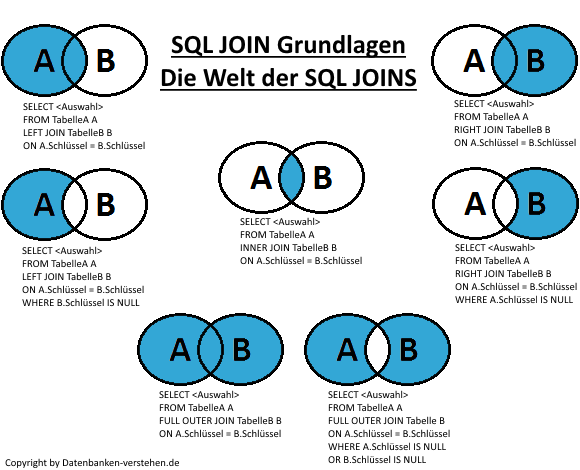
Эквивалент SQL Left Join в Python и его использование при очистке данных
Если вы работали с реляционными базами данных, вы должны знать SQL joins — у них много вариантов использования, но в в данной статье мы сосредоточимся на очистке данных.
При выполнении left, right или full outer joins вы создаете таблицы, в которых присутствуют либо все записи, либо только записи из определенных таблиц. Для строки, в которой нет совпадений, помещается нулевое значение. Таким образом, соединения (Join) чрезвычайно полезны для определения отсутствующих или не связанных значений.
Представьте, что у вас есть таблица users в вашей базе данных, которая содержит всех ваших пользователей. Кроме того, у вас есть несколько других таблиц, которые ссылаются на идентификаторы таблицы users, такие как posts, logins, subscriptions и т.д. Вы заинтересованы в том, чтобы выяснить, кто из пользователей может быть удален из базы данных, поскольку они не взаимодействовали с вашим сайтом осмысленно.
SELECT u.userID AS 'User ID', p.userID AS 'Post table' FROM users AS u LEFT JOIN posts AS p ON u.userID = p.userID -- as users can have multiple posts GROUP BY p.userID;
User ID Post table --------- ---------- 1 Null 2 Null 3 3 4 4 5 Null
Приведенная выше таблица показывает, что пользователи 1, 2, 5 не создали никаких сообщений. Возможно, вы захотите продолжить расследование и добавить logins и subscriptions — это нормально, но если у вас много дополнительных таблиц, к которым вы хотите присоединиться таким образом, у вас могут возникнуть некоторые проблемы с производительностью. СОВЕТ: если вы играете со скриптами SQL, никогда не делайте этого в своей рабочей базе данных, создайте сначала локальная копия.
Анализ таблиц на Python
Если у вас возникают проблемы с производительностью или вам нужны лучшие инструменты для анализа вашей базы данных, одна из идей — обратиться к python, поскольку у него прекрасная экосистема для обработки данных. Вы можете использовать, например, SQLAlchemy или функции SQL magic от Jupyter Notebook для получения записей и сохранения их в списках (или словарях).
