Кодировка (128–255) | Microsoft Learn
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
| Код | Знак | Код | Знак | Код | Знак | Код | Знак |
|---|---|---|---|---|---|---|---|
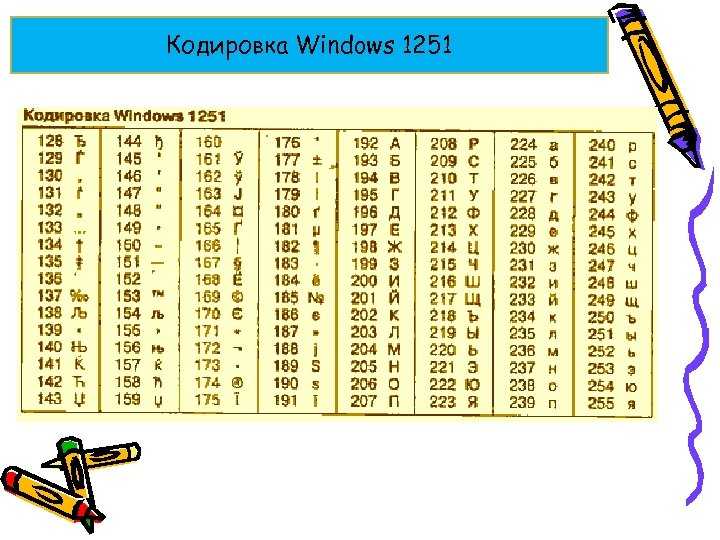
| 128 | € | 160 | [пробел] | 192 | À | 224 | à |
| 129 | 161 | ¡ | 193 | Á | 225 | á | |
| 130 | ‚ | 162 | ¢ | 194 | Â | 226 | Â |
| 131 | Ƒ | 163 | £ | 195 | Ã | 227 | Ã |
| 132 | „ | 164 | ¤ | 196 | Ä | 228 | Ä |
| 133 | … | 165 | ¥ | 197 | Å | 229 | Å |
| 134 | † | 166 | ¦ | 198 | Æ | 230 | Æ |
| 135 | ‡ | 167 | § | 199 | Ç | 231 | ç |
| 136 | ˆ | 168 | ¨ | 200 | È | 232 | È |
| 137 | ‰ | 169 | © | 201 | É | 233 | É |
| 138 | Š | 170 | ª | 202 | Ê | 234 | ê |
| 139 | ‹ | 171 | « | 203 | Ë | 235 | ë |
| 140 | Ё | 172 | ¬ | 204 | Ì | 236 | ì |
| 141 | 173 | | 205 | Í | 237 | í | |
| 142 | Ž | 174 | ® | 206 | Î | 238 | Î |
| 143 | 175 | ¯ | 207 | Ï | 239 | ï | |
| 144 | 176 | ° | 208 | Й | 240 | е | |
| 145 | ‘ | 177 | 209 | Ñ | 241 | Ñ | |
| 146 | ’ | 178 | ² | 210 | Ò | 242 | ò |
| 147 | “ | 179 | ³ | 211 | Ó | 243 | ó |
| 148 | ” | 180 | ´ | 212 | Ô | 244 | Ô |
| 149 | • | 181 | µ | 213 | Õ | 245 | Õ |
| 150 | – | 182 | ¶ | 214 | Ö | 246 | Ö |
| 151 | — | 183 | · | 215 | × | 247 | ÷ |
| 152 | ˜ | 184 | ¸ | 216 | Ø | 248 | Ø |
| 153 | ™ | 185 | ¹ | 217 | Ù | 249 | ù |
| 154 | Š | 186 | º | 218 | Ú | 250 | ú |
| 155 | › | 187 | » | 219 | Û | 251 | û |
| 156 | ов | 188 | ¼ | 220 | Ü | 252 | Ü |
| 157 | 189 | ½ | 221 | Ý | 253 | ý | |
| 158 | ž | 190 | ¾ | 222 | М | 254 | ş |
| 159 | Ÿ | 191 | ¿ | 223 | ß | 255 | ÿ |
Символ 160 — это пробел без перерыва. Символ 173 — это мягкий дефис. Некоторые символы не поддерживаются в Microsoft Windows (символы 129, 141, 143, 144 и 157).
Символ 173 — это мягкий дефис. Некоторые символы не поддерживаются в Microsoft Windows (символы 129, 141, 143, 144 и 157).
В таблице приведены значения Windows по умолчанию. Однако значения в кодировке ANSI после кода 127 определяются кодовой страницей конкретной операционной системы.
- Функция Chr
Поддержка и обратная связь
Есть вопросы или отзывы, касающиеся Office VBA или этой статьи? Руководство по другим способам получения поддержки и отправки отзывов см. в статье Поддержка Office VBA и обратная связь.
