Как сделать ссылку в Word и удалить её
20 декабря Ликбез Технологии
Её можно добавить на какой-то сайт, картинку, фрагмент в тексте и даже другой документ.
В текстовом процессоре Microsoft поддерживается функция гиперссылок, благодаря которой в документах можно вставлять различные ссылки: на веб‑страницы, файлы, определённое место в тексте, другой документ или имейл. Далее рассмотрим их, а также разберёмся, как удалить добавленные ссылки.
Как сделать автоматическую ссылку в Word
Самый простой способ добавить ссылку — просто ввести или вставить адрес на нужную страницу или файл. Поскольку Word автоматически распознаёт URL, адрес сразу же превратится в ссылку. Она будет выглядеть не очень красиво, но когда нужно показать полный URL или просто не хочется заморачиваться — это лучший вариант.
Просто вставьте ссылку, скопировав из адресной строки браузера, или введите вручную с клавиатуры адрес, начиная с www.
Нажмите пробел либо Enter, и текст превратится в подчёркнутую и подсвеченную синим гиперссылку. Кстати, при нажатии Ctrl + Z она снова станет простым текстом. Это на случай, если нужно указать адрес сайта без ссылки.
Кстати, при нажатии Ctrl + Z она снова станет простым текстом. Это на случай, если нужно указать адрес сайта без ссылки.
Как сделать ссылку в Word на веб‑страницу или файл
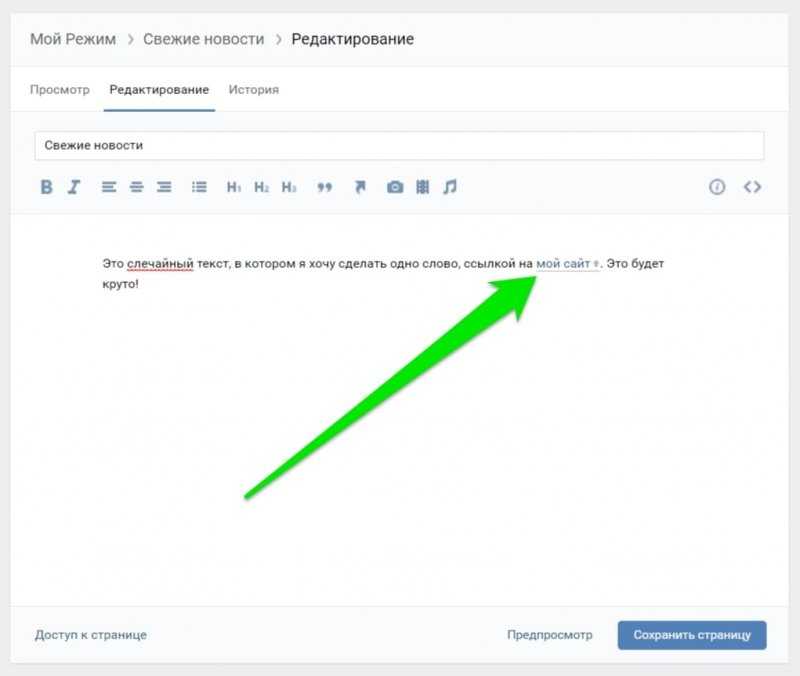
Ссылку не обязательно вставлять напрямую, её можно назначить на какое‑нибудь слово или фразу в тексте, а также картинку. Так будет правильнее, красивее и понятнее для читателя. Сам же процесс ненамного сложнее.
Выделите нужное слово и на вкладке «Вставка» кликните «Ссылки» → «Ссылка», а лучше просто нажмите сочетание Ctrl + K на клавиатуре.
В открывшемся окошке в поле «Адрес» вставьте URL веб‑страницы или файла.
Выбранное слово станет подчёркнутым и окрасится в синий. Теперь по клику на него с зажатой клавишей Ctrl ссылка откроется в браузере.
Как в Word сделать ссылку на место в тексте
Подобно страницам в интернете можно добавить ссылки на листы и даже определённые фрагменты в документе. Это бывает полезно при составлении курсовых и дипломных работ, а также других объёмных файлов с большим количеством разделов.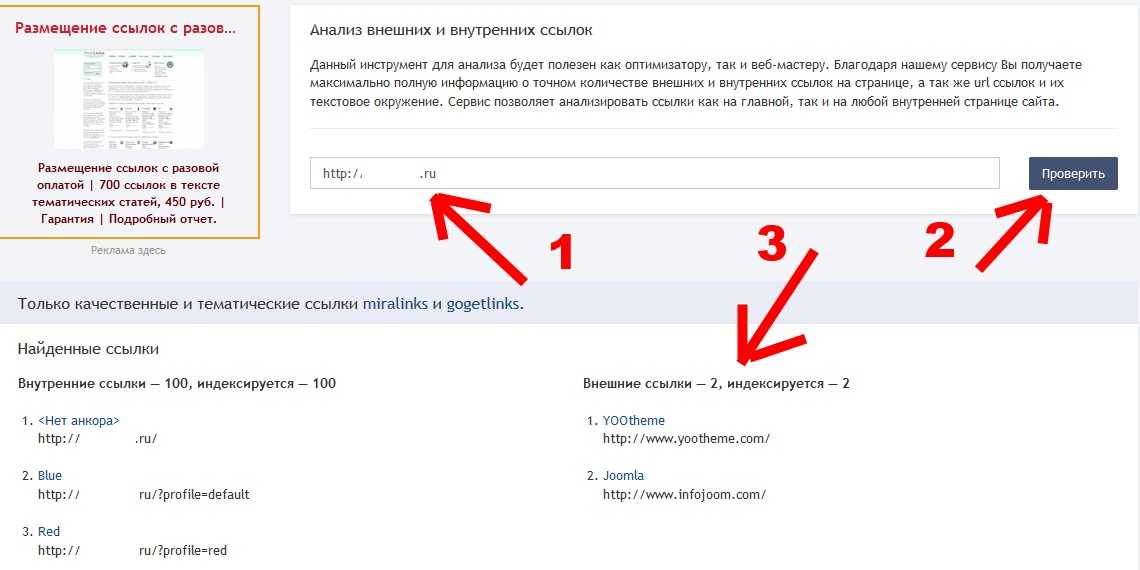 Для реализации подобного можно использовать оглавление или закладки.
