Что такое Unicode и как с ним связана UTF-8
Резюмируя написанное в комментариях и чате. Примечание: данный ответ не претендует на строгую спецификацию, а является объяснением «на пальцах» для улучшения понимания и может содержать неточности, а для разработки программ лучше читать не SO и даже не Википедию, а непосредственно сам стандарт.
В контексте вопроса Unicode — это просто табличка символов и закреплённых за ними целых чисел (не каких-либо байт, а обычных человеческих чисел). (А ещё юникод описывает обработку символов и их преобразования друг в друга, но вопрос не про это.)
Кусочек этой таблички:
Эта табличка не указывает, как именно эти числа переводить в байты, которые можно было бы сохранить в компьютере. Но, чтобы хранить юникод в компьютере, кто-то должен указать, как их всё-таки переводить!
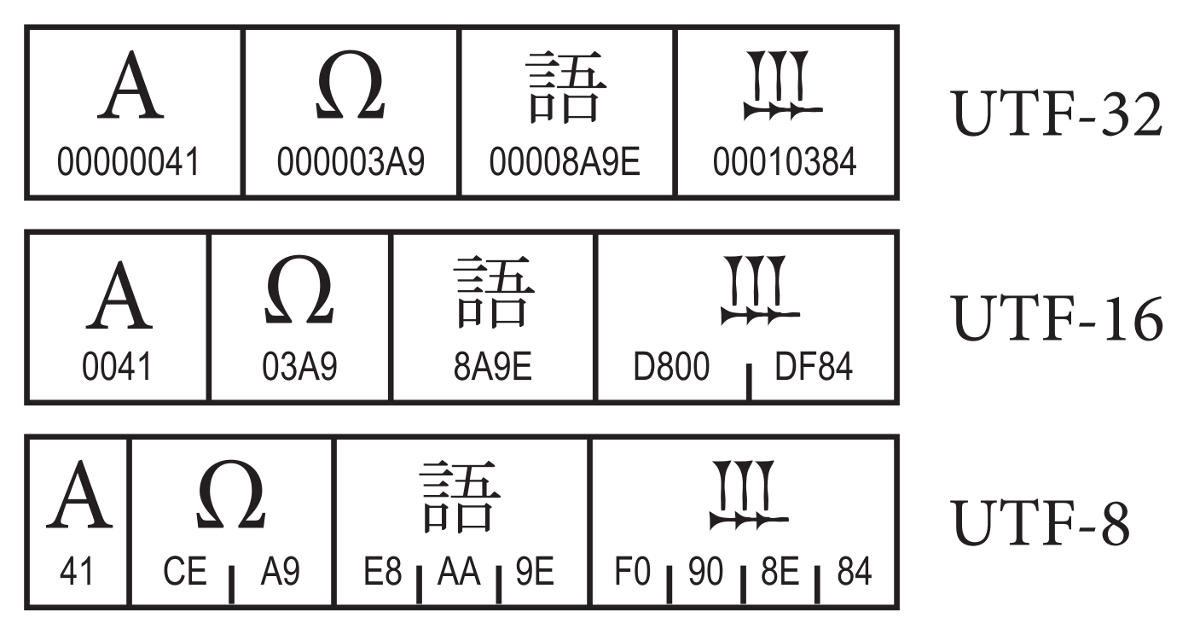
Возьмём числа из этой таблички символов и запихнём их в четыре байта так, чтобы четыре байта представляли беззнаковое целое число (unsigned int, uint32). То есть, например, из кода буквы «Я» 42F16 получаем байты
То есть, например, из кода буквы «Я» 42F16 получаем байты 00 00 04 2F. Таким образом мы получили простейшую кодировку UTF-32 (UTF-32-BE1, UCS-4). Если интерпретировать эти полученные четыре байта как беззнаковое целое число, то мы получим номер символа в табличке Unicode.
С уточнением, что мы используем uint32, можно для себя считать, что UTF-32 = Unicode: каждое число кодируется-декодируется как есть без каких-либо преобразований.
Если мы возьмём числа из таблички и запихнём их в два байта, представляющие беззнаковое целое число (unsigned short, uint16), то мы получили бы первую версию Юникода, которая была в 1991 году. Тогда число символов было ограничено 65536, и все их коды можно было легко представить двумя байтами без дополнительных преобразований.
