Размер int c | CoderNet
Размер int в С может быть разным. В С организована целая система размеров для различных видов данных. В программировании часто применяются различные переменные, которые несут в себе определенную информацию. Каждая объявленная переменная соответствует определенному виду данных. Важно правильно определять тип данных для переменной, потому что от этого будет зависеть, сколько байт памяти необходимо выделить для нее. В Си это имеет особое значение.
Как известно, С-подобные языки — это языки, которые могут быть как высокоуровневыми, так и низкоуровневыми. Низкоуровневое качество этих языков позволяет напрямую воздействовать на память устройства. А это значит, что корректно определить правильный тип данных для переменных — значимое событие при разработке программных продуктов на С-подобных языках.
Типы данных в С
В С присутствует большое разнообразие видов данных, но сегодня нас интересуют численные виды.
Вот основные из них:
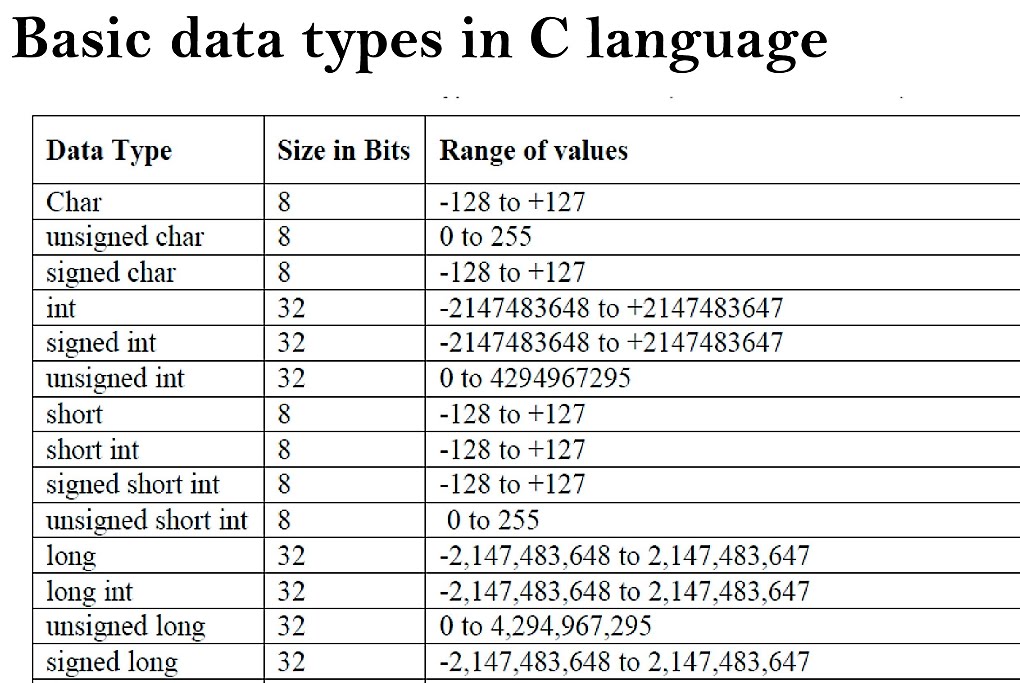
«char» или «signed char» — одиночный численный знак, занимающий 1 байт памяти, содержит численные величины из интервала «-128 – 127»;
«unsigned char» — одиночный численный знак, занимающий 1 байт памяти, хранит значения в интервале «0 – 255»;
«int» — целочисленная величина, однако ее размерность варьируется, а сам вид данных может разделяться еще на несколько видов, поэтому чуть ниже мы распишем его подробнее;
«float» — число с плавающей запятой и одним значением после запятой, занимающее 64 бита памяти;
«double» — число с плавающей запятой и двумя значениями после запятой, занимающее 64 бита памяти;
«long double» — число с плавающей запятой и двумя значениями после запятой, с более широким диапазоном значений, потребляет 80 бит памяти, но иногда может потреблять 96 и 128 бит;
«void» — тип данных без определенного значения;
«bool» — имеет только два значения: «false» и «true», занимает 8 бит памяти;
«wchar_t» — числовой тип данных с интервалом значений «0 – 65535», потребляет 16 бит памяти;
и др.
Размер и размерность int в Си
На типе данных «int» в Си нужно остановиться немного подробнее, потому что его размер варьируется и зависит от многих факторов, включая специальные модификаторы. Важно иметь размерность «int» перед глазами при программировании, чтобы ориентироваться, сколько байт или бит памяти потребляет разный «int». Напомним, что 1 байт равен 8 битам.