Для реализации подобного можно использовать оглавление или закладки.
Поставьте курсор в место, на которое хотите сослаться, и на вкладке «Вставка» кликните «Ссылки» → «Закладка».
Введите удобное для понимания имя закладки и нажмите «Добавить».
Теперь выделите слово, которое хотите сделать ссылкой, нажмите Ctrl + K, а затем кликните «Место в документе», раскройте список закладок и выберите нужную.
После этого по щелчку по указанному слову с зажатым Ctrl Word мгновенно перейдёт к месту в тексте, на котором вы установили закладку.
Как в Word сделать ссылку на другой документ
По такому же принципу в качестве объекта ссылки можно использовать другие документы Word. Этот метод будет полезен для больших работ, которые содержат сразу несколько файлов, и может сэкономить время при взаимодействии с ними.
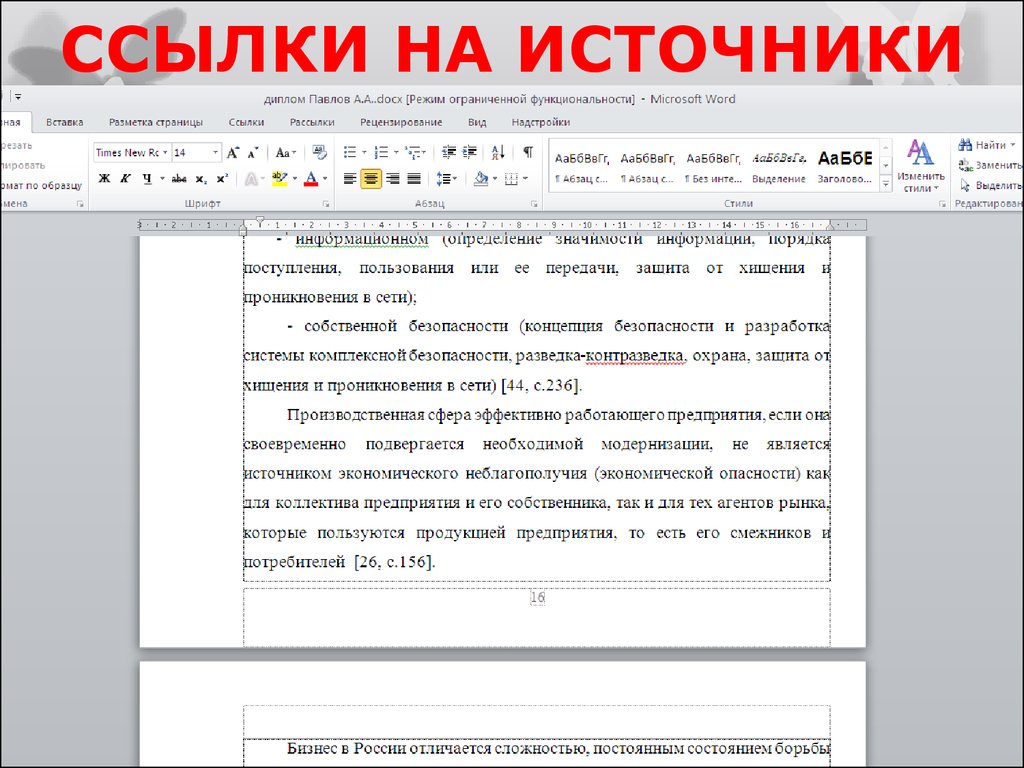
Всё так же выделите слово или фразу и нажмите Ctrl + K.
Выберите документ Word в списке файлов.
Теперь, если зажать Ctrl и кликнуть на ссылку, откроется указанный документ.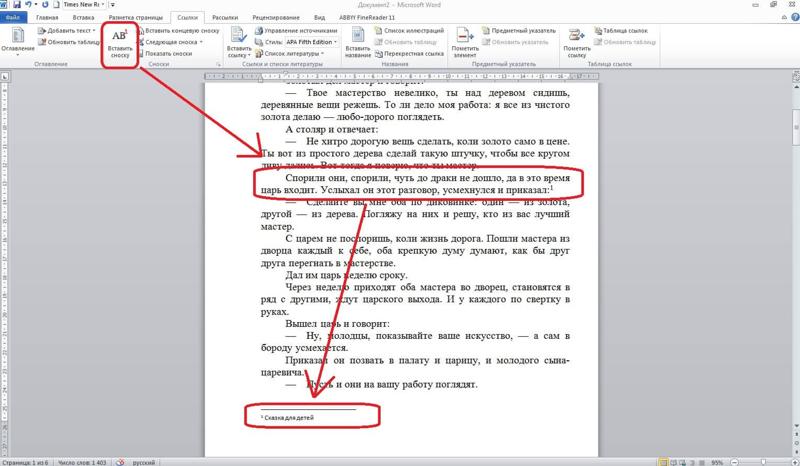
Ещё один вариант использования ссылок — имейл для обратной связи с читателями вашего документа. По клику на такую ссылку у пользователя будет автоматически открываться создание нового письма с заданной темой в почтовом клиенте по умолчанию.
