Тарифы на домашний интернет и телевидение Weba
Отзывы
оставить отзыв
все отзывы
оставить отзыв
Неизвестный гость
ВебаСанкт-Петербург
20.07.2022
Всем привет! :) Не скажу, что я супер активный пользователь интернета, в основном пользуюсь вай-фаем для телефона и телевизора, у вебы отличная связь! У меня подключен автоматический платеж, раз в месяц списывают небольшую денежку. Удобно :)
Отзыв проверен и участвует в подсчёте рейтинга провайдера
Неизвестный гость
ВебаСанкт-Петербург
11.06.2022
Отвратительный провайдер у которого постоянные перебои, даже [другой провайдер] выглядит веселее чем эти интернетчики. Настоятельно не рекомендую пользоваться их услугами!!!
Отзыв проверен и участвует в подсчёте рейтинга провайдера
татьяна о.
ВебаСанкт-Петербург
18.05.2022
побоялассь не ставить звезды телевидению (вдруг это влияет на оценку) сразу оговорюсь,что телевидением от ВЕБЫ я не пользуюсь и говорить могу только за интернет -так вот тут жаловаться грех,пользуемся услугами компании уже без малого года три и пока ни разу не думали о смене на другого провайдера.

Отзыв проверен и участвует в подсчёте рейтинга провайдера
Неизвестный гость
ВебаСанкт-Петербург
20.04.2022
лучший интернет из всех, что доводилось юзать - хорошее соединение, вай-фай летает, иногда бывают сбои НО в отличие от [другого провайдера] у которого решение проблемы сбоя иногда занимал сутки, тут в течение часа все решают стабильно. из удобств - общий чатик в телеге, всегда понятно, что проблема например носит массовый характер, можно все обсудить с другими пользователями и даже с генеральным директором - зачастую даже он сам отвечает. удобная оплата, провайдер исключительно по нашему району, сильно не разбазаривают свои силы. монтажники адекватные, подключили все быстро и без лишней пыли грязи
Отзыв проверен и участвует в подсчёте рейтинга провайдера
Елизавета
ВебаСанкт-Петербург
21.04.2020
Хочу сказать Webа огромное спасибо, за их работу, качество и скорость оказываемых услуг! в 9 утра я позвонила, в 11 ко мне уже приехали монтажники для устранения проблемы, возникшей, кстати, не по вине провайдера Weba! Спасибо!!!
Отзыв проверен и участвует в подсчёте рейтинга провайдера
Неизвестный гость
ВебаСанкт-Петербург
03. 09.2019
09.2019
Замечательная компания. Пользуюсь услугами WEBA с 2006 года и полностью доволен! Несколько лет назад у меня начались просадки по скорости - я обратился в техподдержку и мы тут же выяснили, что проблема была в моем старом роутере. Ребята помогли мне выбрать новый и с тех пор я снова наслаждаюсь доступом в сеть без разрывов :) Кстати, где-то год назад я полностью отказался от обычного телевидения и стал смотреть IPTV от Вебы. Радует что можно выбрать пакет каналов по интересам и платить только за них. А какие салюты они устраивают каждый Новый год возле Типанова 29! Не каждый город может похвастаться таким (не то что компания)! В общем, спасибо тебе, дорогая Веба - я рад что мы встретились :)
Отзыв проверен и участвует в подсчёте рейтинга провайдера
Неизвестный гость
ВебаСанкт-Петербург
20.07.2022
Всем привет! :) Не скажу, что я супер активный пользователь интернета, в основном пользуюсь вай-фаем для телефона и телевизора, у вебы отличная связь! У меня подключен автоматический платеж, раз в месяц списывают небольшую денежку.
 Удобно :)
Удобно :)Отзыв проверен и участвует в подсчёте рейтинга провайдера
Неизвестный гость
ВебаСанкт-Петербург
11.06.2022
Отвратительный провайдер у которого постоянные перебои, даже [другой провайдер] выглядит веселее чем эти интернетчики. Настоятельно не рекомендую пользоваться их услугами!!!
Отзыв проверен и участвует в подсчёте рейтинга провайдера
татьяна о.
ВебаСанкт-Петербург
18.05.2022
побоялассь не ставить звезды телевидению (вдруг это влияет на оценку) сразу оговорюсь,что телевидением от ВЕБЫ я не пользуюсь и говорить могу только за интернет -так вот тут жаловаться грех,пользуемся услугами компании уже без малого года три и пока ни разу не думали о смене на другого провайдера.
Отзыв проверен и участвует в подсчёте рейтинга провайдера
Неизвестный гость
ВебаСанкт-Петербург
20.04.2022
лучший интернет из всех, что доводилось юзать - хорошее соединение, вай-фай летает, иногда бывают сбои НО в отличие от [другого провайдера] у которого решение проблемы сбоя иногда занимал сутки, тут в течение часа все решают стабильно.

Отзыв проверен и участвует в подсчёте рейтинга провайдера
Елизавета
ВебаСанкт-Петербург
21.04.2020
Хочу сказать Webа огромное спасибо, за их работу, качество и скорость оказываемых услуг! в 9 утра я позвонила, в 11 ко мне уже приехали монтажники для устранения проблемы, возникшей, кстати, не по вине провайдера Weba! Спасибо!!!
Отзыв проверен и участвует в подсчёте рейтинга провайдера
Неизвестный гость
ВебаСанкт-Петербург
03.09.2019
Замечательная компания. Пользуюсь услугами WEBA с 2006 года и полностью доволен! Несколько лет назад у меня начались просадки по скорости - я обратился в техподдержку и мы тут же выяснили, что проблема была в моем старом роутере.
 Ребята помогли мне выбрать новый и с тех пор я снова наслаждаюсь доступом в сеть без разрывов :)
Кстати, где-то год назад я полностью отказался от обычного телевидения и стал смотреть IPTV от Вебы. Радует что можно выбрать пакет каналов по интересам и платить только за них.
А какие салюты они устраивают каждый Новый год возле Типанова 29! Не каждый город может похвастаться таким (не то что компания)!
