ISSP \ Домен 09. Безопасность приложений. Часть 2
В этой части рассмотрены следующие вопросы:- Управление базами данных
- Программное обеспечение для управления базами данных
- Модели баз данных
- Интерфейсы программирования баз данных
- Компоненты реляционной базы данных
- Словарь данных
- Первичные и внешние ключи
9. Управление базами данных
Базы данных давно используются для хранения информации, представляющей ценность для компаний, в том числе являющейся интеллектуальной собственностью. Базы данных обычно работают в среде, скрытой ото всех, кроме сетевых администраторов и администраторов баз данных. Чем меньше людей знают о базах данных, тем лучше. Пользователи обычно работают с базами данных не напрямую, а через клиентский интерфейс, их действия ограничены в целях обеспечения конфиденциальности, целостности и доступности данных, хранящихся в базе данных, а также структуры самой базы данных.ПРИМЕЧАНИЕ.Риски возрастают, если компания подключает свою сеть к Интернет, разрешает удаленным пользователям доступ во внутреннюю сеть, предоставляет все больше прав доступа внешним субъектам. Эти действия несут большой риск, поскольку они могут стать косвенной причиной получения злоумышленником доступа к серверу базы данных, находящемуся во внутренней сети компании. Раньше информация клиентов компании хранилась в базах данных, к которым имели доступ только сотрудники компании, а не сами клиенты. В наше время многие компании позволяют клиентам получать доступ к хранящейся в базах данных информации, через веб-браузер. Веб-браузер устанавливает соединение с промежуточным программным обеспечением (middleware) компании, которое соединяется с сервером базы данных.Система управления базами данных (СУБД) представляет собой набор программ, используемых для управления большими объемами структурированных данных и способных выполнять запросы от различных категорий пользователей. Также эти программы позволяют управлять настройками безопасности базы данных.

 Это повышает сложность системы, а доступ к базам данных организуется новым способом.
Это повышает сложность системы, а доступ к базам данных организуется новым способом.Одним из таких примеров являются системы интернет-банкинга. Многие банки хотят идти в ногу со временем и предоставлять новые услуги, которые, по их мнению, будут востребованы у клиентов. Но интернет-банкинг – это не просто еще одна банковская услуга. Внутренняя среда большинства банков является закрытой (или полузакрытой), и организация доступа в нее из сети Интернет является очень сложной задачей. Нужно предусмотреть надежную защиту периметра сети, разработать (или закупить) промежуточное программное обеспечение (шину), настроить доступ к базе данных через межсетевой экран (а лучше – через два межсетевых экрана). Доступ к данным при этом обычно организуется с помощью компонентов шины, которые по запросам клиентов обращаются к базе данных для извлечения / записи в нее нужных данных.
Такой доступ к базе данных может быть ограничен администратором с помощью средств контроля доступа и предоставляться только нескольким разрешенным ролям. При этом каждой роли будут даны определенные права и разрешения, а затем эти роли будут назначены клиентам и сотрудникам. Пользователь, которому не назначена ни одна из таких ролей, не имеет доступа к базе данных. Таким образом, если злоумышленник сможет преодолеть защиту межсетевого экрана и других механизмов защиты периметра сети, и получит возможность выполнять запросы к базе данных, то при условии, что у него не будет учетной записи, которой назначена одна из таких ролей, база данных все еще будет находиться в безопасности. Этот процесс упрощает управление доступом и гарантирует, что ни один пользователь (в т.ч. злоумышленник) не сможет получить доступ к базе данных напрямую, а только с помощью учентной записи, которой назначена соответствующая роль. Рисунок 9-2 иллюстрирует эту концепцию.
При этом каждой роли будут даны определенные права и разрешения, а затем эти роли будут назначены клиентам и сотрудникам. Пользователь, которому не назначена ни одна из таких ролей, не имеет доступа к базе данных. Таким образом, если злоумышленник сможет преодолеть защиту межсетевого экрана и других механизмов защиты периметра сети, и получит возможность выполнять запросы к базе данных, то при условии, что у него не будет учетной записи, которой назначена одна из таких ролей, база данных все еще будет находиться в безопасности. Этот процесс упрощает управление доступом и гарантирует, что ни один пользователь (в т.ч. злоумышленник) не сможет получить доступ к базе данных напрямую, а только с помощью учентной записи, которой назначена соответствующая роль. Рисунок 9-2 иллюстрирует эту концепцию.
Рисунок 9-2. Один из вариантов обеспечения безопасности базы данных использует роли
9.1. Программное обеспечение для управления базами данных
База данных – это набор данных, хранящихся организованным способом, позволяющим множеству пользователей и приложений обращаться к данным, просматривать и изменять их по мере необходимости. Управление базами данных осуществляется специальным программным обеспечением, которое реализует соответствующую функциональность. Это программное обеспечение также реализует возможности для управления доступом, установки ограничений, обеспечивает целостность и избыточность данных, позволяет использовать различные процедуры для управления данными. Это программное обеспечение называется
Управление базами данных осуществляется специальным программным обеспечением, которое реализует соответствующую функциональность. Это программное обеспечение также реализует возможности для управления доступом, установки ограничений, обеспечивает целостность и избыточность данных, позволяет использовать различные процедуры для управления данными. Это программное обеспечение называется База данных предоставляет структуру для хранения собранных данных. Сама эта структура может отличаться для каждой реальной базы данных, поскольку различные компании и приложения работают с различными данными, типами данных, им необходимо выполнять различные действия с информацией. Различные приложения используют различные способы обработки данных, в различных базах данных устанавливаются различные отношения между данными, базы данных могут работать на различных платформах, к ним могут предъявляться различные эксплуатационные требования, а также требования по обеспечению безопасности. Однако любая база данных должна иметь следующие характеристики:
Различные приложения используют различные способы обработки данных, в различных базах данных устанавливаются различные отношения между данными, базы данных могут работать на различных платформах, к ним могут предъявляться различные эксплуатационные требования, а также требования по обеспечению безопасности. Однако любая база данных должна иметь следующие характеристики:
- Обеспечивать централизацию, позволяя не организовывать хранение данные на нескольких различных серверах по всей сети
- Позволять упростить процедуры резервного копирования
- Обеспечивать транзакционную устойчивость (transaction persistence)
- Позволять организовать работу более упорядоченно, поскольку все данные хранятся и сопровождаются в одном централизованном месте
- Обеспечивать отказоустойчивость и возможности для восстановления
- Позволять множеству пользователей совместно использовать данные
- Предоставлять механизмы безопасности, которые осуществляют контроль целостности, управление доступом, обеспечивают необходимый уровень конфиденциальности
ПРИМЕЧАНИЕ.Поскольку потребности и требования к базам данных у различных компаний существенно различаются, могут использоваться различные модели данных, позволяющие увязать структуру данных с потребностями компаний и их бизнес-процессов.Транзакционная устойчивость (transaction persistence) означает, что реализованные в базе данных процедуры, выполняющие транзакции, являются надежными и проверенными. При использовании этих процедур, уровень безопасности базы данных не должен изменяться после выполнения транзакции, должна обеспечиваться целостность транзакций.
