанное курсивом</em>
Следует помнить, что <strong> и <em>, как и тег <b>, имеют влияние на оптимизацию в поиске. Поэтому не рекомендуется использовать их на странице слишком часто. Ведь ПС по ряду причин «питают слабость» к словам, выделенным жирным шрифтом, но за частое их применение страница может быть пессемизирована в результатах выдачи за поисковый спам. Я рекомендую выделять данными тегами важные места в тексте для расстановки акцентов, а не ключевые слова.
Поэтому не рекомендуется использовать их на странице слишком часто. Ведь ПС по ряду причин «питают слабость» к словам, выделенным жирным шрифтом, но за частое их применение страница может быть пессемизирована в результатах выдачи за поисковый спам. Я рекомендую выделять данными тегами важные места в тексте для расстановки акцентов, а не ключевые слова.
Вхождение в URL
Желательно до создания сайта знать его примерную структуру, это позволит продумать URL-адреса разделов и подразделов веб-ресурса. В урлы страниц обязательно нужно включать ключевики, обычно я их вписываю латинскими буквами в таком виде, чтобы они выделялись в выдаче Яндекса при соответствующем запросе. Также важно не переспамить по вхождениям, особенно тогда, когда ключ есть и в названии раздела и заголовке статьи. Нужно стремиться к тому, чтобы одно слово не встречалось в URL более 1-го раза.
Заголовки в HTML: h2 – H6
Каждая статья, вне зависимости от количества символов, должна содержать заголовки. Они являются одним из самых значимых элементов сео-оптимизации. Всего существует 6 тегов для формирования заголовков в зависимости от их уровня: от h2 до h6. А тег заголовка <h2> — будет очередным по степени важности после title в определении рейтинга страницы. При этом заголовок первого уровня может встречаться в тексте только единожды. В виде кода все это выглядит очень просто. Выделяем конкретный отрезок текста тегами заголовков необходимого уровня, и готово. Тег Н1 обязательно должен содержать основной ключ продвигаемой страницы, я рекомендую туда вписывать основное ключевое слово страницы в разбавленном виде, к тому же, он должен отличаться от тега title. Заголовки Н2 – Н6 имеют вес по убыванию и их можно использовать на странице несколько раз. В этих тегах также можно использовать ключевые фразы в сильно разбавленном или уточняющем виде, но не злоупотребляйте, в этих тегах можно обойтись и без ключей, ошибки не будет.
Они являются одним из самых значимых элементов сео-оптимизации. Всего существует 6 тегов для формирования заголовков в зависимости от их уровня: от h2 до h6. А тег заголовка <h2> — будет очередным по степени важности после title в определении рейтинга страницы. При этом заголовок первого уровня может встречаться в тексте только единожды. В виде кода все это выглядит очень просто. Выделяем конкретный отрезок текста тегами заголовков необходимого уровня, и готово. Тег Н1 обязательно должен содержать основной ключ продвигаемой страницы, я рекомендую туда вписывать основное ключевое слово страницы в разбавленном виде, к тому же, он должен отличаться от тега title. Заголовки Н2 – Н6 имеют вес по убыванию и их можно использовать на странице несколько раз. В этих тегах также можно использовать ключевые фразы в сильно разбавленном или уточняющем виде, но не злоупотребляйте, в этих тегах можно обойтись и без ключей, ошибки не будет.
Структурирование контента
В тексте также рекомендую использовать HTML-списки, таблицы и изображения (там, где это уместно).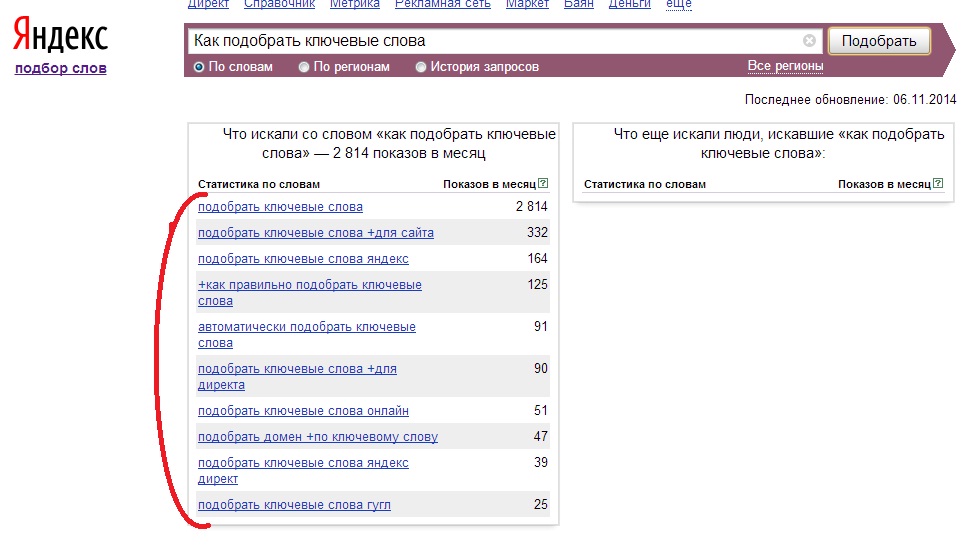 Какого-то значительного влияния на продвижение эти теги не дают, но их наличие говорит поисковой системе, что контент на странице структурирован и удобен для восприятия.
Какого-то значительного влияния на продвижение эти теги не дают, но их наличие говорит поисковой системе, что контент на странице структурирован и удобен для восприятия.
Если речь идет об оптимизации длинных статейных страниц, где эта структуризация необходима, в первую очередь, то рекомендую на каждые 1000 символов делать по одному заголовку h3-h4, ставить на каждые 2-4 абзаца по одной картинке. Также желательно сделать навигацию в виде «Содержания» в начале текста, как это сделано на этой странице.
Оптимизация изображений
Теги Alt и Title стоит прописывать к каждой картинке, так как они могут помочь получить трафик на сайт с поиска по картинкам Яндекса и Google.
- Title – заголовок, отображающийся при наведении на нее курсора;
- Alt – описание, используемое при поиске картинок.
Также они должны влиять на формирование общей релевантности страницы ключевым словам, но точной закономерности нет.
Рекомендую:
Если хотите получить перспективную профессию или освоить новый навык (будь то SEO, HTML, веб-программирование или даже мобильная разработка), то посмотрите ТОП-3 лучших онлайн школ:
- Нетология — одна из старейших школ интернет-профессий.
 Основные направления — маркетинг, управление, дизайн и программирование;
Основные направления — маркетинг, управление, дизайн и программирование; - GeekBrains — специализируется, в первую очередь, на обучении программистов. После интеграции в Mail Group появились и другие профессии;
- SkillBox — наиболее молодая из 3-х перечисленных школ, но обладает наибольшим ассортиментом специальностей. Если услышали о какой-либо экзотической профессии, то наверняка этому уже обучают в Skillbox.
Эти школы выдают дипломы и помогают с трудоустройством, а если вам нужно просто научиться что-то делать для себя больше как хобби, то рекомендую начать с бесплатных курсов, они позволят получить общее представление о профессии и первый практический опыт.
как писать статьи человеческим языком и попадать в топ поисковой выдачи — SEO на vc.ru
Конспект вебинара Кости Солодянникова, Chief Growth Officer IT-Agency, в прошлом руководитель SEO-направления
13 174 просмотров
Как не надо писать
По классическим канонам в ТЗ на текст от SEO должно быть указано:
- количество знаков без пробелов;
- плотность ключевых слов, тошнотность и т.
 д.;
д.; - список ключевых слов;
- список других слов, которые надо использовать.
Иногда ТЗ бывает в виде таблички со списком слов и рекомендациями по их добавлению.
Пример того, как может выглядеть стандартное ТЗ для SEO-текста: оно показывает, сколько раз надо использовать каждое из слов. Например, слово «постов» — один раз, «минимальный» — два и т. д.
