Введение в соединения / Хабр
По материалам статьи Craig Freedman: Introduction to Joins
Соединение (JOIN) — одна из самых важных операций, выполняемых реляционными системами управления базами данных (РСУБД). РСУБД используют соединения для того, чтобы сопоставить строки одной таблицы строкам другой таблицы. Например, соединения можно использовать для сопоставления продаж — клиентам или книг — авторам. Без соединений, имелись бы раздельные списки продаж и клиентов или книг и авторов, но невозможно было бы определить, какие клиенты что купили, или какой из авторов был заказан.
Можно соединить две таблицы явно, перечислив обе таблицы в предложении FROM запроса. Также можно соединить две таблицы, используя для этого всё разнообразие подзапросов. Наконец, SQL Server во время оптимизации может добавить соединение в план запроса, преследуя свои цели.
Это первая из серии статей, которые я планирую посвятить соединениям. Эту статью я собираюсь посвятить азам соединений, описав назначение логических операторов соединениё, поддерживаемых SQL Server.
Inner join
Outer join
Cross join
Cross apply
Semi-join
Anti-semi-join
Для иллюстрации каждого соединения я буду использовать простую схему и набор данных:
create table Customers (Cust_Id int, Cust_Name varchar(10)) insert Customers values (1, 'Craig') insert Customers values (2, 'John Doe') insert Customers values (3, 'Jane Doe') create table Sales (Cust_Id int, Item varchar(10)) insert Sales values (2, 'Camera') insert Sales values (3, 'Computer') insert Sales values (3, 'Monitor') insert Sales values (4, 'Printer')
Внутренние соединения
Внутренние соединения — самый распространённый тип соединений. Внутреннее соединение просто находит пары строк, которые соединяются и удовлетворяют предикату соединения. Например, показанный ниже запрос использует предикат соединения «S.Cust_Id = C.Cust_Id», позволяющий найти все продажи и сведения о клиенте с одинаковыми значениями Cust_Id:
select * from Sales S inner join Customers C on S.Cust_Id = C.Cust_Id Cust_Id Item Cust_Id Cust_Name ----------- ---------- ----------- ---------- 2 Camera 2 John Doe 3 Computer 3 Jane Doe 3 Monitor 3 Jane Doe
Примечания:
Cust_Id = 3 купил два наименования, поэтому он фигурирует в двух строках результирующего набора.
Cust_Id = 1 не купил ничто и потому не появляется в результате.
Для Cust_Id = 4 тоже был продан товар, но поскольку в таблице нет такого клиента, сведения о такой продаже не появились в результате.
Внутренние соединения полностью коммутативны. «A inner join B» и «B inner join A» эквивалентны.
Внешние соединения
Предположим, что мы хотели бы увидеть список всех продаж; даже тех, которые не имеют соответствующих им записей о клиенте. Можно составить запрос с внешним соединением, которое покажет все строки в одной или обеих соединяемых таблицах, даже если не будет существовать соответствующих предикату соединения строку.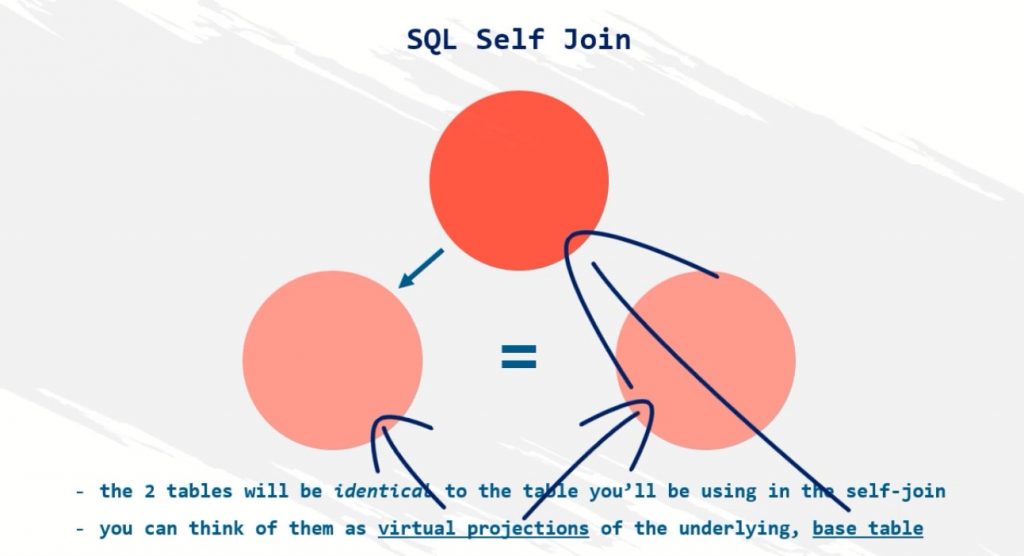 Например:
Например:
select * from Sales S left outer join Customers C on S.Cust_Id = C.Cust_Id Cust_Id Item Cust_Id Cust_Name ----------- ---------- ----------- ---------- 2 Camera 2 John Doe 3 Computer 3 Jane Doe 3 Monitor 3 Jane Doe 4 Printer NULL NULL
Обратите внимание, что сервер возвращает вместо данных о клиенте значение NULL, поскольку для проданного товара ‘Printer’ нет соответствующей записи клиента. Обратите внимание на последнюю строку, у которой отсутствующие значения заполнены значением NULL.
