теория, инструменты и советы от практика
Рассказывает программист Вильям В. Вольд
На протяжении последних шести месяцев я работал над созданием языка программирования (ЯП) под названием Pinecone. Я не рискну назвать его законченным, но использовать его уже можно — он содержит для этого достаточно элементов, таких как переменные, функции и пользовательские структуры данных. Если хотите ознакомиться с ним перед прочтением, предлагаю посетить официальную страницу и репозиторий на GitHub.
Введение
Я не эксперт. Когда я начал работу над этим проектом, я понятия не имел, что делаю, и всё еще не имею. Я никогда целенаправленно не изучал принципы создания языка — только прочитал некоторые материалы в Сети и даже в них не нашёл для себя почти ничего полезного.
Тем не менее, я написал абсолютно новый язык. И он работает. Наверное, я что-то делаю правильно.
В этой статье я постараюсь показать, каким образом Pinecone (и другие языки программирования) превращают исходный код в то, что многие считают магией. Также я уделю внимание ситуациям, в которых мне приходилось искать компромиссы, и поясню, почему я принял те решения, которые принял.
Также я уделю внимание ситуациям, в которых мне приходилось искать компромиссы, и поясню, почему я принял те решения, которые принял.
Текст точно не претендует на звание полноценного руководства по созданию языка программирования, но для любознательных будет хорошей отправной точкой.
Первые шаги
«А с чего вообще начинать?» — вопрос, который другие разработчики часто задают, узнав, что я пишу свой язык. В этой части постараюсь подробно на него ответить.
Компилируемый или интерпретируемый?
Компилятор анализирует программу целиком, превращает её в машинный код и сохраняет для последующего выполнения. Интерпретатор же разбирает и выполняет программу построчно в режиме реального времени.
Технически любой язык можно как компилировать, так и интерпретировать. Но для каждого языка один из методов подходит больше, чем другой, и выбор парадигмы на ранних этапах определяет дальнейшее проектирование. В общем смысле интерпретация отличается гибкостью, а компиляция обеспечивает высокую производительность, но это лишь верхушка крайне сложной темы.
Я хотел создать простой и при этом производительный язык, каких немного, поэтому с самого начала решил сделать Pinecone компилируемым. Тем не менее, интерпретатор у Pinecone тоже есть — первое время запуск был возможен только с его помощью, позже объясню, почему.
%saved0% Кстати, у нас есть краткий обзор серии статей по созданию собственного интерпретатора — это отличное упражнение для тех, кто изучает Python.
Выбор языка
Своеобразный мета-шаг: язык программирования сам является программой, которую надо написать на каком-то языке. Я выбрал C++ из-за производительности, большого набора функциональных возможностей, и просто потому что он мне нравится.
Но в целом совет можно дать такой:
- интерпретируемый ЯП крайне рекомендуется писать на компилируемом ЯП (C, C++, Swift). Иначе потери производительности будут расти как снежный ком, пока мета-интерпретатор интерпретирует ваш интерпретатор;
- компилируемый ЯП можно писать на интерпретируемом ЯП (Python, JS).
 Возрастёт время компиляции, но не время выполнения программы.
Возрастёт время компиляции, но не время выполнения программы.
Проектирование архитектуры
У структуры языка программирования есть несколько ступеней от исходного кода до исполняемого файла, на каждой из которых определенным образом происходит форматирование данных, а также функции для перехода между этими ступенями. Поговорим об этом подробнее.
Лексический анализатор / лексер
Строка исходного кода проходит через лексер и превращается в список токенов.
Первый шаг в большинстве ЯП — это лексический анализ. Говоря по-простому, он представляет собой разбиение текста на токены, то есть единицы языка: переменные, названия функций (идентификаторы), операторы, числа. Таким образом, подав лексеру на вход строку с исходным кодом, мы получим на выходе список всех токенов, которые в ней содержатся.
Обращения к исходному коду уже не будет происходить на следующих этапах, поэтому лексер должен выдать всю необходимую для них информацию.
Flex
При создании языка первым делом я написал лексер. Позже я изучил инструменты, которые могли бы сделать лексический анализ проще и уменьшить количество возникающих багов.
Позже я изучил инструменты, которые могли бы сделать лексический анализ проще и уменьшить количество возникающих багов.
Одним из основных таких инструментов является Flex — генератор лексических анализаторов. Он принимает на вход файл с описанием грамматики языка, а потом создаёт программу на C, которая в свою очередь анализирует строку и выдаёт нужный результат.
Моё решение
Я решил оставить написанный мной анализатор. Особых преимуществ у Flex я в итоге не увидел, а его использование только создало бы дополнительные зависимости, усложняющие процесс сборки. К тому же, мой выбор обеспечивает больше гибкости — например, можно добавить к языку оператор без необходимости редактировать несколько файлов.
Синтаксический анализатор / парсер
Список токенов проходит через парсер и превращается в дерево.
Следующая стадия — парсер. Он преобразует исходный текст, то есть список токенов (с учётом скобок и порядка операций), в абстрактное синтаксическое дерево, которое позволяет структурно представить правила создаваемого языка. Сам по себе процесс можно назвать простым, но с увеличением количества языковых конструкций он сильно усложняется.
Сам по себе процесс можно назвать простым, но с увеличением количества языковых конструкций он сильно усложняется.
Bison
На этом шаге я также думал использовать стороннюю библиотеку, рассматривая Bison для генерации синтаксического анализатора. Он во многом похож на Flex — пользовательский файл с синтаксическими правилами структурируется с помощью программы на языке C. Но я снова отказался от средств автоматизации.
Преимущества кастомных программ
С лексером моё решение писать и использовать свой код (длиной около 200 строк) было довольно очевидным: я люблю задачки, а эта к тому же относительно тривиальная. С парсером другая история: сейчас длина кода для него — 750 строк, и это уже третья попытка (первые две были просто ужасны).
Тем не менее, я решил делать парсер сам. Вот основные причины:
- минимизация переключения контекста;
- упрощение сборки;
- желание справиться с задачей самостоятельно.
В целесообразности решения меня убедило высказывание Уолтера Брайта (создателя языка D) в одной из его статей:
Я бы не советовал использовать генераторы лексических и синтаксических анализаторов, а также другие так называемые «компиляторы компиляторов».
Написание лексера и парсера не займёт много времени, а использование генератора накрепко привяжет вас к нему в дальнейшей работе (что имеет значение при портировании компилятора на новую платформу). Кроме того, генераторы отличаются выдачей не релевантных сообщений об ошибках.
