Символьные типы данных C++
Главная » Программирование и разработка
Программирование и разработкаНа чтение 4 мин Просмотров 177 Опубликовано
Тип данных Char — это тип данных, который используется для хранения одного символа. Он всегда заключен в одинарные кавычки (’ ’).
Синтаксис:
Char variable;
Пример:
С++
#include <iostream>usingnamespacestd;intmain(){charc ='g';cout << c;return0;}
Выход
g
Содержание
- Значение ASCII
- Преобразование символьного значения в соответствующее значение ASCII
- Преобразование значения ASCII в соответствующее значение символа
- Escape-последовательность в C++
Значение ASCII
Значение ASCII означает американский стандартный код для обмена информацией. Он используется для представления числового значения всех символов.
Он используется для представления числового значения всех символов.
ASCII Range of ‘a’ to ‘z’ = 97-122
ASCII Range of ‘A’ to ‘Z’ = 65-90
ASCII Range of ‘0’ to ‘9’ = 48-57
Преобразование символьного значения в соответствующее значение ASCII
Чтобы преобразовать символ в значение ASCII, мы должны привести его к типу, используя int(character), чтобы получить соответствующее числовое значение.
Пример:
С++
#include <iostream>usingnamespacestd;intmain(){charc ='g';cout <<"The Corresponding ASCII value of 'g' : ";cout <<int(c) << endl;c ='A';cout <<"The Corresponding ASCII value of 'A' : ";cout <<int(c) << endl;return0;}
Выход
The Corresponding ASCII value of 'g' : 103 The Corresponding ASCII value of 'A' : 65
Преобразование значения ASCII в соответствующее значение символа
Чтобы преобразовать значение ASCII в соответствующее значение символа, мы должны привести его к типу, используя char(int), чтобы получить соответствующее значение символа.
Пример:
С++
#include <iostream>usingnamespacestd;intmain(){intx = 53;cout <<"The Corresponding character value of x is : ";cout <<char(x) << endl;x = 65;cout <<"The Corresponding character value of x is : ";cout <<char(x) << endl;x = 97;cout <<"The Corresponding character value of x is : ";cout <<char(x) << endl;return0;}
Выход
The Corresponding character value of x is : 5 The Corresponding character value of x is : A The Corresponding character value of x is : a
Escape-последовательность в C++
Escape-последовательности — это символы, которые определяют, как строка должна быть напечатана в окне вывода.
| No | Escape Sequences | Character |
|---|---|---|
| 1. | \n | Newline |
| 2. | \\ | Backslash |
| 3. | \t | Horizontal Tab |
| 4. | \v | Vertical Tab |
| 5. | \0 | Null Character |
Пример:
С++
#include <iostream>usingnamespacestd;intmain(){chara ='G';charb ='\t';charc ='F';chard ='\t';chare ='G';charf ='\n';string s ="is the best";cout << a << b << c << d << e << f << s;return0;}
Выход
G F G is the best
Типы данных в программировании — ProgKids
В программировании типы данных являются фундаментальными понятиями, которые определяют, какие виды данных могут быть использованы в программе и как они могут быть обработаны.
Типы данных в программировании определяются с помощью языка программирования, который вы используете для написания кода.
Существует несколько основных типов данных, используемых в программировании.
В этой статье мы рассмотрим наиболее распространенные типы и то, как они используются в различных языках программирования.
Целочисленные типы данных
Целочисленные типы данных используются для хранения целых чисел без дробной части. Они могут быть знаковыми или беззнаковыми. Знаковые целочисленные типы данных могут хранить отрицательные числа, а беззнаковые целочисленные типы данных могут хранить только положительные числа.
Например, в языке программирования C целочисленный тип «int» используется для хранения целых чисел. В языке Python целочисленные типы можно определить с помощью ключевого слова «int».
Типы данных с плавающей точкой
Типы данных с плавающей точкой используются для хранения чисел с дробной частью. Они также могут быть знаковыми или беззнаковыми.
Например, в языке программирования C тип данных «float» используется для хранения чисел с плавающей точкой одинарной точности, а тип данных «double» используется для хранения чисел с плавающей точкой двойной точности. В языке Python тип данных с плавающей точкой можно определить с помощью ключевого слова «float».
Символьные типы данных
Символьные типы данных используются для хранения символов, таких как буквы, цифры и знаки препинания.
