длительные операции TRUNCATE / Хабр
Вступление
Этой статьей мы начинаем цикл разбора нетривиальных случаев в нашей практике оптимизации производительности ИТ-систем. Возможно, кому-то они пригодятся, так как решения будут нестандартные. Возможно, кто-то узнает свою ситуацию и поделится своими решениями или наведет на интересную мысль. Ведь, коллективный разум – это сила!
Не секрет, что самой популярной и массовой платформой в России для создания ИТ-систем для бизнеса является 1С:Предприятие 8.х. На ней разработано огромное количество отраслевых и самописных решений.
Хочу обратить внимание на одну интересную особенность работы приложений 1С, а именно, очень интенсивную работу с временными таблицами СУБД. Подобной интенсивной работы с tempDB, наверное, нет ни в одном тиражном решении в мире.
С точки зрения кода 1С создание временной таблицы выполняется командой ПОМЕСТИТЬ – менеджер временных таблиц (МВТ) создается не явно и MS SQL создает локальную временную таблицу с одной решеткой (#), например, #tt60. После завершения пакетного запроса неявный МВТ закрывается, платформа автоматически удаляет временную таблицу, отдавая серверу СУБД команду <truncate table>, чтобы освободить ресурсы под следующий запрос:
После завершения пакетного запроса неявный МВТ закрывается, платформа автоматически удаляет временную таблицу, отдавая серверу СУБД команду <truncate table>, чтобы освободить ресурсы под следующий запрос:
TRUNCATE TABLE #tt60
TRUNCATE – это крайне простая и быстрая операция. Даже для таблиц с миллионами строк она длится миллисекунды. Тем не менее, у некоторых своих клиентов мы столкнулись с очень странной ситуацией, когда производительность системы проседает из-за того, что запросы с очисткой временных таблиц могут длиться 5, 10, 20 и более секунд (не миллисекунд, а секунд!). А учитывая масштаб запросов с временными таблицами в ИТ-системе на 1С, это время в совокупности становится просто огромным. А поскольку техподдержка Microsoft для российских пользователей фактически закрыта, то они (пользователи) остаются с проблемой один на один.
Проблематика: немного цифр
Как я сказал выше, проблема наблюдается далеко не у всех. Более того, среди тех, у кого она есть, о ней могут и не знать вовсе. Проблема может быть очень незаметная, отъедающая единицы процентов ресурсов CPU. Замечают ее только очень внимательные сотрудники, которые своими изысканиями вышли как-то на tempDB, записали трассу в профайлере SQL и наткнулись на странные цифры длительности запросов с TRUNCATE.
Проблема может быть очень незаметная, отъедающая единицы процентов ресурсов CPU. Замечают ее только очень внимательные сотрудники, которые своими изысканиями вышли как-то на tempDB, записали трассу в профайлере SQL и наткнулись на странные цифры длительности запросов с TRUNCATE.
А есть, наоборот, очень яркие примеры, где доля потребления ресурсов CPU составляет уже несколько десятков процентов! Такими примерами и займемся. Для анализа используем программу мониторинга PerfExpert, собирающую различные данные 24/7.
Возьмем для примера данные за одну календарную неделю по трассе Duration у одного нашего заказчика. В трассу попадают все запросы длительностью более 5 секунд. На рисунке ниже представлены данные, сгруппированные по типу запроса и отсортированные по доле потребления CPU.
И что мы видим? Запрос типа TRUNCATE TABLE #TT оказался на первом месте по потреблению CPU. Всего таких запросов чуть более 20 тысяч, отъевших процессорного времени на почти 3 дня (колонка Сумма CPU). Еще раз акцентирую внимание, что в мониторинге Perfexpert собираются данные только по запросам длительностью более 5 секунд. А фактически, их гораздо больше. Так что, три дня процессорного времени – это даже не нижняя граница. В любом случае, стоит побороться за такие цифры паразитивной нагрузки на CPU.
Еще раз акцентирую внимание, что в мониторинге Perfexpert собираются данные только по запросам длительностью более 5 секунд. А фактически, их гораздо больше. Так что, три дня процессорного времени – это даже не нижняя граница. В любом случае, стоит побороться за такие цифры паразитивной нагрузки на CPU.
Далее хочу обратить ваше внимание еще на два интересных факта.
Возьмем другую высоконагруженную базу данных, во-первых, чтобы показать, что проблема не единична и ее масштаб схож, а, во-вторых, показать, что клиент пытается на своем уровне как-то бороться с ней. Берем опять одну календарную неделю и группируем все запросы Truncate по дням.
Обратите внимание на колонки Сумма CPU и Сумма длительность. Значения в них почти равные. Например, 19 февраля было зафиксировано ~5 тыс. запросов Truncate длительностью более 5 секунд, и они заняли 10ч 41мин. процессорного времени и почти столько же была их общая длительность – 10ч 55мин.
Это очень важный момент. Равенство данных величин указывает на то, что длительность запросов вызвана не блокировками, не какой-то задержкой со стороны сервера приложений, а процессором на сервере СУБД. Который каждый раз что-то вычислял, и на каждый запрос в среднем в этот день тратил по 7-8 секунд (в максимуме до 46 сек).
