Составление семантического ядра — полное руководство по сбору и разработке
Советы
Руководство с комментариями опытного сеошника
Читайте наc в Telegram
Разбираемся, что происходит в мире рассылок и digital-маркетинга. Публикуем анонсы статей, обзоры, подборки, мнения экспертов.
Смотреть канал
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Семантическое ядро — список поисковых запросов, по которым пользователь может найти сайт. Его собирают для того чтобы понять интересы целевой аудитории, продумать структуру сайта и добавить ключи в текст.
В этом материале подробно разберемся с семантикой. В начале статьи будет теоретическая часть — что это такое, для чего нужно и когда сбор семантики лучше доверить специалисту. Во второй части будет пошаговая инструкция по сбору семантики. Если вам интересна именно эта часть — кликайте: пошаговая инструкция как составить семантическое ядро.
Если вам интересна именно эта часть — кликайте: пошаговая инструкция как составить семантическое ядро.
Статья написана под надзором Lead SEO в Unisender — Сергея Лукашевича. Если после статьи у вас останутся вопросы— задайте их в комментариях Сергею 🙂
Что такое семантическое ядроСемантическое ядро — набор слов, фраз и запросов, которые характеризуют сайт, услугу или страницу в интернете. Использование таких слов на сайте позволит нам попасть в выдачу поисковика, хотя у самой семантики функции шире — о них чуть ниже.
Например, для интернет-магазина, который продает головные уборы, в семантическое ядро будут входить слова «купить шапку», «купить кепку», «шляпы дешево», «все ли шапки одного размера» и так далее.
Для чего собирать семантическое ядроВот основные причины:
1. Исследовать интересы целевой аудитории. Анализ поисковых фраз — простой и достоверный способ узнать, как и что ищет человек: в поиске он не стесняется своих желаний. Более того, можно количественно отследить интерес людей к теме — в этом помогает частотность запросов в месяц:
Более того, можно количественно отследить интерес людей к теме — в этом помогает частотность запросов в месяц:
Анализ семантического ядра дает подсказки в развитии бизнеса: закрыть непопулярные направления (их люди не ищут), открыть популярные — их часто ищут, а это потенциальный источник трафика и оплат.
Сергей Лукашевич
Глобальная цель сбора семантики — понять, что хочет целевая аудитория, что ищут люди и как часто. Возможно, продукт который мы планируем выпустить или который уже есть — никому не нужен. В этом случае стоит сместить вектор развития в сторону популярных запросов.
2. Создать или доработать структуру сайта. Собранное семантическое ядро разбивается на кластеры. Кластер — группа запросов, которые поисковик считает одной темой и показывает по ней похожие результаты.
Кластер — готовая идея для страницы в интернете или статьи. Разбив семантическое ядро на кластеры, мы получим грубую структуру сайта, основанную на интересах аудитории. Следуя этой структуре, мы становимся клиентоориентированными.
Следуя этой структуре, мы становимся клиентоориентированными.
Сергей Лукашевич
Семантика — практически неисчерпаемый источник идей для статей. Причем не просто статей, а статей по темам, на которые есть спрос. В блоге Unisender больше половины всех статей seo-оптимизированные. Эта статья тоже оптимизирована.
3. Оптимизировать текст под поиск. На основе семантического ядра к страницам прописывают заголовок, метатеги, описание статьи, структуру с h3 и h4 подзаголовками. А сама семантика — промежуточный этап в формировании ключевых слов (ключей). А глобально все это нужно для пассивного продвижения сайта в поиске.
Подбор ключей — совсем другой процесс, в котором сеошник анализирует текст конкурентов в выдаче по определенному кластеру. Через SEO-сервисы можно оценить, какие ключи и в каком количестве используются в их статьях. Если целиться на ключи конкурентов из первых мест выдачи, есть шанс, что и наш материал тоже попадет в топ.
Этап подбора ключей возможен только после составления семантического ядра и кластеризации — благодаря им, мы ищем конкурентов.
4. Отслеживать динамику страниц в поисковике. После того как собрано семантическое ядро мы можем следить за движением сайта в выдаче по определенным запросам. Например, в семантику попал запрос «как поставить мат двумя конями в шахматах». Мы написали статью на эту тему и теперь следим, как поисковик ранжирует ее.
Сначала статья будет выше сотой страницы в интернете, потом постепенно будет подниматься до тех пор, пока не достигнет первой страницы и высших строчек — это показатель того, что SEO-стратегия работает. Если же сайт застрял дальше второй-третьей страницы выдачи, мы что-то делаем неправильно. Возможно, неправильно подобраны ключи или есть другие фундаментальные проблемы. Кстати говоря, на пустой доске мат двумя конями поставить невозможно 🙂
А еще может выясниться, что по другим запросам из кластера сайт продвигается медленнее. Это повод докрутить текст, добавить ключей, оптимизировать некоторые предложения под отстающий запрос.
Это повод докрутить текст, добавить ключей, оптимизировать некоторые предложения под отстающий запрос.
Сбор семантики относится к SEO — оптимизации сайта под поисковую выдачу. Чем сайт оптимизированнее, тем выше вероятность, что он окажется на первой странице по ключевому запросу. Соответственно, тем больше переходов на сайт и целевых действий.
Кроме того, органика (люди, которые перешли на сайт по запросу из поисковика) бесплатна и пассивно приносит людей годами. Например, нашу статью про сокращаторы ссылок за полтора года прочитали 120 000 человек. При этом, мы не вкладывали денег в продвижение — просто правильно оптимизировали текст под поиск.
Сбор семантики — это только маленькая часть работы по SEO. На позицию сайта влияют его быстродействие, гигиена страниц, внешняя оптимизация, текстовая оптимизация и активность пользователей. Про все это подробнее можно почитать в нашем гиде по SEO. Если вы плохо ориентируетесь в поисковой оптимизации, рекомендую сначала изучать гид.
Составление семантики — не самый сложный в мире процесс, однако в нем легко запутаться (особенно без опыта):
- Собрать много повторяющихся запросов.
- Упустить перспективные низкочастотные запросы.
- Неправильно отсеять нерелевантные запросы.
- Еще выше вероятность ошибиться на следующих этапах — кластеризации, анализе, формировании страниц в интернете.
Чем больше проект, тем выше вероятность ошибок.
Сергей Лукашевич
Чем больше проект, тем больше нужд в специальном инструментарииЯ пользуюсь Ahrefs, SEMrush и другими. Они достаточно сложные и новичку в них будет сложно разобраться. В большом проекте может потребоваться сбор семантического ядра из 10 тысяч запросов (например, для крупного интернет-магазина) и развитая структура сайта с тысячами страниц.