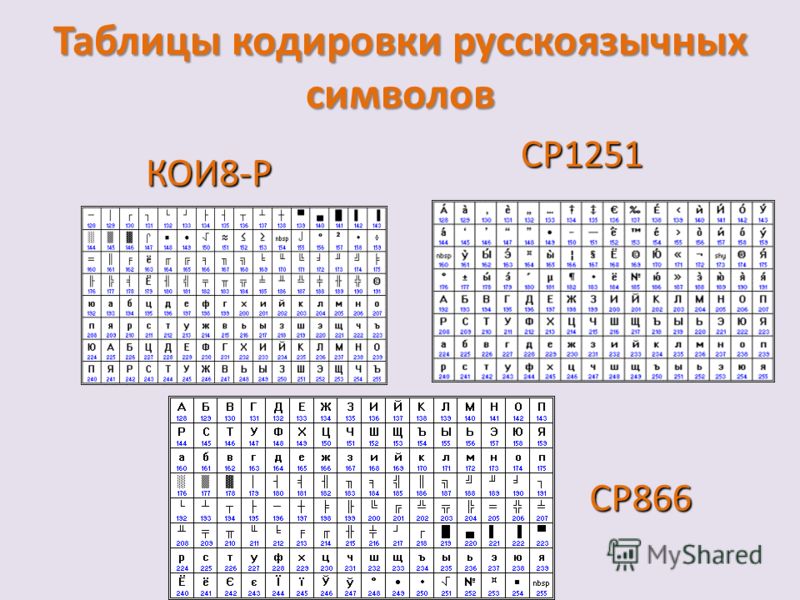
Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрами
Сегодня мы поговорим о том, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная с базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.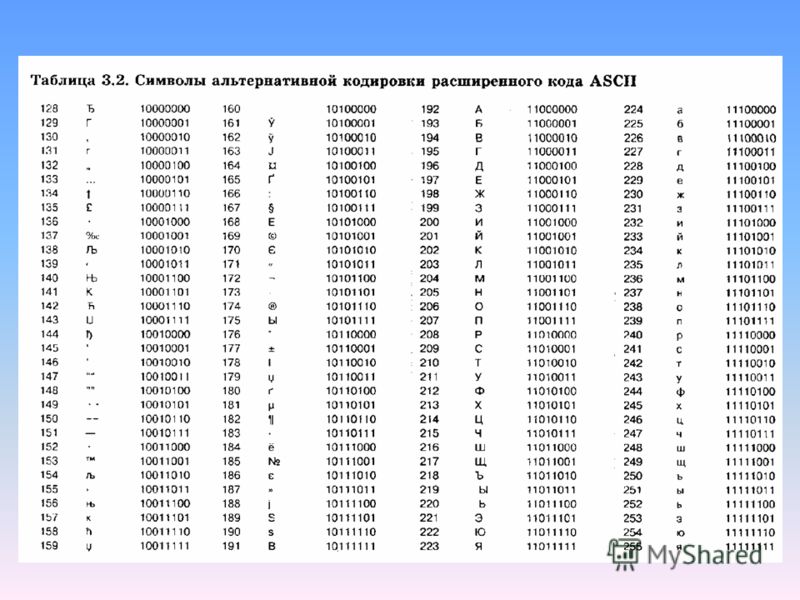 Оглавление:
Оглавление:
- ASCII — базовая кодировка текста для латиницы
- Расширенные версии Аски — кодировки CP866 и KOI8-R
- Windows 1251 — вариация ASCII и почему вылезают кракозябры
- Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
- Кракозябры вместо русских букв — как исправить
Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (нечитаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки неблагозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.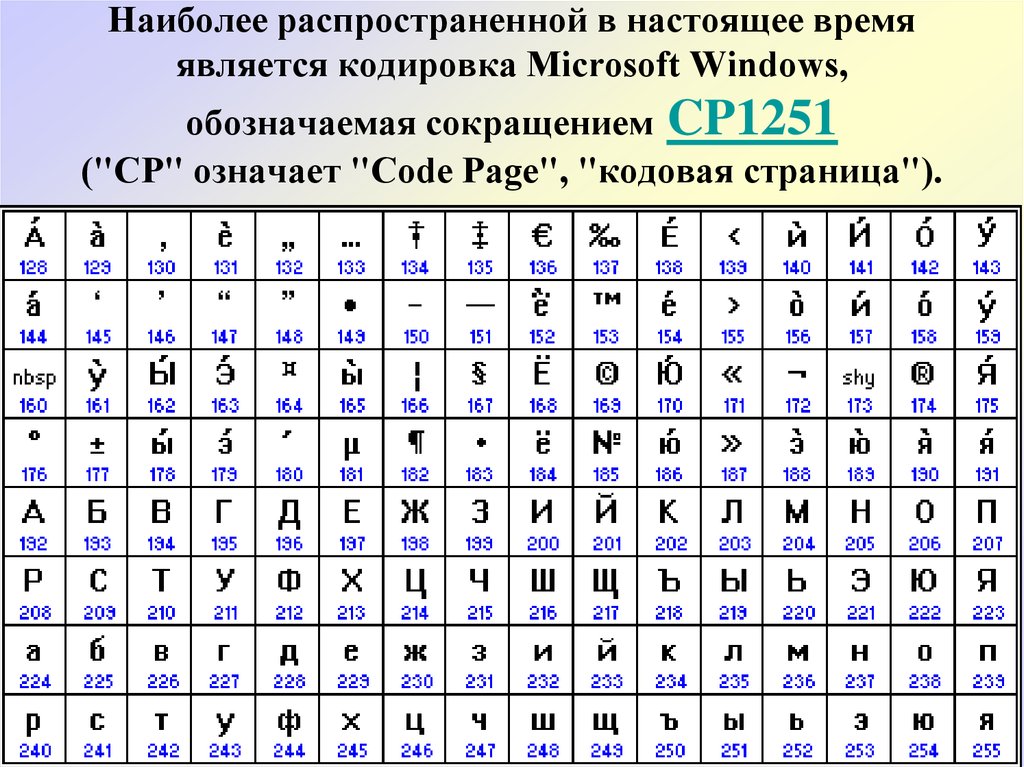 Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую 
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8). Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.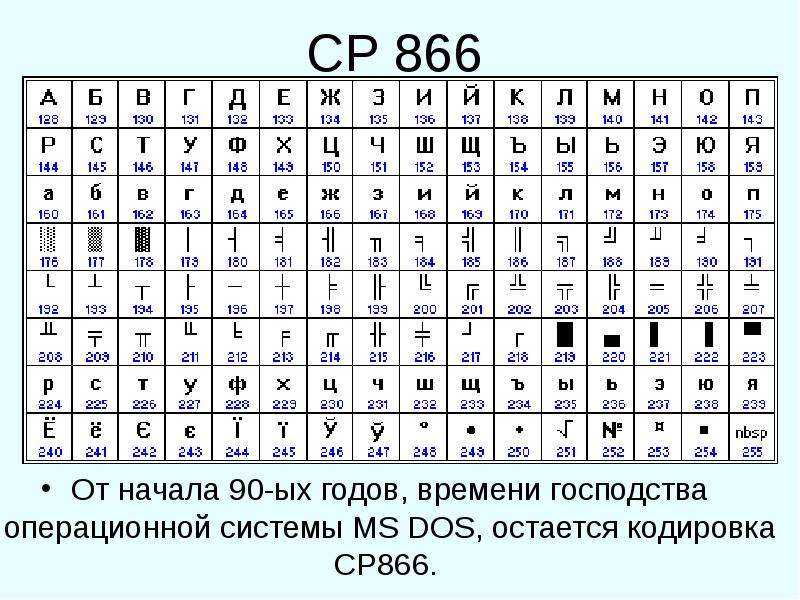
