Отличие ссылок от указателей в языке C++
Очень часто, у тех кто успешно освоил указатели, при изучении ссылок возникает вопросы: а чем ссылки отличаются от указателей? Только синтаксисом использования и невозможностью сущестования неинициализованной ссылки? Каким образом сделаны ссылки и как они работают?
Пролить свет на этот вопрос поможет следующее, достаточно удачное объяснение:
Ссылка — это переменная, которая указывает на другую переменную, хранящуюся в той же памяти.
Следует обратить внимание, что в этом определении нигде не сказано, что значение ссылки — это адрес, указывающий на значение другой переменной. Здесь сказано лишь что переменная указывает на другую переменную. И это важно.
Переменная — это по-сути, именованная ячейка (либо именованный набор соседних ячеек) в памяти компьютера. Когда работает компилятор, он для текущего контекста создает таблицу используемых переменных. Таблица выглядит примерно так:
Имя переменной | Тип | Адрес расположения переменной | |
1 | first | int | 0x50A5B7F2 |
2 | second | long | 0x50A5B804 |
Значение переменной компилятор не хранит — все значения переменных существуют только в момент исполнения программы. Компилятор может только сгенерировать команды инициализации и изменения значений переменных. Поэтому в этой таблице нет столбца со значением переменной.
Компилятор может только сгенерировать команды инициализации и изменения значений переменных. Поэтому в этой таблице нет столбца со значением переменной.
Теперь если добавить переменную-указатель на first, то в таблице переменных появится еще одна запись:
Имя переменной | Тип | Адрес расположения переменной | |
1 | first | int | 0x50A5B7F2 |
2 | second | long | 0x50A5B804 |
3 | pointer_first | int* | 0x50A5BA08 |
То есть, указатель pointer_first — это переменная, у которой есть свой адрес 0x50A5BA08, и по этому адресу (в момент выполнения программы) будет находиться значение, равное 0x50A5B7F2. То есть, указатель указывает не на переменную first, а на значение переменной, которое расположено в памяти по адресу 0x50A5B7F2. Переменная first может даже перестать существовать, и в месте, где лежали ее данные могут быть размещены другие данные. А указатель pointer_first так и будет указывать на ту же самую ячейку (ячейки) памяти с адресом 0x50A5B7F2. И в этом проблема «сырых» указателей, приводящая к утечкам памяти и обращению к неправильным адресам.
То есть, указатель указывает не на переменную first, а на значение переменной, которое расположено в памяти по адресу 0x50A5B7F2. Переменная first может даже перестать существовать, и в месте, где лежали ее данные могут быть размещены другие данные. А указатель pointer_first так и будет указывать на ту же самую ячейку (ячейки) памяти с адресом 0x50A5B7F2. И в этом проблема «сырых» указателей, приводящая к утечкам памяти и обращению к неправильным адресам.
Чтобы в каком-то виде решить эти проблемы, и заодно упростить синтаксис, были придуманы ссылки. Для объяснения работы ссылок, можно создать ссылку на переменную second. В таблице переменных появится еще одна запись:
Имя переменной | Тип | Адрес расположения переменной | |
1 | first | int | 0x50A5B7F2 |
2 | second | long | 0x50A5B804 |
3 | pointer_first | int* | 0x50A5BA08 |
| 4 | link_second | long& | 0x50A5BA10 |
Чтобы было проще, можно сказать, что переменная-ссылка link_second — это переменная, у которой, как и у любой другой переменной, есть свой адрес 0x50A5BA10, в котором хранится некое значение. Но это значение — не адрес, по которому находятся данные переменной second. Нет! В этом значении хранится ссылка на переменную second. Можно считать, что там хранится номер строки таблицы, в данном случае 2.
Но это значение — не адрес, по которому находятся данные переменной second. Нет! В этом значении хранится ссылка на переменную second. Можно считать, что там хранится номер строки таблицы, в данном случае 2.
Из предыдущего абзаца следует, что невозможно создать ссылку на несуществующую переменную, так как ее просто не будет в таблице переменных. Компилятору очень легко контролировать, на какую переменную ссылается переменная-ссылка. Невозможна ситуация, чтобы переменная-ссылка оказалась неинициализирована: ссылка всегда указывает на какую-то другую переменную (т. е. содержит номер уже существующей переменной).