Если ваш проект до 50 страниц, смело можете собирать семантику самостоятельно. Как минимум, это поможет определиться со структурой сайта и понять, на каких продуктах или услугах стоит сосредоточиться. А более тонкую работу можно оставить сеошнику, которого наймете позже.
Составление семантики — работа и она требует времени. Если вы плохо с этим знакомы, вам придется тратить время на изучение. Иногда целесообразнее сразу взять сеошника — пусть даже в рамках разового проекта.
На что обратить внимание при подборе ядраПрежде чем собирать семантическое ядро, нужно синхронизироваться по некоторым терминам. Это теоретическая часть, чтобы лучше понимать инструкцию.
Частотность
Частотность показывает количество запросов в месяц. Запросы в семантическом ядре разделяются на высокочастотные, среднечастотные и низкочастотные. Высокочастотные ищут чаще, чем низкочастотные, а среднечастотные — что-то промежуточное между ними. Деление запросов на эти группы относительное и зависит от сферы. В каких-то сферах, 100 относится к низкочастотным, а в других — к высокочастотным.
В каких-то сферах, 100 относится к низкочастотным, а в других — к высокочастотным.
Ранжирование — сортировка сайтов в выдаче в зависимости от их рейтинга, который подсчитывают алгоритмы поисковика. Чем выше рейтинг сайта, тем лучше он ранжируется — занимает верхние строчки выдачи.
На рейтинг влияют текстовая оптимизация, адаптивность, скорость загрузки, внешние ссылки и другие параметры. Запущенный сайт с идеальными семантическим ядром не попадет в топ — поэтому не фокусируйтесь лишь на одном сборе семантики.
Конкурентность
Конкурентность запроса — величина, которая показывает сложность попасть в топ выдачи. Она зависит от конкурентов — чем их больше и чем качественные их сайты, тем сложнее будет идти продвижение.
Подробнее про конкуретность можете почитать здесь.
Опытные сеошники при сборе семантики указывают сложность (Difficulty). Если вы новичок — не парьтесь. Но если ваша ниша сильно конкурентная, опять же, нужен опытный сеошник.
Интент — это потребность пользователя, которую он хочет решить, когда вводит запрос. Некоторые запросы размыты, например, запрос «что такое осень» — пользователь хочет узнать, что такое осень или он ищет песню группы ДДТ?
Поисковики научились угадывать интент пользователя и даже по обобщенным запросам выдают нужное. И по запросу «что такое осень» все имеют в виду песню — это и показывает поисковик.
Учитывайте интент, иначе в ваше семантическое ядро попадут запросы, к которым вы не имеете отношения. Для этого просто внимательно просматривайте семантику на этапе чистки.
ГеозависимостьГеозависимость — фича поисковиков, чтобы адаптировать выдачу под место проживания пользователя. Если вести «макдональдс адрес» — мне не покажут адреса фастфудов в Сыктывкаре, а покажут в моем городе.
Если у вас локальный бизнес, семантику нужно составлять с учетом геозависимости. Для этого в Яндекс Вордстат есть настройка по региону — информация будет выводиться только по нему.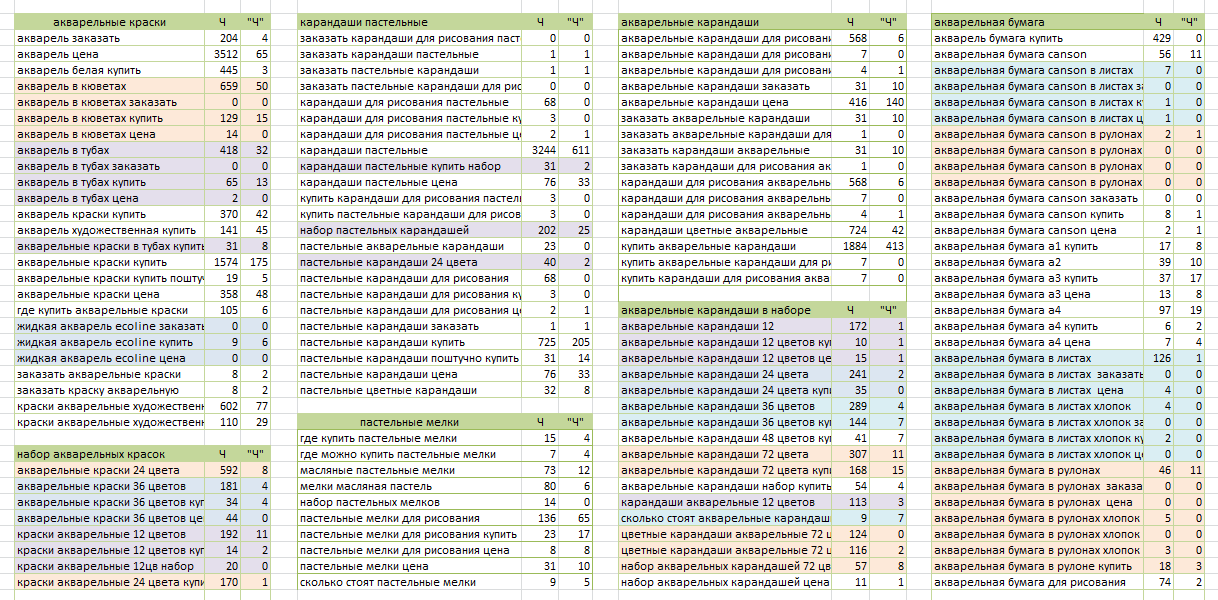 А если у вас онлайн бизнес, то на геозависимость можно не обращать внимания — в Вордстат по умолчанию выбраны все регионы. Но при желании можно добавить еще и страны СНГ.
А если у вас онлайн бизнес, то на геозависимость можно не обращать внимания — в Вордстат по умолчанию выбраны все регионы. Но при желании можно добавить еще и страны СНГ.
Подумайте, какие запросы характеризуют ваш сайт
Составление семантического ядра начинается с мозгового штурма. Ответьте на вопрос: если бы вы искали свой сайт в поисковике, то по каким запросам?
Несколько советов, как охватить все интересные запросы:
- Созвонитесь с командой, особенно с теми, кто участвует в разработке продукта и делает сайт. Попросите их ответить на вопрос выше. Записывайте все идеи и фразы, которые придут в голову.
- Нужны запросы не только в рамках сайта в общем, но и в разрезе конкретных продуктов и частных вопросов клиентов. Например, сайт продает и устанавливает пластиковые окна.
 В семантику можно записать запросы «сколько стоит установка пластиковых окон» и «чем отличаются пластиковые окна». Такие запросы напрямую не связаны с нашими услугами, но все равно могут принести трафик, который позже конвертируется в клиентов.
