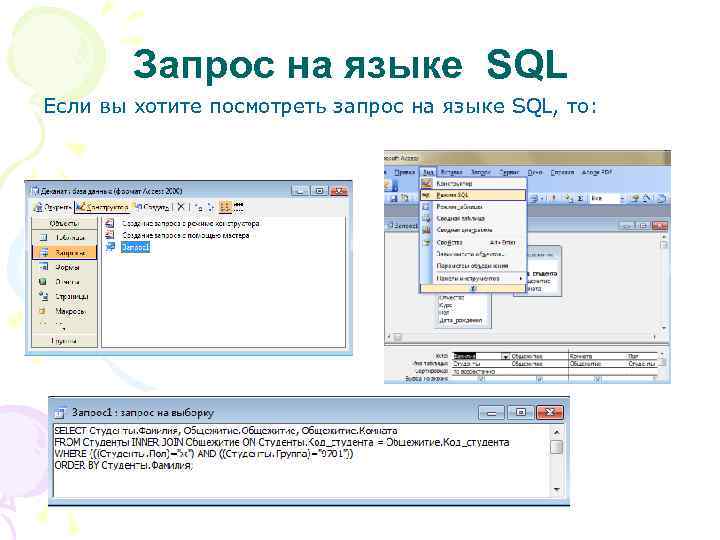
Запрос SQL на добавление и удаление записей
В этой статье мы разберём, пожалуй, одни из самых важных SQL-запросов. Это запросы на добавление и удаление записей из таблицы базы данных. Поскольку, ОЧЕНЬ часто приходится добавлять новые записи в таблицу, причём делать это в автоматическом режиме, то данный материал обязателен к изучению.
Для начала SQL-запрос на добавление новой записи в таблицу:
INSERT INTO users (login, pass) values('TestUser', '123456')При добавлении записи вначале идёт команда «INSERT INTO«, затем название таблицы, в которую мы вставляем запись. Далее идёт в круглых скобках названия полей, которые мы хотим заполнить. А затем в круглых скобках после слова «values» начинаем перечислять значения тех полей, которые мы выбрали. После выполнения этого запроса в нашей таблице появится новая запись.
Иногда требуется обновить запись в таблице, для этого существует следующий SQL-запрос:
UPDATE users SET login = 'TestUser2', pass='1234560' WHERE login='TestUser'Данный запрос является более сложным, так как он имеет конструкцию «WHERE«, но о ней чуть ниже. Вначале идёт команда «UPDATE«, затем имя таблицы, а после «SET» мы описываем значения всех полей, которые мы хотим изменить. Было бы всё просто, но встаёт вопрос: «А какую именно запись следует обновлять?«. Для этого существует «WHERE«. В данном случае мы обновляем запись, поле «login» у которой имеет значение «TestUser«. Обратите внимание, что если таких записей будет несколько, то обновятся абсолютно все! Это очень важно понимать, иначе Вы рискуете потерять свою таблицу.
Вначале идёт команда «UPDATE«, затем имя таблицы, а после «SET» мы описываем значения всех полей, которые мы хотим изменить. Было бы всё просто, но встаёт вопрос: «А какую именно запись следует обновлять?«. Для этого существует «WHERE«. В данном случае мы обновляем запись, поле «login» у которой имеет значение «TestUser«. Обратите внимание, что если таких записей будет несколько, то обновятся абсолютно все! Это очень важно понимать, иначе Вы рискуете потерять свою таблицу.
Давайте немного ещё поговорим о «WHERE«. Помимо простых проверок на равенство существуют так же и неравенства, а также логические операции: AND и OR.
UPDATE users SET login = 'TestUser2', pass='1234560' WHERE id < 15 AND login='TestUser' Данный SQL-запрос обновит те записи, id которых меньше 15 И поле «login» имеет значение «TestUser«. Надеюсь, Вы разобрались с конструкцией «WHERE«, потому что это очень важно. Именно «WHERE» используется при выборке записей из таблиц, а это самая частоиспользуемая задача при работе с базами данных.
Именно «WHERE» используется при выборке записей из таблиц, а это самая частоиспользуемая задача при работе с базами данных.
