Оператор SQL: TOP. — it-black.ru
Оператор SQL: TOP. — it-black.ru Перейти к содержимомуОператор TOP позволяет ограничить выборку числа записей до заданного числа. При использовании оператора TOP совместно с оператором ORDER BY, на вывод пойдет первые N записей отсортированного списка, в противном случае, выведутся первые N строк таблицы.
Данный оператор используется только в СУБД MS SQL Server. Аналогом в MySQL является оператор LIMIT.
// Синтаксис оператора TOP: TOP ( N [PERCENT] ) // Параметр PERCENT позволяет задать количество строк в процентах.
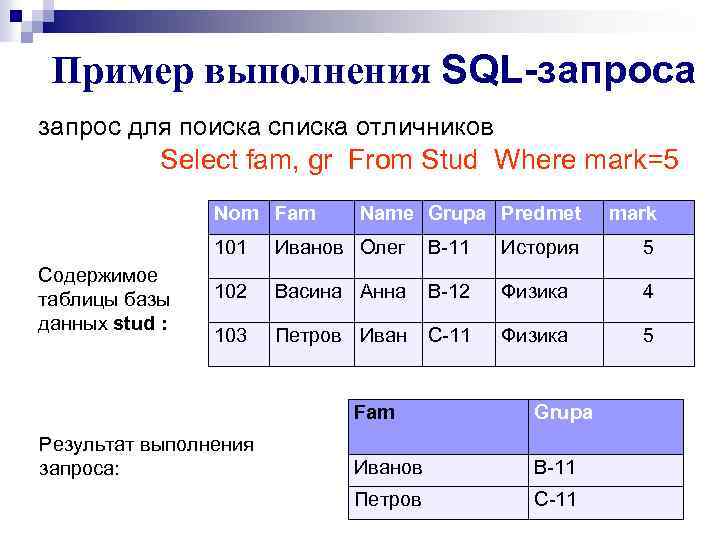
Примеры оператора TOP. Возьмём нашу таблица Artists:
| Singer | Album | Year | Sale |
| The Prodigy | Invaders Must Die | 2008 | 1200000 |
| Drowning Pool | Sinner | 2001 | 400000 |
| Massive Attack | Mezzanine | 1998 | 2300000 |
| The Prodigy | Fat of the Land | 1997 | 600000 |
| The Prodigy | Music For The Jilted Generation | 1994 | 1500000 |
| Massive Attack | 100th Window | 2003 | 1200000 |
| Drowning Pool | Full Circle | 2007 | 800000 |
| Massive Attack | Danny The Dog | 2004 | 1900000 |
| Drowning Pool | Resilience | 2013 | 500000 |
Пример 1. Используя оператор TOP вывести 3 самых свежих альбома (название и год выпуска):
Используя оператор TOP вывести 3 самых свежих альбома (название и год выпуска):
SELECT TOP(3) Album, Year FROM Artists ORDER BY Year;
Результат:
| Album | Year |
| Resilience | 2013 |
| Invaders Must Die | 2008 |
| Full Circle | 2007 |
Пример 2. Используя оператор TOP вывести первые 2 строки таблицы:
SELECT TOP(2) * FROM Artists;
Результат:
| Singer | Album | Year | Sale |
| The Prodigy | Invaders Must Die | 2008 | 1200000 |
| Drowning Pool | Sinner | 2001 | 400000 |
- Виктор Черемных
- 21 июля, 2018
- One Comment
Группа в VK
Обнаружили опечатку?
Сообщите нам об этом, выделите текст с ошибкой и нажмите Ctrl+Enter, будем очень признательны!
Свежие статьи
Облако меток
Instagram Vk Youtube Telegram OdnoklassnikiПолезно знать
Рубрики
Авторы
сервер sql — выберите верхний 1 * vs выберите верхний 1 1
спросил
Изменено 7 лет, 6 месяцев назад
Просмотрено 37 тысяч раз
Я знаю, что таких вопросов много, но я не могу найти ни одного, относящегося к моему вопросу.
Глядя на этот вопрос, имеет ли изменение IF EXIST (SELECT 1 FROM ) на IF EXIST (SELECT TOP 1 FROM) какие-либо побочные эффекты?
Специально ссылаясь на этот раздел в ответе:
выберите * из sys.objects выберите верхний 1 * из sys.objects выберите 1, где существует (выберите * из sys.objects) выберите 1, где существует (выберите верхний 1 * из sys.objects)
Я провожу несколько собственных тестов, чтобы правильно понять это. Как указано в ответе:
выберите 1, где существует (выберите верхний 1 * из sys.objects) выберите 1, где существует (выберите верхний 1 1 из sys.objects)
оба вызывают один и тот же план выполнения, а также вызывают тот же план, что и
выберите 1, где существует (выберите * из sys.objects) выберите 1, где существует (выберите 1 из sys.objects)
Из моего исследования таких вопросов, как этот, «ВЫБЕРИТЕ ВЕРХНИЙ 1 1» VS «ЕСЛИ СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1»). объекты)
Мой первый вопрос: почему это предпочтительнее этого:
выберите 1, где существует (выберите 1 из sys.objects)
Пытаясь понять это, я разбил их на более простые выражения (я использую «top 1», чтобы имитировать план выполнения, напоминающий существующий):
выбрать верхний 1 * из sys.objects выберите верхний 1 1 из sys.objects
Теперь я вижу, что первое занимает 80% времени выполнения (относительно пакета из 2), а второе — только 20%. Тогда не лучше ли использовать
select 1, где существует (выберите 1 из sys.objects)
, как его можно применить к обоим сценариям и тем самым уменьшить возможную человеческую ошибку?
