Transact-SQL группировка данных GROUP BY | Info-Comp.ru
Мы с Вами рассмотрели много материала по SQL, в частности Transact-SQL, но мы не затрагивали такую, на самом деле простую тему как группировка данных GROUP BY. Поэтому сегодня мы научимся использовать оператор group by для группировки данных.
Многие начинающие программисты, когда сталкиваются с SQL, не знают о такой возможности как группировка данных с помощью оператора GROUP BY, хотя эта возможность требуется достаточно часто на практике, в связи с этим наш сегодняшний урок, как обычно с примерами, посвящен именно тому, чтобы Вам было проще и легче научиться использовать данный оператор, так как Вы с этим обязательно столкнетесь. Если Вам интересна тема SQL, то мы, как я уже сказал ранее, не раз затрагивали ее, например, в статьях Язык SQL – объединение JOIN или Объединение Union и union all , поэтому можете ознакомиться и с этим материалом.
И для вступления небольшая теория.
Содержание
- Что такое оператор GROUP BY
- Примеры использования оператора GROUP BY
- Группируем данные с помощью запроса group by
Что такое оператор GROUP BY
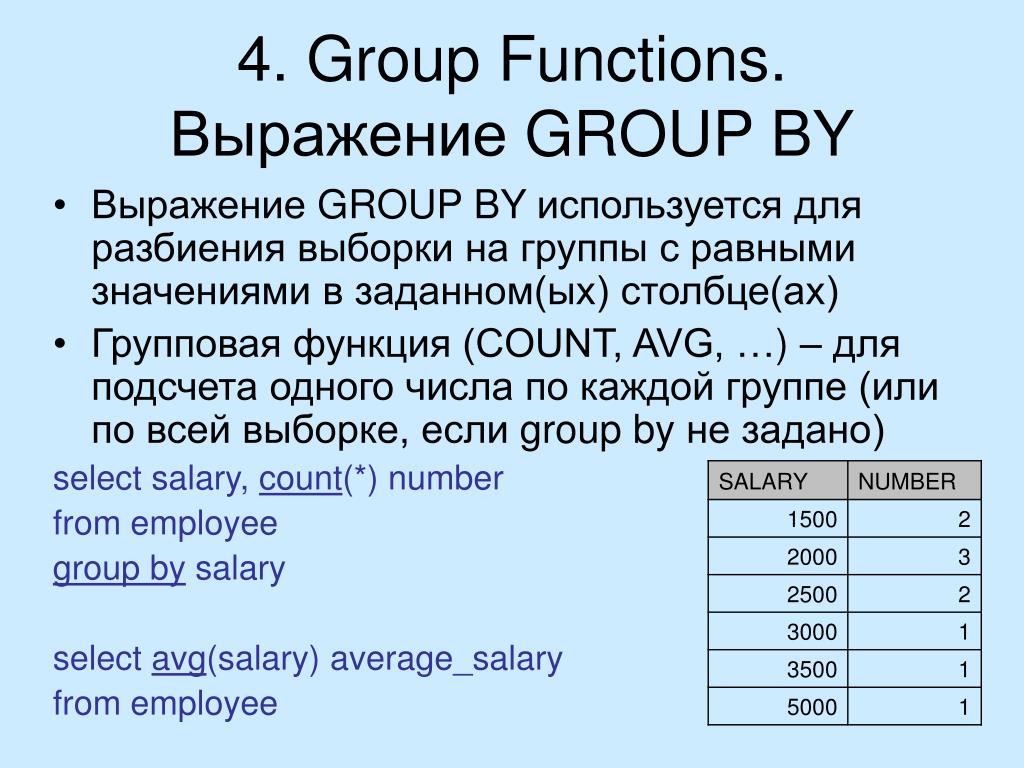
GROUP BY – это оператор (или конструкция, кому как удобней) SQL для группировки данных по полю, при использовании в запросе агрегатных функций, таких как sum, max, min, count и других.
Как Вы знаете, агрегатные функции работают с набором значений, например sum суммирует все значения. А вот допустим, Вам необходимо просуммировать по какому-то условию или сразу по нескольким условиям, именно для этого нам нужен оператор group by, чтобы сгруппировать все данные по полям с выводом результатов агрегатных функций.
