Как искали в 90-х и куда исчезли российские поисковые системы? / Хабр
Если сегодня кто-то говорит «поищи в интернете», обычно подразумевается «Яндекс» или Google. Но так было далеко не всегда. Во второй половине 90-х ассортимент поисковых систем был намного шире: в зарубежном интернете успешно работали AltaVista и Yahoo, Lycos и WebCrawler, а еще Ask.com, HotBot, Excite, Infoseek и множество других. Рунет также переживал бурный расцвет: здесь присутствовало несколько полноценных поисковых систем и целое семейство каталогов ссылок. Прошло время, выжил только «Яндекс», превратившийся в гигантскую мегакорпорацию. Куда делись все остальные?
Для начала давайте определимся с тем, чем все-таки отличались поисковые системы от каталогов. Полноценные поисковики, коих даже в те времена было относительно немного, имели собственного программного робота, самостоятельно бродившего по сети, обходившего ссылки и добавлявшего информацию о найденных веб-страницах в базу данных — индекс поисковой системы. Роботы умели парсить HTML и вычленять из тегов информацию о проиндексированных страницах, но качество автоматически составленных описаний порой оставляло желать лучшего. Да и релевантность поиска не всегда была высокой: порой поисковик выдавал по запросу совсем не то что нужно.
Роботы умели парсить HTML и вычленять из тегов информацию о проиндексированных страницах, но качество автоматически составленных описаний порой оставляло желать лучшего. Да и релевантность поиска не всегда была высокой: порой поисковик выдавал по запросу совсем не то что нужно.
В каталоги, в отличие от поисковых систем, ссылки добавляли вручную сами создатели сайтов, и составляли для них развернутые и подробные описания. Эти описания проверяли модераторы — в каждом тематическом разделе каталога трудился свой. В результате качество поиска в каталоге оказывалось порой выше в сравнении с классическими поисковыми системами, и эта ситуация сохранялась до тех пор, пока роботы поисковиков не «поумнели» и не научились индексировать страницы лучше людей.
Помимо «Яндекса» во второй половине 90-х в Рунете существовало несколько поисковиков, каждый из которых обладал своими индивидуальными чертами и характерными особенностями.
Рамблер
Исторически «Рамблер» стал первой полноценной поисковой системой в Рунете — его запустили в 1996 году, однако при нем действовал и каталог ссылок с рейтингом «Rambler Top100». Идея создания собственного поисковика возникла из-за того, что зарубежные поисковые роботы плохо воспринимали кириллицу и постоянно «путались» в кодировках. Ядро новой поисковой системы написал сотрудник Пущинского микробиологического института Дмитрий Крюков, он же нарисовал для нее логотип. А 26 сентября 1996 года был зарегистрирован домен rambler.ru.
Идея создания собственного поисковика возникла из-за того, что зарубежные поисковые роботы плохо воспринимали кириллицу и постоянно «путались» в кодировках. Ядро новой поисковой системы написал сотрудник Пущинского микробиологического института Дмитрий Крюков, он же нарисовал для нее логотип. А 26 сентября 1996 года был зарегистрирован домен rambler.ru.
В течение долгого времени «Рамблер» был одним из лидеров российского сегмента Всемирной сети, четырежды завоевывал «Премию Рунета». Постепенно из простой поисковой системы он превратился в гигантский медиа-портал, обзавелся собственным телеканалом и кучей всевозможных сервисов, включая почтовый. Очень хорошо внутреннюю жизнь компании описал ее бывший сотрудник, а ныне — известный IT-предприниматель Игорь Ашманов в своей книге «Жизнь внутри пузыря».
Понемногу «Яндекс» потеснил конкурента на рынке поисковых сервисов, а в 2011 году «Рамблер» и вовсе лицензировал для своих нужд поисковую систему «Яндекса» и подключился к РСЯ, окончательно отказавшись от собственного поискового движка. В 2020 году единственным владельцем «Рамблера» стал «Сбербанк», а сам сайт rambler.ru теперь представляет собой новостной и медиа-портал, включающий различные сервисы. Поиск — далеко не главный среди них.
В 2020 году единственным владельцем «Рамблера» стал «Сбербанк», а сам сайт rambler.ru теперь представляет собой новостной и медиа-портал, включающий различные сервисы. Поиск — далеко не главный среди них.