- sql-сервер
- tsql
- производительность базы данных
2
SQL Server обнаруживает предикат EXISTS относительно рано в процессе компиляции/оптимизации запроса и устраняет фактический поиск данных для таких предложений, заменяя их проверкой существования. Итак, ваше предположение:
Теперь я вижу, что первое занимает 80% времени выполнения (относительно пакета из 2), а второе — только 20%.

неверно, потому что в предыдущем сравнении вы фактически извлекли некоторые данные, чего не происходит, если запрос помещается в (не)существует предикат.
В большинстве случаев нет никакой разницы, как проверять наличие строк, за исключением одного, но важного улова. Предположим, вы говорите:
, если существует (выберите * из dbo.SomeTable) ...
где-то в модуле кода (представление, хранимая процедура, функция и т. д.). Затем, позже, когда кто-то еще решит поместить предложение WITH SCHEMABINDING в этот модуль кода, SQL Server не допустит этого и вместо возможной привязки к текущему списку столбцов выдаст ошибку:
Сообщение 1054, уровень 15, состояние 7, процедура BoundView, строка 6
Синтаксис ‘*’ не допускается в объектах, привязанных к схеме.
Итак, вкратце:
, если существует (выберите 0 из ...)
— это самый безопасный, быстрый и универсальный способ проверки существования.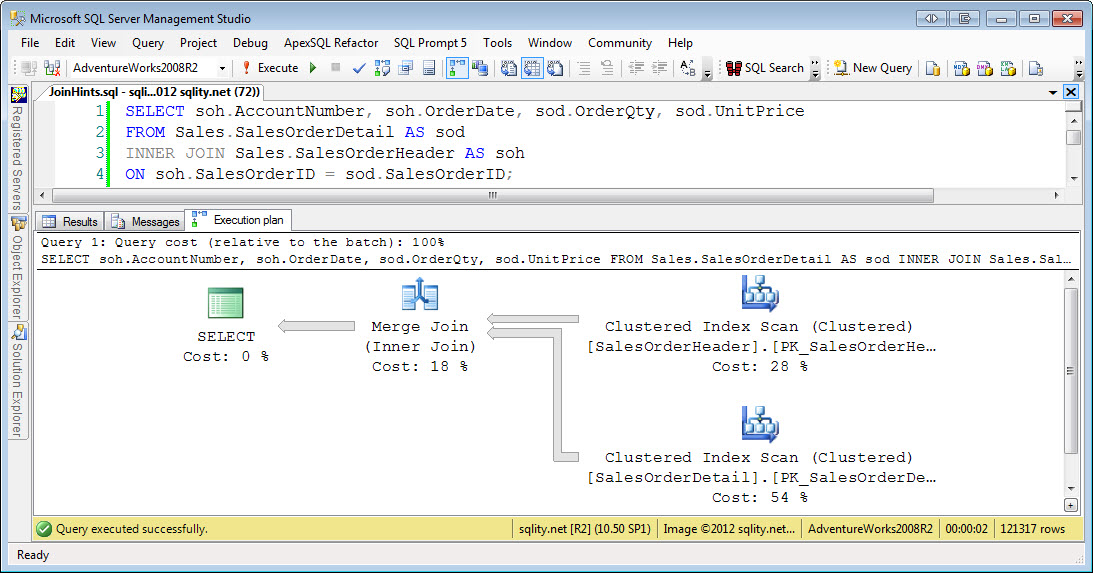
2
Разница между этими двумя:
select top 1 * from sys.objects выберите верхний 1 1 из sys.objects
Дело в том, что в первом предложении SQL-сервер должен извлекать все столбцы из таблицы (из любой случайной строки), а во втором просто можно извлекать «1» из любого индекса.
Все меняется, когда эти предложения находятся внутри . Существует предложение , потому что в этом случае SQL Server знает, что на самом деле ему не нужно извлекать данные, потому что они не будут ни к чему присваиваться, поэтому он может обрабатывать select * the так же он будет обрабатывать select 1 .
Поскольку exists проверяет только одну строку, в нее встроена внутренняя вершина 1, поэтому добавление ее вручную ничего не меняет.
Погода для выбора * или выбора 1 в предложении exists просто основано на мнении, и вместо 1 у вас, конечно, может быть 2 или «X» или что-то еще, что вам нравится. Лично я всегда использую
Лично я всегда использую ... и существует (выберите 1 ...
1
EXISTS — это тип подзапроса, который может возвращать логическое значение только в зависимости от того, возвращаются ли подзапросом какие-либо строки. Выбор 1 или * или что-то еще не имеет значения в этом контексте, потому что результат всегда либо истина, либо ложь.
Вы можете убедиться в этом, проверив, что эти два оператора создают один и тот же план.
