Введение в реляционные базы данных
2 октября, 2021 11:26 дп 374 views | Комментариев нетmySQL | Amber | Комментировать запись
Системы управления базами данных (СУБД) – это программы, которые позволяют пользователям взаимодействовать с БД. СУБД позволяет управлять доступом к базе данных, записывать данные, отправлять запросы и выполнять любые другие задачи, связанные с управлением БД.
Однако для решения любой из этих задач СУБД должна иметь какую-то базовую модель, которая определяет, как организованы данные. Реляционная модель – это один из подходов к организации данных, который появился в конце 1960-х и нашел настолько широкое применение в программном обеспечении СУБД, что на момент написания этой статьи четыре из пяти самых популярных СУБД – реляционные.
В этой статье мы поговорим об истории реляционной модели, о том, как реляционные БД организуют данные и как они используются сегодня.
История реляционной модели
Базы данных – это логически смоделированные кластеры информации. Любая коллекция данных является базой данных, независимо от того, как и где она хранится. Даже физическая папка, содержащая информацию о заработной плате, является базой данных, как и стопка больничных бланков пациентов. До того, как хранение и управление данными с помощью компьютеров стало обычной практикой, физические базы данных, подобные этим, были очень широко распространены.
Примерно в середине ХХ века развитие информатики привело к увеличению вычислительной мощности, а также к увеличению емкости локальной и внешней памяти машин. И тогда ученые начали осознавать потенциал этих машин и стали использовать их для хранения и управления все большими объемами данных.
Однако тогда не было никаких теорий о том, каким образом компьютеры могут логически организовать данные. Одно дело хранить несортированные данные на машине, но разработать систему, которая бы позволили добавлять, извлекать, сортировать и иным образом управлять данными единообразным и практичным способом гораздо сложнее.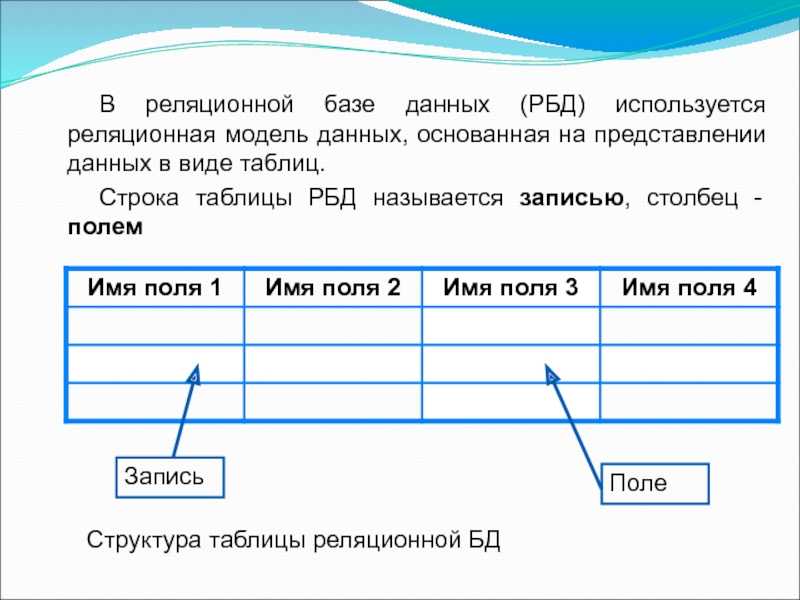
Одной из первых моделей БД была иерархическая модель, данные в которой организованы в древовидную структуру, аналогичную современным файловым системам.
Иерархическая модель широко применялась в ранних СУБД, однако оказалась недостаточно гибкой. Отдельные записи в ней могут иметь несколько дочерних записей, однако по иерархии каждая запись может иметь только одного «родителя». Поэтому ранние иерархические базы данных были ограничены только отношениями «один к одному» и «один ко многим». Отсутствие поддержки отношения «многие ко многим» становилось проблемой при работе с точками данных, которые нужно связать с несколькими родителями.
В конце 1960-х ученый-компьютерщик Эдгар Ф. Кодд, работавший в IBM, разработал реляционную модель управления базами данных. Реляционная модель Кодда позволяет связывать отдельные записи более чем с одной таблицей, тем самым создавая между точками данных отношения «многие ко многим» (в дополнение к отношениям «один ко многим»). Когда дело касалось проектирования структур БД, эта модель обеспечила большую гибкость, чем другие существующие на тот момент модели. Это означало, что реляционные системы управления базами данных (РСУБД) могли удовлетворить гораздо более широкий спектр потребностей.
Когда дело касалось проектирования структур БД, эта модель обеспечила большую гибкость, чем другие существующие на тот момент модели. Это означало, что реляционные системы управления базами данных (РСУБД) могли удовлетворить гораздо более широкий спектр потребностей.
Кодд предложил язык для управления реляционными данными по имени Alpha, который повлиял на развитие более поздних языков БД. Двое коллег Кодда из IBM, Дональд Чемберлин и Рэймонд Бойс, создали свой язык, вдохновленный Alpha. Они назвали его SEQUEL (Structured English Query Language), но такая торговая марка уже существовала, и тогда они сократили название языка до SQL (Structured Query Language).
Из-за аппаратных ограничений ранние реляционные базы данных были очень медленными. Чтобы технология получила широкое распространение, потребовалось некоторое время. Но к середине 1980-х годов реляционная модель Кодда была реализована в ряде коммерческих продуктов для управления базами данных как от IBM, так и от ее конкурентов.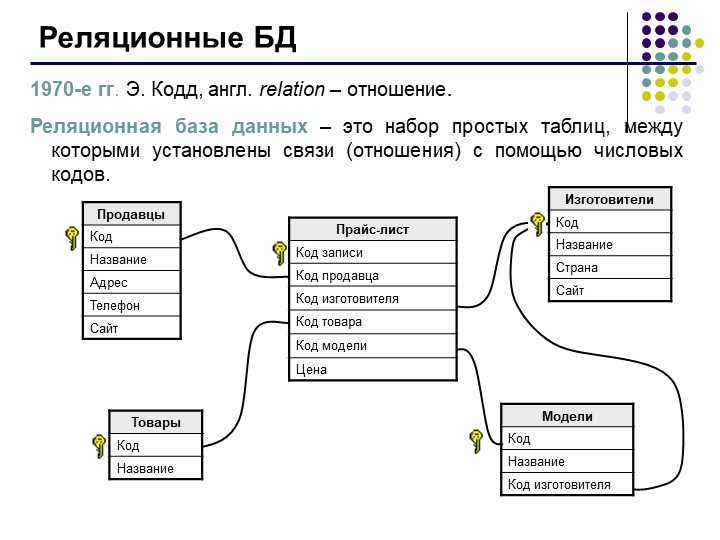 Эти вендоры последовали примеру IBM, разработав и внедрив свои собственные диалекты SQL. К 1987 году и Американский национальный институт стандартов, и Международная организация по стандартизации ратифицировали и опубликовали стандарты для SQL, укрепив его статус как принятого языка для управления СУБД.
Эти вендоры последовали примеру IBM, разработав и внедрив свои собственные диалекты SQL. К 1987 году и Американский национальный институт стандартов, и Международная организация по стандартизации ратифицировали и опубликовали стандарты для SQL, укрепив его статус как принятого языка для управления СУБД.
Благодаря такому широкому использованию реляционной модели во многих отраслях она стала стандартной моделью для управления данными. Даже с появлением баз данных NoSQL реляционные БД остаются доминирующими инструментами для хранения и организации данных.
Как реляционные БД организуют данные
Теперь у вас есть общее представление об истории развития реляционной модели. Давайте же подробнее рассмотрим, как модель организует данные.
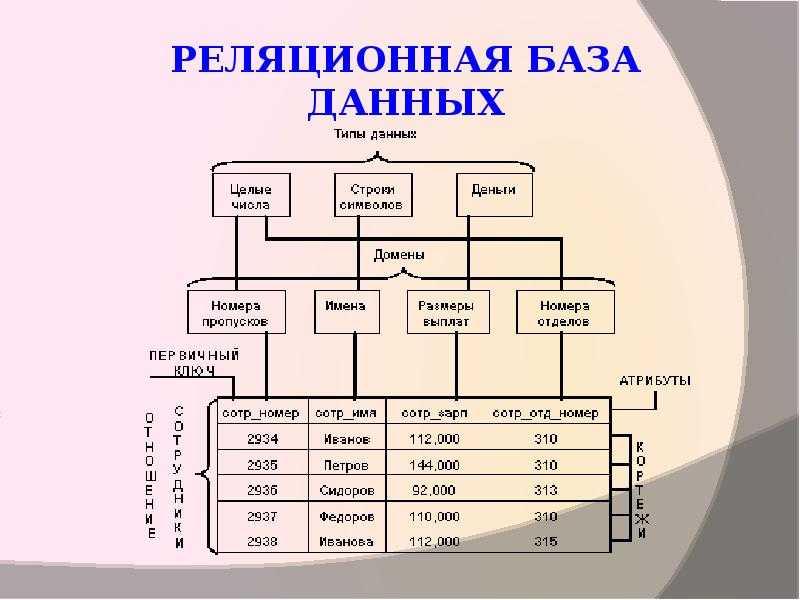
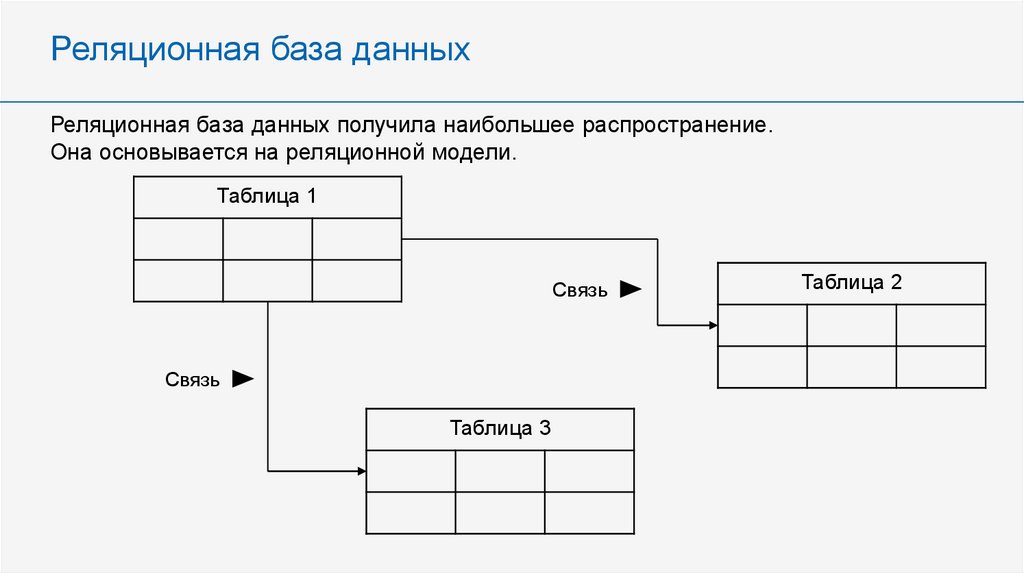
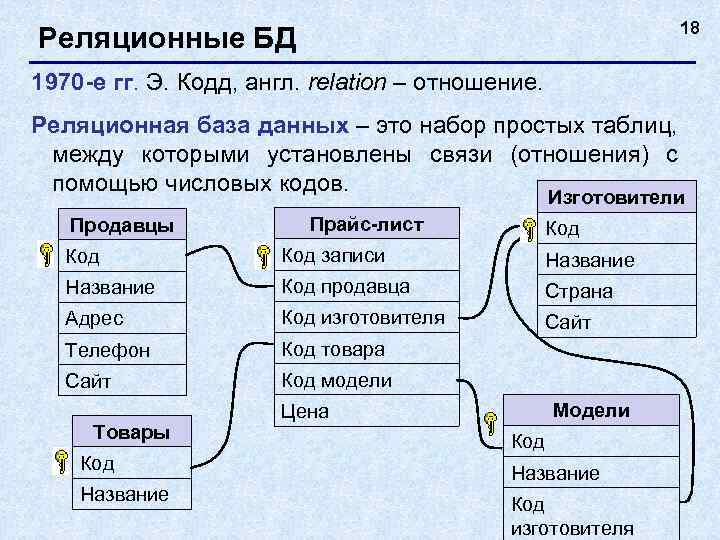
Основными элементами реляционной модели являются отношения (relations), которые пользователи и современные РСУБД распознают как таблицы. Отношение – это набор кортежей или строк в таблице, где каждый кортеж имеет набор атрибутов или столбцов.