В общем, спасибо тебе, дорогая Веба - я рад что мы встретились :)
Ребята помогли мне выбрать новый и с тех пор я снова наслаждаюсь доступом в сеть без разрывов :)
Кстати, где-то год назад я полностью отказался от обычного телевидения и стал смотреть IPTV от Вебы. Радует что можно выбрать пакет каналов по интересам и платить только за них.
А какие салюты они устраивают каждый Новый год возле Типанова 29! Не каждый город может похвастаться таким (не то что компания)!
В общем, спасибо тебе, дорогая Веба - я рад что мы встретились :)Отзыв проверен и участвует в подсчёте рейтинга провайдера
все отзывы
оставить отзыв
все отзывы
оставить отзыв
контакты
Город
Санкт-Петербург
Главный офис
Типанова д. 40
Юридическое наименование
ООО «Сети Веба»
другое
Подключение
+7 (812) 647-00-44
Техподдержка
+7 (812) 647-00-44
Официальный сайт
www.weba.ru
Топ провайдеров в Санкт-Петербурге
Топ провайдеров в Санкт-Петербурге
МТС
билайн
Ростелеком
СкайНет
Недавно подключенные тарифы в Санкт-Петербурге
Название тарифа
СКОРОСТЬ
Каналы
Моб. связь
связь
Стоимость
Рейтинг: 8 место
Отзывы1178
T-100 Lite
СкайНет
100
Мбит/c
550
Р/мес
сравнить
Проверить адрес
Рейтинг: 3 место
Отзывы186
Ракета
еТелеком
100
Мбит/c
550
Р/мес
сравнить
Проверить адрес
Рейтинг: 11 место
Отзывы1090Mega M
Дом.ру
100
Мбит/c
112 + 44HD
Каналов
800
Р/мес
сравнить
Проверить адрес
Отзывы135
Mega M
МНС
100
Мбит/c
112 + 44HD
Каналов
800
Р/мес
сравнить
Проверить адрес
Отзывы50
Цифровой 1.0.1 + Расширенный
ТТК — Северо-Запад
100
Мбит/c
166
Каналов
714
Р/мес
664 *
Р/мес
сравнить
Проверить адрес
Децентрализованный поиск для свободного веба / Хабр
Возможно ли создать поисковую систему, которую на практике нельзя подвергнуть цензуре, влиянию и блокировке?
Говоря техническим языком, возможно ли выполнять полнотекстовый поиск не имея удаленного сервера, удобным для пользователя способом, одновременно храня поисковый индекс в peer-to-peer системе и имея возможность быстро обновлять поисковый индекс?
Да, это возможно!
Существует редкий класс баз данных — peer-to-peer БД.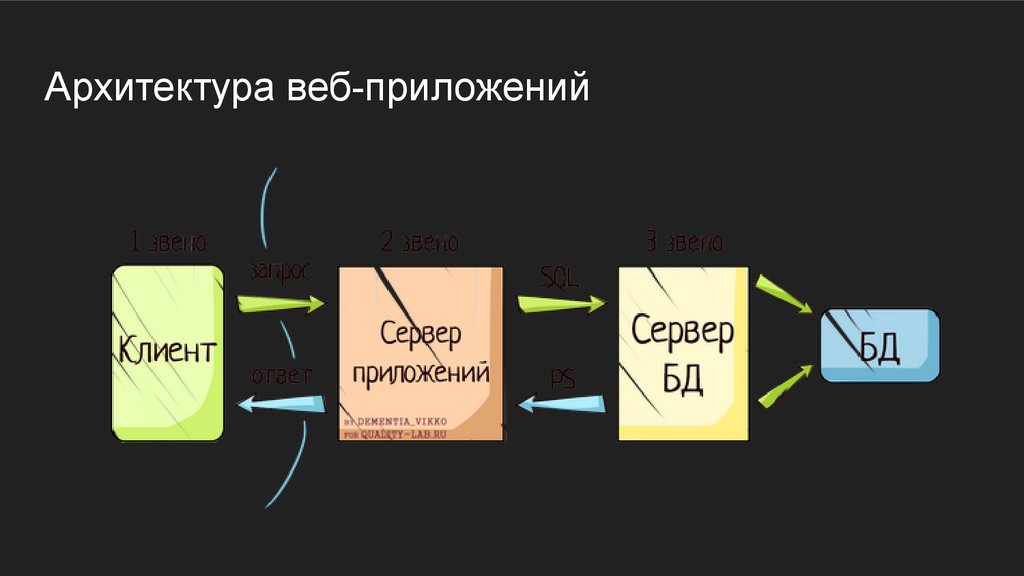 Такие базы проигрывают по большинству параметров обычным БД и используются скорее для экспериментов.
Такие базы проигрывают по большинству параметров обычным БД и используются скорее для экспериментов.
В качестве примера p2p базы данных можно привести Orbit DB. Orbit DB действительно закрывает часть потребностей пользователей обычных БД: в нем реализованы счетчики, append log и KV-хранилище. И все же этого недостаточно для создания полноценных dWeb приложений.
По запросу Distributed Serverless Search найти в Интернете мне ничего не удалось. И раз полнотекстового поиска для dWeb нет, то мы его создадим.
Статья состоит из нескольких частей. В первых частях описаны необходимые для создания децентрализованного поиска и доступные в 2022 году библиотеки и технологии. В последней части техники соединяются в единую поисковую систему и описано как запустить такой поиск самостоятельно.
Я постарался избавить статью от ненужных подробностей и рефлексии, однако за ней стоят долгие месяцы экспериментов и разработки.
Поисковый движок
В 2017 году бывший сотрудник Google опубликовал первую версию Tantivy, поискового движка написанного на Rust. Архитектурно Tantivy похож на Lucene, однако работает быстрее и имеет меньшую кодовую базу.
Архитектурно Tantivy похож на Lucene, однако работает быстрее и имеет меньшую кодовую базу.
