Как проверить возраст и дату создания сайта
Эффективный SEO-аудит предполагает проверку возраста интернет-ресурса и доменного имени, на котором он находится. Как узнать дату создания сайта, для чего это нужно, и какими методами делается — поговорим в нашем материале.
Дата создания сайта: для чего ее нужно знать?
Узнать возраст сайта необходимо для того, чтобы:
- правильно проанализировать трафик и важные seo показатели ресурса;
- определить конкурентные ниши;
- понять, подходит ли проект для развития, и стоит ли его покупать.
Кроме того, проверить возраст онлайн-ресурса стоит тогда, когда есть сомнения в его благонадежности. Проверка поможет понять — стоит ли ему доверять. Такая ситуация может возникнуть при необходимости совершения финансовых операций через сайт, который производит впечатление “однодневки”.
Возраст домена и сайта: какова разница?
Между этими понятиями есть существенные отличия. Возраст домена отсчитывают с момента регистрации url-адреса, а сайта — с того дня, когда на нем был размещен первый контент.
Также различается и продолжительность существования доменного имени и сайта. Ведь после покупки первого, интернет-ресурс мог еще долгое время пребывать в стадии предварительной разработки дизайна, юзабилити и проч. Домен могли продать или перенести сайт на другое доменное имя. Таким образом, один бывает моложе другого, и наоборот.
Влияет ли возраст сайта на его позиции в поисковиках?
Это довольно сложный вопрос, по которому существуют разные мнения. Часть экспертов уверены — чем старше сайт, тем лучше он будет ранжироваться. Ведь новый проект после запуска еще не пользуется доверием поисковиков и первое время находится в выдаче на низких позициях.
В то же время, SEO-аналитик из корпорации Гугл Джон Мюллер считает, что возраст — не приоритетный фактор. Намного важнее уникальность и качество размещенного на нем контента. Если ниша достаточно востребованная, то за счет полезного и востребованного контента сайт может довольно быстро подняться на высокие позиции в поисковой выдаче. Такой подход намного эффективнее, чем покупать старый ресурс и надеяться на выход в ТОП, не уделяя должного внимания контенту.
Такой подход намного эффективнее, чем покупать старый ресурс и надеяться на выход в ТОП, не уделяя должного внимания контенту.
Какой сайт лучше купить — возрастной или новый?
Старый домен обладает своими достоинствами, например:
- уже заработал доверие от поисковых роботов;
- большая вероятность наличия внешних ссылок, приводящих со сторонних ресурсов ( но здесь требуется осторожность и подробный анализ ссылочного профиля потенциального к покупке домена).
Но многие все же предпочитают приобретать новые домены, которые ранее не использовались. Дело в том, что на возрастном сайте вполне могут обнаружиться ранее наложенные санкции. Среди вероятных причин — контент сомнительного содержания, неуникальные статьи, спам и др.
Если вы уже купили сайт, а потом оказалось, что он — под пессимизацией, то по этому вопросу необходимо избавиться от всех причин бана, а затем обратиться в техническую поддержку Яндекс.Вебмастера и Google Search Console. Возможно, что санкции будут сняты, а дальнейшие публикации начнут индексироваться в стандартном режиме. Но так бывает не всегда, поэтому перед покупкой любой домен лучше всего проверить.
Но так бывает не всегда, поэтому перед покупкой любой домен лучше всего проверить.
Как посмотреть дату создания сайта?
Наиболее очевидный метод — посмотреть на даты, которые указаны администратором в футере главной странице. Но у него есть свой недостаток: полную информацию указывают не все, иногда в подвале может быть просто указание на текущий год.
Еще один способ — проверить, когда на сайте опубликованы первые статьи. Это тоже не надежная методика, ведь часть контента могла быть удалена прошлыми владельцами.
Сервисы для проверки возраста сайта
Гораздо действеннее узнать год, когда создан веб-ресурс — воспользоваться специализированными инструментами. Среди них такие сервисы, как:
- Archive.org
- Whois-сервисы
- Site Spy;
- XTOOL;
- Majento.com;
- Bulkseotools.com;
- 2ip.ru
- BE1;
- REG.
