Понятие БД и СУБД, функции СУБД
Определение 1
СУБД (Система управления базами данных) — это комплект программных и лингвистических средств, обеспечивающих управление созданием и использованием баз данных (БД).
Определение 2
Информационная система (ИС) — это система, которая выполнена на основе компьютерного оборудования, предназначена для сохранения, поиска, обработки и трансляции больших информационных объёмов и имеет заданную конкретную область использования.
Определение 3
База данных (БД) – это систематизированный набор информационных данных, который предназначен для длительного сохранения в модулях внешней памяти компьютерного оборудования, а также его оперативного обновления и применения. Базы данных предназначены для хранения и поиска больших объёмов информации.
Классификация баз данных
Информационные базы данных могут быть классифицированы по типу сохраняемой информации на:
- Фактографические базы данных.

- Документальные базы данных. Это базы, содержащие документацию самых разных типов, то есть это может быть текст, графика, звуковые файлы, мультимедиа и так далее.
По методу хранения информации базы данных классифицируются следующим образом:
- Централизованные базы данных, то есть хранимые в одном компьютерном устройстве.
- Распределённые базы данных, то есть используемые в локальной или глобальной компьютерной сети.
По структурной организации данных информационные базы могут классифицироваться на:
Табличные (реляционные) базы данных.
Не табличные (не реляционные) базы данных, которые в свою очередь подразделяются на:.
- иерархические,
- сетевые.
Понятие «реляционный» (от латинского relatio, что означает отношение) обозначает, что данный метод информационного хранения базируется на взаимном отношении составляющих базу элементов.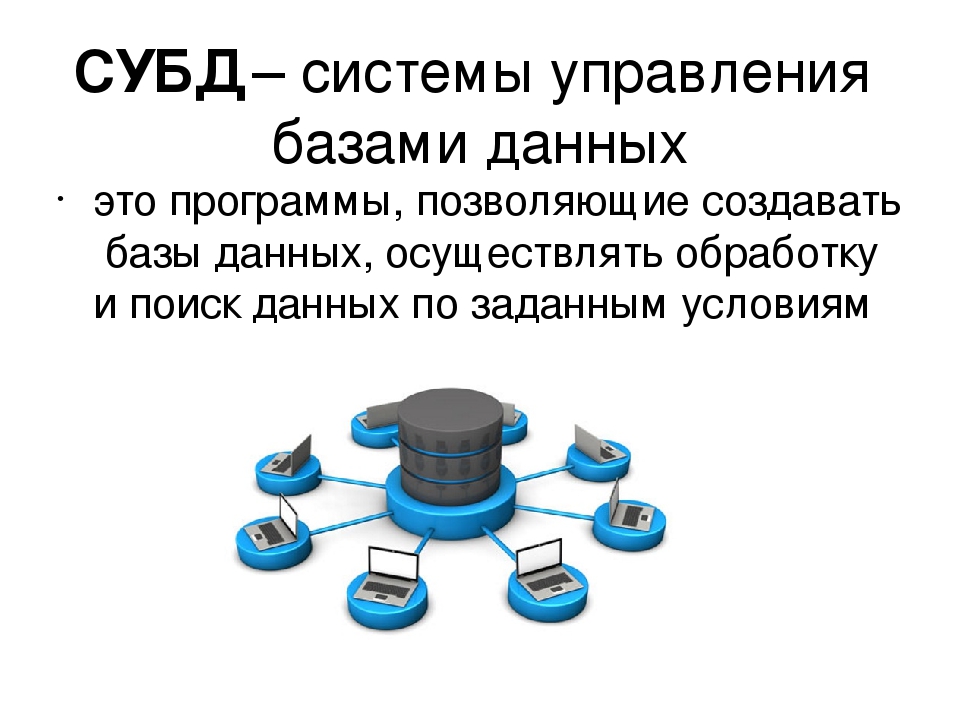
Базы данных, сформированные на основе реляционной модели, обладают следующими свойствами:
- Любой табличный компонент является одним компонентом данных.
- Все табличные поля обладают одним и тем же типом, то есть являются однородными.
- В таблице не может быть одинаковых записей.
- Допускается произвольный порядок табличных записей, и он может быть охарактеризован числом полей и типом данных.
Под «иерархической» понимается база данных, в которой информационные данные упорядочены по такому принципу, что один компонент назначается главным, а все другие являются подчинёнными. При иерархической модели базы данных упорядочивание записей выполняется в определённой последовательности, подобно ступеням лестницы, а информационный поиск может быть осуществлён путём последовательного «спуска» по ступеням.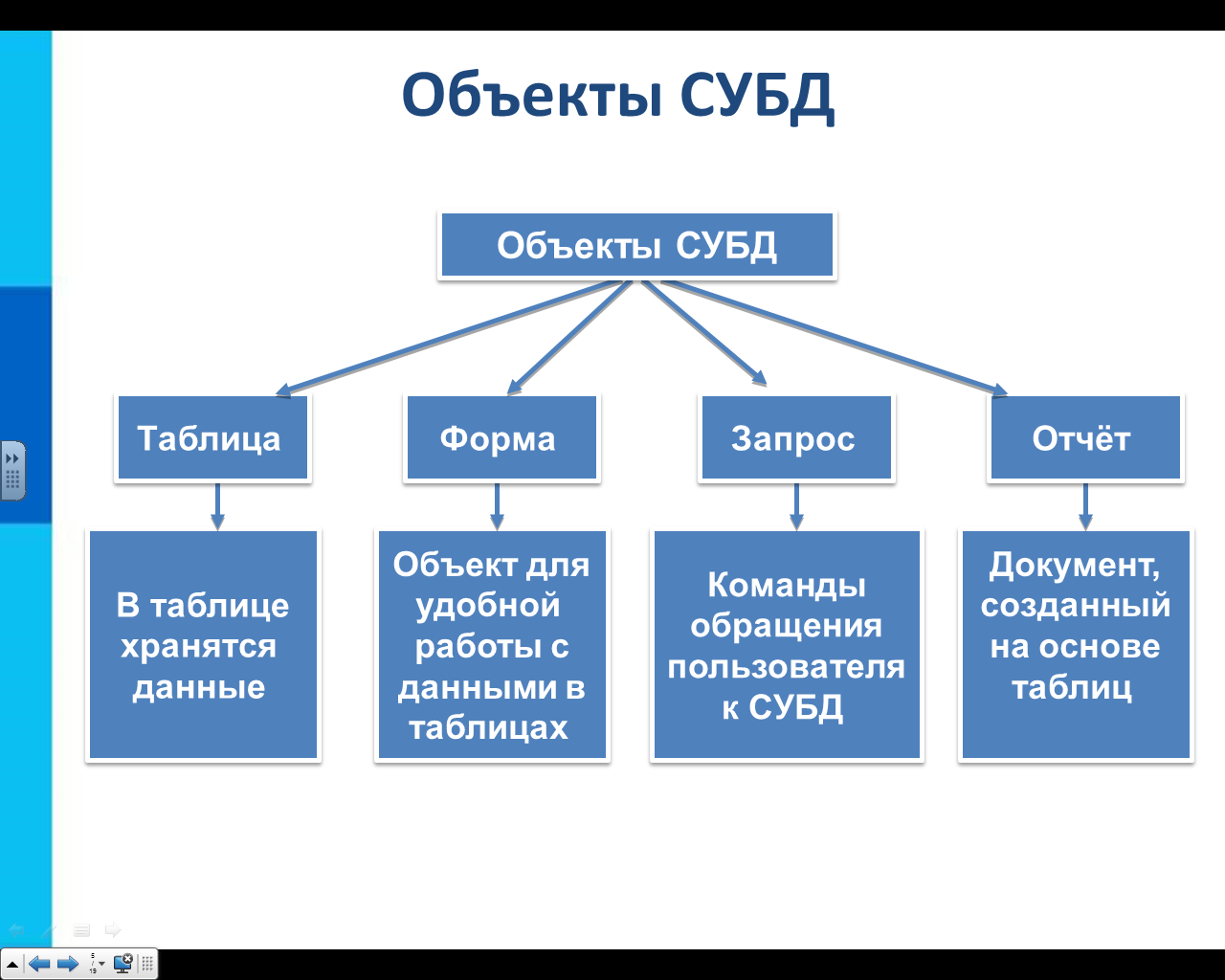
Замечание 1
Узел является информационной моделью компонента, который расположен на данном иерархическом уровне.
Иерархическая модель данных обладает следующими свойствами:
- Ряд узлов низшего уровня соединяется лишь с одним из узлов высшего уровня.
- Дерево иерархии обладает только одной вершиной и не подчиняется никаким другим вершинам.
- Все узлы обладают своими идентификаторами (именами).
- Имеется лишь один путь по направлению от корневой записи к частным записям данных.
Рисунок 1. Виды моделей данных БД. Автор24 — интернет-биржа студенческих работ
Каталог папок Windows считается иерархической базой, с которой возможно работать после запуска Проводника.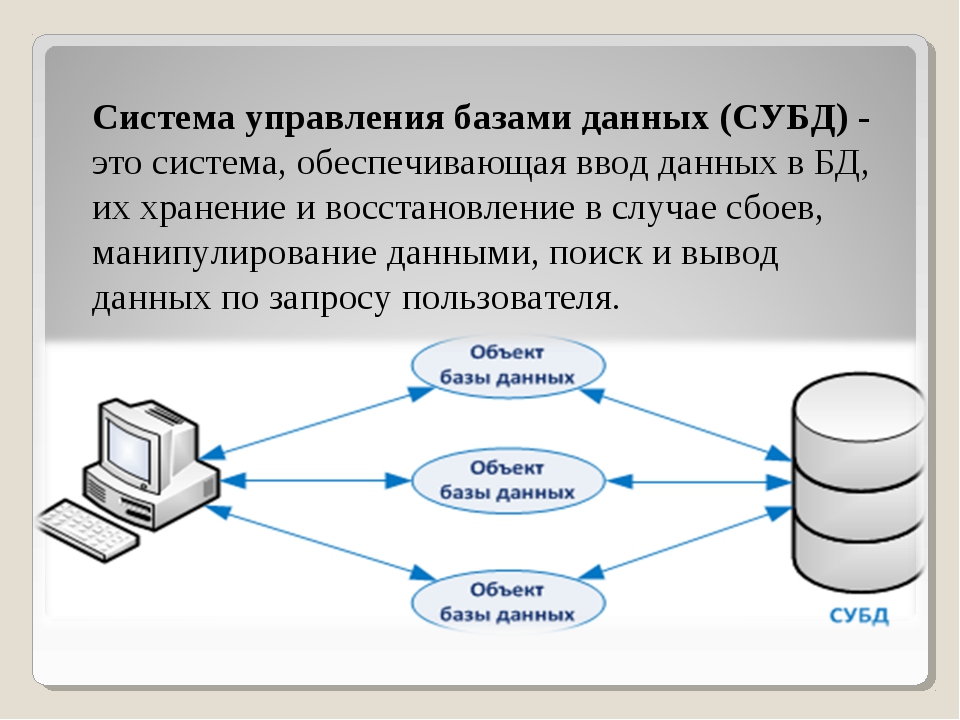 Верхний уровень — это папка «Рабочий стол». Уровнем ниже, то есть на втором уровне, расположены папки «Мой компьютер», «Мои документы», «Сетевое окружение» и «Корзина», являющиеся потомками папки «Рабочий стол» и близнецами, по сути.
Верхний уровень — это папка «Рабочий стол». Уровнем ниже, то есть на втором уровне, расположены папки «Мой компьютер», «Мои документы», «Сетевое окружение» и «Корзина», являющиеся потомками папки «Рабочий стол» и близнецами, по сути.