Апорт
Одна из старейших поисковых систем Рунета, появившаяся на свет в 1996 году благодаря компании Agama. Изначально «Апорт» искал только по сайтам agama.com, но к 1997 году поисковик индексировал уже все сайты российского интернета.
В 1999 году «Апорт» был полностью выкуплен «РОЛ» («Россия-он-Лайн»), после чего все разработки и модификации поисковика были прекращены, и поисковая система стала понемногу сдавать свои позиции. В августе 2011 года «Апорт» совсем отказался от собственного движка, лицензировав поиск «Яндекса», а позже и вовсе закрылся. Теперь по адресу aport.ru расположен маркетплейс.
Нигма
Метапоисковая система nigma.ru была создана студентами факультетов ВМК и психологии МГУ при поддержке Стэнфордского университета и запущена намного позже других своих конкурентов — в 2005 году.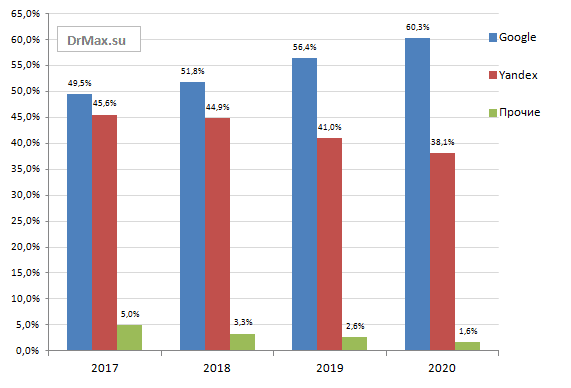 Однако в отличие от других поисковиков, «Нигма» отлично индексировала RSS-ленты и сообщения новостных порталов, предлагая по запросу пользователей актуальные новости, а также позволяла искать с использованием возможностей сразу нескольких альтернативных поисковых систем. Именно «Нигма» первой среди российских поисковиков разработала виджет для мобильной платформы Android.
Однако в отличие от других поисковиков, «Нигма» отлично индексировала RSS-ленты и сообщения новостных порталов, предлагая по запросу пользователей актуальные новости, а также позволяла искать с использованием возможностей сразу нескольких альтернативных поисковых систем. Именно «Нигма» первой среди российских поисковиков разработала виджет для мобильной платформы Android.
Несмотря на определенную популярность, проект держался в основном на энтузиазме его создателя Виктора Лавренко, который его обновлял и поддерживал. В сентябре 2017 года проект прекратил свое существование. Энтузиасты воссоздали внешний вид поисковика на сайте nigma.net.ru (он использует движки Google и Яндекс) — вы можете зайти по этому адресу прямо сейчас и посмотреть, как когда-то выглядела «Нигма».
Каталоги
Несмотря на то, возможности поисковых систем стремительно совершенствовались, каталоги ссылок с собственным локальным поиском были популярны вплоть до середины нулевых. А один из них — ulitka. ru — жив до сих пор. Если вам интересно узнать, как выглядели каталоги-рубрикаторы в старые добрые девяностые, обязательно загляните сюда.
ru — жив до сих пор. Если вам интересно узнать, как выглядели каталоги-рубрикаторы в старые добрые девяностые, обязательно загляните сюда.
Среди популярных каталогов нельзя не отметить «List.ru» (выкуплен Mail.Ru), «Веблист» (один из проектов компании MARK-ITT из Ижевска, ныне закрыт), «Сусанин» (создан петербургский дизайн-студией WebPlus в 1998 году, закрыт в начале «нулевых»), «Look.ru» (закрыт в первой половине нулевых), Up.ru (создан студией Delux, ныне сайт принадлежит компании Unite&Performance).
