Сетевые базы данных.
Главная / Базы данных / Сетевые базы данных.
в Базы данных 14.01.2018 0 11,441 Просмотров
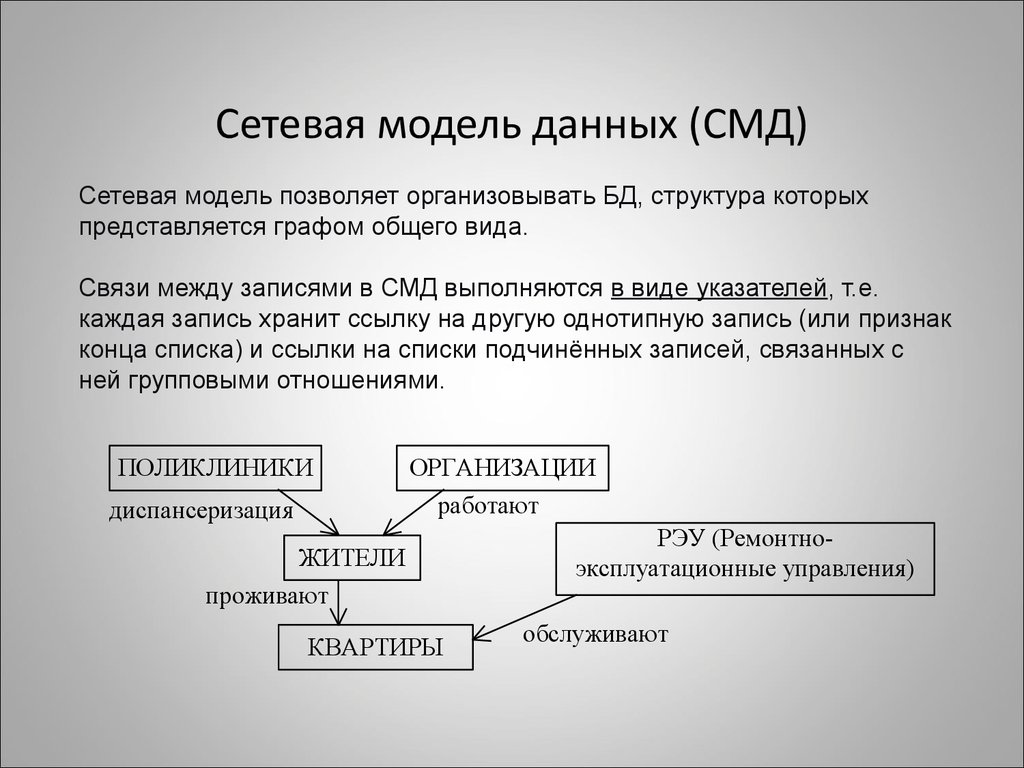
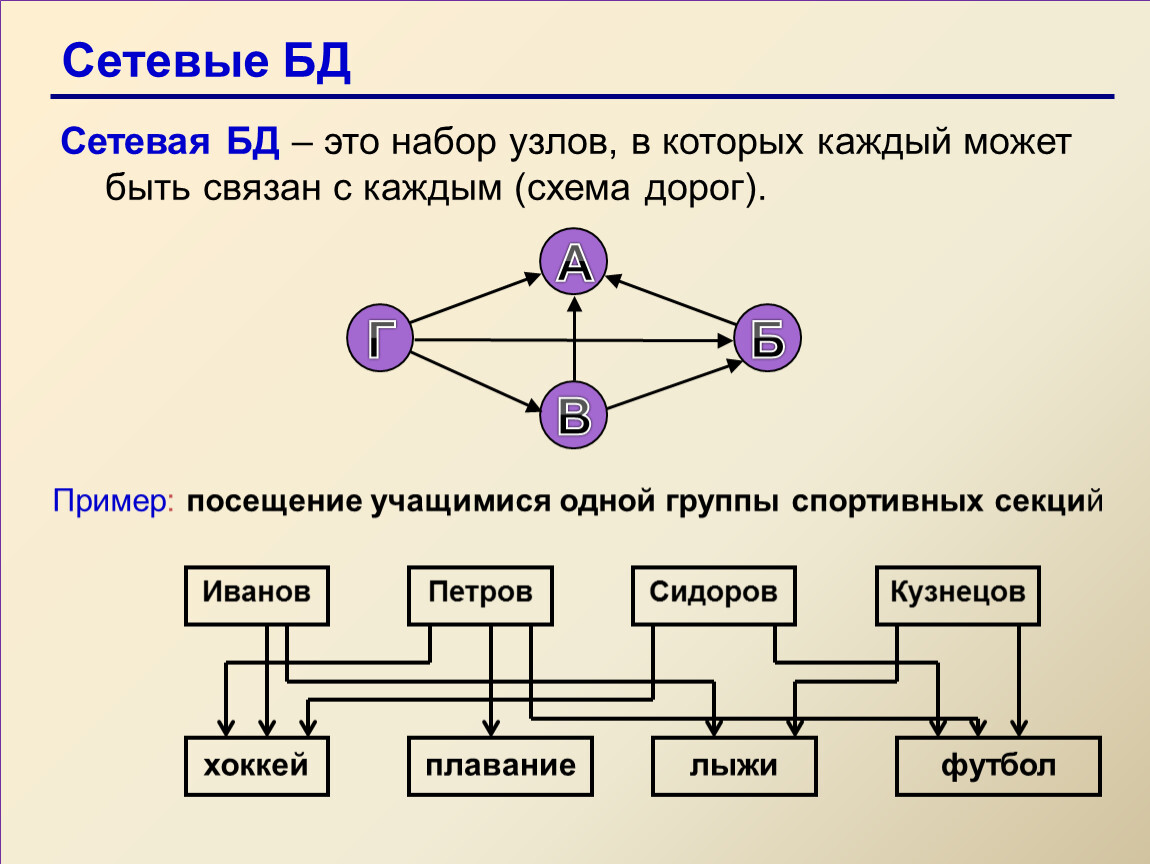
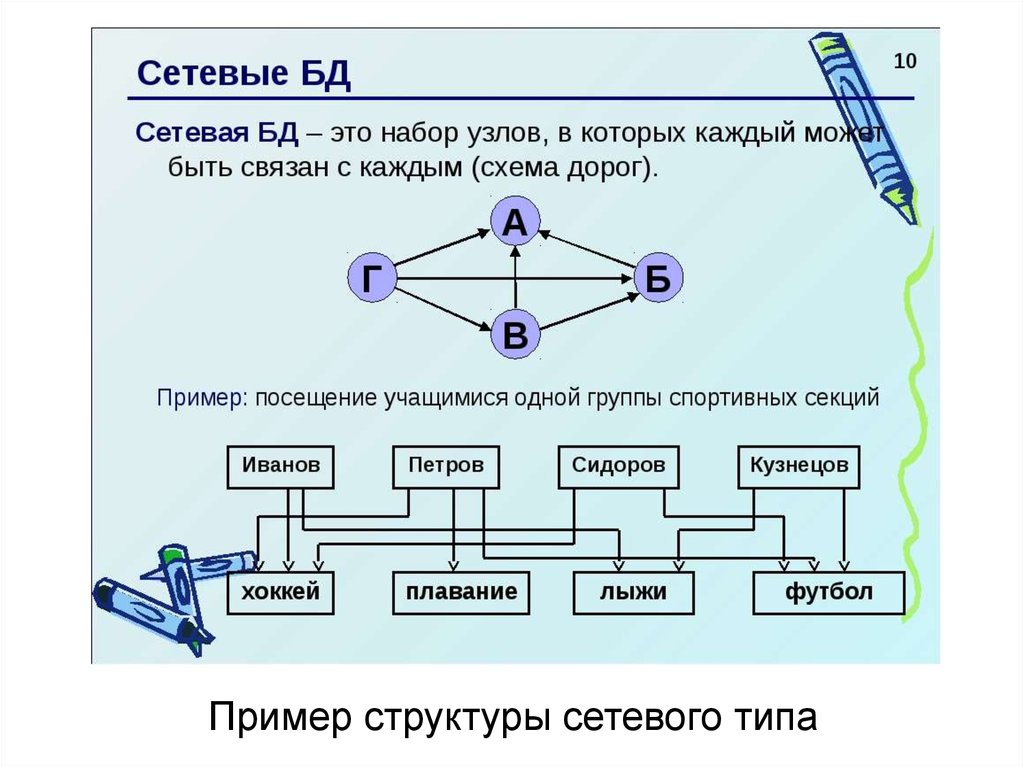
Сетевая база данных – это модель данных, где несколько записей или файлов могут быть связаны с несколькими владельцами файлов и наоборот. Модель может рассматриваться как перевернутое дерево, где каждый член – это отрасли, связанные с владельцем, который находится в нижней части дерева. По сути, это отношения в чистой форме, где один элемент может указывать на множество элементов данных, и само по себе может быть указано несколько элементов данных.
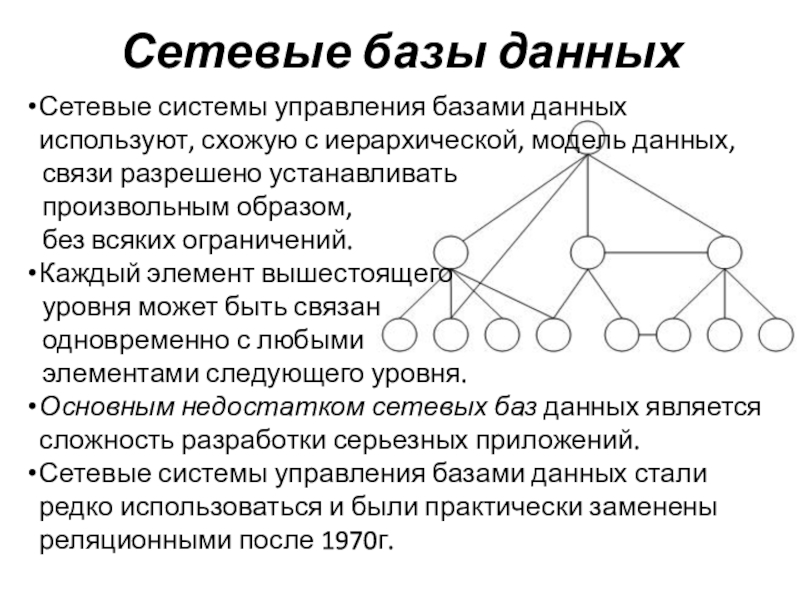
Модель сетевой базы данных позволяет каждой записи иметь несколько родителей и несколько дочерних записей, которые, когда они визуализируются, принимают форму сетевой структуры сетевых записей. В отличие от иерархической модели данных она может иметь только одну родительскую запись, но может иметь много дочерних записей.
