Внутреннее соединение INNER JOIN
В предыдущем уроке мы рассмотрели общую структуру многотабличного запроса:
SELECT поля_таблиц
FROM таблица_1
[INNER] | [[LEFT | RIGHT | FULL][OUTER]] JOIN таблица_2
ON условие_соединения
[INNER] | [[LEFT | RIGHT | FULL][OUTER]] JOIN таблица_n
ON условие_соединения]
Говоря о многотабличном запросе со внутренним соединением общая структура выглядит так:
SELECT поля_таблиц
FROM таблица_1
[INNER] JOIN таблица_2
ON условие_соединения
[INNER] JOIN таблица_n
ON условие_соединения]
Например, запрос может выглядеть следующим образом:
SELECT family_member, member_name FROM Payments
INNER JOIN FamilyMembers
ON Payments.family_member = FamilyMembers.member_id
| family_member | member_name |
|---|---|
| 1 | Headley Quincey |
| 2 | Flavia Quincey |
| 3 | Andie Quincey |
| 4 | Lela Quincey |
| 4 | Lela Quincey |
| 5 | Annie Quincey |
| 2 | Flavia Quincey |
| 2 | Flavia Quincey |
| 5 | Annie Quincey |
| 3 | Andie Quincey |
| 2 | Flavia Quincey |
| 1 | Headley Quincey |
| 3 | Andie Quincey |
| 3 | Andie Quincey |
Так как, по умолчанию, если не указаны какие-либо параметры, JOIN выполняется как INNER JOIN, то при внутреннем соединении INNER является опциональным.
Внутреннее соединение — соединение, при котором находятся пары записей из двух таблиц, удовлетворяющие условию соединения, тем самым образуя новую таблицу, содержащую поля из первой и второй исходных таблиц.
Для наглядности это выглядит следующим образом:
Так как в нашем условии указано равенство полей Payments.good_id и Goods.good_id, то при внутреннем соединении в итоговой выборке окажутся только записи, где в обоих таблица есть одинаковое значение good_id.
Для внутреннего соединения таблиц также можно использовать оператор WHERE. Например, вышеприведённый запрос, написанный с помощью INNER JOIN, будет выглядеть так:
SELECT family_member, member_name FROM Payments, FamilyMembers
WHERE Payments.family_member = FamilyMembers.member_id
| family_member | member_name |
|---|---|
| 1 | Headley Quincey |
| 2 | Flavia Quincey |
| 3 | Andie Quincey |
| 4 | Lela Quincey |
| 4 | Lela Quincey |
| 5 | Annie Quincey |
| 2 | Flavia Quincey |
| 2 | Flavia Quincey |
| 5 | Annie Quincey |
| 3 | Andie Quincey |
| 2 | Flavia Quincey |
| 1 | Headley Quincey |
| 3 | Andie Quincey |
| 3 | Andie Quincey |