Например, в языке программирования C символьный тип данных «char» используется для хранения одного символа. В языке Python символьный тип данных можно определить с помощью ключевого слова «str».
Логические типы данных
Логические типы данных используются для хранения значений истинности, которые могут быть либо истинными, либо ложными.
Например, в языке программирования C логический тип данных «bool» используется для хранения значений истинности. В языке Python логический тип данных тоже «bool» и может принимать значения True (истина) или False (ложь).
Логические типы данных широко используются в программировании для принятия решений на основе условий. Например, вы можете использовать логический тип данных, чтобы проверить, является ли число четным или нечетным. Если число четное, логический тип данных будет истинным, если нечетное – ложным.
Массивы
Массивы – это тип данных, который может содержать множество значений одного типа. Массивы используются для хранения множества значений, которые могут быть обработаны вместе.
Например, в языке программирования C массив может быть определен следующим образом:
int numbers[5] = {1, 2, 3, 4, 5};
Это определение массива «numbers», который содержит 5 целочисленных значений. В языке Python массивы могут быть определены с помощью структуры данных «list».
Структуры данных
Структуры данных – это типы данных, которые объединяют несколько значений различных типов в единую структуру. Структуры данных используются для более сложных операций с данными, таких как хранение информации о пользователе, товарах в магазине или контактах в адресной книге.
Например, в языке программирования C структура данных может быть определена следующим образом:
struct Person {
char name[50];
int age;
float salary;
};
Это определение структуры данных «Person», которая содержит имя (строковое значение), возраст (целочисленное значение) и зарплату (значение с плавающей точкой).
КлассыКлассы – это шаблоны для создания объектов, которые могут содержать данные и методы для их обработки. Классы являются фундаментальным понятием в объектно-ориентированном программировании и используются для моделирования реальных объектов или процессов.
Классы могут содержать переменные, которые называются полями, и методы, которые могут использоваться для выполнения действий с этими полями. Например, класс «Студент» может содержать поля «имя», «фамилия» и «оценки», а метод «средний балл» может использоваться для вычисления среднего балла студента.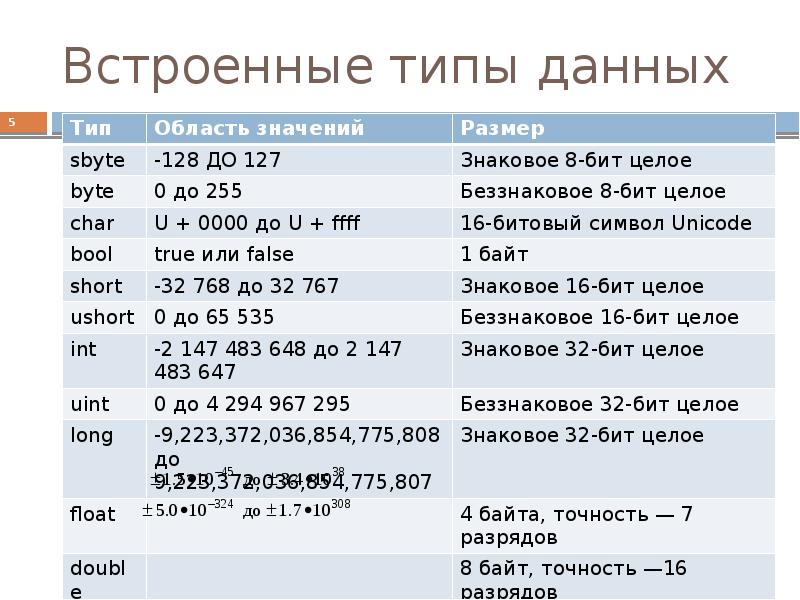
Ссылочные данные
Ссылочные данные – это данные, которые хранятся в памяти и на которые переменные ссылается. В отличие от примитивных типов данных, таких как числа и символы, ссылочные данные не хранятся в переменной напрямую. Вместо этого переменная содержит ссылку на объект в памяти.
Ссылочные данные могут быть использованы для создания сложных структур данных, таких как списки, деревья и графы. Они также позволяют создавать объекты классов, о которых мы говорили ранее.
Типизация
Типизация – это процесс определения типа данных переменной в программе. Типизация может быть статической или динамической. В статической типизации тип переменной определяется во время компиляции, а в динамической тип определяется во время выполнения программы.