выберите 1, где существует (выберите * из sys.objects) выберите 1, где существует (выберите 1 из sys.objects)
То, что вы выбираете во внешнем запросе, имеет значение. Как вы обнаружили, эти два оператора создают очень разные планы выполнения:
select top 1 * from sys.objects выберите верхний 1 1 из sys.objects
Первый будет медленнее, потому что он должен фактически возвращать реальные данные. В этом случае соединение с тремя базовыми таблицами: syspalnames, syssingleobjrefs и sysschobjs.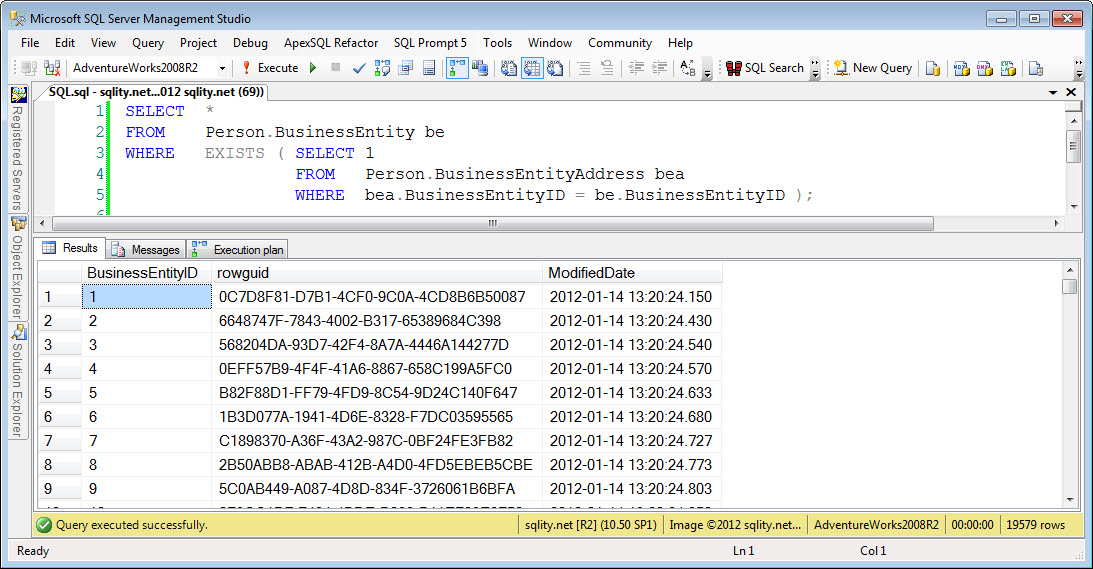
Что касается того, что вы помещаете в свои подзапросы EXISTS — SELECT 1 или SELECT * — это не имеет значения. Обычно я говорю SELECT 1, но SELECT * так же хорош, и вы увидите его во многих документах Microsoft.
Я искал ответ на как раз собственно вопрос, содержащийся в заголовке. Я нашел его по этой ссылке:
Select Top 1 или Top n в основном возвращает первые n строк данных на основе по sql-запросу. Выберите Top 1 1 или Top n s вернет первый n строки с данными в зависимости от запроса sql.
Например, приведенный ниже запрос выдает имя и фамилию первые 10 матчей. Этот запрос вернет имя и фамилию только.
ВЫБЕРИТЕ ПЕРВЫЕ 10 Имя, Фамилия ОТ [tblUser] где адрес электронной почты, например, «Джон%»Теперь посмотрите на этот запрос, выбрав 10 лучших «тестов» — это даст то же количество строк, что и в предыдущем запросе (та же база данных, тот же условие), но значения будут «тестовыми».
ВЫБЕРИТЕ ПЕРВЫЕ 10 «тест» ОТ [tblUser] где адрес электронной почты, например, «Джон%»
Итак, select TOP 1 * возвращает первую строку, а select TOP 1 1 возвращает одну строку , содержащую только «1». Это если запрос возвращает хотя бы одну строку, иначе Null будет возвращено в обоих случаях.
В качестве дополнительного примера:
SELECT TOP 10 'test', FirstName ОТ [tblUser] где адрес электронной почты, например, «Джон%»
вернет таблицу, содержащую столбец, заполненный словом «тест», и еще один столбец, заполненный первыми именами первых 10 совпадений запроса.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Проблема производительности SQL Server TOP с параллелизмом
Основы оператора ТОП
Ключевое слово TOP в SQL Server — это стандартное выражение, отличное от стандарта ANSI, для ограничения результатов запроса некоторым набором предварительно заданных строк. В качестве аргумента принимает от 0 до положительного Bigint (9223372036854775807), а все, что больше или меньше, выдает сообщение об ошибке. TOP без предложения order by в рабочей среде кажется ошибочным, потому что он может выдавать результаты в любом порядке в зависимости от текущей схемы и плана выполнения. Вы также можете указать процент с выражением TOP, которое возвращает только процент выражения строк из набора результатов. Выражения с плавающей запятой, используемые в TOP процентах, округляются до следующего целочисленного значения.
В качестве аргумента принимает от 0 до положительного Bigint (9223372036854775807), а все, что больше или меньше, выдает сообщение об ошибке. TOP без предложения order by в рабочей среде кажется ошибочным, потому что он может выдавать результаты в любом порядке в зависимости от текущей схемы и плана выполнения. Вы также можете указать процент с выражением TOP, которое возвращает только процент выражения строк из набора результатов. Выражения с плавающей запятой, используемые в TOP процентах, округляются до следующего целочисленного значения.
Детерминированный ТОР с порядком по (TOP With TIES)
TOP является детерминированным, только если указан порядок. Только тогда вы можете гарантировать, что результат будет в определенном порядке. Но даже TOP с порядком по может быть недетерминированным, если порядок по столбцу (столбцам) содержит неуникальные значения.
