Виды кодировок символов [АйТи бубен]
В общем случае кодировка или кодовая таблица — это однозначное соответствие между подмножеством целых чисел (как правило, идущих подряд) и некоторым набором символов. Ключевым здесь является понятие символа. Символ может быть буквой (а может и не быть), может соответствовать звуку речи (а может и не соответствовать) и может быть представлен графическим знаком (но может обходиться и без какого бы то ни было видимого образа). Символ — это атом смысла, мельчайшая неделимая частица информации.
Так, латинское «А» и кириллическое «А» — это разные символы, потому что они употребляются в разных контекстах и несут в себе разную информацию.
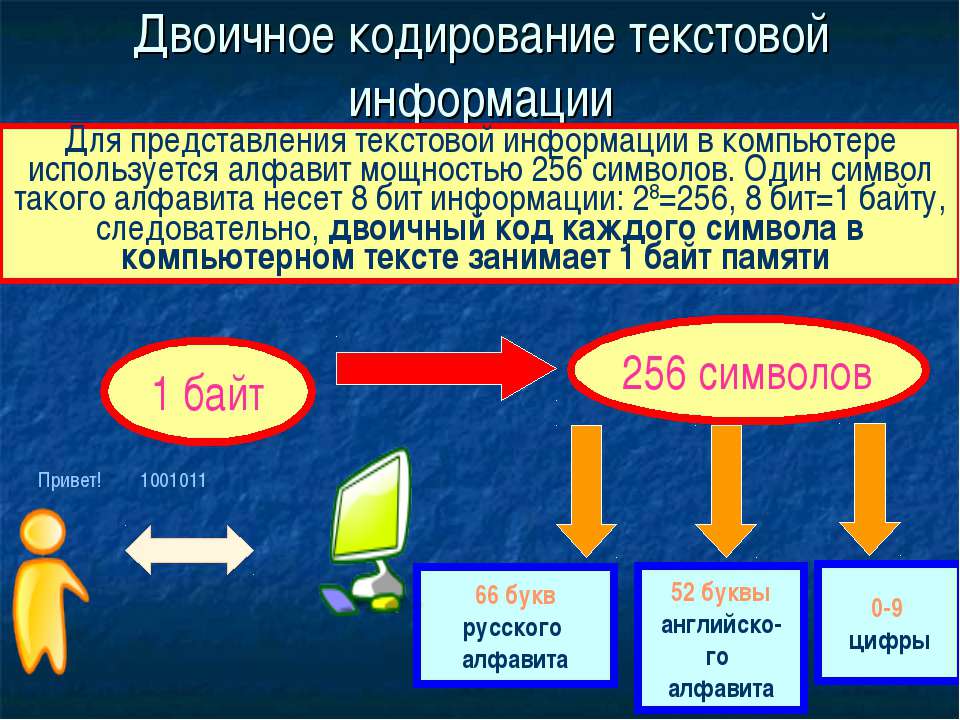
Определяющим для любой кодировки является количество охватываемых ею кодов и, соответственно, символов. Поскольку тексты в компьютере хранятся в виде последовательности байтов, большинство кодировок естественным образом распадаются на однобайтовые, или восьмибитные, способные закодировать не больше 256 символов, и двухбайтовые, или шестнадцатибитные, чья емкость может достигать 65636 знакомест.
Если кодировка ISO 8859-5 для кириллицы так и не прижилась, первая из этой серии — кодировка ISO 8859-1, известная также под именем Latin-1, — сумела стать общепринятым стандартом для кодирования «расширенной» латиницы. В эту кодировку включены почти все символы, употребляющиеся в письменностях западноевропейских языков — французского, немецкого, испанского и т.д.
Внедрение Юникода привело к изменению подхода к традиционным 8-битным кодировкам. Если раньше кодировка задавалась шрифтом, то теперь она задаётся таблицей соответствия между данной кодировкой и Юникодом. Фактически 8-битные кодировки превратились в форму представления некоторого подмножества Юникода. Это намного упростило создание программ, которые должны работать с множеством разных кодировок: теперь, чтобы добавить поддержку ещё одной кодировки, надо всего лишь добавить ещё одну таблицу перекодировки в Юникод.
В 1991 году была предпринята попытка создать единую универсальную двухбайтовую кодировку, охватывающую все алфавиты и иероглифические системы мира. Результатом стал стандарт под названием Unicode, покрывающий не только системы письменности всех живых и большинства мертвых языков мира, но и множество музыкальных, математических, химических и прочих символов. Массовое применение Unicode в документах и программах остается делом будущего, для web- дизайнера эта кодировка имеет особое значение, так как именно она объявлена «стандартной кодировкой документа» в HTML начиная с версии 4.
Результатом стал стандарт под названием Unicode, покрывающий не только системы письменности всех живых и большинства мертвых языков мира, но и множество музыкальных, математических, химических и прочих символов. Массовое применение Unicode в документах и программах остается делом будущего, для web- дизайнера эта кодировка имеет особое значение, так как именно она объявлена «стандартной кодировкой документа» в HTML начиная с версии 4.
В ближайшее время все более важную роль будет играть особый формат Unicode (и ISO 10646) под названием UTF-8. Эта «производная» кодировка пользуется для записи символов цепочками байтов различной длины (от одного до шести), которые с помощью несложного алгоритма преобразуются в Unicode- коды, причем более употребительным символам соответствуют более короткие цепочки. Главное достоинство этого формата — совместимость с 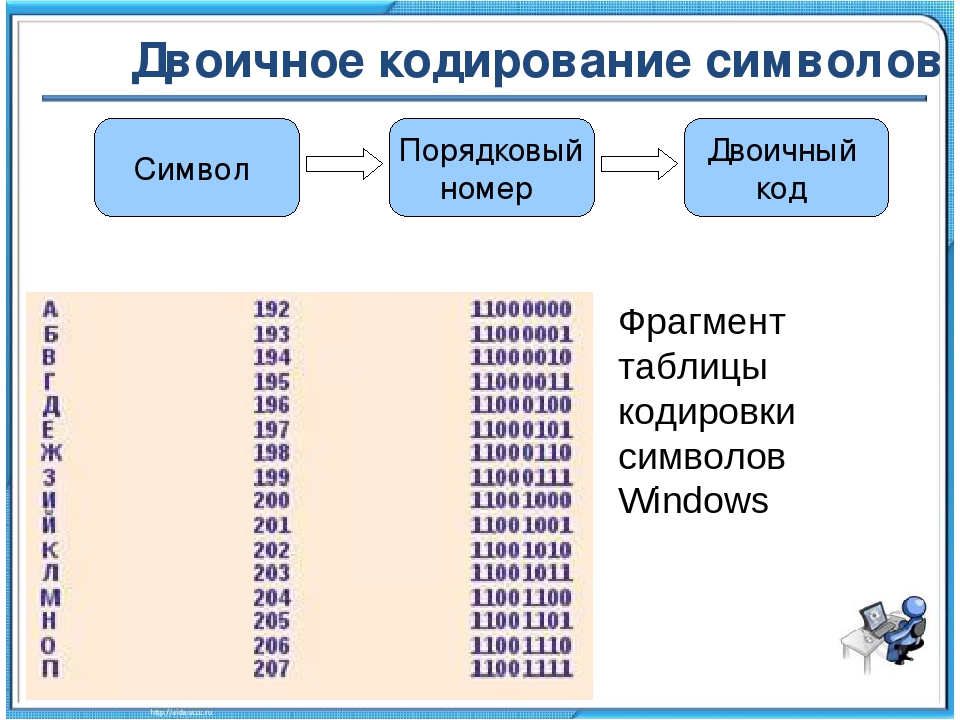
Для указания кодировки символов web-страницы используются следующие обозначения кодовых таблиц:
На web- странице указать кодировку документа можно двумя cпособами:
Элемент meta является дочерним по отношению к разделу заголовка документа (head) и служит для указания типа и кодировки содержимого страницы. Типом содержимого является структурированный текст в формате html (text/html), используемая кодировка кириллица windows (charset=windows-1251).
Обычно используют оба способа одновременно. Например, для указания кодировки КОИ8 для украинского языка на web-странице, используют следующую структуру документа:
<?xml version="1.0" encoding="KOI8-U"?>
<!DOCTYPE html PUBLIC ... >
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Моя перша сторiнка</title>
<meta http-equiv="Content-Type"
content="text/html; charset=KOI8-U" />
</head>
...
</html>При сохранении текста выбирайте ту же кодировку, что указали на web-странице.
Поэкспериментируйте с различными кодировками, и вы убедитесь, что символы латинского алфавита, цифры и знаки пунктуации передаются без изменений в подавляющем большинстве из них.
Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрами
31 июля 2019
- ASCII — базовая кодировка текста для латиницы
- Расширенные версии Аски — кодировки CP866 и KOI8-R
- Windows 1251 — почему вылезают кракозябры
- Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
- Кракозябры вместо русских букв — как исправить
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.
Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.
Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой:
Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8).
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита и она являлась расширенной версией ASCII.
Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика):
Видите, в правом столбце цифры начинаются с 8, т.к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:
Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации.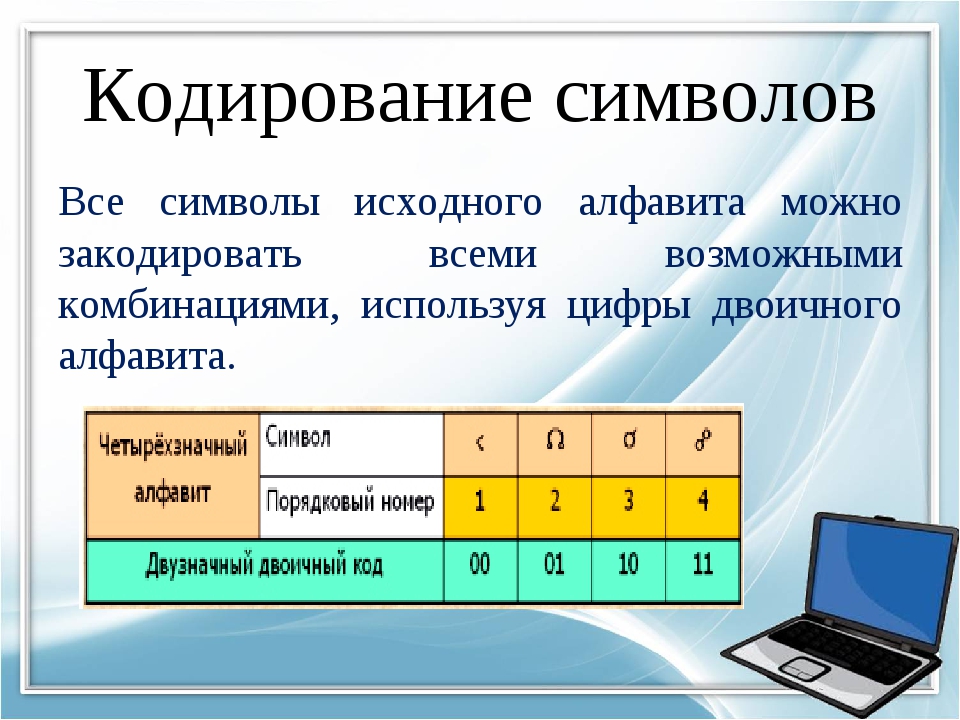 В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Аналогичная ситуация очень часто возникает при создании сайтов на WordPress и Joomla, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. Сейчас в наборы даже эмодзи смайлики добавляют.
