GROUPING (Transact-SQL) — SQL Server
Twitter LinkedIn Facebook Адрес электронной почты- Статья
Применимо к: Конечная точка SQL SQL Server Azure SQL База данныхУправляемый экземпляр SQL AzureAzure Synapse Analyticsв Хранилище Microsoft Fabricв Microsoft Fabric
Указывает, является ли указанное выражение столбца в списке GROUP BY статистическим или нет. В результирующем наборе функция GROUPING возвращает 1 (статистическое выражение) или ноль (нестатистическое выражение). Функция GROUPING может использоваться только в предложениях SELECT <select>, HAVING и ORDER BY, если указано предложение GROUP BY.
В результирующем наборе функция GROUPING возвращает 1 (статистическое выражение) или ноль (нестатистическое выражение). Функция GROUPING может использоваться только в предложениях SELECT <select>, HAVING и ORDER BY, если указано предложение GROUP BY.
Соглашения о синтаксисе Transact-SQL
Синтаксис
GROUPING ( <column_expression> )
Примечание
Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.
Аргументы
<column_expression>
Столбец или выражение, которое содержит столбец в предложении GROUP BY.
Типы возвращаемых данных
tinyint
GROUPING используется, чтобы различать значения NULL, возвращаемые операторами ROLLUP, CUBE или GROUPING SETS, и стандартные значения NULL. Возвращение NULL в качестве результата операции ROLLUP, CUBE или GROUPING SETS является особым случаем использования NULL. Значение служит заполнителем столбца в результирующем наборе и означает «все».
Примеры
В следующем примере суммы группируются SalesQuota и агрегируются SaleYTD в базе данных AdventureWorks2022. Функция GROUPING применяется к столбцу SalesQuota.
SELECT SalesQuota, SUM(SalesYTD) 'TotalSalesYTD', GROUPING(SalesQuota) AS 'Grouping' FROM Sales.SalesPerson GROUP BY SalesQuota WITH ROLLUP; GO
В результирующем наборе показаны два значения NULL в SalesQuota. Первый NULL представляет группу значений NULL из этого столбца в таблице. Второй NULL находится в строке итогов, добавленной операцией ROLLUP. Строка итогов содержит суммы TotalSalesYTD для всех групп SalesQuota и обозначается с помощью 1 в столбце Grouping.
Результирующий набор:
SalesQuota TotalSalesYTD Grouping ------------ ----------------- -------- NULL 1533087.5999 0 250000.00 33461260.59 0 300000.00 9299677.9445 0 NULL 44294026.1344 1 (4 row(s) affected)
См. также:
GROUPING_ID (Transact-SQL)
GROUP BY (Transact-SQL)
SQL-Урок 8. Группировка данных (GROUP BY)
ВВЕРХ❮ ❯
Группировка данных позволяет разделить все данные на логические наборы, благодаря чему становится возможным выполнение статистических вычислений отдельно в каждой группе.
1. Создание групп (GROUP BY)
Группы создаются с помощью предложения GROUP BY оператора SELECT. Рассмотрим на примере.
SELECT Product, SUM(Quantity) AS Product_num FROM Sumproduct GROUP BY Product
Данным запросом мы извлекли информацию о количестве реализованной продукции в каждом месяце. Оператор SELECT приказывает вывести два столбца Product — название продукта и Product_num — расчетное поле, которое мы создали для отображения количества реализованной продукции (формула поля SUM (Quantity)
). Предложение GROUP BY указывает СУБД сгруппировать данные по столбцу Product.
Предложение GROUP BY указывает СУБД сгруппировать данные по столбцу Product.Стоит также отметить, что GROUP BY должен идти после предложения WHERE и перед ORDER BY.
2. Фильтрующие группы (HAVING)
Так же, как мы фильтровали строки в таблице, мы можем осуществлять фильтрацию по сгруппированным данным. Для этого в SQL существует оператор HAVING. Возьмем предыдущий пример и добавим фильтрацию по группам.
SELECT Product, SUM(Quantity) AS Product_num FROM Sumproduct GROUP BY Product HAVING SUM(Quantity) > 4000
Видим, что после того, как была посчитана количество реализованного товара в разрезе каждого продукта, СУБД «отсекла» те продукты, которых было реализовано меньше 4000 шт.