Это свойство иметь несколько ссылок применяется двумя способами: схема и сама база данных может рассматриваться как обобщенный график типов записей, которые связаны типами отношений.
Сетевая модель базы данных
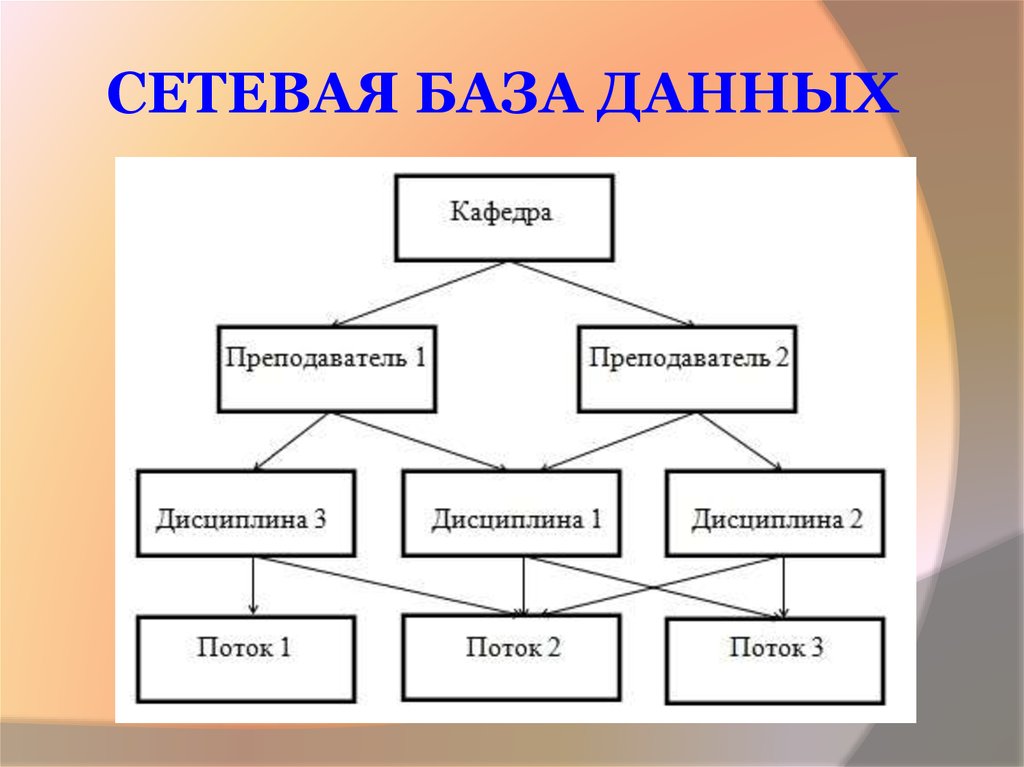
Улучшенная форма иерархической модели данных, сетевая модель представляет данные в виде дерева записей. Связи между таблицами (отчеты) выражаются в виде наборов. В наборе есть одна родительская запись (владелец) и одна или более дочерних записей (члены). Связанные записи в наборе напрямую связаны с указателями, а не путём сопоставления повторяющихся столбцов, как и в случае с реляционной моделью данных.
Записи, связанные с одним владельцем
Модель сетевой базы данных позволяет записям из более чем одной таблицы быть связанными с одним владельцем с записями из другой таблицы.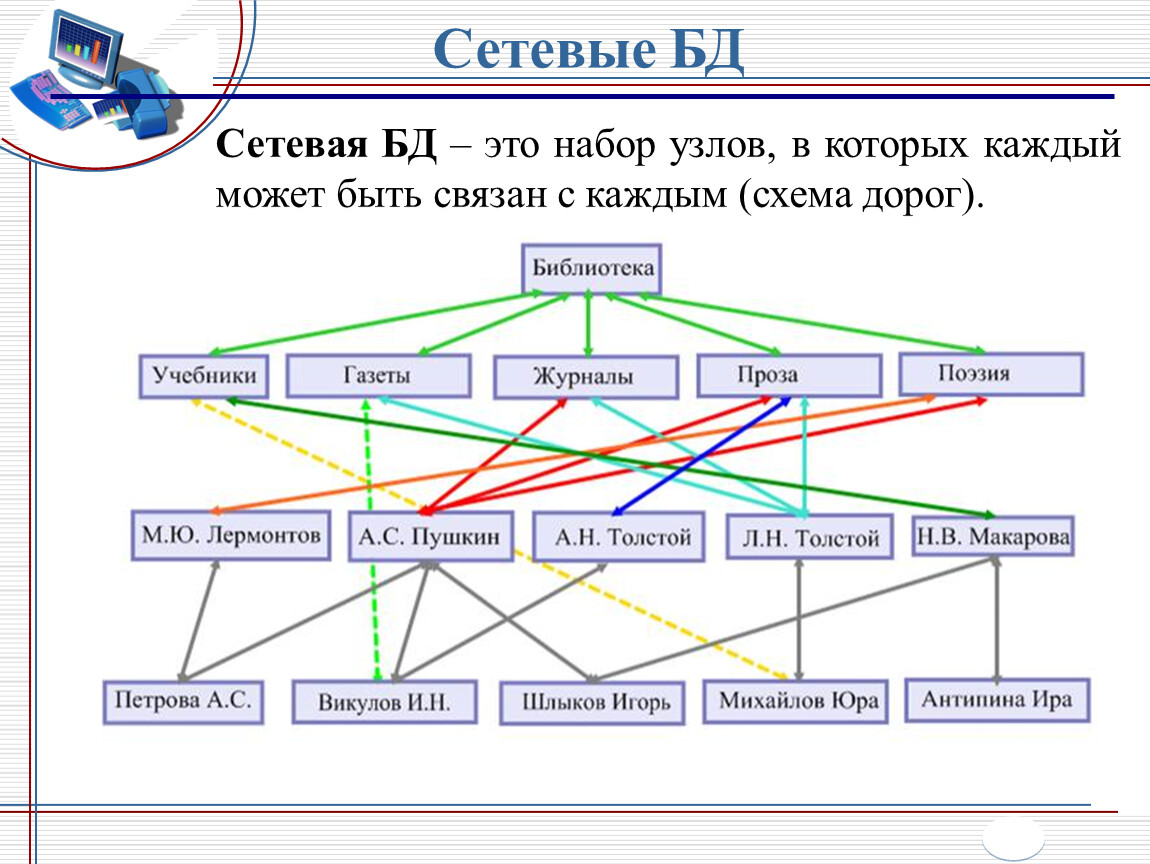 Это обеспечивает определенное преимущество над реляционной базой при запросе результатов из нескольких внешних ключей таблиц, связанных с одним первичным ключом таблицы. В базе данных медиа-коллекции, таких как альбом песен и видео записи, все они могут быть членами собственника в одном комплекте, как показано на рисунке 2. Это означает, что оба альбома и фильмы для данного собственника могут быть получены за одну операцию. При этом отпадает необходимость хранить и потенциально изменять порядок временных результатов в середине операции, что приводит к повышению производительности запросов. Без необходимости хранить и сохранять дубликаты столбцы базы данных также помогают уменьшить дисковое пространство и память.
Это обеспечивает определенное преимущество над реляционной базой при запросе результатов из нескольких внешних ключей таблиц, связанных с одним первичным ключом таблицы. В базе данных медиа-коллекции, таких как альбом песен и видео записи, все они могут быть членами собственника в одном комплекте, как показано на рисунке 2. Это означает, что оба альбома и фильмы для данного собственника могут быть получены за одну операцию. При этом отпадает необходимость хранить и потенциально изменять порядок временных результатов в середине операции, что приводит к повышению производительности запросов. Без необходимости хранить и сохранять дубликаты столбцы базы данных также помогают уменьшить дисковое пространство и память.
Исследование эффективности
Реальные данные показывают, что прирост производительности и экономия ресурсов с использованием сетевых баз данных может быть довольно значительной. В структуре данных, используются трехсторонние отношения между художником, альбомом и таблицами песни, наши разработчики сравнили изменения данных и выполнение запросов в реляционной модели и сетевой базе данных с помощью настольных систем и небольших, потребительских устройств.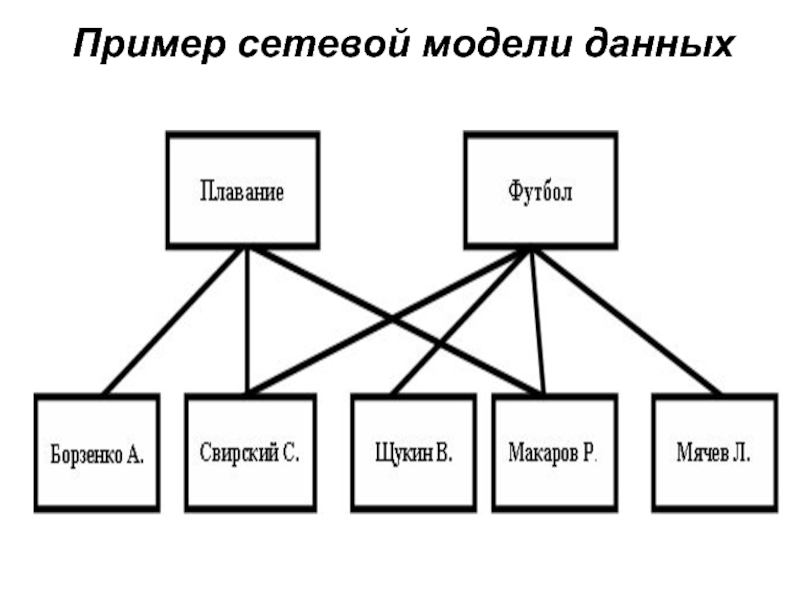 Они обнаружили, что сетевая модель использует на 29% меньше дискового пространства для хранения одинакового количества записей и связей, чем реляционная модель данных. Все сбережения при хранении можно отнести к замене ключевых показателей артист-альбом и альбом-песни зарубежные на установленные указатели.