Вот такого объяснения вполне достаточно для того, чтобы понять отличие ссылки от указателя. Остался только один вопрос: почему при описании внутреннего устройства ссылки использовались такие обтекаемые выражения как «можно сказать», «можно считать, что»? А все дело в том, что ссылки — это, как говорят некоторые программисты — синтаксический сахар, который в конечном итоге компилируется в косвенную адресацию. А как это будет конкретно реализовано — это вопрос к авторам компилятора. Реализация данного механизма может сильно отличаться от компилятора к компилятору. Но так как C++ в некотором смысле высокоуровневый язык, то устройство ссылок можно воспринимать так, как написано выше.
А как это будет конкретно реализовано — это вопрос к авторам компилятора. Реализация данного механизма может сильно отличаться от компилятора к компилятору. Но так как C++ в некотором смысле высокоуровневый язык, то устройство ссылок можно воспринимать так, как написано выше.
Си++: указатель или ссылка :: Александр Набатчиков
Проблематика
Чем отличается ссылка от указателя? Когда использовать то или другое? На первый взгляд, оба инструмента делают одно и то же, приводя к избыточности и без того сложного языка.
«Масла в огонь» подливает амперсанд, который уже встречался и в роли битового И (бинарный
), и в роли логического И (бинарный
), и в роли взятия адреса (унарный префиксный
). Впрочем, последнее кажется логичным: ссылка ведь использует адрес объекта на который ссылается… но ведь для хранения адреса используется указатель?
Погружение
На уровне языка ассемблера (чтобы понять, причём здесь ассемблер, уместно будет прочитать предыдущую заметку), принципиальной разницы в представлении и оперировании указателями и ссылками — нет. Дьюхэрст, правда, утверждает, что в некоторых случаях память под ссылки не выделяется вовсе, но мне спровоцировать подобное не удалось. Могу предположить, что эффект определяется интеллектуальностью транслятора и оптимизацией конкретных ситуаций. В любом случае, это лишь исключение.
Дьюхэрст, правда, утверждает, что в некоторых случаях память под ссылки не выделяется вовсе, но мне спровоцировать подобное не удалось. Могу предположить, что эффект определяется интеллектуальностью транслятора и оптимизацией конкретных ситуаций. В любом случае, это лишь исключение.
Рассмотрим следующий листинг:
Простой пример работы с указателем и ссылкой на языке Си++
123456789101112131415 | #include <iostream>
using namespace std;
int main()
{
int foo = 32;
int &bar = foo;
int *ptr = &foo;
bar = 64;
(*ptr) = 255;
return 0;
}
|
Если вы пользуетесь IDE C::B, то дизассемблер будет представлен во всей красе синтаксиса AT&T. Данное обстоятельство сперва несколько запутывает (после милого сердцу синтаксиса intel), но, со временем, привыкаешь, тем более, что анализировать придётся не самый сложный код.
Вот так выглядит листинг дизассемблера со вставками исходников Си++:
Разберём фрагменты подробнее. Так как стековые push/pop тут не используются, не будем задумываться над ориентацией стека, так же, для простоты, будем считать, что esp (регистр вершины стека) равен нулю:
На вершине стека будет хранится адрес возврата — чтобы не засорять иллюстрацию ненужными подробностями, не будем записывать там какую-либо константу.