Если по такому ТЗ написать статью на злободневную тему о работе на удалёнке, вполне может получится примерно следующее:
Этот текст создал бредогенератор, в который вставлены ключевые слова. Если писать текст строго вокруг ключевых слов, пытаясь втиснуть его в нужное количество знаков, получается что-то похожее
Так делать нельзя, потому что поисковики хоть и относятся к переоптимизированным текстам с некой долей юмора, но наказывают:
Заметка из блога Яндекса о переоптимизированных текстах, написанная в стиле тех самых переоптимизированных текстов.
Проблема переоптимизированных статей встречается в основном на сайтах, которые сплошь состоят из простыней текста. На таких ресурсах непонятно, как сделать заказ или выполнить любое другое целевое действие.
Так быть не должно, потому что подобные тексты не приносят пользу сайтам, не говоря уж о том, сколько «радости» они доставляют редакторам и копирайтерам.
Три мифа о ТЗ, которые мешают писать нормально
В основе этой странной ситуации лежат три мифа о SEO. Разберём каждый из них.
В тексте обязательно должны быть ключевые слова
Этот миф родился очень давно. На заре своего развития поисковики должны были понимать, что человек найдёт ответ на свой запрос на конкретной странице. А самый быстрый способ оценить страницу — посчитать, сколько раз на ней написано слово, которое пользователь использовал при поиске. По этой логике, если если человек учится программировать, то лучшим ответом на его запрос будет страничка, где много раз встречается словосочетание «как научиться программированию».
Это породило целую эпоху SEO-текстов, когда на страницу вставляли совершенно нечитабельный непонятный контент, насыщали его ключевыми словами — и это работало.
Сейчас всё немного не так. Сегодня поисковик пытается понять, решает ли пользователь на странице свою задачу. При этом алгоритм изучает примерно 1500 параметров, и далеко не все они относятся к тексту. Например, на выдачу влияет пользовательская активность. Если на сайт заходят часто, он будет стоять выше в поисковой выдаче. Также учитываются бренд, домен и т. д. То есть текст — далеко не единственная причина, по которой сайт отображается или не отображается в результатах поиска.
Имеет значение количество знаков в тексте
Этот миф возник из-за того, что за текст нужно платить. А общепринятая схема работы на рынке копирайтинга — это плата за знаки.
С точки зрения SEO-шника, писать лонгрид, особенно если он не нужен для достижения результата, невыгодно, поэтому в дело вступает банальная экономия. Количество знаков для определённого текста берётся из среднего числа знаков в статьях, которые находятся в топ-10 поисковой выдачи, или из мифов про 2500 знаков без пробелов.
Количество знаков для определённого текста берётся из среднего числа знаков в статьях, которые находятся в топ-10 поисковой выдачи, или из мифов про 2500 знаков без пробелов.
На самом же деле лучшую формулу для длины текста вывел Максим Ильяхов: «Оптимальная длина текста — пока интересно».
Важны другие тематические слова в тексте
Этот миф возник из-за того, что поисковики, действительно, могут понимать тематику текста не только по ключевым словам из поискового запроса. Например, по запросу «как научиться программировать» Google или Яндекс могут отобразить страницу, где есть слова «php», «Python» и т. д. Они понимают: этот текст о программировании, потому что в нём встречаются названия языков программирования.
Из этого можно сделать вывод: чем больше таких слов будет в тексте, тем больше шансов, что он окажется в топе.
Но это не совсем так. Не всегда и не все тематические слова могут учитываться и обрабатываться, поэтому нет никакого смысла специально гоняться за ними. Они и так окажутся в тексте, если автор хорошо раскроет тему. Сложно написать статью, например, о достопримечательностях Праги, не упомянув Карлов мост или Староместскую площадь.
Они и так окажутся в тексте, если автор хорошо раскроет тему. Сложно написать статью, например, о достопримечательностях Праги, не упомянув Карлов мост или Староместскую площадь.
Значит ли это, что ключевые слова вообще не нужны? Нет. Но они работают по-другому и на них не нужно делать упор при написании контента. Об этом пойдёт речь дальше.
Как надо писать
Чтобы SEO помогало редактору, а не причиняло ему страдания, нужно подходить к созданию контента правильно. Этот процесс делится на три этапа:
- Оценка спроса. Сначала нужно оценить спрос, по которому люди ищут информацию, и превратить идею для статьи в тему для людей.
- Анализ спроса. Затем нужно понять, что именно и как писать в статье, чтобы она была интересной и удовлетворяла изначальный спрос.
- Оформление для поисковиков. Лишь потом можно переходить к той самой SEO-магии, которая включает мета-теги, заголовки, авторство и другое.
Рассмотрим каждый из этих этапов на примере курсов программирования.
У нас есть бизнес-задача привлечь людей на курсы. Это важно сделать на верхнем этапе воронки, поскольку контекстная реклама стоит дорого и может не окупиться, либо потенциал всех платных каналов уже использован. При этом сформированного спроса на обучение ещё нет.
Оценка спроса
Изначальная идея проста: если написать кучу прикольных статей, то люди найдут нас в поиске и после прочтения будут записываться на курсы. То есть гипотеза состоит в том, что контент должен привести к продажам.
Далее, как правило, происходит следующее: редактор смотрит Вордстат, ищет референсы и пишет текст.
Но в таком случае остается много вопросов. Непонятно, нужна одна большая статья или десяток мелких. И каковы гарантии, что контент без SEO-магии будет показываться в поисковиках и принесёт переходы на сайт? Поэтому первое, что нужно сделать — изучить спрос на Вордстате.
Вот несколько примеров того, как люди формулируют свои запросы. Цифры показывают, насколько популярна та или иная формулировка.
Анализ спроса в Яндекс.Вордстат показывает, какие вопросы люди задают поисковику. В данном случае это запросы вокруг фразы «как научиться программированию»
Обычно редакторы умеют и делают это, но дальше дело не заходит. В редких случаях они собирают в табличку слова, по которым пользователи могут искать контент. Но на этом работа заканчивается.
Как правило, редакторы составляют табличку с ключевыми словами, но не знают, что с ней делать дальше
Анализ спроса
Для анализа спроса нам нужно понять, какие сайты показываются на первой странице поисковой выдачи по всем топовым запросам.
Первый вариант — вручную просмотреть результаты поиска по каждому запросу, выписать топ-10 сайтов и найти среди них те, что выдавались в поиске все пять раз.
Второй вариант — использовать для этого один из бесплатных SEO-инструментов, который умеет делать всё это автоматически:
Инструмент на сайте coolakov. ru помогает быстро находить самые продвинутые сайты по списку запросов
ru помогает быстро находить самые продвинутые сайты по списку запросов
Теперь у нас есть список того, что уже сейчас хорошо оценивается поисковиками. С высокой долей вероятности, если мы напишем что-то подобное, наша статья также окажется в десятке.
Обычно в этот момент включается SEO-ошная логика. Люди начинают измерять среднюю длину текстов, количество ключевых слов и т. д. На самом же деле нужно смотреть на другие параметры.
Во-первых, необходимо составить примерный скелет статей из топ-10 и выделить главное. Для этого также существует бесплатный инструмент.
Плагин SEO META in 1 CLICK позволяет посмотреть структуру заголовков в статьях на сайтах-конкурентах
Конкретно в этом примере во всех статьях присутствуют истории людей, обращения или явное указание авторства. Также во всех материалах четко указаны этапы: «делай раз, делай два, делай три». В одной из статей всё размечено по пунктам, в нескольких статьях расписаны циклические истории о том, что конкретно надо делать, чтобы научиться программированию.
Теперь мы сформировали понимание того, что есть у конкурентов. А значит, можно составить примерную структуру своей будущей статьи. По сути это ничем не отличается от обычного редакционного процесса без какого-либо участия SEO.