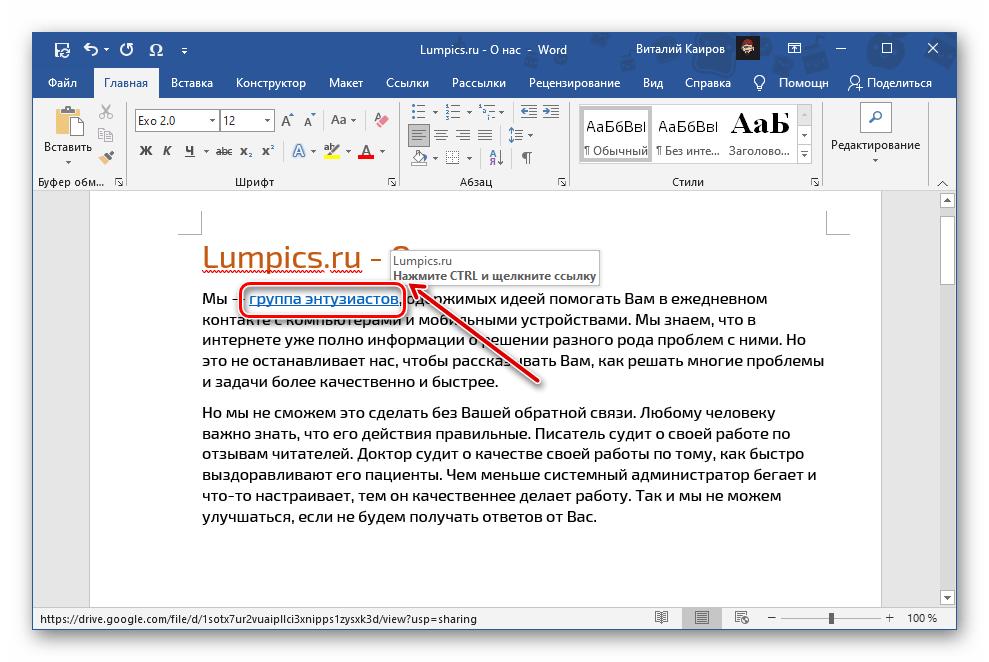
Выделите слово, которое хотите сделать ссылкой, и нажмите Ctrl + K.
Кликните «Электронная почта», укажите имейл (не пугайтесь, к нему спереди добавится mailto:), тему письма и нажмите OK.
После этого по клику на ссылку читатель сможет написать вам письмо и дать обратную связь.
Как удалить ссылку в Word
Обратный процесс гораздо проще и, что примечательно, одинаков для ссылок любых типов.
Выделите слово или фразу со ссылкой, а затем сделайте правый клик и выберите из контекстного меню «Удалить гиперссылку». Либо просто нажмите Ctrl + Shift + F9 на клавиатуре. Кстати, если выделить весь текст (Ctrl + A) и потом использовать это сочетание клавиш, то Word удалит все ссылки в документе.
После удаления ссылки фрагмент превратится в обычный текст.
Читайте также 🧐✏️📄
- Как перевернуть страницу в Word
- Как создать колонки в Word и убрать их
- Как сделать рамку в Word
- Как убрать большие пробелы в Word между словами
- Как удалить пустую страницу в Word
делюсь инструкцией и ссылкой для тестов — Разработка на vc.
 ru
ruПривет! Меня зовут Вова, я разработчик. Не так давно локализовал игру №59 — ту, где сайт на английском загадывает слово, а пользователю нужно его угадать. ИИ при этом подсказывает, насколько близко он оказался к цели. В тексте делюсь своей версией «Русо контексто». Скрины, код и ссылка, чтобы сыграть в слова с ИИ на русском, — тоже внутри.
2367 просмотров
Даже на русском языке игра не самая простая
Используйте навигацию, если нет времени читать текст целиком:
- Как работает игра?
- Текстовые эмбеддинги
- Обработка словаря
- Умный бэкэнд
- Игра на объектном хранилище
- Финальный результат: ссылка на игру
Почему я решил локализовать игру?
Все началось с коллеги, который закинул в локальный чат сообщение, что он сыграл в #59 и угадал слово с 33 попыток и одной подсказки. Игра оказалась простая и сложная одновременно: сайт загадал слово и нужно его отгадать. В поле ввода отправляешь слово, а искусственный интеллект на сайте определяет, насколько отправленное слово близко по смыслу к загаданному.
Игра оказалась простая и сложная одновременно: сайт загадал слово и нужно его отгадать. В поле ввода отправляешь слово, а искусственный интеллект на сайте определяет, насколько отправленное слово близко по смыслу к загаданному.
Интересная игра, тренирующая ассоциативное мышление и умение строить связи. Новое слово появляется каждый день, что в некотором смысле выглядит ограничителем. Также игра доступна только на португальском и английском языках. С одной стороны, это дополнительная практика, а с другой — сомнения «а знаю ли я это слово?» смазывают впечатления от игры.
Так я задумался о локализации игры на русский язык. Свою игру «Русо контексто» я разместил на объектном хранилище, которое более устойчиво примет читателей vc.ru.
Дисклеймер: оригинальная игра расположена по адресу contexto.me. В процессе подготовки статьи я узнал о существовании русскоязычной версии guess-word.com. Но эта версия имеет более ограниченную функциональность.
Как работает игра?