Используя полное внешнее соединение, можно найти всех клиентов (независимо от того, покупали ли они что-нибудь), и все продажи (независимо от того, сопоставлен ли им имеющийся клиент):
select * from Sales S full outer join Customers C on S.Cust_Id = C.Cust_Id Cust_Id Item Cust_Id Cust_Name ----------- ---------- ----------- ---------- 2 Camera 2 John Doe 3 Computer 3 Jane Doe 3 Monitor 3 Jane Doe 4 Printer NULL NULL NULL NULL 1 Craig
Следующая таблица показывает, строки какой из соединяемых таблиц попадут в результирующий набор (у оставшейся таблицы возможны замены NULL), она охватывает все типы внешних соединений:
Соединение | Выводятся … |
A left outer join B | Все строки A |
A right outer join B | Все строки B |
A full outer join B | Все строки A и B |
Полные внешние соединения коммутативны.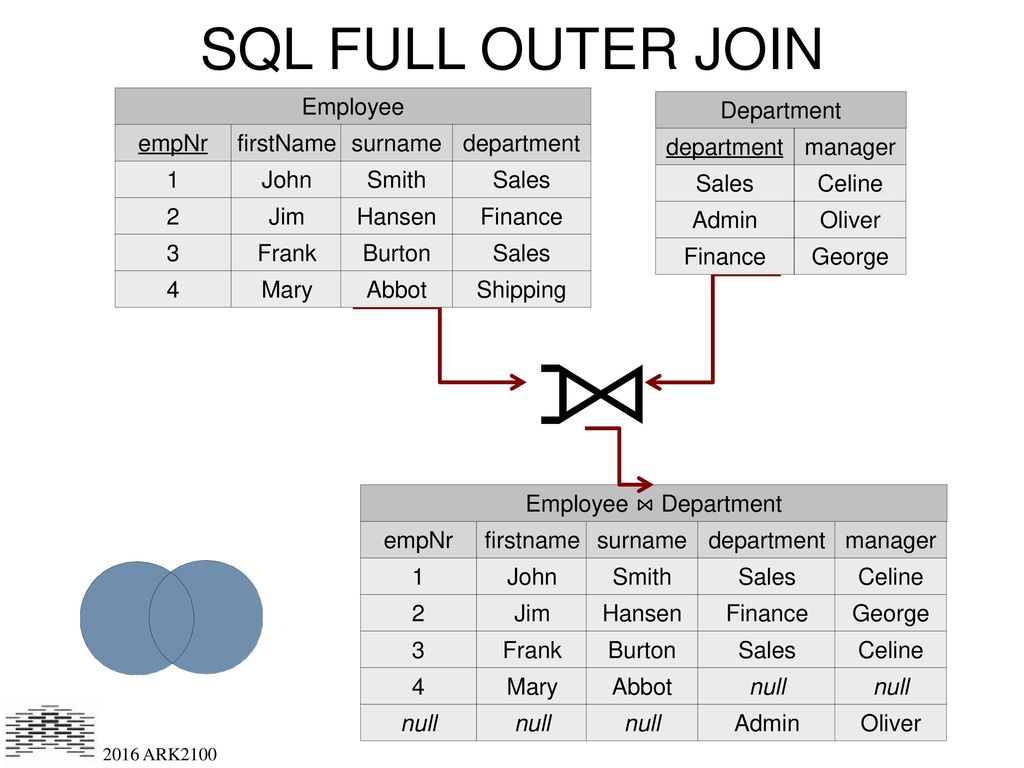
Перекрестные соединения
Перекрестное соединение выполняет полное Декартово произведение двух таблиц. То есть это соответствие каждой строки одной таблицы — каждой строке другой таблицы. Для перекрестного соединения нельзя определить предикат соединения, используя для этого предложение ON, хотя для достижения практически того же результата, что и с внутренним соединением, можно использовать предложение WHERE.
Перекрестные соединения используются довольно редко. Никогда не стоит пересекать две большие таблицы, поскольку это задействует очень дорогие операции и получится очень большой результирующий набор.
select * from Sales S cross join Customers C Cust_Id Item Cust_Id Cust_Name ----------- ---------- ----------- ---------- 2 Camera 1 Craig 3 Computer 1 Craig 3 Monitor 1 Craig 4 Printer 1 Craig 2 Camera 2 John Doe 3 Computer 2 John Doe 3 Monitor 2 John Doe 4 Printer 2 John Doe 2 Camera 3 Jane Doe 3 Computer 3 Jane Doe 3 Monitor 3 Jane Doe 4 Printer 3 Jane Doe
CROSS APPLY
В SQL Server 2005 мы добавили оператор CROSS APPLY, с помощью которого можно соединять таблицу с возвращающей табличное значение функцией (table valued function — TVF), причём TVF будет иметь параметр, который будет изменяться для каждой строки. Например, представленный ниже запрос возвратит тот же результат, что и показанное ранее внутреннее соединение, но с использованием TVF и CROSS APPLY:
Например, представленный ниже запрос возвратит тот же результат, что и показанное ранее внутреннее соединение, но с использованием TVF и CROSS APPLY:
create function dbo.fn_Sales(@Cust_Id int) returns @Sales table (Item varchar(10)) as begin insert @Sales select Item from Sales where Cust_Id = @Cust_Id return end select * from Customers cross apply dbo.fn_Sales(Cust_Id) Cust_Id Cust_Name Item ----------- ---------- ---------- 2 John Doe Camera 3 Jane Doe Computer 3 Jane Doe Monitor
Также можно использовать внешнее обращение — OUTER APPLY, позволяющее нам найти всех клиентов независимо от того, купили ли они что-нибудь или нет. Это будет похоже на внешнее соединение.
select * from Customers outer apply dbo.fn_Sales(Cust_Id) Cust_Id Cust_Name Item ----------- ---------- ---------- 1 Craig NULL 2 John Doe Camera 3 Jane Doe Computer 3 Jane Doe Monitor
Полусоединение и анти-полусоединение
Полусоединение — semi-join возвращает строки только одной из соединяемых таблиц, без выполнения соединения полностью.