Сетевыми считаются базы данных, в которых к вертикальным связям иерархии прибавляются горизонтальные связи. Все объекты могут являться как главными, так и подчинёнными. Всемирная глобальная компьютерная сеть Интернет практически может считаться сетевой базой данных. При помощи гиперссылок огромное количество документов может быть связано между собой в единую распределённую сетевую информационную базу данных.
Система управления базами данных
Программное обеспечение, которое предназначено для обработки информационных баз данных, является системой управления базами данных (СУБД). Такие системы применяются для упорядоченного сохранения и работы с большими информационными объёмами. Системы управления базами данных призваны обеспечить поиск, хранение, коррекцию информации, выработку ответов на поступающие запросы. СУБД должна обеспечивать сохранность и конфиденциальность данных, а также трансляцию данных и реализацию связи с другими программными продуктами.
СУБД должна обеспечивать сохранность и конфиденциальность данных, а также трансляцию данных и реализацию связи с другими программными продуктами.
Главными операциями, которые пользователи могут осуществить при помощи СУБД, являются следующие:
- Формирование структурной организации базы данных.
- Занесение информации в базу данных.
- Коррекция структурной организации и содержимого базы данных.
- Выполнение информационного поиска в базе данных.
- Осуществление сортировки данных в базе.
- Организация защиты базы данных.
- Выполнение операции проверки сохранности базы данных.
Сегодняшние СУБД позволяют добавлять в базы данных помимо текстовой и графической информации также и звуковые и видео данные. Современный интерфейс и встроенные инструментальные функции СУБД дают возможность формировать новые базы данных просто при помощи имеющихся средств без использования дополнительного программирования. СУБД позволяют обеспечить наличие правильной, полной и непротиворечивой информации, а также удобную работу с ней.
БД и СУБД
Основные понятия
В словаре школьной информатики А.П. Ершова дано следующее определение: “
В этом же словаре уточняется понятие “данные”, которые определяются, как “факты или идеи, выраженные средствами формальной системы, обеспечивающей возможность их хранения, обработки или передачи”. Такую формальную систему называют языком представления данных.
Переходя с языка формальных определений на язык неформальных толкований, важно отметить, что для того, чтобы говорить о базе данных, необходимо иметь как сами данные, описанные формальным образом (в несколько упрощенном понимании — строго типизированные), так и способы их организации — структурирования. Фактически БД представляет собой структуру данных. Указанные средства формализации — описания и структуризации данных — определяются используемой системой управления базами данных (СУБД) — специализированной программой для создания и управления БД.
Фактически БД представляет собой структуру данных. Указанные средства формализации — описания и структуризации данных — определяются используемой системой управления базами данных (СУБД) — специализированной программой для создания и управления БД.
Если БД всегда является моделью некоторой предметной области, то СУБД, как правило, носят универсальный характер и способны управлять разнообразными (но основанными на одной модели представления данных — см. ниже) базами данных.
Выше уже было отмечено, что основное назначение БД — “постоянное применение”. Говоря о применении БД, необходимо упомянуть о понятии информационная система (ИС), которая представляет собой комплекс программных, аппаратных, организационных и иных средств, обеспечивающих обработку (понимаемую в широком смысле) данных. Ядром, “сердцем” ИС как раз и является БД. Разумеется, ИС бывают достаточно сложными, в том числе и построенными на нескольких базах данных, но сути это не меняет — БД в принципе можно представить себе как нечто автономное, но невозможно представить ИС, не основанную на БД.
Говоря о том, что БД является моделью предметной области, необходимо упомянуть о двух важнейших этапах проектирования БД. Первый этап — построение инфологической модели системы, отражающей ее основные составляющие — существенные для целей моделирования объекты, их характеристики и связи между объектами. При разработке инфологической модели разработчик волен абстрагироваться от предстоящей компьютерной реализации БД. Например, если в БД придется хранить даты некоторых событий, то на этапе построения инфологической модели разработчик может не заботиться о том, как именно он будет эти даты хранить — в виде чисел, строк или как-то иначе (скорее всего реальное хранение организовано иначе).
По инфологической модели строится даталогическая модель, учитывающая реальные возможности организации данных. В частности, именно на этом этапе разработчик учтет, что для хранения дат, как правило, имеется специальный тип данных.
Таким образом, конкретная СУБД “правит бал” именно на этапе перехода от инфологической модели предметной области к даталогической модели, пригодной для компьютерной реализации.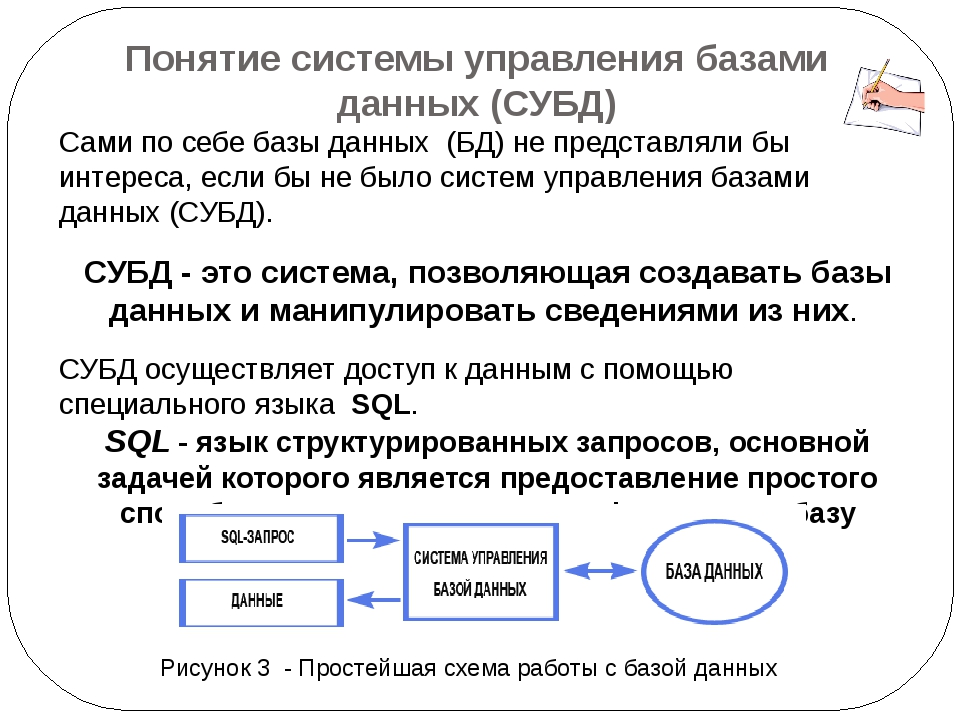 СУБД также отвечает за представление даталогической модели на физическом уровне компьютерной реализации. Ведь как бы абстрактна ни была модель, все равно на физическом уровне она, как правило, сводится к хранению данных в файлах; эти файлы имеют определенную структуру, как-то распределяются по каталогам и т.д. — за все это отвечает СУБД. Подробнее о технологиях проектирования БД можно прочитать в статье “Проектирование БД
СУБД также отвечает за представление даталогической модели на физическом уровне компьютерной реализации. Ведь как бы абстрактна ни была модель, все равно на физическом уровне она, как правило, сводится к хранению данных в файлах; эти файлы имеют определенную структуру, как-то распределяются по каталогам и т.д. — за все это отвечает СУБД. Подробнее о технологиях проектирования БД можно прочитать в статье “Проектирование БД
Классификации БД по моделям данных
Базы данных классифицируются по различным признакам. Отметим, что в ряде случаев правильнее говорить не о классификации баз данных, а о классификации СУБД, поскольку именно СУБД определяют наиболее существенные (в частности — структурные) характеристики управляемых ими баз данных.
Самая интересная с содержательной точки зрения классификация БД — по используемой модели данных, или по структуре организации данных. По указанному критерию сегодня принято выделять базы данных следующих видов: иерархические, сетевые, реляционные и объектно-ориентрованные. Сразу отметим важный факт: указанные виды баз данных возникают на этапе перехода от инфологической модели, инвариантной по отношению к структуре организации данных, к даталогической модели.
Сразу отметим важный факт: указанные виды баз данных возникают на этапе перехода от инфологической модели, инвариантной по отношению к структуре организации данных, к даталогической модели.
Первые производственные СУБД использовали иерархическую модель данных, которая может быть представлена в виде дерева. Самой известной СУБД, использующей модель данных этого типа, является система IMS (Information Management System), разработанная фирмой IBM для поддержки лунного проекта “Аполлон”. Эта СУБД создавалась для управления огромным количеством деталей, иерархически связанных между собой, — из деталей собирались узлы, которые входили в еще более крупные модули, и т.д. Подобные конструкции легко и естественно описываются именно иерархической моделью — тут нет необходимости приводить в пример “Аполлон”, достаточно обычного велосипеда.
Иерархическая модель имеет свои естественные достоинства и недостатки. Если вернуться к идее представления конструкции некоторого устройства, то не сложно ответить на вопрос, из каких деталей состоит данный узел, но весьма затруднительно быстро получить ответ на вопрос, какому узлу принадлежит данная деталь (ведь связи направлены от корня вниз).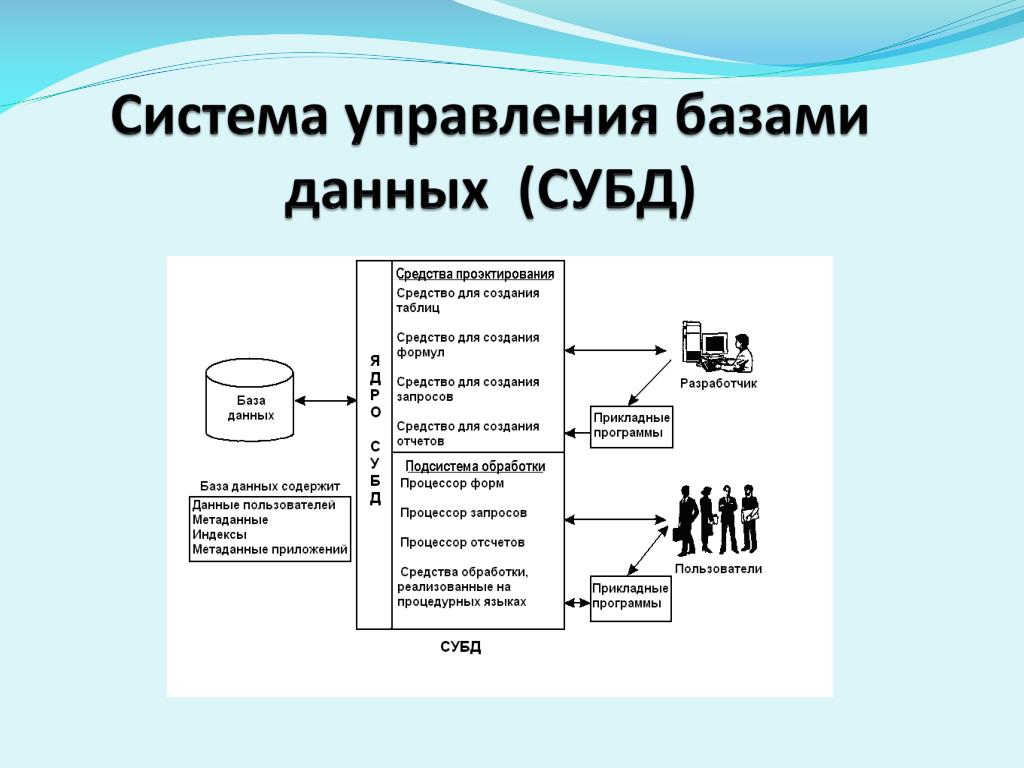 Указанную проблему (но это, конечно, не единственная сложность, возникающая при использовании иерархической модели!) решает сетевая модель организации данных, которая может быть представлена в виде направленного графа произвольного вида (таким образом, в сетевой модели можно расставить связи-стрелочки не только от узла к детали, но и в обратную сторону).