Столбец – это наименьшая организационная структура реляционной базы данных. Он представляет различные аспекты, определяющие записи в таблице. Отсюда их более формальное название – атрибуты. Вы можете рассматривать каждый кортеж как уникальный экземпляр любого типа ассоциаций, содержащихся в таблице. В качестве примера можно привести сотрудников компании, продажи в онлайн-бизнесе или результаты лабораторных тестов. Допустим, в таблице, содержащей записи о школьных учителях, кортежи могут иметь такие атрибуты, как name, subjects, start_date и т.п.
При создании столбцов нужно указать тип данных, который определяет, какие записи разрешено хранить в этом столбце. РСУБД часто поддерживают уникальные типы данных, которые не могут быть напрямую взаимозаменяемы с аналогичными типами данных в других системах. Но есть и общие типы данных, к которым относятся даты, строки, целые числа и логические значения.
В реляционной модели каждая таблица содержит по крайней мере один столбец, который можно использовать для однозначной идентификации каждой строки, он называется первичным ключом.
Если у вас есть две таблицы, которые вы хотите связать друг с другом, вы можете сделать это с помощью внешнего ключа. Внешний ключ – это, по сути, копия первичного ключа одной таблицы (родительской), вставленная в столбец другой таблицы (дочерней).
Если вы попытаетесь добавить запись в дочернюю таблицу, а значение, введенное в столбец внешнего ключа, не существует в первичном ключе родительской таблицы, оператор вставки будет недействительным. Это помогает поддерживать целостность на уровне отношений, поскольку строки в обеих таблицах всегда будут связаны правильно.
Структурные элементы реляционной модели помогают хранить данные в организованном порядке, но хранение данных как таковое полезно только в том случае, если вы можете их извлечь.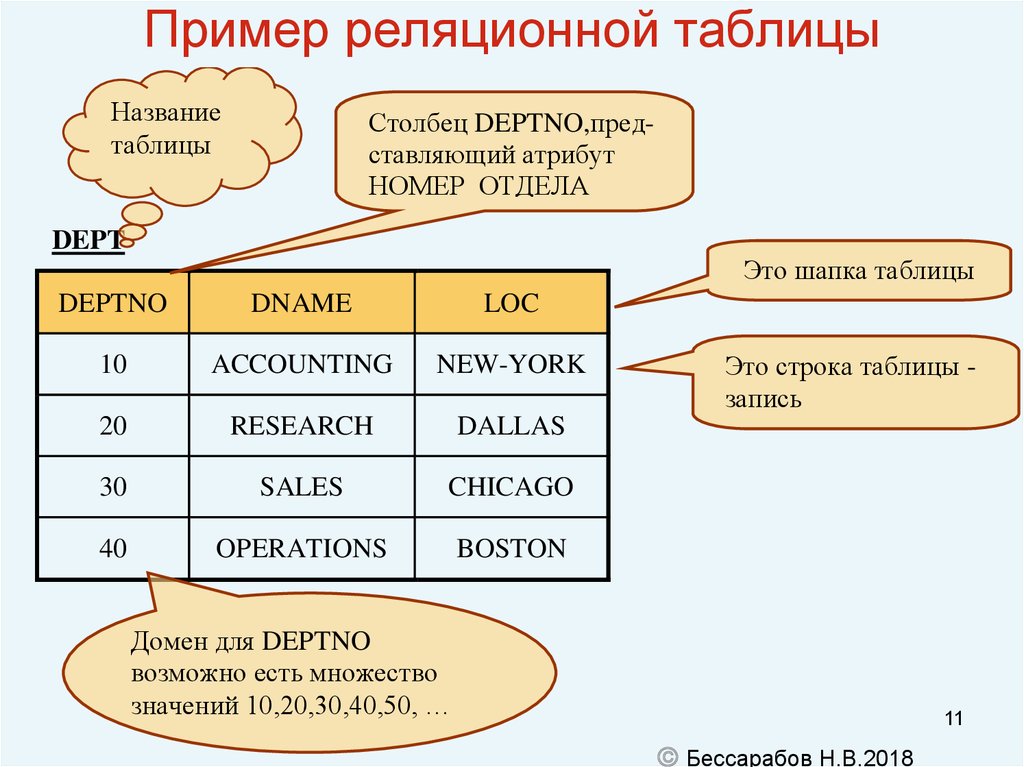 Чтобы получить информацию из СУБД, вы можете отправить запрос. Как упоминалось ранее, для управления данными и запросов к ним большинство реляционных БД используют SQL. SQL позволяет фильтровать и управлять результатами запроса с помощью различных операторов, предикатов и выражений, давая нам точный контроль над тем, какие данные будут отображаться в наборе результатов.
Чтобы получить информацию из СУБД, вы можете отправить запрос. Как упоминалось ранее, для управления данными и запросов к ним большинство реляционных БД используют SQL. SQL позволяет фильтровать и управлять результатами запроса с помощью различных операторов, предикатов и выражений, давая нам точный контроль над тем, какие данные будут отображаться в наборе результатов.
Преимущества и недостатки реляционных баз данных
Ознакомившись с организационной структурой реляционных баз данных, давайте теперь рассмотрим некоторые из их преимуществ и недостатков.
Современный SQL и базы данных, реализующие его, несколько отличаются от реляционной модели Кодда. Например, модель Кодда диктует, что каждая строка в таблице должна быть уникальной, в то время как из соображений практичности большинство современных РБД допускают дублирование строк. Некоторые пользователи не считают базу данных SQL «настоящей» реляционной базой, если она не соответствует каждой из спецификаций реляционной модели, описанной Коддом.
Популярность реляционных баз данных быстро росла, а вместе с этим росла и ценность данных. В связи с этим начали проявляться некоторые недостатки реляционной модели. Во-первых, реляционную базу данных сложно масштабировать по горизонтали. Горизонтальное масштабирование – это практика добавления новых машин к существующему стеку, чтобы распределить нагрузку и обеспечить более быструю обработку трафик.
Примечание: Горизонтальное масштабирование часто противопоставляется вертикальному, которое подразумевает обновление оборудования существующего сервера (обычно путем добавления дополнительной оперативной памяти или процессора).
Причина, по которой реляционную базу данных сложно масштабировать по горизонтали, связана с тем фактом, что реляционная модель предназначена для обеспечения согласованности. Следовательно, клиенты, запрашивающие одну и ту же базу данных, всегда будут получать одни и те же данные.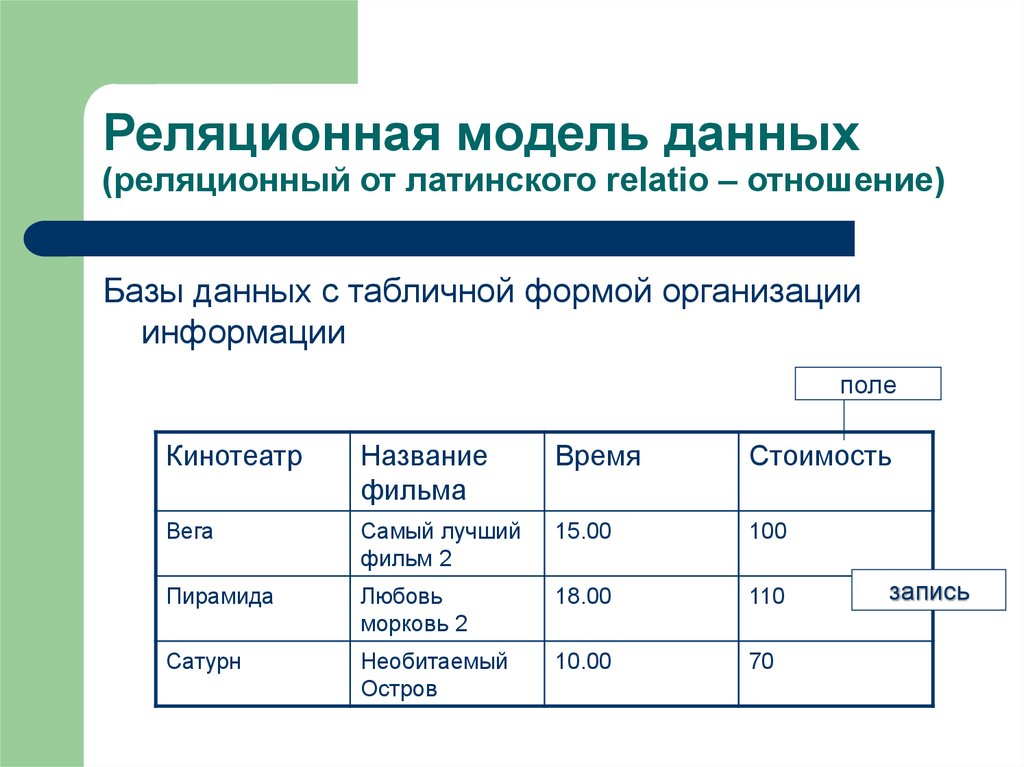 Но если реляционную базу данных масштабировать по горизонтали и разместить на нескольких машинах, ей становится сложно обеспечить согласованность, поскольку клиенты могут записывать данные на одну ноду, но не на другие. Вероятно, между внесением записи и ее отражением на других нодах пройдет некоторое время, а подобная задержка приведет к несогласованности данных.
Но если реляционную базу данных масштабировать по горизонтали и разместить на нескольких машинах, ей становится сложно обеспечить согласованность, поскольку клиенты могут записывать данные на одну ноду, но не на другие. Вероятно, между внесением записи и ее отражением на других нодах пройдет некоторое время, а подобная задержка приведет к несогласованности данных.
Еще одно ограничение, представленное РСУБД, заключается в том, что реляционная модель была разработана для управления структурированными данными (то есть данными, которые соответствуют предопределенному типу или, по крайней мере, организованы некоторым заранее определенным образом, благодаря чему их легко сортировать и искать). Однако с распространением персональных компьютеров и появлением Интернета в начале 1990-х годов широкое распространение получили неструктурированные данные (сообщения электронной почты, фотографии, видео и т.п.).