 Таким образом, строки, которые были изъяты предложением WHERE НЕ будут включены в группу. Итак, операторы WHERE и HAVING могут использоваться в одном предложении. Рассмотрим пример:
Таким образом, строки, которые были изъяты предложением WHERE НЕ будут включены в группу. Итак, операторы WHERE и HAVING могут использоваться в одном предложении. Рассмотрим пример:SELECT Product, SUM(Quantity) AS Product_num FROM Sumproduct WHERE Product 'Skis Long' GROUP BY Product HAVING SUM(Quantity) > 4000
Мы к предыдущему примеру добавили оператор WHERE, где указали товар Skis Long, что в свою очередь повлияло на группирование оператором HAVING. Как результат видим, что товар Skis Long не попал в перечень групп с количеством реализованной продукции больше 4000 шт.
3. Группировка и сортировка
Как и при обычной выборке данных, мы можем сортировать группы после группировки оператором HAVING.
Для этого мы можем использовать уже знакомый нам оператор ORDER BY. В данной ситуации его применения аналогичное предыдущим примерам. К примеру:
В данной ситуации его применения аналогичное предыдущим примерам. К примеру:
SELECT Product, SUM(Quantity) AS Product_num FROM Sumproduct GROUP BY Product HAVING SUM(Quantity) > 3000 ORDER BY SUM(Quantity)
или просто укажем номер поля по порядку, по которому хотим сортировать:
SELECT Product, SUM(Quantity) AS Product_num FROM Sumproduct GROUP BY Product HAVING SUM(Quantity) > 3000 ORDER BY 2
Видим, что для сортировки сводных результатов нам нужно просто прописать предложения с ORDER BY после оператора HAVING.
MS Access не поддерживает сортировку групп по псевдонимами колонок, то есть в нашем примере, чтобы сортировать значения, мы НЕ сможем в конце запроса прописать ORDER BY Product_num .
Статьи по теме:
Group By в SQL Server с примерами CUBE, ROLLUP и GROUPING SETS
Автор: Bhavesh Patel | Комментарии (1) | Связанный: Подробнее > TSQL
Проблема
Предложение GROUP BY в SQL Server позволяет группировать строки запроса. В целом,
GROUP BY используется с агрегатной функцией SQL Server, такой как SUM, AVG и т. д. Кроме того,
GROUP BY также можно использовать с дополнительными компонентами, такими как Cube, Rollup и
Групповые наборы. В этом совете я продемонстрирую различные способы построения ГРУППЫ.
BY вместе с выводом объяснил.
В целом,
GROUP BY используется с агрегатной функцией SQL Server, такой как SUM, AVG и т. д. Кроме того,
GROUP BY также можно использовать с дополнительными компонентами, такими как Cube, Rollup и
Групповые наборы. В этом совете я продемонстрирую различные способы построения ГРУППЫ.
BY вместе с выводом объяснил.
Решение
При построении запросов для отчетов мы часто используем предложение GROUP BY. Там также случаи, когда промежуточные итоги и итоги как часть вывода полезны. и здесь мы будем использовать необязательные операторы, такие как: CUBE, ROLLUP и НАБОРЫ ДЛЯ ГРУППИРОВКИ . Эти варианты похожи, но дают разные результаты.
Создать образец базы данных и данных SQL Server
Сначала мы создадим образец базы данных, таблицы и вставим некоторые данные для наших примеров.
ИСПОЛЬЗОВАТЬ МАСТЕР ИДТИ СОЗДАТЬ БАЗУ ДАННЫХ ИДТИ ИСПОЛЬЗОВАТЬ ИДТИ СОЗДАТЬ ТАБЛИЦУ ( идентификатор INT PRIMARY KEY IDENTITY (1,1), EmpName varchar (200), Отдел варчар(100), Категория символ(1), Зарплата деньги ) ВСТАВИТЬ ВЫБЕРИТЕ «Бхавеш Патель», «IT», «A», 8000 долларов США.СОЮЗ ВСЕХ ВЫБЕРИТЕ «Алпеш Патель», «Продажи», «А», 7000 долларов США. СОЮЗ ВСЕХ ВЫБЕРИТЕ «Калпеш Такор», «IT», «B», 5000 долларов США. СОЮЗ ВСЕХ ВЫБЕРИТЕ «Джей Шах», «Продажи», «B», 4000 долларов. СОЮЗ ВСЕХ ВЫБЕРИТЕ «Рам Наяк», «IT», «C», 3000 долларов США. СОЮЗ ВСЕХ ВЫБЕРИТЕ «Джей Шоу», «Продажи», «C», 2000 долларов.