Равенство данных величин указывает на то, что длительность запросов вызвана не блокировками, не какой-то задержкой со стороны сервера приложений, а процессором на сервере СУБД. Который каждый раз что-то вычислял, и на каждый запрос в среднем в этот день тратил по 7-8 секунд (в максимуме до 46 сек).
Что за сложные вычисления могут быть в команде TRUNCATE? Не понятно и попахивает конспирологией.
Также стоит отметить тот факт, что после перезагрузки сервера СУБД 16 февраля (оранжевая горизонтальная линия на рисунке выше) кол-во длительных TRUNCATE сразу снизилось, но потом постепенно поднялось до исходных значений в 4-5 тыс. в сутки. Этот эффект повторялся каждый раз после перезагрузки сервера. Т.е. наблюдается какой-то накопительный эффект с не очень ясными условиями накопления.
Сама по себе проблема плавающая, наблюдается далеко не у всех. Вероятно, зависит от какой-то характерной последовательности запросов и их интенсивности. Смоделировать её так, чтобы задержка вызывалась именно процессорным временем, на синтетических тестах в полной мере пока не удалось. Вопросов больше, чем ответов.
Вопросов больше, чем ответов.
Сведу в единый список проблемы и наблюдения по разным экспериментам.
Простейшая команда TRUNCATE выполняется непозволительно долго (иногда 40+ сек) на сервере СУБД, что может дать значительную просадку производительности всей системы, учитывая огромное количество запросов с временными таблицами. Это, собственно, основная проблема из-за которой вся статья и написана.
Проблема длительных TRUNCATE наблюдается только на MS SQL Server 2019. На более ранних версиях такого не было – собственноручно наблюдали появление проблемы у клиентов именно после перехода на MS SQL Server 2019. Про более свежие версии пока трудно сказать – статистики не хватает.
Проблема временно рассасывается после перезагрузки сервера SQL, но достаточно быстро (до двух дней) возвращается в исходное состояние.
Время выполнения запроса обусловлено процессорным временем на MS SQL Server. Что само по себе очень подозрительно!
Количество строк во временной таблице не влияет на время выполнения запроса TRUNCATE TABLE.
Проблему не удалось смоделировать синтетическими тестами (как запросами из кода 1С, так и напрямую скриптами на СУБД), в которых временные таблицы создаются, заполняются и очищаются с разной интенсивностью и с разным количеством строк.
Как мы обходили проблему длительных Truncate
В сложившейся ситуации Microsoft фактически не оказывает поддержку клиентам из России. Все вопросы в техподдержку остаются без ответов. А поскольку столь интенсивная работа с tempDB характерна именно для российских систем на 1С:Предприятие, то ожидать в ближайшем будущем Service Pack’ов по данной проблеме не приходится. Пока предлагаю оставить за скобками всякие конспирологические теории и будем рассматривать проблему как ошибку в работе СУБД.
Чем можно заменить Truncate?
Вариант 1: DELETE
Операция DELETE также сохраняет первоначальную структуру таблицы, но при этом логируется и на нее можно накладывать условия. В принципе, тоже достаточно быстрая операция, особенно если не накладывать условий.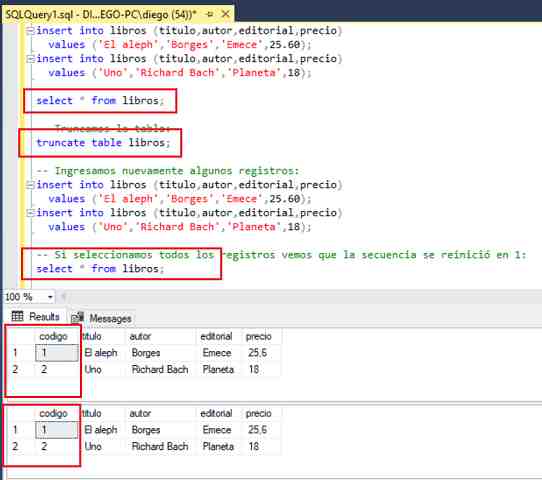 Но тем не менее, не настолько быстрая, как хотелось бы – таблица очищается построчно. Чем больше строк, тем дольше удаление.
Но тем не менее, не настолько быстрая, как хотелось бы – таблица очищается построчно. Чем больше строк, тем дольше удаление.
Суть тестирования была в подмене строк запроса
TRUNCATE TABLE #tt<номер>
на
DELETE FROM #tt<номер>
Как и каким инструментом мы производили подмену опишу чуть ниже, чтобы не отвлекаться от хода эксперимента. Просто пока примите за факт, что это возможно, даже в связке 1C сервер + SQL Server.
В результате первого прогона мы получили кучу пользовательских ошибок. Почти каждый пользователь сразу при открытии 1С:Предприятие получал вот такое замечательное сообщение:
Сразу же появилась мысль, что 1С просто не ожидает, что сервер SQL будет возвращать какую-то информацию о количестве строк и надо добавить в подменный запрос конструкцию SET NOCOUNT ON , чтобы приложение не получало ничего лишнего. На выходе получилось:
SET NOCOUNT ON DELETE FROM #tt<номер>
После подмены и при средней интенсивности запросов TRUNCATE 7…10 тысяч в минуту мы наблюдали в мониторинге резкий рост количества всех sql-запросов в 4-5 раз, а также потребления ресурсов CPU на сервере приложений 1С и на сервере СУБД.