И, напоследок, простой SQL-запрос на удаление записей из таблицы:
DELETE FROM users WHERE login='TestUser2'После команды «DELETE FROM» идёт имя таблицы, в которой требуется удалить записи. Дальше описываем конструкцию «WHERE». Если запись будет соответствовать описанным условиям, то она будет удалена. Опять же обратите внимание, в зависимости от количества записей, удовлетворяющих условию после «WHERE«, может удалиться любое их количество.
Вот Вы и узнали,
Полный курс по PHP и MySQL: http://srs.myrusakov.ru/php
- Создано 16.01.2011 17:44:14
- Михаил Русаков
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov. ru)!
ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
запрос — Большая Энциклопедия Нефти и Газа, статья, страница 2
Cтраница 2
Поскольку этим способом комбинацию операций соединения можно выполнить по многим различным путям доступа, Сэлинджер и др. [90] разработали метод трансляции SQL-запроса в такую программу, которая с выгодой выбирает путь доступа из числа предоставляемых СУБД SYSTEM R. По существу, метод Сэлинджера состоит в выращивании дерева альтернативных комбинаций операций соединения. Цена определяется следующими факторами.
[16]
Цена определяется следующими факторами.
[16]
Блок связи с БД, получения и представления результатов, структурная схема которого приведена на рис. 10.4, состоит из следующих основных процедур: формирование
| Компоненты вкладок Data Access и BDE.| Взаимодействие-компонентов, отображения и доступа к данным. [18] |
Компонент DataSource позволяет оперативно выбирать источник данных, использовать один и тот же компонент, например, DBGrid для отображения данных из таблицы или результата выполнения SQL-запроса к этой таблице. [19]
В начале данной главы я уже говорил о том, что одной из целей ( и одной из проблем) программирования в среде клиент-сервер является корректное разделение нагрузки между компьютерами Когда вы отправляете SQL-запрос ( в котором с Держится SQL-выражение) с клиентского компьютера на сервер, большую часть Работы, связанной с обработкой данных, выполняет сервер При этом вы должны Использовать выражения select таким образом, чтобы набор данных, передаваемых с клиента на сервер, обладал как можно меньшим размером Чем меньше объем Данных, передаваемых между компьютерами, тем ниже нагрузка на сеть.
Состав записей, входящих в пути доступа вариантов поиска, зададим матрицей Е — eSj, где esj 1, если j — я запись логической структуры БД вошла в s — fi план SQL-запроса, esj — 0 — в противном случае. [21]
Если эта операция проводится для таблицы небольшого или среднего размера ( скажем, не более 10000 строк), то такой запрос вполне приемлем, но в крупных таблицах скорость выполнения увеличится, если перенести математические операции из SQL-запроса в код йриложения. [22]
Введем следующие переменные: xrv — 1, если г-я процедура СОД включена в состав и-го модуля, v — 1, V; xrv — 0 — в противном случае; ysv 1, если для — и-го модуля выбирается s — й вариант реализации
| Средство Interactive SQL. [24] |
Все команды, которые будут рассмотрены в этом разделе, будут выполняться в окне Interactive SQL. Для того чтобы выполнить SQL-запрос сделайте следующее.
[25]
Для того чтобы выполнить SQL-запрос сделайте следующее.
[25]
Компонент связи с базой данных хранит информацию об используемом сервере баз данных, а также сведения, необходимые для подключения к серверу. Однонаправленный набор данных хранит базовый SQL-запрос, направляемый серверу баз данных. В ответ на этот запрос сервер передает данные, которые компонент, реализующий однонаправленный набор данных, преобразует в пакет и передает компоненту-провайдеру. Компонент-провайдер является связующим звеном между однонаправленным и клиентским наборами данных. [26]
Сформированное выражение логического условия SQL-запроса направляется для дальнейшей обработки на сервер. Процесс передачи осуществляется как обработка события отправки данных формы. Событие отправки возбуждается программным путем. Для передачи данных используется метод POST, поскольку он позволяет передавать требуемый набор параметров, не зависящий от значений полей формы. [27]
[27]
Переход от использования локальных файлов к использованию SQL-серверов ( в английском языке иногда используется термин upsizing) в основном вызван необходимостью увеличить производительность баз данных и обеспечить возможность хранения больших объемов данных. В предыдущем примере, если системе RDBMS посылается
Закладка содержит поле, в котором отображается SQL-запрос создания представления и окно выбора User-Defined SQL. По умолчанию опция User-Defined SQL выключена, и SQL-запрос генерируется автоматически на основе информации, занесенной в закладки Select, From и Where. Запрос можно задать вручную, включив эту опцию, но в этом случае список полей и связи представления на диаграмме отображаться не будут.
