Что за шрифт? Поиск шрифта по картинке
Category Статьи ФайлыPosted on:
Бывает, откроешь сайт и ловишь себя на мысль, что хочется долго рассматривать его картинки, читать его тексты, любоваться цветовой композицией. Увлекает оригинальный современный дизайн. Особенно привлекательный шрифт. Охота применить для своих проектов, но не понимаешь, как найти шрифт по картинке.
Чтобы не потерять драгоценное время на поиск нужной типографии, я создал небольшую подборку бесплатных онлайн сервисов для быстрого отбора шрифта по картинке. Своеобразие и преимущества каждого из них пригодятся в работе дизайнеру.
Как узнать, что это за шрифт?
- Поинтересоваться у разработчика дизайна, с какими шрифтами он работает. Но не каждый дизайнер охотно с вами поделится.
- Использовать фотошоп. В разделе шрифтов найти функцию поиск шрифта по картинке легко.

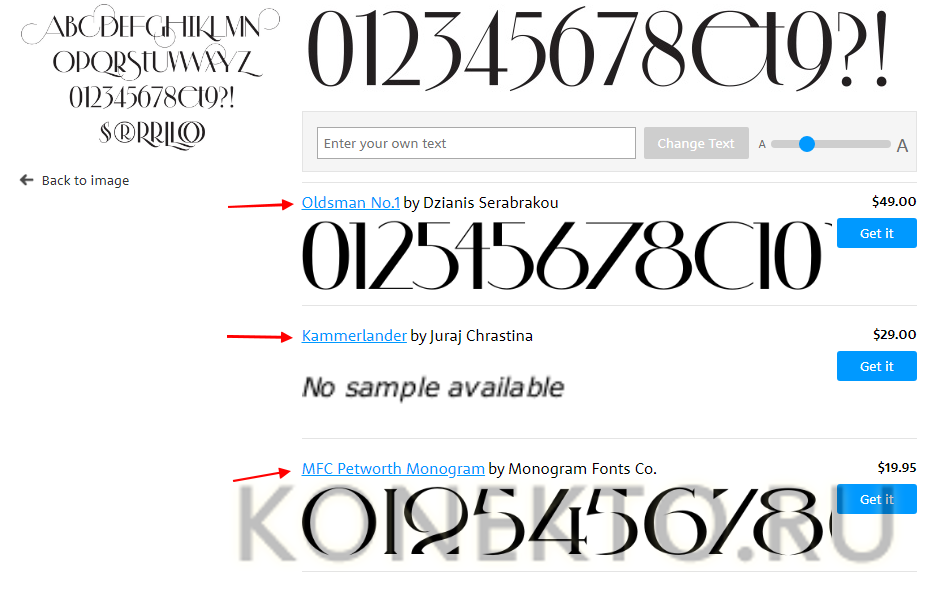
- Отбор шрифта по картинке посредством специальных сайтов. Это наиболее удачный способ найти редкие буквы. Сервис позволяет распознать шрифт путем загрузки изображения и его анализа.

Бесплатные и практичные сервисы распознания шрифта:
WhatTheFont
WhatTheFont один из лучших специалистов по распознаванию шрифтов. Нужно загрузить изображение. Сервис определяет в базе данных самый похожий шрифт. Это удобно, быстро и просто.
Matcherator
Matcherator уникален по простоте использования функции drag and drop. С помощью мышки необходимо перетащить картинку и поместить шрифт, а дальше программа сама все сделает. Преимущество данного сервиса – распознание всевозможных шрифтов с засечками и без.
Identifont
Identifont может отличить все типы шрифтов. Но сделает это он после ответа на вопросы: какая высота, изгибы и засечки буквы. В очередной раз можно изменить свой ответ, нажав на вопрос в левой колонке и проверив нужные параметры.
В очередной раз можно изменить свой ответ, нажав на вопрос в левой колонке и проверив нужные параметры.