Размер «int» зависит от его типа, поэтому варьируется:
«int», иногда называется «sighed» — численная величина в интервале «-2 147 483 648 – 2 147 483 647», потребляет память в 4 байта;
«unsigned int» — численная величина в интервале «0 – 4 294 967 295», потребляет память в 4 байта;
«__int8», оно же «char» — число в интервале «-128 – 127», потребляет память в 1 байт;
«unsigned __int8», или «unsigned char» — численная величина в интервале «0 – 255», потребляет память в 8 бит;
«__int16» имеет несколько других имен: «short», «short int», «signed short int» — численная величина в интервале «-32 768 – 32 767», потребляет память в 2 байта;
«unsigned __int16» имеет несколько других имен: «unsigned short», «unsigned short int» — численная величина в интервале «0 – 65 535», потребляет память в 2 байта;
«__int32», оно же просто «int», поэтому используется в том же диапазоне и потребляет столько же памяти;
«unsigned __int32», оно же «unsigned int», поэтому используется в том же диапазоне и потребляет столько же памяти;
«__int64» имеет несколько других имен: «long long» и «signed long long» — численная величина в интервале «-9 223 372 036 854 775 808 – 9 223 372 036 854 775 807», потребляет памяти 64 бита;
«unsigned __int64», оно же «unsigned long long» — численная величина в интервале «0 – 18 446 744 073 709 551 615», потребляет памяти 64 бита.
Заключение
Размер «int» в С имеет важное значение. В первую очередь он будет зависеть от разрядности системы, для которой разрабатывается программа. Как видно чуть выше, мы можем объявить «int» в 8, 16, 32, 64 бит и использовать его в соответствующих системах.
Имея размерность «int» в С постоянно перед собой, вы без труда сможете узнать, сколько байт потребляет тот или иной вид типа данных «int».


Схожие статьи
Другое
Генератор HTML кода: фон, фигуры, анимации, таблицы и другие элементы
Другое
End-to-end или E2E-процесс: что это? Сквозное тестирование
Другое
Демонизация и демонизировать: что это, создание демон-процесса
Другое
Все про язык Swift: многопоточность, базовые операторы, функции
Digital Chip
Все данные в языке Си имеют свой тип. Переменные определенных типов занимают в памяти какое-то место, разное в зависимости от типа. В Си нет четкого закрепления количества памяти за определенными типами. Это отдано на реализацию конкретного компилятора под конкретную платформу. Например, переменная типа int в одном компиляторе может занимать в памяти 16 бит, в другом — 32 бита, в третьем — 8 бит. Все определяет конкретный компилятор. Правда, все стремятся к универсализации, и в основном в большинстве компиляторов тип int, например, занимает 2 байта, а тип char — один.
В Си нет четкого закрепления количества памяти за определенными типами. Это отдано на реализацию конкретного компилятора под конкретную платформу. Например, переменная типа int в одном компиляторе может занимать в памяти 16 бит, в другом — 32 бита, в третьем — 8 бит. Все определяет конкретный компилятор. Правда, все стремятся к универсализации, и в основном в большинстве компиляторов тип int, например, занимает 2 байта, а тип char — один.
Я в последнее время немного затупил, не мог вспомнить, сколько байт занимает тип double в AVR-GCC. Обычно при программировании контроллеров работаешь с целочисленными типами, типа int и char, а к типам с плавающей точкой прибегаешь не часто, в связи с их ресурсоемкостью.
Поэтому, на будущее, оставлю себе здесь памятку с указанием размеров занимаемой памяти типами данных для компилятора AVR-GCC и диапазон изменения переменных этого типа.
