Русская кодировка в LaTeX/PDF: 1251 — 1252? : TeXнические обсуждения
Сообщения без ответов | Активные темы | Избранное
| dvg |
| ||
14/11/16 |
| ||
|
| |||

| arseniiv |
| |||
27/04/09 |
| |||
|
| ||||

| dmtrkh |
| ||
14/02/16 |
| ||
|
| |||

| Lenchik |
| ||
13/07/14 |
| ||
|
| |||
 Есть ещё фокусы с подключением glyphtounicode.
Есть ещё фокусы с подключением glyphtounicode.| sergei1961 |
| ||
25/08/11 |
| ||
|
| |||

| dvg |
| ||
14/11/16 |
| ||
 винда. Там везде задано в локальных настройках, что местоположение Россия, язык русский и пр., но может чего-то не хватает…
винда. Там везде задано в локальных настройках, что местоположение Россия, язык русский и пр., но может чего-то не хватает…| sergei1961 |
| ||
25/08/11 |
| ||
|
| |||

| Lenchik |
| ||
13/07/14 |
| ||
|
| |||
 https://github.com/AndreyAkinshin/Russi … es.tex#L46
https://github.com/AndreyAkinshin/Russi … es.tex#L46| |
| ||
25/08/11 |
| ||
|
| |||
 А что написать в преамбуле, чтобы скопированный текст из исходника теха переносился корректно в текстовый файл или word?
А что написать в преамбуле, чтобы скопированный текст из исходника теха переносился корректно в текстовый файл или word?| arseniiv |
| |||
27/04/09 |
| |||
|
| ||||
 Скажем, открыть этот файл целиком в ворде, и он, по идее, должен показать диалог с кодировками, где какая-то из них предложена.
Скажем, открыть этот файл целиком в ворде, и он, по идее, должен показать диалог с кодировками, где какая-то из них предложена.| sergei1961 |
| ||
25/08/11 |
| ||
|
| |||
| arseniiv |
| |||
27/04/09 |
| |||
|
| ||||
 Перекодировать на лету на основании его содержимого его не станут — такое поведение было бы просто не user-friendly. Так что это наверняка что-то с редактором, если уж в вашем коде представлены кириллические буквы, т. к. тогда кодировка файла просто не может быть Win1252.
Перекодировать на лету на основании его содержимого его не станут — такое поведение было бы просто не user-friendly. Так что это наверняка что-то с редактором, если уж в вашем коде представлены кириллические буквы, т. к. тогда кодировка файла просто не может быть Win1252.| Показать сообщения за: Все сообщения1 день7 дней2 недели1 месяц3 месяца6 месяцев1 год Поле сортировки АвторВремя размещенияЗаголовокпо возрастаниюпо убыванию |
| Страница 1 из 1 | [ Сообщений: 12 ] |
Модераторы: Karan, Toucan, PAV, maxal, Супермодераторы
Кто сейчас на конференции |
Сейчас этот форум просматривают: нет зарегистрированных пользователей |
| Вы не можете начинать темы Вы не можете отвечать на сообщения Вы не можете редактировать свои сообщения Вы не можете удалять свои сообщения Вы не можете добавлять вложения |
| Найти: |
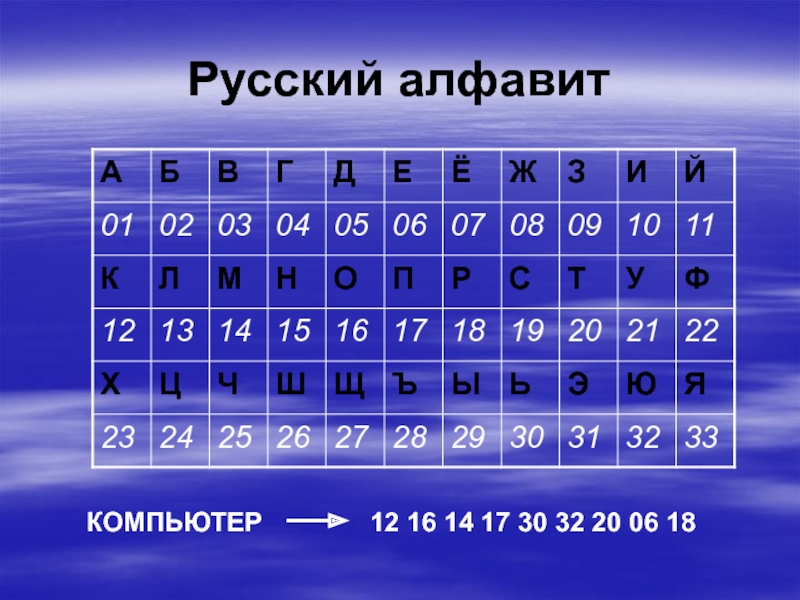
Кодировки, брр.