WhatFontIs
WhatFontIs — хороший сервис, который не только распознает, но и определяет выбор шрифта. Отличительная функция данного сервиса позволяет установить распознавание и отобрать выдачу. Данный сервис имеет и платные функции, но можно найти большой выбор бесплатных решений.
Fount
Fount можно вставить в меню браузера. Это очень удобно в работе дизайнерам для ежедневного поиска шрифтов. Ключевые характеристики каждого шрифта, размер, вес и стиль иероглифов — преимущества данного инструмента.
Остается только: нажать на кнопку «Fount»; выбрать шрифт; отключить «Fount», нажав еще раз.
Fontshop
Fontshop действует по тем же принципам, что и By-Sight. Надо немного повозиться, но можно легко распознать многое в тексте.
Bowfin Printworks
Bowfin Printworks легко и быстро находит любой шрифт. Есть целый список возможностей.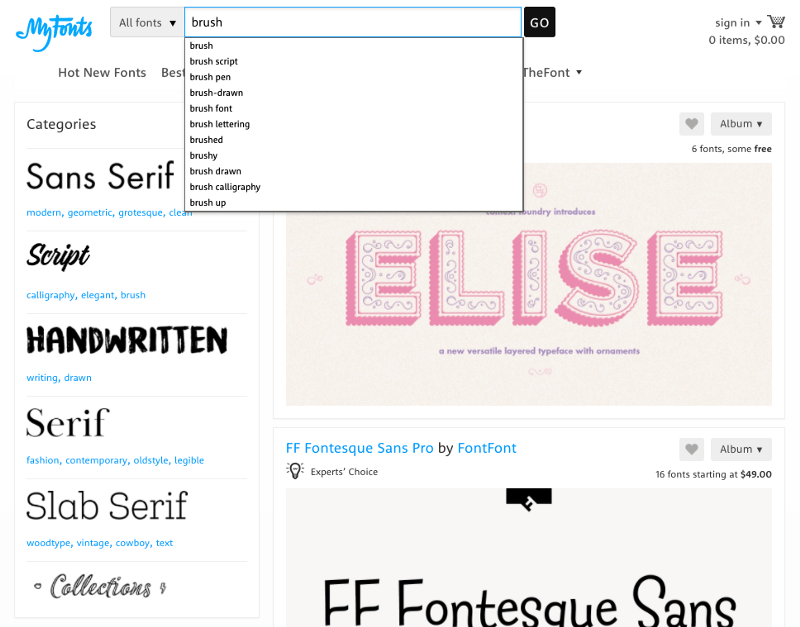 Остается выбрать нужные характеристики.
Остается выбрать нужные характеристики.
Fontmassive (бонус)
Если автоматические сервисы не помогают, то рекомендую русскоязычный сервис, где вы можете загрузить картинку со шрифтом
для того, чтобы спросить у других посетителей название шрифта. Сам пользуюсь данным сервисом, ответ приходит быстро: в среднем 15 минут.
Выводы:
Не думаю, что кому-то охота часами сидеть в интернете и искать красивые подборки шрифтов. Если понравилась какая-нибудь крутая надпись и хочется использовать в своих проектах – лучший способ прибегнуть к онлайн сервисам.