sql — Оптимизация запроса с inner join самой первой записи
Вопрос задан
Изменён 6 месяцев назад
Просмотрен 132 раза
Всем привет, есть таблица «А» которая содержит +11тыс, и есть таблица «Б» которая содержит +400 миллионов записей, получается что таблица «Б» кол.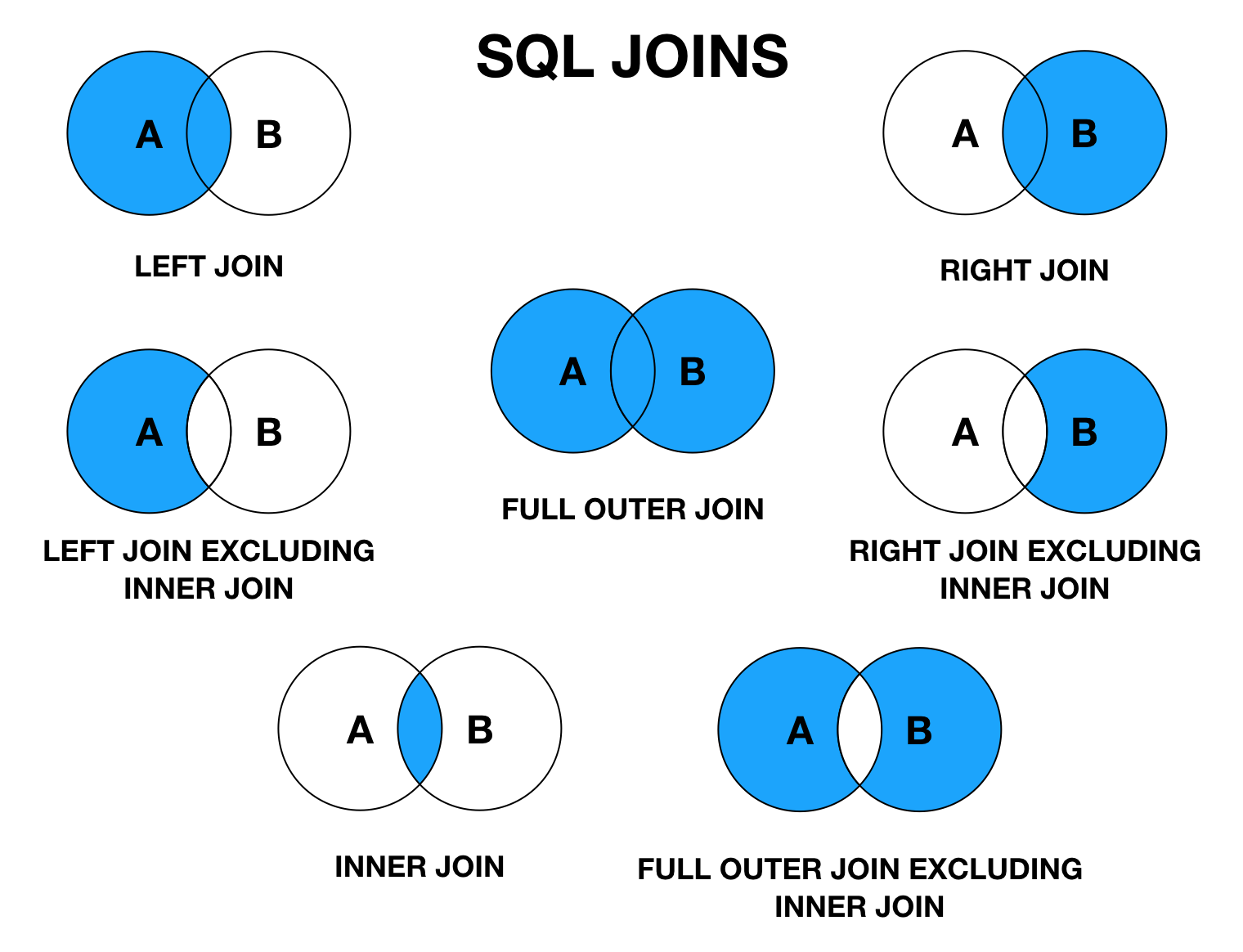 записей / кол. записей «А» = на каждый внешний ключ таблицы «А»
Задача вытащить с лимитом от 10шт до 5000тыс штук из таблицы «А» с привязкой самой 1-ой записи таблицы «Б», накидал запрос, но после 10 минут ожидания сбросил, так и не дождавшись окончания.
записей / кол. записей «А» = на каждый внешний ключ таблицы «А»
Задача вытащить с лимитом от 10шт до 5000тыс штук из таблицы «А» с привязкой самой 1-ой записи таблицы «Б», накидал запрос, но после 10 минут ожидания сбросил, так и не дождавшись окончания.
select "a".*, b.col1, b.col2, b.col3 from "a" inner join b on b.col_table_a_id = a.id and b.id = (select min(id) from b where a.id = b.col_table_a_id) limit 100 offset 0;
Есть идея создать в таблице «Б» поле first и установить туда значение в true у первой записи, но мне кажется это како-то костыль прям жесткий…
- sql
- laravel
- postgresql
А если как-то так попробовать, чтобы без подзапроса было, а просто ещё один inner join вместо этого:
select a.*, b.col1, b.col2, b.col3 from a inner join (select min(b.id) min_b_id, a.id a_id from a inner join b on b.col_table_a_id = a.id group by a.id) j on a.id = j.a_id inner join b on b.col_table_a_id = j.a_id and b.id = j.min_b_id limit 100 offset 0;
Я не настоящий сварщик, может это и хуже будет или вообще не то, но просто как вариант. 🙂
Кстати, индексы все ли нужные созданы, чтобы нормально джойнилось, и план выполнения смотрели?
1Вы стартуете от таблицы a и все тормоз из-за join. Поиграться бы, но генерить 400 лямов строк не охота..
При индексе по полям col_table_a_id, id в таблице b попробуйте:
select a.*, b.* from( select row_number()over(partition by col_table_a_id order by id)rn,* from b )b join a.id = b.col_table_a_id where b.rn=1
Неуверен что оптимизатор постгреса сделает с row_number, можно ещё попробовать с группировкой
select a.*, b.* from( select min(id)id, col_table_a_id from b group by col_table_a_id )t join a on a.id = t.col_table_a_id join b on b.id = t.id
Попробуйте взять не 400 миллионов строк, а лимит, скажем, в 1 миллион в подзапросе на таблицу b.
