отличия и преимущества — Boodet.online
480 auto
Администрирование
SQL или NoSQL — какую базу данных выбрать? В чем заключается их различие. Преимущества SQL и NoSQL. Сравнение и выводы.
IT GIRL 15
Post Views: 26 351
Реляционные vs. нереляционные базы данных: отличия и преимущества Блог 2020-12-24 ru Реляционные vs. нереляционные базы данных: отличия и преимущества
286 104
Boodet Online
+7 (499) 649 09 90
123022,
Москва,
ул. Рочдельская, дом 15, строение 15
Рочдельская, дом 15, строение 15
Реляционные vs. нереляционные базы данных: отличия и преимущества
286 104
Boodet Online +7 499 649 09 90 123022, Москва, ул. Рочдельская, дом 15, строение 15
Поделиться
Твинтнуть
Поделиться
Запинить
Отправить
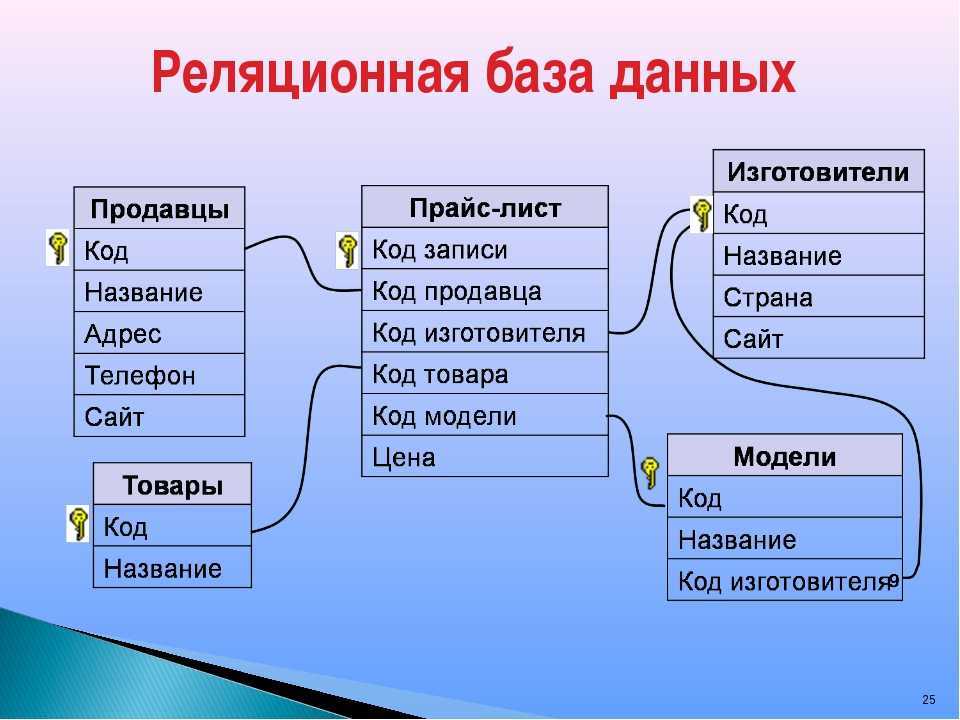
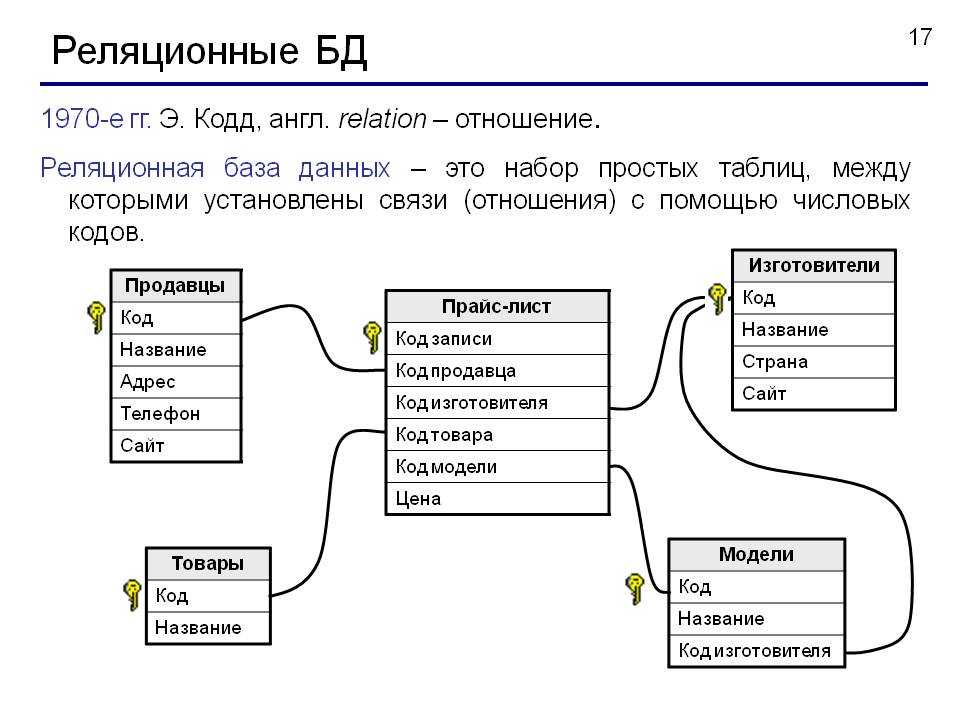
SQL vs NoSQL
Любые компьютерные вычисления связаны с обработкой данных. Они бывают структурированными и неструктурированными. Первые размещают в базах данных, где наравне с информацией хранится ее описание. Говоря о БД, часто можно встретить термины SQL и NoSQL.
SQL — это методика обработки (язык, структура, действия), которая используется для того, чтобы проводить чтение и обработку реляционных и нереляционных (NoSQL) баз данных. Как это все работает и для чего нужно — объясняют специалисты Boodet.Online.
Как это все работает и для чего нужно — объясняют специалисты Boodet.Online.
Понятие реляционных и нереляционных баз данных
Термин «реляционный» пришел из алгебры (теория множеств). В формате БД это значит, что данные реляционных баз хранятся в виде таблиц и строк. Нереляционные БД размещают информацию в коллекциях документов JSON.
Реляционные БД используют язык SQL (структурированных запросов). Структура таких баз данных позволяет связывать информацию из разных таблиц с помощью внешних ключей (или индексов), которые используются для уникальной идентификации любого атомарного фрагмента данных в этой таблице. Другие таблицы могут ссылаться на этот внешний ключ, чтобы создать связь между частями данных и частью, на которую указывает внешний ключ.
Зачем нужны нереляционные БД? Их главное преимущество — высокий уровень безопасности и возможность обойти аппаратные ограничения (с помощью Sharding).
Различия SQL и NoSQL
SQL и NoSQL — это термины, которые описывают совершенно разные способы обработки данных. Чем они отличаются и почему это влияет на работу?
Чем они отличаются и почему это влияет на работу?
Язык
SQL используют универсальный язык структурированных запросов для определения и обработки данных. Это накладывает определенные ограничения: прежде чем начать обработку, данные надо разместить внутри таблиц и описать.
NoSQL таких ограничений не имеет. Динамические схемы для неструктурированных данных позволяют:
ориентировать информацию на столбцы или документы;
основывать ее на графике;
организовывать в виде хранилища KeyValue;
создавать документы без предварительного определения их структуры, использовать разный синтаксис;
добавлять поля непосредственно в процессе обработки.
Структура
SQL основаны на таблицах, а NoSQL — на документах, парах ключ-значение, графовых БД, хранилищах с широкими столбцами.
Масштабируемость
В большинстве случаев базы данных SQL можно масштабировать по вертикали. Что это значит? Можно увеличить нагрузку на один сервер, увеличив таким образом ЦП, ОЗУ или объем накопителя.
Что это значит? Можно увеличить нагрузку на один сервер, увеличив таким образом ЦП, ОЗУ или объем накопителя.
В отличие от SQL базы данных NoSQL масштабируются по горизонтали. Это означает, что больший трафик обрабатывается путем разделения или добавления большего количества серверов. Это делает NoSQL удобнее при работе с большими или меняющимися наборами данных.
В каких случаях используют SQL?
SQL подойдет, если нужна обработка большого количества сложных запросов, или рутинного анализа данных. Выбирайте реляционную БД, если нужна надежная обработка транзакций и ссылочная целостность.
А в каких NoSQL?
Если объем данных большой, лучше использовать NoSQL. Отсутствие явных структурированных механизмов ускорит процесс обработки Big Data. А еще это безопаснее — такие БД сложнее взломать.
Выбирайте NoSQL, если:
необходимо хранить массивы в объектах JSON;
записи хранятся в коллекции с разными полями или атрибутами;
необходимо горизонтальное масштабирование.

Самые распространенные реляционные базы данных
Для работы с реляционными БД лучше всего подойдут:
MySQL
Бесплатный продукт с открытым исходным кодом от Oracle. Отличается стабильностью и хорошим тестированием обновлений до их внедрения. MySQL можно доработать под свои нужды или поискать готовые исправления в обширной библиотеке профильного сообщества.
MySQL работает с любыми ОС: Linux, Windows, Mac, BSD и Solaris. Дружит с Node.js, Ruby, C#, C++, Java, Perl, Python и PHP.
Базу данных MySQL можно реплицировать на несколько узлов, что уменьшает рабочую нагрузку при увеличении доступности приложения.
Oracle
Oracle Database часто используют крупные корпорации. Коммерческий вариант БД часто и грамотно обновляется, есть круглосуточная техническая поддержка.
Oracle применяет свой собственный диалект SQL (PL/SQL). Это дает возможность работать со встроенными функциями, процедурами и переменными. Так же, как и MySQL, работает с любыми операционными системами.
Еще одно важное преимущество Oracle — возможность восстановления предыдущей версии БД. Помимо этого, есть индексация растровых изображений, секционирование, индексацию на основе функций и по обратному ключу, оптимизация приоритетных запросов.
Microsoft SQL Server
Microsoft SQL Server — это отличный вариант для малого и среднего бизнеса. Диалект T-SQL обрабатывает процедуры, встроенные функции и переменные. Есть важное ограничение: Microsoft SQL Server будет работать только с Linux или Windows. Простой интерфейс ускорит процесс миграции БД, если до этого вы пользовались другой системой.