С помощью каждого из них можно проверить:
- данные о хостинге и прежнем владельце;
- индексацию в поисковых системах;
- время создания и простоя доменного имени.

Последний фактор важен. Ведь если домен создали 10 лет назад, использовали 1 год, а потом забросили, то и поисковые роботы сначала воспримут его как новый и ранжироваться он будет соответствующе.
Специалисты советуют применять несколько сервисов проверки одновременно и сравнивать результаты. Это особенно актуально, когда речь идет о сайтах с доменными зонами не первого уровня. В данной ситуации правильно использовать иностранные whois-системы.
Обратитесь к экспертам Clickmedia
Специалисты нашего диджитал-агентства помогут узнать точный возраст интересующего сайта и получить необходимую информацию при помощи профессиональных инструментов.
А если вы уже купили ресурс, то мы сможем вывести его из-под возможных санкций, наполнить контентом и сделать то, что нужно для продвижения в сети.
Понравилась статья? Поделись с друзьями
Как узнать возраст сайта? С какого момента отсчитывается возраст сайта? — Edison Studio на vc.ru
Возраст отсчитывается со дня появления первого контента.
35 просмотров
На что влияет возраст сайта?
Возраст ресурса может быть одним из значимых факторов в SEO-анализе. Например, если в определенной нише вы видите молодого конкурента с большим трафиком, то, возможно, ниша свободна, и в ней можно быстро раскрутить подобный ресурс. Конечно, возраст ресурса – это лишь один из факторов, а для принятия решений нужен более глубокий анализ. Но год создания ресурса, ниша, количество проиндексированных страниц, а также посещаемость помогают быстро оценить его потенциал.
Влияет ли на ранжирование сайта его возраст?
Возраст – один из факторов ранжирования в поисковой системе. По версии официальных представителей поисковых систем, это далеко не первостепенный фактор, но на практике становится понятно, что он связан с другими показателями продвижения, которые более значимы для поисковых систем.
В чем выгода покупки старого или нового домена?
Покупка как старого, так и нового доменного имени имеет свои преимущества.
1. Приобретать новый домен – безопаснее. Роботы поисковых систем с ним еще не знакомы, так что за ним точно не зарегистрировано каких-либо нарушений. Когда вы приобретаете старое доменное имя, есть риск, что оно находится под фильтрами поисковиков из-за публикации, например, запрещенного контента. Эту проблему можно попробовать решить, обратившись в техническую поддержку Яндекса или Google;
2. Покупка старого домена с хорошей историей полезна для продвижения. Красивые лаконичные доменные имена вызывают у пользователей больше доверия, но почти все они заняты, поэтому их придется покупать. Такие домены редко продаются совсем без истории, вполне вероятно, что их уже кто-то использовал.
Как узнать дату создания сайта?
Возраст ресурса может потребоваться в разных ситуациях: для SEO-аудита, анализа конкурентов или проверки ресурса на мошенничество. Для любых способов можно применять одни и те же средства.
1. Спросить у владельца;
Самый очевидный способ узнать дату создания проекта – спросить у владельца или компании. Обычно на сайте указаны контакты, ссылки на мессенджеры, чат-боты. Иногда в футере есть ссылка на разработчиков – можно попытать удачу, задав вопрос им. Но есть вероятность, что вам откажут или хотя бы попытаются выяснить причины интереса. Будьте готовы обосновать свой вопрос. Впрочем, есть более простые и надежные способы.
2. Посмотреть в футере сайта;
Даты работы обычно находятся в подвале сайта – самом нижнем его блоке. В самом низу страниц указан знак копирайта и годы работы ресурса, например, © 2015-2022.Однако дату создания выставляют сами владельцы, поэтому сведения могут быть недостоверными. Особенно если ресурс принадлежит мошенникам – они поставят датой основания хоть 2002 год, даже если он был создан только вчера.
В самом низу страниц указан знак копирайта и годы работы ресурса, например, © 2015-2022.Однако дату создания выставляют сами владельцы, поэтому сведения могут быть недостоверными. Особенно если ресурс принадлежит мошенникам – они поставят датой основания хоть 2002 год, даже если он был создан только вчера.
