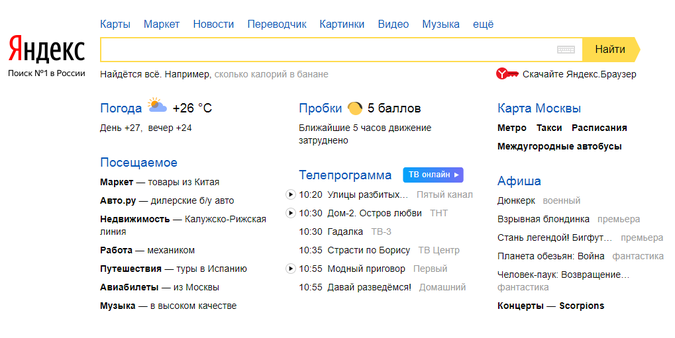
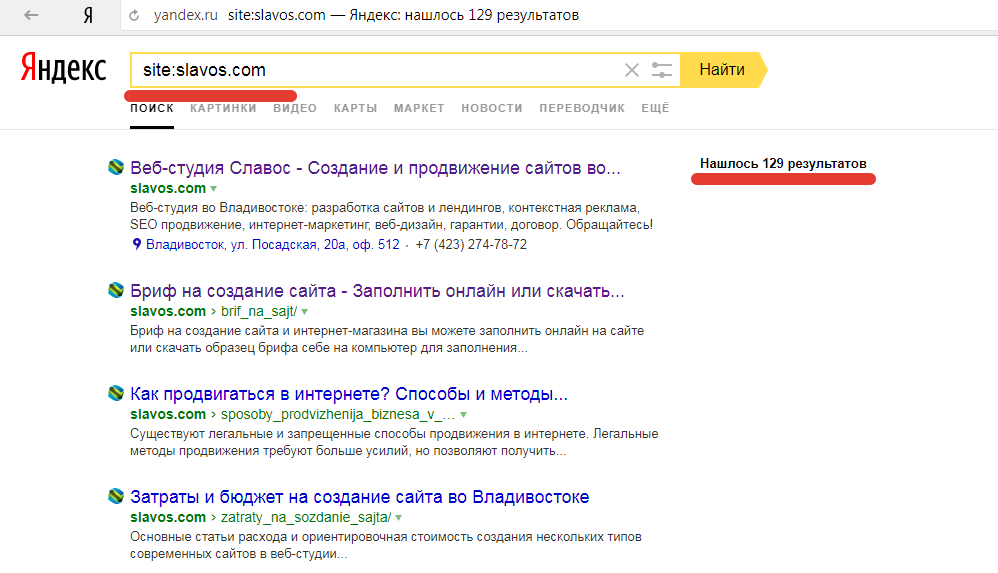
Яндекс — последние новости сегодня
Регистрация пройдена успешно!
Пожалуйста, перейдите по ссылке из письма, отправленного на
За период
материалов
Еще
ЯндексЦИАННью-Йоркская фондовая биржаРоссияNasdaq
Еще
ЯндексКот-д’ИвуарРоссияАбиджанАлексей СалтыковЯндекс.ТаксиТехнологии
Еще
ЯндексNasdaqЭкономикаРоссияНью-Йоркская фондовая биржаHeadHunter
Еще
ЯндексПроисшествияРоссияМосква
Еще
ЯндексЭкономикаРоссияNasdaqУкраинаМосковская биржаВ миреТехнологии
Еще
ЯндексЭкономикаNasdaqРоссияУкраинаМосковская биржаТехнологииВ мире
Еще
ЯндексОбществоТехнологииDelivery Club
Еще
ЯндексНовости компаний — ЭкономикаТехнологииРоссияОбщество
Еще
ЯндексТехнологииUberЯндекс.Такси
Еще
ЯндексТехнологииРоссияПроисшествия
Еще
ЯндексТехнологииDelivery ClubОбщество
Еще
ЯндексТехнологииТашкентУзбекистанРоссияСНГВ миреЭкономика
Еще
ЯндексТехнологииРоссия
ЯндексВ эфиреПодкасты – Радио SputnikКлименко советуетГерман КлименкоРоссияЕвропаКитайОлег ТиньковТехнологии
Еще
ЯндексОбществоМоскваGoogle AndroidApple iOS
Еще
РоссияЗапорожьеАлексей КудринАлексей Нечаев (Лидер партии «Новые люди»)Госдума РФПолитикаПартия «Новые люди»Интервью
Еще
ЯндексТехнологии
Еще
ЯндексForbesWildberriesOzonЭкономика
Еще
ЯндексРоссияСергей ПлуготаренкоФедеральная служба государственной регистрации, кадастра и картографии (Росреестр)ЕГРНЗаконодательство
Еще
ЯндексВ РоссииРоссияСергей СобянинАвто
Еще 20 материалов
Вход на сайт
Почта
Пароль
Восстановить пароль
Зарегистрироваться
Срок действия ссылки истек
Назад
Регистрация на сайте
Почта
Пароль
Я принимаю условия соглашенияВойти с логином и паролем
Ваши данные
Восстановление пароля
Почта
Назад
Восстановление пароля
Ссылка для восстановления пароля отправлена на адрес
Восстановление пароля
Новый пароль
Подтвердите пароль
Написать автору
Тема
Сообщение
Почта
ФИО
Нажимая на кнопку «Отправить», Вы соглашаетесь с Политикой конфиденциальности
Задать вопрос
Ваше имя
Ваш город
Ваш E-mail
Ваше сообщение
Сообщение отправлено!
Спасибо!
Произошла ошибка!
Попробуйте еще раз!
Обратная связь
Чем помочь?
Если ни один из вариантов не подходит,
нажмите здесь для связи с нами
Обратная связь
Чтобы воспользоваться формой обратной связи,
Вы должны войти на сайт.
Разблокировать аккаунт
Вы были заблокированы за нарушение
правил комментирования материалов
Срок блокировки — от 12 до 48 часов, либо навсегда.
Если Вы не согласны c блокировкой, заполните форму.
Назад
Разблокировать аккаунт
Имя в чате
Дата сообщения
Время отправки сообщения
Блокировался ваш аккаунт ранее?
ДаНет
Сколько раз?
Удалили мое сообщение
Ваше сообщение было удалено за нарушение
правил комментирования материалов
Если Вы не согласны c блокировкой, заполните форму.
Назад
Удалили мое сообщение
Чтобы связаться с нами, заполните форму ниже:
Ваше сообщение
Перетащите, или выберите скриншот
Связаться с нами
Если вы хотите пожаловаться на ошибку в материале, заполните форму ниже:
Ссылка на материал
Опишите проблему
Перетащите,
или выберите скриншот
Связаться с нами
Чтобы связаться с нами, заполните форму ниже:
Ваше сообщение
Перетащите,
или выберите скриншот
Новости шоу бизнеса России.
 Светская хроника и новости о звездах
Светская хроника и новости о звездахПесков прокомментировал громкое дело Алексея Москалева, чья дочь оказалась в приюте из-за рисунка против СВО
«Он достал гранату и сказал: «Не спасайте меня»: 19-летний разведчик прикрыл собой пятерых военных на СВО
«Судьбу Романа решают не врачи Коммунарки»: лечением Костомарова занимаются доктора из Германии
Критиковала политику РФ, вступилась за Пугачеву и поругалась с Крутым. За что осуждают Лайму Вайкуле
Когда «Притяжение» иссякло. Почему разошлись Ирина Старшенбаум и Александр Петров
Полковник из «Агента национальной безопасности». Андрей Толубеев обрел любовь, но потерял здоровье
Сейчас читают
«Рядом была несовершеннолетняя Алекса»: Юрий Титов со стыдом вспоминает о сексе на «Фабрике звезд»
Певец крутил роман с Евгенией Волконской.