Но потом решили, что 65 тысяч это как-то мало, и увеличили максимальное количество символов до миллиона. Но ведь миллион в два байта уже никак не запихнёшь, и нужно взять больше байт на символ. Но так как уже успели появиться программы, рассчитывающие на эти самые два байта (например, в Java или Windows NT длина одного символа до сих пор 2 байта), то для сохранения хоть какой-то обратной совместимости из этих двух байт выдрали диапазон D80016..DFFF16 и сказали, что это суррогатные пары, занимающие по четыре байта и обрабатывающиеся по особому алгоритму для символов с кодом 1000016 и больше. И назвали всё это кодировкой UTF-16.
Но так как уже успели появиться программы, рассчитывающие на эти самые два байта (например, в Java или Windows NT длина одного символа до сих пор 2 байта), то для сохранения хоть какой-то обратной совместимости из этих двух байт выдрали диапазон D80016..DFFF16 и сказали, что это суррогатные пары, занимающие по четыре байта и обрабатывающиеся по особому алгоритму для символов с кодом 1000016 и больше. И назвали всё это кодировкой UTF-16.
Таким образом, в UTF-16 числа из таблички юникода, попадающие в диапазоны 000016..D7FF16 и E00016..FFFF16, записываются в два байта как есть, а символы с кодами 1000016 и больше записываются в виде суррогатных пар с использованием диапазона D80016..DFFF16 и занимают четыре байта. Так старые приложения, сделанные под первую двухбайтовую версию Юникода, смогли продолжить и дальше с ним работать, если не используются суррогатные пары.
Таким образом та же буква «Я» (код 42F16) представляется в UTF-16 (UTF-16-BE) как 04 2F, а символ «🔒» с кодом 1F51216, не влезающим в два байта, по алгоритму преобразуется в четыре байта D8 3D DD 12.
Из-за этих самых суррогатных пар с кучей преобразований UTF-16 ≠ Unicode.
UTF-8 была сделана для совместимости с ASCII: в ней коды символов от 0 до 7F16 записываются в один байт как есть, в итоге выдавая этот самый ASCII, а всё остальное кодируется по алгоритмам ещё более хитрым, чем в UTF-16, поэтому UTF-8 ≠ Unicode тоже.
Технически UTF-8 позволяет закодировать числа аж до двух миллиардов, однако Unicode ограничен миллионом символов, и стандартом установлено, что кодировать в UTF-8 числа, не входящие в допустимый диапазон Unicode, запрещено. Поэтому проблемы перевода из UTF-8 в Unicode чисел, не входящих в Unicode, просто нет: хорошо сделанное приложение в таких случаях выкинет ошибку или заменит всё недопустимое символом �.
В Notepad и Notepad++ можно наблюдать кодировку, названную «Unicode», но на самом деле это UTF-16-LE с BOM1.
(клик для увеличения)
Самой распространённой кодировкой вроде как является UTF-8.
1 — числа, занимающие более одного байта, можно записывать с разным порядком байт: например, число 259 можно записать как 01 03 (big endian, BE) или как 03 01 (little endian, LE). То же самое применимо к символам в кодировках UTF-16, UTF-32 и некоторым другим (но не UTF-8). Вышеупомянутый 🔒 кодируется в UTF-16-LE неё как 3D D8 12 DD — в то время как в UTF-16-BE это будет D8 3D DD 12. BOM — это специальный символ FEFF16 в начале текста, который позволяет определить этот самый порядок байт — в big endian он пишется как FE FF, а в little endian как FF FE, а использование символа FFFE16 запрещено, что и позволяет определить порядок байт.