Они обнаружили, что сетевая модель использует на 29% меньше дискового пространства для хранения одинакового количества записей и связей, чем реляционная модель данных. Все сбережения при хранении можно отнести к замене ключевых показателей артист-альбом и альбом-песни зарубежные на установленные указатели.
Удаление этих структур данных, оказало огромное влияние на требования к хранению, поскольку типичный индекс B-дерева требует примерно в 1,3 раза больше пространства, чем индексы. Они также обнаружили, что сетевая модель базы данных увеличила до 23 раз лучше производительность вставки и выросла в 123 раза быстрее производительность запросов, как показано в таблице 1.
Сетевая база данных против реляционной базы данных
Различные требования управления означают разные структуры данных и различные методы хранения и доступа к данным. В результате система может состоять из нескольких таблиц без связей или сотни таблиц, связанных со сложными взаимосвязями. В то время как реляционная модель данных является стандартом де-факто, теперь мы знаем, что она не всегда обеспечивает оптимальные решения для более сложных задач управления данными.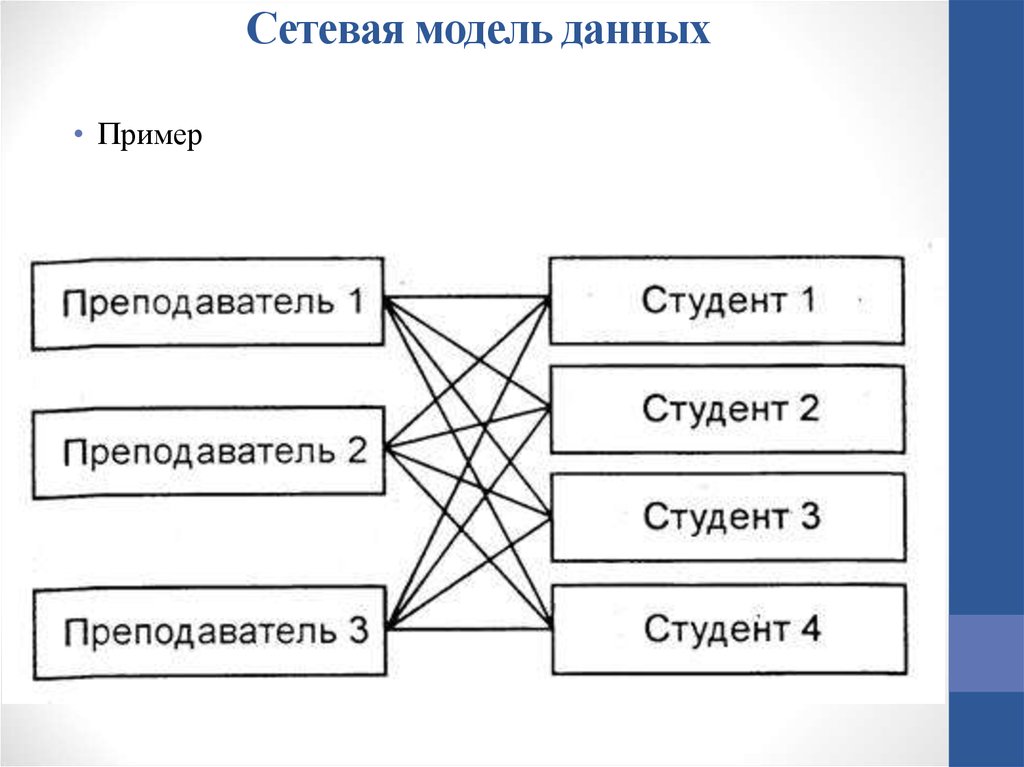 Выбор подходящей модели данных, или даже объединение нескольких моделей, может дать гораздо более эффективный результат, чем реляционная модель данных работающая в одиночку. В результате достигается значительная экономия затрат, повышение качества и увеличение пользовательского опыта.
Выбор подходящей модели данных, или даже объединение нескольких моделей, может дать гораздо более эффективный результат, чем реляционная модель данных работающая в одиночку. В результате достигается значительная экономия затрат, повышение качества и увеличение пользовательского опыта.
Вывод
В то время как реляционная модель данных является очень популярной из-за её простоты использования, она не требует ключа и индексов таблицы, что существенно замедляет работу приложения. Сетевая модель базы данных обеспечивает более быстрый доступ к данным и является оптимальным методом для быстрого применения. Так что если Вы нажмете на любимого артиста, а также если хотите посмотреть список для поиска лишних альбомов и просмотреть названия фильмов на вашем медиа-плеере, это может быть создано сетевыми моделями СУБД.
2018-01-14Предыдущий: Иерархическая база данных.
Следующий: Объектно-ориентированная база данных (ООСУБД).
Сетевая база данных.
 Сетевая модель данных. Концептуальная модель и структура сетевой БД.
Сетевая модель данных. Концептуальная модель и структура сетевой БД.Здравствуйте, уважаемые посетители моего скромного блога для начинающих вебразработчиков и web мастеров ZametkiNaPolyah.ru. Продолжаем рубрику Заметки о MySQL, в которой уже были публикации: Нормальные формы и транзитивная зависимость, избыточность данных в базе данных, типы и виды баз данных, настройка MySQL сервера и файл my.ini, MySQL сервер, установка и настройка, Архитектура СУБД и архитектура баз данных. Сегодня я бы хотел более подробно остановиться на сетевых базах данных, в общем-то, в одной из прошлых публикация я практически вскользь упоминал о них, но особой ясности не вносил. Следует сказать, что сетевая база данных относится к теоретико-графовым моделям, про то, что такое графы я постараюсь объяснить в другой публикации, сейчас этот момент не столь важен, но если хотите, то почитайте учебник математики. В этой публикации я постараюсь доступным и понятным языком рассказать о сетевых базах данных и принципе их работы, как обычно всю математику я сведу к минимуму и все умные термины оставлю за пределами данной публикации.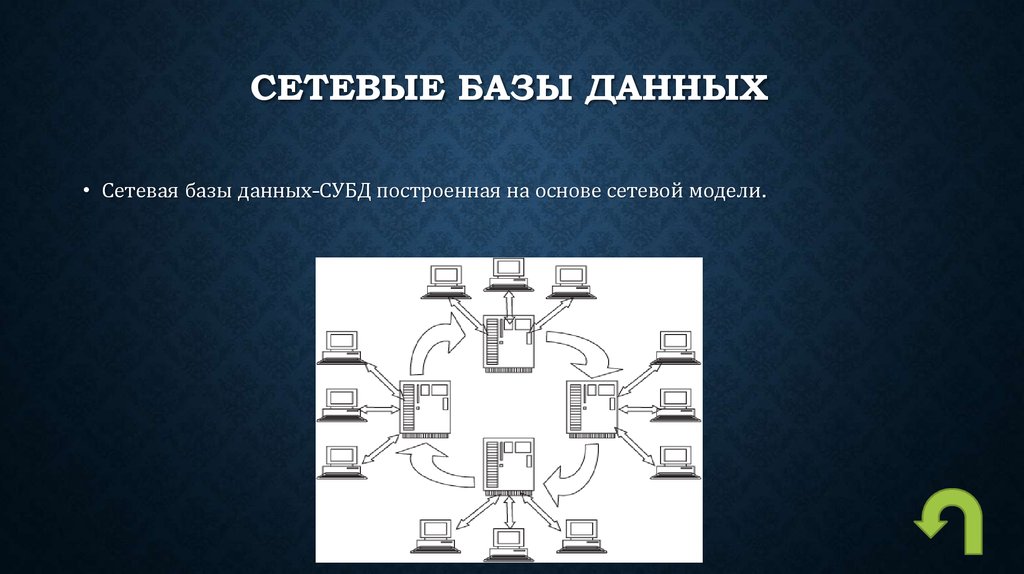 Там, где я не смогу что-то объяснить без специфической терминологии, а такие моменты могут появиться, я все обязательно поясню.
Там, где я не смогу что-то объяснить без специфической терминологии, а такие моменты могут появиться, я все обязательно поясню.
Так вот, сетевые базы данных относятся к теоретико-графовым моделям баз данных, помимо сетевых баз данных сюда еще входят иерархические базы данных. Кстати, на основе математики сетевых баз данных существуют различные СУБД, это в основном коммерческие версии. У сетевых баз данных существуют характерные операции навигации, манипуляции и управления данными, с которыми мы и постараемся разобраться в данной публикации. Стоит сказать, что помимо теоретико-графовой модели баз данных существует еще и теоретико-множественная модель, к которой относятся реляционные базы данных, математика которых заложена в MySQL сервере, но до них мы еще обязательно дойдем. А теперь приступим к рассмотрению сетевой модели данных.
Не забываем подписываться на RSS-ленту и на публичную страницу Вконтакте.