[29]
Запрос можно задать вручную, включив эту опцию, но в этом случае список полей и связи представления на диаграмме отображаться не будут.
[29]
| Измененная SQL-команда возвращает заданное количество записей.| На это предупреждение не стоит обращать внимания. [30] |
Страницы: 1 2 3 4
SQL-запросы в SQL Server — руководство для начинающих
Введение
Создание SQL-запросов — простой процесс. Эта статья написана на SQL Server, но большую часть содержимого можно применяется к Oracle, PostgreSQL, MySQL, MariaDB и другим базам данных с небольшими изменениями. Запросы SQL позволяют нам отправлять запросы к базе данных. В этой статье у нас будет быстрое практическое руководство по выполнению ваших собственных запросов из царапать.
Что такое запросы SQL?
SQL означает S структурированный Q uery L язык. Это язык, используемый
по базам данных, чтобы получить информацию. Мы научимся делать запросы на языке SQL.
Это язык, используемый
по базам данных, чтобы получить информацию. Мы научимся делать запросы на языке SQL.
SQL-запросы в SQL Server
Основой запроса в SQL Server является предложение SELECT, которое позволяет выбрать данные для отображения. Начать при этом мы будем использовать базу данных AdventureWorks, содержащую примеры таблиц и представлений, которые позволят нам иметь одни и те же таблицы и данные. Мы также сможем работать с несколькими уже созданными таблицами.
- Примечание: Дополнительные сведения об установке базы данных AdventureWorks см. в следующей статье — Установка и настройка образца базы данных AdventureWorks2016
Запросы SQL и выбор предложения
Начнем с предложения SELECT, предложение select позволит нам получить данные из таблицы.
Следующий запрос покажет все столбцы из таблицы:
ВЫБЕРИТЕ * ИЗ [Отдел кадров]. |
 [Сотрудник]
[Сотрудник]Попробуйте использовать оператор SELECT в одной строке и оператор FROM в другой строке. Так легче читать. Выбрать * означает показать все столбцы из таблицы. Другой способ сделать то же самое — следующий пример:
ВЫБЕРИТЕ [Сотрудник].* ИЗ [Отдел кадров].[Сотрудник]
|
Квадратные скобки необязательны. Они могут помочь, если в именах столбцов есть пробелы (что не рекомендуется). Ты можешь также выберите определенные имена столбцов, например:
ВЫБЕРИТЕ [Идентификатор входа],[Пол] ИЗ [Отдел кадров].[Сотрудник] |
В предыдущем примере показаны столбцы логин и пол. Как видите, данные разделены запятыми. Вы также можете использовать псевдонимы, чтобы иметь более короткое имя, например:
ВЫБЕРИТЕ e. ИЗ [HumanResources].[Employee] e |
 Gender
GenderВ предыдущем примере используется псевдоним e для таблицы Employee. Мы также можем использовать псевдоним для имен столбцов следующим образом:
ВЫБЕРИТЕ e.Gender g FROM [HumanResources].[Employee] e |
Псевдоним столбца для Пола теперь равен g. В следующем примере будут показаны 2 различных возможных значения в столбце пола (мужской или женский):
ВЫБЕРИТЕ РАЗЛИЧНЫЙ e.Gender g FROM [HumanResources].[Employee] e |
Обратите внимание, что DISTINCT — медленная команда, и если таблица содержит несколько миллионов строк, ее выполнение может занять некоторое время и снизить производительность.