Опубликовано в Статьи ФайлыМетки: бесплатно статья шрифт 28 562CLIP: Соединение текста и изображений
Хотя глубокое обучение произвело революцию в компьютерном зрении, у современных подходов есть несколько серьезных проблем: создание типичных наборов данных для зрения требует больших усилий и затрат при обучении только узкому набору визуальных понятий; стандартные модели зрения хорошо справляются с одной задачей и только с одной задачей и требуют значительных усилий для адаптации к новой задаче; а модели, которые хорошо работают в тестах, имеют разочаровывающе низкую производительность в стресс-тестах, [^reference-1] 9ссылка-4] ставит под сомнение весь подход глубокого обучения к компьютерному зрению.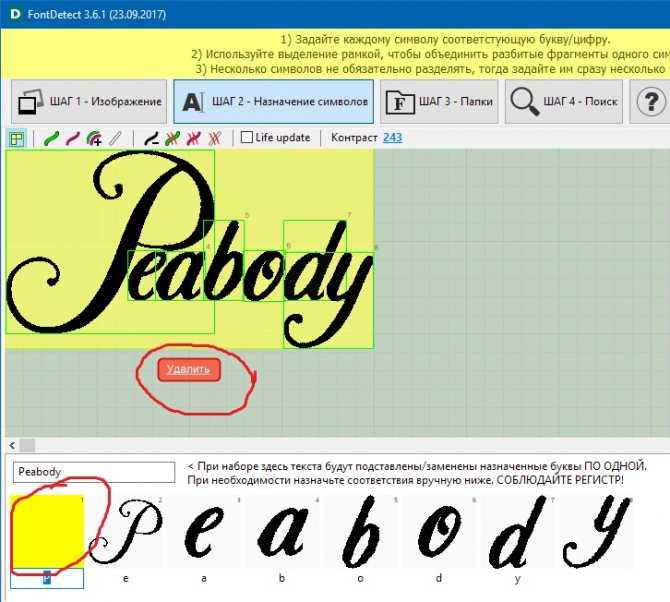
Мы представляем нейронную сеть, которая призвана решить эти проблемы: она обучается на самых разных изображениях с широким спектром контроля естественного языка, которые в изобилии доступны в Интернете. По своему замыслу сеть может быть проинструктирована на естественном языке для выполнения большого количества тестов классификации без прямой оптимизации производительности теста, подобно возможностям «нулевого выстрела» GPT-2 9.reference-7] на нулевом снимке ImageNet без использования каких-либо исходных 1,28-мегапиксельных помеченных примеров.
Хотя обе модели имеют одинаковую точность на тестовом наборе ImageNet, производительность CLIP гораздо лучше отражает то, как он будет работать с наборами данных, которые измеряют точность в разных настройках, отличных от ImageNet. Например, ObjectNet проверяет способность модели распознавать объекты в разных позах и с разным фоном внутри дома, в то время как ImageNet Rendition и ImageNet Sketch проверяют способность модели распознавать более абстрактные изображения объектов.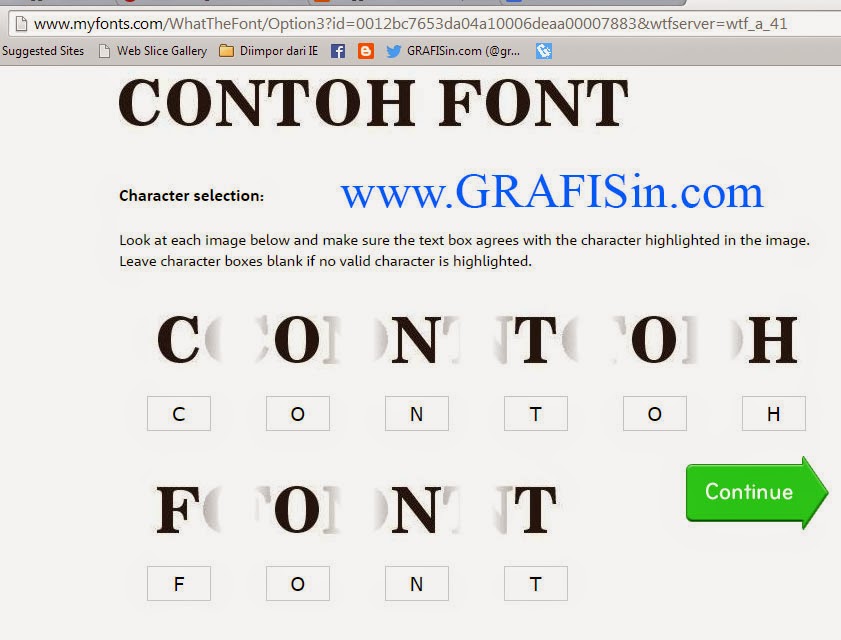 9reference-13] , который в 2016 году продемонстрировал использование функции контроля естественного языка для обеспечения нулевой передачи в несколько существующих наборов данных классификации компьютерного зрения, таких как канонический набор данных ImageNet. Они достигли этого, настроив ImageNet CNN для предсказания гораздо более широкого набора визуальных понятий (визуальных n-грамм) из текста заголовков, описаний и тегов 30 миллионов фотографий Flickr, и смогли достичь точности 11,5% на ImageNet. нулевой выстрел.