Рядом с Tantivy чуть больше года назад я начал пилить сервер Summa. Изначально Summa добавляла в Tantivy GRPC API для поиска и индексации, возможность индексации из топиков Kafka, язык fasteval2 для описания функций ранжирования и некоторые дополнительные функции поиска.
Подробное описание устройства поиска есть в моей более ранней статье, здесь же приведу лишь самые важные для распределенного поиска свойства Tantivy/Summa:
Производительность: уже на тот момент связка работала сильно быстрее Lucene/ES
Иммутабельность данных: после выполнения коммита данные сохраняются в набор файлов, называемых сегментом и далее они не изменяются.
Следующий commit сохраняет новую порцию данных в новые файлы, а факт удаления строки сохранится как бит в битовой маске рядом с уже существующим сегментом. Обновление данных реализуется как DELETE + INSERT, и потому сам сегмент остается неизменным при любых операциях с данными кроме выполнения компакшена (merge в терминах Tantivy).

Локальность запросов: поиск по всей базе данных требует считывания малого количества данных с диска.
Высокая локальность ведет к меньшему количеству чтений с диска. Плохая локальность — основная проблема, не позволяющая просто взять и запустить произвольную БД поверх p2p-системы или сетевой файловой системы. Произвольные чтения перегружают сеть и просто добивают её при сколько-нибудь значимой нагрузке. Комбинируя определенные подходы, в Tantivy получилось достичь высокой локальности для всех компонент поискового индекса.
Поисковый сегмент состоит из нескольких частей: постинг-листов, хранилища документов, словаря термов. На каждый поисковый запрос необходимо найти n постинг-листов, где n — количество слов в запросе, затем считать постинг-листы, выбрать из них необходимые документы и в конце концов вычитать с диска сами документы из хранилища документов.
Локальность словаря термов
Словарь термов — это простой KV-storage, где ключ — слово, а значение — указатель на список документов с этим словом (постинг-лист). KVs для поиска термов должен быть относительно быстрым и сериализуемым на диск. В Tantivy в качестве KVs использовались Finite State Transducers из библиотеки fst.
KVs для поиска термов должен быть относительно быстрым и сериализуемым на диск. В Tantivy в качестве KVs использовались Finite State Transducers из библиотеки fst.
FST — очень крутая штука, быстрая и компактная за счет иммутабельности. Но она оказалась плохо приспособленной для распределенного поиска, так как имела плохую локальность. Поиск терма в fst требует обращений к разрозненным блокам памяти и исправить это никак не возможно, так как свойство заложено в дизайн алгоритма.
Как почетный велосипедостроитель я быстро закостылил это сам заменой KVs на более локальную структуру данных для экспериментов, а спустя несколько месяцев в Tantivy была добавлена реализация KVs на Sorted String Tables (ssTable).
ssTable обладают меньшей производительностью в некоторых ситуациях, что некритично и отличной локальностью, что позволило использовать их в дальнейшем.
Локальность постинг-листа и хранилища документов
С этими двумя структурами все проще, так как они изначально являются сортированными сущностями, снабженными индексом для быстрой навигации по ним. В Tantivy для индексации используются скип-листы, плотность которых можно регулировать, запустив грязные руки в исходники. Смысл регулировки в подборе размера скип-листа и количества хопов по скип-листу таким способом, чтобы считываний из памяти было минимум. Впрочем, сильно улучшить локальность здесь мне не удалось.
В Tantivy для индексации используются скип-листы, плотность которых можно регулировать, запустив грязные руки в исходники. Смысл регулировки в подборе размера скип-листа и количества хопов по скип-листу таким способом, чтобы считываний из памяти было минимум. Впрочем, сильно улучшить локальность здесь мне не удалось.
Достаточно прогрузить в память скип-листы (1 хоп по памяти) и дальше за log(n) от размера мы прыгаем по листам и хранилищу в поисках нужных нам документов. Tantivy из коробки дает еще и поблочное сжатие постинг-листов, что положительно влияет на локальность.
Но и это не все, локальность удалось увеличить еще сильнее агрессивным использованием кеша.
HotCache
Создатель Tantivy спустя пару лет разработки нащупал бизнес-модель и создал Quickwit — поисковик, хранящий поисковые сегменты на Amazon S3. Для меня это оказалось хорошей новостью, так как сеть и хранение индекса в удаленном хранилище теперь стали фичами первого класса в Tantivy.
Довольно скоро после этого в Tantivy появился HotCache — структура данных для быстрого открытия удаленного поискового индекса на чтение.
HotCache — это кеш наиболее часто используемых частей индекса. Tantivy один раз открывает индекс на чтение, прогревает его, а все запросы к файлам кеширует и компактно сохраняет в один файл. Затем этот файл сохраняется и передается репликам, а реплики открывают его и в течении десятков миллисекунд становятся готовыми обслуживать поисковые запросы. Еще одна монетка в копилку локальности.
Последующие тесты показали, что на ~10GB индексе HotCache занимает порядка 10MB, а запросы по высокочастотным термам потребляют по 400-500KB. Пагинация по запросу далее подъедает по 100-150KB на SERP из 10 документов. Это замечательный результат, означающий, что за среднюю поисковую сессию в 6 запросов пользователь совершит чтений на 3-4MB без учета HotCache, заранее загружаемого в память.
IPFS
Поисковый индекс необходимо положить на p2p-систему. Не могу сказать, что я сильно изучал альтернативы, скорее просто выбрал сердцем уже знакомый мне IPFS.
Не могу сказать, что я сильно изучал альтернативы, скорее просто выбрал сердцем уже знакомый мне IPFS.
IPFS — это BitTorrent, но с человеческим лицом. В основе IPFS лежит Kademlia, реализован неплохой десктопный клиент, плагины для Chrome/Firefox, а внутри системы уже много узлов.
У системы есть некоторые проблемы, например плохая работа внутри одной ноды с большим количеством файлов и довольно всратая поддержка сидирования лежащих вне хранилища IPFS файлов. Тем не менее, IPFS можно пользоваться, IPFS работает и работает относительно шустро. Из всех существующих P2P-систем IPFS выглядит наиболее функциональной и перспективной.