Ну что тут сказать. Это был epic fail. Какие-то мысли крутились в голове, но никак не хотели сформироваться во что-то прикладное. Кто догадался – молодец, читаем дальше, не надо сразу бросаться писать комментарии типа «Ну это задача для первоклассника», «Это ж очевидно» и т.п.
На тот момент мы не поняли сразу причину и пошли думать в другую сторону, отбросив вариант с <DELETE> как ущербный.
Вариант 2: DROP TABLE
Данная команда удаляет уже таблицу целиком, а не записи в ней. Поэтому подмена в запросе будет более сложная: копируем структуру исходной таблицы в промежуточную, удаляем исходную и переименовываем вторую таблицу в исходную.
Причем, к этому моменту мы догадались в чем же был косяк с DELETE, и обернули наш подменный запрос в конструкцию <SET NOCOUNT ON … SET NOCOUNT OFF>, чтобы не было ситуации как в предыдущем варианте.
Таким образом одна строчка TRUNCATE TABLE #tt60 превращается в шесть:
SET NOCOUNT ON SELECT Top 0 * into #tt60_temp from #tt60 DROP TABLE #tt60 SELECT Top 0 * into #tt60 from #tt60_temp DROP TABLE #tt60_temp SET NOCOUNT OFF
Мониторинг Perfexpert позволяет собирать свою произвольную трассу запросов по текстовой маске – TextMask. Мы запустили сбор всех подмененных запросов по разным правилам. Сейчас нас интересуют запросы DROP, и на рисунке ниже представлен скрин трассы, записи которой отфильтрованы по вхождению «DROP TABLE #tt».
По началу все шло нормально, но постепенно (примерно за 1 час) длительность новых запросов возрастала все больше и дошла до полутора минут. Система встала колом – появились блокировки, основные запросы перестали выполняться, пользователи расстроились.
Судя по дереву блокировок, узким местом стала системная таблица в базе tempDB. Это и логично – с учетом интенсивности TRUNCATE (сотни в секунду) такое количество пересозданий таблиц и такую интенсивность база tempDB не выдерживает. Причем, ситуация развивалась постепенно, не лавинообразно. SQL Server зависал на какой-то строчке нового запроса и, скорее всего, это была команда создания новых временных таблиц:
Причем, ситуация развивалась постепенно, не лавинообразно. SQL Server зависал на какой-то строчке нового запроса и, скорее всего, это была команда создания новых временных таблиц:
SELECT Top 0 * into #tt60_temp from #tt60
По итогам пришлось правило отключить, т.к. деградация длительности удаления была очевидна и весьма динамична. Вариант с DROP ничего нам не дал, и мы остались с тем же, с чего начали.
Вариант 3: DELETE в комбинации с TRUNCATE
Почему вариант c DELETE нам не зашел в прошлый раз? Во-первых, из-за отсутствия конструкции SET NOCOUNT OFF. Во-вторых, в DELETE удаление данных из таблицы производится построчно. Даже без условия. Поэтому, как только попадалась таблица с большим количеством строк (сотни тысяч и миллионы), то процесс очищения таблицы становился катастрофически длинным и ресурсозатратным. И в довершение проигрывал аналогичному TRUNCATE.
Пробуем DELETE еще раз, но с новшествами. Новая идея состояла в сочетании
Новая идея состояла в сочетании TRUNCATE и DELETE. Сочетание основывается на количестве строк во временной таблице.
Нужно написать такое регулярное выражение в правиле подмены, которое бы в зависимости от количества строк либо оставляло запрос как есть с TRUNCATE, либо меняло его на DELETE.
«Большое количество строк» определялось эмпирически. Мы остановились на цифре 100 000 строк, и подменный запрос принял вид:
SET NOCOUNT ON;
DECLARE @count int
SELECT @count = MAX(row_count)
FROM tempdb.sys.dm_db_partition_stats (nolock)
WHERE object_id = object_id('tempdb.dbo.#tt378')
IF @count < 100000
DELETE FROM #tt<номер таблицы>
ELSE
TRUNCATE TABLE #tt<номер таблицы>
SET NOCOUNT OFF;Вот так выглядит трасса TextMask по всем запросам удаления временных таблиц (TRUNCATE + DELETE) в мониторинге PerfExpert с отсортированной по убыванию длительностью запросов:
За один день в рабочие часы получились такие цифры:
Кол-во запросов – 6,7 млн.
 ;
;Среднее значение длительности –
Максимальное значение длительности – 31 сек.
Распределение длительности в течение дня представлено на рисунке ниже, причем видно, что по всему дню было лишь несколько точечных всплесков.