9reference-13] , который в 2016 году продемонстрировал использование функции контроля естественного языка для обеспечения нулевой передачи в несколько существующих наборов данных классификации компьютерного зрения, таких как канонический набор данных ImageNet. Они достигли этого, настроив ImageNet CNN для предсказания гораздо более широкого набора визуальных понятий (визуальных n-грамм) из текста заголовков, описаний и тегов 30 миллионов фотографий Flickr, и смогли достичь точности 11,5% на ImageNet. нулевой выстрел. Наконец, CLIP является частью группы статей, пересматривающих изучение визуальных представлений на естественном языке в прошлом году. В этом направлении работы используются более современные архитектуры, такие как Transformer 9.ссылка-35] , в котором изучался тот же контрастный объектив, который мы используем для CLIP, но в области медицинской визуализации.
Подход
Мы показываем, что масштабирования простой задачи предварительного обучения достаточно для достижения конкурентоспособной нулевой производительности на большом количестве наборов данных классификации изображений. Наш метод использует широко доступный источник наблюдения: текст в сочетании с изображениями, найденными в Интернете. Эти данные используются для создания следующей прокси-задачи обучения для CLIP: по заданному изображению предсказать, какой из набора из 32 768 случайно выбранных текстовых фрагментов фактически был связан с ним в нашем наборе данных.
Наш метод использует широко доступный источник наблюдения: текст в сочетании с изображениями, найденными в Интернете. Эти данные используются для создания следующей прокси-задачи обучения для CLIP: по заданному изображению предсказать, какой из набора из 32 768 случайно выбранных текстовых фрагментов фактически был связан с ним в нашем наборе данных.
Наша интуиция подсказывает, что для решения этой задачи модели CLIP должны научиться распознавать широкий спектр визуальных понятий в изображениях и ассоциировать их со своими именами. В результате модели CLIP можно применять практически к любым задачам визуальной классификации. Например, если задачей набора данных является классификация фотографий собак и кошек, мы проверяем для каждого изображения, предсказывает ли модель CLIP текстовое описание «фото собаки » или «фото кота ». вероятно, будет в паре с ним.
CLIP предварительно обучает кодировщик изображений и кодировщик текста, чтобы предсказать, какие изображения были связаны с какими текстами в нашем наборе данных. Затем мы используем это поведение, чтобы превратить CLIP в нулевой классификатор. Мы конвертируем все классы набора данных в подписи, такие как «фотография собаки», и предсказываем, класс подписи CLIP оценивает лучшие пары с данным изображением.
Затем мы используем это поведение, чтобы превратить CLIP в нулевой классификатор. Мы конвертируем все классы набора данных в подписи, такие как «фотография собаки», и предсказываем, класс подписи CLIP оценивает лучшие пары с данным изображением.
