Формирование SQL-запроса с помощью конструктора
Формирование SQL-запроса с помощью конструктора Пожалуйста, включите JavaScript в браузере!Формирование SQL-запроса с помощью конструктора
В KUMA вы можете сформировать SQL-запрос для фильтрации событий с помощью конструктора запросов.
Чтобы сформировать SQL-запрос с помощью конструктора:
- В разделе События веб-интерфейса KUMA нажмите на кнопку .
Откроется окно конструктора запросов.
- Сформулируйте поисковый запрос, указав данные в следующих блоках параметров:
- SELECT – поля событий, которые следует возвращать. По умолчанию выбрано значение *, означающее, что необходимо возвращать все доступные поля события. Для оптимизации поиска в раскрывающемся списке вы можете выбрать определенные поля, тогда данные из других полей загружаться не будут.
Выбрав поле события, вы можете в поле справа от раскрывающегося списка указать псевдоним для столбца выводимых данных, а в крайнем правом раскрывающемся списке можно выбрать операцию, которую следует произвести над данными: count, max, min, avg, sum.

Если вы используете в запросе функции агрегации, настройка отображения таблицы событий, сортировка событий по возрастанию и убыванию, получение статистики, а также ретроспективная проверка недоступны.
В режиме детализированного анализа при фильтрации по событиям, связанным с алертами, невозможно производить операции над данными полей событий и присваивать названия столбцам выводимых данных.
- FROM – источник данных. Выберите значение events.
- WHERE – условия фильтрации событий.
Условия и группы условий можно добавить с помощью кнопок Добавить условие и Добавить группу. По умолчанию в группе условий выбрано значение оператора AND, однако если на него нажать, оператор можно изменить. Доступные значения: AND, OR, NOT. Структуру условий и групп условий можно менять, перетаскивая выражения с помощью мыши за значок .
Добавление условий фильтра:
- В раскрывающемся списке слева выберите поле события, которое вы хотите использовать для фильтрации.

- В среднем раскрывающемся списке выберите нужный оператор. Доступные операторы зависят от типа значения выбранного поля события.
- Введите значение условия. В зависимости от выбранного типа поля вам потребуется ввести значение вручную, выбрать его в раскрывающемся списке или выбрать в календаре.
Условия фильтра можно удалить с помощью кнопки . Группы условий удаляются с помощью кнопки Удалить группу.
- В раскрывающемся списке слева выберите поле события, которое вы хотите использовать для фильтрации.
- GROUP BY – поля событий или псевдонимы, по которым следует группировать возвращаемые данные.
Если вы используете в запросе группировку данных, настройка отображения таблицы событий, сортировка событий по возрастанию и убыванию, получение статистики, а также ретроспективная проверка недоступны.
В режиме детализированного анализа при фильтрации по событиям, связанным с алертами, невозможно группировать возвращаемые данные.
- ORDER BY – столбцы, по которым следует сортировать возвращаемые данные. В раскрывающемся списке справа можно выбрать порядок: DESC – по убыванию, ASC – по возрастанию.

- LIMIT – количество отображаемых в таблице строк.
Значение по умолчанию – 250.
Если при фильтрации событий по пользовательскому периоду количество строк в результатах поиска превышает заданное значение, вы можете отобразить в таблице дополнительные строки, нажав на кнопку Показать больше записей. Кнопка не отображается при фильтрации событий по стандартному периоду.
- SELECT – поля событий, которые следует возвращать. По умолчанию выбрано значение *, означающее, что необходимо возвращать все доступные поля события. Для оптимизации поиска в раскрывающемся списке вы можете выбрать определенные поля, тогда данные из других полей загружаться не будут.
- Нажмите на кнопку Применить.
Текущий SQL-запрос будет перезаписан. В поле поиска отобразится сформированный SQL-запрос.
Если вы хотите сбросить настройки конструктора, нажмите на кнопку Запрос по умолчанию.
Если вы хотите закрыть конструктор, не перезаписывая существующий запрос, нажмите на кнопку .
- Для отображения данных в таблице нажмите на кнопку .

В таблице отобразятся результаты поиска по сформированному SQL-запросу.
При переходе в другой раздел веб-интерфейса сформированный в конструкторе запрос не сохраняется. Если вы повторно вернетесь в раздел События, в конструкторе будет отображаться запрос по умолчанию.