 .. | Калина Алексей
.. | Калина АлексейУ меня всегда была фобия взаимодействия с кодировками, особенно программно. Да, я достаточно читал и слышал про условные ASCII и UTF-8, но глубокого понимания как с этим работать, а также полной картины у меня так и не возникло. Для меня любые проблемы, связанные с кодировками, становятся в один ряд с инвалидацией кэша и именованием переменных (гики поймут). И вот на этой неделе такая проблема возникла. Связана она с индексацией различных файлов в Elasticsearch, но суть не в этом. Суть в том, что я твердо решил разобраться в многообразии кодировок и поделюсь этим с вами.
На самом деле все достаточно просто. В любой кодировке символ представляется одним или несколькими байтами. Также в любой кодировке есть набор символов, которые могут быть закодированы, и кодовая таблица, по которой можно распознать каждый символ. Проблема в том, что есть множество языков, и по историческим причинам было придумано большое количество кодировок, покрывающих разные наборы символов и использующие для этого разное количество байт.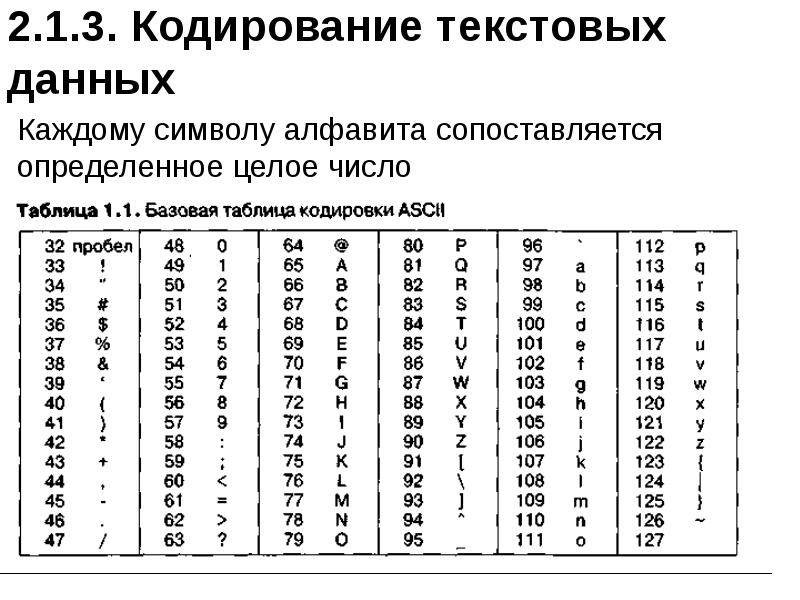
С этой кодировки, расшифровывающейся как American Standard Code for Information Interchange, мы начнем наше погружение в тему. В стандартном ASCII используется только 7 бит, следовательно таблица символов содержит 128 символов. Среди них — латинские буквы, арабские цифры, знаки препинания и различные служебные символы. Причем эти 128 символов являются стандартом, который соблюдается в большинстве других кодировок.
Однако, на свете есть множество других языков кроме английского, а в байте 8 бит… Поэтому появилось большое число расширений ASCII, которые задействовали оставшиеся 128 символов под нужды своего алфавита. Также существуют и другие 7-битные кодировки, которые ориентированы на конкретный алфавит. Рассмотрим некоторые из подобных семейств.
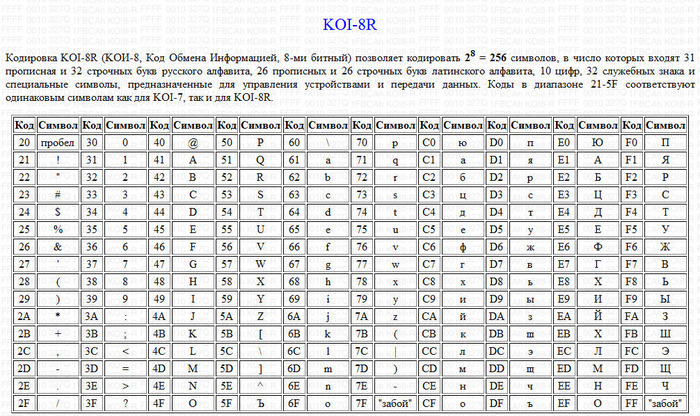
КОИ-8 (код обмена информацией) была широко распространена как основная русская кодировка в Unix-подобных системах. Она расширяла код ASCII таким образом, что буквы русского алфавита располагались в нижней части таблицы на тех же позициях, что и созвучные им английские. Таким образом, если убрать последний бит для каждого символа из текста, написанном в кодировке КОИ-8, получится текст в транслите. Есть несколько вариантов этой кодировки, для разных алфавитов стран СНГ (KOI8-R, KOI8-U, KOI8-T).
Таким образом, если убрать последний бит для каждого символа из текста, написанном в кодировке КОИ-8, получится текст в транслите. Есть несколько вариантов этой кодировки, для разных алфавитов стран СНГ (KOI8-R, KOI8-U, KOI8-T).