Сейчас читают
Топалов о кризисе в браке с Тодоренко: «Ответил Регине: «Развода не дам, мы будем жить с тобой вечно»
Пара задумывалась о расставании.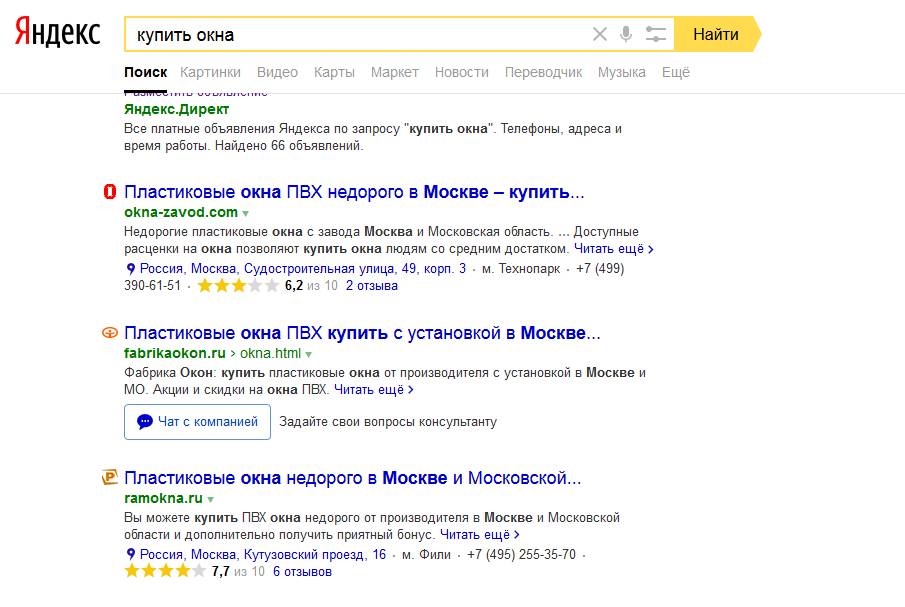
Видео
Дакота об издевательствах Меладзе на «Фабрике»: «Унизил меня в момент, когда я переживала утрату дедушки»
Родственник певицы умер от рака.
31.03.23 06:30
Сейчас читают
Шестилетний сын рэпера Flo Ride выпал из окна пятого этажа
Мать ребенка находится рядом с наследником.
Истории
Критиковала политику РФ, вступилась за Пугачеву и поругалась с Крутым. За что осуждают Лайму Вайкуле
31 марта певице исполняется 69.
31.03.23 05:30
Сейчас читают
Райдер Джанабаевой: закуски, туалет в гримерке и 1 млн. Певица работает, пока Меладзе отменяют в России
Певица замужем за артистом почти 10 лет.
Общество
«Достал этот гребаный нож и полоснул. Все в шоке, я тоже»: жена актера из Улан-Удэ была с ним на сцене
Все в шоке, я тоже»: жена актера из Улан-Удэ была с ним на сцене
Артур Шувалов бунтовал против руководства театра.
31.03.23 04:30
Эксклюзив
Юлия Салибекова: «Тигран на дне рождения сына кричал, чтобы я сдохла, как сдохла моя мать»
Многодетная мама объяснила, почему экс-супруг не общается с детьми.
31.03.23 03:30
«Он не работал, мы жили впроголодь»: жена звезды «ДОМа-2» Венцеслава Венгржановского подала на развод
Дарья Некрасова разочаровалась в экс-участнике реалити.
31.03.23 02:30
Видео
Моргенштерн* в пролете: Дилара громко отметила день рождения со звездами и получила авто в подарок
Бывшей жене рэпера исполнилось 23 года.
31. 03.23 01:30
03.23 01:30
Жена Макаревича* об ужасах перед рождением сына: «Стращало, что стану толстой, с мужем буду ругаться»
Сыну певца и его супруги исполнился год.
31.03.23 00:30
Общество
Мать Маши Москалевой хочет забрать ее из приюта: где женщина была раньше?
Отца девочки, нарисовавшей антивоенный рисунок, задержали.
30.03.23 23:30
Звезда сериала «Король и Шут» Васса Бокова: «Чисто по-женски я бы запала на Горшка»
Актриса получила настоящую роль мечты.
30.03.23 21:30
Все новости«Достал этот гребаный нож и полоснул. Все в шоке, я тоже»: жена актера из Улан-Удэ была с ним на сцене
Артур Шувалов бунтовал против руководства театра.
Мать Маши Москалевой хочет забрать ее из приюта: где женщина была раньше?
«Он достал гранату и сказал: «Не спасайте меня»: 19-летний разведчик прикрыл собой пятерых военных на СВО
Победил рак, бунтовал против нового худрука: как актер Шувалов дошел до кровопролития на сцене театра
Дакота об издевательствах Меладзе на «Фабрике»: «Унизил меня в момент, когда я переживала утрату дедушки»
Моргенштерн* в пролете: Дилара громко отметила день рождения со звездами и получила авто в подарок
У певицы Славы родился внук
«Недоброжелатели превратятся в союзников»: знаки зодиака, которым стоит рассчитывать на удачу до конца весны
Развод Бондарчука, измена Гусева и кризис Арнтгольц. Психолог о признаках того, что отношения изжили себя
Психолог о признаках того, что отношения изжили себя
Из соблазнительной «блестящей» до пышнотелой секси-бомбочки. До и после Анны Семенович
21 марта встречаем новый астрологический год. Как поступить правильно в этот день, чтобы привлечь удачу?
Юлия Салибекова: «Тигран на дне рождения сына кричал, чтобы я сдохла, как сдохла моя мать»
Светлана Пермякова о роли суперженщины в семье, собственной ферме и личном провале
Никас Сафронов показал тяжелобольного Зайцева: «Он нормальный, реагирующий, говорил тихим голосом»
Севиль опровергла уход Артика из Artik & Asti
«Перенюхал и стал просветленным»: Владимир Сычев и другие знакомые о Максиме Лютом, чей ребенок умер от истощения
«Провокации начались с первых минут!»: Константин Гецати о съемках в шоу «Экстрасенсы. Битва сильнейших»
Подписка на рассылкуПодписываясь на рассылку вы принимаете условия пользовательского соглашения
Новости. Mobile Ads SDK
Дата публикации: 14 декабря 2022 г.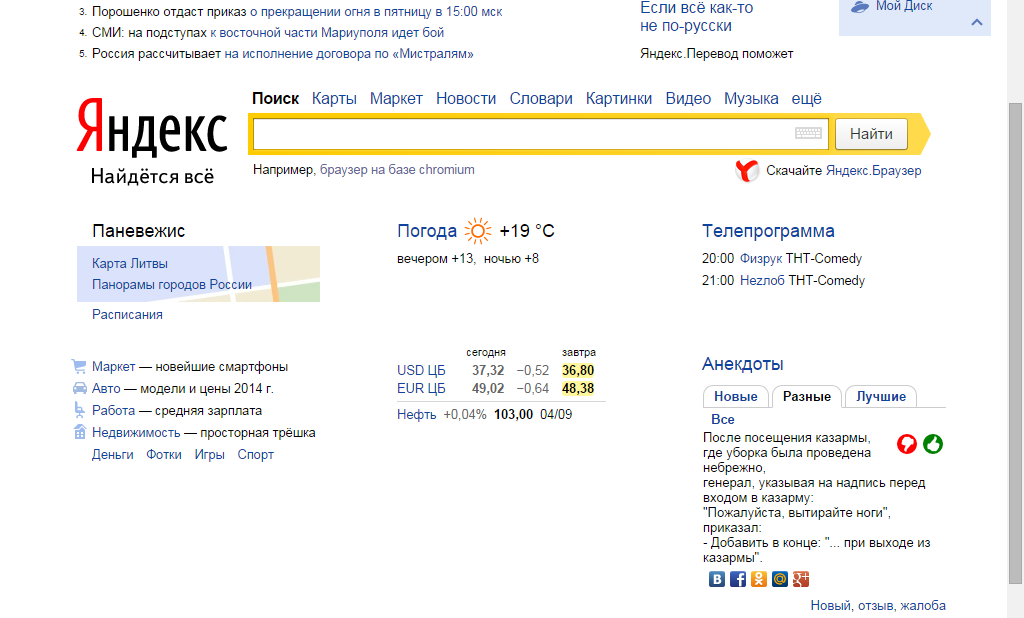
Эта функция доступна, начиная с версии 5.4.1 (Android) и 5.3.1 (iOS).