У сайта минималистичный интерфейс:
- Сведения об игре: номер, количество попыток и количество подсказок.
- Поле ввода слова.
В выпадающем меню есть настройки и дополнительные игровые опции:
- Выбрать игру.
- Взять подсказку.
- Сдаться.
Если отгадать слово, то игра предложит поделиться результатом и взглянуть на ближайшие 500 слов.
Игра очень быстро возвращает ответ и умеет определять начальную форму слова. Иными словами, cat и cats считаются одним словом и выводиятся как cat. Все введенные слова трактуются как существительные, и в списке 500 ближайших слов глагола не встретить.
Это наводит на мысль, что список ближайших слов формируется отдельно, а игра просто обращается к списку. Остается вопрос: как составить список ближайших слов?
Текстовые эмбеддинги
Изначально компьютеры не владеют ни одним человеческим языком.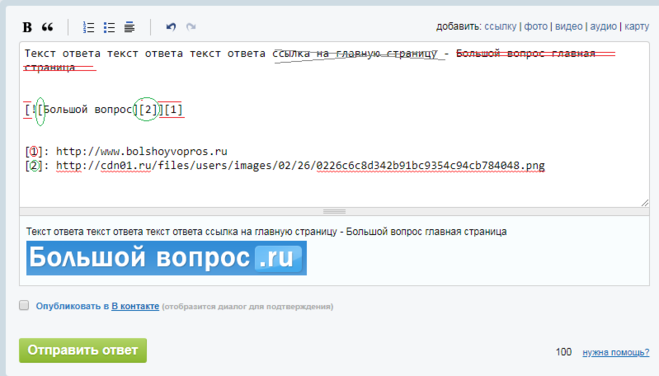 Но человек делает все возможное, чтобы это исправить. Человек может сказать одну команду, используя разные слова и в разном порядке. Машине нужно уметь не просто различать слова, но и понимать смысл, который прячется за этими словами.
Но человек делает все возможное, чтобы это исправить. Человек может сказать одну команду, используя разные слова и в разном порядке. Машине нужно уметь не просто различать слова, но и понимать смысл, который прячется за этими словами.
Здесь на помощь приходят текстовые эмбеддинги. Если упрощать, то эмбеддинг — это превращение слова в набор чисел, который называют кортежем или вектором.
Эти числа задают положение слова в виде точки в пространстве, но не в трехмерном, а в многомерном. Чем ближе две точки, тем ближе слова по смыслу, а компьютеры умеют вычислять.
Дисклеймер: в этом тексте оставим процесс сопоставления слов векторам в виде черного ящика, которым мы хотим пользоваться, но нам неинтересно, как он работает.
После операции сопоставления появляется модель — файл, который описывает соответствие «слово — вектор» или как-то описывает правила сопоставления или вычисления. Для работы модели нужно программное обеспечение, которое понимает формат модели.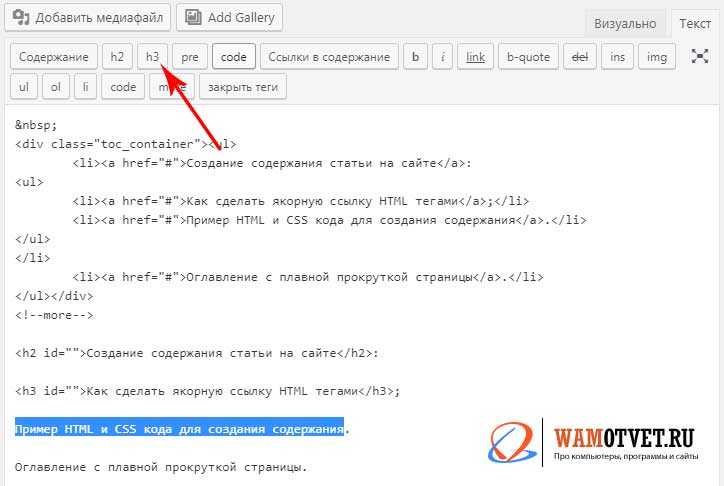
Проще и быстрее всего «потрогать» эмбеддинги на языке Python. Библиотека gensim реализует один из самых популярных подходов — word2vec.
Для работы необходима модель, обученная на достаточном количестве текстов. В документации gensim есть ссылки на англоязычные модели, но нас это не устраивает.
К счастью, проект RusVectores предоставляет модели на русском языке. На сайте представлены контекстуализированные и статические модели. Так как игра принимает на вход одно слово, то нам подходит статическая модель.
Я использовал модель, обученную на Национальном Корпусе Русского Языка (НКРЯ), ее название — ruscorpora_upos_cbow_300_20_2019. Скачиваем архив и распаковываем. Модель представлена в двух видах: бинарном (model.bin) и текстовом (model.txt).
Попробуем воспользоваться этой моделью. Сперва загружаем.
from gensim.models import KeyedVectors model = KeyedVectors.load_word2vec_format(«model.txt», binary=False)
Теперь можем найти слова, ближайшие к слову «провайдер»:
>>> model.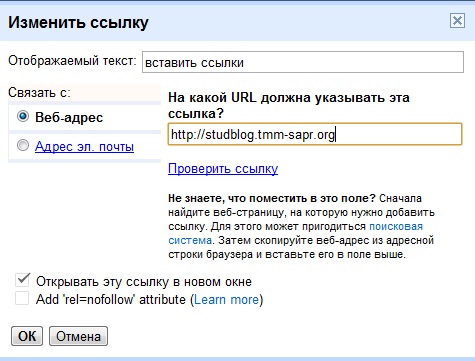 most_similar(positive=[«провайдер»])
…
KeyError: «Key ‘провайдер’ not present in vocabulary»
most_similar(positive=[«провайдер»])
…
KeyError: «Key ‘провайдер’ not present in vocabulary»
К сожалению, такого слова не нашлось. Дело в том, что данная модель принимает слова вместе с меткой, которая определяет часть слова. Это сделано для различия слов с одинаковым написанием. Например, «печь» можно представить как «печь_NOUN» и «печь_VERB», то есть как существительное и глагол соответственно.