Вот данные, которые мы только что создали.
ВЫБЕРИТЕ * ИЗ EmpSalary
SQL Server GROUP BY Пример
Ниже приведен простой групповой запрос, в котором мы СУММИРУЕМ данные о зарплате. В первом запросе мы группируем по отделам, а второй запрос мы группируем по отделам и категориям.
ВЫБЕРИТЕ Отделение, СУММА (зарплата) как зарплата ОТ ЭмпЗарплата СГРУППИРОВАТЬ ПО отделам ВЫБИРАТЬ Отделение, Категория, СУММА (зарплата) как зарплата ОТ ЭмпЗарплата ГРУППА ПО Отделу, Категория
Ниже приведены результаты. Первый запрос возвращает 2 строки по отделам с
Зарплата итоговая, так как есть 2 отдела. Второй запрос возвращает 6 строк
по отделам и категориям с суммой зарплаты, так как есть 2 отдела с
3 категории в каждом отделе.
Второй запрос возвращает 6 строк
по отделам и категориям с суммой зарплаты, так как есть 2 отдела с
3 категории в каждом отделе.
SQL Server GROUP BY с HAVING Пример
В следующем примере мы используем ту же группу, но ограничиваем данные с помощью HAVING который фильтрует данные. В приведенных ниже примерах для первого запроса мы только хотите видеть отделы, где сумма равна 16000, а для второго, где Общее количество отделов и категорий равно 8000.
ВЫБЕРИТЕ Отделение, СУММА (зарплата) как зарплата ОТ ЭмпЗарплата СГРУППИРОВАТЬ ПО отделам СУММА (зарплата) = 16000 ВЫБИРАТЬ Отделение, Категория, СУММА (зарплата) как зарплата ОТ ЭмпЗарплата СГРУППИРОВАТЬ ПО отделам, категориям ИМЕЕМ СУММУ(зарплата) = 8000
Ниже приведены только 2 строки, соответствующие критериям. Мы можем перепроверить это просмотрев результаты запроса из первого набора запросов выше.
SQL Server GROUP BY CUBE Пример
Этот пример позволяет нам показать все комбинации данных.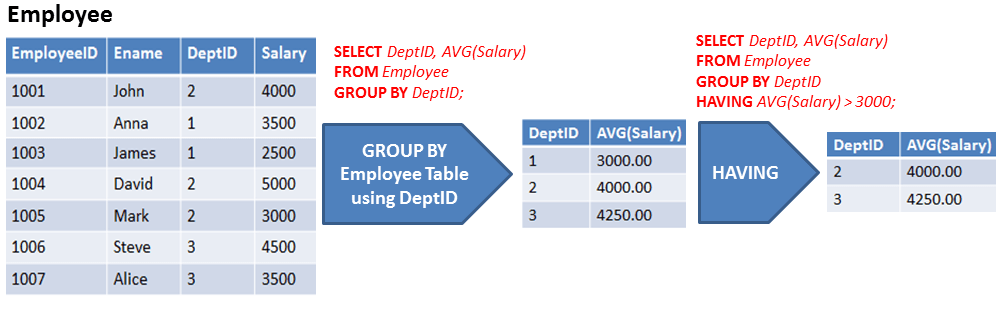
ВЫБЕРИТЕ Отделение, СУММА (зарплата) как зарплата ОТ ЭмпЗарплата СГРУППИРОВАТЬ ПО КУБУ (Отдел) ВЫБИРАТЬ Отделение, Категория, СУММА (зарплата) как зарплата ОТ ЭмпЗарплата СГРУППИРОВАТЬ ПО КУБУ (Отдел, Категория)
Первые результаты запроса показывают 2 отдела и общее количество, а также общий всего по этим 2 отделам. Результаты второго запроса показывают нам все комбинации отдела и категории. Например, мы видим IT (отдел) и А (категория) и 16000 (всего), затем Продажи (отдел) и А (категория) и 7000 (всего), а затем NULL (оба отдела) и А (категория) и 15000 (всего). На диаграмме я разбиваю различные группы, которые являются частью этой секунды. запрос.
SQL Server GROUP BY ROLLUP Пример
Это похоже на Group By Cube, но вы увидите, что результат немного отличается, когда мы не получаем столько строк, возвращаемых для второго запроса.