Flutter — популярная технология для разработки мобильных приложений. Он предназначен для разработчиков программного обеспечения для написания универсального кода, который можно применять к разным операционным системам: как Android, так и iOS.
Теперь монетизировать приложения для Android и iOS, созданные с помощью Flutter, стало еще проще. С помощью плагина, доступного всем партнерам РСЯ, вы можете легко включить монетизацию от Яндекса для своего приложения. Узнайте больше в документации.
Дата публикации: 10 ноября 2022 г.
Эта функция доступна, начиная с версии 5.4.0 (Android).
21 апреля 2000 г. вступил в силу Закон о защите конфиденциальности детей в Интернете (COPPA). Закон регулирует сбор личной информации от детей в возрасте до 13 лет физическими или юридическими лицами в пределах юрисдикции США. В соответствии с Законом оператор приложения должен включить в свою политику конфиденциальности способы получения согласия родителей или опекуна, а также обязательства оператора по защите конфиденциальности и безопасности детей в Интернете, включая маркетинговые ограничения. Мы добавили поддержку COPPA в SDK Yandex Mobile Ads (подробнее об интеграции для Android). Новая функциональность позволит вам ограничить сбор личной информации.
Мы добавили поддержку COPPA в SDK Yandex Mobile Ads (подробнее об интеграции для Android). Новая функциональность позволит вам ограничить сбор личной информации.
Дата публикации: 30 марта 2022 г.
Добавлена предварительная загрузка видеообъявлений. Это поможет вам избежать «черного экрана» при ухудшении связи пользователя.
Теперь требуется меньше времени для инициализации SDK и загрузки рекламы в первый раз.
Мы значительно упростили процесс интеграции видеорекламы InStream при использовании ExoPlayer. Узнайте больше в документации.
Добавлено сообщение о засчитанном показе (
по методу оттиска). Он показывает, что все критерии правильного показа объявления соблюдены.Добавлено сообщение о переходе по объявлению (метод
onAdClicked).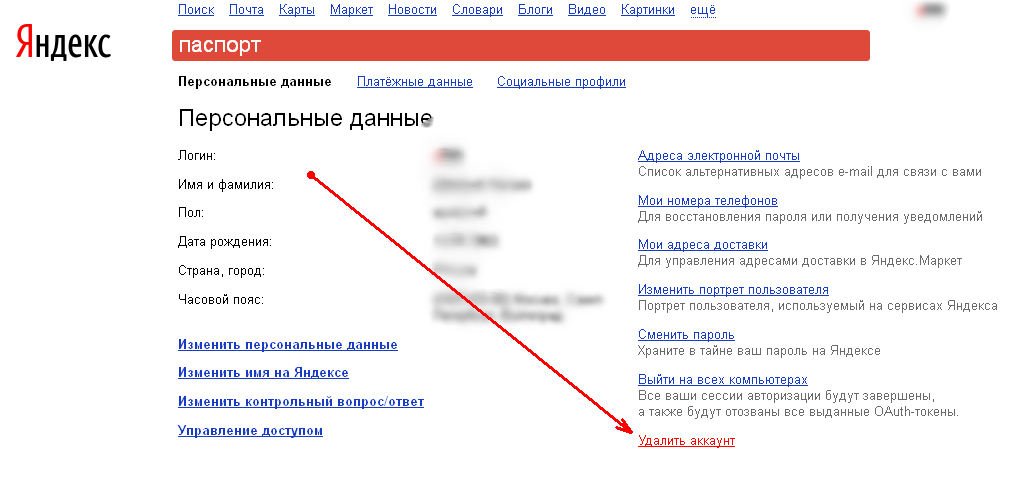
Поддержана архитектура симулятора arm64, чтобы на ноутбуках с процессором M1 можно было запускать Yandex Mobile Ads SDK.
Перенесено на xcframework: быстрый и удобный способ интеграции библиотек.
Поддерживается один метод API для возврата данных о клике по объявлению.
Дата публикации: 24.03.2022.
Рекламная сеть Яндекса до конца апреля 2022 года обновит партнерский интерфейс для работы с мобильными приложениями.
Вместе с переходом на новый интерфейс произойдут некоторые изменения разработан, чтобы помочь вам более гибко управлять показом баннеров на устройствах с разными размерами экрана:
При миграции рекламные блоки «адаптивный приклеенный баннер» и «стандартный баннер» будут автоматически заменены блоками «баннер».
Вы не сможете задать размеры блоков «баннера» в интерфейсе. Однако вы можете сделать это с помощью API.

Подробнее в документации.
Дата публикации: 16 марта 2022 г.
Функционал доступен, начиная с версии 5.0.0-alpha.2 (iOS).
SDK Yandex Mobile Ads теперь поддерживает рекламное посредничество с использованием IronSource. Узнайте больше в документации.
Дата публикации: 11 февраля 2022 г.
Эта функция доступна, начиная с версии 4.5.0 (Android).
SDK Yandex Mobile Ads теперь поддерживает рекламное посредничество с использованием IronSource. Узнайте больше в документации.
Дата публикации: 7 декабря 2021 г.
Службы Google Play обновили свою рекламную политику. Теперь разработчики и рекламные сети не смогут использовать рекламный идентификатор пользователя на телефонах с Android 12, если он отключен в настройках. С 1 апреля 2022 года обновленная политика вступит в силу на всех устройствах Google Play: телефонах, планшетах, Android TV и Wear OS. В результате обновлений сервисов Google Play идентификатор будет доступен только для приложений, которые разрешают его использование.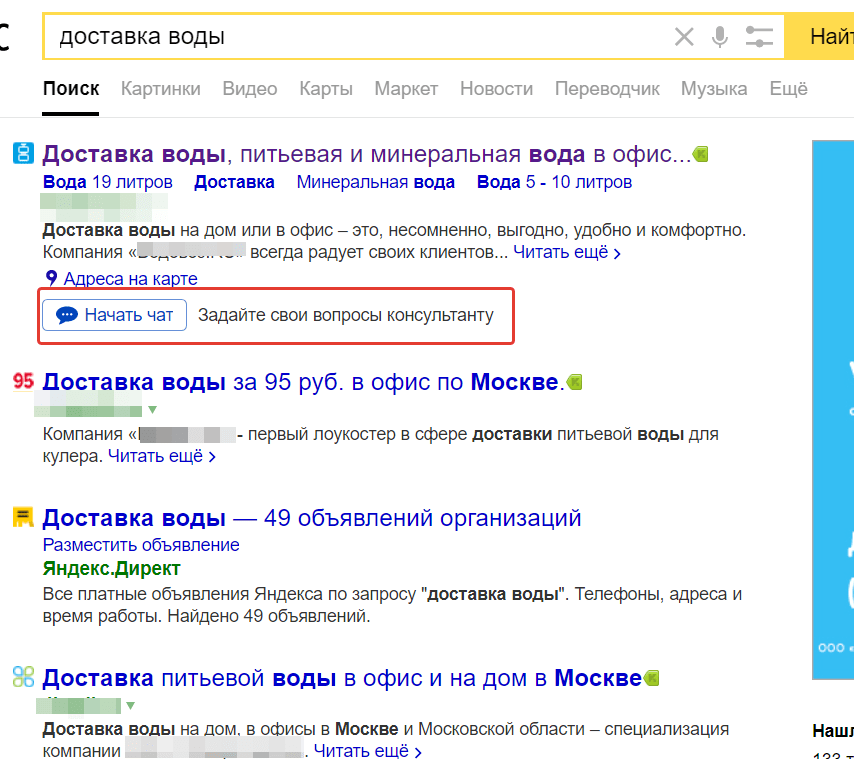 Отсутствие этого разрешения и доступа к идентификатору может снизить релевантность объявлений и, как следствие, ваш доход от монетизации.
Отсутствие этого разрешения и доступа к идентификатору может снизить релевантность объявлений и, как следствие, ваш доход от монетизации.
SDK Yandex Mobile Ads поддерживает обновление политики сервисов Google Play, начиная с версии 4.5.0. Обновите рекламный SDK до последней версии, чтобы com.google.android.gms.permission.AD_ID отображался автоматически. Узнайте больше о разрешении в документации.
Дата публикации: 01.10.2021.
