Нереляционные данные и базы данных NoSQL — Azure Architecture Center
- Чтение занимает 11 мин
В этой статье
Нереляционная база данных — это база данных, в которой в отличие от большинства традиционных систем баз данных не используется табличная схема строк и столбцов.A non-relational database is a database that does not use the tabular schema of rows and columns found in most traditional database systems. В этих базах данных применяется модель хранения, оптимизированная под конкретные требования типа хранимых данных.Instead, non-relational databases use a storage model that is optimized for the specific requirements of the type of data being stored.
Все эти хранилища данных не используют реляционную модель.What all of these data stores have in common is that they don’t use a relational model. Кроме того, они, как правило, поддерживают определенные типы данных. Процесс запроса данных также специфический.Also, they tend to be more specific in the type of data they support and how data can be queried. Например, хранилища данных временных рядов рассчитаны на запросы к последовательностям данных, упорядоченных по времени, а хранилища данных графов — на анализ взвешенных связей между сущностями.For example, time series data stores are optimized for queries over time-based sequences of data, while graph data stores are optimized for exploring weighted relationships between entities. Ни один из форматов не подходит в полней мере при выполнении задач управления данными о транзакциях.
Термин NoSQL применяется к хранилищам данных, которые не используют язык запросов SQL, а запрашивают данные с помощью других языков и конструкций.The term NoSQL refers to data stores that do not use SQL for queries, and instead use other programming languages and constructs to query the data. На практике NoSQL означает «нереляционная база данных», даже несмотря на то, что многие из этих баз данных под держивают запросы, совместимые с SQL.In practice, «NoSQL» means «non-relational database,» even though many of these databases do support SQL-compatible queries. Однако базовая стратегия выполнения запросов SQL обычно значительно отличается от применяемой в системе управления реляционной базой данных (реляционная СУБД).However, the underlying query execution strategy is usually very different from the way a traditional RDBMS would execute the same SQL query.
В разделах ниже описаны основные категории нереляционных баз данных или баз данных NoSQL. The following sections describe the major categories of non-relational or NoSQL database.
The following sections describe the major categories of non-relational or NoSQL database.
Хранилища данных документовDocument data stores
Хранилище данных документов управляет набором значений именованных строковых полей и данных объекта в сущности, которая называется документом.A document data store manages a set of named string fields and object data values in an entity referred to as a document. Обычно данные в этих хранилищах содержатся в виде документов JSON.These data stores typically store data in the form of JSON documents. Каждое значение поля может представлять собой скалярный элемент, например число, или сложный объект, например список или коллекция типа «родитель — потомок».Each field value could be a scalar item, such as a number, or a compound element, such as a list or a parent-child collection. Данные в полях документа можно закодировать разными способами, например в формате XML, YAML, JSON, BSON, или хранить в виде обычного текста.The data in the fields of a document can be encoded in a variety of ways, including XML, YAML, JSON, BSON, or even stored as plain text.
Как правило, документ содержит все данные для сущности.Typically, a document contains the entire data for an entity. Элементы, составляющие сущность, зависят от конкретного приложения.What items constitute an entity are application-specific. Например, сущность может содержать сведения о клиенте, заказе или их сочетание.For example, an entity could contain the details of a customer, an order, or a combination of both. Один документ может содержать сведения, которые в реляционной СУБД обычно распределяются по нескольким реляционным таблицам.A single document might contain information that would be spread across several relational tables in a relational database management system (RDBMS).
Приложение может получать документы по ключу документа.The application can retrieve documents by using the document key. Это уникальный идентификатор документа. Часто к нему применяется хэширование для равномерного распределения данных.This is a unique identifier for the document, which is often hashed, to help distribute data evenly. Некоторые базы данных документов автоматически создают ключ документа.Some document databases create the document key automatically. Другие позволяют указать атрибут документа, который будет использоваться в качестве ключа. Others enable you to specify an attribute of the document to use as the key. Приложение также может запрашивать документы на основе значения одного или нескольких полей.The application can also query documents based on the value of one or more fields. Некоторые базы данных документов поддерживают индексирование, чтобы облегчить быстрый поиск документов по одному или нескольким индексированным полям.Some document databases support indexing to facilitate fast lookup of documents based on one or more indexed fields.
Others enable you to specify an attribute of the document to use as the key. Приложение также может запрашивать документы на основе значения одного или нескольких полей.The application can also query documents based on the value of one or more fields. Некоторые базы данных документов поддерживают индексирование, чтобы облегчить быстрый поиск документов по одному или нескольким индексированным полям.Some document databases support indexing to facilitate fast lookup of documents based on one or more indexed fields.
Многие базы данных документов поддерживают обновления «на месте», то есть позволяют приложению изменять значения отдельных полей без перезаписи всего документа.Many document databases support in-place updates, enabling an application to modify the values of specific fields in a document without rewriting the entire document. Операции чтения и записи для нескольких полей в одном документе обычно являются атомарными.Read and write operations over multiple fields in a single document are typically atomic.
Соответствующие службы Azure:Relevant Azure service:
Столбчатые хранилища данныхColumnar data stores
Столбчатое хранилище данных или хранилище семейств столбцов упорядочивает данные по столбцам и строкам.A columnar or column-family data store organizes data into columns and rows. Столбчатое хранилище данных в простейшей форме почти неотличимо от реляционной базы данных, по крайней мере организационно.In its simplest form, a column-family data store can appear very similar to a relational database, at least conceptually. Настоящее преимущество столбчатого хранилища данных заключается в способности денормализованно структурировать разреженные данные, что связано со столбцово-ориентированным методом хранения данных.The real power of a column-family database lies in its denormalized approach to structuring sparse data, which stems from the column-oriented approach to storing data.
Столбчатое хранилище данных можно представить как набор табличных данных со строками и столбцами, в которых столбцы разделяются на определенные группы или семейства столбцов.
На следующей диаграмме представлен пример таблицы с двумя семействами столбцов: Identity и Contact Info. The following diagram shows an example with two column families,
The following diagram shows an example with two column families, Identity and Contact Info. Данные одной сущности имеют одинаковые ключи строк во всех семействах столбцов.The data for a single entity has the same row key in each column family. Такая структура, в которой строки любого объекта в семействе столбцов могут динамически изменяться, определяет важное преимущество этой категории хранилищ. Семейства столбцов очень хорошо подходят для хранения данных с различными схемами.This structure, where the rows for any given object in a column family can vary dynamically, is an important benefit of the column-family approach, making this form of data store highly suited for storing data with varying schemas.
В отличие от хранилища пар «ключ — значение» и баз данных документов, большинство столбчатых баз данных упорядочивают хранимые данные с помощью самих значений ключей, а не хэш-кодов от них.Unlike a key/value store or a document database, most column-family databases physically store data in key order, rather than by computing a hash. Ключ строки рассматривается как первичный индекс и обеспечивает доступ на основе определенного ключа или их диапазона.The row key is considered the primary index and enables key-based access via a specific key or a range of keys. Некоторые реализации позволяют создавать вторичные индексы по определенным столбцам в семействе столбцов.Some implementations allow you to create secondary indexes over specific columns in a column family. Вторичные индексы позволяют получать данные по значениям столбцов, а не ключам строки.Secondary indexes let you retrieve data by columns value, rather than row key.
Ключ строки рассматривается как первичный индекс и обеспечивает доступ на основе определенного ключа или их диапазона.The row key is considered the primary index and enables key-based access via a specific key or a range of keys. Некоторые реализации позволяют создавать вторичные индексы по определенным столбцам в семействе столбцов.Some implementations allow you to create secondary indexes over specific columns in a column family. Вторичные индексы позволяют получать данные по значениям столбцов, а не ключам строки.Secondary indexes let you retrieve data by columns value, rather than row key.
Все столбцы одного семейства хранятся на диске в одном файле. Каждый файл содержит определенное число строк.On disk, all of the columns within a column family are stored together in the same file, with a certain number of rows in each file. При использовании больших наборов данных этот подход позволяет повысить производительность за счет снижения объема данных, которые необходимо считывать с диска, когда отправляется запрос на получение нескольких столбцов за раз. With large data sets, this approach creates a performance benefit by reducing the amount of data that needs to be read from disk when only a few columns are queried together at a time.
With large data sets, this approach creates a performance benefit by reducing the amount of data that needs to be read from disk when only a few columns are queried together at a time.
Операции чтения и записи для строки обычно являются атомарными в пределах одного семейства столбцов, хотя некоторые реализации обеспечивают атомарность по всей строке, охватывающую несколько семейств столбцов.Read and write operations for a row are typically atomic within a single column family, although some implementations provide atomicity across the entire row, spanning multiple column families.
Соответствующие службы Azure:Relevant Azure service:
Хранилище пар «ключ — значение»Key/value data stores
Хранилище пар «ключ — значение» по сути представляет собой большую хэш-таблицу.A key/value store is essentially a large hash table. Каждое значение сопоставляется с уникальным ключом, и хранилище ключей использует этот ключ для хранения данных, применяя к нему некоторую функцию хэширования. You associate each data value with a unique key, and the key/value store uses this key to store the data by using an appropriate hashing function. Выбор функции хэширования должен обеспечить равномерное распределение хэшированных ключей по хранилищу данных.The hashing function is selected to provide an even distribution of hashed keys across the data storage.
You associate each data value with a unique key, and the key/value store uses this key to store the data by using an appropriate hashing function. Выбор функции хэширования должен обеспечить равномерное распределение хэшированных ключей по хранилищу данных.The hashing function is selected to provide an even distribution of hashed keys across the data storage.
Большинство хранилищ пар «ключ — значение» поддерживают только самые простые операции запроса, вставки и удаления.Most key/value stores only support simple query, insert, and delete operations. Чтобы частично или полностью изменить значение, приложение всегда перезаписывает существующее значение целиком.To modify a value (either partially or completely), an application must overwrite the existing data for the entire value. В большинстве реализаций атомарной операцией считается чтение или запись одного значения.In most implementations, reading or writing a single value is an atomic operation. Запись больших значений занимает относительно долгое время. If the value is large, writing may take some time.
If the value is large, writing may take some time.
Приложение может хранить в наборе значений произвольные данные, но некоторые хранилища пар «ключ — значение» накладывают ограничения на максимальный размер значений.An application can store arbitrary data as a set of values, although some key/value stores impose limits on the maximum size of values. Программное обеспечение хранилища ничего не знает о значениях, которые в нем хранятся.The stored values are opaque to the storage system software. Все сведения о схеме поддерживаются и применяются на уровне приложения.Any schema information must be provided and interpreted by the application. Эти значения по существу являются большими двоичными объектами, которые хранилище извлекает и сохраняет по соответствующему ключу.Essentially, values are blobs and the key/value store simply retrieves or stores the value by key.
Хранилища пар «ключ — значение» рассчитаны на приложения, выполняющие простые операции поиска на основе значения ключа или диапазона ключей, но не очень подходят для систем, которым нужно запрашивать данные из нескольких таблиц хранилищ пар «ключ — значение», например присоединенные данные в нескольких таблицах. Key/value stores are highly optimized for applications performing simple lookups using the value of the key, or by a range of keys, but are less suitable for systems that need to query data across different tables of keys/values, such as joining data across multiple tables.
Key/value stores are highly optimized for applications performing simple lookups using the value of the key, or by a range of keys, but are less suitable for systems that need to query data across different tables of keys/values, such as joining data across multiple tables.
Кроме того, хранилища пар «ключ — значение» неудобны в сценариях, где могут выполняться запросы или фильтрация по значению, а не только по ключам.Key/value stores are also not optimized for scenarios where querying or filtering by non-key values is important, rather than performing lookups based only on keys. Например, с помощью реляционной базы данных можно найти запись, используя предложение WHERE для фильтрации неключевых столбцов, но в хранилищах «ключ-значение» обычно отсутствует возможность поиска в значениях, или, если они есть, требуется медленный Просмотр всех значений.For example, with a relational database, you can find a record by using a WHERE clause to filter the non-key columns, but key/values stores usually do not have this type of lookup capability for values, or if they do, it requires a slow scan of all values.
Одно хранилище пар «ключ — значение» очень легко масштабируется, поскольку позволяет удобно распределить данные среди нескольких узлов на разных компьютерах.A single key/value store can be extremely scalable, as the data store can easily distribute data across multiple nodes on separate machines.
Соответствующие службы Azure:Relevant Azure services:
Хранилища данных графовGraph data stores
Хранилища данных графов управляют сведениями двух типов: узлами и ребрами.A graph data store manages two types of information, nodes and edges. Узлы в этом случае представляют сущности, а ребра определяют связи между ними.Nodes represent entities, and edges specify the relationships between these entities. Узлы и грани имеют свойства, которые предоставляют сведения о конкретном узле или грани, примерно как столбцы в реляционной таблице.Both nodes and edges can have properties that provide information about that node or edge, similar to columns in a table. Грани могут иметь направление, указывающее на характер связи. Edges can also have a direction indicating the nature of the relationship.
Edges can also have a direction indicating the nature of the relationship.
Хранилища данных графов позволяют приложениям эффективно выполнять запросы, которые проходят через сеть узлов и ребер, а также анализировать связи между сущностями.The purpose of a graph data store is to allow an application to efficiently perform queries that traverse the network of nodes and edges, and to analyze the relationships between entities. На схеме ниже представлены данные персонала организации, структурированные в виде графа.The following diagram shows an organization’s personnel data structured as a graph. Сущностями здесь являются сотрудники и отделы, а грани определяют отношения подчинения и отдел, в котором работает каждый сотрудник.The entities are employees and departments, and the edges indicate reporting relationships and the department in which employees work. Стрелки на ребрах этого графа показывают направление связей.In this graph, the arrows on the edges show the direction of the relationships.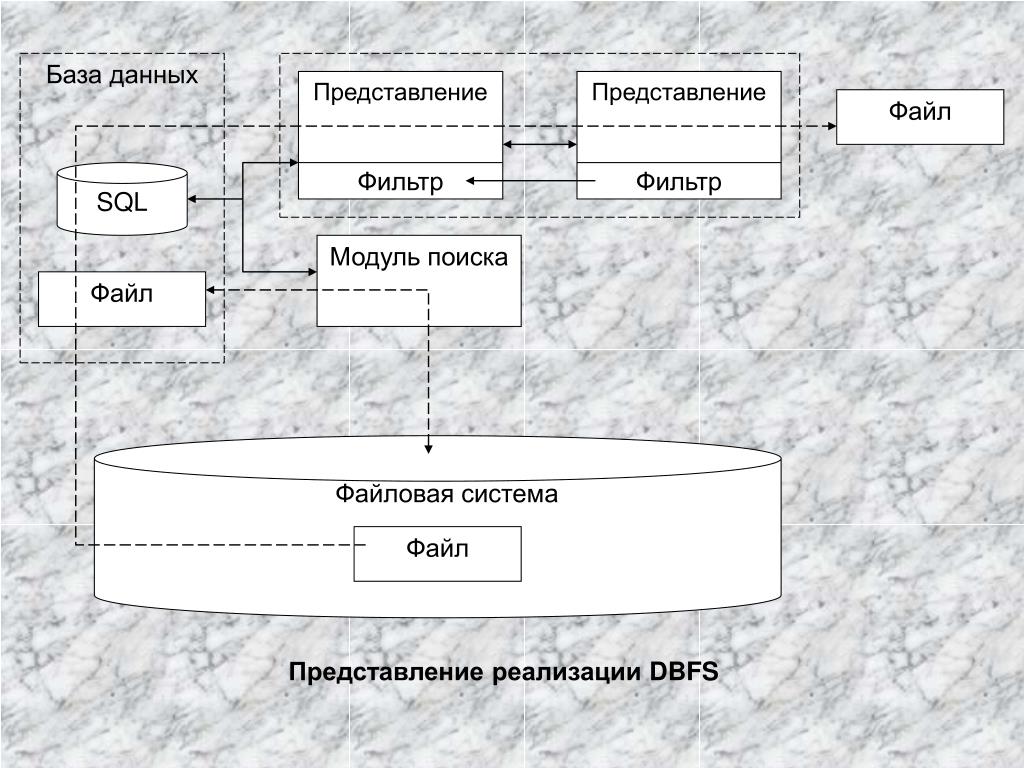
Такая структура позволяет легко выполнять такие запросы, как «найти всех сотрудников, которые прямо или косвенно подчиняются Светлане» или «найти всех, кто работает в одном отделе с Дмитрием».This structure makes it straightforward to perform queries such as «Find all employees who report directly or indirectly to Sarah» or «Who works in the same department as John?» Для больших диаграмм с большим количеством сущностей и связей можно быстро выполнять сложный анализ.For large graphs with lots of entities and relationships, you can perform complex analyses quickly. Многие базы данных графов предоставляют язык запросов, который можно использовать для эффективного обхода сети связей.Many graph databases provide a query language that you can use to traverse a network of relationships efficiently.