Нереляционные базы данных
Согласно рейтингу Boodet.Online, самыми удобными системами для обработки нереляционных баз данных являются: MongoDB, Apache Cassandra и Google Cloud BigTable.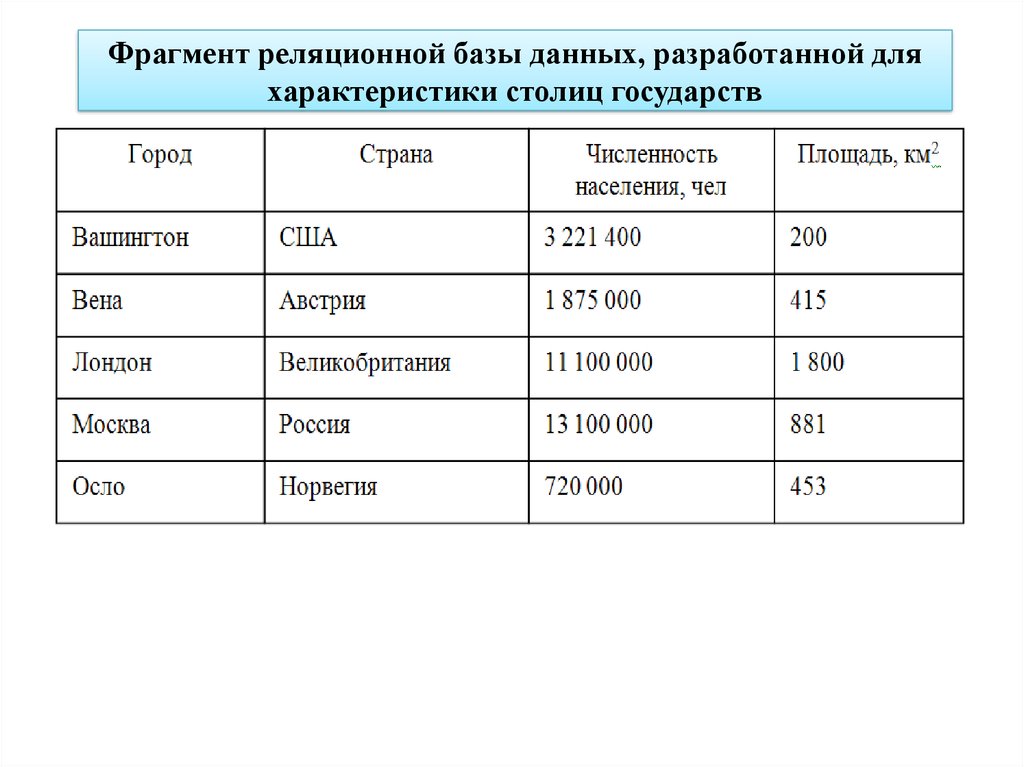
MongoDB
MongoDB — это качественный бесплатный продукт, который чаще всего используют при работе с NoSQL. Решение позволяет менять схемы данных в процессе работы, масштабироваться по горизонтали. Интерфейс очень простой — в нем легко разберется любой сотрудник компании, не обязательно быть IT-профессионалом.
Почему мы поставили Mongo на первое место в списке лидеров обработки нереляционных баз данных? Все дело в новой функции от разработчиков. Теперь в решении есть глобальная облачная БД, что дает возможность развернуть управляемую MongoDB через AWS, Azure, GCP.
Apache Cassandra
Apache Cassandra — это продукт с открытым исходным кодом, а значит, достаточно гибкий, адаптируемый практически для любых задач. Идентичность узлов упрощает масштабирование для наращивания архитектуры БД.
Apache Cassandra подойдет для масштабных проектов. Продукт обеспечивает высокую скорость чтения и записи. Даже если часть решения использует SQL, можно применить подобные SQL операторы: DDL, DML, SELECT.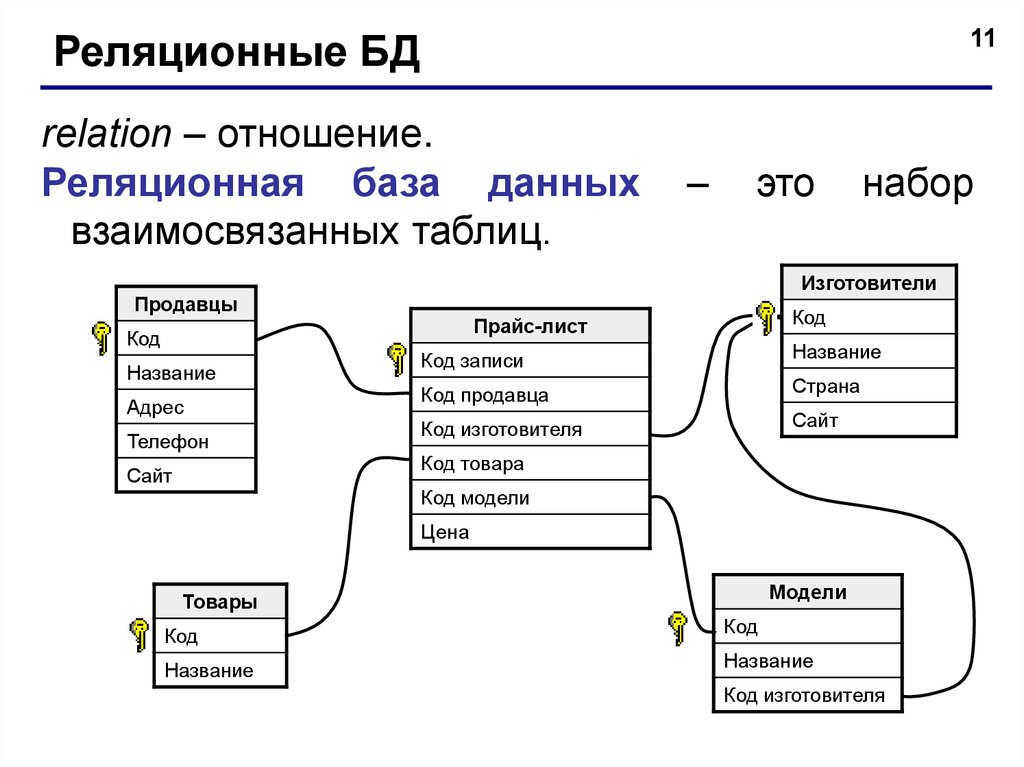 Для более высокого уровня безопасности есть резервное копирование и восстановление.
Для более высокого уровня безопасности есть резервное копирование и восстановление.
Apache Cassandra — это один из немногих инструментов обработки баз данных, который гарантирует безотказность работы (подробнее читайте в своем SLA).
Google Cloud BigTable
Неплохой продукт от Google, который гарантирует задержку обработки не более 10 мс. BigTable уделяют безотказности много внимания. Например, благодаря функции репликации базы данных более долговечны, доступны и устойчивы при зональных сбоях. Это отличный вариант для работы с Big Data в режиме реального времени (машинное зрение, AI) — можно изолировать рабочую нагрузку для приоритетной аналитики.
Так что же лучше?
Специалисты Boodet.Online работают с обоими вариантами баз данных. Основной критерий выбора: подходит ли приложение для решения конкретной задачи. Как мы определяем, что лучше для конкретного проекта:
Если в БД есть предопределенная схема — используем SQL, если схема динамическая — NoSQL.
Выбираем приоритетное направление масштабирования — по горизонтали или по вертикали.
Определяем, что будет использоваться в задаче — неструктурированные данные или многострочные транзакции.
Выводы
Нельзя однозначно сказать, что лучше — SQL или NoSQL. Все зависит от конкретной задачи и типа данных. В некоторых случаях необходимо обработать оба типа БД — тогда рекомендуем выбирать гибридное решение, например, PostgreSQL (объектно-ориентированная СУБД).
Для подробной консультации и помощи в выборе СУБД для своего проекта обратитесь к специалистам Boodet.Online.