И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. Сейчас в наборы даже эмодзи смайлики добавляют.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.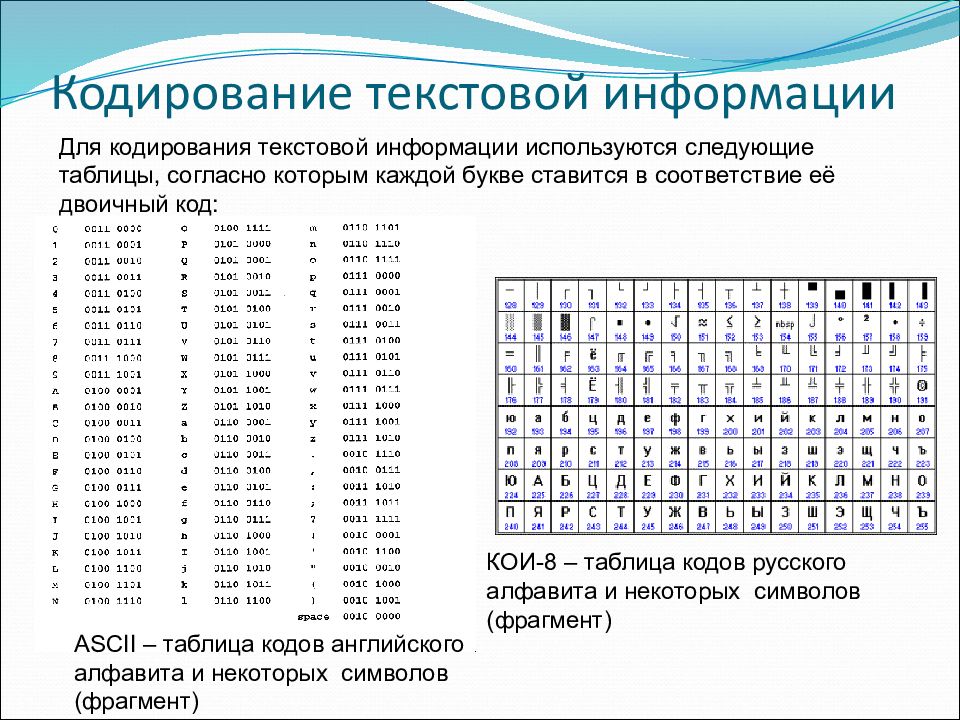
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.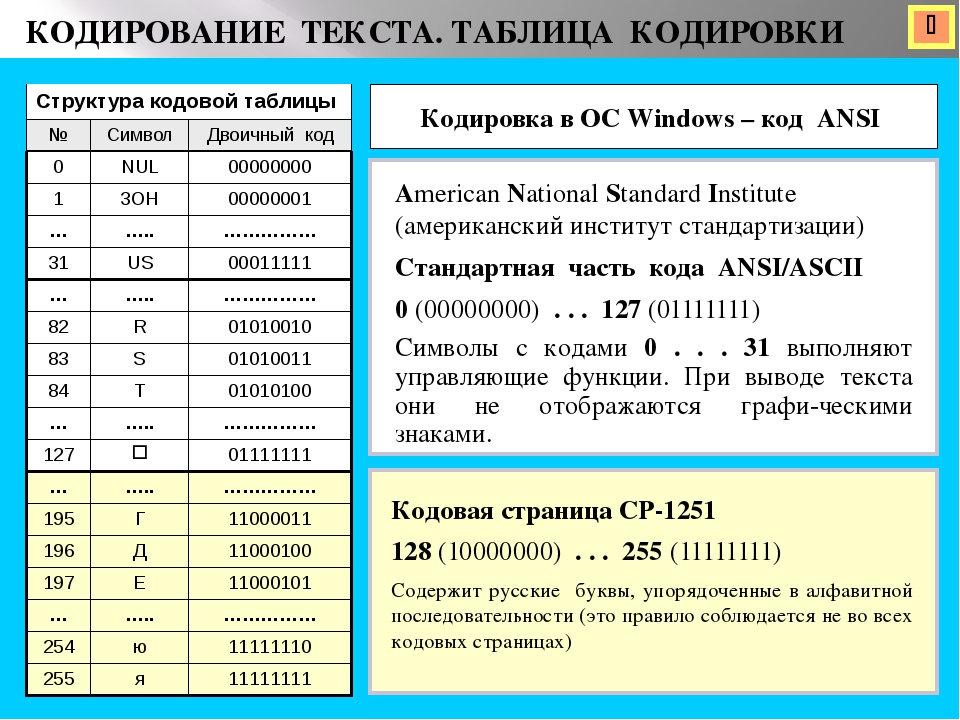
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
<head> ... <meta charset="utf-8"> ... </head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
По идее, элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов.
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Использую для заработка
Что такое кодировка
Факты
· На данный момент не существует метода лечения зависимости, который дает 100% результат или способен вылечить пациента принудительно, без его согласия.
· Успех кодирования в первую очередь зависит от желания пациента, соблюдения им полученных рекомендаций и эффективности работы с психологом.
· Термин «кодирование» введен в медицинскую терминологию благодаря методу избавления от зависимости под гипнозом, запатентованного в 80 годах психологом Довженко.
· Кодирование по методу Довженко основано на внушении пациенту отвращения к алкоголю, наркотикам, табаку на подсознательном уровне в состоянии гипноза.
· На постсоветском пространстве под термином кодирование подразумевают практически любой способ избавления пациента от зависимости.
Что такое кодирование
Кодирование – применяемый в наркологии термин, который подразумевает избавление пациента от любого вида зависимости.
С помощью кодирования зачастую лечат:
· Алкоголизм;
· Наркоманию;
· Табакокурение.
Оптимальный метод лечения подбирает врач – нарколог на основании состояния здоровья, стажа зависимости и индивидуальных особенностей пациента.
Какими методами выполняется кодирование
- Медикаментозными. Кодирование выполняется такими фармакологическими препаратами как Торпеда, Эспераль, Блок, Колме, Лидевин, Тетурам, Алкобарьер. Подробнее о медикаментозных методах лечения алкоголизма, применяемых препаратах, их показаниях и противопоказаниях для назначения мы уже рассказывали.
- Психотерапевтическими. К ним относится кодирование под гипнозом, терапия с психологом, лечение сопутствующих психических проблем на фоне алкоголизма, например депрессии, шизофрении, белой горячки.
- Инструментальными. Выполняются они с помощью транскраниальной стимуляции и магнитно-резонансной терапии.
Наиболее высокий положительный результат в лечении зависимости достигается благодаря комбинации вышеперечисленных методов и длительной психологической работе с пациентом.
Этапы кодирования пациента
Успешная терапия зависимости осуществляется в следующей последовательности:
· Пациент выходит из запоя и проходит очищение организма.
· Зависимому человеку индивидуально подбирается схема лечения и перечень мероприятий, для восстановления здоровья, после употребления токсичных веществ (алкоголя, наркотиков).
· Пациент проходит последующую реабилитацию в стационаре или домашних условиях. На этом этапе предусмотрена работа с психологом и освоение новых навыков трезвой жизни.
На этом этапе предусмотрена работа с психологом и освоение новых навыков трезвой жизни.
Нарушение последовательности мероприятий или игнорирование от одного из трех этапов существенно снижает вероятность длительного отказа от алкоголя или наркотиков. Одним из немаловажных условий успешного кодирования является устранение психологических проблем, которые заставили человека заглушать негативные эмоции с помощью алкоголя или наркотиков.
В случае последующего срыва пациента он быстро возвращается к прежнему образу жизни и начинает употреблять токсичные вещества в еще больших количествах. Узнайте, к чему приводит срыв после кодирования.
Причины срыва после кодирования
Не один существующий на данный момент вид лечения зависимости не дает стопроцентный результат. Факторы, которые провоцируют закодированного вернуться к прежнему образу жизни и употреблению спиртного, индивидуальны для каждого человека. Наиболее распространенные из них это:
· Изначальное отсутствие желания и достаточной мотивации для избавления от зависимости.
· Несоблюдение полученных рекомендаций или досрочное прекращение лечения.
· Отсутствие поддержки со стороны родственников и друзей.
· Стресс, горе, сильное переживание.
· Попадание в негативную среду, люди в которой также имеют зависимость или часто употребляют.
Успешное кодирование может быть произведено при условии согласия и желания самого пациента, квалифицированной помощи нарколога и психолога, поддержки близких людей.
Полезная информация
Наверняка вам будет интересно узнать:
- Характерные признаки и симптомы алкоголизма первой (начальной) и второй (хронической) стадии.
- Как проводится лечение давления с похмелья и можно ли его осуществлять самостоятельно в домашних условиях.
- Применение янтарной кислоты с похмелья, насколько эффективно это средство и от каких симптомов избавляет.
- В чем проявляется алкогольное повреждение печени, к каким последствиям приводит и насколько успешно поддается терапии.

- К каким последствиям приведет употребление алкоголя при диабете или во время беременности (внутриутробный алкоголизм).
Какие существуют способы кодировки от алкоголизма
При кодировании от алкоголизма в организм вводят специальный препарат, который погружает человека в гипнотический сон. Во время того, пока этот яд действует на организм, психиатр вызывает болевые ощущения у пациента, надавливая на глазные яблоки или солнечное сплетение. В это время в подсознании больного формируется чувство страха. Как правило, во время процедуры психиатр произносит фразы, которые устрашают человека. Он может сказать, что во время принятия алкоголя организм может перестать работать, возможна остановка сердца или мучительная, долгая смерть и многое другое. Во время действия яда, психика человека очень восприимчива, поэтому такое кодирование помогает практически всегда.
Обычно оно проходит в специальных лечебных кабинетах, где слышно звук проезжающего транспорта, голоса людей, их разговоры. После того, как яд прекращает свое действие, пациента приводят в сознание, при этом он забывает все то, что происходило с ним во время гипноза. Информация спрятана глубоко в подсознании пациента.
После того, как яд прекращает свое действие, пациента приводят в сознание, при этом он забывает все то, что происходило с ним во время гипноза. Информация спрятана глубоко в подсознании пациента.