Рассмотрим сценарий, когда пользователь приходит с требованием о ТОП-3 продуктах с лучшими продажами для заданных данных о продажах:
Если вы посмотрите на данные выше, ProductID 3 и ProductID 4 совокупные объемы продаж равны 11.
Таким образом, на самом деле оба претендуют на 3-е место, но с обычным TOP с порядком возрастания только 1 будет выбран случайным образом, конечно, есть много способов выполнить требование, но SQL Server имеет TOP с Ties, который полезен, когда вы хотите вернуть две или более строк, которые связывают последнее место в ограниченном наборе результатов.
Ниже приведен результат приведенных выше данных запроса TOP (3) со связями, поскольку мы видим, что 4 строки находятся в приведенном ниже наборе результатов, поскольку ProductID 3 и 4 соответствуют требованиям для 3-го места.
Пример данных
Мы будем использовать две таблицы, table1 и table2, для примера ниже в этой статье. Table2 — это просто копия table1, поэтому обе таблицы имеют одинаковые данные и тип данных. Обе таблицы имеют 300000 строк. Столбец первичного ключа помечен как первичный ключ.
Столбец primarykey и Keycol состоит из числовой последовательности от 1 до 300000, а столбец searchcol содержит некоторые случайные данные. Ниже приведены изображения примеров таблиц и данных.
Ниже приведены изображения примеров таблиц и данных.
Вы можете найти скрипт для заполнения данных ниже в статье.
Среда тестирования
Microsoft SQL SERVER 2014 — 12.0.4100.1 (X64) Developer Edition (64-разрядная версия)
Microsoft SQL SERVER 2016 (SP1) — 13.0.4001.0 (X64) Developer Edition (64-разрядная версия)
Сканирование таблицы/индекса с TOP 1
Сканирование таблицы/индекса обычно неправильно понимают пользователи SQL Server, поскольку оно касается всех страниц данных таблицы/индекса. Иногда вообще не обязательно трогать все строки из сканирования таблицы/индекса, например, полуобъединение или когда вы устанавливаете цель строки. В обоих случаях нет необходимости трогать все страницы данных. Выполнение может завершиться досрочно, когда будет найдена запрошенная строка.
Как указано выше, с недетерминированными запросами выражения TOP он устанавливает Row Goal для возврата N строк, и не имеет значения, в каком порядке, поэтому совершенно необязательно получать все страницы данных. Просто получите N строк и верните их на вкладку результатов SSMS.
Просто получите N строк и верните их на вкладку результатов SSMS.
Я запущу dbcc dropcleanbuffers, чтобы очистить все страницы данных. Обратите внимание, что команду dbcc dropcleanbuffers не рекомендуется использовать на рабочем сервере.
Посмотрите на запрос ниже с STATISTCS IO ON , и вы поймете эту идею.
dbcc dropcleanbuffers; SEt статистика io on; Выберите верхний 1 * из таблицы 1
|
Стол «Таблица1» . Количество сканирований 1, логических операций чтения 3 , физическое чтение 3, опережающее чтение 0, логическое чтение 0 объектов, физическое чтение 0 объектов, упреждающее чтение 0 объектов.
В плане выполнения справа показана стратегия сканирования кластеризованного индекса, используемая для извлечения данных из таблицы. Теперь посмотрите на вывод STATISTICS IO, и вы увидите, что есть только 3 логических чтения. Это подтверждает для приведенного выше выполнения, что при сканировании индекса запроса не были прочитаны все страницы данных из индекса. Он искал только 1 строку и, найдя ее, переставал искать дальше.
Теперь посмотрите на вывод STATISTICS IO, и вы увидите, что есть только 3 логических чтения. Это подтверждает для приведенного выше выполнения, что при сканировании индекса запроса не были прочитаны все страницы данных из индекса. Он искал только 1 строку и, найдя ее, переставал искать дальше.
Как читается план выполнения (рядный режим)
В SQL Server операторы плана выполнения называются итераторами по той причине, что они работают многократно, как итерации, и обрабатывают строку за строкой на основе модели конвейера, управляемой спросом.
Как правило, итерации вызывают три общие функции:
1 OPEN: инициализировать итератор.
2 GETNEXT: получить строку и обработать в соответствии со свойством итератора.
3 ЗАКРЫТЬ: закрыть итератор.
Выполнение начинается с крайнего левого итератора, а управление переходит к следующему итератору, поток данных справа налево.
Итератор TOP помогает ему понять, как план выполнения выполняется слева направо, а не справа налево. Чтобы лучше понять это, мы выполним запрос с выражением TOP и рассмотрим план выполнения. Разогрейте кеш, выполнив хотя бы приведенные ниже запросы.
Чтобы лучше понять это, мы выполним запрос с выражением TOP и рассмотрим план выполнения. Разогрейте кеш, выполнив хотя бы приведенные ниже запросы.
1 2 3 4 5 6 7 8 2 1 0 50002 95 | Выберите верх (2) OT.PrimaryKey, OT.SearchCol, It.SearchCol Из Table1 OT Table2 It On Ot.primaryke .SearchCol < 1000;
|
Выполнение начинается с крайнего левого итератора select, затем управление переходит к итератору TOP.