Сможете спокойно поэкспериментировать с разными вариантами. Не жидая каждую попытку по 10+ минут.
пс: Специально не указал limit, т.к. вы не сказали порядок сортировки.
ппс: Сделать битовую метку не такая уж и плохая идея. При условии, что из таблицы b не будут удаляться записи.
пппс: А ещё можно хранить ссылку из таблички a на первую «свою» строку в табличке b
В общем нашел быстрый способ и без особой заморочки, для этого нужно создать materialized view, запросом выбираем все первые id и заполняем таблицу, дальше в самом запросе меняем таблицу на нашу вьюху и получаем скорость выборку от 500mc до 1 минуты в моем случаи, что на много быстрее чем было, я ждал 10минут и запрос не был завершен.
select "a".*, b.col1, b.col2, b.col3 from "a" inner join b_view as b on b.col_table_a_id = a.id limit 100 offset 0;

Может что-то типа такого
SELECT
"a".*,
b.col1,
b.col2,
b.col3
FROM
"a"
INNER JOIN (
SELECT
b.col_table_a_id,
b.col1,
b.col2,
b.col3
FROM
b
WHERE
a.id = b.col_table_b_id
LIMIT
100
) bb ON bb.col_table_a_id = a.id
1
Зарегистрируйтесь или войдите
Регистрация через Google Регистрация через Facebook Регистрация через почтуОтправить без регистрации
ПочтаНеобходима, но никому не показывается
Отправить без регистрации
ПочтаНеобходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
PostgreSQL INNER JOIN
Сводка : в этом руководстве вы узнаете, как выбирать данные из нескольких таблиц с помощью предложения PostgreSQL INNER JOIN .
Введение в предложение PostgreSQL INNER JOIN
В реляционной базе данных данные обычно распределяются более чем по одной таблице. Чтобы выбрать полные данные, вам часто нужно запрашивать данные из нескольких таблиц.
В этом руководстве мы сосредоточимся на том, как объединить данные из нескольких таблиц с помощью ВНУТРЕННЕЕ СОЕДИНЕНИЕ .
Предположим, что у вас есть две таблицы A и B. В таблице A есть столбец pka, значение которого совпадает со значениями в столбце fka таблицы B.
Чтобы выбрать данные из обеих таблиц, вы используете предложение SELECT следующим образом:
SELECT пка, с1, пкб, с2 ОТ А ВНУТРЕННЕЕ СОЕДИНЕНИЕ B ON pka = fka; Язык кода: SQL (язык структурированных запросов) (sql)
Для соединения таблицы A с таблицей B выполните следующие действия:
- Сначала укажите столбцы из обеих таблиц, данные которых вы хотите выбрать, в предложении
SELECT.
- Во-вторых, укажите основную таблицу, т. е. таблицу
A, в предложенииFROM. - В-третьих, укажите вторую таблицу (таблица
B) в предложенииINNER JOINи укажите условие соединения после ключевого словаON.
Как работает INNER JOIN .
Для каждой строки в таблице A внутреннее соединение сравнивает значение в столбце pka со значением в столбце fka каждой строки в таблице B :
- Если эти значения равны, внутреннее соединение создает новую строку, содержащую все столбцы обеих таблиц, и добавляет ее в набор результатов.
- Если эти значения не равны, внутреннее соединение просто игнорирует их и переходит к следующей строке.
На следующей диаграмме Венна показано, как 9Пункт 0013 INNER JOIN работает.
В большинстве случаев таблицы, к которым вы хотите присоединиться, будут иметь столбцы с одинаковыми именами, например, столбец id , например customer_id .
Если вы ссылаетесь на столбцы с одинаковыми именами из разных таблиц в запросе, вы получите сообщение об ошибке. Чтобы избежать ошибки, вам необходимо полностью определить эти столбцы, используя следующий синтаксис:
имя_таблицы.имя_столбца Кодовый язык: CSS (css)
запрос более читабелен.
Примеры INNER JOIN в PostgreSQL
Давайте рассмотрим несколько примеров использования предложения INNER JOIN .
1) Использование PostgreSQL INNER JOIN для объединения двух таблиц
Давайте посмотрим на таблицы customer и payment в образце базы данных.
В этих таблицах каждый раз, когда покупатель производит платеж, в таблицу платежа вставляется новая строка.