Указанную проблему (но это, конечно, не единственная сложность, возникающая при использовании иерархической модели!) решает сетевая модель организации данных, которая может быть представлена в виде направленного графа произвольного вида (таким образом, в сетевой модели можно расставить связи-стрелочки не только от узла к детали, но и в обратную сторону).
Одной из первых практических реализаций сетевых СУБД стала Integrated Data Store (IDS), созданная компанией General Electric. Архитектура этой СУБД легла в основу деятельности группы Database Task Group, которой конференция по языкам систем данных (Conference on Data Systems Languages — CODASYL) в конце 60-х годов поручила разработать стандарты систем управления базами данных. Этот документ и по сей день используется разработчиками сетевых СУБД, количество которых, по правде говоря… ничтожно. Сетевые СУБД весьма сложны в реализации, не слишком прозрачны не только для проектировщиков и программистов, но и для пользователей. Вследствие этого они оказались на периферии развития технологий после того, как в 1970 г. доктор Э.Ф. Кодд, математик и научный сотрудник фирмы IBM, предложил реляционную модель, основанную на представлении данных в виде таблиц. Одним из основных преимуществ реляционной модели является ее однородность. Все данные хранятся в плоских таблицах и только в них. В настоящее время практически все производственные СУБД различных масштабов используют реляционную модель. Поэтому ей не только посвящена отдельная статья “Реляционные БД” 2, но и в статьях “Описание данных” 2, “Обработка данных”2 и “Проектирование БД” 2 речь идет именно о реляционных БД.
Вследствие этого они оказались на периферии развития технологий после того, как в 1970 г. доктор Э.Ф. Кодд, математик и научный сотрудник фирмы IBM, предложил реляционную модель, основанную на представлении данных в виде таблиц. Одним из основных преимуществ реляционной модели является ее однородность. Все данные хранятся в плоских таблицах и только в них. В настоящее время практически все производственные СУБД различных масштабов используют реляционную модель. Поэтому ей не только посвящена отдельная статья “Реляционные БД” 2, но и в статьях “Описание данных” 2, “Обработка данных”2 и “Проектирование БД” 2 речь идет именно о реляционных БД.
В 1981 г. “за продолжительный фундаментальный вклад в теорию и практику развития СУБД” Кодду была вручена премия Тьюринга — самая престижная международная награда в области информационных технологий. Каждый лауреат этой премии на церемонии вручения читает специальную лекцию. В своей лекции Кодд, в частности, сказал:
“Основной побудительной причиной исследований, результатом которых стало создание реляционной модели данных, было желание четко разграничить логический и физический аспекты управления базами данных, принимая во внимание проблемы создания БД, поиска и обработки информации.
Мы назвали это стремлением к независимости информации.
Вторым нашим желанием было создать структурно простую модель, так чтобы пользователи и программисты любой квалификации одинаково могли бы понимать содержащуюся в ней информацию и общаться друг с другом при помощи базы данных. Мы назвали это стремлением к коммуникабельности.
В-третьих, мы хотели использовать концепции языка высокого уровня (но не специфический синтаксис), чтобы пользователи имели возможность описывать операции сразу над большими порциями информации. Это является основой для способов обработки информации, ориентированных на множества (т.е. возможности при помощи одного оператора задать операцию над несколькими множествами записей одновременно). Мы назвали это стремлением к обработке множеств”.
При разработке реляционной модели Кодд ввел два языка: описания данных и их обработки. В настоящее время для этой цели фактически используется один язык SQL (Structured Query Language). Использование общего языка стало одним из решающих конкурентных преимуществ реляционных СУБД. Фактически разработчики различных систем могут соревноваться в производительности, надежности, удобстве обслуживания и т.д., но пользователи чувствуют себя уверенно, зная, что грамотно организованные и описанные данные могут быть быстро экспортированы/импортированы из системы в систему.
Использование общего языка стало одним из решающих конкурентных преимуществ реляционных СУБД. Фактически разработчики различных систем могут соревноваться в производительности, надежности, удобстве обслуживания и т.д., но пользователи чувствуют себя уверенно, зная, что грамотно организованные и описанные данные могут быть быстро экспортированы/импортированы из системы в систему.
Последней из рассматриваемых станет сравнительно новая технология объектно-ориентированных баз данных. Первый стандарт объектно-ориентированных баз данных ODMG-93 (Object Database Management Group) был принят в 1993 г. В нем, в частности, определены два языка — ODL (Object Data Language) для определения данных (объектов) и OQL (Object Query Language) для манипулирования данными. Язык OQL основан на языке SQL. Одним из принципиальных отличий объектных баз данных от реляционных является возможность создания и использования новых типов данных. При этом новые типы порождаются посредством наследования от базовых. В объектных базах данных также различаются операции над всеми данными типа или над конкретным экземпляром.
При этом новые типы порождаются посредством наследования от базовых. В объектных базах данных также различаются операции над всеми данными типа или над конкретным экземпляром.
Объектная технология и традиционный реляционный подход пока имеют различные сферы применения. Если данные состоят из “обычных” простых полей фиксированной (или легко поддающейся оценке сверху) длины, то наилучшим решением является применение реляционной СУБД. Если же данные содержат вложенные структуры, их размер может изменяться динамически, структуры данных могут определяться пользователем в процессе функционирования БД и т.д., то имеет смысл задуматься о применении объектно-ориентированной СУБД.
Вместе с тем отметим, что реляционная и объектно-ориентированная модели не являются взаимно-исключающими. Уже довольно давно разрабатываются объектно-реляционные СУБД. Самым известным примером в этой области, возможно, является система Postgres: именно на ее основе функционируют федеральные порталы Министерства образования. Эта же СУБД используется в системе сайтов Rambler.
Эта же СУБД используется в системе сайтов Rambler.
В заключение обратим внимание читателя на весьма неформальную, но популярную среди разработчиков схему, предложенную Майклом Стоунбрекером, одним из идеологов и разработчиков гибридных объектно-реляционных СУБД. Несмотря на то, что указанная схема весьма груба, она наглядно демонстрирует текущие тенденции развития технологий БД.
Методические рекомендации
Введение в базы данных — не самая удобная тема базового курса информатики. У учителя всегда возникает естественное желание побыстрее закончить с “общими местами” и перейти к чему-нибудь конкретному. Тем не менее именно на этом этапе необходимо познакомить учащихся с понятиями “база данных” и “система управления базами данных”. Здесь важно обозначить как взаимосвязь, так и различие этих понятий.
Из различных классификаций баз данных, без сомнения, имеет смысл познакомить с классификацией, основанной на структуре организации данных. В учебной литературе можно встретить и другие классификации, целесообразность знакомства с которыми представляется сомнительной. Кратко обоснуем наш сдержанный скепсис.
Кратко обоснуем наш сдержанный скепсис.
Одна из классификаций баз данных, которую можно встретить в учебниках, — по характеру хранимой информации. По указанному критерию различают фактографические и документальные базы данных. Считается, что первые хранят “голые факты” — простые данные (пример “голого факта” — дата рождения), а вторые — документы (пример — биография). Мы употребили слово “считается”, носящее несколько скептический оттенок, потому, что подобная классификация для современных СУБД неактуальна. Как правило, в БД хранятся и факты, и, при необходимости, документы, включающие не только тексты, но объекты мультимедиа и пр.
По способу хранения данных БД часто делятся на централизованные и распределенные. Централизованная БД целиком хранится на одном компьютере, распределенная — на разных. С этой классификацией, вообще говоря, тоже возникает немало проблем, поскольку она имеет отношение к физической организации данных. Например, СУБД, расположенная на одном компьютере, может распределенно хранить данные на нескольких — это ее “личное дело”.
Например, СУБД, расположенная на одном компьютере, может распределенно хранить данные на нескольких — это ее “личное дело”.
Методические вопросы, связанные с изучением реляционных баз данных, рассмотрены в соответствующих статьях. Что же касается иерархической и сетевой модели, то первая замечательно иллюстрируется примером СУБД IMS, упомянутой в статье, а вторую приходится упоминать в связи с очевидными недостатками первой. Хорошего наглядного примера СУБД, основанной на сетевой модели, к сожалению, нет.
Об объектно-ориентированных СУБД в базовом курсе можно лишь упомянуть.
Классификация СУБД — Помощник студента
Система управления базами данных (СУБД) —совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
Примеры СУБД – Oracle, Microsoft Access, Paradox, Firebird, Sqlite, еще очень много.
Назначение СУБД:
- Компактное хранение данных (без дублирования)
- Оптимизация доступа к данным
- Логическая целостность (согласованность данных)
- Универсальный интерфейс (язык или протокол), позволяющий задавать структуру данных, изменять и извлекать их неизвестному заранее алгоритму.
Классификация СУБД (нашел 6 видов классификаций):
- По модели данных (в классической теории баз данных, модель данных есть формальная теория представления и обработки данных в системе управления базами данных (СУБД), которая включает, по меньшей мере, три аспекта:
1) аспект структуры: методы описания типов и логических структур данных в базе данных;
2) аспект манипуляции: методы манипулирования данными;
3) аспект целостности: методы описания и поддержки целостности базы данных.
Аспект структуры определяет, что из себя логически представляет база данных, аспект манипуляции определяет способы перехода между состояниями базы данных (то есть способы модификации данных) и способы извлечения данных из базы данных, аспект целостности определяет средства описаний корректных состояний базы данных. ):
):
- Иерархические
(здесь и ниже внимательно смотрите, что именно я комментирую. СУБД Х типа построена на основе Х типа модели данных. Значит если я описываю модель данных, то это не прямое описание СУБД, а описание модели данных, с которой она работает;
Иерархическая модель данных — это модель данных, где используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами (в программировании применительно к структуре данных дерево устоялось название братья).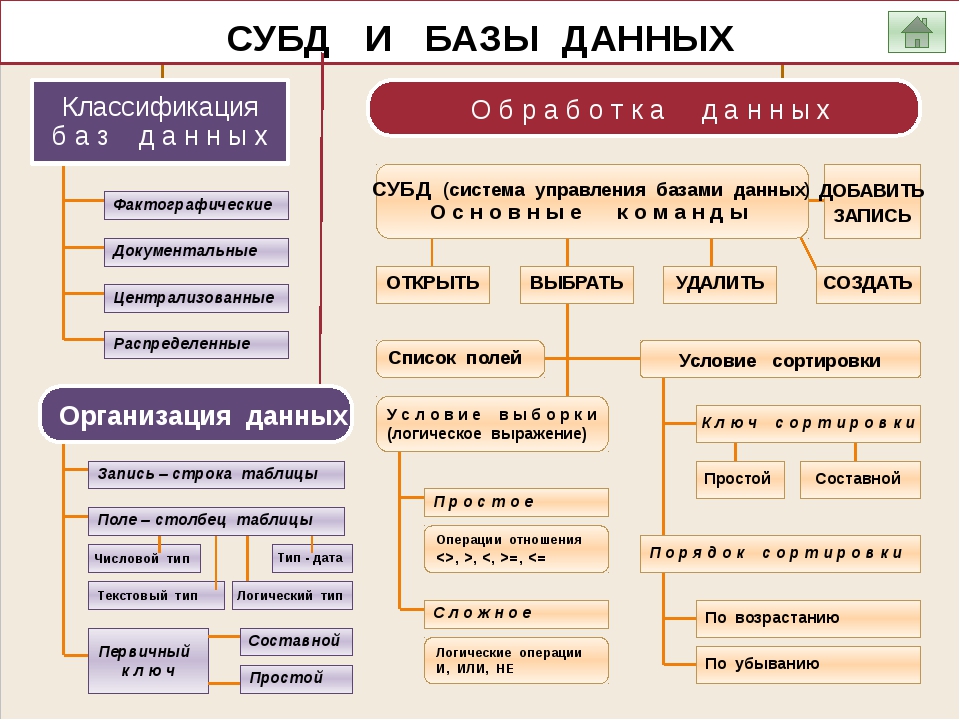
Первые системы управления базами данных использовали иерархическую модель данных.)