Если вы повторно вернетесь в раздел События, в конструкторе будет отображаться запрос по умолчанию.
После обновления KUMA до версии 1.6 при фильтрации событий с помощью SQL-запроса, содержащего условие inSubnet, может возвращаться ошибка Code: 441. DB::Exception: Invalid IPv4 value. В таких случаях необходимо на серверах хранилища (на каждой машине кластера ClickHouse) в файле /opt/kaspersky/kuma/clickhouse/cfg/config.d/users.xml в разделе profiles → default добавить директиву
Подробнее об SQL см. в справке ClickHouse. Также см. поддерживаемые KUMA SQL-функции и операторы.
В началоКак сделать sql запрос к базе данных
Ответы
Сортировать по:
Количеству голосов ▼ Дата создания
Алексей Алешин23 марта 2023
Чтобы выполнить SQL-запрос к базе данных, можно пойти вот таким путем:
- Открыть соединение с базой данных с помощью специального программного обеспечения или драйвера для языка программирования
- Создать SQL-запрос с использованием соответствующего синтаксиса, учитывая структуру таблиц и данные, которые вы хотите получить
- Выполнить запрос, отправив его в базу данных через открытое соединение
- Обработать результаты запроса, которые обычно представляются в виде таблицы
Например, в языке Python для выполнения SQL-запросов к базе данных можно использовать модуль sqlite3. Вот пример кода для создания соединения с базой данных, выполнения запроса и получения результатов:
Вот пример кода для создания соединения с базой данных, выполнения запроса и получения результатов:
import sqlite3
# создаем соединение с базой данных
conn = sqlite3.connect('example.db')
# создаем курсор для выполнения запросов
cur = conn.cursor()
# создаем SQL-запрос
sql_query = "SELECT * FROM users WHERE age > 18"
# выполняем запрос
cur.execute(sql_query)
# получаем результаты
results = cur.fetchall()
# закрываем соединение
conn.close()
# обрабатываем результаты
for row in results:
print(row)
Важно учитывать, что для выполнения запроса к базе данных необходимо иметь права на выполнение соответствующих действий в базе данных. Кроме того, при написании SQL-запроса важно учитывать особенности синтаксиса используемой СУБД.
0 0
Добавьте ваш ответ
Курсы по программированию на Хекслете
Backend-разработка
Разработка серверной части сайтов и веб-приложений
Перейти
Frontend-разработка
Разработка внешнего интерфейса сайтов и веб-приложений и верстка
Перейти
Создание сайтов
Разработка сайтов и веб-приложений на JS, Python, Java, PHP и Ruby on Rails
Перейти
Тестирование
Ручное тестирование и автоматизированное тестирование на JS, Python, Java и PHP
Перейти
Аналитика данных
Сбор, анализ и интерпретация данных на Python
Перейти
Интенсивные курсы
Интенсивное обучение для продолжающих
Перейти
DevOps
Автоматизация настройки локального окружения и серверов, развертывания и деплоя
Перейти
Веб-разработка
Разработка, верстка и деплой сайтов и веб-приложений, трудоустройство для разработчиков
Перейти
Математика для программистов
Обучение разделам математики, которые будут полезны при изучении программирования
Перейти
JavaScript
Разработка сайтов и веб-приложений и автоматизированное тестирование на JS
Перейти
Python
Веб-разработка, автоматическое тестирование и аналитика данных на Python
Перейти
Java
Веб-разработка и автоматическое тестирование на Java
Перейти
PHP
Веб-разработка и автоматическое тестирование на PHP
Перейти
Ruby
Разработка сайтов и веб-приложений на Ruby on Rails
Перейти
Go
Курсы по веб-разработке на языке Go
Перейти
HTML
Современная верстка с помощью HTML и CSS
Перейти
SQL
Проектирование базы данных, выполнение SQL-запросов и изучение реляционных СУБД
Перейти
Git
Система управления версиями Git, регулярные выражения и основы командой строки
Перейти
Похожие вопросы
1
ответ1
ответ1
ответ1
ответВведение в интерфейс SQLite C/C++
Введение в интерфейс SQLite C/C++
► Оглавление 1. Резюме
Резюме
2. Введение
3. Основные объекты и интерфейсы
4. Типичное использование основных подпрограмм и объектов
5. Удобные оболочки вокруг основных подпрограмм
6. Связывание параметров и повторное использование подготовленных операторов
7. Настройка SQLite
8. Расширение SQLite
9. Другие интерфейсы
Следующие два объекта и восемь методов составляют основные элементы интерфейса SQLite:
sqlite3 → Объект подключения к базе данных. Сделано sqlite3_open() и уничтожается sqlite3_close().