Создание автоматической переменной
12 | 7 int foo = 32; 0x00401342 movl $0x20,0x4(%esp) |
Записать значение 20 (представление в 16 с/с эквивалентно 32 в 10 с/с) по адресу, получаемому при сложении числа, хранящегося в регистре
Начиная с 0xc — ссылка на foo
123 | 8 int &bar = foo; 0x0040134A lea 0x4(%esp),%eax 0x0040134E mov %eax,0xc(%esp) |
Вычислить адрес (сложить значение из регистра esp с числом 4) и записать его в регистр eax.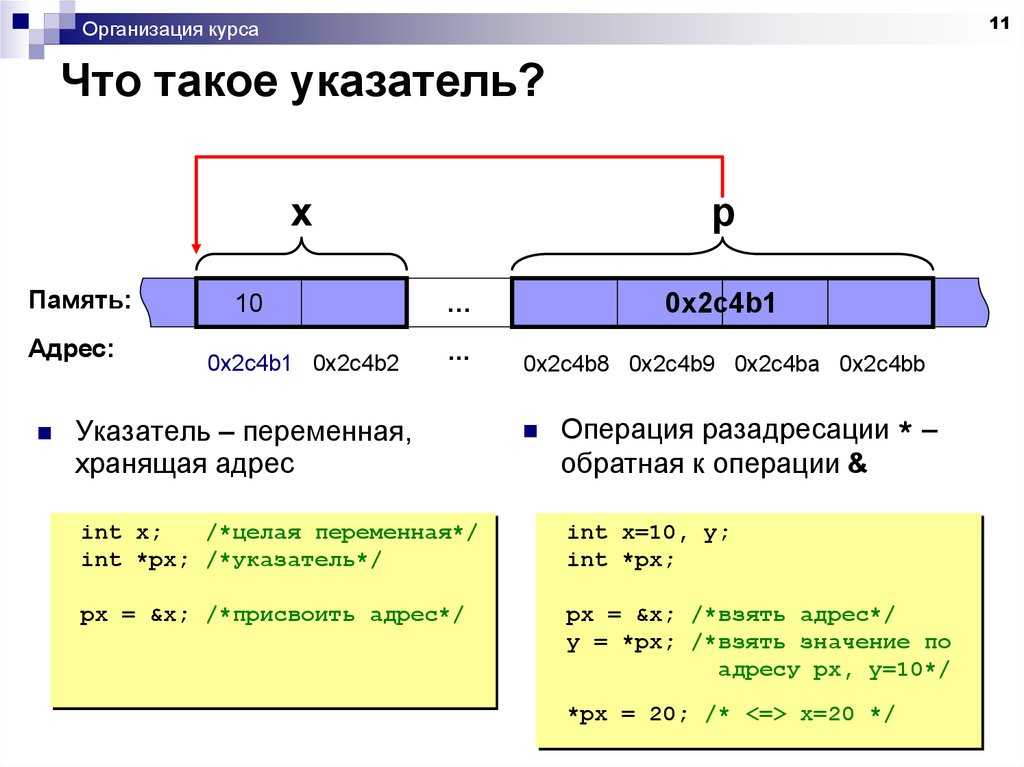
Сохранить значение, хранящееся в регистре eax, по адресу, получаемому при сложении числа, хранящегося в регистре esp и числа 0xc (то есть 12 в 10 с/с).
Начиная с 0x8 — указатель на foo
123 | 9 int *ptr = &foo; 0x00401352 lea 0x4(%esp),%eax 0x00401356 mov %eax,0x8(%esp) |
Вычислить адрес (сложить значение из регистра esp с числом 4) и записать его в регистр eax.
Сохранить значение, хранящееся в регистре eax, по адресу, получаемому при сложении числа, хранящегося в регистре esp и числа 0x8.
Запись значения через ссылку
123 | 11 bar = 64; 0x0040135A mov 0xc(%esp),%eax 0x0040135E movl $0x40,(%eax) |
Сохранить значение, хранящееся по адресу, получаемому сложением содержимого регистра esp и числа 0xc, в регистр eax.
Сохранить значение 0x40 (то есть 64 в 10 с/с) по адресу, записанному в регистре
Запись значения через указатель
123 | 12 (*ptr) = 255; 0x00401364 mov 0x8(%esp),%eax 0x00401368 movl $0xff,(%eax) |
Сохранить значение, хранящееся по адресу, получаемому сложением содержимого регистра esp и числа 0x8, в регистр eax.
Сохранить значение 0xff (то есть 255 в 10 с/с) по адресу, записанному в регистре eax.
Таким образом, на языке ассемблера, код для ссылки и указателя полностью аналогичен. С другой стороны, на уровне Си++, ссылка представляет собой менее гибкий, и от того более безопасный интерфейс доступа к адресу, используемому для косвенной адресации. Синтаксис Си++ даже не позволяет взять адрес ссылки (переменной, хранящей адрес), так как ссылка реализована как синоним объекта, на который она ссылается. Таким образом, не прибегая к трюкачеству со стеком (см.) невозможно испортить значение ссылки и «отвязать» её, в то время как для указателя это штатная функциональность.