IPFS обладает важными для нас особенностями:
IPFS режет файлы на кусочки по N байт и хранит в IPFS уже отдельные кусочки, соединенные DAGом. Обращаться к кусочкам можно по отдельности, таким образом если вам нужны лишь определенные байты из файла то достаточно скачать лишь кусочки, содержащие эти байты
IPFS из коробки имеет удобную концепцию директорий и клиент IPFS напрямую поддерживает публикацию локальных директорий в IPFS.
 Что не менее важно, если две директории имеют общие файлы, то скачивая обе директории, вы не будете скачивать все по два раза. Общие файлы будут скачаны только один раз.
Что не менее важно, если две директории имеют общие файлы, то скачивая обе директории, вы не будете скачивать все по два раза. Общие файлы будут скачаны только один раз.Рядом с IPFS идет IPNS — DNS для IPFS. Любой узел сети IPFS может опубликовать любой файл или директорию под неизменным именем на основе пары ключей и впоследствии выполнять перепубликацию с тем же именем. Это имя может быть разрезолвлено на любом другом узле IPFS.
Пользователи сами становятся сидерами при получение куска данных. Хотя, как и в BitTorrent, здесь можно отключить раздачу, на практике в IPFS пользователи этого не делают и продолжают раздавать скачанные блоки
Все особенности вместе позволяют провернуть следующее: вы можете опубликовать директорию в IPFS, дать ей имя в IPNS и отдать ссылку пользователям. Затем вы обновляете файлы в директории и публикуете их заново под тем же самым IPNS именем. Пользователи, периодически проверяющие IPNS-имя, видят обновление и выкачивают его, по факту скачивая лишь измененные файлы.
Получается, мы теперь можем под постоянным именем выкладывать поисковый индекс в IPFS. Остается избавиться от центрального поискового сервера. Сделал я это в лоб, просто унеся поиск прямо к пользователю под нос.
WASM
Можно было бы сказать, что WASM является одним из многих форматов байт-кода, таким же как LLVM, JVM и десятки других. Но есть у него одна особенность — программу на WASM можно выполнить в браузере.
Разработка WASM началась в 2015 году и спустя несколько лет появились первые рабочие прототипы в популярных браузерах. Уязвимости Meltdown и Spectre притормозили на несколько лет развитие WASM, но последнее время вокруг него опять наблюдается все больше и больше активности.
Нормальный байт-код — это ровно то, что нужно для запуска нормальных программ в браузере. Простите мне мою нелюбовь к JavaScript и давайте спишем ее в личные недостатки.
Звезды и здесь сошлись: в мире Rust существует проект wasm-bindgen. Этот тулинг позволяет собрать программу на Rust в WASM, снабдить ее JavaScript-биндингами и получить на выходе модуль, который можно импортировать и использовать в внутри браузера.
Первые попытки запустить поисковый движок Summa внутри браузера в начале лета 2022 года не увенчались успехом. Браузерный JS исполняется Event Loop’ом по одной таске за раз в один поток, поэтому наивная попытка скомпилировать движок и запустить его в Chrome провалилась же на первом растовом Mutex’e.
Wasm-bindgen был все же еще относительно сырым, а гигантские стектрейсы и чёрти где разыменованные указатели на некоторое время выбили почву у меня из под ног, и идея была отложена в стол. Тем более опыта на Rust на тот момент было с гулькин нос, а JavaScript я всеми силами старался избегать, как вы уже поняли.
Однако иногда упоротая одержимость идеями может брать верх. В сентябре я провел десяток дней за красноглазым курением мануалов wasm-bindgen и его флагов. Я читал треды на GitHub Issues перед сном и выяснял почему флаги компиляции работают через жопу. В приступах помутнения я пытался обмануть компилятор, расставляя unsafe и создавая тут и там примитивы синхронизации в надежде, что хоть в этот раз компилятор расслабится, отвлечется и пропустит мой код. Каждый раз все кончалось ошибками памяти.
Каждый раз все кончалось ошибками памяти.
В приступах прокрастинации я натыкался на треды в Интернете, где мои предшественники пытались запустить что-то сложное на Rust внутри браузера. Эти треды были усеяны черепами и предупреждающими надписями.
В конце концов я распилил зависимости Summa и переложил вагоны JSONов. Слой похода за файлами на диск был заменен на слой, делающий HTTP-Range запросы за файлами.
Ежеминутные проклятия в адрес JavaScript по поводу отсутствующей типизации и семиэтажный мат на жуткий мультитрединг браузера, смехотворно названный Web Worker API, распугали всех моих домашних. Но неделю назад мне таки удалось запихнуть поисковый движок в этот чертов браузер. В тот вечер в голове опрокинулся маленький бочонок с эндорфинами.
Результат страданий — NPM модуль summa-wasm, содержащий tantivy и модуль summa-core (парсер запросов, токензайзеры и рутины для работы с индексом). Библиотека принимает описание того, как ей достучаться до файлов поискового индекса по сети. В ответ она даст вам функцию search, способную выполнить полнотекстовый поиск.
В ответ она даст вам функцию search, способную выполнить полнотекстовый поиск.
Соединяем все вместе
Возможно, вы уже догадались как все должно работать. Исходный код веб-интерфейса, summa и summa-wasm опубликован на GitHub, здесь же я разберу ключевые моменты. Более полноценная документация живет на https://izihawa.github.io, но так как проект я пилю в одно жало и в свободное время, то скорее всего что-нибудь да пропустил. Пишите мне в личку, если будут баги сборки или дыры в документации.
Сборка поискового индекса
Для сборки индекса я буду использовать сервер Summa, но summa-wasm также способен открыть и обычный индекс Tantivy. В Summa реализованы функции, снижающие объемы сетевых обновлений через управление политикой слияния сегментов. Я послал соответствующие патчи в апстрим Tantivy, но гарантий что их примут нет, так что лучше сразу берите в руки Summa.
Кроме Summa я запилил на Python асинхронный клиент aiosumma, который будет использован в примерах дальше. Поехали!
Поехали!