Конечно, ничто из вышеописанного не означает, что реляционные базы данных бесполезны.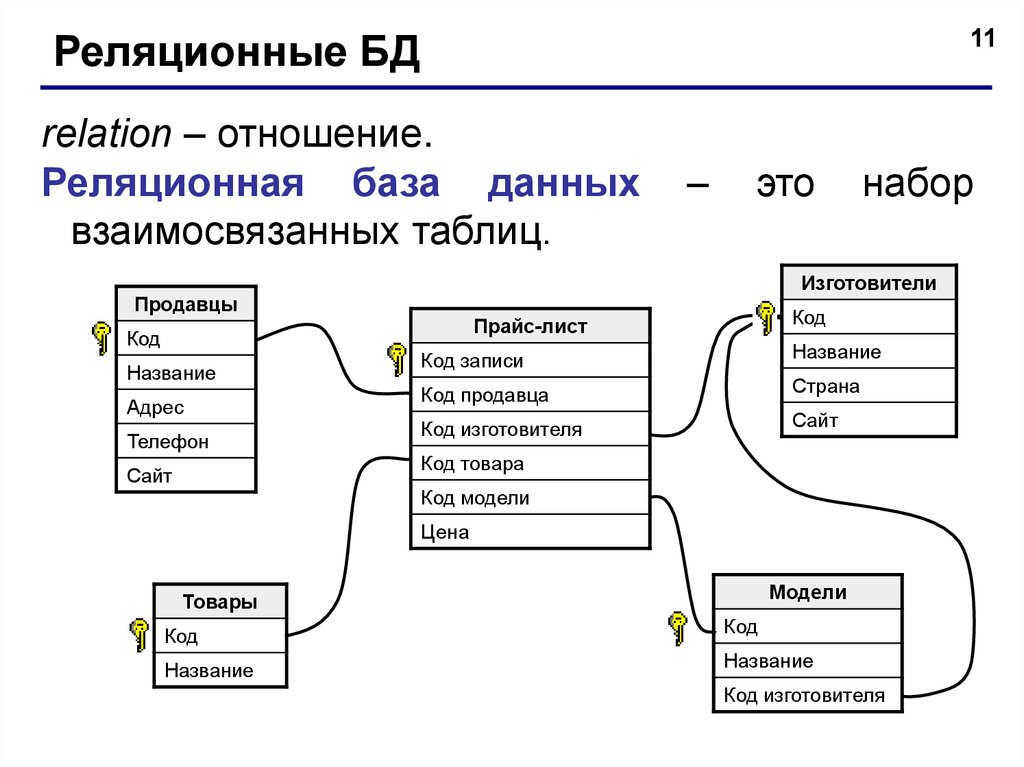 Напротив, даже по прошествии более 50 лет реляционная модель по-прежнему остается доминирующей структурой для управления данными. Ее распространенность и долговечность означают, что реляционные базы данных – зрелая технология, что само по себе является одним из их основных преимуществ. Существует множество приложений, предназначенных для работы с реляционной моделью, а также множество профессионалов и экспертов в области реляционных баз данных. Для тех же, кто хочет начать работу с РДБ, доступен широкий спектр самых разных обучающих и справочных ресурсов.
Напротив, даже по прошествии более 50 лет реляционная модель по-прежнему остается доминирующей структурой для управления данными. Ее распространенность и долговечность означают, что реляционные базы данных – зрелая технология, что само по себе является одним из их основных преимуществ. Существует множество приложений, предназначенных для работы с реляционной моделью, а также множество профессионалов и экспертов в области реляционных баз данных. Для тех же, кто хочет начать работу с РДБ, доступен широкий спектр самых разных обучающих и справочных ресурсов.
Еще одно преимущество реляционных баз данных состоит в том, что почти каждая СУБД поддерживает транзакции. Транзакция состоит из одного или нескольких отдельных SQL-операторов, выполняемых последовательно как единая задача. Транзакции представляют собой подход «все или ничего»: каждый SQL-оператор в транзакции должен быть действительным; в противном случае вся транзакция не будет выполнена. Это обеспечивает целостность данных при внесении изменений в несколько строк или таблиц.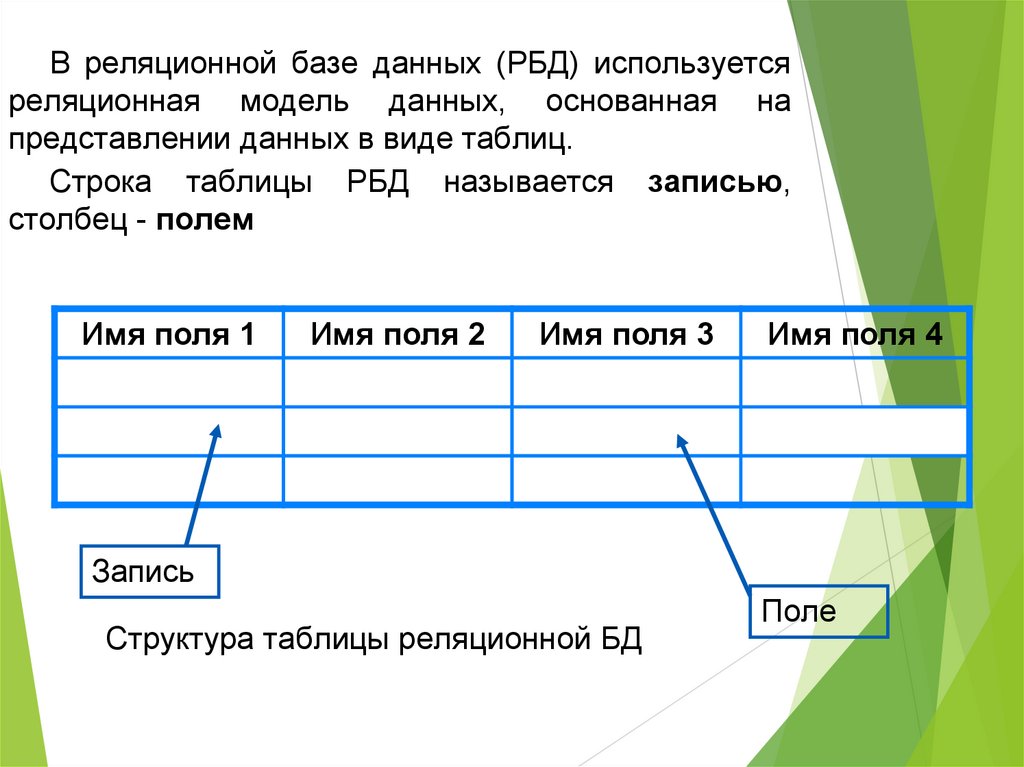
В конце концов, реляционные базы данных чрезвычайно гибки. Они использовались для создания множества приложений и по сей день эффективно справляются даже с очень большими объемами данных. SQL также является чрезвычайно мощным инструментом, он позволяет добавлять и изменять данные на ходу, а также менять структуру схем и таблиц БД, не влияя на существующие данные.
Заключение
Благодаря своей гибкости и дизайну, обеспечивающему целостность данных, даже спустя более 50 лет после выхода реляционные БД остаются основным способом управления и хранения данных. Сегодня существуют более современные базы данных NoSQL, но несмотря на это умение работать с реляционной моделью является ключевым моментом для любого, кто хочет создавать приложения.
Читайте также: Краткий обзор реляционных систем управления базами данных
Tags: SQL|
5.4.1. Реляционные базы данных Все реляционные базы данных используют в качестве модели хранения данных двумерные таблицы.
Каждая строка олицетворяет уникальный элемент данных, который ею и описывается. Столбцы представляют собой отдельные куски информации (атрибуты данных), которые известны о данном элементе. Строки обычно называют записями, а столбцы — полями. Кроме того, для обработки отношений разрешены только следующие операции:
Другие операции с данными обычно не поддерживаются в базах с реляционной структурой. Добавление произвольных данных, которые, например, не соответствуют ни одному полю в описании данных, запрещено. Вообще, лишь немногие реальные базы данных могут быть описаны при помощи единственной таблицы. Большинство приложений используют множество таблиц, которые содержат столбцы (поля) с одинаковым именем. Эти общие данные позволяют объединяя две (или несколько) таблицы, строить осмысленные ассоциации. Лучше всего это иллюстрируется примером. Рассмотрим два отношения «Служащий» и «Отдел», показанные на рис.5.14. Рис. 5.14. Отношения «Служащий» и «Отдел». В этом примере поля Номер Служащего и Номер Отдела выделены; это указывает на то, что эти поля — первичные ключи. Это означает, что элементы данных в этих полях единственным образом определяют запись (т.е. никакие две записи не имеют одинакового элемента данных в ключевом поле). Во многих случаях это объединение не такое простое. Предположим, нам требуется найти способ для определения, кто является Руководителем для любого Служащего. Мы могли бы создать следующую структуру данных (рис.5.15). Эта на вид интуитивная структура может вызвать проблемы из-за избыточности связи отношения «Руководитель», связанного с отношением «Служащий» как напрямую, так и через отношение «Отдел». Эта избыточность позволяет руководителю служащего отличаться от руководителя отдела служащего. Если это не разрешено, то приведенная структура таблиц не подходит. Рис. 5.15. Отношения «Служащий», «Отдел» и «Руководитель». Рис. 5.16. Вместо нее более подходящей была бы структура, представленная на рис. Эта структура удаляет избыточность, которая позволяет Служащему иметь Руководителя, отличного от Руководителя его Отдела. Но делая это, она удаляет прямую связь, которая может быть желательна с точки зрения производительности больших баз данных. Эта взаимосвязь между производительностью и целостностью данных присутствует фактически во всех моделях баз данных. Простой реальный пример может потребовать еще более сложной структуры. Пусть Служащий является членом более чем одного Отдела. Правила соединения в реляционных базах данных не разрешают связей «многие-ко-многим» (которые можно обозначить при помощи стрелки с двойным указателем на каждом конце). Чтобы представить отношение с такими связями (например, каждый Отдел имеет многочисленных Служащих и каждый Служащий может быть членом Многочисленных Отделов), нам надо создать отдельное отношение, которое является гибридом двух столбцов (рис.5.17): Рис. 5.17. Отношения «Служащий», «Назначение», «Отдел» и «Руководитель». Здесь отношение «Назначение» содержит запись для каждого отдела, сотрудником которого является служащий. То есть, если Служащий работает в Отделе, то соответствующие Номер Служащего и Номер отдела обнаруживаются точно в одной записи отношения «Назначение». Поле Номер Назначения фактически не нужно, так как Номер Служащего и Номер Отдела могут вместе служить ключем. В большинстве (но не во всех) СУРБД разрешены отношения с составными ключами. Для тех из них, в которых ключ должен быть представлен обязательно одним полем, структура будет такой, как представлена выше. «Естественный подход» с использованием таблиц может оказаться еще более «притянутым за уши», когда данные — разреженные. Разреженные данные означают, что не каждое поле в каждой записи содержит данные. В некоторых приложениях данные очень разреженные — только несколько из большого числа столбцов, определенных для данного отношения, могут содержать данные в каком-либо заданном ряду. Если в реальном приложении типично, что данные разреженные, то обычно пользователь не рассматривает их как табличные. Реляционные базы данных были бы совсем непригодны, если бы эти разреженные данные действительно хранились внутри прямоугольного массива, так как для этих пустых элементов данных надо было бы выделять пространство. В действительности, большинство современных СУРБД используют таблицы как «логические» структуры, но в качестве внутренних «физических» структур используют структуры, которые могут хранить редкие данные более эффективным способом, таким как В-дерево. |
 Эта модель выбрана потому что она в основном знакома всем пользователям и рассматривается как «естественный» путь представления данных. Любая система данных, не имеет значения какой сложности, может быть сведена к набору таблиц (или «отношений» в терминологии СУРБД) с некоторой избыточностью. Избыточность контролируется путем приведения отношений к канонической «нормальной» форме, которая минимизирует ненужную избыточность без уменьшения связей между элементами данных.
Эта модель выбрана потому что она в основном знакома всем пользователям и рассматривается как «естественный» путь представления данных. Любая система данных, не имеет значения какой сложности, может быть сведена к набору таблиц (или «отношений» в терминологии СУРБД) с некоторой избыточностью. Избыточность контролируется путем приведения отношений к канонической «нормальной» форме, которая минимизирует ненужную избыточность без уменьшения связей между элементами данных. 
 Добавление поля для произвольных данных потребовало бы перестройки (реструктурирования) базы данных. А этот, зачастую очень длительный, процесс может выполняться только когда базой данных никто не пользуется.
