USE (Transact-SQL) — SQL Server
- Чтение занимает 2 мин
В этой статье
Применимо к: SQL Server (все поддерживаемые версии) Управляемый экземпляр SQL Azure Параллельное хранилище данных
Изменяет контекст базы данных на указанную базу данных или моментальный снимок базы данных в SQL Server.
Синтаксические обозначения в Transact-SQL
Синтаксис
USE { database_name }
[;]
Аргументы
database_name
Имя базы данных или моментального снимка базы данных, на который переключается контекст пользователя. Имена баз данных и моментальных снимков базы данных должны соответствовать правилам построения идентификаторов.
В База данных SQL Azure параметр базы данных может ссылаться только на текущую базу данных. Если указана база данных, отличная от текущей, инструкция USE не переключается между базами данных и возвращается код ошибки 40508. Для смены базы данных следует непосредственно подключиться к базе данных. В верхней части этой страницы инструкция USE помечена как неприменимая к базе данных SQL, поскольку даже если инструкция USEвходит в состав пакета, она не выполняет никаких действий.
Примечания
При подключении имени входа SQL Server к SQL Server имя входа автоматически подключается к базе данных по умолчанию и получает контекст безопасности пользователя базы данных. Если для имени входа SQL Server пользователь базы данных не был создан, имя входа подключается как «гость». Если пользователь базы данных не имеет разрешения CONNECT на базу данных, инструкция USE завершится ошибкой. Если с именем входа не была связана никакая база данных по умолчанию, то для него базой данных по умолчанию будет установлена база данных master.
Инструкция USE выполняется как на стадии компиляции, так и на стадии выполнения и вступает в силу немедленно. Иными словами, инструкции, которые содержатся в пакете после инструкции USE, будут выполнены в контексте указанной базы данных.
Разрешения
Необходимо разрешение CONNECT на целевую базу данных.
Примеры
В следующем примере выполняется смена контекста на базу данных AdventureWorks2012.
USE AdventureWorks2012;
GO
См. также:
CREATE LOGIN (Transact-SQL)
CREATE USER (Transact-SQL)
Участники (ядро СУБД)
CREATE DATABASE (SQL Server Transact-SQL)
EXECUTE (Transact-SQL)
Как изменить контекст базы данных в Microsoft SQL Server? Команда USE | Info-Comp.ru
Привет, в этой небольшой заметке я расскажу начинающим программистам и администраторам Microsoft SQL Server о достаточно простом действии, о том, как изменяется контекст базы данных в SQL инструкциях, также я покажу, как это можно сделать в графической среде SQL Server Management Studio.
Если Вы обслуживаете или будете обслуживать несколько баз данных на одном экземпляре SQL Server, то, скорей всего, Вам придётся в своих SQL инструкциях менять контекст подключения к базе данных. Лично я Вам рекомендую во всех своих инструкциях (если у Вас несколько баз данных) принудительно указывать контекст базы данных, иными словами, к какой базе данных относится та или иная SQL инструкция.
В Microsoft SQL Server это делается с помощью команды USE.
Команда USE в T-SQL
USE – команда, с помощью которой можно переключать контекст базы данных в SQL инструкциях. В качестве параметра данной команде необходимо просто передать название базы данных, в контексте которой Вам необходимо выполнить SQL инструкцию.
Следует отметить, что для того чтобы использовать команду USE, у Вас должны быть соответствующие права, а именно: разрешение CONNECT на целевую базу данных, т.е. Вы имеете право подключаться к этой базе данных.
Когда Вы подключаетесь к SQL серверу, Ваш контекст настроен на базу данных по умолчанию, если Вы или администратор Вам не указал такую базу данных для имени входа, то по умолчанию Вы будете подключаться к базе master.
Пример использования команды USE
В качестве примера давайте напишем простую инструкцию, в которой мы подключимся к базе данных TestDB, выполним тестовый запрос (
USE TestDB GO --Инструкции для базы данных TestDB SELECT DB_NAME() AS [Имя базы данных] USE master GO --Инструкции для базы данных master SELECT DB_NAME() AS [Имя базы данных]
Меняем контекст базы данных с помощью Management Studio
Посмотреть, к какой базе данных Вы подключены в данный момент, а также переключить контекст на другую базу данных, Вы можете в среде SQL Server Management Studio.
Данный функционал расположен на панели редактора SQL запросов.
Как сменить контекст подключения к базе данных, мы с Вами рассмотрели, однако мне хотелось бы еще отметить то, что Microsoft SQL Server позволяет в SQL инструкциях обращаться к объектам, которые расположены в разных базах данных на одном экземпляре SQL сервера. Иными словами, не меняя контекст подключения, мы, например, можем запросить данные из таблицы, которая расположена в другой базе данных, вызвать хранимую процедуру или функцию.
Это делается с помощью указания полного четырехсоставного имени объекта, только имя сервера можно не указывать.
Например, следующий запрос выполнится успешно, и мы получим данные из таблицы TestTable, хотя, как Вы понимаете, таблицы TestTable в базе данных master нет (именно на ней будет контекст выполнения).
USE master GO SELECT * FROM TestDB.dbo.TestTable
Где:
- TestDB – имя базы данных;
- dbo –имя схемы;
- TestTable – имя таблицы.

Заметка!
Начинающим рекомендую посмотреть мои видеокурсы по T-SQL, с помощью которых Вы «с нуля» научитесь работать с SQL и программировать на T-SQL.
У меня на этом все, удачи!
Нравится3Не нравитсяПредприятие 8 (устаревшая) по лучшей цене
Описание товара
Основные характеристики
Производитель
Доставим за 1-2 дня
Количество лицензий:
Физическая поставка
Коммерческой организации, Образовательного учреждения, Государственного учреждения
Артикул производителя
Право на использование Лицензия «на ядро» MS SQL Srv 2014 Std Full-use Core (до 4 ядер) для польз. 1С: Предприятие 8
1С: Предприятие 8
Срок действия лицензии
Лицензии Full-use — это лицензии без ограничения на право использования. Пользователь, у которого есть лицензии «1С:Предприятие 8», может использовать Microsoft SQL Server с другими приложениями, помимо «1С:Предприятие 8».
Пользователь, у которого есть лицензии «1С:Предприятие 8», может использовать Microsoft SQL Server с другими приложениями, помимо «1С:Предприятие 8».
SQL Server Tutorial
Добро пожаловать на веб-сайт SQLServerTutorial.Net!
