Виды кодировок символов [АйТи бубен]
- i18n — Интернационализация
- L10n — Локализация
В общем случае кодировка или кодовая таблица — это однозначное соответствие между подмножеством целых чисел (как правило, идущих подряд) и некоторым набором символов. Ключевым здесь является понятие символа. Символ может быть буквой (а может и не быть), может соответствовать звуку речи (а может и не соответствовать) и может быть представлен графическим знаком (но может обходиться и без какого бы то ни было видимого образа). Символ — это атом смысла, мельчайшая неделимая частица информации.
Так, латинское «А» и кириллическое «А» — это разные символы, потому что они употребляются в разных контекстах и несут в себе разную информацию.
Определяющим для любой кодировки является количество охватываемых ею кодов и, соответственно, символов. Поскольку тексты в компьютере хранятся в виде последовательности байтов, большинство кодировок естественным образом распадаются на однобайтовые, или восьмибитные, способные закодировать не больше 256 символов, и двухбайтовые, или шестнадцатибитные, чья емкость может достигать 65636 знакомест.
- ASCII — прежде чем переходить к восьмибитным кодировкам, нужно сказать несколько слов о кодировке под названием ASCII (American Standard Code for Information Interchange) — кодировке также восьмибитной, но охватывающей только 128 символов и потому довольствующейся семью значимыми битами (старший, восьмой бит при этом всегда равен нулю). Важность этой кодировки, включающей латинский алфавит, цифры и основные знаки пунктуации, необычайно велика: почти все остальные (большие по размеру) кодировки совместимы с ней, т. е. размещают на своих первых 128 знакоместах те же самые символы в том же порядке.
КОИ8. Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена информацией, 8-битный»). Эта кодировка применялась еще в доисторические советские времена на компьютерах ЕС ЭВМ, и когда в середине 80-х появились первые русифицированные версии операционной системы UNIX, они унаследовали эту кодировку у своих «предков». В результате КОИ8 является сейчас одной из кодировок, которые обязательно должна поддерживать любая русская web-страница.
Windows-1251. Вторая по значению в русском Интернете (и, безусловно, первая по употребимости на персональных компьютерах) кодировка — это стандартная кириллическая кодировка Microsoft Windows, обозначаемая аббревиатурой СР1251 («СР» расшифровывается как «Code Page», «кодовая страница»). Все Windows- приложения, работающие с русским языком, обязаны понимать эту кодировку без перевода. Благодаря распространенности Windows кодировка СР1251, вместе с КОИ8, входит в абсолютный минимум кодировок, которые приходится поддерживать русскоязычным сайтам.
- Семейство 8859. Latin-1. Похожая ситуация с конкурирующими платформами и операционными системами и, как следствие, с конкурирующими несовместимыми кодировками наблюдается и в других языках, пользующихся своим собственным алфавитом или даже латинским алфавитом с расширениями. Международная организация по стандартизации (International Standards Organization, ISO) попыталась навести порядок в восьмибитных кодировках, создав серию кодировок ISO 8859, расширяющих таблицу ASCII для латинских букв с диакритикой и лигатур (кодировка ISO 8859-1), кириллицы (ISO 8859-5), арабского (ISO 8859-6), греческого (ISO 8859-7), и других алфавитов.
Если кодировка ISO 8859-5 для кириллицы так и не прижилась, первая из этой серии — кодировка ISO 8859-1, известная также под именем Latin-1, — сумела стать общепринятым стандартом для кодирования «расширенной» латиницы. В эту кодировку включены почти все символы, употребляющиеся в письменностях западноевропейских языков — французского, немецкого, испанского и т.д.
Внедрение Юникода привело к изменению подхода к традиционным 8-битным кодировкам. Если раньше кодировка задавалась шрифтом, то теперь она задаётся таблицей соответствия между данной кодировкой и Юникодом. Фактически 8-битные кодировки превратились в форму представления некоторого подмножества Юникода. Это намного упростило создание программ, которые должны работать с множеством разных кодировок: теперь, чтобы добавить поддержку ещё одной кодировки, надо всего лишь добавить ещё одну таблицу перекодировки в Юникод.
В 1991 году была предпринята попытка создать единую универсальную двухбайтовую кодировку, охватывающую все алфавиты и иероглифические системы мира. Результатом стал стандарт под названием Unicode, покрывающий не только системы письменности всех живых и большинства мертвых языков мира, но и множество музыкальных, математических, химических и прочих символов. Массовое применение Unicode в документах и программах остается делом будущего, для web- дизайнера эта кодировка имеет особое значение, так как именно она объявлена «стандартной кодировкой документа» в
В ближайшее время все более важную роль будет играть особый формат Unicode (и ISO 10646) под названием UTF-8. Эта «производная» кодировка пользуется для записи символов цепочками байтов различной длины (от одного до шести), которые с помощью несложного алгоритма преобразуются в Unicode- коды, причем более употребительным символам соответствуют более короткие цепочки. Главное достоинство этого формата — совместимость с ASCII не только по значениям кодов, но и по количеству бит на символ, так как для кодирования любого из первых 128 символов в UTF-8 достаточно одного байта (хотя, например, для букв кириллицы нужно уже по два байта).
Для указания кодировки символов web-страницы используются следующие обозначения кодовых таблиц:
windows-1251 — кириллица Windows
KOI8-U — кодировка КОИ8 для украинского языка
ISO 8859-1 — кодировка Latin-1
ISO 8859-5 — кодировка семейства ISO 8859 для символов кирилицы
На web- странице указать кодировку документа можно двумя cпособами:
Элемент meta является дочерним по отношению к разделу заголовка документа (head) и служит для указания типа и кодировки содержимого страницы. Типом содержимого является структурированный текст в формате html (text/html), используемая кодировка кириллица windows (charset=windows-1251).
Обычно используют оба способа одновременно. Например, для указания кодировки КОИ8 для украинского языка на web-странице, используют следующую структуру документа:
<?xml version="1.0" encoding="KOI8-U"?>
<!DOCTYPE html PUBLIC ... >
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Моя перша сторiнка</title>
<meta http-equiv="Content-Type"
content="text/html; charset=KOI8-U" />
</head>
...
</html>При сохранении текста выбирайте ту же кодировку, что указали на web-странице.
Поэкспериментируйте с различными кодировками, и вы убедитесь, что символы латинского алфавита, цифры и знаки пунктуации передаются без изменений в подавляющем большинстве из них.