Статическая типизация может помочь предотвратить ошибки в программе, связанные с неправильным использованием типов данных, но требует более тщательной работы в процессе разработки. Динамическая типизация более гибкая, но может привести к ошибкам, связанным с неправильным использованием типов данных.
В заключение, типы данных являются фундаментальными понятиями в программировании, которые позволяют нам хранить и обрабатывать различные типы данных.
Различные языки программирования могут иметь свои собственные типы данных, но базовые концепции остаются одинаковыми.
Понимание типов данных и их использование является важным для создания эффективных и надежных программ. Неправильное использование типов данных может привести к ошибкам выполнения, что сделает непредсказуемым результат работы программы.
Кроме того, правильное использование типов данных может помочь ускорить выполнение программы, снизить потребление памяти и улучшить ее производительность.
Ну а если вы хотите научится кодингу на Python, то запишитесь на бесплатный пробный урок в нашей школе программирования для детей ProgKids.
Карен Константин
Преподаватель Progkids
Расчет диапазона для типа данных char
В этой статье давайте обсудим расчет диапазона для типа данных char.
- Мы знаем, что переменная типа char занимает 1 байт памяти.
- Кроме того, тип данных char будет использоваться для хранения 1 байта подписанных данных.
Представление данных со знаком в 1 байт:
Посмотрим, как будут храниться подписанные данные в 1 байте памяти компьютера. Начнем с 1-байтового представления данных со знаком.
1 байт означает 8 бит. Из 8 бит старший бит будет использоваться для представления знака данных. Если он равен 0, то данные считаются положительными. Если он равен 1, то данные считаются отрицательными. А если 7-й бит или старший бит равен 1, то данные считаются отрицательными.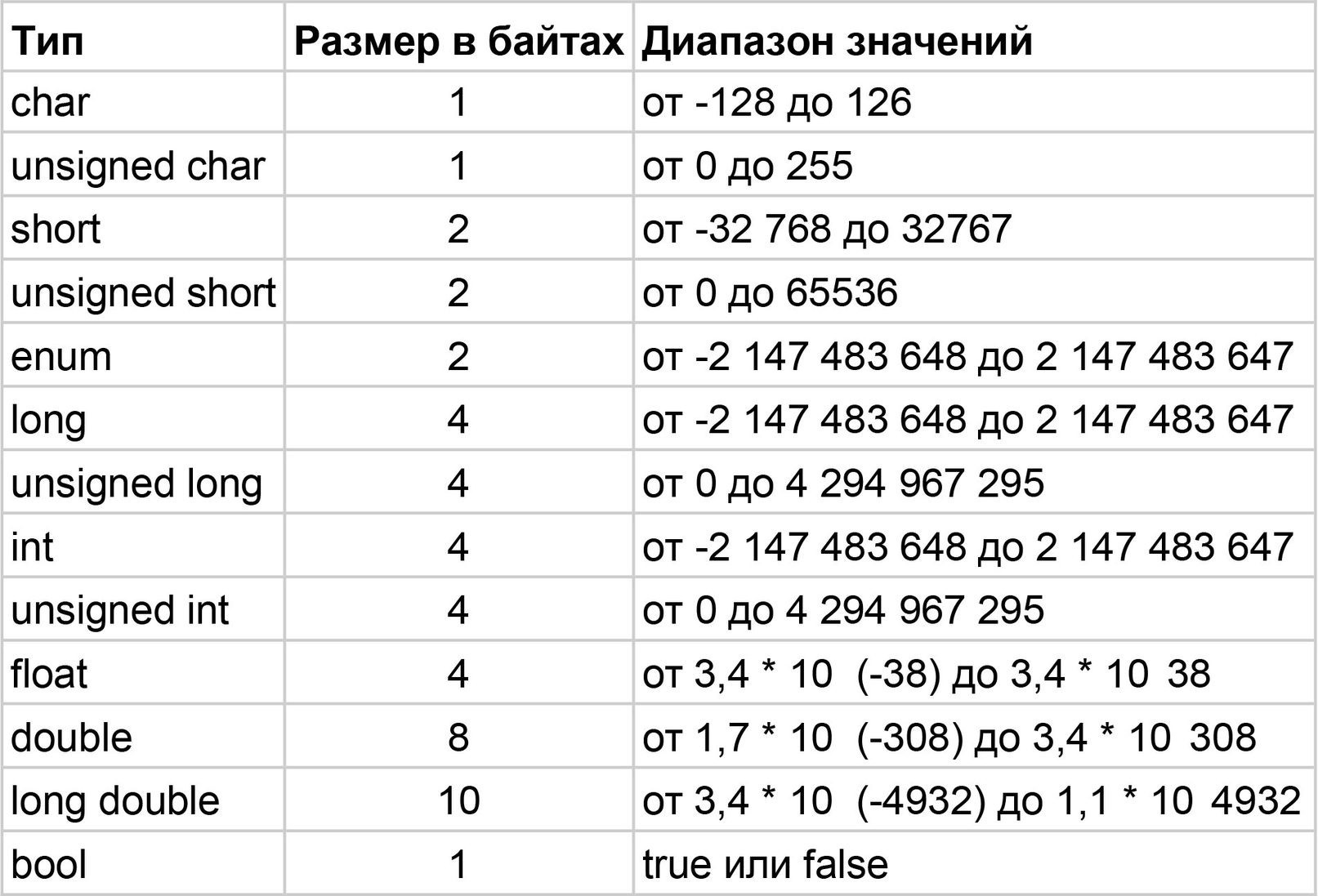 А оставшиеся 7 бит используются для хранения величины.
А оставшиеся 7 бит используются для хранения величины.