- Сетевые
(Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков.
Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L;
каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L)
- Реляционные
(Реляционная модель данных включает следующие компоненты:
Структурный аспект (составляющая) — данные в базе данных представляют собой набор отношений.
Аспект (составляющая) целостности — отношения (таблицы) отвечают определенным условиям целостности. РМД поддерживает декларативные ограничения целостности уровня домена (типа данных), уровня отношения и уровня базы данных.
Аспект (составляющая) обработки (манипулирования) — РМД поддерживает операторы манипулирования отношениями (реляционная алгебра, реляционное исчисление).
Кроме того, в состав реляционной модели данных включают теорию нормализации.)
- Объектно-ориентированные
Объектно-ориентированная (объектная) СУБД — система управления базами данных, основанная на объектной модели данных.
Эта система управления обрабатывает данные как абстрактные объекты, наделённые свойствами и использующие методы взаимодействия с другими объектами окружающего мира.
- Объектно-реляционные
(Объектно-реляционная СУБД (ОРСУБД) — реляционная СУБД (РСУБД), поддерживающая некоторые технологии, реализующие объектно-ориентированный подход: объекты, классы и наследование реализованы в структуре баз данных и языке запросов.
Объектно-реляционными СУБД являются, например, широко известные Oracle Database, Informix, DB2, PostgreSQL.)
- По степени распределенности:
- Локальные СУБД
(все части локальной СУБД размещаются на одном компьютере)
- Распределенные СУБД
(части СУБД на двух и более компьютерах)
- По способу доступа к БД:
- Файл-серверные
(универсальный интерфейс (язык или протокол), позволяющий задавать структуру данных, изменять и извлекать их неизвестному заранее алгоритму. В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД располагается на каждом клиентском компьютере (рабочей станции). Доступ СУБД к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на процессор файлового сервера.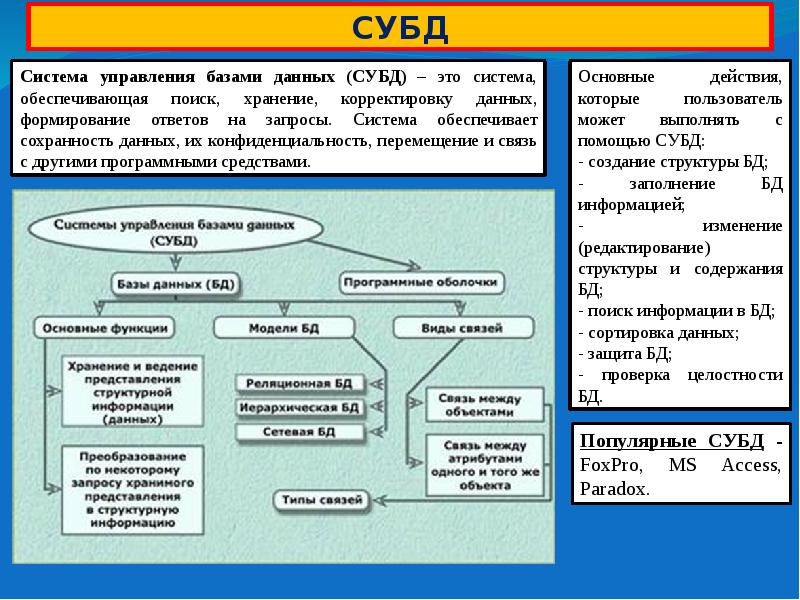 Недостатки: потенциально высокая загрузка локальной сети; затруднённость или невозможность централизованного управления; затруднённость или невозможность обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность. Применяются чаще всего в локальных приложениях, которые используют функции управления БД; в системах с низкой интенсивностью обработки данных и низкими пиковыми нагрузками на БД.
Недостатки: потенциально высокая загрузка локальной сети; затруднённость или невозможность централизованного управления; затруднённость или невозможность обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность. Применяются чаще всего в локальных приложениях, которые используют функции управления БД; в системах с низкой интенсивностью обработки данных и низкими пиковыми нагрузками на БД.
На данный момент файл-серверная технология считается устаревшей, а её использование в крупных информационных системах — недостатком.
Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.)
- Клиент-серверные
(Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет доступ к БД непосредственно, в монопольном режиме. Все клиентские запросы на обработку данных обрабатываются клиент-серверной СУБД централизованно. Недостаток клиент-серверных СУБД состоит в повышенных требованиях к серверу. Достоинства: потенциально более низкая загрузка локальной сети; удобство централизованного управления; удобство обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность.
Достоинства: потенциально более низкая загрузка локальной сети; удобство централизованного управления; удобство обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность.
Примеры: Oracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL, Caché, ЛИНТЕР.)
- Встраиваемые
(Встраиваемая СУБД — СУБД, которая может поставляться как составная часть некоторого программного продукта, не требуя процедуры самостоятельной установки. Встраиваемая СУБД предназначена для локального хранения данных своего приложения и не рассчитана на коллективное использование в сети. Физически встраиваемая СУБД чаще всего реализована в виде подключаемой библиотеки. Доступ к данным со стороны приложения может происходить через SQL либо через специальные программные интерфейсы.
Примеры: OpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server Compact, ЛИНТЕР. )
)
- По степени универсальности:
- Специального назначения
(Ориентированы на какую-либо конкретную предметную область или на информационные потребности конкретной группы пользователей; пример – IMBASE для автоматизации проектных и конструкторских разработок)
- Общего назначения
(не ориентированы на какую-либо… смотри выше)
- По применению (эта классификация есть далеко не во всех источниках, она довольно условна, так что можно и не писать наверное):
- Профессиональные
- Персональные
- По стратегии работы с внешней памятью (не факт, что это является классификацией, это скорее еще один способ деления, но как классификация он ни в одном источнике не указан, советую не расписывать данный пункт, но если вдруг спросят, к сведению принять)
- СУБД с непосредственной записью
(СУБД, в которых все измененные блоки данных незамедлительно записываются во внешнюю память при поступлении сигнала подтверждения любой транзакции. Такая стратегия используется только при высокой эффективности внешней памяти)
Такая стратегия используется только при высокой эффективности внешней памяти)
- СУБД с отложенной записью
(СУБД, в которых изменения аккумулируются в буферах внешней памяти до наступления любого из следующих событий:
1.контрольной точки;
2.конец пространства во внешней памяти, отведенное под журнал — СУБД выполняет контрольную точку и начинает писать журнал сначала, затирая предыдущую информацию;
3.останов (не остановка, а именно «останов», опечатки тут нет) — СУБД ждёт, когда всё содержимое всех буферов внешней памяти будет перенесено во внешнюю память, после чего делает отметки, что останов базы данных выполнен корректно;
4.При нехватке оперативной памяти для буферов внешней памяти.
Такая стратегия позволяет избежать частого обмена с внешней памятью и значительно увеличить эффективность работы СУБД)
Основные функции СУБД (писал с лекций Платоновой):
- Хранение, извлечение и обновление данных
- Каталог, доступный конечным пользователям
- Поддержка транзакций
- Службы управления параллельной работой
- Службы восстановления
- Службы контроля доступа к данным
- Поддержка обмена данными
- Службы поддержки целостности данных
- Службы поддержки независимости от данных
- Вспомогательные службы
Поделиться ссылкой:
Понравилось это:
Нравится Загрузка. ..
..
информатика | Определение, поля и факты
Информатика , изучение компьютеров и вычислений, включая их теоретические и алгоритмические основы, аппаратное и программное обеспечение, а также их использование для обработки информации. Дисциплина информатики включает изучение алгоритмов и структур данных, компьютерное и сетевое проектирование, моделирование данных и информационных процессов, а также искусственный интеллект. Информатика берет некоторые свои основы из математики и инженерии и поэтому включает методы из таких областей, как теория массового обслуживания, вероятность и статистика, а также проектирование электронных схем.Информатика также широко использует проверку гипотез и экспериментирование во время концептуализации, проектирования, измерения и уточнения новых алгоритмов, информационных структур и компьютерных архитектур.
портативный компьютерпортативный персональный компьютер.
© Index OpenПопулярные вопросы
Что такое информатика?
Кто самые известные компьютерные ученые?
Что можно делать с информатикой?
Используется ли информатика в видеоиграх?
Как мне изучить информатику?
Многие университеты по всему миру предлагают степени, которые обучают студентов основам теории информатики и приложениям компьютерного программирования.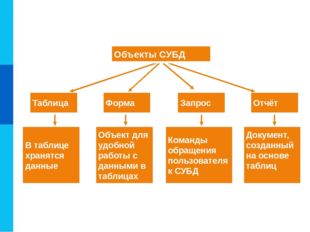 Кроме того, преобладание онлайн-ресурсов и курсов позволяет многим людям самостоятельно изучать более практические аспекты информатики (такие как кодирование, разработка видеоигр и дизайн приложений).
Кроме того, преобладание онлайн-ресурсов и курсов позволяет многим людям самостоятельно изучать более практические аспекты информатики (такие как кодирование, разработка видеоигр и дизайн приложений).
Информатика считается частью семейства из пяти отдельных, но взаимосвязанных дисциплин: компьютерная инженерия, информатика, информационные системы, информационные технологии и разработка программного обеспечения. Это семейство стало известно как дисциплина вычислений.Эти пять дисциплин взаимосвязаны в том смысле, что информатика является их объектом изучения, но они отделены друг от друга, поскольку каждая имеет свою исследовательскую перспективу и направленность учебной программы. (С 1991 года Ассоциация вычислительной техники [ACM], Компьютерное общество IEEE [IEEE-CS] и Ассоциация информационных систем [AIS] сотрудничали для разработки и обновления таксономии этих пяти взаимосвязанных дисциплин и руководящих принципов, которые образовательные учреждения используются во всем мире для своих программ бакалавриата, магистратуры и исследовательских программ. )
)
Основные области информатики включают традиционное изучение компьютерной архитектуры, языков программирования и разработки программного обеспечения. Однако они также включают в себя вычислительную науку (использование алгоритмических методов для моделирования научных данных), графику и визуализацию, взаимодействие человека с компьютером, базы данных и информационные системы, сети, а также социальные и профессиональные вопросы, которые являются уникальными для практики информатики. . Как может быть очевидно, некоторые из этих подполей частично совпадают в своей деятельности с другими современными областями, такими как биоинформатика и вычислительная химия.Эти совпадения являются следствием тенденции компьютерных ученых признавать многочисленные междисциплинарные связи в своей области и действовать в соответствии с ними.
Развитие информатики
Информатика возникла как самостоятельная дисциплина в начале 1960-х годов, хотя электронно-цифровая вычислительная машина, являющаяся объектом ее изучения, была изобретена примерно двумя десятилетиями ранее. Корни информатики лежат, прежде всего, в смежных областях математики, электротехники, физики и информационных систем управления.
Корни информатики лежат, прежде всего, в смежных областях математики, электротехники, физики и информационных систем управления.