загрузка…
kodirovka.txt · Последние изменения: 2018/12/07 16:29 (внешнее изменение)
wiki.dieg.info
Кодировка html сделает ваш у интернет страничку читаемой
Приветствую, читатели и подписчики моего блога. В сегодняшней публикации я решил затронуть очень важную и объемную тему, которую необходимо знать каждому разработчику и верстальщику. Прочитав весь материал, вы узнаете какой бывает кодировка html-документов, для чего она необходима и что меняется при установке того или иного типа кодировки.
С какими проблемами можно столкнуться при неверном выборе, в каких программных продуктах можно изменять этот параметр, а также как ее можно задать в коде. Думаю, настало время приступить к делу!
Почему кодировка так важна и какие существуют типы?
Как только сфера IT начала развиваться, вместе с ней развивались и совершенствовались кодировки. Почему же они так важны для веб-разработки и сайтостроения?
На самом деле корректное отображение символов на дисплее девайсов – это достаточно сложная штука, ведь это не прямой процесс. Любой символ относящийся к кириллице, латинице, цифрам и другим алфавитам формируется благодаря двум параметрам:
- Векторное представление (формы) всевозможных единиц разных алфавитов, которые хранятся в документах со шрифтами на каждом персональном компьютере;
- Номер или код, по которому можно найти указанный символ в этих документах.
Так как за кодирование знаков отвечает не что иное, как операционная система, а после и программы, в которых вы работаете, любой текстовый контент для них выглядит как набор байтов. При этом каждый байт отвечает за конкретный символ. Из этого вы и получаете определенные размеры файлов.

Как же ОС подставляет нужные буквы и знаки? Для нее все очень просто. Осуществляется поиск символа по считанному коду в документе шрифтов и после подставляется.
На сегодняшний день существует несколько основных стандартов кодировок и их подтипов. К ним относятся ASCII и ее дочерние типы CP866, KOI8-R и Windows 1251, Unicode с кодировками UTF. Однако на сегодняшний день все лавры почета достались UTF-8. И это оправдано. Чтобы вы четко понимали сложившуюся ситуацию, переходим к следующей главе.
Досье на Аски
Начну свой рассказ с прародителя описываемого семейства, стоящего во главе символьного отображения.
ASCII (Аски) и первые наследники
В первых версиях Аски было доступно только 128 знаков, среди которых уместились латинские буквы, арабские цифры и дополнительные символы. Однако из-за недостатка значений, кодировка была расширена в 2 раза (т.е. до 256). Вследствие этого появилась возможность добавлять к существующим значениям свои. Наверное поэтому и существует несколько видов таблиц с русскими символами.
Первой в себя включила алфавит русского языка CP866. Помимо этого, в расширенную версию входила и псевдографика.

Вслед за ней свет увидел аналог – KOI8-R. Особенностью KOI8-R является расположение русских букв не по алфавиту, а в примерно тех же столбцах, что и созвучные латинские буквы.
В тот «железный век» IT-технологий не было такого изобилия графических ОС, поэтому псевдографика спасала разработчиков, помогая им создавать более-менее разнообразные веб-страницы.
Переход в современность – Windows 1251
Это еще один расширенный тип стандарта ASCII, однако он связан уже с современными графическими ОС. Что же это означает? А то, что псевдографика больше никому не была нужна.
Windows 1251 еще называют «в народе» кириллицей. Все потому что в данной таблице место ненужных знаков заняли недостающие символы русского и других славянских языков, а также аналогичная типографика.
Я перечислил наиболее популярные типы расширений Аски, однако их существовало намного больше. Вследствие этого началось деление власти и путаница среди используемых кодировок. Это привело к тому, что иногда на экране можно наблюдать появление непонятных значков, которые позже в широких кругах прозвали кракозябрами.
Эти чудовища появляются только тогда, когда неверно установлен тип кодировки. Долгое время эту проблему пытались решить разными способами. Но вслед за одной дилеммой появилась и другая – нехватка 256 байтов для хранения всех существующих символов (например, японского языка).
Приход новой власти
Спасательным кругом оказался новый стандарт кодирования алфавитов – Unicode. Все его кодировки имеют в названии UTF, а после через дефис количество битов для 1-го символа.
Так вот, продвинутые умы того времени скооперировались и создали UTF-32. Конечно это решило проблему нехватки места для тех же объемных иероглифов, однако вызвало другую – размер файлов увеличивался в 4 раза.

После выделяемая память уменьшилась до 16 бит. И наконец дошла до 8.
UTF-8 является стандартом, который не использует фиксированный размер битов для одного символа и в этом ее огромное преимущество: использование переменной длины.
Благодаря этому латиница и другие простые символы кодируются 1-м байтом, как и в ASCII. А вот «тяжелые» знаки могут быть представлены от одного и до шести байт последовательно. Стоит отметить, что помимо алфавитов, в таблицах Юникода можно найти всевозможные закорючки, смайлы, греческие буквы, цветы и другие нестандартные элементы.
Вот мы и разобрали, почему UTF-8 стала лидером.
Программы для перевода текста из одной кодировки в другую
На самом деле изменить формат кодирования файлов очень просто и доступно в большинстве программ: «Блокнот», «Notepad++», «PSPad» и другие аналоги предоставляют такую возможность, а также профессиональные продукты наподобие Visual Studio, IntelliJ IDEA и т.д.
Для новичков подойдет и работа в «Блокноте». Просто откройте нужный файл, выберете «Сохранить как…» и снизу диалогового окна измените вид кодировки.
Для более продвинутых отличным инструментом станет Notepad++. Он предлагает широкий выбор различных кодировок, в том числе UTF-8 с BOM и без него. Хотя предпочтительнее выбирать второй вариант.

Хочу сказать несколько слов о BOM. Полное название Byte Order Mark, что в русскоязычных кругах более известно, как «маркер последовательности (порядка) байтов». Такая метка устанавливается в самом начале документа с текстом и обычно используется для обмена файлами. Она занимает 3 байта, которые выглядят следующим образом: ef bb bf.
Однако, чтобы не было проблем с распознаванием кодировки файлов, стоит использовать UTF-8 без метки.
Набор инструментов для девелоперов
Для того, чтобы в коде задать определенный тип кодирования текстового контента, можно воспользоваться несколькими способами.
Первый вариант – это указать в документе .htaccess «AddDefaultCharset UTF-8».