Сетевая модель данных
Содержание статьи:
- Сетевая модель данных
- Структура сетевых баз данных
- Преобразование концептуальной модели в сетевую модель данных
- Управление сетевыми данными
Прежде чем перейти к описанию процессов, которые происходят внутри сетевой модели данных, давайте ознакомимся со структурой сетевой базы данных, чтобы иметь представление о том, с чем предстоит иметь нам дело.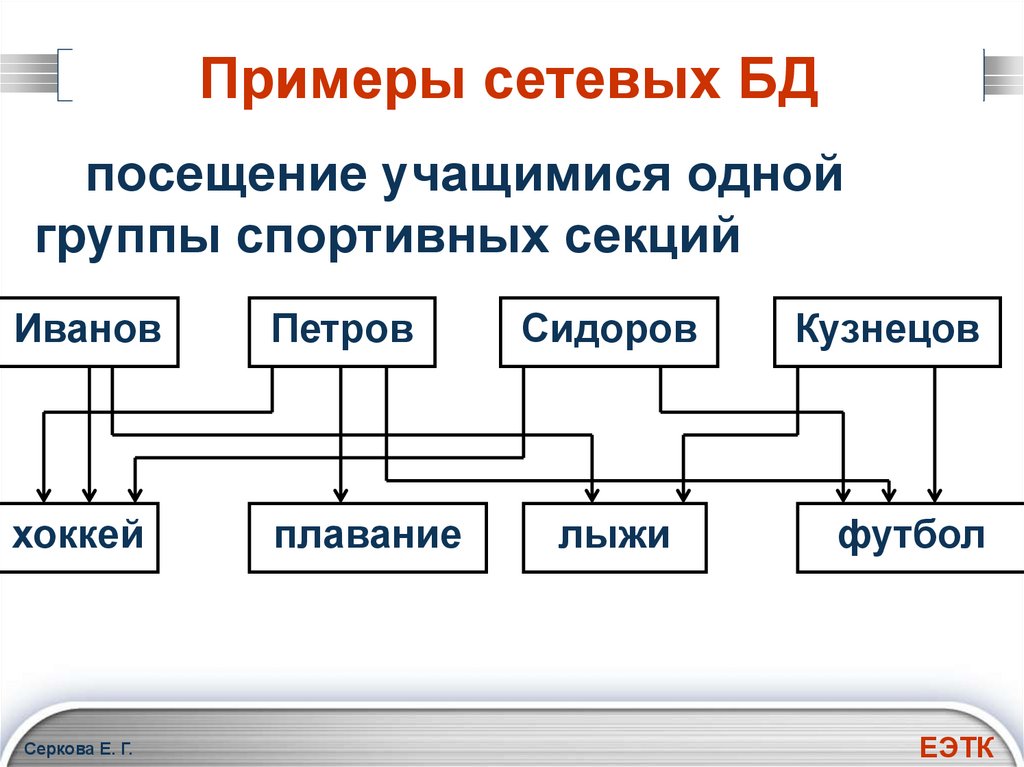 Прежде всего, следует разобраться со словом сети, которое присутствует в название: «сетевая модель». Сети – это естественный способ представления отношений между объектами базы данных и связей между этими объектами. Под словом объекты следует понимать таблицы баз данных или сущности. В общем, как вам удобно, так и называйте, вас везде поймут правильно.
Прежде всего, следует разобраться со словом сети, которое присутствует в название: «сетевая модель». Сети – это естественный способ представления отношений между объектами базы данных и связей между этими объектами. Под словом объекты следует понимать таблицы баз данных или сущности. В общем, как вам удобно, так и называйте, вас везде поймут правильно.
Сетевые базы данных опираются на математику графов, конкретнее, сетевую модель данных можно представить в виде ориентированного графа. Направленный граф состоит из узлов и ребер. Узлы направленного графа – это ни что иное, как объекты сетевой базы данных, а ребра такого графа показывают связи между объектами сетевой модели данных, причем ребра показывают не только саму связь, но и тип связи (связь один к одному или связь один ко многим). Взгляните на рисунок, чтобы лучше осознать суть написанного выше:
Структура сетевой базы данных, пример
Стоит заметить, что иерархическая модель баз данных является частным и упрощенным случаем сетевых баз данных.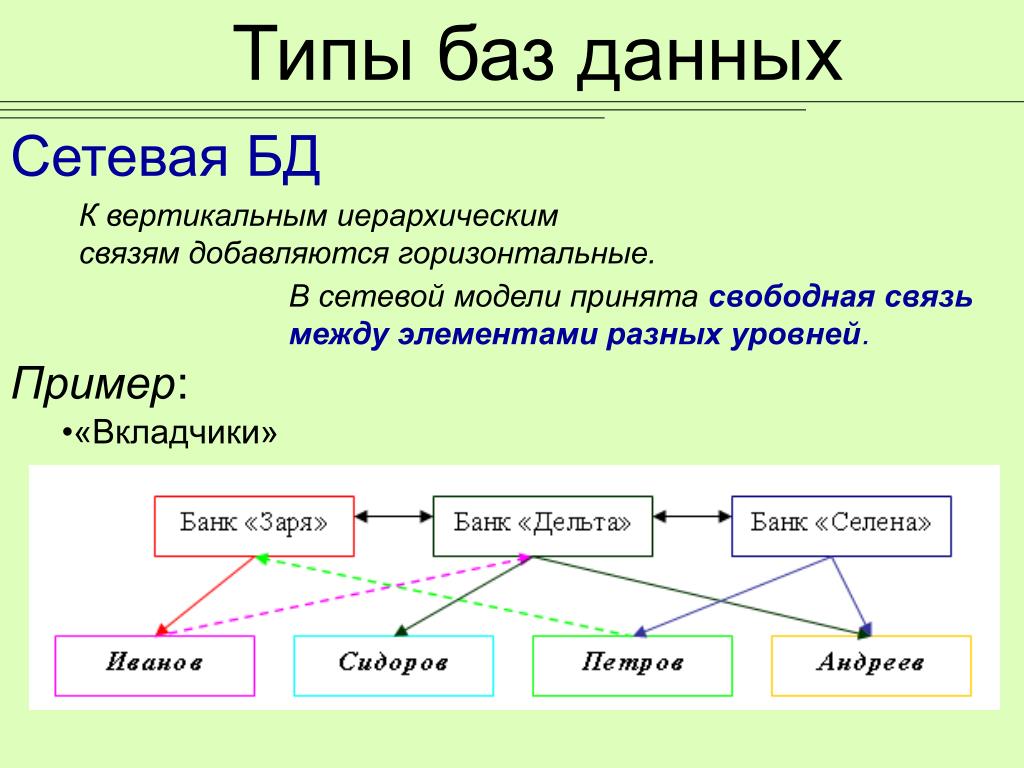
Структура сетевых баз данных
Сетевые базы данных имеют достаточно простую структуру, во всяком случае, сетевая модель имеет более простую структуру, нежели реляционная модель. Структура сетевых баз данных состоит из четырех компонентов, то есть в сетевой модели используют четыре типа структур данных. Два из которых являются главными и два, если можно так сказать, не главными. Главные типы структур сетевых данных – это запись и набор. Вспомогательные типы структур сетевой модели данных, которые используются для построения главных структур – это элемент данных и агрегат данных. Сама структура сетевой базы данных выглядит так:
Сетевая модель данных, пример
Пять элементов структуры сетевой модели данных образуют саму базу данных. Теперь пройдемся по каждому из типов структуры сетевых баз данных.
Элемент данных – это наименьшая информационная именованная единица данных, доступная пользователю, если провести аналогию с файловой системой, то это поле в файловой системе, если проводит аналогию с реляционной базой данных, то элемент данных – один столбец таблицы реляционной БД. Если говорить точнее, то это подстолбец. Не знаю, как правильно выразиться, вообще, я косноязычен.
Если говорить точнее, то это подстолбец. Не знаю, как правильно выразиться, вообще, я косноязычен.
Агрегат данных – это следующий уровень обобщения данных сетевой модели. Агрегат данных – это именованная совокупность данных внутри одной записи. Аналогию с реляционными БД тут не проведешь, поскольку агрегат данных – это столбец над столбцами, который объединяет элементы данных по логике их содержимого, следующий рисунок внесет ясность во все выше написанное:
Агрегат данных сетевой модели данных
На данном рисунке видно, что дата – это агрегат данных структуры сетевой модели, а день, месяц и год – это элемент данных сетевой БД.
Запись в сетевой модели данных – это конечный уровень обобщения данных, что-то наподобие таблицы в реляционной базе данных. Каждая запись в сетевой базе данных должна обладать или содержать в себе, как минимум один именованный элемент данных, если элементов внутри записи более одного, то каждый элемент данных должен обладать уникальным форматом.
Давайте разбираться со структурой сетевых баз данных на примере, поскольку так будет более понятно и доступно. Представим, что мы хотим создать запись в сетевую базу данных, назовем ее скажем «Сотрудник», в которую обязательно должен входить агрегат данных, который представлен на рисунке выше, его мы назовем «Дата». В эту запись нам необходимо будет добавить: табельный номер, ФИО и адрес сотрудника. Выглядеть такая запись в сетеовой модели данных будет следующим образом:
Записей сетевой базы данных
Прежде, чем переходить к набору записей, нужно разобраться с тем, что такое тип записи и для чего нужен тип записи в сетевой базе данных. И так, тип записей – это совокупность логически связанных экземпляров записей. Проще сказать – это все записи, которые связаны между собой по смыслу и, которые дополняют друг друга. Если переложить термин тип записей на реальный мир, то это информационная модель (иначе, полное описание) какого-либо объекта из реального мира, например сотрудника фирмы.
Как видно из рисунка выше: в качестве элементов данных сетевой модели могут быть использованы только простые типы, если хотите данных, но это не совсем так. Потому что в качестве агрегатов данных можно использовать сложные типы. Сложные типы в структуре сетевых баз данных бывают двух видов: вектор и повторяющаяся группа. Агрегат типа вектор соответствует линейному набору элементов данных, такой агрегат вы уже видели, он называется у нас «Дата», ну это чтобы вы представляли себе, что такое линейный набор элементов данных.