Абстрактный семантический граф
Переход от синтаксического дерева к семантическому графу
В этой части я реализовал структуру, по своей сути наиболее близкую к «промежуточному представлению» (intermediate representation) в LLVM. Существует небольшая, но важная разница между абстрактным синтаксическим деревом (АСД) и абстрактным семантическим графом (АСГ).
АСГ vs АСД
Грубо говоря, семантический граф — это синтаксическое дерево с контекстом. То есть, он содержит информацию наподобие какой тип возвращает функция или в каких местах используется одна и та же переменная. Из-за того, что графу нужно распознать и запомнить весь этот контекст, коду, который его генерирует, необходима поддержка в виде множества различных поясняющих таблиц.
Запуск
После того, как граф составлен, запуск программы становится довольно простой задачей. Каждый узел содержит реализацию функции, которая получает некоторые данные на вход, делает то, что запрограммировано (включая возможный вызов вспомогательных функций), и возвращает результат. Это — интерпретатор в действии.
Варианты компиляции
Вы, наверное, спросите, откуда взялся интерпретатор, если я изначально определил Pinecone как компилируемый язык. Дело в том, что компиляция гораздо сложнее, чем интерпретация — я уже упоминал ранее, что столкнулся с некоторыми проблемами на этом шаге.
Написать свой компилятор
Сначала мне понравилась эта мысль — я люблю делать вещи сам, к тому же давно хотел изучить язык ассемблера. Вот только создать с нуля кроссплатформенный компилятор — сложнее, чем написать машинный код для каждого элемента языка. Я счёл эту идею абсолютно не практичной и не стоящей затраченных ресурсов.
LLVM
LLVM — это коллекция инструментов для компиляции, которой пользуются, например, разработчики Swift, Rust и Clang. Я решил остановиться на этом варианте, но опять не рассчитал сложности задачи, которую перед собой поставил. Для меня проблемой оказалось не освоение ассемблера, а работа с огромной многосоставной библиотекой.
Я решил остановиться на этом варианте, но опять не рассчитал сложности задачи, которую перед собой поставил. Для меня проблемой оказалось не освоение ассемблера, а работа с огромной многосоставной библиотекой.
Транспайлинг
Мне всё же нужно было какое-то решение, поэтому я написал то, что точно будет работать: транспайлер (transpiler) из Pinecone в C++ — он производит компиляцию по типу «исходный код в исходный код», а также добавил возможность автоматической компиляции вывода с GCC. Такой способ не является ни масштабируемым, ни кроссплатформенным, но на данный момент хотя бы работает почти для всех программ на Pinecone, это уже хорошо.
Дальнейшие планы
Сейчас мне не достаёт необходимой практики, но в будущем я собираюсь от начала и до конца реализовать компилятор Pinecone с помощью LLVM — инструмент мне нравится и руководства к нему хорошие. Пока что интерпретатора хватает для примитивных программ, а транспайлер справляется с более сложными.
Заключение
Надеюсь, эта статья окажется кому-нибудь полезной.
Вот общие советы от меня (разумеется, довольно субъективные):
- если у вас нет предпочтений и вы сомневаетесь, компилируемый или интерпретируемый писать язык, выбирайте второе. Интерпретируемые языки обычно проще проектировать, собирать и учить;
- с лексерами и парсерами делайте, что хотите. Использование средств автоматизации зависит от вашего желания, опыта и конкретной ситуации;
- если вы не готовы / не хотите тратить время и силы (много времени и сил) на придумывание собственной стратегии разработки ЯП, следуйте цепочке действий, описанной в этой статье. Я вложил в неё много усилий и она работает;
- опять же, если не хватает времени / мотивации / опыта / желания или ещё чего-нибудь для написания классического ЯП, попробуйте написать эзотерический, типа Brainfuck.
 (Советуем помнить, что если язык написан развлечения ради, это не значит, что писать его — тоже сплошное развлечение. — прим. перев.)
(Советуем помнить, что если язык написан развлечения ради, это не значит, что писать его — тоже сплошное развлечение. — прим. перев.)
Я делал довольно много ошибок по ходу разработки, но большую часть кода, на которую они могли повлиять, я уже переписал. Язык сейчас неплохо функционирует и будет развиваться (на момент написания статьи его можно было собрать на Linux и с переменным успехом на macOS, но не на Windows).
О том, что ввязался в историю с созданием Pinecone, ни в коем случае не жалею — это отличный эксперимент, и он только начался.
Перевод статьи: «I wrote a programming language. Here’s how you can, too»
11 шагов и реальные перспективы
В статье рассказывается:- Зачем нужны новые языки программирования
- 11 шагов создания своего языка программирования с нуля
- Книги про создание языка программирования с нуля
- Реально ли в одиночку написать язык программирования
- Онлайн-курсы по изучению и созданию языков программирования
-
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.
Бесплатно от Geekbrains
Про создание языка программирования мечтает каждый второй разработчик, причем, как правило, новичок. Цели преследует каждый свои. Одни желают улучшить уже существующий язык, другие — привнести в этот мир что-то ультрановое и экзотическое, а третьи – заработать миллионы на своей разработке.
Давайте вместе разбираться, реально ли в одиночку с нуля создать свой язык программирования даже на базе уже существующего, какие действия придется совершить, что проанализировать и самое главное – сколько по времени займет весь этот процесс. Хотя вы, наверное, и так уже понимаете, что за полчаса второй Python не создать, но давайте все равно предположим.
Зачем нужны новые языки программирования
На данный момент существуют уже сотни различных языков программирования, и их количество неуклонно растет. Они становятся популярными, широко востребованными. От чего это зависит? Тут влияют самые разные факторы, не всегда постоянные, меняющиеся с течением времени.
На заре развития компьютерных технологий новые языки программирования были крайне необходимы в первую очередь потому, что писать программы с помощью машинных кодов, да и на ассемблере тоже было очень затруднительно, процесс получался слишком сложным.
Требования к созданию языков программирования постепенно менялись по мере того, как стали появляться компьютеры помощнее, более простые и удобные в использовании. К примеру, Fortran придумывался больше для ведения математических вычислений, Basic и Pascal были «заточены» под учебные цели и отличались легкостью изучения, а другие (вроде Си) были хороши своей универсальностью и скоростью работы.
Как только в программировании свершались некие значимые достижения, тут же появлялась куча новых языков. Например, языки C++, Objective C, Java были разработаны в 1980-1990-е годы на фоне открытия парадигмы объектно-ориентированного программирования. Скриптовые языки (вроде PHP, JavaScript, Python) стали бурно развиваться в связи с появившейся необходимостью в создании веб-приложений. Да и сейчас тоже продолжают появляться отличные языки, они быстро пишутся, и программы на них работают просто молниеносно (примеры — Go, Swift, Rust).