Другой пример — предложение TOP. Это предложение используется в SQL Server и не используется в других базах данных, таких как Oracle или MySQL. В следующем примере показаны первые 10 строк таблицы:
В следующем примере показаны первые 10 строк таблицы:
ВЫБЕРИТЕ ПЕРВЫЕ 10 e.[BusinessEntityID], e.Gender g FROM [HumanResources].[Employee] e |
Если мы хотим упорядочить данные по столбцу, порядок по будет очень полезен. В следующем примере показано, как показать BusinessEntityID отсортирован в порядке убывания.
ВЫБЕРИТЕ [BusinessEntityID] ИЗ [HumanResources].[Employee] e ЗАКАЗАТЬ ПО [BusinessEntityID] desc |
- Примечание: Дополнительные сведения о запросах на выборку см. по этой ссылке: Изучение SQL: оператор SELECT
SQL-запросы для фильтрации данных с помощью команды WHERE
Команда where является одним из наиболее распространенных предложений, используемых внутри команды SELECT. Этот пункт позволяет фильтровать данные. В следующем примере показано, как проверить BusinessEntityID сотрудников, занимающих должность инженера-конструктора.
В следующем примере показано, как проверить BusinessEntityID сотрудников, занимающих должность инженера-конструктора.
выберите [BusinessEntityID], [JobTitle] из [HumanResources].[Employee] e , где JobTitle=’Инженер-конструктор’ |
- В примере мы использовали оператор равенства. Полный список операторов T-SQL см. по этой ссылке: Логические операторы (Transact-SQL)
Еще одним мощным оператором является LIKE. Мол, может поможет нам в поисках. В следующем примере показаны BusinessEntityID и Должность сотрудников, должности которых начинаются с Design:
ВЫБЕРИТЕ [BusinessEntityID], [JobTitle] FROM [HumanResources].[Employee] e WHERE JobTitle LIKE ‘Design%’ |
- Дополнительные сведения об операторе LIKE см. по этой ссылке: SQL Like: введение и обзор логического оператора
Оператор IN также является очень распространенным оператором, в следующем примере показаны все сотрудники, чей Должность равна Техническому менеджеру или Старшему конструктору инструментов:
ВЫБЕРИТЕ [BusinessEntityID],JobTitle FROM [HumanResources]. WHERE JobTitle в («Инженерный менеджер», «Старший конструктор инструментов») |
 [Employee] e
[Employee] eЗапросы SQL с агрегатными функциями и оператором use или group by
В запросах SQL нам нужна СУММА строк, среднее значение и другие функции агрегирования. Эти функции часто используются с операторами group by и have.
В первом примере будет показана сумма и среднее значение промежуточного итога таблиц SalesOrderHeader:
ВЫБРАТЬ СУММУ([Промежуточный итог]) КАК ПРОМЕЖУТОЧНЫЙ ИТОГ,СРЕДНИЙ([Промежуточный итог]) КАК СРЕДНИЙПромежуточный итог ИЗ [Продажи].[ЗаголовокЗаказаПродаж] |
В следующем примере показано, как получить сумму столбца orderQty и salesorderid из таблицы salesorderdetail. Мы группируем информацию по salesorderid и упорядочиваем сумму в порядке убывания:
ВЫБРАТЬ СУММУ([OrderQty]) AS Qty, [SalesOrderID] FROM [Sales]. ГРУППИРОВАТЬ ПО [SalesOrderID] ЗАКАЗАТЬ ПО СУММЕ([OrderQty]) DESC |
 [SalesOrderDetail]
[SalesOrderDetail]- Список агрегатных функций см. по этой ссылке: Агрегатные функции (Transact-SQL)
Запросы SQL для получения данных из нескольких таблиц
Одной из наиболее важных особенностей таблиц является то, что вы можете запрашивать несколько таблиц в одном запросе. Для этого мы используем СОЕДИНЕНИЯ. Существует несколько типов СОЕДИНЕНИЙ. ВНУТРЕННЕЕ СОЕДИНЕНИЕ, ВНЕШНЕЕ СОЕДИНЕНИЕ, ЛЕВОЕ СОЕДИНЕНИЕ, ПРАВОЕ СОЕДИНЕНИЕ. Различные типы объединений позволяют соединять таблицы другим способом.