3. Определяем дату по содержанию;
Дата создания сайта отсчитывается с момента публикации первого контента. Поэтому можно попробовать найти самую первую запись, посмотреть дату ее выпуска. Этот способ тоже не отличается точностью – самая первая запись могла быть удалена. Например, ресурс мог приобрести новый владелец, который стер весь имеющийся контент.Иногда записи имеют дату не публикации, а последнего обновления. Если владельцы поддерживают актуальность информации, многие статьи будут иметь свежую дату публикации, даже если были выпущены несколько лет назад.Некоторые компании, напротив, указывают только последний год функционирования – текущий. Тем самым они дают понять, что портал обслуживается и функционирует.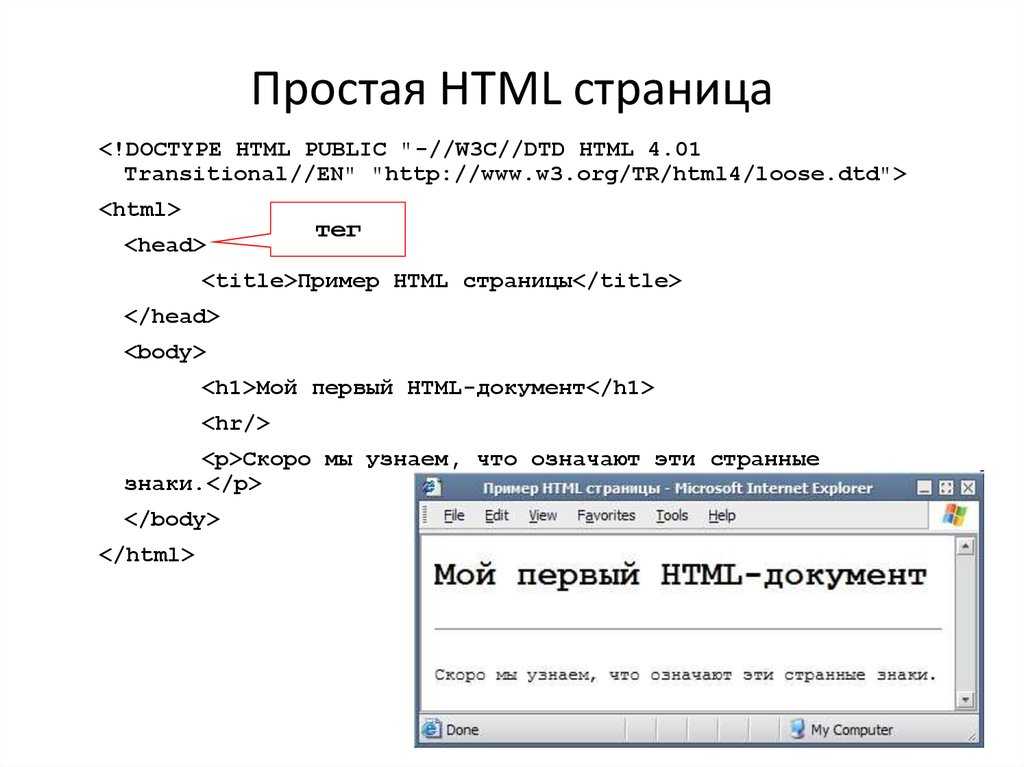
4. Посмотреть по дате индексирования;
Интернет-архивы – это сервисы, которые собирают информацию обо всех веб-ресурсах в различные периоды их функционирования. В разные моменты времени они сохраняют копии сайтов (снапшоты).В веб-архивах можно посмотреть, когда ресурс был впервые проиндексирован – вероятно, он появился близко к той дате. При этом можно увидеть, как он выглядел в разные промежутки времени, какой у него был дизайн, тематика контента.
5. Интернет-архивы.