Величина сохраняется в формате дополнения до 2, если данные отрицательные.
Данные со знаком означают, что для кодирования знака данных используется выделенный 1 бит.
Рисунок 1. 1-байтовое представление данных со знаком
Рассмотрим пример. Представьте данные -25 в 1-байтовом представлении данных со знаком.
Итак, приведены данные -25. Он состоит из двух частей. Одно — знак, а другое — величина. Знак отрицательный (-), а величина равна 25. Поскольку данные отрицательны, величина будет храниться в форме дополнения до 2. Вы должны помнить это. Таким образом, из 8 бит седьмой бит, то есть старший бит, в данном случае будет равен 1. А оставшиеся 7 бит используются для хранения величины 25 в форме дополнения до 2. Давайте посмотрим, как мы можем это сделать.
А оставшиеся 7 бит используются для хранения величины 25 в форме дополнения до 2. Давайте посмотрим, как мы можем это сделать.
Во-первых, приведены данные -25. Здесь давайте представим величину 25 в двоичном формате.
Рисунок 3. Вычисление дополнения до 2 для -25
Двоичная форма числа 25 — 11001. Дополнение до 1 для двоичного числа 25 — 00110.
Для представления числа 25 требуется как минимум 5 бит. Но это 1-байтовое представление, так что оставшиеся 3 бита будут. Давайте рассмотрим их как 0. 00011001 — это представление для 25 или +25.
Теперь возьмем дополнение до 1 этого двоичного формата. Итак, теперь это будет 11100110. Это форма дополнения до 1 числа 25.
Итак, теперь это будет 11100110. Это форма дополнения до 1 числа 25.
Возьмем это в виде дополнения до 2. Таким образом, вы должны добавить 1 к этому. 11100111 — это форма 25, дополненная до 2.
Наконец-то мы получили это число, которое равно 11100111. Это 1-байтовые данные. И обратите внимание на 7-й бит, равный 1 (см. рис. 2). Итак, это знаковый бит, который представляет отрицательные данные.
7-й бит — это бит знака, а остальные биты — это величина. Итак, величина 25 в форме дополнения до 2.
Если я преобразую -25 в шестнадцатеричный формат, что произойдет?