В отличие от других операторов соединений, не существует явного синтаксиса для указания исполнения полусоединения, но SQL Server, в целом ряде случаев, использует в плане исполнения именно полусоединения. Например, полусоединение может использоваться в плане подзапроса с EXISTS:
select *
from Customers C
where exists (
select *
from Sales S
where S.Cust_Id = C.Cust_Id
)
Cust_Id Cust_Name
----------- ----------
2 John Doe
3 Jane DoeВ отличие от предыдущих примеров, полусоединение возвращает только данные о клиентах.
В плане запроса видно, что SQL Server действительно использует полусоединение:
|—Nested Loops(Left Semi Join, WHERE:([S].[Cust_Id]=[C].[Cust_Id]))
|—Table Scan(OBJECT:([Customers] AS [C]))
Существуют левые и правые полусоединения. Левое полусоединение возвращает строки левой (первой) таблицы, которые соответствуют строкам из правой (второй) таблицы, в то время как правое полусоединение возвращает строки из правой таблицы, которые соответствуют строкам из левой таблицы.
Левое полусоединение возвращает строки левой (первой) таблицы, которые соответствуют строкам из правой (второй) таблицы, в то время как правое полусоединение возвращает строки из правой таблицы, которые соответствуют строкам из левой таблицы.
Подобным образом может использоваться анти-полусоединение для обработки подзапроса с NOT EXISTS.
Дополнение
Во всех представленных в статье примерах использовались предикаты соединения, который сравнивали, являются ли оба столбца каждой из соединяемых таблицы равными. Такой тип предикатов соединений принято называть «соединением по эквивалентности». Другие предикаты соединений (например, неравенства) тоже возможны, но соединения по эквивалентности распространены наиболее широко. В SQL Server заложено много альтернативных вариантов оптимизации соединений по эквивалентности и оптимизации соединений с более сложными предикатами.
SQL Server более гибок в выборе порядка соединения и его алгоритма при оптимизации внутренних соединений, чем при оптимизации внешних соединений и CROSS APPLY. Таким образом, если взять два запроса, которые отличаются только тем, что один использует исключительно внутренние соединения, а другой использует внешние соединения и/или CROSS APPLY, SQL Server сможет найти лучший план исполнения для запроса, который использует только внутренние соединения.
Таким образом, если взять два запроса, которые отличаются только тем, что один использует исключительно внутренние соединения, а другой использует внешние соединения и/или CROSS APPLY, SQL Server сможет найти лучший план исполнения для запроса, который использует только внутренние соединения.
mysql — Как можно создать SQL запросы с JOIN и без JOIN
Добрый день. Подскажите, пожалуйста, как можно создать SQL запросы с JOIN и без JOIN. Нужно вывести все записи из QUESTIONS, при условии (question_status = «approved») и если (question_user_id_from НЕ РАВНО NULL AND question_user_id_from = user_id) или (question_user_id_from РАВНО NULL AND question_user_id_from = user_id)
------------------------------------------- QUESTIONS ------------------------------------------- | question_status | question_user_id_from | ------------------------------------------- | approved | 111111 | ------------------------------------------- | approved | 111111 | ------------------------------------------- | approved | NULL | ------------------------------------------- ------------- USERS ------------- | user_id | ------------- | 111111 | -------------
Сделал подобный запрос, как описал в условии, начало выводить по 8 одинаковых результатов у кого question_user_id_from = NULL, при этом у кого question_user_id_from != NULL — вывело все записи. Вопрос, в том как сделать так чтобы выбирало в одному условии и в другом условии, при этом выводил и те и другие результаты.
Вопрос, в том как сделать так чтобы выбирало в одному условии и в другом условии, при этом выводил и те и другие результаты.
UPDATE: Остановился на этом запросе, но он выводит очень много раз информацию где question_user_id_from = NULL (а надо выводить по одной записи), в зависимости от количества строк в таблице USERS.
(SELECT * FROM questions,users WHERE questions.question_status = «approved» AND questions.question_user_id_from IS NULL) UNION (SELECT * FROM questions,users WHERE questions.question_status = «approved» AND questions.question_user_id_from = users.user_id)
- mysql
- sql
- join
2
Допустим есть две таблицы. table1 и table2.
Как соеденить таблицы без join
select * from table1, table2 // Просто соеденить без условий select * from table1, table2 where table2.parent_id = table1.
 id
// Соединить при вхождении одной таблицы в другую
id
// Соединить при вхождении одной таблицы в другую
Как соединить таблицы используя join
select * from table1 /*left right inner*/ join table2 on table2.parent_id = table1.id select * from table1 cross join table2Как соединить используя union
select id from table1 /*where условие 1*/ union select parent_id from table2 /*where условие 2*/
если table1 = table2 то можно переписать это в один select так
select * from table1 where (/*условие1*/ id = 1) or (/*условие2*/ id = 2)
1
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Работа с запросами в SQL Server
В этой статье вы увидите, как использовать различные типы запросов таблиц SQL JOIN для выбора данных из двух или более связанных таблиц.
В реляционной базе данных несколько таблиц связаны друг с другом с помощью ограничений внешнего ключа. Если вы хотите одновременно получать данные из связанных таблиц, будут полезны SQL-запросы таблиц JOIN.
Запросы таблиц SQL JOIN можно разделить на четыре основных типа:
- ВНУТРЕННЕЕ СОЕДИНЕНИЕ
- ЛЕВОЕ СОЕДИНЕНИЕ
- ПРАВОЕ ПРИСОЕДИНЕНИЕ
- ПОЛНОЕ СОЕДИНЕНИЕ
Прежде чем мы увидим запросы таблиц SQL JOIN в действии, давайте создадим фиктивную базу данных.