Соответствующие службы Azure:Relevant Azure service:
Хранилища данных временных рядовTime series data stores
Данными временных рядов называются наборы значений, которые упорядочены по времени.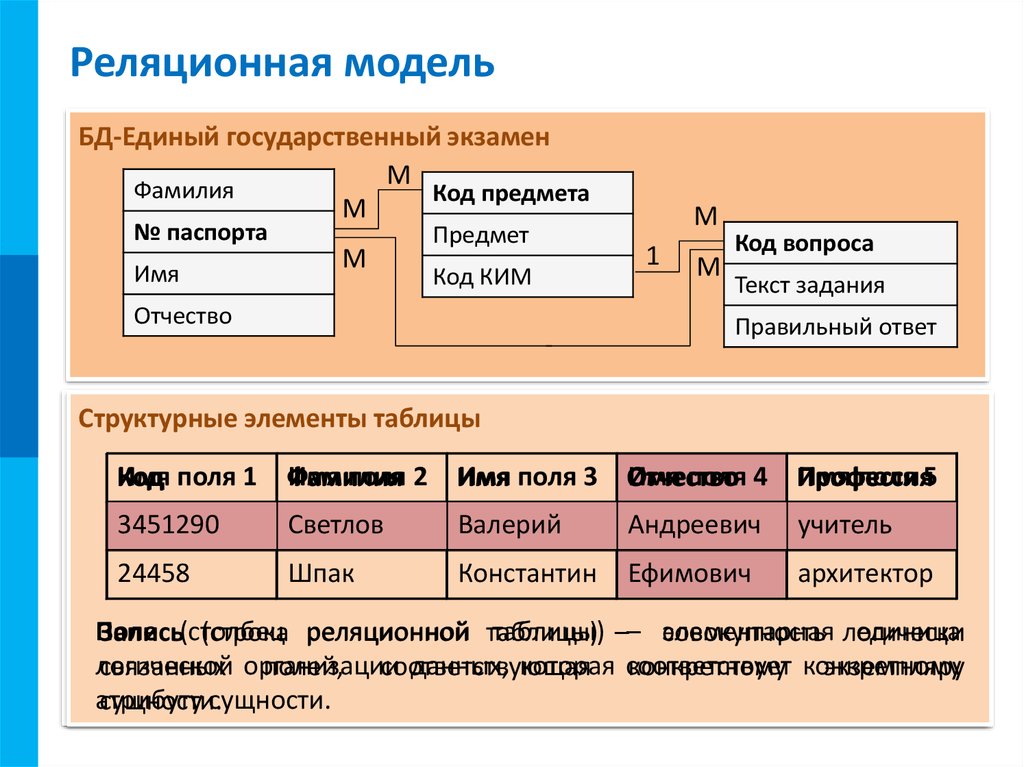 Соответственно хранилища данных временных рядов оптимизированы для хранения данных именно такого типа.Time series data is a set of values organized by time, and a time series data store is optimized for this type of data. Хранилища данных временных рядов должны поддерживать очень большое число операций записи, так как обычно в них в режиме реального времени собирается большой объем данных из большого количества источников.Time series data stores must support a very high number of writes, as they typically collect large amounts of data in real time from a large number of sources. Эти хранилища также хорошо подходят для хранения данных телеметрии.Time series data stores are optimized for storing telemetry data. Например, для сбора данных от датчиков Интернета вещей или счетчиков в приложениях или системах.Scenarios include IoT sensors or application/system counters. Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией.Updates are rare, and deletes are often done as bulk operations.
Соответственно хранилища данных временных рядов оптимизированы для хранения данных именно такого типа.Time series data is a set of values organized by time, and a time series data store is optimized for this type of data. Хранилища данных временных рядов должны поддерживать очень большое число операций записи, так как обычно в них в режиме реального времени собирается большой объем данных из большого количества источников.Time series data stores must support a very high number of writes, as they typically collect large amounts of data in real time from a large number of sources. Эти хранилища также хорошо подходят для хранения данных телеметрии.Time series data stores are optimized for storing telemetry data. Например, для сбора данных от датчиков Интернета вещей или счетчиков в приложениях или системах.Scenarios include IoT sensors or application/system counters. Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией.Updates are rare, and deletes are often done as bulk operations.
Размер отдельных записей в базе данных временных рядов обычно невелик, но их очень много, а значит общий размер данных быстро увеличивается.Although the records written to a time series database are generally small, there are often a large number of records, and total data size can grow rapidly. Хранилища данных временных рядов также обрабатывают данные, полученные вне очереди или несвоевременно, автоматически индексируют точки данных и оптимизируют запросы, полученные в течение определенного промежутка времени.Time series data stores also handle out-of-order and late-arriving data, automatic indexing of data points, and optimizations for queries described in terms of windows of time. Эта последняя возможность позволяет быстро выполнять запросы к миллионам точек данных и нескольким потокам данных, что, в свою очередь, обеспечивает поддержку визуализации временных рядов (стандартный способ потребления данных временных рядов).This last feature enables queries to run across millions of data points and multiple data streams quickly, in order to support time series visualizations, which is a common way that time series data is consumed.
Дополнительные сведения см. в статье Решения для временных рядов.For more information, see Time series solutions
Соответствующие службы Azure:Relevant Azure services:
Хранилище данных объектовObject data stores
Хранилища данных объектов оптимизированы для хранения и извлечения больших двоичных объектов, например изображений, текстовых файлов, видео- и аудиопотоков, объектов данных и документов приложений большого размера, образы дисков виртуальных машин.Object data stores are optimized for storing and retrieving large binary objects or blobs such as images, text files, video and audio streams, large application data objects and documents, and virtual machine disk images. Объект состоит из сохраненных данных, метаданных и уникального идентификатора доступа к объекту.An object consists of the stored data, some metadata, and a unique ID for accessing the object. Хранилища объектов поддерживают отдельные большие файлы, а также позволяют управлять всеми файлами за счет внушительного общего объема хранилища. Object stores are designed to support files that are individually very large, as well provide large amounts of total storage to manage all files.
Object stores are designed to support files that are individually very large, as well provide large amounts of total storage to manage all files.
Некоторые хранилища данных объектов реплицируют определенный большой двоичный объект между несколькими узлами кластера, что обеспечивает быстрое параллельное чтение.Some object data stores replicate a given blob across multiple server nodes, which enables fast parallel reads. Это, в свою очередь, позволяет реализовать масштабируемую архитектуру запроса данных, хранящихся в больших файлах, так как несколько процессов, обычно выполняющихся на разных серверах, могут одновременно запрашивать большие файлы данных.This in turn enables the scale-out querying of data contained in large files, because multiple processes, typically running on different servers, can each query the large data file simultaneously.
Часто хранилища данных объектов используют как сетевые общие папки.One special case of object data stores is the network file share.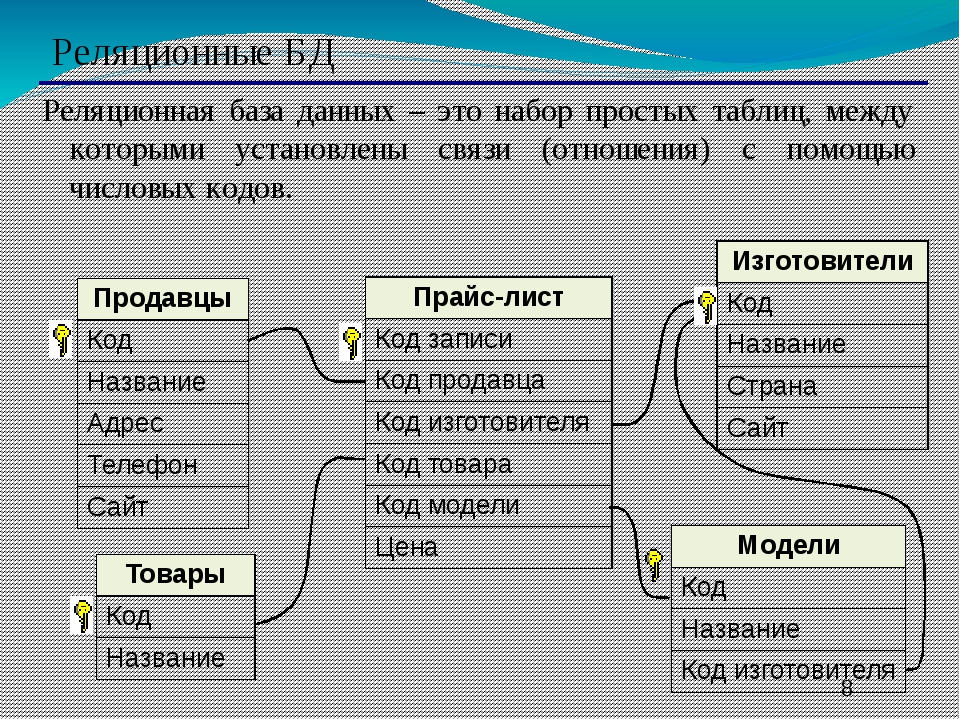 Доступ к файлам, хранящимся в этих папках, можно получить через компьютерную сеть с использованием стандартных сетевых протоколов, например SMB.Using file shares enables files to be accessed across a network using standard networking protocols like server message block (SMB). Учитывая соответствующие механизмы обеспечения безопасности и параллельного управления доступом, совместное использование данных позволяет распределенным службам обеспечить высокую масштабируемость доступа к данным для базовых операций низкого уровня, таких как простые запросы на чтение и запись.Given appropriate security and concurrent access control mechanisms, sharing data in this way can enable distributed services to provide highly scalable data access for basic, low-level operations such as simple read and write requests.
Доступ к файлам, хранящимся в этих папках, можно получить через компьютерную сеть с использованием стандартных сетевых протоколов, например SMB.Using file shares enables files to be accessed across a network using standard networking protocols like server message block (SMB). Учитывая соответствующие механизмы обеспечения безопасности и параллельного управления доступом, совместное использование данных позволяет распределенным службам обеспечить высокую масштабируемость доступа к данным для базовых операций низкого уровня, таких как простые запросы на чтение и запись.Given appropriate security and concurrent access control mechanisms, sharing data in this way can enable distributed services to provide highly scalable data access for basic, low-level operations such as simple read and write requests.
Соответствующие службы Azure:Relevant Azure services:
Хранилища данных внешних индексовExternal index data stores
Хранилища данных внешних индексов позволяют искать информацию, содержащуюся в других хранилищах данных и службах. External index data stores provide the ability to search for information held in other data stores and services. Внешний индекс выступает в роли вторичного индекса любого хранилища данных. Кроме того, с его помощью можно индексировать большие объемы данных и предоставлять доступ к этим индексам почти в реальном времени.An external index acts as a secondary index for any data store, and can be used to index massive volumes of data and provide near real-time access to these indexes.
External index data stores provide the ability to search for information held in other data stores and services. Внешний индекс выступает в роли вторичного индекса любого хранилища данных. Кроме того, с его помощью можно индексировать большие объемы данных и предоставлять доступ к этим индексам почти в реальном времени.An external index acts as a secondary index for any data store, and can be used to index massive volumes of data and provide near real-time access to these indexes.
Например, в файловой системе могут храниться текстовые файлы.For example, you might have text files stored in a file system. По пути файл можно найти быстро, но поиск на основе содержимого выполняется медленно, так как сканируются все файлы.Finding a file by its file path is quick, but searching based on the contents of the file would require a scan of all of the files, which is slow. Внешний индекс позволяет создавать вторичные индексы, а затем быстро искать путь к файлам, соответствующим заданным условиям. An external index lets you create secondary search indexes and then quickly find the path to the files that match your criteria. Рассмотрим еще один пример использования внешнего индекса. Предположим, что хранилища пар «ключ — значение» поддерживают индексирование только по ключу.Another example application of an external index is with key/value stores that only index by the key. Вы можете создать вторичный индекс на основе значений данных и быстро найти ключ, однозначно определяющий каждый соответствующий элемент.You can build a secondary index based on the values in the data, and quickly look up the key that uniquely identifies each matched item.
An external index lets you create secondary search indexes and then quickly find the path to the files that match your criteria. Рассмотрим еще один пример использования внешнего индекса. Предположим, что хранилища пар «ключ — значение» поддерживают индексирование только по ключу.Another example application of an external index is with key/value stores that only index by the key. Вы можете создать вторичный индекс на основе значений данных и быстро найти ключ, однозначно определяющий каждый соответствующий элемент.You can build a secondary index based on the values in the data, and quickly look up the key that uniquely identifies each matched item.