Да и сейчас тоже продолжают появляться отличные языки, они быстро пишутся, и программы на них работают просто молниеносно (примеры — Go, Swift, Rust).
Разумеется, современные новые языки программирования – это не просто «модное» веяние. Часто в них возникает конкретная необходимость, когда требуется решение неких особых задач. К примеру, для автоматической обработки логических суждений создавался Prolog. А Erlang принят как стандарт в сфере разработки ПО для сетевых коммуникаций.
11 шагов создания своего языка программирования с нуля
Для чего и по каким причинам может понадобиться создание собственного языка программирования? Кому-то просто нечем заняться, другие пишут для упрощения своей же работы, а кто-то ставит целью решение конкретных задач. Ниже перечислены 11 шагов по созданию языка программирования, следуя которым, вы можете попробовать написать свой. Кто знает, вдруг это окажется шедевр, который прославит вас на весь мир?
Шаг 1. Ознакомьтесь с устройством компьютера.
Ознакомьтесь с устройством компьютера.
Это обязательное действие для всех, кто решил заняться программированием, не только при написании новых языков. Тут очень важно понимать, как компьютер преобразует коды и затем их исполняет. Вы не сможете принимать адекватные решения, если не исследуете функционал машины.
Шаг 2. Разберитесь в терминах.
Вам придется иметь дело с такими понятиями, как парсеры, лексеры, компиляторы, интерпретаторы, синтаксические деревья и еще много всего прочего. Если вы не будете четко понимать, о чем идет речь, то как сможете вообще этим заниматься, советоваться с другими разработчиками, искать нужные сведения в Интернете? Создание любого языка программирования начинается со знания терминологии и технологий.
Шаг 3. Обозначьте специализацию языка.
То есть определитесь, создаете вы инструмент для решения конкретных задач или это будет язык с широким профилем применения в самых разных областях IT. Прикиньте общий объём работ, обозначьте цели. Тут вот что важно решить: вы стараетесь для всего мира или это чисто проба своих сил в новом направлении?
Тут вот что важно решить: вы стараетесь для всего мира или это чисто проба своих сил в новом направлении?
Шаг 4. Определитесь с основными концептуальными моментами.
Вот вопросы, на которые вам следует дать ответ:
- Задействовать компиляцию или интерпретацию? Компилируемый код пишется так, что машина сразу его «понимает» и исполняет. Интерпретируемый код работает построчно. Что именно использовать – выбирать вам, рассмотрите оба варианта с точки зрения удобства, функциональности, производительности, защищенности и т. п.
- Задавать статическую или динамическую типизацию? При статической пользователь сам указывает типы данных, а для динамической нужно будет создать систему, определяющую типы.
- Для памяти будет предусмотрено ручное управление или автоматическая очистка?
- Какую модель вы собираетесь задействовать: ООП, логическое, структурное или функциональное программирование? Или вы вообще планируете придумать нечто новое, чего раньше еще не было?
- Будет ли ваш язык интегрироваться с другими?
- Предусмотрен ли в языке базовый функционал или всё будет работать за счет внешних библиотек?
- Каким будет архитектурное построение программы?
Продумав все эти моменты, вы сформируете общий вид нового языка. В процессе возникнут и иные важные вопросы, с ними тоже нужно будет разобраться.
В процессе возникнут и иные важные вопросы, с ними тоже нужно будет разобраться.
Шаг 5. Продумайте синтаксис.
Служебные спецсимволы позволят машине работать быстрее, но потенциальных пользователей они могут спугнуть. Это касается и функциональных возможностей, придется выбирать между интуитивно понятными и самыми производительными.
Шаг 6. Придумайте название.
Пожалуй, один из самых простых шагов. Не пытайтесь заложить в название некий углубленный смысл, дайте короткое и простое имя, которое легко запомнится. Именно так, кстати, чаще всего и поступают разработчики. Заумные необычные аббревиатуры и длинные названия быстро забываются и для пользователей выглядят непривлекательно.
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
pdf 3,7mb
doc 1,7mb
Уже скачали 20722
Шаг 7. Определитесь с языком написания языка.
Определитесь с языком написания языка.
Помешанные на высоких технологиях гики готовы задействовать для этого машинные коды или язык ассемблера. Но в современных реалиях есть смысл заниматься созданием языков программирования на компилируемых языках Pascal, C, C++, C#, Swift (для интерпретируемого кода) и на интерпретируемых языках Java, JavaScript, Python, Ruby (для написания компилируемого кода). Это на выходе дает максимальную производительность.
Язык написания языка программированияШаг 8. Создайте лексер и парсер.
Это специальные инструменты в коде. Лексер проводит анализ лексики, следит за разбиением программы на токены (специальные составляющие). Парсер анализирует синтаксис, определяет иерархию токенов и порядок их взаимодействия. На графической схеме всё это выглядит понятнее.
Только не пугайтесь данного шага. Лексеры и парсеры создаются с помощью готовых приложений и библиотек, так что процесс получается не таким сложным, как может показаться на первый взгляд.
Шаг 9. Сформируйте стандартную библиотеку.
В ней необходимо собрать функции, с помощью которых будет возможна примерная демонстрация имеющихся программных возможностей. При этом неважно, предусмотрены в языке встроенные опции для задействования базового функционала или для этого нужно обращаться к внешним библиотекам.
Шаг 10. Напишите громадное количество текстов.
Мало создать язык, важно еще добиться от него корректной работы. А для этого понадобятся специальные тексты, которые будут указывать системе допустимые и недопустимые действия. Еще их задача – исключение возможности возникновения тупиковых для программы ситуаций.
Только до 11.05
Скачай подборку тестов, чтобы определить свои самые конкурентные скиллы
Список документов:
Тест на определение компетенций
Чек-лист «Как избежать обмана при трудоустройстве»
Инструкция по выходу из выгорания
Чтобы получить файл, укажите e-mail:
Подтвердите, что вы не робот,
указав номер телефона:
Уже скачали 7503
Шаг 11. Представьте язык миру.
Представьте язык миру.
Не прячьте свое детище. Пусть вы не ставили перед собой глобальных целей, но публикация откроет перед вами новые возможности. Откликнутся единомышленники, пользователи оставят отзывы, вы поймете, какие места требуют доработок, улучшений. Да и вообще, вы почувствуете свою полезность в качестве программиста.