9.2. Модели баз данных
Модель базы данных определяет отношения между различными элементами данных, указывает, каким образом может осуществляться доступ к данным, определяет допустимые операции, предлагаемый тип целостности, а также определяет, каким образом будут организованы данные. Модель дает формальный способ представления данных в концептуальной форме и предоставляет необходимые средства для работы с данными, хранящимися в базе данных. Базы данных могут быть реализованы на основе следующих моделей:
Базы данных могут быть реализованы на основе следующих моделей:- Реляционная
- Иерархическая
- Сетевая
- Объектно-ориентированная
- Объектно-реляционная
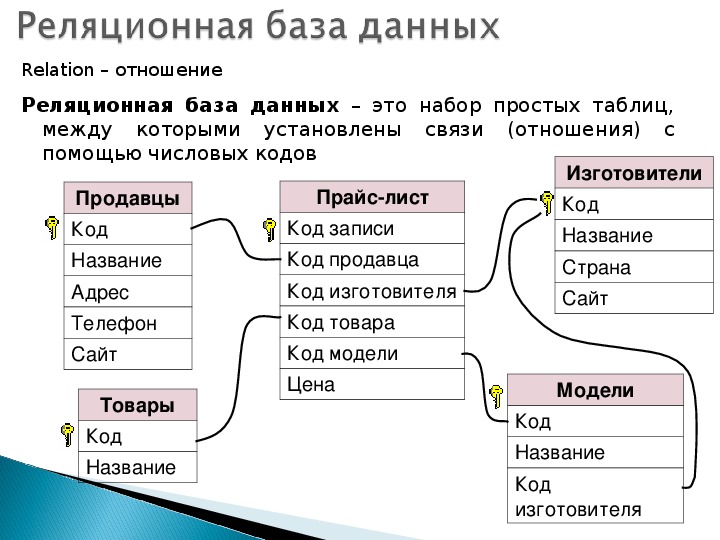
Рисунок 9-3. Реляционная база данных хранит данные в двумерных таблицах
Иерархическая модель базы данных (hierarchial data model) (см. Рисунок 9-4) объединяет связанные записи и поля в логическую древовидную структуру. Эта структура и взаимосвязи между элементами данных, отличаются от тех, которые используются в реляционной базе данных. В иерархической базе данных родительские элементы могут иметь дочерние элементы (один, несколько или ни одного). Древовидная структура имеет ветви, каждая ветвь имеет множество листьев – полей данных. В таких базах данных есть хорошо известные, заранее определенные пути доступа к данным, но они не настолько гибки при создании отношений между элементами данных, по сравнению с реляционными базами данных. Иерархические базы данных целесообразно использовать для хранения данных, имеющих отношения «один-ко-многим».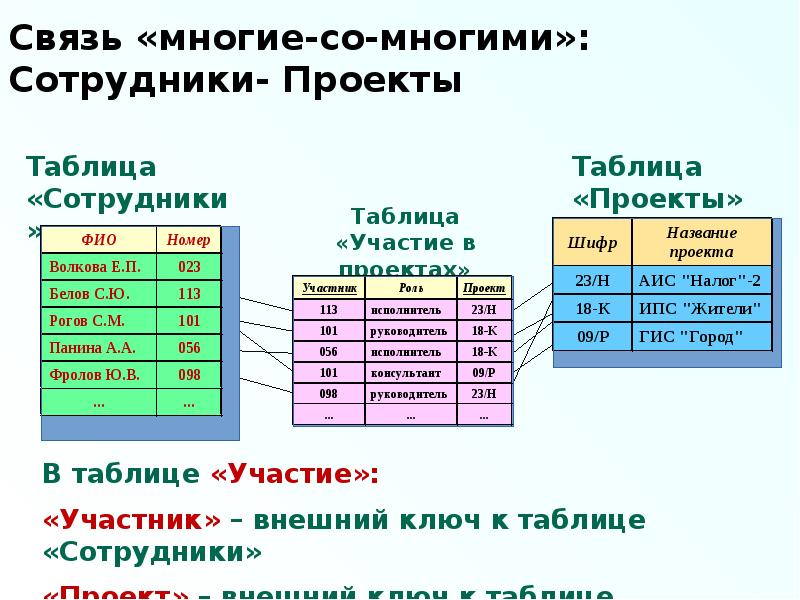
Рисунок 9-4. Иерархическая база данных хранит данные в структуре, имеющей форму деревьев, отношения данных в ней реализованы в виде отношений родительских и дочерних элементов
Иерархическая структура базы данных была одной из первых разработанных моделей, но она не получила такого распространения, как реляционные базы данных. Чтобы получить доступ к элементу данных в иерархической базе данных, необходимо знать с какой ветви начинать и по какому маршруту проходить через каждый уровень, пока не будет достигнут уровень, на котором хранятся нужные данные. В таких базах данных процедуры поиска не используют индексы, в отличие от реляционных баз данных. Кроме того, ссылки (отношения) не могут быть созданы между различными ветвями и листьями на разных уровнях.Наиболее часто используемой реализацией иерархической модели является модель LDAP. Также, иерархическая модель используется в структуре системного реестра Windows и различных файловых системах, но в новых реализациях баз данных она обычно не используется.
Сетевая модель базы данных (network database model) построена на основе иерархической модели данных. Чтобы обойти ограничения иерархической модели, требующие для получения элемента данных знать маршрут перехода с одной ветви в другую, а затем от родительского элемента к дочернему, в сетевой модели каждому элементу данных разрешается иметь несколько родительских и дочерних записей. Это создает избыточную, похожую на сеть структуру, а не жесткую древовидную структуру. Посмотрите на Рисунок 9-5, вы увидите, что сетевая модель создает структуру похожую на полносвязную топологию сети. Это обеспечивает избыточность и дает возможность более быстрого поиска данных по сравнению с иерархической моделью.
Рисунок 9-5. Различные модели баз данных
Эта модель использует конструкции из записей и множеств. Запись содержит поля, которые могут располагаться в иерархической структуре. Множества определяют отношения «один-ко-многим» между различными записями. Одна запись может быть «владельцем» любого количества множеств, при этом тот же «владелец» сам может быть членом различных множеств.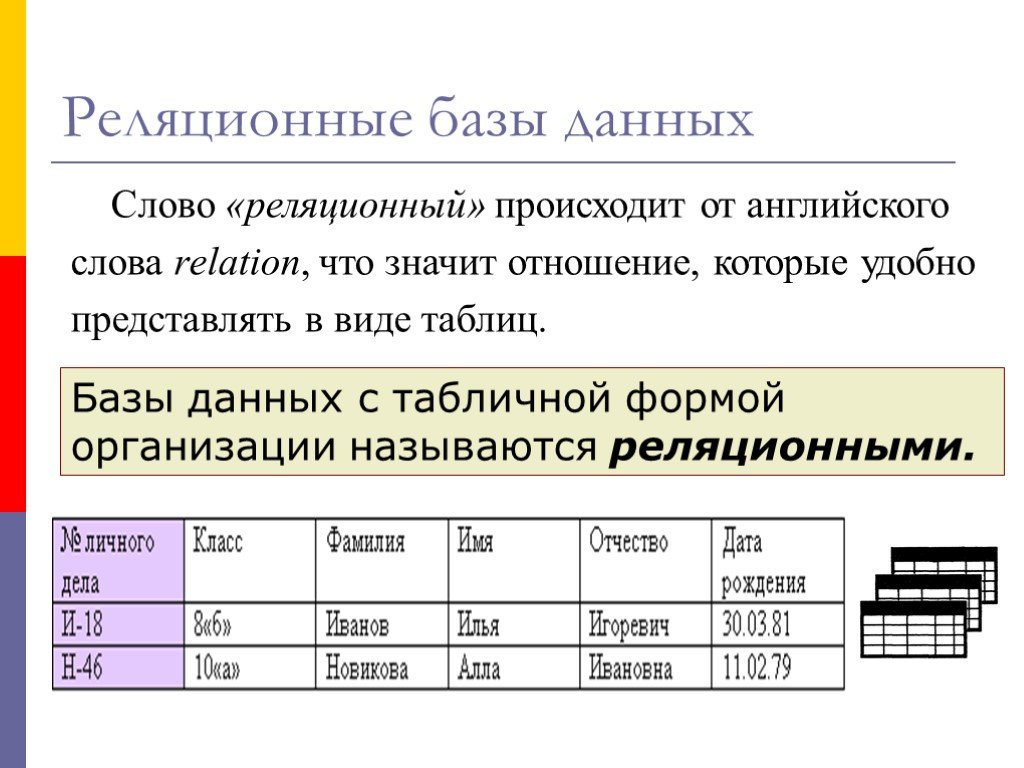 Это означает, что одна запись может быть «главной» и под ней может находиться множество элементов данных, либо эта запись может находиться ниже в иерархии, под различными полями, являющимися для нее «главными». Это предоставляет значительную гибкость при разработке отношений между элементами данных.
Это означает, что одна запись может быть «главной» и под ней может находиться множество элементов данных, либо эта запись может находиться ниже в иерархии, под различными полями, являющимися для нее «главными». Это предоставляет значительную гибкость при разработке отношений между элементами данных.Объектно-ориентированная база данных (object-oriented database) предназначена для работы с различными типами данными (изображения, аудио, документы, видео). Система управления объектно-ориентированными базами данных (ODBMS — object-oriented database management system) более динамична по своей природе, чем реляционная СУБД, поскольку она создает объекты при необходимости, а данные и процедуры (называемые методами) при запросе объекта предоставляются вместе с ним. При работе с реляционной базой данных, приложение должно использовать свои собственные процедуры для получения данных из базы данных и их обработки. Реляционная база данных не предоставляет процедур, как это делает объектно-ориентированная база данных. Объектно-ориентированная база данных использует классы для определения атрибутов и процедур ее объектов.
Объектно-ориентированная база данных использует классы для определения атрибутов и процедур ее объектов.
В качестве аналогии, рассмотрим две компании, в клиентских базах данных которых находятся одинаковые данные. Если вы придете в компанию А (реляционная база данных), менеджер сможет дать вам только лист бумаги, на котором будет указана информация. Вы сами должны понять, что делать с этой информацией и как правильно использовать ее для своих нужд. Если вы придете в компанию B (объектно-ориентированная база данных), менеджер даст вам коробку. В этой коробке будет листок с той же информацией, но кроме него там будет набор инструментов, позволяющих обработать информацию для удовлетворения ваших потребностей, и вам не нужно будет делать это самостоятельно. Таким образом, когда ваше приложение запрашивает данные в объектно-ориентированной базе данных, в ответ оно получает не только данные, но и код для выполнения определенных процедур над этими данными.Мы рассмотрим объектно-ориентированное программирование далее, тогда вы лучше поймете объекты, классы и методы.
Целью создания этой модели была попытка учесть ограничения, которые накладывало использование реляционной базы данных при необходимости хранения и обработки больших объемов данных. Кроме того, объектно-ориентированные базы данных не зависят от SQL, с такими базами данных могут работать приложения, не являющиепся SQL-клиентами.