# Установим клиент `aiosumma` на Python для выполнения запросов к summa pip3 install -U aiosumma # Создадим директорию для индекса mkdir data # Сгенерируем конфиг для Summa docker run izihawa/summa-server:testing generate-config -d /data \ -g 0.0.0.0:8082 -m 0.0.0.0:8084 -i host.docker.internal:5001 > summa.yaml # И запустим Summa docker run -v $(pwd)/summa.yaml:/summa.yaml -v $(pwd)/data:/data \ -p 8082:8082 -p 8084:8084 \ izihawa/summa-server:testing serve /summa.yaml
Дальше берем публично доступный дамп базы данных Wiki Books. Можете зарядить туда свои данные, предварительно нарисовав схему данных по аналогии.
Создание схемы# Download sample dataset CURRENT_DUMP=$(curl -s -L "https://dumps.wikimedia.org/other/cirrussearch/current" | grep -oh '\"enwikibooks.*\content.json\.gz\"' | tr -d '"') wget "https://dumps.wikimedia.org/other/cirrussearch/current/$CURRENT_DUMP" -O enwikibooks.json.gz gunzip enwikibooks.json.gz # Create index schema in file cat << EOF > schema.yaml --- # yamllint disable rule:key-ordering index_name: page compression: Zstd multi_fields: ["category"] default_fields: ["opening_text", "title", "text"] writer_heap_size_bytes: 1073741824 writer_threads: 4 schema: > - name: category type: text options: indexing: fieldnorms: true record: position tokenizer: default stored: true - name: content_model type: text options: indexing: fieldnorms: true record: basic tokenizer: default stored: true - name: opening_text type: text options: indexing: fieldnorms: true record: position tokenizer: default stored: true - name: auxiliary_text type: text options: indexing: fieldnorms: true record: position tokenizer: default stored: true - name: language type: text options: indexing: fieldnorms: true record: basic tokenizer: default stored: true - name: title type: text options: indexing: fieldnorms: true record: position tokenizer: default stored: true - name: text type: text options: indexing: fieldnorms: true record: position tokenizer: default stored: true - name: timestamp type: date options: fast: single fieldnorms: false indexed: true stored: true - name: create_timestamp type: date options: fast: single fieldnorms: false indexed: true stored: true - name: popularity_score type: f64 options: fast: single fieldnorms: false indexed: true stored: true - name: incoming_links type: u64 options: fast: single fieldnorms: false indexed: true stored: true - name: namespace type: u64 options: fast: single fieldnorms: false indexed: true stored: true EOF
И наконец-то — наливка данных. Я взял половину строк, чтобы после начальной публикации можно было долить вторую половину и протестировать инкрементальное обновление данных
Я взял половину строк, чтобы после начальной публикации можно было долить вторую половину и протестировать инкрементальное обновление данных
# Создаем индекс из схемы summa-cli localhost:8082 - create-index-from-file schema.yaml # Грузим каждую 4-ую строку. В исходном дампе половина строк технические, их нужно выкинуть # Наливка индекса займет некоторое время awk 'NR%4==0' enwikibooks.json | summa-cli localhost:8082 - index-document-stream page # Коммит summa-cli localhost:8082 - commit-index page --commit-mode Sync
Проверим работает ли обычный поиск:
summa-cli localhost:8082 - search page '{"match": {"value": "astronomy"}}' '[{"top_docs": {"limit": 10}}, {"count": {}}]'Публикация индекса в IPFS
Для публикации индекса в IPFS необходимо установить IPFS.
После запуска демона IPFS выполним публикацию с копированием файлов внутрь IPFS. Summa также поддерживает —no-copy режим, но из-за ограничений IPFS нужны некоторые приседания, которые здесь хотелось бы опустить.
summa-cli localhost:8082 - publish-index page --copy
В ответ должно вернуться что-то типа
{
"key": {
"name": "page",
"id": "k51qzi5uqu5dg9kaxpau2an7ae09yl4yrgna5x8uunvwn5wy27tr7r8uddxn72"
}
}Для индекса с именем page сервер создал в IPFS пару ключей с именем page и опубликовал индекс в IPNS. Готово, в IPFS выложен поисковый индекс, который может скачать кто угодно.
Сборка веб-интерфейса для поискового индекса
Репозиторий Summa имеет демонстрационный веб-интерфейс. Интерфейс не претендует на функциональность и служит лишь иллюстрацией того, как использовать модуль summa-wasm. Но лучше все-таки посмотреть на него одним глазом — подводных камней я собрал немеренно.
Для использования локального демона IPFS из веб-интерфейса необходимо настроить CORS-заголовки в IPFS. От этого шага возможно будет избавиться после патчей в IPFS, которые добавят в HTTP интерфейс демона нужную функциональность и позволят браузеру ходить в Same Domain, а не в отдельное API на другом порту.
Но пока нужные функции IPFS существуют только в выделенном IPFS API приходится выполнять эти приседания с настройкой демона.
# Патчим CORS # Данные разрешения слишком широкие и возможно вам необходимо будет их настроить под себя ipfs config --json API.HTTPHeaders.Access-Control-Allow-Origin '["*"]' ipfs config --json API.HTTPHeaders.Access-Control-Allow-Methods '["GET", "POST"]'
Затем собираем и запускаем веб-интерфейс. Если захотите собрать интерфейс со своим индексом, то поменяйте IPNS имя на то, которое вы получили в предыдущем пункте
git clone https://github.com/izihawa/summa cd summa/summa-web npm i && npm run dev
Все готово, можно выполнять поиск. Первые разы все будет подтормаживать, так как IPFS необходимо найти пиры и прогрузить первоначальные данные.
Обновление данных
Мы можем долить данные в индекс
awk 'NR%4==2' enwikibooks.json | summa-cli localhost:8082 - index-document-stream page summa-cli localhost:8082 - commit-index page --commit-mode Sync
и после этого заново опубликовать индекс
summa-cli localhost:8082 - publish-index page --copy
Веб-интерфейс в браузере пользователя заново разрезолвит это имя в локальном IPFS, после чего сможет обращаться к уже обновленной базе данных. Приказов сверху от центрального сервера для этого не требуется и интерфейс, собранный единожды, далее может постоянно подтягивать новые данные из IPFS. Да что уж там, сам интерфейс может быть собран и опубликован внутри IPFS.