Второй – в теге meta объявить значение для charset. Данный атрибут появился с выходом в свет html5. В качестве примера я прикрепил программную реализацию.
1 2 3 4 5 6 7 8 9 10 | <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Пример с charset</title> </head> <body> <h3>Привычный вид text-а! Все 4 слова и 2 числа отобразились корректно.<h3> </body> </html> |
<!DOCTYPE html> <html> <head> <meta charset=»utf-8″> <title>Пример с charset</title> </head> <body> <h3>Привычный вид text-а! Все 4 слова и 2 числа отобразились корректно.<h3> </body> </html>
Поэкспериментируйте и подставьте другие названия кодировок.
Если материал статьи был вам полезен и понравился, то подписывайтесь на обновления блога и делитесь ссылкой на статьи с друзьями. Желаю удачи. Пока-пока!
С уважением, Роман Чуешов
Загрузка…Прочитано: 135 раз
romanchueshov.ru
Что нужно знать каждому разработчику о кодировках и наборах символов для работы с текстом
Это первая часть перевода статьи What Every Programmer Absolutely, Positively Needs To Know About Encodings And Character Sets To Work With TextЕсли вы работаете с текстом в компьютере, вам обязательно нужно знать про кодировки. Даже если вы посылаете электронные письма. Даже если вы их только получаете. Необязательно понимать каждую деталь, но надо хотя бы знать, что из себя представляют кодировки. И вот первая хорошая новость: статья может быть немного запутанной, но основная идея очень и очень простая.
Эта статья о кодировках и наборах символов.
Статья Джоеэля Спольски под названием «Абсолютный минимум о Unicode и наборе символов для каждого разработчика(без исключений!)» будет хорошей вводной и мне доставляет большое удовольствие перечитывать ее время от времени. Я стесняюсь отсылать к ней тех людей, которые испытывают трудности с пониманием проблем с кодировкам, хотя она довольно легкая в плане технических деталей. Я надеюсь, эта статья прольет немного света на то, чем именно являются кодировки, и почему все ваши тексты оказываются испорченными в самый ненужный момент. Статья предназначена для разработчиков(главным образом, на PHP), но пользу от нее может получить любой пользователь компьютера.
Основы
Все более или менее слышали об этом, но каким-то образом знание испаряется, когда дело доходит до обсуждения, так что вот вам: компьютер не может хранить буквы, числа, картинки или что-либо еще. Он может запомнить только биты. Бит имеет только два значения: ДА или НЕТ, ПРАВДА или ЛОЖЬ, 1 или 0 или любую другую пару, которую вы можете вообразить. Раз уж компьютер работает с электричеством, бит представлен электрическим зарядом: он либо есть, либо его нет. Людям проще представлять это в виде 1 и 0, так что я буду придерживаться этих обозначений.
Чтобы с помощью битов представлять нечно полезное, нам нужны правила. Надо сконвертировать последовательность бит в что-то похожее на буквы, числа и изображения, используя схему кодирования, или, коротко, кодировку. Вот так, например:
01100010 01101001 01110100 01110011
b i t s
В этой кодировке, 01100010 представляет из себя ‘b’, 01101001 — ‘i’, 01110100 — ‘t’, 01110011 — ‘s’. Конкретная последовательность бит соответствует букве, а буква – конкретной последовательности битов. Если вы можете запомнить последовательности для 26 букв или умеете действительно быстро находить нужное соответствие, то вы сможете читать биты, как книги.
Упомянутая схема носит название ASCII. Строка с нолями и единицами разбивается на части по 8 бит(по байтам). Кодировка ASCII определяет таблицу перевода байтов в человеческие буквы. Вот небольшой кусочек этой таблицы:
bits character 01000001 A
01000010 B
01000011 C
01000100 D
01000101 E
01000110 F
В ней 95 символов, включая буквы от A до Z, в нижнем и верхнем регистре, цифры от 0 до 9, с десяток знаков препинания, амперсанд, знак доллара и прочие. В нее также включены 33 значения, такие как пробел, табуляция, перевод строки, возврат символа и прочие. Это непечатаемые символы, хотя они видимы человеку и используются им. Некоторые значения полезны только компьютеру, такие как коды начала и конца текста. Всего в кодировку ASCII включены 128 символов — прекрасное ровное число для тех, кто смыслит в компьютерах, так как оно использует все комбинации 7ми битов (от 0000000 до 1111111).
Вот вам способ представить человеческую строку, используя только единицы и нули:
01001000 01100101 01101100 01101100 01101111 00100000
01010111 01101111 01110010 01101100 01100100«Hello World»
Важные термины
Для кодирования чего-либо в ASCII двигайтесь справа налево, подменяя буквы на биты. Для декодирования битов в символы, следуйте по таблице слева направо, подменяя биты на буквы.
encode |enˈkōd|
verb [ with obj. ]
convert into a coded form
code |kōd|
noun
a system of words, letters, figures, or other symbols substituted for other words, letters, etc.
Кодирование – это представление чего-либо чем-нибудь другим. Кодировка – это набор правил, описывающий способ перевода одного представления в другое.
Прочие термины, заслуживающие прояснения:
Набор символов, чарсет, charset – Набор символов, который может быть закодирован. «Кодировка ASCII включает набор из 128 символов». Синоним к кодировке.
Кодовая страница – страница кодов, закрепляюшая за символом набор битов. Таблица. Синоним к кодировке.
Строка – пачка чего-нибудь, объединенных вместе. Битовая строка – это пачка бит, такая как 00011011. Символьная строка – это пачка символов, например «Вот эта». Синоним к последовательности.
Двоичный, восьмеричный, десятичный, шестнадцатеричный
Существует множество способов записывать числа. 10011111 – это бинарная запись для 237 в восьмеричной, 159 в десятичной и 9F в шестнадцатиричной системах. Значения у всех этих чисел одинаково, но шестнадцатиричная система короче и проще для понимания, чем двоичная. Я буду придерживаться двоичной системы в этой статье, чтобы улучшить понимание и убрать лишний уровень абстракции. Не пугайтесь, встречая коды символов в других нотациях, все значения эквиваленты.
Excusez-Moi?
Раз уж мы теперь знаем, о чем говорим, заметим: 95 символов – это совсем немного, когда речь идет о языках. Этот набор покрывает базовый английский, но как насчет французских символов? А вот это Straßen¬übergangs¬änderungs¬gesetz из немецкого языка? А приглашение на smörgåsbord в шведском? В-общем, не получится. Не в ASCII. Спецификация на представление é, ß, ü, ä, ö просто отсутствует.
