UTF8 | это… Что такое UTF8?
ТолкованиеПеревод
- UTF8
UTF-8 (от англ. Unicode Transformation Format — формат преобразования Юникода) — в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста.
Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст байт со значением меньше 128 изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байтов (реально только до 4 байт, поскольку использование кодов больше 221 не планируется), в которых первый байт всегда имеет вид
11xxxxxx, а остальные —10xxxxxx.Проще говоря, в формате UTF-8 символы латинского алфавита, знаки препинания и управляющие символы ASCII записываются кодами US-ASCII, a все остальные символы кодируются при помощи нескольких октетов со старшим битом 1.

- Даже если программа не распознаёт Юникод, то латинские буквы, арабские цифры и знаки препинания будут отображаться правильно.
- В случае, если латинские буквы и простейшие знаки препинания (включая пробел) занимают существенный объём текста, UTF-8 даёт выигрыш по объёму по сравнению с [1][2]
- На первый взгляд может показаться, что UTF-16 удобнее, так как в ней большинство символов кодируется ровно двумя байтами. Однако это сводится на нет необходимостью поддержки суррогатных пар, о которых часто забывают при использовании UTF-16, реализовывая лишь поддержку символов UCS-2.[1]
Формат UTF-8 был изобретён 2 сентября 1992 года Кеном Томпсоном и Робом Пайком и реализован в Plan 9[3]. Сейчас стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D.
Символы UTF-8 получаются из Unicode следующим образом:
Unicode UTF-8 0x00000000—0x0000007F0xxxxxxx0x00000080—0x000007FF110xxxxx 10xxxxxx0x00000800—0x0000FFFF1110xxxx 10xxxxxx 10xxxxxx0x00010000—0x001FFFFF11110xxx 10xxxxxx 10xxxxxx 10xxxxxxТакже теоретически возможны, но не включены в стандарты:
Unicode UTF-8 0x00200000—0x03FFFFFF111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx0x04000000—0x7FFFFFFF1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxxЗамечание: Символы, закодированные в UTF-8, могут быть длиной до шести байтов, однако стандарт Unicode не определяет символов выше
Содержание
- 1 Неиспользуемые значения байтов
- 2 Примечания
- 3 Ссылки
- 4 См. также
Неиспользуемые значения байтов
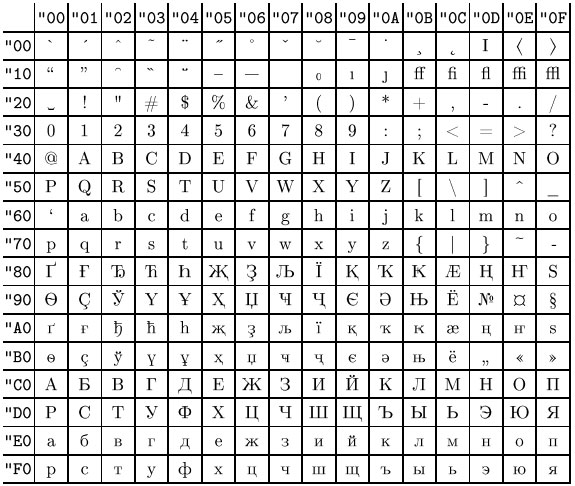
В тексте UTF-8 принципиально не может быть байтов со значениями 254 (0xFE) и 255 (0xFF). Поскольку в Юникоде не определены символы с кодами выше 221, то в UTF-8 оказываются неиспользуемыми также значения байтов от 248 до 253 (0xF8—0xFE). Если запрещены искусственно удлинённые (за счёт добавления ведущих нулей) последовательности UTF-8, то не используются также байтовые значения 192 и 193 (0xC0 и 0xC1).
Примечания
- ↑ 1 2 Well, I’m Back String Theory (англ.). Robert O’Callahan (2008-03-01). Проверено 1 марта 2008.