Начиная с Yandex Mobile Ads SDK 4.4.0 изменилась система версий адаптера. Ранее система не была привязана к версиям SDK рекламных сетей. Теперь версия SDK рекламной сети и версия исправления адаптера используются для управления версиями.
Новый формат: adNetworkSdkVersion.adapterPatch .
Пример: версия SDK рекламной сети AdMob — 8.10.0, а версия патча адаптера — 0. Соответственно, версия адаптера будет выглядеть так: 8.10.0.0.
Дата публикации: 10 марта 2021 г.
- Загрузка рекламы при «холодном старте»
«Холодный старт» происходит, когда пользователь впервые открывает приложение после его полного закрытия. Узнайте больше в документации.
- Загрузка нескольких объявлений одним запросом
В нативной рекламе вы можете использовать один запрос для загрузки нескольких разных объявлений одновременно. Такой подход ускоряет показ рекламы, снижает трафик и экономит заряд батареи смартфона. Узнайте больше в документации.
- Поддержка платформы SKAdNetwork
Новая версия Mobile Ads SDK поддерживает отслеживание установки приложений с помощью платформы SKAdNetwork. Отслеживание установки работает для любого устройства, даже если доступ к IDFA не был предоставлен. SKAdNetwork — это API системы для атрибуции установок iOS. Это помогает показывать рекламу, соответствующую интересам аудитории.
- Загрузка нескольких объявлений одним запросом
В нативной рекламе вы можете использовать один запрос для загрузки нескольких разных объявлений одновременно.
 Такой подход ускоряет показ рекламы, снижает трафик и экономит заряд батареи смартфона. Узнайте больше в документации.
Такой подход ускоряет показ рекламы, снижает трафик и экономит заряд батареи смартфона. Узнайте больше в документации.
Дата публикации: 19 января 2021 г.
С января 2021 г. Apple ограничивает доступ к IDFA на iOS 14. Это означает, что Apple больше не будет предоставлять IDFA по умолчанию. Yandex Mobile Ads SDK использует IDFA, чтобы максимизировать доходы издателей за счет показа более релевантной рекламы.
Чтобы получить IDFA, разработчик приложения теперь должен явно запрашивать разрешение пользователя. Это можно сделать с помощью фреймворка AppTrackingTransparency.
Дополнительные сведения см. в разделе Поддержка iOS 14.
Дата публикации: 2 декабря 2020 г.
Эта функция доступна, начиная с версии 3.1.0 (Android).
Мы в Рекламной сети Яндекса продолжаем предлагать нашим партнерам новые способы монетизации своих мобильных приложений. В нативном RTB-блоке для Android-приложений теперь можно показывать слайдер — набор из нескольких объявлений.
Дополнительные сведения см. в разделе Слайдер и слайдер объявлений.
Дата публикации: 6 августа 2020 г.
С 20 августа Mobile Ads SDK будет автоматически использовать контекстные данные из мобильных приложений Android. Согласно нашим экспериментам, это повысит релевантность рекламы для аудитории вашего приложения и может повысить коэффициент возврата в среднем на 4%.
Для повышения эффективности монетизации SDK будет учитывать тексты интерфейса и их темы, взаимодействие пользователя с контентом и подобную информацию. Это означает, что реклама будет подбираться более точно, как на основе поведения пользователя, так и в зависимости от контекста приложения.
Дополнительные сведения см. в разделе Контекстные данные учета.
Дата публикации: 8 июня 2020 г.
Добавлена поддержка нового формата рекламы «адаптивный баннер» (Android и iOS). Адаптивные баннеры органично вписываются в заданные пользователем размеры блоков. В зависимости от того, как интегрирован адаптивный баннер, определяется оптимальная высота для заданной ширины или используется заданный размер рекламного места.
Дата публикации: 24 мая 2019 г.
Этот функционал доступен с версии 2.91 (Андроид)/2.12.0 (iOS).
Added video support in native advertising for the following ad networks that work via Yandex mediation:
AdMob
MoPub
MyTarget
To display a video:
Use the
актив mediaView(подробности интеграции см. в «Руководстве по интеграции MediaView»).Обновите настройки собственного рекламного блока и включите поддержку видео в партнерском интерфейсе посреднической сети:
AdMob: Настройте MediaType для рекламного блока.
MoPub: включить видео для рекламного блока (Android/iOS).
MyTarget: дополнительная настройка не требуется.
Дата публикации: 14 декабря 2018 г.
Эта функция доступна, начиная с версии 2.80 (Android)/2.11.0 (iOS).
В SDK Yandex Mobile Ads появился новый актив mediaView для показа видео. Мы сделали наш актив универсальным, поэтому теперь он работает как с изображениями, так и с видеоконтентом. Вам больше не нужно использовать отдельный imageView актив для основного изображения.
Внимание.
Поддержка основного изображения с использованием ресурса imageView скоро будет прекращена. Мы рекомендуем переключиться на новый ресурс mediaView .
Дата публикации: 14 декабря 2018 г.
Эта функция доступна, начиная с версии 2.80 (Android)/2.11.0 (iOS).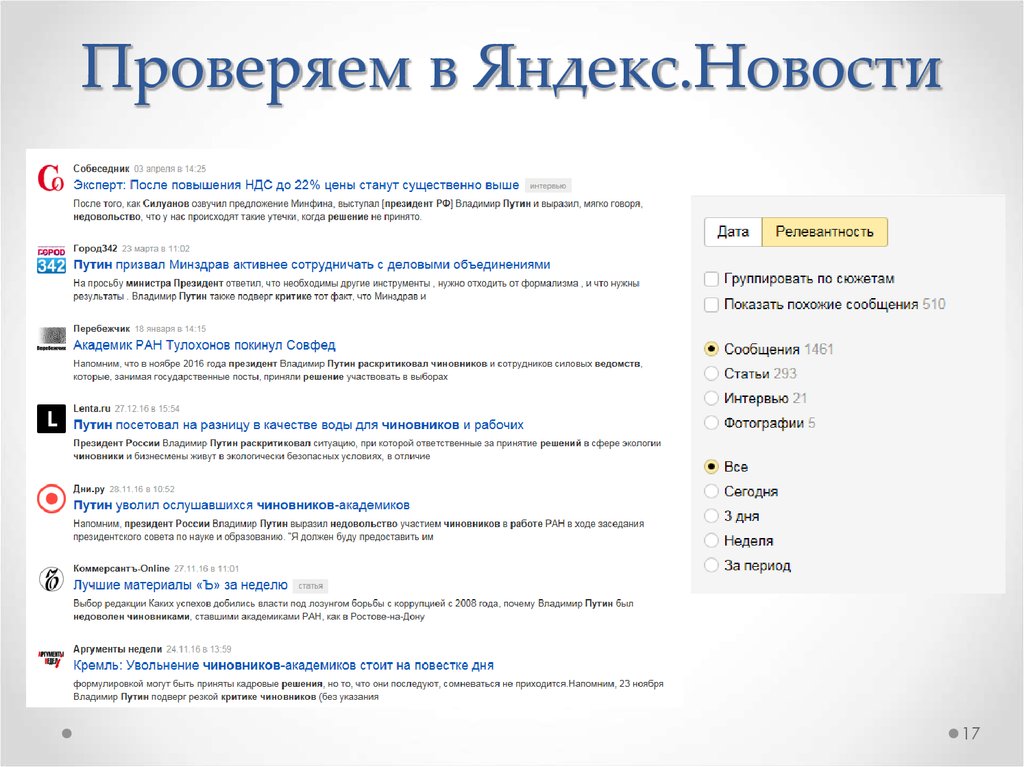
Общий регламент по защите данных (GDPR) вступил в силу весной 2018 года. GDPR регулирует сбор и обработку информации о гражданах Европейской экономической зоны и Швейцарии. Мы добавили поддержку GDPR в SDK Yandex Mobile Ads (подробнее об интеграции для Android и iOS). Новый функционал позволяет ограничить сбор данных о пользователях, находящихся в Европейской экономической зоне и Швейцарии, если они не дали согласия на сбор данных.
Яндекс собирает данные Google и других специалистов по SEO из утечки исходного кода
«Фрагменты» кодовой базы Яндекса просочились в сеть на прошлой неделе. Как и Google, Яндекс — это платформа со многими аспектами, такими как электронная почта, карты, служба такси и т. д. Утечка кода содержала фрагменты всего этого.