Таким образом, не прибегая к трюкачеству со стеком (см.) невозможно испортить значение ссылки и «отвязать» её, в то время как для указателя это штатная функциональность.
Выводы
Исходя из сказанного выше, можно рекомендовать использование ссылки везде, где её функциональности достаточно: создание псевдонима для переменной, передача параметра по ссылке, возвращение l-value. Всё то же самое можно переписать и при помощи указателей, наполнив код кучей разыменований и превратив его в настоящий снегопад (* * * * *). Если Вы создаёте функцию с формальными параметрами из имеющегося фрагмента кода, всё что понадобится — указать нужным аргументам ссылочный тип, если же реализовывать данный рефакторинг при помощи указателей — понадобится просмотреть каждую строчку на предмет необходимости разыменования.
В случае, если возможностей ссылки не хватает — надо задуматься над использованием указателя.
Ситуация, в некотором смысле, напоминает дилемму «стек или куча»: и в ней можно всегда отдавать предпочтение более функциональной куче, но такой код не выглядит обоснованным и безопасным (опрятным).
Свойство CSS-указатели-события
❮ Назад Полное руководство по CSS Далее ❯
Пример
Установить, должен ли элемент реагировать на события указателя:
div.ex1 {
события указателя: нет;
}
div.ex2 {
события указателя: авто;
}
Попробуйте сами »
Определение и использование
Свойство pointer-events определяет, реагирует ли элемент на
события указателя.
| Значение по умолчанию: | авто |
|---|---|
| Унаследовано: | да |
| Анимация: | № Читать о анимируемом |
| Версия: | CSS3 |
| Синтаксис JavaScript: | объект .style.pointerEvents=»нет» Попытайся |
Поддержка браузера
Числа в таблице указывают первую версию браузера, которая полностью поддерживает это свойство.
| Собственность | |||||
|---|---|---|---|---|---|
| указатели-события | 2,0 | 11,0 | 3,6 | 4,0 | 9,0 |
Синтаксис CSS
события указателя: auto|none;
Значения свойств
| Значение свойства | Описание |
|---|---|
| авто | Элемент реагирует на события указателя, такие как :hover и click. Это по умолчанию |
| нет | Элемент не реагирует на события указателя |
| начальный | Устанавливает для этого свойства значение по умолчанию. Читать про начальный |
| унаследовать | Наследует это свойство от родительского элемента. Читать о унаследовать |
❮ Предыдущий Полное руководство по CSS Далее ❯
НОВИНКА
Мы только что запустили
Видео W3Schools
Узнать
ВЫБОР ЦВЕТА
КОД ИГРЫ
Играть в игру
Top Tutorials
Учебник по HTMLУчебник по CSS
Учебник по JavaScript
Учебник How To
Учебник по SQL
Учебник по Python
Учебник по W3.
 CSS
CSS Учебник по Bootstrap
Учебник по PHP
Учебник по Java
Учебник по C++
Учебник по jQuery
Основные ссылки
HTML ReferenceCSS Reference
JavaScript Reference
SQL Reference
Python Reference
W3.CSS Reference
Bootstrap Reference
PHP Reference
HTML Colors
Java Reference
Angular Reference
jQuery Reference
5 Top3 Examples
Примеры HTML
Примеры CSS
Примеры JavaScript
Примеры инструкций
Примеры SQL
Примеры Python
Примеры W3.CSS
Примеры Bootstrap
Примеры PHP
Примеры Java
Примеры XML
Примеры jQuery
FORUM | О
W3Schools оптимизирован для обучения и обучения. Примеры могут быть упрощены для улучшения чтения и обучения.
Учебники, ссылки и примеры постоянно пересматриваются, чтобы избежать ошибок, но мы не можем гарантировать полную правильность всего содержания. Используя W3Schools, вы соглашаетесь прочитать и принять наши условия использования,
куки-файлы и политика конфиденциальности.
Используя W3Schools, вы соглашаетесь прочитать и принять наши условия использования,
куки-файлы и политика конфиденциальности.
Copyright 1999-2022 Refsnes Data. Все права защищены.
W3Schools работает на основе W3.CSS.
Техника двух указателей в связном списке
Два указателя, движущиеся параллельно
Рассмотрим следующую задачу:
Создайте функцию, которая возвращает n-й последний элемент односвязного списка.