 к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Таким образом, у кириллической буквы «М» в CP866 будет код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда графические операционные системы не были распространены как сейчас. А в Досе и подобных ей текстовых операционках псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
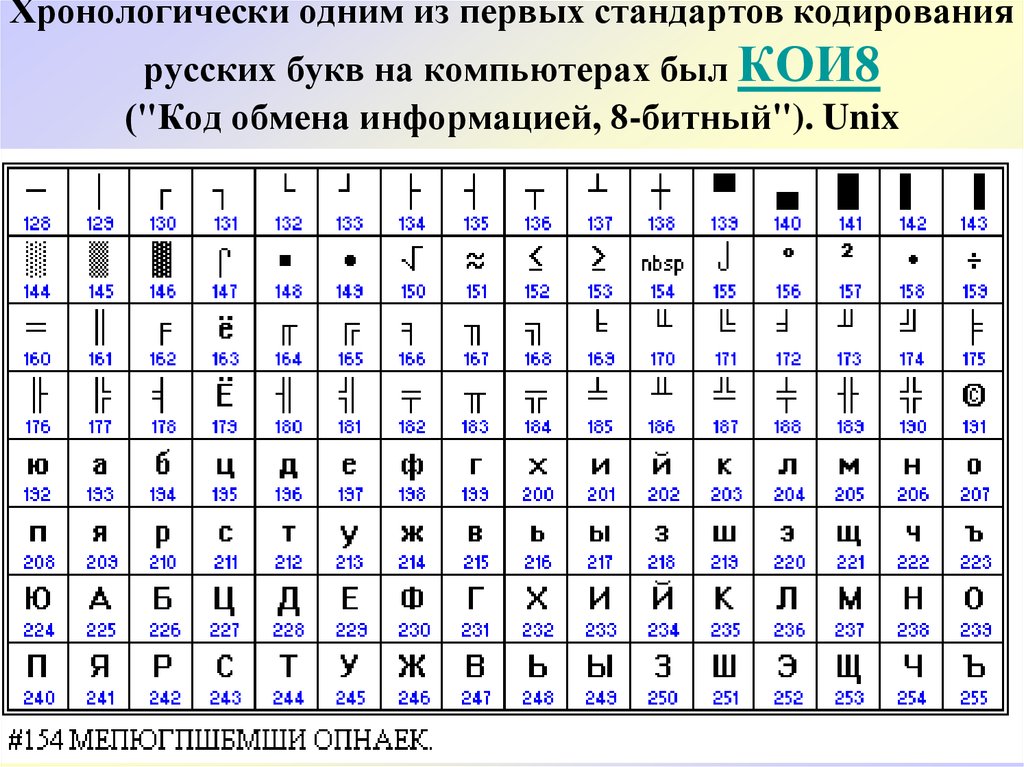
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:
Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом.
к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Таким образом, у кириллической буквы «М» в CP866 будет код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда графические операционные системы не были распространены как сейчас. А в Досе и подобных ей текстовых операционках псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:
Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом.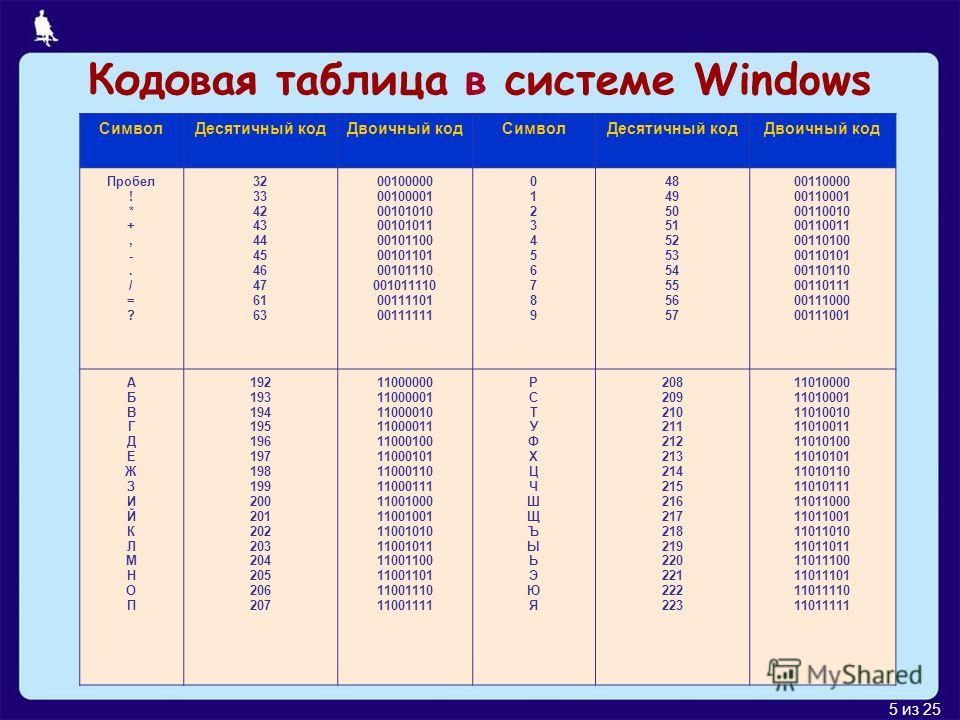 На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что кириллические буквы в ее таблице идут не в алфавитном порядке, как это сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что кириллические буквы в ее таблице идут не в алфавитном порядке, как это сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.