Добавление поля для произвольных данных потребовало бы перестройки (реструктурирования) базы данных. А этот, зачастую очень длительный, процесс может выполняться только когда базой данных никто не пользуется.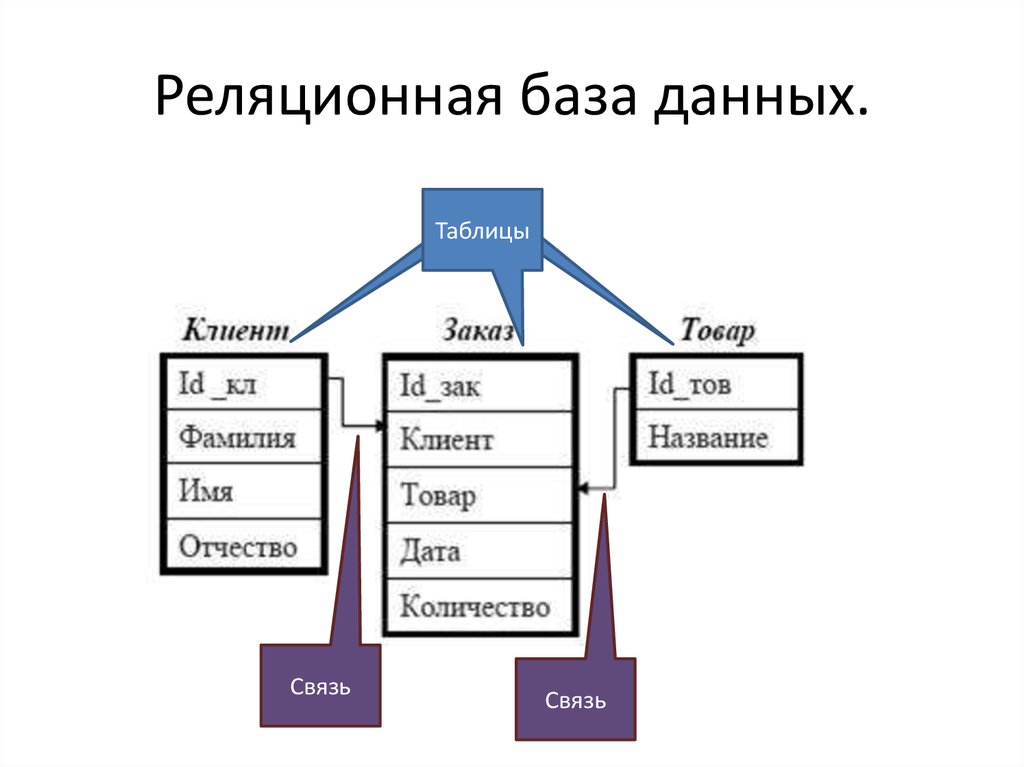 Более того, поле N отдела обнаруживается в обеих таблицах. Это позволяет объединить две таблицы таким образом, чтобы, например, определять Название отдела для любого заданного Служащего.
Более того, поле N отдела обнаруживается в обеих таблицах. Это позволяет объединить две таблицы таким образом, чтобы, например, определять Название отдела для любого заданного Служащего.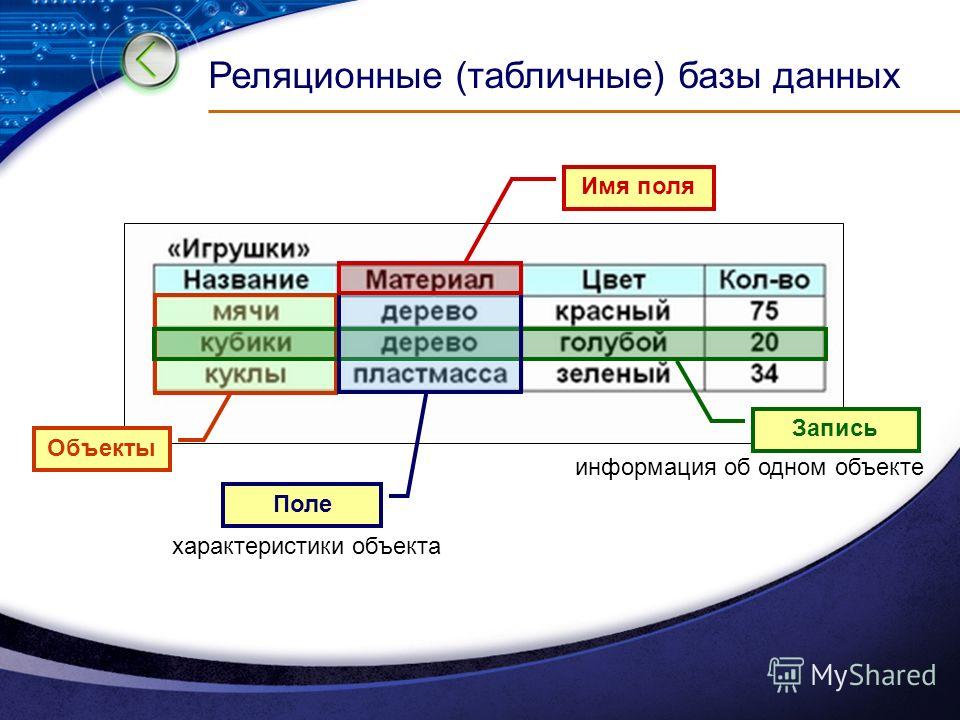 5.16.
5.16.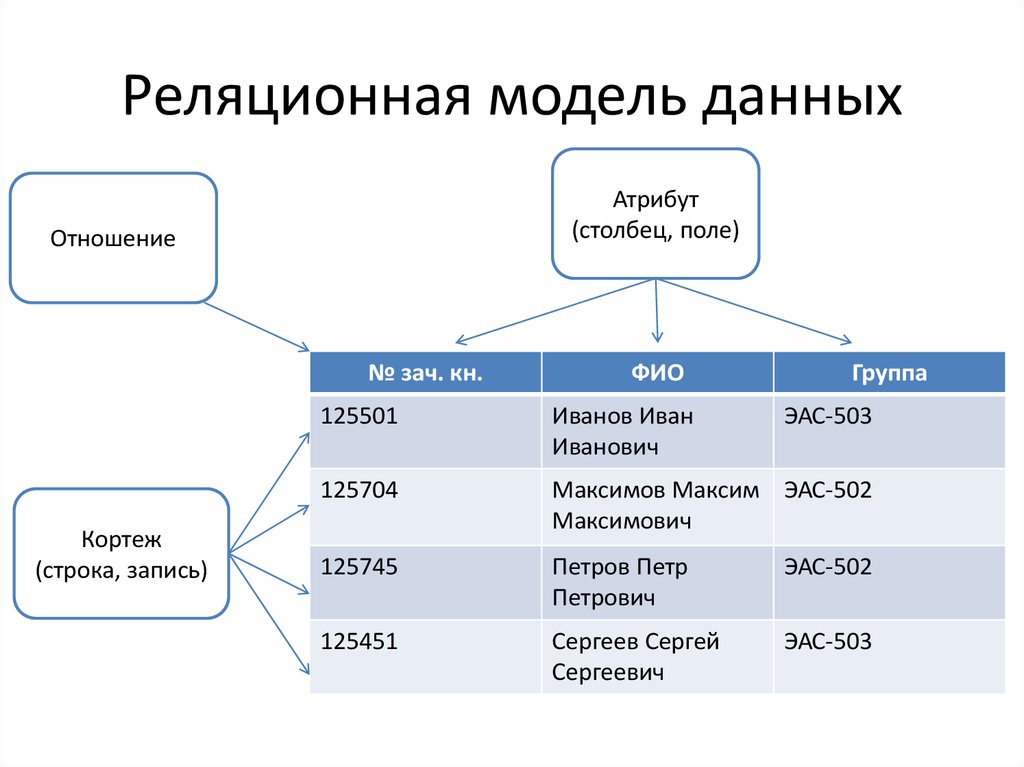
 Например, представим отношение, описывающее посещение пациентом врача. Оно может иметь поля, которые содержат результаты обследования: радиограмма, ультразвук, температура, вес и т.д. Большинство из этих полей может быть пусто для какого-либо пациента. Представить их в качестве полей таблицы в лучшем случае противоестественно. Более естественно представить эти данные в виде списка элементов, чем в качестве полей таблицы. Воплотить в жизнь эту точку зрения пользователя в реляционной базе данных нелегко. Эти различные элементы нельзя занести в одну таблицу, так как они нарушают однородность столбца — данные, хранящиеся в полях, не все одного типа, как это требуется в реляционных таблицах.
Например, представим отношение, описывающее посещение пациентом врача. Оно может иметь поля, которые содержат результаты обследования: радиограмма, ультразвук, температура, вес и т.д. Большинство из этих полей может быть пусто для какого-либо пациента. Представить их в качестве полей таблицы в лучшем случае противоестественно. Более естественно представить эти данные в виде списка элементов, чем в качестве полей таблицы. Воплотить в жизнь эту точку зрения пользователя в реляционной базе данных нелегко. Эти различные элементы нельзя занести в одну таблицу, так как они нарушают однородность столбца — данные, хранящиеся в полях, не все одного типа, как это требуется в реляционных таблицах. Выбор физической структуры иногда предоставляется разработчику БД как возможность оптимизации производительности.
Выбор физической структуры иногда предоставляется разработчику БД как возможность оптимизации производительности.Что такое реляционная база данных? (Определение, варианты)
Реляционные базы данных состоят из таблиц, где каждая таблица содержит строки и столбцы, и каждая строка имеет уникальный идентификатор, известный как первичный ключ.
Давайте представим набор данных, содержащий 100 клиентов с их именами, адресами и любимым продуктом. При использовании реляционной модели одна таблица может содержать список продуктов с четырьмя столбцами для хранения первичного ключа, обзора продукта, названия продукта и идентификатора продукта. Наконец, в другой таблице может быть 100 строк для хранения всех 100 клиентов и четыре столбца для первичного ключа, имени клиента, адреса клиента и идентификатора продукта. Мы можем использовать значение идентификатора продукта, чтобы построить связь между этими двумя таблицами. Мы можем использовать язык структурированных запросов (SQL) для дальнейшего запроса наших таблиц и получения дополнительной информации о продуктах, такой как название продукта или обзор продукта.
Мы можем использовать язык структурированных запросов (SQL) для дальнейшего запроса наших таблиц и получения дополнительной информации о продуктах, такой как название продукта или обзор продукта.
Дополнительная информация из встроенного технического словаря Что такое база данных?
Как работает реляционная база данных?
Реляционные базы данных основаны на реляционной модели данных, которая позволяет специалистам по обработке данных эффективно запрашивать информацию из нескольких таблиц, связанных общими атрибутами.
Для запроса информации из реляционной базы данных обычно используется SQL, первичная точка контакта с реляционной базой данных. Некоторые поставщики создают свои собственные реализации SQL, такие как MySQL, PostgreSQL и Oracle SQL. Эти реализации могут отличаться по своему синтаксису или другим функциям от SQL. Например, PostgreSQL предлагает безопасное для транзакций усечение, которое позволяет пользователям восстанавливать удаленные данные, если что-то пойдет не так с транзакцией, связанной с действием усечения; MySQL не поддерживает эту функцию.
Учебные пособия от встроенных экспертовПочему SQLZoo — лучший способ попрактиковаться в SQL
Почему важны реляционные базы данных?
