c++ — Создание автоматических массивов с неизвестной на этапе компиляции длиной
Вопрос задан
Изменён 5 лет 1 месяц назад
Просмотрен 536 раз
Почему в С++ можно создать одномерный массив с заранее не известной длиной на стеке?
int size; cin>>size; int a[size];
И двумерный тоже создается:
int size; cin>>size; int a[size][size];
Однако при попытке записать туда что-то программа падает из-за Segmentation Fault. Пытался записать массив 2048*2048.На малых размерах массива все работает. При этом компилятор(g++) ни на что не ругался. Разве размер не должен быть известен на этапе компиляции? Пытался создать динамический двумерный массив вот так
int **buffer = new int[s][s];
Однако компилятор начал ругаться:
main.
cpp:9:29: error: array size in new-expression must be constant
 cpp:9:29: error: array size in new-expression must be constant
cpp:9:29: error: array size in new-expression must be constantРазмер же памяти, которую нужно выделить известен, в чем проблема?
Собственно, вопросы:
1) Можно ли создавать автоматические одно-, много- мерные массивы, с заранее не известными размерами?
2) Если компилятор не ругался на создание автоматического массива
int a[size][size];
то почему он ругается на создание такого же массива
int **buffer = new int[s][s];
но только в куче?
P.S. как правильно создавать динамические я знаю, просто мне нужен был двумерный динамический массив в котором элементы расположены в памяти так же, как и в автоматических массивах(элементы расположены построчно).
- c++
- c
- массивы
2
Для начала — нет, массив переменного размера по стандарту создать на стеке нельзя. То, что у вас это компилируется — это расширение C++, существующее в gcc.
-pedantic -Werror.Ну и из смысла операции (выделение 2048 * 2048 * sizeof(int) = 16Mб на стеке) — должно падать по переполнению стека.
Многомерный массив int** — это массив указателей на массивы. Соответственно и выделять его нужно по частям: сначала сам массив указателей, а потом каждый из подмассивов:
int **buffer = new int*[s];
for (int i = 0; i < s; ++i)
buffer[i] = new int[s];
Если вы хотите массив типа int[][], с этим сложнее. Вы можете всё ещё создать его, но для этого все размеры, кроме первого, должны быть известны на этапе компиляции!
int (*buffer)[10] = new int[s][10];
Почему так? Это для того, чтобы компилятор мог подсчитать, по какому же смещению от начала находится элемент buffer[1][0] расположено по смещению, равному размеру строки, от начала buffer!)
Большой обзор по теме (на английском): How do I use arrays in C++?
2
Вот так
int ** i = new int[n][n];
не создаются массивы, как бы вы этого не хотели. Да и тип выражения
Да и тип выражения int[n][n] будет низведен до int*, но не int**.
int ** i = new int*[n]; for(int j = 0; j < n; ++j) i[j] = new int[n];
Судите сами: new выделяет память одним куском. Ваше же int** уже предусматривает, что будет массив указателей, каждый из которых будет указывать на некоторую новую память. И кто, по-вашему, должен этим заниматься? 🙂
Если вы хотите провести аналогию с массивом
int i[N][N];
то тут i приводится к int*, ни никак не к int**, а при обращении к элементам массива компилятор, зная во время компиляции размеры, генерирует код, который обращается к нужному месту в памяти — и это отнюдь не разыменование i[n]…
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
как создавать, формат и базовые операции с матрицами на Питоне
Python — популярный и динамический язык программирования. Он позволяет решать разные задачи по разработке ПО, при выполнении которых часто используются массивы. С их помощью вы сможете добавить однотипные данные и избежать дублирования кода.
Он позволяет решать разные задачи по разработке ПО, при выполнении которых часто используются массивы. С их помощью вы сможете добавить однотипные данные и избежать дублирования кода.
Одномерные массивы в Python представляют собой список элементов. Значения указываются внутри квадратных скобок, где перечисляются через запятую. Как правило, любой элемент можно вызвать по индексу и присвоить ему новое значение.
Пустой список:
a = []
Массив строк в Python:
Prime = ['string1', 'string2', 'string3'] Prime[1] = 'string2'; //true
Чтобы возвратить число элементов внутри списка, используют функцию len():
len(Prime) == 4; // true
Когда нужно перечислить элементы массива, применяют цикл for. В «Питоне» этот цикл перебирает элементы, а не индексы, как в Pascal:
for elem in [1, 4, 67]
Идём дальше. Создать и добавить цикл в Python можно с помощью генератора заполнения списков.
Если говорить про создание не одномерного, а двумерного массива, то он в Python создаётся путём использования вложенных генераторов, и выглядит это так:
[[0 for j in range(m)] for i in range(n)]
Как создаются матрицы в Python?
Добавление и модификация массивов или матриц (matrix) в Python осуществляется с помощью библиотеки NumPy. Вы можете создать таким образом и одномерный, и двумерный, и многомерный массив. Библиотека обладает широким набором пакетов, которые необходимы, чтобы успешно решать различные математические задачи. Она не только поддерживает создание двумерных и многомерных массивов, но обеспечивает работу однородных многомерных матриц.
Чтобы получить доступ и начать использовать функции данного пакета, его импортируют:
import numpy as np
Функция array() — один из самых простых способов, позволяющих динамически задать одно- и двумерный массив в Python. Она создаёт объект типа ndarray:
Она создаёт объект типа ndarray:
array = np.array(/* множество элементов */)
Для проверки используется функция array.type() — принимает в качестве аргумента имя массива, который был создан.
Если хотите сделать переопределение типа массива, используйте на стадии создания dtype=np.complex:
array2 = np.array([ /*элементы*/, dtype=np.complex)
Когда стоит задача задать одномерный или двумерный массив определённой длины в Python, и его значения на данном этапе неизвестны, происходит его заполнение нулями функцией zeros(). Кроме того, можно получить матрицу из единиц через функцию ones(). При этом в качестве аргументов принимают число элементов и число вложенных массивов внутри:
np.zeros(2, 2, 2)
К примеру, так в Python происходит задание двух массивов внутри, которые по длине имеют два элемента:
array([ [[0, 0]] [[0, 0]]] )
Если хотите вывести одно- либо двумерный массив на экран, вам поможет функция print(). Учтите, что если матрица слишком велика для печати, NumPy скроет центральную часть и выведет лишь крайние значения. Дабы увидеть массив полностью, используется функция set_printoptions(). При этом по умолчанию выводятся не все элементы, а происходит вывод только первой тысячи. И это значение массива указывается в качестве аргумента с ключевым словом threshold.