Выводы? Они просты: для выживания поисковые системы должны были не просто превратиться в медиа-корпорации, поддерживающие портал с кучей полезных сервисов, а развивать правильные направления, отвечающие требованиям рынка, которые будут востребованы в будущем. С этим вызовом справилась в полной мере только одна компания. «Рамблер» сделал ставку на телевидение (кто-то еще не выбросил на свалку свой телеприемник?), «Апорт» нашел незаинтересованных в его развитии инвесторов, а «Нигма» вообще решила обойтись без таковых, и в конце концов задохнулась без финансирования.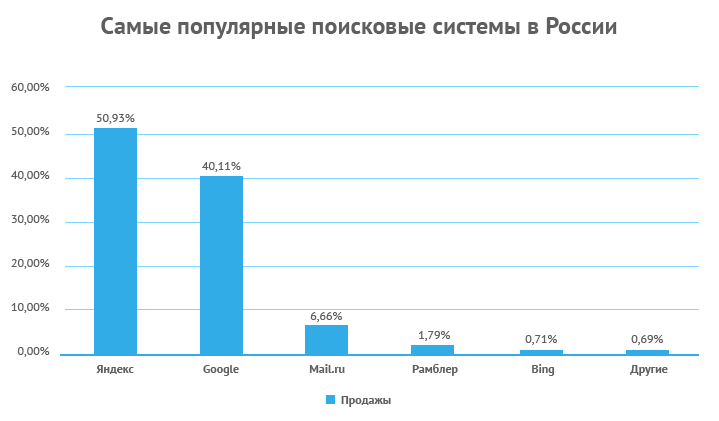 Время же тематических каталогов безвозвратно ушло.
Время же тематических каталогов безвозвратно ушло.
Поисковые системы Интернета: Яндекс, Google, Rambler, Yahoo — информация, принципы работы
1. Введение
2. Понятие и функции поисковой системы
4. Краткая история развития поисковых систем
5. Состав и принципы работы поисковой системы
6. Заключение
1. Введение
Поисковые системы уже давно стали неотъемлемой частью российского Интернета. Поисковые системы сейчас – это огромные и сложные механизмы, представляющие собой не только инструмент поиска информации, но и заманчивые сферы для бизнеса.
Большинство пользователей поисковых систем никогда не задумывались (либо задумывались, но не нашли ответа) о принципе работы поисковых систем, о схеме обработки запросов пользователей, о том, из чего эти системы состоят и как функционируют…
Данный материал призван дать ответ на вопрос о том, как работают поисковые системы.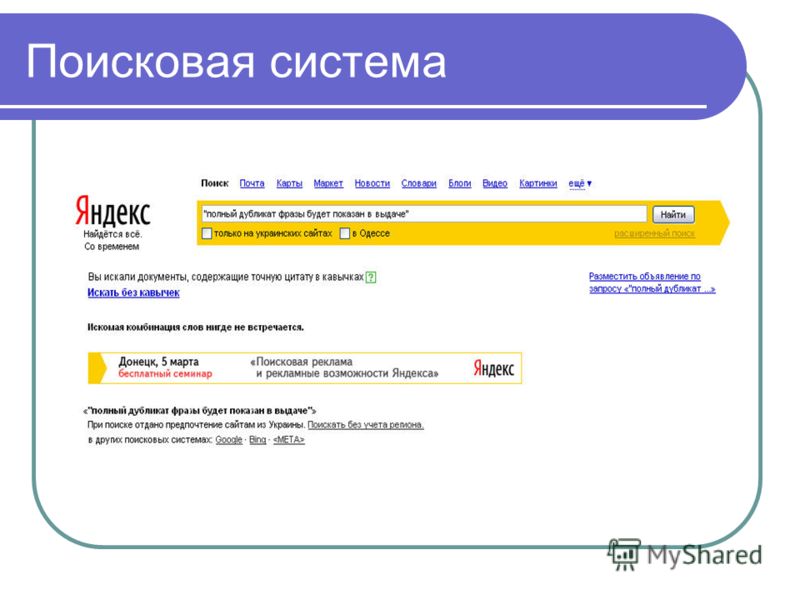 Однако вы не найдете здесь факторов, влияющих на ранжирование документов. И тем более не стоит рассчитывать на подробное объяснение алгоритма работы Яндекса. Его, по словам
Однако вы не найдете здесь факторов, влияющих на ранжирование документов. И тем более не стоит рассчитывать на подробное объяснение алгоритма работы Яндекса. Его, по словам
2. Понятие и функции поисковой системы
Поисковая система – это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). Наиболее крупные международные поисковые системы: «Google», «Yahoo», «MSN». В русском Интернете это – «Яндекс», «Рамблер», «Апорт».
Рассмотрим подробнее понятие поискового запроса на примере поисковой системы «Яндекс». Поисковый запрос должен быть сформулирован пользователем в соответствии с тем, что он хочет найти, максимально кратко и просто.
Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут. А научить пользователей делать «правильные» запросы к системе, т.е. запросы, соответствующие принципам работы поисковых систем, невозможно. Поэтому разработчики создают такие алгоритмы и принципы работы поисковых систем, которые бы позволяли находить пользователям искомую ими информацию.
Это означает, поисковая система должна «думать» так же, как думает пользователь при поиске информации. Когда пользователь обращается с запросом к поисковой машине, он хочет найти то, что ему нужно, максимально быстро и просто. Получая результат, он оценивает работу системы, руководствуясь несколькими основными параметрами. Нашел ли он то, что искал? Если не нашел, то сколько раз ему пришлось перефразировать запрос, чтобы найти искомое? Насколько актуальную информацию он смог найти? Насколько быстро обрабатывала запрос поисковая машина? Насколько удобно были представлены результаты поиска? Был ли искомый результат первым или же сотым? Как много ненужного мусора было найдено наравне с полезной информацией? Найдется ли нужная информация, при обращении к поисковой системе, скажем, через неделю, или через месяц?
Для того, чтобы удовлетворить ответами все эти вопросы, разработчики поисковых машин постоянно совершенствуют алгоритмы и принципы поиска, добавляют новые функции и возможности, всячески пытаются ускорить работу системы.
3. Основные характеристики поисковой системы
Опишем основные характеристики поисковых систем:
- Полнота
Полнота – одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
- Точность
Точность – еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5).
 Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу. - Актуальность
Актуальность – не менее важная составляющая поиска, которая характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. Например, на следующий день после появления интересной новости, большое количество пользователей обратились к поисковым системам с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток, однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию у крупных поисковых систем так называемой «быстрой базы», которая обновляется несколько раз в день.
- Скорость поиска
Скорость поиска тесно связана с его устойчивостью к нагрузкам.
 Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов. - Наглядность
Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска.
Подробные пояснения по странице результатов поиска, например у «Яндекса» можно посмотреть по ссылке http:\/\/help\.yandex\.ru\/search\/?id=481937.
4. Краткая история развития поисковых систем
В начальный период развития Интернет, число его пользователей было невелико, а объем доступной информации сравнительно небольшим. В большинстве своем, доступ к сети Интернет имели лишь сотрудники научно-исследовательской сферы. В это время задача поиска информации в Интернете не была столь актуальной, как в настоящее время.
Одним из первых способов организации доступа к информационным ресурсам сети стало создание открытых каталогов сайтов, ссылки на ресурсы в которых группировались согласно тематике. Первым таким проектом стал сайт Yahoo.com, открывшийся весной 1994 года. После того, как количество сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска нужной информации по каталогу.
Каталоги ссылок широко использовались ранее, однако практически полностью утратили свою популярность в настоящее время. Так как даже современные, огромные по своему объему каталоги, содержат информацию лишь о ничтожно малой части сети Интернет. Самый большой каталог сети DMOZ (его еще называют Open Directory Project) содержит информацию о 5 миллионах ресурсов, тогда как база поисковой системы Google состоит из более чем 8 миллиардов документов.
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в сети Интернет.
В 1997 году Сергей Брин и Ларри Пейдж создали поисковую машину Google в рамках исследовательского проекта в Стэндфордском университете. В настоящий момент Google –самая популярная поисковая система в мире!
В настоящий момент Google –самая популярная поисковая система в мире!
В сентябре 1997 года была официально анонсирована поисковая система Yandex, являющаяся самой популярной в русскоязычном Интернете.
В настоящее время существуют три основные поисковые системы (международные) – Google, Yahoo и MSN, имеющие собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих насчитывается большое количество) использует в том или ином виде результаты трех перечисленных. Например, поиск AOL (search.aol.com) использует базу Google, а AltaVista, Lycos и AllTheWeb – базу Yahoo.
5. Состав и принципы работы поисковой системы
В России основной поисковой системой является «Яндекс», далее – Rambler.ru, Google.ru, Aport.ru, Mail.ru. Причем, на данный момент, Mail.ru использует механизм и базу поиска «Яндекса».