Книги про создание языка программирования с нуля
Возможно, и есть книги с четким описанием процесса создания языка программирования, но пока что не нашлось таких материалов, которые можно было бы привести здесь в качестве примеров. Тут следует понимать, что каждый опыт разработки по-своему уникален, такие процессы просто не бывают абсолютно одинаковыми. Есть все же описания, так или иначе затрагивающие тему проектирования языков.
Например, работа А. В. Хохлова под названием «Как создать язык программирования и транслятор». Книга хорошая, но тут всё же больше про транслятор. Процессам выбора тех или иных решений внимания не уделено, а между тем, было бы интересно проследить за ходом мыслей автора. Может быть в скором времени он об этом еще расскажет.
Может быть в скором времени он об этом еще расскажет.
Если говорить об иностранных авторах, то можно привести в пример «Концепцию языков программирования» от Роберта Себесты. Книга, безусловно, хорошая, ее нужно прочесть. Но опять же, содержание здесь целиком соответствует названию, то есть речь идет не конкретно про создание языков программирования.
Для тех, кто задумался о создании языка программирования, есть неплохая книга «Теоретические основы разработки и реализации языков программирования». Авторы – отечественные разработчики М. М. Гавриков, А. Н. Иванченко, Д. В. Гринченков. Но и здесь следует сделать уточнение, что книга больше не про «разработку», а про «реализацию».
Она состоит из следующих глав: «Способы задания формальных языков», «Основы теории перевода и её применение к синтаксическому анализу», «Конструирование сканеров», «Применение КС-языков и грамматик в разработке языков программирования». Как можно понять по названиям, тематика в полной мере раскрывает процесс создания компиляторов.
Работы интересные, полезные, раскрывающие важные темы, но именно процесс проектирования языков детально в них не описывается.
А реально ли в одиночку написать язык программирования?
Тут стоит упомянуть об одном парадоксальном моменте: как правило, язык с самым простым описанием в применении может оказаться самым сложным. Существуют эзотерические языки с сотнями байт дистрибутива. Их практическое использование вообще не представляется возможным, но в качестве творческой площадки – вполне. С их помощью можно учиться разбираться в создании более сложных кодов.
Написать что-то такое, чем потом можно будет реально пользоваться, очень трудно, и уж тем более – в одиночку. К примеру, неслучайно в Microsoft долгие годы был в ходу язык Си, созданный еще в далеком 1973 году. Да, безусловно, можно привести примеры людей, самостоятельно создававших шедевры. Но процесс разработки ПО за последние десятки лет очень усложнился, и подобные подвиги уже вряд ли возможны. Язык без удобной среды разработки поддерживать никто не станет.
В создании качественных продуктов обычно участвуют целые команды профессионалов-энтузиастов. При необходимости вы найдете их на GitHub. Став членом одной из таких команд, вы найдете практическое применение своим знаниям, попробуете себя в деле.
Онлайн-курсы по изучению и созданию языков программирования
В нынешнее время с учетом эпидемиологической обстановки все большую актуальность приобретает удаленное обучение, причем это работает во многих областях. Данный формат набирает популярность во всем мире, и, пожалуй, это только начало.
Чем хорош удаленный процесс обучения? Тем, что не нужно никуда ехать или идти. На качестве знаний это никак не отражается, главное – самодисциплина и грамотное распределение времени.
Кроме того, здесь вы сами выбираете, кто станет вашим преподавателем. Хотите поменять – пожалуйста. Есть возможность общения с другими слушателями курса. По сути – это такое же обучение, как и офлайн.
Сфера ПО и, в частности, создание языков программирования – тематика сложная, требующая очень серьезного отношения. Айтишники в процессе работы занимаются решением серьезных логических задач, пишут уникальные сложнейшие коды.
И если вы только начинаете осваивать данную тему, вам понадобится всё ваше внимание и сосредоточенность. Обязательно переспрашивайте непонятные моменты, не стесняйтесь активно общаться с преподавателем.
Большое количество курсов и мастер-классов собрано на образовательном портале GeekBrains. Есть и возможность стажировки после обучения.
Продвижение блога — Генератор продаж
Рейтинг: 2
( голосов 4 )
Поделиться статьей
Как я написал свой «правильный» язык программирования
Создание компилятора Bolt: часть 1
10 мая 2020 г.

7 мин чтения быть здание. Что означают все этапы? Я должен изучить OCaml и C++? Подождите, я даже не слышал об OCaml…
Не волнуйтесь. Когда я начал этот проект 6 месяцев назад, я никогда не создавал компилятор и не использовал OCaml или C++ ни в одном серьезном проекте. Я объясню все в свое время.
В этой серии постов мы будем создавать правильный язык программирования . Когда я увидел учебники по языку программирования, в которых был создан игрушечный язык с такими операциями, как сложение и умножение, у меня возникло одно недоумение: хорошо, , но как насчет настоящего языка, такого как Java ?