Если же рассматривать только тяжелые запросы более 5 секунд, как в первоначальных данных, то их почти не осталось:
Кол-во запросов – 74. Менее одной сотни против 20 тыс. двумя днями ранее;
Среднее значение длительности – 8,19 сек;
Максимальное значение длительности – 31 сек.
Распределение длительности в течение дня выглядит так:
Статистически, выбрав пороговое количество строк во временных таблицах как 100 000, мы распределили примерно в равных долях количество запросов c TRUNCATE и с DELETE. Причем, львиная доля запросов с DELETE приходится на таблицы с количеством строк меньше сотни (см.
В результате комбинация DELETE + TRUNCATE позволила очень хорошо обойти, пусть и не полностью, странное поведение (или ограничение?) MS SQL Server 2019 и значительно снизить проблему длительных TRUNCATE.
То есть, перебросив всего половину запросов с операции TRUNCATE на DELETE (с условно небольшим количеством строк), удалось очень заметно снизить нагрузку на систему. Считаю результат весьма достойный.
Как подменять текст запроса T-SQL на лету
Платформа 1С формирует T-SQL запрос к БД самостоятельно и вмешиваться в этот процесс нельзя – программист пишет запрос на языке 1С, а дальше платформа автоматически трансформирует этот запрос к серверу СУБД. Использование прямых запросов к серверу СУБД тоже не вариант, т.к. придется брать на себя фактически все функции компилятора запросов 1С и логики платформы. Например, попробуйте контролировать хотя бы номер временной таблицы. Почему она #tt60, а не #tt218?
Поэтому либо нужно переписывать код 1С и отказываться от временных таблиц, хотя бы в критичных по времени операциях (прецеденты уже есть), либо научиться модифицировать запросы на лету. Мы пошли по второму пути, потому что имеем значительный опыт в этой части.
Мы пошли по второму пути, потому что имеем значительный опыт в этой части.
В нашем портфеле уже много лет есть программа Softpoint QProcessing, которая используют технологии модификации запросов к СУБД «на лету», в результате чего ее внедрение происходит без изменения кода приложения.
QProcessing представляет собой программный прокси-сервер, который устанавливается между сервером приложений и сервером баз данных SQL Server.
На рисунке ниже представлена схема работы QProcessing.
Основные задачи, решаемые Softpoint QProcessing:
Добавление хинтов к запросам SQL, в результате чего появляется возможность задавать:
a) Изменение уровня изоляции транзакции.
b) Подсказки оптимизатору по использованию индексов.
c) Определение опций SQL Server для выполнения запросов.Связывание различных запросов к SQL Server, которое даст возможность:
a) Замены одного текста запроса SQL альтернативным.
b) Изменения имён и параметров в хранимых процедурах.
c) Оптимизация поисковых запросов по подстроке видаLIKE %текст%
Принцип работы QProcessing – перехват всех запросов к СУБД и модификация только определенных, соответствующих условиям, запросов по заложенным правилам. На рисунке выше как раз показан схематично этот процесс – «Запрос 1» проходит как есть без изменений, а «Запрос 2» и «Запрос 3» модифицируются путем добавления подсказок.
QProcessing как точный инструмент хирурга – позволяет подправить запросы, когда нет возможности подобраться к движку приложения, и позволяет ускорить их выполнение в десятки и сотни раз.
Одну из следующих статей обязательно посвятим разбору QProcessing.
Выводы
Проблема, с которой столкнулись наши клиенты достаточно редкая и скорее всего связана с багом внутренних механизмов MS SQL Server 2019 (кстати, в MS SQL Server 2022, как нам сообщили, проблема сохранилась). У кого-то ее нет вообще, у кого-то она есть, но пользователи и администраторы не замечают ее, т. к. критическая масса еще не накоплена. Но те, кто столкнулись с ней, фактически находятся в заложниках – штатных решений для нее нет, а техподдержка MS на заявки из РФ не реагирует и ожидать помощи от них в этой части не стоит в ближайшее время. Поэтому рекомендую очень хорошо взвешивать риски при переходе на следующие версии SQL Server и при установке Service Pack’ов.
к. критическая масса еще не накоплена. Но те, кто столкнулись с ней, фактически находятся в заложниках – штатных решений для нее нет, а техподдержка MS на заявки из РФ не реагирует и ожидать помощи от них в этой части не стоит в ближайшее время. Поэтому рекомендую очень хорошо взвешивать риски при переходе на следующие версии SQL Server и при установке Service Pack’ов.
Возможные решения:
Ничего не делать, принимать жалобы от назойливых пользователей и несколько раз в неделю перегружать сервер СУБД.
Сделать downgrade и откатиться на предыдущие версии MS SQL. Теоретически затея осуществима, но для огромных БД (терабайты) чревата серьезными осложнениями и простоями, т.к. через обычный backup эту процедуру не выполнить. А в маленьких базах этой проблемы скорее всего и нет.
Вычистить код конфигурации 1С и отказаться по максимуму от использования временных таблиц. Очень ресурсозатратное занятие. По времени может растянуться на годы. Плюс любая последующая доработка должна проходить в парадигме «Мы больше не используем у себя временные таблицы» для вот этих операций.