Как мне кажется, наглядней будет это все разобрать на примерах, поэтому давайте перейдем к примерам.
Примечание! Все примеры будем писать в Management Studio SQL сервера 2008.
Примеры использования оператора GROUP BY
И для начала давайте создадим и заполним тестовую таблицу с данными, которой мы будет посылать наши запросы select с использованием группировки group by. Таблица и данные конечно выдуманные, чисто для примера.
Таблица и данные конечно выдуманные, чисто для примера.
Создаем таблицу
CREATE TABLE [dbo].[test_table](
[id] [int] NULL,
[name] [varchar](50) NULL,
[summa] [money] NULL,
[priz] [int] NULL
) ON [PRIMARY]
GO
Я ее заполнил следующими данными:
Где,
- Id –идентификатор записи;
- Name – фамилия сотрудника;
- Summa- денежные средства;
- Priz – признак денежных средств (допустим 1- Оклад; 2-Премия).
Группируем данные с помощью запроса group by
И в самом начале давайте разберем синтаксис group by, т.е. где писать данную конструкцию:
Синтаксис:
Select агрегатные функции
From источник
Where Условия отбора
Group by поля группировки
Having Условия по агрегатным функциям
Order by поля сортировки
Теперь если нам необходимо просуммировать все денежные средства того или иного сотрудника без использования группировки мы пошлем вот такой запрос:
SELECT SUM(summa)as summa FROM test_table WHERE name='Иванов'
А если нужно просуммировать другого сотрудника, то мы просто меняем условие. Согласитесь, если таких сотрудников много, зачем суммировать каждого, да и это как-то не наглядно, поэтому нам на помощь приходит оператор group by. Пишем запрос:
Согласитесь, если таких сотрудников много, зачем суммировать каждого, да и это как-то не наглядно, поэтому нам на помощь приходит оператор group by. Пишем запрос:
SELECT SUM(summa)as summa, name FROM test_table GROUP BY name
Как Вы заметили, мы не пишем никаких условий, и у нас отображаются сразу все сотрудники с просуммированным количеством денежных средств, что более наглядно.
Примечание! Сразу отмечу то, что, сколько полей мы пишем в запросе (т.е. поля группировки), помимо агрегатных функций, столько же полей мы пишем в конструкции group by. В нашем примере мы выводим одно поле, поэтому в group by мы указали только одно поле (name), если бы мы выводили несколько полей, то их все пришлось бы указывать в конструкции group by (в последующих примерах Вы это увидите).
Также можно использовать и другие функции, например, подсчитать сколько раз поступали денежные средства тому или иному сотруднику с общей суммой поступивших средств.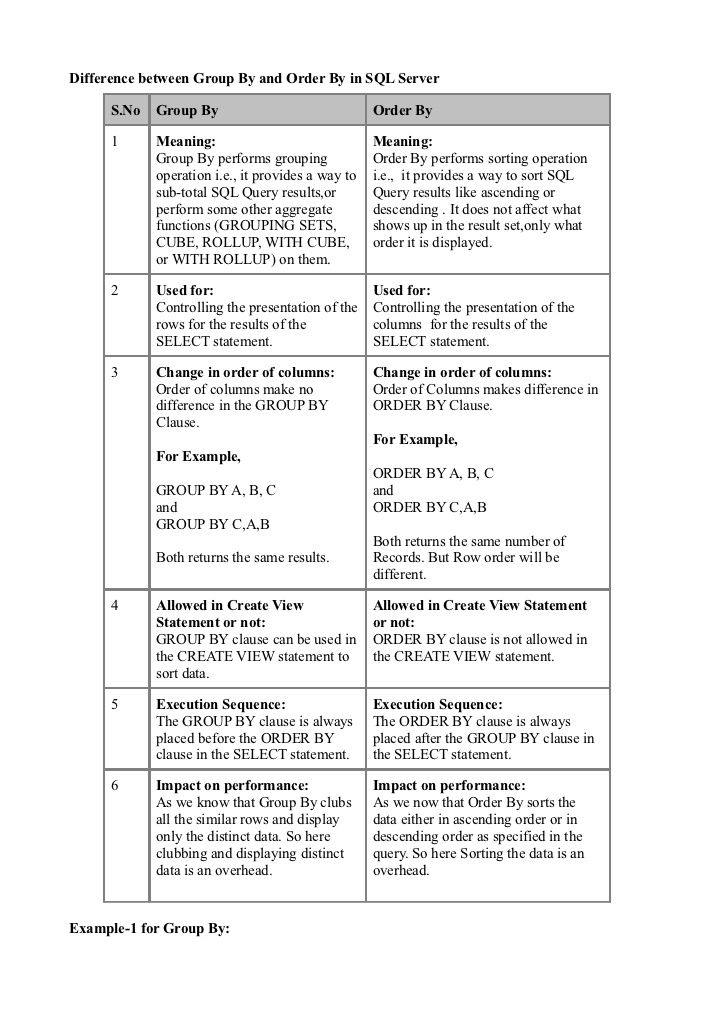 Для этого мы кроме функции sum будем еще использовать функцию count.