В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.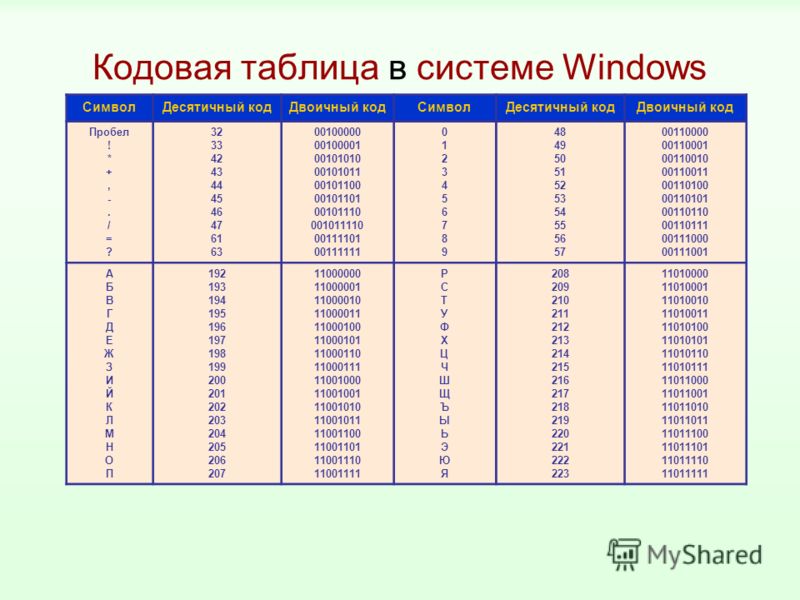 Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Аналогичная ситуация очень часто возникает при создании и настройке сайтов, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Аналогичная ситуация очень часто возникает при создании и настройке сайтов, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.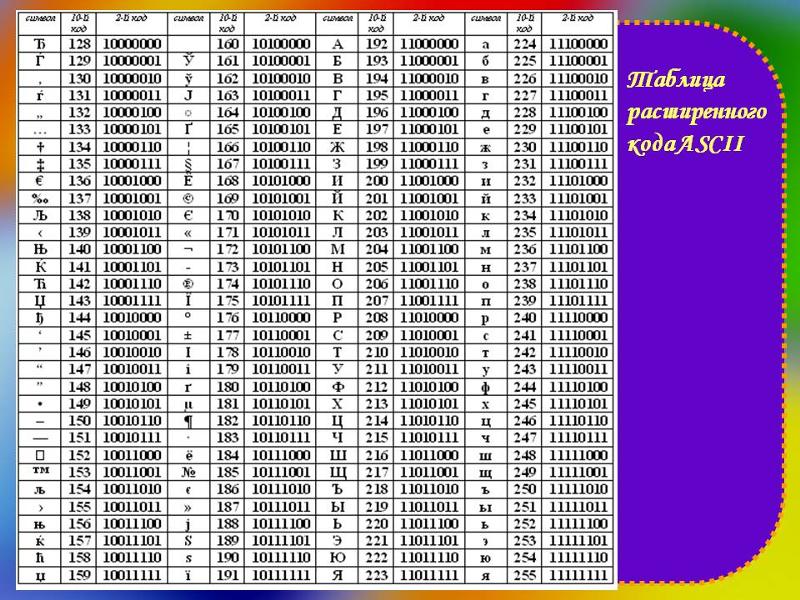 В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет-трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет-трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.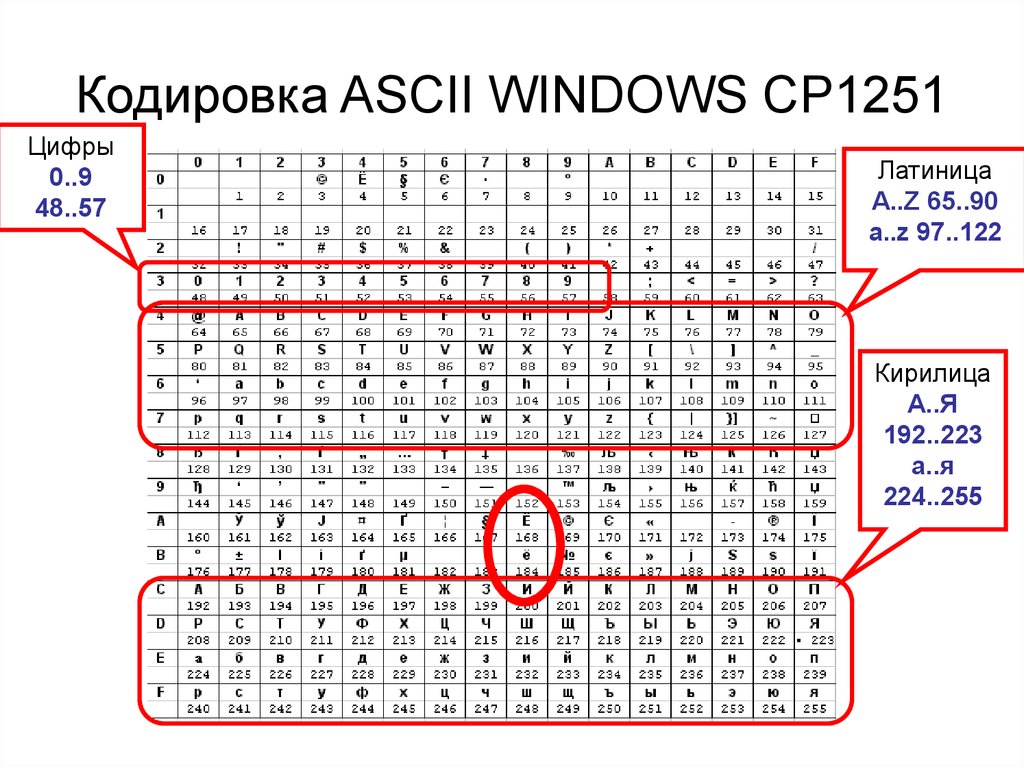 В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде.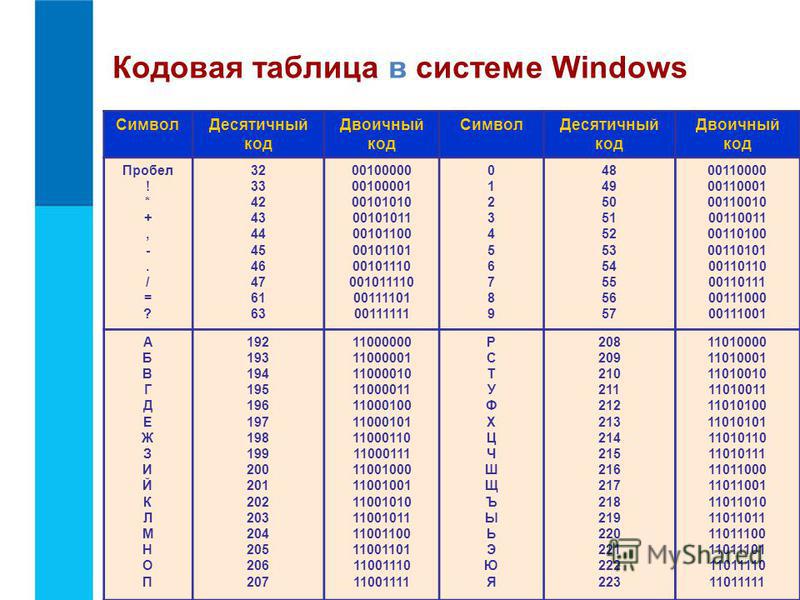 Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. То есть, базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. То есть, базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A).
Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности.
А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка. После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название: Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название: Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, если вы сохраняете документ в принятом по умолчанию юникоде, это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).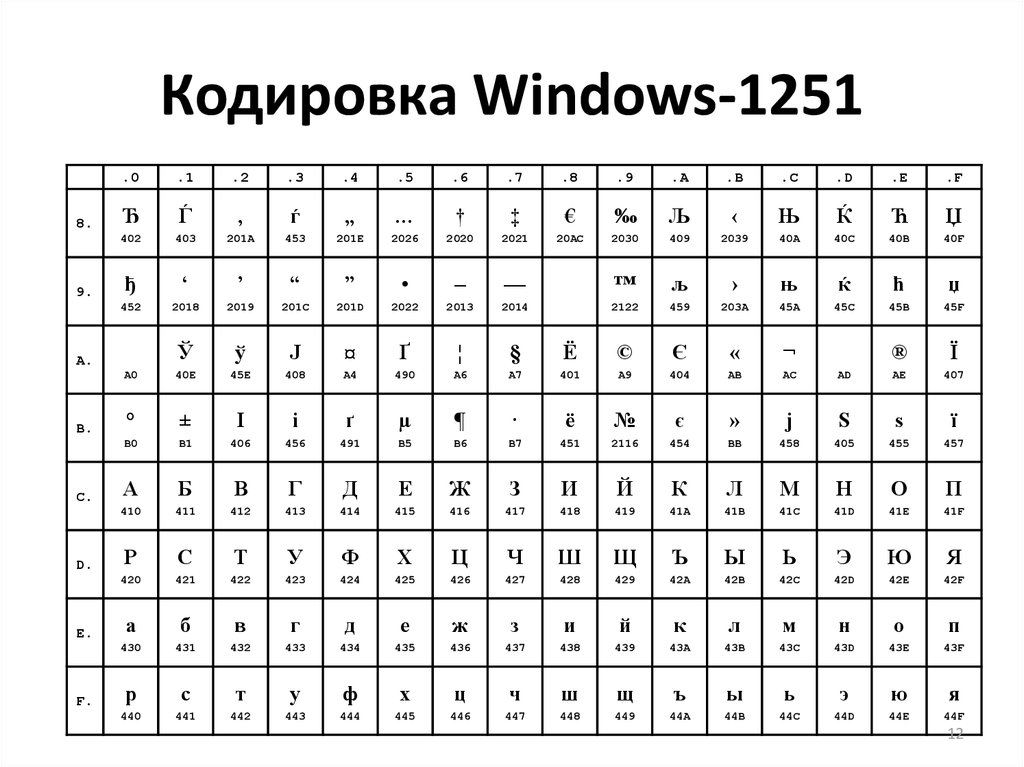 В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
<head> ... <meta charset="utf-8"> ... </head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами. По идее элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов. Ссылка на первоисточник: Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрами
Обзор Windows-1252
Код ASCII
Таблица ASCII
Символы ASCII Искусство ASCIIЧасто задаваемые вопросыФактыИсторияГлоссарийСравнить
Страница обзора и информации о наборе символов Windows-1252, содержащая информацию о поддерживаемых языках, производителях, псевдонимах, классификации и т. д.
д.