“Постойте-ка”, скажут европейцы, “в обычных компьютерах с 8 битами в байте, ASCII никак не использует бит, который всегда равен 0! Мы можем использовать его, чтобы расширить таблицу еще на 128 значений”. И было так. Но способов обозначить звучание гласных еще слишком много. Не все сочетания букв и значений, используемые в европейских языках, влезают в таблицу из 256 записей. Так мир пришел к изобилию кодировок, стандартов, стандартов де-факто и недостандартов, которые покрывают все субнаборы символов. Кому-то понадобилось написать документ на шведском или чешском, и, не найдя нужной кодировки, просто изобрел еще одну. Или я думаю, что все так и произошло.
Не забывайте о русском, хинди, арабском, корейском и множестве других живых языков планеты. Про мертвые уж молчим. Как только вы найдете способ писать документ, использующий несколько языков, попробуйте добавить китайский. Или японский. Оба содержат тысячи символов. И у вас всего 256 значений. Вперед!
Многобайтные кодировки
Для создания таблиц, которые содержат более 256 символов, одного байта просто недостаточно. Двух байтов (16 бит) хватит для кодировки 65536 различных значений. Big-5 например, кодировка двухбайтная. Вместо разбиения последовательности битов в блоки по 8, она использует блоки по 16 битов и содержит большую(я имею ввиду БОЛЬШУЮ) таблицу с соответствием. Big-5 в своем основном виде покрывает большинство символов традиционного китайского. GB18030 – это похожая кодировка, но она включает как традиционный, так и упрощенный китайский. И, прежде чем вы спросите, да, есть кодировки только для упрощенного китайского. А разве одной недостаточно?
Вот кусок таблицы GB18030:
bits character
10000001 01000000 丂
10000001 01000001 丄
10000001 01000010 丅
10000001 01000011 丆
10000001 01000100 丏
GB18030 покрывает довольно большой диапазон символов, включая большую часть латинских символов, но в конце концов, это всего лишь еще одна кодировка среди многих других.
Путаница с Unicode
В итоге тем, кому больше всех надоела эта каша, пришла в голову идея разработать единый стандарт, объединяющий все кодировки. Этим стандартом стал Unicode. Он определяет невероятную таблицу из 1 114 112 пунктов, используемую для всех вариантов букв и символов. Этого хватит для кодирования всех европейских, средне-азиатских, дальневосточных, южных, северных, западных, доисторических и будущих символов, о которых человечеству известно. Unicode позволяет создать документ на любом языке любыми символами, которые можно ввести в компьютер. Это было невозможно, или очень затруднительно до эры Unicode. В стандарте есть даже неофициальная секция под клингонский. Вы поняли, Unicode настолько большой, чтобы допускает неофициальные секции.
Итак, и сколько же байт использует Unicode для кодирования? Нисколько. Потому что Unicode – это не кодировка.
Смущены? Не вы одни. Unicode в первую и главную очередь определяет таблицу пунктов для символов. Это такой способ сказать «65 – A, 66 – B, 9731 – »(я не шучу, так и есть). Как эти пункты кодируются в байты является предметом другого разговора. Для представления 1 114 112 значений двух байт недостаточно. Трех достаточно, но 3 – странное число, так что 4 является комфортным минимумом. Но, пока вы не используете китайский, или другой язык со множеством символов, которые требуют большого количества битов для кодирования, вам никогда не придет в голову использовать толстую колбасу из 4х байт. Если “A” всегда кодируется в 00000000 00000000 00000000 01000001, а “B” – в 00000000 00000000 00000000 01000010, то документ, использующий такую кодировку, распухнет в 4 раза.
Существует несколько способов решения этой проблемы. UTF-32 – это кодировка, которая переводит все символы в наборы из 32 бит. Это простой алгоритм, но изводящий много места впустую. UTF-16 и UTF-8 являются кодировками с переменной длиной кодирования. Если символ может быть закодирован одним байтом(потому что номер пункта символа очень маленький), UTF-8 закодирует его одним байтом. Если нужно 2 байта, то используется 2 байта. Кодировка сообщает старшими битами, сколькими битами кодируется текущий символ. Такой способ экономит место, но так же и тратит его в случае, если эти сигнальные биты часто используются. UTF-16 является компромиссом: все символы как минимум двухбайтные, но их размер может увеличиваться до 4 байт, если нужно.
character encoding bits
A UTF-8 01000001
A UTF-16 00000000 01000001
A UTF-32 00000000 00000000 00000000 01000001
あ UTF-8 11100011 10000001 10000010
あ UTF-16 00110000 01000010
あ UTF-32 00000000 00000000 00110000 01000010
И все. Unicode – это огромная таблица соответствия символов и чисел, а различные UTF кодировки определяют, как эти числа переводятся в биты. В-общем, Unicode – это просто еще одна схема. Ничего особенного, она просто пытается покрыть все, что можно, оставаясь эффективной. И это хорошо.
Пункты
Символы определяются по их Unicode-пунктам. Эти пункты записаны в шестнадцатеричной системе и предварены “ U+” (просто для удобство, не значит ничего, кроме “Это пункт Unicode”). Символ Ḁ имеет пункт U+1E00. Иными(десятичными) словами, это 7680й символ таблицы Unicode. Он официально называется “ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА А С КОЛЬЦОМ СНИЗУ”.
Ниасилил
Суть вышесказанного: любой символ может быть закодирован множеством разных последовательностей бит, и любая последовательность бит может представлять разные символы, в зависимости от используемой кодировки. Причина в том, что разные кодировки используют разное число бит на символ и разные значения для кодирования разных символов.
bits encoding characters11000100 01000010 Windows Latin 1 ÄB
11000100 01000010 Mac Roman ƒB
11000100 01000010 GB18030 腂characters encoding bits
Føö Windows Latin 1 01000110 11111000 11110110
Føö Mac Roman 01000110 10111111 10011010
Føö UTF-8 01000110 11000011 10111000 11000011 10110110
Заблуждения, смущения и проблемы
Имея все вышесказанное, мы приходим к насущным проблемам, которые испытывают множество пользователей и разработчиков каждый день, как они соотносятся с указанным выше, и каковы пути решения. Сама большая проблема – это
Какого черта мой текст нечитаем?
ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ
Если вы откроете документ, и он выглядит так, как текст выше, то причина у этого одна: ваша программа ошиблась с кодировкой. И все. Документ не испорчен(по крайней мере, пока), и не нужно никакое волшебство. Вместо него надо просто выбрать правильную кодировку для отображения текста. Предполагаемый документ выше содержит биты:
10000011 01000111 10000011 10010011 10000011 01010010 10000001 01011011
10000011 01100110 10000011 01000010 10000011 10010011 10000011 01001111
10000010 11001101 10010011 11101111 10000010 10110101 10000010 10101101
10000010 11001000 10000010 10100010
Так, быстренько угадали кодировку? Если вы пожали плечами, то вы правы. Да кто знает?
Попробуем с ASCII. Большая часть этих байтов начинается с 1. Если вы правильно помните, ASCII вообще-то не использует этот бит. Так что ASCII не вариант. Как насчет UTF-8? Большая часть байт не является валидными значениями в этой кодировке. Как насчет Mac Roman(еще одна европейская кодировка)? Хм, для нее эти байты являются правильными значениями. 10000011 декодируетися в ”É”, в “G” и так далее. Так что в Mac Roman текст будет выглядеть так: ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ. Правильно? Нет? Может быть? А компьютер-то откуда знает? Может кто-то хотел написать именно это. Насколько я знаю, это может быть последовательностью ДНК! Так и порешим: это Mac Roman, и это ДНК.
Конечно, это полный бред. Правильный ответ таков: текст закодирован в Japanes Shift-JIS и должен выглядеть как エンコーディングは難しくない. Кто бы мог подумать?
Первая причина нечитаемости текста в том, что кто-то пытается прочитать последовательность байт в неверной кодировке. Компьютеру всегда нужно подсказывать. Сам он не догадается. Некоторые типы документов определяют кодировку своего содержимого, но последовательность байт всегда остается черным ящиком.
Большинство браузеров предоставляют возможность указать кодировку страницы с помощью специального пункта меню. Иные программы тоже имеют аналогичные пункты.
У автора нет разбиения на части, но статья и так длинна. Продолжение будет через пару дней.
habr.com
Краткий экскурс в кодировки текста / Sandbox / Habr
Все мы знаем русский (как минимум) алфавит и при употреблении знаков на письме особо не задумываемся о том, чтобы как-то представлять в своей голове ту или иную закорючку перед начертанием ее на бумаге посредством ручки (карандаша, пера и т.п.).Научили нас сферические Марьи Ивановны в вакууме транслировать мысли с помощью букв, составляющих слова, которые в свою очередь составляют вполне достаточную мысль — предложение. А ведь когда-то цивилизации пришлось придумать этот способ передачи информации, сначала прийдя к графической форме представления,
а затем дойдя до общепринятых для определенных этносов наборов этих символов, названными алфавитами.
Цифры и числа так же разными этническими группами людей представлялись по-разному, для записи чисел существовали свои правила, чтобы можно было проще осуществлять математические операции. На сегодня наиболее распространенным является индийский взгляд на представление цифр и чисел, хоть и претерпевший некоторые изменения.
На этом я не буду останавливаться, так как напрямую не относится к теме моей статьи. При желании всегда можно углубиться и пополнить чашу своих знаний самостоятельно.
Так, цивилизация развивалась, прогресс неумолимо брал свое, в социальных отношениях все более значимую роль начинала играть информация. Вкупе с математикой и научно-техническим прогрессом, информатика (наука о способах передачи, хранения и обработки информации) дала толчок к созданию автоматизированных вычислительных систем, которые позже приспособили для целей информатики — обмена, складирования и преобразования информации. По меркам истории, путь этот оказался достаточно коротким, а для человечества оказался большим рывком вперед. Только подумайте — сеть, охватывающая всю планету! Но не все было так радужно, ведь для каждого языка или набора символов, общего для нескольких языков нужно было как-то представить отдельные знаки и «скормить» их вычислительной машине.
Так, американцы стали первыми, кто смог представить буквы родного алфавита в виде таблицы символов для вычислительной машины и стандартизировать свое детище. В стандарте ISO 646(ASCII) отдельные 7 битов информации кодировали 1 знак таблицы символов. Именно этот стандарт распространился в сфере телекоммуникаций — он был первым, достаточно удобным и пригодным для передачи по телетайпу. Не обошлось и без недостатков — в данном стандарте нашли свое отражение только буквы латинского алфавита, которые использовались в то время не по всему земному шару… Иначе говоря — другие языки и алфавиты обделили внимаением, но американцев можно понять — они сделали это в первую очередь для себя, для своей страны, а остальной мир всех интересует в последнюю очередь, ибо у стран нет друзей и врагов, у стран есть интересы.
В дальнейшем, чтобы перейти к представлению национальных алфавитов плюсом к американской латинице, пришлось добавить еще один бит для кодировки каждого символа — первые 128 символов оставались теми же, что и в ASCII, а символы с 128 по 255 могла занимать нелатинская часть кодовой таблицы. Позже, с оглядкой на ASCII были стандартизированы еще несколько кодировок, как части единого стандарта ISO/IEC 8859, а именно:
Часть 1 (ISO 8859-1): Основана на ASCII, но дополнена для охвата большинства западноевропейских языков (Latin-1 Western European).
Часть 2 (ISO 8859-2): По сути то же самое, но переделана была для поддержки центрально- и восточноевропейских языков (Latin-2 Central European).
Часть 3 (ISO 8859-3): Поддержка южноевропейских языков (Latin-3 South European).
Часть 3 (ISO 8859-3): Аналогично для северной европы (Latin-4 North European).
…
Остальные части стандарта я приводить не стану, скажу лишь, что это был первый серьезный шаг к толерантности в мире информации и сетей.
Так, чехарда стандартов не обошла стороной и нашу с вами кириллицу — для ее представления были составлены следующие таблицы символов:
1. КОИ-7
2. КОИ-8 (в трёх вариантах — KOI8-R, KOI8-U и ISO-IR-111)
3. CP866
4. ISO 8859-5 (как часть стандарта ISO/IEC 8859)
5. MacCyrillic
6. Windows-1251
Маразм крепчал, и лучшие умы человечества думали как поубавить количество встречающихвся в живой природе (откровенно говоря — в вебе) кодировок, а организацией Unicode Consortium был предложен одноименный стандарт кодирования символов, состоящий из универсального набора символов (UCS) и семейства кодировок (UTF), которые были стандартизованы отдельно, но включены в стандарт.