Приказов сверху от центрального сервера для этого не требуется и интерфейс, собранный единожды, далее может постоянно подтягивать новые данные из IPFS. Да что уж там, сам интерфейс может быть собран и опубликован внутри IPFS.
Для примера я собрал и выложил подобную страницу, можете проверить как это работает тут, предварительно установив IPFS Companion.
Зачем все это?
Реализация поиска поверх IPFS обладает несомненными плюсами.
Высокая локальность обеспечивает вменяемое время поиска, а внутреннее устройство IPFS помогает разносить горячие блоки поискового индекса по пользователям. Чем чаще пользователи выполняют запрос, тем больше сидеров будет у блоков c запрошенными документами. Система обладает способностью самостоятельно увеличивать свою пропускную способность в ответ на нагрузку.
Репликация индекса между его пользователями не дает отцензурировать поисковую выдачу. В эру государств-левиафанов, пожирающих свободу информации, такое качество оказывается полезным.
 Да, все еще можно уничтожить источник обновлений, но теперь его можно спрятать далеко и надежно, а за доставку будет отвечать IPFS
Да, все еще можно уничтожить источник обновлений, но теперь его можно спрятать далеко и надежно, а за доставку будет отвечать IPFSИндекс надежно сохраняется на неопределенное время до тех пор, пока есть его пользователи. В мире существуют наборы данных, которые стоило бы сохранять получше — образовательные видео, научные публикации, книги, исходные коды открытого ПО. IPFS и до существования Summa решал эту задачу, однако теперь стало возможно организовать поиск по сохраненному точно таким же децентрализованным способом.
Возможно, это ещё одна разработка в стол. Возможно, нет. Но если вам есть что сохранить или есть что-то, что нужно спрятать от Левиафана, то теперь вы знаете как сделать поиск для этого.
Веб-определение и значение | Dictionary.com
- Верхние определения
- Синонимы
- Викторина
- Связанный контент
- Примеры
- British
- Scientific
- Cultural
Это показывает уровень класса, основанный на сложности слова.
[ Интернет ]
/ wɛb /
Сохранить это слово!
См. синонимы для: web / webbed / webbing на Thesaurus.com
Показывает уровень оценки в зависимости от сложности слова.
сущ.
что-то, образованное или как бы путем переплетения или переплетения.
Тонкий шелковистый материал, сотканный пауками и личинками некоторых насекомых, таких как паутинные черви и тентовые гусеницы; паутина.
Текстиль.
- тканая ткань, особенно цельный кусок ткани в процессе ткачества или после того, как он выходит из ткацкого станка.
- плоская тканая полоса без ворса, часто встречающаяся на одном или обоих концах восточного ковра.
что-то похожее на тканый материал, особенно что-то переплетенное или похожее на решетку: Он посмотрел на паутину ветвей старого дерева.
сложная совокупность обстоятельств, фактов и т. д.: вор был осужден на основании паутины улик. Кто может понять паутину жизни?
Кто может понять паутину жизни?
то, что затягивает или запутывает; ловушка: невинные путешественники, попавшие в паутину международного терроризма.
лямки.
Зоология. перепонка, соединяющая пальцы животного, как пальцы ног водоплавающих птиц.
Орнитология.
- ряд зазубрин на каждой стороне стержня пера.
- ряд с обеих сторон, в совокупности.
неотъемлемая или отдельная часть балки, рельса, фермы или аналогичного изделия, которая образует непрерывное, плоское, узкое, жесткое соединение между двумя более прочными, более широкими параллельными частями, такими как полки конструктивной формы, оголовок и подошва рельса или верхний и нижний пояс фермы.
Машины. рычаг кривошипа, обычно один из пары, удерживающий один конец шатунной шейки на его внешнем конце.
Архитектура. (в своде) любая поверхность, обрамленная оребрением.
большой рулон бумаги, как для непрерывной подачи рулонного пресса.
сеть взаимосвязанных станций, служб, средств связи и т. д., охватывающая регион или страну.
Неофициальный. сеть радио- или телевещательных станций.
Иногда Интернет .Цифровые технологии. World Wide Web (с предшествующим словом the, за исключением случаев, когда оно используется перед существительным).
глагол (используется с дополнением), webbed, web·bing.
покрыть паутиной или как бы паутиной; окутывать.
, чтобы заманить в ловушку или заманить в ловушку.
глагол (используется без дополнения), webbed, web·bing.
для изготовления паутины.
ДРУГИЕ СЛОВА ДЛЯ сети
1 сеть.
5 ткань, клубок, лабиринт.
6 малый барабан.
См. синонимы слова в сети на Thesaurus.com
ВИКТОРИНА
Сыграем ли мы «ДОЛЖЕН» ПРОТИВ. «ДОЛЖЕН» ВЫЗОВ?
Следует ли вам пройти этот тест на «должен» или «должен»? Это должно оказаться быстрым вызовом!
Вопрос 1 из 6
Какая форма обычно используется с другими глаголами для выражения намерения?
Происхождение паутины
Впервые записано до 900 г. ; среднеанглийский (существительное), древнеанглийский; родственен голландскому, нижненемецкому webbe, древнескандинавскому vefr; сродни ткать
; среднеанглийский (существительное), древнеанглийский; родственен голландскому, нижненемецкому webbe, древнескандинавскому vefr; сродни ткать
историческое использование слова паутина
16. См. в Интернете
ДРУГИЕ СЛОВА ИЗ паутины
паутина, прилагательноевеблайк, прилагательноеСлова поблизости паутина Интернет, Web 2.0, веб-адрес, веб-приложение, Webb, веб-интерфейс
Dictionary.com Полный текст Основано на словаре Random House Unabridged Dictionary, © Random House, Inc., 2022
Слова, связанные с паутиной
сеть, сеть, экран, паутина, сложность, запутанность, ткань, волокно, филигрань, паутинка, взаимосвязь, переплетение, участие, лабиринт , кружево, решетка, циновка, лабиринт, сетка, мешворк
Как использовать слова «паутина» в предложении
Сегодня с Google Поиском ничего не меняется, но подумайте об этих изменениях в долгосрочной перспективе и продолжайте улучшать свой веб-сайт.