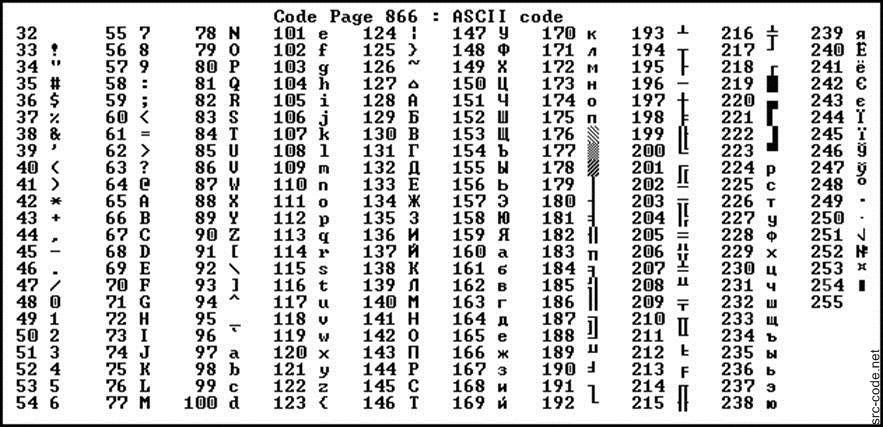
Интересной особенностью этой и некоторых других кодировок того времени (CP866) является наличие среди символов различной псевдографики (палочки, уголочки и так далее). Это связано с тем, что она создавалась тогда, когда были распространены неграфические операционные системы. Тем не менее, текст, написанный в КОИ-8 можно встретить до сих пор. Также существует 7-битный вариант этой кодировки (КОИ-7), который, соответственно, не поддерживает стандарт ASCII, поэтому изжил себя уже достаточно давно.
Еще одно семейство однобайтовых ASCII-совместимых кодировок. Содержит порядка пятнадцати кодовых страниц для разных языков, в том числе и кириллицу (ISO-8859-5). Так как разрабатывалась как средство обмена информацией, она не предназначена для обеспечения высококачественной типографики, при этом содержит много символов управления терминалом. Также как и предыдущее семейство, ISO-8859 использовалось как правило в юниксоподобных системах, хотя в России была распространена именно КОИ-8.
Также как и предыдущее семейство, ISO-8859 использовалось как правило в юниксоподобных системах, хотя в России была распространена именно КОИ-8.
В Windows существует свой набор кодовых страниц, который используется как стандартный в этой ОС. К слову, в MacOS таковой является Mac Cyrillic или Mac Roman. В данном же случае кодировки носят название Windows-125*. Это также восьмибитные варианты ASCII. Для отображения кириллицы используется кодировка Windows-1251, с которой собственно у меня и были проблемы при индексации текстовых файлов.
Глядя на эту картину, мне становится не по себе. При таком обилии кодировок, я не нашел какого-либо эффективного способа проверки того, в какой кодировке был написан конкретный текст. Тем не менее, еще в 1991 году было предложено логичное решение, благодаря которому сейчас все не так уж и плохо.
Именно в 1991 году был создан консорциум Юникод. Благодаря ему был создан стандарт с одноименным названием, который объединял все кодировки. Юникод — это огромная таблица из 1 114 112 элементов, содержащая всевозможные символы, и в которой достаточно места для будущих языков. Однако, это не кодировка, это только кодовая таблица. Другими словами, Юникод говорит о символе только то, под каким номером он стоит в таблице, а каким образом представлять его в байтах уже задача кодировок, о которых мы и поговорим далее.
Юникод — это огромная таблица из 1 114 112 элементов, содержащая всевозможные символы, и в которой достаточно места для будущих языков. Однако, это не кодировка, это только кодовая таблица. Другими словами, Юникод говорит о символе только то, под каким номером он стоит в таблице, а каким образом представлять его в байтах уже задача кодировок, о которых мы и поговорим далее.
Для кодирования такого числа символов нужно не менее трех байт. По понятным причинам программистам все же ближе число 4, поэтому на свет появился UTF-32, в котором под каждый символ отведено 32 бита. При таком подходе очевидна проблема: если пользователь использует только символы из таблицы ASCII, UTF-32 будет хранить в 4 раза больше данных, чем этого требуется.
Для решения этой проблемы были придуманы кодировки с переменной длинной: UTF-8 и UTF-16. UTF-8 позволяет кодировать символы длиной от 1 до 4 байтов. При этом старшие биты сообщают о том, какого размера этот символ. Для ASCII символов происходит экономия памяти, но за счет сигнальных символов двухбайтные значения могут превратиться в трехбайтные. Альтернативой этой кодировке является UTF-16, минимальная длина символа в которой равна двум байтам и может увеличиваться до четырех.
Альтернативой этой кодировке является UTF-16, минимальная длина символа в которой равна двум байтам и может увеличиваться до четырех.
При работе с текстовыми файлами с кодировками, поддерживающими Юникод, иногда существует возможность понять как закодирован текст по первым байтам документа. Маркер последовательности байтов (Byte Order Mark, BOM), расположенный в начале файла, позволяет определить кодировку и порядок байтов (Big/Little Endian). Однако, нужно учитывать, что UTF документы могут и не иметь BOM.