Подводя итог вышеизложенному, в современном рунете наиболее распространены кодировки Windows-1251, ввиду популярности операционной системы от Microsoft Corporation, и UTF-8, которая позволяет закодировать большее количество символов (иначе говоря — позволяет работать с несколькими языками) и имеет большее распространение в не-Windows-мире (я имею в виду дистрибутивы Linux, FreeBSD и Mac OS X), ну а для поддержки еще большего количества языков (ну вдруг вам приспичит!) можно использовать UTF-16, только осторожно.
P.S.
Про американцев так получилось, я патриот, но умалять их достижение не в праве.ы
habr.com
Universal online Cyrillic decoder — recover your texts
Universal online Cyrillic decoder — recover your textsVersion: 20190604
Output
The resulting text will be displayed here…
| Guestbook Please link to this site! | Custom Work For a small fee I can help you quickly recode/recover large pieces of data — texts, databases, websites… or write custom functions you can use (invoice available). Contact me! mailto:5ko [snail] 5ko [period] fr?subject=Custom%20work%20via%202cyr [period] com |
About the program
Welcome! You may find this site useful, if you have recieved some texts that you believe are written in the Cyrillic alphabet, but instead are displayed in some strange combination of bizarre characters. This program will try to guess the encoding, and if it does not, it will show samples, examples of all encoding-combinations, so as you will be able to select the good one.
How to
- Paste the text to decode in the big text area. The first few words will be analyzed so they should be (scrambled) in supposed Cyrillic.
- The program will try to decode the text and will print the result below.
- If the translation is successful, you will see the text in Cyrillic characters and will be able to copy it and save it if it’s important.
- If the translation isn’t successful (still the text is not in Cyrillic but in the same or other unintelligible characters), you can choose from the newly created select-listbox the variant that is in Cyrillic (if there are more than one, select the longest). By pressing the button OK you will have the correct text converted.
- If the text is not totally converted, try all other variants in Cyrillic from the select-listbox.
Limits
- If your text contains question marks «???? ?? ??????», the problem is with the sender and no recovery will be possible. Ask them to resend the text, eventually as an ordinary text file or in LibreOffice/OpenOffice/MSOffice format.
- There is no claim that every text is recoverable, even if you are certain that the text is in Cyrillic.
- The analyzed and converted text is limited to 100 KiB.
- A 100% precision is not always achieved — in a conversion from a codepage to another code page, some characters may be lost, like the Bulgarian quotes or rarely some single letters. Some of this depends on your Windows Clipboard character handling.
- The program will try a maximum of 6776 variants in two or three levels: if there had been a multiple encoding like koi8(utf(cp1251(utf))), it will not be detected or tested. Usually the possible and displayed correct variants are between 32 and 255.
- If a part of the text is encoded with one code page, and another part — with another code page, the program could recognize only one of the parts at a time.
Terms of use
Please notice that this freeware program is created with the hope that it would be useful, but has no warranty, not even an implied warranty for fitness for any particular use. Please use it at your own risk.
If you have very long texts to translate, please make sure you have a backup copy.
What’s new
- October 2017 : Added «Select all / Copy» button.
- July 2016 : SSL Certificate installed, you can now access the Decoder on a secure connection.
- October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text. If you notice any problem, please notify me ASAP.
- March 2013 : My hosting provider sent me a warning that the Decoder is using too much server CPU power and its processes were killed more than 100 times. I am making some changes so that the program will use less CPU, especially when reposting a previously sampled text, however, the decoded form may load somewhat slower. Please contact me if you have some difficulties using the program.
- 2012-08-09 : Added French translation, thanks to Arnaud D.
- 2011-03-06 : Added Belorussian translation, thanks to Зыль and Aliaksandr Hliakau.
- 31.07.10 : Added Serbian translation, thanks to Miodrag Danilovic (Boston — Beograd).
- 07.05.09 : Raised limit of MAX text size to 50 kiB.
- may 2009 : Added Ukrainian interface thanks to Barmalini.
- 2008-2009 : A number of small fixes and tweaks of the detection algorithm. Changed interface to default to automatic decoding.
- 12.08.07 : Fixed Russian language translation, thanks to Petr Vasilyev. This page will be significantly restructured in the near future.
- 10.11.06 : Three new postfilters added: «base64», «unix-to-unix» и «bin-to-hex», theoretically the tested combinations are 4725. Changes to the frequency analysis function (testing).
- 11.10.06 : The main site is on a new hardware server, should run faster.
- 11.09.06 : The program now uses PHP5 and should run times faster.
- 19.08.06 : Because of a broken DNS entry, this site was inaccessible from 06:00 on 15 august up to 15:00 on 18 august. That was the reason for me to set two «mirror» sites (5ko.free.fr/decode and www.accent.bg/decode) with the same program. If the original has a problem, you can find the copies in Google and recover your texts.
- 17.06.06 : Added two more antique Cyrillic encodings, MIK и KOI-7, but you better not need them.
- 03.03.06 : Added Slovak translation, thanks to Martin from KPR Slovakia.
- 15.02.06 : More encodings added and tested.
- 20.10.05 : Small improvement to the frequency-analysis function: for texts, written in all-capital letters.
- 14.10.05 : Two more gmail-Cyrillic encodings were added. Theoretically the tested combinations are 2112.
- 15.06.05 : Russian language interface was added. Big thanks to chAlx!
- 16.02.05 : One more postfilter decoding is added, for strings like this: «%u043A%u0438%u0440%u0438%u043B%u0438%u0446%u0430».
- 05.02.05 : More encodings tests added, the number of tested encodings is doubled, but thus the program may work slightly slower.
- 03.02.05 : The frequency analysis function that detects the original encoding works much better now. Currently the program recognises most of the encodings if the first few words are not too weird. It although still needs some improvement.
- 15.01.05 : The input text limit is raised from 10 to 20 kB.
- 01.12.04 : First public release.
Back to the Latin to Cyrillic convertor.
2cyr.com
Кодирование текстовой информации
Чаще всего кодированию подвергаются тексты, написанные на естественных языках (русском, немецком и др.).
Основные способы кодирования текстовой информации
Существует несколько основных способов кодирования текстовой информации:
- графический, в котором текстовая информация кодируется путем использования специальных рисунков или знаков;
- символьный, в котором тексты кодируются с использованием символов того же алфавита, на котором написан исходник;
- числовой, в котором текстовая информация кодируется с помощью чисел.