Согласно документации, кодовая база Яндекса была объединена в один большой репозиторий под названием Arcadia в 2013 году. Утекшая кодовая база является подмножеством всех проектов в Arcadia, и мы находим в ней несколько компонентов, связанных с поисковой системой в «Ядре», Архивы «Библиотека», «Робот», «Поиск» и «ExtSearch».
Совершенно беспрецедентный ход. С тех пор, как в данных поисковых запросов AOL за 2006 год не было ничего такого, что могло бы стать достоянием общественности, материалы, относящиеся к поисковой системе.
Хотя нам не хватает данных и многих файлов, на которые есть ссылки, это первый пример реального взгляда на то, как современная поисковая система работает на уровне кода.
Лично я не могу смириться с тем, какое фантастическое время для того, чтобы увидеть код, когда я заканчиваю свою книгу «Наука SEO», где я рассказываю о поиске информации, о том, как на самом деле работают современные поисковые системы, и как самому построить простую.
В любом случае, я разбирал код с прошлого четверга, и любой инженер скажет вам, что времени недостаточно, чтобы понять, как все работает. Итак, я подозреваю, что будет еще несколько постов, пока я продолжаю возиться.
Прежде чем мы начнем, я хочу поблагодарить Бена Уиллса из Онтоло за то, что он поделился со мной кодом, указал мне начальное направление, где находится хороший материал, и ходил со мной туда и обратно, пока мы расшифровывали вещи. Не стесняйтесь взять электронную таблицу со всеми данными, которые мы собрали о факторах ранжирования, здесь.
Не стесняйтесь взять электронную таблицу со всеми данными, которые мы собрали о факторах ранжирования, здесь.
Кроме того, спасибо Райану Джонсу за то, что он покопался и поделился со мной некоторыми важными выводами через мгновенные сообщения.
Ладно, приступим!
Это не код Google, так какая нам разница?
Некоторые считают, что просмотр этой кодовой базы отвлекает и что ничто не повлияет на то, как они принимают бизнес-решения. Я нахожу это любопытным, учитывая, что это люди из того же SEO-сообщества, которое использовало модель CTR из данных AOL за 2006 год в качестве отраслевого стандарта для моделирования в любой поисковой системе в течение многих последующих лет.
Тем не менее, Яндекс — это не Google. Тем не менее, эти две современные поисковые системы продолжают оставаться на переднем крае технологий.
Инженеры-программисты обеих компаний участвуют в одних и тех же конференциях (SIGIR, ECIR и т. д.) и делятся результатами и инновациями в области поиска информации, обработки/понимания естественного языка и машинного обучения.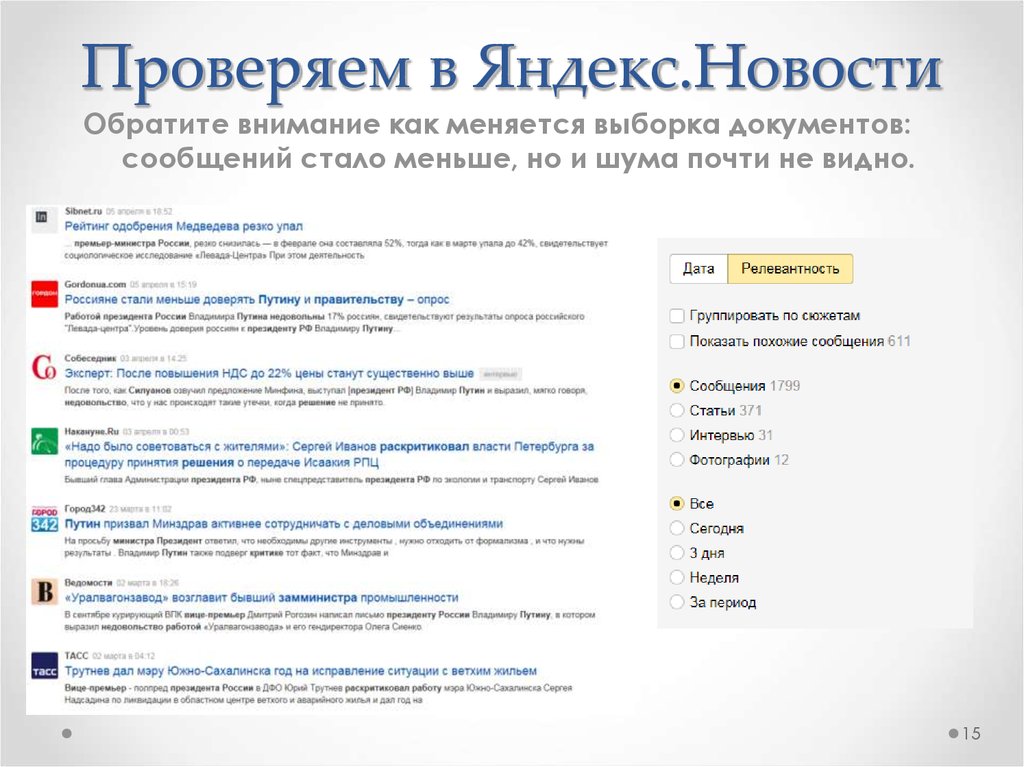 Яндекс также присутствует в Пало-Альто, а Google ранее был в Москве.
Яндекс также присутствует в Пало-Альто, а Google ранее был в Москве.
Быстрый поиск в LinkedIn выявляет несколько сотен инженеров, которые работали в обеих компаниях, хотя мы не знаем, сколько из них на самом деле работали над поиском в обеих компаниях.
При более прямом совпадении Яндекс также использует технологии Google с открытым исходным кодом, которые были критически важны для инноваций в поиске, таких как TensorFlow, BERT, MapReduce и, в гораздо меньшей степени, Protocol Buffers.
Итак, хотя Яндекс — это, конечно, не Google, но и не какой-то случайный исследовательский проект, о котором мы здесь говорим. Изучив эту кодовую базу, мы можем многое узнать о том, как устроена современная поисковая система.
По крайней мере, мы можем избавиться от некоторых устаревших представлений, которые все еще пронизывают инструменты SEO, таких как соотношение текста и кода и соответствие W3C, или общее мнение, что 200 сигналов Google — это просто 200 отдельных функций на странице и за ее пределами, а не классы составных факторов, которые потенциально могут использовать тысячи отдельных показателей.
Некоторый контекст архитектуры Яндекса
Без контекста или возможности успешно скомпилировать, запустить и выполнить пошаговое выполнение исходного кода очень сложно понять.
Как правило, новые инженеры получают документацию, обзоры и занимаются парным программированием, чтобы освоиться с существующей кодовой базой. Кроме того, в архиве документов есть некоторая ограниченная документация по адаптации, связанная с настройкой процесса сборки. Тем не менее, код Яндекса также везде ссылается на внутренние вики, но они не просочились, а комментарии в коде также довольно скудны.
К счастью, Яндекс дает некоторое представление о своей архитектуре в общедоступной документации. Есть также пара патентов, опубликованных в США, которые помогают пролить свет. А именно:
- Реализованный компьютером способ и система для поиска в инвертированном индексе, имеющем множество списков проводок
- Ранжирование результатов поиска
Когда я исследовал Google для своей книги, я получил гораздо более глубокое понимание структуры его систем ранжирования благодаря различным документам, патентам и выступлениям инженеров, основанным на моем опыте SEO.![]()
В документации Яндекса обсуждается двухраспределенная система краулеров. Один для сканирования в реальном времени под названием «Оранжевый краулер», а другой — для обычного сканирования.
Исторически у Google был индекс, разделенный на три сегмента: один для сканирования в реальном времени, один для регулярного сканирования и один для редко сканируемого. Этот подход считается лучшей практикой в IR.
Яндекс и Google различаются в этом отношении, но общая идея сегментированного сканирования, основанная на понимании частоты обновления, сохраняется.
Стоит отметить, что у Яндекса нет отдельной системы рендеринга для JavaScript. Они говорят об этом в своей документации и, хотя у них есть система визуального регрессионного тестирования на основе Webdriver под названием Gemini, они ограничиваются текстовым сканированием.