В семантику можно записать запросы «сколько стоит установка пластиковых окон» и «чем отличаются пластиковые окна». Такие запросы напрямую не связаны с нашими услугами, но все равно могут принести трафик, который позже конвертируется в клиентов. - Забавный источник идей — отдел продаж и служба поддержки. Им всегда задают кучу вопросов и практически всегда эти вопросы популярны в поисковике.
Сергей Лукашевич
Блог покроет информационные запросы и увеличит трафик на сайтДаже если ваш сайт предполагается чисто коммерческим, я все равно рекомендую обратить внимание на информационные запросы, сделать под них специальные страницы или даже вынести в блог. Это в несколько раз ускорит продвижение и существенно увеличит трафик на сайт.
Блог ощутимо ест бюджет, особенно если организовывать собственную редакцию и налаживать регулярный выпуск материалов. Но это и не нужно — достаточно нескольких статей, которые бы отвечали на популярные запросы в поиске.
Производство статей можно отдать на аутсорс, а технически реализовать блог внутри домена несложно и недорого. В таком случае это будет лишь единовременным вложением, а не ежемесячной статьей расходов.
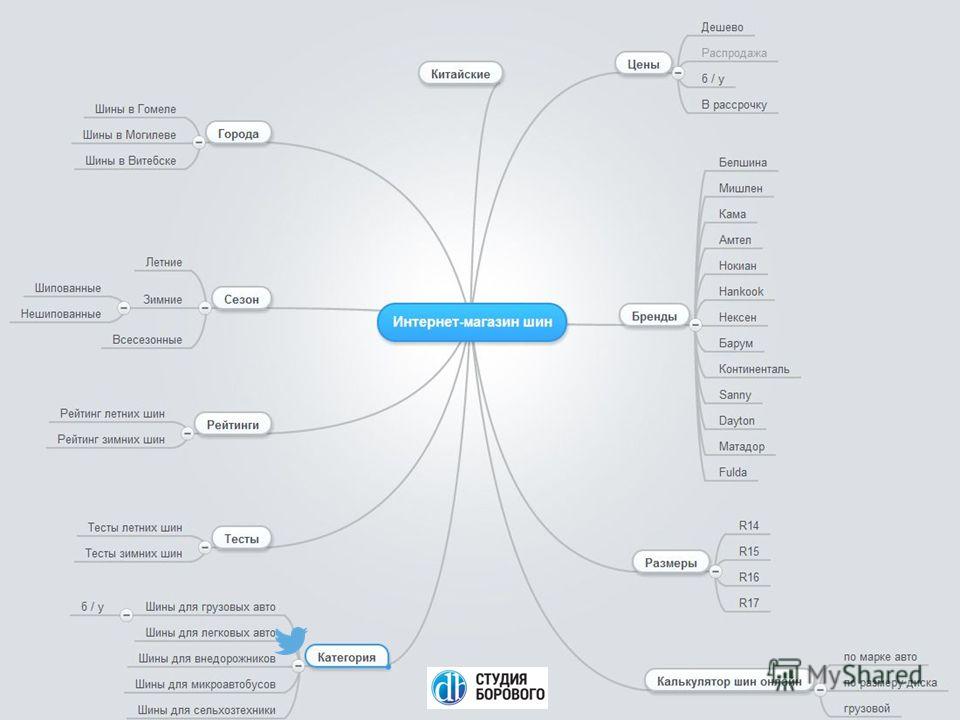
Теперь покажу на примере, что у вас должно получиться на этом этапе. В моем примере я собираю семантику для интернет-магазина пиццы в Оренбурге. Я сгенерировал такие запросы:
Сбор базовых ключевых словВсе запросы, которые мы получили на прошлом этапе, поочередно вбиваем в Яндекс Wordstat или Букварикс. Все сервисы интуитивно понятны.
У Букварикс база Google и Яндекса, но я в нем не нашел функции фильтра по местности. У Яндекса это и есть, однако он раздражает вводом капчи после каждого запроса.
Показываю на примере, как работаю с Яндекс Вордстат. Беру первый запрос из своего документа и ввожу его. Всю статистику из обоих столбцов копирую в Google Таблицы.
Располагайте запросы в один столбец. Пройдитесь по всем запросам из своего документа. Самые общие высокочастотные запросы пробейте дополнительно через Букварикс — в нем можно подсмотреть запросы, которые стоит поискать. Например:
Самые общие высокочастотные запросы пробейте дополнительно через Букварикс — в нем можно подсмотреть запросы, которые стоит поискать. Например:
Важно в процессе подбора запросов не переусердствовать. В какой-то момент это утратит смысл — в таблицу будут попадать фразы-синонимы, странная низкочастотка и другой мусор. Соблюдайте баланс — если расслабитесь слишком рано, не дойдете до перспективных среднечастотных запросов.
Как понять, что пора заканчивать собирать семантическое ядро — вопрос опыта. Тут нет идеального правила. По идее, вы сами почувствуете, что уже перебираете одно и то же — это сигнал, что вы финишировали.
Сергей Лукашевич
Когда я только начал заниматься SEO, то любил собрать тонну запросов и копаться в них. Потом понимаешь, что это бессмыслица. Пускай лучше запросов будет меньше для каждой страницы, но они будут качественные и понятные.
Если сомневаетесь, можете собирать много запросов — мы все равно их удалим при чистке: просто это лишняя работа.
В интернете полно конкурентов — мы можем просканировать их через специальные сервисы и получить почти готовую семантику: важно отбирать только качественные страницы, которые высоко ранжируются в выдаче. Такие сервисы платные и разбирать в статье их функционал мы не будем. Если вам интересно, присмотритесь к следующим сервисам и изучите их самостоятельно:
- SEMRush
- Ahrefs
- Serpstat.
Почерпнуть идеи у конкурентов можно и без специализированных сервисов. Заходите на их сайт и внимательно изучайте — пощелкайте страницы в интернете и посмотрите, что пишут. Вы, скорее всего, отыщете запрос, который стоило бы включить в семантическое ядро, но который сами упустили из виду — обращайте внимание на заголовки страниц.
Удаление дубликатов. Некоторые запросы будут пересекаться. Нам они не нужны, поэтому удалим дубликаты через все тот же раздел «Данные»:
Удалить плюсы. Они будут мешать на этапе кластеризации.
Они будут мешать на этапе кластеризации.
Сортировка. Теперь всю таблицу отсортируем по убыванию частности. Отсортировать можно функционалом Google Таблиц. Этот шаг нужно повторить после следующего пункта «чистка нерелевантных запросов». При удалении запросов у нас появятся в случайных местах таблицы, а сортировка снова сведет всю семантику воедино.