Кодирование от алкоголизма – это последний, завершающий этап в лечении патологической зависимости.
Существует несколько способов кодирования от алкоголизма. Это и имплантация различных препаратов, например, Suspensio Esperle depo, и медикаментозное кодирование препаратами NIT, SIT и MST, и вшивание, «Торпедо», и программирование по разным методам.
Для больных, страдающих алкоголизмом, наиболее действенным способом является метод Довженко. Это процедура гипноза, которая помогает справиться организму с вредной зависимостью с помощью психотерапевта и нарколога.
Вшивание – это введение в организм больного антиалкогольных препаратов, как правило, импортных. Этот препарат зачастую вводят под лопатку или в ягодицу. После укола не остается ни шрамов, ни царапин. Метод оказывает длительное действие на организм человека, потому что в его крови постоянно поддерживается уровень вещества, которое и отторгает спиртные напитки.
«Торпедо» — метод, при котором делается укол. Не всем можно проделывать эту процедуру, сначала нужно полностью обследоваться. В организм пациента вводят вещества, которые не могут быть совместимы с алкоголем. На протяжении некоторого времени больной должен находиться под присмотром лечащего врача. Если пациент выпивает алкоголь, организм отторгает спиртное, нарушается самочувствие.
Двойной блок – кодирование, которое сочетает в себе и метод Довженко, и введение лекарственных средств под кожу человека.
Внутривенное введение таких препаратов как: MST, SIT и NIT происходит с провокацией, то есть, человеку сразу же после введения лекарственного средства дают выпить немного алкоголя. Он чувствует себя плохо и понимает, что пить больше не сможет, потому что возможно не только плохое самочувствие, но и даже остановка сердца.
по кодированию категориальных значений в Python
Введение
Во многих практических мероприятиях по науке о данных набор данных будет содержать категориальные
переменные. Эти переменные обычно хранятся в виде текстовых значений, которые представляют
различные черты характера. Некоторые примеры включают цвет («красный», «желтый», «синий»), размер («маленький», «средний», «большой»).
или географические обозначения (штат или страна). Независимо от того
для чего используется значение, проблема заключается в том, чтобы определить, как использовать эти данные в анализе.Многие алгоритмы машинного обучения могут поддерживать категориальные значения без
дальнейшие манипуляции, но есть еще много алгоритмов, которые этого не делают. Следовательно, аналитик
столкнулся с проблемой определения того, как превратить эти текстовые атрибуты в
числовые значения для дальнейшей обработки.
Эти переменные обычно хранятся в виде текстовых значений, которые представляют
различные черты характера. Некоторые примеры включают цвет («красный», «желтый», «синий»), размер («маленький», «средний», «большой»).
или географические обозначения (штат или страна). Независимо от того
для чего используется значение, проблема заключается в том, чтобы определить, как использовать эти данные в анализе.Многие алгоритмы машинного обучения могут поддерживать категориальные значения без
дальнейшие манипуляции, но есть еще много алгоритмов, которые этого не делают. Следовательно, аналитик
столкнулся с проблемой определения того, как превратить эти текстовые атрибуты в
числовые значения для дальнейшей обработки.
Как и во многих других аспектах мира Data Science, нет однозначного ответа
о том, как подойти к этой проблеме. Каждый подход имеет компромиссы и имеет потенциал
влияние на результат анализа.К счастью, инструменты pandas на Python
и scikit-learn предоставляют несколько подходов, которые можно применить для преобразования
категориальные данные в подходящие числовые значения. Эта статья будет обзором некоторых из самых распространенных (и некоторых более сложных)
подходы в надежде, что это поможет другим применить эти методы к их
проблемы реального мира.
Эта статья будет обзором некоторых из самых распространенных (и некоторых более сложных)
подходы в надежде, что это поможет другим применить эти методы к их
проблемы реального мира.
Набор данных
Для этой статьи мне удалось найти хороший набор данных в репозитории машинного обучения UCI. Этот конкретный автомобильный набор данных включает хорошее сочетание категориальных значений а также непрерывные значения и служит полезным примером, относительно Легко понять.Поскольку понимание предметной области является важным аспектом при принятии решения как кодировать различные категориальные значения — этот набор данных является хорошим примером.
Прежде чем мы начнем кодировать различные значения, нам необходимо data и сделайте небольшую очистку. К счастью, pandas делает это просто:
импортировать панд как pd
импортировать numpy как np
# Определить заголовки, так как данные не имеют
headers = ["symboling", "normalized_losses", "make", "fuel_type", "aspiration",
"num_doors", "body_style", "drive_wheels", "engine_location",
wheel_base, длина, ширина, высота, curb_weight,
"тип_двигателя", "число_цилиндров", "размер_двигателя", "топливная_система",
"диаметр цилиндра", "ход", "степень сжатия", "мощность в лошадиных силах", "пиковая_об / мин"
"city_mpg", "шоссе_mpg", "price"]
# Прочитать CSV-файл и преобразовать "?" в NaN
df = pd.read_csv ("https://archive.ics.uci.edu/ml/machine-learning-databases/autos/imports-85.data",
header = None, names = headers, na_values = "?" )
df.head ()
| обозначение | normalized_losses | марка | fuel_type | стремление | кол-во дверей | body_style | drive_wheels | engine_location | wheel_base | … | размер_двигателя | fuel_system | отверстие | ход | степень сжатия | л.с. | пик_об / мин | city_mpg | шоссе | цена | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | NaN | Альфа-Ромеро | газ | стандарт | два | кабриолет | задний | перед | 88.6 | … | 130 | mpfi | 3,47 | 2,68 | 9,0 | 111,0 | 5000,0 | 21 | 27 | 13495,0 |
| 1 | 3 | NaN | Альфа-Ромеро | газ | стандарт | два | кабриолет | задний | перед | 88,6 | … | 130 | mpfi | 3.47 | 2,68 | 9,0 | 111,0 | 5000,0 | 21 | 27 | 16500,0 |
| 2 | 1 | NaN | Альфа-Ромеро | газ | стандарт | два | хэтчбек | задний | перед | 94,5 | … | 152 | mpfi | 2,68 | 3,47 | 9,0 | 154,0 | 5000.0 | 19 | 26 | 16500,0 |
| 3 | 2 | 164,0 | audi | газ | стандарт | четыре | седан | вперед | перед | 99,8 | … | 109 | mpfi | 3,19 | 3,40 | 10,0 | 102,0 | 5500,0 | 24 | 30 | 13950,0 |
| 4 | 2 | 164.0 | audi | газ | стандарт | четыре | седан | 4wd | перед | 99,4 | … | 136 | mpfi | 3,19 | 3,40 | 8,0 | 115,0 | 5500,0 | 18 | 22 | 17450,0 |
Последняя проверка, которую мы хотим сделать, это посмотреть, какие типы данных у нас есть:
символ int64 normalized_losses float64 сделать объект объект fuel_type объект стремления объект num_doors body_style объект объект drive_wheels объект engine_location wheel_base float64 длина float64 ширина float64 высота float64 curb_weight int64 объект engine_type объект num_cylinders engine_size int64 объект fuel_system поплавок 64 ходовой поплавок64 Compression_ratio float64 мощность поплавка64 peak_rpm float64 city_mpg int64 Highway_mpg int64 цена float64 dtype: объект
Поскольку в этой статье речь идет только о кодировании категориальных переменных,
мы собираемся включить только объект столбцы в нашем фрейме данных.Панды имеют
полезно select_dtypes функция, которую мы можем использовать для создания нового фрейма данных
содержащий только столбцы объекта.
obj_df = df.select_dtypes (include = ['объект']). Copy () obj_df.head ()
| марка | fuel_type | стремление | кол-во дверей | body_style | drive_wheels | engine_location | Тип_ двигателя | число_цилиндров | fuel_system | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Альфа-Ромеро | газ | стандарт | два | кабриолет | задний | перед | dohc | четыре | mpfi |
| 1 | Альфа-Ромеро | газ | стандарт | два | кабриолет | задний | перед | dohc | четыре | mpfi |
| 2 | Альфа-Ромеро | газ | стандарт | два | хэтчбек | задний | перед | ohcv | шесть | mpfi |
| 3 | audi | газ | стандарт | четыре | седан | вперед | перед | ОМН | четыре | mpfi |
| 4 | audi | газ | стандарт | четыре | седан | 4wd | перед | ОМН | пять | mpfi |
Прежде чем идти дальше, в данных есть пара нулевых значений, которые нам нужно убрать.
obj_df [obj_df.isnull (). Any (axis = 1)]
| марка | fuel_type | стремление | кол-во дверей | body_style | drive_wheels | engine_location | Тип_ двигателя | число_цилиндров | fuel_system | |
|---|---|---|---|---|---|---|---|---|---|---|
| 27 | додж | газ | с турбонаддувом | NaN | седан | вперед | перед | ОМН | четыре | mpfi |
| 63 | Mazdaдизель | стандарт | NaN | седан | вперед | перед | ОМН | четыре | иди |
Для простоты заполните значение цифрой 4 (так как это является наиболее частым значением):
obj_df ["num_doors"].value_counts ()
четыре 114 два 89 Имя: num_doors, dtype: int64
obj_df = obj_df.fillna ({"num_doors": "четыре"})
Теперь, когда данные не имеют нулевых значений, мы можем рассмотреть варианты для кодирования категориальных значений.
Подход № 1 — Найти и заменить
Прежде чем мы перейдем к более «стандартным» подходам к кодированию категориальных data, этот набор данных подчеркивает один потенциальный подход, который я называю «найти и заменить».
Есть два столбца данных, где значения представляют собой слова, используемые для представления
числа.В частности, количество цилиндров в двигателе и количество дверей в машине.
Pandas позволяет нам напрямую заменять текстовые значения их
числовой эквивалент с использованием заменить .
Мы уже видели, что данные num_doors включают только 2 или 4 двери. В количество цилиндров включает всего 7 значений, и они легко переводятся в действительные номера:
obj_df ["число_цилиндров"]. Value_counts ()
четыре 159 шесть 24 пять 11 восемь 5 два 4 двенадцать 1 три 1 Имя: num_cylinders, dtype: int64
Если вы просмотрите заменить документации, вы можете видеть, что это мощный
команда с множеством опций.Для наших целей мы собираемся создать
словарь сопоставления, содержащий каждый столбец для обработки, а также словарь
значений для перевода.