Если вы ищете простой, быстрый и эффективный способ освоить SQL Server, вы попали в нужное место.
Наши учебные пособия по SQL Server носят практический характер и включают в себя многочисленные практические занятия.
После изучения всех руководств вы сможете:
SQL Server — это система управления реляционными базами данных (СУБД), разработанная и продаваемая Microsoft. Как сервер базы данных, основная функция SQL Server заключается в хранении и извлечении данных, используемых другими приложениями.
Начало работы с SQL Server
Этот раздел поможет вам быстро начать работу с SQL Server. По завершении этого раздела вы получите хорошее представление о SQL Server и узнаете, как установить SQL Server Developer Edition для практики.
Основы SQL Server
В разделе «Основы SQL-сервера» показано, как использовать Transact-SQL (T-SQL) для взаимодействия с базами данных SQL Server. Вы узнаете, как управлять данными из базы данных, например запрашивать, вставлять, обновлять и удалять данные.
Представления SQL Server
В этом разделе представлены представления SQL Server и обсуждаются преимущества и недостатки представлений базы данных. Вы узнаете все, что вам нужно знать, чтобы эффективно управлять представлениями в SQL Server.
Индексы SQL Server
В этом разделе вы узнаете все, что вам нужно знать об индексах SQL Server, чтобы разработать хорошую стратегию индексации и оптимизировать запросы.
Хранимые процедуры SQL Server
В этом разделе представлены хранимые процедуры SQL Server.После изучения раздела вы сможете разрабатывать сложные хранимые процедуры с использованием конструкций Transact-SQL.
Пользовательские функции SQL Server
В этом разделе вы узнаете о пользовательских функциях SQL Server, включая функции со скалярными значениями и функции с табличными значениями, чтобы упростить разработку.
Триггеры SQL Server
Триггеры SQL Server — это специальные хранимые процедуры, которые автоматически выполняются в ответ на события объекта базы данных, базы данных и сервера.
Функции SQL Server
В этом разделе представлены часто используемые функции SQL Server, включая агрегатные функции, функции даты, строковые функции, системные функции и оконные функции.
Агрегатные функции SQL Server
Это руководство знакомит вас с агрегатными функциями SQL Server и показывает, как их использовать для вычисления агрегатов.
Функции даты SQL Server
На этой странице перечислены наиболее часто используемые функции даты SQL Server, которые позволяют эффективно обрабатывать дату и время.
Строковые функции SQL Server
Это руководство предоставляет множество полезных строковых функций SQL Server, которые позволяют эффективно управлять символьной строкой.
Системные функции SQL Server
На этой странице представлены часто используемые системные функции в SQL Server, которые возвращают объекты, значения и настройки в SQL Server.
Функции окна SQL Server
Функции окна SQL Server вычисляют совокупное значение на основе группы строк и возвращают несколько строк для каждой группы.
SQL: что это?
Язык структурированных запросов, широко известный как SQL, является стандартным языком программирования для реляционных баз данных. Несмотря на то, что он старше многих других типов кода, это наиболее широко используемый язык баз данных.
Поскольку SQL настолько распространен, знание его важно для всех, кто занимается компьютерным программированием или использует базы данных для сбора и организации информации. Узнайте больше о том, что такое SQL, и о возможностях карьерного роста в этой области.
Что такое SQL?
SQL можно использовать для совместного использования и управления данными, особенно данными, которые находятся в системах управления реляционными базами данных, которые включают данные, организованные в таблицы.Несколько файлов, каждый из которых содержит таблицы данных, также могут быть связаны общим полем. Используя SQL, вы можете запрашивать, обновлять и реорганизовывать данные, а также создавать и изменять схему (структуру) системы баз данных и контролировать доступ к ее данным.
Используя SQL, вы можете запрашивать, обновлять и реорганизовывать данные, а также создавать и изменять схему (структуру) системы баз данных и контролировать доступ к ее данным.
В электронную таблицу, такую как Microsoft Excel, можно скомпилировать много информации, но SQL предназначен для компиляции и управления данными в гораздо больших объемах. В то время как электронные таблицы могут стать громоздкими из-за слишком большого количества информации, базы данных SQL могут обрабатывать миллионы или даже миллиарды ячеек данных.
Используя SQL, вы можете хранить данные о каждом клиенте, с которым когда-либо работал ваш бизнес, от основных контактов до сведений о продажах. Так, например, если вы хотите найти каждого клиента, который потратил не менее 5000 долларов на ваш бизнес за последнее десятилетие, база данных SQL могла бы получить эту информацию для вас мгновенно.
Как работает изучение SQL
Язык структурированных запросов более простой, чем другие более сложные языки программирования.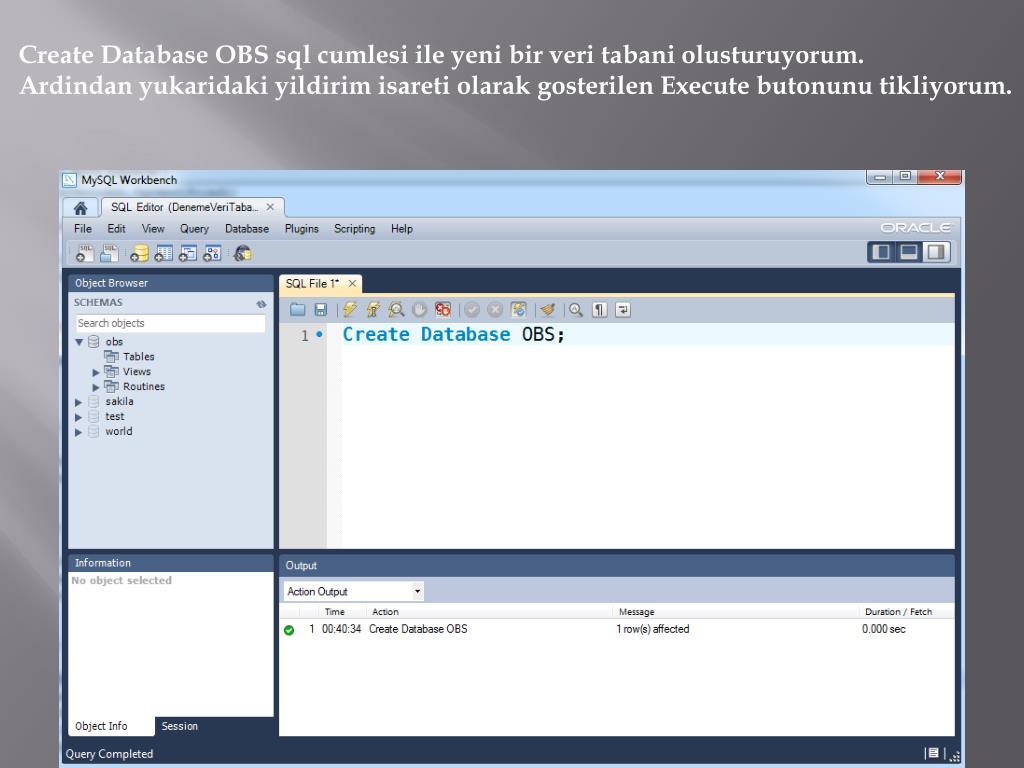 Как правило, новичкам легче изучить SQL, чем им освоить такие языки, как Java, C ++, PHP или C #.