 Для около типовых конфигураций, особенно на поддержке, а также для конфигураций, которые активно дорабатываются сторонними подрядчиками – это утопичная идея, потому что любой программист 1С «с детства» приучен использовать временные таблицы.
Для около типовых конфигураций, особенно на поддержке, а также для конфигураций, которые активно дорабатываются сторонними подрядчиками – это утопичная идея, потому что любой программист 1С «с детства» приучен использовать временные таблицы.Попробовать QProcessing, который без доработки кода 1С позволит на лету модифицировать проблемные запросы. Не только с TRUNCATE, но и любые другие тяжелые запросы, оптимизация которых затруднительна на уровне приложения.
На этом всё. Если вы в своей практике встречались с длительными TRUNCATE и пытались с ними бороться, то буду признателен, если поделитесь в комментариях своим опытом – как удачным, так и неудачным.
Серверsql — зачем использовать TRUNCATE и DROP?
Тестирование TRUNCATE , затем DROP по сравнению с простым выполнением DROP прямо показывает, что первый подход на самом деле имеет небольшое увеличение накладных расходов на журналирование, поэтому может быть даже слегка контрпродуктивным.
Просмотр отдельных записей журнала показывает, что версия DROP , за исключением этих дополнительных записей.
+-----------------+----------------+------------- ------------+ | Операция | Контекст | АллокЮнитнаме | +-----------------+---------------+---------------- ----------+ | LOP_COUNT_DELTA | LCX_CLUSTERED | sys.sysallocunits.clust | | LOP_COUNT_DELTA | LCX_CLUSTERED | sys.sysrowsets.clust | | LOP_COUNT_DELTA | LCX_CLUSTERED | sys.sysrscols.clst | | LOP_COUNT_DELTA | LCX_CLUSTERED | sys.sysrscols.clst | | LOP_HOBT_DDL | LCX_NULL | НУЛЕВОЙ | | LOP_MODIFY_ROW | LCX_CLUSTERED | sys.sysallocunits.clust | | LOP_HOBT_DDL | LCX_NULL | НУЛЕВОЙ | | LOP_MODIFY_ROW | LCX_CLUSTERED | sys.sysrowsets.clust | | LOP_LOCK_XACT | LCX_NULL | НУЛЕВОЙ | +-----------------+---------------+---------------- ----------+
Таким образом, первая версия TRUNCATE в конечном итоге тратит немного усилий на обновление различных системных таблиц следующим образом:
- Обновление
rcmodifiedдля всех столбцов таблицы в- Обновление
rcrowsвsysrowsets- Zero out
pgfirst,pgroot,pgfirstiam,pcused,pcdata,pcreservedвsys. системные единицы
системные единицы - Обновление
Эти строки системной таблицы удаляются только тогда, когда таблица удаляется в следующем операторе.
Полная разбивка журнала, выполненного с помощью TRUNCATE и DROP , приведена ниже. Я также добавил DELETE для сравнения.
+---------------------------------+------+------- ----------------------------+------------------+------------+----- ----------+-------------+----+------ -----+---------------+-------------+ | | | | Байты | Граф | +---------------------------------+-------------------+---------- -----------+------------------+------------+------- --------+-------------+------------------+-------- ---+---------------+-------------+ | Операция | Контекст | АллокЮнитнаме | Обрезать / удалить | Только падение | Только усечение | Удалить только | Обрезать / удалить | Только падение | Только усечение | Удалить только | +---------------------------------+-------------------+---------- -----------+------------------+------------+------- --------+-------------+------------------+-------- ---+---------------+-------------+ | LOP_BEGIN_XACT | LCX_NULL | | 132 | 132 | 132 | 132 | 1 | 1 | 1 | 1 | | LOP_COMMIT_XACT | LCX_NULL | | 52 | 52 | 52 | 52 | 1 | 1 | 1 | 1 | | LOP_COUNT_DELTA | LCX_CLUSTERED | Системная таблица | 832 | | 832 | | 4 | | 4 | | | LOP_DELETE_ROWS | LCX_MARK_AS_GHOST | Системная таблица | 2864 | 2864 | | | 22 | 22 | | | | LOP_DELETE_ROWS | LCX_MARK_AS_GHOST | Т | | | | 8108000 | | | | 1000 | | LOP_HOBT_DDL | LCX_NULL | | 108 | 36 | 72 | | 3 | 1 | 2 | | | LOP_LOCK_XACT | LCX_NULL | | 336 | 296 | 40 | | 8 | 7 | 1 | | | LOP_MODIFY_HEADER | LCX_PFS | Неизвестный блок Alloc | 76 | 76 | | 76 | 1 | 1 | | 1 | | LOP_MODIFY_ROW | LCX_CLUSTERED | Системная таблица | 644 | 348 | 296 | | 5 | 3 | 2 | | | LOP_MODIFY_ROW | LCX_IAM | Т | 800 | 800 | 800 | | 8 | 8 | 8 | | | LOP_MODIFY_ROW | LCX_PFS | Т | 11736 | 11736 | 11736 | | 133 | 133 | 133 | | | LOP_MODIFY_ROW | LCX_PFS | Неизвестный блок Alloc | 92 | 92 | 92 | | 1 | 1 | 1 | | | LOP_SET_BITS | LCX_GAM | Т | 9000 | 9000 | 9000 | | 125 | 125 | 125 | | | LOP_SET_BITS | LCX_IAM | Т | 9000 | 9000 | 9000 | | 125 | 125 | 125 | | | LOP_SET_BITS | LCX_PFS | Системная таблица | 896 | 896 | | | 16 | 16 | | | | LOP_SET_BITS | LCX_PFS | Т | | | | 56000 | | | | 1000 | | LOP_SET_BITS | LCX_SGAM | Неизвестный блок Alloc | 168 | 224 | 168 | | 3 | 4 | 3 | | +---------------------------------+-------------------+---------- -----------+------------------+------------+------- --------+-------------+------------------+-------- ---+---------------+-------------+ | Итого | | | 36736 | 35552 | 32220 | 8164260 | 456 | 448 | 406 | 2003 | +---------------------------------+-------------------+---------- -----------+------------------+------------+------- --------+-------------+------------------+-------- ---+---------------+-------------+
Тест проводился в базе данных с моделью полного восстановления для таблицы из 1000 строк с одной строкой на страницу. Всего таблица занимает 1004 страницы из-за корневой страницы индекса и 3 страниц индекса промежуточного уровня.