Для этого мы кроме функции sum будем еще использовать функцию count.
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник]
FROM test_table
GROUP BY name
Но допустим для начальства этого недостаточно, они еще просят, просуммировать также, но еще с группировкой по признаку, т.е. что это за денежные средства (оклад или премия), для этого мы просто добавляем в группировку еще одно поле, и для лучшего восприятия добавим сортировку по сотруднику, и получится следующее:
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник] ,
Priz [Источник]
FROM test_table
GROUP BY name, priz
ORDER BY name
Теперь у нас все отображается, т.е. сколько денег поступило сотруднику, сколько раз, а также из какого источника.
А сейчас для закрепления давайте напишем еще более сложный запрос с группировкой, но еще добавим названия этого источника, так как согласитесь по идентификаторам признака не понятно из какого источника поступили средства. Для этого мы используем конструкцию case.
SELECT SUM(summa) AS [Всего денежных средств],
COUNT(*) AS [Количество поступлений],
Name [Сотрудник],
CASE WHEN priz = 1 then 'Оклад'
WHEN priz = 2 then 'Премия'
ELSE 'Без источника'
END AS [Источник]
FROM test_table
GROUP BY name, priz
ORDER BY name
Вот теперь все достаточно наглядно и не так уж сложно, даже для начинающих.
Также давайте затронем условия по итоговым результатам агрегатных функций (having). Другими словами, мы добавляем условие не по отбору самих строк, а уже на итоговое значение функций, в нашем случае это sum или count.
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник],
CASE WHEN priz = 1 then 'Оклад'
WHEN priz = 2 then 'Премия'
ELSE 'Без источника'
END AS [Источник]
FROM test_table
GROUP BY name, priz --группируем
HAVING SUM(summa) > 200 --отбираем
ORDER BY name -- сортируем
Теперь у нас вывелись все значения sum(summa), которые больше 200, все просто.
Заметка! Для профессионального изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL.
Надеюсь, после сегодняшнего урока Вам стало понятно, как и зачем использовать конструкцию group by. Удачи! А SQL мы продолжим изучать в следующих статьях.
Удачи! А SQL мы продолжим изучать в следующих статьях.
SQL ошибка column must appear in the GROUP BY clause
SQL ошибка column must appear in the GROUP BY clause1. Введение
1.1 Синтаксис SQL запроса
1.2 Получение данных из таблицы
1.3 Вызов функции
1.4 Конкатенация строк
1.5 Арифметические операции
1.6 Исключение дубликатов
2. Отсечение строк и сортировка
2.1 Выражение WHERE
2.2 Логические операторы
2.3 Порядок условий
2.4 Операции сравнения
2.5 BETWEEN
2.6 IN
2.7 Поиск по шаблону
2.8 Обработка NULL значений
2.9 Сортировка
2.10 Ограничение количества строк LIMIT
2.11 Пропуск первых строк результата
3. Соединения
3.1 Соединение двух таблиц
3.