Итак, примерный каркас статьи о том, как научиться программированию, может выглядеть так:
- Зачем это нужно: рынок, тенденции и т. д.
- Как попробовать самостоятельно: выбор языка, поиск онлайн-курса, справочная литература.
- Что ещё важно знать: где брать портфолио, нужно ли знание английского, ссылки на популярные порталы в соцсетях и интервью классных ребят.
Также важно учитывать следующие SEO-моменты, напрямую связанные с качеством статьи:
- Нужны живые люди — интеграция советов от практиков.
- Данные по рынку труда и зарплате должны быть актуальными.
- В контент должен быть интегрирован продукт, чтобы читатели узнавали о нём по мере решения своей проблемы.

Главное — статья реально должна решать задачу человека.
В сегодняшних реалиях нужно обращать внимание не на конкретные ключевые слова, а на то, по каким параметрам экспертности, авторитетности и доверия поисковики будут оценивать наш контент.
Когда поисковику нужно из 100 000 статей выбрать 10, он смотрит на то, насколько экспертной является площадка, где размещена та или иная статья. Например, если статья о том, как научиться программированию, вышла на Habr, то Google автоматически решит, что это авторитетная площадка, на которой вряд ли опубликуют некачественный нерелевантный контент.
Если у нас новый или малоизвестный бренд, то в ответ на популярные поисковые запросы Google будет предлагать пользователям в первую очередь известные и авторитетные площадки. В таком случае проще попытаться сделать интеграцию своего продукта на этих ресурсах.
Оформление для поисковиков
В целом написание контента для продвижения продукта не отличается от стандартного редакционного процесса. Конкретно для поисковиков оформляется лишь небольшой кусочек материала:
Конкретно для поисковиков оформляется лишь небольшой кусочек материала:
- Название, которое отображается и для читателя, и для поисковика.
- Заголовок, который отображается на странице с результатами поиска.
- Описание, под которое попадает под заголовок на странице поиска.
Название
Название или заголовок h2 — наиболее важно для SEO. Это то, как называется статья непосредственно на сайте:
Пример заголовка статьи по обучению программированию
Если вы пишете для хайпа, то и название должно быть хайповым. Например, название «Топ-10 вещей, которые остановят коронавирус» явно ориентировано не на SEO, а на то, что люди будут активно интересоваться и делиться этой статьёй.
Основное правило — как статью назовешь, столько просмотров и получишь. Хайповые названия приносят больше просмотров в краткосрочной перспективе. Если же писать с точки зрения поисковиков, то можно получить больше просмотров на дистанции в несколько месяцев или год.
Название должно иметь длину 140–160 символов.
Заголовок
Заголовок — это то, что SEO-специалисты называют Title. Именно его пользователи видят в поисковой выдаче.
Title должен быть ёмким и кратко описывать содержание статьи. Он не должен совпадать с названием, а расширять его по смыслу и с учётом спроса. Например, для статьи «Как научиться программировать» может подойти заголовок «Как научиться программировать быстро, с нуля и в домашних условиях».
Описание
Описание (description) — пара предложений, которые максимально коротко и сочно раскрывают смысл и пользу статьи.
В поисковой выдаче описание отображается под заголовком. Именно благодаря ему читатель понимает, нужно ли ему читать данную статью:
Описание статьи не должно совпадать с названием и заголовком. Его оптимальная длина — 170–180 символов, хотя это необязательное требование
«Идеальное SEO — это когда SEO не видно, а позиции, трафик и конверсии есть»
Итак, три принципа правильного SEO:
- Ключевые слова определяются сами собой в результате анализа спроса.
 Невозможно написать статью о том, как учиться программированию, ни разу не упомянув в тексте фразу «научиться программировать».
Невозможно написать статью о том, как учиться программированию, ни разу не упомянув в тексте фразу «научиться программировать». - Тематические слова определяются в результате анализа контента. Изучив материалы, которые уже отображаются в поисковиках, вы без особого труда найдёте слова и термины, которые являются специфическими для данной темы. Например, названия языков программирования. Достаточно писать вдумчиво и с пониманием темы.
- Оформление статьи — название, заголовок и описание — стоит проверять с помощью SEO-специалистов. Причём желательно делать это до публикации. Если статья будет оптимизирована уже после того, как её впервые заметит поисковик, вряд ли он разместит её на первых позициях. В этом случае максимальный эффект будет утерян.
Как масштабировать процесс создания контента с учётом SEO
Предположим, у нас есть алгоритм подготовки качественного контента. Но как сделать так, чтобы он работал постоянно и каждая написанная статья приносила трафик?
Для этого нужно следовать трём правилам:
- Собирать спрос в промышленных масштабах.

- Составлять инструкции для авторов и внедрять их в редакционный процесс через обучение.
- Анализировать и оценивать эффективность того, как работает контент.
Сбор спроса
Первое, что нужно сделать — определить слова, которые описывают продукт. С этим поможет брейншторм или консультация с человеком, который хорошо знает продукт. Например, для курсов программирования такими словами будут «обучение программированию» и названия конкретных языков, которые изучаются.
Также поможет следующий лайфхак: в русском языке всего 23 слова, которыми человек выражает свой интерес к чему-то. Это слова «как», «где», «зачем» и так далее. Статистику всех этих слов в сочетании с нужным нам ключевым термином можно быстро проверить в Вордстате.
Например, вот так выглядит запрос слов интереса в сочетании с термином «php»:
Сбор сброса в промышленном масштабе лучше доверить SEO-специалистам или воспользоваться специальными программами или сервисами.
По результатам такого сбора можно получить список тем, который практически не отличается от обычного редакционного темника. Разница лишь в том, что редактор может заранее ориентироваться в количестве показов, которых стоит ждать от той или иной статьи.
Пример темника, созданного на основе анализа спроса. Кайф в том, что он позволяет оценивать потенциал каждой темы
Подготовка инструкций для авторов
После сбора спроса у нас есть готовый список тем. Чтобы авторы писали примерно одинаково и качественно, редпроцесс должен состоять из следующих этапов:
- Проверка идеи на спрос. Если люди не ищут предложенную идею, то и писать об этом бессмысленно.
- Обсуждение с редактором анализа спроса, конкурентов и структуру будущей статьи.
- Создание самого контента и его соответствующее оформление для поисковиков.
Что касается непосредственно инструкций для авторов, их стоит воспринимать как часть обучения и редпроцесса.
Поначалу авторы должны готовить материалы в четыре руки с редактором или оптимизатором. Это поможет им втянуться в процесс создания контента по новым правилам. Кроме того, главред должен постоянно контролировать качество работы.
Вместе с этим необходимо анализировать статьи после их публикации. Это позволит определить слабые и сильные стороны и понять, что нужно доработать. Пост-аналитика — отличный инструмент для улучшения уже существующего контента.
После цикла создания и запуска контента проходит около трёх месяцев до получения первичных показателей по трафику. После этого проходит еще 3–6 месяцев, когда материал набирает свои максимальные показатели трафика. Потом в течение года статья затухает и наступает момент, когда контент можно дорабатывать.
Аналитика и оценка эффекта
Трафик может быть разным в зависимости от сегмента, но его можно примерно подсчитать, исходя из общего количества показов.
Статистика показывает, что переходов всегда в 20–30 раз меньше, чем показов. Значит, с 24 тыс. показов мы получим примерно 900 переходов на единицу контента в месяц.
Значит, с 24 тыс. показов мы получим примерно 900 переходов на единицу контента в месяц.
Вся трёхступенчатая воронка выглядит следующим образом:
- количество переходов на сайт в 20–30 раз меньше числа показов;
- количество переходов на продукт в 10–20 раз меньше числа переходов на сайт;
- количество заказов продукта в 5–20 раз меньше числа переходов на продуктовую страницу.