ВЫБЕРИТЕ Отделение, СУММА (зарплата) как зарплата ОТ ЭмпЗарплата ГРУППИРОВАТЬ ПО ОБЪЕДИНЕНИЮ(Отдел) ВЫБИРАТЬ Отделение, Категория, СУММА (зарплата) как зарплата ОТ ЭмпЗарплата СГРУППИРОВАТЬ ПО ОБЪЕДИНЕНИЮ(Отдел, Категория)
Мы видим, что результаты первого запроса такие же, как в примере Group By Rollup, но
второй запрос возвращает только 9 строк вместо 12, которые мы получили в Group By Rollup. запрос. Второй запрос выполняет сведение сначала по отделам, а затем по категориям.
что отличается от Group By Cube, которая выполняла сведение в обоих направлениях.
Это позволяет нам получить промежуточные итоги для каждого отдела и общий итог для всех
Департаменты.
запрос. Второй запрос выполняет сведение сначала по отделам, а затем по категориям.
что отличается от Group By Cube, которая выполняла сведение в обоих направлениях.
Это позволяет нам получить промежуточные итоги для каждого отдела и общий итог для всех
Департаменты.
Мы можем изменить второй запрос, как показано ниже, на первый накопительный пакет по категории. а затем Департамент.
ВЫБЕРИТЕ Отделение, SUM(Зарплата) как зарплата ОТ ЭмпЗарплата ГРУППИРОВАТЬ ПО ОБЪЕДИНЕНИЮ(Отдел) ВЫБИРАТЬ Отделение, Категория, SUM(Зарплата) как зарплата ОТ ЭмпЗарплата ГРУППА ПО ОБЪЕДИНЕНИЮ (Категория, Отдел)
Мы можем видеть результаты для второго запроса, теперь делаем группировку на основе категории а затем Департамент. И мы по-прежнему получаем промежуточные итоги и итоги.
SQL Server GROUP BY ROLLUP с GROUPING_ID Пример
Другой вариант — использовать GROUPING_ID как часть набора результатов для отображения каждой группы.
ВЫБЕРИТЕ Отделение, Категория, СУММА (зарплата) как зарплата, GROUPING_ID(Категория, Отдел) как GroupingID ОТ ЭмпЗарплата ГРУППИРОВАТЬ ПО ОБЪЕМУ (Категория, Отдел)
Мы видим, что у нас те же результаты, что и выше, но теперь у нас есть значение группировки для каждой из этих групп.
SQL Server ГРУППИРОВАТЬ ПО НАБОРАМ ГРУППИРОВКИ Пример
С помощью группирующих наборов мы можем определить, как мы хотим, чтобы данные были объединены.
ВЫБЕРИТЕ Отделение, Категория, СУММА (зарплата) как зарплата ОТ ЭмпЗарплата ГРУППИРОВАТЬ ПО НАБОРАМ ГРУППИРОВКИ(Категория, Отдел,(Категория, Отдел),())
Ниже мы видим, что мы сделали группу для категории, еще одну группу для отдела, еще одну группа для категории и отдела и последняя группа для NULL.
Вот еще один пример по отделам и категориям и общей группе для НУЛЕВОЙ.
ВЫБЕРИТЕ Отделение, Категория, СУММА (зарплата) как зарплата ОТ ЭмпЗарплата ГРУППИРОВАТЬ ПО ГРУППИРОВКЕ НАБОРЫ((Отдел, Категория),())
Мы могли бы пойти дальше и использовать CUBE и ROLLUP для различных
групповые наборы.
ВЫБЕРИТЕ Отделение, Категория, СУММА (зарплата) как зарплата ОТ ЭмпЗарплата GROUP BY GROUP SETS(CUBE(Отдел, Категория), ROLLUP(Отдел, Категория))
Вот результат.
Резюме
Согласно цели отчетности за при подготовке сводного вывода мы можем использовать необязательные операторы, такие как CUBE, ROLLUP, и GROUPING SETS в запросе. GROUPING SETS — это управляемая и масштабируемая опция, поэтому я предпочитаю использовать его вместо ROLLUP и CUBE.