- ↑ Ростислав Чебыкин Всем кодировкам кодировка. UTF‑8: современно, грамотно, удобно.. HTML и CSS. Проверено 22 марта 2009.
- ↑ http://www.cl.cam.ac.uk/~mgk25/ucs/utf-8-history.txt (англ.)
Ссылки
- UTF-8 encoding table and Unicode characters
См. также
- Юникод в GNU/Linux
- Юникод в FreeBSD
- Plan 9

Wikimedia Foundation. 2010.
Игры ⚽ Нужно сделать НИР?
- UTF-16 Big Endian
- UTF-32
Полезное
Что такое кодирование символов в Юникоде, UTF, ASCII
Понимание кодировки символов имеет решающее значение для всех, кто печатает на компьютере, особенно на иностранных языках, используя эмодзи или любые другие специальные символы. В этой статье мы расскажем об основах кодировки символов в Юникод, о кодовых точках, кодовых единицах, а также рассмотрим искусство рисовать на ASCII.
Без письменного языка мы не смогли бы написать весь этот текст, и вы не смогли бы его прочитать. Язык – это тот инструмент, благодаря которому люди могут транслировать друг другу то, что существует в их ментальном пространстве. Без языка не было бы общения, но не было бы общения и с языком, если бы собеседник не понимал бы, что вы говорите. Это же относится и к компьютерам.
Без языка не было бы общения, но не было бы общения и с языком, если бы собеседник не понимал бы, что вы говорите. Это же относится и к компьютерам.
Любой разработчик может создать свой язык для своего программного обеспечения. Например, если ваш телефон работает на программном обеспечении одного разработчика, и вы хотите написать сообщение человеку, чей телефон работает на программном обеспечении другого разработчика, то у вас может ничего не получиться. Наверняка у вас были случаи, когда во время переписки с кем-то, вместо смайликов и других символов вы получали бессмысленные символы — «??». Именно для того, чтобы избавиться от возникновения подобных ситуаций, разработчики начали использовать кодировку Юникод.
Юникод — это коды, которые позволяют вашему компьютеру сохранять любые символы, воспринимаемые человеком, в цифровой форме. Это необходимо для того, чтобы ваше устройство могло обмениваться информацией и релевантно показывать полученные данные без раздражающих «??».
Что такое Юникод?
Юникод – это глобальный стандарт кодировки символов, который используется для привязки кода ко всем существующим письменным знакам и символам, содержащимся во всех языках, используемых для письменного общении во всем мире. Юникод является непревзойденным эталоном кодирования и стандартом для поддержки всех языков мира, за исключением ряда уникальных китайских символов. Юникод необходим всем, кто собирается использовать Java, XML, LDAP, JavaScript и другие языки программирования.
Без кодировки символов нет и Юникода. Кодировка символов – это привязка определенного числа (кода) к заданному символу. Юникод – это общепринятая во всем мире система кодировки символов. Например, английской букве «B» соответствует число 6, a=12, s=15 и т. д.