Практически все крупные поисковые системы имеют свою собственную структуру, отличную от других. Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Модуль индексирования
Модуль индексирования состоит из трех вспомогательных программ (роботов):
Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание страницы и извлекает все внутренние ссылки с этой страницы. Скачивается html-код каждой страницы. Для скачивания страниц роботы используют протоколы HTTP. Работает «паук» следующим образом. Робот на сервер передает запрос “get/path/document” и некоторые другие команды HTTP-запроса. В ответ робот получает текстовый поток, содержащий служебную информацию и непосредственно сам документ.
Ссылки извлекаются из тэгов a, area, base, frame, frameset, и др. Наряду со ссылками, многими роботами обрабатываются редиректы (перенаправления). Каждая скачанная страница сохраняется в следующем формате:
- URL страницы
- дата, когда страница была скачана
- http-заголовок ответа сервера
- тело страницы (html-код)
Crawler («путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Indexer (робот- индексатор) – программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т.д.
Таким образом, модуль индексирования позволяет обходить по ссылкам заданное множество ресурсов, скачивать встречающиеся страницы, извлекать ссылки на новые страницы из получаемых документов и производить полный анализ этих документов.
База данных
База данных, или индекс поисковой системы — это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
Поисковый сервер
Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска.
Поисковый сервер работает следующим образом:
- Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (которое и будет впоследствии отображено в виде сниппета, то есть соответствующей запросу текстовой информации на странице выдачи результатов поиска).
- Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
- В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск»).

- Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются.
- Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов.
Как видно, все эти компоненты тесно связаны друг с другом и работают во взаимодействии, образовывая четкий, достаточно сложный механизм работы поисковой системы, требующий огромных затрат ресурсов.
По информации ООО «Рамблер Интернет Холдинг» обработка поискового запроса в системе «Рамблер» происходит, так, как это изображено на рисунке.
Запрос поступает в поисковую систему через маршрутизатор Cisco 6000 series. Cisco передает его наименее загруженной машине первого уровня — frontend (1.1 — 1.3, на рис. машине 1.3). Frontend, в свою очередь, отправляет запрос дальше, на один из восьми proxy-серверов, также выбирая наиболее свободный сервер (2. 1 — 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 — 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 — 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, — backends (5.1.х — 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с «быстрой базой» (6.1 — 6.2).
1 — 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 — 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 — 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, — backends (5.1.х — 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с «быстрой базой» (6.1 — 6.2).
На текущий момент в поиск включено 77 backend’ов. Они сгруппированы по 11 машин, и каждая группа содержит копию одной из частей поискового индекса. Таким образом, информация о сайтах, условно входящих в красный сектор Интернета, находится на backend’ах первой группы (5.1.1 — 5.1.11 на рис), оранжевый сектор — на backend’ах второй группы (5.2.1 — 5.2.11) и т.д. Proxy-сервер выбирает наименее загруженный backend в каждой группе машин и отправляет на него поисковый запрос с результатами ссылочного поиска. На backend’ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
На backend’ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
После того, как запрос обработан на backend’ах, информация о результатах и ранжировании отдается обратно на proxy-сервер. Туда же поступают отсортированные результаты с машин «быстрой базы». Proxy интегрирует данные, полученные с восьми машин: клеит дубли, объединяет зеркала сайтов, переранжирует документы в общий список по весам, рассчитанным на backend’ах. Так, первым в списке найденного может быть документ с машины 5.3.1, вторым и третьим – с 6.1, четвертым — с 5.5.2 и т.д. На proxy-сервере также реализуется построение цитат к документам и подсветка слов запроса в тексте. Полученные результаты отдаются на frontend.
Помимо информации с proxy-сервера, frontend получает результаты из поиска по товарам и из базы Тор 100, отсортированные, с цитатами и подсветкой слов запроса. Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю.
Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю.
При написании мастер-класса были использованы материалы и данные ООО «Рамблер Интернет Холдинг», RuSeo.info
6. Заключение
Теперь подытожим все вышесказанное.
- Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут.