Поделиться
Твинтнуть
Поделиться
Запинить
Отправить
Facebook
YouTube
Telegram
Реляционные базы данных | Computerworld Россия
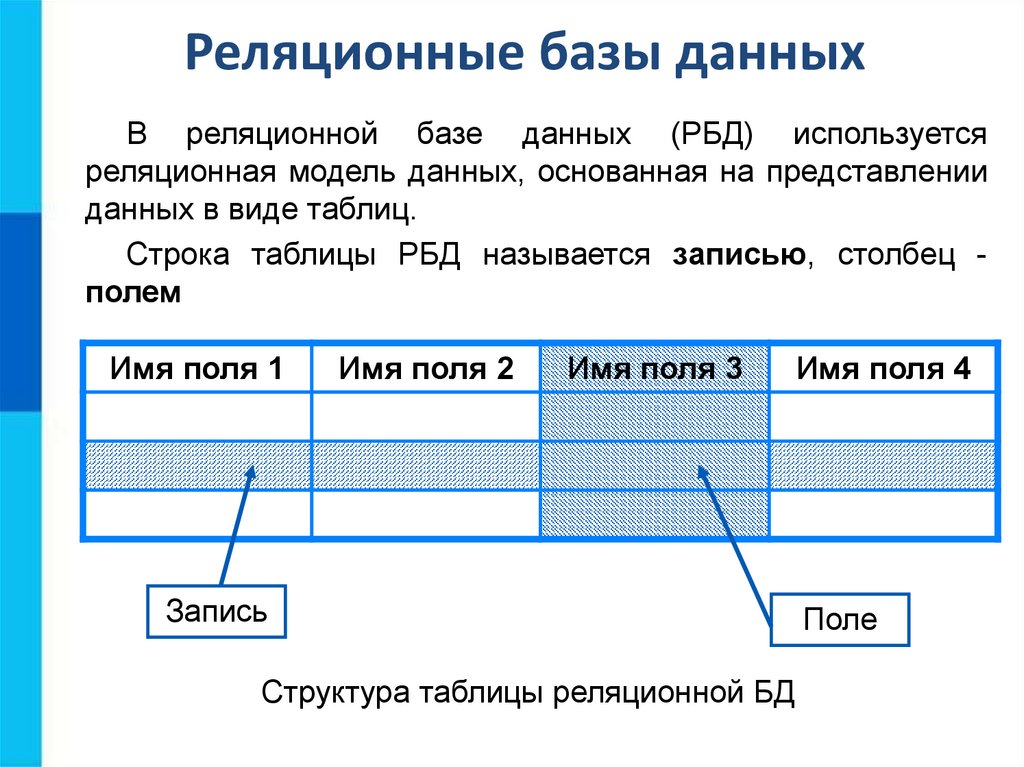
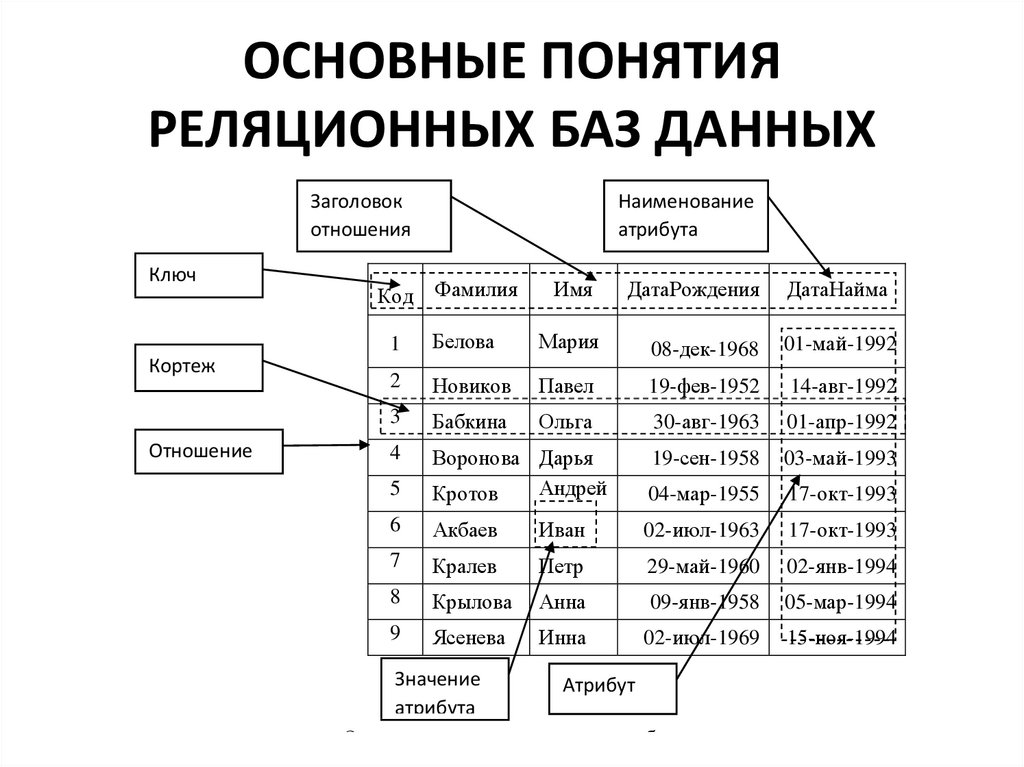
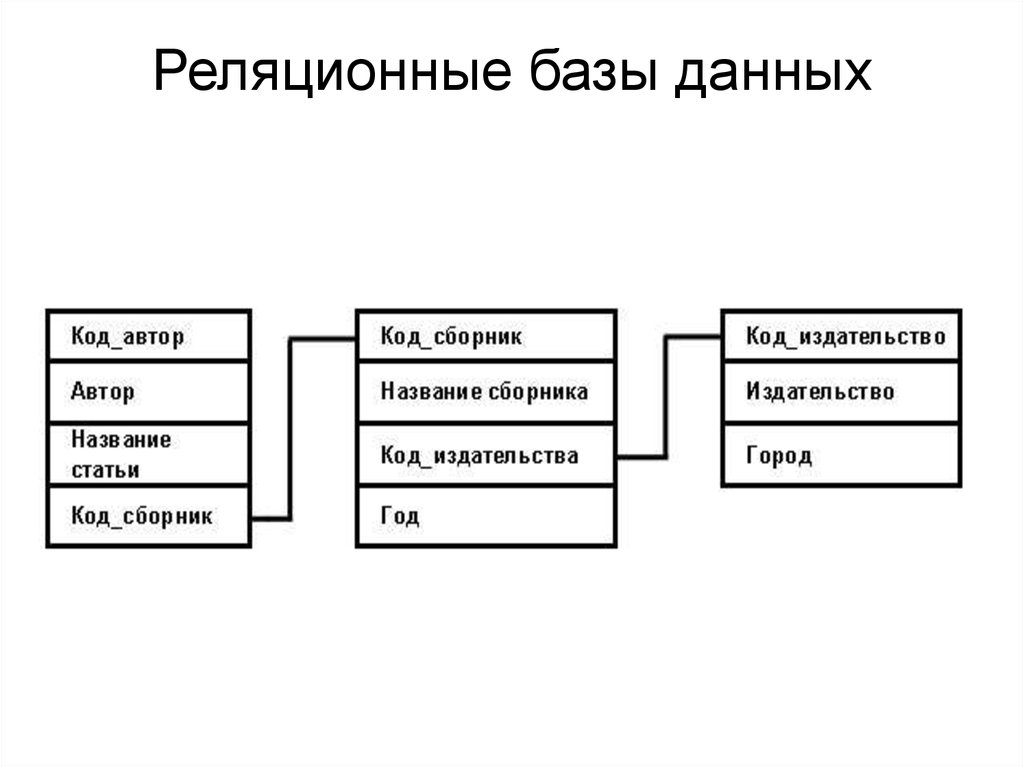
Реляционные базы данных позволяют хранить информацию в нескольких «плоских» (двухмерных) таблицах, связанных между собой посредством совместно используемых полей данных, называемых ключами.
Определение
Реляционные базы данных позволяют хранить информацию в нескольких «плоских» (двухмерных) таблицах, связанных между собой посредством совместно используемых полей данных, называемых ключами. Реляционные базы данных предоставляют более простой доступ к оперативно составляемым отчетам (обычно через SQL) и обеспечивают повышенную надежность и целостность данных благодаря отсутствию избыточной информации
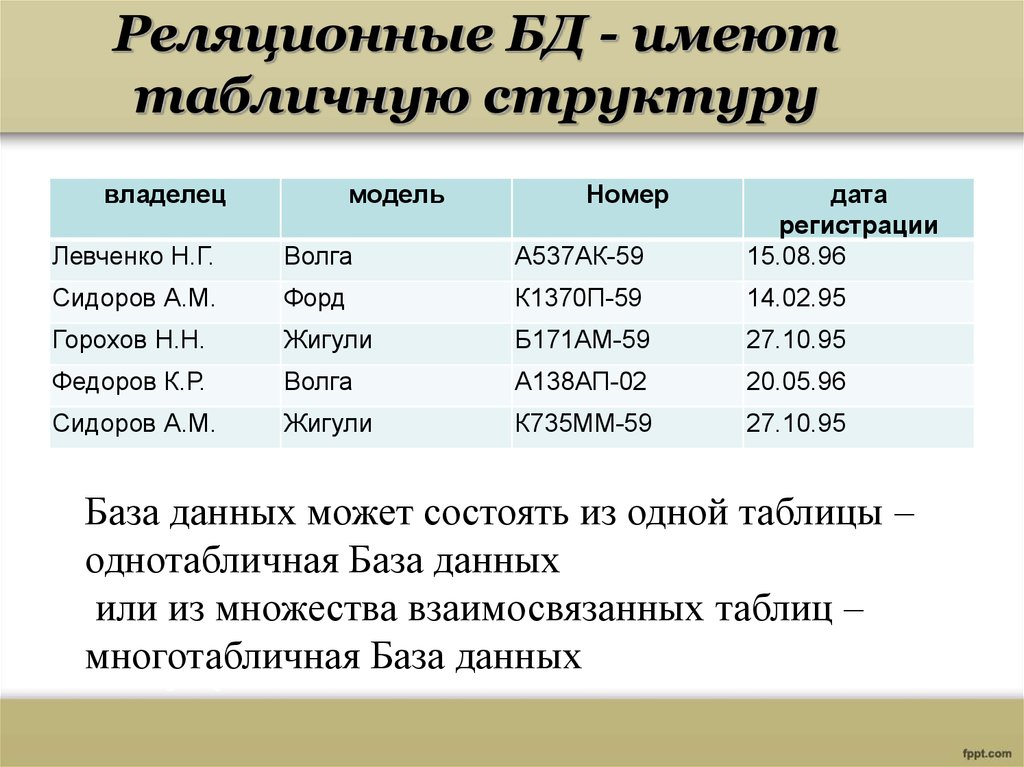
Всем известно, что представляет собой простая база данных: телефонные справочники, каталоги товаров и словари — все это базы данных. Они могут быть структурированными или организованными каким-то иным образом: как плоские файлы, как иерархические или сетевые структуры или как реляционные таблицы. Чаще всего в организациях для хранения информации используются именно реляционные базы данных.
База данных — это набор таблиц, состоящих из столбцов и строк, аналогично электронной таблице. Каждая строка содержит одну запись; каждый столбец содержит все экземпляры конкретного фрагмента данных всех строк. Например, обычный телефонный справочник состоит из столбцов, содержащих телефонные номера, имена абонентов и адреса абонентов. Каждая строка содержит номер, имя и адрес. Эта простая форма называется плоским файлом в силу его двухмерной природы, а также того, что все данные хранятся в одном файле.
Например, обычный телефонный справочник состоит из столбцов, содержащих телефонные номера, имена абонентов и адреса абонентов. Каждая строка содержит номер, имя и адрес. Эта простая форма называется плоским файлом в силу его двухмерной природы, а также того, что все данные хранятся в одном файле.
В идеале каждая база данных имеет по крайней мере один столбец с уникальным идентификатором, или ключом. Рассмотрим телефонную книгу. В ней может быть несколько записей с абонентом Джон Смит, но ни один из телефонных номеров не повторяется. Телефонный номер и служит ключом.
На самом деле все не так просто. Два или несколько человек, использующих один и тот же телефонный номер, могут быть перечислены в телефонном справочнике по отдельности, в силу чего телефонный номер появляется в двух или более местах, поэтому существует несколько строк с ключами, которые не являются уникальными.
Данные создают проблемы
В самых простых базах данных каждая запись занимает одну строку, иными словами, телефонной компании необходимо заводить отдельный столбец для каждого фрагмента бухгалтерской информации. То есть одну — для второго абонента «спаренного» телефона, еще одну — для третьего и т. д., в зависимости от того, сколько дополнительных абонентов понадобится.
То есть одну — для второго абонента «спаренного» телефона, еще одну — для третьего и т. д., в зависимости от того, сколько дополнительных абонентов понадобится.
Это значит, что каждая запись в базе данных должна иметь все эти дополнительные колонки, даже если больше они нигде не используются. Это также означает, что база данных должна быть реорганизована всякий раз, когда компания предлагает новую услугу. Вводится обслуживание тонального набора — и меняется структура базы, поскольку добавляется новая колонка. Вводится поддержка идентификации номера звонящего абонента, ожидания звонка и т. д. — и база данных перестраивается снова и снова.