Как своего рода система, Юникод определяет коды для более 128 000 символов. Кроме того, он имеет различные форматы кодировки, которые называются Форматом преобразования Юникода (Unicode Transformation Format — UTF).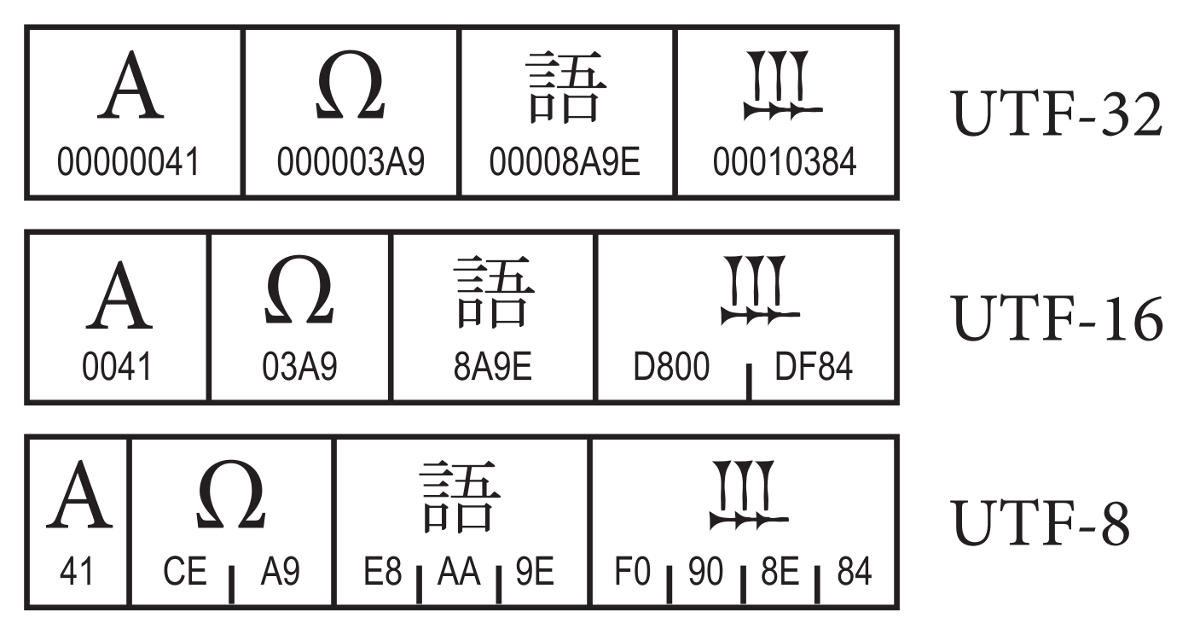 Это такие форматы как:
Это такие форматы как:
- UTF-8. Это наиболее компактный формат для кодирования различных символов. Для кодирования используется от 1 до 4 байт. Все зависит от конкретного символа. Так для кодирования символов латиницы используется всего один байт или 8 бит. Для кодирования символов других алфавитов используются дополнительные серии битов. Этот формат очень популярен в Интернете и в системах электронной почты.
- UTF-16. Этот формат для кодирования символов использует 2 байта или 16 битов. Это позволяет представить огромное количество символов, так как для кодирования каждого символа используется полностью 2 байта во всем диапазоне.
- UTF-32. В этом формате для кодирования символов используется 4 байта или 32 бита. Данный формат появился как расширение технологии кодирования 16 битного формата для решения некоторых его ограничений. Наиболее интересной особенностью этого формата является то, что ему не нужно для представления увеличенных символов использовать пары 32 битных чисел.
 Он вполне способен представить любой символ Юникода как сплошное 32 битное число.
Он вполне способен представить любой символ Юникода как сплошное 32 битное число.
Зачем был создан Юникод?
Американский стандартный код для обмена информацией (ASCII) был первым популярным методом кодирования, но он имел ограничения по символам, используя только 128 кодовых определений. Он хорошо подходил для символов латинского алфавита, но с другими алфавитами возникали проблемы. В результате разработчики из других стран начали создавать свои методы кодирования, подходящие для их собственных языков.
Результатом стали дебри методов кодирования с весьма ограниченной связью за пределами своих изначальных регионов. Таким образом, в качестве компромисса между разработчиками всего мира появился Юникод.
Почему следует использовать Юникод?
Юникод является глобальной системой и как таковой поддерживает множество языков. Благодаря этому разные языки можно комбинировать на одном дыхании, в отличие от того, что было раньше, когда приходилось работать с одним языком за раз. Юникод используется многими гигантами компьютерной промышленности, таких как Apple, Microsoft, HP и так далее. Кроме того, это схема кодирования символов в популярных браузерах, таких как Firefox, Google Chrome и т.д.
Юникод используется многими гигантами компьютерной промышленности, таких как Apple, Microsoft, HP и так далее. Кроме того, это схема кодирования символов в популярных браузерах, таких как Firefox, Google Chrome и т.д.