sqlite3_stmt → Подготовленный объект оператора. Сделано sqlite3_prepare() и уничтожается sqlite3_finalize().
sqlite3_open() → Откройте соединение с новой или существующей базой данных SQLite. Конструктор для sqlite3.
sqlite3_prepare() → Скомпилируйте текст SQL в байт-код, который будет выполнять работу по запросу или обновлению базы данных.
Конструктор для sqlite3_stmt.
sqlite3_bind() → Храните данные приложения в параметры исходного SQL.
sqlite3_step() → Переместите sqlite3_stmt к следующей строке результата или к завершению.
sqlite3_column() → Значения столбцов в текущей строке результатов для sqlite3_stmt.
sqlite3_finalize() → Деструктор для sqlite3_stmt.
sqlite3_close() → Деструктор для sqlite3.
sqlite3_exec() → Функция-оболочка, которая выполняет функции sqlite3_prepare(), sqlite3_step(), sqlite3_column() и sqlite3_finalize() для строка из одного или нескольких операторов SQL.
SQLite имеет более 225 API.
Однако большинство API являются необязательными и очень специализированными.
и могут быть проигнорированы новичками.
Основной API небольшой, простой и легкий в освоении.
В этой статье кратко изложен основной API.
Отдельный документ, The SQLite C/C++ Interface, предоставляет подробные спецификации для всех API-интерфейсов C/C++ для SQLite. Один раз читатель понимает основные принципы работы SQLite, этот документ следует использовать в качестве справочного гид. Эта статья предназначена только для ознакомления и не является полный и авторитетный справочник по SQLite API.
Основная задача ядра базы данных SQL состоит в том, чтобы оценивать операторы SQL. SQL. Для этого разработчику нужны два объекта:
- Объект подключения к базе данных: sqlite3
- Подготовленный объект оператора: sqlite3_stmt
Строго говоря, подготовленный объект оператора не требуется, поскольку
удобные интерфейсы-оболочки, sqlite3_exec или
sqlite3_get_table, можно использовать и эти удобные обертки
инкапсулировать и скрыть подготовленный объект оператора.
Тем не менее, понимание
подготовленные операторы необходимы для полного использования SQLite.
Соединение с базой данных и подготовленные объекты операторов контролируются с помощью небольшого набора подпрограмм интерфейса C/C++, перечисленных ниже.
- sqlite3_open()
- sqlite3_prepare()
- sqlite3_step()
- sqlite3_column()
- sqlite3_finalize()
- sqlite3_close()
Обратите внимание, что приведенный выше список подпрограмм является концептуальным, а не фактическим.
Многие из этих подпрограмм имеют несколько версий.
Например, в приведенном выше списке показана одна подпрограмма
с именем sqlite3_open(), хотя на самом деле это три отдельные процедуры
которые выполняют одно и то же немного разными способами:
sqlite3_open(), sqlite3_open16() и sqlite3_open_v2().
В списке упоминается sqlite3_column()
когда на самом деле такой процедуры не существует.
«sqlite3_column()», показанный в списке, является заполнителем для
целое семейство подпрограмм, которые извлекают столбец
данные в различных типах данных.
Вот краткое изложение того, что делают основные интерфейсы:
sqlite3_open()
Эта рутина открывает соединение с файлом базы данных SQLite и возвращает объект подключения к базе данных. Часто это первый SQLite API. вызов, который делает приложение, и является необходимым условием для большинства других SQLite API. Для многих интерфейсов SQLite требуется указатель на объект подключения к базе данных в качестве их первого параметра и может следует рассматривать как методы объекта подключения к базе данных. Эта подпрограмма является конструктором объекта соединения с базой данных.
sqlite3_prepare()
Эта рутина преобразует текст SQL в подготовленный объект оператора и возвращает указатель к этому объекту. Для этого интерфейса требуется указатель подключения к базе данных. созданный предыдущим вызовом sqlite3_open() и текстовой строкой, содержащей оператор SQL, который необходимо подготовить.