Как правило, новичкам легче изучить SQL, чем им освоить такие языки, как Java, C ++, PHP или C #.
Некоторые онлайн-ресурсы, включая бесплатные учебные пособия и платные курсы дистанционного обучения, доступны для тех, у кого мало опыта программирования, но которые хотят изучить SQL. Официальные курсы университета или колледжа также обеспечат более глубокое понимание языка.
История SQL
История SQL насчитывает более полувека. В 1969 году исследователь IBM Эдгар Ф. Кодд определил модель реляционной базы данных, которая стала основой для разработки языка SQL.Эта модель построена на общих порциях информации (или «ключах»), связанных с различными данными. Например, имя пользователя может быть связано с фактическим именем и номером телефона.
Несколько лет спустя IBM начала работу над новым языком для систем управления реляционными базами данных, основанным на выводах Кодда. Первоначально этот язык назывался SEQUEL, или язык структурированных английских запросов.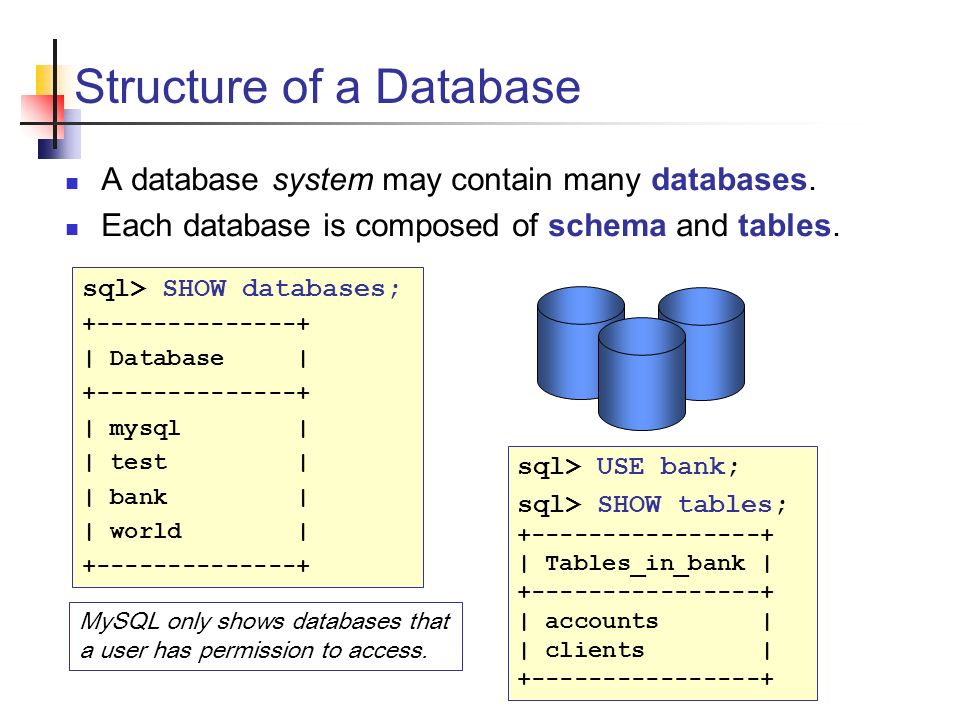 Названный System R, проект претерпел несколько реализаций и изменений, и название языка менялось несколько раз, прежде чем окончательно перейти на SQL.
Названный System R, проект претерпел несколько реализаций и изменений, и название языка менялось несколько раз, прежде чем окончательно перейти на SQL.
После начала тестирования в 1978 году IBM приступила к разработке коммерческих продуктов, включая SQL / DS (1981) и DB2 (1983). Другие производители последовали их примеру, объявив о своих собственных коммерческих предложениях на основе SQL. К ним относятся Oracle, выпустившая свой первый продукт в 1979 году, а также Sybase и Ingres.
SQL в действии: MySQL
Обычное программное обеспечение, используемое для серверов SQL, включает MySQL Oracle, возможно, самую популярную программу для управления базами данных SQL. MySQL — это программное обеспечение с открытым исходным кодом, что означает, что его можно использовать бесплатно и важно для веб-разработчиков, потому что большая часть Интернета и очень много приложений построены на базах данных.
Рассмотрим музыкальную программу, такую как iTunes, которая хранит музыку по исполнителям, песням, альбомам, спискам воспроизведения и т. Д. Как пользователь, вы можете искать музыку по любому из этих и других параметров, чтобы найти то, что ищете. Чтобы создать подобное приложение, вам понадобится программное обеспечение для управления вашей базой данных SQL, и это то, что делает MySQL.
Д. Как пользователь, вы можете искать музыку по любому из этих и других параметров, чтобы найти то, что ищете. Чтобы создать подобное приложение, вам понадобится программное обеспечение для управления вашей базой данных SQL, и это то, что делает MySQL.
Требуемые навыки SQL
Большинству организаций нужен кто-то со знанием SQL. Заработная плата на должностях, основанных на SQL, варьируется в зависимости от типа работы и опыта, но обычно выше среднего.
Некоторые должности, требующие навыков SQL, включают:
- Администратор базы данных (DBA ): это тот, кто специализируется на обеспечении правильного и эффективного хранения и управления данными. Базы данных наиболее ценны, когда они позволяют пользователям быстро и легко извлекать желаемые комбинации данных.
- Инженер по миграции баз данных : Этот человек специализируется на перемещении данных из различных баз данных на сервер SQL.