Математика является источником двух ключевых концепций в развитии компьютера — идеи о том, что всю информацию можно представить в виде последовательностей нулей и единиц, и абстрактного понятия «хранимая программа». В двоичной системе счисления числа представлены последовательностью двоичных цифр 0 и 1 так же, как числа в знакомой десятичной системе представлены цифрами от 0 до 9.Относительная легкость, с которой два состояния (например, высокое и низкое напряжение) могут быть реализованы в электрических и электронных устройствах, естественным образом привела к тому, что двоичная цифра или бит стал основной единицей хранения и передачи данных в компьютерной системе.
Электротехника обеспечивает основы проектирования схем, а именно идею о том, что электрические импульсы, входящие в схему, могут быть объединены с использованием булевой алгебры для получения произвольных выходных сигналов. (Булева алгебра, разработанная в 19 веке, предоставила формализм для разработки схемы с двоичными входными значениями нулей и единиц [ложь или истина, соответственно, в терминологии логики], чтобы получить любую желаемую комбинацию нулей и единиц на выходе.) Изобретение транзистора и миниатюризация схем, наряду с изобретением электронных, магнитных и оптических носителей для хранения и передачи информации, явились результатом достижений электротехники и физики.
(Булева алгебра, разработанная в 19 веке, предоставила формализм для разработки схемы с двоичными входными значениями нулей и единиц [ложь или истина, соответственно, в терминологии логики], чтобы получить любую желаемую комбинацию нулей и единиц на выходе.) Изобретение транзистора и миниатюризация схем, наряду с изобретением электронных, магнитных и оптических носителей для хранения и передачи информации, явились результатом достижений электротехники и физики.
Информационные системы управления, первоначально называвшиеся системами обработки данных, предоставили ранние идеи, на основе которых развились различные концепции информатики, такие как сортировка, поиск, базы данных, поиск информации и графические пользовательские интерфейсы.В крупных корпорациях размещались компьютеры, на которых хранилась информация, играющая ключевую роль в ведении бизнеса — расчет заработной платы, бухгалтерский учет, управление запасами, контроль производства, отгрузка и получение.
Теоретические работы по вычислимости, начатые в 1930-х, обеспечили необходимое распространение этих достижений на проектирование целых машин; важной вехой стала спецификация машины Тьюринга (теоретическая вычислительная модель, выполняющая инструкции, представленные в виде последовательности нулей и единиц) в 1936 году британским математиком Аланом Тьюрингом и его доказательство вычислительной мощности модели. Другим прорывом стала концепция компьютера с хранимой программой, которую обычно приписывают венгерскому американскому математику Джону фон Нейману. Это истоки области информатики, которая позже стала известна как архитектура и организация.
Другим прорывом стала концепция компьютера с хранимой программой, которую обычно приписывают венгерскому американскому математику Джону фон Нейману. Это истоки области информатики, которая позже стала известна как архитектура и организация.
Алан М. Тьюринг, 1951.
Science History Images / Alamy В 1950-е годы большинство пользователей компьютеров работали либо в научно-исследовательских лабораториях, либо в крупных корпорациях. Первая группа использовала компьютеры для выполнения сложных математических вычислений (например,g., траектории ракет), в то время как последняя группа использовала компьютеры для управления большими объемами корпоративных данных (например, платежными ведомостями и запасами). Обе группы быстро поняли, что написание программ на машинном языке нулей и единиц непрактично и не надежно. Это открытие привело к разработке языка ассемблера в начале 1950-х годов, который позволяет программистам использовать символы для инструкций (например, ADD для сложения) и переменных (например, X ).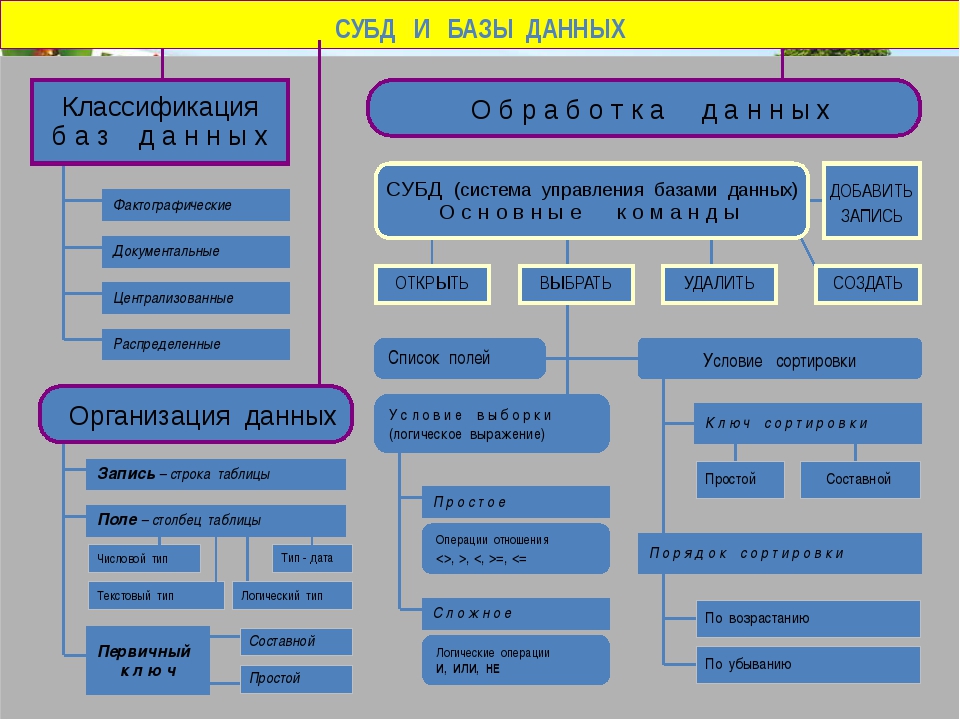 Другая программа, известная как ассемблер, переводила эти символические программы в эквивалентную двоичную программу, шаги которой компьютер мог выполнять, или «выполнять».”
Другая программа, известная как ассемблер, переводила эти символические программы в эквивалентную двоичную программу, шаги которой компьютер мог выполнять, или «выполнять».”
Другие элементы системного программного обеспечения, известные как связывающие загрузчики, были разработаны для объединения частей собранного кода и загрузки их в память компьютера, где они могли быть выполнены. Концепция связывания отдельных частей кода была важна, поскольку позволяла повторно использовать «библиотеки» программ для выполнения общих задач. Это был первый шаг в развитии области компьютерных наук, называемой программной инженерией.
Позже, в 1950-х годах, язык ассемблера оказался настолько громоздким, что разработка языков высокого уровня (близких к естественным языкам) стала поддерживать более легкое и быстрое программирование.FORTRAN стал основным языком высокого уровня для научного программирования, а COBOL стал основным языком бизнес-программирования. Эти языки несли с собой потребность в различном программном обеспечении, называемом компиляторами, которое переводит программы на языке высокого уровня в машинный код. По мере того как языки программирования становились все более мощными и абстрактными, создание компиляторов, которые создают высококачественный машинный код и которые эффективны с точки зрения скорости выполнения и потребления памяти, стало сложной проблемой информатики.Разработка и реализация языков высокого уровня лежит в основе области информатики, называемой языками программирования.
По мере того как языки программирования становились все более мощными и абстрактными, создание компиляторов, которые создают высококачественный машинный код и которые эффективны с точки зрения скорости выполнения и потребления памяти, стало сложной проблемой информатики.Разработка и реализация языков высокого уровня лежит в основе области информатики, называемой языками программирования.
Рост использования компьютеров в начале 1960-х годов послужил толчком для разработки первых операционных систем, которые состояли из резидентного программного обеспечения системы, которое автоматически обрабатывало ввод и вывод и выполняло программы, называемые «заданиями». Потребность в улучшенных вычислительных методах привела к возрождению интереса к численным методам и их анализу, деятельности, которая распространилась настолько широко, что стала известна как вычислительная наука.
В 1970-е и 1980-е годы появились мощные устройства компьютерной графики, как для научного моделирования, так и для других визуальных действий. (Компьютеризированные графические устройства были представлены в начале 1950-х годов с отображением грубых изображений на бумажных графиках и экранах электронно-лучевых трубок [ЭЛТ].) Дорогостоящее оборудование и ограниченная доступность программного обеспечения не позволяли этой области расти до начала 1980-х годов, когда компьютерная память, необходимая для растровой графики (в которой изображение состоит из небольших прямоугольных пикселей), стала более доступной.Технология растровых изображений вместе с экранами с высоким разрешением и развитием графических стандартов, которые делают программное обеспечение менее зависимым от машины, привели к взрывному росту этой области. Поддержка всех этих видов деятельности переросла в область компьютерных наук, известную как графика и визуальные вычисления.
(Компьютеризированные графические устройства были представлены в начале 1950-х годов с отображением грубых изображений на бумажных графиках и экранах электронно-лучевых трубок [ЭЛТ].) Дорогостоящее оборудование и ограниченная доступность программного обеспечения не позволяли этой области расти до начала 1980-х годов, когда компьютерная память, необходимая для растровой графики (в которой изображение состоит из небольших прямоугольных пикселей), стала более доступной.Технология растровых изображений вместе с экранами с высоким разрешением и развитием графических стандартов, которые делают программное обеспечение менее зависимым от машины, привели к взрывному росту этой области. Поддержка всех этих видов деятельности переросла в область компьютерных наук, известную как графика и визуальные вычисления.
С этой областью тесно связано проектирование и анализ систем, которые напрямую взаимодействуют с пользователями, выполняющими различные вычислительные задачи. Эти системы стали широко использоваться в 1980-х и 90-х годах, когда линейное взаимодействие с пользователями было заменено графическими пользовательскими интерфейсами (GUI). Дизайн графического интерфейса пользователя, который был впервые разработан Xerox и позже принят Apple (Macintosh) и, наконец, Microsoft (Windows), важен, потому что он составляет то, что люди видят и делают, когда они взаимодействуют с вычислительным устройством. Разработка соответствующих пользовательских интерфейсов для всех типов пользователей превратилась в область компьютерных наук, известную как взаимодействие человека с компьютером (HCI).
Дизайн графического интерфейса пользователя, который был впервые разработан Xerox и позже принят Apple (Macintosh) и, наконец, Microsoft (Windows), важен, потому что он составляет то, что люди видят и делают, когда они взаимодействуют с вычислительным устройством. Разработка соответствующих пользовательских интерфейсов для всех типов пользователей превратилась в область компьютерных наук, известную как взаимодействие человека с компьютером (HCI).
Xerox Alto был первым компьютером, на котором для управления системой использовались графические значки и мышь — первый графический интерфейс пользователя (GUI).
Предоставлено Xerox Область компьютерной архитектуры и организации также резко изменилась с тех пор, как в 1950-х были разработаны первые компьютеры с хранимыми программами. Так называемые системы с разделением времени появились в 1960-х годах, чтобы позволить нескольким пользователям одновременно запускать программы с разных терминалов, жестко подключенных к компьютеру. В 1970-х годах были разработаны первые глобальные компьютерные сети (WAN) и протоколы для высокоскоростной передачи информации между компьютерами, разделенными на большие расстояния.По мере развития этих видов деятельности они переросли в область компьютерных наук, называемую сетями и коммуникациями. Важным достижением в этой области стало развитие Интернета.
В 1970-х годах были разработаны первые глобальные компьютерные сети (WAN) и протоколы для высокоскоростной передачи информации между компьютерами, разделенными на большие расстояния.По мере развития этих видов деятельности они переросли в область компьютерных наук, называемую сетями и коммуникациями. Важным достижением в этой области стало развитие Интернета.