В документации также обсуждается сегментированная структура базы данных, которая разбивает страницы на инвертированный индекс и сервер документов.
Как и в большинстве других поисковых систем, процесс индексации создает словарь, кэширует страницы, а затем помещает данные в инвертированный индекс таким образом, чтобы были представлены биграммы и тригамы и их размещение в документе.
Это отличается от Google тем, что они давно перешли на индексацию на основе фраз, что означает, что n-граммы могут быть намного длиннее триграмм.
Однако система Яндекса также использует BERT в своем пайплайне, поэтому в какой-то момент документы и запросы конвертируются во вложения, а для ранжирования используются методы поиска ближайших соседей.
Процесс ранжирования становится более интересным.
В Яндексе есть слой под названием Метапоиск , где кешированные популярные результаты поиска обслуживаются после обработки запроса. Если результаты там не найдены, то поисковый запрос отправляется на серию из тысяч разных машин в Базовый поиск слой одновременно. Каждый из них создает списков публикаций релевантных документов, а затем возвращает их в MatrixNet, приложение нейронной сети Яндекса для повторного ранжирования, чтобы построить поисковую выдачу.
Каждый из них создает списков публикаций релевантных документов, а затем возвращает их в MatrixNet, приложение нейронной сети Яндекса для повторного ранжирования, чтобы построить поисковую выдачу.
Судя по видеороликам, в которых инженеры Google рассказывают об инфраструктуре поиска, этот процесс ранжирования очень похож на поиск Google. Они говорят о том, что технология Google находится в общих средах, где различные приложения находятся на каждой машине, а задания распределяются между этими машинами в зависимости от доступности вычислительной мощности.
Одним из вариантов использования является именно это, распределение запросов по набору машин для быстрой обработки соответствующих осколков индекса. Вычисление списков публикации — это первое место, которое нам нужно учитывать для факторов ранжирования.
В кодовой базе 17 854 фактора ранжирования
В пятницу после утечки неподражаемый Мартин Макдональд охотно поделился файлом из кодовой базы под названием web_factors_info/factors_gen. in. Файл взят из архива «Kernel» в утечке кодовой базы и содержит 1,922 фактора ранжирования.
in. Файл взят из архива «Kernel» в утечке кодовой базы и содержит 1,922 фактора ранжирования.
Естественно, SEO-сообщество использовало этот номер и этот файл, чтобы охотно распространять новости о содержащихся в нем сведениях. Многие люди перевели описания и создали инструменты или Google Sheets и ChatGPT, чтобы разобраться в данных. Все они являются прекрасными примерами силы сообщества. Однако число 1922 представляет собой лишь один из многих наборов факторов ранжирования в кодовой базе.
Более глубокое погружение в кодовую базу показывает, что существует множество файлов факторов ранжирования для различных подмножеств систем обработки запросов и ранжирования Яндекса.
Прочесывая их, мы обнаруживаем, что всего существует 17 854 фактора ранжирования. В эти факторы ранжирования входят различные показатели, связанные с:
- Кликами.
- Время ожидания.
- Использование аналога Google Analytics от Яндекса, Метрики.
Существует также серия ноутбуков Jupyter, которые имеют дополнительные 2000 факторов помимо тех, что указаны в основном коде.
Документация Яндекса также поясняет, что у них есть три класса факторов ранжирования: статические, динамические и те, которые связаны конкретно с поиском пользователя и тем, как он был выполнен. По их собственным словам:
В кодовой базе они указаны в файлах ранговых факторов с тегами TG_STATIC и TG_DYNAMIC. Факторы, связанные с поиском, имеют несколько тегов, таких как TG_QUERY_ONLY, TG_QUERY, TG_USER_SEARCH и TG_USER_SEARCH_ONLY.
Несмотря на то, что мы выявили 18 000 потенциальных факторов ранжирования на выбор, в документации, относящейся к MatrixNet, указано, что оценка строится на основе десятков тысяч факторов и настраивается на основе поискового запроса.
Это указывает на то, что среда ранжирования очень динамична, подобно среде Google.
Наконец, учитывая, что в документации упоминаются десятки тысяч факторов ранжирования, мы также должны помнить, что в коде есть много других файлов, которые отсутствуют в архиве. Так что, вероятно, происходит что-то еще, чего мы не можем видеть. Это дополнительно иллюстрируется просмотром изображений в документации по подключению, на которых показаны другие каталоги, которых нет в архиве.
Например, я подозреваю, что в каталоге /semantic-search/ есть еще что-то связанное с DSSM.
Первоначальное взвешивание факторов ранжирования
Сначала я действовал, исходя из предположения, что кодовая база не имеет весов для факторов ранжирования. Затем я был потрясен, увидев, что файл nav_linear.h в каталоге /search/relevance/ содержит начальные коэффициенты (или веса), связанные с факторами ранжирования, в полном отображении.
Этот раздел кода выделяет 257 из 17 000+ факторов ранжирования, которые мы определили. ( Скидка Райану Джонсу за то, что он вытащил их и сопоставил с описаниями факторов ранжирования.) страница оценивается на основе ряда факторов. Хотя это упрощение, следующий снимок экрана является выдержкой из такого уравнения. Коэффициенты показывают, насколько важен каждый фактор, а полученный в результате расчетный балл — это то, что будет использоваться для оценки релевантности страниц выбора.
Жестко закодированные значения позволяют предположить, что это не единственное место, где происходит ранжирование. Вместо этого эта функция, скорее всего, используется там, где первоначальная оценка релевантности выполняется для создания серии списков публикации для каждого сегмента, рассматриваемого для ранжирования. В первом патенте, упомянутом выше, они говорят об этом как о концепции независимой от запроса релевантности (QIR), которая затем ограничивает документы до их просмотра на предмет релевантности запроса (QSR).
Полученные списки сообщений затем передаются в MatrixNet с функциями запроса для сравнения. Таким образом, хотя мы не знаем специфики последующих операций (пока), эти веса по-прежнему ценны для понимания, потому что они говорят вам о требованиях, предъявляемых к странице, чтобы иметь право на набор вознаграждений.
Однако возникает следующий вопрос: что мы знаем о MatrixNet?
В архиве ядра есть код нейронного ранжирования и многочисленные ссылки на MatrixNet и «mxnet», а также множество ссылок на глубоко структурированные семантические модели (DSSM) в кодовой базе.
В описании одного из факторов ранжирования FI_MATRIXNET указано, что MatrixNet применяется ко всем факторам.
Коэффициент {
Индекс: 160
CPPName: «fi_matrixnet»
Имя: «Matrixnet»
Теги: [TG_DOC, TG_DYNAMIC, TG_TRANS, TG_NOT_01, TG_REARR_USE, TG_L3_MODEL_VALUE, TG_FRESHER_POOL_ILIX_BLIX_BLIX_POOL_LIX_LILIX_BLIX_BLIX_FILIX_FILIF_ILIX. }
}
Также есть куча бинарных файлов, которые сами могут быть предварительно обученными моделями, но мне потребуется больше времени, чтобы разобраться в этих аспектах кода.
Сразу становится ясно, что существует несколько уровней ранжирования (L1, L2, L3) и набор моделей ранжирования, которые можно выбрать на каждом уровне.
В файле selection_rankings_model.cpp указано, что на каждом уровне процесса можно рассматривать разные модели ранжирования. Примерно так работают нейронные сети. Каждый уровень — это аспект, который завершает операции, и их комбинированные вычисления дают переупорядоченный список документов, который в конечном итоге отображается в виде поисковой выдачи. Я продолжу более глубокое погружение в MatrixNet, когда у меня будет больше времени. Для тех, кому нужен краткий обзор, ознакомьтесь с патентом ранжирования результатов поиска.
А пока давайте рассмотрим некоторые интересные факторы ранжирования.
Топ-5 факторов начального ранжирования с отрицательным весом
Ниже приводится список факторов начального ранжирования с наибольшим отрицательным весом с их весами и кратким пояснением, основанным на их описаниях, переведенных с русского языка.
- FI_ADV: -0,2509284637 -Этот фактор определяет, есть ли на странице реклама любого рода, и назначает самый высокий взвешенный штраф за один фактор ранжирования.