Типы данных в языке Си для компилятора AVR-GCC
| Тип | Размер в байтах (битах) | Интервал изменения |
|---|---|---|
| char | 1 (8) | -128 .. 127 |
| unsigned char | 1 (8) | 0 .. 255 |
| signed char | 1 (8) | -128 .. 127 |
| int | 2 (16) | -32768 .. 32767 |
| unsigned int | 2 (16) | 0 .. 65535 |
| signed int | 2 (16) | -32768 .. 32767 |
| short int | 2 (16) | -32768 .. 32767 |
| unsigned short int | 2 (16) | 0 .. 65535 |
| signed short int | 2 (16) | -32768 .. 32767 |
| long int | 4 (32) | -2147483648 .. 2147483647 |
| unsigned long int | 4 (32) | 0 . . 4294967295 . 4294967295 |
| 4 (32) | -2147483648 .. 2147483647 | |
| float | 4 (32) | 3.4Е-38 .. 3.4Е+38 |
| double | 4 (32) | 3.4Е-38 .. 3.4Е+38 |
| long double | 10 (80) | 3.4Е-4932 .. 3.4Е+4932 |
[stextbox id=»warning» caption=»Обратите внимание»]Реализация типа double в AVR-GCC отступает от стандарта. По стандарту double занимает 64 бита. В AVR-GCC переменная этого типа занимает 32 бита, и соответственно, она эквивалентна переменной с типом float![/stextbox]
В дополнение к этому, в библиотеках AVR-GCC введено несколько производных от стандартных типов. Они описаны в файле stdint.h. Сделано это, наверно, для улучшения наглядности и уменьшения текста программ (ускорения их написания :)). Вот табличка соответствия:
Производные типы от стандартных в языке Си для компилятора AVR-GCC
| Производный тип | Стандартный тип |
|---|---|
| int8_t | signed char |
| uint8_t | unsigned char |
| int16_t | signed int |
| uint16_t | unsigned int |
| int32_t | signed long int |
| uint32_t | unsigned long int |
| int64_t | signed long long int |
| uint64_t | unsigned long long int |
Тип Void
В языке Си есть еще один тип — тип void. Void используется для указания, что функция не возвращает ничего в качестве результата, или не принимает на вход никаких параметров. Этот тип не применяется для объявления переменных, соответственно он не занимает места в памяти.
Void используется для указания, что функция не возвращает ничего в качестве результата, или не принимает на вход никаких параметров. Этот тип не применяется для объявления переменных, соответственно он не занимает места в памяти.
c++ faq. Что стандарт C++ указывает на размер типа int, long?
Если вас интересует решение на чистом C++, я использовал шаблоны и только стандартный код C++ для определения типов во время компиляции на основе их разрядности. Это делает решение переносимым между компиляторами.
Идея очень проста: создайте список, содержащий типы char, int, short, long, long long (знаковые и неподписанные версии), просмотрите список и с помощью шаблона numeric_limits выберите тип с заданным размером.
Включая этот заголовок, вы получаете 8 типов stdtype::int8, stdtype::int16, stdtype::int32, stdtype::int64, stdtype::uint8, stdtype::uint16, stdtype::uint32, stdtype::uint64.
Если какой-либо тип не может быть представлен, он будет оцениваться как stdtype::null_type, также объявленный в этом заголовке.
КОД НИЖЕ ПРЕДОСТАВЛЯЕТСЯ БЕЗ ГАРАНТИИ, ПОЖАЛУЙСТА, ПРОВЕРЬТЕ ЕГО ДВАЖДЫ.
Я ТАКЖЕ НОВИЧОК В МЕТАПРОГРАММИРОВАНИИ, НЕ СМОТРИТЕ СВОБОДНО ИЗМЕНЯТЬ И ИСПРАВЛЯТЬ ЭТОТ КОД.
Протестировано с DevC++ (поэтому версия gcc около 3.5)
#include <лимиты>
стандартный тип пространства имен
{
использование пространства имен std;
/*
* ЭТОТ КЛАСС ИСПОЛЬЗУЕТСЯ ДЛЯ СЕМАНТИЧЕСКОГО ОПРЕДЕЛЕНИЯ НУЛЕВОГО ТИПА.
* ВЫ МОЖЕТЕ ИСПОЛЬЗОВАТЬ ВСЁ, ЧТО ХОТИТЕ, И ДАЖЕ ПРИГОТОВИТЬ ОШИБКУ КОМПИЛЯЦИИ, ЕСЛИ ОНА БУДЕТ
* ЗАЯВЛЕН/ИСПОЛЬЗУЕТСЯ.
*
* ПОЖАЛУЙСТА, ОБРАТИТЕ ВНИМАНИЕ, что C++ std определяет sizeof пустого класса равным 1.