Чистка нерелевантных запросовВ семантическое ядро так или иначе попадут нерелевантные запросы — такие запросы не характеризуют наш сайт, а люди, когда их вводят, ищут совсем другое. От таких запросов нужно избавляться — трафика они не принесут.
Удаляем такие запросы:
- С упоминаниями конкурентов.
- С товарами или услугами, которые не оказываем.
- С упоминанием города, районов и улиц в которых не работаем.
- Запросы с ошибками. Даже если человек сделает ошибку в запросе, поисковик все равно переведет его на верный запрос.
- Фразы, которые вы не понимаете. С большой вероятностью это не имеет отношения к вашей компании.
- Запросы-синонимы, например, «купить смартфон» и «смартфон купить»
- Микрозапросы — их ищут ничтожно мало, такая сеошная погрешность. Зависит от сферы: например, если наша среднечастотка 200 запросов, то все запросы меньше 10 можно удалять. Тем более, если они похожи на уточнение основного запроса.
Давайте почистим ненужные ключи для нашего примера с пиццерией. Их получилось много:
Плов и шаурму я не продаю. Печку, камень, противень, тесто и коробки для пиццы тоже. Воппер-пиццы нет в моем ассортименте. Удаляем.
Несмотря на то, что я смотрел запросы только по Оренбургу, в результаты Яндекс Вордстата подмешались левые запросы — пицца Сорочинск и Самара. Удаляем.
«Пиццеол» — непонятный запрос, который не прояснился даже после того, как я проверил в Google — удаляем. Еще на этот скриншот попала «Додо пицца» — конкурент. Конкурентов, гораздо больше, все они выше. Конкурентов удаляем, либо переносим их в другой документ: если планируете запускать контекстную рекламу — там пригодится такая семантика.
Конкурентов, гораздо больше, все они выше. Конкурентов удаляем, либо переносим их в другой документ: если планируете запускать контекстную рекламу — там пригодится такая семантика.
Еще встретился запрос «чудо пицца». Я сначала не понял, потом оказалось что это местная пиццерия. Поэтому важно удалять запросы, которые вы не понимаете. Для верности можете загуглить их.
Несколько примеров с запросами под удаление. Они выделены синим:
Если запрос перспективный, но у вас нет таких услуг — переносите его в скоринг-документПри сборе семантики часто всплывают запросы, которые близки нашему бизнесу, но таких услуг у нас еще нет. Если эти запросы перспективны и их часто ищут люди — не удаляйте их, а перенесите в скоринг-документ. Это документ с идеями развития и масштабирования бизнеса с точки зрения SEO.
В нашем примере про пиццу такие запросы — суши и роллы. Люди часто ищут их вместе с пиццей, но если мы занимаемся одной только пиццей — нам они не подходят.
Чистка — рутинный процесс, который может занять много времени. Проверять семантическое ядро нужно вручную, а иногда запросов много — больше тысячи. Ну тут ничего не поделать.
Сергей Лукашевич
Не игнорируйте информационные запросыПри чистке важно сохранять осознанность и не делать это действие на автомате — можете пропустить интересные запросы, которые стоило бы внедрить.
В примере про пиццерию я выяснил, что люди часто ищут рецепты для пиццы — это информационный запрос. Пиццерия вполне может запустить небольшой блог, в котором будет раскрывать похожие темы. Так мы привлечем больше трафика и познакомим аудиторию со своим брендом. Бизнесу ведь нужно повышать узнаваемость — это один из инструментов.
Конечно, если человек ищет рецепт пиццы, он хочет сам ее приготовить, но в конце статьи мы можем предложить человеку купить нашу пиццу, по рецепту который он искал. У человека уже появится лояльность к нашему бренду, а когда его пицца не получится, он закажет ее у нас 😁.
Другой интересный запрос, который я увидел — «рейтинг пиццерий». Мы можем на поддомене написать статью с рейтингом популярных оренбургских пиццерий. Похожую механику мы используем в Unisender: объективно сравниваем себя с конкурентами в статьях из базы знаний.
Если вы видите, что низкочастотные запросы повторяют основные запросы, только в них содержится странный хвост — их тоже можно удалять. В нашем примере про пиццу выяснилось что все запросы с частотой 10 и меньше можно убрать — они так или иначе копируют запросы, которые уже есть.
Также удаляйте запросы-синонимы, в которых слова из запроса одни и те же, но в другой последовательности. Например, «пицца доставка» и «доставка пицца. Их можно искать вручную, но удобнее делать через программу Key Collector (платная) — там есть функция «анализ неявных дублей».
Ссылка на Google-таблицу с семантикой сайта пиццы
На этом сбор семантики закончен. Теперь ее нужно разбить на кластеры.
Кластеризация
Напомню, кластеризация — деление семантического ядра на кластеры. Кластер — группа запросов, которую поисковик считает одной темой и выдает по ней пересекающиеся результаты.
Кластер — группа запросов, которую поисковик считает одной темой и выдает по ней пересекающиеся результаты.
Проверить кластеры можно вручную. В режиме инкогнито вбейте запросы и проверьте выдачу. Например, «заказать пиццу» и «купить пиццу» один кластер, выдача похожа.
Проще всего кластеризовать семантику через специальные сервисы. Советуем KeyAssort — он платный, но с мощным функционалом. Еще можете присмотреться к KeyClusterer, этот уже бесплатный.
Далее будем кластеризовать семантическое ядро на примере KeyAssort. Принцип работы следующий: вы отдаете сервису свою семантику, он в зависимости от заданных параметров, проверяет пересечения, объединяет похожие запросы в кластеры и отдает вам. Вы можете посмотреть видео-инструкцию по работе с программой на официальном сайте, а я здесь кратко перескажу основные действия.
Приведенный ниже пример кластеризации — упрощенная схема. Более сложный и точный подход — когда мы берем частотность и сложность ключевого слова из платных сервисов.
Импорт. Чтобы программа все загрузила верно, лучше работать через шаблон. Скачать шаблон.
В первый столбец копируем запросы, а частотность копируем во второй и третий столбец (Mix search volume и Max search volume) — то есть их нужно продублировать. Поставьте значение «0» во всех остальных ячейках и «low» в Сompetition. Теперь импортируем:
Следующие окна оставляем без изменений:
Получилось так:
Сбор данных. Теперь нужно, чтобы программа проанализировала запросы и выявила среди них кластеры. Нажимаем «Собрать данные» в верхнем меню:
У нас около 200 запросов и сбор данных займет несколько минут. Чем больше семантика — тем больше времени.