Индексы создаются в процессе индексирования,The indexes are created by running an indexing process. который может выполняться по модели извлечения, то есть по требованию хранилища данных, или по модели передачи, то есть по команде из кода приложения.This can be performed using a pull model, triggered by the data store, or using a push model, initiated by application code.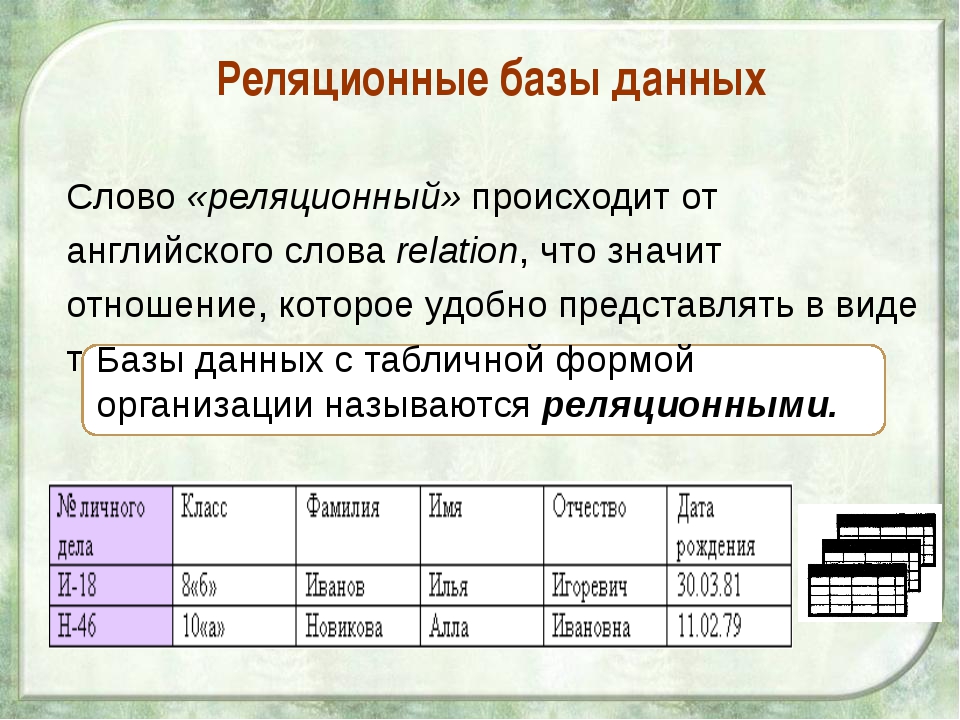 В некоторых системах поддерживаются многомерные индексы и полнотекстовый поиск по большим объемам текстовых данных.Indexes can be multidimensional and may support free-text searches across large volumes of text data.
В некоторых системах поддерживаются многомерные индексы и полнотекстовый поиск по большим объемам текстовых данных.Indexes can be multidimensional and may support free-text searches across large volumes of text data.
Хранилища данных внешнего индекса часто используются для поддержки полнотекстового поиска.External index data stores are often used to support full text and web-based search. В этих случаях поддерживается точный или нечеткий поиск.In these cases, searching can be exact or fuzzy. Нечеткий поиск находит документы, которые соответствуют набору условий, и вычисляет для них коэффициент совпадения с этим набором.A fuzzy search finds documents that match a set of terms and calculates how closely they match. Некоторые внешние индексы также поддерживают лингвистический анализ, который возвращает соответствия с учетом синонимов, категорий (например, при поиске по запросу «собаки» соответствием считается «питомцы») и морфологии (например, при поиске по запросу «бег» соответствием считается «бегущий»).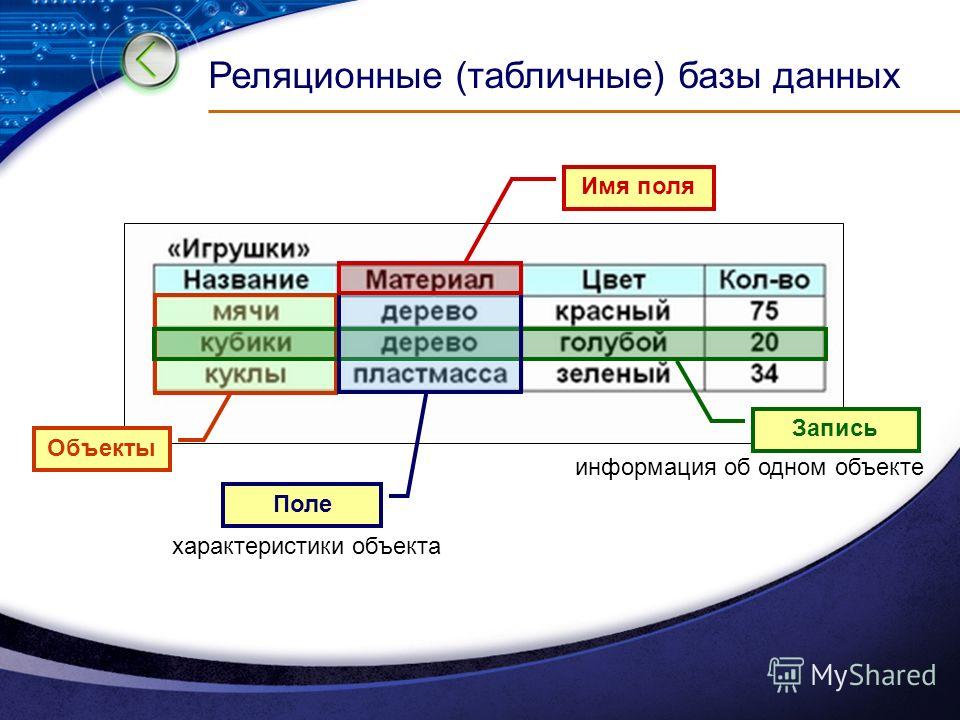 Some external indexes also support linguistic analysis that can return matches based on synonyms, genre expansions (for example, matching «dogs» to «pets»), and stemming (for example, searching for «run» also matches «ran» and «running»).
Some external indexes also support linguistic analysis that can return matches based on synonyms, genre expansions (for example, matching «dogs» to «pets»), and stemming (for example, searching for «run» also matches «ran» and «running»).
Соответствующие службы Azure:Relevant Azure service:
Стандартные требованияTypical requirements
Часто архитектура нереляционных хранилищ данных отличается от архитектуры реляционных баз данных.Non-relational data stores often use a different storage architecture from that used by relational databases. В частности, они обычно не имеют фиксированной схемы.Specifically, they tend toward having no fixed schema. а также не поддерживают транзакции или ограничивают их область. Из соображений масштабируемости они обычно не включают вторичные индексы.Also, they tend not to support transactions, or else restrict the scope of transactions, and they generally don’t include secondary indexes for scalability reasons.
В таблице ниже приведено сравнение требований каждого нереляционного хранилища данных. The following compares the requirements for each of the non-relational data stores:
The following compares the requirements for each of the non-relational data stores:
| ТребованиеRequirement | Хранилище данных документовDocument data | Столбчатое хранилище данныхColumn-family data | Хранилище данных пар «ключ — значение»Key/value data | Хранилище данных графовGraph data |
|---|---|---|---|---|
| НормализацияNormalization | Денормализированные данныеDenormalized | Денормализированные данныеDenormalized | Денормализированные данныеDenormalized | Нормализированные данныеNormalized |
| схемаSchema | Схема при чтенииSchema on read | Семейства столбцов, определенные при записи, схема столбца при чтенииColumn families defined on write, column schema on read | Схема при чтенииSchema on read | Схема при чтенииSchema on read |
| Согласованность (между параллельными транзакциями)Consistency (across concurrent transactions) | Настраиваемый уровень согласованности, гарантии на уровне документаTunable consistency, document-level guarantees | Гарантии на уровне семейства столбцовColumn-family–level guarantees | Гарантии на уровне ключейKey-level guarantees | Гарантии на уровне графаGraph-level guarantees |
| Атомарность (область транзакции)Atomicity (transaction scope) | КоллекцияCollection | ТаблицаTable | ТаблицаTable | ГрафикGraph |
| Стратегия блокировкиLocking Strategy | Оптимистичная (без блокировки)Optimistic (lock free) | Пессимистичная (блокировка строк)Pessimistic (row locks) | Оптимистичная (ETag)Optimistic (ETag) | |
| Шаблон доступаAccess pattern | Прямой доступRandom access | Статистические выражения на основе данных большого форматаAggregates on tall/wide data | Прямой доступRandom access | Прямой доступRandom access |
| ИндексацияIndexing | Первичный и вторичные индексыPrimary and secondary indexes | Первичный и вторичные индексыPrimary and secondary indexes | Только первичный индексPrimary index only | Первичный и вторичные индексыPrimary and secondary indexes |
| Форма представления данныхData shape | ДокументDocument | Таблица с семействами столбцовTabular with column families containing columns | Ключ и значениеKey and value | Граф с ребрами и вершинамиGraph containing edges and vertices |
| разреженные;Sparse | ДаYes | ДаYes | ДаYes | НетNo |
| Масштабность (большое количество столбцов и атрибутов)Wide (lots of columns/attributes) | ДаYes | ДаYes | НетNo | НетNo |
| Размер данныхDatum size | От малого (КБ) до среднего (несколько МБ)Small (KBs) to medium (low MBs) | От среднего (МБ) до большого (несколько ГБ)Medium (MBs) to Large (low GBs) | Небольшой (КБ)Small (KBs) | Небольшой (КБ)Small (KBs) |
| Общий максимальный масштабOverall Maximum Scale | Очень большой (ПБ)Very Large (PBs) | Очень большой (ПБ)Very Large (PBs) | Очень большой (ПБ)Very Large (PBs) | Большой (ТБ)Large (TBs) |
| ТребованиеRequirement | Данные временных рядовTime series data | Хранилище данных объектовObject data | Хранилище данных внешних индексовExternal index data |
|---|---|---|---|
| НормализацияNormalization | Нормализированные данныеNormalized | Денормализированные данныеDenormalized | Денормализированные данныеDenormalized |
| схемаSchema | Схема при чтенииSchema on read | Схема при чтенииSchema on read | Схема при записиSchema on write |
| Согласованность (между параллельными транзакциями)Consistency (across concurrent transactions) | Н/ДN/A | Н/ДN/A | Н/ДN/A |
| Атомарность (область транзакции)Atomicity (transaction scope) | Н/ДN/A | ОбъектObject | Н/ДN/A |
| Стратегия блокировкиLocking Strategy | Н/ДN/A | Пессимистичная (блокировка больших двоичных объектов)Pessimistic (blob locks) | Н/ДN/A |
| Шаблон доступаAccess pattern | Прямой доступ и агрегированиеRandom access and aggregation | Последовательный доступSequential access | Прямой доступRandom access |
| ИндексацияIndexing | Первичный и вторичные индексыPrimary and secondary indexes | Только первичный индексPrimary index only | Н/ДN/A |
| Форма представления данныхData shape | ТаблицаTabular | Большой двоичный объект и метаданныеBlob and metadata | ДокументDocument |
| разреженные;Sparse | нетNo | НедоступноN/A | НетNo |
| Масштабность (большое количество столбцов и атрибутов)Wide (lots of columns/attributes) | НетNo | ДаYes | ДаYes |
| Размер данныхDatum size | Небольшой (КБ)Small (KBs) | От большого (ГБ) до очень большого (ТБ)Large (GBs) to Very Large (TBs) | Небольшой (КБ)Small (KBs) |
| Общий максимальный масштабOverall Maximum Scale | Большой (несколько ТБ)Large (low TBs) | Очень большой (ПБ)Very Large (PBs) | Большой (несколько ТБ)Large (low TBs) |
Тема 3. Общие понятия реляционного подхода к организации бд. Основные концепции и термины
Общие понятия реляционного подхода к организации бд. Основные концепции и термины
10
ЛЕКЦИЯ 3
Примерно до середины 1970-х годов все информационные системы создавались на базе файловых систем и ранних баз данных (в их основе лежали не абстрактные и не реляционные модели данных). В середине 1970-х годов произошло несколько значительных событий, которые привели к качественным изменениям в подходах к разработке БД и созданию на их основе информационных систем. Это произошло не случайно:
с одной стороны, был НАКОПЛЕН ОПЫТ СОЗДАНИЯ ПЕРВЫХ баз данных И ИС (период рождения, характерный для любого нового направления)
с другой стороны, повысился интерес к подобным системам со стороны крупных компаний и государственных структур, которые начали вкладывать в разработки и исследования ЗНАЧИТЕЛЬНЫЕ ИНВЕСТИЦИИ.
 Ранние
БД создавались усилиями отдельных
компаний.
Ранние
БД создавались усилиями отдельных
компаний.
Изменения коснулись трех ключевых элементов:
3. Модель представления данных — появление реляционной модели
4.1. Архитектура – появление трехуровневой модели построения БД
4.2. – 4.4. Состав комплекса БД – появление первых настоящих СУБД. До этого специальные функции ограничивались лишь манипуляцией данными, средствами разработки и библиотеками процедур.
С этого момента начинается, собственно, эпоха современных баз данных.
Ключевым
элементом новых подходов к разработке и созданию
баз данных явилось появление реляционной
модели. Термин
«реляционная модель данных» впервые
появился в 1970 году в статье сотрудника
фирмы IBM
доктора Эдгара Кодда. Реляционная модель
данных сформировалось в результате анализа
опыта создания многочисленных конкретных
баз данных в 1960-1970-х годах.
Одна из основных целей разработчиков: элементы реляционной модели являются абсолютно абстрактными, т.е. ни как не связаны ни с какой конкретной предметной областью, ни с содержимым БД. Это позволило создать мощную УНИВЕРСАЛЬНУЮ реляционную СУБД.
В основе реляционного подхода лежит модель описания данных вида “сущность-связь” (ER-модель). Ее основные элементы (см. рисунок):
множества сущностей,
атрибуты,
связи.
Сущность – это абстрактный объект определенного вида. Набор однородных сущностей образует множество сущностей. Фильмы, актеры, студии.
Каждому множеству сущностей отвечает набор атрибутов, являющихся свойствами отдельных его представителей. Название, год, жанр; ФИО, адрес…
Связи
– это отношения
между двумя или большим числом множеств
сущностей. Снимались,
владеет.
Модель данных – это набор правил и определений, которым подчиняются все объекты, находящиеся внутри базы данных
Реляционная модель данных – это модель данных, включающая три основных компонента (правила): структурный, манипуляционный и целостный.
Структурная составляющая реляционной модели определяет:
Все объекты, хранимые внутри реляционной БД (исходные таблицы, представления, отчеты, формы, запросы, индексы и т.д.) сводятся к совокупности двумерных таблиц особого вида, известных в математике как N-арное нормальное отношение (relation).
Такая таблица представляет собой простое множество. Что это? (атомарность, нет дубликатов)
Манипуляционная составляющая реляционной модели:
Для обработки данных используется стандартный аппарат теории множеств (объединение, пересечение, разность, декартово произведение и т.д.
 ) – реляционная
алгебра и реляционное исчисление.
) – реляционная
алгебра и реляционное исчисление.
Важно! – это позволило унифицировать СУБД, т.е. дало возможность создать механизм манипуляции с данными, независимый от их содержания.
3.1. Элементы структурной составляющей реляционной модели
К элементам структурной составляющей реляционных БД относятся:
Тип данных
Домен
Отношение, атрибут, кортеж, схема отношения и схема БД.