Windows-1252
TableCode ChartCompactGridOverview
Обзор
| MIME/IANA | windows-1252 |
| Alias | Code page 1252 |
| Category | Windows code pages |
| Created by | Microsoft |
| Languages | English, Danish, Irish , итальянский, норвежский, португальский, испанский, шведский, немецкий, финский, исландский, французский, фарерский, люксембургский, албанский, эстонский, суахили, тсвана, каталанский, баскский, окситанский, ротока, ретороманский, голландский и словенский |
| Стандарт | Стандарт кодирования WHATWG |
| Классификация | Расширенный ASCII, Windows-125x |
Макет кодовой страницы ␀ ␁ ␂ ␃ ␄ ␅ ␆ ␇ ␈ ␉ ␊ ␋ 9999999999999999999999999999999999999999999999999999999999999999994999999999999949н. ␏ ␐ ␑ ␒ ␓ ␔ ␕ ␖ ␗ ␘ ␙ ␚ ␛ ␜ ␝ ␞ ␟
! « # $ % и ‘ ( ) * + , — ./ 1 2 3 4 5 6 7 8 : ; = > ? @ A B C D E F G H I J K L M N O Р В Р 9 _ ` a b c d e f g h i j k l m n O P Q R S T U V W x Y Z { | } ~ ␡ € ‚ ƒ „ … † ‡ ˆ ‰ Š ‹ Œ Ž ‘ ‘ “ ” • – — ˜ ™ š › œ ž Ÿ
¡ ¢ £ ¤ ¥ ¦ § ¨ © ª « ¬
® ¯ ° ± ² ³ ´ µ ¶ · ¸ ¹ º » ¼ ½ ¾ ¿ À Á Â Ã Ä Å Æ Ç È É Ê Ë Ì Í Î Ï Ð Ñ Ò Ó Ô Õ Ö × Ø Ù Ú Û Ü Ý Þ ß à á â ã ä å æ ç è Э ê ë ì í î ï ð ñ ò ó ô õ ö ÷ ø ù ú û ü ý þ ÿ | |
 0009 ␎
0009 ␎ Windows-1252, также известная как «CP-1252» или «WinLatin1», представляет собой кодировку символов, используемую для представления латинского алфавита.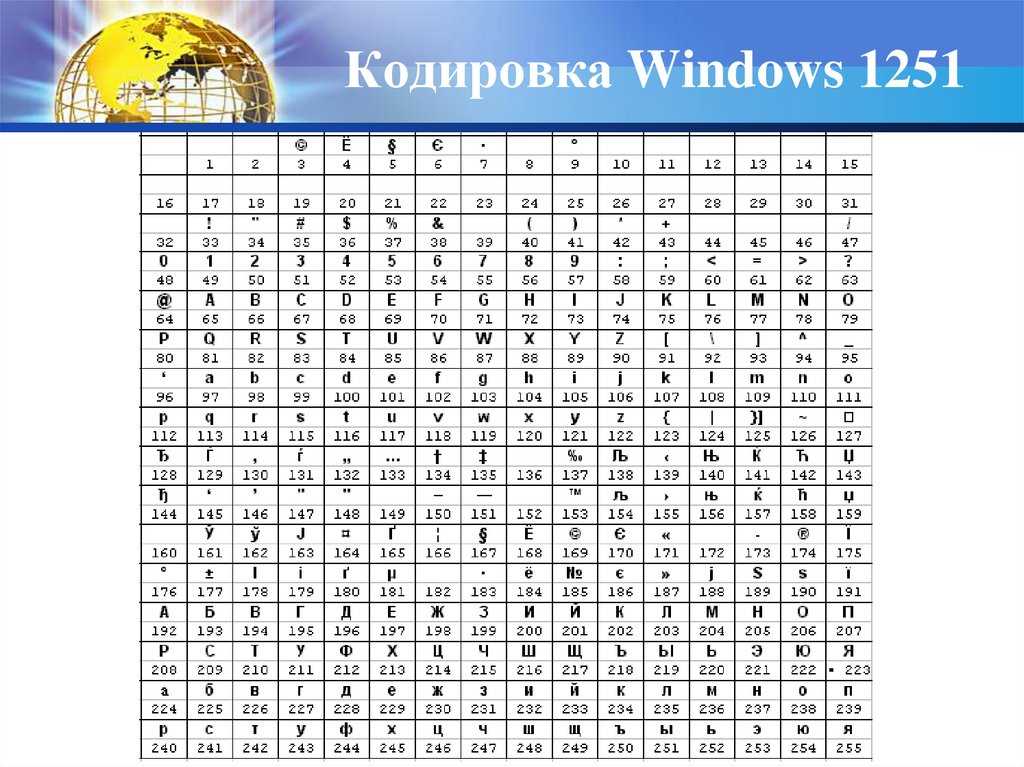 Он был представлен Microsoft в операционной системе Windows и основан на ISO 8859.-1 (Latin-1), но включает некоторые дополнительные символы. Windows-1252 широко используется для западноевропейских языков, включая английский, испанский, французский, немецкий и итальянский.
Он был представлен Microsoft в операционной системе Windows и основан на ISO 8859.-1 (Latin-1), но включает некоторые дополнительные символы. Windows-1252 широко используется для западноевропейских языков, включая английский, испанский, французский, немецкий и итальянский.
Это кодировка символов по умолчанию во многих программных продуктах Microsoft, а также широко используется в веб-разработке. Windows-1252 обеспечивает поддержку ряда знаков и символов, что делает ее пригодной для использования в различных приложениях. Однако важно отметить, что Windows-1252 плохо подходит для языков, отличных от западноевропейских, и может вызвать проблемы при работе с символами из других сценариев.