Вот полный словарь для очистки num_doors и num_cylinders столбцы:
cleanup_nums = {"num_doors": {"четыре": 4, "два": 2},
"num_cylinders": {"четыре": 4, "шесть": 6, "пять": 5, "восемь": 8,
«два»: 2, «двенадцать»: 12, «три»: 3}}
Для преобразования столбцов в числа с помощью заменить :
obj_df = obj_df.заменить (cleanup_nums) obj_df.head ()
| марка | fuel_type | стремление | кол-во дверей | body_style | drive_wheels | engine_location | Тип_ двигателя | число_цилиндров | fuel_system | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Альфа-Ромеро | газ | стандарт | 2 | кабриолет | задний | перед | dohc | 4 | mpfi |
| 1 | Альфа-Ромеро | газ | стандарт | 2 | кабриолет | задний | перед | dohc | 4 | mpfi |
| 2 | Альфа-Ромеро | газ | стандарт | 2 | хэтчбек | задний | перед | ohcv | 6 | mpfi |
| 3 | audi | газ | стандарт | 4 | седан | вперед | перед | ОМН | 4 | mpfi |
| 4 | audi | газ | стандарт | 4 | седан | 4wd | перед | ОМН | 5 | mpfi |
Приятным преимуществом этого подхода является то, что pandas «знает» типы значений в
столбцы так объект сейчас int64
сделать объект объект fuel_type объект стремления num_doors int64 body_style объект объект drive_wheels объект engine_location объект engine_type num_cylinders int64 объект fuel_system dtype: объект
Хотя этот подход может работать только в определенных сценариях, это очень полезная демонстрация. о том, как преобразовать текстовые значения в числовые, когда есть «легкая» человеческая интерпретация данные.Эта концепция также полезна для более общей очистки данных.
Подход № 2 — Кодирование метки
Другой подход к кодированию категориальных значений заключается в использовании метода, называемого кодированием меток.
Кодирование метки — это просто преобразование каждого значения в столбце в число. Например, body_style столбец содержит 5 различных значений. Мы могли бы выбрать кодирование
это так:
- кабриолет -> 0
- жесткая крыша -> 1
- хэтчбек -> 2
- седан -> 3
- вагон -> 4
Этот процесс напоминает мне о том, как Ральфи использовал свое секретное кольцо-декодер в «Рождественской истории»
В пандах можно использовать один трюк: преобразовать столбец в категорию, а затем используйте эти значения категорий для кодировки метки:
obj_df ["body_style"] = obj_df ["body_style"].astype ('категория')
obj_df.dtypes
сделать объект объект fuel_type объект стремления num_doors int64 категория body_style объект drive_wheels объект engine_location объект engine_type num_cylinders int64 объект fuel_system dtype: объект
Затем вы можете назначить закодированную переменную новому столбцу, используя cat.codes аксессуар:
obj_df ["body_style_cat"] = obj_df ["body_style"].cat.codes obj_df.head ()
| марка | fuel_type | стремление | кол-во дверей | body_style | drive_wheels | engine_location | Тип_ двигателя | число_цилиндров | fuel_system | body_style_cat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Альфа-Ромеро | газ | стандарт | 2 | кабриолет | задний | перед | dohc | 4 | mpfi | 0 |
| 1 | Альфа-Ромеро | газ | стандарт | 2 | кабриолет | задний | перед | dohc | 4 | mpfi | 0 |
| 2 | Альфа-Ромеро | газ | стандарт | 2 | хэтчбек | задний | перед | ohcv | 6 | mpfi | 2 |
| 3 | audi | газ | стандарт | 4 | седан | вперед | перед | ОМН | 4 | mpfi | 3 |
| 4 | audi | газ | стандарт | 4 | седан | 4wd | перед | ОМН | 5 | mpfi | 3 |
Приятным аспектом этого подхода является то, что вы получаете преимущества категорий панд (компактный размер данных, возможность заказа, поддержка построения графиков), но может быть легко преобразован в числовые значения для дальнейшего анализа.
Подход № 3 — Одно горячее кодирование
Кодирование метокимеет то преимущество, что оно простое, но имеет недостаток. что числовые значения могут быть «неверно истолкованы» алгоритмами. Например, значение 0, очевидно, меньше значения 4, но действительно ли это соответствует набор данных в реальной жизни? Вес вагона в 4 раза больше в наших расчетах чем кабриолет? В этом примере я так не думаю.
Общий альтернативный подход называется одним горячим кодированием (но также используется несколько разные названия показаны ниже).Несмотря на разные названия, основная стратегия для преобразования каждого значения категории в новый столбец и присвоения 1 или 0 (Истина / Ложь) значение в столбец. Это дает то преимущество, что значение не взвешивается неправильно, но имеет обратную сторону добавления дополнительных столбцов в набор данных.
Pandas поддерживает эту функцию с помощью get_dummies. Эта функция называется таким образом, потому что он создает фиктивные / индикаторные переменные (также известные как 1 или 0).
Надеюсь, простой пример прояснит это.Мы можем посмотреть на столбец drive_wheels где у нас есть значения 4wd , fwd или RWD .
Используя get_dummies мы можем преобразовать это в три столбца с 1 или 0, соответствующими
к правильному значению:
pd.get_dummies (obj_df, columns = ["drive_wheels"]). Head ()
| марка | fuel_type | стремление | кол-во дверей | body_style | engine_location | Тип_ двигателя | число_цилиндров | fuel_system | body_style_cat | drive_wheels_4wd | drive_wheels_fwd | drive_wheels_rwd | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Альфа-Ромеро | газ | стандарт | 2 | кабриолет | перед | dohc | 4 | mpfi | 0 | 0.0 | 0,0 | 1,0 |
| 1 | Альфа-Ромеро | газ | стандарт | 2 | кабриолет | перед | dohc | 4 | mpfi | 0 | 0,0 | 0,0 | 1,0 |
| 2 | Альфа-Ромеро | газ | стандарт | 2 | хэтчбек | перед | ohcv | 6 | mpfi | 2 | 0.0 | 0,0 | 1,0 |
| 3 | audi | газ | стандарт | 4 | седан | перед | ОМН | 4 | mpfi | 3 | 0,0 | 1,0 | 0,0 |
| 4 | audi | газ | стандарт | 4 | седан | перед | ОМН | 5 | mpfi | 3 | 1.0 | 0,0 | 0,0 |
Новый набор данных содержит три новых столбца:
-
drive_wheels_4wd -
drive_wheels_rwd -
drive_wheels_fwd
Эта функция очень эффективна, потому что вы можете передать столько столбцов категорий, сколько захотите.
и выберите способ разметки столбцов с помощью префикс . Правильное именование сделает
остальной анализ просто немного проще.
pd.get_dummies (obj_df, columns = ["body_style", "drive_wheels"], prefix = ["body", "drive"]). Head ()
| марка | fuel_type | стремление | кол-во дверей | engine_location | Тип_ двигателя | число_цилиндров | fuel_system | body_style_cat | кузов с трансмиссией | body_hardtop | кузов_хэтчбек | body_sedan | body_wagon | drive_4wd | drive_fwd | drive_rwd | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Альфа-Ромеро | газ | стандарт | 2 | перед | dohc | 4 | mpfi | 0 | 1.0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 1,0 |
| 1 | Альфа-Ромеро | газ | стандарт | 2 | перед | dohc | 4 | mpfi | 0 | 1,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 1,0 |
| 2 | Альфа-Ромеро | газ | стандарт | 2 | перед | ohcv | 6 | mpfi | 2 | 0.0 | 0,0 | 1,0 | 0,0 | 0,0 | 0,0 | 0,0 | 1,0 |
| 3 | audi | газ | стандарт | 4 | перед | ОМН | 4 | mpfi | 3 | 0,0 | 0,0 | 0,0 | 1,0 | 0,0 | 0,0 | 1,0 | 0,0 |
| 4 | audi | газ | стандарт | 4 | перед | ОМН | 5 | mpfi | 3 | 0.0 | 0,0 | 0,0 | 1,0 | 0,0 | 1,0 | 0,0 | 0,0 |
Еще одна концепция, о которой следует помнить, — это get_dummies возвращает полный фрейм данных
поэтому вам нужно будет отфильтровать объекты с помощью select_dtypes когда ты
готовы сделать окончательный анализ.
Одна горячая кодировка очень полезна, но может привести к увеличению количества столбцов очень важно, если в столбце очень много уникальных значений.По количеству значений в этом примере это не проблема. Однако вы можете видеть, как это получается на самом деле сложно управлять, когда у вас гораздо больше возможностей.
Подход № 4 — Пользовательское двоичное кодирование
В зависимости от набора данных вы можете использовать некоторую комбинацию кодирования этикеток. и одно горячее кодирование для создания двоичного столбца, отвечающего вашим потребностям для дальнейшего анализа.
В этом конкретном наборе данных есть столбец с именем engine_type который содержит
несколько разных значений:
obj_df ["тип_двигателя"].value_counts ()
ohc 148 ohcf 15 ohcv 13 l 12 dohc 12 ротор 4 dohcv 1 Имя: engine_type, dtype: int64
Ради обсуждения, возможно, все, что нас волнует, — это двигатель или нет
является верхний кулачок (OHC) или нет. Другими словами, все версии OHC одинаковы.
для этого анализа. Если это так, то мы могли бы использовать ул. аксессуар
плюс нп, где чтобы создать новый столбец, указывает,
имеет двигатель OHC.
obj_df ["OHC_Code"] = np.where (obj_df ["engine_type"]. Str.contains ("ohc"), 1, 0)
Я считаю, что это удобная функция, которую я использую довольно часто, но иногда забываю о синтаксисе вот график, показывающий, что мы делаем:
Результирующий фрейм данных выглядит следующим образом (показывает только подмножество столбцов):
obj_df [["make", "engine_type", "OHC_Code"]]. Head ()
| марка | Тип_ двигателя | OHC_Code | |
|---|---|---|---|
| 0 | Альфа-Ромеро | dohc | 1 |
| 1 | Альфа-Ромеро | dohc | 1 |
| 2 | Альфа-Ромеро | ohcv | 1 |
| 3 | audi | ОМН | 1 |
| 4 | audi | ОМН | 1 |
Этот подход может быть действительно полезен, если есть возможность консолидироваться в простое значение Y / N в столбце.Это также подчеркивает важность домена знание предназначено для решения проблемы наиболее эффективным способом.
Scikit-Learn
обновления scikit-learn
В предыдущей версии этой статьи использовалось LabelEncoder и LabelBinarizer которые не рекомендуются для кодирования категориальных значений. Эти кодировщики
следует использовать только для кодирования целевых значений, а не значений характеристик.
В примерах ниже используется OrdinalEncoder и OneHotEncoder какой
правильный подход к использованию для кодирования целевых значений.
В дополнение к подходу pandas, scikit-learn предоставляет аналогичную функциональность. Лично я считаю, что использование pandas немного проще для понимания, но подход scikit оптимально, когда вы пытаетесь построить прогнозную модель.