/utf-8 (задайте для исходных и выполняемых наборов символов UTF-8значение )
Twitter LinkedIn Facebook Адрес электронной почты- Статья
Задает как исходный набор символов, так и набор символов выполнения как UTF-8.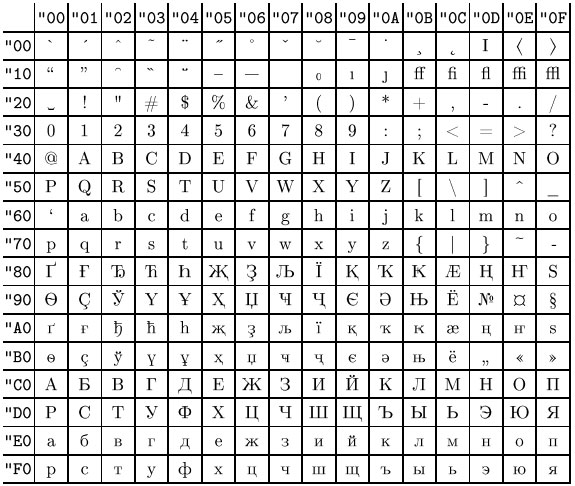
Синтаксис
/utf-8
С помощью /utf-8 параметра можно указать как исходные, так и выполняемые наборы символов в кодировке с помощью UTF-8. Это эквивалентно указанию /source-charset:utf-8 /execution-charset:utf-8 в командной строке. Любой из этих параметров также включает /validate-charset параметр по умолчанию. Список поддерживаемых идентификаторов кодовых страниц и имен наборов символов см. в разделе Кодовые идентификаторы страниц.
По умолчанию Visual Studio обнаруживает метку порядка байтов, чтобы определить, находится ли исходный файл в закодированном формате Юникода, например или UTF-16UTF-8. Если метка порядка байтов не найдена, предполагается, что исходный файл закодирован на текущей пользовательской кодовой странице, если вы не указали кодовую страницу с помощью /utf-8 параметра или /source-charset . Visual Studio позволяет сохранять исходный код C++ в любой из нескольких кодировк. Сведения об исходных и выполняемых наборах символов см. в разделе Наборы символов в документации по языку.
Visual Studio позволяет сохранять исходный код C++ в любой из нескольких кодировк. Сведения об исходных и выполняемых наборах символов см. в разделе Наборы символов в документации по языку.
Установка параметра в Visual Studio или программным способом
Установка данного параметра компилятора в среде разработки Visual Studio
Откройте диалоговое окно Окна свойств проекта. Подробнее см. в статье Настройка компилятора C++ и свойств сборки в Visual Studio.
Выберите страницу свойствC/C++>Command Lineсвойства> конфигурации.
В разделе Дополнительные параметры добавьте
/utf-8параметр , чтобы указать предпочитаемую кодировку.Выберите ОК для сохранения внесенных изменений.
Установка данного параметра компилятора программным способом
- См. раздел AdditionalOptions.
См. также
Параметры компилятора MSVC
Синтаксис командной строки компилятора MSVC/execution-charset (Задать набор символов выполнения)/source-charset (Задать исходный набор символов)/validate-charset (Проверка на наличие совместимых символов)
UTF-8 в MySQL не соответствует действительности
Если вы знакомы с MySQL, вы, вероятно, уже знаете, что в ней используется несколько кодировок символов. Одной из основных кодировок в мире MySQL и в Интернете в целом является UTF-8 — она используется почти во всех веб-приложениях и мобильных приложениях и широко считается вариантом «по умолчанию» для MySQL. UTF-8 также поддерживает несколько наборов символов и имеет несколько других уникальных функций: в этом блоге мы собираемся пройтись по ним, а также мы собираемся подробно рассмотреть одну функцию — тот факт, что MySQL «UTF- 8» не считается «настоящим» UTF-8.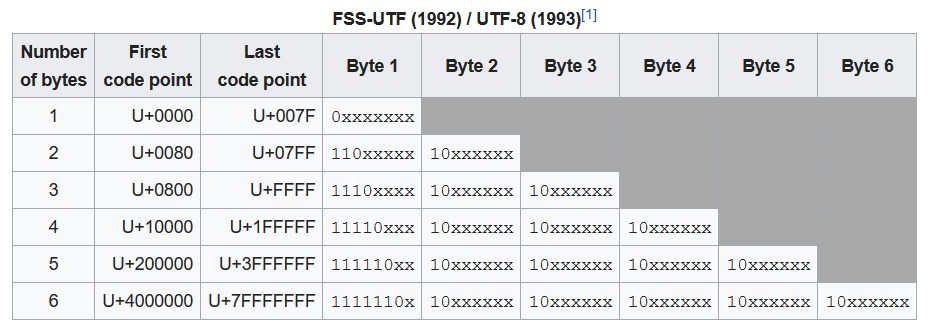 Смущенный? Читай дальше!
Смущенный? Читай дальше!
Что такое UTF-8?