Самые популярные интернет-архивы – это Веб-архив или Wayback Machine. Принцип работы с ними прост – введите в поисковую строку ссылку на ресурс, возраст которого хотите проверить.В результатах поиска вы увидите линейку времени с подсвеченными на ней датами создания снапшота. Вы можете выбрать год, месяц, день, когда был сделан снапшот, и посмотреть, как в это время выглядел ресурс. Самый первый снимок экрана может отражать дату его создания.
Заключение.
Возраст сайта влияет на его продвижение. Конечно, это не единственный и не самый важный параметр, но он может быть значим при анализе конкурентов и ниши. Дату создания полезно знать, чтобы проанализировать подозрительные ресурсы – если к вам обращается с предложением сотрудничества созданный два дня назад ресурс, лучше задуматься о его благонадежности.
Возраст сайта не стоит путать с возрастом домена. Сайт – это сам ресурс, а домен – его имя. Сайты могут менять имена, а домены в разные периоды времени могут принадлежать разным сайтам. Поэтому для достоверного анализа лучше проверить как доменное имя, так и сам ресурс.
Возраст ресурса можно узнать, обратившись к его владельцу или посмотрев на дату в футере. Это информация не всегда достоверна, поэтому можно проанализировать контент – посмотреть дату публикации самых ранних постов. Если такой возможности нет, воспользуйтесь интернет-архивами – это сервисы, которые сохраняют копии веб-страниц в различные периоды их функционирования. Самая ранняя копия может быть близка к дате создания портала.
Самая ранняя копия может быть близка к дате создания портала.
Возраст домена можно узнать на специальных Whois-сервисах. Они предоставляют информацию о том, на кого зарегистрирован домен, кем, когда. Есть отдельные Whois-сервисы, но возраст и историю доменных имен можно также посмотреть в регистраторах или сервисах для SEO-анализа. Лучше всего использовать несколько способов сразу, чтобы сопоставить результаты и получить наиболее точную информацию.
Как найти сайт был опубликован? Вот пути!
- Миниинструмент
- Центр новостей MiniTool
- Как найти сайт был опубликован? Вот пути!
Вера | Подписаться | Последнее обновление
На некоторых веб-страницах не указана дата публикации, но она нужна вам, чтобы узнать действительность или разместить ссылку на своем веб-сайте. Вот почему мы поговорим о том, как узнать, когда сайт был опубликован здесь. MiniTool Solution предложит вам несколько способов, которые помогут вам легко найти дату веб-сайта.
В большинстве случаев легко получить дату, просто зайдя на сайт и найдя дату публикации. Таким образом, вы знаете, насколько недавно была опубликована статья. Однако все становится немного сложнее, если вы не видите дату, указанную на веб-сайте.
Тогда как посмотреть, когда была опубликована веб-страница? Теперь получите ответ из следующей части.
Как узнать, когда сайт был опубликован?
Проверьте страницу и URL-адрес
Первое, что вы можете сделать, это найти дату публикации на самой странице и рядом с ней. Как узнать, когда веб-страница была опубликована по странице и URL-адресу? Смотрите подробное руководство.
1. Просканируйте страницу
Большинство сайтов указывают дату публикации под заголовком статьи рядом с именем автора. Просто проверьте дату прямо в начале текста статьи или под заголовком. В редких случаях дата находится под статьей, поэтому ее следует проверить, если вы не можете найти ее под заголовком.
Просто проверьте дату прямо в начале текста статьи или под заголовком. В редких случаях дата находится под статьей, поэтому ее следует проверить, если вы не можете найти ее под заголовком.
На нашем сайте мы показываем дату публикации под заголовком, как показано на следующем рисунке.
2. Проверьте дату авторского права
Вы также можете перейти к нижней части веб-страницы и проверить указанную информацию. Там может быть информация об авторских правах или примечание к публикации. Просто прочитайте его, чтобы увидеть, предлагается ли оригинальная дата публикации. Но обратите внимание, что вместо даты публикации может быть дата последнего обновления веб-сайта.
3. Проверьте URL-адрес
Некоторые блоги и веб-сайты не отображают отметку времени, но автоматически заполняют веб-адрес датой написания статьи. Вы можете увидеть полную дату. Иногда вы не можете получить точную дату, а просто находите месяц и год. Этого тоже достаточно.