На практике большинство этих понятий легко иллюстрируется (сводится) к обычным житейским понятиям.
Для наглядности покажем смысл этих понятий на примере отношения СОТРУДНИКИ, содержащего информацию о сотрудниках некоторой организации (рис. 03P1 – Иллюстрация основных понятий реляционных БД).
Тип данных
Понятие тип
данных в реляционной модели данных полностью
адекватно понятию типа данных в языках
программирования.
Простые типы данных:
логический, строковый,
численный (целый, вещественный)
дата, время, деньги, интервал (времени) и т.д.
В дальнейшем (1980-е годы) развивается подход к расширению возможностей реляционных систем путем создания абстрактных типов данных.
Структурированные типы данных:
Ссылочные типы данных
Ссылочный тип данных (указатели) предназначен для обеспечения возможности указания на другие данные. Указатели характерны для языков процедурного типа, в которых есть понятие области памяти для хранения данных. Ссылочный тип данных предназначен для обработки сложных изменяющихся структур, например деревьев, графов, рекурсивных структур.
В нашем примере мы имеем дело с данными трех типов: строки символов, целые числа и «деньги». Примеры из СУБД MS Access.
Домен
В реляционной
модели данных с понятием тип данных
тесно связано понятие домена, которое
можно считать уточнением
типа данных. Домен — это семантическое понятие.
Домен — это семантическое понятие.
Домен — это подмножество значений некоторого типа данных имеющих определенный смысл.
Домен характеризуется следующими свойствами:
1) Домен имеет уникальное имя (в пределах базы данных).
2) Домен определен на некотором простом типе данных или на другом домене.
3) Домен может иметь некоторое логическое условие, позволяющее описать подмножество данных, допустимых для данного домена.
4) Домен несет определенную смысловую нагрузку — данные считаются сравнимыми только в том случае, когда они относятся к одному домену.
Если тип данных можно считать множеством всех возможных значений данного типа, то домен определяет подмножество в этом множестве.
Таким образом, домен определяется заданием:
базового типа данных, к которому относятся элементы домена,
произвольного логического выражения, применяемого к элементу типа данных.
 Если вычисление этого логического
выражения дает результат «истина»,
то элемент данных является элементом
домена.
Если вычисление этого логического
выражения дает результат «истина»,
то элемент данных является элементом
домена.
Например, домен «Имена» определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут изображать имя (в частности, такие строки, например, не могут начинаться с мягкого знака).
В нашем примере значения доменов «Номера пропусков» и «Номера групп» относятся к типу целых чисел, но не являются сравнимыми.
Отношение, атрибут, кортеж, схема отношения, схема БД
Фундаментальным понятием реляционной модели данных является понятие отношения (Relation).
Отношение состоит из двух частей — заголовка отношения и тела отношения.
Заголовок отношения — это аналог заголовка обычной таблицы. Заголовок отношения состоит из атрибутов. Количество атрибутов называется степенью отношения (N-арность).
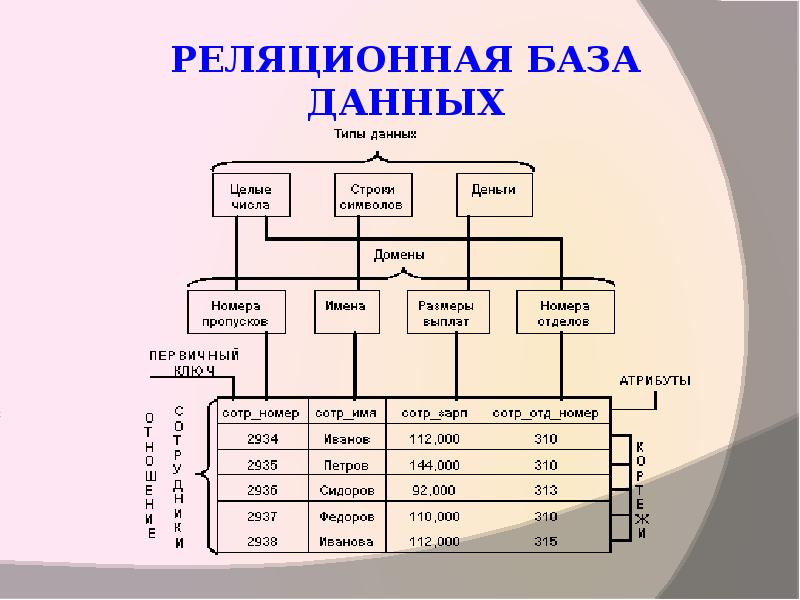
Атрибут – это определение домена для выбранного отношения. Атрибут отношения есть пара вида — <Имя атрибута: Имя домена> или Тип данных (если домен для данного атрибута не определен)>.
Тело отношения — это аналог тела таблицы. Тело отношения состоит из кортежей. Кортеж отношения является аналогом строки таблицы. Количество кортежей отношения называется мощностью отношения.
Кортеж — это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения.
Схема отношения — это именованное множество пар {имя атрибута, имя домена (или типа данных)}.
ЗАМЕЧАНИЕ. Если все атрибуты одного отношения определены на разных доменах, осмысленно использовать для именования атрибутов имена соответствующих доменов (однако, это является всего лишь удобным способом именования и не устраняет различия между понятиями домена и атрибута).

Схема БД (в структурном смысле) — это набор именованных схем отношений.
В нашем примере – «Сотрудники», «Отделы», «Выплаты», «Анкеты» и т.д.
Таким образом, обычным житейским представлением является наличие следующих соотношений понятий:
Как видно, структурные основные понятия реляционной модели данных (если не считать понятия домена) имеют очень простую интуитивную интерпретацию, хотя в теории реляционных БД все они определяются абсолютно формально и точно.
Поэтому иногда говорят «столбец таблицы», имея в виду «атрибут отношения». Когда мы перейдем к рассмотрению практических вопросов организации реляционных баз данных и средств управления, мы будем использовать эту житейскую терминологию. Этой терминологии придерживаются в большинстве коммерческих реляционных СУБД.
Реляционная модель данных — ПИЭ.Wiki
Материал из ПИЭ.Wiki
Реляционная модель данных – логическая модель данных. Впервые была предложена британским учёным сотрудником компании IBM Эдгаром Франком Коддом (E. F. Codd) в 1970 году в статье «A Relational Model of Data for Large Shared Data Banks» (русский перевод статьи, в которой она впервые описана, опубликован в журнале «СУБД» N 1 за 1995 г.). В настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД.
Впервые была предложена британским учёным сотрудником компании IBM Эдгаром Франком Коддом (E. F. Codd) в 1970 году в статье «A Relational Model of Data for Large Shared Data Banks» (русский перевод статьи, в которой она впервые описана, опубликован в журнале «СУБД» N 1 за 1995 г.). В настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД.
В реляционной модели достигается гораздо более высокий уровень абстракции данных, чем в иерархической или сетевой. В упомянутой статье Е.Ф. Кодда утверждается, что «реляционная модель предоставляет средства описания данных на основе только их естественной структуры, т.е. без потребности введения какой-либо дополнительной структуры для целей машинного представления». Другими словами, представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название «реляционная» происходит от английского relation – «отношение»).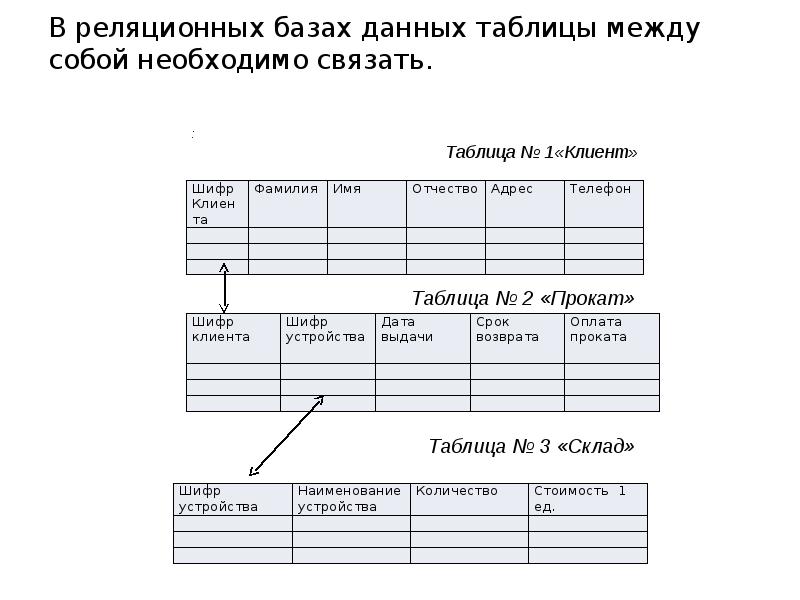
В состав реляционной модели данных обычно включают теорию нормализации.
Состав реляционной модели данных
Кристофер Дейт определил три составные части реляционной модели данных:
- структурная
- манипуляционная
- целостная
Структурная часть модели определяет, что единственной структурой данных является нормализованное n-арное отношение. Отношения удобно представлять в форме таблиц, где каждая строка есть кортеж, а каждый столбец – атрибут, определенный на некотором домене. Данный неформальный подход к понятию отношения дает более привычную для разработчиков и пользователей форму представления, где реляционная база данных представляет собой конечный набор таблиц.
Манипуляционная часть модели определяет два фундаментальных механизма манипулирования данными – реляционная алгебра и реляционное исчисление.
Основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.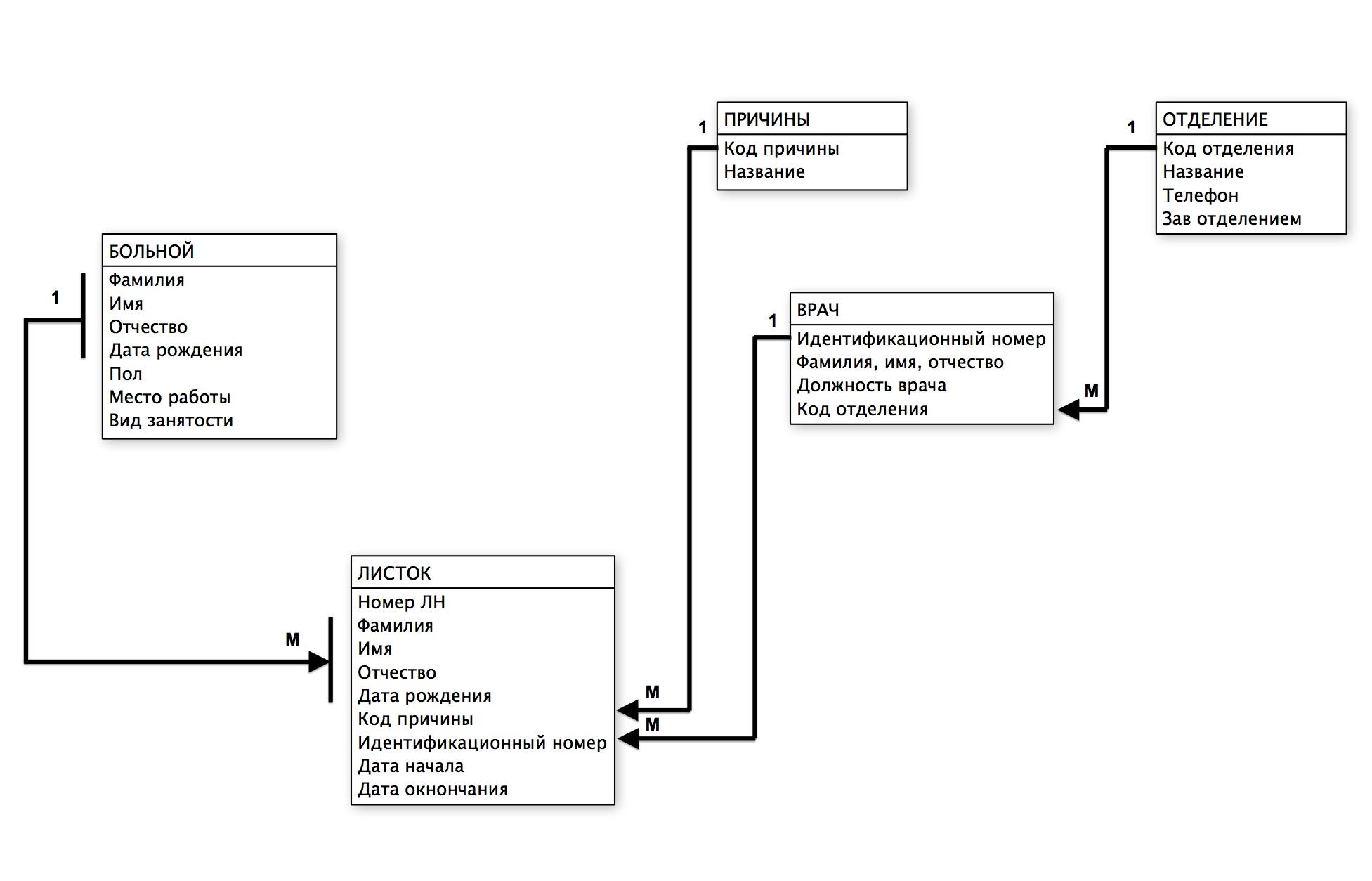
Целостная часть модели определяет требования целостности сущностей и целостности ссылок. Первое требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать).
Структура реляционной модели данных
Можно провести аналогию между элементами реляционной модели данных и элементами модели «сущность-связь». Реляционные отношения соответствуют наборам сущностей, а кортежи – сущностям. Поэтому, также как и в модели «сущность-связь» столбцы в таблице, представляющей реляционное отношение, называют атрибутами.
Основные компоненты реляционного отношения
Каждый атрибут определен на домене, поэтому домен можно рассматривать как множество допустимых значений данного атрибута. Несколько атрибутов одного отношения и даже атрибуты разных отношений могут быть определены на одном и том же домене.
В примере, показанном на рисунке, атрибуты «Оклад» и «Премия» определены на домене «Деньги». Поэтому, понятие домена имеет семантическую нагрузку: данные можно считать сравнимыми только тогда, когда они относятся к одному домену. Таким образом, в рассматриваемом нами примере сравнение атрибутов «Табельный номер» и «Оклад» является семантически некорректным, хотя они и содержат данные одного типа.
Именованное множество пар «имя атрибута – имя домена» называется схемой отношения. Мощность этого множества — называют степенью или «арностью» отношения. Набор именованных схем отношений представляет из себя схему базы данных.
Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом).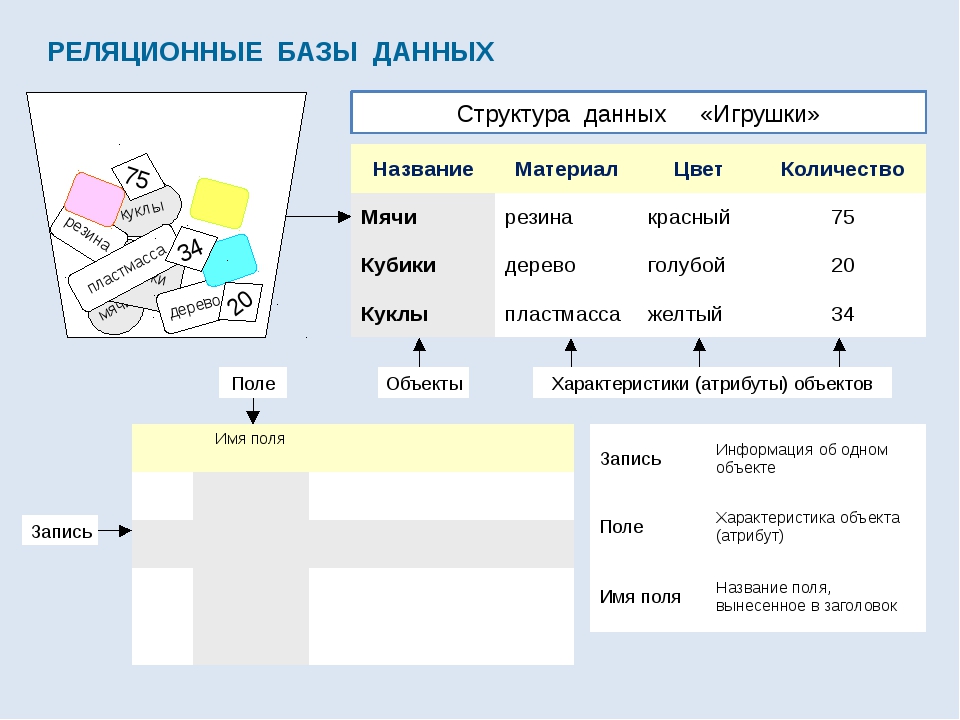 В нашем случае ключом является атрибут «Табельный номер», поскольку его значение уникально для каждого работника предприятия. Если кортежи идентифицируются только сцеплением значений нескольких атрибутов, то говорят, что отношение имеет составной ключ. Отношение может содержать несколько ключей. Всегда один из ключей объявляется первичным, его значения не могут обновляться. Все остальные ключи отношения называются возможными ключами.
В нашем случае ключом является атрибут «Табельный номер», поскольку его значение уникально для каждого работника предприятия. Если кортежи идентифицируются только сцеплением значений нескольких атрибутов, то говорят, что отношение имеет составной ключ. Отношение может содержать несколько ключей. Всегда один из ключей объявляется первичным, его значения не могут обновляться. Все остальные ключи отношения называются возможными ключами.
В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей.
Применение реляционной модели данных
Пример базы данных, содержащей сведения о подразделениях предприятия и работающих в них сотрудниках, применительно к реляционной модели будет иметь вид:
База данных о подразделениях и сотрудниках предприятия
Например, связь между отношениями ОТДЕЛ и СОТРУДНИК создается путем копирования первичного ключа «Номер_отдела» из первого отношения во второе. Таким образом:
Таким образом:
- для того, чтобы получить список работников данного подразделения, необходимо:
- из таблицы ОТДЕЛ установить значение атрибута «Номер_отдела», соответствующее данному «Наименованию_отдела»
- выбрать из таблицы СОТРУДНИК все записи, значение атрибута «Номер_отдела» которых равно полученному на предыдущем шаге
- для того, чтобы узнать в каком отделе работает сотрудник, нужно выполнить обратную операцию:
- определяем «Номер_отдела» из таблицы СОТРУДНИК
- по полученному значению находим запись в таблице ОТДЕЛ
Атрибуты, представляющие собой копии ключей других отношений, называются внешними ключами.
Достоинства и недостатки реляционной модели данных
Достоинства реляционной модели:
- простота и доступность для понимания пользователем. Единственной используемой информационной конструкцией является «таблица»;
- строгие правила проектирования, базирующиеся на математическом аппарате;
- полная независимость данных. Изменения в прикладной программе при изменении реляционной БД минимальны;
- для организации запросов и написания прикладного ПО нет необходимости знать конкретную организацию БД во внешней памяти.
Недостатки реляционной модели:
- далеко не всегда предметная область может быть представлена в виде «таблиц»;
- в результате логического проектирования появляется множество «таблиц». Это приводит к трудности понимания структуры данных;
- БД занимает относительно много внешней памяти;
- относительно низкая скорость доступа к данным.
Ссылки
Введение в СУБД: ЧАСТЬ 3 | Системы управления базами данных
С.Д. Кузнецов
Институт системного программирования РАН, Ассоциация пользователей ОС UNIX (SUUG), Московская секция ACM SIGMOD, [email protected]
Немного теории…
Начиная с этого места, мы приступаем к изучению реляционных баз данных и систем управления реляционными базами данных. Этот подход является наиболее распространенным в настоящее время, хотя наряду с общепризнанными достоинствами обладает и рядом недостатков. К числу наибольших достоинств реляционного подхода можно отнести:
- наличие небольшого набора абстракций, которые позволяют сравнительно просто моделировать большую часть распространенных предметных областей и допускают точные формальные определения, оставаясь интуитивно понятными;
- наличие простого и в то же время мощного математического аппарата, опирающегося главным образом на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных;
- возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти. Реляционные системы далеко не сразу получили широкое распространение. В то время как основные теоретические результаты в этой области были получены еще в 70-х, и тогда же появились первые прототипы реляционных СУБД, долгое время считалось невозможным добиться эффективной реализации таких систем. Однако отмеченные выше преимущества и постепенное накопление методов и алгоритмов организации реляционных баз данных и управления ими привели к тому, что уже в середине 80-х годов реляционные системы практически вытеснили с мирового рынка ранние СУБД. В настоящее время основным предметом критики реляционных СУБД является не их недостаточная эффективность, а присущая этим системам некоторая ограниченность (прямое следствие простоты) при использовании в так называемых нетрадиционных областях применения (наиболее распространенными примерами являются системы автоматизации проектирования), в которых требуются предельно сложные структуры данных. Еще одним часто отмечаемым недостатком реляционных баз данных является невозможность адекватного отражения семантики предметной области. Другими словами, возможности представления знаний о семантической специфике предметной области в реляционных системах очень ограничены. Современные исследования в области постреляционных систем (которые мы не будем затрагивать в этом цикле) главным образом посвящены именно устранению этих недостатков.
Глава 4. Реляционный подход к организации баз данных, или Теория и Интуиция
В этой лекции мы вводим на сравнительно неформальном уровне основные понятия реляционных баз данных, а также определяем существо реляционной модели данных. Основной целью лекции является демонстрация простоты и возможности интуитивной интерпретации этих понятий. В дальнейших лекциях будут приводиться более формальные определения, на которых основывается математическая теория реляционных баз данных.
4.1. Базовые понятия реляционных баз данных
Основными понятиями реляционных баз данных являются:
- тип данных,
- домен,
- атрибут,
- кортеж,
- первичный ключ и
- отношение.
Для начала покажем смысл этих понятий на примере отношения СОТРУДНИКИ,
содержащего некоторую информацию о сотрудниках некоторой организации (Рис. 4.1):
Рисунок 4.1.
Иерархия понятий в базе данных СОТРУДНИКИ
4.1.1 Тип данных
Понятие тип данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как «деньги»), а также специальных «темпоральных» данных (дата, время, временной интервал). Достаточно активно развивается подход к расширению возможностей реляционных систем абстрактными типами данных (соответствующими возможностями обладают, например, системы семейства Ingres/Postgres). В нашем примере мы имеем дело с данными трех типов: строки символов, целые числа и «деньги».
4.1.2 Домен
Понятие домена более специфично для баз данных, хотя и имеет некоторые аналогии с подтипами в некоторых языках программирования. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат «истина», то элемент данных является элементом домена. Наиболее правильной интутивной трактовкой понятия домена является понимание домена как допустимого потенциального множества значений данного типа. Например, домен «Имена» в нашем примере определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут изображать имя (в частности, такие строки не могут начинаться с мягкого знака). Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. В нашем примере значения доменов «Номера пропусков» и «Номера групп» относятся к типу целых чисел, но не являются сравнимыми. Заметим, что в большинстве реляционных СУБД понятие домена не используется, хотя в Oracle V.7 оно уже поддерживается.
4.1.3 Схема отношения, схема базы данных
Схема отношения — это именованное множество пар имя атрибута, имя домена (или типа, если понятие домена не поддерживается). Степень, или «арность» схемы отношения,- мощность этого множества. Степень отношения СОТРУДНИКИ равна четырем, то есть оно является 4-арным. Если все атрибуты одного отношения определены на разных доменах, осмысленно использовать для именования атрибутов имена соответствующих доменов (не забывая, конечно, о том, что это является всего лишь удобным способом именования и не устраняет различия между понятиями домена и атрибута). Схема БД (в структурном смысле) — это набор именованных схем отношений.
4.1.4 Кортеж, отношение
Кортеж, соответствующий данной схеме отношения, — это множество пар имя атрибута, значение, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. «Значение» является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Тем самым, степень, или «арность» кортежа, т.е. число элементов в нем, совпадает с «арностью» соответствующей схемы отношения. Попросту говоря, кортеж — это набор именованных значений заданного типа. Отношение — это множество кортежей, соответствующих одной схеме отношения. Иногда, чтобы не путаться, говорят «отношение-схема» и «отношение-экземпляр», иногда схему отношения называют заголовком отношения, а отношение как набор кортежей — телом отношения. На самом деле, понятие схемы отношения ближе всего к понятию структурного типа данных в языках программирования. Было бы вполне логично разрешать отдельно определять схему отношения, а затем — одно или несколько отношений с данной схемой. Однако в реляционных базах данных это не принято. Имя схемы отношения в таких базах данных всегда совпадает с именем соответствующего отношения-экземпляра. В классических реляционных базах данных после определения схемы базы данных изменяются только отношения-экземпляры. В них могут появляться новые и удаляться или модифицироваться существующие кортежи. Однако во многих реализациях допускается и изменение схемы базы данных: определение новых и изменение существующих схем отношения. Это принято называть эволюцией схемы базы данных. Обычным житейским представлением отношения является таблица, заголовком которой является схема отношения, а строками — кортежи отношения-экземпляра; в этом случае имена атрибутов именуют столбцы этой таблицы. Поэтому иногда говорят «столбец таблицы», имея в виду «атрибут отношения». Когда мы перейдем к рассмотрению практических вопросов организации реляционных баз данных и средств управления, мы будем использовать эту житейскую терминологию. Этой терминологии придерживаются в большинстве коммерческих реляционных СУБД. Реляционная база данных — это набор отношений, имена которых совпадают с именами схем отношений в схеме БД. Как видно, основные структурные понятия реляционной модели данных (если не считать понятия домена) имеют очень простую интуитивную интерпретацию, хотя в теории реляционных БД все они определяются абсолютно формально и точно.
4.2. Фундаментальные свойства отношений
Остановимся теперь на некоторых важных свойствах отношений, которые следуют из приведенных ранее определений.
4.2.1 Отсутствие кортежей-дубликатов
То свойство, что отношения не содержат кортежей-дубликатов, следует из определения отношения как множества кортежей. В классической теории множеств, по определению, каждое множество состоит из различных элементов. Из этого свойства вытекает наличие у каждого отношения так называемого первичного ключа — набора атрибутов, значения которых однозначно определяют кортеж отношения. Для каждого отношения, по крайней мере, полный набор его атрибутов обладает этим свойством. Однако при формальном определении первичного ключа требуется обеспечение его «минимальности», т.е. в набор атрибутов первичного ключа не должны входить такие атрибуты, которые можно отбросить без ущерба для основного свойства,- однозначно определять кортеж. Понятие первичного ключа является исключительно важным в связи с понятием целостности баз данных. Забегая вперед, заметим, что во многих практических реализациях РСУБД допускается нарушение свойства уникальности кортежей для промежуточных отношений, порождаемых неявно при выполнении запросов. Такие отношения являются не множествами, а мультимножествами, что в ряде случаев позволяет добиться определенных преимуществ, но иногда приводит к серьезным проблемам.
4.2.2 Отсутствие упорядоченности кортежей
Свойство отсутствия упорядоченности кортежей отношения также является следствием определения отношения-экземпляра как множества кортежей. Отсутствие требования к поддержанию порядка на множестве кортежей отношения дает дополнительную гибкость СУБД при хранении баз данных во внешней памяти и при выполнении запросов к базе данных. Это не противоречит тому, что при формулировании запроса к БД, например, на языке SQL можно потребовать сортировки результирующей таблицы в соответствии со значениями некоторых столбцов. Такой результат, это вообще говоря, не отношение, а некоторый упорядоченный список кортежей.
4.2.3 Отсутствие упорядоченности атрибутов
Атрибуты отношений не упорядочены, поскольку по определению схема отношения есть множество пар имя атрибута, имя домена. Для ссылки на значение атрибута в кортеже отношения всегда используется имя атрибута. Это свойство теоретически позволяет, например, модифицировать схемы существующих отношений не только путем добавления новых атрибутов, но и путем удаления существующих атрибутов. Однако в большинстве существующих систем такая возможность не допускается, и хотя упорядоченность набора атрибутов отношения явно не требуется, часто в качестве неявного порядка атрибутов используется их порядок в линейной форме определения схемы отношения.
4.2.4 Атомарность значений атрибутов
Значения всех атрибутов являются атомарными. Это следует из определения домена как потенциального множества значений простого типа данных, т.е. среди значений домена не могут содержаться множества значений (отношения). Принято говорить, что в реляционных базах данных допускаются только нормализованные отношения или отношения, представленные в первой нормальной форме. Потенциальный пример ненормализованного отношения показан на Рис. 4.2.1.
Рисунок 4.2.1.
Отношение ОТДЕЛЫ в ненормализованной форме
Рисунок 4.2.2.
Нормализованное отношение СОТРУДНИКИ
Можно сказать, что здесь мы имеем бинарное отношение, значениями атрибута ОТДЕЛЫ которого являются отношения. Заметим, что исходное отношение СОТРУДНИКИ является нормализованным вариантом отношения ОТДЕЛЫ (см. Рис. 4.2.2). Нормализованные отношения составляют основу классического реляционного подхода к организации баз данных. Они обладают некоторыми ограничениями (не любую информацию удобно представлять в виде плоских таблиц), но существенно упрощают манипулирование данными. Рассмотрим, например, два идентичных оператора занесения кортежа:
Зачислить сотрудника Кузнецова (пропуск номер 3000, зарплата 115,000) в отдел номер 320 и Зачислить сотрудника Кузнецова (пропуск номер 3000, зарплата 115,000) в отдел номер 310. Если информация о сотрудниках представлена в виде отношения СОТРУДНИКИ, оба оператора будут выполняться одинаково (вставить кортеж в отношение СОТРУДНИКИ). Если же работать с ненормализованным отношением ОТДЕЛЫ, то первый оператор выразится в занесение кортежа, а второй — в добавление информации о Кузнецове в множественное значение атрибута ОТДЕЛ кортежа с первичным ключом 310.