Следующие шаги
- Группировка в SQL Server
- Агрегатные функции в SQL Server
- Что такое куб и накопительный пакет в SQL Server
- Наличие в SQL Server
Об авторе
Бхавеш Патель — специалист по базам данных SQL Server с более чем 10-летним опытом.Посмотреть все мои советы
Обзор предложения SQL GROUP BY
В этой статье кратко объясняется предложение SQL group by, когда его следует использовать и что следует учитывать при его использовании.
Примечание: Все примеры кода в этой статье сделаны с использованием SQL Server 2019и База данных Stack Overflow 2010 .
Что такое «группировка» в SQL и зачем она нужна?
Учтите, что мы анализируем базу данных веб-сайта QA переполнения стека. Эта база данных содержит несколько таблиц, в которых хранится информация о пользователях сайта, размещенных вопросах, ответах, комментариях и выданных значках.
Например, возьмем таблицу «Сообщения». Эта таблица содержит всю информацию о различных типах сообщений на веб-сайте QA; вопросы, ответы, вики, номинации модераторов… Если мы хотим подсчитать количество сообщений каждого типа, с помощью простого оператора SELECT можно вернуть количество строк одного типа с помощью функции COUNT() помимо фильтрации результата. используя предложение WHERE:
Рисунок 1. Расчет количества строк для одного типа поста
Если мы попытаемся добавить столбец PostTypeId перед COUNT(*), команда SQL не будет выполнена и выдаст следующее исключение, чтобы уведомить пользователя о том, что для выполнения этой операции требуется агрегирование:
Столбец StackOverflow2010.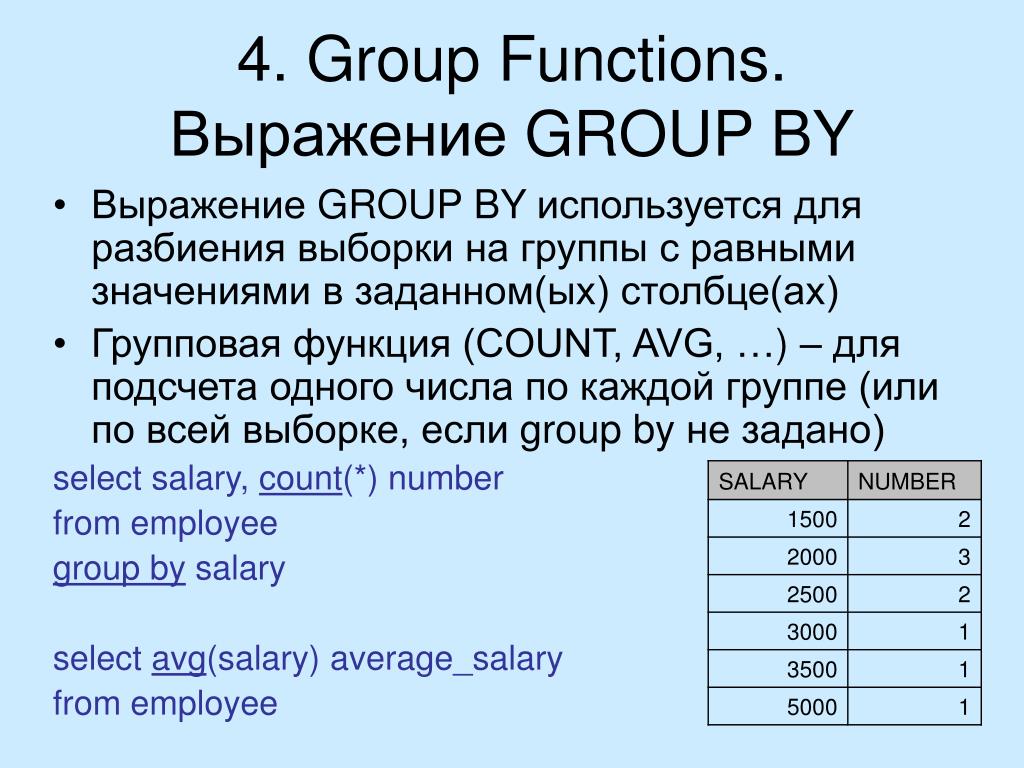 dbo.Posts.PostTypeId недопустим в списке выбора, поскольку он не содержится ни в агрегатной функции, ни в предложении GROUP BY.
dbo.Posts.PostTypeId недопустим в списке выбора, поскольку он не содержится ни в агрегатной функции, ни в предложении GROUP BY.