И напоследок, полезная картинка о том, как распознать в какой кодировке должен был быть открыт текстовый файл по внешнему виду содержимого. Источник
Обилие несовместимых кодировок, из-за которых мы видим вместо текста “крокозябры”, по-прежнему доставляет пользователям проблемы. Однако, благодаря Юникоду сегодня они уже не стоят столь остро. Надеюсь, этот небольшой обзор был вам полезен.
Written on December 23rd , 2017 by Alexey KalinaFeel free to share!
Кириллица (русская) в MS Outlook
Кириллица (русская) в MS OutlookКириллица (русская) в MS Outlook 2000 и выше
Важно! Как было отмечено в разделе моего сайта под названием «Русский в Браузере/Почте/Новостях», где я перечисляю инструкции для некоторых интернет-приложений, включая эту страницу о MS Outlook,
есть нет причин читать о настройке этой программы если вы еще не узнали о самой винде — Кириллица шрифты и русские кодировки .Это описано в разделе моего сайта под названием «Кириллические шрифты и кодировки под Windows».
То есть предполагается, что ваши кириллические шрифты активированы и становятся знаком с кириллицей , кодировки используются под MS Windows.Также предполагается, что у вас русская клавиатура инструменты активированы как описано в разделе «Русская клавиатура» моего сайта, если вы собираетесь на напишите по русски в MS Outlook.
Настройка кириллицы для Outlook 2000 и более поздних версий одинакова, поэтому я буду использовать
«Outlook 2000» в тексте, но то же самое касается Outlook 2002/2003.
Существует одно различие в функциональности (не в этапах настройки) между этими двумя продуктами, и оно будет рассмотрено в тексте.
Окружающая среда. у меня обычный американский английский винда, я делал а не сделать любую русификацию моей винды на
уровень системы.
Текущий пользователь , локаль в моей панели управления — «Английский (США)».
Настройки MS Outlook 2000.
я делал а не ‘руссифицировать’ свой MS Outlook 2000
в любом случае, все исходные настройки не тронуты.
То есть в Tools/Options/MailFormat у меня остался оригинал
« Western » настройки в « International Options » и были
без изменений в « Шрифты «.
Это это можно, под такая нерусская версия винды, отправлять и получать электронную почту на русском языке с помощью MS Outlook 2000.
Ограничение для версий 2000/2002. Кириллица может , а не использоваться в теме электронного письма или в поле имени отправителя. MS Outlook 200 3 больше не имеет такого ограничения.
1. Отправка
MS Outlook 2000 предлагает три формата исходящего сообщения:
- Расширенный текстовый формат
- Формат HTML
- Формат обычного текста
Формат по умолчанию для MS Outlook — Rich Text . Это похоже на MS Word текст. Сам MS Outlook получает электронную почту Rich Text Хорошо,
но другие почтовые программы (большинство из них) , а не используют форматированный текст и могут не понимать кириллицу, отправленную в таком формате.
Это похоже на MS Word текст. Сам MS Outlook получает электронную почту Rich Text Хорошо,
но другие почтовые программы (большинство из них) , а не используют форматированный текст и могут не понимать кириллицу, отправленную в таком формате.
Отправка электронной почты в формате HTML также не рекомендуется — в отличие от формата Rich Text, HTML используется в некоторых системах электронной почты, но многие другие почтовые серверы и программы могут не работать с HTML, поэтому, если вы хотите убедиться, что каждая почтовая программа/сервер примет ваше сообщение, тогда вам следует вместо используйте HTML (если вы знаете, что ваш конкретный корреспондент получает HTML нормально, то вы уверены может использовать формат HTML).
Большинство людей используют обычный текст в своих почтовых программах, поскольку он гарантирует, что
такое сообщение будет обработано нормально и будет доступно для чтения всем и каждому пользователю.
Вот почему перед начинают печатать мою электронную почту, которую я собираюсь отправить в Интернет, Я делаю следующее в моем окно подготовки сообщения :
- в меню заходим Формат и выбираем там «Обычный текст»
Примечание. Я лично использую MS Outlook 2000 на работе, где это наша корпоративная почта, поэтому внутри организации могу отправить Rich Text сообщений на русском языке —
потому что я точно знаю, что мои русскоязычные коллеги будут читать их в MS Outlook 2000
а не в какой-то другой почтовой программе. Rich Text хорош, он позволяет использовать цвета и т. д.
Таким образом, для внутренней электронной почты я делаю , а не , выполняю этот шаг выбора опции Plain Text .
Я отправляю электронную почту во «внешний мир» из MS Outlook 2000 только на очень редком случаю, и каждый раз, когда я это делаю,
Я выполняю этот шаг, выбирая Plain Text в пункте меню «Формат» моего сообщения. окно подготовки, чтобы убедиться, что любая программа электронной почты сможет получить мое сообщение.
окно подготовки, чтобы убедиться, что любая программа электронной почты сможет получить мое сообщение.
Если у вас другая ситуация и используете MS Outlook 2000 часто для отправки
электронная почта во «внешний мир», то вы можете избежать этого шага выбора обычного текста
каждый раз — сделайте Plain Text форматом по умолчанию :
- в главном меню перейдите в Инструменты/Параметры и перейдите на вкладку «Формат почты».