На каждом этапе мы получаем кратное уменьшение. На практике это даёт не очень большие цифры. Например, статья «Как научиться программировать» с 46634 показами за месяц дает нам 932 перехода на сайт. 932 перехода на сайт дают примерно 50 переходов на страницу продукта — курсов программирования. Но далеко не каждый из перешедших запишется на курс. Если конверсия в заказ составляет 3%, то мы получаем цифру 1,5. То есть при огромной цифре в 46 тыс. показов продукт заказывает лишь 1–2 человека.
Очевидно, что одна публикация не даст ощутимого результата..jpg) Один раз написанная статья может принести 18 заказов в год, но если таких статей будет 100, это даст уже 1800 заказов.
Один раз написанная статья может принести 18 заказов в год, но если таких статей будет 100, это даст уже 1800 заказов.
Конечно, это простая линейная воронка. Вы наверняка столкнётесь с другими цифрами, но общие принципы будут соблюдаться.
Кроме того, на каждом этапе воронки на людей можно воздействовать через ретаргетинг. Например, если человек прочитал статью о программировании, то ему начинают показывать рекламу соответствующих курсов.
Наконец, конверсии в переходы на продуктовую страницу и конверсии в заказы могут быть более высокими в зависимости от параметров продукта.
Обязательно ли всё это?
Вовсе нет! Вы можете вообще не публиковать контент. В топе поисковой выдачи уже есть сайты. С этими сайтами вы можете договориться о врезке, разместив свой продукт в уже готовую публикацию.
Это может обойтись намного дешевле. Кроме того, такой подход позволяет быстро проверить гипотезу, оценить трафик и протестировать предложение. Но это уже не SEO, а что-то на стыке контент-маркетинга и пиара.
Кому это нужно
Создание собственного информационного канала с уникальным контентом лучше всего подойдёт компаниям с длинным циклом сделки, которым платная реклама уже не даёт эффект. Например, есть компании, которые занимаются продажей каминов для дач. Клиент, который начинает интересоваться установкой камина, зачастую решается на покупку лишь через пару лет, когда достраивает саму дачу.
Также эта стратегия подойдёт компаниям со сложным продуктом, который требует объяснений. Например, автоматизация маркетинга или дизайн интерьеров.
Кроме того, стратегия будет полезна компаниям, которые после продажи товара или услуги должны обслуживать запросы клиентов. Например, это может быть мобильный оператор, в службу поддержки которого поступает огромное количество вопросов. Публикация информационного контента в его случае позволит снизить нагрузку на колл-центры.
Запись выступления на YouTube
Презентация выступления
Free Keywords Extractor — Инструмент для извлечения ключевых слов: SEO
Что делает этот бесплатный инструмент для извлечения ключевых слов волшебным инструментом?
Этот бесплатный инструмент для извлечения ключевых слов в первую очередь предназначен для оптимизации постов в блогах, веб-страниц и другого онлайн-контента, чтобы обеспечить релевантность и достаточную плотность ключевых слов. Это устраняет дилемму автора, заключающуюся в том, что у него недостаточно ключевых слов или слишком много вхождений ключевых слов перед публикацией сообщения. Полученный в результате вывод облака ключей делает его поистине волшебным инструментом ключевых слов для веб-сайтов и блогов. Это бесплатный инструмент для извлечения ключевых слов, который принимает ввод текста / html и извлекает ключевые слова SEO в порядке относительной важности (в порядке убывания вхождения) и формирует облако ключей.
Это устраняет дилемму автора, заключающуюся в том, что у него недостаточно ключевых слов или слишком много вхождений ключевых слов перед публикацией сообщения. Полученный в результате вывод облака ключей делает его поистине волшебным инструментом ключевых слов для веб-сайтов и блогов. Это бесплатный инструмент для извлечения ключевых слов, который принимает ввод текста / html и извлекает ключевые слова SEO в порядке относительной важности (в порядке убывания вхождения) и формирует облако ключей.
Этот инструмент подсказки ключевых слов для авторов блогов и SEO-энтузиастов в создании качественных SEO-заголовков и позволяет извлекать огромный SEO-трафик. Составление поста требует сосредоточенных и усердных усилий по теме, но написать отличный заголовок для поста — еще более сложная задача. Этот уникальный бесплатный инструмент для определения плотности ключевых слов анализирует сообщения и генерирует облако ключей, списки ключевых слов с их частотой появления.
Этот инструмент для извлечения ключевых слов использует расширенный алгоритм извлечения ключевых слов и методы искусственного интеллекта для извлечения ключевых слов из таких источников, как обзоры, веб-страницы, электронные письма, социальные сети, онлайн-чаты, деловые сделки и т. д. С помощью этого инструмента вы можете извлечь список ключевых слов вашего конкурента, чтобы сравнить и конкурировать с собственным сайтом и страницами.
Этот экстрактор ключевых слов веб-сайта чрезвычайно полезен для блоггеров, веб-сайтов, компаний цифрового маркетинга, предприятий электронной коммерции и SaaS. Бесплатный экстрактор ключевых слов быстро анализирует отзывы клиентов, обзоры, предпочтения и т. д., чтобы найти важные ключи, такие как имена, адреса электронной почты, номера телефонов и т. д., которые полезны для конверсии продаж и дополнительных продаж.
Наилучшее применение Использование
1. Создавайте лучшие заголовки
Этот инструмент извлечения обладает огромной ценностью для профессиональных блоггеров, так как позволяет быстро создавать лучшие заголовки. Найдите облако ключей своей страницы и используйте 20 лучших ключевых слов в заголовке и заголовках. Добавьте между ними несколько интересных слов и прилагательных, чтобы получились суперзаголовки. Это сокращает много времени и усилий на поиск работоспособных заголовков.
Найдите облако ключей своей страницы и используйте 20 лучших ключевых слов в заголовке и заголовках. Добавьте между ними несколько интересных слов и прилагательных, чтобы получились суперзаголовки. Это сокращает много времени и усилий на поиск работоспособных заголовков.
2. Обеспечение комплексного покрытия LSI
LSI также называют логическим семантическим индексом страницы. Это набор ключевых слов, тесно связанных с темой веб-страницы. После того, как вы закончите содержание, вы получите карту ключевых слов страницы (используя этот инструмент извлечения и исследования ключевых слов) и сразу увидите, не пропущено ли что-то важное и связанное с темой, без повторного чтения всего содержимого страницы. Теперь включите все пропущенные ключевые слова LSI. Это помогает сделать естественный SEO-дружественный всеобъемлющий контент.
3. Превзойдите ключевые слова вашего конкурента
Иногда, когда вы отстаете от своих конкурентов, используйте этот экстрактор ключевых слов для исследования ключевых слов на их странице. Узнайте ключевые слова, которых вам не хватает. Примените их к своему контенту лучше, чем контент вашего конкурента. Это простой способ оптимизировать ваш контент для SEO-преимуществ на странице. Это позволяет вам генерировать больше органического SEO-трафика, лидов и продаж.
Узнайте ключевые слова, которых вам не хватает. Примените их к своему контенту лучше, чем контент вашего конкурента. Это простой способ оптимизировать ваш контент для SEO-преимуществ на странице. Это позволяет вам генерировать больше органического SEO-трафика, лидов и продаж.
Извлечение ключевых слов
Как найти самые важные темы в отзывах клиентов с помощью AI
Отзывы клиентов очень важны. К сожалению, это ценно только в том случае, если оно прочитано и понято. Тем, кто понимает каналы обратной связи не только как гигиенический фактор в диалоге со своими клиентами, нужны интеллектуальные инструменты, которые считывают из сотен тысяч индивидуально сформулированных коротких текстов то, что является действенным для бренда, к которому обращаются, и его бренд-менеджмента.