 Этот API на самом деле не оценивает
оператор SQL. Он просто подготавливает оператор SQL для оценки.
Этот API на самом деле не оценивает
оператор SQL. Он просто подготавливает оператор SQL для оценки.Думайте о каждом операторе SQL как о небольшой компьютерной программе. Цель sqlite3_prepare() состоит в том, чтобы скомпилировать эту программу в объектный код. Подготовленный оператор является объектным кодом. Интерфейс sqlite3_step() затем запускает объектный код, чтобы получить результат.
Новые приложения всегда должны вместо этого вызывать sqlite3_prepare_v2() из sqlite3_prepare(). Старый sqlite3_prepare() сохраняется для обратная совместимость. Но sqlite3_prepare_v2() предоставляет много возможностей. лучший интерфейс.
sqlite3_step()
Эта процедура используется для оценки подготовленного оператора, который был ранее созданный интерфейсом sqlite3_prepare(). Заявление оценивается до момента, когда доступна первая строка результатов. Чтобы перейти ко второй строке результатов, снова вызовите sqlite3_step().
 Продолжайте вызывать sqlite3_step(), пока инструкция не будет завершена.
Операторы, не возвращающие результатов (например, INSERT, UPDATE или DELETE).
операторы) выполняются до завершения одним вызовом sqlite3_step().
Продолжайте вызывать sqlite3_step(), пока инструкция не будет завершена.
Операторы, не возвращающие результатов (например, INSERT, UPDATE или DELETE).
операторы) выполняются до завершения одним вызовом sqlite3_step().sqlite3_column()
Эта процедура возвращает один столбец из текущей строки результата. установлен для подготовленного оператора, который оценивается sqlite3_step(). Каждый раз, когда sqlite3_step() останавливается с новой строкой набора результатов, эта процедура можно вызывать несколько раз, чтобы найти значения всех столбцов в этой строке.
Как отмечалось выше, на самом деле не существует такой вещи, как sqlite3_column(). функция в SQLite API. Вместо этого то, что мы здесь называем sqlite3_column(), является заполнителем для целого семейства функций, которые возвращают значение из набора результатов в различных типах данных. Есть и рутины в этом семействе, которые возвращают размер результата (если это строка или BLOB) и количество столбцов в результирующем наборе.

- sqlite3_column_blob()
- sqlite3_column_bytes()
- sqlite3_column_bytes16()
- sqlite3_column_count()
- sqlite3_column_double()
- sqlite3_column_int()
- sqlite3_column_int64()
- sqlite3_column_text()
- sqlite3_column_text16()
- sqlite3_column_type()
- sqlite3_column_value()
sqlite3_finalize()
Эта процедура уничтожает подготовленный оператор, созданный предыдущим вызовом в sqlite3_prepare(). Каждый подготовленный оператор должен быть уничтожен с помощью вызов этой подпрограммы, чтобы избежать утечек памяти.
sqlite3_close()
Эта процедура закрывает соединение с базой данных, ранее открытое вызовом в sqlite3_open(). Все подготовленные заявления, связанные с соединение должно быть завершено до закрытия связь.
Приложение обычно использует
sqlite3_open() для создания одного соединения с базой данных
во время инициализации. Обратите внимание, что sqlite3_open() можно использовать либо для открытия существующей базы данных,
файлов или для создания и открытия новых файлов базы данных.
Хотя многие приложения используют только одно соединение с базой данных,
нет причин, по которым приложение не может вызывать sqlite3_open() несколько раз
чтобы открыть несколько подключений к базе данных — либо к одному и тому же
базу данных или к другим базам данных. Иногда многопоточное приложение
создаст отдельные подключения к базе данных для каждого потока.
Обратите внимание, что одно соединение с базой данных может иметь доступ к двум или более
базы данных с помощью SQL-команды ATTACH, поэтому нет необходимости
иметь отдельное соединение с базой данных для каждого файла базы данных.
Обратите внимание, что sqlite3_open() можно использовать либо для открытия существующей базы данных,
файлов или для создания и открытия новых файлов базы данных.
Хотя многие приложения используют только одно соединение с базой данных,
нет причин, по которым приложение не может вызывать sqlite3_open() несколько раз
чтобы открыть несколько подключений к базе данных — либо к одному и тому же
базу данных или к другим базам данных. Иногда многопоточное приложение
создаст отдельные подключения к базе данных для каждого потока.