Обратите внимание, что нас просят искать не n-й элемент с начала, а n-й элемент с конца. Чтобы сделать это, нам нужен какой-то способ узнать, как далеко мы находимся от конца самого списка. Однако в односвязном списке нет простого способа пройтись по списку, когда вы найдете конец, поэтому нам придется полагаться на что-то, известное как 9.0044 метод двух указателей . Метод двух указателей позволяет нам сохранить два указателя, ссылающихся на два разных места в связанном списке. Если мы смещаем указатели или увеличиваем их с разной скоростью, мы можем решить много интересных задач, которые мы не можем решить с помощью всего лишь одного указателя.
Наименее эффективное решение без указателя
Чтобы лучше понять технику двух указателей и ее эффективность, давайте быстро рассмотрим менее оптимальное решение, которое может прийти на ум первым.
Одним из решений, которое может прийти на ум, является использование массива для хранения представления связанного списка. Затем мы можем просто вернуть узел по индексу с конца минус n .
функция getNodeFromLast (из списка: LinkedList, at n: Int) -> Узел? {
var linkedListArray = [Node?]()
var currentNode = list.head
while currentNode != nil {
linkedListArray.append(currentNode!)
currentNode = currentNode!.next
}
return linkedListArray[linkedListArray.count - n];
}
Несмотря на то, что этот подход приводит к легко читаемой реализации, он также может использовать много памяти, поддерживая двойное представление одних и тех же данных. Если в связанном списке один миллион узлов, нам понадобится один миллион указателей в массиве
Если в связанном списке один миллион узлов, нам понадобится один миллион указателей в массиве ArrayList , чтобы отслеживать его! Подобный подход приводит к дополнительному выделению O(n) пространства.
Решение с двумя указателями
Вместо того, чтобы создавать полностью параллельный список, мы можем решить эту проблему, выполняя итерацию с двумя указателями, один из которых ищет хвост, а другой отстает на n-ю величину.
текущий = ноль
tailSeeker = заголовок связанного списка
количество = 0
в то время как tailSeeker не равен нулю
если количество > n - 1
если текущий == ноль
текущий = заголовок связанного списка
переместить текущий указатель вперед
переместить хвостовую искатель вперед
счетчик приращений
return current Solution
В Swift мы могли бы реализовать функцию nth-last-node-finder как таковую:
функция getNodeFromLast (из списка: LinkedList, at n: Int) -> Узел? {
переменная текущая:узел? = nil
var tailSeeker = list.
head
var count = 0
while tailSeeker != nil {
if count > n - 1 {
if current == nil {
current = list03.head }
current = current!.next
}
tailSeeker = tailSeeker!.next
count += 1
}
return current
}
Используя этот подход, мы можем решить эту задачу эффективно, за O(n) времени (мы должны пройти весь список один раз) и O(1) пространственной сложности (мы всегда использовать только три переменные независимо от размера списка: два указателя и счетчик).