Также возьмем более простой пример с несколькими словами. Зададим два слова: король и женщина. Человек догадается, что женщина-король — это скорее всего королева.
>>> model.most_similar(positive=[«король_NOUN», «женщина_NOUN»], topn=1) [ (‘королева_NOUN’, 0.6674807071685791), (‘королева_ADV’, 0.6368524432182312), (‘принцесса_NOUN’, 0.6262999176979065), (‘герцог_NOUN’, 0.613500714302063), (‘герцогиня_NOUN’, 0.5999450087547302) ]
Метод most_similar выводит список наиболее похожих слов и некоторую метрику расстояния до этого слова. Чем ближе метрика к единице, тем ближе слово. Список слов отсортирован по убыванию этой метрики. Так как сортировка производится при выводе, то значение метрики далее мы использовать не будем.
Аргумент topn позволяет задать количество слов, которые мы хотим получить. Таким образом можно запросить какое-нибудь большое количество слов и получить список, необходимый для создания игры. Давайте зададим более современное слово «киберпространство» и посмотрим на ближайшее слово и на слово, например, на десятитысячной позиции.
>>> result = model.most_similar(positive=[«киберпространство_NOUN»], topn=10000)
>>> result[0]
(‘виртуальный_ADJ’, 0.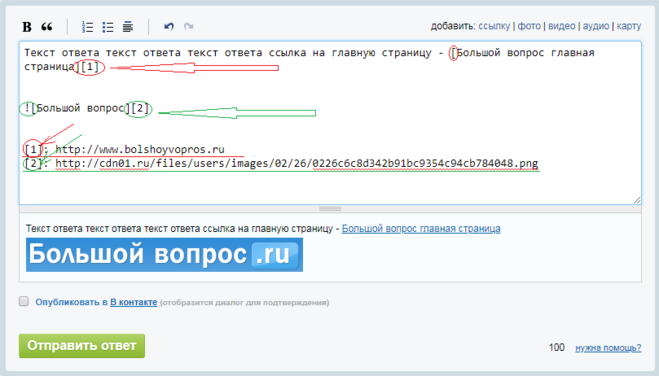 39892229437828064)
>>> result[9998]
(‘европбыть_VERB’, 0.12139307707548141)
>>> result[9999]
(‘татуировкий_NOUN’, 0.12139236181974411)
39892229437828064)
>>> result[9998]
(‘европбыть_VERB’, 0.12139307707548141)
>>> result[9999]
(‘татуировкий_NOUN’, 0.12139236181974411)
Наличие специфичных слов, которые могут шуткой, опечаткой, ошибкой в парсинге или локальным жаргонизмом, неприятно влияет на игру. Нужно очистить словарь от странных слов и оставить только существительные.
Обработка словаря
Один из способов хранения модели word2vec — текстовый. Формат прост: в первой строке задаются два числа — количество строк в документе и количество чисел в векторе. Далее на каждой строке задается слово и далее числа, обозначающие вектор.
Здесь удобно воспользоваться особенностью этой модели, а именно тегами.
Существительные имеют тег _NOUN, что позволяет убрать из модели ненужные слова. Удалить не существительные легко, но как поступить с опечатками и странными словами? Здесь на помощь приходит другой эмбеддинг, который обучался на литературе.
Это эмбеддинг Navec (навек) из проекта Natasha.
from navec import Navec path = ‘navec_hudlit_v1_12B_500K_300d_100q.tar’ navec = Navec.load(path)
Теперь можно проверять слова простым синтаксисом:
>>> «виртуальный» in navec True >>> «европбыть» in navec False >>> «татуировкий» in navec False
Таким образом можно отсеять немалое количество слов, которым в игре не место.
Примеры удаленных слов, многие даже великому гуглу неизвестны:
- цидулка
- зачатокать
- магазей
- антитезть
- завоевателий
- налицотец
- прируба
- цвть
Но вместе с тем теряются и настоящие слова:
- агрокомплекс
- кейтеринг
- фемтосекунда
- углепластик
- электромашиностроение
Алгоритм очистки модели следующий:
- Если у слова тег не NOUN, то отбрасываем это слово.
- Удаляем из слова последовательность _NOUN.
- Проверяем «чистое слово» на наличие в эмбеддинге Navec. Если его там нет, слово отбрасываем.
- Слово, которое прошло все проверки, записываем в файл.
После обработки всех слов в первую строку новой модели записываем два числа: количество оставшихся строк и размерность вектора. Размерность вектора при данной обработке остается неизменной. Если все сделано правильно, то очищенную модель получится загрузить:
model = KeyedVectors.load_word2vec_format(«noun_model.txt», binary=False)
Стало ли после этого лучше?
>>> result = model.most_similar(positive=[«киберпространство»], topn=10000) >>> result[0] (‘виртуальность’, 0.4715898633003235) >>> result[9998] (‘компаунд’, 0.15783849358558655) >>> result[9999] (‘хитрость’, 0.15783214569091797)
Определенно. Для статистики: исходная модель содержит 248 978 токенов, из них 59 104 токенов имеют метку существительног. И только 36 269 прошли «сито» второго эмбеддинга.