Агрегат типа повторяющаяся группа – это совокупность векторов данных (то есть несколько векторов). Для большей ясности давайте представим новый агрегат данных, который назовем, ну скажем «Товар»:
Агрегат типа повторяющаяся группа
Товары обычно хранятся на складе или их продают, зачастую по нескольку штук. Я хочу подвести к тому, что агрегат типа повторяющаяся группа – это несколько агрегатов типа вектор, объединенных вместе, допустим, у нас покупают 5 товаров, значит, если наш агрегат «Товар» будет иметь тип повторяющаяся группа, то он будет состоять из 5 агрегатов типа вектор, примерно так.
Перейдем к дальнейшему рассмотрению структуры сетевой модели данных. Набор записей – это именованная двухуровневая иерархическая структура, которая содержит управляемую и управляющую записи. При помощи наборов указывается тип связи между записями. Что это означает? Проще говоря, набор это две записи, между которыми есть связь: один ко многим или один к одному. Представим, что у нас имеется две записи в сетевой базе данных: запись «Сотрудник», структуру которой я привел выше и запись «Отдел», структура которой в данном контексте нам не важна.
Перед нами стоит задача: осуществить логическую связь между двумя этими записями, то есть определить какая запись будет управляемой, а какая управляющей. Логично предположить, что запись «Отдел» должна быть управляющей, поскольку сотрудник работает в отделе, а не отдел в сотруднике. И понятно, что связь между этими записями должна быть один ко многим, потому что отдел один, а сотрудников много, назовем эту связь «Работает». И так, мы приходим к выводу, что набор записей сетевой модели данных определяет: управляющую запись, в нашем случае это «Отдел», подчиненную запись, которую мы назвали «Сотрудник», а так же тип связи между этими записями, которую мы обозвали «Работает». «Работает» — это не только имя связи, но еще и метка, которая именует сам набор данных сетевой модели. Впрочем, рисунок должны внести ясность в мои несколько путаные пояснения:
«Работает» — это не только имя связи, но еще и метка, которая именует сам набор данных сетевой модели. Впрочем, рисунок должны внести ясность в мои несколько путаные пояснения:
Набор записей сетевой модели данных
В данном случае связь один ко многим говорит нам о том, что с одним экземпляром записи «Отдел» может быть связано ноль, один или несколько экземпляров записи «Сотрудник». Экземпляр записи – это что-то наподобие кортежа (строки таблицы) из реляционной БД. Использую понятия сетевой модели данных, приведенные выше, можно нарисовать набор записей по-другому. На рисунке можно отобразить логические типы данных для обеих записей, структуру записей сетевой модели данных и указать связь между записями, которую мы обозвали «Работает»:
Теперь обобщим все то, что было написано выше про структуру сетевой базы данных, собственно обобщает все база данных. База данных сетевой модели данных – это именованная совокупность экземпляров записей различного типа и экземпляров наборов, хранящих в себе типы связей между записями.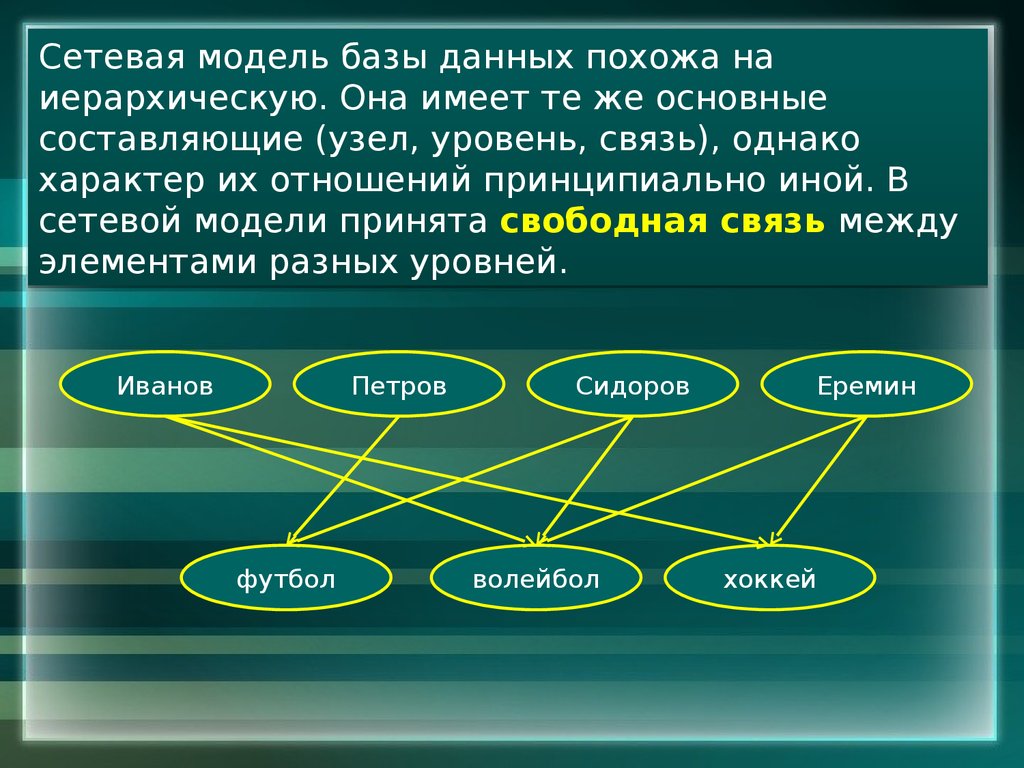 Проще говоря, это все записи и все связи между записями. Что же, мы познакомились со структурой сетевой модели данных, рассмотрели несколько примеров и заодно ознакомились с самыми простыми основами проектирования сетевых баз данных. Жаль, что я ничего не писал про концептуальное проектирование баз данных и концептуальную модель данных. В дальнейшем постараюсь исправить этот недостаток, потому что следующий раздел будет связан с концептуальной моделью.
Проще говоря, это все записи и все связи между записями. Что же, мы познакомились со структурой сетевой модели данных, рассмотрели несколько примеров и заодно ознакомились с самыми простыми основами проектирования сетевых баз данных. Жаль, что я ничего не писал про концептуальное проектирование баз данных и концептуальную модель данных. В дальнейшем постараюсь исправить этот недостаток, потому что следующий раздел будет связан с концептуальной моделью.
Преобразование концептуальной модели в сетевую модель данных
На детальное рассмотрение концептуальное модели данных и концептуального проектирования баз данных может потребоваться пара публикаций, а ограничиваться общими словами я не хочу, поэтому сейчас, уважаемые посетители, я буду считать, что вы имеете представление о том, что такое концептуальная модель, если не знаете, то тут два выхода: либо вы ждете соответствующую публикацию на моем блоге, либо пользуетесь поисковыми системами. Думаю, на других сайтах люди пишут не хуже меня, а может быть и лучше. Если вы ничего не знаете про концептуальную модель данных, то смело пропускайте данный раздел.
Если вы ничего не знаете про концептуальную модель данных, то смело пропускайте данный раздел.
Сетевую модель данных можно легко получить из концептуальной модели, причем нужно соблюсти всего лишь одно условие: в концептуальной модели данных должны использоваться только бинарные связи, которые принадлежат к типам: «один к одному» или «один ко многим». При этом вместо сущностей концептуальной модели данных следует использовать типы записей сетевой базы данных, собственно, имена сущностей из одной будут являться именами типов записей другой модели данных. Атрибуты, которые есть у сущностей (иначе столбцы таблицы) превращаются в поля записей сетевой модели данных, а связи между сущностями становятся связями между типами записей.
Бинарные связи концептуальной модели данных без затруднений переносятся на сетевую модель данных. Связь один ко многим переносится следующим образом: тип записи со стороны один становится управляющей записью, а тип записи со стороны многим становится подчиненной записью. Для связи один к одному запись владелец и подчиненная запись определяется произвольно.
Для связи один к одному запись владелец и подчиненная запись определяется произвольно.
Управление сетевыми данными
И последнее, о чем я бы хотел поговорить в этой публикации – управление сетевыми данными. Стоит сказать, что для манипулирования и управления данными в сетевой модели данных используется ряд типичных операций (о специфических операциях, присущих различным сетевым СУБД, мы говорить не будем), которые присущи для всех систем управления сетевыми базами данных. Все операции с сетевыми данными можно разделить на две группы: навигационные операции с данными и операции модификации данных.
Навигационные операции сетевых баз данных осуществляют переход по связям, определенных в схеме баз данных, в результате таких переходов определяется запись, которую называют текущей (запись сетевой модели, с которой мы будем работать). К навигационным операциям можно отнести:
- найти конкретную запись в наборе однотипных записей и сделать ее текущей;
- перейти от записи-владельца к записи-члену в некотором наборе;
- перейти к следующей записи в некоторой связи;
- перейти от записи-члена к владельцу по некоторой связи.
При помощи операций модификации сетевых баз данных осуществляется добавление новых записей данных, добавление новых наборов данных, удаление записей данных и наборов записей, модификация агрегатов и элементов данных. Для реализации этих операций в системе текущее состояние детализируется путем запоминания трех его составляющих: текущего набора, текущего типа записи, текущего экземпляра типа записи. В такой ситуации возможны следующие операции:
- извлечь текущую запись в буфер прикладной программы для обработки;
- заменить в извлеченной записи значения указанных элементов данных на заданные новые их значения;
- запомнить запись из буфера в БД;
- создать новую запись;
- уничтожить запись;
- включить текущую запись в текущий экземпляр набора;
- исключить текущую запись из текущего экземпляра набора.