CLIP был разработан для смягчения ряда серьезных проблем в стандартном подходе глубокого обучения к компьютерному зрению:
Дорогостоящие наборы данных : Глубокое обучение требует большого количества данных, а модели зрения традиционно обучались на наборах данных, помеченных вручную, которые дорого создавать и обеспечивают только наблюдение за ограниченным числом заранее определенных визуальных концепций. Набор данных ImageNet, один из крупнейших проектов в этой области, потребовал более 25 000 рабочих для аннотирования 14 миллионов изображений для 22 000 категорий объектов. Напротив, CLIP учится на парах текст-изображение, которые уже общедоступны в Интернете. Снижение потребности в дорогостоящих больших размеченных наборах данных было тщательно изучено в предыдущих работах, особенно в обучении с самоконтролем, 9reference-27]
Narrow : Модель ImageNet хороша для прогнозирования 1000 категорий ImageNet, но это все, что она может сделать «из коробки». Если мы хотим выполнить какую-либо другую задачу, специалисту по машинному обучению необходимо создать новый набор данных, добавить выходную головку и точно настроить модель. Напротив, CLIP можно адаптировать для выполнения широкого круга задач визуальной классификации без дополнительных обучающих примеров. Чтобы применить CLIP к новой задаче, все, что нам нужно сделать, это «сообщить» текстовому кодировщику CLIP имена визуальных понятий задачи, и он выведет линейный классификатор визуальных представлений CLIP. Точность этого классификатора часто конкурентоспособна с полностью контролируемыми моделями. 9сноска-1] в тестах машинного зрения, однако при развертывании в реальных условиях их производительность может быть намного ниже ожидаемой, установленной тестом. Другими словами, существует разрыв между «эталонной производительностью» и «реальной производительностью». Мы предполагаем, что этот разрыв возникает из-за того, что модели «мошенничают», оптимизируя только производительность в тесте, как студент, который сдал экзамен, изучая только вопросы экзаменов прошлых лет.
Если мы хотим выполнить какую-либо другую задачу, специалисту по машинному обучению необходимо создать новый набор данных, добавить выходную головку и точно настроить модель. Напротив, CLIP можно адаптировать для выполнения широкого круга задач визуальной классификации без дополнительных обучающих примеров. Чтобы применить CLIP к новой задаче, все, что нам нужно сделать, это «сообщить» текстовому кодировщику CLIP имена визуальных понятий задачи, и он выведет линейный классификатор визуальных представлений CLIP. Точность этого классификатора часто конкурентоспособна с полностью контролируемыми моделями. 9сноска-1] в тестах машинного зрения, однако при развертывании в реальных условиях их производительность может быть намного ниже ожидаемой, установленной тестом. Другими словами, существует разрыв между «эталонной производительностью» и «реальной производительностью». Мы предполагаем, что этот разрыв возникает из-за того, что модели «мошенничают», оптимизируя только производительность в тесте, как студент, который сдал экзамен, изучая только вопросы экзаменов прошлых лет. Напротив, модель CLIP можно оценивать на бенчмарках без необходимости обучения на их данных, поэтому она не может «мошенничать» таким образом. Это приводит к тому, что его эталонная производительность намного лучше отражает его производительность в дикой природе. Чтобы проверить «гипотезу мошенничества», мы также измеряем, как изменяется производительность CLIP, когда он может «обучаться» для ImageNet. Когда линейный классификатор устанавливается в дополнение к функциям CLIP, он повышает точность CLIP на тестовом наборе ImageNet почти на 10%. Однако этот классификатор делает 9reference-30]
Напротив, модель CLIP можно оценивать на бенчмарках без необходимости обучения на их данных, поэтому она не может «мошенничать» таким образом. Это приводит к тому, что его эталонная производительность намного лучше отражает его производительность в дикой природе. Чтобы проверить «гипотезу мошенничества», мы также измеряем, как изменяется производительность CLIP, когда он может «обучаться» для ImageNet. Когда линейный классификатор устанавливается в дополнение к функциям CLIP, он повышает точность CLIP на тестовом наборе ImageNet почти на 10%. Однако этот классификатор делает 9reference-30]
Основные выводы
1. CLIP очень эффективен
CLIP учится на нефильтрованных, сильно различающихся и сильно зашумленных данных и предназначен для использования в режиме нулевого выстрела. Из GPT-2 и 3 мы знаем, что модели, обученные на таких данных, могут достигать убедительных результатов с нулевым выстрелом; однако такие модели требуют значительных обучающих вычислений. Чтобы сократить объем необходимых вычислений, мы сосредоточились на алгоритмических способах повышения эффективности обучения нашего подхода. 9reference-36]
Чтобы сократить объем необходимых вычислений, мы сосредоточились на алгоритмических способах повышения эффективности обучения нашего подхода. 9reference-36]
2. CLIP является гибким и общим
Поскольку они изучают широкий спектр визуальных понятий непосредственно из естественного языка, модели CLIP значительно более гибкие и общие, чем существующие модели ImageNet. Мы обнаруживаем, что они способны с нуля выполнять множество различных задач. Чтобы подтвердить это, мы измерили нулевую производительность CLIP на более чем 30 различных наборах данных, включая такие задачи, как детальная классификация объектов, географическая локализация, распознавание действий в видео и оптическое распознавание символов. 9reference-23] на 20 из 26 различных наборов данных о переносах, которые мы протестировали.