И только 36 269 прошли «сито» второго эмбеддинга.
Время заняться бэкэндом и фронтендом игры.
Умный бэкэнд
Так как Python является моим рабочим языком программирования, бэкэнд я решил реализовать на нем. Поговорим об обработке входных данных. Обрезать пробелы и перевести текст в нижний регистр — само собой разумеющееся. Но как получить начальную форму слова?
Здесь можно воспользоваться инструментом MyStem. Для Python есть обертка pymystem3. Крайне простой инструмент для получения начальной формы слова:
import pymystem3 mystem = pymystem3.Mystem()
Метод lemmatize принимает на вход строку-предложение и возвращает список слов в начальной форме.
>>> mystem.lemmatize(«кот коты котов котах кота») [‘кот’, ‘ ‘, ‘кот’, ‘ ‘, ‘кот’, ‘ ‘, ‘кот’, ‘ ‘, ‘кот’, ‘\n’]
На первый взгляд даже производительность на достойном уровне: на моей виртуальной машине лемматизация одного слова занимает до 10 мс. По меркам современного веба это достаточно быстро.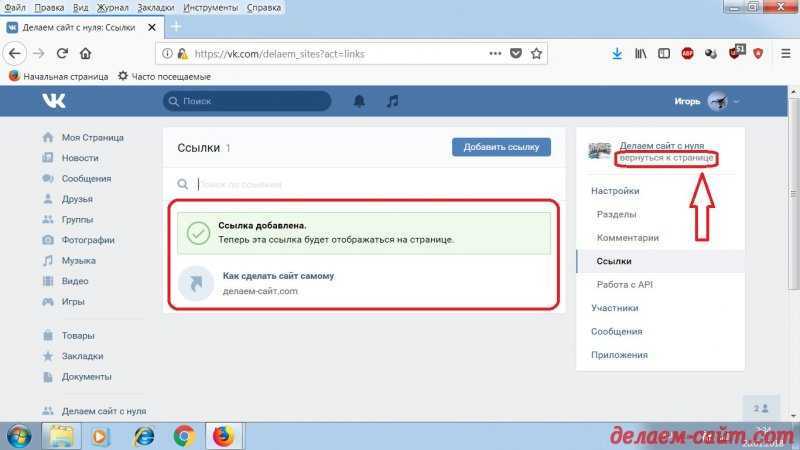
Пока я работал над бэкэндом, по работе пришлось познакомиться с объектным хранилищем, среди функций которого есть возможность размещения статических сайтов. И тут мне пришла интересная мысль.
Игра на объектном хранилище
При разработке бэкэнда я продумывал способы защититься от нечестной игры:
- Сдаться нельзя.
- Список топ-500 ближайших слов получить можно, только предоставив загаданное слово.
- Подсказку можно получить по слову и позиции.
Но вскоре мне показалось это слишком суровым.
На данный момент единственное назначение бэкэнда — приведение слов к начальной форме. Правда, как показало тестирование на коллегах, и это не обязательно: все и так старались писать начальные формы слов. Да и модель эмбеддингов не лемматизирована, то есть игра понимает слова не только в начальной форме.
Получается, игру можно полностью перенести в браузер?
Так как я бэкэнд-разработчик, то отказ от бэкэнда в угоду фронтэнду — это стресс.
Однако от бэкэнда полностью отказаться не получится: генератор близких слов где-то нужно запускать. Генератор принимает на вход загаданное слово и формирует текстовый файл, где на каждой строке по одному слову в порядке смыслового убывания от загаданного. Содержимое этого файла также дублируется в JSON-словарь, где каждому слову соответствует его дистанция от загаданного слова.
JSON-файл на каждую игру занимает до 2 МБ. При открытии игры файл скачивается в браузер и JavaScript реализует логику игры. Этот способ не самый производительный, но после загрузки файла позволяет играть без подключения к интернету.
Я разместил игру в облачном хранилище Selectel, которое более устойчиво к наплыву посетителей.
Заключение
Итоговый результат доступен по адресу words.f1remoon.com, а исходный код — в репозитории.
Сыграйте в игру и поделитесь впечатлениями. А еще подпишитесь на блог Selectel, чтобы не пропустить обзоры, новости, кейсы и полезные гайды из мира IT.

Читайте также:
Словарь WordReference в App Store
Описание
Приложение самого популярного и мощного веб-сайта по переводу словарей. Он предоставляет вам быстрый доступ к нашим обширным словарям и обсуждениям на форуме.
Словари WordReference.com:
с английского на испанский
с английского на французский
с английского на итальянский
с английского на немецкий
с английского на португальский
с английского на польский
с английского на румынский
с английского на чешский
с английского на греческий
с английского на турецкий
с английского на японский
с английского на китайский
с английского на корейский
с английского на арабский
с английского на шведский
с английского на голландский
с испанского на французский
с испанского на португальский
английские определения
испанские определения
итальянские определения
Определения каталонского языка
Спряжения:
Испанское спряжение
Французское спряжение
Итальянское спряжение
Синонимы: английский и испанский
Форумы содержат более 3 миллионов вопросов и ответов об английском языке и переводе.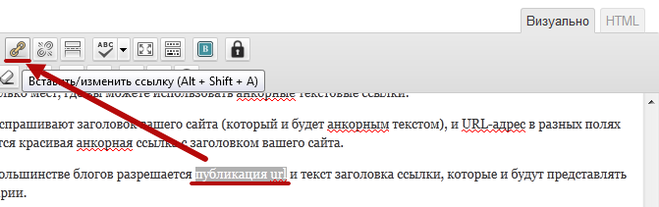 На ваши вопросы уже ответили.