Поддержание ограничений целостности в сетевых моделях в принципе не требуется. На этом всё, спасибо за внимание, надеюсь, что был хоть чем-то полезен и до скорых встреч на страницах блога для начинающих вебразработчиков и вебмастеров ZametkiNaPolyah.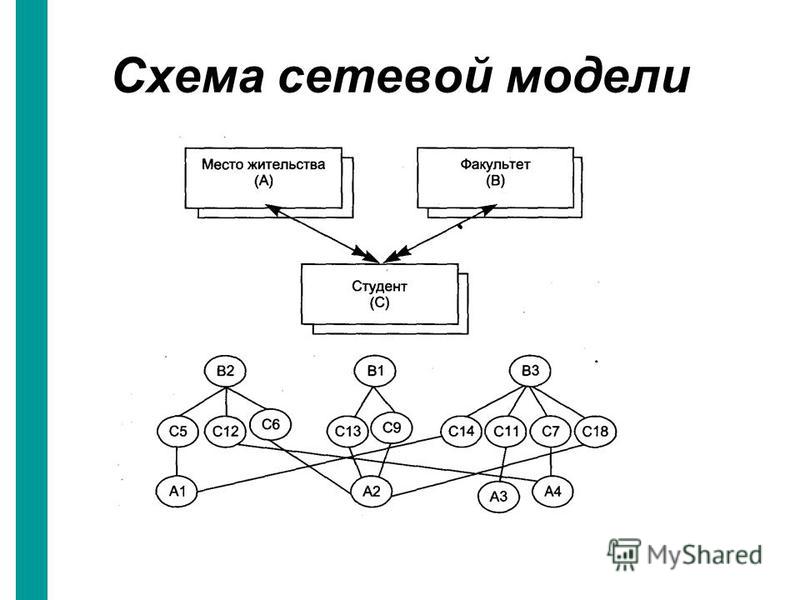 ru. Не забываем комментировать и делиться с друзьями;)
ru. Не забываем комментировать и делиться с друзьями;)
SubD через что-то вроде патча или сетевой поверхности — SubD
samlochner 1
Иногда я создаю 3D-грань (одно непрерывное ребро), разделяя периметр на 4 кривые и затем используя команду сетевой поверхности. Я считаю, что это лучше подходит для достижения точной геометрии края, чем, скажем, для создания обрезанной поверхности с помощью команды patch. Но в итоге я получаю странное расстояние между контрольными точками и различные проблемы, возникающие из-за этого.
image1411×708 93,3 КБ
Учитывая новую функциональность Subd, мне интересно, есть ли лучший способ сделать это сейчас. Не вижу способа создать сабд через кривую сеть, но может я что-то упускаю или он в пути. Есть мысли по этому поводу?
Спасибо,
Сэм
LastBottomNetworkCurves. 3dm (34,3 КБ)
3dm (34,3 КБ)
John_Brock (Джон Брок) 2
Переведен в категорию SubD
самлочнер 3
У кого какие мысли по этому поводу? Я предполагаю, что это невозможно, чем больше я читаю, но был бы признателен за подтверждение от кого-то более знающего.
паскаль (Паскаль Голе) 4
Понятия не имею. Я надеялся, что появится более опытный пользователь SubD, чем я. Я думаю, что Patch с достаточным количеством интервалов является хорошим кандидатом здесь — SubD, похоже, не идеальная вещь, где требуется точность.
-паскаль
самлочнер 5
Спасибо за подтверждение Паскаль.
Я все еще буду слушать здесь, если кто-то наткнется на это с мыслями о том, как это сделать с субд. Например, возможно, существует эффективный алгоритм для перемещения контрольных точек до тех пор, пока трехмерное лицо subd не будет соответствовать…
Сэм
Брайан Джей (Брайан Джеймс) 6
Я подал запрос на SubD NetworkSrf некоторое время назад, но это еще не сделано… https://mcneel.myjetbrains.com/youtrack/issue/RH-57618
NURBS NetworkSrf и создайте SubD с помощью этой команды. Вы не будете точно на граничной кривой, поэтому лучше всего потом перейти к ней с помощью другого SubD, возможно, из SubDLoft или SubD Sweep.
изображение1234×809 433 КБ
1 Нравится
самлочнер 7
Спасибо, Брайан, приятно знать, что это уже обсуждалось! Для меня было бы серьезно упростить и улучшить многие вещи, если бы у меня был SubD NetworkSrf, который может создавать 3D-лица с точными границами.
Решение itermin для четырехъядерной сетки интересно, хотя и сложно получить точную границу, как вы упомянули. Это будет полезно для меня в некоторых ситуациях, но очень надеюсь, что можно будет разработать прямой SubD NetworkSrf.
1 Нравится
Джонатан Хатчинсон (Джонатан) 8
Возможность получить лучшее совпадение с граничной кривой было бы чем-то действительно интересным. @BrianJ
Нет ли на данный момент способа «сопоставить» базовую границу кривой nurbs субкромки (без складок) с кривой в пределах определенного допуска? А затем как бы откатиться назад в режиме subd box, который решает это уравнение кривой?
Брайан Дж. (Брайан Джеймс) 9
Ведутся внутренние дискуссии о согласовании ребра SubD с ребром или кривой NURBS в пределах допуска, подходящего для соединения двух в один полисрф без зазора. Это то, что я зарегистрировал как RH-49943 во время разработки для дальнейшего использования.
Короче говоря, вам нужно иметь много четырехугольников вдоль края, чтобы «сопоставить» кривую NURBS/край srf в пределах типичного допуска . 001 для файлов Rhino. Кривизна SubD и кривизна NURBS не вычисляются одинаково и тем более на открытых краях. Возможно, в будущем появится больше инструментов для сопоставления, но я не могу точно сказать, что возможно. Лично я бы либо строил ребро SubD, соединял его с другим SubD, либо преобразовывал в NURBS и использовал BlendSrf, чтобы перекрыть пробел, если вам нужно сопоставить с polysrf.
001 для файлов Rhino. Кривизна SubD и кривизна NURBS не вычисляются одинаково и тем более на открытых краях. Возможно, в будущем появится больше инструментов для сопоставления, но я не могу точно сказать, что возможно. Лично я бы либо строил ребро SubD, соединял его с другим SubD, либо преобразовывал в NURBS и использовал BlendSrf, чтобы перекрыть пробел, если вам нужно сопоставить с polysrf.
1 Нравится
Джонатан Хатчинсон (Джонатан) 10
FWIW, в обуви / колодках 0,01 мм — хороший допуск. Я был бы полностью доволен этим.
самлочнер 11
Согласен, какое-то сопоставление кромок было бы полезно, даже если допуск не равен 0,001.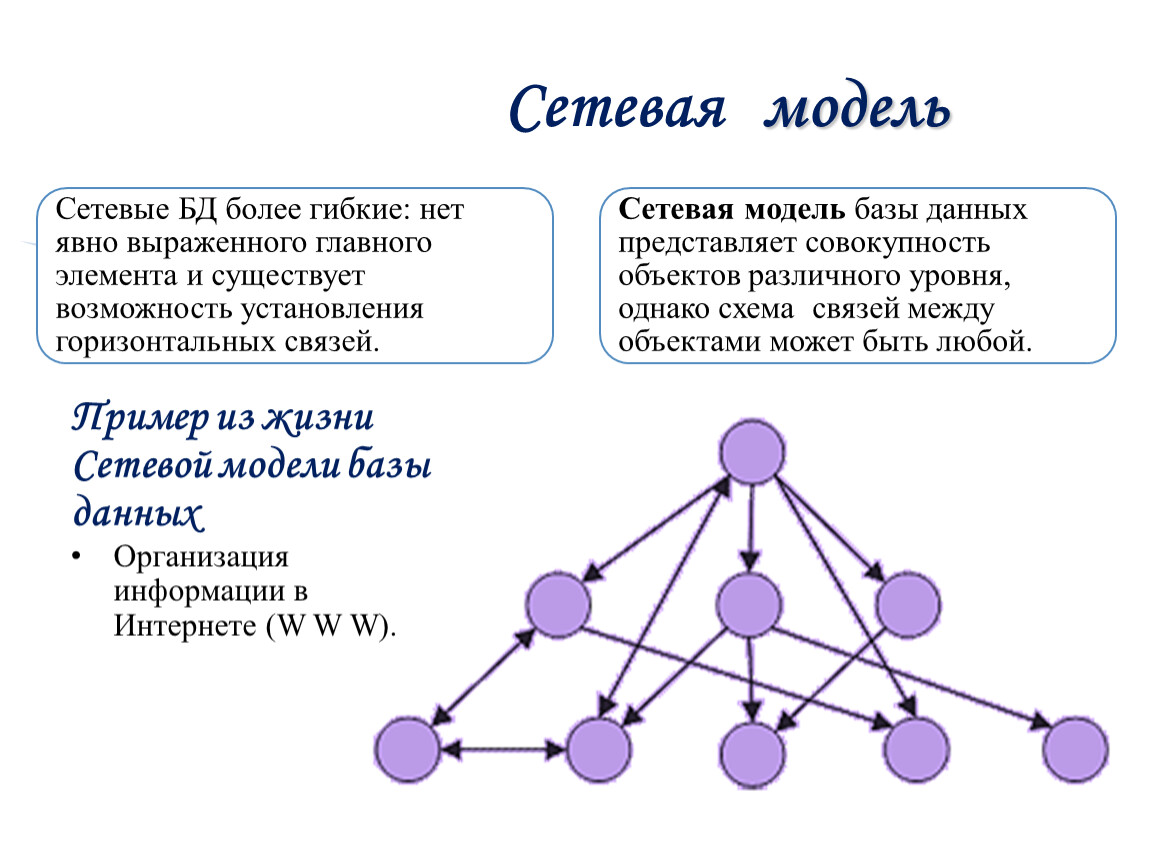
Джонатан_Хатчинсон (Джонатан) 12
Определенно. Я не знаю, можно ли, например, перестроить кривую в соответствии с этим допуском, сделать ее периодической, сделать ее дружественной к субд, а затем выдать ребро прямоугольного режима, которое вызвало бы такое уравнение кривой. Затем используйте это ребро в качестве списка вершин для нового четырехъядерного доминирующего субда.