Главной особенностью реляционной базы данных является способность объединять данные из разных таблиц для создания новых и содержательных выводов. Допустим, компания электронной коммерции имеет реляционную базу данных с тремя таблицами, содержащими данные о продуктах, клиентах и продажах. В таблице продуктов есть список продуктов, содержащий столбцы для идентификатора продукта и количества запасов. В таблице клиентов есть список всех клиентов с контактной информацией и идентификатором клиента. Таблица продаж сообщает нам, какие идентификаторы клиентов и какие идентификаторы продуктов были проданы и по какой цене. С помощью SQL аналитик данных может легко запрашивать эти таблицы и находить полезную информацию, такую как самые продаваемые продукты, самые покупающие клиенты или день недели, когда наблюдается наибольшее количество продаж.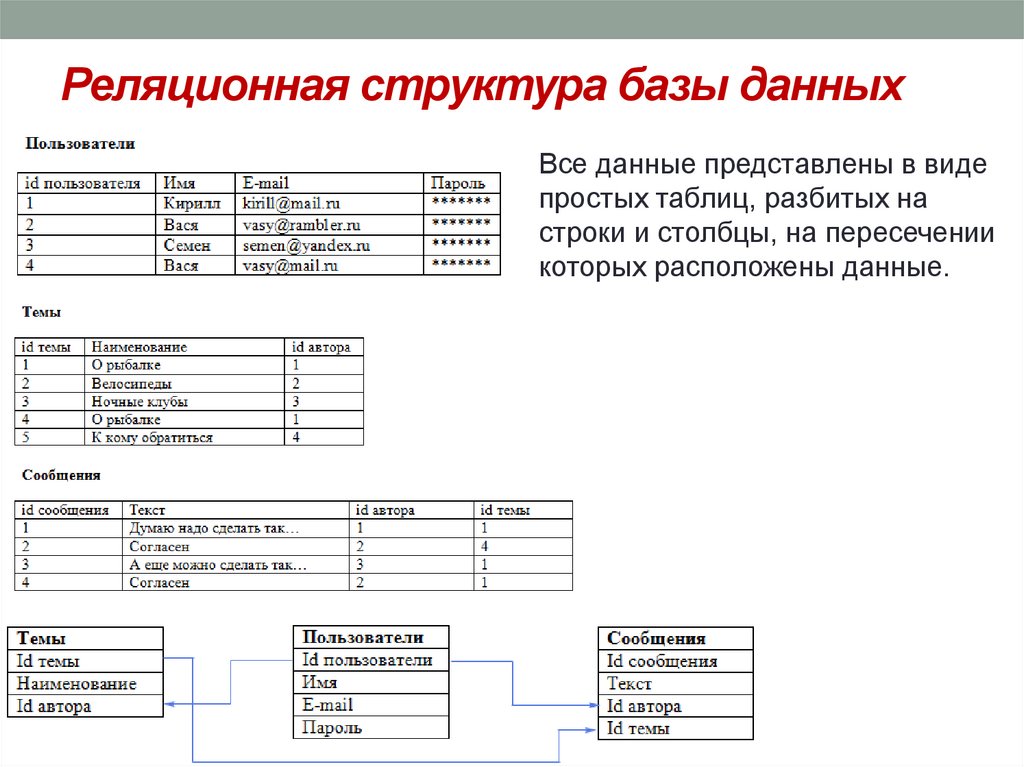
Каковы преимущества реляционных баз данных?
Реляционные базы данных используют первичные и внешние ключи для взаимосвязи таблиц. Это означает, что у нас может быть единственный источник достоверной информации для наших данных. Другими словами, мы можем избежать дублирования данных и быть уверенными в точности наших результатов. Без повторных записей изменить или удалить данные просто, поскольку все связанные записи в других таблицах будут отображать изменение. Вернемся к нашей компании электронной коммерции: клиенту нужно изменить свой адрес электронной почты или имя. Если мы обновим таблицу клиентов, все остальные сведения, такие как клиент, совершающий самые крупные покупки, или имя клиента в таблицах продаж, будут автоматически отражать новые данные о клиентах.
Что такое реляционная база данных? | Видео: IBM Technology
Каковы недостатки реляционных баз данных?
Стоимость может быть серьезным недостатком, поскольку некоторые реляционные базы данных могут быть довольно дорогими. Например, корпоративный сервер Microsoft SQL может быть во много раз дороже стандартной версии.
Например, корпоративный сервер Microsoft SQL может быть во много раз дороже стандартной версии.
Более того, поскольку реляционные базы данных могут объединять данные из многих таблиц с помощью одного запроса, низкая производительность может поставить реляционные базы данных в невыгодное положение. Производительность зависит от многих различных факторов, таких как количество используемых операторов JOIN, правильно ли мы индексируем нашу базу данных или используем ли мы звездочки для выбора столбцов, а не только те поля, которые нам нужны. Существует множество советов по улучшению производительности вашей реляционной базы данных в зависимости от варианта использования. В конце концов, повышение производительности ваших SQL-запросов становится проще с опытом.
Давайте рассмотрим пример. Ниже вы найдете «медленный» запрос, который мы сделаем более эффективным. Представим, что нам нужны три поля из таблицы за первые 15 дней августа 2022 года:
Исходный запрос:
SELECT * FROM SAMPLE_TABLE ГДЕ DATE_TIMESTAMP > "2022-08-01" ЗАКАЗАТЬ ПО DATE_TIMESTAMP ASC
Улучшенный запрос:
ВЫБРАТЬ FIELD_01, FIELD_02, DATE_TIMESTAMP FROM SAMPLE_TABLE ГДЕ DATE_TIMESTAMP МЕЖДУ "2022-08-01" И "2022-08-15" ЗАКАЗАТЬ ПО DATE_TIMESTAMP ASC
Исходный запрос использует SELECT * , который выбирает все поля в таблице, а улучшенный запрос выбирает три определенных поля из таблицы.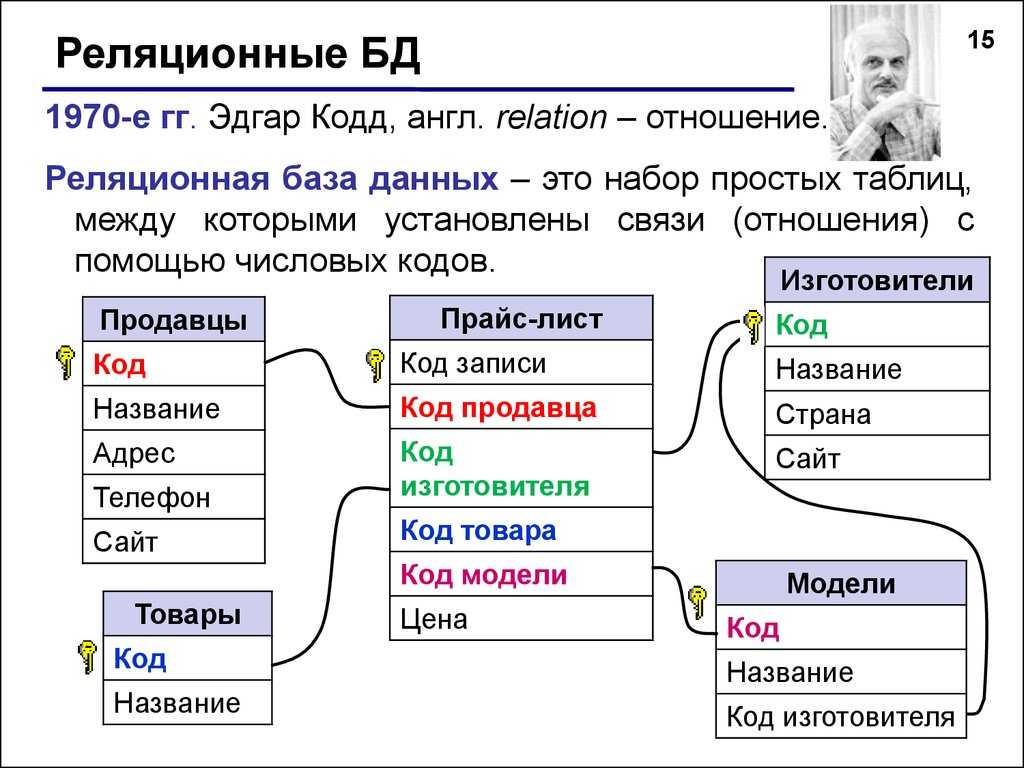 Кроме того, в исходном запросе есть предложение
Кроме того, в исходном запросе есть предложение WHERE , которое разграничивает дату с первого августа 2022 года, но не ограничивает поиск до 15 августа. Это означает, что выполнение исходного запроса займет больше времени, поскольку мы добавим больше данных в стол.
Каковы альтернативы реляционным базам данных?
Существует больше альтернатив для хранения наших данных, которые предлагают определенные преимущества в зависимости от варианта использования. Для неструктурированных данных нереляционная (или NoSQL) база данных может обрабатывать большие объемы данных на высоких скоростях. Другой альтернативой реляционным базам данных является озеро данных (если представляется правильный вариант использования). Мы можем использовать озеро данных для хранения данных в любом масштабе, даже если мы еще не определили назначение данных. В озере данных данные могут быть структурированными, неструктурированными или даже в необработанных файлах.
Если вам нужны реляционные данные и вам нужно выполнить анализ данных, хранилище данных может быть лучшим вариантом.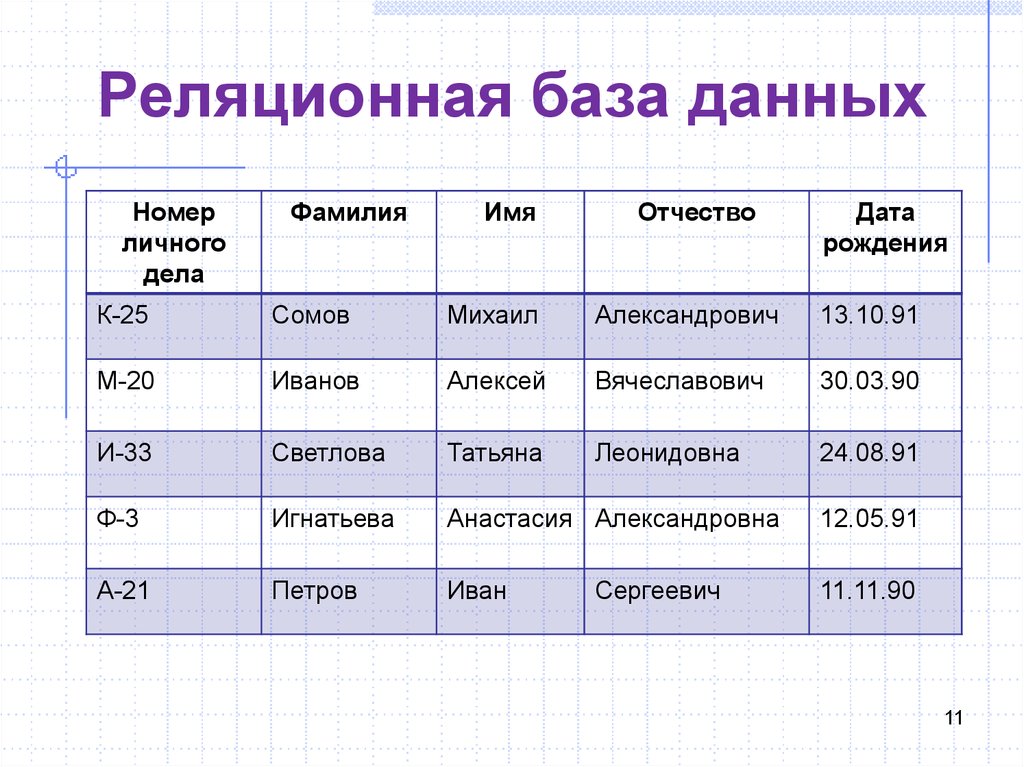 Хранилища данных, как правило, основаны на облаке. Хотя хранилище данных использует реляционную модель, оно предназначено для использования в аналитике данных и поэтому имеет определенные отличия от реляционных баз данных. Например, в хранилище данных чаще собирают исторические данные, а не текущие. Более того, обновления данных планируются, а не создаются всякий раз, когда происходит транзакция. Наконец, хранилища данных создаются путем сбора и преобразования данных из нескольких источников данных для аналитических целей.
Хранилища данных, как правило, основаны на облаке. Хотя хранилище данных использует реляционную модель, оно предназначено для использования в аналитике данных и поэтому имеет определенные отличия от реляционных баз данных. Например, в хранилище данных чаще собирают исторические данные, а не текущие. Более того, обновления данных планируются, а не создаются всякий раз, когда происходит транзакция. Наконец, хранилища данных создаются путем сбора и преобразования данных из нескольких источников данных для аналитических целей.
Связанные материалы от встроенных экспертовSQL и NoSQL: какой из них выбрать?