На ваши вопросы уже ответили.
ПРИМЕЧАНИЕ. Требуется доступ в Интернет.
WordReference часто неправильно пишется как «Word Reference» при поиске.
Версия 5.0.59
исправления ошибок
Рейтинги и обзоры
49Рейтинги
Информация отличная. Приложение разочаровывает
Я использовал это для испанского языка, и это было чрезвычайно полезно для выяснения маленьких нюансов в выборе слов, где одно и то же слово может иметь совершенно разные значения в разных странах Латинской Америки и Испании. В буквальном смысле это помогает даже вести дискуссию об эмоциях в межкультурных отношениях, где не каждое чувство переводится 1:1.
Я просто хочу, чтобы приложение было лучше. Он вылетает, если я нажимаю на одно слово из определения, я не могу просто вернуться на последнюю страницу, мне приходится каждый раз начинать поиск заново. И нет возможности загружать разделы для автономного использования. Это было бы очень полезно, когда вы путешествуете за границей, а данные неоднородны. Для этого я рекомендую Linguee. Кроме того, если вы ищете больше примеров слова в предложении, это приложение Linguee в основном извлекает контекст для J, чтобы слово использовалось в реальных онлайн-статьях.
лучше, чем гугл переводчик
Если вы хотите выучить язык, это приложение будет намного полезнее, чем Google Translate. Вы не можете переводить целые предложения, но он дает вам несколько определений для каждого слова, как это делает обычный словарь. Это действительно отличный ресурс, который я определенно рекомендую
.

Не функционирует
Как учитель языка, я много лет рекомендовал WordReference своим ученикам как лучший вариант для перевода. Это все еще верно для веб-сайта, но приложение просто сломано. После ввода слова для перевода ничего не появляется. Перед написанием этого обзора я пытался сообщить о проблеме по ссылке в приложении, но она не работала. Пожалуйста, исправьте это замечательное приложение»
Разработчик, WordReference.com, LLC, указал, что политика конфиденциальности приложения может включать обработку данных, как описано ниже. Для получения дополнительной информации см. политику конфиденциальности разработчика.
Данные, используемые для отслеживания вас
Следующие данные могут использоваться для отслеживания вас в приложениях и на веб-сайтах, принадлежащих другим компаниям:
Данные, не связанные с вами
Следующие данные могут собираться, но они не связаны с вашей личностью:
Методы обеспечения конфиденциальности могут различаться, например, в зависимости от используемых вами функций или вашего возраста.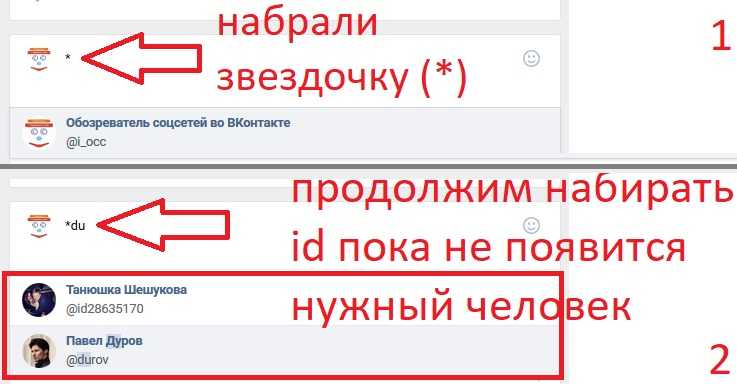 Узнать больше
Узнать больше
Информация
- Продавец
- WordReference.com, ООО
- Размер
- 13,1 МБ
- Категория
- Справка
- Возрастной рейтинг
- 12+ Медицинская информация/лечение нечасто/умеренно Нечастая/умеренная ненормативная лексика или грубый юмор
- Авторское право
- © WordReference.com LLC
- Цена
- Бесплатно
- Сайт разработчика
- Тех. поддержка
- Политика конфиденциальности
Вам также может понравиться
Как использовать WordReference для повышения эффективности изучения языка | Киран Болл | Счастливый лингвист
Когда я учился в университете, изучая иностранные языки, я ежедневно пользовался сайтом WordReference.
БОЛЬШЕ ЗАПИСЕЙ В БЛОГЕ | ГЛАВНАЯ | ЯЗЫКОВЫЕ КУРСЫ
www.wordreference.com онлайн словарьЧто такое WordReference?
WordReference — это, на первый взгляд, онлайн-словарь. Тем не менее, по мере того, как вы копаетесь дальше, вы обнаружите, что это гораздо больше.
При первом посещении www.wordreference.com вы найдете строку поиска и список языковых пар. Вы можете ввести слово на любом языке, а затем выбрать, на какой язык вы хотите его перевести, и готово.
Итак, вы можете ввести «дом», выбрать «английский — испанский», и вы получите «casa». Или вы можете ввести «casa», выбрать «испанский — английский», и вы получите «дом».
Итак, это WordReference на базовом уровне. Но вы можете сделать это в Google Translate. WordReference отличается тем, что он больше похож на словарь, чем на переводчик.
Существительное или глагол?
Слово «дом» — это, очевидно, большая коробка, в которой живут люди. Например, «Этот дом прекрасен». В этом смысле «дом» — это существительное (я всегда помню существительные как слова, перед которыми можно поставить «the»: дом). Однако «дом» также может быть глаголом: «Где вы собираетесь разместить животных?» (Я всегда помню глагол как слово, которое можно поставить «to» перед: to house). Ну, WordReference покрывает это.