Вы можете использовать, например, SQLAlchemy или функции SQL magic от Jupyter Notebook для получения записей и сохранения их в списках (или словарях).Чтобы продемонстрировать, как выполнить левое внешнее соединение в python, в данном случае мы не собираемся подключаться к базе данных, вместо этого создадим некоторые случайные данные и сохраним их в словаре. У нас будет таблица users со всеми возможными идентификаторами пользователей и пять других таблиц, случайным образом ссылающихся на идентификаторы:
import random
import pandas as pd
# defining range for userIDs, one to ten
r = (1, 11)
s, e = r
# creating dict to hold 'tables' and adding all possible user IDs
tables = {}
tables['users'] = list(range(*r))
# generating ten tables with random IDs from the initial defined range of userIDs
for i in range(1, 6):
table = random.sample(range(*r), random.randint(s-1, e-1))
tables[f'table{i}'] = tablePandas
Может показаться очевидным использовать pandas, поскольку это основной пакет для данных в python.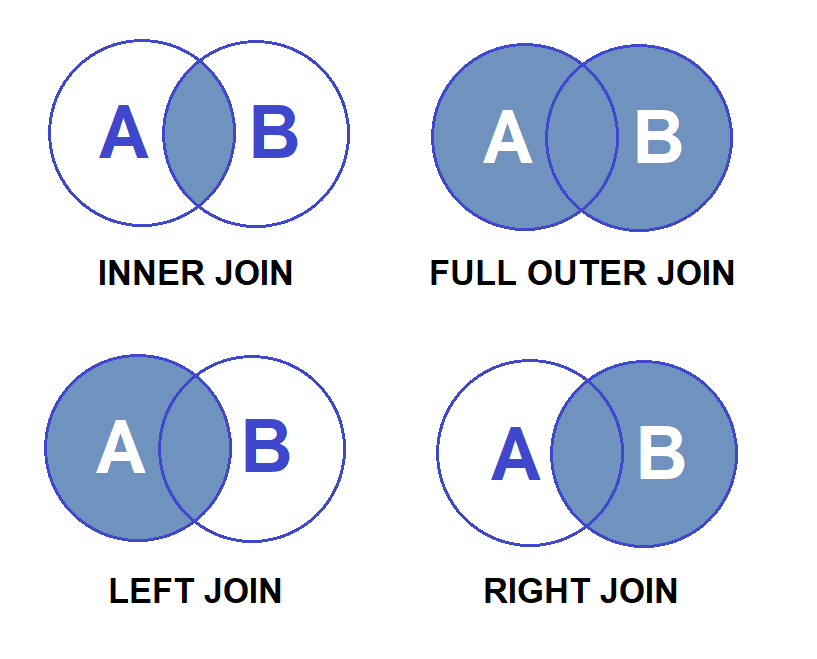 У него есть две функции для объединения таблиц,
У него есть две функции для объединения таблиц, pd.merge() и pd.join() (также pd.concat() — обратите внимание, что это работает немного по-другому), но эти функции работают лучше всего, если у вас есть по крайней мере два столбца, один из которых вы объединяете, а другой содержит ваш ценности. Но это не наш случай, поскольку у нас есть только списки идентификаторов.
Давайте посмотрим, что произойдет, если мы объединим два из этих списков, tables['users'] и tables['table1']
df_users = pd.DataFrame(tables['users']) df_table1 = pd.DataFrame(tables['table1']) pd.merge(df_users, df_table1, how='left')
OUTPUT:
0
---
0 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
9 10Что ж, результат разочаровывает, похоже, это ничего не дало. По умолчанию функция объединяет два DataFrames в единственном столбце, таким образом, мы получаем все идентификаторы пользователей и ничего больше (кроме индекса). Под капотом он действительно выполняет правильное соединение, но поскольку у нас нет дополнительных столбцов, отображать нечего. Нам нужно добавить параметр
Под капотом он действительно выполняет правильное соединение, но поскольку у нас нет дополнительных столбцов, отображать нечего. Нам нужно добавить параметр indicator=True, чтобы увидеть результат:
pd.merge(df_users, df_table1, how='left', indicator=True)
OUTPUT:
0 _merge
--------- ---------
0 1 left_only
1 2 left_only
2 3 both
3 4 both
4 5 left_only
5 6 left_only
6 7 both
7 8 left_only
8 9 left_only
9 10 bothСтолбец _merge показывает, существует ли запись в обоих списках или только в первом. Мы можем сделать результат еще лучше, установив индексы исходных фреймов данных для единственного существующего столбца и объединив их:
pd.merge(df_users.set_index(0), df_table1.set_index(0), how='left', left_index=True, right_index=True, indicator=True)
OUTPUT:
_merge
---------
0
1 left_only
2 left_only
3 both
4 both
5 left_only
6 left_only
7 both
8 left_only
9 left_only
10 bothХотя этот подход работает, он действительно неуклюж, если вы хотите объединить несколько списков (таблиц).
Set
Хотя это не объединение, с помощью наборов Python (обратите внимание, наборы не могут содержать дублирующиеся значения) может быть достигнут желаемый результат — идентификация значений, на которые нет ссылок.set_users = set(tables['users']) set_table1 = set(tables['table1']) unreferenced_ids = set_users - set_table1
Вычтя один набор из другого, вы можете найти разницу между двумя Set — элементами, присутствующими в users, но не в Set table1. Это можно повторить и с остальными таблицами.