В 60-е годы только самые крупные компании могли позволить себе приобретать компьютеры для управления своими данными. Более того, базы данных, построенные на статических моделях данных и с помощью процедурных языков программирования, таких как Кобол, могут оказаться слишком дорогими в том, что касается поддержки, и не всегда надежными. Процедурные языки определяют последовательность событий, через которую компьютер должен пройти, чтобы выполнить задачу.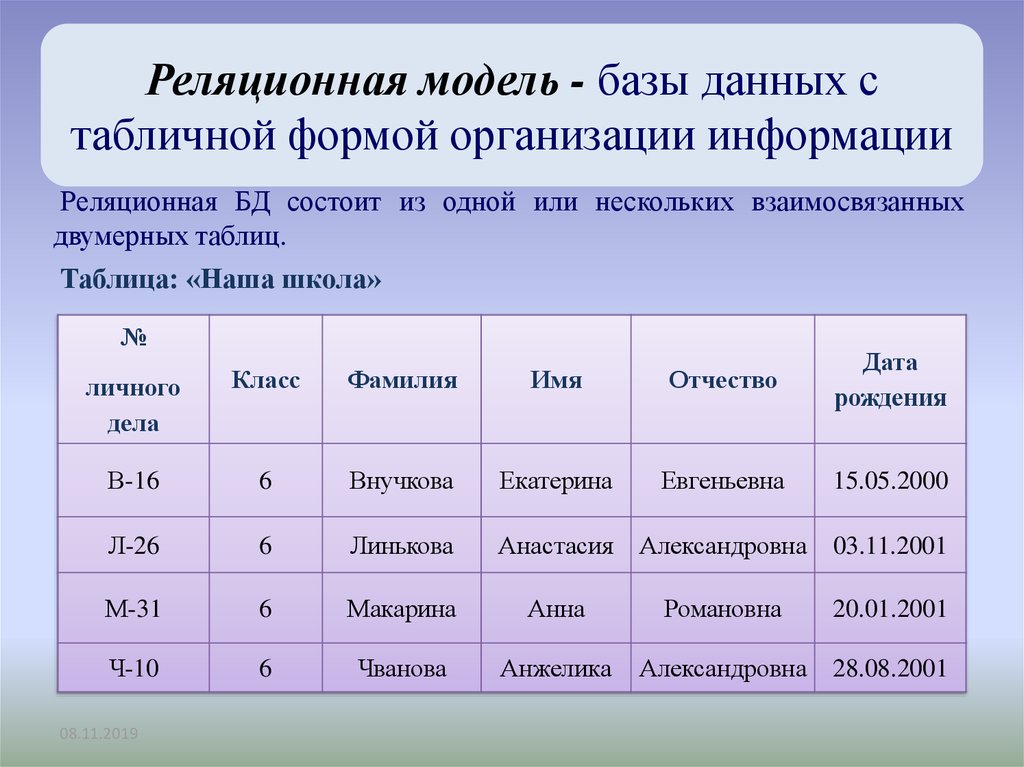 Программирование таких последовательностей было сложным делом, особенно если требовалось менять структуру базы данных или составлять новый вид отчетов.
Программирование таких последовательностей было сложным делом, особенно если требовалось менять структуру базы данных или составлять новый вид отчетов.
Мощные связи
Эдгар Кодд, сотрудник исследовательской лаборатории корпорации IBM в Сан-Хосе, по существу, создал и описал концепцию реляционных баз данных в своей основополагающей работе «Реляционная модель для крупных, совместно используемых банков данных» (A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, июнь 1970).
Кодд предложил модель, которая позволяет разработчикам разделять свои базы данных на отдельные, но взаимосвязанные таблицы, что увеличивает производительность, но при этом внешнее представление остается тем же, что и у исходной базы данных. С тех пор Кодд считается отцом-основателем отрасли реляционных баз данных.
Эта модель работает следующим образом. Телефонная компания может создать основную таблицу, используя в качестве первичного ключа номер телефона, и хранить его с другой базовой информацией о потребителях. Компания может определить отдельную таблицу со столбцами для этого первичного ключа и для дополнительных служб, таких как поддержка идентификации номера звонящего абонента и ожидание звонка. Она также может создать еще одну таблицу для контроля счетов за переговоры, где каждая запись состоит из номера телефона и данных об оплате звонков.
Компания может определить отдельную таблицу со столбцами для этого первичного ключа и для дополнительных служб, таких как поддержка идентификации номера звонящего абонента и ожидание звонка. Она также может создать еще одну таблицу для контроля счетов за переговоры, где каждая запись состоит из номера телефона и данных об оплате звонков.
Конечные пользователи могут легко получить ту информацию, которую они хотят, и в том виде, в каком она им требуется, хотя эти данные хранятся в различных таблицах. Поэтому представитель службы поддержки потребителей телефонной компании может отобразить на одном и том же экране информацию о счетах абонента, а также о состоянии специальных служб или о том, когда была получена последняя оплата.
Кодд сформулировал 12 правил для реляционных баз данных, большинство которых касаются целостности и обновления данных, а также доступа к ним. Первые два достаточно понятны даже пользователям, не обладающим техническими навыками.
Правило 1, информационное правило, указывает, что вся информация в реляционной базе данных представляется как набор значений, хранящихся в таблицах.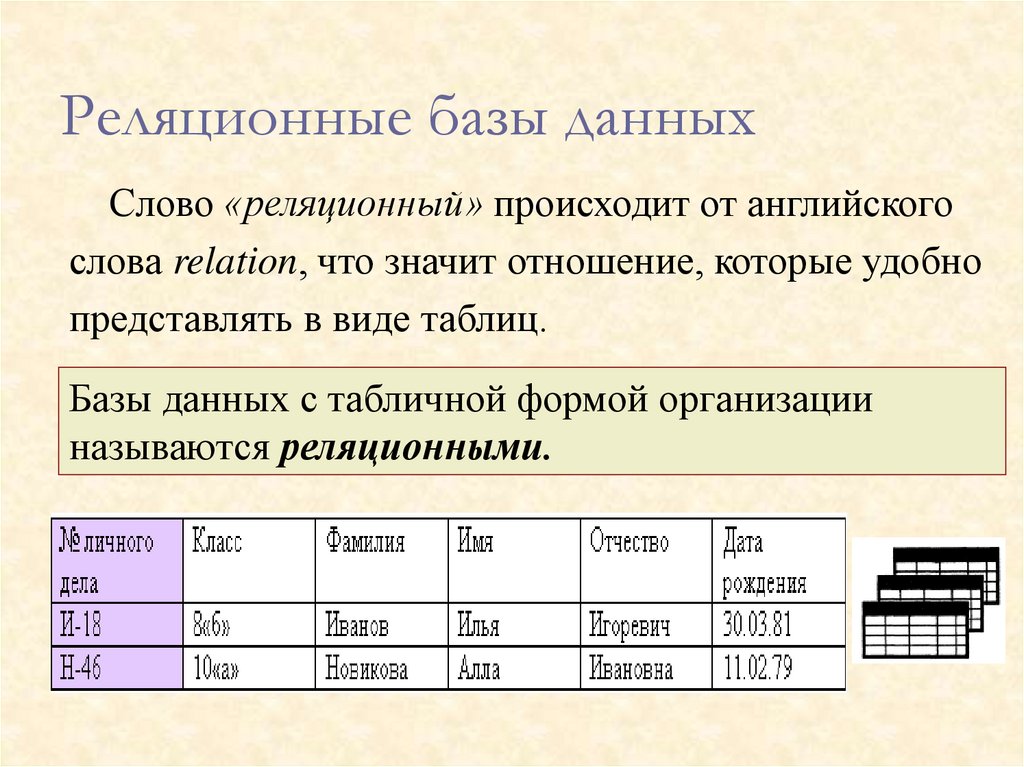
Правило 2, правило гарантии доступа, определяет, что доступ к каждому элементу данных в реляционной базе данных можно получить с помощью имени таблицы, первичного ключа и названия столбца. Другими словами, все данные хранятся в таблицах, и, если известно название таблицы, первичный ключ и столбец, где находится требуемый элемент данных, его всегда можно извлечь.
Суть работы Кодда заключалась в том, что предлагалось с реляционными базами данных использовать декларативные, а не процедурные языки программирования. Декларативные языки, такие как язык запросов SQL (Structured Query Language), дают пользователям возможность, по существу, сообщить компьютеру: «Я хочу получить следующие биты данных из всех записей, которые удовлетворяют определенному набору критериев». Компьютер сам «поймет», какие необходимо совершить шаги, чтобы получить эту информацию из базы данных.
Для работы с огромным количеством активно используемых баз данных применяются программные системы управления реляционными базами данных, созданные такими авторитетными производителями, как Oracle, Sybase, IBM, Informix и Microsoft.
Хотя большую часть вариантов реализаций SQL можно назвать интероперабельными лишь с известным приближением, этот утвержденный в качестве международного стандарта механизм позволяет создавать сложные системы, основу которых составляют базы данных. Удобный для программирования интерфейс между Web-сайтами и реляционными базами данных дает конечным пользователям возможность добавлять новые записи и обновлять существующие, а также создавать отчеты для самых разных служб, таких как выполнение интерактивных торговых операций и доступ к интерактивным библиотечным каталогам.
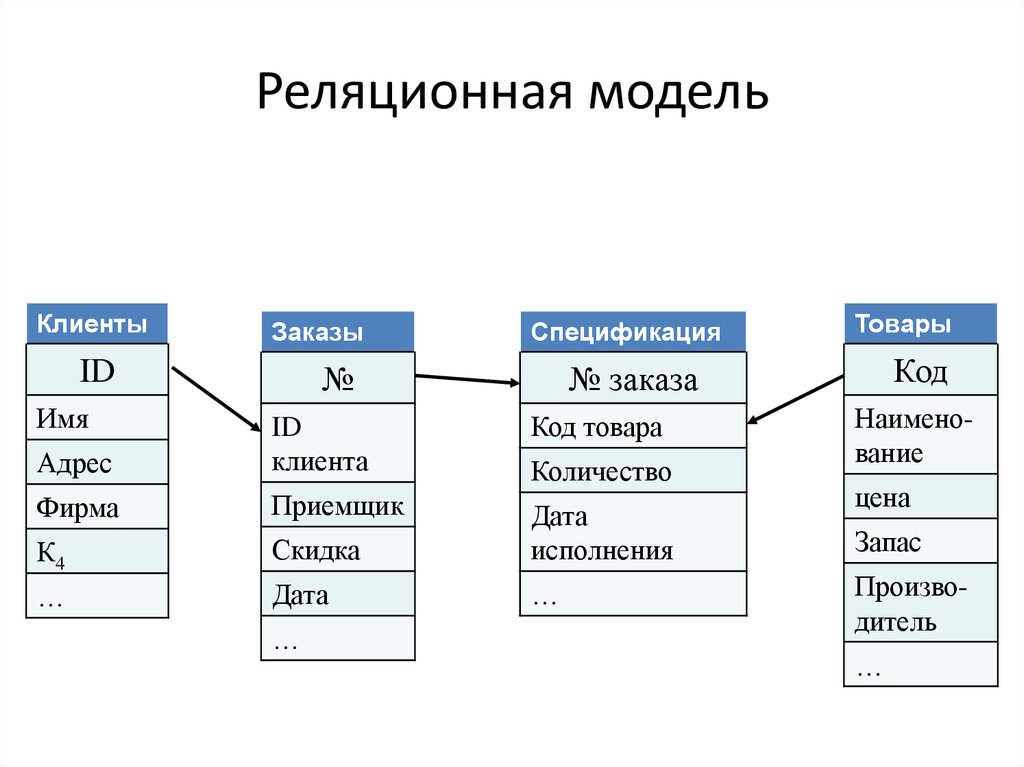
Реляционная модель
Реляционная база данных использует набор таблиц, связанных друг с другом посредством определенного ключа (в данном случае это поле PhoneNumber)
Что такое реляционная база данных? – Amazon Web Services (AWS)
Реляционная база данных представляет собой набор элементов данных с предопределенными отношениями между ними. Эти элементы организованы в виде набора таблиц со столбцами и строками. Таблицы используются для хранения информации об объектах, которые должны быть представлены в базе данных. Каждый столбец в таблице содержит определенный тип данных, а поле хранит фактическое значение атрибута. Строки в таблице представляют набор связанных значений одного объекта или сущности. Каждая строка в таблице может быть помечена уникальным идентификатором, называемым первичным ключом, а строки в нескольких таблицах могут быть связаны с помощью внешних ключей. Доступ к этим данным можно получить различными способами без реорганизации самих таблиц базы данных.