Начнем с того, что UTF-8 — одна из самых распространенных кодировок символов. В UTF-8 каждый имеющийся у нас символ представлен диапазоном от одного до четырех байтов. Таким образом, у нас есть несколько наборов символов:
- utf8, который в прежние времена считался стандартом «де-факто» для MySQL в прошлом. По сути, utf8 также можно считать «псевдонимом» для utf8mb3.
- utf8mb3, который использует от одного до трех байтов на символ.
- utf8mb4, который использует от одного до четырех байтов на символ.
UTF8 был набором символов по умолчанию в прошлом, когда MySQL запускался, и все было отлично. Однако поговорите с администраторами баз данных MySQL в наши дни, и вы быстро поймете, что теперь это уже не так. Проще говоря, utf8 как таковой больше не является набором символов по умолчанию — им является utf8mb4.
utf8 против utf8mb4
Основная причина разделения utf8 и utf8mb4 заключается в том, что UTF-8 отличается от правильной кодировки UTF-8. Это так, потому что UTF-8 не предлагает полной поддержки Unicode, что может привести к потере данных или даже проблемам с безопасностью. Неспособность UTF-8 полностью поддерживать Unicode является настоящим ударом: кодировка UTF-8 требует до четырех байтов на символ, в то время как кодировка «utf8», предлагаемая MySQL, поддерживает только три. Видите проблему на этом фронте? Другими словами, если мы хотим хранить смайлики, представленные так:
Это так, потому что UTF-8 не предлагает полной поддержки Unicode, что может привести к потере данных или даже проблемам с безопасностью. Неспособность UTF-8 полностью поддерживать Unicode является настоящим ударом: кодировка UTF-8 требует до четырех байтов на символ, в то время как кодировка «utf8», предлагаемая MySQL, поддерживает только три. Видите проблему на этом фронте? Другими словами, если мы хотим хранить смайлики, представленные так:
Мы не можем этого сделать — MySQL не будет хранить его в формате «???» или аналогичный, но он не будет хранить его полностью и выдаст сообщение об ошибке, подобное следующему:
Неверное строковое значение: '\x77\xD0' для столбца 'demo_column' в строке 1
С этим сообщением об ошибке , MySQL говорит: «Ну, я не узнаю символы, из которых состоит этот смайлик. Извините, я ничего не могу здесь сделать» — в этот момент вам может быть интересно, что делается для решения такой проблемы? MySQL вообще знает о его существовании? Действительно, было бы ложью сказать, что MySQL не знает об этой проблеме — скорее, они знают, но разработчики MySQL так и не удосужились ее исправить. Вместо этого они выпустили обходной путь более десяти лет назад вместе с MySQL 5.5.3.
Вместо этого они выпустили обходной путь более десяти лет назад вместе с MySQL 5.5.3.
Этот обходной путь называется «utf8mb4». utf8mb4 почти такой же, как и его более старый аналог — utf8 — просто в кодировке используется от одного до четырех байтов на символ, что по сути означает, что он может поддерживать более широкий спектр символов и символов.
Используйте MySQL 8.0, немного поработайте с данными, и вы быстро заметите, что действительно utf8mb4 является набором символов по умолчанию, доступным в MySQL — более того, предполагается, что в ближайшем будущем utf8mb4 станет ссылкой на стандарт utf8 в MySQL.
Варианты utf8mb4
Поскольку время идет, и utf8 опережает utf8mb4 почти по всем фронтам, естественно, что есть несколько вариантов сортировки, которые можно использовать. По сути, эти сопоставления действуют как своего рода «набор» правил сортировки, разработанных для лучшего соответствия конкретным наборам данных. utf8mb4 также имеет пару:
-
utf8mb4_general_ciориентирован на более «общее» использование MySQL и utf8. Считается, что этот набор символов использует «ярлыки» для хранения данных, что в некоторых случаях может привести к ошибкам сортировки для повышения скорости.
Считается, что этот набор символов использует «ярлыки» для хранения данных, что в некоторых случаях может привести к ошибкам сортировки для повышения скорости. -
utf8mb4_unicode_ciпредназначен для «продвинутых» пользователей, то есть это набор сопоставлений, основанный на Unicode, и мы можем быть уверены, что наши данные будут обработаны должным образом, если это сопоставление используется.