Использование loop
Решение, которое сработало лучше всего, — это перебирать списки (таблицы) и добавлять значения None для идентификаторов без ссылок. Это возможно, потому что списки упорядочены, и мы можем перебирать все идентификаторы пользователей и проверять, существуют ли они в других таблицах.
# creating a new dict
final_tables = {}
# transfering user IDs
final_tables['users'] = tables.pop('users')
# looping through the tables
for key, value in tables.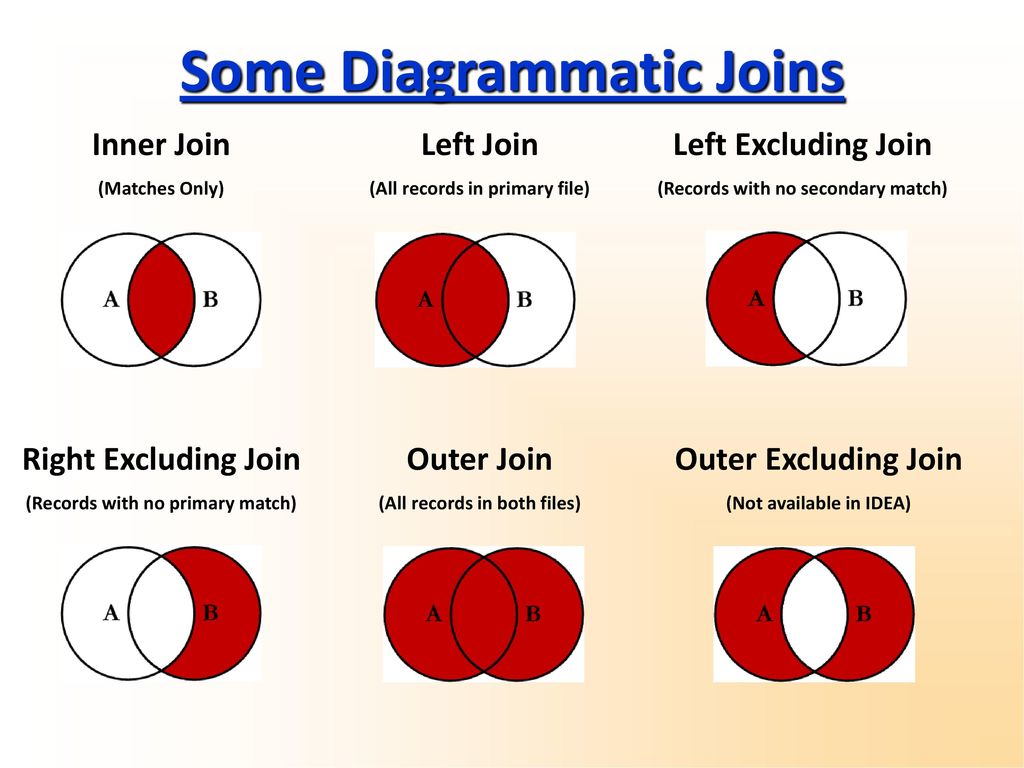
items():
# creating a new column
column = []
# checking values against all user IDs
for user in final_tables['users']:
# adding True if ID is referenced
if user in value:
column.append(True)
# adding None if ID is not referenced
else:
column.append(None)
final_tables[key] = column
# converting the new dict holding the processed tables to a dataframe
df = pd.DataFrame.from_dict(final_tables).set_index('users')OUTPUT:
table1 table2 table3 table4 table5
------ ------ ------ ------ ------
users
1 True True True True True
2 True None Nooe True None
3 None True True None True
4 None None True True True
5 True None None True None
6 True True True None True
7 None None True True True
8 True True None True None
9 True None True None None
10 None None True True None Таблица, показывающая, как идентификаторы пользователей ссылаются на другие таблицы в фрейме данных pandas.
Подводя итог, если вы привыкли выполнять left table joins в своей реляционной базе данных и хотите достичь чего-то подобного в Python, у вас есть несколько вариантов. Существует pandas, но, на удивление, выполнить объединение двух отдельных столбцов, чтобы найти значения без ссылок, непросто. В качестве альтернативы вы можете использовать наборы, чтобы получить разницу уникальных значений двух столбцов. Но, вероятно, ваш лучший вариант — использовать простые циклы, особенно если вы хотите идентифицировать несопоставимые записи в нескольких таблицах.