Процесс чтения текста представляет собой процесс, обратный его написанию, в результате которого письменный текст преобразуется в устную речь. Чтение – это ничто иное, как декодирование письменного текста.
А сейчас обратите внимание на то, что существует много способов кодирования одного и того же текста на одном и том же языке.
Пример 1
Поскольку мы русские, то и текст привыкли записывать с помощью алфавита своего родного языка. Однако тот же самый текст можно записать, используя латинские буквы. Иногда это приходится делать, когда мы отправляем SMS по мобильному телефону, клавиатура которого не содержит русских букв, или же электронное письмо на русском языке за границу, если у адресата нет русифицированного программного обеспечения. Например, фразу «Здравствуй, дорогой Саша!» можно записать как: «Zdravstvui, dorogoi Sasha!».
Стенография
Определение 1
Стенография — это один из способов кодирования текстовой информации с помощью специальных знаков. Она представляет собой быстрый способ записи устной речи. Навыками стенографии могут владеть далеко не все, а лишь немногие специально обученные люди, которых называют стенографистами. Эти люди успевают записывать текст синхронно с речью выступающего человека, что, на наш взгляд, достаточно сложно. Однако для них это не проблема, поскольку в стенограмме целое слово или сочетание букв могут обозначаться одним знаком. Скорость стенографического письма превосходит скорость обычного в $4-7$ раз. Расшифровать (декодировать) стенограмму может только сам стенографист.
Пример 2
На рисунке представлен пример стенографии, в которой написано следущее: «Говорить умеют все люди на свете. Даже у самых примитивных племен есть речь. Язык — это нечто всеобщее и самое человеческое, что есть на свете»:
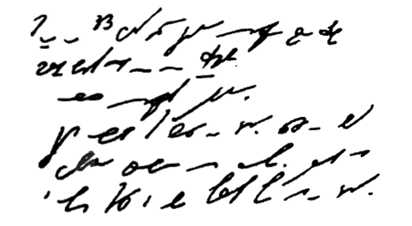
Рисунок 1.
Стенография позволяет не только вести синхронную запись устной речи, но и рационализировать технику письма.
Замечание 1
Приведёнными примерами мы проиллюстрировали важное правило: для кодирования одной и той же информации можно использовать разные способы, при этом их выбор будет зависеть от цели кодирования, условий и имеющихся средств.
Если нам нужно записать текст в темпе речи, сделаем это с помощью стенографии; если нужно передать текст за границу, воспользуемся латинским алфавитом; если необходимо представить текст в виде, понятном для грамотного русского человека, запишем его по всем правилам грамматики русского языка.
Также немаловажен выбор способа кодирования информации, который, в свою очередь, может быть связан с предполагаемым способом её обработки.
Пример 3
Рассмотрим пример представления чисел количественной информации. Используя буквы русского алфавита, можно записать число «тридцать пять». Используя же алфавит арабской десятичной системы счисления, запишем: $35$. Допустим нам необходимо произвести вычисления. Естественно, что для выполнения расчётов мы выберем удобную для нас запись числа арабскими цифрами, хотя можно примеры описывать и словами, но это будет довольно громоздко и не практично.
Замечание 2
Заметим, что приведенные выше записи одного и того же числа используют разные языки: первая — естественный русский язык, вторая — формальный язык математики, не имеющий национальной принадлежности. Переход от представления на естественном языке к представлению на формальном языке можно также рассматривать как кодирование.
Криптография
В некоторых случаях возникает потребность засекречивания текста сообщения или документа, для того чтобы его не смогли прочитать те, кому не положено. Это называется защитой от несанкционированного доступа. В таком случае секретный текст шифруется. В давние времена шифрование называлось тайнописью.
Определение 2
Шифрование представляет собой процесс превращения открытого текста в зашифрованный, а дешифрование — процесс обратного преобразования, при котором восстанавливается исходный текст. Шифрование — это тоже кодирование, но с засекреченным методом, известным только источнику и адресату. Методами шифрования занимается наука криптография.
Определение 3
Криптография — это наука о методах и принципах передачи и приема зашифрованной с помощью специальных ключей информации. Ключ — секретная информация, используемая криптографическим алгоритмом при шифровании/расшифровке сообщений.
Числовое кодирование текстовой информации
В каждом национальном языке имеется свой алфавит, который состоит из определенного набора букв, следующих друг за другом, а значит и имеющих свой порядковый номер.
Каждой букве сопоставляется целое положительное число, которое называют кодом символа. Именно этот код и будет хранить память компьютера, а при выводе на экран или бумагу преобразовывать в соответствующий ему символ. Помимо кодов самих символов в памяти компьютера хранится и информация о том, какие именно данные закодированы в конкретной области памяти. Это необходимо для различия представленной информации в памяти компьютера (числа и символы).
Используя соответствия букв алфавита с их числовыми кодами, можно сформировать специальные таблицы кодирования. Иначе можно сказать, что символы конкретного алфавита имеют свои числовые коды в соответствии с определенной таблицей кодирования.
Однако, как известно, алфавитов в мире большое множество (английский, русский, китайский и др.). Соответственно возникает вопрос, каким образом можно закодировать все используемые на компьютере алфавиты.
Чтобы ответить на данный вопрос, нам придется заглянуть назад в прошлое.
В $60$-х годах прошлого века в американском национальном институте стандартизации (ANSI) была разработана специальная таблица кодирования символов, которая затем стала использоваться во всех операционных системах. Эта таблица называется ASCII (American Standard Code for Information Interchange, что означает в переводе с английского «американский стандартный код для обмена информацией»).
В данной таблице представлен $7$-битный стандарт кодирования, при использовании которого компьютер может записать каждый символ в одну $7$-битную ячейку запоминающего устройства. При этом известно, что в ячейке, состоящей из $7$ битов, можно сохранять $128$ различных состояний. В стандарте ASCII каждому из этих $128$ состояний соответствует какая-то буква, знак препинания или же специальный символ.
В процессе развития вычислительной техники стало ясно, что $7$-битный стандарт кодирования достаточно мал, поскольку в $128$ состояниях $7$-битной ячейки нельзя закодировать буквы всех письменностей, имеющихся в мире.
Чтобы решить эту проблему, разработчики программного обеспечения начали создавать собственные 8-битные стандарты кодировки текста. За счет дополнительного бита диапазон кодирования в них был расширен до $256$ символов. Во избежание путаницы, первые $128$ символов в таких кодировках, как правило, соответствуют стандарту ASCII. Оставшиеся $128$ — реализуют региональные языковые особенности.