Этого тоже достаточно.
4. Проверьте комментарии
Это не точно, но все же полезно, и вы можете посмотреть комментарии, чтобы оценить дату публикации. Смотрите первый комментарий, чтобы узнать, когда он написан, и вы можете узнать ближайшую дату публикации.
Посмотреть исходный код
Как узнать дату веб-сайта по исходному коду? Выполните следующие действия:
- Перейдите на веб-страницу и щелкните ее правой кнопкой мыши, чтобы выбрать Просмотреть исходный код страницы .
- Нажмите Ctrl + F , чтобы открыть окно поиска.
- Введите , опубликуйте и нажмите . Введите , чтобы выделить каждую строку, и вы сможете проверить, знаете ли вы, когда веб-сайт был опубликован.
Используйте Google
Вы можете использовать Google, чтобы показать дату публикации с помощью простого поиска. Как узнать, когда веб-страница была создана через Google? Полные инструкции здесь.
- Скопируйте URL-адрес веб-сайта и вставьте его в окно поиска Google.
- Введите inurl: перед URL-адресом страницы и нажмите «Поиск». Появится результат поиска.
- Перейдите к адресной строке, добавьте &as_qdr=y15 в конец и нажмите Введите . Теперь вы можете видеть, что результат поиска включает дату публикации.
Конец
Как узнать, когда сайт был опубликован? Прочитав этот пост, вы точно знаете ответ. Просто следуйте этим методам, упомянутым выше, чтобы узнать дату публикации веб-страницы.
- Твиттер
- Линкедин
- Реддит
Об авторе
Комментарии пользователей:
узнать дату публикации веб-страниц — документация htmldate 1.4.1
Найти оригинальные и обновленные даты публикации любой веб-страницы. В командной строке или в Python включены все необходимые шаги от загрузки веб-страницы до синтаксического анализа HTML, очистки и анализа текста.
В командной строке или в Python включены все необходимые шаги от загрузки веб-страницы до синтаксического анализа HTML, очистки и анализа текста.
В двух словах
С Python:
>>> из импорта htmldate find_date
>>> find_date('http://blog.python.org/2016/12/python-360-is-now-available.html')
'2016-12-23'
В командной строке:
$ htmldate -u http://blog.python.org/2016/12/python-360-is-now-available.html '2016-12-23'
Особенности
Многоязычный, надежный и эффективный (используется при производстве миллионов документов)
URL-адреса, файлы HTML или деревья HTML предоставляются в качестве входных данных (включая пакетную обработку)
Вывод в виде строки в любом формате даты (по умолчанию ISO 8601 YMD)
Обнаружение как исходных, так и обновленных дат
Совместим со всеми последними версиями Python
htmldate может проверять разметку и текст. Он предоставляет следующие способы датирования HTML-документа:
Он предоставляет следующие способы датирования HTML-документа:
Разметка в заголовке : общие шаблоны используются для идентификации соответствующих элементов (например,
ссылкаиметаэлементы), включая атрибуты протокола Open Graph и большое количество особенностей CMSHTML-код : Затем весь документ ищется по структурным маркерам:
аббриливремяэлементов и ряд атрибутов (например,постметаданные)Чистый HTML-контент : Эвристика выполняется для текста и разметки:
Вывод тщательно проверяется с точки зрения правдоподобия и адекватности. Если найдена допустимая дата, библиотека выводит строку даты, соответствующую либо последнему обновлению, либо исходному заявлению о публикации (по умолчанию) в нужном формате.
Извлечение на основе разметки является многоязычным по своей природе, уточнения на основе текста для лучшего охвата в настоящее время поддерживают немецкий, английский и турецкий языки.