Создание фиктивной базы данных
В этом разделе мы создадим простую базу данных для воображаемого книжного магазина. Имя базы данных будет BookStore. Следующий скрипт создает нашу базу данных:
СОЗДАТЬ БАЗУ ДАННЫХ BookStore |
База данных будет содержать три таблицы: Книги, Категории и Авторы.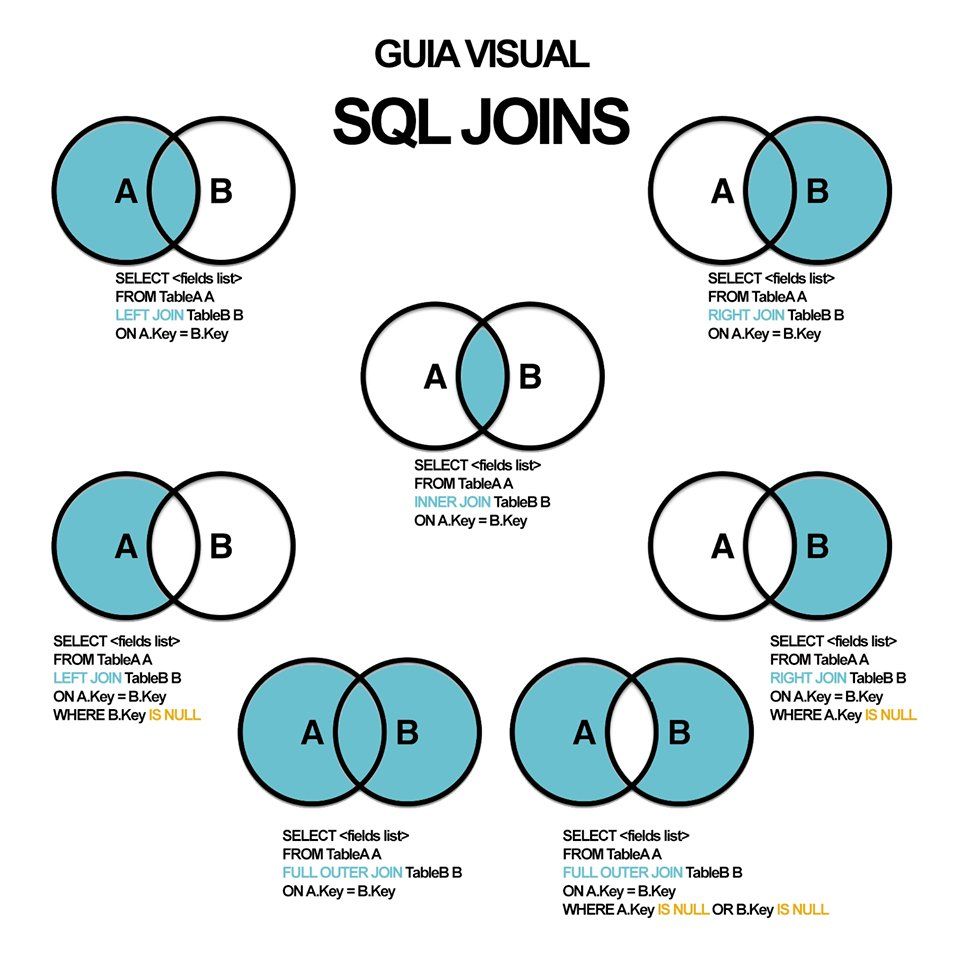 Следующий скрипт создает таблицу Books:
Следующий скрипт создает таблицу Books:
1 2 3 4 5 6 7 8 9 9 0003 | USE BookStore CREATE TABLE Books ( Id INT PRIMARY KEY IDENTITY(1,1), Name VARCHAR (50) NOT NULL, Price INT, CategoryId INT, AuthorId INT 900 03 ) |
Таблица Books содержит четыре столбца: Id, Name, Price CategoryId и AuthorId.
Аналогичным образом выполните следующий скрипт, чтобы создать таблицы категорий и авторов:
1 2 3 4 5 6 7 8 9 10 900 02 1112 13 | USE BookStore CREATE TABLE Категории ( Id INT PRIMARY KEY, Name VARCHAR (50) NOT NULL, )
USE BookStore CREATE TABLE Authors ( Id INT ПЕРВИЧНЫЙ КЛЮЧ, Имя VARCHAR (50) НЕ NULL, ) |
Давайте теперь вставим несколько фиктивных записей в таблицу «Категории»:
1 2 3 4 5 6 7 8 9 9 0003 10 | ВСТАВИТЬ В Категории ЗНАЧЕНИЯ (1, ‘Категория-A’), (2, ‘Категория-B’), (3, ‘Категория-C’), (7, ‘Категория- Д’), (8, «Кат-Е»), (4, кат-F), (10, кат-G), (12, кат-H), (6, кат-I) |
Аналогичным образом запустите следующий скрипт, чтобы вставить записи в таблицу авторов:
1 2 3 4 5 6 | ВСТАВИТЬ В Авторы ЗНАЧЕНИЯ (1, ‘Автор-А’), (2, ‘Автор-Б’), (3, ‘Автор-С’), (10, «Автор-D»), (12, «Автор-E») |
Наконец, чтобы добавить фиктивные записи в таблицу Books, запустите следующий скрипт:
1 2 3 4 5 6 7 8 9 9 0003 10 | ВСТАВИТЬ В Книги ЗНАЧЕНИЯ («Книга-A», 100, 1, 2), («Книга-B», 200, 2, 2), («Книга-C», 150, 3, 2), («Книга-D», 100, 3,1), («Книга-E», 200, 3,1), (‘Книга-F’, 150, 4,1), (‘Книга-G’, 100, 5,5), (‘Книга-H’, 200, 5,6), (‘ Книга I’, 150, 7,8) |
Примечание. Поскольку столбец Id книги имеет свойство Identity, нам не нужно указывать значение для столбца Id.
Поскольку столбец Id книги имеет свойство Identity, нам не нужно указывать значение для столбца Id.