У каждого клиента может быть ноль или много платежей. Однако каждый платеж принадлежит одному и только одному клиенту. столбец customer_id устанавливает связь между двумя таблицами.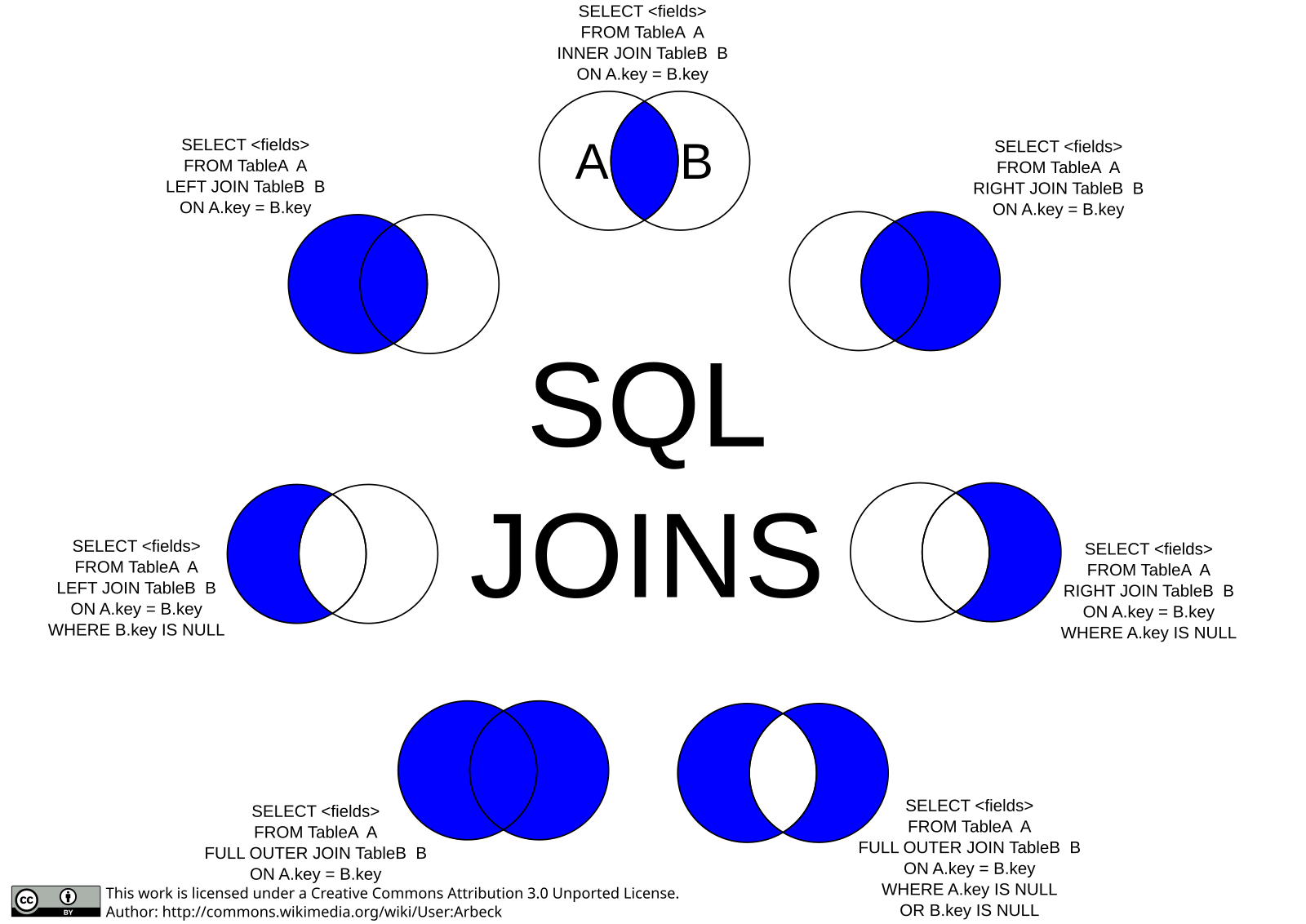
Следующая инструкция использует предложение INNER JOIN для выбора данных из обеих таблиц:
SELECT
клиент.customer_id,
имя,
фамилия,
количество,
payment_date
ОТ
клиент
ВНУТРЕННЕЕ СОЕДИНЕНИЕ оплата
ПО payment.customer_id = customer.customer_id
ЗАКАЗАТЬ ПО payment_date; Язык кода: SQL (язык структурированных запросов) (sql) Следующий запрос возвращает тот же результат. Однако он использует псевдонимы таблиц:
ВЫБОР
c.customer_id,
имя,
фамилия,
электронная почта,
количество,
payment_date
ОТ
клиент с
ВНУТРЕННЕЕ СОЕДИНЕНИЕ оплата p
ВКЛ p.customer_id = c.customer_id
ГДЕ
c.customer_id = 2; Язык кода: SQL (язык структурированных запросов) (sql) Поскольку обе таблицы имеют один и тот же столбец customer_id , вы можете использовать синтаксис USING :
SELECT Пользовательский ИД, имя, фамилия, количество, payment_date ОТ клиент INNER JOIN оплата с использованием (customer_id) ЗАКАЗАТЬ ПО payment_date; ..