Использование Юникода увеличивает ваши шансы быть понятым на всех известных устройствах.
Что такое «кодовые точки»?
Кодовая точка — это значение, которое приписывается символу в схеме кодирования символов Юникод. Кодовые точки разбиты на 17 различных секций, называемых плоскостями, которые содержат до 65 536 кодовых точек. Эти плоскости нумируются числовыми значениями от 0 до 16. При этом в плоскости с номером 0, содержатся часто повторяющиеся коды.
Что такое «кодовые единицы»?
Обратите внимание, что кодовые единицы могут быть изменены на кодовые точки, а методы кодирования символов содержат кодовые единицы. Эти единицы указывают, где находится символ внутри плоскости.
Рисование при помощи символов ASCII
Если вы заявите, что рисование при помощи символов ASCII уже неактуально, то вы рискуете получить ту же реакцию, что и компания Microsoft, которая сделав подобное заявление в 1998 году, получила множество негативных комментариев, а Билла Гейтса назвали чрезмерно усердным человеком, отчаянно пытающимся навязать людям свои шрифты Microsoft.
В свое время искусство рисовать при помощи символов ASCII оказало сильное влияние на развитие алгоритмов создания современных компьютерных изображений. И в настоящее время подобный способ создания картинок все еще широко используется. Кроме того, нынешние эмодзи являются потомками старых ASCII-смайликов. В действительности на некоторых устройствах до сих пор используются старые ASCII-смайлики.
.-"""-.
/ \
\ /
.-"""-.-`.-.-.< _
/ _,-\ ()()_/:)
\ / , ` `|
'-..-| \-.,___, /
\ `-.__/ /
`-.__.-'`
Изначально рисование при помощи символов ASCII придумывалось вовсе не для того, чтобы создать новый вид искусства. Его функция приблизительно была той же, что сегодня делают современные принтеры. Креативность привела к рождению ASCII и его влияние похоже исчезнет еще не скоро. Некоторые разработчики даже создают специальные приложения, которые трансформируют произведения современного искусства в их версии на ASCII.
░█▄▒▄█░▄▀▀░█░▀█▀▒██▀▒█▀▄░░▒█▀▄░█▒█
░█▒▀▒█▒▄██░█░▒█▒░█▄▄░█▀▄░▄░█▀▄░▀▄█
Приведенное изображение создано при помощи Конвертера текста.
Проблемы переполнения в CSS и способы их решения
4 простых правила оформления текста на сайте
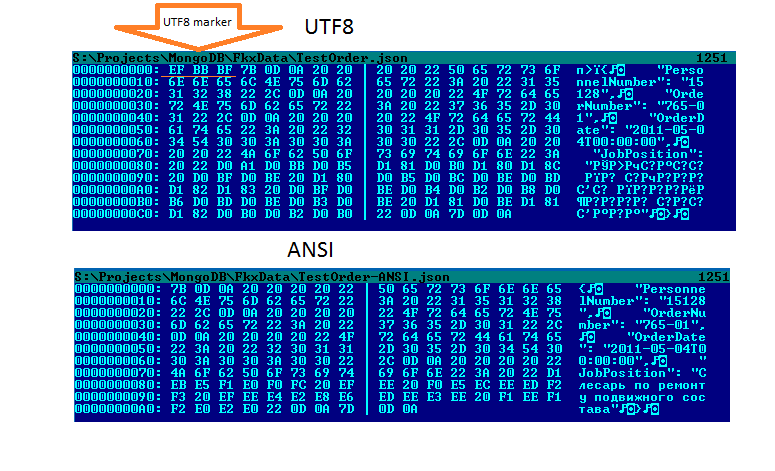
Как работает кодировка Unicode UTF-8
UTF-8 — это умный способ кодирования текста Unicode. Я упоминал об этом пару раз в последнее время, но я не писал в блоге об UTF-8 как таковой. Вот оно.