Например, если мы хотим сделать эквивалентную кодировке этикетки на марке автомобиля, нам нужно
для создания экземпляра OrdinalEncoder объект и fit_transform данные:
из sklearn.preprocessing import OrdinalEncoder ord_enc = OrdinalEncoder () obj_df ["make_code"] = ord_enc.fit_transform (obj_df [["make"]]) obj_df [["make", "make_code"]]. head (11)
| марка | make_code | |
|---|---|---|
| 0 | Альфа-Ромеро | 0 |
| 1 | Альфа-Ромеро | 0 |
| 2 | Альфа-Ромеро | 0 |
| 3 | audi | 1 |
| 4 | audi | 1 |
| 5 | audi | 1 |
| 6 | audi | 1 |
| 7 | audi | 1 |
| 8 | audi | 1 |
| 9 | audi | 1 |
| 10 | bmw | 2 |
Scikit-learn также поддерживает двоичное кодирование с помощью OneHotEncoder. Мы используем тот же процесс, что и выше, для преобразования данных, но процесс создания
DataFrame pandas добавляет пару дополнительных шагов.
из sklearn.preprocessing import OneHotEncoder oe_style = OneHotEncoder () oe_results = oe_style.fit_transform (obj_df [["body_style"]]) pd.DataFrame (oe_results.toarray (), columns = lb_style.categories _). head ()
| кабриолет | жесткая крыша | хэтчбек | седан | универсал | |
|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 | 0 |
| 3 | 0 | 0 | 0 | 1 | 0 |
| 4 | 0 | 0 | 0 | 1 | 0 |
Следующим шагом будет присоединение этих данных обратно к исходному фрейму данных.Вот пример:
obj_df = obj_df.join (pd.DataFrame (oe_results.toarray (), columns = oe_style.categories_))
Ключевым моментом является то, что вам нужно использовать toarray () преобразовать результаты в формат
которые можно преобразовать в DataFrame.
Продвинутые подходы
Есть еще более продвинутые алгоритмы категориального кодирования. у меня нет много личного опыта с ними, но в завершение этого руководства я хотел включить их.В этой статье представлены некоторые дополнительные технические задний план. Еще один приятный момент заключается в том, что автор статьи создал пакет contrib scikit-learn под названием category_encoders, который реализует многие из этих подходов. Это очень хороший инструмент для достижения этой цели. проблема с другой точки зрения.
Вот краткое введение в использование библиотеки для некоторых других типов кодирования. В первом примере мы попробуем выполнить кодирование обратной разницы.
Сначала мы получаем чистый фрейм данных и настраиваем BackwardDifferenceEncoder :
import category_encoders as ce # Получить новый чистый фрейм данных obj_df = df.select_dtypes (include = ['объект']). copy () # Укажите столбцы для кодирования, затем поместите и трансформируйте encoder = ce.BackwardDifferenceEncoder (cols = ["engine_type"]) encoder.fit_transform (obj_df, verbose = 1) .iloc [:, 8:14] .head ()
| engine_type_0 | engine_type_1 | Тип_двигателя_2 | тип_двигателя_3 | тип_двигателя_4 | engine_type_5 | |
|---|---|---|---|---|---|---|
| 0 | -0,857143 | -0.714286 | -0,571429 | -0,428571 | -0,285714 | -0,142857 |
| 1 | -0,857143 | -0,714286 | -0,571429 | -0,428571 | -0,285714 | -0,142857 |
| 2 | 0,142857 | -0,714286 | -0,571429 | -0,428571 | -0,285714 | -0,142857 |
| 3 | 0,142857 | 0.285714 | -0,571429 | -0,428571 | -0,285714 | -0,142857 |
| 4 | 0,142857 | 0,285714 | -0,571429 | -0,428571 | -0,285714 | -0,142857 |
Интересно то, что видно, что результат не стандартный 1 и 0 мы видели в предыдущих примерах кодирования.
Если мы попробуем полиномиальное кодирование, мы получим другое распределение используемых значений для кодирования столбцов:
Кодировщик= ce.PolynomialEncoder (cols = ["engine_type"]) encoder.fit_transform (obj_df, verbose = 1) .iloc [:, 8:14] .head ()
| engine_type_0 | engine_type_1 | Тип_двигателя_2 | тип_двигателя_3 | тип_двигателя_4 | engine_type_5 | |
|---|---|---|---|---|---|---|
| 0 | -0,566947 | 0,545545 | -0,408248 | 0,241747 | -0,109109 | 0,032898 |
| 1 | -0.566947 | 0,545545 | -0,408248 | 0,241747 | -0,109109 | 0,032898 |
| 2 | -0,377964 | 0,000000 | 0,408248 | -0,564076 | 0,436436 | -0,197386 |
| 3 | -0,188982 | -0,327327 | 0,408248 | 0,080582 | -0,545545 | 0,4 |
| 4 | -0.188982 | -0,327327 | 0,408248 | 0,080582 | -0,545545 | 0,4 |
В этот пакет включено несколько различных алгоритмов и лучший способ учиться — это попробовать их и посмотреть, поможет ли это вам с точностью вашего анализ. Приведенный выше код должен помочь вам в том, как подключить другие подходы и посмотрите, какие результаты вы получите.
конвейеров scikit-learn
Использование трубопроводов
Этот раздел был добавлен в ноябре 2020 года.Цель — показать, как интегрировать Функции кодирования функций scikit-learn в простой конвейер построения модели.
Как упоминалось выше, категориальные кодировщики scikit-learn позволяют включать преобразование в ваши конвейеры, что может упростить процесс построения модели и избежать некоторых ошибок. Я рекомендую это видео Data School в качестве хорошего вступления. Это также служит основой для подхода изложены ниже.
Вот очень быстрый пример того, как подключить OneHotEncoder и OrdinalEncoder в трубопровод и используйте cross_val_score для анализа результатов:
из sklearn.составить импорт make_column_transformer
из sklearn.linear_model import LinearRegression
из sklearn.pipeline import make_pipeline
из sklearn.model_selection импорт cross_val_score
# для целей этого анализа используйте только небольшой набор функций
feature_cols = [
'fuel_type', 'make', 'aspiration', 'route_mpg', 'city_mpg',
'curb_weight', 'drive_wheels'
]
# Удаляем пустые строки с ценами
df_ml = df.dropna (subset = ['цена'])
X = df_ml [feature_cols]
y = df_ml ['цена']
Теперь, когда у нас есть данные, давайте построим преобразователь столбцов:
column_trans = make_column_transformer ((OneHotEncoder (handle_unknown = 'ignore'),
['fuel_type', 'make', 'drive_wheels']),
(OrdinalEncoder (), ['стремление']),
остаток = 'сквозной')
В этом примере показано, как применять разные типы кодировщиков для определенных столбцов.Используя остаток = 'сквозной' аргумент для передачи всех числовых значений через конвейер
без изменений.
Для модели мы используем простую линейную регрессию, а затем строим конвейер:
linreg = Линейная регрессия () pipe = make_pipeline (column_trans, linreg)
Выполните перекрестную проверку 10 раз, используя отрицательную среднюю абсолютную ошибку в качестве нашей оценки. функция. Наконец, возьмите среднее из 10 значений, чтобы увидеть величину ошибки:
cross_val_score (pipe, X, y, cv = 10, scoring = 'neg_mean_absolute_error').среднее (). круглый (2)
, что дает значение -2937,17.
Очевидно, что здесь можно провести гораздо больший анализ, но он предназначен для иллюстрации как использовать функции scikit-learn в более реалистичном конвейере анализа.
Заключение
Кодирование категориальных переменных — важный шаг в процессе анализа данных. Поскольку существует несколько подходов к кодированию переменных, важно понять различные варианты и способы их реализации на собственных наборах данных.В экосистеме науки о данных Python есть много полезных подходов к решению этих проблем. Я призываю вас помнить об этих идеях в следующий раз, когда вы обнаружите, что анализируете категориальные переменные. Чтобы узнать больше о коде в этой статье, не стесняйтесь просмотреть ноутбук.
Изменения
- 28 ноября 2020 г .: исправлены неработающие ссылки и обновлен раздел scikit-learn. Включенный пример трубопровода. Незначительные изменения кода для согласованности.
Ссылка на кодировку URL-адресов HTML
URL — унифицированный указатель ресурсов
Веб-браузеры запрашивают страницы с веб-серверов, используя URL-адрес.
URL-адрес — это адрес веб-страницы, например: https://www.w3schools.com.
Кодировка URL (процентное кодирование)
КодировкаURL преобразует символы в формат, который можно передавать через Интернет.
URL-адресов можно отправить только через Интернет с помощью Набор символов ASCII.
Поскольку URL-адреса часто содержат символы вне набора ASCII, URL-адрес должен быть преобразован в допустимый формат ASCII.
Кодировка URL заменяет небезопасные символы ASCII на «%», за которым следуют два
шестнадцатеричные цифры.
URL-адреса не могут содержать пробелов. Кодировка URL-адреса обычно заменяет пробел на знак плюс (+) или% 20.
Попробуйте сами
Если вы нажмете кнопку «Отправить» ниже, браузер закодирует вводимые данные. перед отправкой на сервер. Страница на сервере отобразит полученные ввод.
Попробуйте ввести другие данные и снова нажмите «Отправить».
Функции кодирования URL
В JavaScript, PHP и ASP есть функции, которые можно использовать для URL закодировать строку.
PHP имеет функцию rawurlencode (), а ASP — функцию Server.URLEncode ().
В JavaScript вы можете использовать функцию encodeURIComponent () .
Нажмите кнопку «Кодировать URL», чтобы увидеть, как функция JavaScript кодирует текст.
Примечание: Функция JavaScript кодирует пробел как% 20.
Ссылка на кодировку ASCII
Ваш браузер будет кодировать ввод в соответствии с набор символов, используемый на вашей странице.