- в поле «Отправить в этом формате сообщения» выберите « Plain Text »
Теперь каждые Новое сообщение , которое вы подготовите, уже будет иметь флажок «Обычный текст» в разделе «Формат».
Примечание. Но это а не дело за Ответить (или Переслать) — там MS Outlook 2000
будет использовать формат исходного сообщения, поэтому вам необходимо убедиться, что «Обычный текст»
выбирается в разделе «Формат» после нажатия кнопки «Ответить» (или «Переслать»).
Это был шаг выбора формата .
Теперь мне нужно выбрать один из Кодировки кириллицы для использования в MS Outlook
при отправке моего письма в сеть
(ситуация с кириллическими кодировками подробно описана на моей странице
«Кириллица шрифты и кодировки под MS Windows).
Наиболее распространенная русская кодировка для сообщений, «путешествующих» по Интернету, KOI8-R (кириллица (KOI8-R)), но вместо этого вы можете использовать Кодировка Windows-1251 (кириллица(Windows)), если ты знайте наверняка, что именно этого ожидает ваш корреспондент:
- в меню вашего окна подготовки сообщения перейдите в Формат/Кодировка и выберите там « Кириллица(KOI8-R) »
или « Cyrillic(Windows) » (что означает кодировку Windows-1251)
Если вы часто отправляете электронные письма на русском языке, вы можете не делать этот выбор кодировки каждый раз —
можно сделать, скажем, KOI8-R a кодировка по умолчанию для исходящих сообщений:
- в главном меню перейдите в Инструменты/Параметры и перейдите на вкладку «Формат почты».

- там нажмите кнопку «Международные параметры»
- в поле «Использовать эту кодировку для исходящих сообщений» выберите нужную русскую кодировку — Кириллица(KOI8-R) или Кириллица (Windows)
Теперь каждое подготовленное вами сообщение New будет иметь уже эту русскую кодировку предварительно установлен, поэтому вам не нужно переходить к формату/кодированию в окне подготовки сообщения.
Примечание. Но это а не дело за Ответить (или Переслать) — там MS Outlook 2000 будет использовать кодировку исходного сообщения, поэтому вам необходимо убедиться, что вам нужна кириллическая кодировка в Format/Encoding после того, как вы нажмете «Ответить» (или «Переслать»).
Вот и все. Теперь вы можете напечатать свое письмо, используя в нем английские и русские символы.
Помните, что в Subject 9 русский язык запрещен.0010 вашего электронного письма.
Примечание. Вы должны , а не использовать Unicode в качестве кодировки для вашего кириллического e-mail:
многие почтовые программы , а не смогут показать его читателю.
Вы должны , а не использовать Unicode в качестве кодировки для вашего кириллического e-mail:
многие почтовые программы , а не смогут показать его читателю.
Вы должны использовать кодировку KOI8-R (предпочтительно) или Windows-1251.
2. Получение
MS Outlook не , а не нуждается в настройке здесь, вы можете просто нормально читать электронное письмо на русском языке, отправленное либо в кодировке KOI8-R, либо в кодировке Windows-1251.
Исключение: Если отправитель также использовал русский язык в Теме сообщения, то вы получите , а не уметь читать такую Тему.
Важно. Иногда вы можете получить русскоязычное электронное письмо, в котором кодирует как , а не указано правильно.
Например, учетные записи электронной почты в Интернете, такие как Yahoo! Почта
или HotMail позволяет печатать на русском языке — используя кодировку KOI8-R или Windows-1251
кодировка (в зависимости от того, что вы выбрали в браузер ), но когда вы нажимаете «Отправить»,
эти веб-почтовые системы всегда пишут «encoding= Western »
в системном заголовке этого электронного письма.
В панели предварительного просмотра MS Outlook затем показывает вам какую-то тарабарщину вместо русского языка для таких
входящее электронное письмо.
Но вы все еще можете прочитать это в своем Outlook 2000 — просто дважды щелкните по этому электронному письму, чтобы открыть его в отдельном окне а затем попытайтесь сделать текст читабельным:
Примечание. Outlook 2000 и Outlook 2002
Насколько я слышал, новый Outlook XP (он же Outlook 2002) делает , а не . разрешить такой обходной путь для сообщений, в которых указана неправильная кодировка, как мой Outlook 2000 делает.
То есть вы не сможете читать такие входящие сообщения.
Но в более новом Outlook 2003 такой проблемы нет, здесь он ведет себя как Outlook 2000.
Итак, чтобы решить эту проблему в Outlook 2002:
если вы умеете пользоваться MS Outlook макросы (у меня нет), можно попробовать
используйте макрос, который делает некоторые из таких сообщений доступными для чтения в Outlook 2002.
Это для сообщений с русским текстом KOI8-R внутри и состояниями заголовка системы.
что это сообщение в «западной» кодировке.