Учтите, что если матрица слишком велика для печати, NumPy скроет центральную часть и выведет лишь крайние значения. Дабы увидеть массив полностью, используется функция set_printoptions(). При этом по умолчанию выводятся не все элементы, а происходит вывод только первой тысячи. И это значение массива указывается в качестве аргумента с ключевым словом threshold.
Базовые операции в NumPy
Все действия, производимые над компонентами массива, оборачиваются созданием нового массива. При этом массивы и матрицы взаимодействуют в том случае, если имеют один и тот же размер:
array1 = np.array([[1, 2, 3], [1, 2, 3]]) array2 = np.array([[1, 2, 3], [1, 2, 3], [1, 2, 3]])
Если выполнить array1 + array2, компилятор скажет об ошибке, а всё потому, что размер первого matrix равен двум, а второго трём.
array1 = np.array([1, 2, 5, 7]) array2 = arange([1, 5, 1])
В данном случае array1 + array2 вернёт нам массив со следующими элементами: 2, 4, 8, 11. Здесь не возникнет ошибки, т. к. матрицы имеют одинаковые размеры. Причём вместо ручного сложения часто применяют функцию, входящую в класс ndarray sum():
Здесь не возникнет ошибки, т. к. матрицы имеют одинаковые размеры. Причём вместо ручного сложения часто применяют функцию, входящую в класс ndarray sum():
np.array(array1 + array1) == array1 + array2
В ndarray входит большая библиотека методов, необходимых для выполнения математических операций.
Форма матрицы в Python
Lenght matrix (длина матрицы) в Python определяет форму. Длину матрицы проверяют методом shape().
Массив с 2-мя либо 3-мя элементами будет иметь форму (2, 2, 3). И это состояние изменится, когда в shape() будут указаны аргументы: первый — число подмассивов, второй — размерность каждого подмассива.
Те же задачи и ту же операцию выполнит reshape(). Здесь lenght и другие параметры matrix определяются числом столбцов и строк.
Есть методы и для манипуляции формой. Допустим, при манипуляциях с двумерными или многомерными массивами можно сделать одномерный путём выстраивания внутренних значений последовательно по возрастанию. А чтобы поменять в матрице строки и столбцы местами, применяют transpose().
А чтобы поменять в матрице строки и столбцы местами, применяют transpose().
Операции со срезами matrix в Python
Часто мы работаем не с целым массивом, а с его компонентами. Эти операции выполняются с помощью метода слайс (срез). Он пришел на замену циклу for, при котором каждый элемент подвергался перебору. Метод позволяет получать копии matrix, причём манипуляции выполняются в виде [start:stop:step]. В данном случае
Допустим, имеем целочисленный массив otus = [1, 2, 3, 4]. Для копирования и вывода используем otus[:]. В итоге произойдёт вывод последовательности [1, 2, 3, 4]. Но если аргументом станет отрицательное значение, допустим, -2, произойдёт вывод уже других данных:
otus[-2]; //[4]
Возможны и другие операции. Например, если добавить ещё одно двоеточие, будет указан шаг копируемых элементов. Таким образом, otus[::2] позволит вывести матрицу [1, 3].
Например, если добавить ещё одно двоеточие, будет указан шаг копируемых элементов. Таким образом, otus[::2] позволит вывести матрицу [1, 3].
Если ввести отрицательное значение, к примеру, [::-2] отсчёт начнётся с конца, и в результате произойдёт вывод [3, 1]. Остаётся добавить, что метод среза позволяет гибко работать с матрицами и вложенными списками в Python.
Хотите узнать гораздо больше? Записывайтесь на курс «Разработчик Python»!
2D-массивы в C — проектирование встроенной системы с использованием конечного автомата UML
В этой статье мы узнаем о двумерных массивах в «C». рассмотрим баллов uint8_t[3] = {10, 20, 30}; Здесь scores[3] — это одномерный массив из 3 элементов типа uint8, один байт данных. Итак, scores[3] — это массив из трех элементов, каждый из которых имеет размер 1 байт. И баллы указывают имя массива; его тип является типом указателя. Но здесь scores — это имя массива, а 10, 20, 30 — инициализация. И мы называем это одномерным массивом, потому что вы не можете индексировать этот массив только в одном измерении; вы называете это x измерением.
Но здесь scores — это имя массива, а 10, 20, 30 — инициализация. И мы называем это одномерным массивом, потому что вы не можете индексировать этот массив только в одном измерении; вы называете это x измерением.
Здесь 10 — 0-й элемент, 20 — первый элемент, 30 — второй элемент. Если вы наберете 0 баллов, вы получите значение 10. Если вы наберете 1 балл, вы получите значение 20. Мы называем это индексированием. Индексация может быть выполнена только в одном измерении. Вот почему он называется одномерным массивом. Речь идет об одномерном массиве.
Двумерный массив:
Двумерный массив — это структура данных в C, которая используется или полезна при представлении набора данных в виде таблицы.
Таблица: Таблица имеет несколько строк и несколько столбцов.
Рассмотрим пример, показанный на рисунке 2. Здесь scores — это имя двумерного массива, [2] → указывает количество строк в таблице, а [ 3] → указывает количество столбцов таблицы. Таблица — это не что иное, как некоторое расположение данных.
С помощью поля [2] вы можете переключаться между разными строками, а с помощью поля [3] вы можете переключаться между разными столбцами. Следовательно, он называется двумерным массивом, потому что есть две точки переключения. Вы можете переключаться в направлении y или переключаться в направлении x. И двумерные массивы инициализируются так. Сначала инициализируйте первую строку, поставьте запятую и инициализируйте вторую строку. 10, 20, 30 эти значения данных первой строки должны быть заключены в фигурные скобки.
Рисунок 3. Пример 2-мерного массива
Допустим, если я пишу типа scores[0][1], то данные 0-й строки, первого столбца, я получаю 20, как показано на рисунке 3.
Рисунок 4. Пример двумерного массива
Если я делаю баллы[1][2], это означает строку 1, столбец 2. Значение, которое он предоставляет, равно 45 (рисунок 4). Вы можете сделать индексацию следующим образом.
Почему это полезно?