*/
класс null_type{};
/*
* Шаблон для создания списков типов
*
* T тип для удержания
* S — следующий тип type_list *
* Пример:
* Создание списка с типом int и char:
* typedef type_list > test;
* тест::значение //целое
* test::next::value //char
*/
template struct type_list
{
значение typedef T;
typedef S следующий;
};
/*
* Объявление структуры шаблона для выбора типа из списка
*/
template struct select_type;
/*
* Найти тип с указанным битом "b" в списке "list"
*
*
*/
template <список имен типов, int b> struct find_type
{
частный:
// Удобное имя для типа во главе списка
typedef typename list::value cur_type;
//Количество битов типа в заголовке
// ИЗМЕНИТЬ ЭТО (время компиляции) exp ДЛЯ ИСПОЛЬЗОВАНИЯ ДРУГОГО ТИПА LEN COMPUTING
enum {cur_type_bits = numeric_limits ::digits};
публичный:
//Выбираем тип в заголовке if b == cur_type_bits else
//вызов select_type find_type с помощью list::next
typedef typename select_type::type type;
};
/*
* Это специализация для пустого списка, вернуть null_type
* OVVERRIDE эту структуру, чтобы ДОБАВИТЬ ПОЛЬЗОВАТЕЛЬСКОЕ ПОВЕДЕНИЕ для случая TYPE NOT FOUND
* (т. е. поиск типа с 17 битами на обычных арках)
*/
шаблон
е. поиск типа с 17 битами на обычных арках)
*/
шаблон struct find_type
{
typedef тип null_type;
};
/*
* Первичный шаблон для выбора типа во главе списка, если
* соответствует запрошенным битам (b == ctl)
*
* Если b == ctl, вычисляется частичный указанный шаблон, поэтому здесь мы имеем
* б != ctl. Мы вызываем find_type для следующего элемента списка
*/
template <список типов, int b, int ctl> struct select_type
{
typedef typename find_type::type type;
};
/*
* Этот частично заданный шаблон используется для выбора верхнего типа списка
* вызывается find_type со списком значений (потребляется при каждом вызове)
* запрошенные биты (b) и длина текущего типа (верхний тип) в битах
*
* Мы специализируемся на случае b == ctl
*/
template <список типов, int b> struct select_type<список, b, b>
{
typedef список имен типов:: тип значения;
};
/*
* Это список типов, чтобы избежать возможной двусмысленности (некоторые странные арки)
* мы разделили подписанные и неподписанные
*/
#define UNSIGNED_TYPES type_list<беззнаковый символ, \
type_list<короткий без знака, \
type_list<беззнаковое целое, \
type_list<длинный без знака, \
type_list > > > >
#define SIGNED_TYPES type_list > > > >
/*
* На самом деле это typedef, используемый в программах. *
* Номенклатура — [u]intN, где u, если присутствует, означает беззнаковое, N — это
* количество битов в целом числе
*
* find_type используется просто путем указания сначала type_list, а затем числа
* биты для поиска.
*
* Примечание. Для каждого типа в списке типов должен быть указан шаблон
* numeric_limits, так как он используется для вычисления типа len в (двоичной) цифре.
*/
typedef find_type
*
* Номенклатура — [u]intN, где u, если присутствует, означает беззнаковое, N — это
* количество битов в целом числе
*
* find_type используется просто путем указания сначала type_list, а затем числа
* биты для поиска.
*
* Примечание. Для каждого типа в списке типов должен быть указан шаблон
* numeric_limits, так как он используется для вычисления типа len в (двоичной) цифре.
*/
typedef find_type::type uint8;
typedef find_type::type uint16;
typedef find_type::type uint32;
typedef find_type::type uint64;
typedef find_type::type int8;
typedef find_type::type int16;
typedef find_type::type int32;
typedef find_type::type int64;
}
битов, размеров, со знаком и без знака
битов, размеров, со знаком и без знака Дело в том, что переменные на компьютере имеют ограниченное количество битов. Если значение становится больше, чем может поместиться в этих битах, дополнительные биты «переполняются» и по умолчанию игнорируются.
Если значение становится больше, чем может поместиться в этих битах, дополнительные биты «переполняются» и по умолчанию игнорируются.
Например:
целочисленное значение=1; /* значение для проверки, начиная с первого (младшего) бита */
for (целое число бит=0;бит<100;бит++) {
std::cout<<"в бите "< (Попробуйте сейчас в NetRun!)
Поскольку "int" в настоящее время имеет 32 бита, если вы начнете с одного и добавите переменную к себе 32 раза, один переполнится и будет полностью потерян.
В ассемблере есть удобная инструкция "jo" (переход при переполнении) для проверки переполнения из предыдущей инструкции. Однако компилятор C++ не удосуживается использовать jo!