Дэвидкоки (Дэвид Кокки) 13
Открытые кривые, совместимые с SubD, имеют нулевую кривизну на концах, поэтому обычно требуется больше контрольных точек и узлов при восстановлении дружественных SubD для заданной точности, чем при построении не дружественных SubD.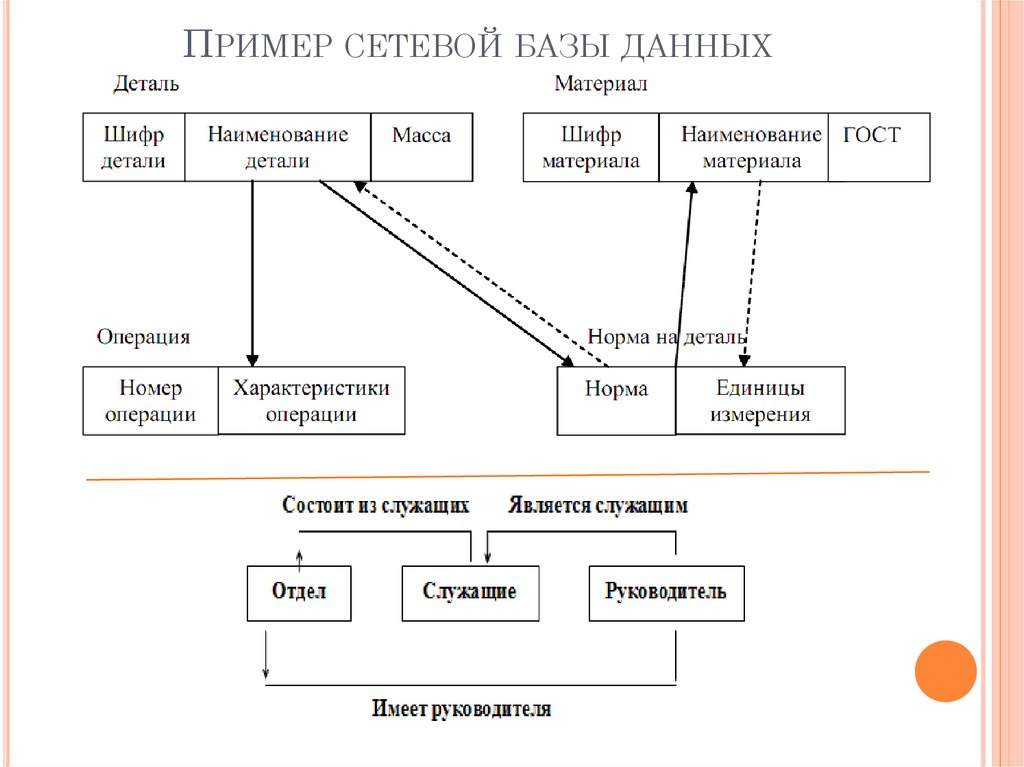
Брайан Дж. (Брайан Джеймс) 14
Вы также можете использовать команду «Выровнять» > параметр «По кривой», чтобы выровнять ребро или петлю ребра по кривой. Вершины, видимые в режиме прямоугольника (он же полигон управления), — это то, что притягивается к кривой. Больше баллов = более точное соответствие.
снаружи (Кайл Хученс) 15
или просто смоделировать его в плоском виде, а затем придать форму (мой предпочтительный метод)
davidcockey (Дэвид Кокки) 16
Поверхности SubD имеют фундаментальное ограничение при согласовании с поверхностью NURBS. Ребро поверхности SubD, которое не образует замкнутую кривую, всегда будет иметь нулевую кривизну в углах. Это означает, что он не может точно соответствовать краю или кривой, которые также не имеют нулевой кривизны в этом месте. При достаточном количестве точек поверхность SubD может быть установлена в пределах допуска согласуемой кромки или кривой.
Что такое подсети? — NetworkCalc
Мэтью Фишер — 22 августа 2021 г.местное_предложение Подсети
Подсеть — это логическое подразделение более крупной сети на непересекающиеся диапазоны IP-адресов. Это может быть как один хост, так и большая сеть.
Современные сети строятся так, чтобы их можно было разделить на подсети, известные как подсети. В этой статье описываются концепции и расчеты, связанные с созданием подсетей и управлением ими.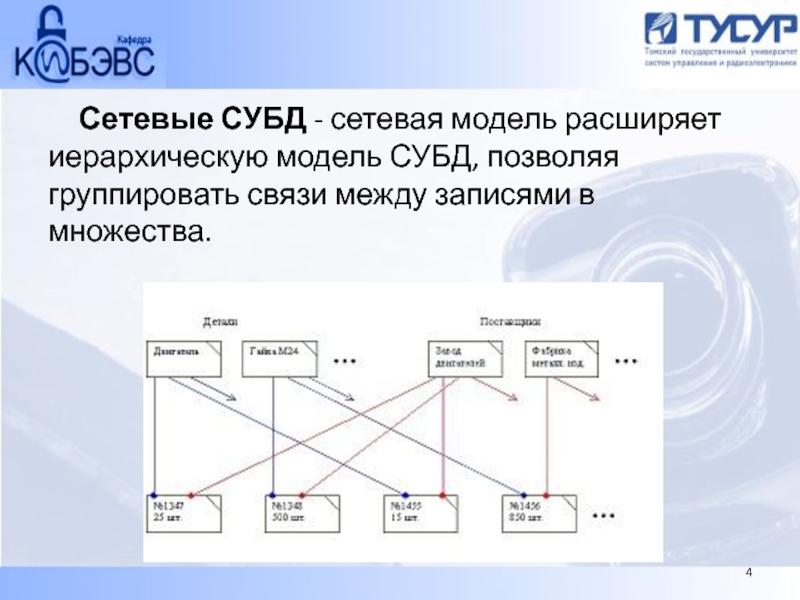
В качестве дополнения к этой подробной статье загрузите мою бесплатную схему подсетей в формате PDF, которая является отличным справочником по подсетям.
IP-сети
IP-адреса
Прежде всего, давайте поговорим об адресах Интернет-протокола (IP-адресах) и сетях IP-адресов.
IP-адрес — это сетевой адрес устройства, указанный в виде десятичной записи с точками (www.xxx.yyy.zzz) или в виде двоичного числа . Сетевым устройством может быть сервер, часть сетевого оборудования, клиентский компьютер, мобильный телефон или что-то еще. Любому устройству, способному обмениваться данными в IP-сети, для участия в сети требуется IP-адрес.
Существуют как общедоступные, так и частные IP-адреса. Общедоступные IP-адреса видны в общедоступном Интернете. Знаете ли вы свой общедоступный IP-адрес?
Сети
Далее давайте создадим концепцию сети. Рассмотрим следующую диаграмму сети:
Предположим, у вас есть два компьютера, MyComputer и YourComputer.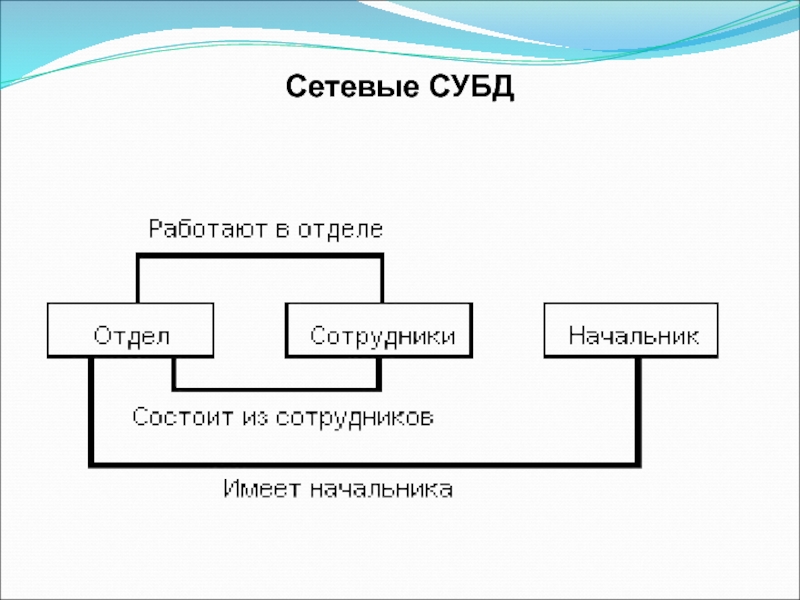 Компьютеры должны иметь возможность взаимодействовать друг с другом, поэтому им присваиваются IP-адреса (MyComputer получает 192.168.1.5, а YourComputer — 19).2.168.1.22). Два компьютера имеют уникальные IP-адреса в сети, но не могут отправлять и получать данные.
Компьютеры должны иметь возможность взаимодействовать друг с другом, поэтому им присваиваются IP-адреса (MyComputer получает 192.168.1.5, а YourComputer — 19).2.168.1.22). Два компьютера имеют уникальные IP-адреса в сети, но не могут отправлять и получать данные.
Коммутатор — это сетевое устройство, которое соединяет устройства путем ретрансляции пакетов, которые они посылают, на другие устройства в сети . В этом примере MyComputer и YourComputer подключены к коммутатору через сетевой кабель. Это позволяет MyComputer отправлять данные на YourComputer, отправляя пакет по сетевому кабелю. Коммутатор перехватит пакет и перешлет его другим подключенным к нему устройствам.
Теперь предположим, что этой сети нужен сервер для размещения веб-сайта, к которому могут получить доступ MyComputer и YourComputer:
Следуя тому же сетевому принципу, что и раньше, MyComputer, YourComputer и ServerA подключены сетевым кабелем к коммутатору. Любая связь между устройствами в этой сети обрабатывается коммутатором и ретранслируется на соответствующий хост или хосты.