Рисунок 5. Маркировочный лист Испытания-1 по номерам валков
Рассмотрим этот пример: оценочный лист теста-1 вашего класса в виде номеров бросков, как показано на рис. 5. Есть четыре ученика; Номера рулонов от 0 до 3 и 4 предмета. Код предмета по математике — 0. Код по физике — 1. Код по химии — 2. Код по экономике — 3. А остальное — это оценки, выставленные учащимся.
5. Есть четыре ученика; Номера рулонов от 0 до 3 и 4 предмета. Код предмета по математике — 0. Код по физике — 1. Код по химии — 2. Код по экономике — 3. А остальное — это оценки, выставленные учащимся.
Как вы это делаете?
uint8_t marksheet_of_test[16] = {34, 56, 77, 99, 67, 34, 89 …… 21,43};
Можно сохранить 16 данных. Вот почему вы создаете один массив из 16 байт и начинаете хранить значения. Во-первых, вы сохраняете 34,56, 77, вот так, вплоть до последних чисел.
Недостатком этого метода является то, что вы хотите получить некоторые значения, например, какую оценку набрал Бросок номер 1 по химии? Теперь, как узнать, используете ли вы одномерный массив? Это возможно, но это немного сложно. Вот как вы собираетесь это вычислить. Итак, вы должны отработать это.
Вот как вы собираетесь это вычислить. Итак, вы должны отработать это.
Прежде всего, оценка, выставленная по броску номер 1, означает, что вы должны сначала получить 67. Как вы получаете 67? Вы можете прийти сюда по указанному ряду.
uint8_t mark = marksheet_of_test1[1*4+2];
Номер рулона 1, умноженный на общее количество столбцов. Вы должны умножить это. 1 умножается на общее количество столбцов 4 и затем добавляется код темы. Вы хотите химии; химия равна 2. Вы добавляете к ней 2. Затем вы достигаете точки 89, вот так.
Например, какая оценка выставляется за бросок номер 3 по физике?
Рисунок 7. Пример двумерного массива
Пример двумерного массива
Во-первых, вы должны прийти к 98. Как вы сюда попали? Строка в вопросе 3, умноженная на общее количество столбцов 4, равна 12. Это массив из 12.
Массив из 12 равен 98, а затем добавьте код темы. Код темы 1. Итак, добавляем 1. 45 (рисунок 7).
Это означает, что таблица также может быть представлена в виде одномерного массива, без проблем. Но вам придется немного потрудиться, чтобы узнать нужную координату. Для этой цели язык программирования C предоставил вам двумерную структуру данных массива.
Рисунок 8. Пример двумерного массива
В приведенном выше примере двумерный массив определяется как четыре строки и четыре столбца и инициализируются значения.
Предположим, я хочу получить отметку по химическому тесту за второй бросок. Здесь это очень просто; укажите номер строки и номер столбца. Строка номер 2 и номер столбца тоже 2, что дает мне 30. Это очень просто, если вы используете двумерный массив. Это помогло бы, если бы вы не боролись с получением этих координат.
Давайте разберемся, как двумерный массив сохраняется в памяти.
Рис. 9. Хранение двумерного массива в памяти
Память, выделенная для одномерного массива, по своей природе непрерывна. Например, посмотрите на рисунок 9. В этом массиве 3 элемента данных, и 3 байта памяти будут выделены рядом друг с другом. И здесь имя массива содержит адрес первого элемента массива.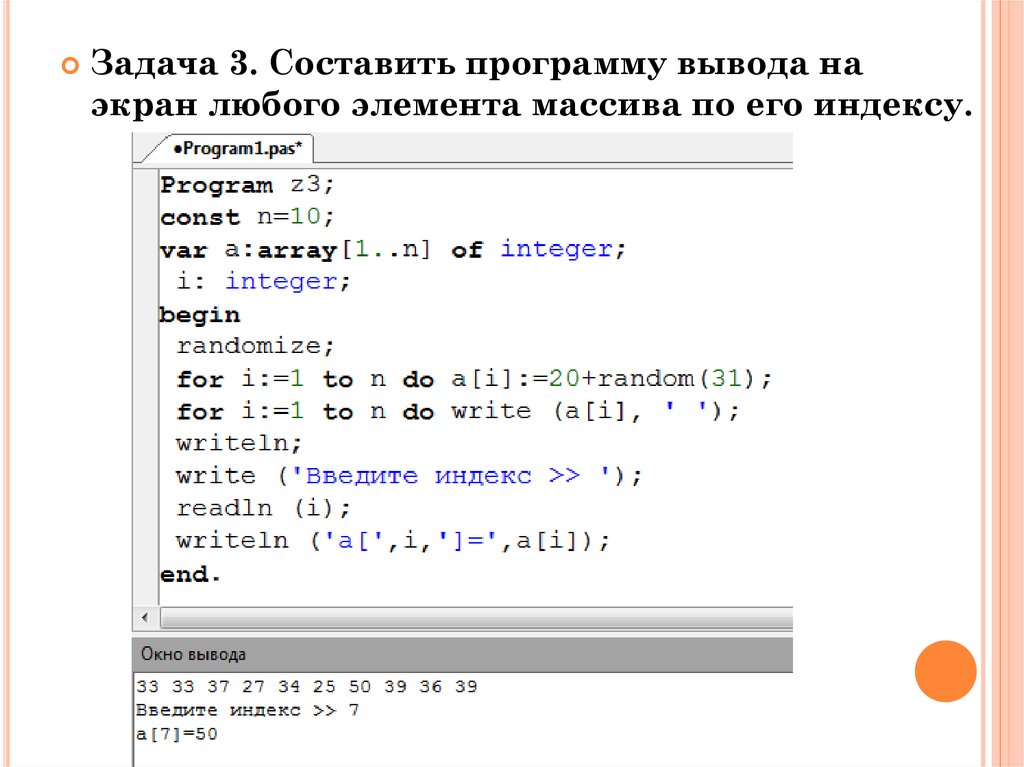
Выделение памяти точно такое же, если рассматривать двумерный массив.
Например, uint8_t items[2][2] — это двумерный массив с двумя строками и двумя столбцами; это означает, что имеется 4 элемента данных, как вы можете видеть на рис. 9. В памяти данные хранятся построчно. Здесь выкладывается первый ряд, примыкающий ко второму ряду. А память носит непрерывный характер. Память размещается построчно. Это очень просто понять.
По этой причине всякий раз, когда вы инициализируете двумерный массив, вам не нужно упоминать информацию о строке. Это может быть необязательно. Но информация столбца является обязательной.