Вот что эта серия призвана исправить. Язык Bolt, который я написал в рамках своей диссертации на третьем курсе, представляет собой параллельный объектно-ориентированный язык в стиле Java. Некоторые из основных моментов этой серии:
- Мы внедряем объектов и классы, с наследством и переосмыслением метода
- Параллелизм (насколько я мог судить при написании этого, без других учебников по языку программирования)
- : класс типа
LinkedList, а затем создание его экземпляра с помощьюLinkedList,LinkedListи так далее.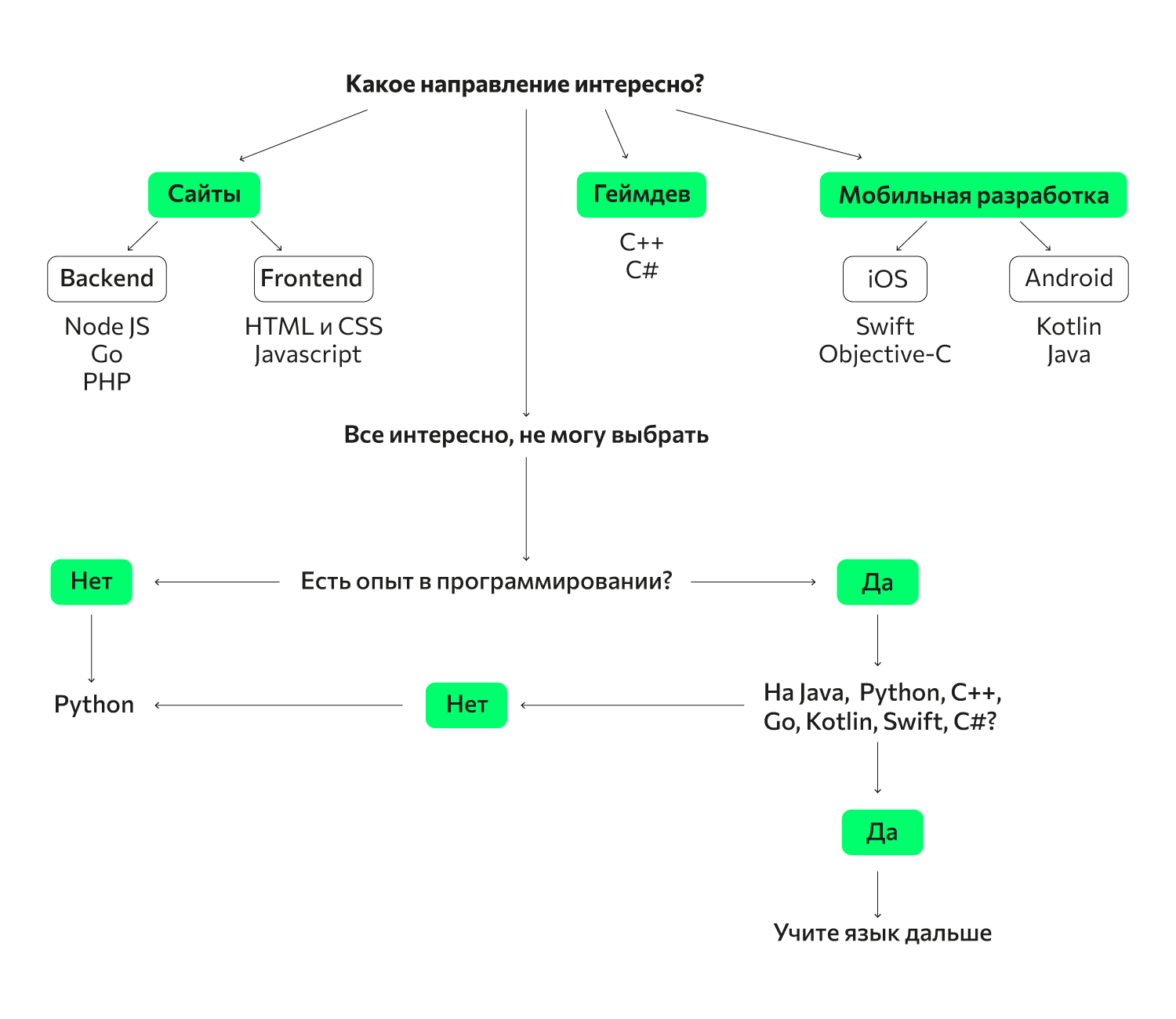
- Введение в проверку типов в компиляторе
- Компиляция в LLVM (этот пост занял второе место в Hacker News!) — LLVM используется C, C++, Swift, Rust и многими другими языками.
Поэтому я рекомендую вам перейти по ссылкам в обзоре «Серии», чтобы узнать об этих конкретных функциях. Оставшаяся часть этого поста будет направлена на то, чтобы убедить вас, почему стоит написать собственный язык программирования, а в следующем посте будет описана структура компилятора.
Зачем вам писать свой собственный язык программирования?
Вопрос, который мы действительно должны задать, это зачем создавать свой собственный язык ? Возможные ответы:
- Это весело
- Это круто иметь свой собственный язык программирования
- Это хороший боковой проект
Mental Models
, в то время как все три из них (или нет!) мотивация: наличие правильных ментальных моделей . Видите ли, когда вы изучаете свой первый язык программирования, вы смотрите на программирование через призму этого языка. Перенесемся к вашему второму языку, и это кажется сложным, вам нужно заново выучить синтаксис, а этот новый язык делает вещи по-другому. Используя больше языков программирования, вы понимаете, что языки имеют общие темы. В Java и Python есть объекты, Python и JavaScript не требуют написания типов, список можно продолжить. Погружаясь глубже в теорию языков программирования, вы читаете о существующих языковых конструкциях — Java и Python — объектно-ориентированные языки программирования, а также Python и JavaScript имеют динамическую типизацию .
Перенесемся к вашему второму языку, и это кажется сложным, вам нужно заново выучить синтаксис, а этот новый язык делает вещи по-другому. Используя больше языков программирования, вы понимаете, что языки имеют общие темы. В Java и Python есть объекты, Python и JavaScript не требуют написания типов, список можно продолжить. Погружаясь глубже в теорию языков программирования, вы читаете о существующих языковых конструкциях — Java и Python — объектно-ориентированные языки программирования, а также Python и JavaScript имеют динамическую типизацию .
Языки программирования, которые вы использовали, основаны на идеях, присутствующих в более старых языках, о которых вы, возможно, не слышали. Simula и Smalltalk представили концепцию объектно-ориентированных языков программирования. Лисп ввел понятие динамической типизации. И постоянно появляются новые исследовательские языки, которые вводят новые концепции. Более распространенный пример: Rust строит безопасность памяти в низкоуровневый язык системного программирования.
Создание собственного языка (особенно если вы добавляете новые идеи) помогает вам более критически относиться к языковому дизайну, поэтому, когда вы начинаете изучать новый язык, это становится намного проще. Например, я никогда не программировал на Hack до своей стажировки в Facebook прошлым летом, но знание этих концепций языка программирования значительно облегчило освоение.
Что такое компиляторы?
Итак, вы разработали свой модный новый язык, и он совершит революцию в мире, но есть одна проблема. Как вы его запускаете? Это роль компилятора. Чтобы объяснить, как работают компиляторы, давайте сначала вернемся в 19 век, в эпоху телеграфа. Вот у нас есть этот причудливый новый телеграф, но как мы будем отправлять сообщения? Та же проблема, другой домен. Телеграфист должен взять речь, преобразовать ее в азбуку Морзе и выстукивать код. Первое, что делает оператор, — это осмысливает речь — он разбивает ее на слова ( лексинг ), а затем понимает, как эти слова используются в предложении ( parsing ) — являются ли они частью именной группы, придаточного предложения и т. д. Они проверяют, имеет ли смысл классификация слов по категориям или типам (прилагательное, существительное, глагол) и проверяют, имеет ли предложение грамматический смысл (мы можем не используйте «runs» для описания существительного, так как это глагол, а не существительное). Наконец, они переводят ( компилируют ) каждое слово в точки и тире (азбуку Морзе), которые затем передаются по проводу.
д. Они проверяют, имеет ли смысл классификация слов по категориям или типам (прилагательное, существительное, глагол) и проверяют, имеет ли предложение грамматический смысл (мы можем не используйте «runs» для описания существительного, так как это глагол, а не существительное). Наконец, они переводят ( компилируют ) каждое слово в точки и тире (азбуку Морзе), которые затем передаются по проводу.