Spark SQL Левое внешнее соединение с примером
Spark SQL Левое внешнее соединение (левое, левое внешнее, левое_внешнее) объединение возвращает все строки из левого фрейма данных независимо от совпадения, найденного в правом фрейме данных, когда выражение соединения не совпадает, оно присваивает null для этой записи и удаляет записи справа, где совпадение не найдено.
В этой статье Spark я объясню, как выполнить левое внешнее соединение (left, leftouter, left_outer) на двух кадрах данных с помощью примера Scala.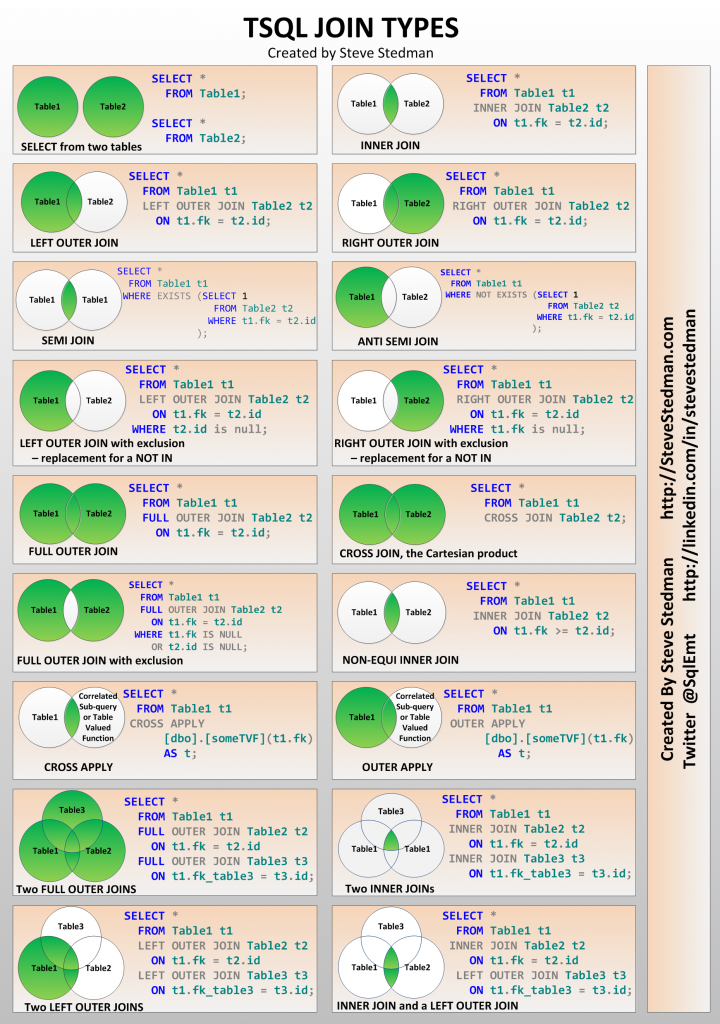
Прежде чем мы прыгнем в 9Примеры 0007 Spark Left Outer Join . Во-первых, давайте создадим кадры данных emp и dept. здесь столбец emp_id уникален для emp, а dept_id уникален для набора данных отдела, а emp_dept_id из emp имеет ссылку на dept_id в наборе данных отдела.