Извлечение ключевых слов — один из этих интеллектуальных инструментов для лучшего понимания больших текстовых данных. Это автоматизированный процесс определения наиболее актуальных тем и выражений в текстах. Чтобы иметь возможность продолжать понимать клиентов и целевые группы без увеличения усилий в условиях растущей обратной связи с клиентами, использование искусственного интеллекта необходимо. Если вы хотите назначить тексты определенным категориям, например, для запросов в службу поддержки или электронных писем, метод Text Classification , вероятно, подходит. Читайте нашу статью о том, как Text Classification ускоряет компании в обработке документов и какую роль в этом играет машинное обучение.
Чтобы иметь возможность продолжать понимать клиентов и целевые группы без увеличения усилий в условиях растущей обратной связи с клиентами, использование искусственного интеллекта необходимо. Если вы хотите назначить тексты определенным категориям, например, для запросов в службу поддержки или электронных писем, метод Text Classification , вероятно, подходит. Читайте нашу статью о том, как Text Classification ускоряет компании в обработке документов и какую роль в этом играет машинное обучение.
Узнайте в этой статье, как вы можете использовать Извлечение ключевых слов, чтобы просмотреть большое количество отзывов клиентов, преобразовать потенциальных клиентов и улучшить общение с вашими клиентами.
- Введение в извлечение ключевых слов
— Что такое извлечение ключевых слов?
— Как быстро и легко понять отзывы клиентов? - Как это работает
- Варианты использования и приложения
— Тестирование продукта
— Отзывы клиентов
— Выборочное тестирование - Инструменты и ресурсы для извлечения ключевых слов
Введение в извлечение ключевых слов
Что такое извлечение ключевых слов?
Извлечение ключевых слов, также известное как определение ключевых слов или анализ ключевых слов, позволяет сократить текст до соответствующих тем и выражений. Эта процедура позволяет резюмировать тексты таким образом, чтобы можно было легко понять основные сообщения и частоту их появления. С помощью глубокого обучения и обработки естественного языка нормальный человеческий повседневный язык из опросов, комментариев в социальных сетях, обзоров или отзывов клиентов в очень больших количествах может быть проанализирован за короткое время.
Эта процедура позволяет резюмировать тексты таким образом, чтобы можно было легко понять основные сообщения и частоту их появления. С помощью глубокого обучения и обработки естественного языка нормальный человеческий повседневный язык из опросов, комментариев в социальных сетях, обзоров или отзывов клиентов в очень больших количествах может быть проанализирован за короткое время.
Как быстро и легко понять отзывы клиентов?
Существуют различные методы анализа текстовых данных с использованием искусственного интеллекта. Их всех объединяет то, что все они сокращают количество требуемого времени и усилий. При извлечении ключевых слов основное внимание уделяется пониманию содержания обратной связи. На какие темы говорят мои клиенты? Какие темы становятся актуальными прямо сейчас? Какие ассоциации у моих целевых групп?
Как это работает
Введение
Извлечение ключевых слов подготавливает неструктурированный текст таким образом, чтобы содержание было полностью понятным, а поиск соответствующих тем был легким. Этот метод можно применять к текстовым данным, таким как отзывы клиентов, опросы, комментарии в социальных сетях, обзоры или общение, включая чаты и электронные письма.
Извлечение ключевых слов позволяет определять действия и рабочие процессы на основе триггеров содержимого. Таким образом, запросы клиентов могут быть направлены в соответствующие области специализации на основе тем, например, или более срочные запросы могут быть приоритетными. Это значительно снижает риск клиентов, у которых осталось 90 049 , позволяет компаниям быстрее реагировать на соответствующие запросы и повышает удобство работы пользователей в долгосрочной перспективе. Кроме того, извлечение ключевых слов позволяет лучше понять ситуации клиентов, их опыт и мнения, что является основой для принятия более эффективных бизнес-решений.
Благодаря использованию машинного обучения и обработки естественного языка извлечение ключевых слов автоматизировано, что снижает усилия и увеличивает скорость независимо от объема данных.
Можно различать различные методы автоматического извлечения ключевых слов. Подходы варьируются от простого подсчета слов до сложных методов глубокого обучения, которые непрерывно и самообучающимся образом улучшаются с новыми данными. Для каждого случая применения следует рассматривать применение различных методов. Благодаря техническому прогрессу последних лет даже сложные модели глубокого обучения теперь доступны по цене и сразу же применимы благодаря обучению с нулевым выстрелом и, таким образом, подходят для большого количества случаев применения.
В следующем разделе вы узнаете о различных методах извлечения ключевых слов. Основное внимание уделяется моделям, основанным на машинном обучении и глубоком обучении, которые также применяются в Caufliflower.
Варианты использования и приложения
Введение
Являетесь ли вы менеджером по продукту и хотите оценивать свои продукты с помощью мнений потребителей, вы маркетолог, планирующий следующую кампанию, или вы и ваша команда CX ежедневно получаете сотни отзывов по различным каналам . Извлечение ключевых слов может помочь вам получить обзор всех текстов, понять наиболее важные темы и найти определенные фразы.
Благодаря извлечению ключевых слов команды становятся более эффективными и могут сконцентрироваться на своей работе, делая выводы и привнося результаты в организацию. Избавьте свою команду от лишних задач и предоставьте им интересные и обобщенные идеи из неструктурированных и детализированных текстовых данных.
Ниже приведены некоторые распространенные области применения извлечения ключевых слов:
- Тестирование продукта
- Отзывы клиентов
- Выборочное тестирование
Люди оставляют свои отзывы о продуктах через такие платформы, как Amazon, а также в интернет-магазинах. Кроме того, определенные целевые группы могут быть специально опрошены, чтобы оценить их собственные продукты или концепции продуктов. Здесь полезно использовать извлечение ключевых слов.
Представьте, что вы менеджер по продукту и планируете новый набор продуктов для продажи в вашем собственном интернет-магазине и в ваших собственных магазинах. Ассортимент уже прописан. Чтобы лучше понять конкуренцию в этом сегменте, вы выбрали эталонные продукты на Amazon. С помощью очистки Amazon Reviews можно создать базу данных для подробного анализа. Используя метод извлечения ключевых слов, теперь можно узнать, какие темы играют роль в ассортименте, какие темы имеют наибольшую актуальность и как пользователи описывают темы в конкретных терминах. Результаты идеально служат основой для концепции нового набора продуктов.
«Angel Audio» — вымышленный производитель высококачественных аудиоколонок и наушников премиум-класса. Angel Audio планирует новый набор, состоящий из наушников и портативных колонок. Анализируя обзоры продуктов конкурентов на Amazon, Angel Audio получает хорошую оценку одной из актуальных тем. Результаты извлечения ключевых слов показывают самые популярные темы и их долю в данных: звук, громкость и бас.Ассоциации конкретизируют образ продукции: звук: хороший / бас: насыщенный / громкость: слабая
Для тестирования концепций новых продуктов или ваших собственных продуктов лучше всего провести тестирование продукта на целевой случайной выборке. С такими вопросами, как привлекательность, вероятность покупки или соответствие бренду, вы можете получить оценку своих продуктов. Если вы включите такие показатели, как осведомленность о бренде, рассмотрение и покупка вашего собственного бренда, вы можете провести различие между покупателями, потенциальными клиентами и теми, кто знает только ваш бренд.
Марка X нравится.
Полностью согласен
Частично согласен
- Не согласен или не согласен
- Частично не согласен
- Абсолютно не согласен
Насколько вероятно, что вы купите этот товар за X €?
- Весьма вероятно
- Вероятно
- Ни то, ни другое
- Маловероятно
- Очень маловероятно
По вашему мнению, какие продукты вообще не подходят к марке X?
Насколько хорошо вы знаете марку Х?