Видите ли, здесь я даже могу написать вроде элементов[][2] , оставить строку пустой и даже написать столбец равным 2, это и приравнять к тому, что я хочу инициализировать.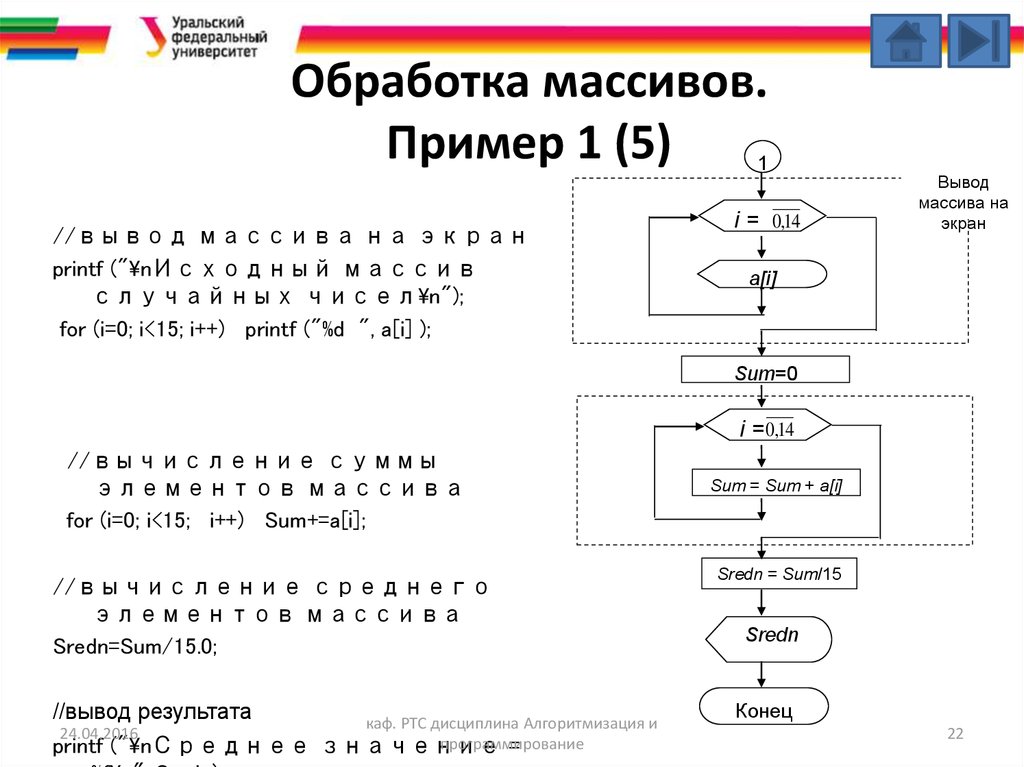 Всякий раз, когда компилятор видит этот оператор, компилятор понимает, что есть две строки. Вот почему вам не нужно упоминать эту информацию строки.
Всякий раз, когда компилятор видит этот оператор, компилятор понимает, что есть две строки. Вот почему вам не нужно упоминать эту информацию строки.
Рисунок 10. Инициализация двумерного массива
Первая строка {1, 2} и инициализация второй строки {2,3}.
uint8_t элементов[2][2] → Когда компилятор увидит это определение на первом шаге, он должен понять, что оно состоит из двух строк и двух столбцов.
uint8_t items[][] → Когда вы упомянете это определение, оно выдаст ошибку, если вы его скомпилируете. И что говорит об ошибке, вы должны предоставить информацию о столбце. Информация о столбце, внешняя граница, которую вы можете увидеть здесь, границы, которые вы должны указать.
uint8_t items[][2] → Вы указываете 2 в информации столбца и компилируете. Хорошо. Это не приводит к ошибкам. Почему? Когда компилятор это видит, он понимает, что строк две. Поэтому он сам заполнит эту информацию. Но вы должны указать информацию о столбце. Поскольку в строке две записи, это не означает, что в ней два столбца. Это также правильно.
uint8_t items[][4] → Это определение также хорошо компилируется. Что это значит? Это означает, что есть две строки. Это исправлено. Но есть четыре столбца, из которых два инициализированы, а остальные инициализированы 0. В этом и смысл. Это внешняя граница.
Помните, что при инициализации двумерного массива обязательно указывать информацию о столбцах, а информацию о строках можно не указывать. Информация о столбце помогает компилятору определить границу каждой строки во время выделения памяти для этого двумерного массива.
Информация о столбце помогает компилятору определить границу каждой строки во время выделения памяти для этого двумерного массива.
Курсы FastBit Embedded Brain Academy
Нажмите здесь: https://fastbitlab.com/course1
2. Создание массивов Numpy | Численное программирование
Автор Бернд Кляйн . Последнее изменение: 24 марта 2022 г.
На этой странице ➤
В предыдущей главе нашего руководства по Numpy мы уже видели, что можем создавать массивы Numpy из списков и кортежей. Теперь мы хотим представить дополнительные функции для создания базовых массивов.
Numpy предоставляет функции для создания массивов с равномерно распределенными значениями в пределах заданного интервала. Один «аранж» использует заданное расстояние, а другой «linspace» нуждается в количестве элементов и создает расстояние автоматически.
Создание массивов с равномерно распределенными значениями
ряд
Синтаксис arange:
arange([start,] stop[ step], [ dtype=None])
arange возвращает равномерно распределенные значения в пределах заданного интервала. Значения генерируются
в полуоткрытом интервале ‘[старт, стоп)’
Если функция используется с целыми числами, она почти эквивалентна встроенной функции Python.
range, но arange возвращает ndarray, а не итератор списка, как это делает range.
Если параметр «старт» не указан, он будет установлен в 0. Конец интервала определяется параметром «стоп». Обычно интервал не будет включать это значение, за исключением некоторых случаев, когда «шаг» не является целым числом, а округление с плавающей запятой влияет на длину выходного ndarray. Расстояние между двумя соседними значениями выходного массива задается необязательным параметром «шаг». Значение по умолчанию для «шага» равно 1. Если
задан параметр «шаг», параметр «начало» не может быть необязательным, т.е. он также должен быть задан. Тип выходного массива можно указать с помощью параметра ‘dtype’. Если он не указан, тип будет автоматически выведен из других входных аргументов.