Google теперь использует BERT для сопоставления историй с проверкой фактов|Барри Шварц|10 сентября 2020 г.
 |Search Engine Land
|Search Engine LandДля сбора фактов ИИ Diffbot читает Интернет так же, как человек, но намного быстрее.
Этот всезнайка ИИ учится, читая всю сеть без остановки|Will Heaven|4 сентября 2020|MIT Technology Review
уже заменены или, по крайней мере, деактивированы.
Европейские регуляторы конфиденциальности формируют рабочую группу для рассмотрения жалоб на код Google и Facebook|Дэвид Мейер|4 сентября 2020 г.|Fortune
Комната представляет собой двухмерный пиксельный рисунок, отображаемый в веб-браузере.
Создайте свою собственную музыку для карантина с помощью искусственного интеллекта Google|Карен Хао|4 сентября 2020 г.|MIT Technology Review быть связанным с Cygilant.
Стартап киберугроз Cygilant атакован программой-вымогателем|Зак Уиттакер|3 сентября 2020 г.|TechCrunch
Он имел в виду веб-цензуру за Великим брандмауэром.
Интернет в Китае свободнее, чем вы думаете|Брендон Хонг|27 декабря 2014 г.
 |DAILY BEAST
|DAILY BEASTБлагодаря обширной сети ресурсов и услуг, включая группы поддержки, Центр часто помогает спасать жизни этих людей.
ЛГБТ-центр, изменивший нашу жизнь|Джастин Джонс|22 декабря 2014 г.|DAILY BEAST
Как на ваш опыт повлияли цифровые знакомства и социальные сети?
Невыносимая белизна протеста|Равия Камеир, Джадник Мэйард|10 декабря 2014 г.|DAILY BEAST
Звонивший упомянул мою работу, которая была сосредоточена в основном на потребительских товарах, мобильных приложениях, новых стартапах и веб-тенденциях.
Новая веха писательницы: ее первая угроза смерти|Энни Гаус|1 декабря 2014|DAILY BEAST
Это заставляет нас задаться вопросом, почему галактики и их черные дыры каким-то образом «знают», где они находятся в космической сети.
Танго черной дыры|Мэттью Р. Фрэнсис|24 ноября 2014|DAILY BEAST
Неудивительно, что он чувствовал себя как дома в утином пруду, созданном для перепончатых людей.
Сказка о дедушке Кроте|Артур Скотт Бейли
«Сейчас не удручающе спокойно», — сказали сверхпрочные рамы — их называли паутинными рамами — в машинном отделении.
Рассказы и стихи Киплинга, которые должен знать каждый ребенок, Книга II|Rudyard Kipling
Прикосновение к мягкой ткани успокоило его: она была мягкой, словно соткана из паутины, и прочной, как стальные волокна.
Поразительные истории, май 1931 года|Разное
Эти нити в паутине промышленности, впервые засиявшие в тот день, были жизнями двух маленьких детей.
Подземный мир|Джеймс С. Уэлш
Сначала балки имели сплошные или пластинчатые стенки, но для пролетов более 100 футов теперь стенка всегда состоит из распорных стержней.
Encyclopaedia Britannica, 11th Edition, Volume 4, Part 3|Various
Британский словарь определений слова web
web
/ (wɛb) /
структура, конструкция, и т. д. 1 существительное 900 путем или как бы путем переплетения или переплетения Родственные прилагательные: retiary
д. 1 существительное 900 путем или как бы путем переплетения или переплетения Родственные прилагательные: retiary
сетка из тонких прочных нитей склеропротеина, построенная пауком из жидкости, выделяемой его фильерами, и используемая для ловли насекомых См. также паутину (по определению 1)
подобная сеть нитей, сплетенная личинками определенных насекомых, например тутового шелкопряда
ткань, особенно в процессе ткачества
перепонка, соединяющая пальцы ног некоторых водоплавающих птиц или пальцы таких водных млекопитающих, как выдра
лопасть птичьего пера
архитектор поверхность ребристого свода, расположенная между ребрами
центральная часть двутавровой или двутавровой балки, соединяющая две полки балки
любая перемычка фасонная часть отливки, используемая для армирования
радиальная часть кривошипа, соединяющая шатунную шейку с коленчатым валом
тонкий кусок лишнего материала, прикрепленный к поковке; плавник
- непрерывная полоса бумаги, сформированная на бумагоделательной машине или подаваемая с рулона в некоторые печатные машины
- (в качестве модификатора) офсетная лента; паутинный пресс
тканый край, без ворса, некоторых ковров
- паутина (часто заглавная) сокращение от World Wide Web
- (в качестве модификатора) веб-сайт; веб-страницы
любое сооружение, сооружение и т. д., представляющее собой замысловатую или сложную паутину интриг
д., представляющее собой замысловатую или сложную паутину интриг
глагольные паутины, паутины или паутины
(tr) покрывать паутиной или как бы паутиной
(tr) запутывать или заманивать в ловушку
(intr) построить паутину
Производные формы паутины
webless, прилагательноеweblike, прилагательноеПроисхождение слова для паутины
Староанглийское webb; связанные со старосаксонским , древневерхненемецким webbi , древнескандинавским vefr
Английский словарь Коллинза — полное и полное цифровое издание 2012 г. © William Collins Sons & Co. Ltd. 1979, 1986 © HarperCollins Publishers 1998, 2000, 2003, 2005, 2006, 2007, 2009, 2012
Научные определения паутины
паутина
[ wĕb ]
Структура из тонких, цепких, эластичных, нитевидных волокон . Личинки некоторых насекомых также плетут паутину, которая служит защитным убежищем для кормления и может включать в себя листья или другие части растений.