Набор символов по умолчанию в HTML5 — UTF-8.
| Персонаж | из Windows-1252 | из UTF-8 |
|---|---|---|
| место | % 20 | % 20 |
| ! | % 21 | % 21 |
| « | % 22 | % 22 |
| # | % 23 | % 23 |
| $ | % 24 | % 24 |
| % | % 25 | % 25 |
| и | % 26 | % 26 |
| ‘ | % 27 | % 27 |
| ( | % 28 | % 28 |
| ) | % 29 | % 29 |
| * | % 2A | % 2A |
| + | % 2B | % 2B |
| , | % 2C | % 2C |
| – | % 2D | % 2D |
| . | % 2Э | % 2Э |
| / | % 2Ф | % 2Ф |
| 0 | % 30 | % 30 |
| 1 | % 31 | % 31 |
| 2 | % 32 | % 32 |
| 3 | % 33 | % 33 |
| 4 | % 34 | % 34 |
| 5 | % 35 | % 35 |
| 6 | % 36 | % 36 |
| 7 | % 37 | % 37 |
| 8 | % 38 | % 38 |
| 9 | % 39 | % 39 |
| : | % 3A | % 3A |
| ; | % 3B | % 3B |
| < | % 3C | % 3C |
| = | % 3D | % 3D |
| > | % 3Э | % 3Э |
| ? | % 3F | % 3F |
| @ | % 40 | % 40 |
| А | % 41 | % 41 |
| B | % 42 | % 42 |
| С | % 43 | % 43 |
| D | % 44 | % 44 |
| E | % 45 | % 45 |
| F | % 46 | % 46 |
| G | % 47 | % 47 |
| H | % 48 | % 48 |
| I | % 49 | % 49 |
| Дж | % 4A | % 4A |
| К | % 4B | % 4B |
| л | % 4C | % 4C |
| M | % 4D | % 4D |
| № | % 4Э | % 4Э |
| O | % 4F | % 4F |
| п. | % 50 | % 50 |
| Q | % 51 | % 51 |
| R | % 52 | % 52 |
| S | % 53 | % 53 |
| т | % 54 | % 54 |
| U | % 55 | % 55 |
| В | % 56 | % 56 |
| Вт | % 57 | % 57 |
| х | % 58 | % 58 |
| Y | % 59 | % 59 |
| Z | % 5A | % 5A |
| [ | % 5B | % 5B |
| \ | % 5C | % 5C |
| ] | % 5D | % 5D |
| ^ | % 5E | % 5E |
| _ | % 5F | % 5F |
| ` | % 60 | % 60 |
| а | % 61 | % 61 |
| б | % 62 | % 62 |
| с | % 63 | % 63 |
| г | % 64 | % 64 |
| e | % 65 | % 65 |
| f | % 66 | % 66 |
| г | % 67 | % 67 |
| ч | % 68 | % 68 |
| я | % 69 | % 69 |
| j | % 6A | % 6A |
| к | % 6Б | % 6Б |
| л | % 6C | % 6C |
| м | % 6D | % 6D |
| n | % 6Э | % 6Э |
| или | % 6F | % 6F |
| п. | % 70 | % 70 |
| q | % 71 | % 71 |
| r | % 72 | % 72 |
| с | % 73 | % 73 |
| т | % 74 | % 74 |
| u | % 75 | % 75 |
| в | % 76 | % 76 |
| Вт | % 77 | % 77 |
| х | % 78 | % 78 |
| y | % 79 | % 79 |
| z | % 7A | % 7A |
| { | % 7B | % 7B |
| | | % 7C | % 7C |
| } | % 7D | % 7D |
| ~ | % 7Э | % 7Э |
| % 7F | % 7F | |
| ` | % 80 | % E2% 82% AC |
| % 81 | % 81 | |
| ‚ | % 82 | % E2% 80% 9A |
| ƒ | % 83 | % C6% 92 |
| „ | % 84 | % E2% 80% 9E |
| … | % 85 | % E2% 80% A6 |
| † | % 86 | % E2% 80% A0 |
| ‡ | % 87 | % E2% 80% A1 |
| ˆ | % 88 | % CB% 86 |
| ‰ | % 89 | % E2% 80% B0 |
| Š | % 8A | % C5% A0 |
| ‹ | % 8B | % E2% 80% B9 |
| Π| % 8C | % C5% 92 |
| % 8D | % C5% 8D | |
| Ž | % 8E | % C5% BD |
| % 8F | % 8F | |
| % 90 | % C2% 90 | |
| ‘ | % 91 | % E2% 80% 98 |
| ’ | % 92 | % E2% 80% 99 |
| “ | % 93 | % E2% 80% 9C |
| ” | % 94 | % E2% 80% 9D |
| • | % 95 | % E2% 80% A2 |
| – | % 96 | % E2% 80% 93 |
| – | % 97 | % E2% 80% 94 |
| ˜ | % 98 | % CB% 9C |
| ™ | % 99 | % E2% 84 |
| š | % 9A | % C5% A1 |
| › | % 9В | % E2% 80 |
| œ | % 9C | % C5% 93 |
| % 9D | % 9D | |
| × | % 9Э | % C5% BE |
| Ÿ | % 9F | % C5% B8 |
| % A0 | % C2% A0 | |
| ¡ | % A1 | % C2% A1 |
| ¢ | % A2 | % C2% A2 |
| £ | % A3 | % C2% A3 |
| ¤ | % A4 | % C2% A4 |
| ¥ | % A5 | % C2% A5 |
| ¦ | % A6 | % C2% A6 |
| § | % A7 | % C2% A7 |
| ¨ | % A8 | % C2% A8 |
| © | % A9 | % C2% A9 |
| ª | % AA | % C2% AA |
| « | % AB | % C2% AB |
| ¬ | % AC | % C2% AC |
| % нашей эры | % C2% AD | |
| ® | % AE | % C2% AE |
| ¯ | % AF | % C2% AF |
| ° | % B0 | % C2% B0 |
| ± | % B1 | % C2% B1 |
| ² | % B2 | % C2% B2 |
| ³ | % B3 | % C2% B3 |
| ´ | % B4 | % C2% B4 |
| мкм | % B5 | % C2% B5 |
| ¶ | % B6 | % C2% B6 |
| · | % B7 | % C2% B7 |
| ¸ | % B8 | % C2% B8 |
| ¹ | % B9 | % C2% B9 |
| º | % BA | % C2% BA |
| » | % BB | % C2% BB |
| ¼ | % BC | % C2% BC |
| ½ | % BD | % C2% BD |
| ¾ | % БЫТЬ | % C2% BE |
| ¿ | % BF | % C2% BF |
| À | % C0 | % C3% 80 |
| Á | % C1 | % C3% 81 |
| Â | % C2 | % C3% 82 |
| Ã | % C3 | % C3% 83 |
| Ä | % C4 | % C3% 84 |
| Å | % C5 | % C3% 85 |
| Æ | % C6 | % C3% 86 |
| Ç | % C7 | % C3% 87 |
| È | % C8 | % C3% 88 |
| É | % C9 | % C3% 89 |
| Ê | % CA | % C3% 8A |
| Ë | % CB | % C3% 8B |
| Ì | % CC | % C3% 8C |
| Í | % CD | % C3% 8D |
| Î | % CE | % C3% 8E |
| Ï | % CF | % C3% 8F |
| ì | % D0 | % C3% 90 |
| Ñ | % D1 | % C3% 91 |
| Ò | % D2 | % C3% 92 |
| Ó | % D3 | % C3% 93 |
| Ô | % D4 | % C3% 94 |
| Õ | % D5 | % C3% 95 |
| Ö | % D6 | % C3% 96 |
| × | % D7 | % C3% 97 |
| Ø | % D8 | % C3% 98 |
| Ù | % D9 | % C3% 99 |
| Ú | % DA | % C3% 9A |
| Û | % DB | % C3% 9B |
| Ü | % ПВ | % C3% 9C |
| Ý | % DD | % C3% 9D |
| Þ | % DE | % C3% 9E |
| ß | % DF | % C3% 9F |
| à | % E0 | % C3% A0 |
| á | % E1 | % C3% A1 |
| â | % E2 | % C3% A2 |
| ã | % E3 | % C3% A3 |
| ä | % E4 | % C3% A4 |
| å | % E5 | % C3% A5 |
| æ | % E6 | % C3% A6 |
| ç | % E7 | % C3% A7 |
| и | % E8 | % C3% A8 |
| é | % E9 | % C3% A9 |
| ê | % EA | % C3% AA |
| ë | % EB | % C3% AB |
| мм | % EC | % C3% AC |
| до | % ПВ | % C3% AD |
| до | % EE | % C3% AE |
| • | % EF | % C3% AF |
| ð | % F0 | % C3% B0 |
| ñ | % F1 | % C3% B1 |
| шт | % F2 | % C3% B2 |
| — | % F3 | % C3% B3 |
| ô | % F4 | % C3% B4 |
| х | % F5 | % C3% B5 |
| ö | % F6 | % C3% B6 |
| ÷ | % F7 | % C3% B7 |
| ø | % F8 | % C3% B8 |
| ù | % F9 | % C3% B9 |
| ú | % FA | % C3% BA |
| û | % FB | % C3% BB |
| ü | % FC | % C3% BC |
| ý | % FD | % C3% BD |
| þ | % FE | % C3% BE |
| ÿ | % FF | % C3% BF |
Ссылка на кодирование URL-адресов
Управляющие символы ASCII % 00-% 1F изначально были разработаны для аппаратные устройства управления.
Управляющим символам нечего делать внутри URL.