мов эди,1 ; переменная цикла
дв акс,0 ; прилавок
начинать:
добавить eax,1 ; приращение битового счетчика
добавить эди, эди ; добавить переменную к себе
Джо нет ; проверьте наличие переполнения в приведенном выше добавлении
cmp эди,0
начало
рет
нет: ; призвал к переполнению
мов акс,999
рет
(Попробуйте сейчас в NetRun!)
Обратите внимание, что приведенная выше программа возвращает 999 при переполнении, которое должен проверить кто-то другой. (Правильно реагировать на переполнение на самом деле довольно сложно — см., например, взрыв Ariane 5, вызванный обнаруженным переполнением.)
(Правильно реагировать на переполнение на самом деле довольно сложно — см., например, взрыв Ariane 5, вызванный обнаруженным переполнением.)
Размер хранилища C++
Восемь бит составляют «байт» (примечание: это произносится точно так же, как «укус», но всегда пишется с «у»), хотя в некоторых редких сетевых руководствах (и на французском языке) те же восемь битов будут называться «октет». " (размеры жестких дисков указаны в гигабайтах "Go" при продаже на французском языке). В программировании для DOS и Windows 16 бит — это «WORD», 32 бита — это «DWORD» (двойное слово), а 64 бита — это «QWORD»; но в других контекстах «слово» означает естественный размер двоичной обработки машины, который в настоящее время колеблется от 32 до 64 бит. «слово» теперь следует считать двусмысленным. Указание фактического количества битов - лучший подход («Файл начинается с 32-битного двоичного целого числа, описывающего ...»).
Объект Имя С++ Биты байт
(8 бит) Шестнадцатеричные цифры
(4 бита) Восьмеричные цифры
(3 бита) Диапазон без знака Диапазон со знаком Бит нет! 1 меньше 1 меньше 1 меньше 1 0. .1
.1 -1..0 Байт или октет символ 8 1 2 две и две трети 255 -128 .. 127 Windows СЛОВО короткий 16 2 4 пять и одна треть 65535 -32768 .. +32767 Двойное слово Windows между 32 4 8 десять и две трети >4 миллиарда -2Г . . +2Г
. +2Г Windows QWORD длинный 64 8 16 двадцать одна и одна треть >16 квадриллионов -8Q .. +8Q
Размеры регистров в сборке
Как и переменные C++, регистры доступны в нескольких размерах:
- rax — это 64-битный регистр «длинного» размера. Он был добавлен в 2003 году. Ниже я отметил красным цветом добавленные с 64-разрядными регистрами.
- eax - это 32-битный регистр размера "int". Он был добавлен в 1985 году. Я привык использовать этот размер регистра, так как они также работают в 32-битном режиме, хотя мне, вероятно, следует использовать более длинные регистры rax для всего.
- axe — это 16-битный регистр «короткого» размера. Он был добавлен в 1979 году.
- al и ah - это 8-битные части регистра размером "char".
 al — младшие 8 бит (например, ax&0xff), ah — старшие 8 бит (например, ax>>8). Они оригинальные до 1972.
al — младшие 8 бит (например, ax&0xff), ah — старшие 8 бит (например, ax>>8). Они оригинальные до 1972.
Любопытно, что вы можете записать 64-битное значение в rax, а затем считать младшие 32 бита из eax, или младшие 16 битx из ax, или младшие 8 бит из al — это всего лишь один регистр, но они сохраняют при продлении!
ракс: 64-бит eax: 32-битный топор: 16-битный
Например,
мов rcx,0xf00d00d2beefc03; загрузить 64-битную константу
mov eax,ecx; вытащить младшие 32 бита
рет
(Попробуйте сейчас в NetRun!)
Вот полный список регистров x86. 64-битные регистры показаны красным. Регистры «Scratch», которые вы можете перезаписывать и использовать для чего угодно. Сохраненные регистры " служат какой-то важной цели в другом месте, поэтому, как мы поговорим на следующей неделе, вы должны вернуть их обратно ("сохранить" регистр), если вы их используете - пока просто оставьте их в покое!
64-битные регистры показаны красным. Регистры «Scratch», которые вы можете перезаписывать и использовать для чего угодно. Сохраненные регистры " служат какой-то важной цели в другом месте, поэтому, как мы поговорим на следующей неделе, вы должны вернуть их обратно ("сохранить" регистр), если вы их используете - пока просто оставьте их в покое!