Установка
Основная упаковка
Этот пакет Python протестирован на системах Linux, macOS и Windows; он совместим с Python 3.6 и выше. Он доступен в репозитории пакетов PyPI и, в частности, может быть установлен с помощью pip или pipenv :
$ pip install htmldate # pip3 install в системах, где установлены и Python 2, и Python 3. $ pip install --upgrade htmldate # чтобы убедиться, что у вас установлена последняя версия $ pip install git+https://github.com/adbar/htmldate.git # последний доступный код (см. статус сборки выше)
Дополнительно
Можно установить дополнительную библиотеку cchardet (или ее форк faust-cchardet ) для повышения скорости выполнения. Они могут работать не на всех платформах, поэтому были выделены, хотя установка рекомендуется:
$ pip install htmldate[скорость] # установка с дополнительным функционалом
Вы также можете установить или обновить пакеты по отдельности, htmldate определит, какие из них присутствуют в вашей системе, и выберет наилучшую доступную комбинацию.
Пакет dateparser заметно медленнее в своих последних версиях, для скорости рекомендуется версия 1.1.2 .
Для получения информации об управлении зависимостями пакетов Python см. эту ветку обсуждения.
Экспериментальный
Экспериментальная компиляция с mypyc , так как использование предварительно скомпилированной библиотеки может сократить скорость обработки:
Установить
mypy:pip3 установить mypyСкомпилируйте пакет:
python setup.py --use-mypyc bdist_wheelИспользуйте только что созданное колесо:
pip3 install dist/...
С Python
найти_дата Если веб-страница содержит легко читаемые метаданные в заголовке, извлечение выполняется просто. Иногда требуется более глубокий анализ структуры документа:
>>> из импорта htmldate find_date
>>> find_date('http://blog. python.org/2016/12/python-360-is-now-available.html')
# DEBUG анализ: пятница, 23 декабря 2016 г.
# Результат ОТЛАДКИ: 2016-12-23
'2016-12-23'
python.org/2016/12/python-360-is-now-available.html')
# DEBUG анализ: пятница, 23 декабря 2016 г.
# Результат ОТЛАДКИ: 2016-12-23
'2016-12-23'
htmldate может прибегнуть к догадке, основанной на полном просмотре документа (параметр extended_search ), который можно деактивировать:
>>> find_date('https://creativecommons.org/about/')
'2017-08-11' # был обновлен с
>>> find_date('https://creativecommons.org/about/', extended_search=False)
>>>
Уже проанализированный HTML (то есть объект дерева LXML):
# простой HTML-документ в виде строки >>> htmldoc = '12 июля 2016 г.' >>> find_date(htmldoc) '2016-07-12' # анализируемое LXML-дерево >>> из lxml импортировать html >>> mytree = html.fromstring('12 июля 2016 г.') >>> найти_дата (мое дерево) '2016-07-12'
Формат вывода
Измените вывод на формат, известный модулю Python datetime , по умолчанию %Y-%m-%d :
>>> find_date('https://www. gnu.org/licenses/gpl-3.0.en.html', outputformat='%d %B %Y')
«18 ноября 2016 г.» # могло измениться с тех пор
gnu.org/licenses/gpl-3.0.en.html', outputformat='%d %B %Y')
«18 ноября 2016 г.» # могло измениться с тех пор
Оригинальные и обновленные даты
Хотя разница во времени между исходной публикацией и информацией «последнее изменение» обычно составляет несколько часов или дней, может быть полезно установить приоритет дата первоначальной публикации :
>>> find_date('https://netzpolitik.org/2016/die-cider-connection-abmahnungen-gegen-nutzer-von-creative-commons-bildern/', original_date=True) # изменено поведение
'2016-06-23'
Для получения дополнительной информации см. страницу параметров.