импортировать org.apache.spark.sql.SparkSession
val искра = SparkSession.builder
.appName("sparkbyexamples.com")
.мастер("местный")
.getOrCreate()
val emp = Seq((1,"Смит",-1,"2018","10","M",3000),
(2,"Роза",1,"2010","20","М",4000),
(3, "Уильямс", 1, "2010", "10", "М", 1000),
(4, «Джонс», 2, «2005», «10», «Ж», 2000),
(5,"Браун",2,"2010","40","",-1),
(6,"Браун",2,"2010","50","",-1)
)
val empColumns = Seq("emp_id","имя","uperior_emp_id","year_joined",
"emp_dept_id", "пол", "зарплата")
импортировать spark.sqlContext.implicits._
val empDF = emp.toDF(empColumns:_*)
empDF.show(ложь)
val отдел = Seq(("Финансы",10),
(«Маркетинг», 20),
(«Продажи», 30),
("ИТ", 40)
)
val deptColumns = Seq("dept_name", "dept_id")
val deptDF = dept.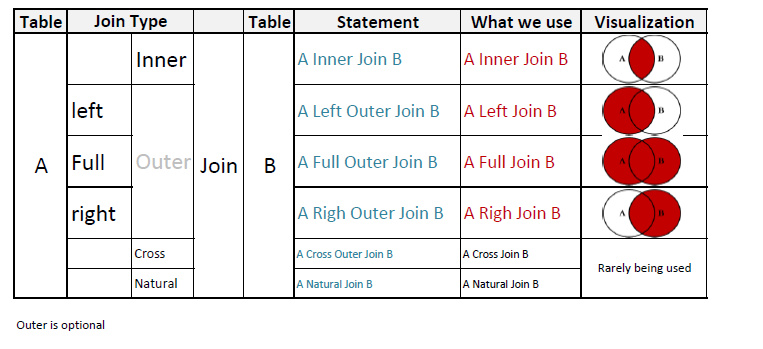 toDF("deptColumns")
deptDF.show(ложь)
toDF("deptColumns")
deptDF.show(ложь)
Выводит на консоль
Эмп набор данных +------+--------+----------------+-----------+----- ------+------+------+ |emp_id|имя |superior_emp_id|year_joined|emp_dept_id|пол|зарплата| +------+--------+----------------+-----------+----- ------+------+------+ |1 |Смит |-1 |2018 |10 |М |3000 | |2 |Роза |1 |2010 |20 |М |4000 | |3 |Уильямс|1 |2010 |10 |М |1000 | |4 |Джонс |2 |2005 |10 |F |2000 | |5 |Коричневый |2 |2010 |40 | |-1 | |6 |Коричневый |2 |2010 |50 | |-1 | +------+--------+----------------+-----------+----- ------+------+------+ Набор данных отдела +---------+-------+ |имя_отдела|идентификатор_отдела| +---------+-------+ |Финансы |10 | |Маркетинг|20 | |Продажи |30 | |ИТ |40 | +---------+-------+
Пример левого внешнего соединения Spark DataFrame
Ниже приведен пример использования левого внешнего соединения (left, leftouter, left_outer) в Spark DataFrame.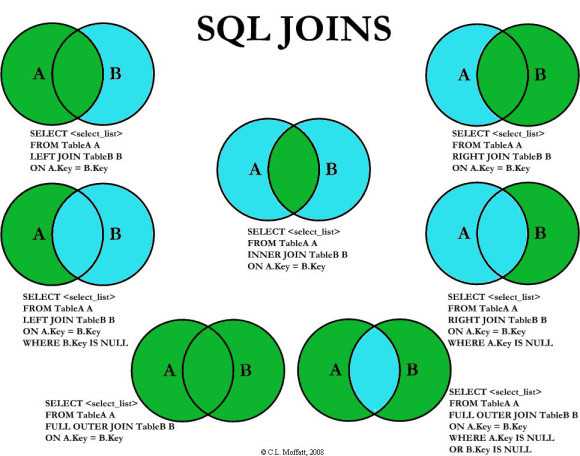
empDF.join(deptDF,empDF("emp_dept_id") === deptDF("dept_id"),"left")
.show(ложь)
empDF.join(deptDF,empDF("emp_dept_id") === deptDF("dept_id"),"leftouter")
.show(false) Из нашего набора данных emp_dept_id 6o не имеет записи в наборе данных отдела, следовательно, эта запись содержит нуль в столбцах отдела (dept_name и dept_id). и dept_id 30 из набора данных отдела удалены из результатов. Ниже приведен результат приведенного выше выражения Join.