- Специалист по анализу данных : Эта должность очень похожа на должность аналитика данных, но перед специалистами по обработке данных обычно стоит задача обрабатывать данные в гораздо больших объемах и накапливать их с гораздо большей скоростью.

- Архитектор больших данных : Кто-то в этой роли создает продукты для обработки больших объемов данных.
Ключевые выводы
- Язык структурированных запросов (SQL) — стандартный и наиболее широко используемый язык программирования для реляционных баз данных.
- Он используется для управления и организации данных во всех видах систем, в которых существуют различные отношения данных.
- SQL — ценный язык программирования с хорошими карьерными перспективами.
SQL | Предложение WITH — GeeksforGeeks
Предложение SQL WITH было введено Oracle в базу данных Oracle 9i выпуска 2. Предложение SQL WITH позволяет дать блоку подзапроса имя (процесс, также называемый рефакторингом подзапроса), на которое можно ссылаться в нескольких местах в основном SQL-запросе.
- Предложение используется для определения временного отношения, так что выходные данные этого временного отношения доступны и используются запросом, связанным с предложением WITH.

- Запросы, связанные с предложением WITH, также могут быть написаны с использованием вложенных подзапросов, но это усложняет чтение / отладку SQL-запроса.
- Предложение WITH поддерживается не всеми системами баз данных.
- Имя, присвоенное подзапросу, обрабатывается так, как если бы оно было встроенным представлением или таблицей
- Предложение SQL WITH было введено Oracle в базу данных Oracle 9i выпуска 2.
Синтаксис:
С временной таблицей (среднее значение) как
(ВЫБРАТЬ СРЕД. (Attr1)
ИЗ таблицы)
ВЫБРАТЬ Attr1
Из таблицы
ГДЕ Таблица.Attr1> timeTable.averageValue;
В этом запросе предложение WITH используется для определения временного отношения временная таблица, имеющая только 1 атрибут averageValue. Среднее значение содержит среднее значение столбца Attr1, описанное в таблице отношений. Оператор SELECT, следующий за предложением WITH, будет создавать только те кортежи, в которых значение Attr1 в таблице отношений больше среднего значения, полученного из оператора предложения WITH.
Примечание: Когда выполняется запрос с предложением WITH, сначала оценивается запрос, упомянутый в предложении, и результат этой оценки сохраняется во временном отношении.После этого, наконец, выполняется основной запрос, связанный с предложением WITH, который будет использовать созданное временное отношение.
Запросы
Пример 1: Найдите всех сотрудников, зарплата которых превышает среднюю зарплату всех сотрудников.
Имя отношения: Сотрудник
| Идентификатор сотрудника | Имя | Заработная плата | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100011 | Smith | 50000 | |||||||||||||||||||||||||
| 50000 | |||||||||||||||||||||||||||
| 9017 9017 | Сэм70550 | ||||||||||||||||||||||||||
| 100845 | Уолден | 80000 | |||||||||||||||||||||||||
| 115585 | Эрик | 60000 | |||||||||||||||||||||||||
| 1100070 | 1100070 | Кейт С временной таблицей (среднее значение) как
(ВЫБРАТЬ СРЕД. (Зарплата)
от сотрудника)
ВЫБЕРИТЕ EmployeeID, имя, зарплату
ОТ Сотрудника, временная таблица
ГДЕ Сотрудник.Заработная плата> временная таблица.среднее значение; (Зарплата)
от сотрудника)
ВЫБЕРИТЕ EmployeeID, имя, зарплату
ОТ Сотрудника, временная таблица
ГДЕ Сотрудник.Заработная плата> временная таблица.среднее значение; Выход :
Запрос SQL: С totalSalary (Авиакомпания, всего) как
(ВЫБЕРИТЕ авиакомпанию, сумма (Зарплата)
ОТ Пилота
ГРУППА ПО авиакомпаниям),
авиакомпанияAverage (avgSalary) как
(ВЫБРАТЬ СРЕД. Выход : Пояснение: Общая зарплата всех пилотов Airbus 380 = 298 830 и Boeing = 45000. Средняя зарплата всех пилотов в таблице Pilot = 57305. Так как только общая зарплата всех пилотов Airbus 380 превышает полученную среднюю зарплату, поэтому Airbus 380 находится в производственном соотношении. Важные моменты:
Автор статьи: Mayank Kumar . Если вам нравится GeeksforGeeks и вы хотели бы внести свой вклад, вы также можете написать статью, используя write. Пожалуйста, напишите комментарии, если вы обнаружите что-то неправильное, или если вы хотите поделиться дополнительной информацией по теме, обсуждаемой выше. Вниманию читателя! Не прекращайте учиться сейчас. Получите все важные концепции теории CS для собеседований SDE с курсом CS Theory Course по приемлемой для студентов цене и будьте готовы к работе в отрасли. Как запрашивать данные с помощью инструкции SELECT в SQL ServerОператор SELECT в SQL является наиболее часто используемым из операторов DML и используется для выборки данных из таблиц в SQL Server. Эта статья предназначена для администраторов баз данных и разработчиков, которые хотят познакомиться со всеми основными компонентами оператора SELECT и его сутью. Введение в SELECT Синтаксис оператора SELECT может быть довольно сложным, но давайте кратко рассмотрим некоторые из основных ключевых слов, используемых в операторе SELECT, а затем мы перейдем к SQL Server Management Studio, чтобы увидеть, как можно резюмировать основные предложения в код. SELECT в SQLИтак, SELECT просто начинает оператор, и за ним, вероятно, следует звездочка (*) AKA «splat». Это в основном означает получение всех столбцов из таблицы.Если есть несколько таблиц, из которых мы выбираем, звездочка выберет все столбцы из всех таблиц, например. при объединении двух и более таблиц. Однако желательно НЕ выбирать все из таблиц. «Почему?» это отдельная тема. Скажем так, минусов гораздо больше, чем плюсов, которые можно найти в Интернете с помощью простого исследования. Поэтому старайтесь не выделять все, а используйте определенные имена столбцов с запятыми, которые вернут только столбцы в зависимости от того, что находится в списке. Более того, очень часто, когда нет списка столбцов, у нас есть ключевое слово TOP, за которым следует число (n) после оператора SELECT в SQL, который возвращает первые (n) записи из таблицы. Обычно это используется с предложением ORDER BY, потому что, например, если мы хотим получить десятку лучших продаж по количеству, это могут быть большие числа. ИЗЧасть FROM оператора SELECT в SQL просто используется для указания SQL Server, из какой таблицы следует выбирать данные. JOIN используется, когда мы хотим получить данные из нескольких таблиц. Есть три разных типа объединений:
ГДЕПредложение WHERE действует как фильтр для списка данных, возвращаемых из таблиц. Мы можем отфильтровать один или несколько столбцов, что повлияет на данные в наборе результатов. ГРУППА ПОПредложение GROUP BY связано с агрегатами. Если мы хотим сделать что-то вроде SUM, AVERAGE, MIN, MAX и т. Д., Это все агрегатные функции, а GROUP BY позволяет нам объединять идентичные данные в группы.В дополнение к этому у нас также есть предложение HAVING, которое в значительной степени является предложением WHERE для групп. Это позволяет нам применять фильтры к группам. ПримерыВыше приведен краткий обзор оператора SELECT в SQL. Давайте запустим SQL Server Management Studio и посмотрим, как мы можем использовать некоторые из этих вещей. Во всех следующих примерах используется образец базы данных AdventureWorks2012 . Этот первый пример настолько прост, насколько он получает и возвращает все строки и столбцы с использованием (*) из таблицы Product : ВЫБРАТЬ * ОТ ПРОИЗВОДСТВА. Набор результатов заполняется всеми столбцами из таблицы Product . Список довольно длинный, всего 25 столбцов, которые можно увидеть при прокрутке вправо: Чтобы выбрать определенные столбцы из таблицы, просто перечислите имена столбцов с запятыми: ВЫБРАТЬ Product.ProductID ,Наименование товара , Product.ProductNumber , Product.MakeFlag , Product.FinishedGoodsFlag ОТ ПРОИЗВОДСТВА.Продукт; На этот раз возвращается только подмножество столбцов: Мы могли бы добавить предложение WHERE , как показано ниже, чтобы выбрать определенные столбцы из таблицы с фильтром: ВЫБРАТЬ Product.ProductID ,Наименование товара , Product.ProductNumber , Product.MakeFlag , Product.FinishedGoodsFlag ОТ ПРОИЗВОДСТВА. ГДЕ Product.Name НРАВИТСЯ "Mountain%"; Обратите внимание, что мы используем оператор LIKE в предложении WHERE , и поэтому мы должны указать подстановочный знак.В этом примере ключевое слово LIKE говорит найти все, что начинается с «Гора», и после этого это может быть что угодно: Использование регулярных выражений может быть более полезным, чем указание равенства строк, и позволяет расширенный поиск и манипуляции с текстом. Перейдем к запросам данных с помощью объединений. Это позволяет нам объединять данные из двух или более таблиц в общих столбцах. Помните, что SQL Server выполняет INNER JOIN , если указано только ключевое слово JOIN . Следующий запрос возвращает все названия продуктов и идентификаторы заказов на продажу из двух таблиц и объединяет их в общем столбце ProductID : ВЫБЕРИТЕ p.Name
, sod.SalesOrderID
ИЗ ПРОИЗВОДСТВА.
ПРИСОЕДИНЯЙТЕСЬ к Sales.SalesOrderDetail sod НА p.ProductID = sod.ProductID; Мы также можем вернуть все данные из обеих таблиц, просто поставив звездочку. Это не видно на снимке ниже, но набор результатов заполняется данными из таблицы Product , за которыми следуют данные таблицы SalesOrderDetail : ВЫБРАТЬ *
ОТ ПРОИЗВОДСТВА.Продукт p
ПРИСОЕДИНЯЙТЕСЬ к Sales.SalesOrderDetail sod НА p.ProductID = sod.ProductID; Если мы хотим вернуть данные только из таблицы Product , добавьте «p». перед значком, как показано ниже: ВЫБРАТЬ стр. *
ИЗ ПРОИЗВОДСТВА.
ПРИСОЕДИНЯЙТЕСЬ к Sales.SalesOrderDetail sod НА p.ProductID = sod.ProductID; Эти небольшие выделенные элементы в запросе называются псевдонимами. Они полезны, когда у нас длинные имена таблиц, делающие код более читаемым и понятным.Псевдонимы также необходимы для баз данных с именами схем, таких как этот образец базы данных AdventureWorks2012 : Например, рассмотрите возможность синтаксического анализа следующего запроса и посмотрите, что произойдет: ВЫБРАТЬ ID продукта
,Имя
ИЗ ПРОИЗВОДСТВА.
ПРИСОЕДИНЯЙТЕСЬ к Sales.SalesOrderDetail sod НА p.ProductID = sod.ProductID; В наборе результатов написано: «Команды выполнены успешно», так что все должно работать нормально, не так ли? Не совсем так.Если мы запустим запрос, мы получим сообщение об ошибке «Неоднозначное имя столбца« ProductID »». как показано ниже, даже если синтаксис правильный: Это в основном означает, что два столбца имеют одинаковое имя столбца ProductID . SQL Server не понимает, какой ProductID из двух разных таблиц, о которых мы говорим. Если мы добавим псевдоним, чтобы указать, из какой таблицы следует извлекать столбец, запрос будет выполняться нормально: ВЫБРАТЬ стр.Идантификационный номер продукта ,
Имя
ИЗ ПРОИЗВОДСТВА.
ПРИСОЕДИНЯЙТЕСЬ к Sales.SalesOrderDetail sod НА p.ProductID = sod.ProductID; Давайте продолжим и посмотрим на инструкцию SELECT в SQL, использующую левое внешнее соединение. Этот тип соединения извлекает все из левой таблицы и только те записи, которые совпадают в правой таблице: ВЫБЕРИТЕ p.Name
, sod.SalesOrderID
ИЗ ПРОИЗВОДСТВА.
ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ к Sales.SalesOrderDetail sod НА p.ProductID = sod.Идантификационный номер продукта
ЗАКАЗАТЬ ПО ИМЕНИ; В этом примере он объединяет две таблицы в столбце ProductID и извлекает каждый продукт, независимо от того, продается он или нет, и сохраняет несопоставленные строки из левой таблицы: Действительно ли нам нужен пример оператора SELECT в SQL с использованием правого внешнего соединения? Мы упоминали ранее, что это полная противоположность. Но все же давайте посмотрим на пример: ВЫБРАТЬ ул. Имя КАК Территория
, sp.BusinessEntityID
ОТ Продажи.ПродажаТерритория ул.