Жаргон баз данных. Ниже приведены некоторые ключевые понятия, используемые при работе с базами данных:Объектно-ориентированные базы данных не так распространены, как реляционные базы данных, они используются в основном в таких областях, как машиностроение, биология, а также для удовлетвонения некоторых потребностей финансового сектора.ПРИМЕЧАНИЕ.
- Запись (Record) – набор связанных элементов данных
- Файл (File) – набор однотипных записей
- База данных (Database) – набор данных, связанных с перекрестными ссылками (cross-referenced)
- СУБД (DBMS) – система управления и работы с базой данных
- Запись (Tuple) – строка в двумерной базе данных
- Атрибут (Attribute) – столбец в двумерной базе данных
- Первичный ключ (Primary key) – столбец, который делает каждую строку уникальной (каждая строка таблицы должна содержать первичный ключ)
- Представление (View) – виртуальное представление информации, определенное администратором для ограничения просмотра субъектами определенных данных
- Внешний ключ (Foreign key) – атрибут одной таблицы, связаный с первичным ключом другой таблицы
- Ячейка (Cell) – пересечение строки и столбца
- Схема (Schema) – определяет структуру базы данных
- Словарь данных (Data dictionary) – центральное хранилище (репозиторий) элементов данных и их взаимосвязей
Язык структурированных запросов (Structured Query Language, SQL) представляет собой стандартный язык программирования, используемый для организации взаимодействия клиентов с базой данных. Большинство реализаций баз данных поддерживают SQL. SQL позволяет клиентам выполнять такие операции, как вставка, замена, поиск и добавление данных.
Теперь давайте рассмотрим объектно-реляционные базы данных. Объектно-реляционная база данных (object-relational database, ORD) или объектно-реляционная система управления базами данных (object-relational database management system, ORDBMS) – это реляционная база данных с фронтальным программным обеспечением (интерфейсом), написанным на объектно-ориентированном языке программирования. Но зачем нужны такие комбинации? Реляционная база данных содержит данные в статических двумерных таблицах. При обращении к данным, они должны подвергаться какой-либо последующей обработке, иначе зачем получать эти данные? Если у нас есть интерфейс, предоставляющий процедуры (методы) обработки данных, тогда приложению, которое обращается к этой базе данных, не нужны аналогичные собственные процедуры.
При обращении к данным, они должны подвергаться какой-либо последующей обработке, иначе зачем получать эти данные? Если у нас есть интерфейс, предоставляющий процедуры (методы) обработки данных, тогда приложению, которое обращается к этой базе данных, не нужны аналогичные собственные процедуры.
Различным компаниям требуется различная бизнес-логика для работы с данными. Возможность разработать такого фронтального программного обеспечения позволяет приложениям использовать процедуры бизнес-логики и данные базы данных. Например, если у нас есть реляционная база данных, в которой хранятся данные инвентаризации товаров на складе, нам хотелось бы иметь возможность использовать эти данные для различных бизнес-целей. Одно приложение может обращаться к базе данных, чтобы просто проверить количество имеющихся в наличии единиц товара А. Можно создать интерфейсный объект, который будет выполнять эту процедуру, обращаясь за данными в базу данных и предоставляя готовый ответ запрашивающему приложению. Также может существовать потребность проведения аналитических расчетов на основании данных инвентаризации, например, провести анализ наиболее востребованных товаров. Для этого может быть разработан другой объект, который будет собирать из базы данных нужные данные, проводить расчеты и предоставлять их результаты запрашивающему приложению. Для выполнения других расчетов и подготовки отчетов могут быть созданы другие объекты. На Рисунке 9-6 показаны различные объекты данных, выполняющие различные команды бизнес-логики.
Также может существовать потребность проведения аналитических расчетов на основании данных инвентаризации, например, провести анализ наиболее востребованных товаров. Для этого может быть разработан другой объект, который будет собирать из базы данных нужные данные, проводить расчеты и предоставлять их результаты запрашивающему приложению. Для выполнения других расчетов и подготовки отчетов могут быть созданы другие объекты. На Рисунке 9-6 показаны различные объекты данных, выполняющие различные команды бизнес-логики.
Рисунок 9-6. Объектно-реляционная модель позволяет включать в объекты бизнес-логику и функции
9.3. Интерфейсы программирования баз данных
Данные бесполезны, если вы не можете их использовать. Приложения должны иметь возможность получать и работать с информацией, хранимой в базах данных. Они также нуждаются в некотором интерфейсе и механизме передачи информации. Ниже мы рассмотрим некоторые из таких интерфейсов:- Open Database Connectivity (ODBC) – это интерфейс прикладного программирования (API – application programming interface), который позволяет приложению взаимодействовать с базой данных локально или удаленно.
 Приложение посылает запросы к ODBC API, ODBC определяет необходимый для конкретной базы данных драйвер, позволяющий выполнить трансляцию запросов, затем этот драйвер выполняет указанную трансляцию запросов в команды базы данных, понятные для этой базы данных.
Приложение посылает запросы к ODBC API, ODBC определяет необходимый для конкретной базы данных драйвер, позволяющий выполнить трансляцию запросов, затем этот драйвер выполняет указанную трансляцию запросов в команды базы данных, понятные для этой базы данных. - Object Linking and Embedding Database (OLE DB) разделяет данные на компоненты, которые работают как промежуточное программное обеспечение (middleware) на клиенте или сервере. Это предоставляет низкоуровневый интерфейс для связи информации, хранящейся в различных базах данных, и обеспечивает доступ к данным независимо от того, где они хранятся и в каком формате. Ниже приведены некоторые характеристики OLE DB:
- Он заменяет ODBC, расширяет набор функций для поддержки более широкого круга нереляционных баз данных, таких как объекты баз данных и таблицы, которые не обязательно поддерживают SQL
- Набор основанных на COM интерфейсов, которые предоставляют приложениям унифицированный доступ к данным, хранящимся в различных источниках данных (см.
 Рисунок 9-7)
Рисунок 9-7)
Рисунок 9-7. OLE DB предоставляет интерфейс, позволяющий приложениям взаимодействовать с различными источниками данных
- Поскольку OLE DB основан на COM, он ограничен использованием клиентских средств, разработанных для платформы Microsoft Windows
- Разработчик обращается к сервисам OLE DB через объекты данных ActiveX (ADO – ActiveX Data Objects)
- Это позволяет различным приложениям использовать различные типы и источники данных
- ActiveX Data Objects (ADO) – это API, позволяющий приложениям получать доступ к серверам баз данных. Он представляет собой набор интерфейсов ODBC, которые позволяют использовать функциональность источников данных посредством доступных объектов. ADO для соединения с базой данных использует интерфейс OLE DB, он может быть использован в процессе разработки на множестве различных языков сценариев. Ниже приведены некоторые характеристики ADO:
- Это высокоуровневый программный интерфейс доступа к лежащей ниже технологии, реализующей доступ к данным (такой как OLE DB)
- Это набор COM-объектов для доступа к источникам данных, а не просто доступа к базе данных
- Он позволяет разработчикам писать программы доступа к данным, не зная, каким образом реализована сама база данных
- Команды SQL не требуются для доступа к базе данных при использовании ADO
- Java Database Connectivity (JDBC) – это API, который позволяет Java-приложениям взаимодействовать с базами данных.
 Приложение может обращаться к базе данных через ODBC или напрямую. Ниже приведены некоторые характеристики JDBC:
Приложение может обращаться к базе данных через ODBC или напрямую. Ниже приведены некоторые характеристики JDBC: - Это API, который обеспечивает функциональность, аналогичную ODBC, но он специально разработан для использования приложениями баз данных на Java
- Он позволяет использовать независимые от базы данных соединения между платформой Java и широким кругом баз данных
- JDBC представляет собой Java API, который позволяет Java-программам выполнять SQL-выражения
9.4. Компоненты реляционной базы данных
Как и любое программное обеспечение, базы данных разрабатываются с помощью языков программирования. Большинство языков программирования баз данных включает язык описания данных (DDL – data definition language), который определяет схему; язык манипулирования данными (DML – data manipulation language), который анализирует данные и определяет, как эти данные могут обрабатываться в базе данных; язык управления данными (DCL – data control language), который определяет внутреннюю организацию базы данных; специальный язык запросов (QL – query language), который определяет запросы, позволяющие пользователям получить доступ к данным в базе данных.
Каждая модель базы данных может иметь множество других отличий, обусловленных, в том числе, разными подходами различных производителей. Однако большинство из них включает следующую базовую функциональность:
- Язык описания данных (DDL) определяет структуру и схему базы данных. Структуру может определять размер таблицы, размещение ключа, представления, отношения элементов данных. Схема описывает тип данных, которые будут храниться и обрабатываться, а также их свойства. DDL определяет структуру базы данных, операции доступа и процедуры целостности.
- Язык манипулирования данными (DML) содержит все команды, позволяющие пользователю просматривать, управлять и использовать базу данных (команды view, add, modify, sort, delete).