Кажется, что это работает, потому что так много автоматический для людей. Компиляторы работают так же, за исключением того, что для этого нам нужно явно запрограммировать компьютеры. В приведенном выше примере описан простой компилятор, состоящий из 4 этапов: lex, parse, type-check и затем трансляция в машинные инструкции. Оператору также нужны дополнительные инструменты, чтобы набирать азбуку Морзе; для языков программирования это среда выполнения .
На практике оператор, вероятно, создает некоторую стенографическую запись, которую он знает, как преобразовать в азбуку Морзе. Теперь вместо того, чтобы напрямую преобразовывать речь в азбуку Морзе, они преобразуют речь в свою стенографию, а затем преобразуют стенографию в азбуку Морзе. Во многих практических языках вы не можете просто перейти от исходного кода к машинному коду, у вас есть дешугаризация или понижение стадий, когда вы поэтапно удаляете языковые конструкции (например, развертывание циклов for), пока не останется небольшой набор инструкций, которые можно выполнить. Дешугаризация значительно упрощает более поздние этапы, поскольку они оперируют более простым представлением. Этапы компиляции сгруппированы в разделы внешнего интерфейса, среднего уровня и внутреннего интерфейса, где внешний интерфейс выполняет большую часть синтаксического анализа/проверки типов, а средний и внутренний уровни упрощают и оптимизируют код.
Теперь вместо того, чтобы напрямую преобразовывать речь в азбуку Морзе, они преобразуют речь в свою стенографию, а затем преобразуют стенографию в азбуку Морзе. Во многих практических языках вы не можете просто перейти от исходного кода к машинному коду, у вас есть дешугаризация или понижение стадий, когда вы поэтапно удаляете языковые конструкции (например, развертывание циклов for), пока не останется небольшой набор инструкций, которые можно выполнить. Дешугаризация значительно упрощает более поздние этапы, поскольку они оперируют более простым представлением. Этапы компиляции сгруппированы в разделы внешнего интерфейса, среднего уровня и внутреннего интерфейса, где внешний интерфейс выполняет большую часть синтаксического анализа/проверки типов, а средний и внутренний уровни упрощают и оптимизируют код.
Варианты конструкции компилятора
На самом деле мы можем сформулировать многие языки и дизайн компилятора в терминах приведенной выше аналогии:
Переводит ли оператор слова на лету в азбуку Морзе по мере их передачи, или он заранее преобразует слова в азбуку Морзе , а потом передать азбукой Морзе? Интерпретируемые языков, таких как Python, делают первое, в то время как компилируемых с опережением времени языков, таких как C (и Bolt), делают второе. Java на самом деле находится где-то посередине — она использует точно в срок , который выполняет большую часть работы заранее, переводит программы в байт-код, а затем во время выполнения компилирует байт-код в машинный код.
Java на самом деле находится где-то посередине — она использует точно в срок , который выполняет большую часть работы заранее, переводит программы в байт-код, а затем во время выполнения компилирует байт-код в машинный код.
Теперь рассмотрим сценарий, в котором появилась новая азбука Лорзе, являющаяся альтернативой азбуке Морзе. Если операторов учат, как преобразовать стенографию в код Лорзе, говорящему не нужно знать, как это делается, они получают это бесплатно. Точно так же человеку, говорящему на другом языке, просто нужно сказать оператору, как перевести его в стенографию, и тогда он получает перевод на лорс 9.0018 и азбуки Морзе! Вот как работает LLVM . LLVM IR (промежуточное представление) действует как ступенька между программой и машинным кодом. C, C++, Rust и целый ряд других языков (включая Bolt) нацелены на LLVM IR, который затем компилирует код для различных архитектур машин.
Статическая или динамическая типизация? В первом случае оператор либо проверяет, имеют ли слова грамматический смысл, прежде чем начать постукивать. Или они этого не делают, а затем на полпути говорят: «Да, это не имеет смысла» и останавливаются. Динамическую типизацию можно рассматривать как более быструю для экспериментов (например, Python, JS), но когда вы отправляете это сообщение, вы не знаете, остановится ли оператор на полпути (сбой).
Или они этого не делают, а затем на полпути говорят: «Да, это не имеет смысла» и останавливаются. Динамическую типизацию можно рассматривать как более быструю для экспериментов (например, Python, JS), но когда вы отправляете это сообщение, вы не знаете, остановится ли оператор на полпути (сбой).
Я объяснил это на примере воображаемого телеграфиста, но любая аналогия работает. Создание этой интуиции имеет большое значение для понимания того, какие языковые функции подходят для вашего языка: если вы собираетесь экспериментировать, то, возможно, динамическая типизация лучше, так как вы можете двигаться быстрее. Если вы используете большую кодовую базу, ее сложнее вычитывать, и вы с большей вероятностью сделаете ошибки, поэтому вам, вероятно, следует перейти на статическую типизацию, чтобы избежать поломок.
Типы
Наиболее интересной частью компилятора (на мой взгляд) является проверка типов. В нашей аналогии оператор классифицировал слова как части речи (прилагательные, существительные, глаголы), а затем проверял, правильно ли они используются. Типы работают так же, мы классифицируем программные значения на основе поведения, которое мы хотели бы, чтобы они имели. Например.
Типы работают так же, мы классифицируем программные значения на основе поведения, которое мы хотели бы, чтобы они имели. Например. int для чисел, которые можно перемножать, String для потоков символов, которые можно объединять вместе. Роль средства проверки типов состоит в том, чтобы предотвратить нежелательное поведение, например объединение int s или умножение String s вместе — эти операции не имеют смысла, поэтому их нельзя допускать. С типом , проверяющим , программист аннотирует значения типами, а компилятор проверяет их правильность. При выводе типа компилятор выводит и проверяет типы. Мы называем правила, которые проверяют типы суждениями о типах , и их совокупность (вместе с самими типами) образует систему типов.
На самом деле оказывается, что можно сделать гораздо больше: системы типов не просто проверяют, int s или String s используются правильно. Более богатые системы типов могут доказать более сильные инварианты о программах: они завершатся, безопасно получат доступ к памяти или что они не содержат гонок данных. Например, система типов Rust гарантирует безопасность памяти и свободу от гонки данных, а также проверку традиционных типов
Например, система типов Rust гарантирует безопасность памяти и свободу от гонки данных, а также проверку традиционных типов int s и String s.
Я создаю материалы о своем путешествии в области разработки программного обеспечения в своем информационном бюллетене!
Советы из Кембриджа и Facebook, а также ранний доступ к техническим руководствам по машинному обучению, компиляторам и не только.