Перепонка или кожная складка, соединяющая пальцы ног у некоторых животных, особенно плавающих, таких как водоплавающие птицы и выдры. Паутина улучшает способность стопы отталкиваться от воды.
также Web Всемирная паутина.
Научный словарь American Heritage® Авторские права © 2011. Опубликовано издательством Houghton Mifflin Harcourt Publishing Company. Все права защищены.
Культурные определения для Интернета
См. Интернет.
Новый словарь культурной грамотности, третье издание Авторское право © 2005 г., издательство Houghton Mifflin Harcourt Publishing Company. Опубликовано издательством Houghton Mifflin Harcourt Publishing Company. Все права защищены.
Службы облачных вычислений — Amazon Web Services (AWS)
Ознакомьтесь с платформой AWS, облачными продуктами и возможностями
Начало работы
Ускорьте получение аналитических сведений с помощью быстрого, простого и безопасного облачного хранилища данных в любом масштабе
Начало работы
Amazon S3 Object Lambda
Добавьте собственный код для обработки данных, полученных из Amazon S3, перед их возвратом в приложение
Подробнее
AWS Skill Builder — изучайте AWS, работая с AWS
Получите доступ к более чем 100 лабораториям AWS Builder, которые быстро отточат ваши навыки работы с облачными средами в безопасной изолированной среде
Подпишитесь сегодня
Посмотреть наши решения
По отраслям
Посмотреть все отрасли
По категориям технологий
Посмотреть все решения
Посмотреть наши продукты
Рекомендуемые услуги
Аналитика
Управление облачными финансами
Вычислить
Контейнеры
База данных
Внешний интерфейс для Интернета и мобильных устройств
Интернет вещей
Машинное обучение
Сеть и доставка контента
Безопасность, идентификация и соответствие требованиям
Бессерверный
Хранение
В этой категории товаров не найдено.

Просмотреть все категории товаров
В этой категории товаров не найдено.
Просмотреть все продукты Analytics
В этой категории товаров не найдено.
Посмотреть все облачные продукты для управления финансами
В этой категории товаров не найдено.
Просмотреть все вычислительные продукты
В этой категории товаров не найдено.
Посмотреть все контейнеры Продукция
В этой категории товаров не найдено.

Просмотреть все продукты баз данных
В этой категории товаров не найдено.
Просмотреть все интерфейсные веб- и мобильные продукты
В этой категории товаров не найдено.
Просмотреть все продукты Интернета вещей
В этой категории товаров не найдено.
Посмотреть все продукты для машинного обучения
В этой категории товаров не найдено.
Просмотреть все продукты для сетей и доставки контента
В этой категории товаров не найдено.

Просмотреть все продукты для обеспечения безопасности, идентификации и соответствия требованиям
В этой категории товаров не найдено.
Посмотреть все бессерверные продукты
В этой категории товаров не найдено.
Посмотреть все продукты для хранения
Обучение и сертификация
Для строителей
Для лиц, принимающих решения
Для строителей
Для разработчиков, специалистов по обработке и анализу данных, архитекторов решений и всех, кто хочет узнать, как строить на AWS уже сегодня
Для лиц, принимающих решения
Для технических и бизнес-лидеров, которые развивают облачные навыки в своей организации, чтобы обеспечить инновации и преобразования
Поддержка инноваций для клиентов
Рекомендуемые инновации для клиентов
Реклама и маркетинг
Аэрокосмическая и спутниковая промышленность
Сельское хозяйство
Автомобильная промышленность
Образование
Энергия
Финансовые услуги
Правительство
Здравоохранение и медико-биологические науки
Производство
СМИ и развлечения
Розничная торговля | Потребительские товары в упаковке
Путешествия и гостиничный бизнес
В этой категории товаров не найдено.

Просмотреть все истории клиентов
В этой категории товаров не найдено.
В этой категории товаров не найдено.
В этой категории товаров не найдено.
В этой категории товаров не найдено.
В этой категории товаров не найдено.
В этой категории товаров не найдено.

В этой категории товаров не найдено.
В этой категории товаров не найдено.
В этой категории товаров не найдено.
В этой категории товаров не найдено.
В этой категории товаров не найдено.
В этой категории товаров не найдено.

В этой категории товаров не найдено.
Разработано с учетом самых высоких требований
Глобальная сеть регионов AWS
Облако AWS охватывает 87 зон доступности в 27 географических регионах по всему миру. Объявленные планы по открытию еще 24 зон доступности и 8 регионов AWS в Австралии, Канаде, Индия, Израиль, Новая Зеландия, Испания, Швейцария и Таиланд.
Пропустить карту
Войдите в консоль
Узнайте об AWS
- Что такое AWS?
- Что такое облачные вычисления?
- AWS Разнообразие, равенство и инклюзивность
- Что такое DevOps?
- Что такое контейнер?
- Что такое озеро данных?
- Облачная безопасность AWS
- Что нового
- Блоги
- Пресс-релизы
Ресурсы для AWS
- Начало работы
- Обучение и сертификация
- Портфель решений AWS
- Архитектурный центр
- Часто задаваемые вопросы по продуктам и техническим вопросам
- Аналитические отчеты
- Партнеры AWS
Разработчики на AWS
- Центр разработчиков
- SDK и инструменты
- .
 NET на AWS
NET на AWS - Python на AWS
- Java на AWS
- PHP на AWS
- JavaScript на AWS
Помощь
- Свяжитесь с нами
- Подать заявку в службу поддержки
- Центр знаний
- AWS re: Сообщение
- Обзор поддержки AWS
- Юридический
- Карьера в AWS
Amazon — работодатель с равными возможностями: Меньшинства / Женщины / Инвалидность / Ветеран / Гендерная идентичность / Сексуальная ориентация / Возраст.
- Конфиденциальность
- |
- Условия сайта
- |
- Настройки файлов cookie
- |
- © 2022, Amazon Web Services, Inc. или ее дочерние компании. Все права защищены.
Поддержка AWS для Internet Explorer заканчивается 31.