4.3. Реляционная модель данных
Когда в предыдущих разделах мы говорили об основных понятиях реляционных баз данных, мы не опирались на какую-либо конкретную реализацию. Эти рассуждения в равной степени относились к любой системе, при построении которой использовался реляционный подход. Другими словами, мы использовали понятия так называемой реляционной модели данных. Модель данных описывает некоторый набор родовых понятий и признаков, которыми должны обладать все конкретные СУБД и управляемые ими базы данных, если они основываются на этой модели. Наличие модели данных позволяет сравнивать конкретные реализации, используя один общий язык. Хотя понятие модели данных является общим, и можно говорить о иерархической, сетевой, некоторой семантической и т.д. моделях данных, нужно отметить, что это понятие было введено в обиход применительно к реляционным системам и наиболее эффективно используется именно в этом контексте. Попытки прямолинейного применения аналогичных моделей к дореляционным организациям показывают, что реляционная модель слишком «велика» для них, а для постреляционных организаций она оказывается «мала».
4.3.1 Общая характеристика
Наиболее распространенная трактовка реляционной модели данных, по-видимому, принадлежит Дейту, который воспроизводит ее (с различными уточнениями) практически во всех своих книгах. Согласно Дейту, реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части. В структурной части модели фиксируется, что единственной структурой данных, используемой в реляционных БД, является нормализованное n-арное отношение. По сути дела, в предыдущих двух разделах этой лекции мы рассматривали именно понятия и свойства структурной составляющей реляционной модели. В манипуляционной части модели утверждаются два фундаментальных механизма манипулирования реляционными БД — реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств (с некоторыми уточнениями), а второй — на классическом логическом аппарате исчисления предикатов первого порядка. Далее мы рассмотрим эти механизмы более подробно, а пока лишь заметим, что основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
4.3.2 Целостность сущности и ссылок
Наконец, в целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД. Первое требование называется требованием целостности сущностей. Объекту или сущности реального мира в реляционных БД соответствуют кортежи отношений. Конкретно требование состоит в том, что любой кортеж любого отношения должен быть отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Как мы видели в предыдущем разделе, это требование автоматически удовлетворяется, если в системе не нарушаются базовые свойства отношений. Второе требование называется требованием целостности по ссылкам и является несколько более сложным. Очевидно, что при соблюдении нормализованности отношений сложные сущности реального мира представляются в реляционной БД в виде нескольких кортежей нескольких отношений. Например, представим, что нам требуется представить в реляционной базе данных сущность ОТДЕЛ с атрибутами ОТД_НОМЕР (номер отдела), ОТД_КОЛ (количество сотрудников) и ОТД_СОТР (набор сотрудников отдела). Для каждого сотрудника нужно хранить СОТР_НОМЕР (номер сотрудника), СОТР_ИМЯ (имя сотрудника) и СОТР_ЗАРП (заработная плата сотрудника). Как мы вскоре увидим, при правильном проектировании соответствующей БД в ней появятся два отношения: ОТДЕЛЫ (ОТД_НОМЕР, ОТД_КОЛ) (первичный ключ — ОТД_НОМЕР) и СОТРУДНИКИ (СОТР_НОМЕР, СОТР_ИМЯ, СОТР_ЗАРП, СОТР_ОТД_НОМ) (первичный ключ — СОТР_НОМЕР). Как видно, атрибут СОТР_ОТД_НОМ появляется в отношении СОТРУДНИКИ не потому, что номер отдела является собственным свойством сотрудника, а лишь для того, чтобы иметь возможность восстановить при необходимости полную сущность ОТДЕЛ. Значение атрибута СОТР_ОТД_НОМ в любом кортеже отношения СОТРУДНИКИ должно соответствовать значению атрибута ОТД_НОМ в некотором кортеже отношения ОТДЕЛЫ. Атрибут такого рода называется внешним ключом, поскольку его значения однозначно характеризуют сущности, представленные кортежами некоторого другого отношения (т.е. задают значения их первичного ключа). Говорят, что отношение, в котором определен внешний ключ, ссылается на соответствующее отношение, в котором такой же атрибут является первичным ключом. Требование целостности по ссылкам, или требование внешнего ключа, состоит в том, что для каждого значения внешнего ключа, появляющего в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть полностью неопределенным (т.е. ни на что не указывать). Для нашего примера это означает, что если для сотрудника указан номер отдела, то этот отдел должен существовать. Ограничения целостности сущности и по ссылкам должны поддерживаться СУБД. Для соблюдения целостности сущности достаточно гарантировать отсутствие в любом отношении кортежей с одним и тем же значением первичного ключа. С целостностью по ссылкам дела обстоят несколько более сложно. Понятно, что при обновлении ссылающегося отношения (вставке новых кортежей или модификации значения внешнего ключа в существующих кортежах) достаточно следить за тем, чтобы не появлялись некорректные значения внешнего ключа. Но как быть при удалении кортежа из отношения, на которое ведет ссылка? Здесь существуют три подхода, каждый из которых поддерживает целостность по ссылкам. Первый подход заключается в том, что запрещается производить удаление кортежа, на который существуют ссылки (т.е. сначала нужно либо удалить ссылающиеся кортежи, либо соответствующим образом изменить значения их внешнего ключа). При втором подходе при удалении кортежа, на который имеются ссылки, во вс
Нормализация баз данных – что это такое и зачем нормализовать базу данных? | Info-Comp.ru
Приветствую всех посетителей сайта Info-Comp.ru! Сегодня мы с Вами поговорим о нормализации базы данных, узнаем, что это такое, какие нормальные формы базы данных существуют и зачем вообще проводить нормализацию базы данных.
Постоянные посетители данного сайта знают, что я здесь публикую достаточно много различных материалов, связанных с языком SQL и системами управления базами данных, однако статей, связанных с теорией баз данных, на текущий момент, к сожалению, нет, поэтому я решил это исправить, и начать цикл статей, посвященных теории баз данных.
Начну я с нормализации баз данных. В этом материале мы поговорим в целом о процессе нормализации, узнаем, зачем проводить нормализацию базы данных, что такое нормальная форма базы данных, а также какие нормальные формы существуют. В следующих материалах я подробно и с примерами расскажу про каждую нормальную форму.
Реляционная база данных
В целом под базой данных можно понимать любой набор информации, которую можно найти в этой базе данных и воспользоваться ей, однако если говорить в контексте SQL, то речь будет идти, конечно, о реляционных базах данных, а что же это такое?
Реляционная база данных – это упорядоченная информация, связанная между собой определёнными отношениями.
Логически такая база данных представлена в виде таблиц, в которых и лежит вся эта информация.
Примечание! Если Вас интересует язык SQL, рекомендую пройти мой онлайн-курс по основам SQL, который ориентирован на изучение SQL как стандарта, таким образом, Вы сможете работать в любой системе управления базами данных. Курс включает много практики: онлайн-тестирование, задания и многое другое.
Нормализация баз данных
В реляционных базах данных есть такое понятия, как «Нормализация».
Нормализация – это процесс удаления избыточных данных.
Также нормализацию можно рассматривать и с позиции проектирования базы данных, в таком случае мы можем сформулировать определение нормализации следующим образом.
Нормализация – это метод проектирования базы данных, который позволяет привести базу данных к минимальной избыточности.
Избыточность устраняется, как правило, за счёт декомпозиции отношений (таблиц), т.е. разбиения одной таблицы на несколько.
Зачем нормализовать базу данных?
У Вас может возникнуть вопрос – а зачем вообще нормализовать базу данных и бороться с этой избыточностью?
Дело в том, что избыточность данных создает предпосылки для появления различных аномалий, снижает производительность, и делает управление данными не гибким и не очень удобным. Отсюда можно сделать вывод, что нормализация нужна для:
- Устранения аномалий
- Повышения производительности
- Повышения удобства управления данными
Теперь давайте поговорим о самой избыточности данных, что же это такое.
Избыточность данных – это когда одни и те же данные хранятся в базе в нескольких местах, именно это и приводит к аномалиям.
Так как в этом случае необходимо добавлять, изменять или удалять одни и те же данные в нескольких местах. Например, если не выполнить операцию в каком-нибудь одном месте, то возникает ситуация, когда одни данные не соответствуют вроде как точно таким же данным в другом месте.
Давайте рассмотрим пример. Допустим, у нас есть следующая таблица, она хранит информацию о предметах мебели, в частности наименование предмета и материал, из которого изготовлен этот предмет.
| Идентификатор предмета | Наименование предмета | Материал |
| 1 | Стул | Металл |
| 2 | Стол | Массив дерева |
| 3 | Кровать | ЛДСП |
| 4 | Шкаф | Массив дерева |
| 5 | Комод | ЛДСП |
А теперь допустим, что у нас возникла необходимость подкорректировать название материала, вместо «Массив дерева» нужно написать «Натуральное дерево», и чтобы это сделать нам необходимо внести изменения сразу в несколько строк, так как предметов, изготовленных из массива дерева, несколько, а именно 2: стол и шкаф.
А теперь представьте, что по каким-то причинам мы внесли изменения только в одну строку, в итоге в нашей таблице будет и «Массив дерева», и «Натуральное дерево».
| Идентификатор предмета | Наименование предмета | Материал |
| 1 | Стул | Металл |
| 2 | Стол | Натуральное дерево |
| 3 | Кровать | ЛДСП |
| 4 | Шкаф | Массив дерева |
| 5 | Комод | ЛДСП |
Какое из этих названий будет правильным? А если представить, что мы можем внести еще какое-то новое значение при добавлении новых записей, например, просто «Дерево».
В этом случае в нашей таблице в скором времени будет и «Массив дерева», и «Натуральное дерево», и просто «Дерево», и вообще, что угодно, ведь это просто текст.
| Идентификатор предмета | Наименование предмета | Материал |
| 1 | Стул | Металл |
| 2 | Стол | Натуральное дерево |
| 3 | Кровать | ЛДСП |
| 4 | Шкаф | Массив дерева |
| 5 | Комод | ЛДСП |
| 6 | Тумба | Дерево |
Однако по своей сути это один и тот же материал, мы просто решили или подкорректировать его название, или ошиблись при добавлении новой записи. Это и есть аномалия, когда одни данные в одном месте не соответствуют вроде как точно таким же данным в другом месте. Это всего лишь один вид аномалии, однако в процессе добавления, изменения и удаления данных может возникать много других противоречивых ситуаций, т.е. аномалий.
При этом, обязательно стоит отметить, что в нашей таблице всего 5 записей, а теперь представьте, что их миллион!
Заметка! Как создать таблицу в PostgreSQL с помощью pgAdmin 4.
Именно поэтому мы должны устранять избыточность данных в базе, т.е. проводить так называемую нормализацию базы данных.
В данном конкретном случае мы должны название материала, из которого изготовлены предметы мебели, вынести в отдельную таблицу, а в таблице с предметами сделать всего лишь ссылку на нужный материал, тем самым, соотнеся эту ссылку с исходной записью, мы будем понимать, из какого материала сделан тот или иной предмет.
Предметы мебели.
| Идентификатор предмета | Наименование предмета | Идентификатор материала |
| 1 | Стул | 2 |
| 2 | Стол | 1 |
| 3 | Кровать | 3 |
| 4 | Шкаф | 1 |
| 5 | Комод | 3 |
Материалы, из которых изготовлены предметы мебели.
| Идентификатор материала | Материал |
| 1 | Массив дерева |
| 2 | Металл |
| 3 | ЛДСП |
В этом случае когда нам потребуется изменить название материала, мы будем вносить изменение только в одном месте, т.е. править только одну строку.
Таким образом, представляя материалы в виде отдельной сущности и создавая для нее отдельную таблицу, мы устраняем описанную выше аномалию.
Другими словами, каждая сущность должна храниться отдельно, а в случае необходимости использования этой сущности в другой таблице на нее делается всего лишь ссылка, т.е. выстраивается связь.
Нормальные формы базы данных
В целом процесс нормализации базы данных выглядит следующим образом: мы, следуя определённым правилам и соблюдая определенные требования, проектируем таблицы в базе данных.
При этом все эти правила и требования можно сгруппировать в несколько наборов, и если спроектировать базу данных с соблюдением всех правил и требований, которые включаются в тот или иной набор, то база данных будет находиться в определённом состоянии, т.е. форме, и такая форма называется нормальная форма базы данных.
Иными словами, следуя определённым правилам и соблюдая определенные требования мы приводим базу данных к определенной нормальной форме.
Нормальная форма базы данных – это набор правил и критериев, которым должна отвечать база данных.
Каждая следующая нормальная форма содержит более строгие правила и критерии, тем самым приводя базу данных к определённой нормальной форме мы устраняем определённый набор аномалий.
Отсюда можно сделать вывод, что чем выше нормальная форма, тем меньше аномалий в базе будет.
Процесс нормализации – это последовательный процесс приведения базы данных к эталонному виду, т.е. переход от одной нормальной формы к следующей.
Иными словами, процесс перехода от одной нормальной формы к следующей – это усовершенствование базы данных. Так как если база данных находится в какой-то определённой нормальной форме – это означает, что в базе данных отсутствует определенный вид аномалий.
Существует 5 основных нормальных форм базы данных:
- Первая нормальная форма (1NF)
- Вторая нормальная форма (2NF)
- Третья нормальная форма (3NF)
- Четвертая нормальная форма (4NF)
- Пятая нормальная форма (5NF)
Однако выделяют еще дополнительные нормальные формы:
- Ненормализованная форма или нулевая нормальная форма (UNF)
- Нормальная форма Бойса-Кодда (BCNF)
- Доменно-ключевая нормальная форма (DKNF)
- Шестая нормальная форма (6NF)
Заметка! Установка и настройка PostgreSQL на Windows 10.
Если объединить оба этих списка и упорядочить нормальные формы от менее нормализованной до самой нормализованной, т.е. начиная с формы, при которой база данных по своей сути не является нормализованной, и заканчивая самой строгой нормальной формой, то мы получим следующий перечень:
- Ненормализованная форма или нулевая нормальная форма (UNF)
- Первая нормальная форма (1NF)
- Вторая нормальная форма (2NF)
- Третья нормальная форма (3NF)
- Нормальная форма Бойса-Кодда (BCNF)
- Четвертая нормальная форма (4NF)
- Пятая нормальная форма (5NF)
- Доменно-ключевая нормальная форма (DKNF)
- Шестая нормальная форма (6NF)
База данных считается нормализованной, если она находится как минимум в третьей нормальной форме (3NF).
В реальном мире нормализация до третьей нормальной формы (3NF) является обычной, стандартной практикой, так как 3NF устраняет достаточное количество аномалий, при этом производительность базы данных, а также удобство ее использования не снижается, что нельзя сказать о всех последующих формах.
Ситуации, при которых требуется нормализовать базу данных до четвертой нормальной формы (4NF), в реальном мире встречаются достаточно редко.