Примеры реляционных баз данных
Некоторые примеры популярных реляционных баз данных включают Microsoft SQL Server, Oracle Database, MySQL, Amazon Relational Database Service (RDS), PostgreSQL, базу данных Azure SQL и многие другие. RDS и база данных SQL Azure являются облачными, тогда как сервер Microsoft SQL, MySQL и PostsgreSQL предназначены для локальной установки. PostgreSQL и MySQL имеют открытый исходный код, а сервер Microsoft SQL — нет. Кроме того, облачные среды, такие как Google Cloud Platform, Amazon Web Services или Microsoft Azure, также могут поддерживать локальные базы данных.
PostgreSQL и MySQL имеют открытый исходный код, а сервер Microsoft SQL — нет. Кроме того, облачные среды, такие как Google Cloud Platform, Amazon Web Services или Microsoft Azure, также могут поддерживать локальные базы данных.
Реляционная база данных против нереляционной базы данных
Реляционная база данных или нереляционная база данных: что вы должны использовать для своих проектов? Это распространенный вопрос. При выборе типа базы данных, соответствующего вашим требованиям, важно понимать различия между ними.
Оба типа баз данных применимы в различных ситуациях и вариантах использования и имеют общие черты. Оба они также широко реализованы, с рядом различных вариантов поставщиков, доступных для предприятий и разработчиков, которым необходимо хранить, получать доступ или анализировать данные. Ниже вы найдете необходимую информацию, необходимую для принятия обоснованного решения о выборе базы данных, соответствующей вашим потребностям в управлении данными.
Что такое реляционная база данных?
Всем базам данных необходимы следующие функции:
- Возможность хранения нескольких типов — в идеале всех типов — данных
- Легкий и быстрый доступ к данным, хранящимся в базе данных
- Полезность: обеспечивают ли хранимые данные стратегические бизнес-преимущества или ценную информацию?
Другими словами, база данных, в которой хранятся только частичные, недоступные или бесполезные данные, бесполезна. Бизнес-базы данных должны иметь возможность хранить и предоставлять доступ как к операционным, так и к аналитическим данным, чтобы максимизировать их полезность.
Бизнес-базы данных должны иметь возможность хранить и предоставлять доступ как к операционным, так и к аналитическим данным, чтобы максимизировать их полезность.
Оперативные данные — это данные, которые помогают выполнять повседневные бизнес-операции, такие как данные о продажах, уровне запасов или кадровой информации. Аналитические данные обычно представляют собой данные, связанные с взаимодействием клиентов или клиентов с продуктами или услугами компании. Это может включать информацию о трафике блога, тенденциях в отношении продуктов или прогнозах, основанных на покупательском поведении клиентов. Данные хранятся в необработанном виде в хранилищах данных или озерах данных и становятся доступными и пригодными для действий при переносе в базы данных.
Система управления реляционными базами данных, или RDBMS, является одним из способов хранения и обеспечения доступа к этому огромному количеству цифровых данных. СУРБД хранят данные в таблицах. Эти таблицы часто содержат схожую информацию, что приводит к формированию отношений между таблицами — отсюда и название реляционной базы данных .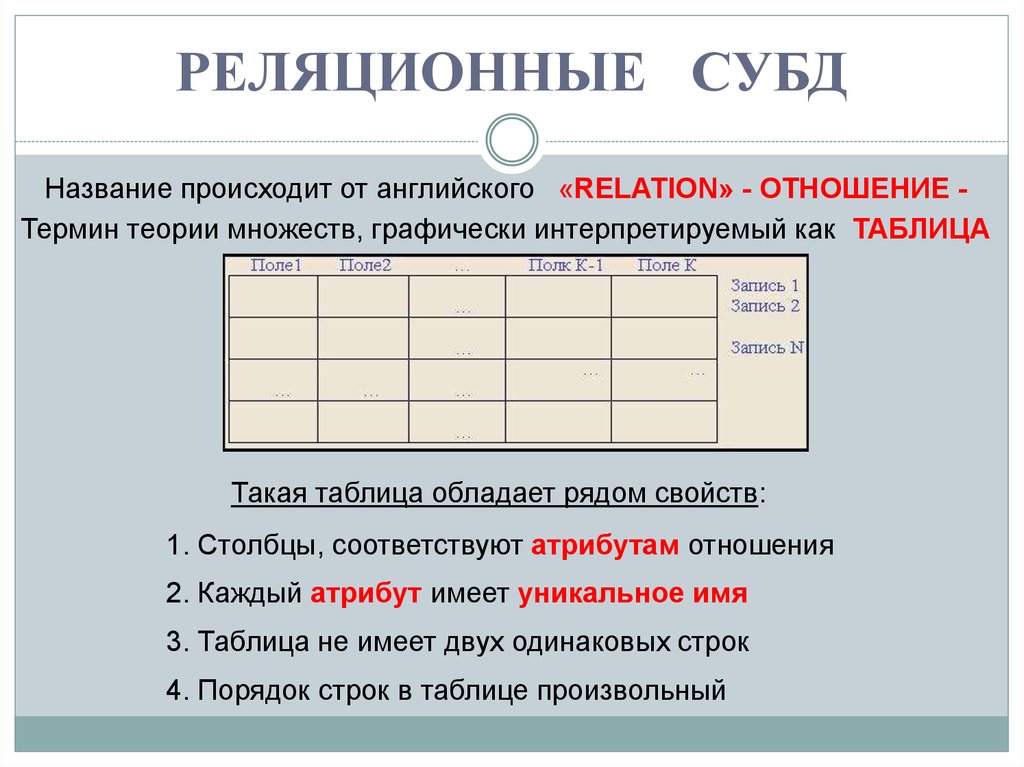 Как и следовало ожидать, в каждой таблице есть и строки, и столбцы. Данные хранятся в строках, а столбцы определяют, что это за данные. Один столбец содержит уникальную определяющую информацию и называется первичным ключом. Когда этот ключ используется в другой таблице, он называется внешним ключом, и между таблицами формируется связь.
Как и следовало ожидать, в каждой таблице есть и строки, и столбцы. Данные хранятся в строках, а столбцы определяют, что это за данные. Один столбец содержит уникальную определяющую информацию и называется первичным ключом. Когда этот ключ используется в другой таблице, он называется внешним ключом, и между таблицами формируется связь.
Разработчики и менеджеры реляционных баз данных обычно используют язык структурированных запросов (SQL) для выполнения, создания, чтения, обновления или удаления (CRUD) операций.
Реляционные базы данных гораздо больше подходят для оперативных данных, поскольку некоторые аналитические данные могут поступать в неструктурированном формате, непригодном для хранения в таблицах.
Преимущества реляционных баз данных
Реляционные базы данных помогают защитить от дублирования информации . Использование первичных и внешних ключей создает отношения, обеспечивающие точность данных.
Сокращение дублирования или репликации данных снижает затраты на хранение и должно уменьшить ресурсы, необходимые для работы базы данных.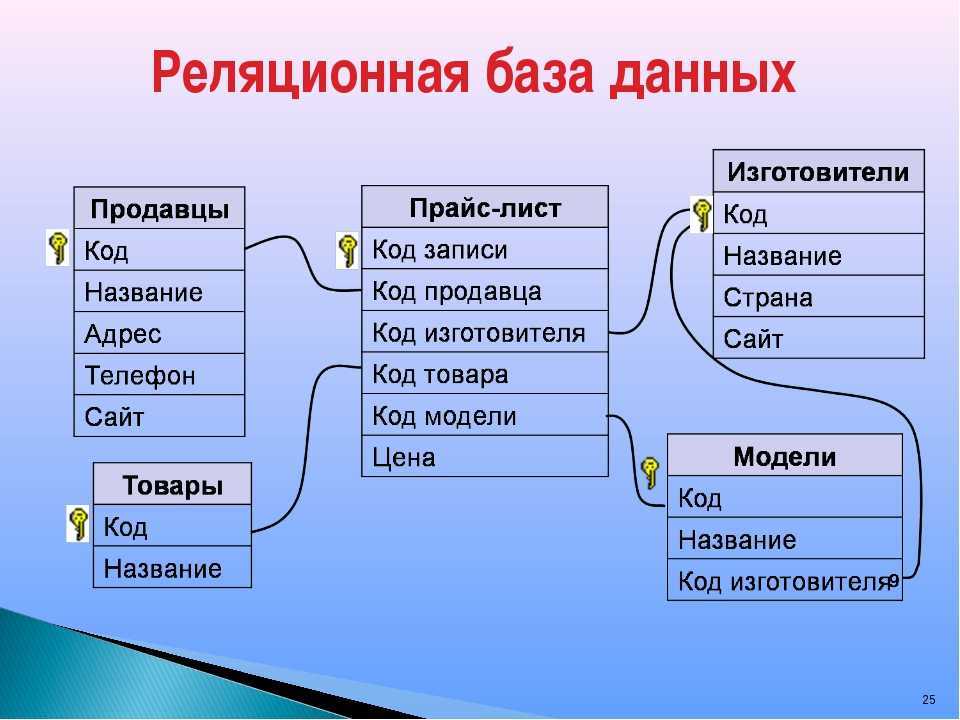
Базы данных РСУБД хорошо зарекомендовали себя, а это означает, что для всех, кто хочет спроектировать или использовать реляционную базу данных, имеется множество средств поддержки.
Реляционные базы данных соответствуют стандарту ACID . ACID означает атомарность, согласованность, изоляцию и долговечность. Это стандарт, по которому измеряется надежность транзакций базы данных. Например, неверный запрос или запрос на изменение не должен повреждать другие данные в базе данных; данные должны быть стабильными и не зависеть от неудачных транзакций.
Недостатки реляционных баз данных
Реляционные базы данных плохо масштабируются . По мере роста объема данных, поступающих в ваш бизнес, вам может быть сложно увеличить базу данных вместе с большими объемами данных, с которыми вам приходится работать. Учитывая, что Statista прогнозирует, что к 2025 году мир будет производить 181 зеттабайт данных, отсутствие масштабируемости может стать настоящим ограничением для компаний, которые хотят оставаться гибкими по мере своего роста.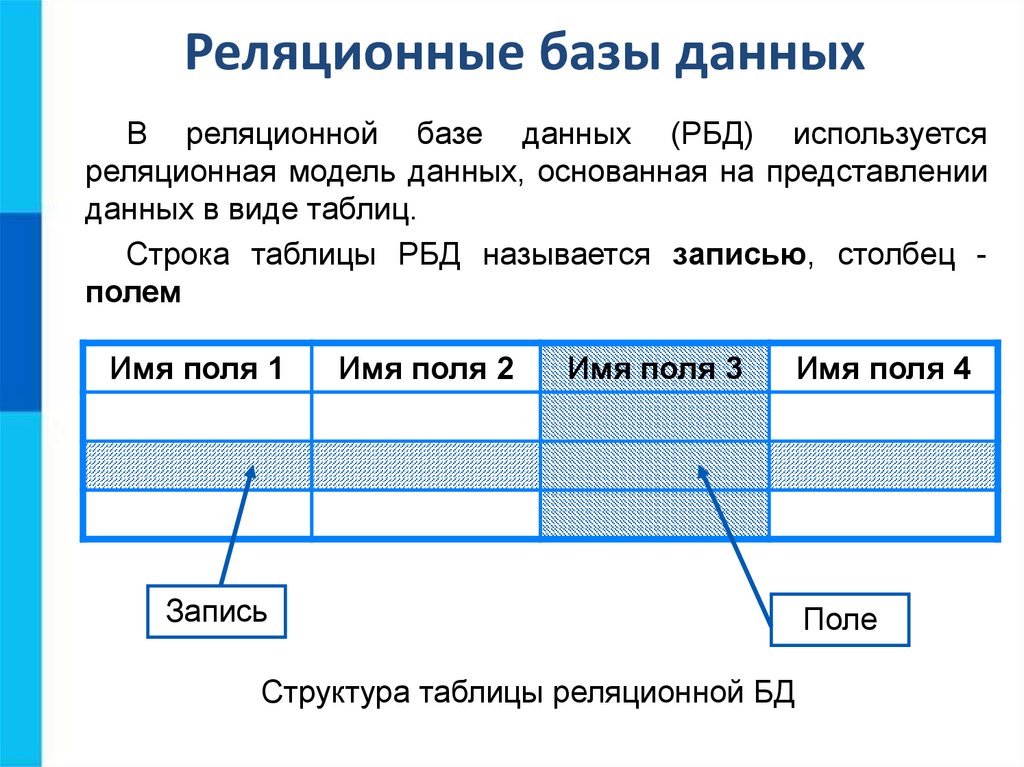
В реляционных базах данных также отсутствует гибкость . По определению, реляционные базы данных следуют жесткой схеме, основанной исключительно на столбцах и таблицах. Это дает как преимущества, так и недостатки. В конечном счете это означает, что после того, как база данных будет создана в соответствии с вашим желаемым дизайном, вы не сможете внести изменения позже, не переводя базу данных в автономный режим и не корректируя все данные в соответствии с новыми критериями.