+------+--------+----------------+-----------+----- ------+------+------+---------+-------+ |emp_id|имя |superior_emp_id|year_joined|emp_dept_id|пол|зарплата|dept_name|dept_id| +------+--------+----------------+-----------+----- ------+------+------+---------+-------+ |1 |Смит |-1 |2018 |10 |M |3000 |Финансы |10 | |2 |Роза |1 |2010 |20 |M |4000 |Маркетинг|20 | |3 |Уильямс|1 |2010 |10 |M |1000 |Финансы |10 | |4 |Джонс |2 |2005 |10 |F |2000 |Финансы |10 | |5 |Коричневый |2 |2010 |40 | |-1 |ИТ |40 | |6 |Коричневый |2 |2010 |50 | |-1 |нуль |нуль | +------+--------+----------------+-----------+----- ------+------+
Использование левого внешнего соединения Spark SQL
Давайте посмотрим, как использовать левое внешнее соединение в выражении Spark SQL .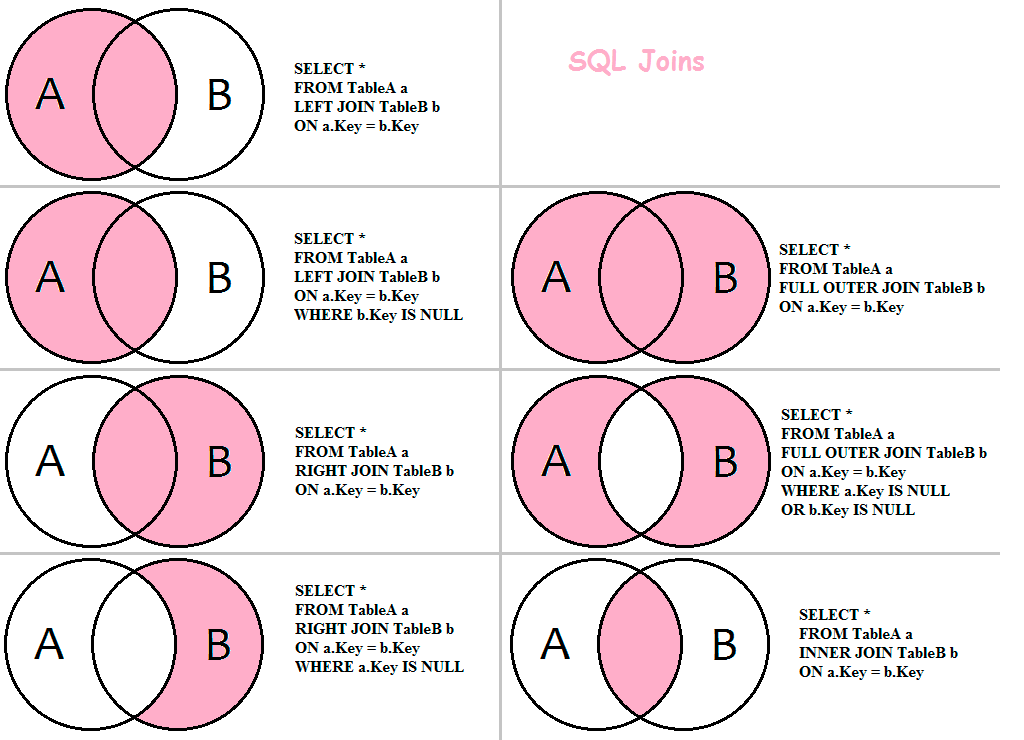 Для этого сначала давайте создадим временное представление для таблиц EMP и DEPT.
Для этого сначала давайте создадим временное представление для таблиц EMP и DEPT.
empDF.createOrReplaceTempView("EMP")
deptDF.createOrReplaceTempView("ОТДЕЛ")
val joinDF2 = spark.sql("SELECT e.* FROM EMP e LEFT OUTER JOIN DEPT d ON e.emp_dept_id == d.dept_id")
.show(усечение=ложь)
Это также возвращает тот же вывод, что и выше.
Вывод
В этой статье Spark вы узнали, что левое внешнее соединение используется для получения всех строк из левого набора данных независимо от совпадения, найденного в правом наборе данных, когда выражение соединения не совпадает.
Надеюсь, вам понравится !!