Примечания 64-разрядный
длинный 32-разрядный
целое число 16-битный
короткий 8-бит
символов Значения возвращаются из функций в этом регистре. Инструкции умножения также помещают сюда младшие биты результата. ракс еакс топор ах и ал Типовой рабочий регистр. Некоторые инструкции используют его как счетчик (например, SAL или REP). РКС ЕСХ сх ч. и кл. Скретч-регистр. Инструкции умножения помещают сюда старшие биты результата.
Инструкции умножения помещают сюда старшие биты результата. РДС эдкс дх ДХ и ДЛ Сохраненный регистр: не используйте его без сохранения! рбкс ebx бх ш и бл Указатель стека. Указывает на вершину стека (подробности на следующей неделе!) рсп исп сп спл Сохранился реестр. Иногда используется для хранения старого значения указателя стека или «базы». рбп эбп бп баррель Скретч-регистр. Также используется для передачи аргумента функции #2 в 64-битном режиме (в Linux). рупий ЕСИ и или Скретч-регистр.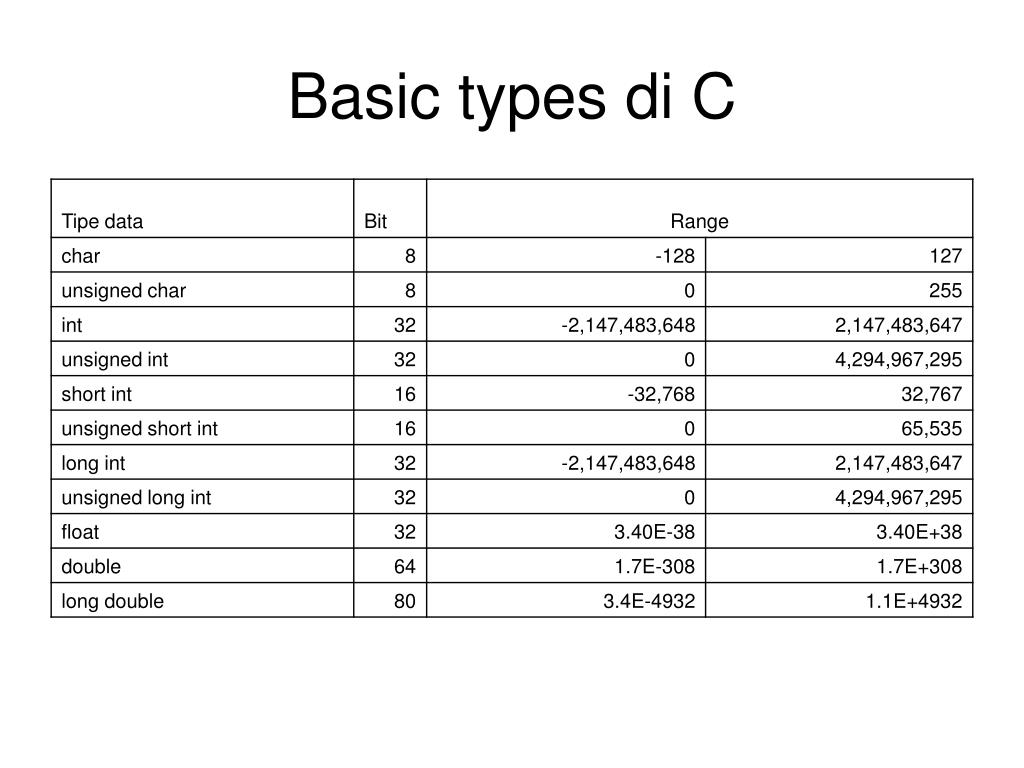 Аргумент функции №1.