В приведенном выше плане выполнения используется выражение TOP 2, которое устанавливает цель строки для 2 строк, затем управление передается итератору соединения вложенного цикла, затем инициируется таблица1 (сканирование кластеризованного индекса) и начинается запрос данных для фильтра ( [TEST] .[dbo].[table1]. [SearchCol] как [ot].[SearchCol]<(1000) ) в Table1.
[SearchCol] как [ot].[SearchCol]<(1000) ) в Table1.
Первая строка, удовлетворяющая критериям фильтра, — 616 (результат может отличаться в вашей системе). Он связан со значением столбца первичного ключа 72, поэтому соединение вложенного цикла инициировало поиск значения 72 в таблице2, поскольку таблица2 индексируется по столбцу первичного ключа, поэтому поиск произошел и передал весь столбец запроса итератору соединения вложенного цикла. Соединение с вложенным циклом получает данные и отправляет их итератору TOP, а итератор TOP передает их для выбора оператора, затем снова отфильтровывает, применяя к таблице 1 (сканирование индекса кластера), и возвращает данные соединению вложенного цикла, после чего они соответствуют таблице 2. затем верните совпадения в итератор TOP. Поскольку в выражении TOP было указано только 2, оно сигнализирует о закрытии соединения с вложенным циклом, и этот сигнал передается как внешней, так и внутренней таблицам.
Однако в моей системе для предиката [ot]. [SearchCol]<(1000) в таблице присутствует 3077 фактических чисел или строк, но поскольку выполнение следует конвейерной модели, управляемой спросом, итератор соединения вложенного цикла создал только 2 строки. к итератору TOP и выключать сканирование, когда родительские итераторы сигнализируют о его завершении.
[SearchCol]<(1000) в таблице присутствует 3077 фактических чисел или строк, но поскольку выполнение следует конвейерной модели, управляемой спросом, итератор соединения вложенного цикла создал только 2 строки. к итератору TOP и выключать сканирование, когда родительские итераторы сигнализируют о его завершении.
Обратите внимание, что результат может отличаться в зависимости от вашей системы, поскольку приведенные выше результаты запроса не являются детерминированными. Если вы хотите узнать больше об этом, вы можете увидеть эту ссылку Планы выполнения запросов SQL Server — Понимание и чтение планов.
TOP 1 проблема с агрегацией и соединением параллельных вложенных циклов
В этой части статьи мы увидим конкретную ситуацию с ТОП 1, когда окончательный выбранный план оптимизатора запросов работает очень медленно. Мы попытаемся изучить окончательный самый дешевый выбранный план оптимизатора запросов для выраженного ниже запроса и действительно ли он масштабируется и работает хорошо, если нет, то мы попытаемся выяснить причину этого и доступную альтернативу, если этот шаблон вас беспокоит.
Рассмотрим сценарий, в котором вам нужно подсчитать количество вхождений максимального числового значения в столбце searchcol таблицы1 после присоединения к таблице2. Что делать, если у вас есть эта задача в руках, и вам нужно сделать это вручную, как бы это сделать? Скорее всего, ответ будет таким:
Получить оба входа
Шаг 1: соединить два входа
Шаг 2: Сгруппируйте результат вывода в столбце поиска
Шаг 3: упорядочить по столбцу по убыванию
Шаг 4: получить ТОП 1
Существует множество альтернативных вариантов выражения вышеуказанного требования в запросе, но наиболее естественным мне кажется написанное ниже. Теперь давайте посмотрим, как это реализуется оптимизатором запросов с предполагаемым планом выполнения запроса и планом выполнения ниже:
1 2 3 4 5 6 | Выберите Top 1 T1. Соединение Table2 T2 на t1.keycol = t2.keycol Группа по T1.searchcol Порядок по t1.searchcol descest |
 Searchcol, Count_big (T1.SearchCol) из Table1 T1
Searchcol, Count_big (T1.SearchCol) из Table1 T1Шаг 1: Получите таблицу 1
Шаг 2: Сортировка таблицы 1
Шаг 3: соединение таблицы 2 (неблокируемое на основе потока) с соединением вложенного цикла
Шаг 4: сгруппируйте результат вывода
Шаг 5: получить ТОП 1
Более подробное описание ниже: (мы будем отлаживать это как перспективу потока данных)
Оптимизатор запросов выбирает план параллельного выполнения. Выбранный метод на самом деле является очень разумным подходом для двух больших таблиц (Оптимизатор запросов объединяет только 2 таблицы за раз, если в запросе более 2 таблиц, то дерево соединений таблиц основано исключительно на стоимости).
Что касается приведенного выше выраженного запроса, нет необходимости объединять все строки, поэтому разумно просто отсортировать один вход (здесь оптимизатор запросов использует полную сортировку внешней таблицы после того, как все внешние строки отсортированы, а затем переходит к вложенной соединение цикла по строке по запросу) , как указано в предложении order by, затем отобразите вывод.
Этот тип реализации с неблокирующим соединением цикла подходит лучше всего, поскольку он сохраняет внешний порядок (в некоторых случаях NL не сохраняет внешний порядок, но здесь он сохраняет внешний порядок), а затем группируется с глобальным потоком. в совокупности (требуется тот же набор значений в том же рабочем потоке, каким-то образом за это отвечает его дочерний итератор, он не блокирует, а требует отсортированного ввода) и передает отсортированную первую группу итератору TOP.