ПРАВО ПРИСОЕДИНЯЙТЕСЬ к Sales.SalesPerson sp НА st.TerritoryID = sp.TerritoryID; На этот раз он объединяет две таблицы в столбце TerritoryID и извлекает все из правой таблицы и только те записи, которые совпадают в левой таблице. В результирующем наборе появляются все продавцы, независимо от того, назначена ли им территория или нет: Запрос данных с использованием стороннего расширенияЭто известный факт, что никто не любит писать и читать кучу беспорядочного, неформатированного текста.Когда дело доходит до написания сложного кода SQL, эта проблема может стать еще более сложной. Для беспрепятственного выполнения запросов к данным и написания кода SQL требуются годы практики и опыта. К счастью, есть более простой способ запроса данных с помощью оператора SELECT в SQL Server. В этом разделе мы рассмотрим сторонний инструмент, который поможет нам легко писать код SQL. Как часть набора инструментов ApexSQL Fundamentals Toolkit для SQL Server, расширение ApexSQL Complete для SSMS и VS — это хорошо известный инструмент повышения производительности, который ускоряет написание кода SQL за счет автоматического выполнения операторов SQL, заполнения фрагментов кода SQL и т. Д. После установки полного расширения кода SQL на один или несколько хостов оно подавит встроенный Microsoft IntelliSense и возьмет на себя завершение кода. Хватит разговоров, давайте рассмотрим новый запрос и посмотрим, как он работает. Начните с простого оператора SELECT в SQL Server, к которому вы подключены. Как только начинается набор текста, завершенный интеллектуальный код SQL показывает список подсказок с контекстно-зависимыми подсказками: Список подсказок предоставляет объекты (имя, тип, схема) на основе текущего содержимого запроса.Дважды щелкните или введите выделенный объект, и он будет вставлен, как показано ниже: ЕГЭ AdventureWorks2012 ИДТИ ВЫБРАТЬ * ИЗ ПРОДУКЦИИ. Изделие p Помните, насколько важны псевдонимы в некоторых случаях? Автозаполнение по умолчанию создает их автоматически. Если из списка подсказок выбрано длинное имя таблицы, она сгенерирует псевдоним, используя заглавные буквы имени объекта: SELECT * FROM Production.ProductModelProductDescriptionCulture pmpdc Если вам не нужны псевдонимы, вы можете отключить их, перейдя в Параметры > Вставки и сняв флажок «Автоматически создавать псевдонимы»: Если вам нужны псевдонимы, здесь вы также можете настроить поведение при их создании следующим образом: ВЫБРАТЬ * ИЗ ПРОИЗВОДСТВА.Продукт pro ВЫБРАТЬ * ОТ Person.Person P ВЫБРАТЬ * ОТ ЛИЦА КАК p Кроме того, вы можете вручную настроить глобальные псевдонимы на вкладке Псевдонимы окна Параметры . Здесь вам нужно указать сервер, базу данных, объект и псевдоним, как показано ниже: Глобальные псевдонимы имеют приоритет над автоматически сгенерированными, поэтому, если мы выполним еще один оператор SELECT в SQL Server, мы получим следующее: ВЫБРАТЬ * ИЗ ПРОИЗВОДСТВА.Продукт pp Двигаясь дальше, чтобы выбрать определенные столбцы из таблицы, удалите звездочку, и в списке подсказок будут показаны все доступные столбцы. Отсюда просто отметьте только необходимые, и они будут вставлены: Помните, как мы говорили ранее, что список подсказок зависит от контекста? Это означает, что с точки зрения синтаксиса завершенный код SQL будет перечислять допустимые предложения в своем списке подсказок. Если мы продолжим вводить предложение WHERE в приведенном выше примере, в нем будут перечислены соответствующие имена столбцов, ключевые слова и т. Д.: Автозаполнение не только заполнит ключевые слова и имена SQL, но также поможет вам писать сложные запросы, такие как операторы JOIN или запросы между базами данных:
ЗаключениеВ этой статье мы освежили нашу память о том, как запрашивать данные с помощью оператора SELECT в SQL Server. Мы начали с краткого введения и обзора всех основных компонентов, а затем перешли в SSMS и посмотрели, как написать все, от простого оператора SELECT в SQL до всех различных типов объединений. Затем мы рассмотрели расширение из набора инструментов ApexSQL Fundamentals Toolkit для SQL Server, ApexSQL Complete, которое сокращает набор текста за счет автоматического выполнения операторов SQL за нас. Кроме того, он автоматически вставляет полные имена объектов и псевдонимы на уровне сервера или базы данных. Этот инструмент предоставляет набор параметров, которые упрощают написание операторов SELECT на языке SQL. 4 января 2021 г.Что такое SQL (язык структурированных запросов)?SQL (язык структурированных запросов) — это стандартизированный язык программирования, который используется для управления реляционными базами данных и выполнения различных операций с данными в них.Первоначально созданный в 1970-х годах, SQL регулярно используется не только администраторами баз данных, но и разработчиками, пишущими сценарии интеграции данных, и аналитиками данных, которые хотят создавать и выполнять аналитические запросы. Использование SQL включает изменение таблиц базы данных и структур индексов; добавление, обновление и удаление строк данных; и получение подмножеств информации из базы данных для приложений обработки транзакций и аналитики. Запросы и другие операции SQL принимают форму команд, записанных в виде операторов — обычно используемые операторы SQL включают в себя выбор, добавление, вставку, обновление, удаление, создание, изменение и усечение. SQL стал де-факто стандартным языком программирования для реляционных баз данных после их появления в конце 1970-х — начале 1980-х годов. Реляционные системы, также известные как базы данных SQL, состоят из набора таблиц, содержащих данные в строках и столбцах. Каждый столбец в таблице соответствует категории данных, например имени или адресу клиента, в то время как каждая строка содержит значение данных для пересекающегося столбца. Стандартные и проприетарные расширения SQLОфициальный стандарт SQL был принят Американским национальным институтом стандартов (ANSI) в 1986 году, а затем Международной организацией по стандартизации, известной как ISO, в 1987 году.С тех пор двумя органами по разработке стандартов было выпущено более полдюжины совместных обновлений стандарта; на момент написания этой статьи самой последней версией является SQL: 2011, утвержденная в этом году.