Аргумент функции №1. рди эди из по Скретч-регистр. Они были добавлены в 64-битном режиме, поэтому названия немного отличаются. р8 р8д р8в р8б Скретч-регистр. р9 р9д р9в р9б Скретч-регистр. р10 р10д р10в р10б Скретч-регистр. р11 р11д р11в р11б Сохранился реестр. r12 р12д р12в р12б Сохранился реестр. р13 р13д р13в р13б Сохранился реестр. р14 р14д р14в р14б Сохранился реестр.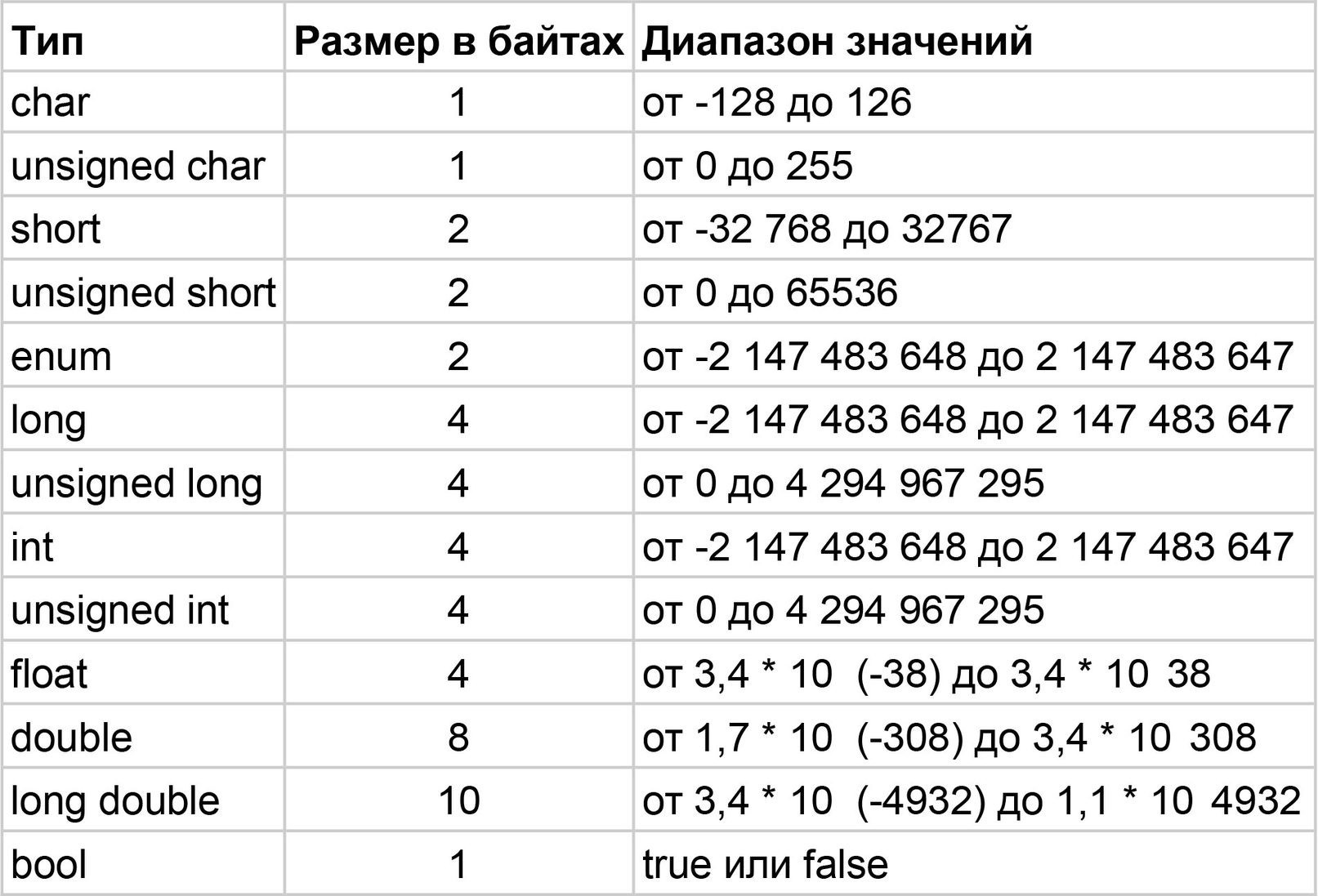
р15 р15д р15в р15б
Подписанные и неподписанные числа
Если вы внимательно посмотрите прямо перед переполнением, вы увидите кое-что забавное:
значение символа со знаком = 1; /* значение для проверки, начиная с первого (младшего) бита */
for (целое число бит=0;бит<100;бит++) {
std::cout<<"в бите "< (Попробуйте сейчас в NetRun!)
Напечатает:
в бите 0 значение равно 1
в бите 1 значение равно 2
в бите 2 значение равно 4
в бите 3 значение равно 8
в бите 4 значение равно 16
в бите 5 значение равно 32
в бите 6 значение равно 64
в бите 7 значение равно -128
Программа завершена. Возврат 0 (0x0)
Подождите, значение последнего бита равно -128? Да, это действительно так!