- Язык запросов (QL) дает пользователям возможность делать запросы в базу данных.
- Генератор отчетов готовит печатные формы с данными определенным пользователем образом.
Словарь данных
Словарь данных (data dictionary) является централизованным набором определений элементов данных, объеков схемы, а также ключей ссылок (reference keys). Объекты схемы могут содержать таблицы, представления, индексы, процедуры, функции и триггеры. Словарь данных может содержать значения по умолчанию для столбцов, информацию целостности, имена пользователей, привилегии и роли пользователей, информацию аудита. Это инструмент, используемый для централизованного управления частями базы данных посредством управления данными о данных (именуемыми метаданными) в базе данных. Он обеспечивает перекрестные ссылки между группами элементов данных и базами данных.
Объекты схемы могут содержать таблицы, представления, индексы, процедуры, функции и триггеры. Словарь данных может содержать значения по умолчанию для столбцов, информацию целостности, имена пользователей, привилегии и роли пользователей, информацию аудита. Это инструмент, используемый для централизованного управления частями базы данных посредством управления данными о данных (именуемыми метаданными) в базе данных. Он обеспечивает перекрестные ссылки между группами элементов данных и базами данных.Программное обеспечение, управляющее базой данных, создает и читает словарь данных, чтобы выяснить, какие существуют объекты схемы, а также проверить, имеют ли конкретные пользователи права доступа, необходимые для их просмотра (см. Рисунок 9-8). При просмотре пользователями базы данных, они могут быть ограничены определенными представлениями. Различные параметры представлений для каждого пользователя хранятся в словаре данных. При добавлении новых таблиц, новых строк, или новой схемы, словарь данных обновляется – в него вносятся соответствующие изменения.
Рисунок 9-8. Словарь данных – это централизованное хранилище, которое содержит информацию о базе данных
Первичные и внешние ключи
Первичный ключ (primary key) – это идентификатор строки, он используется для индексации в реляционных базах данных. Каждая строка должна иметь уникальный первичный ключ, который должен представлять строку, как единое целое. Когда пользователь делает запрос на просмотр записи, база данных находит нужную запись по ее уникальному первичному ключу. Если первичный ключ не был бы уникальным, база данных не знала бы, какие записи нужно предоставить пользователю. На приведенном ниже рисунке, первичным ключом для таблицы А является кличка собаки. Каждая строка (запись) содержит характеристики каждой собаки. Поэтому, когда пользователь осуществляет поиск собаки «Бобик», ему будут предоставлена информация о породе, весе, цвете и хозяине соответствующей собаки. Первичный ключ отличается от внешнего ключа, хотя они тесно связаны между собой. Если атрибут в одной таблице, имеет значение, соответствующее первичному ключу в другой таблице, и между этими двумя таблицами установлены отношения, этот атрибут называется внешним ключом (foreign key). Этот внешний ключ не обязательно является первичным ключом в своей таблице. Просто он должен содержать ту же информацию, которая содержится в первичном ключе другой таблицы, и быть связанным с первичным ключом в этой другой таблице. На приведенном ниже рисунке, первичным ключом Таблицы А является «Шарик». Поскольку Таблица B имеет атрибут, содержащий те же данные, что и этот первичный ключ, и между этими двумя ключами установлена связь, он называется внешним ключом. Это еще один способ для отслеживания взаимосвязей между данными, хранящимися в базе данных. Можно представить это в виде веб-страницы, которая содержит данные из Таблицы B. Если нам нужно больше узнать о собаке по кличке Шарик, мы дважды щелкаем по этому значению и браузер выдает характеристики этой собаки, которые хранятся в Таблице А.
Если атрибут в одной таблице, имеет значение, соответствующее первичному ключу в другой таблице, и между этими двумя таблицами установлены отношения, этот атрибут называется внешним ключом (foreign key). Этот внешний ключ не обязательно является первичным ключом в своей таблице. Просто он должен содержать ту же информацию, которая содержится в первичном ключе другой таблицы, и быть связанным с первичным ключом в этой другой таблице. На приведенном ниже рисунке, первичным ключом Таблицы А является «Шарик». Поскольку Таблица B имеет атрибут, содержащий те же данные, что и этот первичный ключ, и между этими двумя ключами установлена связь, он называется внешним ключом. Это еще один способ для отслеживания взаимосвязей между данными, хранящимися в базе данных. Можно представить это в виде веб-страницы, которая содержит данные из Таблицы B. Если нам нужно больше узнать о собаке по кличке Шарик, мы дважды щелкаем по этому значению и браузер выдает характеристики этой собаки, которые хранятся в Таблице А.
Это позволяет создавать взаимосвязи между различными элементами данных в базе данных по своему усмотрению.
<<< Предыдущий раздел • Содержание • Следующий раздел >>>
Реляционные и нереляционные базы данных: отличие и сравнение NoSQL vs SQL
В статье мы подробно поговорим про их особенности и отличия.
Отличия SQL и NoSQL
Для определения различий между разными видами БД необходимо рассматривать их в отдельности, со всеми уникальными особенностями, возможностями и преимуществами.
Реляционные предназначены для хранения структурированных данных, способных представлять объекты из окружающего физического мира. К примеру, в такую БД можно включить сведения о конкретном человеке или о товарах, добавленных потенциальным покупателем в корзину. Такие данные можно группировать в специальных таблицах.
Нереляционные базы устроены иначе. В них хранящаяся информация напрямую зависит от особенностей самой базы данных. К примеру, в случае с документоориентированной БД информация может быть представлена в виде иерархии и описывать различные объекты с разными параметрами.
В этом заключается главное отличие NoSQL от SQL и ее же преимущество. Такие базы дают возможность хранить почти неограниченные по объему данные в виде одной сущности. В SQL для хранения большого объема данных необходимо создание множества отдельных, но связанных между собой таблиц.
Особенности SQL
В первую очередь нужно подробно поговорить про реляционные базы. Они характеризуются тем, что вся хранимая информация внутри них четко структурируется и всегда связана с другими данными. В каждой таблице всегда присутствуют столбцы с указанием типа данных и строки с конкретными записями, а данные в каждую ячейку вносятся по установленному шаблону.
Целостность информации
Вся хранимая информация в реляционных базах отличается целостностью, то есть она характеризуется единообразностью, полнотой и точностью.
Для поддержания целостности в базе используются специнструменты: первичные / внешние ключи и другие. А также используются специальные ограничения.
Ограничения необходимы, так как позволяют использовать эффективные правила к хранимым внутри базы и таблиц сведениям.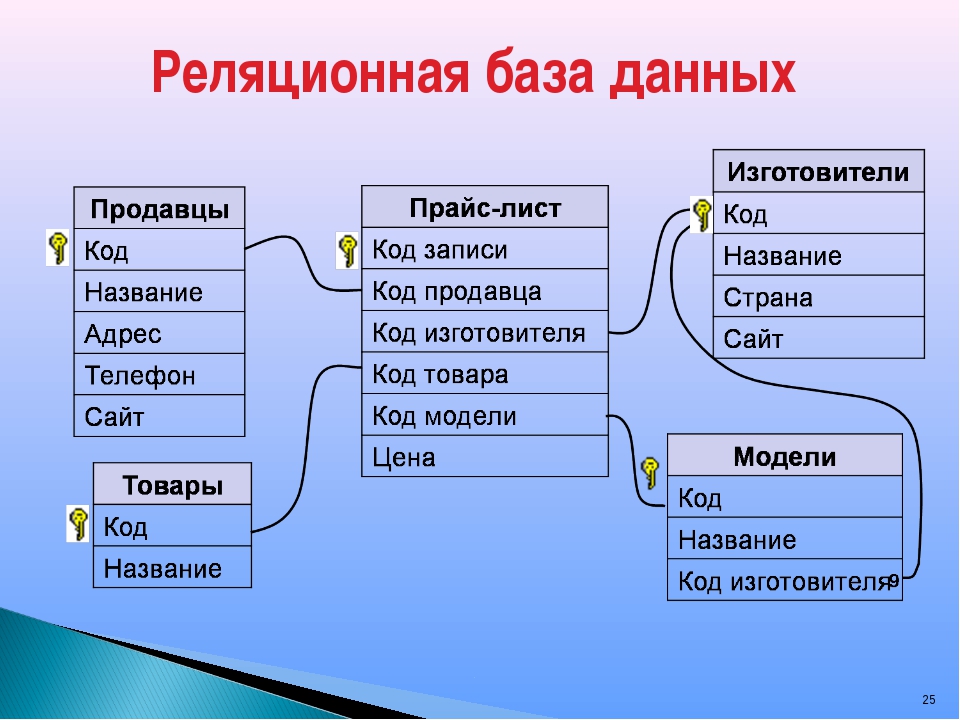 Именно они обеспечивают сохранение точности всех представленных данных.
Именно они обеспечивают сохранение точности всех представленных данных.
Транзакции
Транзакцией в БД принято называть упорядоченную последовательность операторов обработки информации, которая может перевести БД из одного состояния в другое.