Теперь давайте запустим запрос с Maxdop 2, чтобы ограничить запрос и включить фактический план выполнения:
1 2 3 4 5 6 7 | Выберите Top 1 T1. Соединение Table2 T2 на t1.keycol = t2.keycol Группа по T1.searchcol Порядок по T1.searchcol Descest вариант (maxdop 2)
|
 Searchcol, Count_big (T1.SearchCol) из Table1 T1
Searchcol, Count_big (T1.SearchCol) из Table1 T1Что-то пошло не так, так как для завершения выполнения в моей системе потребовалось 1:13 минуты, так что же было не так в приведенном выше выполнении. Возможно, мы работаем с Maxdop 2. Давайте используем максимальную мощность процессора системы и проверим, насколько улучшилась производительность запросов.
1 2 3 4 5 6 7 | Выберите Top 1 T1.SearchCol, Count_BIG (T1.SearchCol) из Table1 T1 СОЕДИНЕНИЕ TABLE2 T2 ON T1.KEYCOL = T2.KEYCOL Группа T1.SearchCOL Порядок по T1.Searchcol Descest опция (maxdop 4)
|
Здесь на выполнение экзекуции ушло 3:56 минуты. Если на вашей машине более 4 процессоров, попробуйте запустить ее с максимально доступным логическим процессором. Если ваш запрос имеет тот же шаблон, то я уверен, что он будет хуже при увеличении DOP. Мы используем машину с четырьмя логическими процессорами, доступными для SQL Server.
Если на вашей машине более 4 процессоров, попробуйте запустить ее с максимально доступным логическим процессором. Если ваш запрос имеет тот же шаблон, то я уверен, что он будет хуже при увеличении DOP. Мы используем машину с четырьмя логическими процессорами, доступными для SQL Server.
Почему это время выполнения запроса становится хуже с увеличением DOP? Означает ли это, что параллелизм — это плохо?
Нисколько. Параллелизм является преимуществом SQL Server и сам по себе реализован очень хорошо. SQL Server использует горизонтальный параллелизм для каждого итератора. Каждому работнику назначается отдельная часть работы, а частичные результаты объединяются в окончательный набор результатов. Для запросов, включающих большие наборы данных, SQL Server обычно масштабируется линейно или почти линейно.
Итак, давайте вернемся назад и попробуем понять, почему запрос занял так много времени, как показано ниже:
Вы можете видеть, что количество выполнений на внутренней стороне таблицы2 вложенного цикла присоединяется к 8290, а расчетное количество выполнений равно 2,10229. Это означает, что оптимизатор запросов поставляется с этим окончательным планом выполнения с соединением с вложенным циклом, потому что он оценил, что соединение с вложенным циклом будет выполняться только около 2,10229 раз, но на самом деле он выполнил 829 раз.0 раз в моей системе. Имейте в виду, что обе таблицы имеют идеальную статистику. Тем не менее, мы видим огромную разницу в фактическом предполагаемом количестве выполнений VS.
Это означает, что оптимизатор запросов поставляется с этим окончательным планом выполнения с соединением с вложенным циклом, потому что он оценил, что соединение с вложенным циклом будет выполняться только около 2,10229 раз, но на самом деле он выполнил 829 раз.0 раз в моей системе. Имейте в виду, что обе таблицы имеют идеальную статистику. Тем не менее, мы видим огромную разницу в фактическом предполагаемом количестве выполнений VS.
Итак, наконец, выясняется, что соединение вложенных циклов является основным виновником низкой производительности запроса.
Как указано выше, TOP, SET ROWCOUNT, Fast N и IF EXISTS включают цель строки, и это изменяет модель оптимизации для создания плана запроса только для указанных строк в некоторых конкретных случаях. После включения цели строки запрос может занять много времени. бежать. Корпорация Майкрософт знает об этой проблеме, поэтому существует флаг TRACE FLAG 4138 для отключения цели строки. Давайте запустим приведенный выше запрос с этим флагом трассировки и посмотрим фактический план выполнения.
1 2 3 4 5 6 7 | Выберите Top 1 T1.SearchCol, Count_BIG (T1.SearchCol) из Table1 T1 СОЕДИНЕНИЕ TABLE2 T2 ON T1.KEYCOL = T2.KEYCOL Группа T1.SearchCOL Порядок по T1.Searchcol Descest опция (QueryTraceON 4138)
|
Он использует те же шаги, что и мы ожидали в самом первом предположении:
Получить оба входа
Шаг 1: соедините два входа
Шаг 2: Сгруппируйте результат вывода в столбце поиска
Шаг 3: упорядочить по убыванию
Шаг 4: попасть в ТОП 1
Подробнее:
Оптимизатор запросов снова выбирает план параллельного выполнения, так как в запросе не указан предикат.
Вот последовательность операций
• Вся таблица2 представляет собой входные данные для сопоставления хеша,
• Затем строки распределяются по схеме на основе запроса всем доступным потокам поставщиком параллельных страниц,
• Затем обменный итератор (хеш-итератор, подробности об итераторе обмена хэшей мы сообщим позже),
• Затем применяется совпадение хэшей (хеш-соединения распараллеливаются и масштабируются лучше, чем любой другой тип физического соединения, и отлично подходят для максимизации пропускной способности в хранилищах данных) в качестве типа физического соединения, поскольку хэш-соединение является блокирующим итератором для входных данных сборки, и это необходимо. дополнительная память для построения хеш-таблицы в памяти.