Замечание 3
Как мы знаем национальных алфавитов огромное количество, поэтому и расширенные таблицы ASCII-кодов представлены множеством вариантов. Так для русского языка существует также несколько вариантов, наиболее распространенные Windows-$1251$ и Koi8-r. Большое количество вариантов кодировочных таблиц создает определенные трудности. К примеру, мы отправляем письмо, представленное в одной кодировке, а получатель при этом пытается прочесть его в другой. В результате на экране у него появляется непонятная абракадабра, что говорит о том, что получателю для прочтения письма требуется применить иную кодировочную таблицу.
Существует и другая проблема, которая заключается в том, что алфавиты некоторых языков содержат слишком много символов, которые не позволяют помещаться им в отведенные позиции с $128$ до $255$ однобайтовой кодировки.
Следующая проблема возникает тогда, когда в тексте используют несколько языков (например, русский, английский и немецкий). Нельзя же использовать обе таблицы сразу.
Для решения этих проблем в начале $90$-х годов прошлого столетия был разработан новый стандарт кодирования символов, который назвали Unicode. С помощью этого стандарта стало возможным использование в одном тексте любых языков и символов.
Данный стандарт для кодирования символов предоставляет $31$ бит, что составляет $4$ байта за минусом $1$ бита. Количество возможных комбинаций при использовании данной кодировочной таблицы очень велико: $231 = 2 \ 147 \ 483 \ 684$ (т.е. более $2$ млрд.). Это возможно стало в связи с тем, что Unicode описывает алфавиты всех известных языков, даже «мертвых» и выдуманных, включает многие математические и другие специальные символы. И все-таки информационная емкость $31$-битового Unicode слишком велика, И как следствие, наиболее часто используют именно сокращенную $16$-битовую версию ($216 = 65 \ 536$ значений), в которой представлены все современные алфавиты. В Unicode первые $128$ кодов совпадают с таблицей ASCII.
spravochnick.ru
Кодировка текста — что это такое: как и где её правильно применять
Наши компьютеры понимают только собственный язык нулей и единиц. А чтобы работать с остальными языками, переводят их на свой, вплоть до символа. Это и называется кодировка текста, какого угодно, где каждому символу отведен свой числовой код. Все буквы и остальные знаки хранятся в виде цифр.
Системы кодировок бывают разные. Иногда сайт или текстовая программа неправильно определяют кодировку. Тогда вместо текста мы видим непонятный набор символов.
Чтобы превратить их в читабельный текст, нужно подобрать правильную кодировку. Проще всего сделать это онлайн. На сайте любого декодера нужно только вставить испорченный текст. Декодер сам подберет нужную кодировку и решит проблему.
Кодировка из девяностых
Самый распространённый и широко охватывающий большинство языков стандарт кодировки текста — unicode. В далёком 1991-м году он был предложен как способный вместить в себе любой символ, от иероглифов до специальных знаков музыкальной нотации. Теперь это самая популярная система кодирования текста в интернете. Сохраняя текст в этом стандарте вы скорее всего избежите проблем с декодированием.

Закодировать текст легко
Кодировку текста легко задать почти во всех текстовых редакторах, даже в блокноте. В меню «файл», в разделе кодировки выбирайте подходящую для вас. После чего весь набранный текст будет сохраняться с заданным параметром. Если такого пункта меню вашего блокнота нет, кодировку можно установить при сохранении. Нужно нажать «сохранить как», появится окошко, где выбирается название, тип файла и кодировка.
В более продвинутых текстовых редакторах менять кодировку так же легко. В программе word задать кодировку можно при сохранении. Для этого в меню «файл» (или «ms office» в новых версиях) нужно выбрать пункт «сохранить как…». Теперь нужно вписать название, выбрать тип файла «обычный текст» и нажать кнопку «сохранить». Появится окно, где можно будет выбрать нужную кодировку.
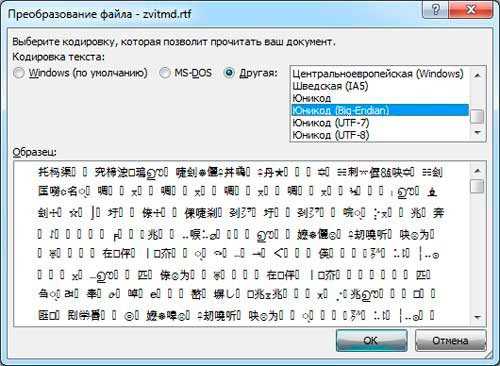
Иногда некорректно отображается текст в excel файлах. Чтобы исправить это, нужно открыть саму программу, выбрать там вкладку «данные» и для получения внешних данных выбрать пункт «из текста». В открывшемся окне отыскиваем наш проблемный файл, выделяем и жмём кнопку «импорт». Теперь для этого файла можно подобрать кодировку, визуально контролируя процесс в окне предварительного просмотра. После останется только сохранить.
Закодированные тексты на ваших сайтах
Так как вычислительные системы понимают только переведённый в цифры текст, один и тот же материал в разных кодировках будет выглядеть для них по-разному. Эта особенность используется некоторыми для плагиата. Всё ещё есть роботы, проверяющие уникальность, которые могут не отличить текст с непривычной им кодировкой. Но если его скопировать в блокнот, он станет нечитабельным или обрастет лишними символами.

Браузер воспринимает текст сайта тоже через кодировку. Если она будет неправильно подобрана, вместо текста будут вопросы или непонятные знаки. Кодировка задается в head, в теге. В кавычках может быть любой стандарт, но utf-8 самый распространенный из них. Поэтому для своих русскоязычных проектов используйте её. Тогда ваши сайты будут корректно отображаться в любом браузере.
Чтобы детальнее разобраться с особенностями кодировки для вашего сайта, смотрите видеоуроки. В них наглядно разбираются вероятные проблемы и их решения. На портале у Михаила Русакова есть целый ряд таких уроков. Там можно найти ответы на множество вопросов по верстке сайтов.

А то, что уже умеете, сможете делать качественнее и быстрее, учась у профессионалов. Все уроки вы сможете сохранить в компьютере, просматривая при необходимости снова.
Подписывайтесь на обновления моего блога, чтобы не пропустить самое интересное. Также добавляйтесь в мою группу Вконтакте, где свежие дублируются свежие обновления. Так вы сможете видеть их прямо в своей ленте новостей.
start-luck.ru