Всего таблица занимает 1004 страницы из-за корневой страницы индекса и 3 страниц индекса промежуточного уровня.
8 из этих страниц представляют собой одностраничные распределения в смешанных экстентах, а остальные распределены по 125 унифицированным экстентам. 8 отмен распределения отдельных страниц отображаются как 8 записей журнала LOP_MODIFY_ROW, LCX_IAM . Освобождение 125 экстентов как LOP_SET_BITS LCX_GAM, LCX_IAM . Обе эти операции также требуют обновления соответствующей страницы PFS , следовательно, объединенных записей 133 LOP_MODIFY_ROW, LCX_PFS . Затем, когда таблица фактически удалена, метаданные о ней должны быть удалены из различных системных таблиц, следовательно, 22 записи журнала LOP_DELETE_ROWS системной таблицы (учитываются, как показано ниже)
+------------- ----------+---------------+-----+---- ---------------+ | Объект | строки удалены | Количество индексов | Удалить операции | +----------------------+---------------+----------- ----------------------+-----+ | sys.sysallocunits | 1 | 2 | 2 | | sys.syscolpars | 2 | 2 | 4 | | sys.sysidxstats | 1 | 2 | 2 | | sys.sysiscols | 1 | 2 | 2 | | sys.sysobjзначения | 1 | 1 | 1 | | sys.sysrowsets | 1 | 1 | 1 | | sys.sysrscols | 2 | 1 | 2 | | sys.sysschobjs | 2 | 4 | 8 | +----------------------+---------------+----------- ----------------------+-----+ | | | | 22 | +----------------------+---------------+----------- ----------------------+-----+
Полный сценарий ниже
DECLARE @Results TABLE
(
Проверка int NOT NULL,
Операция nvarchar(31) NOT NULL,
Контекст nvarchar(31) NULL,
AllocUnitName nvarchar(1000) NULL,
СуммаLen целое NULL,
Целое число NULL
)
ОБЪЯВИТЬ @I INT = 1
ПОКА @I <= 4
НАЧИНАТЬ
ЕСЛИ OBJECT_ID('T','U') IS NULL
CREATE TABLE T(N INT PRIMARY KEY,Filler char(8000) NULL)
ВСТАВИТЬ В T(N)
ВЫБЕРИТЕ ОТЛИЧНЫЙ ТОП 1000 номеров
ОТ master..spt_values
КОНТРОЛЬНО-ПРОПУСКНОЙ ПУНКТ
ОБЪЯВИТЬ @allocation_unit_id БОЛЬШОЙ
ВЫБЕРИТЕ @allocation_unit_id = распределение_unit_id
ИЗ sys. partitions AS p
ВНУТРЕННЕЕ СОЕДИНЕНИЕ sys.allocation_units КАК
ПО p.hobt_id = a.container_id
ГДЕ p.object_id = object_id('T')
ОБЪЯВИТЬ @LSN NVARCHAR(25)
ОБЪЯВИТЬ @LSN_HEX NVARCHAR(25)
ВЫБЕРИТЕ @LSN = МАКС([Текущий LSN])
ОТ fn_dblog(ноль, ноль)
ВЫБЕРИТЕ @LSN_HEX=
CAST(CAST(CONVERT(varbinary,SUBSTRING(@LSN, 1, 8),2) AS INT) AS VARCHAR) + ':' +
CAST(CAST(CONVERT(varbinary,SUBSTRING(@LSN, 10, 8),2) AS INT) AS VARCHAR) + ':' +
CAST(CAST(CONVERT(varbinary,SUBSTRING(@LSN, 19), 4),2) КАК INT) КАК VARCHAR)
НАЧАТЬ ТРАН
ЕСЛИ @I = 1
НАЧИНАТЬ
ТАБЛИЦА ОБРЕЗАНИЯ T
СТОЛ Т
КОНЕЦ
ЕЩЕ
ЕСЛИ @I = 2
НАЧИНАТЬ
СТОЛ Т
КОНЕЦ
ЕЩЕ
ЕСЛИ @I = 3
НАЧИНАТЬ
ТАБЛИЦА ОБРЕЗАНИЯ T
КОНЕЦ
ЕЩЕ
ЕСЛИ @I = 4
НАЧИНАТЬ
УДАЛИТЬ ИЗ Т
КОНЕЦ
СОВЕРШИТЬ
ВСТАВЬТЕ В @Results
ВЫБЕРИТЕ @I,
СЛУЧАЙ
КОГДА ГРУППИРОВКА (Операция) = 1, ТОГДА «Всего»
ИНАЧЕ Операция
КОНЕЦ,
контекст,
СЛУЧАЙ
КОГДА AllocUnitId = @allocation_unit_id, ТО 'T'
КОГДА AllocUnitName LIKE 'sys.