Если тоже надо разобраться с сообщениями такого типа у которых русский windows-1251 текст внутри, вы можете либо написать свой собственный макрос, используя существующий в качестве примера,
или свяжись с автором макроса есть ли у него для windows-1251 тоже.
Вот информация об этом макросе ( по русски ) — видел в группе новостей microsoft.public.ru.russian.outlook:
- Начало
- Продолжение
Кстати, если вам любопытно, то вы сами можете убедиться, что кодировка такого письма
ошибочно указан как «западный»:
в меню перейдите к View/Options и посмотрите «Заголовки Интернета»
поле внизу. Вы увидите что-то вроде «charset=us-ascii» или «кодировка=iso-8859-1» . Оба варианта означают одно и то же — кодировку «Западный» набор символов .
То есть, если отправитель правильно настроил свою программу электронной почты , то такая русская почта читается везде — в MS Outlook, в Netscape, в Outlook Express и т. д.
Но если сообщение проблемное , то:
- , если сообщение на кириллице было отправлено с веб-службы электронной почты, такой как Yahoo! Почта или HotMail, и поэтому в его системном заголовке указана неправильная кодировка («западная»), тогда вы можете использовать обходной путь, описанный выше
- если отправитель допустил большую ошибку и испортил кириллицу на своей стороне,
то ничего не сделаешь — электронная почта будет нечитаема.
Известный пример: вы получаете электронное письмо, в котором видите только вопросительные знаки ‘?’ вместо русского. Это настоящих вопросительных знаков, ничего не поделаешь делай кириллицу из них 🙂Обычно это происходит, когда отправитель использовал программу электронной почты Outlook Express и использовал это неправильно .
 Он/она не знал, как отправить обычную кириллицу по электронной почте из Outlook Express
и таким образом создал текст с серией вопросительных знаков.
Он/она не знал, как отправить обычную кириллицу по электронной почте из Outlook Express
и таким образом создал текст с серией вопросительных знаков.
Эта ситуация (и решение) объясняется в самом начале моей страницы «Кириллица (русская) в Outlook Express».
URL Кодировка «кириллицы» — Онлайн
Познакомьтесь с декодированием и кодированием URL, простым онлайн-инструментом, который делает именно то, что говорит: декодирует из кодировки URL, а также быстро и легко кодирует в нее. URL кодирует ваши данные без проблем или декодирует их в удобочитаемый формат. Кодирование URL-адресов, также известное как «процентное кодирование», представляет собой механизм кодирования информации в универсальном идентификаторе ресурса (URI). Хотя это известно как кодирование URL-адресов, на самом деле оно более широко используется в основном наборе унифицированных идентификаторов ресурсов (URI), который включает в себя как унифицированный указатель ресурса (URL), так и унифицированное имя ресурса (URN). Как таковой он также используется при подготовке данных медиа-типа «application/x-www-form-urlencoded», который часто используется при отправке данных формы HTML в HTTP-запросах.
Как таковой он также используется при подготовке данных медиа-типа «application/x-www-form-urlencoded», который часто используется при отправке данных формы HTML в HTTP-запросах.
Дополнительные параметры
- Набор символов: Наш веб-сайт использует набор символов UTF-8, поэтому ваши входные данные передаются в этом формате. Измените этот параметр, если вы хотите преобразовать данные в другой набор символов перед кодированием. Обратите внимание, что в случае текстовых данных схема кодирования не содержит набора символов, поэтому вам может потребоваться указать соответствующий набор в процессе декодирования. Что касается файлов, то по умолчанию используется двоичный вариант, который исключает любое преобразование; эта опция необходима для всего, кроме обычных текстовых документов.
- Разделитель новой строки: В системах Unix и Windows используются разные символы разрыва строки, поэтому перед кодированием любой вариант будет заменен в ваших данных выбранным параметром.
 Для раздела файлов это частично не имеет значения, так как файлы уже содержат соответствующие разделители, но вы можете определить, какой из них использовать для функций «кодировать каждую строку отдельно» и «разбить строки на куски».
Для раздела файлов это частично не имеет значения, так как файлы уже содержат соответствующие разделители, но вы можете определить, какой из них использовать для функций «кодировать каждую строку отдельно» и «разбить строки на куски». - Каждую строку кодировать отдельно: Даже символы новой строки преобразуются в их процентно-кодированные формы. Используйте эту опцию, если вы хотите закодировать несколько независимых записей данных, разделенных разрывами строк. (*)
- Разделить строки на части: Закодированные данные станут непрерывным текстом без пробелов, поэтому отметьте этот параметр, если хотите разбить его на несколько строк. Применяемое ограничение на количество символов определено в спецификации MIME (RFC 2045), в которой указано, что длина закодированных строк не должна превышать 76 символов. (*)
- Режим реального времени: Когда вы включаете эту опцию, введенные данные немедленно кодируются встроенными функциями JavaScript вашего браузера, без отправки какой-либо информации на наши серверы.
 В настоящее время этот режим поддерживает только набор символов UTF-8.
В настоящее время этот режим поддерживает только набор символов UTF-8.