Как проприетарные системы, так и системы управления реляционными базами данных с открытым исходным кодом, построенные на базе SQL, доступны для использования организациями. В их числе: Однако многие из этих продуктов баз данных поддерживают SQL с собственными расширениями стандартного языка для процедурного программирования и других функций.Например, Microsoft предлагает набор расширений под названием Transact-SQL (T-SQL), а расширенная версия стандарта Oracle — PL / SQL. В результате различные варианты SQL, предлагаемые поставщиками, не полностью совместимы друг с другом. Команды и синтаксис SQL КомандыSQL делятся на несколько различных типов, в том числе операторы языка обработки данных (DML) и языка определения данных (DDL), средства управления транзакциями и меры безопасности. Словарь DML используется для извлечения данных и управления ими, а операторы DDL предназначены для определения и изменения структур базы данных.Средства управления транзакциями помогают управлять обработкой транзакций, гарантируя, что транзакции будут либо завершены, либо откатаны в случае возникновения ошибок или проблем. Операторы безопасности используются для управления доступом к базе данных, а также для создания пользовательских ролей и разрешений. Синтаксис SQL — это формат кодирования, используемый при написании операторов. На рисунке 1 показан пример оператора DDL, написанного на языке Microsoft T-SQL для изменения таблицы базы данных в SQL Server 2016: . Рисунок 1. Пример кода T-SQL в SQL Server 2016.Это код для опции ALTER TABLE WITH (ONLINE = ON | OFF). Инструменты SQL-on-Hadoop Механизмы запросовSQL-on-Hadoop — это новое ответвление SQL, которое позволяет организациям с архитектурой больших данных, построенной на системах Hadoop, использовать его преимущества вместо того, чтобы использовать более сложные и менее знакомые языки, в частности, среду программирования MapReduce. для разработки приложений пакетной обработки. Более дюжины инструментов SQL-on-Hadoop стали доступны через поставщиков распространения Hadoop и других поставщиков; многие из них представляют собой программное обеспечение с открытым исходным кодом или коммерческие версии таких технологий.Кроме того, механизм обработки Apache Spark, который часто используется вместе с Hadoop, включает модуль Spark SQL, который аналогичным образом поддерживает программирование на основе SQL. В целом, SQL-on-Hadoop все еще является новой технологией, и большинство доступных инструментов не поддерживают все функции, предлагаемые в реляционных реализациях SQL. Но они становятся регулярным компонентом развертываний Hadoop, поскольку компании стремятся привлечь разработчиков и аналитиков данных с навыками SQL для программирования приложений для больших данных. Каковы наиболее частые применения SQL сегодня?Каковы наиболее частые применения SQL сегодня?Наибольшее применение сегодня языка структурированных запросов (SQL) связано с использованием давно устоявшегося традиционного языка для реляционных баз данных в новых корпоративных ИТ-средах, таких как облачные системы, виртуальные сети и т. Д. По сути, SQL — это используется для получения данных или иного взаимодействия с реляционной базой данных. В качестве стандарта, восходящего к 1970-м годам, SQL — это популярный способ получения информации из систем реляционных баз данных. Реляционные базы данных настроены с определенной структурой — каждая запись имеет ряд ключей, которые связаны друг с другом согласованным образом и помещены в «таблицу», визуально представленную в сетке. Язык SQL написан для анализа содержимого таблиц в обычной базе данных. SQL широко используется в бизнесе и в других типах администрирования баз данных. Это часто инструмент по умолчанию для «работы» с традиционной базой данных, для изменения табличных данных, извлечения данных или иного манипулирования существующим набором данных. Итак, одна из причин того, что SQL по-прежнему так популярен спустя столько лет после его создания, — это его повсеместное распространение в современных ИТ-системах. Среды, возможно, сильно изменились, но технологии реляционных баз данных менялись медленнее. Еще одна важная часть основного использования SQL сегодня заключается в его простоте. Простые команды SQL, такие как SELECT, ORDER BY и INSERT (все из которых обычно отображаются заглавными буквами), помогают администраторам перенаправлять данные в таблицу базы данных и из нее. Это происходит на всех типах платформ и является основной частью предоставления результатов данных в сегодняшних облачных и гибридных распределенных системах. Согласно опросам разработчиков последних лет, SQL остается одним из наименее «страшных» языков. Благодаря довольно простому синтаксису и простоте использования администраторы могут сосредоточиться на теории построения базы данных и логистическом аспекте передачи данных в систему и из нее. Со временем появилась альтернатива SQL под названием NoSQL.(Также прочтите: NoSQL 101.) Идея состоит в том, что данные, которые не представлены в таблицах в реляционной базе данных, могут не нуждаться в SQL в качестве языка запросов. Таким образом, в наибольшей степени SQL используется в спектре, который можно назвать «меньшими» системами баз данных. Другой способ объяснить это состоит в том, что SQL не «бесконечно масштабируется». Таким образом, по этому принципу SQL используется для традиционных систем БД, а другие методы используются для более крупных систем баз данных NoSQL, где проверки данных строго не выполняются. (Также прочтите: В чем разница между базой данных NoSQL и традиционной системой управления базами данных?) Однако NoSQL не привел к устареванию самого SQL.Напротив, те же самые базовые математические принципы и синтаксические методы, которые всегда использовались в SQL во времена «голых» серверов, по-прежнему применяются к системам реляционных баз данных, работающим в контейнерах, виртуальных машинах или во всем остальном. Самый простой способ объяснить это состоит в том, что системы баз данных SQL остаются популярными «устаревшими» компонентами в корпоративных ИТ, и что теперь они часто поддерживаются по-разному, будь то через облако, через модели SaaS или иным образом. Например: AWS разработала AWS Lambda, сервис для бессерверных вычислений.Онлайн-эксперты говорят о возможности разработки «SQL to Lambda» для использования радикально нового метода взаимодействия с реляционной базой данных традиционными способами. Используя AWS SDK для вызова функций Lambda и передачи данных в виде строк JSON, эти системы демонстрируют, как современная утилита SQL может работать как универсальный компонент передовых архитектур. Pandas против SQL: когда специалисты по данным должны использовать каждый инструментМэтью Пшибила, старший научный сотрудник компании Favor Delivery . Фото rigel на Unsplash. Оба этих инструмента важны не только для специалистов по данным, но и для тех, кто занимает схожие должности, например, для анализа данных и бизнес-аналитики. С учетом сказанного, когда специалисты по данным должны использовать pandas вместо SQL и наоборот? В некоторых ситуациях вы можете обойтись простым использованием SQL, а в других случаях pandas намного проще в использовании, особенно для специалистов по данным, которые сосредоточены на исследованиях в настройках Jupyter Notebook.