Предложение SQL GROUP BY упорядочивает аналогичные данные, хранящиеся в одном или нескольких столбцах, в группы, где для создания сводок применяется агрегатная функция. Например, подсчет количества постов для каждого пользователя.
Рисунок 2 – Расчет количества постов каждого типа
Порядок выполнения SQL-запроса
Прежде чем объяснять предложение SQL GROUP BY и когда мы должны его использовать, нам нужно знать, как SQL-запрос выполняется механизмом базы данных. После запроса на выполнение команды SQL механизм базы данных анализирует различные ее части в следующем порядке:
- ОТ / ПРИСОЕДИНЯЙТЕСЬ
- ГДЕ
- ГРУППА ПО
- НАЛИЧИЕ
- ВЫБИРАТЬ
- ОТЧЕТЛИВЫЙ
- СОРТИРОВАТЬ ПО
- КОМПЕНСИРОВАТЬ
Пункт GROUP BY
Как определено в официальной документации Microsoft, команда SELECT — GROUP BY — это предложение оператора SELECT, которое делит результат запроса на группы строк, обычно для выполнения одной или нескольких агрегаций в каждой группе. Оператор SELECT возвращает одну строку на группу».
Оператор SELECT возвращает одну строку на группу».
Синтаксис предложения GROUP BY следующий:
1 2 3 4 5 6 7 8 9 9 0003 |
GROUP BY { выражение-столбца | ROLLUP ( | CUBE ( | НАБОРЫ ГРУППИРОВКИ ( | HAVING ( <выражение фильтра> ) }
|
Предложение SQL GROUP BY можно использовать для выполнения агрегирования по каждой группе или даже для удаления повторяющихся строк на основе выражения группировки. Например, предположим, что нам нужно извлечь все различные местоположения пользователей Stack Overflow. Мы можем просто добавить ключевое слово DISTINCT после термина SELECT.
SELECT DISTINCT [Расположение] FROM [StackOverflow2010].
|
 [dbo].[Пользователи]
[dbo].[Пользователи]Или мы можем использовать команду SELECT – GROUP BY для достижения того же результата:
Выберите [местоположение] из [Stackoverflow2010]. |
Стоит отметить, что оба запроса имеют одинаковый план выполнения.
Рисунок 3 – Сравнение планов выполнения
Теперь мы можем добавить функцию агрегации в предложение SELECT, чтобы выполнять ее для каждой группы.
SELECT [Location], COUNT(*) FROM [StackOverflow2010].[dbo].[Users] GROUP BY [Location]
|
Как показано на изображении ниже, все значения NULL считаются равными и собираются в одну группу.
Рисунок 4. Добавление агрегатной функции к команде SELECT — GROUP BY
Проверяя план выполнения команды, мы видим, что после агрегирования данных внутри групп к каждой группе применяется скалярная функция.
Рисунок 5 – План выполнения, показывающий вычисление функции агрегации
ГРУППИРОВАТЬ ПО столбцам
Самый простой способ использовать SQL-предложение GROUP BY — выбрать столбцы, необходимые для операции группировки. Все столбцы, указанные в предложении SELECT, кроме функций агрегирования, должны быть указаны в предложении GROUP BY. Например, если мы выполним следующий запрос:
SELECT [Id], [Location],COUNT(*) FROM [StackOverflow2010].[dbo].[Users] GROUP BY [Location];
|
Выдается следующее исключение:
Столбец StackOverflow2010.dbo.Users.Id недопустим в списке выбора, поскольку он не содержится ни в агрегатной функции, ни в предложении GROUP BY.
Еще одна вещь, о которой стоит упомянуть, это то, что псевдонимы столбцов нельзя использовать в предложении SQL GROUP BY, поскольку оно вычисляется механизмом SQL перед предложением SELECT.
ГРУППИРОВКА ПО пользовательским функциям
Мы также можем использовать определяемые пользователем скалярные функции вместе со столбцами, указанными в предложениях SELECT и GROUP BY. Например, мы создали следующую функцию, чтобы узнать, есть ли у вопроса ответ или нет:
1 2 3 4 5 6 7 8 9 9 0003 10 11 12 13 14 15 16 17 |
CREATE FUNCTION isSolved ( @PostID INT) ВОЗВРАЩАЕТ BIT AS 90 003 BEGIN
DECLARE @Exists BIT
SELECT @Exists = CASE WHEN AcceptedAnswerId =0 THEN 0 ELSE 1 END FROM [StackOverflow2010].[dbo].[Posts] WHERE [Id] = @PostID
RETURN @Exists
END
|
Следующий запрос может быть успешно выполнен.