 2 Псевдонимы таблиц
2 Псевдонимы таблиц3.3 Добавляем WHERE
3.4 Несколько условий соединения
3.5 Использование таблицы несколько раз
3.6 Типы соединения
3.7 RIGHT JOIN
3.8 FULL JOIN
3.9 Декартово произведение
3.10 Синтаксис через WHERE
4. Агрегатные функции
4.1 Агрегатные функции
4.2 NULL значения в агрегатных функциях
4.3 Количество уникальных значений
4.4 Отсутствие строк
4.5 GROUP BY
4.6 Дополнительные столбцы в списке выборки с GROUP BY
4.7 GROUP BY и WHERE
4.8 GROUP BY по нескольким выражениям
4.9 NULL значения в GROUP BY
4.10 HAVING
4.11 ROLLUP
4.12 CUBE
4.13 GROUPING SETS
5. Операции над множествами
5.1 Доступные операции над множествами
5.
 2 Из какого запроса строка?
2 Из какого запроса строка?5.3 Пересечение строк
5.4 Исключение строк
5.5 Дубликаты строк
5.6 Совпадение типов данных столбцов
5.7 Сортировка
5.8 Несколько операций
6. Подзапросы
6.1 Подзапрос одиночной строки
6.2 Коррелированный подзапрос
6.3 Подзапрос вернул более одной строки
6.4 Подзапрос не вернул строк
6.5 Попадание в список значений
6.6 Отсутствие в списке значений
6.7 NULL значения в NOT IN
6.8 Проверка существования строки
6.9 Проверка отсутствия строки
7. Строковые функции
7.1 CONCAT — конкатенация строк
7.2 Преобразование регистра букв
7.3 LENGTH — определение длины строки
7.4 Извлечение подстроки
7.5 POSITION — поиск подстроки
7.
 !)
!)8.5 Получение числа из строки
8.6 ROUND — округление числа
8.7 TRUNC — усечение числа
8.8 CEIL — следующее целое число
8.9 FLOOR — предыдущее целое число
8.10 GREATEST — определение большего числа
8.11 LEAST — определение меньшего числа
8.12 ABS — модуль числа
8.13 TO_CHAR — форматирование числа
9. Рекурсивные подзапросы
9.1 Подзапрос во фразе FROM
9.2 Введение в WITH
9.3 Несколько подзапросов в WITH
9.4 Простейший рекурсивный запрос
9.5 Рекурсивный запрос посложнее
9.6 Строим иерархию объектов
9.7 Путь до элемента
9.8 Сортировка (плохая)
9.9 Сортировка (надежная)
9.10 Форматирование иерархии
9.11 Нумерация вложенных списков
9.12 Листовые строки CONNECT_BY_ISLEAF
10.
 Оконные функции
Оконные функции10.1 Получение номера строки
10.2 Номер строки в рамках группы
10.3 Составляем рейтинг — RANK
10.4 Несколько человек на место — DENSE_RANK
10.5 Разделение на группы — NTILE
10.6 Агрегатные оконные функции
10.7 Обработка NULL значений
10.8 Нарастающий итог SUM + ORDER BY
10.9 Неуникальные значения в нарастающем итоге SUM + ORDER BY
10.10 Собираем строки через разделитель — STRING_AGG
10.11 WITHIN GROUP
- Оглавление
- Агрегатные функции
Немного усложним запрос про получение количества товаров в категории из предыдущего задания. Исходный запрос:
SELECT category_id,
count(*) as count_products
FROM product
GROUP BY category_id
Идентификаторы малоинформативны и обычно никому не интересны.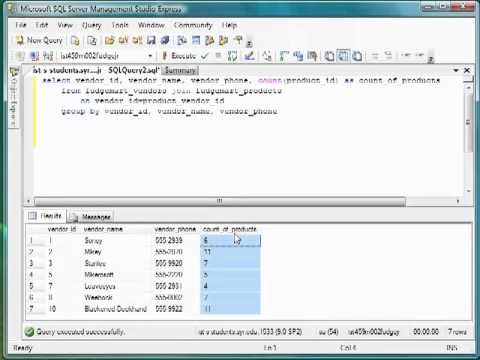 Давай в дополнение к идентификатору категории добавим еще название. Для этого нужно присоединить таблицу
Давай в дополнение к идентификатору категории добавим еще название. Для этого нужно присоединить таблицу category:
SELECT p.category_id,
c.name,
count(*) AS count_products
FROM product p
JOIN category c
ON c.category_id = p.category_id
GROUP BY p.category_id
ORDER BY p.category_id
Но в результате получим ошибку:
column "c.name" must appear in the GROUP BY clause or be used in an aggregate function
Ошибка возникла потому, что мы в списке выборки указали c.name, но не добавили это поле в GROUP BY. Исправим это:
SELECT p.category_id,
c.name,
count(*) AS count_products
FROM product p
JOIN category c
ON c.category_id = p.category_id
GROUP BY p.category_id, c.name
ORDER BY p.category_id
P.S. Ошибка бы не возникла, если вместо
GROUP BY p.category_id
написать
GROUP BY c.category_id
СУБД PostgreSQL поймет, что c.category_id является первичным ключом в таблице category и по c. можно однозначно определить  category_id
category_idc.name. Но так лучше не делать, т.к. в других версиях PostgreSQL это может не работать, как это не работает в других СУБД, например в Oracle.