В РБД так может называться оператор/операторы, которые выполнены в виде последовательных операций, представляющих единую задачу.
Операторы должны выполняться одновременно и как целое. Они могут быть записаны в БД вместе или не записываются вообще ни в каком виде.
Соответствие требованиям
Чтобы соблюдать целостность, все транзакции внутри БД должны соответствовать нескольким требованиям:
- Атомарность. Условие, позволяющее транзакции успешно выполняться целиком либо отменяющее всю транзакцию, если хотя бы одна ее часть не может быть выполнена.
- Единообразие. В соответствии с этим условием, все записываемые сведения в процессе одной транзакции должны соответствовать всем правилам и нормам.
- Изолированность.
 Только при изолированности можно контролировать согласованность выполняемых транзакций.
Только при изолированности можно контролировать согласованность выполняемых транзакций. - Надежность. Условие, подразумевающее, что все изменения, вносимые в БД, считаются совершенными.
Особенности NoSQL
Если сравнивать нереляционные базы с SQL, то здесь данные хранятся кардинально иным образом. Они могут не иметь какой-то четкой структуры, заранее установленной и определенной, а также четких связей. Информация хранится не в виде таблиц, а в качестве текстовых документов, файлов или публикаций в сети.
Такой формат дает возможность хранить в базах сведения любого типа, формата и объема. Именно поэтому базы активно используются в современных приложениях и программах под различное оборудование и устройства.
NoSQL отлично подходят в случаях, когда необходимо не только хранить данные структурировано, а требуется хранить их внутри гибкой и легко масштабируемой базы с высокой мощностью.
Гибкость
Благодаря высокой гибкости NoSQL дают возможность выполнять разработку намного быстрее, допускают реализацию в несколько этапов. Модели с хорошей гибкостью подходят для хранения как неструктурированных, так и не полностью структурированных сведений.
Модели с хорошей гибкостью подходят для хранения как неструктурированных, так и не полностью структурированных сведений.
Масштабируемость
Нереляционные базы отлично подходят для масштабирования, в том числе с применением распределенных кластеров. Отдельные разработчики облачных технологий даже выполняют операции в фоновом режиме, благодаря чему сервис получает максимальный контроль и управляемость.
Эффективность
Нереляционные базы могут быть оптимизированы для хранения данных определенного типа или по установленному стандарту / шаблону. Это позволяет добиться значительно большей производительности, чем в SQL.
Виды SQL
Выделяют несколько наиболее распространенных и часто используемых SQL-баз:
- Microsoft SQL Server или MS SQL. Система управления реляционными базами данных, разработанная Microsoft. Пользуется большой популярностью, так как позволяет эффективно работать с БД разных размеров — от личных до уровня БД крупных предприятий.
 Основной используемый язык запросов — Transact-SQL, созданный в сотрудничестве с Sybase.
Основной используемый язык запросов — Transact-SQL, созданный в сотрудничестве с Sybase. - MySQL. Пожалуй, сегодня является наиболее популярной БД с открытой лицензией. Преимущественно используется для малых проектов и проектов среднего масштаба, которым требуется доступное средство для работы с БД. Поддерживает разные типы таблиц и огромное число всевозможных расширений.
- PostgreSQL. Имеет очень широкий функционал. Отлично подходит для случаев, когда необходимо работать с данными сложной структуры, требуется обеспечить всей информации высокий уровень сохранности. Может применяться для самых больших проектов.
Виды NoSQL
Выделяют несколько различных видов НБД:
- БД «ключ-значение». Данный тип НБД предполагает, что в каждой записи будут присутствовать значение и ключ. Обычно такие базы применяются в ситуациях, когда быстродействие является основным приоритетом разработчиков. Недостаток базы в том, что она плохо подходит для хранения сложных данных.

- Графовые. Графовые модели преимущественно используются в проектах, когда данные имеют естественную графовую структуру. К примеру, к таким проектам относятся социальные сети или семантические паутины. Ее главные достоинства — простота внесения изменений, производительность и наглядность.
- Колоночные. Отличный вариант для обработки больших данных, так как характеризуются производительностью, качественным сжатием и высокой масштабируемостью.
- Документно-ориентированные БД. Записи в них хранятся в качестве отдельных документов с уникальным набором полей, отличных для разных записей.
Популярные нереляционные базы данных
На рынке представлено большое количество нереляционных баз, рассмотреть или хотя бы упомянуть каждую из них в одной публикации не представляется возможным. Поэтому мы перечислим лишь наиболее известные и популярные:
- ElasticSearch. Система нереляционных баз, распространяемая с открытым исходным кодом. Представляет собой интерфейс протокола передачи гипертекста и бесплатных документов.

- MongoDB. Кроссплатформенное программное обеспечение, предназначенное для работы с базами. Может быть использовано как на Windows и Linux, так и на Solaris.
- Amazon DynamoDB. ПО, принадлежащее Amazon, предназначенное для использования в небольших приложениях. Позволяет обрабатывать огромное количество инструкций в кратчайшие сроки.
- Cassandra. Система БД с открытым кодом, разработанная в Facebook. Дает возможность эффективно управлять огромными массивами данных. Используется сотнями компаний по всему миру.
- HBase. Система на Java с открытым кодом и практически бесконечными возможностями масштабирования.
SQL vs NoSQL — как выбрать?
Очень часто пользователи думают о том, что SQL и NoSQL — это конкурирующие между собой продукты. Однако между реляционными и нереляционными базами отсутствует конкуренция. Они предназначены для использования в различных случаях и закрывают разные потребности пользователей:
- РБД — структурированное хранение информации;
- НБД — хранение большого объема данных с нечеткими требованиями.
Очень часто SQL и NoSQL используются разработчиками в рамках одного проекта, так как дают возможность решать различные проблемы.
реляционных и нереляционных баз данных | Insightsoftware
В чем разница между реляционной и нереляционной базой данных? Система управления реляционными базами данных (RDBMS) организует данные в отдельные таблицы, обеспечивая гибкий доступ и повторную сборку в соответствии с определяемыми пользователем реляционными таблицами. Напротив, нереляционная база данных использует архитектуру, которая не использует таблицы в качестве своей основной структуры.
Представьте, что ваши данные — это собака. Перед ним вы кладете лист Excel и документ Word. К кому пойдет собака?
Это может быть немного глупо, но это хороший способ точно понять, какие данные подходят для двух основных типов баз данных — реляционных и нереляционных. Давайте рассмотрим разницу между реляционными базами данных и нереляционными системами баз данных, а также перечислим некоторые ключевые вопросы, на которые должен ответить каждый бизнес, прежде чем выбирать реляционную базу данных по сравнению с нереляционной базой данных.
Реляционные базы данных
Вернемся к вашей «собаке данных». Может быть, он предпочитает лист Excel. Почему? Потому что он хорошо вписывается в строки и столбцы.
Реляционная база данных — это база данных, в которой данные хранятся в таблицах. Отношения между каждой точкой данных ясны, и поиск по этим отношениям относительно прост. Связь между таблицами и типами полей называется схемой . Для реляционных баз данных схема должна быть четко определена. Давайте рассмотрим пример:
Здесь мы видим три таблицы, каждая из которых содержит уникальную информацию о конкретной собаке. Затем пользователь реляционной базы данных может получить представление базы данных в соответствии со своими потребностями. Например, я могу захотеть просмотреть или сообщить обо всех собаках весом более 100 фунтов. Или вы можете посмотреть, какие породы едят сухой корм. Реляционные базы данных позволяют относительно легко отвечать на подобные вопросы.