Идея о том, что инструкции, а также данные могут храниться в памяти компьютера, была критически важна для фундаментальных открытий о теоретическом поведении алгоритмов. То есть такие вопросы, как «Что можно / нельзя вычислить?» были формально решены с использованием этих абстрактных идей. Эти открытия положили начало области компьютерных наук, известной как алгоритмы и сложность.Ключевой частью этой области является изучение и применение структур данных, подходящих для различных приложений. Структуры данных, наряду с разработкой оптимальных алгоритмов для вставки, удаления и размещения данных в таких структурах, являются серьезной проблемой для компьютерных ученых, потому что они так активно используются в компьютерном программном обеспечении, особенно в компиляторах, операционных системах, файловых системах, и поисковые системы.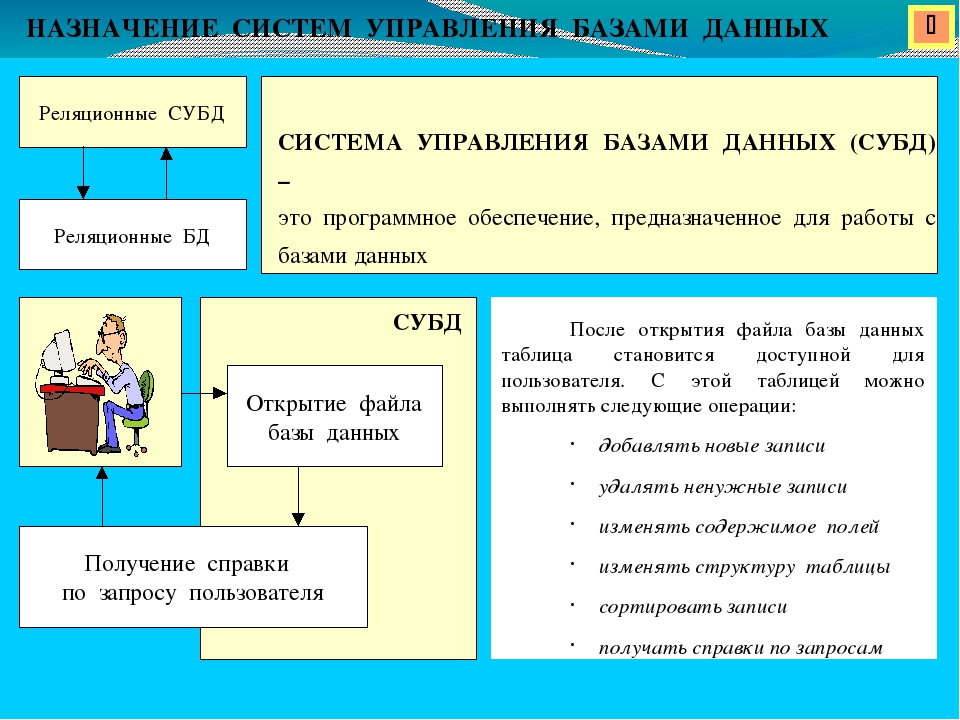
В 1960-х годах изобретение магнитных дисков обеспечило быстрый доступ к данным, расположенным в произвольном месте на диске.Это изобретение привело не только к более грамотно спроектированным файловым системам, но и к разработке баз данных и систем поиска информации, которые позже стали важными для хранения, извлечения и передачи больших объемов и разнообразных данных через Интернет. Эта область информатики известна как управление информацией.
Другая долгосрочная цель исследований в области информатики — создание вычислительных машин и роботизированных устройств, которые могут выполнять задачи, которые обычно считаются требующими человеческого интеллекта.К таким задачам относятся движение, зрение, слух, говорение, понимание естественного языка, мышление и даже проявление человеческих эмоций. Область информатики интеллектуальных систем, первоначально известная как искусственный интеллект (ИИ), на самом деле предшествовала появлению первых электронных компьютеров в 1940-х годах, хотя термин искусственный интеллект не был введен до 1956 года.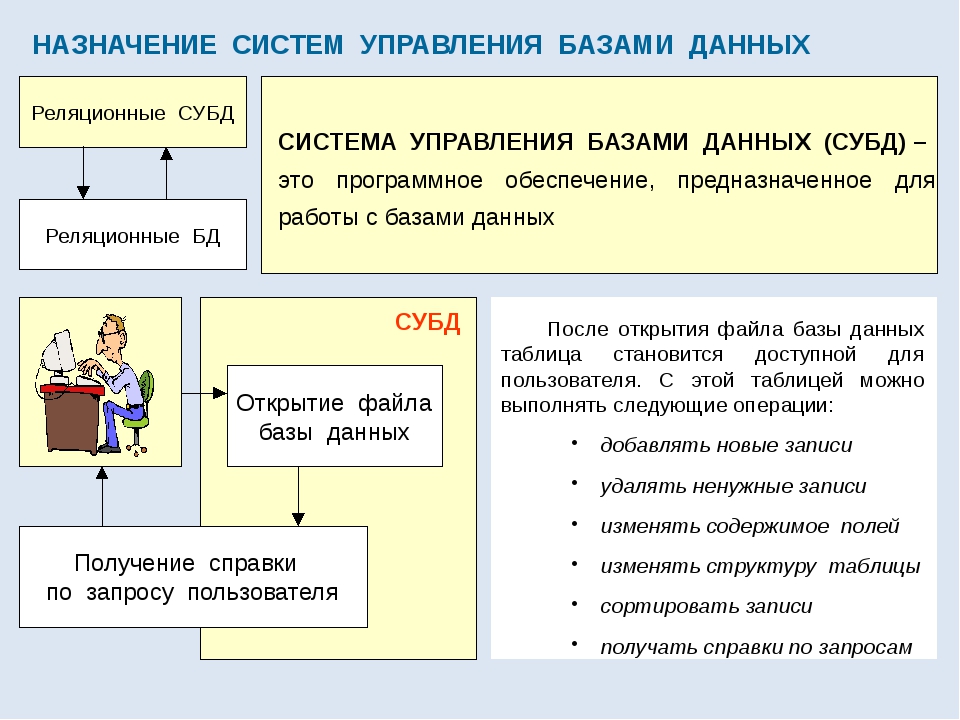
Три развития вычислительной техники в начале 21 века — мобильные вычисления, вычисления клиент-сервер и взлом компьютеров — способствовали появлению трех новых областей в компьютерных науках: разработка на основе платформ, параллельные и распределенные вычисления и безопасность. и информационное обеспечение.Платформенная разработка — это изучение особых потребностей мобильных устройств, их операционных систем и приложений. Параллельные и распределенные вычисления связаны с разработкой архитектур и языков программирования, которые поддерживают разработку алгоритмов, компоненты которых могут работать одновременно и асинхронно (а не последовательно), чтобы лучше использовать время и пространство. Обеспечение безопасности и информации связано с проектированием вычислительных систем и программного обеспечения, которые защищают целостность и безопасность данных, а также конфиденциальность лиц, которые характеризуются этими данными.
Наконец, на протяжении всей истории информатики особое внимание уделялось уникальному влиянию на общество, которое сопровождает исследования в области информатики и технологические достижения.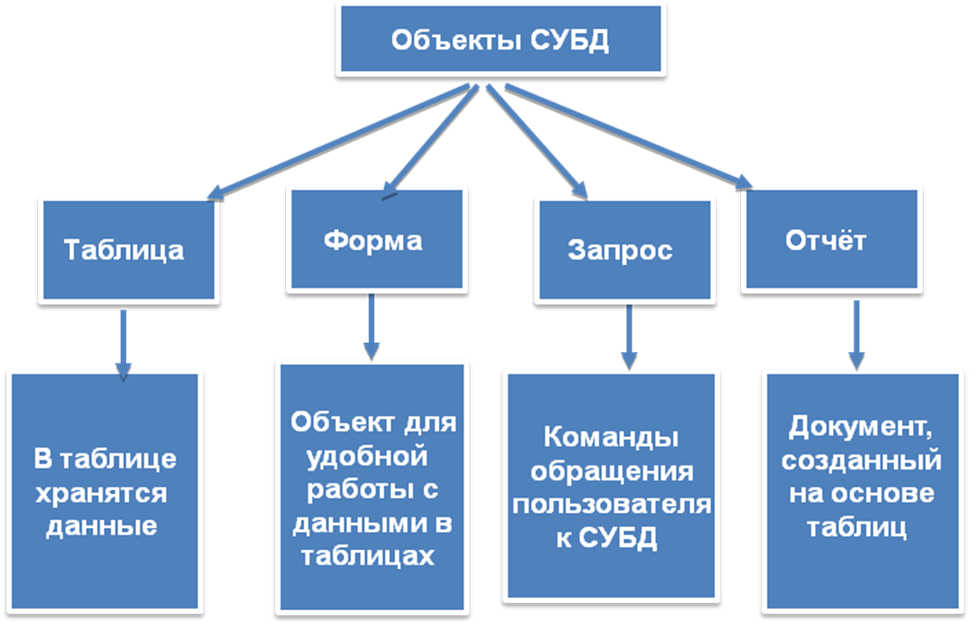 Например, с появлением Интернета в 1980-х годах разработчикам программного обеспечения потребовалось решить важные вопросы, связанные с информационной безопасностью, личной конфиденциальностью и надежностью системы. Кроме того, вопрос о том, является ли компьютерное программное обеспечение интеллектуальной собственностью, и связанный с ним вопрос «Кому оно принадлежит?» дала начало совершенно новой правовой области лицензирования и стандартов лицензирования, которые применяются к программному обеспечению и связанным с ним артефактам.Эти и другие проблемы составляют основу социальных и профессиональных вопросов информатики и проявляются почти во всех других областях, указанных выше.
Например, с появлением Интернета в 1980-х годах разработчикам программного обеспечения потребовалось решить важные вопросы, связанные с информационной безопасностью, личной конфиденциальностью и надежностью системы. Кроме того, вопрос о том, является ли компьютерное программное обеспечение интеллектуальной собственностью, и связанный с ним вопрос «Кому оно принадлежит?» дала начало совершенно новой правовой области лицензирования и стандартов лицензирования, которые применяются к программному обеспечению и связанным с ним артефактам.Эти и другие проблемы составляют основу социальных и профессиональных вопросов информатики и проявляются почти во всех других областях, указанных выше.
Итак, чтобы подвести итог, дисциплина информатики превратилась в следующие 15 отдельных областей:
Алгоритмы и сложность
Архитектура и организация
Вычислительные науки
Графика и визуальные вычисления
Взаимодействие человека и компьютера
Управление информацией
- Интеллектуальные системы
Сеть и связь
Операционные системы
Параллельные и распределенные вычисления
Разработка на базе платформы
Языки программирования
Безопасность и обеспечение информации
Программная инженерия
- Социальные и профессиональные вопросы
Информатика по-прежнему имеет сильные математические и инженерные корни. Программы бакалавриата, магистратуры и докторантуры по информатике обычно предлагаются высшими учебными заведениями, и эти программы требуют от студентов прохождения соответствующих курсов математики и инженерии, в зависимости от их специализации. Например, все студенты бакалавриата по информатике должны изучать дискретную математику (логику, комбинаторику и элементарную теорию графов). Многие программы также требуют от студентов завершения курсов по расчету, статистике, числовому анализу, физике и принципам инженерии в начале учебы.
Программы бакалавриата, магистратуры и докторантуры по информатике обычно предлагаются высшими учебными заведениями, и эти программы требуют от студентов прохождения соответствующих курсов математики и инженерии, в зависимости от их специализации. Например, все студенты бакалавриата по информатике должны изучать дискретную математику (логику, комбинаторику и элементарную теорию графов). Многие программы также требуют от студентов завершения курсов по расчету, статистике, числовому анализу, физике и принципам инженерии в начале учебы.