- Я очень хорошо знаю эту марку
- Я хорошо знаю эту марку
- Я немного знаю эту марку
- Я знаю эту марку только по названию
- Я не знаю эту марку
Какие из этих поставщиков подходят для вас при покупке [Категория товара]?
Открытые вопросы подходят для получения точных и индивидуальных отзывов об отдельных продуктах. С помощью спонтанного ассоциативного вопроса вы сможете лучше понять, что поражает потенциальных покупателей. Используя симпатии и антипатии, можно определить очень конкретные плюсы и минусы продуктов. Это крой, материал, цвет, принт или просто отсутствие необходимости? Также можно спросить об этих аспектах с помощью закрытых вопросов. Но только с открытыми вопросами вы получаете конкретные причины для оценки из собственных слов людей и, таким образом, конкретные выводы для адаптации продуктов или спецификации для разработки новых продуктов, а также темы, которые вы, возможно, вообще не заметили.
С помощью спонтанного ассоциативного вопроса вы сможете лучше понять, что поражает потенциальных покупателей. Используя симпатии и антипатии, можно определить очень конкретные плюсы и минусы продуктов. Это крой, материал, цвет, принт или просто отсутствие необходимости? Также можно спросить об этих аспектах с помощью закрытых вопросов. Но только с открытыми вопросами вы получаете конкретные причины для оценки из собственных слов людей и, таким образом, конкретные выводы для адаптации продуктов или спецификации для разработки новых продуктов, а также темы, которые вы, возможно, вообще не заметили.
Чтобы получить еще более точную обратную связь, вы можете использовать бота для исследования цветной капусты в рамках опросов. Это позволяет вам задать конкретный вопрос по определенной теме в ответ на ответ респондента:
Открытые вопросы создают ценную, но также неструктурированную обратную связь в форме комментариев. Для того, чтобы понять, что вам нравится и что не нравится в продуктах, подходит использование извлечения ключевых слов. Группируя термины, связанные по содержанию, мы можем сразу увидеть, какие темы особенно негативны, а какие работают особенно хорошо. Благодаря ранжированию наиболее частых ключевых слов среди лайков и антипатий доступен выбор релевантных тем. При изучении отдельных ключевых слов конкретная обратная связь становится ясной.
Surveybot. Чтобы сделать еще один шаг вперед, отзывы, собранные о продуктах, можно сопоставить с данными о продажах в прошлом. При обучении конкретной модели глубокого обучения можно делать прогнозы об успехе продукта на основе оценок продукта. Прочитайте этот пост, чтобы узнать, как Cauliflower использует метод Tchibo, чтобы найти 80% провальных продуктов во время разработки продукта.
Непрерывная оцифровка позволяет собирать отзывы на всех этапах взаимодействия с клиентом. Будь то на iPad в магазине, во всплывающем окне в интернет-магазине или по электронной почте после контакта — возможные точки контакта для сбора отзывов практически безграничны. Будь то после доставки продукта, после звонка в службу поддержки, на веб-сайте с новым дизайном, после миграции платформы или после удаления корзины покупок — количество баллов также не ограничено. Результатом является точная обратная связь о реальном опыте. Эльдорадо для измерения опыта, что было невообразимо еще несколько лет назад.
Будь то после доставки продукта, после звонка в службу поддержки, на веб-сайте с новым дизайном, после миграции платформы или после удаления корзины покупок — количество баллов также не ограничено. Результатом является точная обратная связь о реальном опыте. Эльдорадо для измерения опыта, что было невообразимо еще несколько лет назад.
Способы сбора отзывов разнообразны. Классически как Net Promoter Score (NPS), который является одним из самых популярных способов сбора отзывов клиентов и измерения лояльности клиентов, с помощью школьных оценок или звездных рейтингов, вплоть до дифференцированной оценки отдельных аспектов (дружелюбие, понятность, компетентность, качество, ожидание время и др.). Общим для всех этих методов является простая возможность агрегировать значения для получения среднего значения, разбивать показатели на отдельные группы, такие как разные местоположения, команды или источники, и сравнивать их собственную производительность с эталонными показателями.
NPS, для которого существует множество отраслевых эталонных показателей, особенно подходит для этой цели. Из простого вопроса по шкале от 0 до 10 выводятся три типа промоутеров, пассивов и противников ликвидности.
Из простого вопроса по шкале от 0 до 10 выводятся три типа промоутеров, пассивов и противников ликвидности.
Насколько вероятно, что вы порекомендуете X другу или коллеге?
Чего не хватает в обзоре этих различных показателей, так это обоснования оценки. Поэтому часто добавляют свободное текстовое поле для обратной связи. С помощью этого текстового поля предоставляется возможность дать общий отзыв или обосновать предыдущую оценку.
Что приходит вам на ум, когда вы думаете о новом веб-сайте?
Что мы можем улучшить в нашем процессе заказа?
Расскажите нам, почему вы поставили нам 7.
Эти тексты являются ценным кладезем данных. Ни один другой источник не дает такой достоверной и в то же время ситуативной информации. Инсайты, которые следуют внутренней мотивации потребителей дать отзыв о конкретном опыте в конкретный момент. Особенно словесная обратная связь, устная или письменная, настолько богата нюансами, что позволяет делать выводы о конкретных аспектах, их ценности и контексте. Это информация, которая может заполнить пробелы, которые открываются, когда мы говорим об опыте бренда. Эти сообщения в обратной связи конкретизируют образ и проблемы клиента и делают это на родном языке потребителя, а не на абстрактном маркетинговом языке.
Это информация, которая может заполнить пробелы, которые открываются, когда мы говорим об опыте бренда. Эти сообщения в обратной связи конкретизируют образ и проблемы клиента и делают это на родном языке потребителя, а не на абстрактном маркетинговом языке.
Использование извлечения ключевых слов позволяет нам извлекать соответствующий контент из множества отзывов, чтобы решать наиболее актуальные проблемы, возвращать клиентов или сравнивать различные дизайны. Комбинируя оценку процесса доставки, можно использовать Извлечение ключевых слов, чтобы определить, какие центры доставки работают лучше и по каким причинам с точки зрения клиента. Новый дизайн веб-сайта воспринимается не так хорошо, как старый. При извлечении ключевых слов точные причины более низкой производительности могут быть получены из отзывов. Благодаря автоматизации извлечения ключевых слов острые проблемы сразу становятся видны, и можно принимать важные решения, не теряя времени.
« еда была вкусной , но время доставки было слишком долгим »
Понимание того, хорошо ли воспринят ролик и передает ли он ключевые сообщения, имеет решающее значение. . От отзывов о видимости нового продукта, восприятии бренда до привлекательности отзыва, музыки или монтажа. Взаимодействие различных критериев делает ролик успешным.
. От отзывов о видимости нового продукта, восприятии бренда до привлекательности отзыва, музыки или монтажа. Взаимодействие различных критериев делает ролик успешным.
Поскольку затраты на размещение рекламы высоки, имеет смысл протестировать веб-ролик или, что еще лучше, разные версии нового ролика, прежде чем размещать его в разных каналах. Для этой цели подходит онлайн-опрос конкретных целевых групп, которые должны быть охвачены рекламой. Чтобы иметь возможность поместить оценки респондентов в правильный контекст, в дополнение к наиболее важным социально-демографическим показателям, таким как пол, возраст и состояние, отношение или покупательское поведение в соответствующей категории, а также использование наиболее важные бренды также должны быть собраны.
Онлайн-опросы можно использовать для оценки рекламы несколькими способами. Далее мы хотели бы представить 4 категории для измерения телевизионной рекламы: (1) вовлеченность, (2) влияние на бренд, (3) оценка и (4) ассоциации
Приверженность
респонденты с показанным пятном. Чувствуют ли зрители сильное участие или они остаются эмоционально незатронутыми роликом? Существуют различные методы измерения этого участия. В нейромаркетинге активность мозга во время спота измеряется с помощью ЭКГ для измерения бессознательного состояния. Другой метод — отслеживание глаз и эмоций. Измеряя физиологические реакции, можно сделать выводы об эмоциональной оценке показанного стимула (телевизионный ролик). Эти методы требуют соответствующей тестовой среды под наблюдением экспертов. Менее сложным подходом является цифровое измерение того, просматриваются ли веб-ролики до конца или ролик завершается преждевременно. В дополнение к тестируемой точке для сравнения должны быть протестированы другие текущие эталонные точки.