Реляционные базы данных также называются базами данных SQL .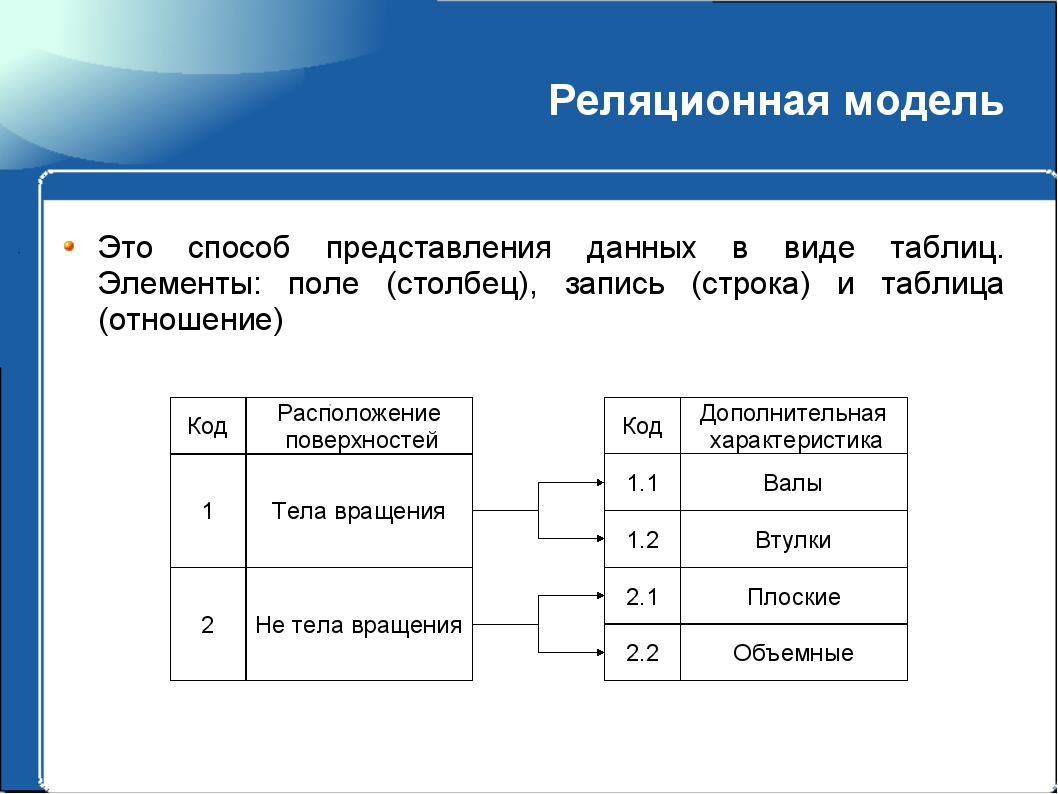 SQL означает язык структурированных запросов, и это язык, на котором написаны реляционные базы данных. SQL используется для выполнения запросов, извлечения данных и редактирования данных путем обновления, удаления или создания новых записей.
SQL означает язык структурированных запросов, и это язык, на котором написаны реляционные базы данных. SQL используется для выполнения запросов, извлечения данных и редактирования данных путем обновления, удаления или создания новых записей.
Раннее внедрение и широкое использование делают базы данных SQL популярной системой управления данными. Отчасти это связано с отсутствием необходимой подготовки для работников, поскольку многие специалисты по обработке и анализу данных изучают SQL на раннем этапе. Давайте еще раз разберем реляционные и нереляционные базы данных 9.0013 .
Популярные реляционные базы данных/базы данных SQL
SQL Server
SQL Server — система управления реляционными базами данных, разработанная Microsoft. Системы управления реляционными базами данных предлагают несколько версий с различными функциями для разных пользователей.
Плюсы: SQL Server может похвастаться богатым пользовательским интерфейсом и может обрабатывать большие объемы данных.
Минусы: это может быть дорого — уровень предприятия стоит тысячи долларов.
MySQL
MySQL, впервые выпущенная в 1995 году, представляет собой бесплатное программное обеспечение с открытым исходным кодом и одну из самых популярных баз данных в мире. Он используется многими веб-сайтами с высоким трафиком, такими как Facebook и YouTube.
Плюсы: это бесплатно и с открытым исходным кодом. Там также много документации и онлайн-поддержки.
Минусы: Плохо масштабируется. MySQL имеет тенденцию переставать работать, когда ему дается слишком много операций в данный момент времени.
PostgreSQL
Если MySQL основана на реляционной модели, то PostgreSQL – на объектно-реляционной модели. Еще одна бесплатная база данных с открытым исходным кодом, PostgreSQL, была выпущена в 1996 с упором на расширяемость. Он способен обрабатывать сложные рабочие нагрузки данных благодаря своим разнообразным функциям расширения.
Плюсы: Как мы уже говорили, расширяемый. Если вам нужны дополнительные функции в PostgreSQL, вы можете добавить их самостоятельно — для большинства баз данных это сложная задача.
Если вам нужны дополнительные функции в PostgreSQL, вы можете добавить их самостоятельно — для большинства баз данных это сложная задача.
Минусы: Для новичков установка и настройка могут быть затруднены. Также не так много документации, как по более популярным базам данных, таким как MySQL.
Нереляционные базы данных
Вернемся к вашей «собаке данных». На этот раз он перешел к документу Word. Почему? Всем простор! Данные бывают разных форм и размеров — им нужно место для распространения.
Нереляционная база данных – это любая база данных, в которой не используется табличная схема строк и столбцов, как в реляционных базах данных. Скорее, его модель хранения оптимизирована для типа данных, которые он хранит.
Нереляционные базы данных также известны как базы данных NoSQL , что означает «Не только SQL». Там, где реляционные базы данных используют только SQL, нереляционные базы данных могут использовать другие типы языка запросов.
Существует четыре различных типа баз данных NoSQL.
- Базы данных, ориентированные на документы . Эта база данных, также известная как хранилище документов, предназначена для хранения, поиска и управления информацией, ориентированной на документы. Базы данных документов обычно связывают каждый ключ со сложной структурой данных (называемой документом).
- Хранилища ключей и значений – это база данных, в которой используются разные ключи, где каждый ключ связан только с одним значением в коллекции. Думайте об этом как о словаре. Это один из самых простых типов баз данных среди баз данных NoSQL.
- Хранилища с широкими столбцами – в этой базе данных используются таблицы, строки и столбцы, но, в отличие от реляционной базы данных, имена и формат столбцов могут различаться от строки к строке одной и той же таблицы.
- Хранилища графов – База данных графов использует структуры графов для семантических запросов с узлами, ребрами и свойствами для представления и хранения данных.

Нереляционные базы данных становятся все более популярными, поскольку все больше и больше предприятий начинают использовать большие данные для анализа и составления отчетов. Поскольку важные данные не всегда хорошо вписываются в заранее определенную схему, базы данных NoSQL обеспечивают большую гибкость.
Популярные нереляционные базы данных/базы данных NoSQL
MongoDB
MongoDB — это хранилище документов и в настоящее время самый популярный механизм базы данных NoSQL. Он использует JSON-подобные документы для хранения данных и работает на нескольких серверах. MongoDB допускает автоматическое сегментирование, которое представляет собой тип разделения базы данных, который разделяет очень большие базы данных на более мелкие, более быстрые и более простые в управлении части, называемые сегментами данных.
Плюсы: MongoDB очень прост в настройке и предоставляет профессиональную поддержку.
Минусы: не разрешается объединение. Соединения используются для объединения данных или строк из двух или более таблиц на основе общего поля между ними. В MongoDB есть функция ПРОСМОТР, но она говорит своим пользователям не полагаться на нее.
Соединения используются для объединения данных или строк из двух или более таблиц на основе общего поля между ними. В MongoDB есть функция ПРОСМОТР, но она говорит своим пользователям не полагаться на нее.
Redis
Redis — удаленный сервер словарей — представляет собой хранилище ключей и значений. Он поддерживает различные виды абстрактных структур данных, такие как строки, списки, карты, наборы, отсортированные наборы и многое другое. Это также с открытым исходным кодом.
Плюсы: Он поддерживает большое количество типов данных и прост в установке.
Минусы: Как и MongoDB, он не поддерживает соединения. Также требуется знание Lua, языка программирования высокого уровня.
Реляционные и нереляционные базы данных
Подводя итог различиям между реляционными и нереляционными базами данных: реляционные базы данных хранят данные в строках и столбцах, как электронные таблицы, в то время как нереляционные базы данных не хранят данные, используя модель хранения (одна из четыре), который лучше всего подходит для типа данных, которые он хранит.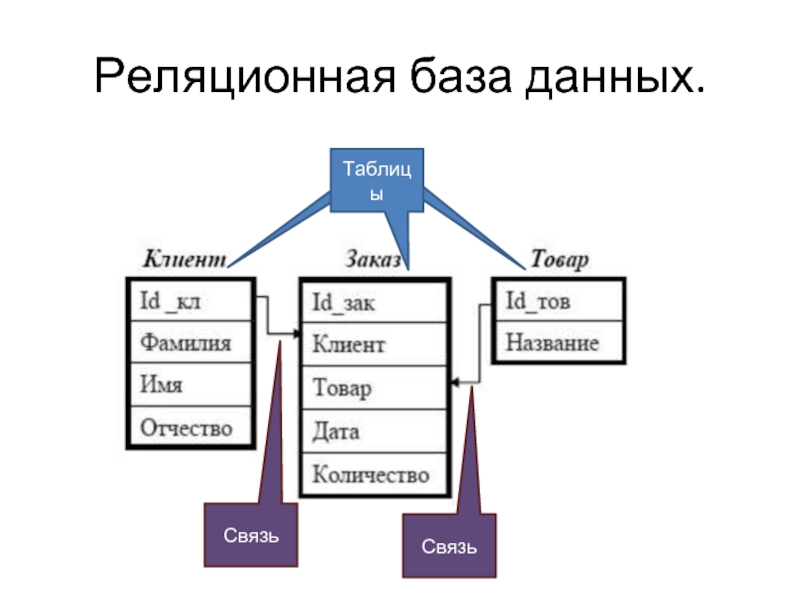
Вопросы, на которые необходимо ответить перед выбором базы данных
Какой тип данных вы будете анализировать?
Удобны ли ваши данные в строках и столбцах? Или он лучше подходит для более гибкого пространства? Ответ подскажет, нужна ли вам реляционная или нереляционная база данных.