partitions AS p
ВНУТРЕННЕЕ СОЕДИНЕНИЕ sys.allocation_units КАК
ПО p.hobt_id = a.container_id
ГДЕ p.object_id = object_id('T')
ОБЪЯВИТЬ @LSN NVARCHAR(25)
ОБЪЯВИТЬ @LSN_HEX NVARCHAR(25)
ВЫБЕРИТЕ @LSN = МАКС([Текущий LSN])
ОТ fn_dblog(ноль, ноль)
ВЫБЕРИТЕ @LSN_HEX=
CAST(CAST(CONVERT(varbinary,SUBSTRING(@LSN, 1, 8),2) AS INT) AS VARCHAR) + ':' +
CAST(CAST(CONVERT(varbinary,SUBSTRING(@LSN, 10, 8),2) AS INT) AS VARCHAR) + ':' +
CAST(CAST(CONVERT(varbinary,SUBSTRING(@LSN, 19), 4),2) КАК INT) КАК VARCHAR)
НАЧАТЬ ТРАН
ЕСЛИ @I = 1
НАЧИНАТЬ
ТАБЛИЦА ОБРЕЗАНИЯ T
СТОЛ Т
КОНЕЦ
ЕЩЕ
ЕСЛИ @I = 2
НАЧИНАТЬ
СТОЛ Т
КОНЕЦ
ЕЩЕ
ЕСЛИ @I = 3
НАЧИНАТЬ
ТАБЛИЦА ОБРЕЗАНИЯ T
КОНЕЦ
ЕЩЕ
ЕСЛИ @I = 4
НАЧИНАТЬ
УДАЛИТЬ ИЗ Т
КОНЕЦ
СОВЕРШИТЬ
ВСТАВЬТЕ В @Results
ВЫБЕРИТЕ @I,
СЛУЧАЙ
КОГДА ГРУППИРОВКА (Операция) = 1, ТОГДА «Всего»
ИНАЧЕ Операция
КОНЕЦ,
контекст,
СЛУЧАЙ
КОГДА AllocUnitId = @allocation_unit_id, ТО 'T'
КОГДА AllocUnitName LIKE 'sys. %' THEN 'Системная таблица'
ИНАЧЕ АллокЮнитнаме
КОНЕЦ,
COALESCE(SUM([Длина записи журнала]), 0) AS [Размер в байтах],
COUNT(*) КАК Cnt
ОТ fn_dblog(@LSN_HEX, null) КАК D
ГДЕ [Текущий номер LSN] > @LSN
ГРУППИРОВАТЬ ПО НАБОРАМ ГРУППИРОВКИ((Операция, Контекст,
СЛУЧАЙ
КОГДА AllocUnitId = @allocation_unit_id, ТО 'T'
КОГДА AllocUnitName LIKE 'sys.%' THEN 'Системная таблица'
ИНАЧЕ АллокЮнитнаме
КОНЕЦ),())
УСТАНОВИТЬ @I+=1
КОНЕЦ
ВЫБЕРИТЕ операцию,
контекст,
AllocUnitName,
AVG(CASE WHEN Testing = 1 THEN SumLen END) AS [Truncate/Drop Bytes],
AVG(CASE WHEN Testing = 2 THEN SumLen END) AS [Drop Bytes],
AVG(CASE WHEN Testing = 3 THEN SumLen END) AS [Truncate Bytes],
AVG(CASE WHEN Testing = 4 THEN SumLen END) AS [Удалить байты],
AVG(CASE WHEN Testing = 1 THEN Cnt END) AS [Truncate/Drop Count],
AVG(CASE WHEN Testing = 2 THEN Cnt END) AS [Drop Count],
AVG(CASE WHEN Testing = 3 THEN Cnt END) AS [Truncate Count],
AVG(CASE WHEN Testing = 4 THEN Cnt END) AS [Удалить счетчик]
ОТ @Результаты
СГРУППИРОВАТЬ ПО Операции,
контекст,
АллокЮнитнаме
ORDER BY Операция, Контекст, AllocUnitName
СТОЛ Т
%' THEN 'Системная таблица'
ИНАЧЕ АллокЮнитнаме
КОНЕЦ,
COALESCE(SUM([Длина записи журнала]), 0) AS [Размер в байтах],
COUNT(*) КАК Cnt
ОТ fn_dblog(@LSN_HEX, null) КАК D
ГДЕ [Текущий номер LSN] > @LSN
ГРУППИРОВАТЬ ПО НАБОРАМ ГРУППИРОВКИ((Операция, Контекст,
СЛУЧАЙ
КОГДА AllocUnitId = @allocation_unit_id, ТО 'T'
КОГДА AllocUnitName LIKE 'sys.%' THEN 'Системная таблица'
ИНАЧЕ АллокЮнитнаме
КОНЕЦ),())
УСТАНОВИТЬ @I+=1
КОНЕЦ
ВЫБЕРИТЕ операцию,
контекст,
AllocUnitName,
AVG(CASE WHEN Testing = 1 THEN SumLen END) AS [Truncate/Drop Bytes],
AVG(CASE WHEN Testing = 2 THEN SumLen END) AS [Drop Bytes],
AVG(CASE WHEN Testing = 3 THEN SumLen END) AS [Truncate Bytes],
AVG(CASE WHEN Testing = 4 THEN SumLen END) AS [Удалить байты],
AVG(CASE WHEN Testing = 1 THEN Cnt END) AS [Truncate/Drop Count],