Эти элементы организованы в виде набора таблиц со столбцами и строками. Таблицы используются для хранения информации об объектах, которые должны быть представлены в базе данных. Каждый столбец в таблице содержит определенный тип данных, а поле хранит фактическое значение атрибута. Строки в таблице представляют набор связанных значений одного объекта или сущности. Каждая строка в таблице может быть помечена уникальным идентификатором, называемым первичным ключом, а строки в нескольких таблицах могут быть связаны с помощью внешних ключей. Доступ к этим данным можно получить различными способами без реорганизации самих таблиц базы данных.
6:44
Понимание Amazon Relational Database Service (RDS) SQL или язык структурированных запросов — это основной интерфейс, используемый для связи с реляционными базами данных. SQL стал стандартом Американского национального института стандартов (ANSI) в 1986 году. Стандарт ANSI SQL поддерживается всеми популярными механизмами реляционных баз данных, и некоторые из этих механизмов также имеют расширение ANSI SQL для поддержки функций, специфичных для этого механизма. SQL используется для добавления, обновления или удаления строк данных, извлечения подмножеств данных для приложений обработки транзакций и аналитики, а также для управления всеми аспектами базы данных.
Стандарт ANSI SQL поддерживается всеми популярными механизмами реляционных баз данных, и некоторые из этих механизмов также имеют расширение ANSI SQL для поддержки функций, специфичных для этого механизма. SQL используется для добавления, обновления или удаления строк данных, извлечения подмножеств данных для приложений обработки транзакций и аналитики, а также для управления всеми аспектами базы данных.
Целостность данных
Целостность данных — это полная полнота, точность и согласованность данных. Реляционные базы данных используют набор ограничений для обеспечения целостности данных в базе данных. К ним относятся первичные ключи, внешние ключи, ограничение «Not NULL», ограничение «Unique», ограничение «Default» и ограничение «Check». Эти ограничения целостности помогают применять бизнес-правила к данным в таблицах для обеспечения точности и надежности данных. В дополнение к этому, большинство реляционных баз данных также позволяют встраивать пользовательский код в триггеры, которые выполняются на основе действия в базе данных.
Транзакции
Транзакция базы данных — это один или несколько операторов SQL, которые выполняются как последовательность операций, формирующих единую логическую единицу работы. Транзакции обеспечивают предложение «все или ничего», что означает, что вся транзакция должна завершиться как единое целое и быть записана в базу данных, иначе ни один из отдельных компонентов транзакции не должен пройти. В терминологии реляционной базы данных результатом транзакции является COMMIT или ROLLBACK. Каждая транзакция обрабатывается последовательно и надежно независимо от других транзакций.
Соответствие ACID
Все транзакции базы данных должны быть совместимы с ACID или быть атомарными, непротиворечивыми, изолированными и устойчивыми для обеспечения целостности данных.
Атомарность требует, чтобы либо транзакция в целом была успешно выполнена, либо в случае сбоя части транзакции вся транзакция была признана недействительной. Согласованность требует, чтобы данные, записываемые в базу данных как часть транзакции, соответствовали всем определенным правилам и ограничениям, включая ограничения, каскады и триггеры. Изоляция имеет решающее значение для достижения контроля параллелизма и гарантирует, что каждая транзакция независима сама от себя. Долговечность требует, чтобы все изменения, внесенные в базу данных, были постоянными после успешного завершения транзакции.
Согласованность требует, чтобы данные, записываемые в базу данных как часть транзакции, соответствовали всем определенным правилам и ограничениям, включая ограничения, каскады и триггеры. Изоляция имеет решающее значение для достижения контроля параллелизма и гарантирует, что каждая транзакция независима сама от себя. Долговечность требует, чтобы все изменения, внесенные в базу данных, были постоянными после успешного завершения транзакции.
Amazon Aurora
Amazon Aurora — это механизм реляционной базы данных, совместимый с MySQL и PostgreSQL, который сочетает в себе скорость и доступность высококачественных коммерческих баз данных с простотой и экономичностью баз данных с открытым исходным кодом. Amazon Aurora обеспечивает в пять раз более высокую производительность, чем MySQL, а также безопасность, доступность и надежность коммерческой базы данных при стоимости в десять раз меньше. Узнать больше »
Oracle
Amazon RDS позволяет развертывать несколько выпусков базы данных Oracle за считанные минуты с помощью экономически эффективных и масштабируемых аппаратных ресурсов. Вы можете использовать существующие лицензии Oracle или платить за использование лицензий по часам. RDS позволяет вам сосредоточиться на разработке приложений, управляя сложными задачами администрирования базы данных, включая выделение ресурсов, резервное копирование, установку исправлений, мониторинг и масштабирование оборудования. Узнать больше »
Вы можете использовать существующие лицензии Oracle или платить за использование лицензий по часам. RDS позволяет вам сосредоточиться на разработке приложений, управляя сложными задачами администрирования базы данных, включая выделение ресурсов, резервное копирование, установку исправлений, мониторинг и масштабирование оборудования. Узнать больше »
Microsoft SQL Server
Amazon RDS для SQL Server упрощает настройку, эксплуатацию и масштабирование SQL Server в облаке. Вы можете развернуть несколько выпусков SQL Server, включая Express, Web, Standard и Enterprise. Поскольку Amazon RDS для SQL Server предоставляет вам прямой доступ к собственным возможностям SQL Server, ваши приложения и инструменты должны работать без каких-либо изменений. Узнать больше »
MySQL — это система управления реляционными базами данных (RDBMS) с открытым исходным кодом, используемая очень большим количеством веб-приложений. Amazon RDS для MySQL предоставляет вам доступ к возможностям знакомого ядра базы данных MySQL.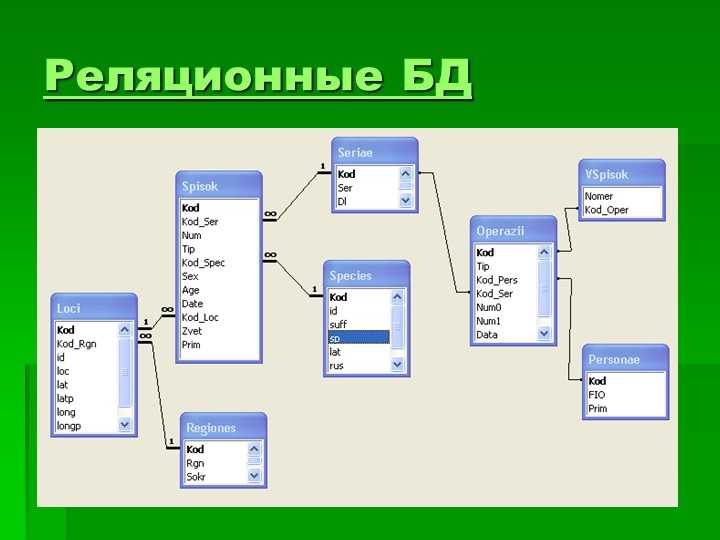 Это означает, что код, приложения и инструменты, которые вы уже используете сегодня с существующими базами данных, можно использовать с Amazon RDS без каких-либо изменений. Узнать больше »
Это означает, что код, приложения и инструменты, которые вы уже используете сегодня с существующими базами данных, можно использовать с Amazon RDS без каких-либо изменений. Узнать больше »
PostgreSQL
PostgreSQL — это мощная система объектно-реляционных баз данных корпоративного класса с открытым исходным кодом, ориентированная на расширяемость и соответствие стандартам. PostgreSQL может похвастаться множеством сложных функций и запускает хранимые процедуры более чем на дюжине языков программирования, включая Java, Perl, Python, Ruby, Tcl, C/C++ и собственный PL/pgSQL, аналогичный PL/SQL Oracle. Узнать больше »
MariaDB
MariaDB — это MySQL-совместимая база данных, которая является ответвлением MySQL и разрабатывается первоначальными разработчиками MySQL. Amazon RDS упрощает настройку, эксплуатацию и масштабирование развертываний MariaDB в облаке. С помощью Amazon RDS вы можете за считанные минуты развернуть масштабируемые базы данных MariaDB, используя экономичную аппаратную емкость с изменяемым размером. Узнать больше »
Узнать больше »
Начать работу с Amazon RDS просто. Следуйте нашему Руководству по началу работы, чтобы создать свой первый инстанс Amazon RDS за несколько кликов.
Поддержка AWS для Internet Explorer заканчивается 31.07.2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari. Подробнее »
Что такое реляционная база данных?