Значения генерируются
в полуоткрытом интервале ‘[старт, стоп)’
Если функция используется с целыми числами, она почти эквивалентна встроенной функции Python.
range, но arange возвращает ndarray, а не итератор списка, как это делает range.
Если параметр «старт» не указан, он будет установлен в 0. Конец интервала определяется параметром «стоп». Обычно интервал не будет включать это значение, за исключением некоторых случаев, когда «шаг» не является целым числом, а округление с плавающей запятой влияет на длину выходного ndarray. Расстояние между двумя соседними значениями выходного массива задается необязательным параметром «шаг». Значение по умолчанию для «шага» равно 1. Если
задан параметр «шаг», параметр «начало» не может быть необязательным, т.е. он также должен быть задан. Тип выходного массива можно указать с помощью параметра ‘dtype’. Если он не указан, тип будет автоматически выведен из других входных аргументов.
импортировать numpy как np а = np.arange (1, 10) печать (а) х = диапазон (1, 10) print(x) # x - итератор распечатать (список (х)) # дальнейшие примеры упорядочивания: х = np.arange (10.4) печать (х) х = np.arange (0,5, 10,4, 0,8) печать (х)
ВЫВОД:
[1 2 3 4 5 6 7 8 9] диапазон(1, 10) [1, 2, 3, 4, 5, 6, 7, 8, 9] [ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.] [0,5 1,3 2,1 2,9 3,7 4,5 5,3 6,1 6,9 7,7 8,5 9,3 10,1]
Будьте осторожны, если вы используете значение с плавающей запятой для шага 9 0168, как видно из следующего примера:
np.оранжевый(12.04, 12.84, 0.08)
ВЫВОД:
массив([12.04, 12.12, 12.2, 12.28, 12.36, 12.44, 12.52, 12.6, 12.68,
12.76, 12.84])
Справка arange должна сказать следующее для параметра стоп : "Конец интервала. Интервал не включает это значение, за исключением некоторых случаев, когда шаг не является целым числом и округлением с плавающей запятой влияет на длину из . Это то, что произошло в нашем примере.
Следующие варианты использования в диапазоне немного необычны. Почему мы должны использовать значения с плавающей запятой, если мы хотим, чтобы в результате были целые числа. В любом случае, результат может быть запутанным. Перед запуском аранжа он будет округлять начальное значение, конечное значение и размер шага:
В любом случае, результат может быть запутанным. Перед запуском аранжа он будет округлять начальное значение, конечное значение и размер шага:
х = np.arange (0,5, 10,4, 0,8, целое число) печать (х)
ВЫВОД:
[0 1 2 3 4 5 6 7 8 9 10 11 12]
Этот результат не поддается никакому логическому объяснению. Здесь также помогает взгляд на справку: «При использовании нецелого шага, такого как 0,1, результаты часто не будут согласовываться. Лучше использовать numpy.linspace для этих случаев. Использование linspace в некоторых ситуациях не является простым обходным путем, поскольку необходимо знать количество значений.
линспейс
Синтаксис linspace:
linspace(start, stop, num=50, endpoint=True, retstep=False)
linspace возвращает ndarray, состоящий из 'num' равноотстоящих отсчетов в закрытом интервале [start, stop] или полуоткрытом интервале [start, stop). Будет ли возвращен закрытый или полуоткрытый интервал, зависит от
является ли «конечная точка» True или False. Параметр start определяет начальное значение создаваемой последовательности. 'stop' будет конечным значением последовательности, если для 'endpoint' не установлено значение False. В последнем случае результирующая последовательность будет состоять из всех, кроме последнего, равноотстоящих отсчетов num + 1. Это означает, что «стоп» исключен. Обратите внимание, что размер шага изменяется, когда «конечная точка» имеет значение False. Количество генерируемых выборок может быть установлено с помощью 'num', которое по умолчанию равно 50. Если необязательный параметр 'endpoint' установлен в True (по умолчанию), 'stop' будет последней выборкой последовательности. В противном случае он не включается.
Параметр start определяет начальное значение создаваемой последовательности. 'stop' будет конечным значением последовательности, если для 'endpoint' не установлено значение False. В последнем случае результирующая последовательность будет состоять из всех, кроме последнего, равноотстоящих отсчетов num + 1. Это означает, что «стоп» исключен. Обратите внимание, что размер шага изменяется, когда «конечная точка» имеет значение False. Количество генерируемых выборок может быть установлено с помощью 'num', которое по умолчанию равно 50. Если необязательный параметр 'endpoint' установлен в True (по умолчанию), 'stop' будет последней выборкой последовательности. В противном случае он не включается.
импортировать numpy как np # 50 значений от 1 до 10: печать (np.linspace (1, 10)) # 7 значений от 1 до 10: печать (np.linspace (1, 10, 7)) # исключая конечную точку: печать (np.linspace (1, 10, 7, конечная точка = ложь))
ВЫВОД:
[ 1. 1,18367347 1,36734694 1,55102041 1,73469388 1,91836735 2,10204082 2,28571429 2,46938776 2,65306122 2,83673469 3,02040816 3,20408163 3,3877551 3,57142857 3,75510204 3,93877551 4,12244898 4,30612245 4,48979592 4,67346939 4,85714286 5,04081633 5,2244898 5,40816327 5,59183673 5,7755102 5,95918367 6,14285714 6,32653061 6,51020408 6,69387755 6,87755102 7,06122449 7,24489796 7,42857143 7,6122449 7,79591837 7,97959184 8,16326531 8,34693878 8,53061224 8,71428571 8,89795918 9,08163265 9,26530612 9,44897959 9,63265306 9.81632653 10. ] [ 1. 2.5 4. 5.5 7. 8.5 10. ] [1. 2,28571429 3,57142857 4,85714286 6,14285714 7,42857143 8.71428571]
Пока мы не обсудили один интересный параметр. Если установлен необязательный параметр 'retstep', функция также вернет значение интервала между соседними значениями. Итак, функция вернет кортеж («выборки», «шаг»):
импортировать numpy как np выборки, интервал = np.linspace(1, 10, retstep=True) печать (интервал) образцы, интервал = np.linspace(1, 10, 20, endpoint=True, retstep=True) печать (интервал) образцы, интервал = np.linspace(1, 10, 20, endpoint=False, retstep=True) печать (интервал)
ВЫВОД:
0,1836734693877551 0,47368421052631576 0,45
Live Python training
Нравится эта страница? Мы предлагаем интерактивных учебных курсов Python , охватывающих содержание этого сайта.