дополнительная память для построения хеш-таблицы в памяти.
Обратите внимание, что это может попасть в базу данных tempdb, если во время выполнения недостаточно памяти для хэш-соединения. Один совет, который мы должны помнить при работе с параллельным хеш-соединением, заключается в том, что память делится между потоками поровну, поэтому хеш-соединение может рассыпаться, даже если для хеш-соединения рассчитано достаточно памяти, но строки по какой-либо причине перекошены между потоками.
Однако в приведенном выше примере это не так, поскольку строки равномерно распределяются между потоками, а хеш-соединение полностью выполняется в памяти, как показано в плане выполнения, итератор глобального потока, используемый для агрегирования строк (поскольку перед объединением двух хэш-таблиц применяется раздел, который является детерминированной функцией, которая гарантирует, что значения не перекрываются между потоками), а расчетная стоимость, рассчитанная для этой версии плана выполнения, составляет 22,59. 83 единицы, выделение памяти для этого запроса в моей системе составляет 83,328 МБ, и он выполнялся всего 583 мс. Таким образом, это было значительное улучшение без какого-либо индекса.
83 единицы, выделение памяти для этого запроса в моей системе составляет 83,328 МБ, и он выполнялся всего 583 мс. Таким образом, это было значительное улучшение без какого-либо индекса.
Давайте вернемся к первому запросу, который выбирает соединение с вложенным циклом, и попробуем углубиться и понять план выполнения.
Обе таблицы, используемые в запросе, идентичны и представляют один и тот же набор данных, так почему же это заняло столько времени и после увеличения параметра maxdop и почему это хуже?
На этот раз мы будем использовать DMV sys.dm_os_waiting_tasks для получения более подробной информации. Мы запустим нашу очередь, а в другом сеансе запустим dmv и попытаемся интерпретировать его результат.
1 2 3 4 5 6 |
Выберите TOP 1 T1.SearchCol , COUNT_BIG(T1.SearchCol) из Table1 T1 присоедините Table2 T2 к T1.Keycol = T2. Группировка по T1.SearchCol порядок по T1.SearchCol desc
|
 Keycol
Keycol DMV показывает идентификатор контекста выполнения от 5 до 8, заблокированный в ожидании CXPACKET с идентификатором контекста выполнения 1, и идентификатор контекста выполнения 0, заблокированный в ожидании ожидания CXPACKET контекстом выполнения 8. Нулевой контекст выполнения — это координирующий поток, который выполняет последовательную часть плана выполнения. к самому левому оператору Gather Streams. CXPACKET (пакет обмена классами) означает, что поток вовлечен в ожидание, связанное с параллелизмом. Вы можете найти более подробную информацию в столбце resource_description для идентификатора контекста выполнения с 5 по 8, в нем говорится, что идентификатор узла 3 ожидает получения строк, просмотрев план выполнения, подтвердите, что идентификатор узла 3 является итератором обмена (хэш-раздел).
Итак, теперь давайте углубимся в итератор обмена:
Итератор Exchange уникален во многих отношениях, поскольку он сильно отличается от других итераторов. На самом деле это два итератора: производитель и потребитель. Производитель считывает входные строки из своей ветки и отправляет данные на сторону потребителя итератора обмена, в то время как большинство итераторов следуют модели, управляемой спросом. Поток данных между производителем обмена и итератором-потребителем следует методу на основе push из соображений эффективности. Он заполняет пакет строками (поэтому итераторы параллелизма всегда требовали дополнительной памяти) и передает его стороне потребителя. Сторона потребителя получает пакеты, удаляет строки из этих пакетов и возвращает строки своему родительскому итератору на основе модели конвейера, управляемой спросом. Здесь необходимо понимать одну важную деталь: пакет строк у производителя передается только тогда, когда пакет заполнен или в дочернем итераторе заканчиваются данные.
На самом деле это два итератора: производитель и потребитель. Производитель считывает входные строки из своей ветки и отправляет данные на сторону потребителя итератора обмена, в то время как большинство итераторов следуют модели, управляемой спросом. Поток данных между производителем обмена и итератором-потребителем следует методу на основе push из соображений эффективности. Он заполняет пакет строками (поэтому итераторы параллелизма всегда требовали дополнительной памяти) и передает его стороне потребителя. Сторона потребителя получает пакеты, удаляет строки из этих пакетов и возвращает строки своему родительскому итератору на основе модели конвейера, управляемой спросом. Здесь необходимо понимать одну важную деталь: пакет строк у производителя передается только тогда, когда пакет заполнен или в дочернем итераторе заканчиваются данные.
Теперь снова посмотрите на план выполнения, а теперь более конкретно на узел 3, как указано выше в sys.dm_os_waiting_tasks dmv. Узел с идентификатором 3 в приведенном выше плане выполнения является итератором параллелизма (обмена). Итератор параллелизма (обмена) с типом хеш-раздела направляет входящие строки во все доступные потоки, используя хэш-функцию (детерминированную) в столбце раздела. Чтобы строки не смешивались с другими потоками, в нашем столбце раздела запроса есть столбец searchcol.
Узел с идентификатором 3 в приведенном выше плане выполнения является итератором параллелизма (обмена). Итератор параллелизма (обмена) с типом хеш-раздела направляет входящие строки во все доступные потоки, используя хэш-функцию (детерминированную) в столбце раздела. Чтобы строки не смешивались с другими потоками, в нашем столбце раздела запроса есть столбец searchcol.