Управление даннымиК
- Бен Луткевич, Технические характеристики Писатель
- Жаклин Бискобинг, Старший управляющий редактор, Новости
Реляционная база данных — это набор информации, который организует точки данных с определенными отношениями для легкого доступа. В модели реляционной базы данных структуры данных, включая таблицы данных, индексы и представления, остаются отдельными от структур физического хранилища, что позволяет администраторам баз данных редактировать физическое хранилище данных, не затрагивая логическую структуру данных.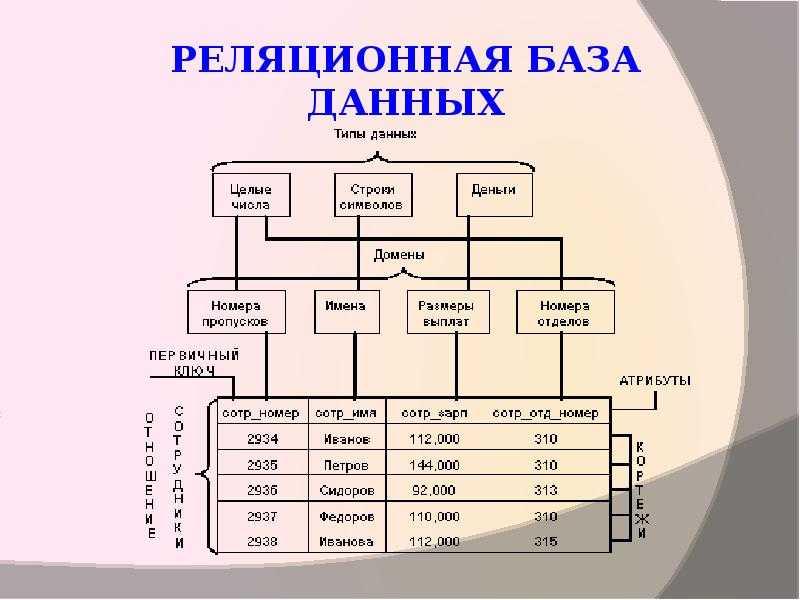
На предприятии реляционные базы данных используются для организации данных и определения взаимосвязей между ключевыми точками данных. Они упрощают сортировку и поиск информации, что помогает организациям более эффективно принимать бизнес-решения и минимизировать затраты. Они хорошо работают со структурированными данными.
Как работает реляционная база данных?Таблицы данных, используемые в реляционной базе данных, хранят информацию о связанных объектах. Каждая строка содержит запись с уникальным идентификатором, известным как ключ, а каждый столбец содержит атрибуты данных. Каждая запись присваивает значение каждой функции, что упрощает определение отношений между точками данных.
Стандартным интерфейсом пользователя и прикладной программы (API) реляционной базы данных является язык структурированных запросов. Операторы кода SQL используются как для интерактивных запросов информации из реляционной базы данных, так и для сбора данных для отчетов. Для обеспечения точности и доступности реляционной базы данных необходимо соблюдать определенные правила целостности данных.
Для обеспечения точности и доступности реляционной базы данных необходимо соблюдать определенные правила целостности данных.
Э. Ф. Кодд, в то время молодой программист в IBM, изобрел реляционную базу данных в 1970 году. В своей статье «Реляционная модель данных для больших общих банков данных» Кодд предложил перейти от хранения данных в иерархических или навигационных структурах к организации данных в таблицы, содержащие строки и столбцы.
Каждая таблица, иногда называемая отношением , в реляционной базе данных содержит одну или несколько категорий данных в столбцах или атрибуты .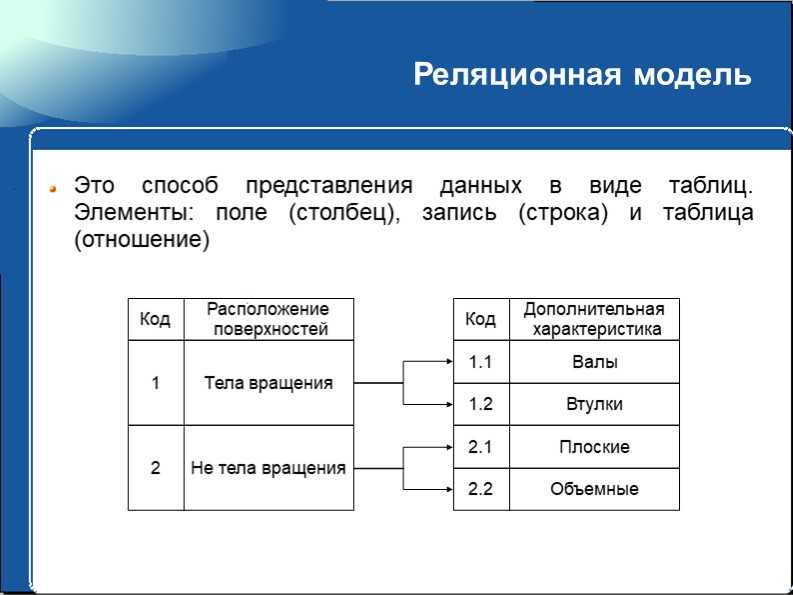 Каждая строка, также называемая записью или кортежем , содержит уникальный экземпляр данных — или ключ — для категорий, определенных столбцами. Каждая таблица имеет уникальный первичный ключ, который идентифицирует информацию в таблице. Отношения между таблицами можно установить с помощью внешних ключей — поля в таблице, которое ссылается на первичный ключ другой таблицы.
Каждая строка, также называемая записью или кортежем , содержит уникальный экземпляр данных — или ключ — для категорий, определенных столбцами. Каждая таблица имеет уникальный первичный ключ, который идентифицирует информацию в таблице. Отношения между таблицами можно установить с помощью внешних ключей — поля в таблице, которое ссылается на первичный ключ другой таблицы.
Например, типичная база данных записей бизнес-заказов будет включать таблицу, описывающую клиента, со столбцами для имени, адреса, номера телефона и т. д. Другая таблица будет описывать заказ, включая такую информацию, как продукт, клиент, дата и цена продажи.
Пользователь может получить отчет базы данных, содержащий необходимые ему данные. Например, менеджеру филиала может потребоваться отчет обо всех клиентах, купивших товары после определенной даты. Менеджер по финансовым услугам в той же компании может из тех же таблиц получить отчет о счетах, которые необходимо оплатить.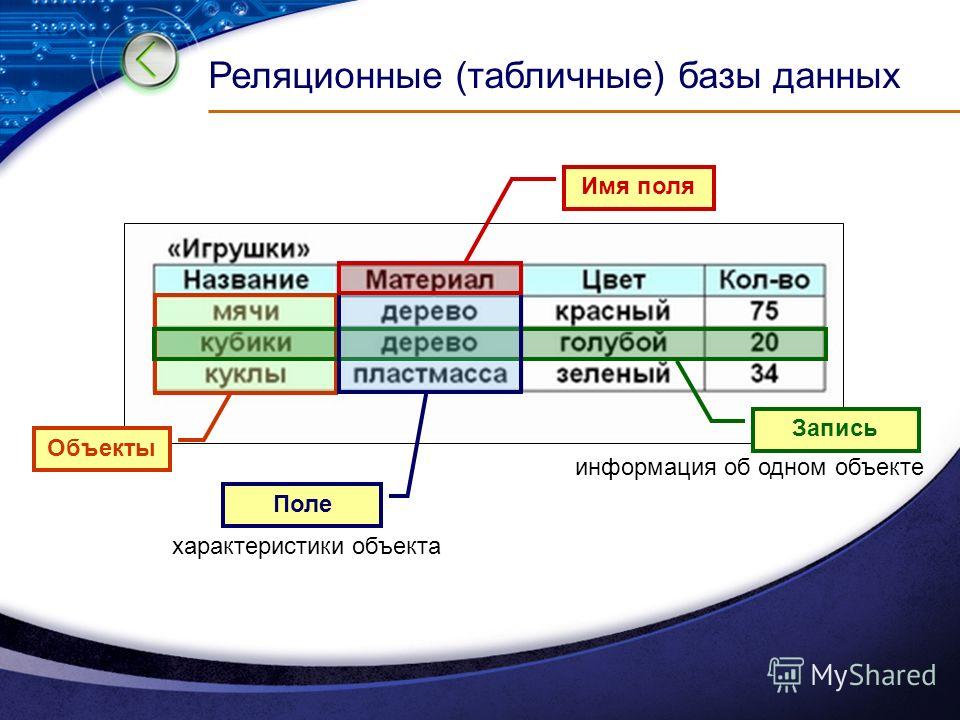
При создании реляционной базы данных пользователи определяют область возможных значений в столбце данных и ограничения, которые могут применяться к этому значению данных. Например, домен возможных клиентов может допускать до 10 возможных имен клиентов, но в одной таблице он ограничен возможностью указания только трех из этих имен клиентов.
Два ограничения относятся к целостности данных и первичным и внешним ключам:
- Целостность объекта гарантирует, что первичный ключ в таблице уникален и его значение не равно нулю.
- Ссылочная целостность требует, чтобы каждое значение в столбце внешнего ключа находилось в первичном ключе таблицы, из которой оно произошло.
Кроме того, реляционные базы данных обладают физической независимостью от данных. Это относится к способности системы вносить изменения во внутреннюю схему без изменения внешних схем или прикладных программ. Изменения внутренней схемы могут включать следующее:
- использование новых запоминающих устройств;
- изменение индексов;
- переход с определенного метода доступа на другой;
- с использованием разных структур данных; и
- с использованием различных структур хранения или организации файлов.

Независимость от логических данных — это способность системы управлять концептуальной схемой без изменения внешней схемы или прикладных программ. Концептуальные изменения схемы могут включать добавление или удаление новых отношений, сущностей или атрибутов без изменения существующих внешних схем или переписывания прикладных программ.
Какие существуют типы баз данных?Существует несколько категорий баз данных, от простых плоских файлов, которые не являются реляционными, до NoSQL и более новых графовых баз данных, которые считаются еще более реляционными, чем стандартные реляционные базы данных. Некоторые типы баз данных включают следующие:
База данных плоских файлов. Эти базы данных состоят из одной таблицы данных, между которыми нет взаимосвязи — обычно это текстовые файлы. Этот тип файла позволяет пользователям указывать атрибуты данных, такие как столбцы и типы данных.