Обратите внимание, что одно соединение с базой данных может иметь доступ к двум или более
базы данных с помощью SQL-команды ATTACH, поэтому нет необходимости
иметь отдельное соединение с базой данных для каждого файла базы данных.
Многие приложения разрушают свои соединения с базой данных, используя вызовы
sqlite3_close() при завершении работы. Или, например, приложение, которое
использует SQLite, так как его формат файла приложения может
открывать соединения с базой данных в ответ на действие меню File/Open
а затем уничтожить соответствующее соединение с базой данных в ответ
в меню Файл/Закрыть.
Чтобы запустить инструкцию SQL, приложение выполняет следующие шаги:
- Создайте подготовленный оператор, используя sqlite3_prepare().
- Оцените подготовленный оператор, вызвав sqlite3_step() один или более раз.
- Для запросов извлекайте результаты, вызывая sqlite3_column() между ними два вызова sqlite3_step().
- Уничтожить подготовленный оператор с помощью sqlite3_finalize().
Вышеизложенное — это все, что действительно нужно знать, чтобы использовать SQLite. эффективно. Все остальное оптимизация и детализация.
Интерфейс sqlite3_exec() — это удобная оболочка, которая выполняет
все четыре вышеуказанных шага с помощью одного вызова функции. Обратный звонок
функция, переданная в sqlite3_exec(), используется для обработки каждой строки
набор результатов. sqlite3_get_table() — еще одна удобная оболочка.
который выполняет все четыре вышеуказанных шага. Интерфейс sqlite3_get_table()
отличается от sqlite3_exec() тем, что сохраняет результаты запросов
в куче памяти, а не вызывать обратный вызов.
Важно понимать, что ни sqlite3_exec(), ни sqlite3_get_table() делает все, что не может быть выполнено с помощью основные процедуры. На самом деле эти обертки реализованы исключительно в с точки зрения основных процедур.
В предыдущем обсуждении предполагалось, что каждый оператор SQL подготавливается один раз, оценивается, затем уничтожается. Однако SQLite позволяет то же самое. подготовленный оператор для многократной оценки. Это выполнено используя следующие подпрограммы:
- sqlite3_reset()
- sqlite3_bind()
После того, как подготовленный оператор был оценен одним или несколькими вызовами
sqlite3_step(), его можно сбросить для повторной оценки с помощью
вызов sqlite3_reset().
Думайте о sqlite3_reset() как о перемотке подготовленной программы операторов.
вернуться к началу.
Использование sqlite3_reset() для существующего подготовленного оператора, а не
создание нового подготовленного оператора позволяет избежать ненужных вызовов
sqlite3_prepare(). Для многих операторов SQL время, необходимое
для запуска sqlite3_prepare() равно или превышает время, необходимое
sqlite3_step(). Поэтому избегание вызовов sqlite3_prepare() может дать
значительное улучшение производительности.
Для многих операторов SQL время, необходимое
для запуска sqlite3_prepare() равно или превышает время, необходимое
sqlite3_step(). Поэтому избегание вызовов sqlite3_prepare() может дать
значительное улучшение производительности.
Обычно нецелесообразно оценивать точных одинаковых SQL-запросов. утверждение более одного раза. Чаще хочется оценить похожие заявления. Например, вы можете захотеть оценить оператор INSERT. несколько раз с разными значениями. Или вы хотите оценить один и тот же запрос несколько раз, используя другой ключ в предложении WHERE. Разместить это, SQLite позволяет операторам SQL содержать параметры которые «привязаны» к значениям до их оценки. Эти значения могут позже может быть изменен, и тот же подготовленный оператор может быть оценен второй раз, используя новые значения.
SQLite допускает параметр везде, где строковый литерал,
допускается литерал BLOB, числовая константа или NULL
в запросах или операторах модификации данных. (DQL или DML)
(Параметры нельзя использовать для имен столбцов или таблиц,
или как значения для ограничений или значений по умолчанию. (ДДЛ))
Параметр принимает одну из следующих форм:
(DQL или DML)
(Параметры нельзя использовать для имен столбцов или таблиц,
или как значения для ограничений или значений по умолчанию. (ДДЛ))
Параметр принимает одну из следующих форм:
- ?