Если выражение используется в списке выборки, то его нужно включить в GROUP BY, либо вызвать агрегатную функцию от этого выражения. Обратное не требуется: использованное в GROUP BY выражение не обязательно должно присутствовать в списке выборки. В нашем запросе category_id можно было не включать в список выборки SELECT, но в GROUP BY его стоит оставить (название категории может повторяться в рамках таблицы category, и если в GROUP BY оставить только c.name, то останется только одна строка с таким названием, а количество товаров будет равно количеству товаров во всех категориях с таким названием).
Практическое задание
GROUP BY с соединением таблиц
4. 5 GROUP BY
5 GROUP BY
4.7 GROUP BY и WHERE
Сделано ребятами из Сибири© 2023 LearnDB
SQL GROUP BY Multiple Columns
SQL GROUP BY по нескольким столбцам — это метод, с помощью которого мы можем получить суммарный набор результатов из базы данных с помощью SQL-запроса, который включает группировку значений столбцов, выполненную с учетом нескольких столбцов в качестве критериев группировки. . Группировка выполняется для объединения записей, которые имеют одинаковые значения критериев, определенных для группировки. Если для группировки рассматривается один столбец, то записи, содержащие одно и то же значение для этого столбца, для которого определены критерии, группируются в одну запись для набора результатов. Точно так же, когда критерии группировки определены более чем для одного столбца, все значения этих столбцов должны быть такими же, как и в других столбцах, чтобы их можно было сгруппировать в одну запись. В этой статье мы узнаем о синтаксисе, использовании и реализации предложения GROUP BY, которое включает указание нескольких столбцов в качестве критериев группировки с помощью некоторых примеров.
Синтаксис:
SELECT
столбец1, столбец2,..., столбецm, агрегатная_функция(столбец)
ИЗ
целевая_таблица
ГДЕ
условия_или_ограничения
ГРУППА1,...критерий_столбца_критериев BY;
Синтаксис предложения GROUP BY показан выше. Это необязательное предложение, используемое в предложении select всякий раз, когда нам нужно обобщить и сократить набор результатов. Его всегда следует размещать после предложений FROM и WHERE в предложении SELECT. Некоторые из терминов, используемых в приведенном выше синтаксисе, объясняются ниже –
- столбец1, столбец2,…, столбец — это имена столбцов таблицы target_table, которые необходимо получить и выбрать в наборе результатов.
- агрегатная_функция (столбец) — это агрегатные функции, определенные для столбцов целевой_таблицы, которые необходимо получить из запроса SELECT.
- target_table – Имя таблицы, из которой должен быть получен результат.
- conditions_or_constraints — если вы хотите применить определенные условия к определенным столбцам, их можно указать в необязательном предложении WHERE.
столбец критериев1 , столбец критериев2,…, столбец критериевj — это столбцы, которые будут рассматриваться как критерии для создания групп в запросе MYSQL. Может быть одно или несколько имен столбцов, к которым необходимо применить критерии. Мы можем даже упомянуть выражения в качестве критериев группировки. SQL не позволяет использовать псевдоним в качестве критерия группировки в предложении GROUP BY. Обратите внимание, что несколько критериев группировки следует указывать через запятую.