Что такое информатика? в США
Информатика — третья по популярности специальность среди иностранных студентов, приезжающих в США. Состояния. Существует множество причин, по которым информатика так популярна, в том числе исключительная безопасность работы, что редко высокие стартовые зарплаты и разнообразные возможности трудоустройства в разных отраслях. Однако иностранный студент намереваясь изучать информатику, нужно спросить себя: «Что такое информатика?»
Итак, что такое информатика? Вообще говоря, информатика — это изучение компьютерных технологий, как аппаратных
и программное обеспечение. Однако информатика — это разнообразная область; необходимые навыки актуальны и востребованы
практически во всех отраслях современного технологически зависимого мира. Таким образом, область информатики
разделены на ряд суб-дисциплин, большинство из которых являются полноценными специализированными дисциплинами в
самих себя. Область компьютерных наук охватывает несколько основных областей: теория компьютеров, аппаратные системы, программное обеспечение.
системы и научные вычисления. Студенты будут выбирать кредиты из этих субдисциплин с различными
уровни специализации в зависимости от желаемого приложения степени информатики.Хотя самый строгий
специализация происходит на уровне выпускника, точно зная, что такое информатика (и где студент
интересы попадают в эту обширную область) имеет первостепенное значение для изучения информатики.
Однако информатика — это разнообразная область; необходимые навыки актуальны и востребованы
практически во всех отраслях современного технологически зависимого мира. Таким образом, область информатики
разделены на ряд суб-дисциплин, большинство из которых являются полноценными специализированными дисциплинами в
самих себя. Область компьютерных наук охватывает несколько основных областей: теория компьютеров, аппаратные системы, программное обеспечение.
системы и научные вычисления. Студенты будут выбирать кредиты из этих субдисциплин с различными
уровни специализации в зависимости от желаемого приложения степени информатики.Хотя самый строгий
специализация происходит на уровне выпускника, точно зная, что такое информатика (и где студент
интересы попадают в эту обширную область) имеет первостепенное значение для изучения информатики.
Дисциплины информатики
Дисциплины, охватываемые степенью информатики, невероятно обширны, и иностранный студент должен знать
как изучать информатику или, другими словами, как эффективно ориентироваться в этом море суб-дисциплин
и специализации. Вот несколько возможных областей специализации, доступных студентам, изучающим информатику.
градусы:
Вот несколько возможных областей специализации, доступных студентам, изучающим информатику.
градусы:
- Прикладная математика
- Цифровое изображение / звук
- Искусственный интеллект
- Микропрограммирование
- Биоинформатика
- Сети и администрирование
- Компьютерная архитектура Сети
- Криптография
- Компьютерная инженерия
- Операционные системы
- Разработка компьютерных игр
- Робототехника
- Компьютерная графика
- Симуляторы и моделирование
- Программирование
- Разработка программного обеспечения
- Программные системы
- Управление данными
- Веб-разработка
- Базы данных проектирования
- Параллельное программирование
- Разработка под iOS
- Мобильная разработка
- Системы памяти
- Вычислительная физика
Имея так много доступных вариантов, уделяя особое внимание при изучении информатики в Соединенных Штатах
лучший план действий для любого иностранного студента, надеющегося серьезно подготовиться к своему будущему на работе
рынок. Знание того, как изучать информатику и эффективное планирование того, какую степень получить, будет зависеть от
от того, насколько хорошо студент понимает дисциплину информатики, и от того, какая степень подходит для
студент — это шаг, который определит, на какую карьеру в информатике он имеет право
выпускной. Следовательно, крайне важно спланировать конкретную степень по информатике, которая позволит
чтобы сделать карьеру, которую вы хотите.
Знание того, как изучать информатику и эффективное планирование того, какую степень получить, будет зависеть от
от того, насколько хорошо студент понимает дисциплину информатики, и от того, какая степень подходит для
студент — это шаг, который определит, на какую карьеру в информатике он имеет право
выпускной. Следовательно, крайне важно спланировать конкретную степень по информатике, которая позволит
чтобы сделать карьеру, которую вы хотите.
Несмотря на, казалось бы, бесконечное разнообразие приложений и дисциплин, иностранный студент изучает компьютер
наука в Соединенных Штатах должна будет ориентироваться, задавая важные вопросы, например: «Что такое информатика?» является
отличный способ начать успешное образование и, в конечном итоге, карьеру.Более того, есть много бесплатных ресурсов
доступны для изучения информатики. Например, отличный ресурс для иностранных студентов, пытающихся учиться.
информатика в Соединенных Штатах может быть веб-сайтами конкретных учреждений. Эти сайты будут не только
сообщают, какие степени по информатике доступны в их учреждении (а также по любым специальностям), они
также часто есть страницы, специально предназначенные для помощи заинтересованным иностранным студентам. Кредит курса программы
сбои, стипендии и возможности стажировки, текущие исследования, все эти важные факты об учреждении
можно найти на сайте их программы по информатике.
Кредит курса программы
сбои, стипендии и возможности стажировки, текущие исследования, все эти важные факты об учреждении
можно найти на сайте их программы по информатике.
Еще один отличный ресурс для иностранных студентов — это Изучите руководство по информатике. Гид — это множество информация по темам, начиная от вопросов о том, где изучать информатику, до предоставления стажировки и карьерный совет.
Изучение компьютерных наук в США
Компьютерные науки и компьютерная инженерия: в чем разница?
Вопрос, который я часто получаю в последнее время, связан с различиями и сходством между компьютерными науками и компьютерной инженерией.Рискуя чрезмерно упростить различия, я написал это руководство, чтобы объяснить, чем похожи компьютерные науки и компьютерная инженерия и чем они отличаются.
Что такое компьютерная инженерия?
Компьютерная инженерия — это союз компьютерных наук и электротехники. Он фокусируется на вычислениях во всех формах, от микропроцессоров до встраиваемых вычислительных устройств, портативных и настольных систем и суперкомпьютеров. По сути, это касается электротехнических соображений о том, как микропроцессоры работают, спроектированы и оптимизированы; как данные передаются между электронными компонентами; как проектируются интегрированные системы электронных компонентов и как они работают для обработки инструкций, выраженных в программном обеспечении; и как программное обеспечение пишется, компилируется и оптимизируется для конкретных аппаратных платформ.Следовательно, компьютерные инженеры — это инженеры-электрики, которые специализируются на разработке программного обеспечения, проектировании оборудования или проектировании систем, которые объединяют и то, и другое.
По сути, это касается электротехнических соображений о том, как микропроцессоры работают, спроектированы и оптимизированы; как данные передаются между электронными компонентами; как проектируются интегрированные системы электронных компонентов и как они работают для обработки инструкций, выраженных в программном обеспечении; и как программное обеспечение пишется, компилируется и оптимизируется для конкретных аппаратных платформ.Следовательно, компьютерные инженеры — это инженеры-электрики, которые специализируются на разработке программного обеспечения, проектировании оборудования или проектировании систем, которые объединяют и то, и другое.
Что такое информатика?
Информатика — это исследование того, как данные и инструкции обрабатываются, хранятся и передаются компьютерными устройствами. Современный потомок прикладной математики и электротехники, информатика занимается алгоритмами обработки данных, символическим представлением данных и инструкций, проектированием языков инструкций для обработки данных, методами написания программного обеспечения, обрабатывающего данные на различных вычислительных платформах, протоколы для надежной и безопасной передачи данных по сетям, организация данных в базах данных различных типов и масштабов, имитация человеческого интеллекта и обучения с помощью компьютерных алгоритмов, статистическое моделирование данных в больших базах данных для поддержки вывода тенденций и методы защиты содержание и достоверность данных. Таким образом, компьютерные ученые — это ученые и математики, которые разрабатывают способы обработки, интерпретации, хранения, передачи и защиты данных.
Таким образом, компьютерные ученые — это ученые и математики, которые разрабатывают способы обработки, интерпретации, хранения, передачи и защиты данных.
Перекрытие площадей
Поскольку и компьютерные инженеры, и компьютерные ученые в конечном итоге работают с данными и в конечном итоге пытаются извлечь из них значение, существует значительное совпадение курсовых работ, выполняемых студентами в этих двух областях, а также в карьере, которую они преследуют. Это не умаляет отличительного характера этих двух дисциплин.Это просто признание того факта, что эти типы компьютерных профессионалов находят контекст и цель в похожих проектах или в различных аспектах одних и тех же проектов.
Потенциально упрощающее, но полезное различие
И инженеры-компьютерщики, и ученые-компьютерщики продвигают вычислительные технологии и решают проблемы с помощью компьютерных технологий. Если рассматривать компьютерные технологии с точки зрения масштаба, компьютерные инженеры часто работают на микроскопических и макроскопических концах спектра, тогда как компьютерные ученые работают в средних частях спектра.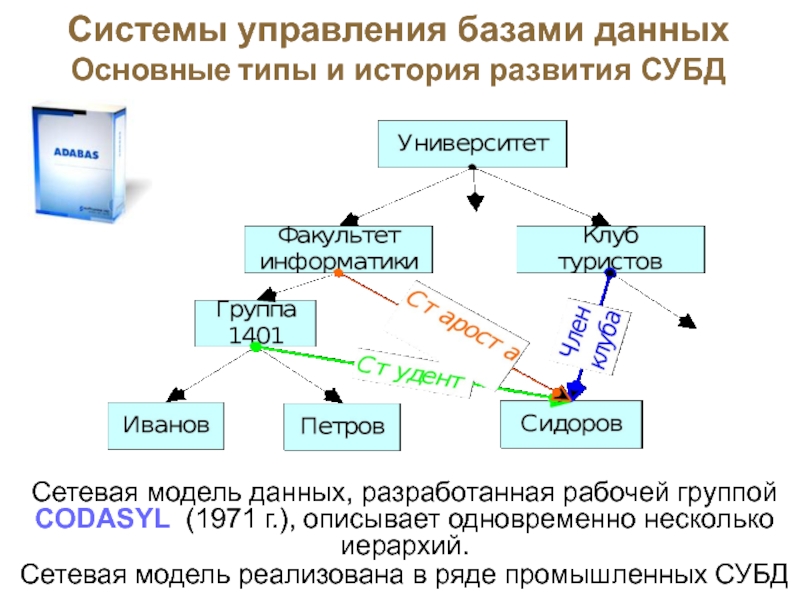 В частности, компьютерные инженеры занимаются физикой полупроводниковой электроники, чтобы они могли проектировать аппаратное обеспечение на уровне интегральной схемы (небольшого), а также с интеграцией аппаратного и программного обеспечения, оптимизированного для работы на нем, для реализации полных, специализированных вычислений. системы (большие). Компьютерные ученые пишут программное обеспечение, проектируют базы данных, разрабатывают алгоритмы, форматируют сообщения и защищают данные, которые обрабатываются аппаратным обеспечением, чтобы интегрированная система функционировала.
В частности, компьютерные инженеры занимаются физикой полупроводниковой электроники, чтобы они могли проектировать аппаратное обеспечение на уровне интегральной схемы (небольшого), а также с интеграцией аппаратного и программного обеспечения, оптимизированного для работы на нем, для реализации полных, специализированных вычислений. системы (большие). Компьютерные ученые пишут программное обеспечение, проектируют базы данных, разрабатывают алгоритмы, форматируют сообщения и защищают данные, которые обрабатываются аппаратным обеспечением, чтобы интегрированная система функционировала.