9reference-23] на 20 из 26 различных наборов данных о переносах, которые мы протестировали.
CLIP-ViT
ViT (ImageNet-21k)
CLIP-ResNet
SimCLRv2
BiT-M 0Net-9istuis
Efficient 02 BYOL
BiT-S
EfficientNet
MoCo
ResNet
В наборе из 27 наборов данных, измеряющих такие задачи, как детальная классификация объектов, оптическое распознавание символов, распознавание действий в видео и геолокация, мы обнаружили, что модели CLIP изучают более широко полезные представления изображений. Модели CLIP также более эффективны с точки зрения вычислений, чем модели из 10 предыдущих подходов, с которыми мы сравниваем.
Ограничения
В то время как CLIP обычно хорошо справляется с распознаванием обычных объектов, он испытывает трудности с более абстрактными или систематическими задачами, такими как подсчет количества объектов на изображении, и с более сложными задачами, такими как предсказание, насколько близко находится ближайший автомобиль.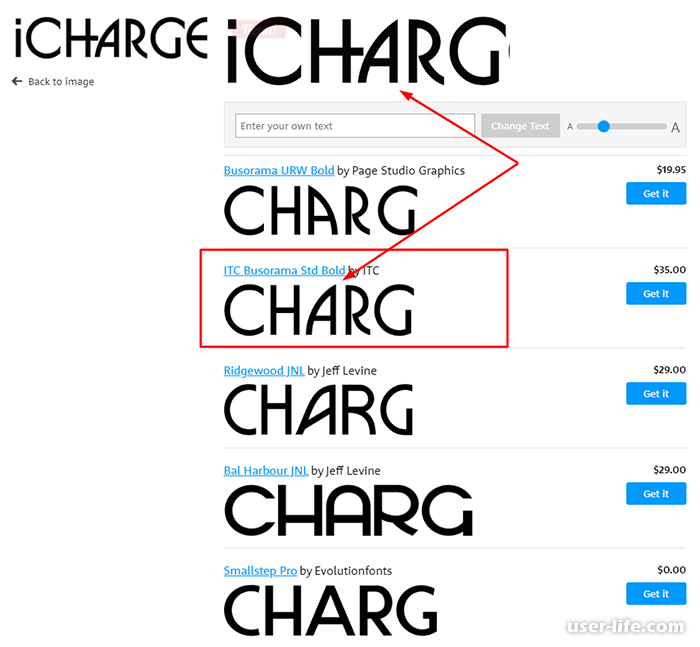 фото. В этих двух наборах данных CLIP с нулевым выстрелом лишь немного лучше, чем случайное угадывание. Zero-shot CLIP также имеет трудности по сравнению с моделями для конкретных задач при очень тонкой классификации, например, в определении различий между моделями автомобилей, вариантами самолетов или видами цветов.
фото. В этих двух наборах данных CLIP с нулевым выстрелом лишь немного лучше, чем случайное угадывание. Zero-shot CLIP также имеет трудности по сравнению с моделями для конкретных задач при очень тонкой классификации, например, в определении различий между моделями автомобилей, вариантами самолетов или видами цветов.