Рисунок 4. Преобразование -25 в шестнадцатеричный формат
1110 — младший полубайт, 0111 — старший полубайт.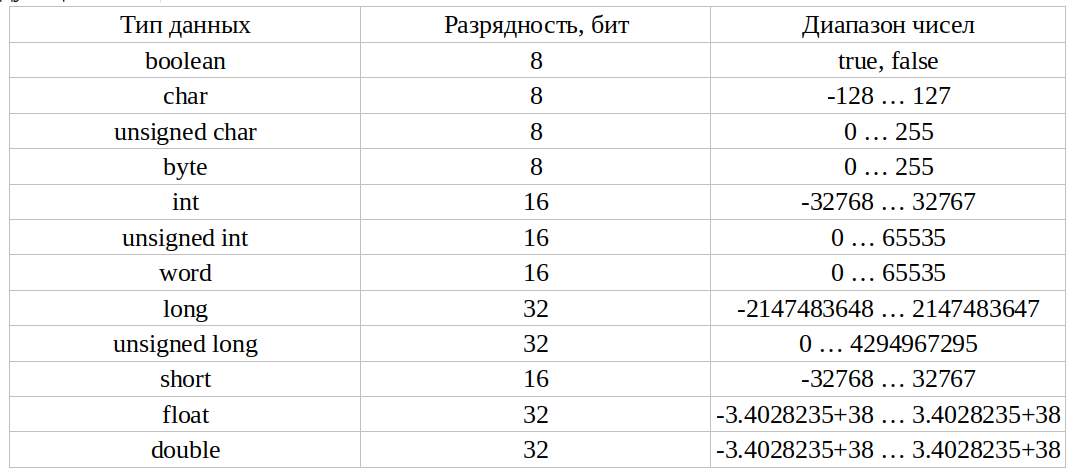 1110 оказывается 7, а 1110 оказывается 14. 14 означает E. 11100111 оказывается 0xE7. 0xE7 — это шестнадцатеричное значение десятичного числа -25.
1110 оказывается 7, а 1110 оказывается 14. 14 означает E. 11100111 оказывается 0xE7. 0xE7 — это шестнадцатеричное значение десятичного числа -25.
Это очень просто. Помните, что в представлении данных со знаком зарезервирован выделенный 1 бит для кодирования знака, и у вас остается только семь бит для представления величины.
Теперь давайте посмотрим на другой пример. Представьте данные 25 в 1-байтовом представлении данных со знаком. То есть +25.
Рис. 5. Пример
Здесь знак положительный. Вот почему старший бит будет равен 0. А поскольку данные положительные, вам не нужно преобразовывать величину в форму дополнения до 2. Итак, вы конвертируете это в двоичный формат здесь. 00011001 — это двоичный формат 25.
00011001 — это двоичный формат 25.
Если я преобразую 00011001 в шестнадцатеричный формат, 1001 будет 9, а 0001 будет 1. Таким образом, получится 0x19 , что является шестнадцатеричным значением для десятичного числа +25.
Теперь, исходя из этого, давайте обсудим диапазон типов данных char.
Рисунок 6. Диапазон типов данных Char при знаке +ve
При положительном знаке седьмой бит будет равен нулю. Таким образом, наименьшее значение, которое мы можем сохранить, это все нули. Вот почему величина будет равна 0. Это наименьшая возможная величина.
И самым высоким значением будет заполнение всех битов величины 1. Поэтому самым высоким положительным значением будет 127.
отрицательно, седьмой бит будет равен 1. Наименьшее возможное значение равно -128. -128 означает, что все биты величины заполнены нулями. Итак, 10000000 — это формат дополнения до 2 для -128.
Максимально возможное отрицательное значение -1. Итак, когда он равен -1, все биты модуля заполняются 1. 11111111 — это формат дополнения до 2 для -1.
Теперь у нас есть два диапазона для положительных и отрицательных значений. Для положительных значений это может быть от 0 до 127. Для отрицательных значений диапазон будет от 0 до -128. Таким образом, диапазон типа данных char составляет от -128 до 127. Это диапазон для char или подписанного char (рис. 8).
Рис. 8. Диапазон типов данных Char
Unsigned char Диапазон:
- Тип данных unsigned char используется для хранения 1 байта данных без знака.
- В беззнаковом представлении данных ни один конкретный бит не используется специально для кодирования знака.