См.: Обзор курсов Live Python
Зарегистрируйтесь здесь
Нульмерные массивы в Numpy
В numpy можно создавать многомерные массивы. Скаляры нульмерны. В следующем примере мы создадим скаляр 42. Применив метод ndim к нашему скаляру, мы получим размерность массива. Мы также можем видеть, что это тип «numpy.ndarray».
Скаляры нульмерны. В следующем примере мы создадим скаляр 42. Применив метод ndim к нашему скаляру, мы получим размерность массива. Мы также можем видеть, что это тип «numpy.ndarray».
импортировать numpy как np
х = np.массив (42)
напечатать("х: ", х)
print("Тип x: ", type(x))
print("Размерность x:", np.ndim(x))
ВЫХОД:
х: 42 Тип x:Размер х: 0
Одномерные массивы
В нашем первоначальном примере мы уже встречались с одномерным массивом, более известным некоторым как векторы. До сих пор мы не упоминали, но вы могли предположить, что массивы numpy являются контейнерами элементов одного и того же типа, например. только целые числа. Однородный тип массива можно определить с помощью атрибута «dtype», как мы можем узнать из следующего примера:
F = np.массив([1, 1, 2, 3, 5, 8, 13, 21])
V = np.массив ([3.4, 6.9, 99.8, 12.8])
печать("Ф: ", Ф)
печать("В: ", В)
print("Тип F: ", F.dtype)
print("Тип V: ", V. dtype)
print("Размерность F: ", np.ndim(F))
print("Размерность V: ", np.ndim(V))
dtype)
print("Размерность F: ", np.ndim(F))
print("Размерность V: ", np.ndim(V))
ВЫВОД:
F: [ 1 1 2 3 5 8 13 21] В: [3,4 6,9 99,8 12,8] Тип F: int64 Тип V: float64 Размер F: 1 Размер V: 1
Live Python training
Нравится эта страница? Мы предлагаем живых обучающих курсов Python , охватывающих содержание этого сайта.
См.: Обзор интерактивных курсов Python
Предстоящие онлайн-курсы
Python для инженеров и ученых
Анализ данных с помощью Python
Зарегистрироваться здесь
Двух- и многомерные массивы
Конечно, массивы NumPy не ограничены одним измерением. Они произвольной размерности. Мы создаем их, передавая вложенные списки (или кортежи) в метод массива numpy.
A = np.array([[3.4, 8.7, 9.9],
[1,1, -7,8, -0,7],
[4.1, 12.3, 4.8]])
печать(А)
печать (A.ndim)
ВЫВОД:
[[ 3,4 8,7 9,9] [ 1,1 -7,8 -0,7] [ 4,1 12,3 4,8]] 2
B = np.array([[[[111, 112], [121, 122]], [[211, 212], [221, 222]], [[311, 312], [321, 322]] ]) печать(Б) печать (B.ndim)
ВЫВОД:
[[[111 112] [121 122]] [[211 212] [221 222]] [[311 312] [321 322]]] 3
Форма массива
Функция "shape" возвращает форму массива. Фигура представляет собой кортеж целых чисел. Эти числа обозначают длину соответствующего измерения массива. Другими словами: «Форма» массива — это кортеж с количеством элементов на ось (размерность). В нашем примере форма равна (6, 3), т.е. у нас 6 строк и 3 столбца.
х = np.массив([ [67, 63, 87],
[77, 69, 59],
[85, 87, 99],
[79, 72, 71],
[63, 89, 93],
[68, 92, 78]])
печать (np.shape (х))
ВЫХОД:
(6, 3)
Существует также эквивалентное свойство массива:
печать (x.shape)
ВЫХОД:
(6, 3)
Форма массива также говорит нам кое-что о порядке, в котором обрабатываются индексы, т. е. сначала строки, затем столбцы и, наконец, последующие измерения.
е. сначала строки, затем столбцы и, наконец, последующие измерения.
«форма» также может использоваться для изменения формы массива.
x.shape = (3, 6) печать (х)
ВЫВОД:
[[67 63 87 77 69 59] [85 87 99 79 72 71] [63 89 93 68 92 78]]
x.shape = (2, 9) печать (х)
ВЫВОД:
[[67 63 87 77 69 59 85 87 99] [79 72 71 63 89 93 68 92 78]]
Вы уже могли догадаться, что новая фигура должна соответствовать количеству элементов массива, т.е. общий размер нового массива должен быть таким же, как у старого. Мы создадим исключение, если это не так.
Давайте рассмотрим еще несколько примеров.
Форма скаляра представляет собой пустой кортеж:
х = np.массив (11) печать (np.shape (х))
ВЫХОД:
B = np.array([[[111, 112, 113], [121, 122, 123]],
[[211, 212, 213], [221, 222, 223]],
[[311, 312, 313], [321, 322, 323]],
[[411, 412, 413], [421, 422, 423]]])
печать (B. форма)
форма)
ВЫХОД:
(4, 2, 3)
Живое обучение Python
Нравится эта страница? Мы предлагаем интерактивных учебных курсов Python , охватывающих содержание этого сайта.
См.: Обзор курсов Live Python
Зарегистрируйтесь здесь
Индексация и нарезка
Назначение и доступ к элементам массива аналогичны другим последовательным типам данных Python, то есть спискам и кортежам. У нас также есть много вариантов индексации, что делает индексацию в Numpy очень мощной и похожей на индексацию списков и кортежей.
Одиночное индексирование ведет себя так, как вы, скорее всего, ожидаете:
F = np.массив([1, 1, 2, 3, 5, 8, 13, 21]) # напечатать первый элемент F печать (F [0]) # напечатать последний элемент F печать (F[-1])
ВЫХОД:
Индексирование многомерных массивов:
A = np.array([[3.4, 8.7, 9.9],
[1,1, -7,8, -0,7],
[4.1, 12.3, 4.8]])
печать (А [1] [0])
ВЫХОД:
Мы обратились к элементу во второй строке, т. е. к строке с индексом 1 и первому столбцу (индекс 0). Мы получили к нему доступ таким же образом, как и с элементом вложенного списка Python.
е. к строке с индексом 1 и первому столбцу (индекс 0). Мы получили к нему доступ таким же образом, как и с элементом вложенного списка Python.