| Символ ASCII | Описание | URL-кодировка |
|---|---|---|
| NUL | нулевой символ | % 00 |
| SOH | начало заголовка | % 01 |
| STX | начало текста | % 02 |
| ETX | конец текста | % 03 |
| EOT | конец передачи | % 04 |
| ENQ | запрос | % 05 |
| ACK | подтвердить | % 06 |
| БЕЛ | звонок (кольцо) | % 07 |
| BS | backspace | % 08 |
| HT | горизонтальный язычок | % 09 |
| LF | перевод строки | % 0A |
| VT | вертикальный язычок | % 0B |
| FF | подача формы | % 0C |
| CR | возврат каретки | % 0D |
| SO | сдвинуть | % 0E |
| SI | смена | % 0Ф |
| DLE | выход канала передачи данных | % 10 |
| DC1 | Устройство управления 1 | % 11 |
| DC2 | Устройство управления 2 | % 12 |
| DC3 | Устройство управления 3 | % 13 |
| DC4 | Устройство управления 4 | % 14 |
| НАК | отрицательное подтверждение | % 15 |
| SYN | синхронизировать | % 16 |
| ETB | блок передачи конца | % 17 |
| CAN | отменить | % 18 |
| EM | конец среднего | % 19 |
| ПОД | заменить | % 1A |
| ESC | побег | % 1B |
| ФС | разделитель файлов | % 1С |
| GS | разделитель групп | % 1D |
| RS | разделитель записей | % 1Э |
| США | блок сепаратора | % 1Ф |
| ISO-10646-UCS-4 | ISO 10646 | Универсальный набор символов с 31-битным кодовым пространством, стандартизованный как UCS-4 по ISO / IEC 10646.Он синхронизируется с последней версией Карта кодов Unicode. | Если это имя используется в средстве преобразования кодировки, конвертер пытается идентифицировать предыдущую спецификацию (метка порядка байтов), в котором следуют последующие байты представлены. |
| ISO-10646-UCS-4 | UCS-4 | См. Выше. | В отличие от UCS-4 , строки всегда предполагаются
быть в форме с прямым порядком байтов. |
| ISO-10646-UCS-4 | UCS-4 | См. Выше. | В отличие от UCS-4 , строки всегда предполагаются
быть в форме с прямым порядком байтов. |
| ISO-10646-UCS-2 | UCS-2 | Универсальный набор символов с 16-битным кодовым пространством, стандартизованный как UCS-2 по ISO / IEC 10646. Он синхронизируется с последней версией карта кодов юникода. | Если это имя используется в средстве преобразования кодировки, конвертер пытается идентифицировать предыдущую спецификацию (метка порядка байтов), в котором следуют последующие байты представлены. |
| ISO-10646-UCS-2 | UCS-2 | См. Выше. | В отличие от UCS-2 , строки всегда предполагаются
быть в форме с прямым порядком байтов. |
| ISO-10646-UCS-2 | UCS-2 | См. Выше. | В отличие от UCS-2 , строки всегда предполагаются
быть в форме с прямым порядком байтов. |
| UTF-32 | Юникод | Формат преобразования Unicode с шириной 32-битного блока, пространство кодирования которого относится к стандарту кодового набора Unicode. Эта схема кодирования не была идентичен UCS-4, потому что кодовое пространство Unicode было ограничено 21-битное значение. | Если это имя используется в средстве преобразования кодировки, конвертер пытается идентифицировать предыдущую спецификацию (метка порядка байтов), в котором следуют последующие байты представлены. |
| UTF-32BE | Юникод | См. Выше | В отличие от UTF-32 , строки всегда предполагаются
быть в форме с прямым порядком байтов. |
| UTF-32LE | Юникод | См. Выше | В отличие от UTF-32 , строки всегда предполагаются
быть в форме с прямым порядком байтов. |
| UTF-16 | Юникод | Формат преобразования Unicode шириной 16 бит.Стоит отметить что UTF-16 больше не соответствует спецификации UCS-2, потому что суррогатный механизм был введен с Unicode 2.0 и UTF-16 теперь относится к 21-битному пространству кода. | Если это имя используется в средстве преобразования кодировки, конвертер пытается идентифицировать предыдущую спецификацию (метка порядка байтов), в котором следуют последующие байты представлены. |
| UTF-16BE | Юникод | См. Выше. | В отличие от UTF-16 , строки всегда предполагаются
быть в форме с прямым порядком байтов. |
| UTF-16LE | Юникод | См. Выше. | В отличие от UTF-16 , строки всегда предполагаются
быть в форме с прямым порядком байтов. |
| UTF-8 | Юникод / UCS | Формат преобразования Unicode шириной 8 бит. | нет |
| UTF-7 | Юникод | Безопасный для почты формат преобразования Unicode, указанный в »RFC2152. | нет |
| (нет) | Юникод | Вариант UTF-7, который предназначен для использования в »Протокол IMAP. | нет |
| US-ASCII (предпочтительное имя MIME) / iso-ir-6 / ANSI_X3.4-1986 / ISO_646.irv: 1991 / ASCII / ISO646-US / us / IBM367 / CP367 / csASCII | ASCII / ISO 646 | Американский стандартный код для обмена информацией — широко используемый 7-битное кодирование. Также стандартизирован как международный стандарт ISO 646. | (нет) |
| EUC-JP (предпочтительное имя MIME) / Extended_UNIX_Code_Packed_Format_for_Japanese / csEUCPkdFmtЯпонский | Соединение US-ASCII / JIS X0201: 1997 (часть ханкаку кана) / JIS X0208: 1990 / JIS X0212: 1990 | Как видите, название происходит от аббревиатуры Extended UNIX Code. Упакованный формат для японского языка, эта кодировка в основном используется в UNIX или похожие платформы.Исходная схема кодирования, расширенный код UNIX, разработан на основе ISO 2022. | Набор символов, на который ссылается EUC-JP, отличается от IBM932 / CP932, которые используются OS / 2® и Microsoft® Windows®. Для обмена информацией с этими платформами используйте вместо этого EUCJP-WIN. |
| Shift_JIS (предпочтительное имя MIME) / MS_Kanji / csShift_JIS | Соединение JIS X0201: 1997 / JIS X0208: 1997 | Shift_JIS был разработан в начале 80-х, в то время личное японское слово процессоров были выведены на рынок, чтобы поддерживать совместимость с устаревшей схемой кодирования JIS X 0201: 1976.Согласно определению IANA кодовый набор Shift_JIS немного отличается от IBM932 / CP932. Однако имена «SJIS» / «Shift_JIS» часто ошибочно используется для обозначения этих кодовых наборов. | Для кодовой карты CP932 используйте вместо этого SJIS-WIN. |
| (нет) | Соединение JIS X0201: 1997 / JIS X0208: 1997 / Расширения IBM / Расширения NEC | Хотя эта «кодировка» использует ту же схему кодирования, что и EUC-JP, базовый набор символов отличается.То есть карта некоторых кодовых точек на символы, отличные от EUC-JP. | нет |
| Окна-31J / csWindows31J | Соединение JIS X0201: 1997 / JIS X0208: 1997 / Расширения IBM / Расширения NEC | Хотя эта «кодировка» использует ту же схему кодирования, что и Shift_JIS, базовый набор символов отличается. Это означает некоторый код указывает карту на символы, отличные от Shift_JIS. | (нет) |
| ISO-2022-JP (предпочтительное имя MIME) / csISO2022JP | US-ASCII / JIS X0201: 1976 / JIS X0208: 1978 / JIS X0208: 1983 | »RFC1468 | (нет) |
| JIS | |||
| ISO-8859-1 | |||
| ISO-8859-2 | |||
| ISO-8859-3 | |||
| ISO-8859-4 | |||
| ISO-8859-5 | |||
| ISO-8859-6 | |||
| ISO-8859-7 | |||
| ISO-8859-8 | |||
| ISO-8859-9 | |||
| ISO-8859-10 | |||
| ISO-8859-13 | |||
| ISO-8859-14 | |||
| ISO-8859-15 | |||
| ISO-8859-16 | |||
| byte2be | |||
| byte2le | |||
| байт 4be | |||
| byte4le | |||
| BASE64 | |||
| HTML-ОБЪЕКТЫ | |||
| 7 бит | |||
| 8 бит | |||
| EUC-CN | |||
| CP936 | |||
| Гц | |||
| EUC-TW | |||
| CP950 | |||
| БОЛЬШОЙ-5 | |||
| EUC-KR | |||
| UHC (CP949) | |||
| ISO-2022-KR | |||
| Окна-1251 (CP1251) | |||
| Окна-1252 (CP1252) | |||
| CP866 (IBM866) | |||
| КОИ8-Р | |||
| КОИ8-У |
Инструмент кодирования / декодирования.Анализируйте проблемы и ошибки кодировки символов.
Что такое кодовая страница?
Кодовая страница — это еще одно название для кодировки символов. Он состоит из таблицы значений который описывает набор символов для определенного языка.
Что такое кодировка символов?
Кодировка символов — это процесс кодирования набора символов в соответствии с системой кодирования. Этот процесс обычно объединяет числа с символами для кодирования информации, которая может использоваться компьютером.
Зачем нужно кодировать символы?
Поскольку компьютеры могут интерпретировать только необработанные нули и единицы (например, 01100110), слова и предложения необходимо кодировать при вводе информации в компьютер. Символы в этих словах и предложениях сгруппированы в набор символов, который компьютер может распознать.
Что такое кодировки символов?
Кодировки символов позволяют нам понять кодировку, используемую в компьютерах. Из-за наличия множества кодировок символов могут возникать ошибки при кодировании с помощью одной кодировки символов и декодировании с помощью другой.Вышеупомянутый инструмент можно использовать для моделирования, если возникнут какие-либо ошибки при кодировании с любой кодировкой символов и декодировании с помощью другой.
Типы кодировок символов
Существует множество кодировок, которые можно использовать для кодирования или декодирования строки символов, включая UTF-8, ASCII и ISO 9959-1.
Примеры популярных кодировок символов:
- ASCII: Американский стандартный код для обмена информацией
- ANSI: Американский национальный институт стандартов
- Unicode (внутренние текстовые коды, используемые операционными системами)
- UTF -8 (формат преобразования Unicode, в котором для представления символов используется 1 байт)
- UTF-16 (формат преобразования Unicode, который использует 2 байта для представления символов)
- UTF-32 (формат преобразования Unicode, который использует 4 байта для представления символов)
Хотя это, безусловно, популярные кодировки, бывают случаи, когда строки кода кодируются с помощью кодировок, которые не так широко используются, например x-IA5-Norgwegian или DOS-720.Это может вызвать путаницу и возможные ошибки, поэтому важно понимать, как уменьшить эти ошибки, предварительно моделируя их с помощью инструмента кодирования / декодирования символов String Functions.
Как использовать инструмент кодирования / декодирования символов
Чтобы использовать инструмент кодирования / декодирования символов String Functions, начните с ввода строки символов в текстовое поле. Затем выберите из раскрывающихся меню, какую систему кодирования и декодирования вы хотите использовать для моделирования.
Посмотрите наш индекс кодировки символов
Для просмотра таблиц кодировки от одной кодировки к другой используйте наш индекс таблицы кодировки символов.
Политика конфиденциальности Карта сайта
Content-Encoding — HTTP | MDN
Заголовок объекта Content-Encoding используется для сжатия медиа-типа. Когда он присутствует, его значение указывает, какие кодировки были применены к телу объекта. Он позволяет клиенту знать, как выполнить декодирование, чтобы получить тип носителя, на который ссылается заголовок Content-Type .
Рекомендуется максимально сжать данные и, следовательно, использовать это поле, но некоторые типы ресурсов, такие как изображения jpeg, уже сжаты.Иногда использование дополнительного сжатия не уменьшает размер полезной нагрузки и даже может увеличить ее длину.
Кодирование содержимого: gzip Кодирование содержимого: сжатие Кодирование содержимого: deflate Content-Encoding: личность Кодирование содержимого: br // Множественные, в том порядке, в котором они были применены Кодирование содержимого: gzip, идентификация Кодирование содержимого: deflate, gzip
-
gzip - Формат, использующий кодирование Лемпеля-Зива (LZ77) с 32-битным CRC. Это исходный формат программы UNIX gzip .Стандарт HTTP / 1.1 также рекомендует, чтобы серверы, поддерживающие такое кодирование содержимого, распознавали
x-gzipкак псевдоним для целей совместимости. -
компресс - Формат, использующий алгоритм Лемпеля-Зива-Велча (LZW). Имя значения было взято из программы UNIX compress , в которой реализован этот алгоритм. Подобно программе сжатия, которая исчезла из большинства дистрибутивов UNIX, эта кодировка содержимого не используется сегодня многими браузерами, отчасти из-за проблемы с патентом (срок ее действия истек в 2003 году).
-
сдувать - Использование структуры zlib (определенной в RFC 1950) с алгоритмом сжатия deflate (определенным в RFC 1951).