- Основные характеристики поисковых систем:
- Полнота
- Точность
- Актуальность
- Скорость поиска
- Наглядность
- Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
- В состав поисковой системы входят компоненты:
- Модуль индексирования
- База данных
- Поисковый сервер
Надеемся, наш материал позволит вам поближе познакомиться с понятием ПС, лучше узнать основные функции, характеристики и принцип работы поисковых систем.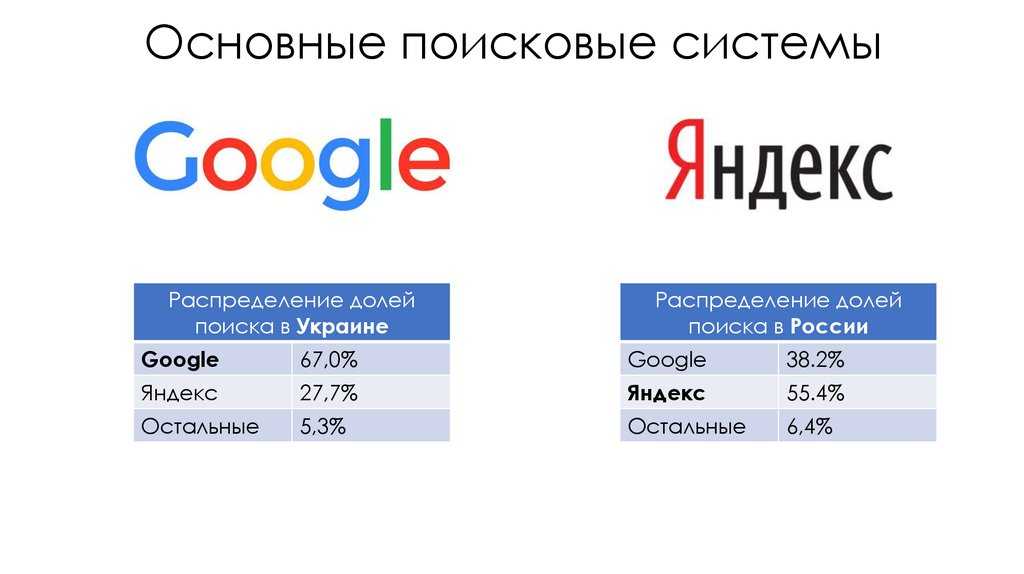
Массовая утечка кода Яндекса раскрыла факторы ранжирования российской поисковой системы
SEO — это война
Кевин Парди —
Увеличить / Российский логотип Яндекса, крупнейшей в стране поисковой системы и технологической компании с множеством подразделений, внутри штаб-квартиры компании.
SOPA Images / Getty Images
Почти 45 ГБ файлов с исходным кодом, предположительно украденных бывшим сотрудником, раскрыли основы многих приложений и сервисов российского технологического гиганта «Яндекс». Он также выявил ключевые факторы ранжирования для поисковой системы Яндекса, которые почти никогда не раскрываются публично.
«Гит-исходники Яндекса» были опубликованы в виде торрент-файла 25 января и показывают файлы, якобы снятые в июле 2022 года и относящиеся к февралю 2022 года. Инженер-программист Арсений Шестаков утверждает, что он проверил с нынешними и бывшими сотрудниками Яндекса, что некоторые архивы « наверняка содержат современный исходный код для сервисов компании». Яндекс сообщил блогу безопасности BleepingComputer, что «Яндекс не был взломан» и что утечка произошла от бывшего сотрудника. «Яндекс» заявил, что «не видит угрозы для пользовательских данных или производительности платформы».
Инженер-программист Арсений Шестаков утверждает, что он проверил с нынешними и бывшими сотрудниками Яндекса, что некоторые архивы « наверняка содержат современный исходный код для сервисов компании». Яндекс сообщил блогу безопасности BleepingComputer, что «Яндекс не был взломан» и что утечка произошла от бывшего сотрудника. «Яндекс» заявил, что «не видит угрозы для пользовательских данных или производительности платформы».
Файлы, в частности, датируются февралем 2022 года, когда Россия начала полномасштабное вторжение в Украину. Бывший руководитель Яндекса сказал BleepingComputer, что утечка была «политической», и отметил, что бывший сотрудник не пытался продать код конкурентам Яндекса. Код защиты от спама также не просочился.
Хотя неясно, имеет ли раскрытие исходного кода Яндекса последствия для безопасности или структуры, утечка 1922 факторов ранжирования в алгоритме поиска Яндекса, безусловно, наделала много шума. Консультант по SEO Мартин Макдональд описал взлом в Твиттере как «вероятно, самое интересное, что произошло в SEO за последние годы» (как отмечает Search Engine Land). В ветке, подробно описывающей некоторые из наиболее заметных факторов, исследователь Алекс Буракс предполагает, что «есть много полезной информации и для Google SEO».