Ниже я расскажу, когда вам следует использовать SQL, а когда — панды. Имейте в виду, что у обоих этих инструментов есть определенные варианты использования, но во многих случаях их функциональность пересекается, и это то, что я также буду сравнивать ниже. ПандыФото Калена Кемпа на Unsplash. Pandas — это инструмент анализа данных с открытым исходным кодом на языке программирования Python. Преимущество pandas начинается тогда, когда у вас уже есть основной набор данных, обычно из запроса SQL.Это основное различие может означать, что эти два инструмента работают отдельно. Однако вы также можете выполнять несколько одинаковых функций в каждом соответствующем инструменте. Например, вы можете создавать новые функции из существующих столбцов в пандах, возможно, проще и быстрее, чем в SQL. Важно отметить, что я не сравниваю то, что делает pandas, чего не может делать SQL, и наоборот. Я выберу инструмент, который может выполнять эту функцию более эффективно или предпочтительнее для работы в области науки о данных — на мой взгляд, исходя из личного опыта. Вот случаи, когда использование pandas более выгодно, чем SQL, но при этом имеет ту же функциональность, что и SQL:
При включении более сложного SQL-запроса вы часто также включаете подзапросы, чтобы разделить значения из разных столбцов. В pandas вы можете просто разделить функции намного проще, например, следующим образом: df ["новый_столбец"] = df ["первый_столбец"] / df ["второй_столбец"] Приведенный выше код показывает, как можно разделить два отдельных столбца и присвоить эти значения новому столбцу.В этом случае вы выполняете создание объекта для всего набора данных или фрейма данных. Вы можете использовать эту функцию как для исследования функций, так и для разработки функций в процессе анализа данных. Также относится к подзапросам, группировка по в SQL может стать довольно сложной и потребовать строк и строк кода, которые могут быть визуально подавляющими. В пандах вы можете просто сгруппировать по одной строчке кода. Я имею в виду не «группировать по» в конце простого запроса выбора из таблицы, а запрос, в котором задействовано несколько подзапросов. df.groupby (by = "first_column"). Mean () Этот результат будет возвращать среднее значение first_column для каждого столбца в кадре данных. Есть много других способов использования этой функции группировки, которые хорошо описаны в документации pandas. В SQL вам часто придется приводить типы, но иногда может быть немного яснее увидеть, как панды размещают типы данных в вертикальном формате, а не прокручивают горизонтальный вывод в SQL.Вы можете ожидать, что вернет примеров типов данных, которые будут int64, float64, datetime64 [ns] и object. Хотя все это довольно простые функции pandas и SQL, в SQL они особенно сложны, а иногда их гораздо проще реализовать в фреймворке pandas. Теперь давайте посмотрим, какой SQL лучше работает. SQLФото Каспара Камилла Рубина на Unsplash. SQL, вероятно, является языком, который чаще всего используется в большинстве различных позиций.Например, инженер по обработке данных может использовать SQL, разработчик Tableau или менеджер по продукту. При этом специалисты по обработке данных часто используют SQL. Важно отметить, что существует несколько разных версий SQL, обычно все они имеют схожую функцию, только слегка отформатированы по-разному. Вот случаи, когда использование SQL более выгодно, чем pandas, но при этом имеет ту же функциональность, что и pandas: Это предложение в SQL часто используется, а также может выполняться в пандах.Однако в пандах это немного сложнее или менее интуитивно понятно. Например, вам нужно написать избыточный код, тогда как в SQL вам просто понадобится WHERE . ВЫБРАТЬ идентификатор ИЗ таблицы ГДЕ id> 100 В пандах это будет примерно так: Да, оба варианта просты, но SQL чуть более интуитивно понятен. УPandas есть несколько способов соединения, которые могут быть немного сложными, тогда как в SQL вы можете выполнять простые соединения, такие как следующие: INNER , LEFT , RIGHT. ВЫБРАТЬ one.column_A, two.column_B ИЗ первой_таблицы ВНУТРЕННЕЕ СОЕДИНЕНИЕ second_table two ON two.id = one.id В этом коде присоединение немного легче читать, чем в pandas, где вам нужно объединить фреймы данных, и особенно когда вы объединяете более двух фреймов данных, это может быть довольно сложным в pandas. SQL может выполнять несколько соединений, будь то INNER и т. Д., В одном запросе. Все эти примеры, будь то SQL или pandas, можно использовать, по крайней мере, в части исследовательского анализа данных процесса науки о данных, а также для разработки функций и запроса результатов модели после их сохранения в базе данных. СводкаЭто сравнение панд и SQL — это больше личное предпочтение. При этом вы можете почувствовать противоположное моему мнению. Тем не менее, я надеюсь, что он по-прежнему проливает свет на различия между pandas и SQL, а также на то, что вы можете сделать одинаково в обоих инструментах, используя немного разные методы кодирования и совсем другой язык. Подводя итог, мы сравнили преимущества использования pandas перед SQL и наоборот для некоторых общих функций:
Оригинал.Размещено с разрешения. Связанный: . Оставить комментарий
|
 (Зарплата)
ОТ Пилота)
ВЫБЕРИТЕ авиакомпанию
ИЗ общейЗарплата, авиакомпанияСреднее
ГДЕ totalSalary.итого> AirlinesAverage.avgSalary;
(Зарплата)
ОТ Пилота)
ВЫБЕРИТЕ авиакомпанию
ИЗ общейЗарплата, авиакомпанияСреднее
ГДЕ totalSalary.итого> AirlinesAverage.avgSalary;  geeksforgeeks.org, или отправить свою статью по адресу
geeksforgeeks.org, или отправить свою статью по адресу 
 Итак, если мы оставим порядок сортировки по умолчанию, сначала мы получим маленькие числа. Однако, если мы скажем «упорядочить» по убыванию по количеству, мы получим десять лучших записей по количеству.Мы также используем DISTINCT в некоторых случаях после SELECT, что дает нам уникальные значения в списке выбора.
Итак, если мы оставим порядок сортировки по умолчанию, сначала мы получим маленькие числа. Однако, если мы скажем «упорядочить» по убыванию по количеству, мы получим десять лучших записей по количеству.Мы также используем DISTINCT в некоторых случаях после SELECT, что дает нам уникальные значения в списке выбора. Это противоположно левому соединению
Это противоположно левому соединению Продукт;
Продукт;