Ознакомьтесь с предыдущими выпусками!
Адрес электронной почты
Подписываясь, вы соглашаетесь с Условиями обслуживания и Политикой конфиденциальности Revue.
Куда подходит Болт?
Языки программирования до сих пор не решили проблему написания безопасного параллельного кода. Bolt, как и Rust, предотвращает гонки данных (объясняется в этом документе Rust), но использует более детальный подход к параллелизму. До того, как воины-клавишники набросятся на меня в Твиттере, я думаю, что Rust проделал блестящую работу, начав разговор об этом — хотя Bolt, скорее всего, никогда не станет мейнстримом, он демонстрирует другой подход.
Если мы сейчас посмотрим на конвейер, то увидим, что Bolt содержит этапы лексирования, синтаксического анализа и дешугаринга/понижения. Он также содержит несколько фаз сериализации и десериализации Protobuf: они предназначены исключительно для преобразования между OCaml и C++. Он нацелен на LLVM IR, а затем мы подключаем пару библиотек времени выполнения (pthreads и libc) и, наконец, выводим наш объектный файл , двоичный файл, содержащий машинный код.
Однако, в отличие от большинства компиляторов, Bolt имеет не один, а два этапа проверки типа ! Bolt имеет как традиционные типы, так и возможности , которые неофициально представляют собой еще один набор типов для проверки типов данных. Я написал диссертацию, в которой это рассматривается более формально, если вам интересна теория, если нет, вы можете пропустить посты, посвященные проверке гонки данных в этой серии. Сначала мы проверяем традиционные типы, немного упрощаем язык на этапе дешугаринга, а затем выполняем проверку типов на основе гонки данных.
А как насчет этой серии?
Эту серию статей можно рассматривать с двух точек зрения: во-первых, мы будем обсуждать дизайн языка и сравнивать Bolt с Java, C++ и другими языками. Во-вторых, это практическое пошаговое руководство по созданию собственного компилятора. В отличие от многих руководств по сборке собственного компилятора, в которых рассказывается, как создать игрушечный язык , некоторые темы, рассматриваемые в этом руководстве, составляют основу параллельных объектно-ориентированных языков, таких как Java: как реализуются классы, как работает наследование. , универсальные классы и даже то, как параллелизм реализован под капотом.
Болт также не выводит игрушечные инструкции, а вместо этого нацелен на LLVM IR . На практике это означает, что Bolt использует удивительные оптимизации, присутствующие в компиляторах C/C++. LLVM API является мощным, но также очень сложно ориентироваться в документации. Я провел много долгих ночей, реконструируя программы на C++ — надеюсь, эта серия поможет хотя бы одному человеку пройти через эту боль!
В следующей части мы рассмотрим практические аспекты настройки проекта компилятора — я пройдусь по репозиторию Bolt и объясню почему мы используем OCaml всех языков для внешнего интерфейса.
Создайте свой собственный язык программирования
Конечно, некоторые изобретатели языков программирования, такие как Деннис Ритчи или Гвидо ван Россум, являются рок-звездами информатики! Но тогда стать рок-звездой информатики было проще. Давным-давно я слышал следующий доклад от участника второй конференции History of Programming Languages: Все пришли к единому мнению, что область языков программирования мертва. Все важные языки уже изобретены . Это было доказано вопиющей неправотой год или два спустя, когда на сцену вышла Java, и, возможно, еще дюжину раз с тех пор, когда появились такие языки, как Go. По прошествии всего лишь шести десятилетий было бы неразумно утверждать, что наша область зрела и что нет ничего нового, что можно было бы изобретать, что могло бы сделать вас знаменитым.
Тем не менее, известность — плохой повод для создания языка программирования. Шансы получить известность или богатство благодаря изобретению языка программирования невелики. Любопытство и желание узнать, как все устроено, являются вескими причинами, если у вас есть время и желание, но, возможно, лучшие причины для создания собственного языка программирования — потребность и необходимость.
Любопытство и желание узнать, как все устроено, являются вескими причинами, если у вас есть время и желание, но, возможно, лучшие причины для создания собственного языка программирования — потребность и необходимость.
Некоторым людям нужно создать новый язык или новую реализацию существующего языка программирования, чтобы ориентироваться на новый процессор или конкурировать с конкурирующей компанией. Если это не вы, то, возможно, вы смотрели на лучшие языки (и компиляторы или интерпретаторы), доступные для какой-то области, для которой вы разрабатываете программы, и в них отсутствуют некоторые ключевые функции для того, что вы делаете, и эти недостающие функции причиняя тебе боль. Каждый раз в голубой луне кто-то придумывает совершенно новый стиль вычислений, для которого новая парадигма программирования требует нового языка.
Пока мы обсуждаем ваши мотивы создания языка, давайте поговорим о различных типах языков, организации и примерах, которые эта книга будет использовать в качестве руководства. Каждая из этих тем заслуживает внимания.
Каждая из этих тем заслуживает внимания.
Типы реализаций языков программирования
Какими бы ни были ваши причины, прежде чем создавать язык программирования, вы должны выбрать лучшие инструменты и технологии, которые вы можете найти для выполнения этой работы. В нашем случае эта книга подберет их для вас. Во-первых, есть вопрос о языке реализации, на котором вы строите свой язык. Исследователи языков программирования любят хвастаться тем, что пишут свой язык на самом этом языке, но обычно это только полуправда (или кто-то был очень непрактичным и хвастаться заодно). Также возникает вопрос, какую именно реализацию языка программирования строить:
- Чистый интерпретатор , который сам выполняет исходный код
- Собственный компилятор и система выполнения, например C
- Транспилятор , который переводит ваш язык на какой-либо другой язык высокого уровня
- Компилятор байт-кода с сопутствующей машиной байт-кода, такой как Java
Первый вариант веселый, но обычно слишком медленный. Второй вариант самый лучший, но обычно он слишком трудоемкий; хороший собственный компилятор может потребовать многих человеко-лет усилий.
Второй вариант самый лучший, но обычно он слишком трудоемкий; хороший собственный компилятор может потребовать многих человеко-лет усилий.
Хотя третий вариант, безусловно, самый простой и, вероятно, самый веселый, и я успешно использовал его раньше, если это не прототип, то это своего рода читерство. Конечно, первая версия C++ была транспилером, но он уступил место компиляторам, и не только потому, что содержал ошибки. Как ни странно, создание высокоуровневого кода делает ваш язык еще более зависимым от базового языка, чем другие варианты, а языки — движущиеся цели. Хорошие языки умерли, потому что лежащие в их основе зависимости от них исчезли или безвозвратно сломались. Это может быть смерть от тысячи маленьких порезов.