Заметка! Если Вас интересует язык SQL, рекомендую почитать мою книгу «SQL код», которая ориентирована на изучение SQL как стандарта, после прочтения книги Вы сможете писать SQL запросы в любой системе управления базами данных.
Если говорить о всех последующих нормальных формах (5NF, DKNF, 6NF), то в реальной жизни трудно даже представить ситуации, при которых потребуется нормализовать базу данных до этих форм.
Иными словами, 5NF, DKNF, 6NF – это в большей степени теоретические нормальные формы, немного отстраненные от реального мира.
Стоит отметить, что приведение базы данных к какой-то конкретной нормальной форме, обязательно требует, чтобы эта база данных уже находилась в предыдущей нормальной форме. Другими словами, если Вы хотите нормализовать базу данных до третьей нормальной формы, то база уже должна находиться во второй нормальной форме, т.е. нельзя нормализовать базу данных до третьей формы, если она еще не нормализована до второй.
Описание нормальных форм базы данных
В следующих статьях представлено подробное описание каждой нормальной формы и приведены примеры.
- Ненормализованная форма или нулевая нормальная форма (UNF)
- Первая нормальная форма (1NF)
- Вторая нормальная форма (2NF)
- Третья нормальная форма (3NF)
- Нормальная форма Бойса-Кодда (BCNF)
- Четвертая нормальная форма (4NF)
- Пятая нормальная форма (5NF)
- Доменно-ключевая нормальная форма (DKNF)
- Шестая нормальная форма (6NF)
Опрос. Какой операционной системой Вы пользуетесь?
На сегодня это все, надеюсь, материал был Вам полезен и интересен, пока!
Нравится32Не нравитсяЧто такое реляционная база данных
Реляционная база данных — это тип базы данных, в которой хранятся точки данных, которые связаны друг с другом, и предоставляется доступ к ним. Реляционные базы данных основаны на реляционной модели, интуитивно понятном и простом способе представления данных в таблицах. В реляционной базе данных каждая строка в таблице представляет собой запись с уникальным идентификатором, который называется ключом . Столбцы таблицы содержат атрибуты данных, и каждая запись обычно имеет значение для каждого атрибута, что упрощает установление отношений между точками данных.
Как устроены реляционные базы данных
Реляционная модель означает, что логические структуры данных — таблицы данных, представления и индексы — отделены от физических структур хранения. Это разделение означает, что администраторы баз данных могут управлять физическим хранилищем данных, не влияя на доступ к этим данным как к логической структуре. Например, переименование файла базы данных не приводит к переименованию хранящихся в нем таблиц.
Различие между логическими и физическими также применимо к операциям с базой данных, которые представляют собой четко определенные действия, позволяющие приложениям манипулировать данными и структурами базы данных.Логические операции позволяют приложению указывать необходимый контент, а физические операции определяют, как к этим данным следует обращаться, а затем выполняют задачу.
Чтобы обеспечить точность и доступность данных, реляционные базы данных следуют определенным правилам целостности. Например, правило целостности может указывать, что в таблице не допускаются повторяющиеся строки, чтобы исключить возможность попадания в базу данных ошибочной информации.
Реляционная модель
В первые годы существования баз данных каждое приложение хранило данные в своей уникальной структуре.Когда разработчики хотели создавать приложения для использования этих данных, им нужно было много знать о конкретной структуре данных, чтобы найти нужные данные. Эти структуры данных были неэффективными, их трудно было поддерживать и сложно оптимизировать для обеспечения хорошей производительности приложений. Модель реляционной базы данных была разработана для решения проблемы множественных произвольных структур данных.
Реляционная модель предоставляет стандартный способ представления и запроса данных, который может использоваться любым приложением.С самого начала разработчики осознавали, что главная сила модели реляционной базы данных заключается в использовании таблиц, которые представляют собой интуитивно понятный, эффективный и гибкий способ хранения структурированной информации и доступа к ней.
Со временем появилась еще одна сильная сторона реляционной модели, поскольку разработчики начали использовать язык структурированных запросов (SQL) для записи и запроса данных в базе данных. В течение многих лет SQL широко использовался как язык для запросов к базам данных. Основанный на реляционной алгебре, SQL предоставляет внутренне непротиворечивый математический язык, который упрощает повышение производительности всех запросов к базе данных.Для сравнения, другие подходы должны определять индивидуальные запросы.
Преимущества реляционных баз данных
Простая, но мощная реляционная модель используется организациями всех типов и размеров для удовлетворения самых разнообразных информационных потребностей. Реляционные базы данных используются для отслеживания запасов, обработки транзакций электронной торговли, управления огромными объемами критически важной информации о клиентах и многого другого. Реляционная база данных может быть рассмотрена для любых информационных потребностей, в которых точки данных связаны друг с другом и должны управляться безопасным, согласованным и основанным на правилах способом.
Реляционные базы данных существуют с 1970-х годов. Сегодня преимущества реляционной модели по-прежнему делают ее наиболее широко принятой моделью для баз данных.
Согласованность данных
Реляционная модель лучше всего поддерживает согласованность данных между приложениями и копиями баз данных (так называемые экземпляры ). Например, когда клиент кладет деньги в банкомат, а затем просматривает баланс счета на мобильном телефоне, клиент ожидает, что этот депозит немедленно отразится в обновленном балансе счета.Реляционные базы данных отличаются такой согласованностью данных, гарантируя, что несколько экземпляров базы данных всегда будут иметь одни и те же данные.
Для других типов баз данных сложно поддерживать такой уровень своевременной согласованности с большими объемами данных. Некоторые современные базы данных, такие как NoSQL, могут обеспечить только «конечную согласованность». Согласно этому принципу, когда база данных масштабируется или когда несколько пользователей получают доступ к одним и тем же данным одновременно, данным требуется некоторое время, чтобы «наверстать упущенное».«Конечная согласованность приемлема для некоторых целей, например, для ведения списков в каталоге продуктов, но для критически важных бизнес-операций, таких как транзакции корзины покупок, реляционная база данных по-прежнему остается золотым стандартом.
Обязательства и атомарность
Реляционные базы данных обрабатывают бизнес-правила и политики на очень детальном уровне, со строгими политиками около обязательства (то есть постоянное изменение базы данных). Например, рассмотрим базу данных инвентаризации, в которой отслеживаются три части, которые всегда используются вместе.Когда одна часть вытаскивается из инвентаря, две другие также нужно вытащить. Если одна из трех частей недоступна, не следует извлекать ни одну из частей — все три части должны быть доступны до того, как база данных сделает какие-либо обязательства. Реляционная база данных не выполняет фиксацию для одной части, пока не знает, что может выполнить фиксацию для всех трех. Эта возможность многогранного обязательства называется атомарностью . Атомарность — ключ к сохранению точности данных в базе данных и обеспечению их соответствия правилам, положениям и политикам бизнеса.
Хранимые процедуры и реляционные базы данных
Доступ к данным включает в себя множество повторяющихся действий. Например, простой запрос для получения информации из таблицы данных может потребоваться повторить сотни или тысячи раз для получения желаемого результата. Эти функции доступа к данным требуют определенного кода для доступа к базе данных. Разработчики приложений не хотят писать новый код для этих функций в каждом новом приложении. К счастью, реляционные базы данных позволяют хранить хранимые процедуры, которые представляют собой блоки кода, к которым можно получить доступ с помощью простого вызова приложения.Например, одна хранимая процедура может обеспечить согласованную маркировку записей для пользователей нескольких приложений. Хранимые процедуры также могут помочь разработчикам гарантировать, что определенные функции данных в приложении реализованы определенным образом.
Блокировка базы данных и параллелизм
Конфликты могут возникать в базе данных, когда несколько пользователей или приложений пытаются одновременно изменить одни и те же данные. Методы блокировки и параллелизма снижают вероятность конфликтов при сохранении целостности данных.
Блокировка предотвращает доступ других пользователей и приложений к данным во время их обновления. В некоторых базах данных блокировка применяется ко всей таблице, что отрицательно сказывается на производительности приложения. Другие базы данных, такие как реляционные базы данных Oracle, применяют блокировки на уровне записей, оставляя другие записи в таблице доступными, что помогает обеспечить лучшую производительность приложений.
Параллелизм управляет активностью, когда несколько пользователей или приложений одновременно вызывают запросы к одной и той же базе данных.Эта возможность обеспечивает правильный доступ для пользователей и приложений в соответствии с политиками, определенными для управления данными.
На что обращать внимание при выборе реляционной базы данных
Программное обеспечение, используемое для хранения, управления, запроса и извлечения данных, хранящихся в реляционной базе данных, называется системой управления реляционной базой данных (RDBMSf) . РСУБД обеспечивает интерфейс между пользователями, приложениями и базой данных, а также административные функции для управления хранением данных, доступом и производительностью.
При выборе между типами баз данных и продуктами реляционных баз данных ваше решение может зависеть от нескольких факторов. Выбранная вами СУБД будет зависеть от потребностей вашего бизнеса. Задайте себе следующие вопросы:
- Каковы наши требования к точности данных? Будет ли хранение и точность данных зависеть от бизнес-логики? Есть ли у наших данных строгие требования к точности (например, финансовые данные и правительственные отчеты)?
- Нужна ли масштабируемость? Каков масштаб данных, которыми нужно управлять, и каков его ожидаемый рост? Будет ли модель базы данных должна поддерживать зеркальные копии базы данных (как отдельные экземпляры) для масштабируемости? Если да, может ли он поддерживать согласованность данных в этих экземплярах?
- Насколько важен параллелизм? Потребуется ли одновременный доступ к данным нескольким пользователям и приложениям? Поддерживает ли программное обеспечение базы данных параллелизм при защите данных?
- Каковы наши потребности в производительности и надежности? Нужен ли нам высокопроизводительный и надежный продукт? Каковы требования к производительности запроса-ответа? Каковы обязательства поставщика в отношении соглашений об уровне обслуживания (SLA) или внеплановых простоев?
Реляционная база данных будущего: самоуправляемая база данных
Что такое реляционная база данных
Реляционная база данных — это тип базы данных, в которой хранятся точки данных, которые связаны друг с другом, и предоставляется доступ к ним.Реляционные базы данных основаны на реляционной модели, интуитивно понятном и простом способе представления данных в таблицах. В реляционной базе данных каждая строка в таблице представляет собой запись с уникальным идентификатором, который называется ключом . Столбцы таблицы содержат атрибуты данных, и каждая запись обычно имеет значение для каждого атрибута, что упрощает установление отношений между точками данных.
Как устроены реляционные базы данных
Реляционная модель означает, что логические структуры данных — таблицы данных, представления и индексы — отделены от физических структур хранения.Это разделение означает, что администраторы баз данных могут управлять физическим хранилищем данных, не влияя на доступ к этим данным как к логической структуре. Например, переименование файла базы данных не приводит к переименованию хранящихся в нем таблиц.
Различие между логическими и физическими также применимо к операциям с базой данных, которые представляют собой четко определенные действия, позволяющие приложениям манипулировать данными и структурами базы данных. Логические операции позволяют приложению указывать необходимый контент, а физические операции определяют, как к этим данным следует обращаться, а затем выполняют задачу.
Чтобы обеспечить точность и доступность данных, реляционные базы данных следуют определенным правилам целостности. Например, правило целостности может указывать, что в таблице не допускаются повторяющиеся строки, чтобы исключить возможность попадания в базу данных ошибочной информации.
Реляционная модель
В первые годы существования баз данных каждое приложение хранило данные в своей уникальной структуре. Когда разработчики хотели создавать приложения для использования этих данных, им нужно было много знать о конкретной структуре данных, чтобы найти нужные данные.Эти структуры данных были неэффективными, их трудно было поддерживать и сложно оптимизировать для обеспечения хорошей производительности приложений. Модель реляционной базы данных была разработана для решения проблемы множественных произвольных структур данных.
Реляционная модель предоставляет стандартный способ представления и запроса данных, который может использоваться любым приложением. С самого начала разработчики осознавали, что главная сила модели реляционной базы данных заключается в использовании таблиц, которые представляют собой интуитивно понятный, эффективный и гибкий способ хранения структурированной информации и доступа к ней.
Со временем появилась еще одна сильная сторона реляционной модели, поскольку разработчики начали использовать язык структурированных запросов (SQL) для записи и запроса данных в базе данных. В течение многих лет SQL широко использовался как язык для запросов к базам данных. Основанный на реляционной алгебре, SQL предоставляет внутренне непротиворечивый математический язык, который упрощает повышение производительности всех запросов к базе данных. Для сравнения, другие подходы должны определять индивидуальные запросы.
Преимущества реляционных баз данных
Простая, но мощная реляционная модель используется организациями всех типов и размеров для удовлетворения самых разнообразных информационных потребностей.Реляционные базы данных используются для отслеживания запасов, обработки транзакций электронной торговли, управления огромными объемами критически важной информации о клиентах и многого другого. Реляционная база данных может быть рассмотрена для любых информационных потребностей, в которых точки данных связаны друг с другом и должны управляться безопасным, согласованным и основанным на правилах способом.
Реляционные базы данных существуют с 1970-х годов. Сегодня преимущества реляционной модели по-прежнему делают ее наиболее широко принятой моделью для баз данных.
Согласованность данных
Реляционная модель лучше всего поддерживает согласованность данных между приложениями и копиями баз данных (так называемые экземпляры ). Например, когда клиент кладет деньги в банкомат, а затем просматривает баланс счета на мобильном телефоне, клиент ожидает, что этот депозит немедленно отразится в обновленном балансе счета. Реляционные базы данных отличаются такой согласованностью данных, гарантируя, что несколько экземпляров базы данных всегда будут иметь одни и те же данные.
Для других типов баз данных сложно поддерживать такой уровень своевременной согласованности с большими объемами данных. Некоторые современные базы данных, такие как NoSQL, могут обеспечить только «конечную согласованность». Согласно этому принципу, когда база данных масштабируется или когда несколько пользователей получают доступ к одним и тем же данным одновременно, данным требуется некоторое время, чтобы «наверстать упущенное». Конечная согласованность приемлема для некоторых целей, например для ведения списков в каталоге продуктов, но для критически важных бизнес-операций, таких как транзакции корзины покупок, реляционная база данных по-прежнему остается золотым стандартом.
Обязательства и атомарность
Реляционные базы данных обрабатывают бизнес-правила и политики на очень детальном уровне, со строгими политиками около обязательства (то есть постоянное изменение базы данных). Например, рассмотрим базу данных инвентаризации, в которой отслеживаются три части, которые всегда используются вместе. Когда одна часть вытаскивается из инвентаря, две другие также нужно вытащить. Если одна из трех частей недоступна, не следует извлекать ни одну из частей — все три части должны быть доступны до того, как база данных сделает какие-либо обязательства.Реляционная база данных не выполняет фиксацию для одной части, пока не знает, что может выполнить фиксацию для всех трех. Эта возможность многогранного обязательства называется атомарностью . Атомарность — ключ к сохранению точности данных в базе данных и обеспечению их соответствия правилам, положениям и политикам бизнеса.