CLIP также по-прежнему плохо обобщает изображения, не включенные в его набор данных для предварительной подготовки. Например, хотя CLIP изучает способную систему OCR, при оценке рукописных цифр из набора данных MNIST нулевая точность CLIP достигает только 88% точности, что намного ниже 99,75% людей в наборе данных. Наконец, мы заметили, что классификаторы нулевого выстрела CLIP могут быть чувствительны к формулировкам или формулировкам и иногда требуют проб и ошибок «оперативного проектирования» для хорошей работы.
 Однако когда мы добавляем класс «дочерний» в список возможных классов, это поведение снижается до ~8,7%.
Однако когда мы добавляем класс «дочерний» в список возможных классов, это поведение снижается до ~8,7%. Кроме того, учитывая, что CLIP не нуждается в данных об обучении для конкретной задачи, он может с большей легкостью разблокировать определенные нишевые задачи. Некоторые из этих задач могут создавать риски, связанные с конфиденциальностью или слежкой, и мы изучаем эту проблему, изучая эффективность CLIP в отношении идентификации знаменитостей. CLIP занимает первое место по точности 59.0,2% для классификации изображений знаменитостей «в дикой природе» при выборе из 100 кандидатов и точность топ-1 43,3% при выборе из 1000 возможных вариантов. Хотя достижение этих результатов с помощью предобучения, не зависящего от задачи, заслуживает внимания, эта производительность неконкурентоспособна по сравнению с широко доступными моделями производственного уровня. Мы дополнительно исследуем проблемы, которые CLIP ставит в нашей статье, и мы надеемся, что эта работа мотивирует будущие исследования по характеристике возможностей, недостатков и предубеждений таких моделей.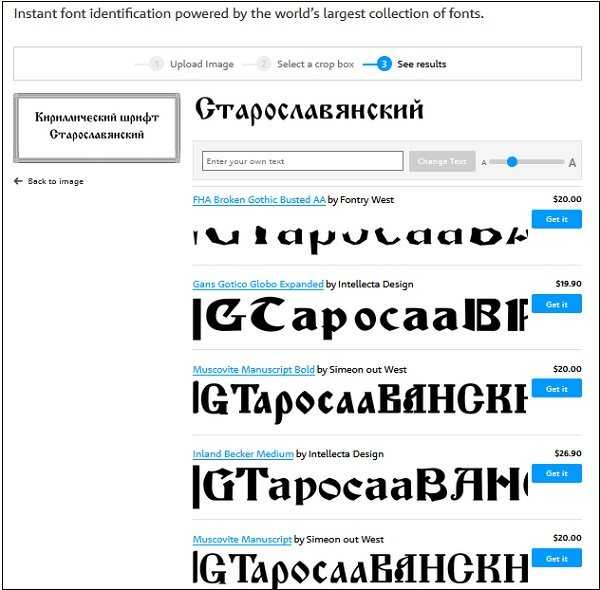 Мы рады взаимодействовать с исследовательским сообществом по таким вопросам.
Мы рады взаимодействовать с исследовательским сообществом по таким вопросам.
Заключение
С помощью CLIP мы проверили, можно ли использовать независимую от задач предварительную подготовку на естественном языке в масштабе Интернета, которая привела к недавнему прорыву в НЛП, для повышения производительности глубокого обучения в других областях. . Мы в восторге от результатов, которые мы уже видели, применяя этот подход к компьютерному зрению. Как и семейство GPT, CLIP изучает широкий спектр задач во время предварительной подготовки, которую мы демонстрируем с помощью переноса с нулевым выстрелом. Нас также обнадеживают наши результаты на ImageNet, которые предполагают, что нулевая оценка является более репрезентативной мерой возможностей модели.
Что происходит на этой картинке?
Реклама
Продолжить чтение основного сюжета
The Learning Network
Изображения Intriguing Times без подписей — и приглашение учащимся обсудить их в прямом эфире.