Переменные
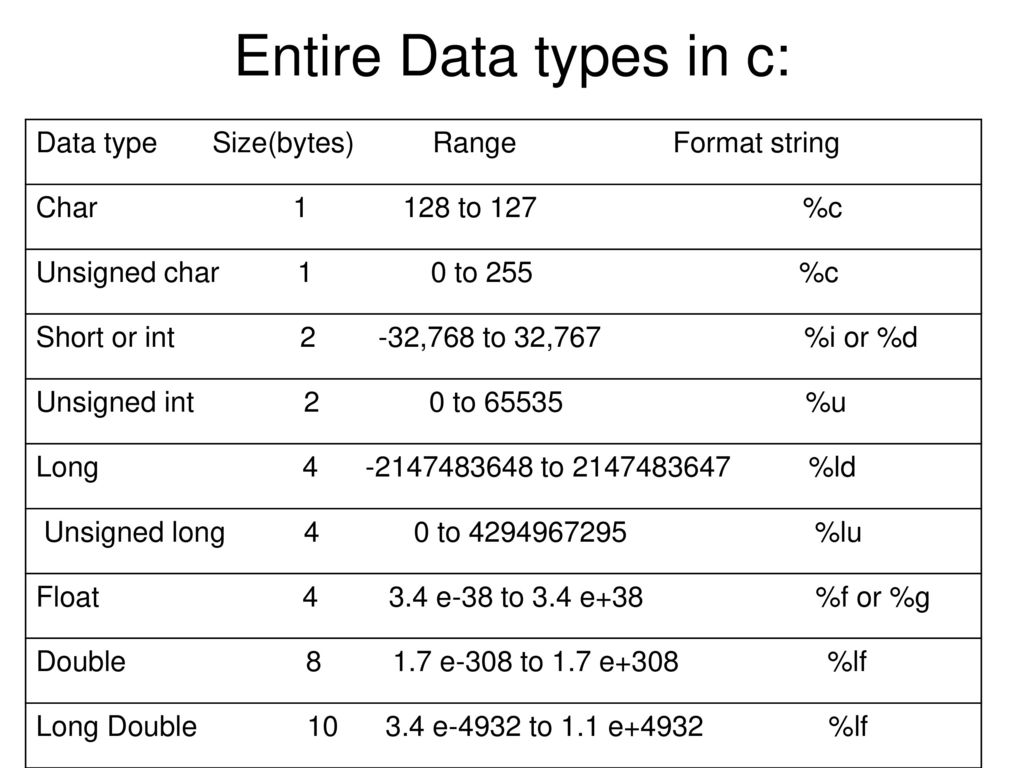
Переменная в C++ — это имя, данное данным, которые мы хотим использовать. Он действует как дескриптор информации хранится там. Имя переменной не имеет ничего общего с информацией, которую она может содержать. Все объявленные переменные в C++ имеют связанный с ними тип данных. C++ поддерживает множество типов данных, как встроенных, так и встроенных. включая библиотеки.
Все объявления переменных имеют схожий синтаксис. Это всегда тип данных, за которым следует имя переменной. После этого они могут иметь список имен переменных, разделенных запятыми, точку с запятой в конце строки или присваивание. оператор (=), придающий переменной некоторое начальное значение.
Пример использования int: целое число;
int число1, число2, число3,. ..;
..;
целое число = -2; Собственные типы данных
Собственные типы данных — это простые типы информации, которые C++ распознает без включение дополнительных библиотек. Данные могут быть представлены как числовые (целые и десятичные числа), буквенные символы (ABC, 123 и т. д.) и логические значения (True или False).
| Имя | Ключевое слово | Представление | Пример |
| Целое число | инт | Целые числа от -2 147 483 648 до 2 147 483 647 | целое число; |
| Беззнаковое целое | беззнаковое целое, беззнаковое | Целые числа от 0 до 4,294 967 295 | беззнаковое целое число; число без знака; |
| Плавать | плавать | Десятичные числа. 1,0, 3,14, 1,001 и т. д. | плавающее число; |
| Двойной | двойной | Десятичные числа. Содержит более точные значения, чем числа с плавающей запятой. | двойное число; |
| Персонажи | уголь | Буквенно-цифровые символы. Специальные символы экранируются ‘\n’, ‘\0’ и т. д. Все символы заключаются в одинарные кавычки Таблица ASCII | символ альфа = ‘а’; |
| логический | логический | True, False, 1, 0. Любой числовой или буквенный символ, отличный от нуля, равен True. | логический тф = Истина; логический tf = 0; логическое значение TF = 3; (Это то же самое, что и правда) |
Специальные типы данных C++
Библиотеки C++ позволяют нам использовать более сложные структуры данных для решения общих задач намного проще, чем с собственными типами данных.
Двумя такими типами данных являются строки и потоки. Строка C++ происходит из библиотеки string и может содержать любое количество
символы (char). Строки C++ можно сравнивать друг с другом с помощью ==, они могут сказать вам, сколько символов содержит строка,
и может даже искать подстроки.