Например, «Этот дом прекрасен». В этом смысле «дом» — это существительное (я всегда помню существительные как слова, перед которыми можно поставить «the»: дом). Однако «дом» также может быть глаголом: «Где вы собираетесь разместить животных?» (Я всегда помню глагол как слово, которое можно поставить «to» перед: to house). Ну, WordReference покрывает это.
Когда вы вводите слово в WordReference, он дает вам все возможные варианты использования этого слова и способы его произнесения на испанском языке (или на любом языке, который вы изучаете). Каждый раз, когда вы ищете слово, оно сообщит вам его во всех формах, в которых оно может быть. Он использует код, найденный в большинстве словарей, чтобы помочь вам увидеть, является ли это существительным, глаголом, прилагательным и т. д. Например, вы увидите «n» для существительного, «v» для глагола и «adj» для прилагательного.
Если вы не грамматик и не уверены на 100%, что означают эти слова, не бойтесь; WordReference предоставляет небольшую фразу, чтобы показать синоним слова, которое вы ищете, а также несколько примеров предложений с используемым словом.
Давайте посмотрим на «дом» в «испанский — английский» в качестве примера:
Итак, вы видите маленькую синюю «н» после слова «дом». Это значит, что это существительное. В скобках, правда, потом еще написано: (жилой дом), на всякий случай, если вы не уверены, что такое дом. Затем справа у вас есть испанский перевод «casa», и вы заметите «nf», что означает «существительное — женский род». Это означает, что это существительное женского рода в испанском языке.
Под основной записью вы увидите светло-серую примерную фразу, чтобы вы могли видеть используемое слово: В их новом доме три ванные комнаты — Su nueva casa tiene tres baños.
После следующей записи стоят буквы «втр», что означает «глагол — переходный». Если вы не знаете, что это значит, вы можете навести курсор на буквы, и появится всплывающее окно с объяснением.
Здесь объясняется, что переходный глагол — это глагол, который может принимать прямое дополнение.
Затем он дает еще один синоним глагола «дом»: предоставить место для хранения, и дает испанский перевод. У этого на самом деле есть два варианта на испанском языке: «guardar» или «almacenar». Ниже приведен еще один пример предложения: В этом шкафу хранятся все наши канцелярские принадлежности — El armario almacena todo nuestro material de papelería.
У этого на самом деле есть два варианта на испанском языке: «guardar» или «almacenar». Ниже приведен еще один пример предложения: В этом шкафу хранятся все наши канцелярские принадлежности — El armario almacena todo nuestro material de papelería.
Еще больше примеров
Однако WordReference хорош тем, что на этом он не останавливается. Если вы прокрутите вниз, вы получите сотни примеров фраз и предложений, содержащих слово «дом», так что вы сможете найти именно то, что ищете.
Вот лишь несколько примеров фраз, которые вы получаете для слова «дом» на испанском языке.
Щелкните любое слово
Еще одна бонусная функция WordReference заключается в том, что вы можете щелкнуть любое слово, которое вы видите на всем экране, независимо от того, где оно находится.
Если вы видите один из переводов и не уверены, что означает одно из слов, вы можете просто щелкнуть по нему. Если вы нажмете на слово, вы автоматически перейдете к его испанско-английскому переводу. Например, скажем, в приведенном ниже примерном предложении вы не знали, что означает слово «edificios». Просто нажмите на него:
Например, скажем, в приведенном ниже примерном предложении вы не знали, что означает слово «edificios». Просто нажмите на него:
Вы перейдете к переводу слова «edificios». Это говорит вам, что это существительное мужского рода, которое означает «здание». И, опять же, вы получаете еще одно примерное предложение, содержащее слово «edificio».
Возможно, вы также заметили маленький символ динамика и слово «ESCUCHAR». Слово «escuchar» означает «слушать», и если нажать на динамик, можно услышать произносимое слово.
Спряжения
Наконец, еще одна чрезвычайно полезная функция WordReference — кнопка «спряжение». Если вы введете любой глагол, в любом времени и в любом лице, вы получите маленькую кнопку, которая называется «спряжение». Если вы нажмете здесь, вы увидите спряжение глагола во всех временах и для всех лиц. Давайте посмотрим на «хаблар». Итак, вы вводите «хаблар», а затем нажимаете кнопку «спряжение»:
Появится экран, на котором показаны все формы глагола:
Если вы проделаете это с неправильным глаголом, появится еще одна вещь. Например, если мы напечатаем глагол «contar», означающий «считать», мы увидим, что некоторые буквы отображаются синим цветом. Если вы видите синие буквы, это означает, что эта часть глагола является неправильным битом, который не соответствует обычным моделям спряжения глаголов.
Например, если мы напечатаем глагол «contar», означающий «считать», мы увидим, что некоторые буквы отображаются синим цветом. Если вы видите синие буквы, это означает, что эта часть глагола является неправильным битом, который не соответствует обычным моделям спряжения глаголов.
Сколько языков?
Итак, это WordReference. Просто введите www.wordreference.com в любом браузере, и вы получите доступ к одному из лучших словарей в Интернете.
Вы можете использовать WordReference для поиска переводов на следующие языки и со следующих языков:
1. Французский
2. Итальянский
3. Португальский
4. Румынский
5. Немецкий
6. Голландский
7. Шведский
8. Русский
9. Испанский
10. Польский
11. Чешский
12. Греческий
13. Турецкий
14. Китайский
15. Японский
16. Корейский
17. Арабский
Приятного обучения!
Если вы хотите прочитать больше моих статей или хотите выучить язык с помощью одного из моих курсов под названием «Языки за 3 минуты», вы можете найти их все на моем веб-сайте www.