С каким объемом данных вы имеете дело?
Есть хорошее эмпирическое правило: чем больше набор данных, тем больше вероятность того, что нереляционная база данных подойдет лучше. Нереляционные базы данных могут хранить неограниченное количество наборов данных любого типа и могут гибко изменять тип данных.
Но реляционные базы данных работают лучше всего при выполнении интенсивных операций чтения/записи с наборами данных небольшого или среднего размера.
Какие ресурсы вы можете выделить для настройки и обслуживания вашей базы данных?
Вот еще одно хорошее практическое правило: чем меньше ваша команда инженеров, тем больше вероятность, что реляционная база данных подойдет лучше. Почему? Во-первых, управление реляционными базами данных требует меньше времени. Кроме того, SQL является более известным языком запросов. Скорее всего, ваша команда уже знает это.
Почему? Во-первых, управление реляционными базами данных требует меньше времени. Кроме того, SQL является более известным языком запросов. Скорее всего, ваша команда уже знает это.
Для нереляционных баз данных могут потребоваться дополнительные знания в области программирования, а это означает, что вашей команде, возможно, придется изучить другие типы языков запросов. Или вам нужно будет нанять кого-то с большим опытом работы с кодом.
Вам нужны данные в режиме реального времени?
Серьезный ажиотаж вокруг аналитики в реальном времени. Нельзя недооценивать конкурентное преимущество, которое она дает, и ее влияние на принятие решений. Однако важно отметить, что не каждой организации нужны данные в режиме реального времени. Возможно, ваши данные не сильно изменились. Возможно, вас больше интересует анализ прошлых наборов данных. В этом случае реляционные базы данных работают хорошо.
Logi Symphony: использование всего облака в отчетах и информационных панелях
Logi Symphony — это продукт, предлагаемый/пакет от Insightsoftware, специально созданный для встраивания в ваше приложение и предоставления аналитики и отчетов самообслуживания вашим конечным пользователям. Logi Symphony позволяет как простым, так и опытным пользователям создавать надежные отчеты и находить полезную информацию для принятия более эффективных бизнес-решений.
Logi Symphony позволяет как простым, так и опытным пользователям создавать надежные отчеты и находить полезную информацию для принятия более эффективных бизнес-решений.
Менеджеры по продуктам расширяют ассортимент своих продуктов с помощью Logi Symphony, чтобы подключаться практически к любому источнику данных напрямую или с помощью REST API. Кроме того, Logi Symphony содержит слой данных ETL-lite, который предоставляет множество функций для решения проблем, связанных с данными, которые могут возникнуть при использовании встроенных отчетов и потребностей бизнес-аналитики. Используя уровень данных Logi Symphony, вы можете:
- Повысьте и оптимизируйте производительность данных с помощью запатентованных кубов памяти.
- Повысьте производительность и надежность данных с помощью встроенного хранилища данных и автоматического индексирования данных.
- Дополняйте и расширяйте данные для лучшего анализа с помощью встроенных преобразований для решения распространенных проблем с данными.

- Включите прогностическую аналитику, искусственный интеллект и машинное обучение или настраиваемые правила данных поверх ваших данных, используя такие языки программирования, как C#, Python или R.
- Создайте индивидуальный пользовательский интерфейс, защитив данные пользователя с помощью безопасности на уровне строк/столбцов.
Получить демонстрацию
Узнайте, как компании переносят оперативные данные из своих ERP-систем в Excel и ежемесячно закрывают свои бухгалтерские книги на 4 дня быстрее.
Какой выбрать?
С тех пор, как Э. Ф. Кодд представил первую реляционную модель хранения данных в IBM в 1970 году, отрасль подхватила технологию баз данных и использовала ее для получения конкурентного преимущества.
Система управления реляционными базами данных, или РСУБД, долгое время была технологией по умолчанию для хранения и доступа к данным.
Он поддерживал хранение транзакционных данных, создание продуктов данных и был моделью для данных, которая использовалась при принятии решений на основе данных.
Все изменилось с бумом Интернета в 2000-х.
Данные производились быстрее, в большем количестве и с большим разнообразием, чем когда-либо прежде. Компании генерировали, собирали и анализировали данные, которые были не только текстом и цифрами, как это было в прошлом, но также изображениями, видео и аудиоклипами, производимыми массами в социальных сетях.
Реляционная модель данных оказалась неспособной справиться со скоростью, объемом и разнообразием (3V) эпохи больших данных.
Именно тогда мы стали свидетелями возрождения модели нереляционной базы данных. Эта технология существовала некоторое время (1990-е годы), но компании воспользовались нереляционными базами данных для удовлетворения потребностей обработки данных в современных приложениях.
В этой статье мы глубоко заглянем за кулисы, чтобы лучше понять различные системы баз данных и их сравнение.
Чтобы ответить на главный вопрос: что выбрать?
Характеристики реляционных баз данных
Системы реляционных баз данных хранят данные в таблицах, которые выглядят как файлы Excel: каждая строка представляет одну сущность (например, покупателя), а столбцы представляют собой атрибуты или характеристики этой сущности (например, date_of_first_purchase, customer_email , и т. д.).
д.).
Реляционные базы данных отличаются от Excel внутренней оптимизацией, которая значительно ускоряет запросы к данным.
Каждая таблица имеет первичный ключ (в приведенном выше примере «customer_id»), который однозначно идентифицирует каждую запись в таблице. Данные в таблице связаны с другими таблицами через отношения (отсюда и название реляционные), состоящие из пар первичный ключ — внешний ключ.
Итак, если мы хотим проверить, сколько купил Джон (customer_id = 1), мы будем искать внешний ключ «customer_id», принадлежащий Джону, в таблице «заказы»:
Создавая отношения между таблицами, реляционные базы данных избегают избыточность (информация о Джоне сохраняется только в таблице клиентов, все остальное запрашивается через пары первичный-внешний ключ, поэтому требуется меньше места на жестком диске) и сделать данные более устойчивыми к повреждению (более высокая целостность данных).
Реляционные базы данных используют SQL (язык структурированных запросов) — специализированный язык программирования для запросов к системам реляционных баз данных.
Популярные примеры баз данных SQL включают MySQL, PostgreSQL, Oracle, Microsoft SQL Server и IBM Db2.
Характеристики нереляционных баз данных
Нереляционные базы данных (также называемые базами данных NoSQL) относятся к семейству различных типов баз данных, которые имеют одну общую черту: они не хранят данные в виде записей строк в таблицах.
Базы данных NoSQL были в основном созданы для неструктурированных данных, таких как потоки событий, видеоданные или текстовые документы в формате RTF, и это лишь некоторые из них.
Существуют различные типы нереляционных баз данных, и каждый тип оптимизирован для хранения различных структур данных, которые по своей сути не являются реляционными (читай: табличными).
Типы нереляционных баз данных
Существует четыре основных типа нереляционных баз данных
1. Хранилища ключей-значений
Пара «ключ-значение» хранит данные в виде пар «ключ-значение».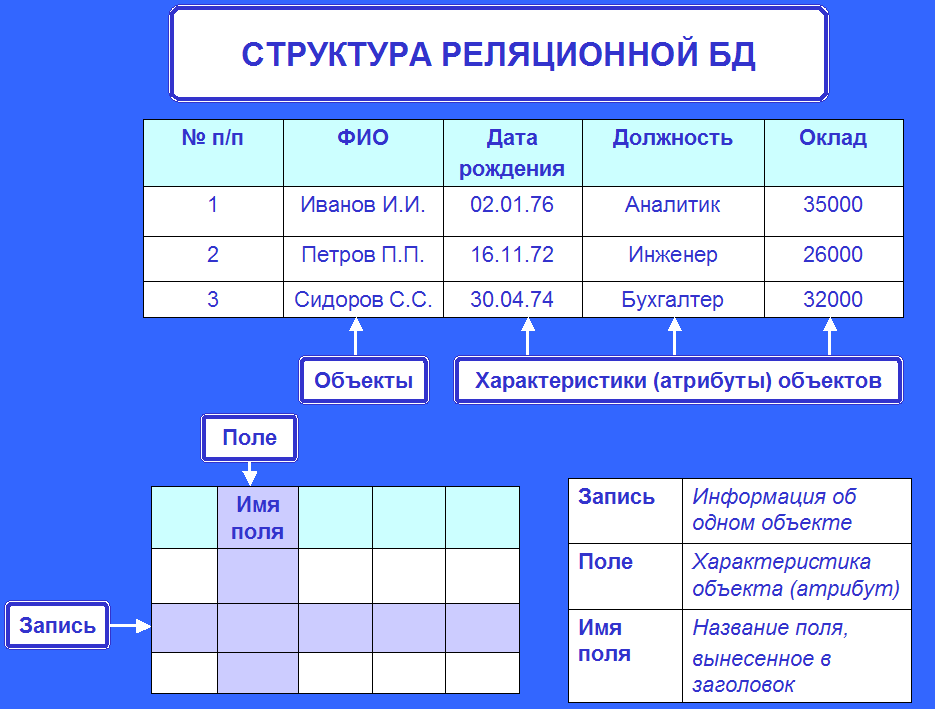 Каждый ключ уникален и связан со значением.