AVG(CASE WHEN Testing = 2 THEN Cnt END) AS [Drop Count],
AVG(CASE WHEN Testing = 3 THEN Cnt END) AS [Truncate Count],
AVG(CASE WHEN Testing = 4 THEN Cnt END) AS [Удалить счетчик]
ОТ @Результаты
СГРУППИРОВАТЬ ПО Операции,
контекст,
АллокЮнитнаме
ORDER BY Операция, Контекст, AllocUnitName
СТОЛ Т
Усечение даты для настраиваемых периодов времени, таких как год, квартал, месяц и т.
 д. · Расширенный SQL · SILOTA
д. · Расширенный SQL · SILOTA- Рецепты SQL
- Совместимость с базой данных
- SQL Server: усечение даты для настраиваемых периодов времени, таких как год, квартал, месяц и т. д.
Oracle имеет функцию trunc , а PostgreSQL/Redshift имеет функцию date_trunc , которая позволяет урезать метку времени до определенной единицы измерения, такой как год, квартал, месяц, неделя и т. д. Эти функции удобны при свертывании и агрегирование данных для настраиваемых интервалов.
Если вам нужна аналогичная функция для SQL Server, вы можете использовать этот макрос:
выберите датудобавить({период}, datediff({период}, 0, {поле}), 0)
Где {период} — это интересующий период, например ГОД, КВАРТАЛ, МЕСЯЦ, ДЕНЬ, ЧАС и т. д., а {поле} — интересующий столбец.
Примеры
| Отметка времени | Интервал | SQL | Результат |
|---|---|---|---|
| 2017-05-13T01:17:42Z | ГОД | выберите dateadd(YEAR, datediff(YEAR, 0, {поле}), 0) | 2017-01-01T00:00:00Z |
| 2017-05-13T01:17:42Z | КВАРТАЛ | выберите датудобавить(КВАРТАЛ,датадифф(КВАРТАЛ,0,{поле}),0) | 2017-04-01T00:00:00Z |
| 2017-05-13T01:17:42Z | МЕСЯЦ | выберите датудобавить(МЕСЯЦ,датадифф(МЕСЯЦ,0,{поле}),0) | 2017-05-01T00:00:00Z |
| 2017-05-13T01:17:42Z | НЕДЕЛЯ | выберите dateadd(WEEK, datediff(WEEK, 0, {поле}), 0) | 2017-05-08T00:00:00Z |
| 2017-05-13T01:17:42Z | ДЕНЬ | выберите dateadd(DAY, datediff(DAY, 0, {field}), 0) | 2017-05-13T00:00:00Z |
| 2017-05-13T01:17:42Z | ЧАС | выберите dateadd(HOUR, datediff(HOUR, 0, {поле}), 0) | 2017-05-13T01:00:00Z |
SQL-макрос Silota для усечения даты
Silota делает это очень просто с нашими макросами SQL. Например:
Например:
объявить @dt как datetime = '2017-05-13T01:17:42Z';
выберите @dt в качестве оригинала,
«год» как период,
[@dt:year] как Результат
союз
выберите @dt в качестве оригинала,
«четверть» как период,
[@dt:quarter] как Результат
союз
выберите @dt в качестве оригинала,
«месяц» как период,
[@dt:month] как результат
союз
выберите @dt в качестве оригинала,
«неделя» как период,
[@dt:week] как результат
союз
выберите @dt в качестве оригинала,
«день» как период,
[@dt:day] как результат
союз
выберите @dt в качестве оригинала,
«час» как период,
[@dt:hour] как результат
👋 Никакой суеты, только SQL Мы используем открытый исходный код, исходя из опыта работы с клиентами нашего агентства. Они тратят тысячи долларов, чтобы получить такой уровень подробного анализа, который теперь вы можете получить бесплатно.