SELECT dbo.IsSolved([Id]), COUNT(*) FROM [StackOverflow2010].[dbo].[Posts] GROUP BY dbo.IsSolved ([Идентификатор])
|
Рисунок 6 – Группировка по определяемой пользователем функции
GROUP BY выражения столбца
Другой способ сгруппировать результат — использовать выражения столбца. Например, если мы хотим сгруппировать столбцы на основе определенного вычисления, такого как математическое выражение или выражение CASE WHEN, мы можем просто использовать его аналогично одному столбцу. Например, предположим, что мы хотим подсчитать количество решаемых вопросов и количество открытых вопросов на веб-сайте Stack Overflow. Обратите внимание, что таблица сообщений содержит только столбец с именем AccetpedAnswerId, который содержит идентификатор ответа.
SELECT CASE WHEN AcceptedAnswerId =0 THEN 0 ELSE 1 END , COUNT(*) FROM [StackOverflow2010]. GRO UP BY CASE WHEN AcceptedAnswerId = 0 THEN 0 ELSE 1 END |
 [dbo].[Posts]
[dbo].[Posts]Рисунок 7 – Группировка по выражению CASE WHEN
ГРУППА ПО НАЛИЧИИ
Мы не можем использовать предложение WHERE в этой операции для фильтрации результата запроса на основе результата групповой агрегированной функции, поскольку ядро базы данных выполняет предложение WHERE перед применением агрегирующей функции. Вот почему было найдено предложение HAVING.
Предложение HAVING можно использовать только с предложением SQL GROUP BY. Например, нам нужно получить местоположения, упомянутые более чем в 1000 и менее чем в 10000 профилях пользователей.
1 2 3 4 5 6 7 |
SELECT [Location],COUNT(*) FROM [StackOverflow2010].[dbo].[Users] GROUP BY [Location] ИМЕЕТ СЧЕТЧИК(*) ОТ 1000 ДО 10000 ПОРЯДОК ПО СЧЕТУ(*) DESC;
|
Рисунок 8. Использование ключевого слова HAVING для фильтрации результата операции группирования
Использование ключевого слова HAVING для фильтрации результата операции группирования
НАБОРЫ ГРУППИРОВКИ, КУБА И ГРУППИРОВКИ
Чтобы объяснить параметры ROLLUP, CUBE и GROUPING SETS, мы создадим представление из таблиц Posts и Users со следующей структурой:
Сообщения.Id | Posts.CreationDate | Сообщения.PostType | Пользователи.Расположение |
ГРУППИРОВКА ПО СВОДКЕ
Предположим, мы хотим создать отчет, показывающий количество сообщений в каждом году, квартале и месяце для каждого типа сообщения. Результат должен быть следующим:
Создание_год | Creation_quarter | Создание_Месяц | Тип сообщения | Количество сообщений |
SQL GROUP BY ROLLUP позволяет нам создавать комбинации, которые существуют в данных, в дополнение к объединению в иерархическом порядке, который мы определяем в операторе ROLLUP. Например, попробуем выполнить следующий запрос:
Например, попробуем выполнить следующий запрос:
1 2 3 4 5 6 7 8 |
SELECT YEAR([CreationDate]) as Creation_year, DATEPART(QUarter,[CreationDate]) as Creation_quarter, MONTH([CreationDate]) as Creation_month, 9000 3 COUNT(*) as Number_of_posts ОТ [ StackOverflow2010].[dbo].[vPosts] СГРУППИРОВАТЬ ПО ОБЪЕМУ (ГОД ([Дата Создания]) , ЧАСТЬ ДАТЫ (Квартал, [Дата Создания]) , МЕСЯЦ ([Дата Создания]))
|
Как показано на изображении ниже, результат включает три уровня агрегации:
- Количество постов в месяц
- Количество постов в квартал
- Количество постов в год
Рисунок 9. Использование оператора ROLLUP для применения агрегации на разных иерархических уровнях
ГРУППА ПО КУБУ
Теперь давайте предположим, что нас попросили создать отчет, который показывает количество сообщений для каждого местоположения пользователя, тип сообщения или и то, и другое.