Давайте теперь подробно рассмотрим каждый из запросов таблиц SQL JOIN.
Тип запроса таблиц SQL JOIN 1 — INNER JOIN
Запрос INNER JOIN извлекает записи только из тех строк обеих таблиц в запросе JOIN, где найдено совпадение между значениями столбцов, к которым применяется INNER JOIN.
Это может показаться сложным, но не волнуйтесь, на практике все довольно просто.
Давайте получим значения столбцов CategoryId и Name из таблицы Books, а также столбцов Id и Name из таблицы Categories, где значения столбца CateogryId таблицы Books и столбца Id таблицы Categories совпадают:
SELECT Books.CategoryId, Books.Name, Categories.Id, Categories.Name FROM Books INNER JOIN Categories ON Books.CategoryId = Categories.Id |
Вот набор результатов:
Вы можете видеть, что из таблицы «Книги» записи для книг с идентификатором категории 5 не отображаются, поскольку столбец «Идентификатор» таблицы «Категории» не содержит 5.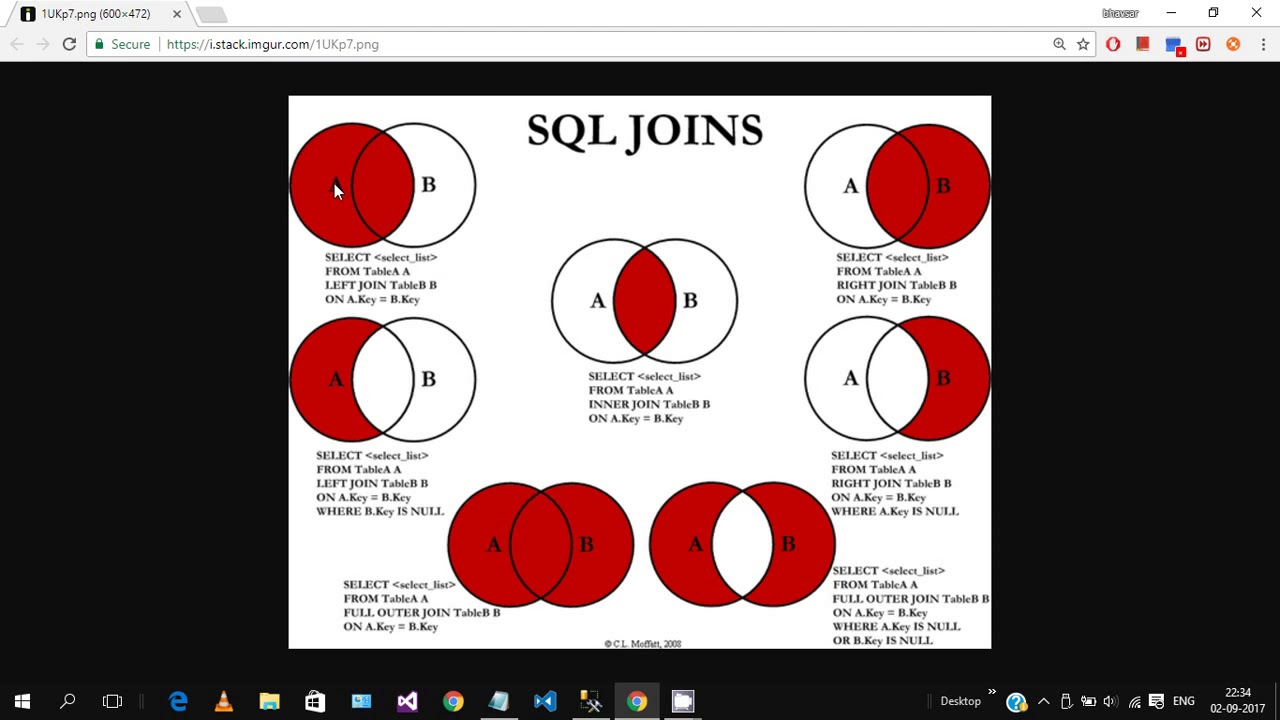 Аналогично, из таблиц «Категории» категории со значением идентификатора 8 , 10, 12 и 16 не отображаются, так как столбец CateogryId из таблицы Books не содержит этих значений.
Аналогично, из таблиц «Категории» категории со значением идентификатора 8 , 10, 12 и 16 не отображаются, так как столбец CateogryId из таблицы Books не содержит этих значений.
Следовательно, для ВНУТРЕННЕГО СОЕДИНЕНИЯ из обеих таблиц выбираются только те строки, в которых значения столбцов, задействованных в запросе ВНУТРЕННЕЕ СОЕДИНЕНИЕ, совпадают.
Тип запроса таблиц SQL JOIN 2 — LEFT JOIN
В LEFT JOIN извлекаются все записи из таблицы слева от предложения LEFT JOIN.
Напротив, из таблицы справа от предложения LEFT JOIN выбираются только те строки, в которых значения столбцов, задействованных в запросе LEFT JOIN, совпадают.
Например, если вы применяете LEFT JOIN к столбцу CategoryId таблицы Books и столбцу Id таблицы Categories. Все записи из таблицы Books (таблица слева) будут извлечены, тогда как из таблицы Categories (таблица справа) будут извлечены только те записи, в которых столбец CategoryId таблицы Books и столбец Id таблицы Таблица категорий имеет те же значения.
Посмотрите на следующий скрипт:
SELECT Books.CategoryId, Books.Name, Categories.id, Categories.Name FROM Books LEFT JOIN Categories ON Books.CategoryId = Categories.Id |
Вот набор результатов:
Из результата видно, что отображаются все записи из таблицы books. Для столбцов id и Name таблицы Categories отображаются только совпадающие записи. Поскольку таблица «Категории» не содержит 5 в столбце «Идентификатор», значения NULL были добавлены в столбцы таблицы «Категории».