- FI_DATER_AGE: -0,2074373667 — этот коэффициент представляет собой разницу между текущей датой и датой документа, определенной функцией датирования. Значение равно 1, если дата документа совпадает с сегодняшней, 0, если документ старше 10 лет или если дата не определена. Это говорит о том, что Яндекс отдает предпочтение более старому контенту.
- FI_QURL_STAT_POWER: -0,1943768768 — этот коэффициент представляет собой количество показов URL-адреса, связанного с запросом. Похоже, они хотят понизить URL-адрес, который появляется во многих поисковых запросах, чтобы повысить разнообразие результатов.
- FI_COMM_LINKS_SEO_HOSTS: -0,1809636391 — этот коэффициент представляет собой процент входящих ссылок с «коммерческим» якорным текстом.
 Коэффициент возвращается к 0,1, если доля таких ссылок превышает 50%, в противном случае устанавливается в 0,
Коэффициент возвращается к 0,1, если доля таких ссылок превышает 50%, в противном случае устанавливается в 0, - FI_GEO_CITY_URL_REGION_COUNTRY: -0,168645758 — этот фактор — географическое совпадение документа и страны, из которой пользователь выполнял поиск. Это не совсем понятно, если 1 означает, что документ и страна совпадают.
Таким образом, эти факторы показывают, что для наилучшего результата вам следует:
- Избегать рекламы.
- Обновляйте старый контент, а не создавайте новые страницы.
- Убедитесь, что большинство ваших ссылок имеют фирменный анкорный текст.
Все остальное в этом списке находится вне вашего контроля.
Топ-5 положительно взвешенных факторов начального ранжирования
В дополнение, вот список положительных факторов ранжирования с наибольшим весом.
- FI_URL_DOMAIN_FRACTION: +0,5640952971 — этот фактор представляет собой странное маскирующее перекрытие запроса по сравнению с доменом URL-адреса.
 В качестве примера приведена Челябинская лотерея, сокращенно chelloto. Чтобы вычислить это значение, Яндекс находит перекрытые трехбуквенные слова (че, хел, лот, оло), смотрит, какая доля всех трехбуквенных сочетаний приходится на доменное имя.
В качестве примера приведена Челябинская лотерея, сокращенно chelloto. Чтобы вычислить это значение, Яндекс находит перекрытые трехбуквенные слова (че, хел, лот, оло), смотрит, какая доля всех трехбуквенных сочетаний приходится на доменное имя. - FI_QUERY_DOWNER_CLICKS_COMBO: +0.3690780393 — Описание этого фактора таково: «умное сочетание FRC и псевдо-CTR». Непосредственных указаний на то, что такое FRC, нет.
- FI_MAX_WORD_HOST_CLICKS: +0.3451158835 — этот фактор кликабельность самого важного слова в домене. Например, для всех запросов, в которых есть слово «википедия», нажмите на страницы википедии.
- FI_MAX_WORD_HOST_YABAR: +0.3154394573 — В описании фактора указано «наиболее характерное слово запроса, соответствующее сайту, согласно бару». Я предполагаю, что это означает ключевое слово, которое чаще всего ищут в панели инструментов Яндекса, связанную с сайтом.
- FI_IS_COM: +0.
 2762504972 – Дело в том, что домен .COM.
2762504972 – Дело в том, что домен .COM.
Другими словами:
- Играйте в словесные игры со своим доменом.
- Убедитесь, что это точка ком.
- Поощряйте людей искать ваши целевые ключевые слова в Яндекс Баре.
- Продолжайте получать клики.
Существует множество неожиданных начальных факторов ранжирования
Что более интересно в начальных взвешенных факторах ранжирования, так это неожиданные факторы. Ниже приводится список из семнадцати выделяющихся факторов.
- FI_PAGE_RANK: +0,1828678331 — PageRank — 17-й по значимости фактор в Яндексе. Ранее они полностью удалили ссылки из своей системы ранжирования, поэтому неудивительно, насколько низко она находится в списке.
- FI_SPAM_KARMA: +0.00842682963 — Спам-карма названа в честь «антиспамеров» и представляет собой вероятность того, что хост является спамом; на основе информации Whois
- FI_SUBQUERY_THEME_MATCH_A: +0,1786465163 — Насколько тесно тематически совпадают запрос и документ.
 это 19й наивысший взвешенный фактор.
это 19й наивысший взвешенный фактор. - FI_REG_HOST_RANK: +0,1567124399 — у Яндекса есть фактор ранжирования хоста (или домена).
- FI_URL_LINK_PERCENT: +0,08940421124 — Отношение ссылок, анкорный текст которых является URL-адресом (а не текстом), к общему количеству ссылок.
- FI_PAGE_RANK_UKR: +0.08712279101 — Есть конкретный украинский PageRank
- FI_IS_NOT_RU: +0.08128946612 — Хорошо, если домен не .RU. Судя по всему, русский поисковик не доверяет русским сайтам.
- FI_YABAR_HOST_AVG_TIME2: +0,07417219313 — это среднее время пребывания, согласно ЯндексБар
- FI_LERF_LR_LOG_RELEV: +0,06059448504 — это релевантность ссылки на основе качества каждой ссылки
- FI_NUM_SLASHES: +0,05057609417 — количество косых черт в URL является фактором ранжирования.
- FI_ADV_PRONOUNS_PORTION: -0,001250755075 — Доля местоимений на странице.
- FI_TEXT_HEAD_SYN: -0.01291908335 — Наличие [запросных] слов в заголовке с учетом синонимов
- FI_PERCENT_FREQ_WORDS: -0.02021022114 – Процент количества слов, которые являются 200 наиболее часто встречающимися словами языка, от количества всех слов текста.
- FI_YANDEX_ADV: -0.09426121965 – Уточняя неприязнь к рекламе, Яндекс наказывает страницы с рекламой Яндекса.
- FI_AURA_DOC_LOG_SHARED: -0,09768630485 – логарифм количества черепиц (областей текста) в документе, которые не являются уникальными.
- FI_AURA_DOC_LOG_AUTHOR: -0.09727752961 – Логарифм количества гонтов, на которых этот владелец документа признан автором.
- FI_CLASSIF_IS_SHOP: -0.1339319854 — Судя по всему, Яндекс будет меньше любить вас, если ваша страница — магазин.
Главный вывод из рассмотрения этих странных факторов ранжирования и множества факторов, доступных в кодовой базе Яндекса, заключается в том, что есть много вещей, которые могут быть факторами ранжирования.
Я подозреваю, что заявленные Google «200 сигналов» на самом деле представляют собой 200 классов сигналов, где каждый сигнал является составным, состоящим из множества других компонентов. Во многом так же, как Google Analytics имеет параметры со многими связанными показателями, Google Search, вероятно, имеет классы сигналов ранжирования, состоящие из многих функций.
Яндекс очищает Google, Bing, YouTube и TikTok
Кодовая база также показывает, что у Яндекса есть много парсеров для других веб-сайтов и их соответствующих сервисов. Для жителей Запада наиболее заметными из них являются те, которые я перечислил в заголовке выше. Кроме того, у Яндекса есть парсеры для множества незнакомых мне сервисов, а также парсеры для его собственных сервисов.
Что сразу бросается в глаза, так это то, что синтаксические анализаторы полностью укомплектованы. Извлекается каждый значимый компонент поисковой выдачи Google. На самом деле, любой, кто рассматривает возможность парсинга любого из этих сервисов, может сделать все возможное, чтобы просмотреть этот код.
Существует другой код, который указывает, что Яндекс использует некоторые данные Google как часть расчетов DSSM, но сами по себе 83 названных Google фактора ранжирования ясно показывают, что Яндекс довольно сильно опирался на результаты Google.
Очевидно, что Google никогда не станет копировать результаты Bing из другой поисковой системы и не будет полагаться на одну из них для расчетов основного рейтинга.
Яндекс имеет анти-SEO верхние границы для некоторых факторов ранжирования
315 факторов ранжирования имеют пороговые значения, при которых любое вычисленное значение, превышающее это, указывает системе, что эта функция страницы переоптимизирована. 39 из этих факторов ранжирования являются частью первоначально взвешенных факторов, которые могут препятствовать включению страницы в первоначальный список публикаций. Вы можете найти их в электронной таблице, на которую я дал ссылку выше, отфильтровав по столбцу «Коэффициент ранжирования» и «Анти-SEO».