Использование GROUP BY Multiple Columns
Если критерии группировки определены более чем для одного столбца или выражения, то все записи, которые совпадают и имеют одинаковые значения для соответствующих столбцов, упомянутых в критериях группировки, группируются в одну запись. Предложение group by чаще всего используется вместе с агрегатными функциями, такими как MAX(), MIN(), COUNT(), SUM() и т. д., для получения сводных данных из таблицы или нескольких таблиц, объединенных вместе. Группировка по нескольким столбцам чаще всего используется для формирования запросов к отчетам, информационным панелям и т. д.
Группировка по нескольким столбцам чаще всего используется для формирования запросов к отчетам, информационным панелям и т. д.
Примеры
Рассмотрим таблицу с именем educba_learning, содержимое и структура которой показаны в выходных данных следующего оператора запроса select –
SELECT * FROM educba_learning;
Вывод выполнения приведенного выше оператора запроса выглядит следующим образом, показывая структуру и содержимое таблицы educba_learning –
Теперь мы сгруппируем набор результатов содержимого таблицы educba_learnning на основе столбцов сеансов и expert_name, чтобы извлеченные записи будут только одной записью для строк, имеющих одинаковые значения для сеансов и expert_name в совокупности. Наш оператор запроса будет следующим —
ВЫБЕРИТЕ
сеансов,
имя_эксперта
ИЗ
educba_learning
СГРУППИРОВАТЬ ПО сеансам,
имя_эксперта ;
Вывод приведенного выше оператора запроса в SQL, как показано ниже, содержит уникальные записи для каждого сеанса, значения столбца имени эксперта —
Обратите внимание, что при использовании критериев группировки важно получить записи по в котором определено предложение группировки. Использование приведенного выше оператора для извлечения всех записей приведет к следующей ошибке, если для режима SQL задана только полная группа —
Использование приведенного выше оператора для извлечения всех записей приведет к следующей ошибке, если для режима SQL задана только полная группа —
ВЫБЕРИТЕ
*
ИЗ
educba_learning
СГРУППИРОВАТЬ ПО сеансам,
expert_name ;
Вывод приведенного выше оператора запроса в SQL показан ниже:
Давайте воспользуемся агрегатными функциями в предложении group by с несколькими столбцами. Мы рассмотрим тот же вышеприведенный пример, в котором мы применим агрегатную функцию SUM() к столбцу сеансов, чтобы получить общее количество сеансов этого имени эксперта, для которого в таблице присутствует такое же количество сеансов. Это означает, что для эксперта с именем Payal будут получены две разные записи, поскольку в таблице educba_learning есть два разных значения количества сеансов: 750 и 9.50. Из них есть две записи с именем эксперта Payal и количеством сеансов 750, поэтому они обе будут объединены из-за оператора группировки и приведут к одной записи с общим значением счетчика сеансов как 1500.
Давайте выполним следующее оператор запроса и изучите вывод и подтвердите, приводит ли он к выводу, как описано выше –
SELECT
SUM(sessions),
expert_name
FROM
educba_learning
GROUP BY Sessions,
expert_name ;
Результат выполнения приведенного выше оператора запроса выглядит следующим образом:
Мы можем заметить, что для эксперта с именем Payal извлекаются две записи с количеством сеансов 1500 и 950 соответственно. Аналогичная работа применима и к другим экспертам и записям. Обратите внимание, что агрегатные функции используются в основном для столбцов с числовыми значениями, когда используется предложение group by.
Заключение
Мы можем сгруппировать набор результатов в SQL по нескольким значениям столбцов. Когда мы определяем критерии группировки для более чем одного столбца, все записи, имеющие одинаковое значение для столбцов, определенных в предложении group by, представляются вместе с помощью одной записи в выходных данных запроса. Все значения столбцов, определенные как критерии группировки, должны совпадать со значениями столбцов других записей, чтобы сгруппировать их в одну запись. В большинстве случаев предложение group by используется вместе с агрегатными функциями для получения суммы, среднего значения, количества, минимального или максимального значения из содержимого таблицы нескольких таблиц, объединенных выходными данными запроса.