-
идентификационный номер - Обозначает функцию идентификации (т.е. отсутствие сжатия или модификации). Этот токен, за исключением случаев, когда он явно указан, всегда считается приемлемым.
-
br - Формат, использующий алгоритм Бротли.
Сжатие с помощью gzip
На стороне клиента вы можете объявить список схем сжатия, которые будут отправлены вместе с HTTP-запросом.Заголовок Accept-Encoding используется для согласования кодирования содержимого.
Accept-Encoding: gzip, deflate
Сервер отвечает по используемой схеме, указанной в заголовке ответа Content-Encoding .
Кодирование содержимого: gzip
Обратите внимание, что сервер не обязан использовать какой-либо метод сжатия. Сжатие сильно зависит от настроек сервера и используемых серверных модулей.
Таблицы BCD загружаются только в браузере
Кодирование и декодирование URL — онлайн
Около
Встречайте URL Decode and Encode, простой онлайн-инструмент, который делает именно то, что написано; декодирует из кодировки URL и кодирует в нее быстро и легко.URL-адрес кодирует ваши данные простым способом или декодирует их в удобочитаемый формат. Кодирование URL-адреса, также известное как процентное кодирование, представляет собой механизм кодирования информации в унифицированном идентификаторе ресурса (URI) при определенных обстоятельствах. Хотя это называется кодировкой URL, на самом деле она используется в более общем плане в основном наборе универсальных идентификаторов ресурсов (URI), который включает как универсальный указатель ресурса (URL), так и универсальное имя ресурса (URN). В качестве такового он также используется при подготовке данных типа носителя «application / x-www-form-urlencoded», как это часто бывает при отправке данных HTML-формы в HTTP-запросах.
Дополнительные параметры
- Набор символов: На нашем веб-сайте используется набор символов UTF-8, ваши входные данные передаются в этом формате. Измените этот параметр, если вы хотите преобразовать его в другой перед кодированием. Обратите внимание, что в случае текстовых данных схема кодирования не содержит их набора символов, поэтому вам, возможно, придется указать выбранный в процессе декодирования. Что касается файлов, по умолчанию используется двоичный параметр, при котором любое преобразование не выполняется; это требуется для всего, кроме текстовых документов.
- Разделитель новой строки: В системах Unix и Windows используются разные символы разрыва строки, предыдущая кодировка любого варианта будет заменена в ваших данных выбранным параметром. В разделе файлов это частично не имеет значения, поскольку они содержат предполагаемые версии, но вы можете определить, какую из них использовать для кодирования каждой строки отдельно и разделения строк на функции фрагментов.
- Кодируйте каждую строку отдельно: Даже символы новой строки преобразуются в их процентную кодированную форму.Используйте эту опцию, если вы хотите закодировать несколько независимых записей данных, разделенных переносом строки. (*)
- Разделить строки на фрагменты: Закодированные данные будут представлять собой непрерывный текст без пробелов. Отметьте этот параметр, если хотите разбить его на несколько строк. Применяемое ограничение на количество символов определено в спецификации MIME (RFC 2045), в которой указывается, что длина закодированных строк не должна превышать 76 символов. (*)
- Живой режим: Когда вы включаете эту опцию, введенные данные немедленно кодируются с помощью встроенных функций JavaScript вашего браузера — без отправки какой-либо информации на наши серверы.В настоящее время этот режим поддерживает только набор символов UTF-8.
Надежно и надежно
Все коммуникации с нашими серверами осуществляются через безопасные зашифрованные соединения SSL (https). Загруженные файлы удаляются с наших серверов сразу после обработки, а полученный загружаемый файл удаляется сразу после первой попытки загрузки или 15 минут бездействия.Мы никоим образом не храним и не проверяем содержимое введенных данных или загруженных файлов. Прочтите нашу политику конфиденциальности ниже для получения более подробной информации.
Совершенно бесплатно
Наш инструмент можно использовать бесплатно. Теперь вам не нужно загружать какое-либо программное обеспечение для таких задач.
Подробная информация о кодировке URL-адреса
Типы символов URI
Допустимые символы в URI либо зарезервированы, либо не зарезервированы (или символ процента как часть процентного кодирования).Зарезервированные символы — это те символы, которые иногда имеют особое значение. Например, символы прямой косой черты используются для разделения различных частей URL-адреса (или, в более общем смысле, URI). Незарезервированные символы не имеют такого значения. При использовании процентного кодирования зарезервированные символы представляются с помощью специальных последовательностей символов. Наборы зарезервированных и незарезервированных символов, а также обстоятельства, при которых определенные зарезервированные символы имеют особое значение, незначительно менялись с каждой версией спецификаций, управляющих URI и схемами URI.
| RFC 3986 раздел 2.2 Зарезервированные символы (январь 2005 г.) | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
! | * | ' | ( | ) | ; | : | @ | и | = | + | $ | , | / | ? | # | [ | ] |
| RFC 3986 раздел 2.3 незарезервированных персонажа (январь 2005 г.) | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
А | В | К | Д | E | Факс | г | H | I | Дж | К | л | M | N | О | -п. | К | R | S | т | U | В | Вт | Х | Y | Z |
| б | с | д | e | f | г | ч | i | j | к | л | м | n | или | п | q | r | с | т | u | v | w | х | y | z |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | – | _ | . | ~ | ||||||||||||
Другие символы в URI должны быть закодированы в процентах.
Зарезервированные символы с процентным кодированием
Когда символ из зарезервированного набора («зарезервированный символ») имеет особое значение («зарезервированное назначение») в определенном контексте, а схема URI сообщает, что необходимо использовать этот символ для какой-то другой цели, тогда этот символ должен быть закодирован в процентах. Процентное кодирование зарезервированного символа включает преобразование символа в соответствующее ему байтовое значение в ASCII и последующее представление этого значения в виде пары шестнадцатеричных цифр.Цифры, которым предшествует знак процента («%»), затем используются в URI вместо зарезервированного символа. (Для символа, отличного от ASCII, он обычно преобразуется в свою последовательность байтов в UTF-8, а затем каждое значение байта представляется, как указано выше.)
Зарезервированный символ «/», например, если он используется в пути « «компонент URI, имеет особое значение как разделитель между сегментами пути. Если в соответствии с заданной схемой URI «/» должен находиться в сегменте пути, тогда в этом сегменте должны использоваться три символа «% 2F» или «% 2f» вместо необработанного «/».
| Зарезервированные символы после процентного кодирования | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
! | # | $ | и | ' | ( | ) | * | + | , | / | : | ; | = | ? | @ | [ | ] |
% 21 | % 23 | % 24 | % 26 | % 27 | % 28 | % 29 | % 2A | % 2B | % 2C | % 2F | % 3A | % 3B | % 3D | % 3F | % 40 | % 5B | % 5D |
Зарезервированные символы, которые не имеют зарезервированной цели в конкретном контексте, также могут быть закодированы в процентах, но семантически не отличаются от тех, которые не имеют.
В компоненте «запрос» URI (часть после символа?), Например, «/» по-прежнему считается зарезервированным символом, но обычно он не имеет зарезервированного назначения, если в конкретной схеме URI не указано иное. Символ не нужно кодировать в процентах, если он не имеет зарезервированной цели.
URI, которые отличаются только тем, является ли зарезервированный символ закодированным в процентах или выглядит буквально, обычно считаются не эквивалентными (обозначающими один и тот же ресурс), если не может быть определено, что рассматриваемые зарезервированные символы не имеют зарезервированной цели.Это определение зависит от правил, установленных для зарезервированных символов отдельными схемами URI.
Процентное кодирование незарезервированных символов
Символы из незарезервированного набора никогда не нуждаются в процентном кодировании.
URI, которые различаются только тем, является ли незарезервированный символ закодированным в процентах или выглядит буквально, эквивалентны по определению, но процессоры URI на практике могут не всегда распознавать эту эквивалентность. Например, потребители URI не должны трактовать «% 41» иначе, чем «A» или «% 7E» иначе, чем «~», но некоторые это делают.Для максимальной совместимости производителям URI не рекомендуется использовать процентное кодирование незарезервированных символов.
Процентное кодирование символа процента
Поскольку символ процента («%») служит индикатором для октетов, закодированных в процентах, он должен быть закодирован в процентах как «% 25», чтобы этот октет использовался в качестве данных внутри URI.
Процентное кодирование произвольных данных
Большинство схем URI включают представление произвольных данных, таких как IP-адрес или путь к файловой системе, как компоненты URI.Спецификации схемы URI должны, но часто этого не делать, предоставлять явное соответствие между символами URI и всеми возможными значениями данных, представленными этими символами.
Двоичные данные
С момента публикации RFC 1738 в 1994 году было указано [1], что схемы, которые обеспечивают представление двоичных данных в URI, должны разделять данные на 8-битные байты и кодировать их в процентах. byte таким же образом, как указано выше. Например, байтовое значение 0F (шестнадцатеричное) должно быть представлено как «% 0F», а байтовое значение 41 (шестнадцатеричное) может быть представлено как «A» или «% 41».Использование незакодированных символов для буквенно-цифровых и других незарезервированных символов обычно предпочтительнее, так как это приводит к более коротким URL-адресам.
Символьные данные
Процедура процентного кодирования двоичных данных часто экстраполировалась, иногда неправильно или не полностью, для применения к символьным данным. В годы становления Всемирной паутины при работе с символами данных в репертуаре ASCII и использовании соответствующих им байтов в ASCII в качестве основы для определения последовательностей, закодированных в процентах, эта практика была относительно безвредной; просто предполагалось, что символы и байты отображаются взаимно однозначно и взаимозаменяемы.Однако потребность в представлении символов вне диапазона ASCII быстро росла, и схемы и протоколы URI часто не обеспечивали стандартных правил подготовки символьных данных для включения в URI. Следовательно, веб-приложения начали использовать различные многобайтовые кодировки, кодировки с отслеживанием состояния и другие несовместимые с ASCII кодировки в качестве основы для процентного кодирования, что привело к неоднозначности и трудностям надежной интерпретации URI.
Например, многие схемы и протоколы URI, основанные на RFC 1738 и 2396, предполагают, что символы данных будут преобразованы в байты в соответствии с некоторой неопределенной кодировкой символов до того, как будут представлены в URI незарезервированными символами или байтами с процентной кодировкой.Если схема не позволяет URI предоставлять подсказку о том, какая кодировка использовалась, или если кодировка конфликтует с использованием ASCII для процентного кодирования зарезервированных и незарезервированных символов, то URI не может быть надежно интерпретирован. Некоторые схемы вообще не учитывают кодирование и вместо этого просто предлагают, чтобы символы данных отображались непосредственно на символы URI, что оставляет на усмотрение реализации решение о том, следует ли и как кодировать символы данных в процентах, которые не входят ни в зарезервированные, ни в незарезервированные наборы.