Стрелки с разной скоростью
Использование двух указателей, движущихся со смещением, но параллельно, было хорошим решением предыдущей проблемы. Однако есть и другие проблемы, когда два указателя, перемещающиеся параллельно, не были бы так полезны. Давайте рассмотрим одну из этих проблем и рассмотрим новую стратегию, в которой используются два указателя, движущиеся с разной скоростью.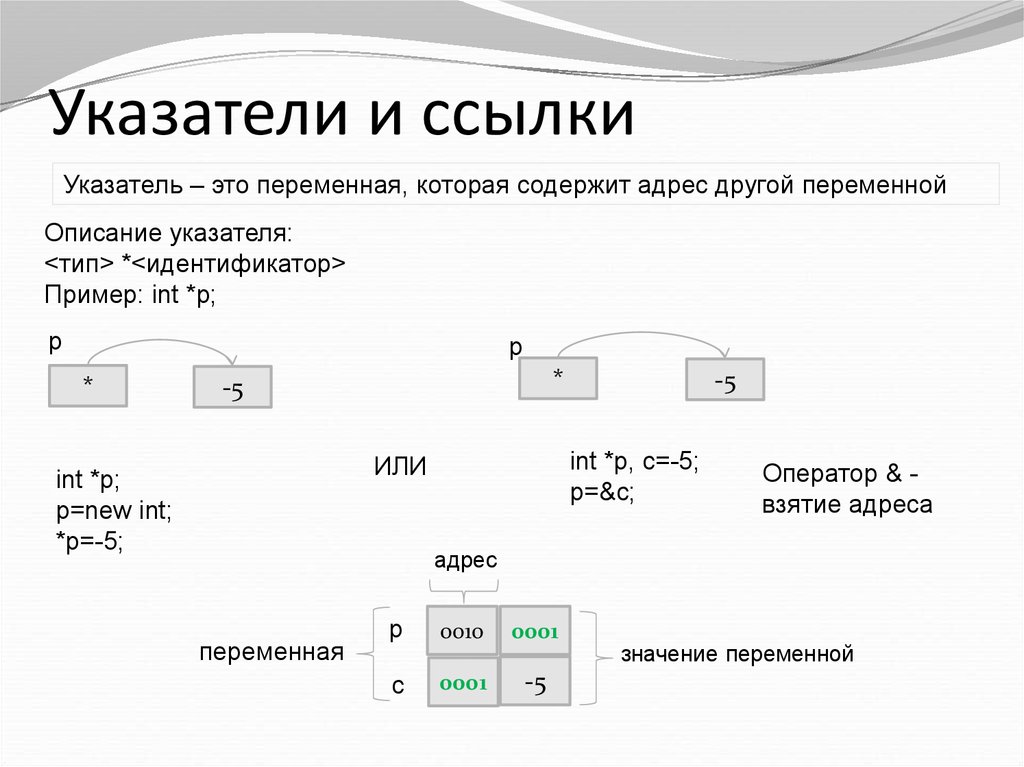
Попробуйте найти средний узел связанного списка.
Как и прежде, можно найти решение, перебрав весь список, создав представление массива и затем вернув средний индекс. Но, как и прежде, это потенциально может занять много дополнительного места:
create array в то время как связанный список не был полностью повторен через добавить текущий элемент в массив двигаться вперед на один узел return array[length / 2]
Подход: быстрые и медленные указатели
Вместо этого мы можем использовать два указателя для перемещения по списку. Первый указатель делает два шага по списку на каждый один шаг, который делает второй, поэтому он выполняет итерацию в два раза быстрее.
fastPointer = заголовок списка
slowPointer = заголовок списка
в то время как fastPointer не равен нулю
переместить быстрый указатель вперед
если конец списка не достигнут
снова переместить fastPointer вперед
двигаться медленноУказатель вперед
return slowPointer Когда первый указатель достигает конца списка, «более медленный» второй указатель будет указывать на средний элемент. Давайте визуализируем шаги алгоритма:
Давайте визуализируем шаги алгоритма:
Начальное состояние
F С 1 2 3 4 5 6 7
Первый тик
F С 1 2 3 4 5 6 7
Второй тик
F
С
1 2 3 4 5 6 7 Третий тик
F
С
1 2 3 4 5 6 7 Финальный тик
F
С
1 2 3 4 5 6 7 nil Пока мы всегда сначала перемещаем быстрый указатель и проверяем, что он не равен нулю, прежде чем снова перемещать его и медленный указатель, мы завершим итерацию в нужное время и получим ссылка на средний узел с медленным указателем.
Решение и альтернативы
функция getMiddleNode(из списка:LinkedList) -> Узел? {
var fast = list.head
var slow = list.
head
while fast != nil {
fast = fast?.next
if fast != nil {
fast = fast?.next
slow = slow?.next
}
}
return slow
}
Как и в предпоследнем решении, это решение имеет O(n) временная сложность и O(1) пространственная сложность, поскольку создаются только два узла независимо от размера входного списка.
Half-Speed
Другим не менее правильным решением является перемещение быстрого указателя один раз при каждой итерации цикла, но перемещение медленного указателя только при каждой второй итерации:
func getMiddleNode(from list:LinkedList) -> Node ? {
var count = 0
var fast = list.head
var slow = list.head
while fast != nil {
fast = fast?.next
if count % 2 != 0 {
slow = slow?.next
}
count += 1
0 3 return slow
}
Подведение итогов
Многие проблемы со связанными списками можно решить с помощью метода двух указателей.