В командной строке
Включен интерфейс командной строки:
$ htmldate -u http://blog.python.org/2016/12/python-360-is-now-available.html '2016-12-23' $ wget -qO- "http://blog.python.org/2016/12/python-360-is-now-available.html" | htmlдата '2016-12-23'
Инструкции по использованию см. в htmldate -h :
$ htmldate --help
htmldate [-h] [-f] [-i ВХОДНОЙ ФАЙЛ] [--original] [-min MINDATE] [-max MAXDATE] [-u URL] [-v] [--version]
необязательные аргументы:
-h, --help показать это справочное сообщение и выйти
-f, --fast быстрый режим: отключить расширенный поиск
-i ВХОДНОЙ ФАЙЛ, --inputfile ВХОДНОЙ ФАЙЛ
имя входного файла для пакетной обработки (аналогично wget -i)
--исходная исходная дата имеет приоритет
-min ДАТА, --mindate ДАТА
самая ранняя приемлемая дата (ISO 8601 YMD)
-max МАКС. ДАТА, --maxdate МАКС.ДАТА
последняя приемлемая дата (ISO 8601 YMD)
-u URL-адрес, --URL URL-адрес настраиваемый URL-адрес загрузки
-v, --verbose увеличить детализацию вывода
--version показать информацию о версии и выйти
ДАТА, --maxdate МАКС.ДАТА
последняя приемлемая дата (ISO 8601 YMD)
-u URL-адрес, --URL URL-адрес настраиваемый URL-адрес загрузки
-v, --verbose увеличить детализацию вывода
--version показать информацию о версии и выйти
Пакетный режим -i принимает один URL-адрес на строку в качестве входных данных и возвращает один результат на строку в формате, разделенном табуляцией:
$ htmldate --fast -i список-адресов.txt
Лицензия
htmldate распространяется под Стандартной общественной лицензией GNU v3.0. Если вы хотите распространять эту библиотеку, но чувствуете себя ограниченным условиями лицензии, попробуйте взаимодействовать на расстоянии вытянутой руки, использовать несколько лицензий с совместимыми лицензиями или связаться со мной.
См. также GPL и лицензирование бесплатного программного обеспечения: что это дает бизнесу?
Автор
Эта попытка является частью методов извлечения информации из веб-документов для создания текстовых баз данных для исследований (главным образом лингвистический анализ и обработка естественного языка). Извлечение и предварительная обработка веб-текстов в соответствии со строгими стандартами научных исследований представляет собой серьезную проблему для тех, кто проводит такие исследования. Существуют веб-страницы, для которых ни URL-адрес, ни ответ сервера не дают надежного способа узнать, когда документ был опубликован или изменен. Для получения дополнительной информации:
Извлечение и предварительная обработка веб-текстов в соответствии со строгими стандартами научных исследований представляет собой серьезную проблему для тех, кто проводит такие исследования. Существуют веб-страницы, для которых ни URL-адрес, ни ответ сервера не дают надежного способа узнать, когда документ был опубликован или изменен. Для получения дополнительной информации:
@article{barbaresi-2020-htmldate,
title = {{htmldate: пакет Python для извлечения дат публикации с веб-страниц}},
автор = "Барбарези, Адриан",
journal = "Журнал программного обеспечения с открытым исходным кодом",
объем = 5,
число = 51,
страницы = 2439,
URL = {https://doi.org/10.21105/joss.02439},
издатель = {Открытый журнал},
год = 2020,
}
Барбарези, А. «htmldate: пакет Python для извлечения дат публикации с веб-страниц», Journal of Open Source Software, 5 (51), 2439, 2020. DOI: 10.21105/joss.02439
Барбарези, А. «Извлечение универсального веб-контента с помощью программного обеспечения с открытым исходным кодом», Труды KONVENS 2019, Kaleidoscope Abstracts, 2019.

Барбарези, А. «Эффективное создание веб-корпусов с расширенными метаданными», Труды 10-го семинара «Веб как корпус» (WAC-X), 2016 г.
Вы можете связаться со мной через мою контактную страницу или GitHub.
Содействие
Участие приветствуется!
Не стесняйтесь сообщать о проблемах на специальной странице. Спасибо участникам, которые представили функции и исправления!
Преимущество следующих программных библиотек:
lxml, анализатор даты
Несколько шаблонов получены из библиотек python-goose, metascraper,gazeta и articleDateExtractor. Этот модуль значительно расширяет их охват и надежность.
Идем дальше
Известные предостережения
Детализация может не всегда соответствовать желаемому выходному формату. Если можно найти только информацию о годе, а выбранный формат даты требует вывода месяца и дня, результат «дополняется» до середины года, в этом случае 1 января.