По мере роста реляционной базы данных ее производительность снижается . Это означает, что для очень сложных баз данных с многочисленными таблицами может потребоваться много времени для выполнения запросов, что снижает скорость получения полезных бизнес-идей.
Что такое нереляционная база данных?
Нереляционные базы данных — это базы данных любого типа, в которых не используется структурированный стиль управления данными реляционных баз данных, ориентированный на отношения. Нереляционные базы данных не ограничиваются таблицами, столбцами и строками. Это означает, что они могут обрабатывать неструктурированные данные, которые не соответствуют какой-либо конкретной схеме. Неструктурированные данные могут включать ответы на автоматизированные кампании по электронной почте или текстовые сообщения. Для этих данных нет заданных параметров, и часто предприятиям приходится использовать инструменты бизнес-аналитики (BI) для просеивания этих неструктурированных данных в поисках закономерностей, которые могут привести к важным для бизнеса выводам и прогнозам.
Нереляционные базы данных не ограничиваются таблицами, столбцами и строками. Это означает, что они могут обрабатывать неструктурированные данные, которые не соответствуют какой-либо конкретной схеме. Неструктурированные данные могут включать ответы на автоматизированные кампании по электронной почте или текстовые сообщения. Для этих данных нет заданных параметров, и часто предприятиям приходится использовать инструменты бизнес-аналитики (BI) для просеивания этих неструктурированных данных в поисках закономерностей, которые могут привести к важным для бизнеса выводам и прогнозам.
Таблица с набором определений того, как данные должны отображаться и представляться, бесполезна для неструктурированных данных. Нереляционная база данных представляет собой альтернативу, которая поддерживает данные, не соответствующие фиксированной схеме.
Существует множество типов нереляционных баз данных, но вот плюсы и минусы общей концепции.
Преимущества нереляционных баз данных
Нереляционные базы данных лучше подходят для облачной среды .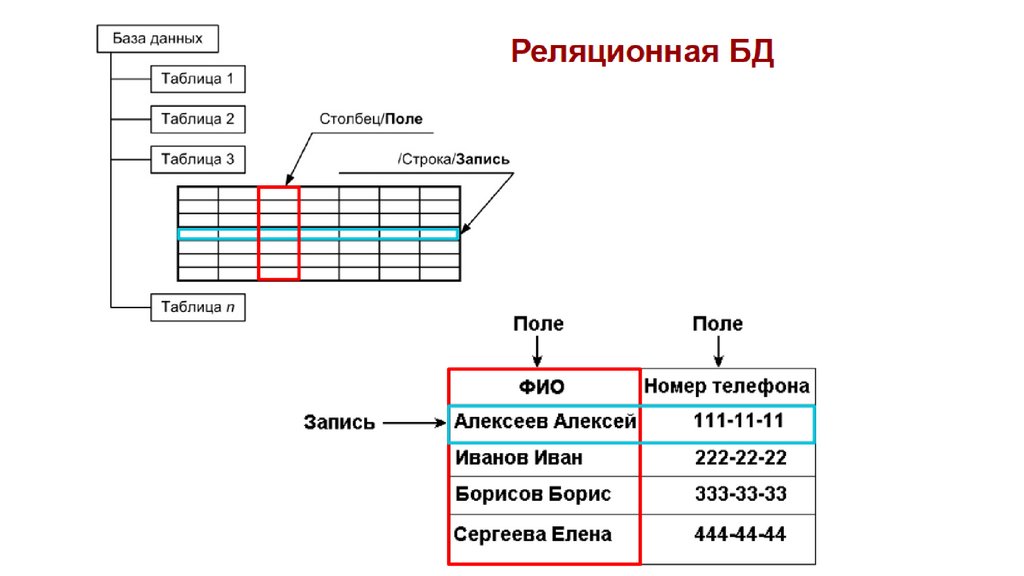 Этот тип базы данных может работать со многими типами данных, включая данные с устройств через Интернет вещей (IoT) и множество SaaS и приложений. Это позволяет разработчикам с легкостью управлять совершенно разрозненными системами или приложениями.
Этот тип базы данных может работать со многими типами данных, включая данные с устройств через Интернет вещей (IoT) и множество SaaS и приложений. Это позволяет разработчикам с легкостью управлять совершенно разрозненными системами или приложениями.
Масштабируемость становится намного проще с нереляционной базой данных. Этот метод хранения данных идеально подходит для больших объемов данных и не ограничен типом данных.
Поскольку нереляционные базы данных могут обрабатывать большие и более сложные формы данных, они работают лучше , быстрее и предоставляют бизнесу больше информации в режиме реального времени в сочетании с соответствующими инструментами BI или экспертными менеджерами данных.
Недостатки нереляционных баз данных
Надежность не гарантируется для нереляционной базы данных. Могут быть случаи, когда корректировка данных вызывает проблемы с другими записями. Чтобы предотвратить это, разработчики могут захотеть закодировать свои собственные непредвиденные обстоятельства, что немного усложнит создание нереляционной базы данных.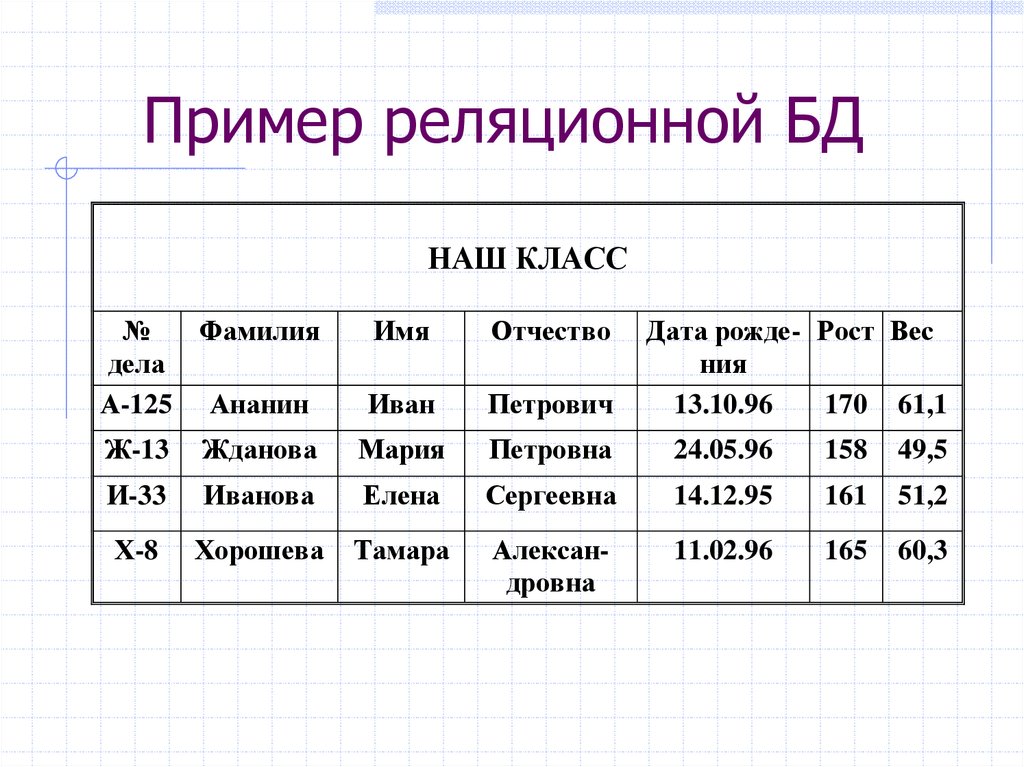
Важным моментом в отношении нереляционных баз данных является то, что они не совместимы с ACID .
Наконец, поддержка меньше доступны для нереляционных баз данных просто потому, что они не существуют так долго. Сообщество разработчиков все еще растет, поэтому создание, запуск и обслуживание базы данных такого типа может показаться более сложной задачей.
Каковы самые большие различия?
Масштабируемость : Хотя вы всегда можете добавить больше строк данных в реляционную базу данных, сделав ее вертикально масштабируемой, чем больше столбцов или таблиц вы добавляете, тем хуже она работает. Нереляционные базы данных могут быть гораздо более сложными и оказывать гораздо меньшее влияние на производительность.
Надежность : Реляционные базы данных соответствуют отраслевым стандартам надежности (ACID). Нереляционные базы данных не имеют таких гарантий, что побуждает программистов разрабатывать собственный код для обеспечения надежности.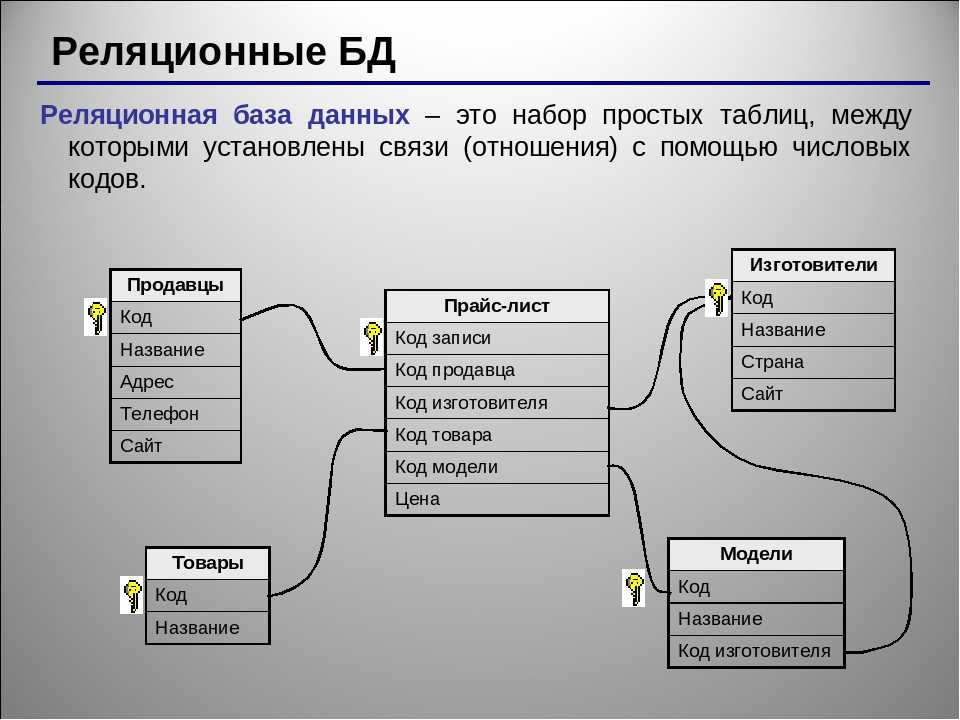
Самая большая разница между реляционными и нереляционными базами данных заключается в способе структурирования данных . Данные в реляционных базах данных всегда должны соответствовать предопределенной структуре столбца в таблице. Например, нельзя было поместить чье-то имя в столбец с номером телефона. Стол не принял.
И наоборот, нереляционные базы данных извлекают и представляют данные множеством способов. Давайте рассмотрим это подробнее в следующем разделе.
Архитектура для реляционных баз данных и нереляционных баз данных
Реляционные базы данных содержат данные, метаданные (данные о данных), а также компилятор для преобразования запросов SQL, чтобы база данных могла понять запрос и предоставить необходимую информацию. Данные всегда структурированы в виде таблиц, построенных из столбцов и строк.