От дочернего итератора (соединение вложенного цикла) итератор параллелизма получает 8484 строки, но передает только 45 строк родительскому итератору (агрегированному потоком) по причине, указанной выше. Сторона производителя итератора обмена отправляет строки потребителю только в пакете, когда либо пакет заполнен, либо у дочернего итератора заканчиваются данные, поэтому сторона производителя итератора параллелизма ждала соединения вложенного цикла, чтобы заполнить пакет данных. Когда пакет данных заполнен строками, затем он отправляется на сторону потребителя итератора параллелизма, сторона потребителя обмена получает пакет(ы) данных и удаляет строки из пакета(ов), а затем отправляет его родительскому итератору (агрегированный поток) на основе спроса.
Таким образом, если бы мы каким-то образом смогли уменьшить размер пакета (что невозможно) на стороне производителя итератора обмена или увеличить размер данных в столбце searchcol, тогда сторона производителя отправила бы пакет стороне потребителя раньше. Здесь мы проведем небольшой тест для раннего заполнения производителя обмена, изменив тип данных во время выполнения на максимальную емкость числового типа данных на строку, чтобы пакет обмена мог заполниться раньше и отправить пакет раньше.
1 2 3 4 5 6 7 |
Выберите TOP 1 SearchCol = convert (decimal(38,0),T1.SearchCol) , Count= COUNT_BIG(T1.SearchCol) из Table1 T1 присоедините Table2 T2 к T1.Keycol = T2.Keycol5 by convert (decimal(38,0),T1.SearchCol)порядок by convert (decimal(38,0),T1.SearchCol) desc option (циклическое соединение)
|
Форма плана выполнения идентична нашему первому запросу соединения с параллельным вложенным циклом. Существует только один дополнительный скалярный итератор вычислений после итератора сортировки, у скаляра вычислений есть задача преобразовать целочисленный столбец searchcol в десятичный, а новое значение помечено как [Expr1002].
Существует только один дополнительный скалярный итератор вычислений после итератора сортировки, у скаляра вычислений есть задача преобразовать целочисленный столбец searchcol в десятичный, а новое значение помечено как [Expr1002].
Теперь обратите внимание, что тип раздела итератора Exchange (параллелизм) также является типом Hash, а столбец раздела — [Expr1002]. Фактическое количество строк, подаваемых на итератор обмена, составляет 3614, тогда как в последнем запросе фактическое количество строк было 8484. Это произошло потому, что теперь сторона производителя обмена может отправить пакет данных на сторону потребителя обмена раньше, потому что строка теперь размер увеличен. Следовательно, пакет данных заполняется несколькими строками и выталкивает раннее сравнение с последним планом выполнения. Этот запрос выполнялся в моей системе за 1:40 минуты.
Как уже говорилось, для проблемы, специфичной для вышеизложенного, с этим набором данных соединение с вложенным циклом было бы лучшей стратегией. Нам нужно исключить итератор обмена (параллелизм) из плана запроса, поэтому мы снова запустим запрос с maxdop 1, чтобы заставить SQL Server выбрать последовательную версию, а не параллельную версию выполнения по умолчанию.
Нам нужно исключить итератор обмена (параллелизм) из плана запроса, поэтому мы снова запустим запрос с maxdop 1, чтобы заставить SQL Server выбрать последовательную версию, а не параллельную версию выполнения по умолчанию.
1 2 3 4 5 6 |
Выбрать первую первую ot.SearchCol , COUNT_BIG(ot.SearchCol) из Table1 или присоединиться к Table2 in1 по ot.Keycol =in1.Keycol максдоп 1)
|
Если вы выполняете этот запрос на SQL Server 2012/2016, вы можете увидеть, что сортировка передается в базу данных tempdb, как сообщается в моей системе. В нем говорится: «Оператор использовал tempdb для сброса данных во время выполнения с уровнем сброса 1 и потоками 1, Sort записал 766 страниц и прочитал 766 страниц из tempdb с предоставленной памятью 22552 КБ и используемой памятью 22552 КБ». Это странно, так как предполагаемое количество строк и средний размер строки точны, а в системе достаточно памяти, но она все равно переливается в базу данных tempdb.
На самом деле это ошибка в SQL Server, которая появляется при определенных условиях и исправляется в последующих обновлениях. Чтобы включить это исправление, необходимо использовать флаг трассировки 7470, однако этот флаг трассировки не следует включать на уровне сервера, так как это увеличивает требования к памяти для запросов сортировки и может повлиять на доступность памяти для параллельных запросов.
Кроме того, как и ожидалось, план идентичен соединению с параллельным вложенным циклом. Это идеально выглядящая форма плана, поскольку внутренняя сторона соединения вложенного цикла выполняется дважды и передает 2 строки в агрегированный поток, и, что более важно, запрос выполняется за 273 миллисекунды.
Я видел, как эти параллельные вложенные циклы соединяются с целью строки, работающей в течение длительного времени и потребляющей все ресурсы ЦП. он не работает медленно, но влияет и на другие параллельные запросы, конкурируя за ресурсы. Я надеюсь, что в этой статье мы все получили представление о том, как цель строки может повлиять на производительность вашего запроса и как с этим бороться.