Чувствуют ли зрители сильное участие или они остаются эмоционально незатронутыми роликом? Существуют различные методы измерения этого участия. В нейромаркетинге активность мозга во время спота измеряется с помощью ЭКГ для измерения бессознательного состояния. Другой метод — отслеживание глаз и эмоций. Измеряя физиологические реакции, можно сделать выводы об эмоциональной оценке показанного стимула (телевизионный ролик). Эти методы требуют соответствующей тестовой среды под наблюдением экспертов. Менее сложным подходом является цифровое измерение того, просматриваются ли веб-ролики до конца или ролик завершается преждевременно. В дополнение к тестируемой точке для сравнения должны быть протестированы другие текущие эталонные точки.
Влияние бренда
Чтобы реклама не только привлекала внимание, но и работала на конкретный бренд, важно измерять влияние бренда. Реклама целой товарной категории не очень эффективна. С другой стороны, ролик со слишком большим побочным эффектом на конкурентов даже вреден. Чтобы измерить влияние бренда, можно провести различие между неавтоматизированным и вспомогательным методом. Для процедуры без посторонней помощи задается открытый вопрос о рекламируемом бренде.
Чтобы измерить влияние бренда, можно провести различие между неавтоматизированным и вспомогательным методом. Для процедуры без посторонней помощи задается открытый вопрос о рекламируемом бренде.
Ролик какого бренда вы только что видели?
При использовании защищенной процедуры запрашивается выбор предопределенных марок. Следует позаботиться о рандомизации различных брендов среди респондентов, чтобы исключить эффекты последовательности. С помощью вспомогательной процедуры категории ответов могут быть определены заранее, чтобы сделать результаты более точными: точно, возможно, определенно нет.
Кроме этих методов подходят и другие вопросы, такие как вопрос о конкретном рекламном содержании для отдельных брендов или отнесение отдельных кадров из рекламы к брендам.
Оценка и ассоциации
Чтобы проверить, соответствует ли ролик правильным ценностям, необходимо оценить целевые восприятия. Следует различать эмоциональные и содержательные измерения.
Следует различать эмоциональные и содержательные измерения.
Эмоциональное измерение. Записываются аффективные аспекты пятна с вопросами об эмоциональных реакциях. Ролик смешной, драматичный, энергичный, грустный, привлекательный или тревожный? Подходит ли место для моего бренда? Выделяется ли место среди конкурентов?
Размер контента. Вопросы на понимание содержания проверяют, передан ли посыл рекламного ролика. Передает ли ролик информацию и содержание, к которым обращается? Воспринимаются и понимаются ли рекламируемые товары или услуги?
Конечно, можно собрать утверждения по шкале Лайкерта, чтобы получить конкретную обратную связь по отдельным измерениям. Для получения прямой обратной связи собственными словами респондентов подходит набор открытых текстовых полей. Имеет смысл получить от респондента краткое изложение содержания. Это дает понять, что застревает в глазах аудитории. Кроме того, также желательно спрашивать конкретно о лайках и антипатиях:
Что вам больше всего нравится в этом рекламном ролике?
Что вам меньше всего нравится в этом рекламном ролике?
Ассоциации. Использование открытых вопросов также подходит для измерения эмоциональных реакций на рекламу. В особенности при записи чувств готовые варианты ответов или очень конкретные утверждения оказываются суксессивными и, таким образом, оказывают влияние. Для того, чтобы действительно понять, что вызывает телесюжет, подойдет незаданный вопрос о мыслях респондентов:
Использование открытых вопросов также подходит для измерения эмоциональных реакций на рекламу. В особенности при записи чувств готовые варианты ответов или очень конкретные утверждения оказываются суксессивными и, таким образом, оказывают влияние. Для того, чтобы действительно понять, что вызывает телесюжет, подойдет незаданный вопрос о мыслях респондентов:
Какие ассоциации, мысли или чувства возникают у вас после просмотра этого ролика?
Есть несколько вариантов ответа на этот вопрос. Предусмотрено либо от 3 до 10 текстовых полей, в которые респонденты могут вводить короткие ассоциации. Кроме того, вы можете предоставить текстовое поле большего размера, чтобы получать отзывы в непрерывном тексте. Иногда бывает интересно мотивировать респондентов «дать волю своим мыслям».
Открытые вопросы подходят для получения точной и индивидуальной обратной связи по отдельным точкам. На основе симпатий и антипатий можно определить очень конкретные плюсы и минусы телевизионного ролика. Монтаж, музыка, актеры или просто сюжет? Вы также можете спросить об этих аспектах с помощью закрытых вопросов. Но только с открытыми вопросами вы получаете конкретные причины для оценки в словах людей и, таким образом, конкретные выводы для адаптации роликов или ориентиры для концепции новых роликов, а также темы, которые вы, возможно, вообще не заметили.
Монтаж, музыка, актеры или просто сюжет? Вы также можете спросить об этих аспектах с помощью закрытых вопросов. Но только с открытыми вопросами вы получаете конкретные причины для оценки в словах людей и, таким образом, конкретные выводы для адаптации роликов или ориентиры для концепции новых роликов, а также темы, которые вы, возможно, вообще не заметили.
Surveybot также можно использовать в рамках спотового тестирования для получения еще более точной обратной связи с помощью специально обученного чат-бота. Это позволяет задать конкретный вопрос по конкретной теме в ответ на ответ респондента.
Каким бы полезным ни было использование открытых вопросов для сбора мнений, они также влекут за собой сложные процессы оценки. Ручная оценка открытых ответов требует времени, структурированных планов кода и обученного персонала. Чтобы понять, что содержится в открытой обратной связи, Можно использовать извлечение ключевых слов на основе ИИ . Модели Deep Learning или Machine Learning , обученные понимать язык, могут за короткое время автоматически группировать связанные с содержанием термины. Это позволяет сразу увидеть, что работает особенно хорошо, а что плохо в том или ином месте. Ассоциации с телерекламой становятся поддающимися количественной оценке, поскольку отдельным темам можно точно определить долю упоминаний. Для разработки таких моделей нужны специалисты в области науки о данных и обработки естественного языка. Но и без таких специалистов можно извлечь выгоду из последних разработок в области искусственного интеллекта. Используя программное обеспечение для извлечения ключевых слов , собственные данные могут быть проанализированы с небольшими усилиями и по низкой цене.
Модели Deep Learning или Machine Learning , обученные понимать язык, могут за короткое время автоматически группировать связанные с содержанием термины. Это позволяет сразу увидеть, что работает особенно хорошо, а что плохо в том или ином месте. Ассоциации с телерекламой становятся поддающимися количественной оценке, поскольку отдельным темам можно точно определить долю упоминаний. Для разработки таких моделей нужны специалисты в области науки о данных и обработки естественного языка. Но и без таких специалистов можно извлечь выгоду из последних разработок в области искусственного интеллекта. Используя программное обеспечение для извлечения ключевых слов , собственные данные могут быть проанализированы с небольшими усилиями и по низкой цене.
Инструменты и ресурсы для извлечения ключевых слов
Теперь, когда вы знаете об извлечении ключевых слов, вы готовы сделать свои первые шаги. Есть несколько способов сделать это. Вы можете разработать целую пользовательскую систему с нуля, которая будет работать в вашей системе. Преимущество этого подхода в том, что он идеально подходит для ваших потребностей и инфраструктуры. Но такой подход требует больших усилий.