Каждый ключ уникален и связан со значением.
Хранилищам «ключ-значение» не нужны ни первичные, ни внешние ключи, и они очень эффективны при извлечении данных.
Примеры хранилищ ключей и значений включают Aerospike, Apache Cassandra, Berkeley DB, Couchbase Server и Redis.
Они часто используются для данных сеанса (где session_id — это ключ).
2. Базы данных документов
Базы данных документов оптимизированы для хранения форматированных текстовых документов как таковых. Документ переводится из текстовой или pdf-версии в машиночитаемый формат, такой как JSON, BSON или XML.
Каждый документ является отдельной единицей, и хранилища документов не подходят для хранения взаимосвязей между документами. Но они отлично подходят для быстрого чтения документов и извлечения информации из большого массива текстов.
Наиболее известные базы данных документов включают MongoDB и CouchDB.
3. Базы данных графов
Базы данных графов лучше всего использовать для моделирования данных, которые выглядят как — ну — графики! Подумайте о социальных сетях, где один человек может быть связан с другими людьми, и каждый из друзей может иметь свою сеть друзей.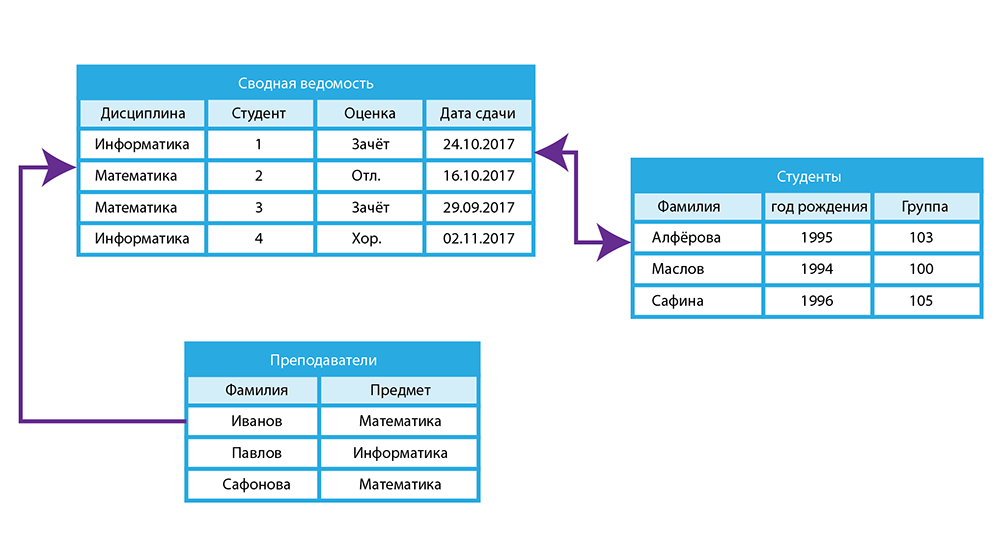
Графовые базы данных особенно полезны для создания динамической схемы — вам не нужно знать, как будут выглядеть ваши данные, прежде чем вы начнете их хранить (необходимое условие для реляционных баз данных). Вместо этого ваша графовая модель может развиваться вместе с вашим сбором данных.
Наиболее ярким примером графовой базы данных является Neo4j.
4. Хранилища с широкими столбцами
Хранилища с широкими столбцами могут выглядеть как таблица, поскольку они хранят информацию в строках и столбцах. Но в отличие от реляционных баз данных хранилища с широкими столбцами оптимизированы для строк, которые имеют разные значения в разных столбцах.
Они оптимизированы для разреженных данных. Вы можете думать о разреженных данных на примере Netflix — каждый человек видел пару фильмов, но не все люди видели все фильмы. Итак, если у вас есть таблица, где каждая строка — это пользователь Netflix, а каждый столбец — это фильм, большинство ячеек будут пустыми (выделены серым цветом в таблице).
Разреженные наборы данных создают проблемы для баз данных SQL, поскольку они снижают производительность при добавлении новых столбцов и строк.
Наиболее яркими примерами хранилищ с широкими столбцами являются Apache HBase с открытым исходным кодом (по образцу Google Bigtable: распределенная система хранения структурированных данных) и Amazon DynamoDB.
Сравнение: реляционная и нереляционная базы данных
Базы данных NoSQL содержат несколько различных технологических решений, но в целом мы можем сравнить два типа баз данных на 5 уровнях: реляционные базы данных обеспечивают высокую доступность. Базы данных NoSQL распределены по дизайну. Это означает, что они хранят реплики данных на нескольких серверах или узлах. Нереляционные базы данных обеспечивают высокую доступность — они всегда доступны для запросов на чтение и запись, даже если сетевые разделы (читай: сбой сети) или некоторые узлы переходят в автономный режим.
Их высокая доступность достигается за счет согласованности.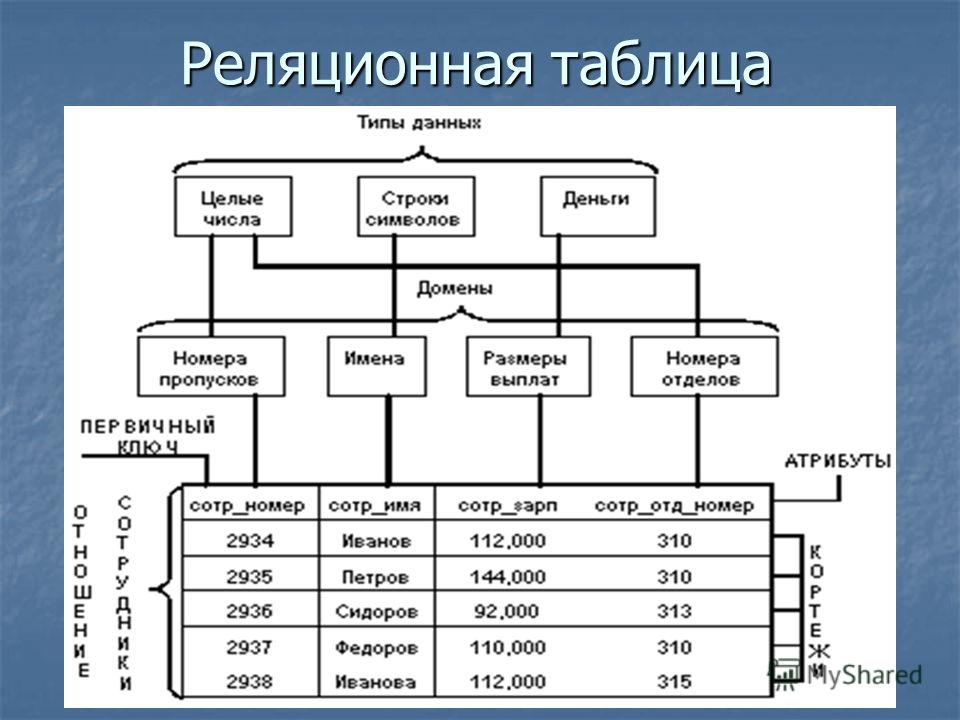 Иногда целостность данных нарушается, чтобы обеспечить их доступность.
Иногда целостность данных нарушается, чтобы обеспечить их доступность.
В отличие от нереляционных баз данных, базы данных SQL ориентированы на высокую согласованность. Они будут отдавать предпочтение целостности данных, а не доступности через свои ACID-транзакции (незнакомо? Подробнее читайте здесь).
2. Масштабирование
Реляционные базы данных обычно развертываются на одном сервере или узле, поэтому они могут масштабироваться только вертикально — путем добавления большего количества ЦП или ОЗУ к существующей инфраструктуре. Вертикальное масштабирование медленнее и дороже.
С другой стороны, нереляционные базы данных распределяются по замыслу, поэтому их можно легко масштабировать по вертикали, добавляя в систему новую машину или сервер. Этот тип масштабирования быстрее и дешевле.
3. Структура данных
Реляционные базы данных лучше всего подходят для структурированных данных, которые хорошо моделируются табличной моделью.
Нереляционные базы данных, с другой стороны, хорошо обрабатывают неструктурированные данные и лучше всего подходят для различных структур данных.
4. Гибкость схемы
Базы данных SQL плохо адаптируются к изменяющимся схемам данных (общая структура ваших данных во всех таблицах).
Базы данных NoSQL хорошо справляются с динамическими изменениями схемы, потому что они не предполагают заданную структуру данных заранее.
5. Объем данных
Нереляционные базы данных были разработаны для обработки безумно больших объемов данных — тех объемов, которые обычно ломают базу данных SQL.
Зачем использовать нереляционную базу данных вместо реляционной?
Окончательный выбор между нереляционной и реляционной базой данных будет зависеть от вариантов использования в вашем бизнесе.
Если вашему приложению требуется высокая доступность (но не обязательно согласованность), простая масштабируемость и гибкость модели, вам лучше использовать нереляционную базу данных.