Хранимые процедуры и реляционные базы данных
Доступ к данным включает в себя множество повторяющихся действий. Например, простой запрос для получения информации из таблицы данных может потребоваться повторить сотни или тысячи раз для получения желаемого результата.Эти функции доступа к данным требуют определенного кода для доступа к базе данных. Разработчики приложений не хотят писать новый код для этих функций в каждом новом приложении. К счастью, реляционные базы данных позволяют хранить хранимые процедуры, которые представляют собой блоки кода, к которым можно получить доступ с помощью простого вызова приложения. Например, одна хранимая процедура может обеспечить согласованную маркировку записей для пользователей нескольких приложений. Хранимые процедуры также могут помочь разработчикам гарантировать, что определенные функции данных в приложении реализованы определенным образом.
Блокировка базы данных и параллелизм
Конфликты могут возникать в базе данных, когда несколько пользователей или приложений пытаются одновременно изменить одни и те же данные. Методы блокировки и параллелизма снижают вероятность конфликтов при сохранении целостности данных.
Блокировка предотвращает доступ других пользователей и приложений к данным во время их обновления. В некоторых базах данных блокировка применяется ко всей таблице, что отрицательно сказывается на производительности приложения.Другие базы данных, такие как реляционные базы данных Oracle, применяют блокировки на уровне записей, оставляя другие записи в таблице доступными, что помогает обеспечить лучшую производительность приложений.
Параллелизм управляет активностью, когда несколько пользователей или приложений одновременно вызывают запросы к одной и той же базе данных. Эта возможность обеспечивает правильный доступ для пользователей и приложений в соответствии с политиками, определенными для управления данными.
На что обращать внимание при выборе реляционной базы данных
Программное обеспечение, используемое для хранения, управления, запроса и извлечения данных, хранящихся в реляционной базе данных, называется системой управления реляционной базой данных (RDBMSf) .РСУБД обеспечивает интерфейс между пользователями, приложениями и базой данных, а также административные функции для управления хранением данных, доступом и производительностью.
При выборе между типами баз данных и продуктами реляционных баз данных ваше решение может зависеть от нескольких факторов. Выбранная вами СУБД будет зависеть от потребностей вашего бизнеса. Задайте себе следующие вопросы:
- Каковы наши требования к точности данных? Будет ли хранение и точность данных зависеть от бизнес-логики? Есть ли у наших данных строгие требования к точности (например, финансовые данные и правительственные отчеты)?
- Нужна ли масштабируемость? Каков масштаб данных, которыми нужно управлять, и каков его ожидаемый рост? Будет ли модель базы данных должна поддерживать зеркальные копии базы данных (как отдельные экземпляры) для масштабируемости? Если да, может ли он поддерживать согласованность данных в этих экземплярах?
- Насколько важен параллелизм? Потребуется ли одновременный доступ к данным нескольким пользователям и приложениям? Поддерживает ли программное обеспечение базы данных параллелизм при защите данных?
- Каковы наши потребности в производительности и надежности? Нужен ли нам высокопроизводительный и надежный продукт? Каковы требования к производительности запроса-ответа? Каковы обязательства поставщика в отношении соглашений об уровне обслуживания (SLA) или внеплановых простоев?
Реляционная база данных будущего: самоуправляемая база данных
RDBMS (Система управления реляционными базами данных) Определение
означает «Система управления реляционными базами данных.«СУБД — это СУБД, разработанная специально для реляционных баз данных. Следовательно, СУБД являются подмножеством СУБД.
Реляционная база данных — это база данных, в которой данные хранятся в структурированном формате с использованием строк и столбцов. Это упрощает поиск и доступ к определенным значениям в базе данных. Он «реляционный», потому что значения в каждой таблице связаны друг с другом. Таблицы также могут быть связаны с другими таблицами. Реляционная структура позволяет выполнять запросы сразу к нескольким таблицам.
В то время как реляционная база данных описывает тип базы данных, которой управляет RDMBS, СУБД относится к самой программе базы данных. Это программное обеспечение, которое выполняет запросы к данным, включая добавление, обновление и поиск значений. РСУБД также может предоставлять визуальное представление данных. Например, он может отображать данные в виде таблиц, таких как электронная таблица, что позволяет просматривать и даже редактировать отдельные значения в таблице. Некоторые программы RDMBS позволяют создавать формы, которые могут упростить ввод, редактирование и удаление данных.
Наиболее известные приложения СУБД относятся к категории СУБД. Примеры включают Oracle Database, MySQL, Microsoft SQL Server и IBM DB2. Некоторые из этих программ поддерживают нереляционные базы данных, но в основном они используются для управления реляционными базами данных.
Примеры нереляционных баз данных: Apache HBase, IBM Domino и Oracle NoSQL Database. Базы данных этого типа управляются другими программами DMBS, поддерживающими NoSQL, которые не попадают в категорию СУБД.
Обновлено: 16 декабря 2017 г.
TechTerms — Компьютерный словарь технических терминов
На этой странице содержится техническое определение РСУБД. Он объясняет в компьютерной терминологии, что означает РСУБД, и является одним из многих программных терминов в словаре TechTerms.
Все определения на веб-сайте TechTerms составлены так, чтобы быть технически точными, но также простыми для понимания. Если вы найдете это определение РСУБД полезным, вы можете ссылаться на него, используя приведенные выше ссылки для цитирования.Если вы считаете, что термин следует обновить или добавить в словарь TechTerms, напишите в TechTerms!
Подпишитесь на информационный бюллетень TechTerms, чтобы получать избранные термины и тесты прямо в свой почтовый ящик. Вы можете получать электронную почту ежедневно или еженедельно.
Подписаться
шагов к созданию реляционной схемы
Что такое реляционная схема? Как создать эффективную базу данных?
Не существует единой структуры базы данных, которая была бы всегда более эффективной , чем любая другая.Это связано с тем, что тип и объем хранимых данных изменяют оптимальную структуру базы данных.
Однако существует большая разница между построением базы данных, оптимизированной для производительности, и базой данных, оптимизированной для объема данных.
Используя реляционную схему в MySQL, вы можете создать базу данных, оптимизированную для объема данных. Это идеально в ситуациях, когда стоимость хранения, обработки и памяти непомерно высока.
Хотя это уже не относится к стандартной электронике, все еще существует множество ситуаций, когда программисты и разработчики захотят использовать реляционную схему.Хотя память, вычислительная мощность и память недороги для пользователей обычных компьютеров, эти вещи очень дороги в мире квантовых вычислений.
Кроме того, реляционная схема важна в базах данных MySQL, которые полагаются на отношения для создания смысла. Например, записи о сотрудниках и академических кругах можно легко представить как сети отношений, которые лучше описать с помощью реляционной схемы, чем, например, базы данных типа ключ-значение или графы.
Что такое реляционная схема?
Реляционная схема — это первичный элемент реляционной базы данных.Эти базы данных управляются с использованием языка и структуры, согласующейся с логикой первого порядка. Это позволяет управлять базой данных на основе отношений сущностей, что упрощает их организацию по объему.
Реляционная схема относится к метаданным, которые описывают структуру данных в определенном домене. Это план базы данных, который описывает способ организации данных в таблицы в ее структуре.
Преобразование сильных типов сущностей в реляционную схему
Например, если ваша база данных содержит записи о сотрудниках для крупного предприятия, тогда у вас могут быть отношения сущностей, описывающие каждого сотрудника как сильную сущность, например:
- Имя сотрудника
- ID номер
- Адрес
- Набор навыков сотрудников
- Дата приема на работу
- Годы службы
В этом примере у вас будет два атрибута данных реляционной схемы.Во-первых, у вас будет атрибут Employee , который является первичным ключом таблицы (поскольку все связано с сотрудником), и атрибут Address , который представляет собой составной атрибут, состоящий из разных элементов.
Атрибут Address будет состоять из следующих значений:
- Город
- улица (индекс )
- Адресный номер
- Почтовый индекс
Зная это, вы готовы сопоставить диаграмму отношений сущностей с реляционной схемой.Хотелось бы выглядеть так:
- Сотрудник (имя, идентификационный номер, адрес, улица, город, почтовый индекс, дата приема на работу)
- Набор навыков сотрудника (идентификационный номер, набор навыков)
Обратите внимание, что лет службы исключены из этого списка. Это связано с тем, что это производный атрибут, который можно рассчитать путем вычитания Даты найма из текущей даты. Причина, по которой Employee Skillset имеет свою собственную схему, заключается в том, что это многозначный атрибут.
Для реляционной схемы каждый тип сущности становится своей собственной таблицей, а каждый однозначный атрибут является столбцом в этой таблице. Производные атрибуты можно спокойно игнорировать, а многозначные атрибуты становятся отдельными таблицами.
Преобразование слабых типов сущностей в реляционную схему
Метод преобразования слабых типов сущностей в реляционную схему аналогичен процессу, описанному выше, за исключением того, что слабые типы сущностей становятся собственными таблицами, а первичный ключ сильной сущности действует как внешний ключ в таблице.
Это означает, что для сильного объекта Employee вы должны создать составной первичный ключ, состоящий из внешнего ключа Dependent и ключа самой слабой сущности. Схема будет выглядеть так:
- Сотрудник (имя, идентификационный номер, адрес, улица, город, почтовый индекс, дата приема на работу)
- Зависимый (сотрудник, идентификатор иждивенца, имя, адрес)
Здесь существует корреляция между идентификационным номером в таблице Employee и элементом Employee таблицы Dependent .
Когда эта работа сделана, вы готовы начать преобразование отношений. Для этого необходимо понимать мощность и степень каждой взаимосвязи.
- Возможны три мощности: 1: 1, 1: M, 1: N
- Существует три возможных степени: унарная, двоичная и троичная.
Примеры относительных степеней и мощностей
двоичный 1: 1
Продолжая приведенный выше пример, Employee может быть объединен с новой таблицей Department для формирования двоичного отношения 1: 1.Если сотрудник управляет определенным отделом, то его или ее можно охарактеризовать как частичного участника, а отдел — как полного участника.
Реляционная схема будет выглядеть так:
- Сотрудник ( Имя, идентификационный номер, номер адреса, улица, город, почтовый индекс, дата приема на работу )
- Отдел ( Идентификационный номер менеджера, идентификатор отдела, название, адрес )
В этом случае первичный ключ частичного участника становится внешним ключом всего участника.Идентификационный номер менеджера соответствует идентификационному номеру соответствующего сотрудника .
Это демонстрирует важную часть создания реляционной схемы. Первичный ключ одного из участников двоичного отношения 1: 1 может стать внешним ключом другого. Другой способ описания вышеприведенной взаимосвязи — использование Manages в качестве внешнего ключа под Employee , коррелирующего с первичным ключом Department ID под Department .
двоичный 1: N
Примером двоичного отношения 1: N может быть соотношение между учителем , преподающим предмет . В конкретном классе учителя могут преподавать более одного предмета разным ученикам, но все предметы имеют одинаковые отношения с учителем.
В приведенном выше двоичном соотношении 1: 1 у каждого отдела был уникальный менеджер. Благодаря этому двоичному соотношению 1: N разное количество учеников может работать с одним и тем же учителем.Первичным ключом Учитель будет Teacher ID , который будет соответствовать внешнему ключу Subject под Teacher .
Двоичный M: N
Чтобы описать двоичную связь M: N, представьте студента, записывающегося на курс. Создайте новую таблицу с описанием Студент и другую таблицу с описанием курса . Обе эти таблицы связаны посредством регистрации, и обе имеют внешние ключи.
- Внешний ключ для Student — это идентификатор студента .
- Внешний ключ для курса — это идентификатор курса .
Первичный ключ новой таблицы — это комбинация внешних ключей каждой сущности. Вы бы описали его как (студенческий билет , идентификатор курса ). Это уникальная бинарная реляционная схема M: N, которая связывает отдельных студентов с курсами.
Это работает, потому что идентификаторы по своей природе созданы с целью быть внешними ключами в реляционных базах данных.
Как насчет схемы со ссылками на себя?
Вы можете использовать реляционную схему, чтобы описать отношения со ссылками на себя.Например, два сотрудника, состоящие в браке друг с другом, могут иметь внешний ключ Spouse . Для обоих внешних ключей этих сотрудников ссылка будет на , идентификатор сотрудника другого сотрудника, который является первичным ключом соответствующей таблицы каждого сотрудника.
Это также работает в схеме отношений с числом элементов 1: N. В этом случае само поле первичного ключа станет внешним ключом той же таблицы. Это то же самое, что и унарная схема 1: 1.
Например, Сотрудник , который является менеджером Подчиненного , может иметь manager в качестве своего внешнего ключа.В этом случае Employee ID будет первичным ключом в той же таблице.
Для связи M: N с саморегулированием требуются две таблицы. Один должен представлять рассматриваемый объект, а другой должен представлять отношение M: N.
Представьте себе сотрудника, который отвечает за обеспечение качества определенного продукта или услуги. Это отношение должно включать как гарант , так и бенефициар в качестве внешних ключей, которые в совокупности коррелируют с идентификатором Employee ID таблицы Employee .И Гарант , и Получатель будут действовать как первичный и внешний ключи во вновь созданной таблице реляционной схемы.
Объяснение троичных таблиц
Хотя бинарные и унарные отношения просто описать с помощью реляционной схемы с одной или двумя таблицами. Для тернарных таблиц требуется третья, новая таблица.
Первичный ключ этой новой таблицы состоит из сложенных вместе внешних ключей каждого участвующего объекта. Это означает, что новая таблица должна содержать три внешних ключа для сопоставления.
Например, отношения между врачом и его пациентом фактически состоят из трех сущностей: Доктор , Пациент и Медицина . Чтобы правильно описать это отношение как реляционную схему, вы должны назначить внешние ключи каждому из этих объектов и сопоставить их с новой таблицей под названием Prescription .
Это простой способ визуализации работы тернарной таблицы. Первичный ключ вновь созданной таблицы Prescription — ( Doctor ID, Patient ID, Drug ID ).Любая схема, которая не включает эти три важных элемента данных, упускает важную часть головоломки.
Этот подход позволит менеджеру базы данных создать организованный архив рецептов, который учитывает определенные типы лекарств, немедленно соотносится с именами пациентов, которые их используют, и предлагает имена врачей, выписавших их.
Для полноты картины вы можете добавить дату истечения срока действия в таблицу Medicine , чтобы эти данные были доступны в основной матрице.Вы можете добавить Next Appointment или Refill Date к таблице рецепта . Логично было бы добавить Дата рождения, Адрес, и другие важные реляционные данные в таблицу Пациент .
Все эти инструменты в совокупности делают возможным создание баз данных, ориентированных на отношения, в MySQL. Вы можете попрактиковаться в создании собственных баз данных MySQL в Интернете с помощью любого браузера, использующего SQLDBM.
.