Этот отрицательный старший бит называется «знаковым битом» и имеет отрицательное значение в числах со знаком, дополненных до двух.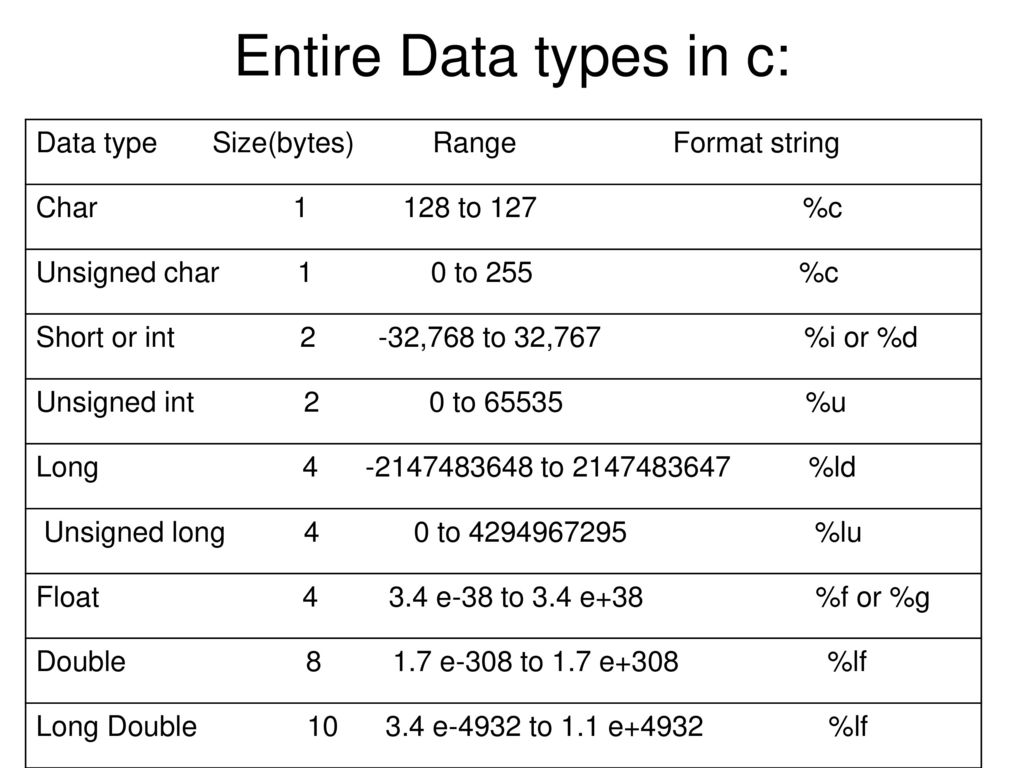 Это означает, что для представления -1, например, вы устанавливаете не только старший бит, но и все остальные биты: в беззнаковом, это максимально возможное значение. Причина, по которой двоичный код 11111111 представляет собой -1, та же самая, по которой вы можете выбрать 9.999 для представления -1 на 4-значном одометре: если вы добавите единицу, вы сделаете круг и достигнете нуля.
Это означает, что для представления -1, например, вы устанавливаете не только старший бит, но и все остальные биты: в беззнаковом, это максимально возможное значение. Причина, по которой двоичный код 11111111 представляет собой -1, та же самая, по которой вы можете выбрать 9.999 для представления -1 на 4-значном одометре: если вы добавите единицу, вы сделаете круг и достигнете нуля.
Очень интересная вещь в дополнении до двух: сложение — одна и та же операция , независимо от того, знаковые числа или беззнаковые — мы просто интерпретируем результат по-разному. Вычитание также идентично для знакового и беззнакового. Имена регистров идентичны в ассемблере для подписанных и неподписанных. Однако, когда вы изменяете размеры регистров с помощью такой инструкции, как «movsxd rax,eax», когда вы проверяете переполнение, когда вы сравниваете числа, умножаете или делите или сдвигаете биты, вам нужно знать, подписано ли число (имеет ли знак бит) или без знака (без бита знака, без отрицательных чисел).
Подпись Без знака Язык целое число Целое число без знака C++, «int» по умолчанию имеет знак. подписанный символ беззнаковый символ C++, «char» может быть подписанным или беззнаковым. мовскд мовзд Сборка, расширение знака или расширение нуля для изменения размера регистра. ио джк Сборка, «переполнение» вычисляется для значений со знаком, «перенос» — для значений без знака. Оставить комментарий
Оставить комментарий