С концептуальной точки зрения не будет надуманным ожидать, что все современные поисковые системы устанавливают пороговые значения для определенных факторов, которыми оптимизаторы исторически злоупотребляли, таких как анкорный текст, CTR или наполнение ключевыми словами. Например, говорят, что Bing использует злоупотребление мета-ключевыми словами как негативный фактор.
Например, говорят, что Bing использует злоупотребление мета-ключевыми словами как негативный фактор.
Яндекс продвигает «Vital Hosts»
В кодовой базе Яндекса есть ряд механизмов повышения. Это искусственные улучшения определенных документов, чтобы обеспечить более высокие оценки при рассмотрении для ранжирования.
Ниже приведен комментарий «мастера повышения», в котором говорится, что более мелкие файлы лучше всего выигрывают от алгоритма повышения.
Есть несколько типов бустов; Я видел один буст, связанный со ссылками, и я также видел серию «HandJobBoosts», которые, я могу только предположить, являются странным переводом «ручных» изменений.
Один из этих бонусов, который показался мне особенно интересным, связан с «Жизненно важными хостами». Где важным хостом может быть любой указанный сайт. В переменных конкретно упоминается NEWS_AGENCY_RATING, что наводит меня на мысль, что Яндекс дает повышение, которое искажает его результаты в пользу определенных новостных организаций.
Если не вдаваться в геополитику, это очень отличается от Google тем, что они были непреклонны в отношении того, чтобы не вводить подобные предубеждения в свои системы ранжирования.
Структура сервера документов
Кодовая база показывает, как документы хранятся на сервере документов Яндекса. Это полезно для понимания того, что поисковая система не просто делает копию страницы и сохраняет ее в своем кеше, она фиксирует различные функции в качестве метаданных, которые затем используются в последующем процессе ранжирования.
На приведенном ниже снимке экрана выделено подмножество тех функций, которые особенно интересны. Другие файлы с SQL-запросами предполагают, что сервер документов имеет около 200 столбцов, включая дерево DOM, длину предложений, время выборки, серию дат и оценку защиты от спама, цепочку перенаправления и информацию о том, переведен ли документ. Самый полный список, который мне встречался, находится в файле /robot/rthub/yql/protos/web_page_item.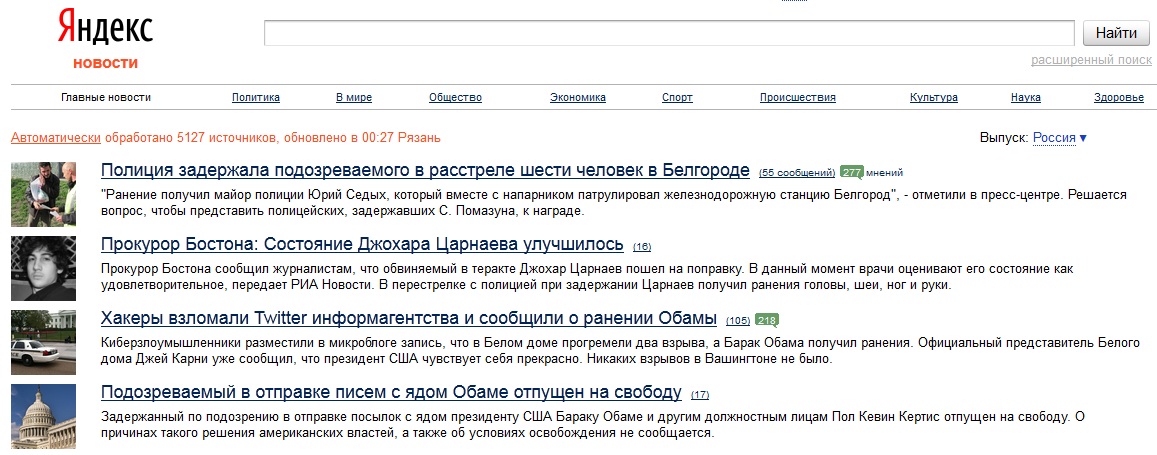 proto.
proto.
Что самое интересное в подмножестве здесь, так это количество используемых симхэшей. Симхэши — это числовые представления контента, и поисковые системы используют их для молниеносного сравнения для определения дублирующегося контента. В архиве роботов есть различные экземпляры, указывающие на то, что дублированный контент явно понижен.
Кроме того, в рамках процесса индексации кодовая база включает TF-IDF, BM25 и BERT в конвейере обработки текста. Непонятно, почему все эти механизмы существуют в коде, потому что в их использовании есть некоторая избыточность.
Кодовая база также содержит много информации о факторах ссылок и о том, как ссылки расставляются по приоритетам.
Калькулятор ссылочного спама Яндекса учитывает 89 факторов. Все, что помечено как SF_RESERVED, устарело. Там, где это предусмотрено, вы можете найти описания этих факторов в таблице Google, указанной выше.
Примечательно, что у Яндекса есть рейтинг хоста и некоторые баллы, которые, по-видимому, сохраняются в течение длительного времени после того, как сайт или страница заработали репутацию спама.
Еще одна вещь, которую делает Яндекс, — это просмотр копии на домене и определение наличия дублированного контента с этими ссылками. Это могут быть размещения ссылок по всему сайту, ссылки на дубликаты страниц или просто ссылки с одинаковым анкорным текстом с одного и того же сайта.
Это показывает, насколько тривиально не учитывать несколько ссылок из одного и того же источника, и разъясняет, насколько важно нацеливаться на большее количество уникальных ссылок из более разнообразных источников.
Что мы можем применить от Яндекса к тому, что мы знаем о Google?
Естественно, этот вопрос до сих пор у всех на уме. Хотя, безусловно, между Яндексом и Google есть много аналогов, по правде говоря, только инженер-программист Google, работающий над поиском, может окончательно ответить на этот вопрос.
Но это неправильный вопрос.
Действительно, этот код должен помочь нам расширить наши представления о современном поиске. Коллективное понимание поиска во многом основано на том, что SEO-сообщество узнало в начале 2000-х посредством тестирования и из уст поисковых инженеров, когда поиск был гораздо менее непрозрачным. Это, к сожалению, не поспевает за быстрым темпом инноваций.
Это, к сожалению, не поспевает за быстрым темпом инноваций.
Понимание многих особенностей и факторов утечки Яндекса должно дать больше гипотез о вещах, которые нужно проверить и рассмотреть для ранжирования в Google. Они также должны ввести больше вещей, которые можно анализировать и измерять с помощью SEO-сканирования, анализа ссылок и инструментов ранжирования.
Например, мера косинусного сходства между запросами и документами с использованием встраивания BERT может быть полезной для понимания по сравнению со страницами конкурентов, поскольку это то, что делают сами современные поисковые системы.
Во многом так же, как журналы поиска AOL уводят нас от угадывания распределения кликов в поисковой выдаче, кодовая база Яндекса уводит нас от абстрактного к конкретному, и наши утверждения «это зависит» могут быть лучше квалифицированы.
С этой целью эта кодовая база является подарком, который будет продолжаться. Прошли только выходные, а мы уже почерпнули очень убедительные выводы из этого кода.
Я ожидаю, что некоторые амбициозные SEO-инженеры, располагающие гораздо большим количеством свободного времени, будут продолжать копаться и, возможно, даже дополнять недостающее, чтобы скомпилировать эту штуку и заставить ее работать. Я также считаю, что инженеры различных поисковых систем также изучают и анализируют инновации, на которых они могут учиться и добавлять в свои системы.
Одновременно юристы Google, вероятно, готовят агрессивные письма о прекращении и воздержании, связанные со всей очисткой данных.
Мне не терпится увидеть эволюцию нашего пространства, которой руководят любознательные люди, которые максимально используют эту возможность.
Но, эй, если получение информации из фактического кода не имеет для вас ценности, вы можете вернуться к чему-то более важному, например, спорить о поддоменах и подкаталогах.
Мнения, высказанные в этой статье, принадлежат приглашенному автору и не обязательно принадлежат Search Engine Land. Штатные авторы перечислены здесь.