В этом случае обратите внимание на окончание « _ci » в направлении сопоставления: это означает «без учета регистра». Нечувствительность к регистру связана с сортировкой и сравнением.
Эти два «разновидности» utf8mb4 используются все чаще и чаще — по мере выпуска новых версий MySQL мы также можем видеть, что 9Сопоставление 0026 utf8mb4_unicode_ci является предпочтительным для большинства людей, работающих с MySQL сегодня. Одно можно сказать наверняка — не все люди, использующие MySQL таким образом, знают о функциональных возможностях и преимуществах, предоставляемых utf8mb4 по сравнению с его аналогом utf8, но они, безусловно, увидят разницу, когда будут импортировать данные с необычными символами! Мы уже убедили вас перейти в царство utf8mb4?
Правильная работа с данными на основе utf8mb4
Вот как некоторые разработчики создают базы данных и таблицы на основе utf8mb4:
Создание баз данных и таблиц с помощью ArctypeЗа исключением того, что этот запрос выдает нам ошибку (под запросом), которая часто сбивает с толку как начинающих, так и опытных разработчиков — MySQL, по сути, говорит, что когда мы используем сопоставление на основе utf8mb4, мы также должен использовать совместимый набор символов, и в этом случае latin1 недействителен, поэтому, что бы вы ни делали, помните об этих моментах:
- utf8mb4 не является настоящим utf8 в MySQL и его разновидностях (MariaDB и Percona Server) : utf8 поддерживает только 3 байта данных, utf8mb4 поддерживает 4 байта, что и должно делать utf8 в первую очередь.
 Если используется utf8, некоторые символы могут отображаться неправильно.
Если используется utf8, некоторые символы могут отображаться неправильно. - Когда мы решим использовать utf8mb4 вместо utf8 в MySQL, мы также должны убедиться, что используем соответствующий набор символов (utf8mb4). Обратите внимание на сообщение об успешном выполнении под запросом:
Теперь все готово — мы можем хранить все виды символов внутри нашей базы данных и не иметь ошибки MySQL с ошибкой «Неверное строковое значение»! Ууууу!
Сводка
UTF-8 в MySQL не работает — он не может поддерживать четыре байта на символ, как предполагается в UTF-8. «utf8mb4» можно использовать для решения этой проблемы, и, как правило, с ним довольно легко работать — просто выберите конкретную сортировку (в этом случае выберите либо общую, если вы используете MySQL для личного проекта или небольшого веб-сайта, либо Unicode). сопоставления, или если вы используете его для чего-то более технического, или если вы хотите довести MySQL до предела. )
)
Однако, прежде чем доводить MySQL до предела, имейте в виду, что помимо документации существует еще несколько блогов, таких как тот, который предоставляет Arctype, в которых содержится информация о том, как работать с системой управления реляционными базами данных и всеми ее разновидностями. . Мы рассказываем, как работать с MySQL и большими данными, как оптимизировать схемы вашей базы данных и многое другое!
Если вы занимаетесь базами данных, обязательно следите за блогом Arctype, позаботьтесь как о производительности, так и о безопасности экземпляров вашей базы данных, если вы беспокоитесь о безопасности данных, принадлежащих вам или компании. с которым вы работаете, обязательно запустите поиск через одну из крупнейших поисковых систем для взлома данных в мире — BreachDirectory — чтобы обеспечить вашу безопасность, и мы увидим вас в следующем!
пакет utf8 — unicode/utf8 — пакеты Go
Пакет utf8 реализует функции и константы для поддержки текста, закодированного в
УТФ-8. Он включает в себя функции для перевода между рунами и последовательностями байтов UTF-8.
См. https://en.wikipedia.org/wiki/UTF-8.
Он включает в себя функции для перевода между рунами и последовательностями байтов UTF-8.
См. https://en.wikipedia.org/wiki/UTF-8.