Изображения Intriguing Times без подписей — и приглашение для студентов обсудить их в прямом эфире.
Основные моменты
- PhotoCreditRajesh Kumar Singh/Associated Press Посмотрите внимательно на это изображение без подписи и присоединяйтесь к модерируемому разговору о том, что видите вы и другие учащиеся.
От The Learning Network
- PhotoCreditD. Gorton
Новое слайд-шоу из наших любимых «Что происходит на этой картинке?» сообщения, отобранные из изображений за последние четыре года.
The Learning Network
- Фото: По часовой стрелке, сверху слева: Брайан Дентон для The New York Times, Эннио Леанза/European Pressphoto Agency, Алехандро Сегарра для The New York Times, Мухаммед Мухейсен/Associated Press, Michael Paulsen/Houston Chronicle, Адам Дин для The New York Times
Хотите использовать интригующие фотографии, чтобы помочь учащимся практиковать визуальное мышление и навыки внимательного чтения? Это руководство может помочь вам начать работу.
От The Learning Network
- PhotoCredit
Хотите узнать больше об этом популярном студенческом мероприятии? Посмотрите это короткое вступительное видео и начните использовать эту мультимедийную функцию в своем классе.
От The Learning Network
- PhotoCreditD. Gorton
- PhotoCreditBogdan Cristel/Reuters
Посмотрите внимательно на это изображение без подписи и присоединяйтесь к модерируемому разговору о том, что видите вы и другие учащиеся.
От The Learning Network
- PhotoCreditFayaz Kabli/Reuters
Посмотрите внимательно на это изображение без подписи и присоединяйтесь к модерируемому обсуждению того, что видите вы и другие учащиеся.
От The Learning Network
- Фото: Роберт Уокер/The New York Times
Посмотрите внимательно на это изображение без подписи и присоединяйтесь к модерируемому разговору о том, что видите вы и другие учащиеся.
Учебной сети
- PhotoCreditDeSean McClinton-Holland для The New York Times Посмотрите внимательно на это изображение без подписи и присоединитесь к модерируемому разговору о том, что вы и другие студенты видите.

От The Learning Network
- PhotoCreditKhaled Abdullah/Reuters
Слайд-шоу некоторых из наших любимых «Что происходит на этой картинке?» сообщения, отобранные из 10-летних изображений.
Михаил Гончар
Реклама
Продолжить чтение основной истории
Что происходит на этой картинке? | 24 апреля 2023 г.
Посмотрите внимательно на это изображение без подписи и присоединитесь к модерируемому обсуждению того, что видите вы и другие учащиеся.
The Learning Network
Что происходит на этом изображении? | 6 марта 2023 г.
Посмотрите внимательно на это изображение без подписи и присоединитесь к модерируемому обсуждению того, что видите вы и другие учащиеся.
Сеть обучения
Что происходит на этой картинке? | 27 февраля 2023 г.
Посмотрите внимательно на это изображение без подписи и присоединитесь к модерируемому обсуждению того, что видите вы и другие учащиеся.
The Learning Network
Что происходит на этом изображении? | 13 февраля 2023 г.
Посмотрите внимательно на это изображение без подписи и присоединитесь к модерируемому обсуждению того, что видите вы и другие учащиеся.
The Learning Network
Что происходит на этом изображении? | 6 февраля 2023 г.
Посмотрите внимательно на это изображение без подписи и присоединитесь к модерируемому обсуждению того, что видите вы и другие учащиеся.
The Learning Network
Что происходит на этом изображении? | 30 января 2023 г.
Посмотрите внимательно на это изображение без подписи и присоединитесь к модерируемому обсуждению того, что видите вы и другие учащиеся.
The Learning Network
Что происходит на этом изображении? | 23 января 2023 г.
Посмотрите внимательно на это изображение без подписи и присоединитесь к модерируемому обсуждению того, что видите вы и другие учащиеся.