Часто задаваемые вопросы
Нет, ANSI и Windows-1252 — это не одно и то же. ANSI — это термин, обозначающий различные стандарты кодировки символов, использовавшиеся в ранних версиях Microsoft Windows. Windows-1252, с другой стороны, представляет собой особый стандарт кодировки символов, который использовался в западноевропейских версиях Windows.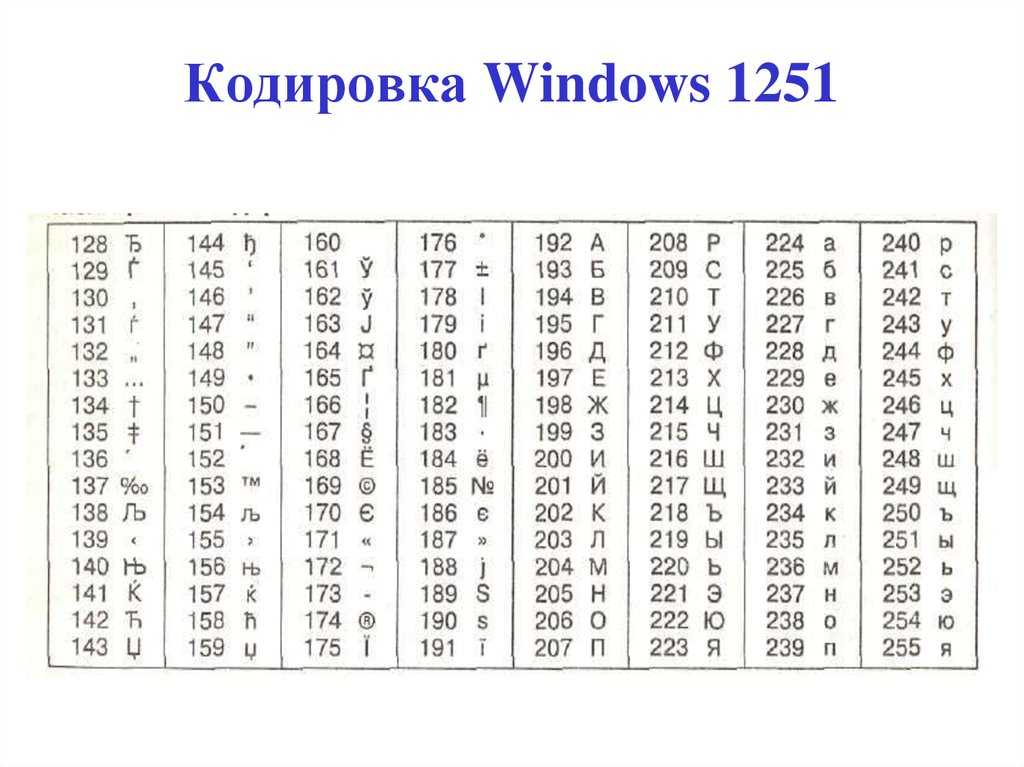 Хотя Windows-1252 является типом кодировки ANSI, не все кодировки ANSI совпадают с кодировкой Windows-1252.
Хотя Windows-1252 является типом кодировки ANSI, не все кодировки ANSI совпадают с кодировкой Windows-1252.
Обычно для большинства приложений рекомендуется использовать кодировку UTF-8 вместо Windows-1252. Если вам нужно поддерживать символы из нескольких скриптов и языков или если вы разрабатываете для глобальной аудитории, UTF-8 является более подходящим выбором. Однако, если вам нужна поддержка только западноевропейских языков, можно использовать Windows-1252.
Windows-1252 — это стандарт кодировки символов, используемый в основном в странах Западной Европы и широко используемый в ранних версиях Microsoft Windows, что делает его широко используемой кодировкой для западноевропейских языков. Он также известен как CP-1252 или «ANSI» в некоторых контекстах.
Windows-1252 — это система кодирования символов, в которой для представления каждого символа используется один байт (8 бит). Это схема кодирования с фиксированной шириной, что означает, что каждый символ представлен ровно одним байтом, что обеспечивает простую и эффективную обработку текста.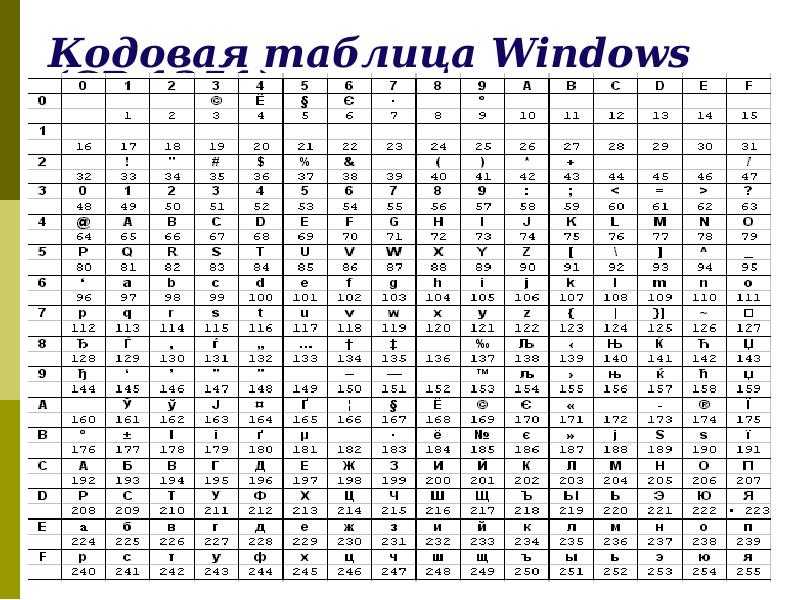 В Windows-1252 каждому символу присваивается уникальный двоичный код, соответствующий его положению в наборе символов. Первые 128 символов (0-127) совпадают с набором символов ASCII, а остальные 128 символов (128-255) используются для представления дополнительных символов, используемых в западноевропейских языках, таких как буквы с диакритическими знаками, знаки препинания и денежная единица. символы.
В Windows-1252 каждому символу присваивается уникальный двоичный код, соответствующий его положению в наборе символов. Первые 128 символов (0-127) совпадают с набором символов ASCII, а остальные 128 символов (128-255) используются для представления дополнительных символов, используемых в западноевропейских языках, таких как буквы с диакритическими знаками, знаки препинания и денежная единица. символы.
ISO-8859-1 и Windows-1252 являются стандартами кодирования символов, используемыми для представления текста на компьютерах. Таким образом, основное различие между ISO-8859-1 и Windows-1252 заключается в количестве символов, которые они могут представлять, и в конкретных символах, включенных в каждый стандарт. Windows-1252 включает несколько дополнительных символов, которые не являются частью стандарта ISO-8859-1, но в остальном в значительной степени совместимы с ним.
Windows-1252 и UTF-8 — это разные стандарты кодировки символов, используемые для представления текста на компьютерах. Основное различие между Windows-1252 и UTF-8 заключается в количестве символов, которые они могут представлять, и в их совместимости с различными сценариями и языками. UTF-8 — более универсальная и широко используемая кодировка по сравнению с Windows-1252.
Основное различие между Windows-1252 и UTF-8 заключается в количестве символов, которые они могут представлять, и в их совместимости с различными сценариями и языками. UTF-8 — более универсальная и широко используемая кодировка по сравнению с Windows-1252.