- Константы
- func AppendRune(p [] байт, r руна) [] байт
- func DecodeLastRune(p []byte) (r руна, размер int)
- func DecodeLastRuneInString(s string) (r руна, размер int)
- func DecodeRune(p []byte) (r руна, размер int)
- func DecodeRuneInString(s string) (r руна, размер int)
- func EncodeRune (p [] байт, r руна) целое число
- func FullRune(p []byte) bool
- func FullRuneInString(s string) bool
- func RuneCount(p []byte) int
- func RuneCountInString(s string) (n int)
- func RuneLen(r руна) int
- func RuneStart(b byte) bool
- func Valid(p []byte) bool
- func ValidRune(r руна) bool
- func ValidString(s string) bool
- AppendRune
- DecodeLastRune
- Декоделаструнеинстринг
- DecodeRune
- Декодерунинстринг
- EncodeRune
- Энкодруне (вне диапазона)
- FullRune
- FullRuneInString
- Счетчик рун
- Рунекаунтинстринг
- РунеЛен
- РунСтарт
- Действительный
- ValidRune
- Действительная строка
константа ( RuneError = '\uFFFD' // руна "ошибка" или "символ замены Unicode" RuneSelf = 0x80 // символы ниже RuneSelf представлены как сами собой в одном байте.MaxRune = '\U0010FFFF' // Максимально допустимая кодовая точка Unicode. UTFMax = 4 // максимальное количество байтов символа Unicode в кодировке UTF-8. )
Числа, лежащие в основе кодирования.
Этот раздел пуст.
func AppendRune(p []byte, r rune) []byte
AppendRune добавляет кодировку UTF-8 r к концу p и возвращает расширенный буфер. Если руна вне досягаемости, он добавляет кодировку RuneError.
Пример ¶
основной пакет
Импортировать (
"ФМТ"
"юникод/utf8"
)
основная функция () {
buf1:= utf8.AppendRune(ноль, 0x10000)
buf2:= utf8.AppendRune([]byte("init"), 0x10000)
fmt.Println (строка (buf1))
fmt.Println (строка (buf2))
}
Выход: 𐀀 инициировать𐀀
func DecodeLastRune(p []byte) (r rune, size int)
DecodeLastRune распаковывает последнюю кодировку UTF-8 в p и возвращает руну и
его ширина в байтах. Если p пусто, возвращается (RuneError, 0). В противном случае, если
кодировка недействительна, он возвращает (RuneError, 1). Оба невозможны
результаты для правильного, непустого UTF-8.
Оба невозможны
результаты для правильного, непустого UTF-8.
Кодировка недействительна, если она неверна UTF-8, кодирует руну, которая вне допустимого диапазона или не является самой короткой кодировкой UTF-8 для ценить. Никакая другая проверка не выполняется.
основной пакет
Импортировать (
"ФМТ"
"юникод/utf8"
)
основная функция () {
b := []byte("Привет, 世界")
для len(b) > 0 {
г, размер := utf8.DecodeLastRune(b)
fmt.Printf("%c %v\n", r, размер)
b = b[:len(b)-размер]
}
}
Выход: № 3 № 3 1 , 1 о 1 л 1 л 1 е 1 Н 1
func DecodeLastRuneInString(s string) (r rune, size int)
DecodeLastRuneInString аналогичен DecodeLastRuneInString, но его вводом является строка. Если s пуст, он возвращает (RuneError, 0). В противном случае, если кодировка недействительна, он возвращает (RuneError, 1). Оба результата невозможны для правильного, непустой UTF-8.
Кодировка недействительна, если она неверна UTF-8, кодирует руну, которая
вне допустимого диапазона или не является самой короткой кодировкой UTF-8 для
ценить. Никакая другая проверка не выполняется.
Никакая другая проверка не выполняется.
основной пакет
Импортировать (
"ФМТ"
"юникод/utf8"
)
основная функция () {
str := "Привет, 世界"
для len(str) > 0 {
г, размер: = utf8.DecodeLastRuneInString (строка)
fmt.Printf("%c %v\n", r, размер)
str = str[:len(str)-size]
}
}
Выход: № 3 № 3 1 , 1 о 1 л 1 л 1 е 1 Н 1
func DecodeRune(p []byte) (r rune, size int)
DecodeRune распаковывает первую кодировку UTF-8 в p и возвращает руну и его ширина в байтах. Если p пусто, возвращается (RuneError, 0). В противном случае, если кодировка недействительна, он возвращает (RuneError, 1). Оба невозможны результаты для правильного, непустого UTF-8.
Кодировка недействительна, если она неверна UTF-8, кодирует руну, которая вне допустимого диапазона или не является самой короткой кодировкой UTF-8 для ценить. Никакая другая проверка не выполняется.