В этой книге выбран четвертый вариант: мы создадим компилятор байт-кода с сопутствующей машиной байт-кода, потому что это лучшее место, которое дает наибольшую гибкость, но при этом обеспечивает достойную производительность. Для тех из вас, кому требуется максимально быстрое выполнение, включена глава о компиляции собственного кода.
Понятие машины байт-кода очень старо; он прославился, среди прочего, реализацией Pascal от UCSD и классической реализацией SmallTalk-80. Он стал повсеместным до такой степени, что стал доступен непрофессиональному английскому языку с обнародованием Java JVM. Машины байт-кода — это абстрактные процессоры, интерпретируемые программным обеспечением; их часто называют виртуальные машины (как в Виртуальная машина Java ), хотя я не буду использовать эту терминологию, потому что она также используется для обозначения программных инструментов, которые используют наборы реальных аппаратных инструкций, таких как классические платформы IBM или более современные инструменты, такие как Виртуальный ящик .
Машина байт-кода обычно имеет более высокий уровень, чем аппаратное обеспечение, поэтому реализация байт-кода обеспечивает большую гибкость. Давайте быстро посмотрим, что нужно для этого…
Организация реализации языка байт-кода
В значительной степени организация этой книги соответствует классической организации компилятора байт-кода и соответствующей ему виртуальной машины. Эти компоненты определены здесь, а затем приведена диаграмма, чтобы обобщить их:
Эти компоненты определены здесь, а затем приведена диаграмма, чтобы обобщить их:
- Лексический анализатор считывает символы исходного кода и выясняет, как они сгруппированы в последовательность слов или токенов.
- Синтаксический анализатор считывает последовательность токенов и определяет, является ли эта последовательность допустимой в соответствии с грамматикой языка. Если токены находятся в правильном порядке, создается синтаксическое дерево.
- Семантический анализатор проверяет, являются ли все используемые имена допустимыми для операций, в которых они используются. Он проверяет их типы, чтобы точно определить, какие операции выполняются. Вся эта проверка делает синтаксическое дерево тяжелым, перегруженным дополнительной информацией о том, где объявлены переменные и каковы их типы.
- Генератор промежуточного кода вычисляет ячейки памяти для всех переменных и всех мест, где программа может резко изменить поток выполнения, таких как циклы и вызовы функций.
 Он добавляет их в синтаксическое дерево, а затем проходит по этому еще более толстому дереву перед построением списка машинно-независимых инструкций промежуточного кода.
Он добавляет их в синтаксическое дерево, а затем проходит по этому еще более толстому дереву перед построением списка машинно-независимых инструкций промежуточного кода. - Генератор окончательного кода преобразует список инструкций промежуточного кода в фактический байт-код в формате файла, который будет эффективен для загрузки и выполнения.
Независимо от шагов этого компилятора виртуальной машины байт-кода, интерпретатор байт-кода написан для загрузки и выполнения программ. Это гигантский цикл с оператором switch внутри, но для экзотических языков программирования компилятор может не иметь большого значения, и вся магия будет происходить в интерпретаторе байт-кода. Всю организацию можно представить следующей диаграммой:
Рисунок 1.1 – Фазы и поток данных в простом языке программирования
Потребуется много кода, чтобы проиллюстрировать, как построить машину байт-кода для реализации языка программирования. То, как представлен этот код, важно и подскажет вам, что вам нужно знать, и многое из того, что вы можете узнать, прочитав эту книгу.
Языки, использованные в примерах
В этой книге приведены примеры кода на двух языках с использованием модели параллельных переводов . Первый язык — Java , потому что этот язык распространен повсеместно. Надеюсь, вы знаете его или C++ и сможете читать примеры на среднем уровне. Второй пример языка — это собственный язык автора, Unicon . Читая эту книгу, вы сможете сами решить, какой язык лучше подходит для создания собственного языка программирования. Максимально возможное количество примеров будет предоставлено на обоих языках, и примеры на двух языках будут написаны максимально похоже. Иногда это будет в пользу меньшего языка.
Различия между Java и Unicon будут очевидны, но их значение несколько уменьшится благодаря средствам построения компилятора, которые мы будем использовать. Мы будем использовать современные потомки почтенных инструментов Lex и YACC для создания нашего сканера и синтаксического анализатора, и, придерживаясь инструментов для Java и Unicon, которые остаются максимально совместимыми с оригинальными Lex и YACC, внешние интерфейсы нашего компилятора будут почти идентичными. на обоих языках. Lex и YACC — это декларативные языки программирования, которые решают некоторые из наших сложных проблем на более высоком уровне, чем Java или Unicon.
на обоих языках. Lex и YACC — это декларативные языки программирования, которые решают некоторые из наших сложных проблем на более высоком уровне, чем Java или Unicon.
Пока мы используем Java и Unicon в качестве языков реализации, нам нужно будет поговорить еще об одном языке: языке-примере, который мы создаем. Это замена для любого языка, который вы решите создать. Несколько произвольно я введу для этой цели язык под названием Jzero . Никлаус Вирт изобрел игрушечный язык под названием PL/0 (язык программирования ноль ; название является риффом от названия языка PL/1 ), который использовался в курсах по созданию компиляторов. Jzero будет крошечным подмножеством Java, которое служит той же цели. я посмотрел довольно сложно (то есть я погуглил Jzero , а затем компилятор Jzero ), чтобы увидеть, не опубликовал ли кто-то определение Jzero, которое мы могли бы использовать, и не нашел его с таким именем, поэтому мы просто придумаем как мы идем вперед.
Примеры Java в этой книге будут протестированы с использованием OpenJDK 14; возможно, другие версии Java (например, OpenJDK 12 или Oracle Java JDK) будут работать так же, а возможно и нет. Вы можете получить OpenJDK с http://openjdk.java.net, или, если вы работаете в Linux, ваша операционная система, вероятно, имеет пакет OpenJDK, который вы можете установить. Дополнительные инструменты построения языков программирования (Jflex и byacc/j), необходимые для примеров Java, будут представлены в последующих главах по мере их использования. Реализации Java, которые мы будем поддерживать, могут быть больше ограничены тем, какие версии будут запускать эти инструменты построения языка, чем что-либо еще.
Примеры Unicon в этой книге работают с Unicon версии 13.2, которую можно загрузить с http://unicon.org. Чтобы установить Unicon в Windows, необходимо загрузить файл .msi и запустить программу установки. Чтобы установить в Linux, вы обычно делаете git-клон исходников и набираете make .