В типичной архитектуре СУБД запросы могут исходить от администратора базы данных, аналитика данных или разработчика приложений.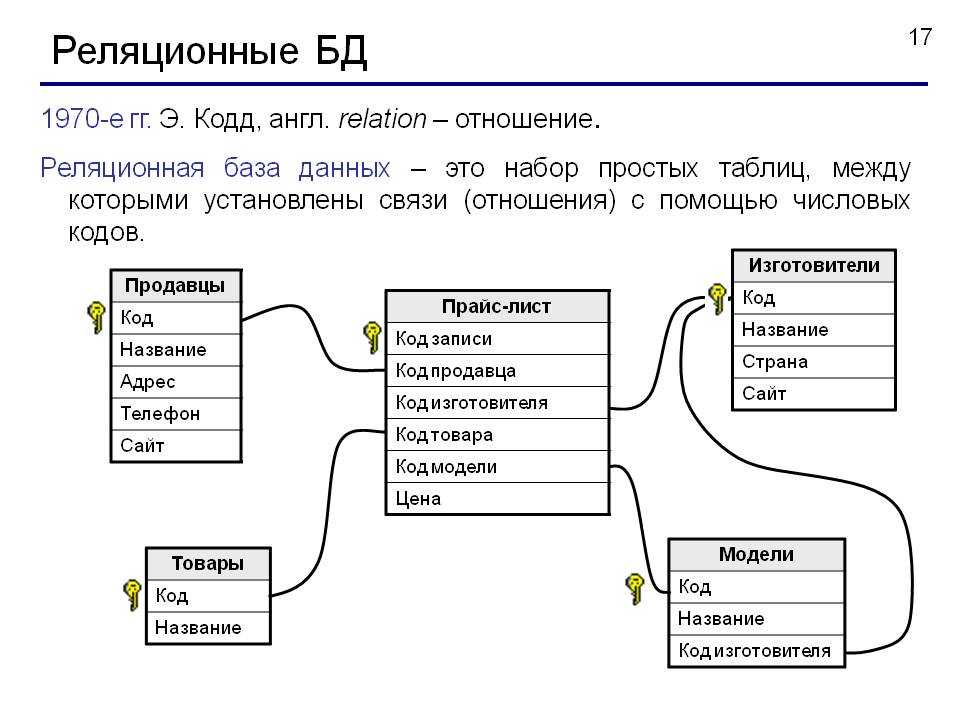
Запросы могут проходить через компилятор запросов или компилятор прикладной программы. RDBSM будет иметь оптимизаторы запросов, которые преобразуют запрос и запускают его через систему выполнения RDBMS. Эта часть базы данных выполняет запросы или команды из других приложений и соответственно извлекает данные.
Также будет журнал, в котором будут записаны выполненные запросы и любые проблемы, такие как сбои транзакций или выключения системы. Это позволяет менеджерам данных понять, как используется база данных, и решить любые проблемы с надежностью.
Наконец, типичная RDBSM будет иметь встроенный менеджер восстановления для обеспечения надежности после сбоя.
Архитектура нереляционной базы данных различается, так как существует несколько типов. Вот почему их также называют базами данных NoSQL, где NoSQL означает не только SQL — или не только фиксированную схему и критерии.
Самая простая база данных NoSQL — это база данных «ключ-значение» .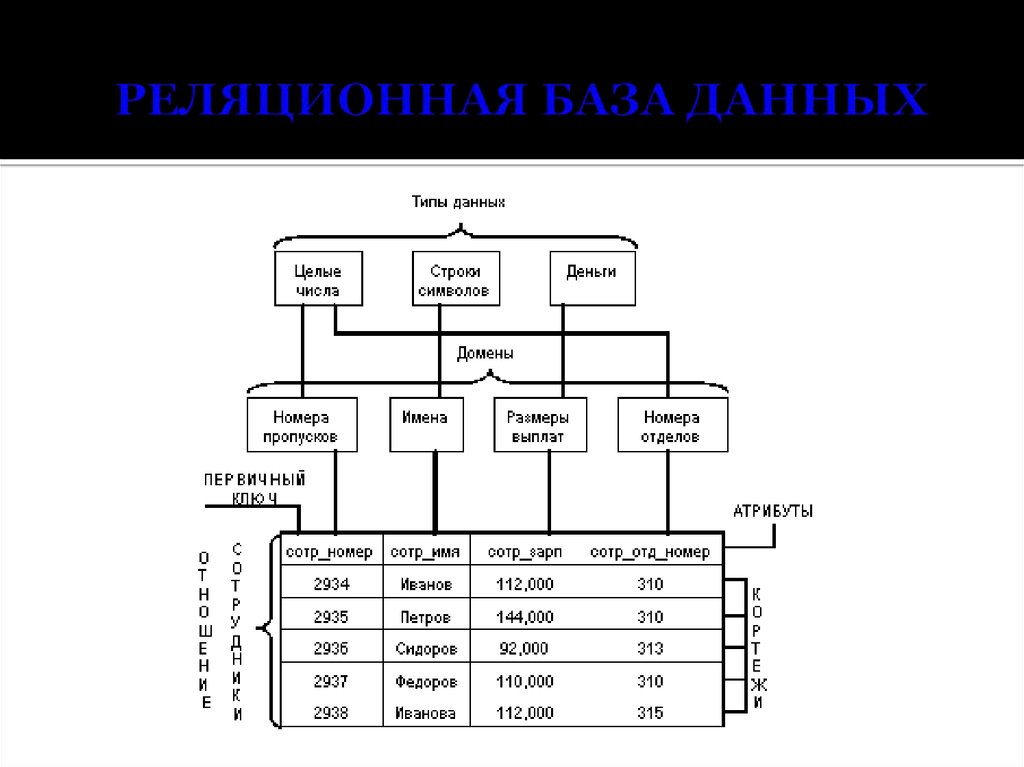 Ключи данных связаны со значениями данных — записями в базе данных. Доступ к каждому значению данных возможен только с помощью определенного ключа, относящегося к этой точке данных. Это обеспечивает быстрый доступ к данным, но ограничивает сложность сохраняемых данных.
Ключи данных связаны со значениями данных — записями в базе данных. Доступ к каждому значению данных возможен только с помощью определенного ключа, относящегося к этой точке данных. Это обеспечивает быстрый доступ к данным, но ограничивает сложность сохраняемых данных.
Базы данных с широкими столбцами по существу являются более гибкой версией реляционной базы данных. Они также соответствуют стандартной таблице с форматом столбцов и строк. Однако, в отличие от структуры реляционной базы данных, каждый столбец может содержать разные типы данных. Они могут хранить все виды данных, но это может замедлить их, когда придет время их извлечь.
Базы данных документов , возможно, представляют собой наиболее гибкую архитектуру баз данных. Данные хранятся в виде JSON-подобных документов, которые могут обрабатывать несколько типов данных. Строки, числа, массивы и вложенные документы могут храниться в базе данных документов. Один документ в базе данных такого типа может содержать все данные клиента, что упрощает и ускоряет получение этой информации.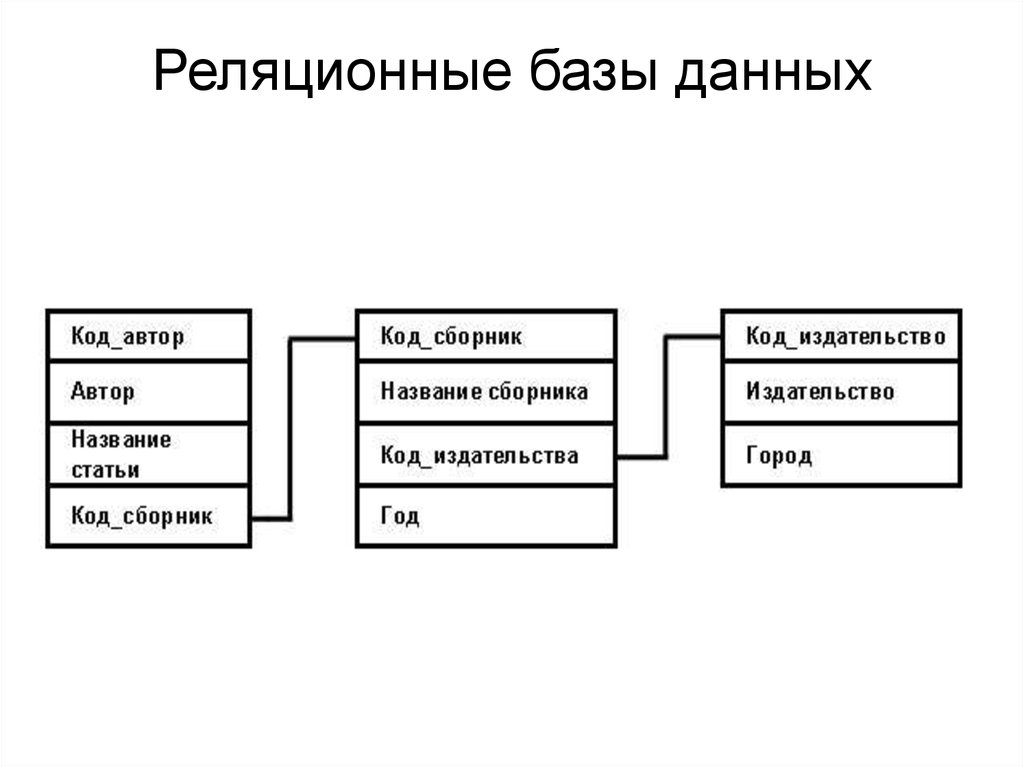 API-интерфейсы запросов могут извлекать эти данные, подробно описывая критерии, по которым данные должны быть отфильтрованы, и поля, которые должен увидеть аналитик данных после извлечения данных.
API-интерфейсы запросов могут извлекать эти данные, подробно описывая критерии, по которым данные должны быть отфильтрованы, и поля, которые должен увидеть аналитик данных после извлечения данных.
Данные в базе данных документов хорошо организованы, легко просматриваются и доступны. Нет никаких причин, по которым вы не можете просматривать одни и те же данные на нескольких серверах, что помогает разрушить или даже предотвратить разрозненность данных в организациях и сделать разработку приложений более гибкой.
Какой тип базы данных MongoDB/NoSQL?
MongoDB — это облачная база данных как услуга, предназначенная для подключения к другим облачным службам, таким как AWS, Google Cloud, Azure и другим службам, используемым предприятиями. Особое внимание уделяется безопасности данных, объектно-ориентированной разработке и изоляции рабочих нагрузок. Но является ли MongoDB реляционной или нереляционной?
MongoDB — это нереляционная база данных с высокой степенью масштабируемости. Он предназначен для предприятий, которым необходимо хранить огромные объемы данных, что проще с нереляционной архитектурой базы данных. MongoDB — это база данных NoSQL, поскольку данные хранятся и извлекаются не только в таблицах. В частности, MongoDB — это база данных документов, позволяющая предприятиям хранить практически неограниченные формы данных.
Он предназначен для предприятий, которым необходимо хранить огромные объемы данных, что проще с нереляционной архитектурой базы данных. MongoDB — это база данных NoSQL, поскольку данные хранятся и извлекаются не только в таблицах. В частности, MongoDB — это база данных документов, позволяющая предприятиям хранить практически неограниченные формы данных.
Реляционная база данных по сравнению с нереляционной базой данных: какой тип базы данных следует использовать?
Принятие обоснованного решения о типе используемой базы данных означает понимание основных различий.
Короче говоря, оба типа баз данных подходят для облачных приложений, но оба имеют свои преимущества и недостатки. Реляционные базы данных реализованы более широко и соответствуют стандартам соответствия ACID. Однако нереляционные базы данных больше подходят для больших объемов неструктурированных данных, которые становятся все более распространенными по мере экспоненциального роста объема данных, принимаемых предприятиями.