Кластеризация. Нажимаем в верхнем меню «Кластеризация» и начинаем эксперименты с настройками. Цель — получить адекватную сборку кластеров . Мы можем менять вид кластеризации, силу группировки и другие параметры — подробнее об этом читайте в справке KeyAssort.
Меняйте настройки пока не увидите адекватную сборку кластеров. Иногда приходится вручную перебрасывать запросы из одного кластера в другой чтобы получить лучший результат.
Иногда приходится вручную перебрасывать запросы из одного кластера в другой чтобы получить лучший результат.
В нашем примере получился такой результат:
Структура будущего сайта получилась точной, но большая часть запросов попала на главную страницу — это особенность региональных проектов.
Что дальшеТеперь у вас есть собранная и кластеризованная семантика. Можно:
- Продумать структуру сайта. Под каждый кластер — своя страница.
- Отслеживать движение сайта в выдаче по ключевым запросам.
- Подумать над созданием продуктов, которые близки нашему бизнесу.
- Писать технические задания с ключевыми словами и вставлять их в страницу — но это уже совсем другая тема, в этой статье мы ее касаться не будем.
Статья получилась большой, пробежимся по основным выводам.
Что касается базовой теории:
- Семантика — набор запросов и фраз, которые характеризуют наш сайт или конкретную страницу.

- Семантика помогает продумать структура сайта, отслеживать продвижение сайта по ключевым запросам в поиске, а также это необходимый этап перед формированием сео-ключей. Собранное ядро — отличный советник по бизнес-идеям: на разработке каких продуктов и страниц, нужно сосредоточить внимание, а от каких наоборот отказаться.
- Если у вас не очень крупный проект, есть желание и время погрузиться в SEO — собрать семантику можно самостоятельно. В остальных случаях нужен сеошник хотя бы на разовый проект.
- Собранное семантическое ядро открывает путь к текстовой оптимизации страниц — добавлению SEO-ключей и метатегов, проработке структуры статьи, ее объема и другое. Это сложнее сбора семантики и тут нужные более глубокие знания. Скорее всего, придется звать сеошника и не факт, что его устроит собранная вами семантика.
Как собрать семантику за 6 шагов:
- Обсудите с коллегами и сотрудниками, какие запросы характеризуют ваш сайт.
 Ответьте на вопрос: «если бы вы искали свой сайт в поисковике, то по каким запросам?»
Ответьте на вопрос: «если бы вы искали свой сайт в поисковике, то по каким запросам?» - Вбейте все фразы из предыдущего этапа в Яндекс Вордстат и скопируйте все предложенные запросы в Google Таблицы. Дополнительно используйте Букварикс.
- Посмотрите конкурентов — изучите их разделы, вам наверняка придет идея, как расширить свою семантику.
- Шлифовка и сортировка. Удаляем дубли, микрозапросы, символы «+» из Яндекс Вордстат.
- Чистка. Удаляем непонятные фразы и все, что наш сайт дать пользователю не может. Перспективные запросы, но которые сейчас не описывают наши услуги, переносим в скоринг-документ.
- Кластеризируем семантику через KeyClusterer.
SEO-продвижение не ограничивается одной лишь семантикой и текстовой оптимизацией — это более многогранный процесс, который охватывает работу с технической и контентной частью сайта. А еще желательно публиковаться на внешних ресурсах — блогах и каталогах.
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
Статьи почтой
Раз в неделю присылаем подборку свежих статей и новостей из блога. Пытаемся шутить, но получается не всегда
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
цены, примеры, как собрать по шагам
Если вы хотите:
✓ Увеличить продажи вашего интернет-магазина?
✓ Победить агрегаторы и маркетплейсы в ТОПе?
✓ Получить клиентов с минимальными затратами?
✓ Найти популярные товары с низкой конкуренцией?
✓ Найти молодых и быстро растущих конкурентов?
Что мы можем предложить?
✓ Опыт. С 2013 года составили 850+ ядер для интернет-магазинов.
С 2013 года составили 850+ ядер для интернет-магазинов.
✓ Максимальная полнота семантики и охват ниши (25+ источников ключей).
✓ Поиск «правильных» запросов (минимум агрегаторов/больших ИМ в ТОПе).
✓ Учет: синонимов, терминов, сокращений, разных написаний — для маркеров.
✓ В ядре остаются запросы с коммерческим интентом, которые приводят к покупке.
✓ Главные триггеры: купить, цена, заказать, дешево, стоимость, с доставкой …
✓ Семантику собираем для: разделов/категорий, фильтров, тегов, карточек товара.
✓ Кластеризация по ТОПам + ручная доработка под бизнес + финальная проверка.
✓ Сбор + расчет параметров: коммерческость, сложность продвижения, сезонность.
✓ Семантическое ядро подходит для seo продвижения и контекстной рекламы.
✓ Построение структуры и меню, исходя из спроса, а не «фантазий» сеошников.
✓ ТЗ на копирайт покажет: нужен ли контент для разделов и карточек товаров.
✓ Бесплатная консультация от руководителя агентства по работе с семантикой.
Ручная доработка и проверка
семантического ядра
1. После «автомата» идет ручная проработка ядра.
Этап занимает до 60% времени.
Семантист учитывает: URLы в ТОПе + интент + специфику бизнеса.
2. Отдел контроля проверит «ручную» доработку первого семантиста.
Этап занимает: 30-35% времени.
Устраняется от 10 до 20% ошибок и «спорных» моментов.
Play Video about Видеообзор ручной доработки семантики 1
Проиграть видео
Приоритет внедрения семантики на сайт
Отчет «Сезонность» — позволяет быстро понять, в каких периодах у нас максимальный и минимальный спрос на соответствующий товар.
Это позволит заблаговременно создать посадочные страницы, оптимизировать их под seo + настроить контекстную рекламу.
Например: «дефлекторы окон» — максимальный спрос с 4 по 8 месяц, минимальный – с 12 по 2 месяц.
Поиск и анализ близких «онлайн» конкурентов.
Отчет «Топ доменов» — позволяет быстро (без сводных таблиц) найти и проанализировать самых видимых по нашему ядру молодых и быстрорастущих «онлайн» конкурентов.
Пример: для интернет-магазина автозапчастей в ТОП20 есть много «молодых» сайтов с RANKом до 4.
Это: original-detal.ru, ladatuningshop.ru, car-team.ru, autorx.ru
Наше ядро, как основа построения
«правильной» структуры и меню
Важно! После составления семантического ядра, его надо правильно внедрить на сайт.
Строить структуру магазина, формировать меню, организовать фильтры и перелинковку необходимо на базе семантики,
а не «фантазий» или «предположений» сеошников.
Стоимость семантического ядра
для интернет-магазина
* Оплата в других валютах рассчитывается по курсу на день оплаты
Что входит в услугу семантика для ИМ?