Вы должны знать, что доступ к многомерным массивам может быть очень неэффективным. Причина в том, что мы создаем промежуточный массив A[1], из которого мы обращаемся к элементу с индексом 0. Таким образом, он ведет себя примерно так:
тмп = А[1] печать (tmp) печать (tmp [0])
ВЫХОД:
[ 1,1 -7,8 -0,7] 1.1
Есть еще один способ доступа к элементам многомерных массивов в Numpy: Мы используем только одну пару квадратных скобок и все индексы разделяются запятыми:
печать (А [1, 0])
ВЫХОД:
Мы предполагаем, что вы знакомы с нарезкой списков и кортежей. Синтаксис тот же, что и в numpy для одномерных массивов, но его можно применять и к нескольким измерениям.
Общий синтаксис для одномерного массива А выглядит следующим образом:
А[старт:стоп:шаг]
Проиллюстрируем принцип работы «нарезки» на нескольких примерах. Начнем с самого простого случая, т. е. с нарезки одномерного массива:
Начнем с самого простого случая, т. е. с нарезки одномерного массива:
S = np.массив([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) печать (С [2: 5]) печать (С [: 4]) печать (С [6:]) печать (С [:])
ВЫХОД:
[2 3 4] [0 1 2 3] [6 7 8 9] [0 1 2 3 4 5 6 7 8 9]
Мы проиллюстрируем многомерные срезы на следующих примерах. Диапазоны для каждого параметра разделены запятыми:
А = np.массив([ [11, 12, 13, 14, 15], [21, 22, 23, 24, 25], [31, 32, 33, 34, 35], [41, 42, 43, 44, 45], [51, 52, 53, 54, 55]]) печать (А [: 3, 2:])
ВЫВОД:
[[13 14 15] [23 24 25] [33 34 35]]
печать (А [3:, :])
ВЫВОД:
[[41 42 43 44 45] [51 52 53 54 55]]
печать (А [:, 4:])
ВЫВОД:
[[15] [25] [35] [45] [55]]
В следующих двух примерах используется третий параметр «шаг». Функция reshape используется для построения двумерного массива. Мы объясним изменение формы в следующем подразделе:
X = np.arange(28).reshape(4, 7) печать (Х)
ВЫВОД:
[[ 0 1 2 3 4 5 6] [ 7 8 9 10 11 12 13] [14 15 16 17 18 19 20] [21 22 23 24 25 26 27]]
печать (X[::2, ::3])
ВЫВОД:
[[ 0 3 6] [14 17 20]]
печать (X[::, ::3])
ВЫВОД:
[[ 0 3 6] [ 7 10 13 ] [14 17 20] [21 24 27]]
Если количество объектов в кортеже выбора меньше измерения N, то : предполагается для любых последующих измерений:
А = np.массив(
[[[45, 12, 4], [45, 13, 5], [46, 12, 6] ],
[[46, 14, 4], [45, 14, 5], [46, 11, 5]],
[[47, 13, 2], [48, 15, 5], [52, 15, 1] ] ])
A[1:3, 0:2] # эквивалентно A[1:3, 0:2, :]
ВЫВОД:
массив([[[46, 14, 4],
[45, 14, 5]],
[[47, 13, 2],
[48, 15, 5]]])
Внимание:
В то время как нарезка списков и кортежей создает новые объекты, операция нарезки массива создает представление исходного массива. Так мы получаем еще одну возможность доступа к массиву, а лучше к части массива. Из этого следует, что если мы изменим представление, исходный массив также будет изменен.
Так мы получаем еще одну возможность доступа к массиву, а лучше к части массива. Из этого следует, что если мы изменим представление, исходный массив также будет изменен.
А = np.массив([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) С = А[2:6] С[0] = 22 С[1] = 23 печать(А)
ВЫВОД:
[0 1 22 23 4 5 6 7 8 9]
Проделывая то же самое со списками, мы видим, что получаем копию:
лст = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] лст2 = лст[2:6] лст2[0] = 22 лст2[1] = 23 печать (слева)
ВЫВОД:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Если вы хотите проверить, используют ли два имени массива один и тот же блок памяти, вы можете использовать функцию np.may_share_memory.
np.may_share_memory(A, B)
Чтобы определить, могут ли два массива A и B совместно использовать память, вычисляются границы памяти A и B. Функция возвращает True, если они перекрываются, и False в противном случае. Функция может давать ложные срабатывания, т. е. если она возвращает True, это просто означает, что массивы могут быть одинаковыми.
е. если она возвращает True, это просто означает, что массивы могут быть одинаковыми.
np.may_share_memory(A,S)
ВЫХОД:
Следующий код показывает случай, когда использование may_share_memory весьма полезно:
А = np.arange(12) B = A. изменить форму (3, 4) А[0] = 42 печать(Б)
ВЫВОД:
[[42 1 2 3] [ 4 5 6 7] [ 8 9 10 11]]
Мы видим, что A и B каким-то образом делят память. Атрибут массива «данные» является указателем объекта на начало данных массива.
Но мы видели, что если мы изменим элемент одного массива, то изменится и другой. Этот факт отражает may_share_memory:
np.may_share_memory(A, B)
ВЫХОД:
Приведенный выше результат является "ложноположительным" примером для may_share_memory в том смысле, что кто-то может подумать, что массивы одинаковы, что не так.
Создание массивов с единицами, нулями и пустыми
Существует два способа инициализации массивов нулями или единицами. Метод one(t) берет кортеж t в форме массива и соответственно заполняет массив единицами. По умолчанию он будет заполнен единицами типа float. Если вам нужны целые единицы, вы должны установить необязательный параметр dtype в int:
Метод one(t) берет кортеж t в форме массива и соответственно заполняет массив единицами. По умолчанию он будет заполнен единицами типа float. Если вам нужны целые единицы, вы должны установить необязательный параметр dtype в int:
импортировать numpy как np E = np.ones ((2,3)) печать (Е) F = np.ones((3,4),dtype=int) печать (Ф)
ВЫВОД:
[[1. 1. 1.] [1. 1. 1.]] [[1 1 1 1] [1 1 1 1] [1 1 1 1]]
То, что мы сказали о методе one(), аналогично применимо и к методу zeros(), как мы можем видеть в следующем примере:
Z = np.zeros((2,4)) печать (Z)
ВЫВОД:
[[0. 0. 0. 0.] [0. 0. 0. 0.]]