Оператор SQL GROUP BY CUBE создает все возможные комбинации между столбцами, упомянутыми в операторе CUBE. Например, давайте попробуем следующую команду:
1 2 3 4 5 6 |
SELECT [Расположение], [Тип], COUNT(*) as Number_of_posts FROM [StackOverflow2010].[dbo].[vPosts] 9000 2 ГРУППА ПО КУБУ([Местоположение], [Тип])
|
Как показано на изображении ниже, результаты содержат три группы:
- Количество постов на локацию
- Количество постов каждого типа
- Количество постов на место и тип
Рисунок 10. Использование оператора GROUP BY CUBE
ГРУППИРОВКА ПО НАБОРАМ
Иногда нас попросят создать отчет только для определенной комбинации столбцов и выражений.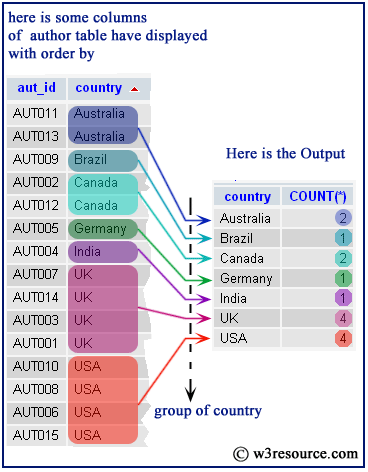 В этом случае использование CUBE или ROLLUP может быть неэффективным и занимать много времени.
В этом случае использование CUBE или ROLLUP может быть неэффективным и занимать много времени.
По этой причине мы можем использовать оператор GROUPING SETS, где мы должны явно определить каждую комбинацию. Например, мы хотим только создать отчет, показывающий количество сообщений по местоположению, по типу и общее количество сообщений.
1 2 3 4 5 6 7 8 9 9 0003 10 |
ВЫБЕРИТЕ [Местоположение], [Тип], COUNT(*) as Number_of_posts ИЗ [StackOverflow2010].[dbo].[vPosts] 90 002 ГРУППИРОВКА ПО НАБОРАМ ГРУППИРОВКИ((), — — Общее количество постов ([Расположение]), ([Тип]))
|
Как показано на изображении ниже, первые пять строк показывают количество сообщений для каждого типа, строка 6 th показывает общее количество сообщений, а остальные показывают количество сообщений для каждого местоположения.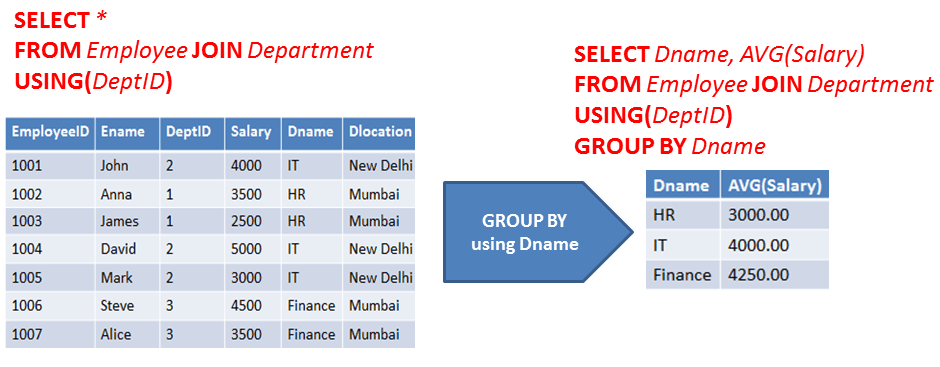
Рисунок 11 – использование оператора GROUPING SETS
Сводка
В этой статье кратко объясняется предложение SQL GROUP BY и то, как его использовать для выполнения статистических функций над данными. Мы также продемонстрировали доступные параметры, такие как группировка по набору столбцов, выражения и пользовательские функции. Кроме того, мы объяснили, как использовать ключевое слово HAVING для фильтрации и параметры ROLLUP, CUBE и GROUPING SETS для создания отчетов.
Чтобы узнать больше о функции SQL GROUP BY, вы можете обратиться к следующим статьям, ранее опубликованным в SQL Shack:
- Изучение SQL: агрегатные функции (Эмиль Дркусич)
- GROUP BY ROLLUP для анализа данных (Динеш Асанка)
- Автор
- Последние сообщения
Хади Фадлаллах
Хади — профессионал SQL Server с более чем 10-летним опытом. Его основная специализация — интеграция данных.