✓ Исследование ниши.
✓ Формирование маркеров.
✓ Парсинг запросов.
✓ Парсинг выдачи и параметров.
✓ Чистка от мусора.
✓ Утверждение запросов.
✓ Кластеризация запросов по ТОПам.
✓ Ручная доработка семантистом.
✓ Проверка ядра отделом качества.
✓ Расчет сложности продвижения, Rank.
✓ Формирование ядра, Excel формат.
✓ Бесплатное ТЗ копирайтеру.
✓ Консультации и поддержка 24/7.
до 8000 запросов
$ / запрос
Заказать семантику
от 8000 запросов
$ / запрос
Заказать семантику
Внимание! Минимальный заказ: 70 $. На англоязычное ядро под бурж: 80 $.
Примеры нашей семантики для ИМ
Автозапчасти
Одежда
Ювелирные изделия
Инструменты
Мебель
Стройматериалы
Косметика
Семантическое ядро для интернет магазина автозапчастей.
✓ Наш опыт в данной тематике: 4 проекта в 3 регионах.
✓ Регионы сбора: Россия, Украина, Беларусь.
Закажите семантику
Примеры запросов:
✓ Заказать дефлекторы окон.
✓ Подлокотник лада гранта.
✓ Колпаки r15 цена.
✓ Дефлекторы боковых окон.
✓ Подлокотник лада гранта.
✓ Купить бортовой компьютер на гранту.
✓ Задний бампер приора.
Конкуренты (Rank):
✓ princessdress.ru (2)
✓ belpodium.ru (3)
✓ krasotka-dress.ru (1)
✓ fasone.ru (1)
✓ fabrika-mody.ru (3)
✓ 1001dress.ru (3)
✓ velesmoda.ru (3)
Семантическое ядро для интернет магазина одежды
✓ Наш опыт в данной тематике: 5 проектов в 4 регионах.
✓ Регионы сбора: Украина, Россия, Казахстан, США.
Закажите семантику
Примеры запросов:
✓ Женский костюм тройка.
✓ Платье женское летнее.
✓ Вечернее платье купить.
✓ Брючный костюм для полных.
✓ Купить женские брюки.
✓ Пиджак женский цена.
✓ Пижамы женские италия.
Конкуренты (Rank):
✓ timeturbo.ru (5)
✓ original-detal.ru (4)
✓ ladatuningshop.ru (2)
✓ car-team.ru (3)
✓ nvs-car.ru (4)
✓ autorx.ru (3)
✓ bamper-msk.ru (1)
Семантическое ядро для интернет магазина ювелирных изделий
✓ Наш опыт в данной тематике: 3 проекта в 2 регионах.
✓ Регионы сбора: Киев, Москва.
Закажите семантику
Примеры запросов:
✓ Кольцо с бриллиантом цена.
✓ Золотой браслет женский.
✓ Купить обручальные кольца.
✓ Купить серьги пусеты.
✓ Серьги серебро цена.
✓ Детские золотые сережки.
✓ Пирсинг купить.
Конкуренты (Rank):
✓ bronnitsy.com (4)
✓ 585zolotoy.ru (4)
✓ zoloto585.ru (4)
✓ diamant-online.ru (4)
✓ adamas.ru (4)
✓ zolotodiskont.ru (1)
✓ piercingmarket.ru (2)
Семантическое ядро для интернет магазина инструментов
✓ Наш опыт в данной тематике: 3 проекта в 3 регионах.
✓ Регионы сбора: Казахстан, Украина, Россия.
Закажите семантику
Примеры запросов:
✓ Заказать триммер для травы.
✓ Культиватор цена.
✓ Купить мотоблок.
✓ Заказать сучкорез.
✓ Ножницы кусторез заказать.
✓ Культиватор ручной для дачи.
✓ Сплошной культиватор цена.
Конкуренты (Rank):
✓ leroymerlin.kz (2)
✓ komfort.kz (3)
✓ sravni.kz (2)
✓ masterok.kz (1)
✓ kz.e-katalog.com (4)
✓ blizko.kz (2)
✓ otvertka.kz (2)
Семантическое ядро для интернет магазина мебели
✓ Наш опыт в данной тематике: 6 проектов в 3 регионах.
✓ Регионы сбора: Москва и МО, Киев, Минск.
Закажите семантику
Примеры запросов:
✓ Купить шкаф купе.
✓ Шкаф купе с зеркалом.
✓ Столешница из дсп цена.
✓ Заказать мебель для кафе.
✓ Мебель для ресторанов.
✓ Мебель для бара.
✓ Гардеробная деревянная.
Конкуренты (Rank):
✓ shkaf-kupe. ru (3)
ru (3)
✓ klenmarket.ru (4)
✓ newbar.ru (1)
✓ otdelka4u.ru (0)
✓ restoracia.ru (2)
✓ ldsp-shop.ru (1)
✓ chiedocover.ru (2)
Семантическое ядро для интернет магазина стройматериалов
✓ Наш опыт в данной тематике: 6 проектов в 4 регионах.
✓ Регионы сбора: Киев, Москва, Алматы, Санкт-Петербург.
Закажите семантику
Примеры запросов:
✓ Декоративная штукатурка.
✓ Купить песок.
✓ Заказать клей для плитки.
✓ Фасадная штукатурка цена.
✓ Наливные полы цена.
✓ Цемент мешок 25 кг заказать.
✓ Жидкий пол цена.
Конкуренты (Rank):
✓ st-par.ru (6)
✓ glavsnab.net (3)
✓ cem-cement.ru (1)
✓ cement-snab.ru (2)
✓ moscow-beton.ru (2)
✓ gruzzillo.ru (0)
✓ mosnerud.ru (0)
Семантическое ядро для интернет магазина косметики
✓ Наш опыт в данной тематике: 7 проектов в 4 регионах.