Вы можете разработать целую пользовательскую систему с нуля, которая будет работать в вашей системе. Преимущество этого подхода в том, что он идеально подходит для ваших потребностей и инфраструктуры. Но такой подход требует больших усилий.
В области машинного обучения и обработки естественного языка существует большое сообщество с открытым исходным кодом, которое постоянно разрабатывает и публикует библиотеки. Если у вас есть соответствующий опыт в области науки о данных, вы можете найти несколько интересных статей здесь. Присоединяйтесь к нашей встрече по обработке естественного языка, чтобы обменяться идеями с другими специалистами по данным в области обработки естественного языка и следить за интересными докладами.
Если у вас нет опыта программирования или у вас нет подходящей команды для создания подходящего решения с нуля, мы представляем две удобные альтернативы, которые помогут вам сразу приступить к работе: Используйте инструменты извлечения ключевых слов для анализа ваших собственных данные и распространяйте идеи в своей организации или подключайте API-интерфейсы извлечения ключевых слов для реализации существующих алгоритмов в ваших решениях. С обоими решениями вы можете приступить к работе сразу же, вам не требуется никакого кода или требуется очень мало кода, они стоят гораздо меньше и масштабируемы.
С обоими решениями вы можете приступить к работе сразу же, вам не требуется никакого кода или требуется очень мало кода, они стоят гораздо меньше и масштабируемы.
Средства извлечения ключевых слов
Чтобы выбрать правильный инструмент, вы должны четко представлять себе варианты использования. Все инструменты различаются по области применения и имеют как преимущества, так и недостатки. Мы рекомендуем вам попробовать инструмент. Зарегистрируйтесь бесплатно на сайте Cauliflower, чтобы начать работу с извлечением ключевых слов.
- Цветная капуста
- DiscoverText
- Mozenda
- PrediCX
- WordStat
- MonkeyLearn
Цветная капуста
Фокус: Компании любого размера, которые хотят анализировать многоязычные текстовые данные (опросы, обзоры, отзывы клиентов, новостные статьи, социальные сети и т. д.) с извлечением ключевых слов и анализом настроений в интуитивно понятной графике.
Cauliflower — это простая в использовании платформа SaaS для мгновенного анализа текста. Вы можете сразу приступить к извлечению ключевых слов, а благодаря собственной методологии Cauliflower вы можете анализировать данные из нескольких источников без необходимости обучения или настройки модели.
Использование обработки естественного языка и глубокого машинного обучения сочетает в себе масштабируемость для большого количества наборов данных с качеством анализа человеческого анализа. С его использованием вы можете значительно сократить усилия в своей компании по доступной цене. Благодаря автоматически создаваемым привлекательным информационным панелям вы можете легко распространять информацию по всей организации.
Кроме того, предоставляется API для связи различных аналитических данных и моделей Cauliflower с приложениями в вашей инфраструктуре. Благодаря простой документации вы можете начать внедрение всего за несколько шагов.
DiscoverText
Фокус: Компании из списка Fortune 1000, ученые и государственные учреждения, которым нужны аналитические решения, которые оптимизируют процесс сбора, хранения и совместной работы над текстовыми данными на естественном языке.
DiscoverText — это система совместной текстовой аналитики на базе Интернета, которая позволяет ученым, компаниям и правительствам планировать выборку из Twitter, импорт из SurveyMonkey, электронной почты или электронных таблиц для поиска, фильтрации, кластеризации, человеческого кода и машинного кодирования. классифицировать текст. Патент Texifter CoderRank фокусируется на алгоритмических методах, аналогичных Google PageRank для веб-поиска, но предназначенных для улучшения крупномасштабной совместной текстовой аналитики за счет улучшенного машинного обучения и геймификации краудсорсингового кодирования. (Источник: capterra.com)
Mozenda
Фокус: Отдельные лица и команды в компаниях любого размера. Mozenda доверяют тысячи предприятий и более 30% компаний из списка Global Fortune 500.
Mozenda — это программное обеспечение и сервис для веб-скрейпинга. Нам доверяют 1/3 компаний из списка Fortune 500 и пятизвездочная служба поддержки клиентов. Mozenda предоставляет: 1) программное обеспечение, размещенное в облаке; 2) программное обеспечение, установленное на предприятии; (Источник: capterra.com)
Mozenda предоставляет: 1) программное обеспечение, размещенное в облаке; 2) программное обеспечение, установленное на предприятии; (Источник: capterra.com)
PrediCX
Фокус: Компании, которые хотят получить больше информации от своих клиентов, чтобы улучшить их взаимодействие с клиентом, сократить расходы и улучшить работу своего колл-центра.
PrediCX предлагает автоматическую классификацию входящих данных о клиентах по любому каналу. Поймите, что на самом деле говорят ваши клиенты, почти в реальном времени. Получайте заблаговременные предупреждения о проблемах, быстро отслеживайте любые жалобы или срочные запросы и с первого раза настройте правильный канал связи с клиентом. CSat улучшился на 20 %, FCR улучшился на 50 %, AHT снизился на 35 %, а отток клиентов сократился на 18 %. (Источник: capterra.com)
WordStat
Фокус: Предназначен для академических учреждений, государственных предприятий, НПО и исследователей, использующих интеллектуальный анализ текста и качественный анализ данных для поиска тем, тенденций и тем в неструктурированных текстовых данных.
WordStat — это программа, которая помогает людям анализировать очень большие объемы письменных документов. например, опросы клиентов, политические выступления, научные статьи, электронные письма или твиттер-каналы. Программное обеспечение помогает людям находить общие темы, темы и скрытые значения в неструктурированных текстовых данных. Гостиничная сеть может иметь 100 000 отзывов клиентов об их номерах, питании или объектах на открытом воздухе. Программное обеспечение помогает искать эти ответы и генерировать общие темы или темы, чтобы нацеливать их на то, что нужно улучшить. (Источник: capterra.com)
MonkeyLearn
Фокус: Малые и средние компании, которым необходимо преобразовать текст в данные для действий. Пользователи варьируются от маркетологов до продавцов, групп поддержки клиентов, аналитиков данных, разработчиков и других.
MonkeyLearn — это платформа искусственного интеллекта, которая позволяет анализировать текст с помощью машинного обучения для автоматизации бизнес-процессов и экономии часов ручной обработки данных. Такие клиенты, как Clearbit, Segment и Drift, используют MonkeyLearn для классификации и извлечения полезных данных из необработанных текстов, таких как электронные письма, чаты, веб-страницы, документы, твиты и многое другое! MonkeyLearn можно легко интегрировать с помощью таких интеграций, как Google Sheets, Zapier, Zendesk или Rapidminer (кодирование не требуется) или с помощью нашего прекрасного API и SDK. (Источник: capterra.com)
Такие клиенты, как Clearbit, Segment и Drift, используют MonkeyLearn для классификации и извлечения полезных данных из необработанных текстов, таких как электронные письма, чаты, веб-страницы, документы, твиты и многое другое! MonkeyLearn можно легко интегрировать с помощью таких интеграций, как Google Sheets, Zapier, Zendesk или Rapidminer (кодирование не требуется) или с помощью нашего прекрасного API и SDK. (Источник: capterra.com)
Начните с извлечения ключевых слов
Извлечение ключевых слов можно использовать для структурирования больших объемов данных, чтобы сделать видимой важную информацию. Благодаря извлечению ключевых слов можно понять отзывы клиентов, автоматизировать процессы, а ресурсы можно сохранить и использовать для более важных задач. В этой статье вы изучили основы извлечения ключевых слов и познакомились с методами из области компьютерной лингвистики и науки о данных. С примерами использования из области тестирования продукта, обратной связи с клиентами и выборочного тестирования вы узнали о возможных применениях в области поддержки клиентов, маркетинга и исследования рынка.