В ветке, подробно описывающей некоторые из наиболее заметных факторов, исследователь Алекс Буракс предполагает, что «есть много полезной информации и для Google SEO».
Яндекс, четвертая по объему поисковая система, якобы нанимает нескольких бывших сотрудников Google. Яндекс отслеживает многие факторы ранжирования Google, идентифицируемые в его коде, и активно конкурирует с Google. Российское подразделение Google недавно объявило о банкротстве после потери банковских счетов и платежных сервисов. Буракс отмечает, что первым фактором в списке факторов ранжирования Яндекса является «PAGE_RANK», который, по-видимому, связан с основополагающим алгоритмом, созданным соучредителями Google.
Как подробно описал Буракс (в двух темах), движок Яндекса отдает предпочтение страницам, которые:
- Не слишком старые
- Иметь много органического трафика (уникальных посетителей) и меньше поискового трафика
- В URL-адресе должно быть меньше цифр и косых черт
- Иметь оптимизированный код, а не «жесткую пессимизацию» с «PR=0»
- Размещаются на надежных серверах
- Случается, что это страницы Википедии или ссылки из Википедии
- Размещены или связаны со страницами более высокого уровня в домене
- Иметь ключевые слова в своем URL (до трех)
Вы можете искать и щелкать по всем факторам в скомпилированном поисковом инструменте Роба Усби. Вы могли заметить, что почти 1000 факторов ранжирования имеют тег «TG_DEPRECATED», а более 200 указаны как «TG_UNUSED». Поскольку код датирован февралем 2022 года и был получен в июле 2022 года, с тех пор поиск Яндекса, безусловно, изменился. Но утечка дает редкий взгляд на то, как составляются поисковые рейтинги на сайте, который обслуживает одну из крупнейших стран мира.
Вы могли заметить, что почти 1000 факторов ранжирования имеют тег «TG_DEPRECATED», а более 200 указаны как «TG_UNUSED». Поскольку код датирован февралем 2022 года и был получен в июле 2022 года, с тех пор поиск Яндекса, безусловно, изменился. Но утечка дает редкий взгляд на то, как составляются поисковые рейтинги на сайте, который обслуживает одну из крупнейших стран мира.
В 2015 году код поисковой системы Яндекса исчез, когда бывший сотрудник попытался продать его на черном рынке за 28 000 долларов, чтобы профинансировать собственный стартап. Удивительно низкая цифра для основного кода основного продукта Яндекса свидетельствовала о том, что он не знал о его реальной ценности. Этот сотрудник был приговорен к двум годам лишения свободы условно, и кодекс никогда не публиковался.
Кевин Парди Кевин — технический репортер и специалист по продуктам в Ars Technica с более чем 15-летним опытом написания статей о технологиях. Реклама← Предыдущая история Следующая история →
Яндекс: Русская поисковая система ⭐
Если вы перечислите известные вам поисковые системы, вы, скорее всего, подумаете о Yahoo или Bing, Ask for questions and answer, YouTube для видео и, конечно же, Google, на долю которого в настоящее время приходится 90% поиски ведутся по всему миру.
Но сегодня мы хотим поговорить о Яндекс, самой используемой поисковой системе в России, а также других странах бывшего Советского Союза.
Яндекс, русский Google
Яндекс — поисковая система, созданная одноименной компанией, основанной Аркадием Воложем и Ильей Сегаловичами в 1997 году. Эта транснациональная компания специализируется на услугах и продуктах, связанных с Интернетом. Яндекс — крупнейшая технологическая компания России. И один из самых важных и крупных в Европе. У компании 20 офисов по всему миру и около 10 000 сотрудников.
С учетом количества посещений и проникновения в Интернет, Яндекс является наиболее используемой поисковой системой в России и в некоторых странах бывшего Советского Союза . У него 65% рынка в России, что делает его основным конкурентом Google. А в мировом рейтинге Яндекс занимает пятую позицию самых используемых поисковых систем, после Google, Baidu, Bing и Yahoo!
Почему Яндекс обогнал Google в России?