- Пример кадра данных внутреннего соединения Spark SQL
- Примеры самостоятельного соединения Spark SQL
- Примеры Spark SQL Left Anti Join
- Полное внешнее соединение Spark SQL с примером
- Spark SQL Правое внешнее соединение с примером
- Spark SQL like() Пример с использованием подстановочных знаков
- Spark SQL like() Пример с использованием подстановочных знаков
Ссылки:
- https://spark.
 apache.org/docs/latest/sql-ref-syntax-qry- select-join.html
apache.org/docs/latest/sql-ref-syntax-qry- select-join.html
0 Акции
- Более
Помощник SQL Server
Сообщения об ошибках SQL Server — сообщение 537 Сообщение об ошибке Сервер: сообщение 537, уровень 16, состояние 2, строка 1 Неверный параметр длины передан в LEFT или SUBSTRING функция. Причины Строковая функция LEFT возвращает левую часть строки символов с указанным количеством символов. Точно так же строковая функция SUBSTRING возвращает часть строки символов из заданного начального местоположения и с указанным количеством символов. |
 Синтаксис каждой строковой функции следующий:
Синтаксис каждой строковой функции следующий:ЛЕВЫЙ (, ) ПОДСТРОКА (<выражение_символа>, <начало>, <длина>)
В обеих функциях
Если значение, переданное параметру
ОБЪЯВИТЬ @FullName VARCHAR(50)
DECLARE @Length INT
SET @FullName = 'Микки Маус'
SET @Length = CHARINDEX(' ', @FullName)
SELECT LEFT(@FullName, @Length - 1) AS [Имя]
А это вывод этого скрипта.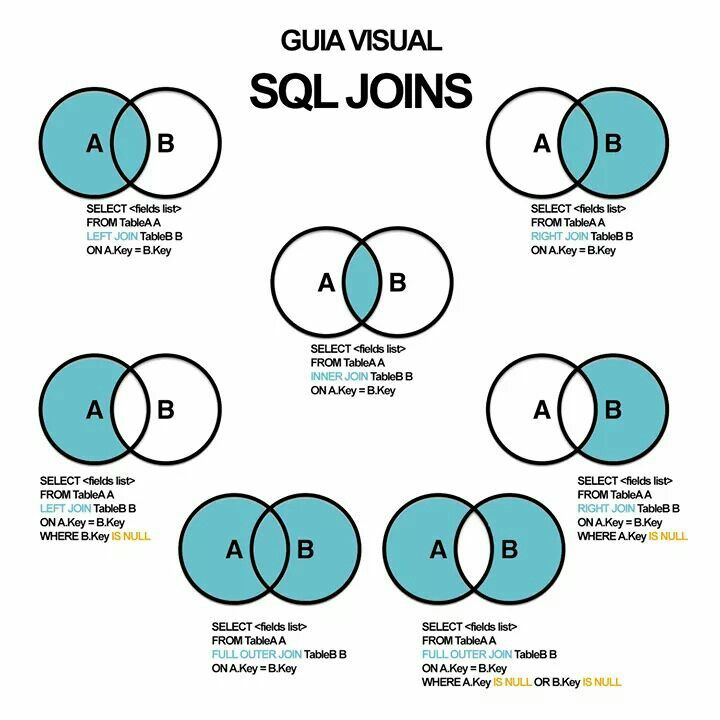
Имя ---------- Микки
При использовании этого скрипта и изменении значения анализируемой строки, в данном случае полного имени, и присвоении ему значения, в котором нет пробела, будет сгенерирована эта ошибка.
ЗАЯВИТЬ @FullName VARCHAR(50)
DECLARE @Length INT
SET @FullName = 'Гуфи'
SET @Length = CHARINDEX(' ', @FullName)
SELECT LEFT(@FullName, @Length - 1) AS [Имя]
Сообщение 537, уровень 16, состояние 2, строка 12 В функцию LEFT или SUBSTRING передан недопустимый параметр длины.
Поскольку в значении @FullName нет пробела, строковая функция CHARINDEX вернет значение 0, так как не смогла найти строку поиска (в данном случае пробел) из переданного строкового выражения. Вычитание из него 1 дает значение -1, что недопустимо в качестве длины в функции LEFT.
Изменение сценария для использования функции строки SUBSTRING вместо функции строки LEFT также приведет к тому же сообщению об ошибке:
ЗАЯВИТЬ @FullName VARCHAR(50)
DECLARE @Length INT
SET @FullName = 'Плутон'
SET @Length = CHARINDEX(' ', @FullName)
ВЫБЕРИТЕ ПОДСТРОКУ(@FullName, 1, @Length - 1) КАК [Имя]
Сообщение 537, уровень 16, состояние 2, строка 12 В функцию LEFT или SUBSTRING передан недопустимый параметр длины.