- ? ННН
- : ААА
- $ ААА
- @ ААА
В приведенных выше примерах NNN является целым числом и AAA — это идентификатор. Изначально параметр имеет значение NULL. Перед вызовом sqlite3_step() в первый раз или сразу после sqlite3_reset() приложение может вызывать Интерфейсы sqlite3_bind() для прикрепления значений к параметрам. Каждый вызов sqlite3_bind() переопределяет предыдущие привязки того же параметра.
Приложение может заранее подготовить несколько операторов SQL.
и оценивать их по мере необходимости.
Нет произвольного ограничения на количество непогашенных
подготовленные заявления.
Некоторые приложения вызывают sqlite3_prepare() несколько раз при запуске, чтобы
создать все подготовленные операторы, которые им когда-либо понадобятся. Другой
приложения сохраняют кеш самых последних использованных подготовленных операторов
а затем повторно использовать подготовленные операторы из кеша, когда они доступны.
Другой подход заключается в повторном использовании подготовленных операторов только тогда, когда они
внутри петли.
Другой
приложения сохраняют кеш самых последних использованных подготовленных операторов
а затем повторно использовать подготовленные операторы из кеша, когда они доступны.
Другой подход заключается в повторном использовании подготовленных операторов только тогда, когда они
внутри петли.
Конфигурация по умолчанию для SQLite отлично подходит для большинства приложений. Но иногда разработчики хотят настроить установку, чтобы попытаться выжать немного больше производительности, или воспользоваться какой-то малоизвестной функцией.
Интерфейс sqlite3_config() используется для создания глобальных, общепроцессных изменения конфигурации для SQLite. Интерфейс sqlite3_config() должен вызываться до того, как будут созданы какие-либо соединения с базой данных. Интерфейс sqlite3_config() позволяет программисту делать такие вещи, как:
- Отрегулируйте способ выделения памяти SQLite, включая настройку
альтернативные распределители памяти, подходящие для критически важных с точки зрения безопасности
встроенные системы реального времени и определяемые приложениями распределители памяти.

- Настройте журнал ошибок для всего процесса.
- Укажите определяемый приложением кэш страниц.
- Отрегулируйте использование мьютексов, чтобы они подходили для различных резьбовые модели или заменить определяемая приложением система мьютексов.
После завершения настройки всего процесса и подключения к базе данных были созданы, отдельные подключения к базе данных могут быть настроены с помощью вызовы sqlite3_limit() и sqlite3_db_config().
SQLite включает в себя интерфейсы, которые можно использовать для расширения его функциональности. К таким процедурам относятся:
- sqlite3_create_collation()
- sqlite3_create_function()
- sqlite3_create_module()
- sqlite3_vfs_register()
Интерфейс sqlite3_create_collation() используется для создания новых
сопоставление последовательностей для сортировки текста.
Интерфейс sqlite3_create_module() используется для регистрации новых
реализации виртуальных таблиц. Интерфейс sqlite3_vfs_register() создает новые VFS.
Интерфейс sqlite3_vfs_register() создает новые VFS.
Интерфейс sqlite3_create_function() создает новые функции SQL — либо скалярные, либо агрегатные. Реализация новой функции обычно использует следующие дополнительные интерфейсы:
- sqlite3_aggregate_context()
- sqlite3_result()
- sqlite3_user_data()
- sqlite3_value()
Все встроенные SQL-функции SQLite созданы именно с использованием эти самые интерфейсы. Обратитесь к исходному коду SQLite и, в частности, в дата.с и Исходные файлы func.c Например.
Общие библиотеки или библиотеки DLL можно использовать в качестве загружаемых расширений для SQLite.
В этой статье упоминаются только самые важные и наиболее часто
используемые интерфейсы SQLite.
Библиотека SQLite включает множество других API, реализующих полезные
особенности, которые здесь не описаны.