Узнайте о преимуществах и недостатках плоских файлов и реляционных баз данных.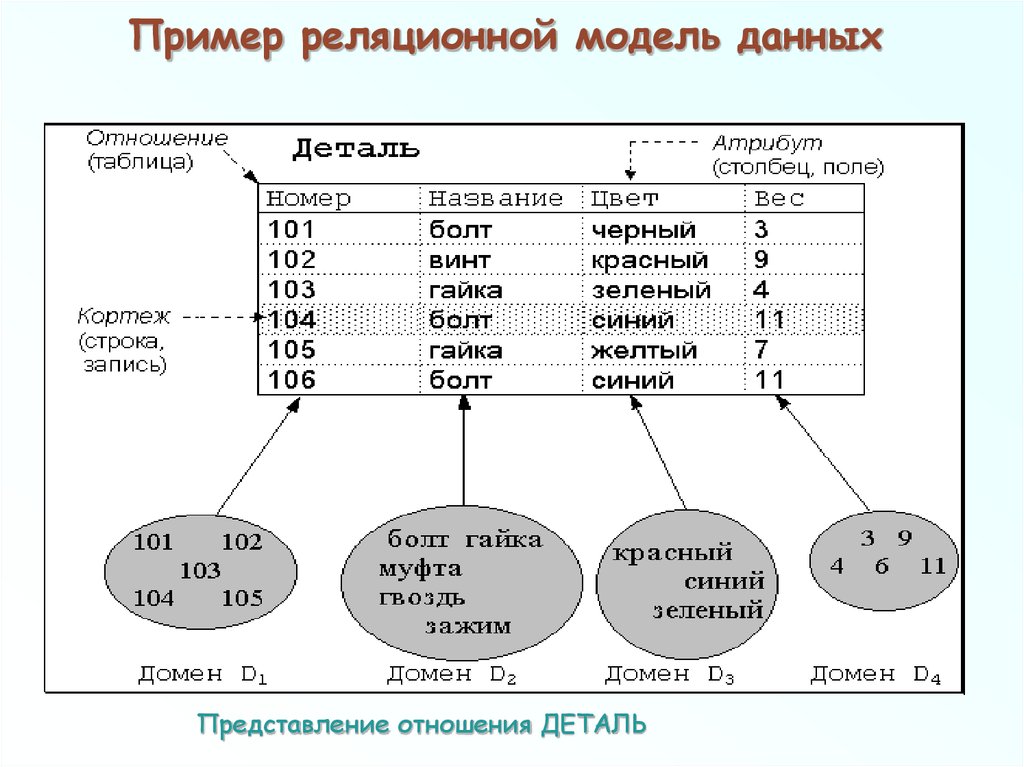
База данных NoSQL. Этот тип базы данных является альтернативой, которая особенно полезна для больших распределенных наборов данных. Базы данных NoSQL поддерживают различные модели данных, включая форматы «ключ-значение», «документ», «столбец» и «график».
Графическая база данных. Выход за рамки традиционных моделей реляционных данных на основе столбцов и строк; эта база данных NoSQL использует узлы и ребра, которые представляют связи между отношениями данных и могут обнаруживать новые отношения между данными. Графовые базы данных более сложны, чем реляционные базы данных. Они используются для обнаружения мошенничества или механизмов веб-рекомендаций.
Сравните графовые и реляционные базы данных. Объектно-реляционная база данных (ORD). ORD состоит как из системы управления реляционной базой данных (RDBMS), так и из системы управления объектно-ориентированной базой данных (OODBMS). Он содержит характеристики моделей РСУБД и ООСУБД. Для хранения данных используется традиционная база данных. Затем к нему обращаются и манипулируют с помощью запросов, написанных на языке запросов, таком как SQL. Поэтому базовый подход ORD основан на реляционной базе данных.
Он содержит характеристики моделей РСУБД и ООСУБД. Для хранения данных используется традиционная база данных. Затем к нему обращаются и манипулируют с помощью запросов, написанных на языке запросов, таком как SQL. Поэтому базовый подход ORD основан на реляционной базе данных.
Однако ORD также можно рассматривать как объектное хранилище, особенно для программного обеспечения, написанного на объектно-ориентированном языке программирования, что, таким образом, опирается на объектно-ориентированные характеристики. В этой ситуации для хранения и извлечения данных используются API.
См. характеристики РСУБД по сравнению с СУБД и их совпадение. Каковы преимущества реляционных баз данных?Ключевые преимущества реляционных баз данных включают следующее:
- Классификация данных . Администраторы баз данных могут легко классифицировать и хранить данные в реляционной базе данных, которые затем можно запрашивать и фильтровать для извлечения информации для отчетов.
 Реляционные базы данных также легко расширяются и не зависят от физической организации. После создания исходной базы данных можно добавить новую категорию данных без изменения существующих приложений.
Реляционные базы данных также легко расширяются и не зависят от физической организации. После создания исходной базы данных можно добавить новую категорию данных без изменения существующих приложений. - Точность . Данные сохраняются только один раз, исключая дедупликацию данных в процедурах хранения.
- Простота использования. Пользователям легко выполнять сложные запросы с помощью SQL, основного языка запросов, используемого в реляционных базах данных.
- Сотрудничество. Несколько пользователей могут получить доступ к одной и той же базе данных.
- Безопасность. Прямой доступ к данным в таблицах в СУБД может быть ограничен определенными пользователями.
К недостаткам реляционных баз данных относятся следующие:
- Структура. Реляционные базы данных требуют большой структуры и определенного уровня планирования, поскольку столбцы должны быть определены, а данные должны правильно вписываться в довольно жесткие категории.
 Структура хороша в некоторых ситуациях, но создает проблемы, связанные с другими недостатками, такими как обслуживание и отсутствие гибкости и масштабируемости.
Структура хороша в некоторых ситуациях, но создает проблемы, связанные с другими недостатками, такими как обслуживание и отсутствие гибкости и масштабируемости. - Проблемы с обслуживанием. Разработчики и другой персонал, ответственный за базу данных, должен тратить время на управление и оптимизацию базы данных по мере добавления в нее данных.
- Негибкость. Реляционные базы данных не идеальны для обработки больших объемов неструктурированных данных. Данные, которые в значительной степени являются качественными, трудно определяемыми или динамическими, не являются оптимальными для реляционных баз данных, потому что по мере изменения или развития данных схема должна развиваться вместе с ними, что требует времени.
- Отсутствие масштабируемости . Реляционные базы данных плохо масштабируются по горизонтали в физических структурах хранения с несколькими серверами. Трудно управлять реляционными базами данных на нескольких серверах, потому что по мере того, как набор данных становится больше и более распределенным, структура нарушается, а использование нескольких серверов влияет на производительность (например, время отклика приложений) и доступность.
Стандартные реляционные базы данных позволяют пользователям управлять предопределенными отношениями данных между несколькими базами данных. Популярные примеры стандартных реляционных баз данных включают Microsoft SQL Server, Oracle Database, MySQL и IBM DB2.
Облачные реляционные базы данных или база данных как услуга также широко используются, поскольку они позволяют компаниям передавать на аутсорсинг обслуживание базы данных, установку исправлений и поддержку инфраструктуры. Облачные реляционные базы данных включают Amazon Relational Database Service, Google Cloud SQL, IBM DB2 on Cloud, SQL Azure и Oracle Cloud.
В чем разница между реляционными базами данных, нереляционными базами данных и NoSQL? Наиболее важное различие между системами реляционных баз данных и системами нереляционных баз данных заключается в том, что реляционные базы данных нормализованы.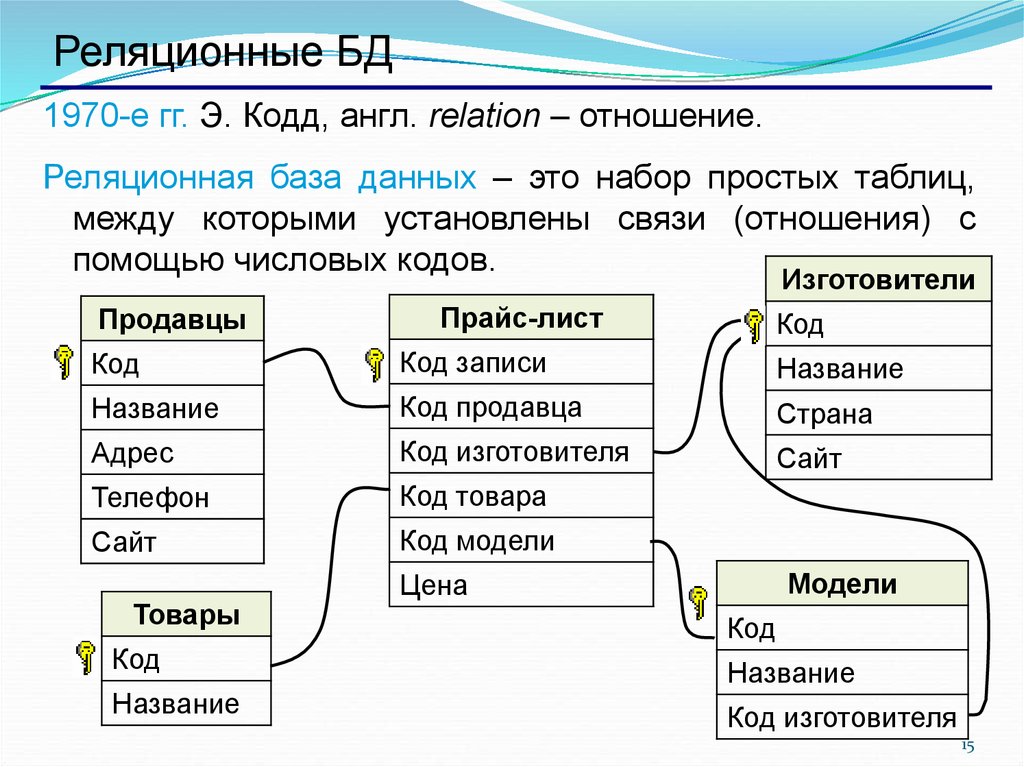 То есть они хранят данные в табличной форме, организованной в виде таблицы со строками и столбцами. Нереляционная база данных хранит данные в виде файлов.
То есть они хранят данные в табличной форме, организованной в виде таблицы со строками и столбцами. Нереляционная база данных хранит данные в виде файлов.
Другие отличия включают следующее:
- Использование первичных ключей. Каждая таблица реляционной базы данных имеет идентификатор первичного ключа. В нереляционной базе данных данные обычно хранятся в иерархической или навигационной форме без использования первичных ключей.
- Отношения между значениями данных. Поскольку данные в реляционной базе данных хранятся в таблицах, связь между этими значениями данных также сохраняется. Поскольку нереляционная база данных хранит данные в виде файлов, между значениями данных нет никакой связи.
- Ограничения целостности. В реляционной базе данных ограничениями целостности являются любые ограничения, обеспечивающие целостность базы данных. Они определены с целью атомарности, согласованности, изоляции и долговечности или ACID.
 Нереляционные базы данных не используют ограничения целостности.
Нереляционные базы данных не используют ограничения целостности. - Структурированные и неструктурированные данные. Реляционные базы данных хорошо работают со структурированными данными, которые соответствуют предопределенной модели данных и мало изменяются. Нереляционные базы данных лучше подходят для неструктурированных данных, которые не соответствуют предопределенной модели данных и не могут храниться в СУБД. Примеры неструктурированных данных включают текст, электронные письма, фотографии, видео и веб-страницы.
Нереляционные базы данных также называются базами данных NoSQL. Термины используются взаимозаменяемо, но есть различия.