Пример ¶
основной пакет
Импортировать (
"ФМТ"
"юникод/utf8"
)
основная функция () {
b := []byte("Привет, 世界")
для len(b) > 0 {
г, размер := utf8.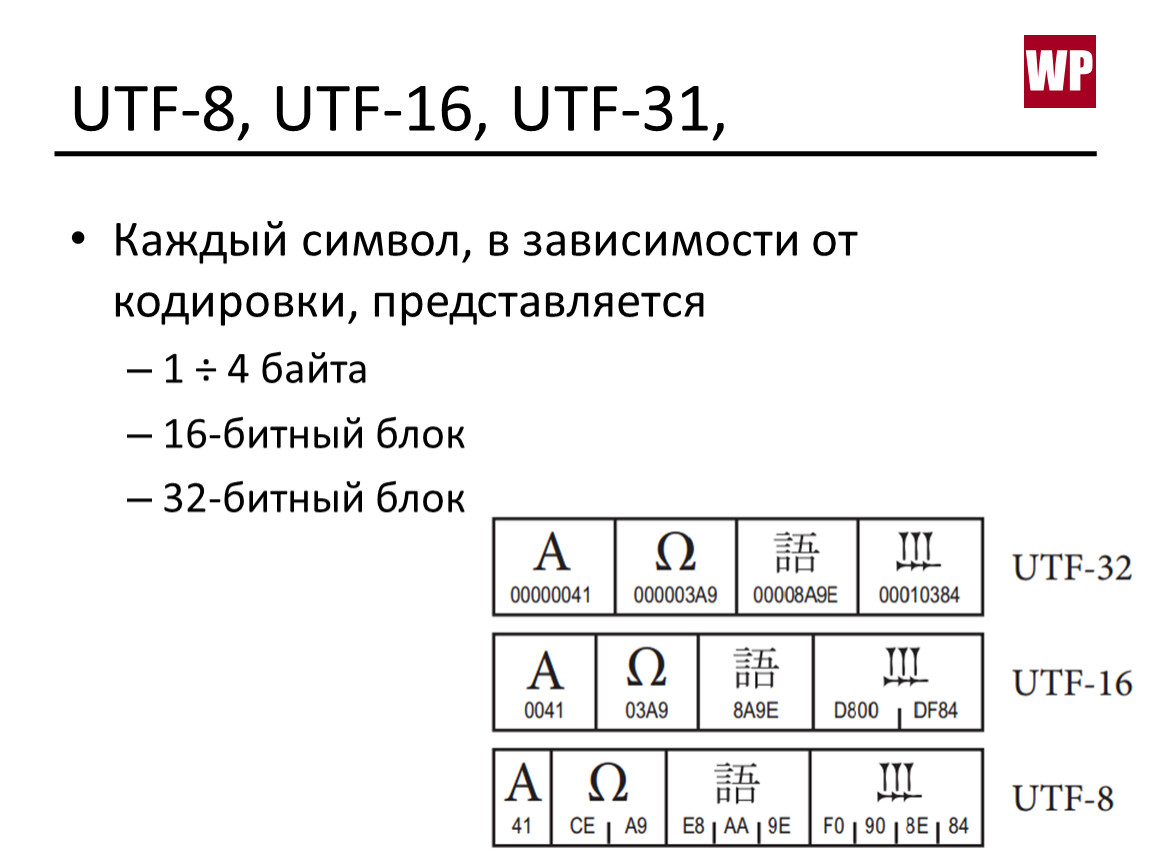
DecodeRune(b)
fmt.Printf("%c %v\n", r, размер)
б = б[размер:]
}
}
Выход: Н 1 е 1 л 1 л 1 о 1 , 1 1 № 3 № 3
func DecodeRuneInString(s string) (r rune, size int)
DecodeRuneInString аналогичен DecodeRune, но его вводом является строка. Если с возвращается пустой (RuneError, 0). В противном случае, если кодировка недействительна, она возвращает (RuneError, 1). Оба результата невозможны для правильного, непустого УТФ-8.
Кодировка недействительна, если она неверна UTF-8, кодирует руну, которая вне допустимого диапазона или не является самой короткой кодировкой UTF-8 для ценить. Никакая другая проверка не выполняется.