Надежно и надежно
Вся связь с нашими серверами осуществляется через безопасные зашифрованные соединения SSL (https). Мы удаляем загруженные файлы с наших серверов сразу после их обработки, а полученный загружаемый файл удаляется сразу после первой попытки загрузки или 15 минут бездействия (в зависимости от того, что короче). Мы никоим образом не храним и не проверяем содержимое отправленных данных или загруженных файлов. Ознакомьтесь с нашей политикой конфиденциальности ниже для получения более подробной информации.
Совершенно бесплатно
Наш инструмент можно использовать бесплатно. Отныне вам не нужно скачивать какое-либо программное обеспечение для таких простых задач.
Сведения о кодировке URL
Типы символов URI
Символы, разрешенные в URI, либо зарезервированы, либо незарезервированы (или символ процента как часть кодировки процента). Зарезервированные символы — это символы, которые иногда имеют особое значение. Например, символы косой черты используются для разделения разных частей URL-адреса (или, в более общем смысле, URI). Незарезервированные символы не имеют такого специального значения. Используя процентное кодирование, зарезервированные символы представляются с помощью специальных последовательностей символов. Наборы зарезервированных и незарезервированных символов, а также обстоятельства, при которых определенные зарезервированные символы имеют специальное значение, немного меняются с каждой новой редакцией спецификаций, регулирующих URI и схемы URI.
Зарезервированные символы — это символы, которые иногда имеют особое значение. Например, символы косой черты используются для разделения разных частей URL-адреса (или, в более общем смысле, URI). Незарезервированные символы не имеют такого специального значения. Используя процентное кодирование, зарезервированные символы представляются с помощью специальных последовательностей символов. Наборы зарезервированных и незарезервированных символов, а также обстоятельства, при которых определенные зарезервированные символы имеют специальное значение, немного меняются с каждой новой редакцией спецификаций, регулирующих URI и схемы URI.
Другие символы в URI должны быть закодированы в процентах.
Зарезервированные символы с процентным кодированием
Если символ из зарезервированного набора («зарезервированный символ») имеет особое значение («зарезервированное назначение») в определенном контексте, а схема URI говорит, что этот символ необходимо использовать для какой-либо другой цели, тогда этот символ должен быть закодирован в процентах. Процентное кодирование зарезервированного символа означает преобразование символа в соответствующее ему байтовое значение в ASCII, а затем представление этого значения в виде пары шестнадцатеричных цифр. Цифры, которым предшествует знак процента («%»), затем используются в URI вместо зарезервированного символа. (Для символа, отличного от ASCII, он обычно преобразуется в последовательность байтов в UTF-8, а затем каждое значение байта представляется, как указано выше.)
Процентное кодирование зарезервированного символа означает преобразование символа в соответствующее ему байтовое значение в ASCII, а затем представление этого значения в виде пары шестнадцатеричных цифр. Цифры, которым предшествует знак процента («%»), затем используются в URI вместо зарезервированного символа. (Для символа, отличного от ASCII, он обычно преобразуется в последовательность байтов в UTF-8, а затем каждое значение байта представляется, как указано выше.)
Зарезервированный символ «/», например, если он используется в компоненте «путь» URI, имеет особое значение, поскольку он является разделителем между сегментами пути. Если в соответствии с заданной схемой URI в сегменте пути должен быть символ «/», то в сегменте должны использоваться три символа «%2F» (или «%2f») вместо «/».
Зарезервированные символы, которые не имеют зарезервированного назначения в конкретном контексте, также могут быть закодированы в процентах, но семантически не отличаются от других символов.

В компоненте «запрос» URI (часть после символа «?»), например, «/» по-прежнему считается зарезервированным символом, но обычно не имеет зарезервированного назначения (если в конкретной схеме URI не указано иное). Символ не нужно кодировать в процентах, если он не имеет зарезервированного назначения.
URI, отличающиеся только тем, является ли зарезервированный символ процентным кодированием или нет, обычно считаются неэквивалентными (обозначающими один и тот же ресурс), за исключением случаев, когда рассматриваемые зарезервированные символы не имеют зарезервированного назначения. Это определение зависит от правил, установленных для зарезервированных символов отдельными схемами URI.
Незарезервированные символы с процентным кодированием
Символы из незарезервированного набора никогда не нуждаются в процентном кодировании.
URI, отличающиеся только тем, является ли незарезервированный символ процентным кодированием или нет, эквивалентны по определению, но на практике процессоры URI не всегда могут обрабатывать их одинаково. Например, потребители URI не должны рассматривать «%41» иначе, чем «A» («%41» — это процентное кодирование «A») или «%7E» иначе, чем «~», но некоторые это делают. Поэтому для обеспечения максимальной совместимости производителям URI не рекомендуется использовать процентное кодирование незарезервированных символов.
Например, потребители URI не должны рассматривать «%41» иначе, чем «A» («%41» — это процентное кодирование «A») или «%7E» иначе, чем «~», но некоторые это делают. Поэтому для обеспечения максимальной совместимости производителям URI не рекомендуется использовать процентное кодирование незарезервированных символов.