Тип запроса таблиц SQL JOIN 3 — RIGHT JOIN
Предложение RIGHT JOIN полностью противоположно предложению LEFT JOIN.
В RIGHT JOIN извлекаются все записи из таблицы справа от предложения RIGHT JOIN. И наоборот, из таблицы слева от предложения RIGHT JOIN выбираются только те строки, в которых значения столбцов, задействованных в запросе RIGHT JOIN, совпадают.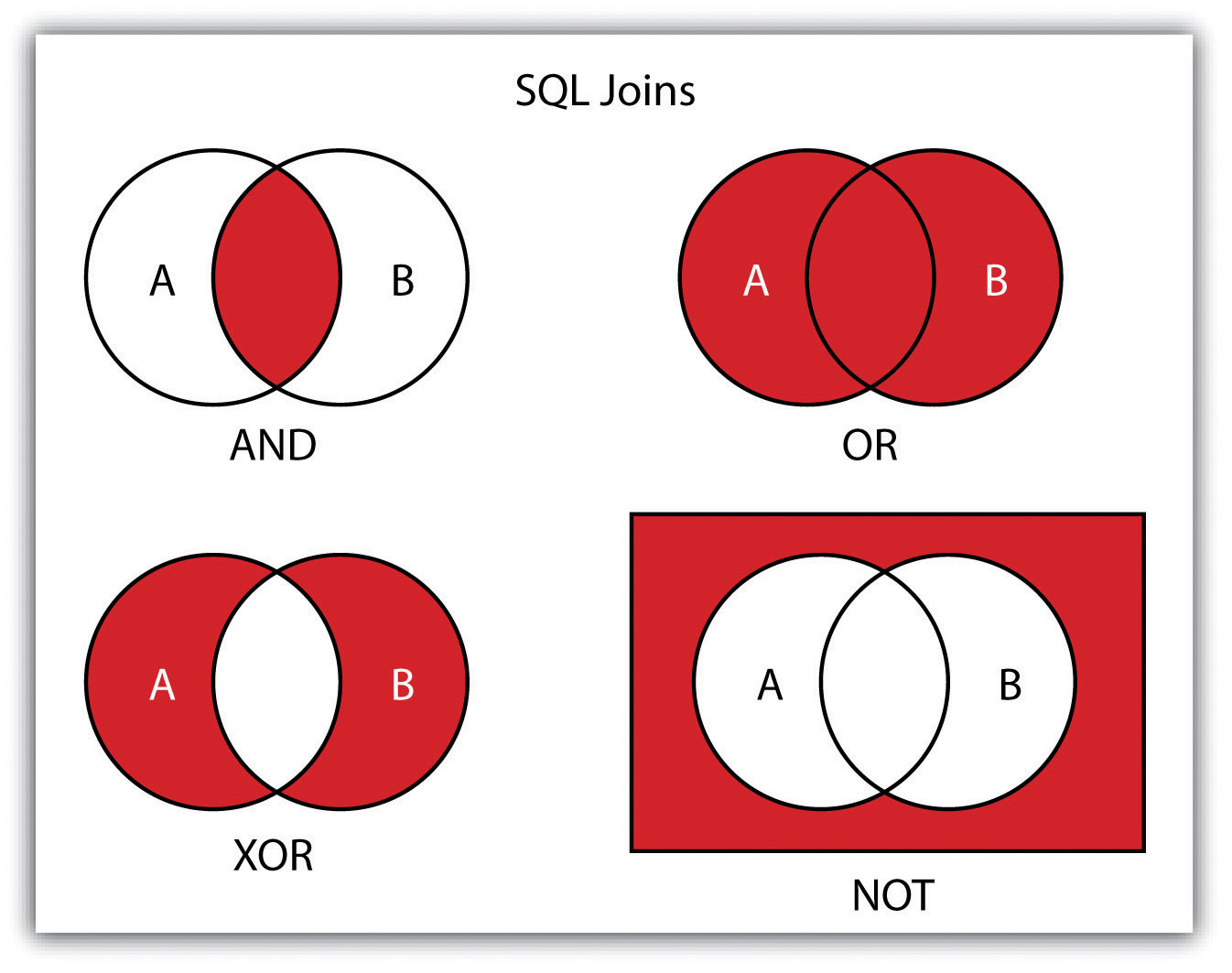
Например, если вы применяете ПРАВОЕ СОЕДИНЕНИЕ к столбцу CategoryId таблицы Books и столбцу Id таблицы Categories. Все записи из таблицы «Категории» (таблица справа) будут извлечены, тогда как из таблицы «Книги» (таблица слева) будут извлечены только те записи, в которых столбец «Идентификатор категории» таблицы «Книги» и столбец «Идентификатор» таблицы Таблица категорий имеет те же значения.
Посмотрите на следующий скрипт:
ВЫБЕРИТЕ Books.CategoryId, Books.Name, Categories.id, Categories.Name FROM Books RIGHT JOIN Categories ON Books.CategoryId = Categories.Id |
Вот набор результатов:
Из вывода видно, что отображаются все записи из столбцов таблицы «Категории». Для столбцов CategoryId и Name таблицы Books отображаются только совпадающие записи. Поскольку в таблице Books нет записей со значениями 6, 8, 10 или 12, в столбце CategoryId в столбцах из таблицы Books были добавлены значения NULL.
Запрос таблиц SQL JOIN 4 — ПОЛНОЕ СОЕДИНЕНИЕ
Предложение FULL JOIN извлекает все записи из обеих таблиц независимо от совпадения значений в столбцах, используемых в предложении FULL JOIN.