Все значения столбцов, определенные как критерии группировки, должны совпадать со значениями столбцов других записей, чтобы сгруппировать их в одну запись. В большинстве случаев предложение group by используется вместе с агрегатными функциями для получения суммы, среднего значения, количества, минимального или максимального значения из содержимого таблицы нескольких таблиц, объединенных выходными данными запроса.
Рекомендуемые статьи
Это руководство по SQL GROUP BY Multiple Columns. Здесь мы обсуждаем введение, синтаксис и примеры с реализацией кода соответственно. Вы также можете ознакомиться со следующими статьями, чтобы узнать больше:
- Временная таблица SQL
- Разделение таблицы SQL
- Триггер SQL ПОСЛЕ ОБНОВЛЕНИЯ
- SQL Select Top
СГРУППИРОВАТЬ ПО в SQL Server
В SQL Server предложение GROUP BY используется для получения сводных данных на основе одной или нескольких групп.
Группы могут быть сформированы на одной или нескольких колонках. Например, запрос GROUP BY будет использоваться для подсчета количества сотрудников в каждом отделе или для получения общей заработной платы по отделам.
Например, запрос GROUP BY будет использоваться для подсчета количества сотрудников в каждом отделе или для получения общей заработной платы по отделам.
Вы должны использовать агрегатные функции, такие как COUNT() , MAX() , MIN() , SUM() , AVG() и т. д., в запросе SELECT.
Результат предложения GROUP BY возвращает одну строку для каждого значения столбца GROUP BY.
Синтаксис:
ВЫБЕРИТЕ столбец1, столбец2,... столбецN ИЗ имя_таблицы [ГДЕ] [ГРУППИРОВАТЬ ПО столбцу1, столбцу2...столбцуN] [ИМЕЮЩИЙ] [СОРТИРОВАТЬ ПО]
Предложение SELECT может включать столбцы, которые используются с предложением GROUP BY. Итак, чтобы включить другие столбцы в предложение SELECT, используйте агрегатные функции, такие как COUNT() , MAX() , MIN() , SUM() , AVG() с этими столбцами.
- Предложение GROUP BY используется для формирования групп записей.
- Предложение GROUP BY должно стоять после предложения WHERE, если оно присутствует, и перед предложением HAVING.
- Предложение GROUP BY может включать один или несколько столбцов для формирования одной или нескольких групп на основе этих столбцов.
- В предложение SELECT можно включать только столбцы GROUP BY. Чтобы использовать другие столбцы в предложении SELECT, используйте с ними агрегатные функции.
Для демонстрации мы будем использовать следующие таблицы Employee и Department во всех примерах.
Рассмотрим следующий запрос GROUP BY.
ВЫБЕРИТЕ DeptId, COUNT(EmpId) как «Число сотрудников» ОТ Сотрудника СГРУППИРОВАТЬ ПО DeptId; --следующий запрос вернет те же данные, что и выше ВЫБЕРИТЕ DeptId, COUNT (*) как «Количество сотрудников» ОТ Сотрудника СГРУППИРОВАТЬ ПО DeptId;
Приведенный выше запрос включает предложение GROUP BY DeptId , поэтому в предложение SELECT можно включить только DeptId . Вам нужно использовать агрегатные функции для включения других столбцов в предложение SELECT, поэтому
Вам нужно использовать агрегатные функции для включения других столбцов в предложение SELECT, поэтому COUNT(EmpId) включен, потому что мы хотим подсчитать количество сотрудников в одном и том же DeptId . «Количество сотрудников» является псевдонимом столбца COUNT(EmpId) . Запрос отобразит следующий результат.
Следующий запрос получает название отдела вместо DeptId в результате.
SELECT dept.DeptName как «Отдел», count(emp.empid) как «Число сотрудников» ОТ Сотрудник ип, отдел отдела ГДЕ emp.deptid = dept.DeptId ГРУППА по dept.DeptName
Таким же образом следующий запрос получает общую зарплату по отделам.
SELECT dept.DeptName, sum(emp.salary) as 'Общая зарплата' ОТ Сотрудник ип, отдел отдела ГДЕ emp.deptid = dept.DeptId ГРУППА по dept.DeptName
Следующий запрос вызовет ошибку, поскольку dept.