✓ Регионы сбора: Минск, Алматы, Киев, Санкт-Петербург.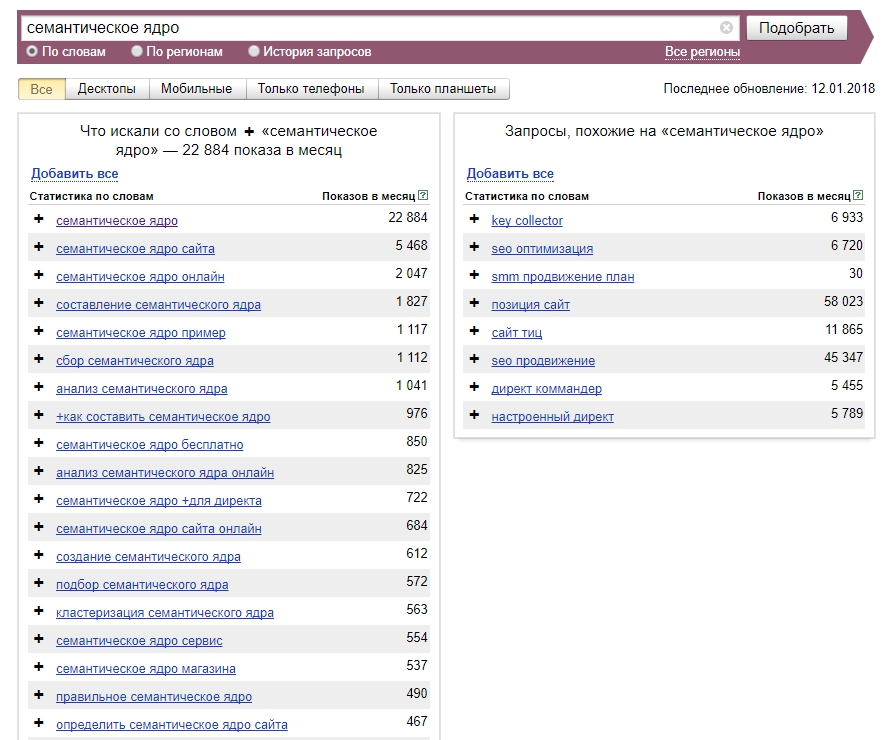
Закажите семантику
Примеры запросов:
✓ Купить массажное масло
✓ Эко косметика заказать
✓ Безсульфатный шампунь купить
✓ Натуральная косметика
✓ Набор косметики в подарок
✓ крем для загара купить
✓ кондиционер для волос цена
Конкуренты (Rank):
✓ proficosmetics.ru (5)
✓ goldapple.ru (5)
✓ 4fresh.ru (4)
✓ rivegauche.ru (5)
✓ beauty365.ru (1)
✓ ecoville.ru (2)
✓ eco-list.ru (3)
Самые популярные вопросы — ответы:
Подать бриф на семантику:
Telegram
Сбор ядраГруппировка семантического ядраТЗ для копирайтера (Excel+Tskb)
Промокод
* Вы соглашаетесь с «Политикой конфиденциальности» и Соглашением.
Бесплатная консультация от руководителя
Отвечу на вопросы по заказу и составлению семантического ядра.
3 шага к построению семантического ядра | Манолис Симиониди | Блог Asodesk 🚀
Прежде чем мы углубимся в этапы создания (построения) вашего семантического ядра, давайте сначала выясним, что такое семантическое ядро на самом деле.
Семантическое ядро — набор ключевых слов (ключевых фраз), максимально точно описывающих приложение. Как вы, наверное, уже поняли, это одна из самых важных задач в ASO, потому что после создания семантического ядра мы выбрали, какие ключевые слова мы используем или можем пропустить.
Теперь, когда мы разобрались с определением семантического ядра, давайте посмотрим на этапы его создания.
Подбор ключевых слов — первый и самый ответственный шаг в создании семантического ядра. Перед запуском спросите себя «Кто будет использовать мое приложение?» . Ответив на этот простой (но иногда сложный) вопрос, мы можем начать с добавления ключевых слов. Ключевые слова будут варьироваться в зависимости от темы вашего приложения (тема, идея). Давайте выберем приложение и используем его в качестве примера; мы будем использовать 9Приложение 0013 WhatsApp . Для этого приложения мы можем выбрать ключевые слова, такие как мессенджер, звонки, текстовые сообщения, видеозвонки и т. д. высокий трафик.
д. высокий трафик.
Если ваше приложение является игрой, то ваше семантическое ядро будет намного больше, чем неигровое приложение. Почему? Просто потому, что в играх можно использовать гораздо более широкий набор ключевых слов. Например, если у того, у кого есть приложение для путешествий, на первых этапах создания семантического ядра будет 100 ключевых слов, у того, кто создает семантическое ядро игр, будет 300 ключевых слов, большая разница, верно?
Теперь вы можете подумать, откуда у ASO-маркетологов в семантическом ядре тысячи ключевых слов? Что ж, используя инструменты ASOdesk , такие как органический отчет или автоматические предложения ключевых слов , вы можете просто добавить множество релевантных ключевых слов в свое приложение. Инструмент Органический отчет , например, может показать 30 лучших ключевых слов, которые используются для поиска вашего приложения, а Автопредложения ключевых слов покажет вам ключевые слова с высоким трафиком, которые имеют отношение к вашему приложению.
При создании семантического ядра вы должны задать себе еще один вопрос «С кем конкурирует наше приложение?» . При таком большом росте мобильного рынка вы можете задавать этот вопрос каждый день 😊 а если серьезно, то выбирайте своих приложений основных конкурентов, рынок может меняться каждый день, поэтому лучше обновлять их хотя бы раз в неделю.
Если вы используете ASOdesk, , вы можете посмотреть их органический отчет и узнать, какие у них 30 самых популярных запросов по ключевым словам. На основе трафика ключевых слов вы можете добавить несколько ключевых слов от ваших конкурентов, которые будут полезны для вашего семантического ядра.
Несколько дней назад, я проводил вебинар по ASO тогда как пример я использовал игру The Elder Scrolls: Legends , используя органический отчет своих конкурентов я успешно создал семантическое ядро этого приложения всего за несколько минут.
Наконец, переходим к третьему шагу — анализу вашего семантического ядра. Используя инструмент ASOdesks Keywords Analytics , мы можем отслеживать показатель трафика каждого ключевого слова в нашем семантическом ядре. Трафик отображается как точное значение, поэтому вам не нужно сидеть и смотреть на оценочное значение, чтобы понять, сколько людей делает тот или иной поисковый запрос.
Удалить бесполезные ключевые слова; это ключевые слова со слишком маленьким трафиком. В процессе анализа вашего семантического ядра вы всегда можете использовать функцию Предложения ключевых слов , чтобы добавить больше вариантов ключевого слова, тем самым увеличив свое семантическое ядро.
Теперь, если вы прочитали эту статью, у вас не должно возникнуть проблем с созданием вашего первого семантического ядра, и вы должны быть готовы к работе с нашим анализом ключевых слов! Но об этом мы напишем более подробно в отдельной статье.
Чтобы узнать больше об ASO и о том, как работают все инструменты ASOdesk, перейдите по ссылке: www.asodesk.com Создайте учетную запись и запланируйте живую демонстрацию или задайте любые вопросы, касающиеся ASO, в нашу службу поддержки по внутренней связи, они будут более чем рады чтобы помочь вам! 😉
Хорошего дня!