Конкретный пример: iPhone
Рассмотрим iPhone. Apple нанимает как компьютерных ученых, так и компьютерных инженеров для разработки каждой новой версии iPhone. Компьютерные инженеры (и инженеры-электрики) разработали микросхемы, в которых размещены интегральные схемы, обеспечивающие функционирование различных компонентов iPhone (сотового радио, экрана, элементов управления, памяти, микропроцессора), и они выяснили, как заставить различные компоненты работать друг с другом. . Это предполагает рассмотрение устройства как на микроскопическом уровне, так и на уровне интегрированных систем.Компьютерные ученые написали операционную систему, которая управляет памятью и одновременно запущенными приложениями, приложениями в магазине приложений, которые работают поверх этой операционной системы, упаковкой и распаковкой данных в пакеты для сетевой связи и шифрованием данных, чтобы любопытные глаза не вижу этого. Ученые-информатики предоставляют клеящие элементы, которые превращают начальный продукт компьютерных инженеров — конструкции компонентов — в конечный продукт компьютерных инженеров — устройство, на котором люди пишут текст, просматривают веб-страницы и играют в Angry Birds.
. Это предполагает рассмотрение устройства как на микроскопическом уровне, так и на уровне интегрированных систем.Компьютерные ученые написали операционную систему, которая управляет памятью и одновременно запущенными приложениями, приложениями в магазине приложений, которые работают поверх этой операционной системы, упаковкой и распаковкой данных в пакеты для сетевой связи и шифрованием данных, чтобы любопытные глаза не вижу этого. Ученые-информатики предоставляют клеящие элементы, которые превращают начальный продукт компьютерных инженеров — конструкции компонентов — в конечный продукт компьютерных инженеров — устройство, на котором люди пишут текст, просматривают веб-страницы и играют в Angry Birds.
Из этого примера легко представить, почему при такой большой зависимости функций друг друга при реализации готового продукта существует значительное совпадение курсовых работ, которые берут на себя инженеры-компьютерщики и компьютерные ученые, и возможностей карьерного роста, которые они преследуют.
Полезная перспектива компьютерной инженерии
Я нашел веб-сайт http://www.ohio.edu/eecs/undergraduate/documents/upload/whatCpEsDo-better%20version.pdf, который содержит особенно полезное описание компьютерной инженерии, которое определяет виды работ, которые работают инженеры-компьютерщики, компании которые нанимают их, и зарплаты, которые они зарабатывают.
Эта страница начинается с полезного списка областей специализации в области компьютерной инженерии. Я скопировал этот список специализаций сюда, но я отметил звездочкой (*) те, на которых также специализируются компьютерные ученые. Во всех случаях совпадения компьютерные ученые больше сосредотачиваются на аспектах своей специализации, связанных с разработкой программного обеспечения, а компьютерные инженеры изучают проектирование оборудования и интеграцию аппаратного и программного обеспечения, необходимого для реализации этой специализации.
- Микропроцессорные и микроконтроллерные системы
- Язык ассемблера (*)
- Кодирование, криптография и защита информации (*)
- Распределенные вычисления (*)
- Компьютерное зрение и распознавание образов (*)
- Компьютерная графика и мультимедийные приложения (*)
- Компьютерный Интернет и беспроводные сети (*)
- Компьютерная архитектура и проектирование встроенных цифровых систем
- Сетевая безопасность и конфиденциальность (*)
- Системы реального времени (*)
- Дизайн СБИС, VHDL и ASICS
- Межсетевое взаимодействие компьютеров и сетевые протоколы (*)
- Встроенное ПО для микроконтроллеров реального времени (*)
- Алгоритмы, компиляторы и операционные системы (*)
- Взаимодействие человека с компьютером (*)
На этом же сайте представлен ряд других интересных данных по компьютерной инженерии. Например, эта таблица выражает отношения между электротехникой, вычислительной техникой и компьютерными науками с точки зрения классов, которые занимают каждое из основных направлений, и процента этих классов, которые попадают в категории аппаратного и программного обеспечения.
Например, эта таблица выражает отношения между электротехникой, вычислительной техникой и компьютерными науками с точки зрения классов, которые занимают каждое из основных направлений, и процента этих классов, которые попадают в категории аппаратного и программного обеспечения.
Вы видите, что тема «информатика — это программное обеспечение, а компьютерная инженерия — это аппаратное обеспечение» снова воспроизводится в этой таблице. Это самый простой способ различить два поля. И тем не менее, существует достаточное совпадение, чтобы гарантировать, что оба типа студентов найдут множество возможностей в широком спектре карьеры в компьютерной сфере.
В чем разница между информационными технологиями и компьютерными науками?
I.T. против информатики: в чем разница между этими двумя терминами и в какой области есть лучшие возможности для многообещающей карьеры? Эти две области частично совпадают, но есть некоторые существенные различия, и вы можете быть привлечены к одному или другому из-за вашей личности и способностей.
Информатика полностью сосредоточена на эффективном программировании компьютеров с использованием математических алгоритмов.Работа в области информатики часто требует самостоятельной работы.
Карьера в ИТ включает установку, организацию и обслуживание компьютерных систем, а также проектирование и эксплуатацию сетей и баз данных. Информационные технологии могут больше понравиться людям, которые предпочитают работать в команде или напрямую с клиентами и заказчиками.
Информатика как бы создает строительные блоки, а ИТ складывает эти блоки, формируя здания, мосты и другие структуры, необходимые для функционирования города.«Город» на иллюстрации — это наше глобальное сообщество. Это включает в себя бизнес, системы здравоохранения, отдых и искусство, а также другие элементы общества, которые стали цифровыми.
Карьера в сфере ИТ не обязательно требует степени информатики (CS), хотя степень CS открывает определенные двери, которые в противном случае были бы недоступны. ИТ-специалисты обычно работают в бизнес-среде, устанавливая внутренние сети и компьютерные системы и, возможно, занимаясь программированием. Ученые-компьютерщики работают в более широком диапазоне сред, от предприятий до университетов и компаний, занимающихся разработкой видеоигр.Обе эти профессии имеют отличный потенциал роста и высокие зарплаты, а разработчики программного обеспечения несколько опережают ИТ-специалистов по доходам.
ИТ-специалисты обычно работают в бизнес-среде, устанавливая внутренние сети и компьютерные системы и, возможно, занимаясь программированием. Ученые-компьютерщики работают в более широком диапазоне сред, от предприятий до университетов и компаний, занимающихся разработкой видеоигр.Обе эти профессии имеют отличный потенциал роста и высокие зарплаты, а разработчики программного обеспечения несколько опережают ИТ-специалистов по доходам.
Карьера в области информатики
Степень информатики дает студентам серьезное образование в области дискретной математики и теории информатики. Большинство выпускников CS становятся разработчиками программного обеспечения или веб-программистами, а те, кто продолжает обучение в аспирантуре, имеют возможность проводить исследования или работать в более специализированных ролях, таких как продвинутое программирование искусственного интеллекта.
«Искусственный интеллект достигнет человеческого уровня примерно к 2029 году.
Далее, скажем, к 2045 году мы умножим интеллект, человеческий биологический машинный интеллект нашей цивилизации в миллиард раз». —Рэй Курцвейл (Forbes, июль 2017 г.)
Получив четырехлетнюю степень в области CS, студенты могут найти работу в качестве программистов, инженеров-программистов или ИТ-специалистов. Однако, чтобы стать разработчиком программного обеспечения, выпускники обычно должны немного научиться программированию.Обучение CS готовит студентов к выбору правильных шаблонов проектирования, алгоритмов и структур данных для программ, но большинство студентов заканчивают обучение, зная только один или два языка программирования, обычно C ++, Python или Java. Для большинства задач корпоративного программирования может быть достаточно одного C ++, но профессиональный разработчик программного обеспечения должен знать несколько других языков, включая HTML, CSS, JavaScript, MySQL, PHP, Python и Java.
Некоторые популярные вакансии в области информатики:
• Программист : Программисты создают коды для программ, используя «языки», упомянутые выше.
• Инженер по аппаратному обеспечению : Инженеры по аппаратному обеспечению — это профессионалы, которые проектируют компьютеры, контролируют их производство и установку, а также проводят испытания новых продуктов.
• Разработчики программного обеспечения или инженеры программного обеспечения : Разработчики программного обеспечения и инженеры программного обеспечения занимаются проектированием и созданием программ, приложений и операционных систем для компьютеров.
• Системные менеджеры : Работа системного менеджера включает в себя планирование, использование и сопровождение компьютерных операций и координацию технологий, чтобы они работали без сбоев вместе.По прогнозам BLS, эта конкретная работа вырастет на 11 процентов в следующие десять лет.
• Веб-разработчик : Веб-разработчики создают веб-сайты, как внешний вид, так и функционирование. Это предполагает использование принципов художественного дизайна и создание ссылок на соответствующую информацию.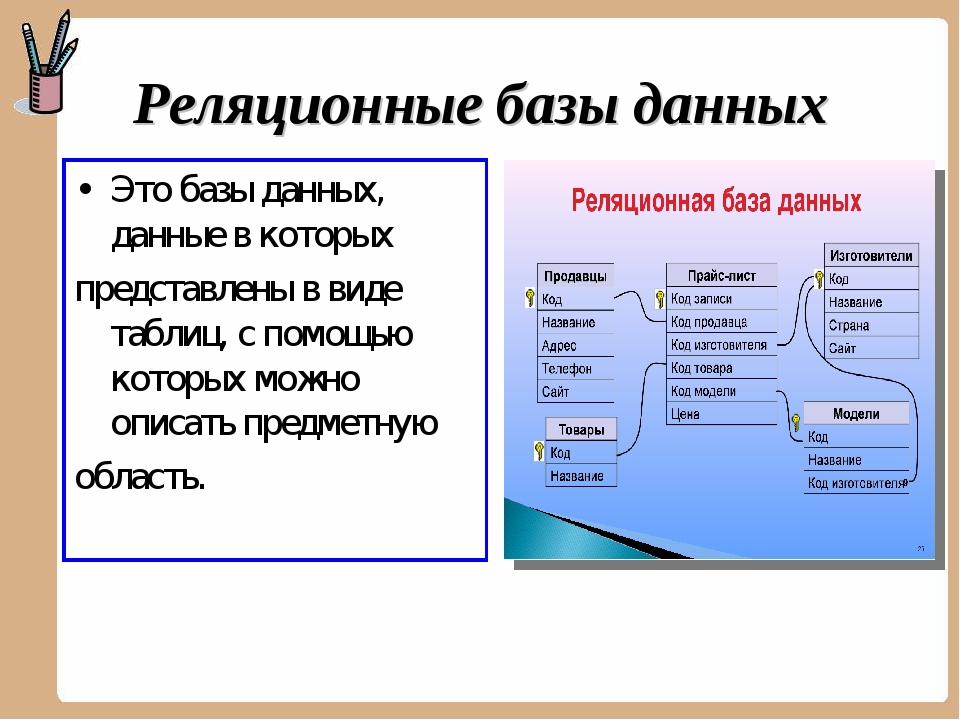
• Администратор базы данных : Работа администратора базы данных сосредоточена на создании соответствующей базы данных для организации или бизнеса, организации и обновлении данных, понимании и использовании облачного хранилища, а также устранении неполадок.
Необходимые навыки
Люди, которые занимаются проектированием и сборкой компьютеров в области информатики, должны обладать навыками управления проектами, включая управление временем и умение доводить до конца задачи. Также очень важно уметь распознавать мелкие детали и уделять им внимание. Те, кто занят в сфере информационных технологий, также должны обладать некоторыми «навыками работы с людьми». Например, одна работа в сфере информационных технологий — это специалист по компьютерной поддержке. Для этой должности люди должны обладать навыками общения и обслуживания клиентов.
Обе области требуют знания языков программирования, хотя для работы в области информатики требуется больше.
Образование, необходимое для работы в области компьютерных наук и информационных технологий
Существуют рабочие места начального уровня в области компьютерных наук и информационных технологий, которые можно получить со степенью бакалавра.