Проблема, которую решает UTF-8
Американские клавиатуры часто могут отображать 101 символ, что означает, что 101 символа будет достаточно для большинства текстов на английском языке. Семи бит будет достаточно, чтобы закодировать эти символы, поскольку 2 7 = 128, а именно это и делает ASCII . Он представляет каждый символ 8 битами, поскольку компьютеры работают с битами в группах размеров, которые являются степенью двойки, но первый бит всегда равен 0, потому что он не нужен. Расширенный ASCII использует оставшееся пространство в ASCII для кодирования дополнительных символов.
В общей сложности 256 символов могут быть полезны некоторым пользователям, но они не позволят вам представлять, например, китайский язык. Первоначально Unicode хотел использовать два байта вместо одного байта для представления символов, что дало бы 2 16 = 65 536 возможностей, что было бы достаточно для охвата многих систем письма в мире. Но не все, и поэтому Юникод расширен до четырех байт.
Если бы вы хранили текст на английском языке, используя два байта для каждой буквы, половина пространства была бы потеряна для хранения нулей. И если бы вы использовали четыре байта на букву, три четверти пространства были бы потрачены впустую. Без какой-либо кодировки каждый файл, содержащий английский тест, был бы в два-четыре раза больше необходимого . И не только английский, но и все языки, которые могут быть представлены с помощью ASCII.
UTF-8 — это способ кодирования Unicode, при котором текстовый файл ASCII кодирует сам себя. Никакого лишнего пространства, кроме начального бита каждого байта, который ASCII не использует. И если ваш файл в основном представляет собой текст ASCII с добавлением нескольких символов, отличных от ASCII, символы, отличные от ASCII, просто сделают ваш файл немного длиннее. Вам не нужно внезапно заставлять каждый символ занимать в два или четыре раза больше места только потому, что вы хотите использовать, скажем, знак евро € (U+20AC).
И если ваш файл в основном представляет собой текст ASCII с добавлением нескольких символов, отличных от ASCII, символы, отличные от ASCII, просто сделают ваш файл немного длиннее. Вам не нужно внезапно заставлять каждый символ занимать в два или четыре раза больше места только потому, что вы хотите использовать, скажем, знак евро € (U+20AC).
Как это делает UTF-8
Поскольку первый бит символов ASCII установлен в ноль, байты с первым битом, установленным в 1, не используются и могут использоваться специально.
Когда программа, читающая кодировку UTF-8, встречает байт, начинающийся с 1, она подсчитывает, сколько единиц следует за ней, прежде чем встретится с 0. Например, в байте вида 110xxxxx за начальной 1 следует одна 1. Пусть  То есть для представления символа Unicode с использованием UTF-8 требуется не более четырех байтов.
То есть для представления символа Unicode с использованием UTF-8 требуется не более четырех байтов.
Таким образом, байт вида 110xxxxx говорит о том, что первые пять битов символа Юникода хранятся в конце этого байта, а остальные биты идут в следующем байте.
Байт вида 1110xxxx содержит четыре бита символа Unicode и говорит о том, что остальные биты приходятся на следующие два байта.
Байт вида 11110xxx содержит три бита символа Unicode и говорит о том, что остальные биты приходятся на следующие три байта.
После начального байта, уведомляющего о начале символа, распределенного по нескольким байтам, биты сохраняются в байтах формы 10xxxxxx. Поскольку начальные байты многобайтовой последовательности начинаются с двух битов 1, двусмысленности нет: байт, начинающийся с 10, не может обозначать начало новой многобайтовой последовательности. То есть UTF-8 является самопунктуирующим.
Итак, многобайтовые последовательности имеют одну из следующих форм.
110ххххх 10хххххх
1110хххх 10хххххх 10хххххх
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Если посчитать крестики в нижнем ряду, их 21. Таким образом, эта схема может представлять только числа длиной до 21 бита. Разве нам не нужны 32 бита? Оказывается, нет.