Процентное кодирование символа процента
Поскольку символ процента («%») служит индикатором октетов с процентным кодированием, он должен быть закодирован как «%25», чтобы этот октет можно было использовать в качестве данных в URI.
Процентное кодирование произвольных данных
Большинство схем URI включают представление произвольных данных, таких как IP-адрес или путь к файловой системе, в виде компонентов URI. Спецификации схемы URI должны, но часто не обеспечивают явное сопоставление между символами URI и всеми возможными значениями данных, представленными этими символами.
Двоичные данные
После публикации RFC 1738 в 1994 г.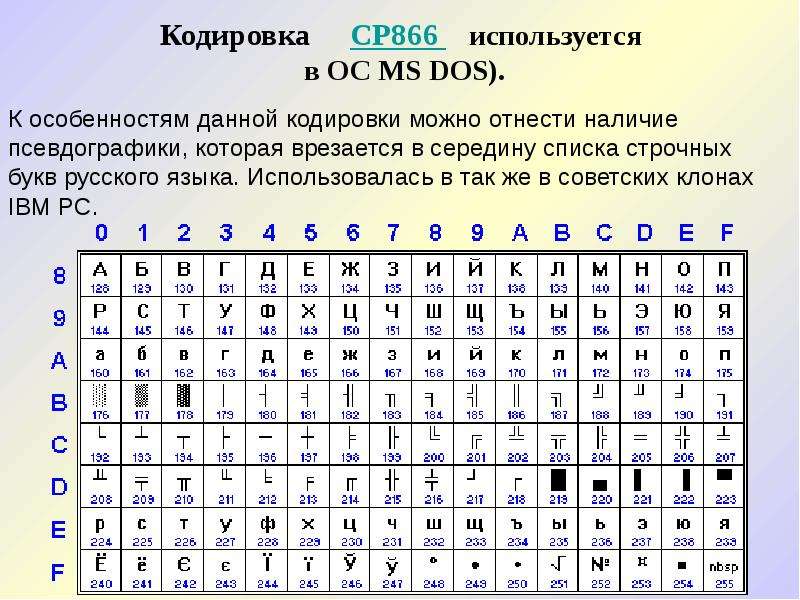 было указано, что схемы, обеспечивающие представление двоичных данных в URI, должны делить данные на 8-битные байты и кодировать каждый байт в процентах таким же образом, как описано выше. Значение байта 0F (шестнадцатеричное), например, должно быть представлено как «%0F», но значение байта 41 (шестнадцатеричное) может быть представлено как «A» или «%41». Использование незакодированных символов для буквенно-цифровых и других незарезервированных символов обычно предпочтительнее, поскольку это приводит к более коротким URL-адресам.
было указано, что схемы, обеспечивающие представление двоичных данных в URI, должны делить данные на 8-битные байты и кодировать каждый байт в процентах таким же образом, как описано выше. Значение байта 0F (шестнадцатеричное), например, должно быть представлено как «%0F», но значение байта 41 (шестнадцатеричное) может быть представлено как «A» или «%41». Использование незакодированных символов для буквенно-цифровых и других незарезервированных символов обычно предпочтительнее, поскольку это приводит к более коротким URL-адресам.
Символьные данные
Процедура процентного кодирования двоичных данных часто экстраполируется, иногда неуместно или без полного уточнения, для применения к символьным данным. В годы становления World Wide Web при работе с символами данных в репертуаре ASCII и использовании соответствующих им байтов в ASCII в качестве основы для определения последовательностей с процентным кодированием эта практика была относительно безвредной; многие люди предполагали, что символы и байты сопоставляются один к одному и взаимозаменяемы. Однако потребность в представлении символов за пределами диапазона ASCII быстро росла, и схемы и протоколы URI часто не могли обеспечить стандартные правила подготовки символьных данных для включения в URI. Следовательно, веб-приложения начали использовать различные многобайтовые кодировки, кодировки с отслеживанием состояния и другие кодировки, несовместимые с ASCII, в качестве основы для процентного кодирования, что привело к неоднозначности, а также к трудностям с надежной интерпретацией URI.
Однако потребность в представлении символов за пределами диапазона ASCII быстро росла, и схемы и протоколы URI часто не могли обеспечить стандартные правила подготовки символьных данных для включения в URI. Следовательно, веб-приложения начали использовать различные многобайтовые кодировки, кодировки с отслеживанием состояния и другие кодировки, несовместимые с ASCII, в качестве основы для процентного кодирования, что привело к неоднозначности, а также к трудностям с надежной интерпретацией URI.
Например, многие схемы и протоколы URI, основанные на RFC 1738 и 2396, предполагают, что символы данных будут преобразованы в байты в соответствии с некоторой неуказанной кодировкой символов, прежде чем они будут представлены в URI незарезервированными символами или байтами с процентным кодированием. Если схема не позволяет URI предоставить подсказку о том, какая кодировка использовалась, или если кодировка конфликтует с использованием ASCII для процентного кодирования зарезервированных и незарезервированных символов, то URI нельзя надежно интерпретировать.