SQL — это язык запросов, который используется с реляционными базами данных. Реляционные базы данных и их системы управления почти всегда используют SQL в качестве основного языка запросов. Базы данных NoSQL или не только SQL используют SQL и другие языки запросов.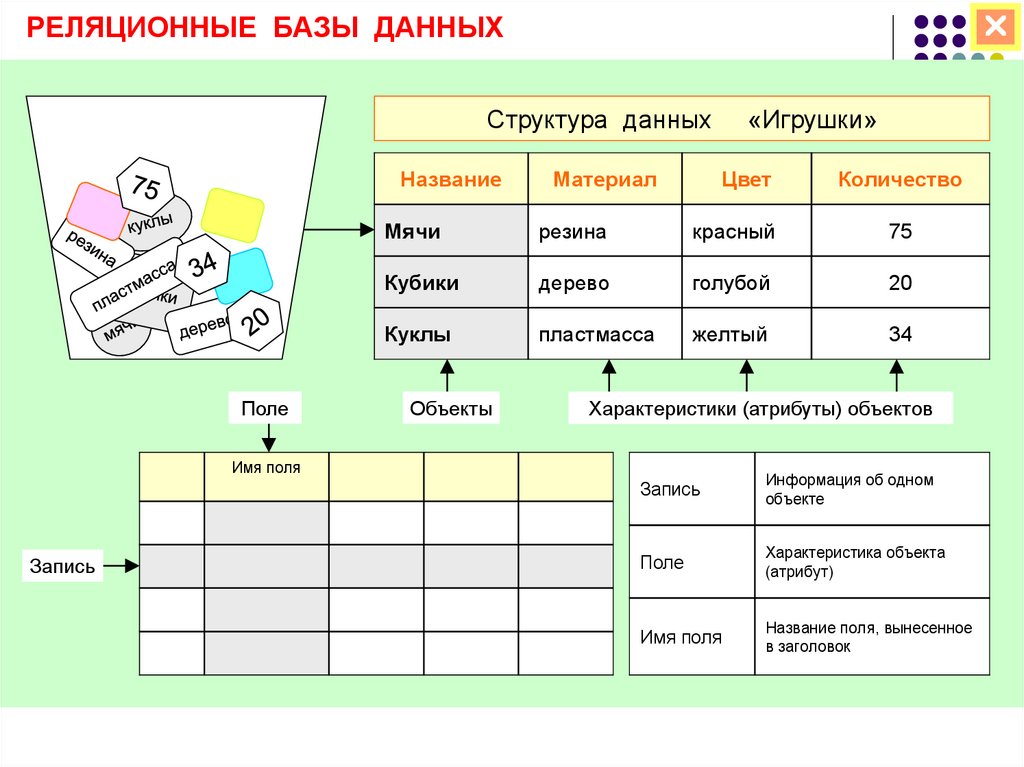 Например, программа управления базой данных NoSQL MongoDB использует документы, подобные JSON, для хранения и организации данных. (Технически он использует вариант вызова JSON BSON или двоичный JSON.)
Например, программа управления базой данных NoSQL MongoDB использует документы, подобные JSON, для хранения и организации данных. (Технически он использует вариант вызова JSON BSON или двоичный JSON.)
Обозначение баз данных как нереляционных и реляционных приводит к их категоризации на основе их архитектуры, а обращение к ним как к базам данных SQL и NoSQL приводит к их классификации на основе языка запросов, будь то исключительно SQL или не только SQL. Часто реляционную базу данных можно назвать базой данных SQL, поскольку многие из них используют SQL, а нереляционные базы данных можно назвать базами данных NoSQL. NoSQL и нереляционные базы данных хорошо работают с более изменчивыми моделями данных, такими как инженерные детали и молекулярное моделирование, где данные постоянно меняются.
Как реляционные, так и нереляционные платформы баз данных имеют свои недостатки. Базы данных NewSQL стремятся обеспечить преимущества обоих типов, предлагая целостность данных и управление доступом к приложениям, которые предлагают реляционные базы данных, и горизонтальную масштабируемость, которую обеспечивают нереляционные платформы или платформы NoSQL.
Реляционные базы данных работают со структурированными данными с определенными отношениями, которые можно организовать в табличном формате. Однако выбор правильной архитектуры базы данных — это гораздо больше, чем просто выбор между реляционной и нереляционной базой данных. Тип используемых или разрабатываемых данных и приложений являются ключевыми факторами, которые следует учитывать. Узнайте о некоторых других факторах, которые следует учитывать при выборе модели базы данных для корпоративного приложения.
Некоторые инициативы требуют особого внимания при выборе программного обеспечения базы данных. Например, в инициативах IoT возникает проблема между SQL и NoSQL, а также между статическими и потоковыми данными.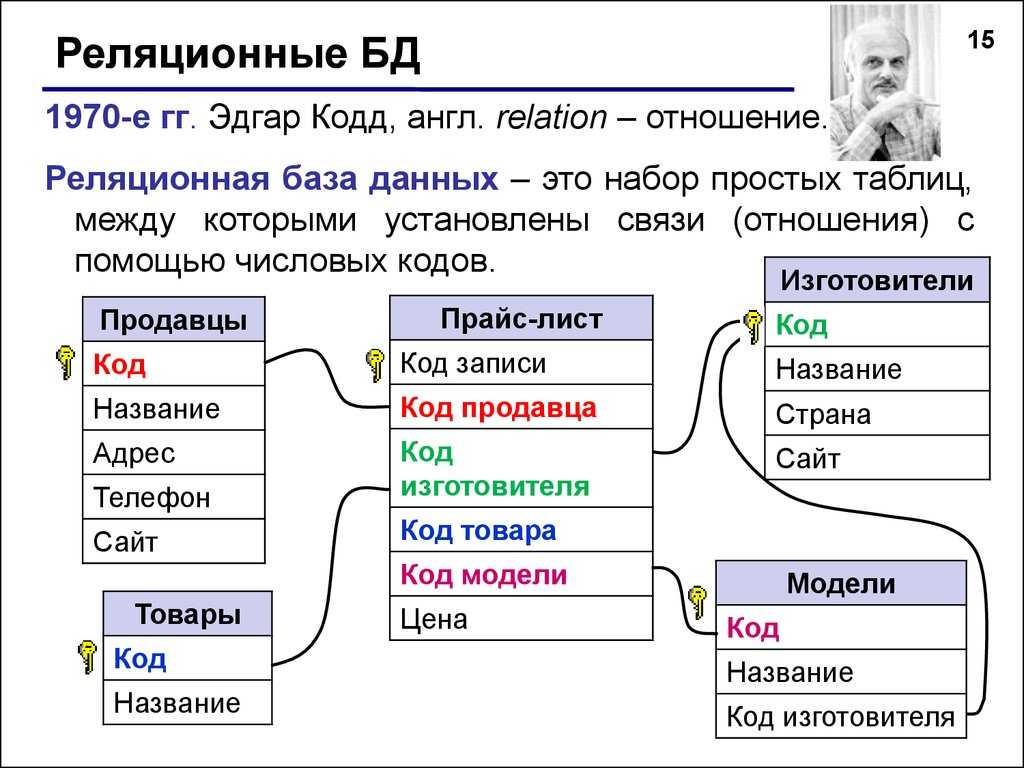 Узнайте, на что следует обращать внимание при выборе базы данных для проекта Интернета вещей.
Узнайте, на что следует обращать внимание при выборе базы данных для проекта Интернета вещей.
Последнее обновление: июнь 2021 г.
Продолжить чтение О реляционной базе данных- Разработчики программного обеспечения борются с наследием реляционных баз данных
- Хранилище данных и озеро данных: основные различия
- Машина времени DBA и будущее данных
- Графовая база данных и реляционная база данных: ключевые отличия
- Сравнение баз данных NoSQL, чтобы помочь вам выбрать правильный магазин
МонгоДБ
Автор: Александр Гиллис
база данных (БД)
Автор: Бен Луткевич
Сравнение СУБД и РСУБД: ключевые отличия
Автор: Крейг Стедман
Сравнение типов баз данных NoSQL в облаке
Автор: Курт Марко
Бизнес-аналитика
- Databricks запускает новый домик у озера для производства
Платформа для производственных компаний поставляется с диагностическим обслуживанием и возможностями цифрового двойника и является .
 ..
.. - Fivetran, Монте-Карло нацелены на наблюдаемость данных при приеме
Интеграция между поставщиками позволяет совместным пользователям получать представление о своих данных по мере их поступления в конвейер данных …
- Domo добавляет в пакет аналитики инструменты с низким кодом и «про-кодом»
Поставщик запустил 10 новых функций совместно с пользовательской конференцией, начиная от инструментов с низким кодом, которые упрощают анализ данных…
ПоискAWS
- AWS Control Tower стремится упростить управление несколькими учетными записями
Многие организации изо всех сил пытаются управлять своей огромной коллекцией учетных записей AWS, но Control Tower может помочь. Услуга автоматизирует…
- Разбираем модель ценообразования Amazon EKS
В модели ценообразования Amazon EKS есть несколько важных переменных.
 Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу…
Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу… - Сравните EKS и самоуправляемый Kubernetes на AWS
Пользователи AWS сталкиваются с выбором при развертывании Kubernetes: запускать его самостоятельно на EC2 или позволить Amazon выполнять тяжелую работу с помощью EKS. См…
Управление контентом
- 8 лучших практик SharePoint Syntex
Чтобы использовать сервисы искусственного интеллекта контента SharePoint — Syntex — организациям следует определить свои болевые точки и тщательно спланировать работу конечного пользователя…
- Почему контроль версий необходим в управлении цифровыми активами
Творческие группы часто используют разные версии своих цифровых ресурсов в разных маркетинговых каналах. Узнайте, как контролировать версии в DAM…
- Сравните недостатки и преимущества SharePoint Syntex
Корпорация Майкрософт продвигает свои службы искусственного интеллекта для контента SharePoint — Syntex — как способ упростить управление контентом в экономичном .
 ..
..
ПоискOracle
- Oracle ставит перед собой высокие национальные цели в области ЭУЗ с приобретением Cerner
Приобретя Cerner, Oracle нацелилась на создание национальной анонимной базы данных пациентов — дорога, заполненная …
- Благодаря Cerner Oracle Cloud Infrastructure получает импульс
Oracle планирует приобрести Cerner в рамках сделки на сумму около 30 миллиардов долларов. Второй по величине поставщик электронных медицинских карт в США может вдохнуть новую жизнь в …
- Верховный суд встал на сторону Google в иске о нарушении авторских прав на Oracle API
Верховный суд постановил 6-2, что API-интерфейсы Java, используемые в телефонах Android, не подпадают под действие американского закона об авторском праве, в связи с чем …
ПоискSAP
- Переходить на S/4HANA или нет? Немного реального опыта
Поскольку поддержка ECC приближается к концу, для некоторых начинается гонка за S/4HANA.