Таким образом, эта схема может представлять только числа длиной до 21 бита. Разве нам не нужны 32 бита? Оказывается, нет.
Хотя символ Unicode якобы является 32-битным числом, на самом деле для кодирования символа Unicode требуется не более 21 бита по причинам, описанным здесь. Вот почему
Эффективность
UTF-8 позволяет вам взять обычный файл ASCII и считать его файлом Unicode, закодированным с помощью UTF-8. Таким образом, UTF-8 так же эффективен, как ASCII, с точки зрения пространства. Но не по времени. Если программа знает, что файл на самом деле является ASCII, она может принимать каждый байт по номинальной стоимости, не проверяя, является ли он первым байтом многобайтовой последовательности.
И хотя обычный ASCII допустим в UTF-8, расширенный ASCII — нет. Таким образом, расширенные символы ASCII теперь будут занимать два байта вместо одного. Мой предыдущий пост был о путанице, которая может возникнуть из-за того, что программное обеспечение интерпретирует файл в кодировке UTF-8 как расширенный файл ASCII.
Таким образом, расширенные символы ASCII теперь будут занимать два байта вместо одного. Мой предыдущий пост был о путанице, которая может возникнуть из-за того, что программное обеспечение интерпретирует файл в кодировке UTF-8 как расширенный файл ASCII.
Похожие сообщения
- Безнадежная задача консорциума Unicode
- Сколько символов Unicode возможно?
- Примеры кода префикса
Что такое UTF-8?
UTF-8 — это формат преобразования Unicode, в котором для представления символа используются 8-битные блоки.
Под символами здесь понимаются буквы алфавита, цифры и числовые значения, знаки препинания, специальные символы (валюты, математические символы, эмодзи…).
С 2009 года UTF-8 является доминирующей кодировкой (любой, а не только кодировки Unicode) для Интернета, и по состоянию на март 2020 года на ее долю приходится 95,0% всех веб-страниц. UTF-8 превзошла все остальные кодировки в 2008 г.
Кодировка символов
Кодировка символов является обязательным информационным пунктом для всех, кто планирует создавать контент за пределами языков, использующих основные символы латинского алфавита. Кодировка символов относится к правильной читаемости символов в тексте пользователями, машинами и поисковыми системами.
Компьютеры хранят символы как одиночные или сгруппированные байты. Кодировка символов — это способ правильного отображения этих байтов (символов).
Важно различать шрифты и кодировка символов — хотя у вас может быть правильная кодировка символов, выбранный шрифт может не отображать правильный символ, а вместо этого предлагать нечитаемые значки, такие как пустые квадраты, вопросительные знаки и т. д.
ASCII основы
В начале был ASCII — американский стандартный код для обмена информацией. ASCII — это стандарт кодирования символов для цифровой связи. ASCII включает в себя основные символы, знаки препинания, цифры и буквы, которые присутствуют в английском алфавите.
ASCII включает в себя основные символы, знаки препинания, цифры и буквы, которые присутствуют в английском алфавите.
Однако по мере того, как Интернет расширялся от основ английского языка, миллиарды пользователей почти не использовали латинские символы для доступа к соответствующему контенту, и на смену ASCII пришла новая кодировка символов.
Полезно знать, что первые 256 кодовых точек (уникальные числа для каждого символа) ASCII, ISO-8859 и UTF-8 идентичны. Хотя ISO-8859 охватывает большинство языков, использующих арабскую письменность, UTF-8 еще больше расширяется и охватывает большинство живых языков и письменностей в мире.
Если вы еще не думали о своей целевой аудитории (текущей и будущей), самое время это сделать.
Что такое UTF-8?
Формат преобразования UTF-8 или Unicode является расширением ASCII. UTF-8 кодирует кодовые точки от одного до четырех байтов.
Структура UTF-8:
Один байт : первые 128 символов (соответствующих символам ASCII).