- Каждый сотрудник обрабатывает ноль или много платежей. И каждый платеж обрабатывается одним и только одним сотрудником.
- Каждый клиент сделал ноль или много платежей. Каждый платеж производится одним клиентом.
Чтобы соединить три таблицы, вы помещаете второе предложение
INNER JOINпосле первого предложенияINNER JOINв виде следующего запроса:SELECT c.customer_id, c.first_name имя_клиента, c.last_name клиент_last_name, s.first_name staff_first_name, s.last_name staff_last_name, количество, payment_date ОТ клиент с ВНУТРЕННЕЕ СОЕДИНЕНИЕ оплата p ВКЛ p.customer_id = c.customer_id ВНУТРЕННЕЕ СОЕДИНЕНИЕ ВКЛ p.staff_id = s.staff_id ЗАКАЗАТЬ ПО payment_date; Язык кода: SQL (язык структурированных запросов) (sql)Для объединения более трех таблиц применяется тот же метод.
Из этого руководства вы узнали, как выбирать данные из нескольких таблиц с помощью предложения PostgreSQL
INNER JOIN.Было ли это руководство полезным?
Объяснение вложенных соединений
Объяснение вложенных соединений 26 мая 2022 г. by Robert GravelleКогда вы думали, что знаете все типы соединений, вот и еще один! Возможно, вы слышали о вложенных соединениях или даже о планах запросов с вложенными циклами и интересовались, что они из себя представляют. Ну, не удивляйтесь больше. Сегодняшний блог раскроет тайну раз и навсегда!
В мире реляционных баз данных одно и то же может называться по-разному. Соединения не являются исключением из этого правила. На самом деле, когда дело доходит до вложенных соединений, мнения специалистов по базам данных расходятся. Некоторые говорят, что такой вещи не существует; другие более прагматичны и признают, что это просто альтернативный термин для объединения нескольких таблиц.
По всей вероятности, этот термин возник при упоминании планов запросов с вложенным циклом. Они часто используются обработчиком запросов для ответа на соединения.
В самом грубом виде вложенный цикл выглядит примерно так:
для всех строк во внешней таблице для всех строк во внутренней таблице если внешняя_строка и внутренняя строка удовлетворяют условию соединения испускать строки следующий внутренний следующий внешнийЭто самый простой, но и самый медленный тип вложенного цикла. Между тем, многотабличные соединения с вложенными циклами работают еще хуже, потому что они ужасно масштабируются по мере роста произведения количества строк во всех задействованных таблицах.
Более эффективная форма вложенного цикла — вложенный цикл по индексу:
для всех строк, которые проходят фильтр из внешней таблицы использовать квалификатор соединения из строки внешней таблицы по индексу во внутренней таблице если строка найдена с помощью поиска по индексу испускать строки следующий внешнийТеперь, когда мы установили, что термин «вложенные соединения» просто относится к соединениям между более чем двумя таблицами, давайте кратко рассмотрим их синтаксис.
Обычно, когда нам нужно соединить несколько таблиц и/или представлений, мы перечисляем их один за другим, используя этот общий формат:
ИЗ Таблицы1 [тип соединения] JOIN Table2 Состояние включения2 [тип соединения] JOIN Table3 Состояние включения3Но это не единственный способ. Официальный стандарт синтаксиса ANSI для SQL предлагает другой допустимый способ написания вышеуказанного соединения:
. ИЗ Таблицы1 [тип соединения] JOIN Table2 [тип соединения] JOIN Table3 Состояние включения3 Состояние включения2Чтобы сделать приведенный выше стиль соединения более понятным для человека, мы можем добавить круглые скобки и отступ, чтобы сделать смысл более понятным:
ИЗ Таблицы1 [ тип соединения ] ПРИСОЕДИНЯЙТЕСЬ ( Table2 [тип соединения] JOIN Table3 Состояние включения3 ) Состояние включения2Теперь легче увидеть, что соединение между Table2 и Table3 указывается первым и должно быть выполнено в первую очередь, перед соединением с Table1.