Маршрутизация и коммутация
Добавим к этому еще одну деталь — требование отделять трафик рабочей станции от трафика сервера:
Переключает релейные пакеты данных на все напрямую подключенные устройства. Чтобы обеспечить разделение связи между устройствами, используется маршрутизатор. Маршрутизатор — это сетевое устройство, которое выбирает сетевой путь для обмена данными на основе определенного набора правил . На приведенной выше диаграмме маршрутизатор будет отвечать за маршрутизацию данных по пути A или пути B на основе набора правил. Примеры правил, которым может следовать маршрутизатор:
- Разрешить веб-трафик с вашего компьютера на сервер B.
- Запретить любой SSH-трафик с пути A на путь B.
Общие правила маршрутизации и коммутации следующие:
- Коммутатор позволяет осуществлять сетевое взаимодействие между подключенными хостами.
- Маршрутизатор позволяет осуществлять сетевое взаимодействие между сегментами сети в соответствии с правилами маршрутизации.
Подсети
С каждой стороны маршрутизатора в этой сети находится подразделение сети или подсеть. Все рабочие станции могут взаимодействовать напрямую друг с другом, все серверы могут взаимодействовать напрямую друг с другом, но трафик между подсетями должен проходить через маршрутизатор и подчиняться набору правил маршрутизатора. Ниже мы опишем механизм разделения сети на подсети.
С этой точки зрения сеть представляет собой систему взаимосвязанных устройств, каждое из которых имеет IP-адрес, связь между которыми осуществляется посредством сетевого оборудования, такого как маршрутизаторы и коммутаторы .
Сетевое подразделение
Подсети
Подсеть — это логическое подразделение более крупной сети на непересекающиеся диапазоны IP-адресов . Это может быть как один хост, так и целая сеть. Желательно разделить сеть по многим причинам. Основными причинами разделения сети являются:
- Для повышения эффективности маршрутизации за счет уменьшения количества устройств, напрямую взаимодействующих друг с другом.
- Для создания изоляции между логически связанными устройствами, такими как рабочие станции и серверы.
Каждый IP-адрес в сети имеет как минимум два определяющих его компонента: IP-адрес и маску подсети. Маска подсети — это 32-битное двоичное число, указывающее, как сеть должна быть разделена на подсети .
Рассмотрим пример:
Сетевой адрес сети
10.0.1.0/24.
Эта сеть имеет сетевой адрес (первый адрес в сети) 10.0.1.0. «/24» — это часть нотации CIDR, указывающая, что 24 бита должны использоваться для маски подсети. Учитывая маску подсети, равную 24, мы можем заключить, что первые 24 из 32 битов в адресе используются для различения разных подсетей, а оставшиеся 8 бит используются для различения хостов внутри подсети. Мы используем биты в подсети, так как IP-адреса и маски подсети могут быть представлены в двоичной записи:
IP-адрес:
10.0.1.0
00001010 00000000 00000001 00000000 Маска подсети:
/24
255. 255.255.0
11111111 11111111 11111111 00000000
255.255.0
11111111 11111111 11111111 00000000 При разделении сетей каждый дополнительный бит, используемый для маски подсети, дает в два раза больше подсетей, каждая из которых вдвое меньше . Подсеть /24 (читай: «слэш двадцать четыре») может быть разделена путем добавления одного бита к маске подсети, что делает ее подсетью /25. При этом 256 адресов в одной подсети становятся 128 адресами в двух подсетях. Разделение /25 на /26 также удваивает количество подсетей и вдвое уменьшает количество адресов в каждой подсети. Следующая таблица иллюстрирует этот процесс подразделения:
Загрузите БЕСПЛАТНУЮ диаграмму подсети в формате PDF, чтобы использовать ее в качестве печатного справочника для расчетов подсети.
Процедура разделения сети на подсети следующая:
- Увеличить количество битов подсети на 1.
- Каждый раз, когда вы добавляете 1 бит подсети, результирующее адресное пространство будет иметь в два раза больше подсетей с вдвое меньшим количеством адресов в каждой.
Расчеты подсети
Расчеты подсети возможны, если мы преобразуем IP-адреса из десятичного представления с точками в двоичные числа. Поскольку IP-адрес состоит из четырех октетов в диапазоне от 0 до 255, разделенных точкой, тот же IP-адрес может быть представлен путем преобразования каждого октета в 8-значное двоичное число и удаления точек между октетами.
В этом примере мы преобразуем IP-адрес 10.0.1.0/24 из десятичного представления с точками в двоичное:
10.0.1.0
00001010 00000000 00000001 00000000 Затем мы преобразуем маску подсети в двоичный код, перечислив 24 единицы, за которыми следуют 8 нулей:
/24
11111111 11111111 11111111 00000000 Теперь, если мы объединим сетевой адрес и маску подсети, мы увидим, что все биты IP-адреса, соответствующие единице в маске подсети, используются для определения подсети. Остальные биты соответствуют определенному IP-адресу в подсети:
00001010 00000000 00000001 00000000
11111111 11111111 11111111 00000000 Весь этот процесс упрощается с помощью онлайн-калькулятора подсети, но давайте продолжим эти расчеты. Введите адрес CIDR или IP-адрес ниже, чтобы найти сведения о сети.
Введите адрес CIDR или IP-адрес ниже, чтобы найти сведения о сети.
Онлайн-калькулятор подсети
Используйте нотацию CIDR для быстрого поиска сведений о подсетях IPv4 и блоках CIDR.
Инструмент просмотра
Что такое сетевой адрес для подсети?
Чтобы определить сетевой адрес (сетевой префикс) для подсети, выполните побитовое логическое И между IP-адресом в подсети и маской подсети, представленными в двоичном формате . Выполните следующие действия, чтобы найти сетевые адреса:
- Преобразуйте IP-адрес в двоичный формат.
- Получите маску подсети для сети в двоичном представлении.
- Выполните побитовое логическое И для IP-адреса и маски подсети.
- Преобразование полученного адреса обратно в десятичное представление с точками. Это сетевой адрес.
Пример
Предположим, мы хотим найти сетевой адрес для 10.0.1.15 в сети, используя 24 бита для маски подсети.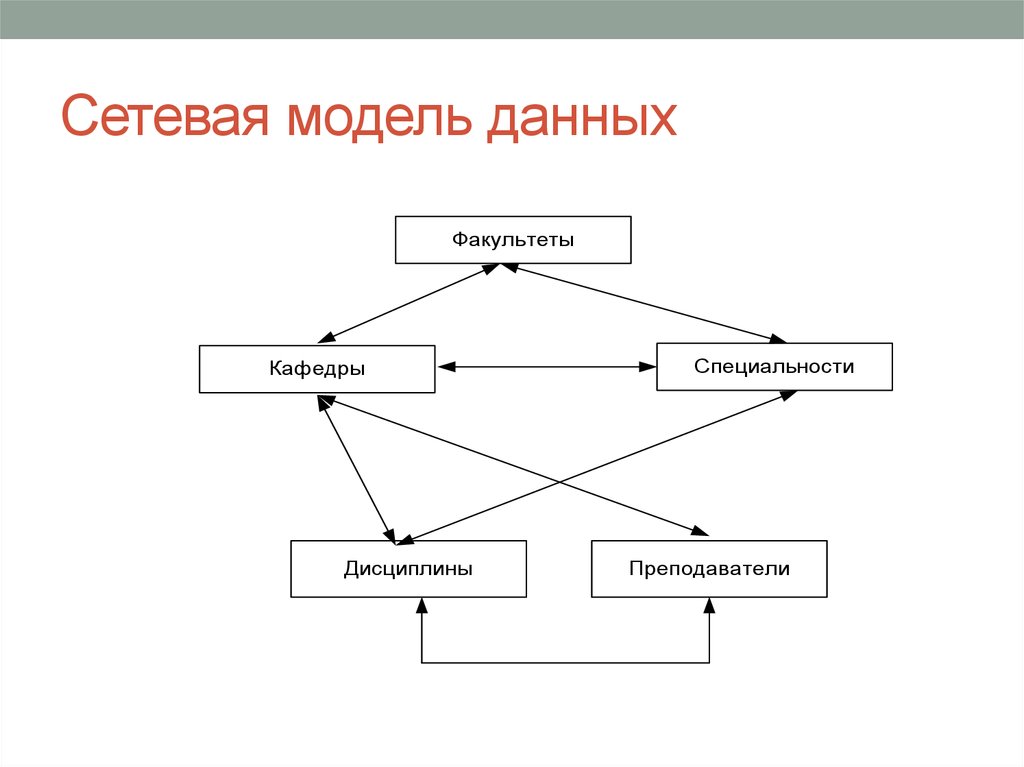 Шаги показаны ниже.
Шаги показаны ниже.
IP-адрес:
10.0.1.15/24
1. Преобразуйте IP-адрес в двоичный формат:
00001010 00000000 00000001 00001111
2. Получите маску подсети в двоичном представлении:
11111111 11111111 11111111 00000000
3. Выполните побитовое логическое И:
00001010 00000000 00000001 00001111
11111111 11111111 11111111 00000000
--------------------------------------------------
00001010 00000000 00000001 00000000
4. Преобразование в десятичную запись с точками:
10.0.1.0 Что такое широковещательный адрес для подсети?
Чтобы определить широковещательный адрес для подсети, преобразуйте IP-адрес в подсети в двоичный формат и установите все биты в хостовой части адреса на 1 . Выполните следующие действия, чтобы найти широковещательные адреса:
- Преобразуйте IP-адрес в двоичный формат.
- Получите маску подсети для сети в двоичном представлении.
- Установите все биты в 1 в хостовой части IP-адреса (где соответствующий бит подсети равен 0).