- Для этих типов соединений мы создали специальную статью. Дополнительные сведения см. по следующей ссылке: Несколько объединений SQL для начинающих с примерами
Заключение
В этой статье мы изучили SQL-запросы, используемые в SQL Server для получения данных. Мы только что рассмотрели основы, но T-SQL — сложная работа, требующая больших знаний для обеспечения хорошей производительности. Тем не менее, мы изучили самые основные и полезные запросы.
Тем не менее, мы изучили самые основные и полезные запросы.
- Автор
- Последние сообщения
Даниэль Кальбимонте
Дэниел Кальбимонте — Microsoft Most Valuable Professional, Microsoft Certified Trainer и Microsoft Certified IT Professional for SQL Server. Он опытный автор SSIS, преподаватель ИТ-академий и имеет более чем 13-летний опыт работы с различными базами данных.Он работал на правительство, нефтяные компании, веб-сайты, журналы и университеты по всему миру. Дэниел также регулярно выступает на конференциях и в блогах, посвященных SQL Server. Он пишет учебные материалы по SQL Server для сертификационных экзаменов.
Он также помогает с переводом статей SQLShack на испанский язык
Просмотреть все сообщения Daniel Calbimonte
Последние сообщения Daniel Calbimonte (посмотреть все)
Как найти повторяющиеся значения в таблице SQL
Как правило, рекомендуется накладывать уникальные ограничения на таблицу для предотвращения дублирования строк. Однако вы можете столкнуться с тем, что работаете с базой данных, в которой повторяющиеся строки были созданы из-за человеческой ошибки, ошибки в вашем приложении или неочищенных данных из внешних источников. Этот учебник научит вас, как найти эти повторяющиеся строки.
Однако вы можете столкнуться с тем, что работаете с базой данных, в которой повторяющиеся строки были созданы из-за человеческой ошибки, ошибки в вашем приложении или неочищенных данных из внешних источников. Этот учебник научит вас, как найти эти повторяющиеся строки.
Чтобы продолжить, вам потребуется доступ для чтения к вашей базе данных и инструмент для запроса вашей базы данных.
Определить повторяющиеся критерии
Первый шаг — определить критерии для повторяющейся строки. Вам нужно, чтобы комбинация двух столбцов была уникальной вместе, или вы просто ищете дубликаты в одном столбце? В этом примере мы ищем дубликаты в двух столбцах нашей таблицы «Пользователи»: имя пользователя и адрес электронной почты.
Запрос на запись для проверки существования дубликатов
Первый запрос, который мы собираемся написать, — это простой запрос для проверки наличия дубликатов в таблице. Для нашего примера мой запрос выглядит так:
SELECT имя пользователя, адрес электронной почты, COUNT(*) ОТ пользователей СГРУППИРОВАТЬ ПО имени пользователя, электронной почте СЧЕТЧИК(*) > 1
НАЛИЧИЕ важно здесь, потому что в отличие от ГДЕ , НАЛИЧИЕ фильтрует агрегатные функции.
Если возвращаются какие-либо строки, это означает, что у нас есть дубликаты. В этом примере наши результаты выглядят так:
| имя пользователя | электронная почта | количество |
|---|---|---|
| Пит | [email protected] | 2 |
| Джессика | джессика@example.com | 2 |
| Мили | [email protected] | 2 |
Список всех строк, содержащих дубликаты
На предыдущем шаге наш запрос вернул список дубликатов. Теперь мы хотим вернуть всю запись для каждой повторяющейся строки.
Для этого нам нужно выбрать всю таблицу и соединить ее с нашими повторяющимися строками. Наш запрос выглядит так:
SELECT a.* ОТ пользователей ПРИСОЕДИНЯЙТЕСЬ (ВЫБЕРИТЕ имя пользователя, адрес электронной почты, СЧЕТЧИК (*) ОТ пользователей СГРУППИРОВАТЬ ПО имени пользователя, электронной почте ИМЕЕТ count(*) > 1 ) b ON a.