Windows-1252, также известная как CP-1252, представляет собой стандарт кодирования символов, используемый в основном в странах Западной Европы. Он широко использовался в ранних версиях Microsoft Windows и часто считается вариантом или расширением ISO-8859-1. Кодовая страница Windows-1252 может содержать до 256 символов, включая символы, используемые в западноевропейских языках, таких как французский, немецкий и испанский. Он включает в себя ряд символов и символов, не встречающихся в стандарте ISO-8859-1, таких как изогнутые кавычки и символ евро.
Ссылки
https://en.wikipedia.org/wiki/Extended_ASCII
https://en.wikipedia.org/wiki/Windows-1252
https://www.unicode.org/ Public/MAPPINGS/VENDORS/MICSFT/WINDOWS/CP1252.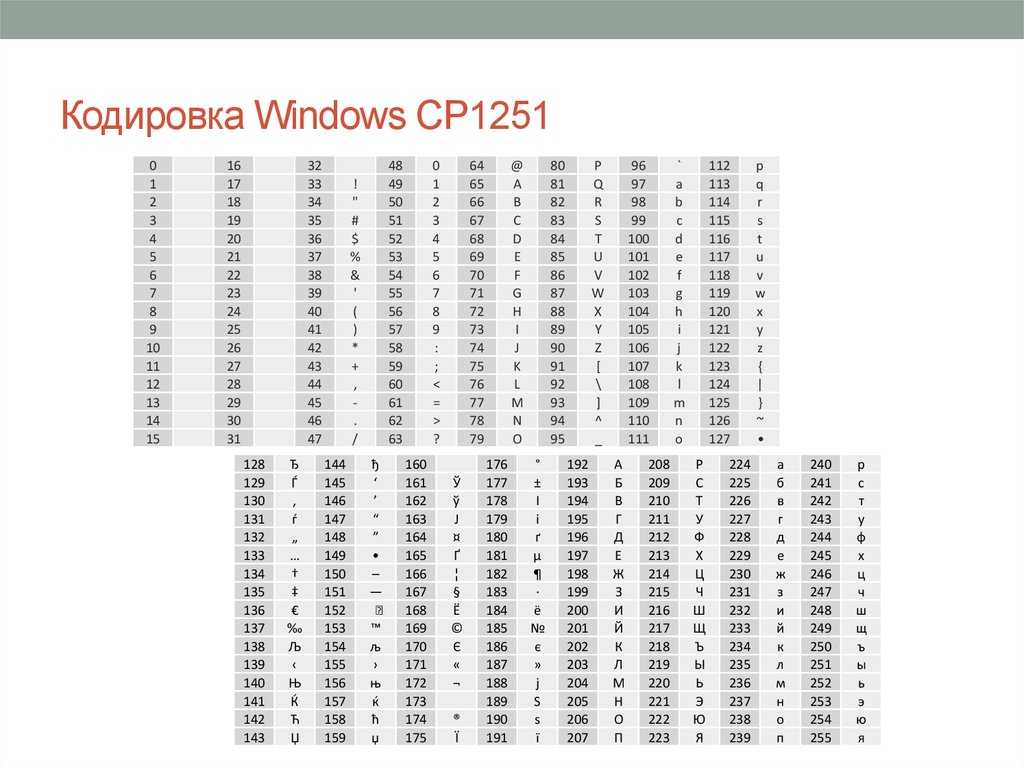 TXT
TXT
https://www.iana.org/assignments/character-sets/character-sets.xhtml
Набор символов (128–255)
Редактировать
Твиттер LinkedIn Фейсбук Электронная почта
- Статья
- 2 минуты на чтение
| Код | Символ | Код | Символ | Код | Символ | Код | Символ |
|---|---|---|---|---|---|---|---|
| 128 | € | 160 | [пробел] | 192 | À | 224 | и |
| 129 | 161 | ¡ | 193 | Á | 225 | а | |
| 130 | ‚ | 162 | ¢ | 194 | Â | 226 | — |
| 131 | ƒ | 163 | £ | 195 | Ã | 227 | ã |
| 132 | „ | 164 | ¤ | 196 | Ä | 228 | и |
| 133 | … | 165 | ¥ | 197 | Å | 229 | х |
| 134 | † | 166 | ¦ | 198 | Æ | 230 | æ |
| 135 | ‡ | 167 | § | 199 | Ç | 231 | и |
| 136 | ˆ | 168 | ¨ | 200 | È | 232 | и |
| 137 | ‰ | 169 | © | 201 | Э | 233 | и |
| 138 | Ш | 170 | ª | 202 | К | 234 | ê |
| 139 | ‹ | 171 | « | 203 | Ë | 235 | — |
| 140 | – | 172 | ¬ | 204 | М | 236 | х |
| 141 | 173 | 205 | Í | 237 | и | ||
| 142 | Ž | 174 | ® | 206 | О | 238 | î |
| 143 | 175 | ¯ | 207 | О | 239 | ï | |
| 144 | 176 | ° | 208 | Р | 240 | ð | |
| 145 | ‘ | 177 | ± | 209 | С | 241 | – |
| 146 | ’ | 178 | ² | 210 | Т | 242 | х |
| 147 | » | 179 | ³ | 211 | О | 243 | — |
| 148 | » | 180 | ´ | 212 | Ô | 244 | х |
| 149 | • | 181 | µ | 213 | х | 245 | х |
| 150 | – | 182 | ¶ | 214 | . .. .. | 246 | или |
| 151 | — | 183 | · | 215 | × | 247 | ÷ |
| 152 | ~ | 184 | ¸ | 216 | Ø | 248 | ø |
| 153 | ™ | 185 | № | 217 | Ù | 249 | х |
| 154 | š | 186 | º | 218 | Ú | 250 | ú |
| 155 | › | 187 | » | 219 | Û | 251 | х |
| 156 | – | 188 | = | 220 | О | 252 | и |
| 157 | 189 | ½ | 221 | Ý | 253 | х | |
| 158 | ž | 190 | ¾ | 222 | Þ | 254 | + |
| 159 | Ÿ | 191 | À | 223 | ß | 255 | ÿ |
Символ 160 — неразрывный пробел.