Следующий скрипт применяет ПОЛНОЕ соединение к столбцу CategoryId таблицы Books и столбцу Id таблицы Categories:
SELECT Books.CategoryId, Books.Name, Categories.id, Categories.Name FROM Books FULL JOIN Categories ON Books.CategoryId = Categories.Id |
Вот набор результатов:
Вывод показывает, что все записи были извлечены из таблиц «Книги» и «Категории». Для строк, в которых не найдено совпадение между столбцом CategoryId таблицы Books и столбцом Id таблицы Categories, были добавлены значения NULL.
Заключение
Запросы таблиц SQL JOIN используются для извлечения связанных данных из нескольких таблиц.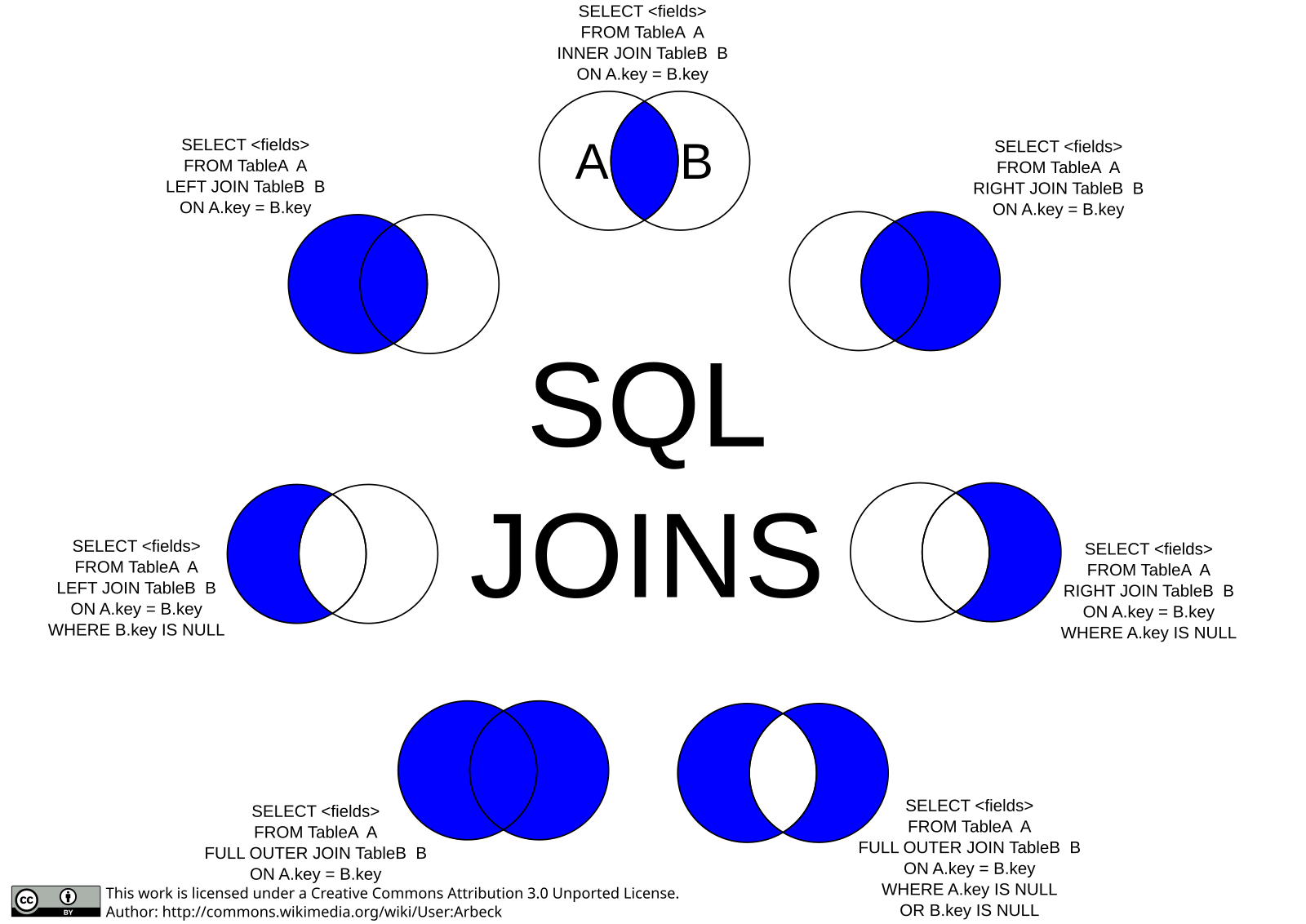 В этой статье вы увидели, как реализовать различные типы запросов таблиц SQL JOIN в Microsoft SQL Server с помощью различных примеров.
В этой статье вы увидели, как реализовать различные типы запросов таблиц SQL JOIN в Microsoft SQL Server с помощью различных примеров.