Полный список функций, образующих SQLite
Интерфейс прикладного программирования находится на
Спецификация интерфейса C/C++.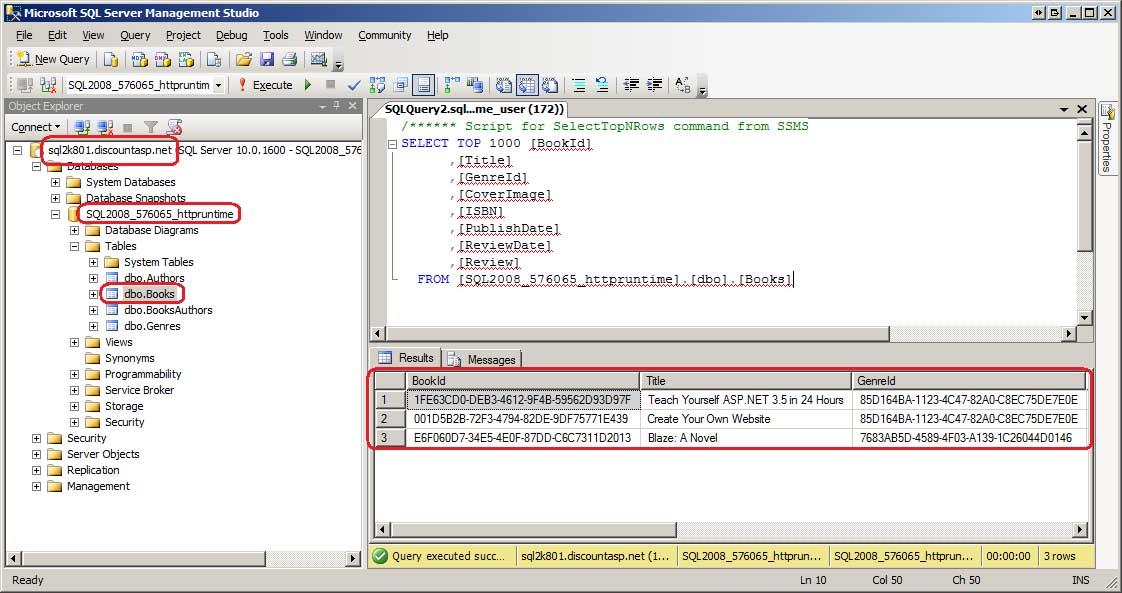 Обратитесь к этому документу за полной и достоверной информацией о
все интерфейсы SQLite.
Обратитесь к этому документу за полной и достоверной информацией о
все интерфейсы SQLite.
Последнее изменение этой страницы: 31.12.2022, 21:51:03 UTC
SQL Parser Ansi C/C++ версия для GCC, VC, Objective C, сборщик Borland C/C++ и др.
Версия General SQL Parser C/C++ написана на ANSI-C, поэтому эта библиотека SQL может использоваться большинством компиляторов C/C++, включая но не ограничиваясь компоновщиком GCC, Objective-C, Mircosoft VC, Borland C++. Эта библиотека SQL может использоваться на различных платформах. такие как Liunx, HP-UX, IBM AIX, SUN Solaris, MAC-OS и Windows.
Версия General SQL Parser C/C++ ценна тем, что обеспечивает глубокий и подробный анализ сценариев SQL для различных баз данных,
включая Oracle, SQL Server, DB2, MySQL, PostgreSQL, Teradata и Access. Без такого полного анализатора запросов, как этот,
такая задача будет невыполнима. Теперь у вас есть возможность полностью интегрировать этот синтаксический анализатор SQL Ansi C/C++ в свои продукты, мгновенно добавляя мощные возможности обработки SQL в свои программы на C и C++.
Программа форматирования SQL легко интегрируется в ваше приложение для получения макета с цветовой кодировкой, по которому легко ориентироваться, что придает вашему продукту профессиональный вид.
Ваше приложение сможет проверять синтаксис SQL до того, как база данных выполнит запрос. Это очень полезно, особенно если ваш SQL был построен динамически на основе пользовательского ввода.
Избегайте уязвимости для SQL-инъекций в приложениях ASP.NET или Java с помощью автоматическое обнаружение вредоносного сегмента SQL с помощью нашей готовой к использованию библиотеки.
Точно определить и переименовать каждую таблицу и столбец в сохраненных операторах SQL очень сложно с большим количеством вложений и подзапросов, но мы можем сделать это без проблем для вас.
Разберите объекты SQL, влияющие на SQL, в файле SQL, который может иметь множество различных
типов SQL (выбрать, вставить, создать, удалить и т. д.) и помочь определить, что затрагивается, включая, помимо прочего, схему, таблицу, столбец.