Основная причина, по которой Яндекс является предпочтительной поисковой системой для россиян, заключается в том, что создатели Яндекса уделили большое внимание разработке поисковой системы, которая прекрасно понимала кириллицу, включая сложные морфологические флексии, которые содержит русский язык. Немедленное распознавание интонации русского языка в поисковых запросах.
Немедленное распознавание интонации русского языка в поисковых запросах.
Гугл взялся за эту задачу намного позже, но было уже поздно, потому что Яндекс уже захватил рынок, завоевав русскоязычную сеть и позиционируя себя даже выше своих самых непосредственных российских конкурентов; Рамблер, портал, который был на рынке в течение года, и Mail.ru,a. И все это, несмотря на то, что они уже закрепились на рынке.
Услуги Яндекса
В настоящее время Яндекс предоставляет своим пользователям многочисленные услуги на своем онлайн-портале и в мобильных приложениях, доступных на английском и русском языках.
Яндекс предлагает некоторые очень похожие на Google функции, такие как бесплатная электронная почта , (почта yandex) карты трафика в реальном времени, (карты yandex) музыка, (музыка yandex) видео, (видео yandex) хранилище фотографий, (изображение yandex) и т. д.
В 2012 году Яндекс запустил Яндекс Браузер, собственный веб-браузер , который в настоящее время доступен для основных операционных систем, настольных или мобильных: Windows, OS X, iOS, Android и т. д.
В 2017 году Яндекс запустил собственного личного помощника с искусственным интеллектом , Алиса, который был только на русском языке и был доступен на всех основных мобильных платформах и Microsoft Windows.
Яндекс также хотел расширить , попробовать другие технологические и сервисные направления, поэтому в 2018 году решил объединить Яндекс Такси и Uber Russia в одну компанию , чтобы попытаться предоставить пользователю наилучший сервис мобильности. Но соглашение было не только для России, оно было распространено на другие страны, такие как; Азербайджан, Грузия, Армения, Беларусь и Казахстан.
Яндекс стремится совершенствоваться каждый день, поэтому постоянно развивается в поиске новых услуг, в разработке новых технологий, облегчающих жизнь своим пользователям.
Кроме того, компания хотела пойти еще дальше и работать вне технологии поисковых систем. А теперь он присутствует во многих других областях, таких как машинный перевод, продажа и доставка продуктов на дом, доставка еды, поиск и вызов такси, поиск фильма и даже помогает вам с образованием всей вашей семьи, благодаря его огромная база данных.
Избранные инструменты Яндекса
Существует множество инструментов, которые предлагает эта поисковая система и которые широко используются в сфере цифрового маркетинга как в России, так и за рубежом.
Некоторые из наиболее интересных:
- Яндекс Метрика, используется в основном для измерения результатов и выполнения углубленной веб-аналитики.
- Яндекс Вебмастер ; для индексации нужных веб-сайтов с помощью файла robot.txt.
- Яндекс Директ — платформа для управления спонсируемой рекламой.
- Yandex Wordstat для организации и планирования ключевых слов.
- Компания также разработала голосового помощника под названием Алиса , который является эквивалентом Siri от Apple или Alexa от Amazon. И автономный автомобиль на испытаниях.
- Он также имеет мощный переводчик , который работает онлайн и работает с 80 различными языками.

- Иммерсивная система поиска изображений, превосходящая Google . Используя чрезвычайно точную технологию распознавания лиц . Получение результатов даже с людьми, ранее не пользовавшимися Яндексом.
История Яндекса
Разработка российской поисковой системы Яндекс восходит к 1990 году и шла от рук двух бывших сотрудников компании Аркадия, занимавшихся поисками в Библии и в разных патентных делах. Они были; Аркадий Волож и Илья Сегалович.
Но не было до 1997 о том, что поисковая система Яндекс была представлена общественности и начала выходить на рынок.
Изначально поисковик был разработан CompTek . Но позже, в 2000 году, Яндекс был зарегистрирован Аркадием Воложем как независимая компания.
Его любопытное название происходит от набора букв , который происходит от «еще один индексатор», что означает («еще один индексатор», по-английски), они сделали это как аббревиатуру и заменили первые две оригинальные буквы на русский буква Я («Я»), («йо»), чтобы дать начало Яндексу, который в конечном итоге стал Яндексом.