Как разместить список ключевых слов на вашем веб-сайте
7002
| Как сделать | – 9 минут чтения |
Читать позже
Исследование ключевых слов является одной из основных задач SEO, так как от эффективности подбора и распределения ключевых слов зависит видимость сайта в результатах поиска и его посещаемость.
В этом посте мы рассмотрим основы сбора, кластеризации и распределения ключевых слов на вашем веб-сайте.
Что такое список ключевых слов?
Список ключевых слов включает все ключевые слова, используемые для SEO-оптимизации. Количество ключевых слов в списке зависит от тематики сайта; для крупных веб-сайтов он может состоять из миллионов поисковых запросов.
Количество ключевых слов в списке зависит от тематики сайта; для крупных веб-сайтов он может состоять из миллионов поисковых запросов.
Основной целью сбора ключевых слов для поисковой оптимизации является создание стратегии оптимизации, которая поможет повысить видимость веб-сайта в результатах обычного поиска.
Как составить список ключевых слов? Оптимизаторы используют различные инструменты, наиболее популярными из которых являются Планировщик ключевых слов, Google Ads, Keyword Research by Serpstat , Key Collector и другие.
Список ключевых слов веб-сайта обычно состоит из запросов с низким, средним и большим объемом запросов. Объем поиска определяется средним количеством ежемесячных показов в поисковых системах.
Для таких популярных тем, как одежда или игрушки, запросы большого объема означают десятки тысяч показов в месяц. В некоторых случаях сверхпопулярные ключевые слова могут запрашиваться миллионы раз в месяц.
Если веб-сайт посвящен необычной нишевой теме с небольшой целевой аудиторией, высоким объемом поиска будут считаться ключевые слова, которые поисковая система показывает 300–500 раз в месяц:
Использование Google Ads для создания списка ключевых слов
Планировщик ключевых слов позволяет выбирать запросы на основе заданной темы и заданных ключевых слов. Сначала нажмите Начать сейчас :
Сначала нажмите Начать сейчас :
Затем нажмите Инструменты и настройки s и выберите Планировщик ключевых слов :
Затем выберите Откройте для себя новые ключевые слова :
3 9 интернет-магазин, в котором есть три категории товаров: мотоциклы, скутеры и спортивные мотоциклы.
Введем перечисленные ключевые слова и нажмем «Получить результаты»:
Планировщик предложил более трех тысяч запросов по интересующей теме:
Вы можете использовать результаты для создания списка ключевых слов для веб-сайта и запуска рекламной кампании. В отчете отображаются ключевые слова, среднемесячные поисковые запросы, конкуренция и цена за клик для объявлений.
Можно применять фильтры, например, по уровню конкуренции. Вы также можете просмотреть группы ключевых слов с общей темой:
Группировка ключевых слов позволит распределить ключевые слова по разделам и страницам сайта:
Для дальнейшей работы загрузите варианты ключевых слов в формате . csv:
csv:
Расширение списка ключевых слов с помощью отчета Serpstat по связанным ключевым словам
Этот отчет можно найти в разделе Исследование ключевых слов → Исследование SEO → Связанные ключевые слова. Введите интересующее ключевое слово, нажмите Искать и получите статистику по всем похожим ключевым словам из ТОП-20 результатов поиска:
После получения новых вариантов ключевых слов, необходимо добавить их в этот же файл, отсортировав по алфавиту и удалить дубликаты. Затем вы можете приступить к группировке (кластеризации) запросов.
Введите любое ключевое слово, чтобы начать работу с инструментом:
Расширенный SEO-аудит: полное руководство по всем этапам анализа [инфографика]
Подробнее Веб-сайт Группировка ключевых слов Для успешной оптимизации все ранее собранные ключевые слова должны быть правильно сгруппированы. Исследование ключевых слов помогает правильно определить структуру сайта: высокообъемные и среднеобъемные запросы должны быть включены в названия категорий и подкатегорий сайта, а малообъемные запросы должны использоваться на страницах сайта. При сборе списка ключевых слов и распределении ключевых слов по веб-сайту следует придерживаться следующих рекомендаций: Несколько страниц одновременно не должны оптимизироваться под одно и то же ключевое слово. В противном случае это приведет к каннибализации ключевых слов. Вам необходимо разделить запросы на две группы:
Вам необходимо разделить ключевые слова на группы, где каждая группа (кластер) содержит похожие по смыслу запросы. Затем разместите их на страницах сайта. Помимо текстов для страниц продуктов, категорий и статей, ключевые слова используются для внутренних ссылок и тегов. Запросы среднего и малого объема, которые вы не использовали для названий категорий, можно использовать в качестве тегов для объединения похожих групп товаров или статей. Кластеризация ключевых слов с помощью Serpstat Вы можете упростить и автоматизировать процесс группировки ключевых слов с помощью инструмента кластеризации ключевых слов Serpstat. Нажимаем Создать проект, вводим название, выбираем регион и поисковик: Далее указываем силу соединения и тип кластеризации. Сильный Надежность соединения требует более распространенных URL-адресов в первых 30 результатах поиска по ключевому слову, а Слабый требует меньше. При выборе параметра Soft ключевые слова объединяются в кластер, если хотя бы одна пара кластеризованных ключевых слов имеет одинаковый URL в поисковой выдаче. При Hard -кластеризации все ключевые слова в одном кластере должны иметь общие URL-адреса в результатах. Затем добавьте ключевые слова вручную или импортировав файл.
Каждый кластер имеет показатель однородности, т.е. степень семантической связности ключевых слов. В отчете также можно просмотреть сайты-лидеры по кластерным запросам (вкладка «Метатоп»). Полученные кластеры можно экспортировать в удобный формат. Хотите использовать Serpstat для сбора списка ключевых слов? Подпишитесь на 7-дневную пробную версию ЗаключениеПолный и должным образом сгруппированный список ключевых слов является основой внутренней оптимизации контента и общей SEO-оптимизации веб-сайта. Список ключевых слов помогает веб-сайту удовлетворить потребности и ожидания целевой аудитории и каждого этапа пути покупателя, а также предоставить им всю информацию, которую они ищут. Чтобы составить подходящий список ключевых слов, вам необходимо собрать все подходящие ключевые слова, сгруппировать их в кластеры и использовать их в различных формах для названий категорий, контента веб-сайта, метатегов, фильтров категорий, карточек продуктов и целевых страниц. Оставить комментарий
|

 Такие запросы могут содержать такие слова, как «Как», «Где», «Почему», «Инструкции» и т. д.
Такие запросы могут содержать такие слова, как «Как», «Где», «Почему», «Инструкции» и т. д.
 org/ImageObject»>
org/ImageObject»>