Есть еще один интересный способ создать массив с единицами или нулями, если он должен иметь ту же форму, что и другой существующий массив 'a'. Numpy предоставляет для этой цели методы one_like(a) и zeros_like(a).
х = np.массив ([2,5,18,14,4]) E = np.ones_like (x) печать (Е) Z = np.zeros_like (х) печать (Z)
ВЫХОД:
[1 1 1 1 1] [0 0 0 0 0]
Существует также способ создания массива с помощью пустой функции . Он создает и возвращает ссылку на новый массив заданной формы и типа без инициализации записей. Иногда записи нули, но вы не должны вводить в заблуждение. Обычно это произвольные значения.
Он создает и возвращает ссылку на новый массив заданной формы и типа без инициализации записей. Иногда записи нули, но вы не должны вводить в заблуждение. Обычно это произвольные значения.
нп.пусто((2, 4))
ВЫВОД:
массив([[0., 0., 0., 0.],
[0., 0., 0., 0.]])
Live Python training
Нравится эта страница? Мы предлагаем интерактивных учебных курсов Python , охватывающих содержание этого сайта.
См.: Обзор курсов Live Python
Зарегистрируйтесь здесь
Копирование массивов
numpy.copy()
копия(объект, заказ='K')
Возвращает копию массива данного объекта 'obj'.
| Параметр | Значение |
|---|---|
| объект | массив_подобных входных данных. |
| заказ | Возможные значения: {'C', 'F', 'A', 'K'}. Этот параметр управляет размещением копии в памяти. «C» означает C-порядок, «F» означает порядок Fortran, «A» означает «F», если объект «obj» является непрерывным Fortran, «C» в противном случае. «K» означает максимально точное соответствие макету «obj». «C» означает C-порядок, «F» означает порядок Fortran, «A» означает «F», если объект «obj» является непрерывным Fortran, «C» в противном случае. «K» означает максимально точное соответствие макету «obj». |
импортировать numpy как np x = np.array([[42,22,12],[44,53,66]], порядок='F') у = х.копировать () х[0,0] = 1001 печать (х) печать (у)
ВЫВОД:
[[1001 22 12] [ 44 53 66]] [[42 22 12] [44 53 66]]
печать (x.flags['C_CONTIGUOUS']) печать (y.flags ['C_CONTIGUOUS'])
ВЫВОД:
Ложь Истинный
ndarray.copy()
Существует также метод ndarray «copy», который можно напрямую применить к массиву. Она похожа на приведенную выше функцию, но значения по умолчанию для аргументов порядка отличаются.
a.copy(order='C')
Возвращает копию массива 'a'.
| Параметр | Значение |
|---|---|
| заказ | То же, что и с numpy. copy, но "C" является значением по умолчанию для порядка. copy, но "C" является значением по умолчанию для порядка. |
импортировать numpy как np x = np.array([[42,22,12],[44,53,66]], порядок='F') у = х.копировать () х[0,0] = 1001 печать (х) печать (у) печать (x.flags ['C_CONTIGUOUS']) печать (y.flags ['C_CONTIGUOUS'])
ВЫВОД:
[[1001 22 12] [ 44 53 66]] [[42 22 12] [44 53 66]] ЛОЖЬ Истинный
Идентификационный массив
В линейной алгебре единичная матрица или единичная матрица размера n представляет собой квадратную матрицу размера n × n с единицами на главной диагонали и нулями в других местах.
В Numpy есть два способа создания массивов идентификаторов:
- идентификатор
- глаз
Функция идентификации
Мы можем создавать массивы идентификаторов с помощью функции identity:
тождество(n, dtype=нет)
Параметры:
| Параметр | Значение |
|---|---|
| нет | Целое число, определяющее количество строк и столбцов вывода, т. е. 'n' x 'n' е. 'n' x 'n' |
| тип | Необязательный аргумент, определяющий тип выходных данных. По умолчанию используется значение «с плавающей запятой» | .
Результат identity представляет собой массив n x n с главной диагональю, равной единице, и всеми остальными элементами, равными 0.
импортировать numpy как np np.identity (4)
ВЫВОД:
массив([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
np.identity(4, dtype=int) # эквивалентно np.identity(3, int)
ВЫВОД:
массив([[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]])
Функция глаза
Еще один способ создания идентификационных массивов — функция eye. Эта функция также создает диагональные массивы, состоящие исключительно из единиц.
Возвращает двумерный массив с единицами по диагонали и нулями в других местах.
глаз (N, M=нет, k=0, dtype=плавающая)
| Параметр | Значение |
|---|---|
| Н | Целое число, определяющее строки выходного массива. |
| М | Необязательное целое число для установки количества столбцов в выходных данных. Если это None, по умолчанию используется значение 'N'. |
| к | Определение положения диагонали. По умолчанию 0. 0 относится к главной диагонали. Положительное значение относится к верхней диагонали, а отрицательное значение — к нижней диагонали. |
| тип | Необязательный тип данных возвращаемого массива. |
eye возвращает ndarray формы (N,M). Все элементы этого массива равны нулю, кроме 'k'-й диагонали, значения которой равны единице.
импортировать numpy как np np.eye(5, 8, k=1, dtype=int)
ВЫВОД:
массив([[0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0]])
Принцип действия параметра «d» функции глаза показан на следующей схеме:
Live Python training
Нравится эта страница? Мы предлагаем интерактивных учебных курсов Python , охватывающих содержание этого сайта.
См.: Обзор курсов Live Python
Зарегистрируйтесь здесь
Упражнения:
1) Создайте произвольный одномерный массив с именем "v".
2) Создать новый массив, состоящий из нечетных индексов ранее созданного массива "v".
3) Создать новый массив в обратном порядке от версии
4) Что выведет следующий код:
а = np.массив ([1, 2, 3, 4, 5]) б = а[1:4] б[0] = 200 печать (а [1])
5) Создайте двумерный массив с именем "m".
6) Создать новый массив из m, в котором элементы каждой строки расположены в обратном порядке.
7) Еще один, где ряды в обратном порядке.
8) Создайте массив из m, где столбцы и строки расположены в обратном порядке.
9) Вырезать первую и последнюю строку и первый и последний столбец.
Решения к упражнениям:
1)
импортировать numpy как np а = np.массив ([3,8,12,18,7,11,30])
2)
нечетные_элементы = а[1::2]
3) обратный_порядок = а[::-1]
4) Вывод будет 200, потому что срезы представляют собой представления в numpy, а не копии.