- Автор
- Последние сообщения
Бен Ричардсон
Бен Ричардсон управляет Acuity Training, ведущим поставщиком обучения SQL в Великобритании. Он предлагает полный спектр обучения SQL от вводных курсов до продвинутого обучения администрированию и работе с хранилищами данных — см. здесь для получения более подробной информации. Acuity имеет офисы в Лондоне и Гилфорде, графство Суррей. Он также иногда пишет в блоге Acuity 9.0003
Просмотреть все сообщения Бена Ричардсона
Последние сообщения Бена Ричардсона (посмотреть все)
PostgreSQL: Документация: 15: 2.6. Соединения между таблицами
До сих пор наши запросы обращались только к одной таблице за раз. Запросы могут обращаться к нескольким таблицам одновременно или обращаться к одной и той же таблице таким образом, что несколько строк таблицы обрабатываются одновременно. Запросы, которые обращаются к нескольким таблицам (или к нескольким экземплярам одной и той же таблицы) одновременно, называются присоединяются к запросам. Они объединяют строки из одной таблицы со строками из второй таблицы с выражением, указывающим, какие строки должны быть объединены в пары. Например, чтобы вернуть все записи о погоде вместе с местоположением соответствующего города, база данных должна сравнить столбец
Запросы, которые обращаются к нескольким таблицам (или к нескольким экземплярам одной и той же таблицы) одновременно, называются присоединяются к запросам. Они объединяют строки из одной таблицы со строками из второй таблицы с выражением, указывающим, какие строки должны быть объединены в пары. Например, чтобы вернуть все записи о погоде вместе с местоположением соответствующего города, база данных должна сравнить столбец city каждой строки таблицы Weather со столбцом name всех строк в городах. и выберите пары строк, в которых эти значения совпадают. [4] Это можно сделать с помощью следующего запроса:
ВЫБЕРИТЕ * ИЗ ПОГОДЫ ПРИСОЕДИНЯЙТЕСЬ к городам ON city = name;
город | temp_lo | temp_hi | пркп | дата | имя | расположение
---------------+---------+----------+------+------- -----+---------------+-----------
Сан-Франциско | 46 | 50 | 0,25 | 1994-11-27 | Сан-Франциско | (-194,53)
Сан-Франциско | 43 | 57 | 0 | 1994-11-29 | Сан-Франциско | (-194,53)
(2 ряда)
Обратите внимание на две особенности результирующего набора:
Нет строки результатов для города Хейворд.
 Это связано с тем, что в таблице
Это связано с тем, что в таблице городовдля Хейворда нет соответствующей записи, поэтому объединение игнорирует несопоставленные строки в таблицепогоды. Вскоре мы увидим, как это можно исправить.Есть две колонки, содержащие название города. Это правильно, потому что списки столбцов из таблиц
Weatherигородовобъединены. На практике это нежелательно, поэтому вы, вероятно, захотите указать выходные столбцы явно, а не использовать*:ВЫБЕРИТЕ город, temp_lo, temp_hi, prcp, дату, местоположение ОТ ПОГОДЫ ПРИСОЕДИНЯЙТЕСЬ к городам ПО city = name;
Поскольку все столбцы имели разные имена, синтаксический анализатор автоматически нашел, к какой таблице они принадлежат. Если бы в двух таблицах были повторяющиеся имена столбцов, вам нужно было бы квалифицировать имена столбцов, чтобы показать, какой из них вы имели в виду, например:
ВЫБЕРИТЕ погода.город, погода.temp_lo, погода.temp_hi, погода.prcp, погода.дата, города.местоположение ИЗ ПОГОДЫ ПРИСОЕДИНЯЙТЕСЬ к городам ПО Weather.city = city.name;
Считается хорошим стилем уточнять все имена столбцов в запросе на соединение, чтобы запрос не завершился ошибкой, если позже в одну из таблиц будет добавлено повторяющееся имя столбца.
Запросы на соединение того вида, который мы видели до сих пор, также можно записать в такой форме:
ВЫБИРАТЬ *
ОТ погоды, городов
ГДЕ город = имя;
Этот синтаксис предшествует синтаксису JOIN / ON , который был представлен в SQL-92. Таблицы просто перечислены в ОТ , а выражение сравнения добавляется к предложению WHERE . Результаты этого старого неявного синтаксиса и более нового явного синтаксиса JOIN / ON идентичны. Но для читателя запроса явный синтаксис облегчает понимание его смысла: условие соединения вводится собственным ключевым словом, тогда как ранее условие было смешано с предложением WHERE вместе с другими условиями.
Теперь мы выясним, как вернуть записи Хейворда. Мы хотим, чтобы запрос сканировал погода таблицы и для каждой строки, чтобы найти соответствие городов строк. Если подходящая строка не найдена, мы хотим, чтобы некоторые «пустые значения» были заменены на столбцы таблицы городов . Такой запрос называется внешним соединением . (Соединения, которые мы видели до сих пор, это внутренних соединений .) Команда выглядит так:
ВЫБИРАТЬ *
ОТ погоды ЛЕВЫЙ ВНЕШНИЙ СОЕДИНЯЙТЕ города НА Weather.city = city.name;
город | temp_lo | temp_hi | пркп | дата | имя | расположение
---------------+---------+----------+------+------- -----+---------------+-----------
Хейворд | 37 | 54 | | 1994-11-29 | |
Сан-Франциско | 46 | 50 | 0,25 | 1994-11-27 | Сан-Франциско | (-194,53)
Сан-Франциско | 43 | 57 | 0 | 1994-11-29 | Сан-Франциско | (-194,53)
(3 ряда)
Этот запрос называется левым внешним соединением , потому что таблица, указанная слева от оператора соединения, будет иметь каждую из своих строк в выходных данных по крайней мере один раз, тогда как таблица справа будет иметь только те строки, которые соответствуют некоторую строку левой таблицы. При выводе строки левой таблицы, для которой нет совпадения с правой таблицей, столбцы правой таблицы заменяются пустыми (нулевыми) значениями.
При выводе строки левой таблицы, для которой нет совпадения с правой таблицей, столбцы правой таблицы заменяются пустыми (нулевыми) значениями.
Упражнение: Существуют также правые внешние соединения и полные внешние соединения. Попробуйте узнать, что они делают.
Мы также можем объединить таблицу против себя. Это называется самосоединением . В качестве примера предположим, что мы хотим найти все записи о погоде, которые находятся в температурном диапазоне других записей о погоде. Поэтому нам нужно сравнить столбцы temp_lo и temp_hi каждой строки Weather с temp_lo и temp_hi 9.0432 столбца всех остальных погода строки. Мы можем сделать это с помощью следующего запроса:
ВЫБЕРИТЕ w1.city, w1.temp_lo как низкий, w1.temp_hi как высокий, w2.city, w2.temp_lo низкий уровень AS, w2.temp_hi высокий уровень AS ОТ погоды w1 ПРИСОЕДИНЯЙТЕСЬ к погоде w2 ON w1.