Пример ¶
основной пакет
Импортировать (
"ФМТ"
"юникод/utf8"
)
основная функция () {
str := "Привет, 世界"
для len(str) > 0 {
г, размер: = utf8.DecodeRuneInString (строка)
fmt.Printf("%c %v\n", r, размер)
ул = ул[размер:]
}
}
Выход: Н 1 е 1 л 1 л 1 о 1 , 1 1 № 3 № 3
func EncodeRune(p []byte, r rune) int
EncodeRune записывает в p (который должен быть достаточно большим) кодировку руны UTF-8. Если руна вне диапазона, пишет кодировку RuneError.
Возвращает количество записанных байтов.
Если руна вне диапазона, пишет кодировку RuneError.
Возвращает количество записанных байтов.
основной пакет
Импортировать (
"ФМТ"
"юникод/utf8"
)
основная функция () {
г: = '世'
буфер := сделать ([] байт, 3)
n := utf8.EncodeRune(buf, r)
fmt.Println(buf)
fmt.Println(n)
}
Выход: [228 184 150] 3Пример (вне диапазона) ¶
основной пакет
Импортировать (
"ФМТ"
"юникод/utf8"
)
основная функция () {
руны := []руна{
// Меньше 0, вне диапазона.
-1,
// Больше 0x10FFFF, вне допустимого диапазона.
0x110000,
// Символ замены Unicode.
utf8.RuneError,
}
для i, c := диапазон рун {
буфер := сделать ([] байт, 3)
размер: = utf8.EncodeRune (buf, c)
fmt.Printf("%d: %d %[2]s %d\n", i, buf, размер)
}
}
Выход: 0: [239 191 189] � 3 1: [239 191 189] � 3 2: [239 191 189] � 3
func FullRune(p []byte) bool
FullRune сообщает, начинаются ли байты в p с полной кодировки руны UTF-8.
Недопустимая кодировка считается полной руной, поскольку она будет преобразована в руну ошибки ширины 1.
основной пакет
Импортировать (
"ФМТ"
"юникод/utf8"
)
основная функция () {
buf := []byte{228, 184, 150} // 世
fmt.Println(utf8.FullRune(buf))
fmt.Println(utf8.FullRune(buf[:2]))
}
Выход: истинный ЛОЖЬ
func FullRuneInString(s string) bool
FullRuneInString аналогичен FullRune, но его вводом является строка.
Пример ¶
основной пакет
Импортировать (
"ФМТ"
"юникод/utf8"
)
основная функция () {
ул := "世"
fmt.Println(utf8.FullRuneInString(str))
fmt.Println(utf8.FullRuneInString(str[:2]))
}
Выход: истинный ЛОЖЬ
func RuneCount(p []byte) int
RuneCount возвращает количество рун в p. Ошибочный и короткий кодировки рассматриваются как одиночные руны шириной 1 байт.
Пример ¶
основной пакет
Импортировать (
"ФМТ"
"юникод/utf8"
)
основная функция () {
buf := []byte("Привет, 世界")
fmt.Println ("байты =", длина (buf))
fmt.Println("руны =", utf8.RuneCount(buf))
}
Выход: байт = 13 руны = 9
func RuneCountInString(s string) (n int)
RuneCountInString похож на RuneCount, но на входе есть строка.
основной пакет
Импортировать (
"ФМТ"
"юникод/utf8"
)
основная функция () {
str := "Привет, 世界"
fmt.Println("байты =", len(str))
fmt.Println("руны =", utf8.RuneCountInString(str))
}
Выход: байт = 13 руны = 9
func RuneLen(r rune) int
RuneLen возвращает количество байтов, необходимых для кодирования руны. Он возвращает -1, если руна не является допустимым значением для кодирования в UTF-8.
Пример ¶
основной пакет
Импортировать (
"ФМТ"
"юникод/utf8"
)
основная функция () {
fmt.Println(utf8.RuneLen('a'))
fmt.Println(utf8.RuneLen('界'))
}
Выход: 1 3
func RuneStart(b byte) bool
RuneStart сообщает, может ли байт быть первым байтом закодированного, возможно неверная руна. Второй и последующие байты всегда имеют два старших бит установлен на 10.
Пример ¶ основной пакет
Импортировать (
"ФМТ"
"юникод/utf8"
)
основная функция () {
buf := []байт("a界")
fmt.Println(utf8.RuneStart(buf[0]))
fmt.